
Introduzione
L’archiviazione è una considerazione importante quando si configura un server. Quasi tutte le informazioni importanti che interessano verranno prima o poi scritte su un dispositivo di archiviazione per essere salvate per un successivo recupero. I dischi singoli possono essere utili se le esigenze sono semplici. Tuttavia, se hai requisiti di ridondanza o prestazioni più complessi, soluzioni come RAID possono essere utili.
In questa guida parleremo della terminologia e dei concetti RAID comuni. Discuteremo alcuni vantaggi e svantaggi della disposizione dei dispositivi in array RAID, parleremo delle differenze nelle tecnologie di implementazione e esamineremo il modo in cui i diversi livelli RAID influiscono sull’ambiente di archiviazione.
Cos’è il RAID?
RAID sta per Array ridondanti di dischi indipendenti (Redundant Arrays of Independent Disks). Combinando le unità in modelli diversi, gli amministratori possono ottenere prestazioni o ridondanza maggiori rispetto a quelle che l’insieme di unità può offrire se gestite individualmente. Il RAID è implementato come uno strato intermedio tra le unità o le partizioni grezze e lo strato del file system.
Quando il RAID è una buona idea?
I valori principali forniti dal RAID sono la ridondanza dei dati e il miglioramento delle prestazioni.
La ridondanza ha lo scopo di contribuire ad aumentare la disponibilità dei dati. Ciò significa che durante determinate condizioni di guasto, come quando un’unità di archiviazione diventa difettosa, le informazioni sono ancora accessibili e il sistema nel suo insieme può continuare a funzionare fino alla sostituzione dell’unità. Questo non è inteso come un meccanismo di backup (con RAID sono sempre consigliati backup separati come con qualsiasi altro tipo di archiviazione), ma è inteso invece a ridurre al minimo le interruzioni quando si verificano problemi.
L’altro vantaggio offerto dal RAID in alcuni scenari riguarda le prestazioni. L’I/O di archiviazione è spesso limitato dalla velocità di un singolo disco. Con RAID, i dati sono ridondanti o distribuiti, il che significa che è possibile consultare più dischi per ogni operazione di lettura, aumentando il throughput totale. Le operazioni di scrittura possono anche essere migliorate in alcune configurazioni poiché a ogni singolo disco potrebbe essere richiesto di scrivere solo una frazione dei dati totali.
Alcuni svantaggi del RAID includono una maggiore complessità di gestione e spesso una riduzione della capacità disponibile. Ciò si traduce in costi aggiuntivi per la stessa quantità di spazio utilizzabile. Ulteriori spese potrebbero essere sostenute attraverso l’uso di hardware specializzato quando l’array non è gestito interamente tramite software.
Un altro svantaggio delle configurazioni di array incentrate sulle prestazioni senza ridondanza è l’aumento del rischio di perdita totale dei dati. In questi scenari un insieme di dati dipende interamente da più di un dispositivo di archiviazione, aumentando il rischio totale di perdita
RAID hardware, RAID software e RAID software assistito da hardware
Gli array RAID possono essere creati e gestiti utilizzando alcune tecnologie diverse.
RAID hardware
È possibile utilizzare hardware dedicato chiamato controller RAID o schede RAID per impostare e gestire il RAID in modo indipendente dal sistema operativo. Questo è noto come RAID hardware. I veri controller RAID hardware avranno un processore dedicato per la gestione dei dispositivi RAID.
Ciò presenta una serie di vantaggi:
- Prestazioni: i controller RAID hardware originali non hanno bisogno di occupare cicli della CPU per gestire i dischi sottostanti. Ciò significa nessun sovraccarico per la gestione dei dispositivi di archiviazione collegati. I controller di alta qualità forniscono anche un’ampia memorizzazione nella cache, che può avere un enorme impatto sulle prestazioni.
- Eliminazione della complessità: un altro vantaggio derivante dall’utilizzo dei controller RAID è che astraggono la disposizione del disco sottostante dal sistema operativo. Il RAID hardware può presentare l’intero gruppo di unità come una singola unità logica di archiviazione. Non è necessario che il sistema operativo comprenda la disposizione RAID; può semplicemente interfacciarsi con l’array come se fosse un singolo dispositivo.
- Disponibilità all’avvio: poiché l’array è gestito interamente al di fuori del software, sarà disponibile all’avvio, consentendo al filesystem root stesso di essere facilmente installato su un array RAID.
Il RAID hardware presenta anche alcuni svantaggi significativi.
- Vincolo del fornitore: poiché la disposizione RAID è gestita dal firmware proprietario sull’hardware stesso, un array è in qualche modo bloccato sull’hardware utilizzato per crearlo. Se un controller RAID muore, nella quasi totalità dei casi, deve essere sostituito con un modello identico o compatibile. Alcuni amministratori consigliano di acquistare uno o più controller di backup da utilizzare nel caso in cui il primo abbia un problema.
- Costo elevato: i controller RAID hardware di qualità tendono ad essere piuttosto costosi.
RAID software
Il RAID può anche essere configurato dal sistema operativo stesso. Poiché la relazione tra i dischi è definita all’interno del sistema operativo e non del firmware di un dispositivo hardware, si parla di RAID software .
Alcuni vantaggi del RAID software:
- Flessibilità: poiché il RAID è gestito all’interno del sistema operativo, può essere facilmente configurato dallo spazio di archiviazione disponibile senza riconfigurare l’hardware, da un sistema in esecuzione. Il RAID software Linux è particolarmente flessibile e consente molti tipi diversi di configurazione RAID.
- Open source: anche le implementazioni RAID software per sistemi operativi open source come Linux e FreeBSD sono open source. L’implementazione RAID non è nascosta e può essere facilmente letta e implementata su altri sistemi. Ad esempio, l’array RAID creato su una macchina Ubuntu può essere facilmente importato in un server CentOS in un secondo momento. Ci sono poche possibilità di perdere l’accesso ai tuoi dati a causa delle differenze del software.
- Nessun costo aggiuntivo: il RAID software non richiede hardware speciale, quindi non aggiunge costi aggiuntivi al server o workstation.
Alcuni svantaggi del RAID software sono:
- Specifico dell’implementazione: sebbene il RAID software non sia legato a un hardware specifico, tende ad essere legato all’implementazione software specifica del RAID. Linux utilizza
mdadm, mentre FreeBSD utilizza RAID basato su GEOM e Windows ha la propria versione di RAID software. Sebbene in alcuni casi le implementazioni open source possano essere trasferite o lette, il formato stesso probabilmente non sarà compatibile con altre implementazioni RAID software. - Sovraccarico delle prestazioni: storicamente, il RAID software è stato criticato per la creazione di ulteriore sovraccarico. Per gestire l’array sono necessari cicli della CPU e memoria, che potrebbero essere utilizzati per altri scopi. Implementazioni come
mdadmsull’hardware moderno, tuttavia, annulla in gran parte queste preoccupazioni. Il sovraccarico della CPU è minimo e nella maggior parte dei casi insignificante.
RAID software assistito da hardware (Fake RAID)
È disponibile anche un terzo tipo di RAID chiamato RAID software assistito da hardware , RAID firmware o RAID falso. In genere, questo si trova nella funzionalità RAID all’interno delle schede madri stesse o in schede RAID poco costose. Il RAID software assistito da hardware è un’implementazione che utilizza il firmware sul controller o sulla scheda per gestire il RAID, ma utilizza la normale CPU per gestire l’elaborazione.
Vantaggi del RAID software assistito da hardware:
- Supporto per più sistemi operativi: poiché il RAID viene attivato durante l’avvio iniziale e quindi trasferito al sistema operativo, più sistemi operativi possono utilizzare lo stesso array, cosa che potrebbe non essere possibile con il RAID software.
Svantaggi del RAID software assistito da hardware:
- Supporto RAID limitato: solitamente sono disponibili solo RAID 0 o RAID 1.
- Richiede hardware specifico: come il RAID hardware, il RAID software assistito da hardware è legato all’hardware utilizzato per crearlo e gestirlo. Questo problema è ancora più problematico se incluso in una scheda madre, poiché un guasto del controller RAID può significare che è necessario sostituire l’intera scheda madre per accedere nuovamente ai dati.
- Sovraccarico delle prestazioni: come il RAID software, nessuna CPU è dedicata alla gestione del RAID. L’elaborazione deve essere condivisa con il resto del sistema operativo.
La maggior parte degli amministratori si tiene alla larga dal RAID software assistito dall’hardware poiché soffre di una combinazione delle insidie delle altre due implementazioni.
Terminologia
La familiarità con alcuni concetti comuni aiuterà a comprendere meglio RAID. Di seguito sono riportati alcuni termini comuni che potresti incontrare:
- Livello RAID: il livello RAID di un array si riferisce alla relazione imposta sui dispositivi di archiviazione che lo compongono. Le unità possono essere configurate in molti modi diversi, portando a diverse ridondanze dei dati e caratteristiche prestazionali. Consultare la sezione sui livelli RAID per ulteriori informazioni.
- Striping: lo striping è il processo di divisione delle scritture sull’array su più dischi sottostanti. Questa strategia viene utilizzata da diversi livelli RAID. Quando i dati vengono distribuiti su un array, vengono suddivisi in blocchi e ciascun blocco viene scritto su almeno uno dei dispositivi sottostanti.
- Dimensione blocco: durante lo striping dei dati, la dimensione del blocco definisce la quantità di dati che ogni blocco conterrà. La regolazione della dimensione del blocco in modo che corrisponda alle caratteristiche di I/O previste può contribuire a influenzare le prestazioni relative dell’array.
- Parità: la parità è un meccanismo di integrità dei dati implementato calcolando le informazioni dai blocchi di dati scritti nell’array. Le informazioni sulla parità possono essere utilizzate per ricostruire i dati in caso di guasto di un’unità. La parità calcolata viene posizionata su un dispositivo separato rispetto ai dati da cui viene calcolata e, nella maggior parte delle configurazioni, viene distribuita tra le unità disponibili per prestazioni e ridondanza migliori.
- Array degradati: gli array dotati di ridondanza possono subire diversi tipi di guasti delle unità senza perdere dati. Quando un array perde un dispositivo ma è ancora operativo, si dice che sia in modalità degradata. Gli array danneggiati possono essere ricostruiti in condizioni pienamente operative una volta sostituito l’hardware guasto, ma nel frattempo potrebbero subire una riduzione delle prestazioni.
- Resilvering: Resilvering, o risincronizzazione, è il termine utilizzato per ricostruire un array danneggiato. A seconda della configurazione RAID e dell’impatto del guasto, ciò avviene copiando i dati dai file esistenti nell’array oppure calcolando i dati valutando le informazioni di parità.
- Array annidati: gruppi di array RAID possono essere combinati in array più grandi. Questo di solito viene fatto per sfruttare le funzionalità di due o più livelli RAID diversi. Di solito, gli array con ridondanza (come RAID 1 o RAID 5) vengono utilizzati come componenti per creare un array RAID 0 per migliorare le prestazioni.
- Span: Sfortunatamente, span ha un significato diverso quando si parla di array.
- In determinati contesti, “span” può significare unire due o più dischi insieme end-to-end e presentarli come un unico dispositivo logico, senza miglioramenti in termini di prestazioni o ridondanza. Questa è anche conosciuta come disposizione lineare quando si ha a che fare con Linux
mdadmimplementazione. - Uno “span” può anche riferirsi al livello inferiore di array combinati per formare il livello successivo quando si parla di livelli RAID nidificati, come RAID 10.
- In determinati contesti, “span” può significare unire due o più dischi insieme end-to-end e presentarli come un unico dispositivo logico, senza miglioramenti in termini di prestazioni o ridondanza. Questa è anche conosciuta come disposizione lineare quando si ha a che fare con Linux
- Scrubbing: lo scrubbing, o controllo, è il processo di lettura di ogni blocco in un array per assicurarsi che non vi siano errori di coerenza. Ciò aiuta a garantire che i dati siano gli stessi su tutti i dispositivi di archiviazione e previene situazioni in cui errori silenziosi possono causare danni, soprattutto durante procedure delicate come le ricostruzioni.
Livelli RAID
Le caratteristiche di un array sono determinate dalla configurazione e dalla relazione dei dischi, nota come livello RAID . I livelli RAID più comuni sono:
RAID 0
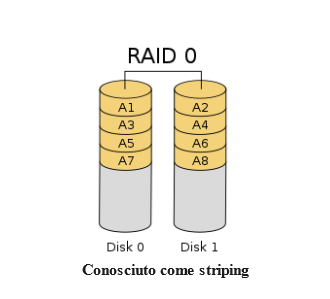
RAID 0 combina due o più dispositivi distribuendo i dati su di essi. Come accennato in precedenza, lo striping è una tecnica che suddivide i dati in blocchi e quindi li scrive alternativamente su ciascun disco dell’array. Il vantaggio di ciò è che, poiché i dati sono distribuiti, l’intera potenza di ciascun dispositivo può essere utilizzata sia per le letture che per le scritture. Il profilo prestazionale teorico di un array RAID 0 è semplicemente la prestazione di un singolo disco moltiplicata per il numero di dischi (le prestazioni nel mondo reale saranno inferiori a questo). Un altro vantaggio è che la capacità utilizzabile dell’array è semplicemente la capacità combinata di tutte le unità che lo compongono.
Sebbene questo approccio offra ottime prestazioni, presenta anche alcuni svantaggi molto importanti. Poiché i dati vengono suddivisi e divisi tra ciascuno dei dischi dell’array, il guasto di un singolo dispositivo causerà il guasto dell’intero array e tutti i dati andranno persi. A differenza della maggior parte degli altri livelli RAID, gli array RAID 0 non possono essere ricostruiti, poiché nessun sottoinsieme di dispositivi componenti contiene informazioni sufficienti sul contenuto per ricostruire i dati. Se si utilizza un array RAID 0, i backup diventano estremamente importanti, poiché l’intero set di dati dipende in egual misura dall’affidabilità di ciascuno dei dischi dell’array.
RAID 1
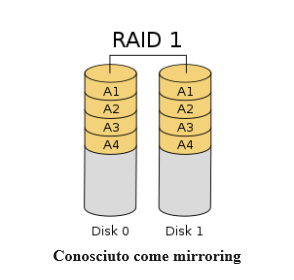
RAID 1 è una configurazione che rispecchia i dati tra due o più dispositivi. Tutto ciò che viene scritto nell’array viene posizionato su ciascuno dei dispositivi del gruppo. Ciò significa che ogni dispositivo ha un set completo di dati disponibili, offrendo ridondanza in caso di guasto del dispositivo. In un array RAID 1, i dati saranno comunque accessibili finché un singolo dispositivo nell’array funziona correttamente. L’array può essere ricostruito sostituendo le unità guaste, a quel punto i dispositivi rimanenti verranno utilizzati per copiare i dati sul nuovo dispositivo.
Questa configurazione presenta anche alcune penalità. Come RAID 0, la velocità di lettura teorica può ancora essere calcolata moltiplicando la velocità di lettura di un singolo disco per il numero di dischi. Per le operazioni di scrittura, tuttavia, le prestazioni massime teoriche saranno quelle del dispositivo più lento dell’array. Ciò è dovuto al fatto che l’intero dato deve essere scritto su ciascuno dei dischi dell’array. Inoltre, la capacità totale dell’array sarà quella del disco più piccolo. Pertanto un array RAID 1 con due dispositivi di uguali dimensioni avrà la capacità utilizzabile di un singolo disco. L’aggiunta di ulteriori dischi può aumentare il numero di copie ridondanti dei dati, ma non aumenterà la quantità di capacità disponibile.
RAID 5
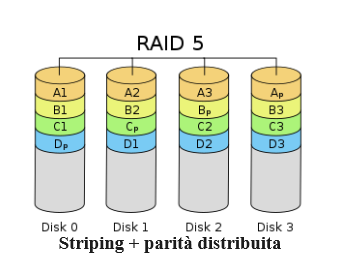
RAID 5 presenta alcune caratteristiche dei due livelli RAID precedenti, ma presenta un profilo prestazionale diverso e diversi inconvenienti. In RAID 5, i dati vengono distribuiti sui dischi più o meno allo stesso modo di un array RAID 0. Tuttavia, per ogni striscia di dati scritta sull’array, le informazioni sulla parità, un valore calcolato matematicamente che può essere utilizzato per la correzione degli errori e la ricostruzione dei dati, verranno scritte su uno dei dischi. Il disco che riceve il blocco di parità calcolata anziché un blocco dati ruoterà con ogni stripe scritto.
Ciò presenta alcuni vantaggi importanti. Come altri array con striping, le prestazioni di lettura traggono vantaggio dalla capacità di leggere da più dischi contemporaneamente. Gli array RAID 5 gestiscono la perdita di qualsiasi disco nell’array. Se ciò accade, i blocchi di parità consentono la ricostruzione completa dei dati. Poiché la parità è distribuita (alcuni livelli RAID meno comuni utilizzano un’unità di parità dedicata, nella fattispecie RAID 4), ogni disco dispone di una quantità bilanciata di informazioni sulla parità. Mentre la capacità di un array RAID 1 è limitata alla dimensione di un singolo disco (tutti i dischi hanno copie identiche dei dati), con la parità RAID 5 è possibile ottenere un livello di ridondanza al costo dello spazio di un solo disco. Pertanto, quattro unità da 100 G in un array RAID 5 produrrebbero 300 G di spazio utilizzabile (gli altri 100 G sarebbero occupati dalle informazioni di parità distribuite).
Come gli altri livelli, RAID 5 presenta alcuni inconvenienti significativi che devono essere presi in considerazione. Le prestazioni del sistema possono rallentare notevolmente a causa dei calcoli di parità al volo. Ciò può influire su ogni operazione di scrittura. Se un disco si guasta e l’array entra in uno stato degradato, verrà introdotta anche una penalità significativa per le operazioni di lettura (i dati mancanti dovranno essere calcolati dai dischi rimanenti). Inoltre, quando l’array viene riparato dopo la sostituzione di un’unità guasta, è necessario leggere ciascuna unità e utilizzare la CPU per calcolare i dati mancanti e ricostruirli. Ciò può stressare le unità rimanenti, portando talvolta a ulteriori guasti, con conseguente perdita di tutti i dati.
RAID 6
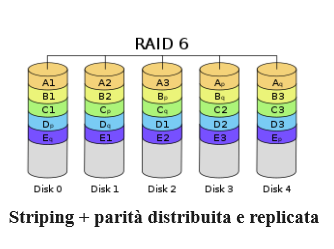
RAID 6 utilizza un’architettura simile a RAID 5, ma con informazioni di doppia parità. Ciò significa che l’array può sopportare il guasto di due dischi qualsiasi. Si tratta di un vantaggio significativo dovuto alla maggiore probabilità che si verifichi un ulteriore guasto del disco durante il processo di ricostruzione intensivo dopo che si è verificato un errore. Come altri livelli RAID che utilizzano lo striping, le prestazioni di lettura sono generalmente buone. Tutti gli altri vantaggi del RAID 5 esistono anche per il RAID 6.
Per quanto riguarda gli svantaggi, RAID 6 compensa la doppia parità aggiuntiva con la capacità di un disco aggiuntivo. Ciò significa che la capacità totale dell’array corrisponde allo spazio combinato delle unità coinvolte, meno due unità. Il calcolo per determinare i dati di parità per RAID 6 è più complesso di RAID 5, il che può portare a prestazioni di scrittura peggiori rispetto a RAID 5. RAID 6 soffre di alcuni degli stessi problemi di degrado di RAID 5, ma la ridondanza del disco aggiuntivo protegge contro la probabilità che ulteriori errori cancellino i dati durante le operazioni di ricostruzione.
RAID 10
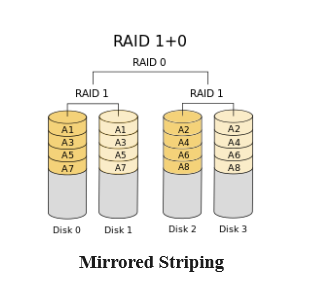
RAID 10 può essere implementato in diversi modi, che influiscono sulle sue caratteristiche generali:
- RAID nidificato 1+0
Tradizionalmente, RAID 10 si riferisce a un RAID nidificato, creato impostando prima due o più mirror RAID 1 e quindi utilizzandoli come componenti per creare un array RAID 0 con striping su di essi. A volte questo viene ora chiamato RAID 1+0 per essere più espliciti su questa relazione. A causa di questa progettazione, sono necessari almeno quattro dischi per formare un array RAID 1+0 (RAID 0 con striping su due array RAID 1 costituiti da due dispositivi ciascuno).
Gli array RAID 1+0 hanno le caratteristiche di prestazioni elevate di un array RAID 0, ma invece di fare affidamento su singoli dischi per ciascun componente dello stripe, viene utilizzato un array con mirroring, fornendo ridondanza. Questo tipo di configurazione può gestire i guasti del disco in qualsiasi set RAID 1 con mirroring purché almeno un disco in ciascun RAID 1 rimanga disponibile. L’array complessivo è tollerante agli errori in modo sbilanciato, il che significa che può gestire un numero diverso di errori a seconda di dove si verificano.
Poiché RAID 1+0 offre sia ridondanza che prestazioni elevate, di solito è un’ottima opzione se il numero di dischi richiesti non è proibitivo.
- RAID 10 di mdadm
Quello di Linux mdadmoffre la propria versione di RAID 10, che porta avanti lo spirito e i vantaggi di RAID 1+0, ma altera l’effettiva implementazione per essere più flessibile e offrire alcuni vantaggi aggiuntivi.
Come RAID 1+0, mdadmRAID 10 consente copie multiple e dati con striping. Tuttavia, i dispositivi non sono disposti in termini di coppie speculari. L’amministratore decide invece il numero di copie che verranno scritte per l’array. I dati vengono suddivisi in blocchi e scritti sull’array in più copie, assicurandosi che ciascuna copia di un blocco venga scritta su un dispositivo fisico diverso. Il risultato finale è che esiste lo stesso numero di copie, ma l’array non è vincolato tanto dalla nidificazione sottostante.
Questa concezione del RAID 10 presenta alcuni notevoli vantaggi rispetto al RAID 1+0 nidificato. Poiché non si basa sull’utilizzo di array come elementi costitutivi, può utilizzare un numero dispari di dischi e ha un numero minimo di dischi inferiore (sono richiesti solo 3 dispositivi). Anche il numero di copie da conservare è configurabile. La gestione è semplificata poiché è necessario indirizzare un solo array ed è possibile allocare parti di riserva che possono essere utilizzate per qualsiasi disco dell’array invece che per un solo array componente.