Come creare array RAID con mdadm su Ubuntu 22.04
Introduzione
L’utility mdadmpuò essere utilizzata per creare e gestire array di archiviazione utilizzando le funzionalità RAID del software Linux. Gli amministratori hanno una grande flessibilità nel coordinare i propri dispositivi di storage individuali e nel creare dispositivi di storage logici con maggiori prestazioni o caratteristiche di ridondanza.
In questa guida eseguirai diverse configurazioni RAID che possono essere configurate utilizzando un server Ubuntu 22.04.
Prerequisiti
Per seguire i passaggi di questa guida, avrai bisogno di:
- Un utente non root con privilegi
sudosu un server Ubuntu 22.04. - Una conoscenza di base della terminologia e dei concetti RAID. Per saperne di più sul RAID e sul livello RAID adatto a te, leggi l’articolo introduzione alla terminologia e ai concetti.
- Più dispositivi di archiviazione raw disponibili sul tuo server. Gli esempi in questo tutorial dimostrano come configurare vari tipi di array sul server. Pertanto, avrai bisogno di alcune unità da configurare.
- A seconda del tipo di array, saranno necessari da due a quattro dispositivi di archiviazione . Non è necessario formattare queste unità prima di seguire questa guida.
Reimpostazione dei dispositivi RAID esistenti
Puoi saltare questa sezione per ora se non hai ancora configurato alcun array. Questa guida introdurrà una serie di diversi livelli RAID. Se desideri seguire e completare ogni livello RAID per i tuoi dispositivi, probabilmente vorrai riutilizzare i dispositivi di archiviazione dopo ogni sezione. È possibile fare riferimento a questa sezione specifica Reimpostazione dei dispositivi RAID esistenti per reimpostare i dispositivi di archiviazione prima di testare un nuovo livello RAID.
Attenzione: questo processo distruggerà completamente l’array e tutti i dati scritti su di esso. Assicurati di stare operando sull’array corretto e di aver copiato tutti i dati che devi conservare prima di distruggere l’array.
Inizia trovando gli array attivi nel file /proc/mdstatfile:
cat /proc/mdstat
Output
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid0 sdc[1] sdd[0]
209584128 blocks super 1.2 512k chunks
unused devices: <none>Quindi smonta l’array dal filesystem:
sudo umount /dev/md0
Ora termina e rimuovi l’array:
sudo mdadm --stop /dev/md0
Trova i dispositivi utilizzati per costruire l’array con il seguente comando:
Avvertimento: Tieni presente che i nomi /dev/sd* possono cambiare ogni volta che si riavvia. Controllali ogni volta per assicurarti di utilizzare i dispositivi corretti.
lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
Output
NAME SIZE FSTYPE TYPE MOUNTPOINT
sda 100G linux_raid_member disk
sdb 100G linux_raid_member disk
sdc 100G disk
sdd 100G disk
vda 25G disk
├─vda1 24.9G ext4 part /
├─vda14 4M part
└─vda15 106M vfat part /boot/efi
vdb 466K iso9660 diskDopo aver scoperto i dispositivi utilizzati per creare un array, azzera il loro superblocco per ripristinarli alla normalità
sudo mdadm --zero-superblock /dev/sdc
sudo mdadm --zero-superblock /dev/sdd
Dovresti rimuovere tutti i riferimenti persistenti all’array. Modifica il file /etc/fstabe commenta o rimuovi il riferimento al tuo array:
sudo nano /etc/fstab
. . .
# /dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0
Inoltre, commenta o rimuovi la definizione dell’array dal file /etc/mdadm/mdadm.conf:
sudo nano /etc/mdadm/mdadm.conf
. . .
# ARRAY /dev/md0 metadata=1.2 name=mdadmwrite:0 UUID=7261fb9c:976d0d97:30bc63ce:85e76e91Infine aggiorna ancora il initramfs:
sudo update-initramfs -u
A questo punto dovresti essere pronto per riutilizzare i dispositivi di archiviazione singolarmente o come componenti di un array diverso.
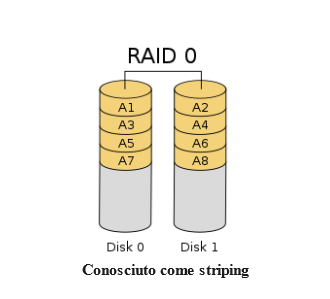
Creazione di un array RAID 0
L’array RAID 0 funziona suddividendo i dati in blocchi e distribuendoli sui dischi disponibili. Ciò significa che ogni disco contiene una parte dei dati e che durante il recupero delle informazioni verrà fatto riferimento a più dischi.
- Requisiti: minimo 2 dispositivi di archiviazione
- Vantaggio principale: prestazioni
- Cose da tenere a mente: assicurati di disporre di backup funzionali. Un singolo guasto del dispositivo distruggerà tutti i dati nell’array.
Identificare i dispositivi
Per iniziare, trova gli identificatori per i dischi raw che utilizzerai:
lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
Output
NAME SIZE FSTYPE TYPE MOUNTPOINT
sda 100G disk
sdb 100G disk
vda 25G disk
├─vda1 24.9G ext4 part /
├─vda14 4M part
└─vda15 106M vfat part /boot/efi
vdb 466K iso9660 disk In questo esempio, hai due dischi senza filesystem, ciascuno di 100 GB. A questi dispositivi sono stati assegnati gli identificatori /dev/sdaE /dev/sdb per questa sessione e saranno i componenti raw utilizzati per costruire l’array.
Creazione dell’array
Per creare un array RAID 0 con questi componenti, passali al comando mdadm --create. Dovrai specificare il nome del dispositivo che desideri creare, il livello RAID e il numero di dispositivi. In questo esempio di comando, nominerai il dispositivo /dev/md0 e includerai i due dischi che costruiranno l’array:
sudo mdadm --create --verbose /dev/md0 --level=0 --raid-devices=2 /dev/sda /dev/sdb
Conferma che il RAID è stato creato correttamente controllando il file /proc/mdstat:
cat /proc/mdstat
Output
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid0 sdb[1] sda[0]
209584128 blocks super 1.2 512k chunks
unused devices: <none>Questo output rivela che il dispositivo /dev/md0 è stato creato nella configurazione RAID 0 utilizzando i dispositivi /dev/sda e /dev/sdb.
Creazione e montaggio del filesystem
Successivamente, crea un filesystem sull’array:
sudo mkfs.ext4 -F /dev/md0
Quindi, crea un punto di montaggio per collegare il nuovo filesystem:
sudo mkdir -p /mnt/md0
Puoi montare il filesystem con il seguente comando:
sudo mount /dev/md0 /mnt/md0
Successivamente, controlla se il nuovo spazio è disponibile:
df -h -x devtmpfs -x tmpfs
Output
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 25G 1.4G 23G 6% /
/dev/vda15 105M 3.4M 102M 4% /boot/efi
/dev/md0 196G 61M 186G 1% /mnt/md0
Il nuovo filesystem è ora montato e accessibile.
Salvataggio del layout dell’array
Per assicurarti che l’array venga riassemblato automaticamente all’avvio, dovrai modificare il file /etc/mdadm/mdadm.conf. È possibile eseguire automaticamente la scansione dell’array attivo e aggiungere il file con quanto segue:
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
Successivamente è possibile aggiornare il file initramfso file system RAM iniziale, in modo che l’array sia disponibile durante il processo di avvio:
sudo update-initramfs -u
Aggiungi le nuove opzioni di montaggio del filesystem al file /etc/fstabper il montaggio automatico all’avvio:
echo '/dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0' | sudo tee -a /etc/fstab
Il tuo array RAID 0 ora assemblerà e monterà automaticamente ogni avvio.
Ora hai finito con la configurazione del RAID. Se desideri provare un RAID diverso, segui le istruzioni di ripristino all’inizio di questo tutorial per procedere con la creazione di un nuovo tipo di array RAID.
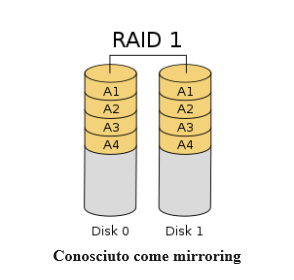
Creazione di un array RAID 1
Il tipo di array RAID 1 viene implementato eseguendo il mirroring dei dati su tutti i dischi disponibili. Ogni disco in un array RAID 1 riceve una copia completa dei dati, fornendo ridondanza in caso di guasto del dispositivo.
- Requisiti: minimo 2 dispositivi di archiviazione .
- Vantaggio principale: ridondanza tra due dispositivi di archiviazione.
- Cose da tenere a mente: poiché vengono conservate due copie dei dati, solo la metà dello spazio su disco sarà utilizzabile.
Identificazione dei dispositivi
Per iniziare, trova gli identificatori per i dischi raw che utilizzerai:
lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
Output
NAME SIZE FSTYPE TYPE MOUNTPOINT
sda 100G disk
sdb 100G disk
vda 25G disk
├─vda1 24.9G ext4 part /
├─vda14 4M part
└─vda15 106M vfat part /boot/efi
vdb 466K iso9660 disk In questo esempio, hai due dischi senza filesystem, ciascuno di 100 GB. A questi dispositivi è stato assegnato gli identificatori /dev/sdaE /dev/sdb per questa sessione e saranno i componenti raw utilizzati per creare l’array.
Creazione dell’array
Per creare un array RAID 1 con questi componenti, passali al comando mdadm --create. Dovrai specificare il nome del dispositivo che desideri creare, il livello RAID e il numero di dispositivi. In questo esempio di comando, nominerai il dispositivo /dev/md0e includerai i dischi che costruiranno l’array:
sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda /dev/sdb
Se i dispositivi che stai utilizzando non sono partizioni con il flagbootabilitato, probabilmente riceverai il seguente avviso. È sicuro rispondere con ye continua:
Output
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 104792064K
Continue creating array? y
Il tool mdadm inizierà a eseguire il mirroring delle unità. Il completamento dell’operazione può richiedere del tempo, ma durante questo periodo è possibile utilizzare l’array. È possibile monitorare l’avanzamento del mirroring controllando il file /proc/mdstat:
cat /proc/mdstat
Output
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sdb[1] sda[0]
104792064 blocks super 1.2 [2/2] [UU]
[====>................] resync = 20.2% (21233216/104792064) finish=6.9min speed=199507K/sec
unused devices: <none>Nella prima riga evidenziata, il dispositivo /dev/md0 è stato creato nella configurazione RAID 1 utilizzando i dispositivi /dev/sdae /dev/sdb. La seconda riga evidenziata rivela lo stato di avanzamento del mirroring. Puoi continuare con il passaggio successivo mentre il processo viene completato.
Creazione e montaggio del filesystem
Successivamente, crea un filesystem sull’array:
sudo mkfs.ext4 -F /dev/md0
Quindi, crea un punto di montaggio per collegare il nuovo filesystem:
sudo mkdir -p /mnt/md0
È possibile montare il filesystem eseguendo quanto segue:
sudo mount /dev/md0 /mnt/md0
Verifica se il nuovo spazio è disponibile:
df -h -x devtmpfs -x tmpfs
Output
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 25G 1.4G 23G 6% /
/dev/vda15 105M 3.4M 102M 4% /boot/efi
/dev/md0 99G 60M 94G 1% /mnt/md0
Il nuovo filesystem è montato e accessibile.
Salvataggio del layout dell’array
Per assicurarti che l’array venga riassemblato automaticamente all’avvio, devi modificare il file /etc/mdadm/mdadm.conf. È possibile eseguire automaticamente la scansione dell’array attivo e aggiungere il file con quanto segue:
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
Successivamente è possibile aggiornare il file initramfso file system RAM iniziale, in modo che l’array sia disponibile durante il processo di avvio:
sudo update-initramfs -u
Aggiungi le nuove opzioni di montaggio del filesystem al file /etc/fstab per il montaggio automatico all’avvio:
echo '/dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0' | sudo tee -a /etc/fstab
L’array RAID 1 ora assemblerà e monterà automaticamente ogni avvio.
Ora hai finito con la configurazione del RAID. Se desideri provare un RAID diverso, segui le istruzioni di ripristino all’inizio di questo tutorial per procedere con la creazione di un nuovo tipo di array RAID.
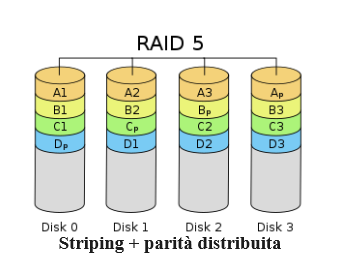
Creazione di un array RAID 5
Il tipo di array RAID 5 viene implementato eseguendo lo striping dei dati sui dispositivi disponibili. Un componente di ciascun stripe è un blocco di parità calcolato. Se un dispositivo si guasta, il blocco di parità e i blocchi rimanenti possono essere utilizzati per calcolare i dati mancanti. Il dispositivo che riceve il blocco di parità viene ruotato in modo che ciascun dispositivo disponga di una quantità bilanciata di informazioni sulla parità.
- Requisiti: minimo 3 dispositivi di archiviazione .
- Vantaggio principale: ridondanza con maggiore capacità utilizzabile.
- Cose da tenere a mente: mentre le informazioni sulla parità vengono distribuite, per la parità verrà utilizzata la capacità di un disco. RAID 5 può presentare prestazioni molto scarse quando si trova in uno stato degradato.
Identificazione dei dispositivi
Per iniziare, trova gli identificatori per i dischi raw che utilizzerai:
lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
Output
NAME SIZE FSTYPE TYPE MOUNTPOINT
sda 100G disk
sdb 100G disk
sdc 100G disk
vda 25G disk
├─vda1 24.9G ext4 part /
├─vda14 4M part
└─vda15 106M vfat part /boot/efi
vdb 466K iso9660 diskHai tre dischi senza filesystem, ciascuno di 100 GB. A questi dispositivi sono stati assegnato gli identificatori /dev/sda, /dev/sdb e /dev/sdc per questa sessione e saranno i componenti raw utilizzati per creare l’array.
Creazione dell’array
Per creare un array RAID 5 con questi componenti, passali al comando mdadm --create. Dovrai specificare il nome del dispositivo che desideri creare, il livello RAID e il numero di dispositivi. In questo esempio di comando, nominerai il dispositivo /dev/md0e includerai i dischi che costruiranno l’array:
sudo mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sda /dev/sdb /dev/sdc
Il tool mdadm inizierà a configurare l’array. Utilizza il processo di ripristino per creare l’array per motivi di prestazioni. Il completamento dell’operazione può richiedere del tempo, ma durante questo periodo è possibile utilizzare l’array. È possibile monitorare l’avanzamento del mirroring controllando il file /proc/mdstat:
cat /proc/mdstat
Output
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdc[3] sdb[1] sda[0]
209582080 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [UU_]
[>....................] recovery = 0.9% (957244/104791040) finish=18.0min speed=95724K/sec
unused devices: <none>Nella prima riga evidenziata, il dispositivo /dev/md0è stato creato nella configurazione RAID 5 utilizzando i dispositivi/dev/sda, /dev/sdbe /dev/sdc. La seconda riga evidenziata mostra l’avanzamento della compilazione.
Avvertenza: a causa del modo in cui mdadm crea gli array RAID 5, mentre l’array è ancora in fase di creazione, il numero di unità di riserva nell’array verrà riportato in modo impreciso. Ciò significa che è necessario attendere il completamento dell’assemblaggio dell’array prima di aggiornare il file /etc/mdadm/mdadm.conf. Se aggiorni il file di configurazione mentre l’array è ancora in fase di creazione, il sistema avrà informazioni errate sullo stato dell’array e non sarà in grado di assemblarlo automaticamente all’avvio con il nome corretto.
Puoi continuare la guida mentre questo processo viene completato.
Creazione e montaggio del filesystem
Successivamente, crea un filesystem sull’array:
sudo mkfs.ext4 -F /dev/md0
Crea un punto di montaggio per collegare il nuovo filesystem:
sudo mkdir -p /mnt/md0
È possibile montare il filesystem con quanto segue:
sudo mount /dev/md0 /mnt/md0
Verifica se il nuovo spazio è disponibile:
df -h -x devtmpfs -x tmpfs
Output
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 25G 1.4G 23G 6% /
/dev/vda15 105M 3.4M 102M 4% /boot/efi
/dev/md0 197G 60M 187G 1% /mnt/md0
Il nuovo filesystem è montato e accessibile.
Salvataggio del layout dell’array
Per assicurarti che l’array venga riassemblato automaticamente all’avvio, devi modificare il file /etc/mdadm/mdadm.conf.
Avvertenza: come accennato in precedenza, prima di modificare la configurazione, controllare nuovamente per assicurarti che l’array abbia terminato l’assemblaggio. Il completamento dei seguenti passaggi prima della creazione dell’array impedirà al sistema di assemblare correttamente l’array al riavvio.
È possibile monitorare l’avanzamento del mirroring controllando il file /proc/mdstat:
cat /proc/mdstat
Output
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdc[3] sdb[1] sda[0]
209584128 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>Questo output rivela che la ricostruzione è completa. Ora puoi scansionare automaticamente l’array attivo e aggiungere il file:
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
Successivamente è possibile aggiornare il file initramfso file system RAM iniziale, in modo che l’array sia disponibile durante il processo di avvio:
sudo update-initramfs -u
Aggiungi le nuove opzioni di montaggio del filesystem al file /etc/fstabper il montaggio automatico all’avvio:
echo '/dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0' | sudo tee -a /etc/fstab
L’array RAID 5 ora assemblerà e monterà automaticamente ad ogni avvio.
Ora hai finito con la configurazione del RAID. Se desideri provare un RAID diverso, segui le istruzioni di ripristino all’inizio di questo tutorial per procedere con la creazione di un nuovo tipo di array RAID.
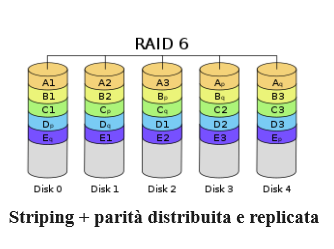
Creazione di un array RAID 6
Il tipo di array RAID 6 viene implementato eseguendo lo striping dei dati sui dispositivi disponibili. Due componenti di ciascun stripe sono blocchi di parità calcolati. Se uno o due dispositivi si guastano, i blocchi di parità e i blocchi rimanenti possono essere utilizzati per calcolare i dati mancanti. I dispositivi che ricevono i blocchi di parità vengono ruotati in modo che ciascun dispositivo disponga di una quantità bilanciata di informazioni sulla parità. È simile a un array RAID 5, ma consente il guasto di due unità.
- Requisiti: minimo 4 dispositivi di archiviazione .
- Vantaggio principale: doppia ridondanza con maggiore capacità utilizzabile.
- Cose da tenere a mente: mentre le informazioni sulla parità vengono distribuite, per la parità verrà utilizzata la capacità di due dischi. RAID 6 può presentare prestazioni molto scarse quando si trova in uno stato degradato.
Identificazione dei dispositivi
Per iniziare, trova gli identificatori per i dischi raw che utilizzerai:
lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
Output
NAME SIZE FSTYPE TYPE MOUNTPOINT
sda 100G disk
sdb 100G disk
sdc 100G disk
sdd 100G disk
vda 25G disk
├─vda1 24.9G ext4 part /
├─vda14 4M part
└─vda15 106M vfat part /boot/efi
vdb 466K iso9660 disk In questo esempio, hai quattro dischi senza filesystem, ciascuno di 100 GB. A questi dispositivi sono stati assegnati gli identificatori /dev/sda, /dev/sdb, /dev/sdc e /dev/sdd per questa sessione e saranno i componenti raw utilizzati per costruire l’array.
Creazione dell’array
Per creare un array RAID 6 con questi componenti, passali al comando mdadm --create. Devi specificare il nome del dispositivo che desideri creare, il livello RAID e il numero di dispositivi. Nel seguente esempio di comando, nominerai il dispositivo /dev/md0e includere i dischi che costruiranno l’array:
sudo mdadm --create --verbose /dev/md0 --level=6 --raid-devices=4 /dev/sda /dev/sdb /dev/sdc /dev/sdd
Il tool mdadm inizierà a configurare l’array. Utilizza il processo di ripristino per creare l’array per motivi di prestazioni. Il completamento dell’operazione può richiedere del tempo, ma durante questo periodo è possibile utilizzare l’array. È possibile monitorare l’avanzamento del mirroring controllando il file /proc/mdstat:
cat /proc/mdstat
Output
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid6 sdd[3] sdc[2] sdb[1] sda[0]
209584128 blocks super 1.2 level 6, 512k chunk, algorithm 2 [4/4] [UUUU]
[>....................] resync = 0.6% (668572/104792064) finish=10.3min speed=167143K/sec
unused devices: <none>Nella prima riga evidenziata, il dispositivo /dev/md0è stato creato nella configurazione RAID 6 utilizzando i dispositivi /dev/sda, /dev/sdb, /dev/sdce /dev/sdd. La seconda riga evidenziata mostra l’avanzamento della creazione. Puoi continuare la guida mentre questo processo viene completato.
Creazione e montaggio del filesystem
Successivamente, crea un filesystem sull’array:
sudo mkfs.ext4 -F /dev/md0
Crea un punto di montaggio per collegare il nuovo filesystem:
sudo mkdir -p /mnt/md0
È possibile montare il filesystem con quanto segue:
sudo mount /dev/md0 /mnt/md0
Verifica se il nuovo spazio è disponibile:
df -h -x devtmpfs -x tmpfs
Output
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 25G 1.4G 23G 6% /
/dev/vda15 105M 3.4M 102M 4% /boot/efi
/dev/md0 197G 60M 187G 1% /mnt/md0
Il nuovo filesystem è montato e accessibile.
Salvataggio del layout dell’array
Per assicurarti che l’array venga riassemblato automaticamente all’avvio, dovrai modificare il file /etc/mdadm/mdadm.conf. Puoi scansionare automaticamente l’array attivo e aggiungere il file digitando:
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
Successivamente è possibile aggiornare il file initramfso file system RAM iniziale, in modo che l’array sia disponibile durante il processo di avvio:
sudo update-initramfs -u
Aggiungi le nuove opzioni di montaggio del filesystem al file /etc/fstab per il montaggio automatico all’avvio:
echo '/dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0' | sudo tee -a /etc/fstab
L’array RAID 6 ora assemblerà e monterà automaticamente ogni avvio.
Ora hai finito con la configurazione del RAID. Se desideri provare un RAID diverso, segui le istruzioni di ripristino all’inizio di questo tutorial per procedere con la creazione di un nuovo tipo di array RAID.
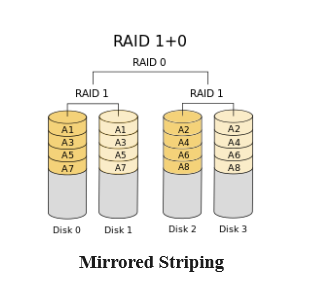
Creazione di un array RAID 10 complesso
Il tipo di array RAID 10 viene tradizionalmente implementato creando un array RAID 0 con striping composto da set di array RAID 1. Questo tipo di array annidato offre ridondanza e prestazioni elevate, a scapito di grandi quantità di spazio su disco. L’utility mdadmdispone di un proprio tipo RAID 10 che fornisce lo stesso tipo di vantaggi con maggiore flessibilità. Non viene creato annidando array, ma ha molte delle stesse caratteristiche e garanzie. Utilizzerai il mdadmRAID 10 di sequito.
- Requisiti: minimo 3 dispositivi di archiviazione .
- Vantaggio principale: prestazioni e ridondanza.
- Cose da tenere a mente: l’entità della riduzione della capacità dell’array è definita dal numero di copie dei dati che si sceglie di conservare. Il numero di copie archiviate con RAID 10 in stile
mdadmè configurabile.
Per impostazione predefinita, due copie di ciascun blocco di dati verranno archiviate in quello che viene chiamato layout vicino (near). I possibili layout che determinano la modalità di memorizzazione di ciascun blocco dati sono i seguenti:
- near: la disposizione predefinita. Le copie di ciascun blocco vengono scritte consecutivamente durante lo striping, il che significa che le copie dei blocchi di dati verranno scritte nella stessa parte di più dischi.
- far: la prima copia e quelle successive vengono scritte in parti diverse dei dispositivi di archiviazione nell’array. Ad esempio, il primo pezzo potrebbe essere scritto vicino all’inizio di un disco, mentre il secondo pezzo potrebbe essere scritto a metà su un disco diverso. Ciò può fornire alcuni miglioramenti nelle prestazioni di lettura per i tradizionali dischi rotanti a scapito delle prestazioni di scrittura.
- offset: ogni stripe viene copiato e spostato di un’unità. Ciò significa che le copie sono sfalsate l’una dall’altra, ma ancora vicine sul disco. Ciò aiuta a ridurre al minimo la ricerca eccessiva durante alcuni carichi di lavoro.
Puoi scoprire di più su questi layout controllando la sezione RAID10 della pagina man:
man 4 md
Oppure qui.
Identificazione dei dispositivi
Per iniziare, trova gli identificatori per i dischi raw che utilizzerai:
lsblk -o NAME,SIZE,FSTYPE,TYPE,MOUNTPOINT
Output
NAME SIZE FSTYPE TYPE MOUNTPOINT
sda 100G disk
sdb 100G disk
sdc 100G disk
sdd 100G disk
vda 25G disk
├─vda1 24.9G ext4 part /
├─vda14 4M part
└─vda15 106M vfat part /boot/efi
vdb 466K iso9660 disk In questo esempio, hai quattro dischi senza filesystem, ciascuno di 100 GB. A questi dispositivi sono stati assegnati gli identificatori /dev/sda, /dev/sdb, /dev/sdc, E /dev/sddper questa sessione e saranno i componenti raw utilizzati per costruire l’array.
Creazione dell’array
Per creare un array RAID 10 con questi componenti, passali al comando mdadm --create. Devi specificare il nome del dispositivo che desideri creare, il livello RAID e il numero di dispositivi. Nel seguente esempio, nominerai il dispositivo /dev/md0e includerai i dischi che costruiranno l’array:
È possibile impostare due copie utilizzando il layout vicino senza specificare un layout e un numero di copia:
sudo mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sda /dev/sdb /dev/sdc /dev/sdd
Se desideri utilizzare un layout diverso o modificare il numero di copie, dovrai utilizzare l’opzione --layout=, che accetta un layout e un identificatore di copia. I layout sono nper vicino, fper lontano, e oper compensazione. Il numero di copie da archiviare viene aggiunto successivamente.
Ad esempio, per creare un array con tre copie nel layout offset, il comando includerebbe quanto segue:
sudo mdadm --create --verbose /dev/md0 --level=10 --layout=o3 --raid-devices=4 /dev/sda /dev/sdb /dev/sdc /dev/sdd
Il tool mdadminizierà a configurare l’array. Utilizza il processo di ripristino per creare l’array per motivi di prestazioni. Il completamento dell’operazione può richiedere del tempo, ma durante questo periodo è possibile utilizzare l’array. È possibile monitorare l’avanzamento del mirroring controllando il file /proc/mdstat:
cat /proc/mdstat
Output
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : active raid10 sdd[3] sdc[2] sdb[1] sda[0]
209584128 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU]
[===>.................] resync = 18.1% (37959424/209584128) finish=13.8min speed=206120K/sec
unused devices: <none>Nella prima riga evidenziata, il dispositivo /dev/md0è stato creato nella configurazione RAID 10 utilizzando i disositivi /dev/sda, /dev/sdb, /dev/sdce /dev/sdd. La seconda area evidenziata mostra il layout utilizzato per questo esempio (due copie nella configurazione near). La terza area evidenziata mostra lo stato di avanzamento della costruzione. Puoi continuare la guida mentre questo processo viene completato.
Creazione e montaggio del filesystem
Successivamente, crea un filesystem sull’array:
sudo mkfs.ext4 -F /dev/md0
Crea un punto di montaggio per collegare il nuovo filesystem:
sudo mkdir -p /mnt/md0
È possibile montare il filesystem in questo modo:
sudo mount /dev/md0 /mnt/md0
Verifica se il nuovo spazio è disponibile:
df -h -x devtmpfs -x tmpfs
Output
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 25G 1.4G 23G 6% /
/dev/vda15 105M 3.4M 102M 4% /boot/efi
/dev/md0 197G 60M 187G 1% /mnt/md0
Il nuovo filesystem è montato e accessibile.
Salvataggio del layout dell’array
Per assicurarti che l’array venga riassemblato automaticamente all’avvio, dovrai modificare il file /etc/mdadm/mdadm.conf. È possibile eseguire automaticamente la scansione dell’array attivo e aggiungere il file eseguendo quanto segue:
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
Successivamente è possibile aggiornare il file initramfso file system RAM iniziale, in modo che l’array sia disponibile durante il processo di avvio:
sudo update-initramfs -u
Aggiungi le nuove opzioni di montaggio del filesystem al file /etc/fstab per il montaggio automatico all’avvio:
echo '/dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0' | sudo tee -a /etc/fstab
L’array RAID 10 verrà ora assemblato e montato automaticamente ogni avvio.