
Nel mondo odierno, dove la dipendenza dalla tecnologia è crescente, la cybersecurity è diventata un pilastro fondamentale. La sicurezza informatica non riguarda solo la protezione di dati e risorse, ma anche la gestione delle vulnerabilità che emergono nei sistemi e nelle applicazioni software. Uno degli errori comuni è la fiducia cieca nella fonte da cui si ottiene il software: installare programmi da fonti non verificate può esporre a gravi rischi, poiché software dannosi come trojan e virus sono spesso distribuiti tramite siti web malevoli o email fraudolente. In questi casi, la vulnerabilità risiede non solo nel software ma anche negli utenti, i quali, se non adeguatamente formati, possono commettere errori nella valutazione delle fonti e dei rischi associati.
La sicurezza della fonte e le minacce nascoste
Affidarsi solo all’affidabilità della fonte di download non è sufficiente. Anche quando scarichiamo software da siti web legittimi, potremmo comunque trovarci esposti a minacce come attacchi “man in the middle” che compromettono il file durante il trasferimento. Inoltre, errori logici interni al software o input inattesi (non è detto che l’input sia fidato, ovvero “soddisfi le precondizioni”), possono compromettere l’intero sistema. Pertanto, la correttezza del software, intesa come aderenza ai requisiti funzionali e prevenzione degli errori, diventa un aspetto cruciale.
Gestione delle vulnerabilità: l’intervento di CERT e CSIRT
Quando una vulnerabilità viene scoperta, l’utente deve segnalarla a un team di risposta agli incidenti informatici, come i CERT (Computer Emergency Response Team) o i CSIRT (Computer Security Incident Response Team). Questi enti, spesso supportati da università o enti governativi, verificano la presenza della vulnerabilità e avvisano i produttori del software, prima di pubblicare un avviso di sicurezza. Tuttavia, esiste anche un mercato illecito per queste vulnerabilità, detto mercato degli “zero-day”, dove le falle sconosciute e non documentate possono essere vendute e sfruttate dai criminali.
Il cybercrime market e le minacce digitali
L’economia del crimine informatico non si limita alle vulnerabilità zero-day. Esistono veri e propri mercati per exploit, malware, botnet e credenziali rubate, spesso venduti come servizi “as-a-service”. Questi mercati prosperano nel dark web, sfruttando reti anonime come TOR per garantire la segretezza e l’intracciabilità delle transazioni. Ad esempio, i dati delle carte di credito o gli account compromessi possono essere venduti a prezzi che variano a seconda del livello di compromissione e del valore dell’account.
Il database delle vulnerabilità e i framework di sicurezza
Per catalogare e analizzare le vulnerabilità, sono stati sviluppati database come il National Vulnerability Database (NVD) e il Common Vulnerabilities and Exposures (CVE), che documentano le vulnerabilità note e forniscono indicazioni su come mitigare i rischi. Le vulnerabilità vengono inoltre classificate tramite il Common Vulnerability Scoring System (CVSS), un sistema di valutazione che attribuisce un punteggio alla gravità del rischio, guidando le aziende nelle priorità di intervento.
Il Common Weakness Enumeration (CWE): una tassonomia delle debolezze del software
Il Common Weakness Enumeration (CWE) è un elenco standardizzato delle debolezze più comuni nella sicurezza del software, sviluppato per facilitare l’identificazione e la prevenzione di vulnerabilità. A differenza del CVE, che si concentra su vulnerabilità specifiche e istanze particolari in software o sistemi, il CWE descrive debolezze generali che possono essere sfruttate in una vasta gamma di contesti. Tra le debolezze più rilevanti troviamo problemi come il “buffer overflow”, che può portare a corruzione della memoria e attacchi di esecuzione arbitraria di codice, la “SQL Injection”, dove l’immissione di comandi non validati può compromettere database e sistemi, e l’“out-of-bounds write”, dove l’accesso a memoria al di fuori dei limiti previsti può causare crash o vulnerabilità critiche. Il CWE non solo funge da linguaggio comune per discutere di questi problemi, ma fornisce anche una base per sviluppare strumenti di testing e pratiche di sicurezza, aiutando gli sviluppatori a progettare sistemi più robusti e resilienti fin dalle fasi iniziali di sviluppo.
Sfide e falsi miti sulla sicurezza del software
Uno dei miti più diffusi è che un software sia “sicuro” se funziona come previsto. Tuttavia, affidabilità e sicurezza non sono sinonimi: un software può soddisfare i requisiti funzionali ma essere comunque vulnerabile ad abusi e attacchi. Inoltre, la sicurezza non dipende solo dalle caratteristiche visibili come la crittografia o il controllo degli accessi, ma anche dall’integrazione sicura di ogni funzione. Le minacce derivano anche dall’imprevedibilità dell’uso del software: moderni sistemi connessi e complessi sono difficili da proteggere completamente.
Alcuni “falsi miti” e la realtà
- Funziona in modo affidabile, soddisfacendo tutti i requisiti funzionali.
Affidabilità non vuol dire sicurezza: “Il software affidabile fa quello che deve fare. Il software sicuro fa quello che deve fare e nient’altro” (Ivan Arce). Non si tratta solo di come il software deve essere usato, ma anche di come può essere abusato: in quanto i requisiti funzionali sono guidati dai casi d’uso, mentre i requisiti di sicurezza sono guidati da casi di abuso. - Dispone di tutte le caratteristiche di sicurezza appropriate.
Funzionalità di sicurezza non vuol dire funzionalità sicure: le funzionalità di sicurezza sono caratteristiche direttamente collegate agli obiettivi di sicurezza, come l’uso della crittografia, la gestione delle password, il controllo degli accessi, ecc. Devono essere implementate con attenzione, ma lo sviluppo non può concentrarsi solo sulle caratteristiche di sicurezza (Seven Pernicious Kingdoms). Le funzionalità sicure sono qualsiasi funzionalità, anche se non direttamente correlate a un requisito di sicurezza, che possono mettere a rischio la sicurezza. - I possibili utilizzi sono ben noti e sotto controllo.
Non è possibile prevedere tutti i possibili usi di un sistema software. Il software moderno è soggetto alla “The Trinity of Trouble” (ToT) (Trinità dei problemi) :
- Connettività: i sistemi software sono connessi.
- Complessità: la loro organizzazione può essere intricata e complessa.
- Estensibilità: si evolvono e possono essere estesi in modo imprevedibile.
Tutti questi aspetti sono naturalmente correlati tra loro.
- Abbiamo previsto tutte le minacce.
Non è possibile prevedere tutte le possibili minacce. Howard e Leblanc “The attacker’s advantage and the defender’s dilemma” riassumono il problema in 4 principi:
- Principio n. 1: il difensore deve difendere tutti i punti; l’attaccante può scegliere il punto più debole.
- Principio n. 2: il difensore può difendersi solo da attacchi noti; l’attaccante può sondare le vulnerabilità sconosciute.
- Principio n. 3: il difensore deve essere costantemente vigile; l’attaccante può colpire a piacimento.
- Principio n. 4: il difensore deve rispettare le regole; l’attaccante può giocare sporco.
- Il codice è “chiuso” e le versioni binarie sono offuscate. Anche i nostri meccanismi di crittografia sono segreti.
“Security by design vs security by obscurity”: security by obscurity si basa sulla segretezza come metodo generale per la sicurezza. Funziona come deterrente, aumenta il lavoro dell’attaccante, ma i segreti sono difficili da mantenere a lungo (ad es. considerare le fughe di notizie, le tecniche di reverse engineering). In generale, ricordiamo i principi dei “vantaggi dell’attaccante”. Security by design si basa su 10 principi generali di sicurezza:
- Semplicità
- Design Open
- Suddivisione
- Esposizione minima
- Minimo privilegio
- Minima fiducia e massima affidabilità
- Difetti sicuri e a prova di errore
- Mediazione completa
- Nessun singolo punto di errore
- Tracciabilità
- Per quanto riguarda la sicurezza, conduciamo un pentest approfondito alla fine del ciclo di sviluppo del software.
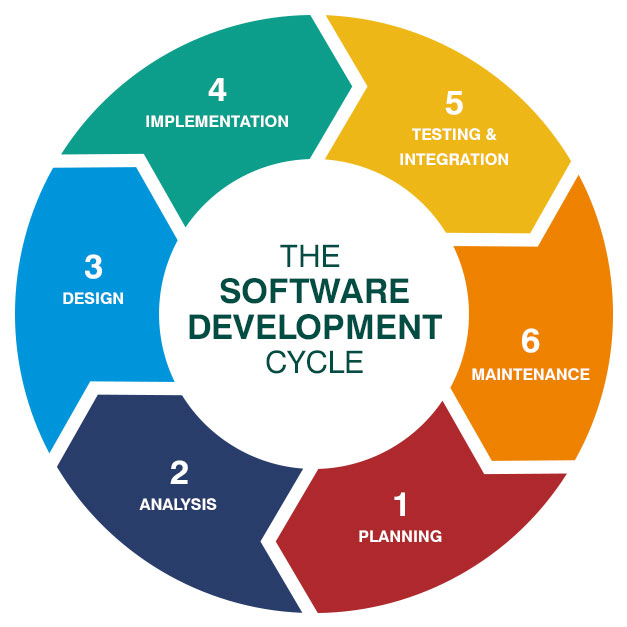
Software development life cycle (SDLC) e il “modello touchpoint”. Il Software Development Life Cycle (SDLC) è un processo strutturato per lo sviluppo di software di alta qualità. Include una serie di fasi che gli sviluppatori seguono per pianificare, progettare, costruire, testare e distribuire un software. L’SDLC fornisce una mappa per il team di sviluppo e garantisce che il prodotto finale soddisfi i requisiti e sia affidabile. Le fasi tipiche dell’SDLC sono:
- Pianificazione e analisi dei requisiti: si identificano le esigenze del cliente e si definiscono i requisiti che il software deve soddisfare. Si stabiliscono obiettivi, risorse e tempistiche.
- Progettazione: si pianifica l’architettura del software, definendo l’organizzazione del sistema, l’interfaccia utente e il flusso di dati.
- Implementazione e codifica: in questa fase si scrive il codice del software. Gli sviluppatori traducono il progetto in codice funzionante, seguendo standard e pratiche di programmazione.
- Test: si eseguono vari tipi di test (unit testing, integration testing, system testing, ecc.) per verificare che il software funzioni correttamente e soddisfi i requisiti.
- Deployment (distribuzione): una volta che il software è stato testato e considerato pronto, viene distribuito agli utenti finali.
- Manutenzione e supporto: dopo il rilascio, il software entra in una fase di manutenzione in cui si correggono bug, si ottimizza il funzionamento e si gestiscono aggiornamenti.

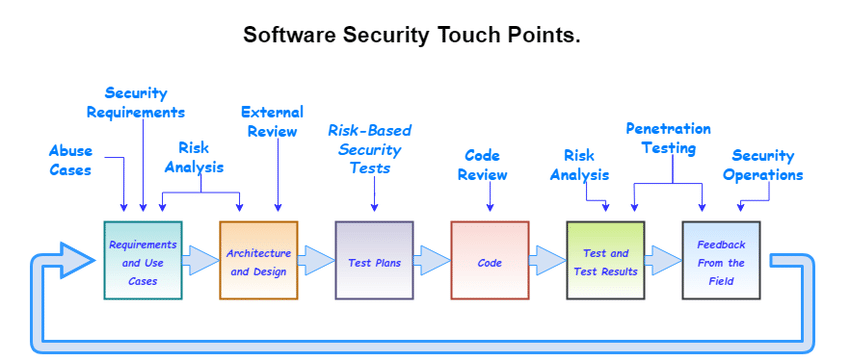
Il modello Touchpoint, sviluppato da Gary McGraw, è una metodologia per incorporare la sicurezza in ogni fase dell’SDLC. A differenza di un approccio “a cascata”, dove la sicurezza è spesso trattata come una fase separata o come un controllo finale, il modello touchpoint incoraggia la sicurezza come parte integrante di tutte le fasi dello sviluppo. I “touchpoint” sono punti strategici dell’SDLC in cui vengono applicate pratiche di sicurezza specifiche. Le principali attività di sicurezza nel modello touchpoint includono:
- Code review (revisione del codice): effettuare revisioni del codice manuali o automatiche per identificare vulnerabilità, come SQL injection o buffer overflow. Questo consente di correggere errori di sicurezza direttamente nel codice.
- Design review (revisione del progetto): rivedere l’architettura e la progettazione del software per assicurarsi che le decisioni di design non introducano vulnerabilità. Questo può includere un’analisi dei controlli di accesso, della crittografia e delle interazioni con altri sistemi.
- Testing di sicurezza: durante i test funzionali, è essenziale includere anche test di sicurezza, come penetration testing o test di fuzzing, per verificare che il software non sia vulnerabile a exploit.
- Gestione delle minacce (threat modeling): in questa fase si identificano e valutano le potenziali minacce al sistema, pianificando contromisure e strategie di mitigazione. Il threat modeling può avvenire in diverse fasi, ma è tipicamente più efficace nella fase di progettazione.
- Configurazione sicura (security configuration): assicurarsi che i componenti del software, così come i server e le reti, siano configurati in modo sicuro, riducendo al minimo le superfici di attacco.
- Incident response planning (piano di risposta agli incidenti): peparare un piano di risposta agli incidenti per gestire eventuali attacchi e violazioni. Avere questo piano in atto sin dalle prime fasi consente di ridurre l’impatto di eventuali exploit.
- Formazione sulla sicurezza per gli sviluppatori: assicurarsi che il team di sviluppo sia informato sulle migliori pratiche di sicurezza, per evitare errori comuni durante la scrittura del codice.
- Abbiamo appena rilasciato una patch che ha risolto tutti i problemi di sicurezza ed è protetta contro ogni exploit conosciuto.
Finestra di vulnerabilità, exploit zero-day. La finestra di vulnerabilità è un concetto utilizzato in sicurezza informatica per descrivere l’intervallo di tempo in cui una vulnerabilità è nota ma non ancora corretta. Durante questo periodo, i sistemi e le applicazioni che presentano la vulnerabilità sono a rischio di attacco, poiché i difetti possono essere sfruttati dagli attaccanti prima che i proprietari del sistema o i fornitori del software rilascino una patch o una correzione.
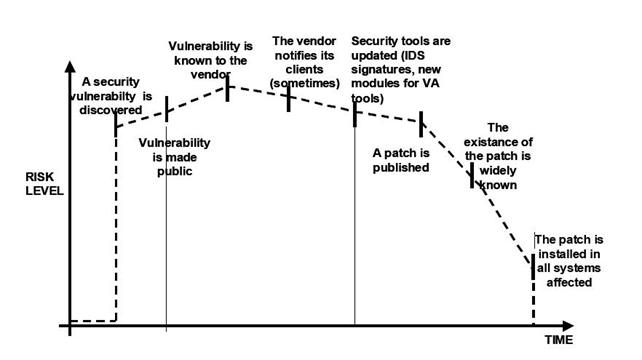
Caratteristiche della finestra di vulnerabilità
- Inizio della finestra: la finestra di vulnerabilità inizia nel momento in cui una falla di sicurezza è scoperta e viene resa pubblica o comunque conosciuta dagli attaccanti.
- Fine della finestra: la finestra termina quando viene distribuita e applicata una patch di sicurezza che corregge la vulnerabilità su tutti i sistemi interessati.
- Durata variabile: la durata della finestra di vulnerabilità può variare. In alcuni casi, i fornitori rilasciano rapidamente una patch, riducendo il tempo di esposizione. In altri casi, la correzione può richiedere più tempo, prolungando la finestra e aumentando il rischio.
Un exploit zero-day (o attacco zero-day) è una tipologia di attacco che sfrutta una vulnerabilità nel software non ancora conosciuta dai produttori o dal pubblico. In altre parole, si tratta di una vulnerabilità “a giorno zero” perché non è stata ancora scoperta o affrontata con un aggiornamento di sicurezza, lasciando il sistema completamente esposto.
Caratteristiche degli Exploit Zero-Day
- Ignoranza del fornitore: un exploit zero-day sfrutta una vulnerabilità di cui il fornitore non è ancora a conoscenza. Questo significa che non esiste alcuna patch o correzione disponibile al momento dell’attacco.
- Alta efficacia: gli exploit zero-day sono particolarmente pericolosi perché possono bypassare le misure di sicurezza esistenti, proprio perché non sono ancora stati catalogati né gestiti.
- Difficoltà di rilevamento: questi exploit sono difficili da rilevare e mitigare, poiché le soluzioni di sicurezza non hanno ancora aggiornamenti o regole specifiche per bloccare l’attacco.
Relazione tra finestra di vulnerabilità ed exploit zero-day. Quando viene scoperta una vulnerabilità zero-day, si apre immediatamente una finestra di vulnerabilità. Finché la falla non è nota pubblicamente, il rischio è limitato a un numero ristretto di attaccanti che conoscono l’exploit. Tuttavia, quando l’exploit diventa di dominio pubblico, la finestra di vulnerabilità può aumentare considerevolmente in termini di esposizione.
Mitigazione della finestra di vulnerabilità e degli exploit zero-day. Per gestire la finestra di vulnerabilità e ridurre il rischio associato agli exploit zero-day, è possibile adottare le seguenti misure:
- Patch management: implementare un sistema di gestione delle patch efficace per applicare rapidamente gli aggiornamenti di sicurezza appena disponibili.
- Threat intelligence: utilizzare fonti di threat intelligence per rimanere aggiornati sulle nuove minacce e sugli exploit zero-day che potrebbero colpire i sistemi.
- Implementazione di sicurezza multi-livello: avere sistemi di sicurezza su più livelli, come firewall, sistemi di rilevamento e prevenzione delle intrusioni (IDS/IPS) e controlli di accesso rigorosi, può ridurre l’impatto di un exploit zero-day.
- Analisi del comportamento e anomaly detection: tecniche di rilevamento basate sull’analisi del comportamento aiutano a identificare attività anomale anche se un attacco zero-day cerca di eludere i controlli di sicurezza convenzionali.
- Segmentazione della rete: segmentare la rete può limitare i danni che un attaccante può causare in caso di sfruttamento di una vulnerabilità zero-day.
La “Security by Design” e il Ciclo di Sviluppo Sicuro
È quindi necessario sviluppare software secondo i principi della “security by design”, in contrasto alla “security by obscurity”. I principi di sicurezza da incorporare includono semplicità, suddivisione dei privilegi, esposizione minima, tracciabilità e l’assenza di punti di errore singoli. A differenza del classico test di sicurezza svolto a fine sviluppo, un ciclo di vita dello sviluppo del software (SDLC) ben pianificato include la sicurezza in ogni fase, minimizzando le vulnerabilità di design.
In sintesi, la cybersecurity non è un obiettivo raggiungibile con un unico intervento. Essa richiede un approccio integrato, che combini formazione, adozione di tecniche sicure nello sviluppo e costante monitoraggio delle minacce emergenti. Una comprensione profonda delle vulnerabilità e l’implementazione di una sicurezza “by design” rappresentano i fondamenti per proteggere i sistemi in un panorama digitale in continua evoluzione.
Seven Pernicious Kingdoms
Una tassonomia creata per aiutare gli sviluppatori a comprendere gli errori di programmazione più comuni che influiscono sulla sicurezza.
Il modello del Seven Pernicious Kingdoms è un framework utilizzato per classificare le principali categorie di vulnerabilità nel codice, in particolare in ambito di sicurezza applicativa. Sviluppato dai ricercatori di Cigital (in particolare Gary McGraw), il modello è un modo per raggruppare le vulnerabilità in base alla loro natura e impatto. I “Sette Regni” rappresentano tipi distinti di difetti nel codice, che possono essere utilizzati per strutturare e migliorare la sicurezza del software.
Ecco i sette “regni” di vulnerabilità:
- Input validation and representation: si riferisce ai difetti che derivano da una gestione impropria dei dati di input o dalla rappresentazione inadeguata dei dati, portando a vulnerabilità come SQL injection, command injection e cross-site scripting (XSS).
- API abuse: riguarda l’uso improprio delle API, spesso dovuto a una mancata comprensione dei limiti o delle modalità d’uso corrette delle stesse, che può consentire exploit a livello di API.
- Security features: include difetti legati all’implementazione errata delle caratteristiche di sicurezza, come l’autenticazione, la gestione delle sessioni, e il controllo degli accessi. Difetti in questo “regno” possono portare a problemi come session hijacking o bypass delle restrizioni di accesso.
- Time and state: questo “regno” riguarda vulnerabilità legate alla gestione del tempo e degli stati. Problemi come race conditions (condizioni di corsa) o gestione inadeguata delle risorse possono far sì che un utente malintenzionato prenda il controllo di una risorsa o esegua azioni dannose.
- Errors: si riferisce alla gestione errata degli errori, come la visualizzazione di messaggi d’errore dettagliati che rivelano informazioni sensibili o la mancanza di controllo su errori imprevisti, che possono facilitare l’enumerazione o l’accesso a dettagli interni.
- Code quality: questo “regno” comprende le vulnerabilità derivanti da una scarsa qualità del codice, come buffer overflow, pointer dereferencing e altri errori che possono portare a comportamenti imprevisti o a falle di sicurezza.
- Encapsulation: si riferisce a difetti nella separazione dei dati e nella gestione dell’accesso. Problemi di incapsulamento possono portare a fughe di informazioni o all’alterazione di dati interni che dovrebbero essere inaccessibili all’utente.
(torna su)