La digital forensics è una branca della Criminalistica caratterizzata dall’adozione di metodi scientificamente derivati finalizzati all’identificazione, acquisizione e/o repertamento, preservazione, validazione, verifica, analisi, l’interpretazione, documentazione e presentazione del contenuto informativo di sistemi informatici o telematici, al fine di evidenziare l’esistenza di fonti di prova digitali resistenti ad eventuali contestazioni circa la propria attendibilità e capacità probatoria sia in ambito civile che penale.
Corte di Cassazione (Sez. VI n. 3067 del 14.12.1999; Sez. V n. 31135 del 6.7.2007)
«… deve ritenersi “sistema informatico”, … , un complesso di apparecchiature destinate a compiere una qualsiasi funzione utile all’uomo, attraverso l’utilizzazione (anche parziale) di tecnologie informatiche, che sono caratterizzate – per mezzo di un’attività di “codificazione” e “decodificazione” – dalla “registrazione” o “memorizzazione”, per mezzo di impulsi elettronici, su supporti adeguati, di “dati”, cioè di rappresentazioni elementari di un fatto, effettuata attraverso simboli (bit), in combinazione diverse, e dalla elaborazione automatica di tali dati, in modo da generare “informazioni”, costituite da un insieme più o meno vasto di dati organizzati secondo una logica che consenta loro di esprimere un particolare significato per l’utente …».
«… è “sistema telematico” l’insieme di più sistemi informatici collegati tra loro per lo scambio di informazioni, purché siano connessi in modo permanente, e purché lo scambio di informazioni sia il mezzo necessario per conseguire i fini operativi del sistema. …»
Digital Investigation: si attua prima (attività preventiva volta all’acquisizione di elementi indiziari), durante il fatto reato (possono richiedere garanzie difensive);
Digital Forensics: si attua dopo il fatto reato, ossia il dispositivo scientifico arriva sempre a fatto compiuto (c.d. post-mortem) e concentra la sua azione su un specifico evento al fine di determinarne le cause. Essa può essere a sua volta in modalità:
Live: il sistema informatico non si può spegnere, quindi si è costretti ad operare sulla scena del crimine;
Dead o Static: il sistema informatico è spento, quindi cristallizzato e si può operare in laboratorio.
Ruoli e responsabilità
DEFR (Digital Evidence First Responder) ISO 27037:2012 Pt. 3.7
Definito a volte come Addetto ai Rilievi Tecnici, questi viene coinvolto nelle fasi di identificazione, repertamento e/o acquisizione e preservazione della fonte di prova digitale. Tale figura professionale non dovrebbe necessariamente svolgere un’attività di analisi.
DES (Digital Evidence Specialist) ISO 27037:2012 Pt. 3.8
Definito a volte come “Analista”, questi fornisce supporto tecnico al DEFR nelle fasi di identificazione, repertamento e/o acquisizione e preservazione delle fonti di prova digitale. Il DES deve essere caratterizzato da una formazione di tipo accademico e di comprovata esperienza nel settore tecnico-investigativo.
Il dato è la rappresentazione oggettiva di un fatto o evento che consenta la sua trasmissione oppure interpretazione da parte di un soggetto umano o di uno strumento informatico.
L’informazione è l’interpretazione e il significato assegnato a uno o più dati.
Le fasi
Identificazione (ISO 27037:2012 pt. 3.12): ricerca, riconoscimento e documentazione della fonte di prova digitale e rispettiva pertinenza (priorizzare le attività sulla base dell’ordine di volatilità dei dati, mitigare l’impatto sia sul sistema che sulle fonti di prova digitali).
Acquisizione (ISO 27037:2012 pt. 3.1): duplicazione del contenuto informativo della fonte di prova digitale. Consiste nell’adozione di misure tecniche, il più possibile riproducibili e/o verificabili, dirette alla duplicazione del contenuto informativo, o parte di esso, di sistemi informatici e/o telematici su adeguati supporti, tale che assicuri la conformità della copia all’originale.
Con il termine “duplicato informatico” (art. 1 lett. i-quinquies D. Lgs. 7 marzo 2005, n. 82 – C.A.D.) s’intende l’operazione di memorizzazione, su dispositivi diversi, della medesima sequenza di valori binari del dato informatico originario.
Affinché il dato non sia condizionato dal nuovo ambiente di lavoro, vi è la necessità che questi venga memorizzato all’interno di un c.d. “forensic container”, creando così un vero e proprio “reperto virtuale”.
Repertamento (ISO 27037:2012 pt. 3.3.): attività volta ad assicurare la fonte di prova digitale e la rispettiva pertinenza, consiste nella rimozione della fonte di prova digitale e sue pertinenze dall’ambiente originario ad uno controllato (es. un laboratorio) per la successiva acquisizione ed analisi. Non sempre è possibile repertare.
Preservazione (ISO 27037:2012 p.t. 3.15): attività volta a garantire l’integrità e/o le condizioni originali della fonte di prova digitale mediante misure tecniche dirette ad: assicurare la conservazione e l’immodificabilità (conservazione dello stato dei luoghi) e impedire l’alterazione (dolo) e l’accesso incontrollato (colpa).
Validazione (ISO 27037:2012 pt. 3.24): attività di valutazione del rapporto di “pertinenzialità” tra gli elementi assicurati ed il contesto investigativo (ISO / IEC 27004: 2016).
Verifica (ISO 27041:2015 pt. 3.20): si accerta che la fonte di prova digitale ha conservato la sua integrità (ISO / IEC 27004: 2016).
Analisi (ISO 27042:2015 pt. 3.1 and ISO 27043:2015 pt. 3.3): il processo di valutazione oggettiva delle fonte di prova digitali a finché queste possano confermare, o confutare, un tesi accusatoria.
Interpretazione (ISO 27042:2015 pt. 3.9): è il processo in cui si contestualizzano le risultanze oggettive derivate dall‘attività di analisi e le si proietta in più ampio quadro accusatorio (es. Correlazione tra risultanze di più dispositivi informatici analizzati e dati forniti da terze parti).
Documentazione (es. artt. 136, 137 e 357 c.p.p.): insieme di atti e documenti in genere volti a storicizzare le attività svolte
Presentazione (es. artt. 196-198 c.p.p.): è l’esposizione, generalmente orale, delle risultanze tecnico-investigative in ambito processuale
La Catena di Custodia (CoC – ISO 27037:2012 pt. 6.1) è un documento o una serie di questi che attesta, in un dato arco temporale, la responsabilità di un soggetto nella gestione di uno o più reperti. Essa ha inizio con l’esercizio dell’attività assicurativa e si conclude con la confisca e distruzione, ovvero la restituzione all’avente diritto del reperto.
Principi (ISO 27037):
Gli attori che intervengono sulla scena del crimine informatico, dovranno garantire i seguenti principi comuni alla maggior parte dei sistemi giurisdizionali internazionali:
Rilevanza/Pertinenza (Relevance): secondo cui bisogna dimostrare di aver acquisito e/o repertato solo elementi di pertinenza con il contesto d’indagine, avendo cura di motivarne le ragioni.
Affidabilità/Attendibilità (Reliability): secondo cui ogni processo che caratterizza la scena del crimine informatico dovrebbe essere verificabile e ripetibile. L’attuazione di tali processi dovrebbe garantire l’intera riproducibilità dell’attività tecnico-investigativa.
Sufficienza/Proporzionalità (Sufficiency): in cui il DEFR si assicura di avere a disposizione sufficiente materiale su cui svolgere le indagini.
I requisiti:
Verificabilità (Auditability): secondo cui dovrebbe essere possibile per una parte terza, indipendente alla componente di Polizia Giudiziaria ed autorizzata dall’A.G. (es. il Consulente Tecnico), poter accertare tutte le attività poste in essere sia dal DEFR che dal DES sulla scena del crimine informatico.
Ripetibilità (Repeatability): secondo cui si producono gli stessi risultati con lo stesso test nello stesso ambiente.
Riproducibilità (Riproducibility): secondo cui si producono gli stessi risultati al variare sia dell’ambiente che degli strumenti.
Giustificabilità (Justifiability): secondo cui il DEFR dovrebbe essere in grado di poter giustificare la metodologia attuata per quel particolare contesto investigativo caratterizzato da vincoli giuridici, tecnologici e logistici, oltreché di competenze tecniche dello stesso operatore.
Hashing
Nel linguaggio scientifico, l’hash (ISO/IEC 10118-3:2018) è una funzione «one way», ossia che non può essere invertita, atta alla trasformazione di un testo di lunghezza arbitraria in una stringa di lunghezza fissa, relativamente limitata.
Tale stringa rappresenta una sorta di «impronta digitale» (o «sigillo elettronico») del contenuto di un file, e viene comunemente denominata come:
codice di hash;
checksum crittografico;
message digest.
Il codice hash, riportato nel report del Forensic Container, fa riferimento al contenuto informativo del dispositivo acquisito e non al container stesso.
Tipi di acquisizione
Acquisizione manuale: consiste nella documentazione realizzata mediante rilievi descrittivi e tecnici (foto e video)
Acquisizione logica: consente di estrarre dati allocati e che sono accessibili tipicamente tramite:
API del sistema operativo (c.d. logica semplice);
File system (c.d. logica avanzata).
Sono da considerarsi dati allocati tutti quelli non cancellati ed accessibili tramite file system.
Un’eccezione a questa definizione è che alcuni file, come ad esempio un database SQLite, possono essere assegnate e ancora contengono record eliminati nel database.
Siamo in grado di eseguire due tipi di acquisizione logica:
semplice, che viene effettuata per mezzo di una acquisizione selettiva sui dati specifici dell’area utente (ad esempio contatti, agenda, registri chiamate e così via). Il risultato di questo tipo di acquisizione è simile a sistemi di backup (ad esempio iTunes, Kies, …) che usano le API specifiche e non ha bisogno di privilegi amministrativi;
avanzata (o del file system), che necessita il più delle volte di privilegi amministrativi, in quanto consente di estendere il suo raggio di azione non soltanto ad ristretto numero di file, ma ad una o più partizioni di un volume.
Acquisizione fisica: un’acquisizione c.d. «fisica» fornisce l’accesso integrale al contenuto informativo del supporto di memorizzazione, consentendo così di recuperare anche i dati non più allocati (cancellati o obsoleti) e ottenere un dump esadecimale.
Tali tecniche possono essere attuate tramite soluzioni:
software, i quali vengono eseguiti con privilegi amministrativi al fine di ottenere un’estrazione integrale dei dati presenti nella memoria di massa;
hardware, che consistono in un collegamento o estrazione fisica della memoria di massa.
La vera difficoltà di questa tipologia di acquisizione consiste nel riuscire a decodificare, e quindi ricostruire, i dati acquisiti.
In ambito di accertamenti tecnici può accadere che quella che è considerata un’attività ripetibile, spesso non lo è in termini giuridici
La disciplina normativa sugli atti non ripetibili (art. 360 c.p.p. ed art. 117 disp. att. c.p.p.) tende a:
evitare che le prove “urgenti” vengano disperse;
garantire il rispetto del principio del contraddittorio (art. 111 Cost.);
Presupposti:
indifferibilità = ora o mai più (art. 354 c.p.p.) “se non lo fai subito non lo puoi più fare”, cioè l’inerzia la prova andrebbe comunque dispersa;
non reiterabilità = ora e mai più (art. 360 c.p.p.) “se lo fai non lo puoi più fare”, cioè l’attività che si compie comporta, necessariamente o con un’elevata probabilità, l’alterazione o la distruzione della fonte di prova.
Riseup Pad (accessibile su pad.riseup.net) è un servizio di editing collaborativo in tempo reale basato sul software open source Etherpad. Consente a più utenti di creare e modificare simultaneamente documenti condivisi (“pad”) tramite un semplice link, senza necessità di registrazione. L’accesso al pad avviene esclusivamente tramite connessione HTTPS cifrata (TLS), garantendo che il traffico sia protetto durante la trasmissione. Inoltre, per maggiore sicurezza e anonimato, Riseup consiglia di utilizzare la propria VPN o la rete Tor quando si accede al servizio: è disponibile un indirizzo .onion dedicato per usare i pad attraverso Tor.
Quanto alla gestione dei contenuti inseriti dagli utenti, i pad esistono per un periodo limitato: i documenti vengono eliminati automaticamente dopo 60 giorni di inattività. In fase di creazione, è possibile scegliere una durata di vita del pad (ad esempio 1 giorno, 60 giorni o 1 anno) trascorsa la quale il contenuto viene cancellato dal server. Questa politica assicura che i testi condivisi non rimangano conservati indefinitamente. Riseup inoltre non richiede informazioni personali per utilizzare il pad (basta scegliere un nome univoco per il pad) e non associa i contenuti ad account utente, favorendo un utilizzo anonimo. Non risultano meccanismi di indicizzazione pubblica dei pad: l’URL segreto funge da unica chiave di accesso, nota solo ai partecipanti. In linea con i principi generali di Riseup, il contenuto delle comunicazioni non viene attivamente monitorato o analizzato dallo staff (analogamente a come Riseup dichiara di non leggere né controllare le email degli utenti, se non per filtri anti-spam/virus o su richiesta di supporto tecnico).
Dati raccolti: IP, cookie e log
Una caratteristica fondamentale di Riseup Pad è la minimizzazione dei dati raccolti sugli utenti. In particolare, non vengono registrati gli indirizzi IP di chi accede al pad. Questa pratica fa parte di una policy più ampia di Riseup: nessun servizio Riseup conserva indirizzi IP degli utenti, riducendo drasticamente la possibilità di tracciare l’identità o la posizione di chi utilizza i suoi strumenti.
Per quanto riguarda i cookie e identificatori di sessione, Riseup non utilizza cookie di terze parti né tracking esterno di alcun tipo. Sul browser dell’utente può essere impostato solo un identificatore di sessione temporaneo (ad esempio, quando si effettua il login ad altri servizi Riseup), ma nel contesto di pad.riseup.net – che non richiede autenticazione – l’uso di cookie è limitato al minimo necessario per la funzionalità del pad. In ogni caso, i cookie di sessione eventualmente usati non contengono dati personali e vengono eliminati alla fine della sessione.
Anche i file di log vengono gestiti con una filosofia di forte minimizzazione. Riseup afferma di non mantenere log dettagliati delle attività degli utenti, a differenza di molti provider commerciali. In generale non vengono conservate informazioni che possano identificare in modo univoco un utente o tracciarne le attività. Ad esempio, Riseup non registra nei log gli IP di connessione e non conserva impronte digitali del browser (browser fingerprint) degli utenti. Eventuali log tecnici aggiuntivi possono essere attivati temporaneamente solo per risolvere problemi (ad es. debug o troubleshooting) e vengono eliminati immediatamente dopo l’uso. L’unica forma di logging continuo menzionata nella privacy policy riguarda i server email di Riseup: per mitigare abusi di spam, i server conservano temporaneamente i metadati di routing (indirizzi mittente/destinatario) delle email, ma tali log di transito vengono cancellati ogni giorno. In sintesi, per il servizio Etherpad non risultano log applicativi persistenti a lungo termine: l’attività sui pad non è registrata in database di lungo periodo, ad eccezione della memorizzazione necessaria a tenere disponibile il contenuto del pad fino alla sua scadenza.
Politica sulla privacy di Riseup
Riseup pubblica una Privacy Policy ufficiale che si applica a tutti i servizi offerti, incluso pad.riseup.net. Tale politica enfatizza la tutela della riservatezza degli utenti e la filosofia del “data minimization”. In sintesi, Riseup raccoglie il minor numero possibile di informazioni personali sugli utenti, utilizzandole solo per fornire il servizio e mai per condividerle o monetizzarle. Viene dichiarato esplicitamente che nessuno dei dati raccolti viene venduto o condiviso con terze parti; perfino all’interno del collettivo Riseup, l’accesso a informazioni sensibili è limitato ai soli membri che ne hanno stretta necessità operativa.
Un aspetto peculiare della policy di Riseup è l’invito agli utenti a non lasciare informazioni personali sul servizio più del necessario. Ad esempio, quando un utente crea un account email Riseup (operazione che richiede di fornire qualche dato di contatto), può successivamente eliminare quei dati dal proprio profilo, e Riseup incoraggia a farlo, sottolineando che meno dati possiedono, meno dati potranno essere richiesti da terzi. Questa filosofia – “se non abbiamo i tuoi dati, non potremo essere costretti a consegnarli” – mostra l’impegno di Riseup nel limitare a monte la raccolta e conservazione di informazioni potenzialmente sensibili.
La Privacy Policy conferma inoltre altre misure di sicurezza e riservatezza importanti: tutti i dati utente memorizzati sui server Riseup vengono conservati in forma crittografata. In particolare, il contenuto delle comunicazioni (ad esempio le email salvate sul server), la rubrica contatti e i backup sono cifrati; dal 2017, le caselle di posta dei nuovi account Riseup sono cifrate end-to-end con una chiave unica per ogni utente, il che significa che nemmeno Riseup è in grado di leggere il contenuto archiviato per quegli account senza il consenso dell’utente. Questa attenzione alla crittografia potrebbe estendersi anche ad altri servizi: sebbene il contenuto dei pad Etherpad non sia legato ad un account specifico, è ragionevole assumere che i server di Riseup utilizzino dischi o database cifrati, aggiungendo un ulteriore livello di protezione ai dati temporaneamente archiviati.
Infine, Riseup ribadisce che non monitora l’attività né il contenuto delle comunicazioni degli utenti nelle sue piattaforme. Ad eccezione di controlli automatici per virus e spam sulle email in entrata/uscita, lo staff non esamina né analizza il contenuto dei messaggi o dei documenti degli utenti, a meno che non sia l’utente stesso a richiederlo per assistenza tecnica. Questo approccio vale presumibilmente anche per i pad: il collettivo non interviene né sorveglia i testi scritti nei pad, rispettando la privacy e l’anonimato dei collaboratori.
Conservazione dei dati (data retention)
La data retention presso Riseup è ridotta al minimo indispensabile per erogare il servizio. Nel caso specifico di pad.riseup.net, come già evidenziato, il contenuto dei pad viene conservato solo temporaneamente, per la durata di vita del pad stesso. Trascorso il periodo di inattività definito (massimo 60 giorni senza modifiche, se non specificato diversamente), il pad viene definitivamente eliminato dal server. Ciò implica che Riseup non mantiene archivi storici dei documenti condivisi tramite Etherpad oltre la finestra temporale di utilizzo prevista.
Anche per gli altri servizi, la politica è di non mantenere dati oltre il necessario. La privacy policy indica ad esempio che le informazioni fornite per la registrazione di un account vengono in parte rimosse dopo alcuni mesi (richieste di account eliminate dopo 4 mesi, eventuali codici di invito dopo 1 mese). Analogamente, i log delle email (limitati ai soli indirizzi mittente/destinatario per fini anti-spam) vengono cancellati quotidianamente e non vengono conservati registri di accesso comprensivi di IP o timestamp precisi degli accessi utente. Riseup conserva solo informazioni aggregate o di basso dettaglio necessarie a far funzionare i servizi o a scopi di sicurezza (ad esempio, l’ultimo trimestre dell’ultimo accesso effettuato a un account email, per poter individuare ed eliminare account dormienti), ma non l’ora o il giorno esatto dell’accesso. Tutto questo si traduce in una assenza di archivi a lungo termine sui comportamenti individuali: non esistono log che possano rivelare quali pad sono stati creati da quale IP, o chi abbia scritto cosa e quando, oltre il breve periodo di attività del pad stesso.
In sostanza, la conservazione dei dati da parte di Riseup è impostata su periodi molto brevi e con forte attenzione alla privacy. Laddove possibile, i dati vengono automaticamente cancellati dopo un certo lasso di tempo, e molti dati non vengono proprio raccolti all’origine, eliminando così il problema della conservazione.
Rapporti con autorità di polizia e governi
Riseup adotta una posizione estremamente ferma riguardo a richieste di dati da parte di autorità governative o forze dell’ordine. In base alle dichiarazioni ufficiali del collettivo, Riseup non collabora attivamente con nessuna agenzia governativa nella sorveglianza degli utenti: “We would rather stop being Riseup before we did that”, affermano, ossia preferirebbero chiudere l’attività piuttosto che collaborare con operazioni di sorveglianza di massa. Storicamente, dichiarano di non aver mai acconsentito a consegnare informazioni sugli utenti su semplice richiesta e di aver anzi contestato in sede legale ogni tentativo di ottenere dati, vincendo ogni volta queste sfide. Grazie alla loro politica di “no log”, anche in caso di una richiesta da parte dell’A.G., le informazioni identificative disponibili sarebbero molto limitate (non essendoci log di IP, cronologie di accesso o contenuti non cifrati da fornire).
Va sottolineato che i server di Riseup, pur essendo fisicamente collocati (in gran parte) negli Stati Uniti, sono gestiti direttamente dal collettivo e non in hosting cloud di terze parti. Ciò significa che Riseup mantiene il controllo fisico e amministrativo completo delle macchine, riducendo il rischio di accessi non autorizzati o imposizione di backdoor a sua insaputa. Inoltre, la situazione giuridica negli USA – per paradosso – ha aiutato Riseup a proteggere meglio i dati: diversamente da vari Paesi europei, negli Stati Uniti non esistono leggi di data retention che obblighino i provider a conservare i log delle attività degli utenti. Riseup evidenzia che questa assenza di obblighi legali, unita alla propria scelta etica, ha permesso di attuare da anni una rigorosa politica di non conservazione dei log. In sintesi, Riseup non fornisce volontariamente dati alle autorità e oppone resistenza formale a decreti o richieste, entro i limiti consentiti: la sua filosofia è privilegiare la privacy degli attivisti e utenti, anche a costo di cessare il servizio piuttosto che tradirne la fiducia.
Naturalmente, Riseup è comunque soggetta alle leggi vigenti: in caso di ordine legalmente vincolante i membri del collettivo dovrebbero valutarne il rispetto. Tuttavia, la trasparenza fornita agli utenti suggerisce che finora non si sia mai verificato un caso di consegna forzata di dati: nessun dato utente è mai stato consegnato a terzi o a autorità nei più di vent’anni di attività. Questo impegno è rafforzato da un’iniziativa significativa: la pubblicazione di un Warrant Canary.
Misure per la protezione dell’anonimato e contro la sorveglianza
Riseup adotta diverse misure concrete per tutelare l’anonimato degli utenti e contrastare la sorveglianza. Riassumendo le principali:
niente log identificativi: come visto, Riseup non registra indirizzi IP né altri dati che possano identificare gli utilizzatori dei suoi servizi. Ciò significa che, anche in caso di monitoraggio esterno, risulta più difficile collegare le azioni su pad.riseup.net a una persona o indirizzo specifico. Inoltre, l’assenza di log persistenti implica che non esiste uno “storico” delle attività utente che possa essere analizzato a posteriori per fini di sorveglianza;
accesso anonimo e cifrato: il servizio pad non richiede alcuna registrazione né inserimento di dati personali, permettendo un utilizzo anonimo di fatto. Tutte le connessioni avvengono su HTTPS obbligatorio, prevenendo intercettazioni del traffico in chiaro. Per chi desidera massimizzare la privacy, Riseup offre un endpoint sulla rete Tor (un servizio .onion), grazie al quale è possibile usare i pad in modo anonimizzato tramite Tor – nascondendo sia l’identità dell’utente sia il contenuto del traffico a potenziali sorveglianti di rete. L’organizzazione gestisce anche una propria VPN gratuita, che può essere usata per cifrare tutto il traffico internet dell’utente (incluso l’accesso ai pad) aggiungendo un ulteriore livello di protezione della provenienza della connessione;
crittografia dei dati archiviati: tutti i dati conservati sui sistemi Riseup sono memorizzati in forma crittografata. Questo significa che, anche nell’eventualità di un accesso fisico ai server o di un sequestro degli stessi, i contenuti salvati (email, file, e verosimilmente anche i dati temporanei dei pad) non sono leggibili senza le chiavi in possesso di Riseup. Per i servizi con account utente, è implementata anche la crittografia lato server per singolo account (personal storage encryption), che impedisce persino agli amministratori di Riseup di accedere ai dati sensibili memorizzati senza autorizzazione;
policy di eliminazione dei dati: la filosofia di cancellare presto ciò che non serve (pads inattivi eliminati dopo 60 giorni, log email eliminati giornalmente, ecc.) riduce la quantità di informazioni disponibili in qualsiasi momento su cui un’attività di sorveglianza potrebbe mettere le mani. In altri termini, ciò che non viene conservato non può essere analizzato. Questa è considerata una buona pratica per la privacy, seguita anche da altri collettivi affini;
resistenza attiva alla sorveglianza: Riseup dichiara espressamente che difenderà i dati degli utenti. Nella sua Privacy Policy si impegna a opporsi con tutti i mezzi legali a qualsiasi tentativo di obbligare l’azienda a divulgare informazioni o log degli utenti. Questa postura si è tradotta in azioni concrete: come menzionato, quando Riseup ha ricevuto richieste di dati in passato, ha reagito sfidandole in tribunale (riuscendo a evitare la divulgazione). Inoltre, Riseup ha affermato di non aver mai installato backdoor, strumenti di monitoraggio o accessi segreti a beneficio di forze dell’ordine sui propri sistemi. I server non sono mai stati compromessi o requisiti e tutti i componenti dell’infrastruttura rimangono sotto il controllo diretto del collettivo;
warrant canary: come ulteriore misura di trasparenza anti-sorveglianza, Riseup pubblica periodicamente un Canary Statement firmato digitalmente (PGP). In questo documento, aggiornato ogni pochi mesi, Riseup conferma che non vi sono state compromissioni della sicurezza o interferenze governative segrete. In particolare, il canary attesta che Riseup non è stata costretta a modificare i propri sistemi per consentire accessi o fughe di dati a terzi e che non ha divulgato chiavi crittografiche o informazioni sensibili sotto coercizione. Qualora Riseup ricevesse un cosiddetto gag order (un ordine con divieto di divulgazione) o altre ingiunzioni segrete, l’assenza di aggiornamenti del canary servirebbe da segnale implicito alla comunità che qualcosa non va. Nelle FAQ del canary, Riseup ribadisce che “law enforcement has not taken our servers; [it] does not, and has never had access to them”, aggiungendo ancora una volta che preferirebbe cessare di esistere piuttosto che permettere installazioni di monitoraggi forzati. Questa strategia del canary dimostra l’impegno proattivo di Riseup nell’ informare gli utenti e nel resistere alla sorveglianza statale, anche in scenari estremi.
Conclusione
Quanto in questo articolo si basa sulla documentazione e le policy pubblicate da Riseup – inclusa la pagina informativa di Riseup Pad[1], la Privacy Policy ufficiale[2] e le FAQ/dichiarazioni di Riseup riguardo ai rapporti con i governi e la sicurezza (come il loro warrant canary e comunicati correlati)[3][4]. Queste fonti confermano l’attenzione di Riseup alla privacy, l’assenza di raccolta di dati sensibili, la cancellazione a breve termine dei dati dei pad, e la volontà di opporsi strenuamente a qualunque forma di sorveglianza o richiesta coercitiva di dati.
In conclusione, pad.riseup.net appare progettato e gestito per offrire uno strumento di collaborazione il più anonimo e sicuro possibile, in linea con la missione di Riseup di proteggere le comunicazioni e la privacy degli utenti.
Standard internazionali e processi di Incident Response (NIST SP 800-61, ISO/IEC 27035)
Una gestione efficace degli incidenti informatici richiede processi strutturati e aderenza a standard internazionali riconosciuti. Il NIST SP 800-61 (Computer Security Incident Handling Guide) definisce un processo ciclico per l’Incident Response, articolato in quattro fasi fondamentali: Preparazione, Rilevamento e Analisi, Contenimento, Eradicazione e Ripristino, e Attività Post-Incidente. La fase di Preparazione consiste nel predisporre politiche, procedure e risorse (come un team CSIRT formato, strumenti di monitoraggio, playbook) per poter gestire efficacemente eventuali incidenti. Segue la fase di Rilevamento e Analisi, in cui si monitorano gli eventi di sicurezza, identificando possibili segnali d’incidente e raccogliendo evidenze; qui il team valuta i sintomi per determinare se si tratti effettivamente di un incidente e ne classifica la gravità. Durante la fase di Contenimento,Eradicazione e Ripristino si mettono in atto misure per limitare i danni (ad esempio isolando sistemi compromessi), eliminare la minaccia (rimuovendo malware, chiudendo vulnerabilità) e ripristinare operatività e dati colpiti (ad es. da backup puliti). Infine, la fase di Post-Incidente prevede attività di lesson learned: analisi retrospettiva dell’incidente e della risposta fornita, al fine di estrarre insegnamenti, migliorare procedure interne e prevenire il ripetersi di attacchi analoghi. Questo ciclo ricalca l’approccio di miglioramento continuo (ciclo di Deming Plan-Do-Check-Act) tipico anche degli standard ISO di gestione, evidenziando come l’Incident Response sia un processo iterativo in cui l’esperienza di ogni incidente rafforza la preparazione per il futuro.
In parallelo al NIST, lo standard internazionale ISO/IEC 27035 offre linee guida complete per l’Information Security Incident Management. Esso enfatizza l’importanza di una preparazione proattiva, di strategie di risposta chiare e di piani di recupero strutturati allineati alle politiche di sicurezza organizzative. La serie ISO 27035 (aggiornata nel 2023 in più parti) copre l’intero ciclo di gestione: dalla pianificazione e preparazione (ISO 27035-2 fornisce dettagli su come prepararsi, rilevare e segnalare gli incidenti) fino alle attività di risposta, mitigazione e miglioramento continuo. In sostanza, ISO 27035 integra e approfondisce i controlli di Incident Response già accennati in ISO/IEC 27001/27002, fornendo un framework operativo che assicura che le organizzazioni siano pronte a identificare, gestire e recuperare efficacemente da un incidente di sicurezza. Aderire a standard come NIST SP 800-61 e ISO 27035 aiuta le organizzazioni a definire ruoli e responsabilità (ad esempio l’istituzione di un CSIRT/SOC interno), instaurare procedure di escalation e comunicazione (verso il top management e verso enti esterni), e garantire la conformità a normative di settore. Questi standard rappresentano dunque un riferimento imprescindibile per un reaponsabile per la prevenzione e gestione di incidenti in contesti critici, fornendo sia un linguaggio comune sia best practice riconosciute a livello internazionale.
Indicatori di compromissione e firme di attacco (IoC, YARA, SIGMA, Snort)
Un aspetto centrale nell’identificazione e risposta agli incidenti informatici è l’utilizzo degli Indicatori di Compromissione (IoC) e delle signature di attacco. Gli IoC sono evidenze osservabili che suggeriscono con buona probabilità che si sia verificata una compromissione; esempi tipici includono hash di file maligni, indirizzi IP o domini di command and contro!, chiavi di registro anomale, stringhe univoche di malware, ecc. Riconoscere tempestivamente questi indicatori permette ai team di sicurezza di individuare attacchi in corso o passati e di attivare misure di contenimento prima che il danno si propaghi. A tal fine, la comunità di cybersecurity ha sviluppato vari formati standardizzati per esprimere e condividere IoC e regole di rilevamento, tra cui spiccano YARA, SIGMA e Snort.
YARA (acronimo ricorsivo di “YARA is Another Recursive Acronym”) è uno strumento pensato per aiutare i ricercatori e analisti malware nell’identificazione di file malevoli attraverso pattern noti. Le regole YARA sono scritte in un linguaggio dedicato che consente di definire firme basate su pattern di byte,stringhe testuali o espressioni regolari presenti in un file. In pratica, una regola YARA descrive caratteristiche distintive di una famiglia di malware (ad esempio stringhe uniche nel codice, impronte binarie, sequenze in memoria), così che scansionando file o processi in un sistema si possano “far scattare” allarmi quando vi è match con le firme definite. YARA viene ampiamente usato nei CERT/SOC per analizzare campioni sospetti: ad esempio, dopo un incidente si possono ricavare regole YARA dai file malware individuati e distribuirle per verificare se altri sistemi siano stati infetti dallo stesso attacco. Questo strumento ha trovato impiego in numerosi casi operativi anche in Italia, dove CERT-AgID e CSIRT Italia hanno pubblicato regole YARA per identificare vari malware osservati nelle campagne malevole rivolte alla Pubblica Amministrazione.
Mentre YARA si focalizza su pattern statici in file e payload malevoli, SIGMA affronta il problema della detection in modo diverso, operando a livello di !og e eventi. SIGMA è infatti un formato di regole generico e indipendente dal fornitore, pensato per descrivere pattern sospetti nei log in un linguaggio unificato (sintassi YAML) che poi può essere tradotto nelle query specifiche di diversi sistemi SIEM. L’obiettivo di SIGMA è fornire una “lingua franca” per le regole di correlazione, in modo da condividere facilmente tra organizzazioni schemi di rilevamento per attacchi noti. Ad esempio, una regola SIGMA può definire la ricerca di eventi di autenticazione anomali (come molti tentativi falliti seguiti da un accesso riuscito – sintomo di brute forcing) o l’uso sospetto di comandi di PowerShell in una macchina Windows. Tali regole, una volta scritte in SIGMA, vengono poi convertite con appositi tool (es. sigmac) nei linguaggi di query di prodotti come Splunk, Elastic, QRadar, ecc., permettendo a qualsiasi SOC di implementare rapidamente controlli anche senza doverli riscrivere da zero per la propria piattaforma. L’uso di SIGMA sta favorendo la condivisione di conoscenza sulle minacce: community internazionali e anche il CERT-AgID pubblicano di frequente regole SIGMA per rilevare gli IoC di campagne attive, consentendo ai difensori di reagire in modo uniforme.
Un altro pilastro del rilevamento basato su firme è rappresentato da Snort, uno dei più diffusi motori IDS/IPS open-source a livello di rete. Snort utilizza un linguaggio di regole proprietario ma abbastanza leggibile, con cui si possono descrivere pattern di traffico malevolo o anomalo. Una regola Snort è tipicamente composta da un header (che specifica l’azione da intraprendere – ad es. a!ert vs drop –, il protocollo, IP/porta sorgente e destinazione) e da un blocco di opzioni che definiscono la condizione di matching (es. contenuto di pacchetto, sequenze di byte, flag TCP, stringhe nel payload, espressioni regolari). Grazie a questo meccanismo, Snort può effettuare analisi in tempo reale del traffico direte, confrontando ogni pacchetto con la libreria di firme: al rilevamento di una corrispondenza, può generare allarmi o bloccare il traffico se usato in modalità IPS. La forza di Snort risiede nella grande comunità che sviluppa e aggiorna continuamente regole per nuove minacce (es. per individuare exploit noti, pattern di comunicazione di botnet, tentativi di SQL injection, scansioni di porte, ecc.). In un SOC aziendale o in un CSIRT nazionale, Snort (o il suo successore Suricata) è uno strumento chiave per la rilevazione degli attacchi sulla rete, complementare alle analisi host-based come quelle guidate da YARA e alle correlazioni su log abilitate da SIGMA.
Questi strumenti e formati evidenziano l’importanza degli IoC nella cyber difesa moderna. La capacità di generare, condividere e utilizzare efficacemente IoC e signature consente ai team di Incident Response di rilevare attacchi noti in modo rapido e di contenerli prima che producano danni gravi. In contesti governativi come quello italiano, ad esempio, il CERT-AgID mantiene un feed IoC pubblico e collabora con il CSIRT Italia per diffondere indicatori relativi a campagne malevole correnti, permettendo alle varie amministrazioni di aggiornare i propri sistemi di detection. Il valore di questa condivisione è tangibile: nel solo 2024, il CERT-AgID ha individuato ben 1.767 campagne malevole indirizzate alle PA e condiviso 19.939 indicatori di compromissione con la comunità, segno di un’intensa attività di threat intelligence a supporto della difesa collettiva. In definitiva, IoC e firme (YARA, SIGMA, Snort) rappresentano il “linguaggio operativo” quotidiano in cui si concretizza l’Incident Response: dal malware analizzato in laboratorio (YARA), ai log di sistema (SIGMA), fino al traffico internet (Snort), ogni traccia viene codificata e utilizzata per rilevare e bloccare le minacce quanto prima possibile.
La Cyber Kill Chain e le fasi di un’intrusione cyber
Per comprendere come si svolge un attacco informatico e dove intervenire per fermarlo, è utile fare riferimento a modelli concettuali come la Cyber Kill Chain. Sviluppata dal team di ricerca Lockheed Martin circa un decennio fa, la Cyber Kill Chain descrive le sette fasi tipiche di un’intrusione mirata . Queste fasi rappresentano il percorso seguito da un avversario, dalla pianificazione iniziale fino agli obiettivi finali, e sono così denominate:
Ricognizione (Reconnaissance): l’aggressore raccoglie informazioni sul bersaglio, studiandone l’infrastruttura, individuando possibili vulnerabilità e punti d’ingresso. In questa fase preliminare rientrano attività come l’OSINT (raccolta di dati pubblici da siti web e social), scansioni di rete, identificazione di sistemi esposti e ricerca di credenziali o dati trapelati nel dark web. L’obiettivo è conoscere l’ambiente della vittima per preparare un attacco efficace.
Armamento (Weaponization): sulla base delle informazioni raccolte, l’attaccante prepara effettivamente il “carico offensivo”. Ciò può consistere nello sviluppo o adattamento di un malware, nella costruzione di un exploit per una vulnerabilità nota, oppure nella creazione di un documento esca maligno (ad esempio un PDF o documento Office infetto) da inviare al bersaglio. In pratica, in questa fase si crea l’arma digitale da utilizzare contro la vittima, spesso combinando un exploit con un payload (es. un trojan) da consegnare successivamente.
Consegna (Delivery): è la fase in cui l’attaccante invia il payload al target. I vettori di delivery più comuni includono l’invio di email phishing con allegati maligni o link a siti compromessi, l’ingegneria sociale per far scaricare un file infetto, l’upload di un exploit tramite un servizio esposto su internet, o l’utilizzo di supporti fisici (drop USB). La delivery rappresenta il momento in cui il bersaglio viene effettivamente raggiunto dal contenuto malevolo preparato in precedenza.
Sfruttamento (Exploitation): una volta consegnato, il malware o exploit viene attivato sfruttando una vulnerabilità sul sistema della vittima. Può trattarsi dell’esecuzione di codice attraverso una falla (buffer overflow, RCE, ecc.), dell’apertura inconsapevole di un documento con macro dannose da parte dell’utente, o di un’esecuzione automatica di codice al collegamento di una periferica USB. Lo sfruttamento segna il passaggio in cui l’attaccante ottiene un primo accesso al sistema bersaglio compromettendone la sicurezza.
Installazione (Installation): in questa fase, l’attaccante consolida la propria presenza inserendo malware persistente nel sistema compromesso. Ad esempio, installa una backdoor, un trojan, o modifica configurazioni in modo da mantenere l’accesso anche dopo reboot o nel lungo periodo. L’installazione spesso coinvolge anche l’ottenimento di privilegi elevati (escalation di privilegi) per assicurarsi il controllo dell’host. Al termine di questa fase, l’attaccante dispone di un punto d’appoggio stabile all’interno dell’infrastruttura vittima.
Comando e Controllo (Command & Control): il malware installato stabilisce una comunicazione con l’infrastruttura dell’attaccante (server C2). Tipicamente, tramite canali cifrati o camuffati (HTTP/HTTPS, DNS tunneling, ecc.), il sistema infetto contatta un server di comando per ricevere istruzioni aggiuntive o esfiltrare informazioni iniziali. Questa fase consente all’aggressore di controllare da remoto i sistemi compromessi, impartendo comandi, spostandosi lateralmente su altre macchine e così via.
Azioni sull’obiettivo (Actions on Objective): è l’ultima fase, in cui l’attaccante realizza i suoi scopi finali una volta ottenuto pieno accesso. A seconda della motivazione, queste azioni possono consistere in furto di dati sensibili (esfiltrazione di database, email, IP aziendale), sabotaggio e distruzione (cifratura ransomware, cancellazione di dati, interferenza con operazioni critiche), spionaggio prolungato, o uso delle risorse compromesse per ulteriori attacchi (es. per sferrare attacchi verso terzi). È il momento in cui l’intrusione raggiunge il suo obiettivo ultimo, che sia lucro finanziario, spionaggio o danneggiamento.
Il modello della Cyber Kill Chain è prezioso per i difensori poiché offre una visione strutturata dell’attacco, aiutando a identificare punti di intervento in ciascuna fase. Ad esempio, durante la ricognizione si possono rilevare e bloccare attività sospette (come scansioni di port scan), in fase di consegna si può puntare a filtrare email phishing o oggetti malevoli, durante il comando e controllo si possono individuare e bloccare le comunicazioni con IP malevoli, e così via. Spezzare anche uno solo degli anelli della “catena di uccisione” può fermare l’attacco prima che giunga a compimento. Inoltre, il framework Kill Chain è utile in fase di post-mortem: analizzando un incidente si possono mappare le azioni dell’attaccante sulle sette fasi, per capire dove la difesa ha fallito e come migliorare (ad es. se un attacco è arrivato fino all’esfiltrazione dati, significa che tutte le difese nelle fasi precedenti non hanno rilevato/fermato l’avversario). In ambienti di sicurezza avanzati, si utilizzano anche simulazioni di attacco ispirate alla Kill Chain (come i penetration test o esercizi red team) per testare la resilienza: ciò consente di valutare se i controlli presenti riescono a individuare o mitigare le azioni in ciascuna fase e, in caso contrario, di colmare le lacune. In definitiva, la Cyber Kill Chain fornisce al coordinatore CSIRT/SOC un quadro di riferimento per orchestrare difese e risposte calibrate su ogni stadio di un’intrusione, trasformando un concetto militare (kill chain) in uno strumento operativo di cyber defense.
Tattiche, Tecniche e Procedure (TTP) degli attaccanti
Accanto alla prospettiva “temporale” fornita dalla Kill Chain, un responsabile di Incident Response deve anche comprendere la natura e le modalità delle azioni compiute dall’attaccante. In gergo di cyber threat intelligence si parla di Tattiche, Tecniche e Procedure (TTP) per descrivere i comportamenti e le metodologie degli attori malevoli. Le Tattiche rappresentano gli obiettivi o scopi di alto livello che l’avversario cerca di conseguire (ad es. movimento laterale, raccolta credenziali, esfiltrazione dati); le Tecniche sono i modi specifici con cui l’attaccante realizza una certa tattica (ad esempio, per la tattica “movimento laterale”, una tecnica potrebbe essere l’uso di credenziali rubate per accedere ad altri host); infine, le Procedure sono i dettagli esecutivi di basso livello di una tecnica, ovvero la particolare implementazione o variante utilizzata (ad esempio lo script o comando preciso usato per eseguire la tecnica di dump delle password in memoria). In altre parole, i TTP forniscono un sistema gerarchico di categorizzazione del “come” operano i threat actor: dalla strategia generale (tattica), passando per il metodo concreto (tecnica), fino all’esecuzione specifica (procedura).
Questa tassonomia è fondamentale in un contesto di risposta agli incidenti e intelligence, perché consente di profilare gli attacchi e collegarli potenzialmente a gruppi avversari noti. Ad esempio, si potrà dire che un certo attacco ha utilizzato la tattica “Initial Access” con la tecnica “Spear Phishing Attachment” e una procedura consistente in un documento di Microsoft Word contenente macro malevole. Riconoscere queste caratteristiche permette di confrontarle con database di minacce note: spesso gruppi APT (Advanced Persistent Threat) ricorrono a insiemi specifici di TTP che diventano la loro “firma” operativa. Per un coordinatore SOC, sapere che un incidente presenta TTP coerenti con quelli di un dato attore (es. un APT statale noto per colpire il settore energetico) può orientare la risposta, far elevare il livello di allerta e attivare collaborazioni con l’intelligence. Viceversa, l’analisi dei TTP consente di passare dall’indicatore puntuale (es. un hash malware) alla tecnica generale: questo aiuta a predisporre difese più robuste. Ad esempio, invece di limitarsi a bloccare l’hash di un singolo malware (che un attaccante può facilmente modificare), focalizzarsi sulla tecnica soggiacente (es. “utilizzo di strumenti Living-off-the-Land come Mimikatz per furto di credenziali”) permette di implementare controlli e rilevamenti più ampi (monitoraggio chiamate sospette alle API di Windows per estrarre credenziali).
Le TTP sono quindi il linguaggio comune tra threat intelligence e incident response. Un analista forense, nel suo rapporto post-incidente, non si limiterà a elencare gli IoC trovati, ma li inquadrerà nelle tecniche e tattiche utilizzate dall’avversario. Allo stesso modo, un threat hunter nel SOC conduce le sue ricerche ipotizzando la presenza di certe tecniche in rete (es. “cerca evidenze di lateral movement via Pass-the-Hash”). Questa formalizzazione è talmente importante che attorno ai TTP si è sviluppato un intero framework di conoscenza: il MITRE ATT&CK, divenuto riferimento de facto per catalogare e condividere le tattiche e tecniche avversarie a livello mondiale.
Il framework MITRE ATT&CK
Il MITRE ATT&CK è una knowledge base globale e continuamente aggiornata dei comportamenti ostili noti, nata per catalogare in modo sistematico le Tattiche, Tecniche (e relative Sottotecniche) impiegate dai vari attaccanti informatici. Il nome stesso “ATT&CK” è un acronimo che sta per “Adversarial Tactics, Techniques & Common Knowledge”, indicativo del focus sugli elementi comuni di conoscenza delle tecniche avversarie. In pratica, MITRE ATT&CK elenca e organizza, in una struttura a matrice, tutte le tattiche che compongono il ciclo di vita di un attacco informatico, e per ciascuna tattica fornisce l’insieme delle tecniche conosciute con cui può essere perseguita. Ad esempio, una tattica è “Privilege Escalation” (Escalation di privilegi): ATT&CK raccoglie tutte le diverse tecniche con cui un malware o attore può ottenere privilegi più elevati su un sistema (dall’exploit del kernel, al bypass di UAC, alla modifica di token di accesso, ecc.), ciascuna documentata con descrizione, esempi di uso reale e riferimenti a gruppi e campagne noti.
Il framework copre l’intero spettro di un attacco, dalla fase iniziale di ricognizione e ottenimento dell’accesso (tattiche di Initial Access, Execution, Persistence, ecc.) fino alle fasi finali (esfiltrazione, impatto sull’obiettivo). Originato inizialmente per ambienti Windows enterprise, si è esteso con matrici specifiche per altri domini: esiste la matrice Enterprise generale (che include sotto-matrici per Windows, Linux, macOS, ambienti cloud, container, ecc.), una matrice Mobile per attacchi su dispositivi mobili, e una matrice ICS per sistemi di controllo industriale. Questa strutturazione permette di adattare l’analisi dei TTP ai diversi contesti tecnologici.
Uno degli aspetti chiave di MITRE ATT&CK è che non si limita a essere un elenco statico, ma piuttosto funge da linguaggio comune e base di partenza per molte applicazioni pratiche nella difesa informatica. Ad esempio:
I team di threat hunting usano ATT&CK per pianificare le loro ipotesi di ricerca, assicurandosi di coprire tecniche specifiche (es: “cerchiamo evidenze di tecniche di Persistence come Registry Run Keys nei log degli endpoint”).
I red team e gli esercizi di adversary simulation mappano i propri scenari di attacco in termini di tecniche ATT&CK, così da testare se il SOC riesce a rilevarle.
Nella risposta agli incidenti, al momento di riportare un incidente o condividerne i dettagli con altri enti, si possono indicare le tecniche ATT&CK osservate (es: T1566.001 Spear Phishing Attachment, T1218.011 “Rundll32”, etc.) per dare immediata chiarezza sulle modalità dell’attacco.
Molti strumenti di sicurezza (SIEM, EDR, XDR) integrano MITRE ATT&CK nelle loro interfacce: ad esempio, correlano alert o rilevamenti con le tecniche corrispondenti, fornendo al SOC un quadro consolidato. Questo aiuta a capire rapidamente quali fasi dell’attacco siano state rilevate e quali possano essere sfuggite.
La valenza strategica di MITRE ATT&CK risiede inoltre nel permettere di identificare aree di miglioramento nelle difese. Mappando i controlli di sicurezza esistenti sulle tecniche della matrice, un’organizzazione può individuare tecniche per le quali non ha visibilità o contromisure – queste diventano priorità da colmare (concetto di coverage ATT&CK). Allo stesso modo, consente di seguire l’evoluzione delle minacce: il framework viene aggiornato man mano che emergono nuove tecniche o varianti, riflettendo lo stato dell’arte del comportamento avversario.
Dal punto di vista di un coordinatore CSIRT/SOC, ATT&CK è dunque uno strumento fondamentale di knowledge management: offre un vocabolario standardizzato per descrivere gli attacchi e una mappa su cui costruire sia le capacità di detection che le procedure di risposta. Ad esempio, se emergono segnalazioni di nuove campagne di attacco globali, il reaponsabile può rapidamente comprendere di cosa si tratta leggendo le tecniche ATT&CK coinvolte (che spesso sono riportate negli advisory), e verificare se la propria organizzazione ha già predisposto controlli per quelle specifiche tecniche. IBM Security in un suo whitepaper in italiano sintetizza bene questo concetto, affermando che il framework MITRE ATT&CK fornisce una base di conoscenza accessibile per modellare, rilevare, impedire e contrastare le minacce sulla base dei comportamenti noti dei criminali informatici. Inoltre, la tassonomia ATT&CK crea un linguaggio comune attraverso cui i professionisti di sicurezza possono condividere informazioni e collaborare in modo più efficace nella prevenzione e risposta alle minacce.
In sintesi, MITRE ATT&CK incarna e integra tutti i concetti discussi finora: suddivide le attività malevole nelle varie fasi/tattiche (richiamando la Kill Chain), elenca tecniche e procedure (TTP) per ciascuna fase, e alimenta la definizione di indicatori di compromissione e regole di detection (molte regole YARA/ Sigma sono categorizzate secondo tecniche ATT&CK). Per un responsabile dell’Incident Response, una solida familiarità con ATT&CK è oggi requisito essenziale, sia per comunicare con efficacia (all’interno e con l’ecosistema esterno) sia per valutare in modo completo le proprie difese e le mosse dell’avversario.
Esperienze operative e contesto italiano (CSIRT Italia, CERT-AgID, ACN)
In Italia, la gestione degli incidenti di sicurezza informatica a livello nazionale fa riferimento al quadro normativo introdotto dal Perimetro di Sicurezza Nazionale Cibernetica e al ruolo centrale dell’Agenzia per la Cybersicurezza Nazionale (ACN), istituita nel 2021. L’ACN ospita al suo interno il CSIRT Italia (Computer Security Incident Response Team Italia), che funge da team di riferimento nazionale per la gestione e prevenzione degli incidenti cyber, in coordinamento con i CERT settoriali (come il CERT-AgID per la Pubblica Amministrazione). Un responsabile per la prevenzione e gestione di incidenti informatici deve quindi conoscere non solo i framework internazionali, ma anche come questi vengono applicati praticamente nel contesto italiano.
Negli ultimi anni, il CSIRT Italia è stato protagonista nella risposta a numerosi incidenti significativi, spesso in collaborazione con altri enti e con le forze dell’ordine. Ad esempio, nel maggio 2022 il sito istituzionale del CSIRT Italia stesso è finito nel mirino del collettivo hacker filorusso Killnet, nell’ambito di una campagna di attacchi DDoS contro varie infrastrutture italiane. Grazie alle contromisure predisposte e a un monitoraggio costante, l’attacco (durato oltre 10 ore) è stato mitigato con successo dai sistemi anti-DDoS, senza interrompere la disponibilità del portale per gli utenti legittimi . Questo episodio – poi pubblicamente riconosciuto dagli stessi attaccanti con un paradossale “complimento” alla competenza tecnica del team italiano – dimostra l’efficacia di una pronta risposta coordinata: il CSIRT aveva già emanato alert preventivi sulle minacce DDoS in corso e raccomandato misure di protezione, e al momento dell’attacco ha saputo contenerlo, proteggendo sia i propri sistemi sia, per estensione, la fiducia nella capacità di reazione del Paese.
Un altro caso emblematico si è verificato a febbraio 2023, quando una ondata di attacchi ransomware su scala mondiale (campagna ESXiArgs) ha preso di mira migliaia di server VMware ESXi non aggiornati. L’ACN, attraverso il CSIRT Italia, ha lanciato immediatamente un allarme pubblico evidenziando la gravità della minaccia e sollecitando tutte le organizzazioni italiane a applicare le patch e verificare i propri sistemi 30 31 . Questa tempestiva azione di allerta – ripresa anche da agenzie di stampa internazionali – ha permesso a molti amministratori di sistema di attivarsi preventivamente, limitando l’impatto nazionale di un attacco che altrove ha causato ingenti danni. Contestualmente, il CSIRT ha coordinato lo scambio di indicatori di compromissione relativi al ransomware (come indirizzi IP di server di comando e hash dei file di criptazione) in modo che i CERT aziendali potessero aggiornare le loro difese (ad esempio caricando regole Snort per bloccare traffico verso gli IP malevoli e regole YARA per individuare il malware ESXiArgs sui server). Questo approccio proattivo è proprio quanto previsto dalle best practice NIST/ISO: preparazione (piano di patch management), detection (uso di IoC condivisi), contenimento (isolamento host vulnerabili) e post-analisi (rapporto sull’accaduto per migliorare i processi).
Per quanto riguarda il CERT-AgID, esso svolge un ruolo cruciale nel contesto della Pubblica Amministrazione italiana, operando come CERT settoriale dedicato. Negli ultimi anni CERT-AgID ha gestito e supportato numerosi incidenti che hanno coinvolto enti pubblici, tra cui campagne di phishing mirate a PEC istituzionali, ransomware che hanno colpito infrastrutture regionali e comunali, nonché massicce compromissioni di siti web della PA utilizzati per diffondere malware. Un esempio rilevante è la serie di attacchi ransomware avvenuti nel 2021-2022 a danno di aziende sanitarie locali e pubbliche amministrazioni (tra cui il noto attacco alla Regione Lazio nell’estate 2021): in tali frangenti, il CERT-AgID ha fornito supporto tecnico nell’analisi del malware, nella triage degli indicatori e nel ripristino, fungendo da tramite tra le strutture colpite, il CSIRT nazionale e i venditori di soluzioni di sicurezza. Inoltre, CERT-AgID cura un report periodico sulle campagne malevole che funge da panoramica strategica del threat landscape verso la PA. Questi rapporti non solo quantificano le minacce (come visto, quasi 1.800 campagne e 20 mila IoC condivisi in un anno), ma dettagliano le tecniche prevalenti, i vettori di attacco usati (es. percentuale di phishing via email, supply chain compromise, etc.) e trend emergenti. Tali informazioni sono preziose per un responsabile, che può calibrare le misure di prevenzione sapendo quali sono le minacce più probabili per il proprio settore.
Va sottolineato come il quadro italiano dell’Incident Response sia ormai strettamente allineato agli standard internazionali. L’ACN ha emanato linee guida, come la recente Guida alla notifica degliincidenti al CSIRT Italia, che definisce procedure e tempistiche per comunicare gli incidenti significativi al team nazionale, in ottemperanza anche alla direttiva NIS e alla normativa nazionale. Questo garantisce un flusso informativo centralizzato e rapido, permettendo di attivare supporto ed eventualmente diffondere early warning ad altri enti a rischio. In parallelo, si investe in formazione e addestramento del personale SOC/CSIRT su temi come quelli trattati in questo elaborato: conoscere e applicare framework come NIST e MITRE ATT&CK, saper scrivere e utilizzare regole YARA/Sigma, interpretare una kill chain e riconoscere i TTP di un attacco. L’Italia partecipa inoltre attivamente a network europei e internazionali di condivisione cyber (come la rete dei CSIRT europei sotto ENISA), consapevole che le minacce sono globali e la cooperazione è fondamentale.
In conclusione, un responsdabile per la prevenzione e gestione di incidenti informatici dovrà padroneggiare sia gli aspetti teorici che quelli pratico-operativi dell’Incident Response. Ciò significa saper coniugare le best practice codificate nei principali standard (NIST 800-61, ISO 27035) con l’uso efficiente di strumenti e indicatori (IoC, YARA, Sigma, Snort), mantenere una visione d’insieme sulle fasi di un attacco (Cyber Kill Chain) e sui pattern di comportamento avversario (TTP, MITRE ATT&CK), e infine muoversi con sicurezza nel contesto organizzativo italiano, orchestrando la collaborazione tra CSIRT Italia, CERT-AgID, forze dell’ordine e soggetti privati. Questo insieme organico di conoscenze e competenze tecniche, unite a capacità di coordinamento, comunicazione e visione strategica, costituisce la base per fronteggiare con successo le sfide poste dagli incidenti cyber.
La digital forensics è la disciplina che si occupa di individuare, preservare ed esaminare le evidenze digitali al fine di ricostruire eventi e azioni compiute su sistemi informatici. In particolare, nel contesto della risposta agli incidenti informatici, le tecniche forensi permettono di capire cosa è accaduto durante un attacco, quali sistemi sono stati compromessi e in che modo, fornendo informazioni critiche per prevenire futuri incidenti. A livello internazionale esistono standard e linee guida che definiscono le migliori pratiche in questo campo: ad esempio lo standard ISO/IEC 27042:2015 fornisce “linee guida per l’analisi e l’interpretazione delle evidenze digitali” mentre ISO/IEC 27043:2015 definisce “principi e processi di indagine sugli incidenti”. Analogamente, la guida NIST SP 800-86 del National Institute of Standards and Technology – intitolata “Guide to Integrating Forensic Techniques into Incident Response” – descrive processi efficaci per svolgere analisi forensi su vari tipi di dati (file, sistemi operativi, traffico di rete, applicazioni) e integrare queste attività nell’ambito di un’indagine di sicurezza . Questi riferimenti enfatizzano un approccio metodico e strutturato all’analisi forense, essenziale affinché le evidenze raccolte abbiano validità e siano utili sia in ottica tecnica sia, se necessario, in sede legale.
Analisi di file system
L’analisi forense di un file system consiste nell’esaminare la struttura e il contenuto di supporti di memoria (dischi fissi, SSD, pen drive, ecc.) al fine di scoprire tracce digitali significative. Ogni file e directory su un sistema operativo è organizzato secondo un file system (come NTFS per Windows, EXT4 per Linux, APFS per macOS, ecc.), il quale mantiene metadati cruciali: nomi dei file, dimensioni, permessi e timestamp (date di creazione, modifica, accesso, ecc.). L’analista forense ispeziona queste informazioni per ricostruire le attività svolte sul sistema e individuare anomalie. Ad esempio, nei file system NTFS di Windows il Master File Table (MFT) registra record per ogni file, includendo fino a quattro timestamp principali per ciascuno (creazione, ultima modifica, ultimo accesso, ultima modifica del record MFT). Questi dati temporali consentono di costruire una timeline degli eventi sul disco. In un’analisi tipica, si cercano file sospetti (ad esempio programmi malevoli camuffati), si esaminano gli attributi e i contenuti dei file e si analizzano gli artefatti del file system (come i journal di NTFS, la $Recycle.Bin, i punti di ripristino, ecc.) alla ricerca di evidenze. Inoltre, si verifica la presenza di file nascosti o di istanze di steganografia (informazioni occultate dentro file leciti) e si controlla l’integrità dei file confrontandone gli hash crittografici con valori noti.
Un aspetto fondamentale del file system forensics è il recupero di file cancellati. Molti utenti pensano che quando un file viene eliminato dal sistema scompaia definitivamente, ma in realtà non è così: l’eliminazione rimuove il riferimento al file dalla tabella di allocazione (ad esempio la File Allocation Table su FAT o la MFT su NTFS) ma i dati binari del file restano sui settori del disco finché non vengono sovrascritti. I file (o frammenti di essi) permangono nelle aree non allocate del disco e, con gli strumenti appropriati, è difficile ma non impossibile ricostruirli. Ciò significa che è spesso possibile recuperare documenti o altri artefatti anche dopo la cancellazione, soprattutto su supporti di grande capacità dove può trascorrere molto tempo prima che i blocchi vengano riutilizzati per nuovi dati.
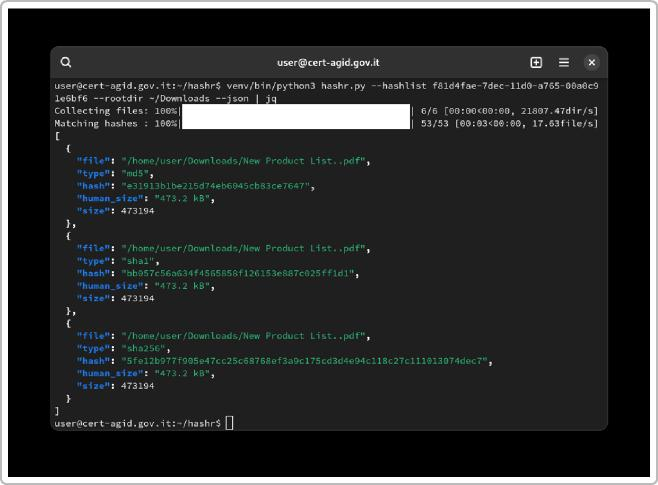
L’analista forense utilizza tecniche di data carving (descritte più avanti) per scandagliare queste porzioni libere alla ricerca di header e footer noti di file (come le intestazioni JPEG, PDF, ecc.) e ricostruire file eliminati o corrotti. Un altro approccio consiste nel calcolare gli hash (MD5, SHA-1, SHA-256) di tutti i file presenti e confrontarli con database di indicatori di compromissione (IOC) noti o con liste di hash di software benigni, così da individuare rapidamente malware noti o file anomali. In contesto italiano, ad esempio, il CERT-AgID (Computer Emergency Response Team dell’Agenzia per l’Italia Digitale) fornisce alle Pubbliche Amministrazioni un servizio di feed IoC contenente hash di file malevoli osservati nelle campagne di attacco più recenti. Questo feed, combinato con appositi tool, consente di identificare file compromessi nei sistemi oggetto di analisi. Hashr è uno di questi strumenti sviluppati dal CERT-AgID: permette di cercare, all’interno di un filesystem, file noti come malevoli confrontando i loro hash con una lista di impronte note. L’uso di hashr è risultato particolarmente utile sia nelle indagini di sicurezza informatica sia nell’analisi forense, ad esempio per verificare l’integrità di grandi volumi di dati e scovare rapidamente malware presenti su disco.
Figura 1: Schermata di output dello strumento hashr (open source di CERT-AGID) in azione. In questo esempio, l’utility ha analizzato la directory Downloads confrontando ogni file con una lista di hash indicanti malware noti, restituendo per ciascun file corrispondenze di hash MD5, SHA1 e SHA256. Tale strumento può velocizzarel’identificazione di file infetti all’interno di file system di grandi dimensioni, ed è utilizzabile anche a fini di verifica dell’integrità dei file.
Dal punto di vista operativo, l’analisi forense dei file system inizia con una corretta acquisizione della memoria di massa da esaminare. Si procede creando una copia forense bit-a-bit del supporto originale (disk image), operazione effettuata tipicamente a sistema spento (analisi dead) utilizzando tool come dd (in ambienti Unix) o strumenti dedicati (ad es. FTK Imager, Guymager), spesso impiegando un write-blocker hardware o software per evitare qualsiasi modifica accidentale al disco originale. L’immagine ottenuta viene poi sottoposta a hash (es. SHA-256) per calcolarne l’impronta univoca, che servirà a garantirne l’integrità: confrontando il valore hash della copia con quello calcolato sul disco originale, si verifica che la copia sia esatta e che nessuna alterazione sia avvenuta durante l’acquisizione. Solo a questo punto gli investigatori lavorano sull’immagine duplicata, lasciando intatto l’originale (principio fondamentale per assicurare la validità probatoria delle evidenze). Una volta montata o caricata l’immagine in appositi software, l’analisi può procedere: si passa in rassegna la struttura di directory, si cercano file sospetti (anche in base a nome, tipo o hash), si analizzano i contenuti con visualizzatori esadecimali o strumenti di parsing (per esempio analizzando il registro di configurazione di Windows, i file di Prefetch, i log di sistema, ecc.), e si ricostruiscono le attività avvenute sul file system. Il risultato finale è spesso una ricostruzione dettagliata (timeline) delle azioni svolte su quel supporto (creazione, modifica, cancellazione di file, installazione di programmi, collegamenti di dispositivi USB, ecc.), utile per comprendere la dinamica di un incidente e attribuire eventuali responsabilità.
Analisi di dump di memoria (memory forensics)
L’analisi forense della memoria RAM è una componente sempre più centrale nelle investigazioni digitali. La memory forensics si occupa di studiare il contenuto della memoria volatile di un sistema (dump RAM catturato da un computer o dispositivo) allo scopo di estrarre informazioni sulle attività in corso o recenti, spesso impossibili da reperire altrove. Infatti qualsiasi operazione compiuta da un sistema informatico – processi eseguiti, connessioni di rete, utilizzo di credenziali, ecc. – transita attraverso la RAM e può persistere in memoria per un certo tempo anche dopo la conclusione dell’evento. La RAM di un computer può contenere quindi una quantità enorme di dati utili: l’elenco dei processi e thread in esecuzione (con i relativi programmi e moduli caricati), le connessioni di rete attive o recentemente chiuse (comprese informazioni su indirizzi IP e porte remote), le chiavi crittografiche in uso, password in chiaro temporaneamente presenti, il contenuto della clipboard (appunti) e persino tracce di malware in esecuzione – inclusi rootkit o altri codici malevoli che potrebbero occultarsi al file system. In altri termini, la memoria è spesso il luogo migliore dove cercare le attività di un software malevolo: anche se un malware tenta di nascondersi eliminando file dal disco o operando solo in memoria (fileless malware), deve comunque essere caricato e mantenuto nella RAM per poter agire. Attraverso la memory forensics è possibile mettere in luce evidenze altrimenti invisibili, come malware residenti unicamente in memoria, sessioni di navigazione web in modalità incognita (che non lasciano cronologia su disco) o conversazioni in chat volatile, e persino modifiche apportate a chiavi di registro di Windows che risiedono solo in memoria e non ancora scritte su disco.
Le fasi di un’analisi della memoria includono innanzitutto l’acquisizione del dump: se il sistema è live, si utilizzano tool appositi (ad es. Magnet RAM Capture, FTK Imager in modalità live, Belkasoft RAM Capturer o comandi di sistema) per estrarre un’immagine completa della RAM e dei file di swap/paging, evitando per quanto possibile di alterare lo stato della macchina. Una volta ottenuto il file di dump grezzo, si passa alla fase di estrazione delle evidenze: qui entrano in gioco framework specializzati come Volatility o Rekall. Volatility, in particolare, è un framework open source scritto in Python, dotato di una collezione di plug-in che permettono di estrarre artefatti dal dump di memoria volatile. Tramite Volatility, l’analista può elencare tutti i processi attivi al momento dell’acquisizione (e quelli terminati di recente ma ancora residenti in memoria), ispezionare l’area di memoria di ciascun processo alla ricerca di stringhe o moduli caricati, ricostruire la lista delle connessioni di rete aperte (socket TCP/ UDP con relativi IP/porta), recuperare informazioni sui driver e i kernel module caricati, estrarre il contenuto della clipboard, delle cache DNS e molto altro. Si possono anche cercare firme note di malware in memoria o rilevare tecniche di offuscamento, come process injection, hooking di funzioni di sistema, presenza di eseguibili packed, ecc. Un esempio concreto: grazie all’analisi RAM è possibile recuperare credenziali o token di autenticazione temporanei che risiedono in memoria (ad esempio password di utenti o chiavi di sessione), elemento che talvolta consente di comprendere l’entità di una compromissione o di effettuare escalation controllate in laboratorio per studiare un attacco. L’analisi della memoria viene condotta preferibilmente off-line sull’immagine catturata, utilizzando i profili adeguati (profiling) per interpretare le strutture dati in base al sistema operativo target. Ad esempio, Volatility richiede di specificare il profilo (p.es. Windows 10 x64 build 19041) per poter tradurre correttamente indirizzi di memoria e simboli: un passaggio fondamentale, poiché l’uso di un profilo errato può portare a output incompleti o incoerenti.
Un aspetto importante è la correlazione delle evidenze di memoria con altre fonti. Spesso, i risultati dell’analisi RAM vanno messi in relazione con quanto emerge dall’analisi del disco e dei log di rete, al fine di costruire un quadro unificato dell’incidente. Ad esempio, processi sospetti individuati in RAM (come un powershell.exe lanciato con comandi anomali, oppure un processo senza file su disco indicativo di un malware fileless) dovrebbero poi essere cercati nelle evidenze del file system (esiste un file corrispondente su disco? Ci sono riferimenti nel Prefetch o nel registro di sistema?) e nei log (ci sono eventi che mostrano l’esecuzione di quel processo da parte di un certo utente?). Solo tramite questa visione d’insieme si può capire appieno l’accaduto. Nel contesto italiano, l’uso della memory forensics è ormai prassi sia nelle operazioni di incident response: ad esempio, per malware analysis su campioni attivi intercettati in sistemi compromessi o per identificare in tempo reale minacce come il malware Agent.Tesla o Ursnif che negli ultimi anni hanno preso di mira enti pubblici e privati.
Analisi di log di sicurezza e di rete
I log – registri degli eventi prodotti da sistemi operativi, applicazioni e dispositivi di rete – costituiscono una fonte informativa primaria nella gestione e analisi degli incidenti informatici. Ogni componente IT (e anche molti dispositivi non-IT) genera infatti una notevole quantità di informazioni sotto forma di log, che vengono tipicamente classificati per categorie e livelli di severità. Ad esempio, un server web produce log delle richieste HTTP con indicazione di timestamp, URL richiesto, indirizzo IP del client e codice di risposta; un firewall registra gli accessi consentiti o negati per ogni connessione (con dati su IP, porte, protocolli); un sistema operativo mantiene log di sicurezza (tentativi di login riusciti o falliti, cambi di privilegi, eventi del kernel) e così via. Analizzare questi log di sicurezza significa estrarre dai dati grezzi le informazioni rilevanti per un determinato incidente, identificare correlazioni tra eventi e riconoscere pattern anomali che possano indicare attività malevole o malfunzionamenti.
Un esempio concreto: in caso di sospetta intrusione su un server, l’analisi incrociata dei log potrebbe rivelare che un certo utente ha effettuato un login fuori orario (voce nel security log), subito seguito dall’esecuzione di comandi insoliti registrati nella shell history e da connessioni verso un IP esterno annotati nel log del firewall. Ciascun singolo evento, preso a sé, potrebbe passare inosservato; la correlazione temporale e funzionale tra i vari log permette invece di ricostruire la sequenzadell’attacco (es. accesso iniziale – movimenti laterali – esfiltrazione di dati) e di identificarne la sorgente. Per un responsabile CSIRT/SOC, saper orchestrare questa attività di analisi log è fondamentale: significa dover gestire potenzialmente decine di migliaia di eventi al secondo, filtrare i falsi positivi e isolare gli indicatori critici. A tal fine, ci si avvale comunemente di sistemi SIEM (Security Information and Event Management). Un SIEM è una piattaforma software che colleziona i log da sorgenti disparate, li normalizza (cioè li traduce in un formato comune), li correla in base a regole predefinite e spesso applica motori di analisi comportamentale per individuare minacce in tempo reale. In pratica, il SIEM funge da concentratore: al suo interno confluiscono log da firewall, IDS/IPS, sistemi endpoint, database, applicazioni, ecc., e l’analista può consultare da un’unica console l’andamento degli eventi. Ad esempio, il SIEM può generare un alert qualora rilevi, entro uno stesso intervallo temporale, più tentativi di accesso falliti su diversi sistemi seguiti da un accesso riuscito con un account amministrativo: segnale tipico di un possibile brute forcing andato a segno. Oppure può correlare l’apparizione di un file sospetto in un host (rilevato dall’antivirus) con una connessione uscente su porta non standard (dal log del proxy): anche qui producendo un avviso di possibile data exfiltration. I moderni SIEM integrano inoltre feed di threat intelligence (indicatori di minaccia esterni forniti da CERT e vendor) e funzionalità di orchestrazione automatica (SOAR), così da arricchire gli eventi grezzi con informazioni contestuali e, in alcuni casi, reagire automaticamente (per esempio isolando un host infetto).
Nell’analisi forense vera e propria, i log rivestono anche un ruolo chiave come evidenze: costituiscono spesso prova documentale di un’azione (si pensi ai log di autenticazione nel caso di accessi non autorizzati, o ai log di transazione di un database in caso di frodi). È importante perciò assicurarne la corretta conservazione e autenticità: un responsabile deve garantire che i log siano archiviati in forma write-once (immutabile) e con riferimenti temporali affidabili (sincronizzazione oraria via NTP, uso di timestamp in UTC, ecc.), in modo che possano essere esibiti come prova qualora necessario. Un aspetto non banale è la gestione dei tempi e della sincronizzazione: se i sistemi coinvolti in un incidente non hanno orologi allineati, la ricostruzione temporale può risultare complicata. Idealmente tutti i server e dispositivi devono sincronizzare l’ora con un time server preciso (via protocollo NTP); in pratica può capitare di trovare orologi sfasati. In fase di analisi forense occorre pertanto tener conto di eventuali offset temporali tra log diversi, effettuando opportune conversioni per costruire una timeline coerente degli eventi . Questo evidenzia ulteriormente l’importanza di un approccio sistematico e metodico nell’analisi dei log.
In Italia, il CERT-AgID e l’ACN/CSIRT Italia incoraggiano fortemente l’adozione di sistemi di logging centralizzato e di SIEM negli enti pubblici, fornendo anche indicazioni su come configurare al meglio il monitoraggio. Ad esempio, ACN ha pubblicato nel 2022 la Guida alla notifica degli incidenti al CSIRT Italia, che tra le varie cose elenca i tipi di log ed evidenze che gli enti devono raccogliere e conservare per facilitare le investigazioni post-incidente . Vi sono stati anche casi concreti in cui l’analisi dei log ha permesso di scoprire attacchi sofisticati: ad esempio, l’indagine su una serie di attacchi alle caselle PEC (Posta Elettronica Certificata) nel 2023 – coordinata da CERT-AgID in collaborazione con la Polizia Postale – ha visto come elemento chiave l’esame dei log di accesso ai server di posta e delle tracce lasciate dai malware nei log antivirus, consentendo di individuare i punti di ingresso dei criminali e di rafforzare le difese delle infrastrutture coinvolte.
Analisi del traffico di rete
L’analisi forense della rete (Network Forensics) riguarda la cattura, l’ispezione e l’interpretazione del traffico di rete con l’obiettivo di ottenere prove digitali relative a eventuali attacchi o attività malevole che si sono svolte attraverso i sistemi di comunicazione. In sostanza, mentre l’analisi dei log spesso si basa su dati già registrati dai sistemi, l’analisi del traffico va direttamente alla fonte: i pacchetti di rete scambiati tra sorgenti e destinazioni. Questa disciplina permette di determinare, ad esempio, l’origine di un attacco, le modalità di comunicazione di un malware con i server di comando e controllo (C2), o l’eventuale esfiltrazione di dati sensibili tramite canali nascosti. L’investigatore di rete inizia tipicamente con l’acquisizione del traffico: può trattarsi di file di cattura (.pcap) ottenuti mettendo in ascolto una scheda di rete in modalità promiscua (con strumenti di packet capture come tcpdump o Wireshark), oppure di flussi di log generati da sonde IDS/IPS, NetFlow, ecc. Spesso, durante un incidente, il team forense configura dei packet sniffer nei punti chiave (ad esempio sulla porta di uno switch core, o attivando port mirroring) per raccogliere tutto il traffico in transito da e verso i sistemi compromessi. I dati così acquisiti – idealmente corredati di timestamp precisi e sincronizzati – vengono poi analizzati nel dettaglio.
Nell’analisi del traffico di rete, alcuni elementi chiave da esaminare includono: i protocolli utilizzati in comunicazione (HTTP, HTTPS, DNS, SMTP, etc.), gli indirizzi IP sorgente e destinazione, i numeri di porta coinvolti, i timestamp delle connessioni, nonché il contenuto dei pacchetti stessi (payload) se in chiaro. Ad esempio, in un file PCAP catturato durante un attacco potremmo filtrare tutto il traffico HTTP non cifrato e ritrovare richieste sospette verso URL esterni, oppure osservare in un dump DNS delle richieste a domini anomali (indizi di malware che cerca il suo dominio di controllo). Strumenti come Wireshark forniscono potenti capacità di filtraggio e decodifica per ispezionare i pacchetti: l’analista può ricomporre flussi TCP, estrarre file trasferiti (ad esempio file scaricati via HTTP o FTP) e seguire la sequenza delle chiamate di rete. Esistono anche strumenti specializzati detti Network Forensic Analysis Tool (NFAT) – un esempio open source è Xplico – il cui scopo principale è estrarre e ricostruire automaticamente tutti i dati applicativi significativi da un’acquisizione di rete. Xplico, ad esempio, è in grado di ricavare da un file pcap tutto il contenuto delle email transitanti (protocolli SMTP/ POP/IMAP), le pagine web e i file scambiati via HTTP, le conversazioni VOIP (protocollo SIP/RTP) convertendole in registrazioni audio, e così via 23 24 . Ciò risulta estremamente utile per presentare le evidenze in forma comprensibile: piuttosto che sfogliare migliaia di pacchetti, l’analista può ottenere direttamente i messaggi e-mail inviati dall’attaccante o i file trafugati.
Un aspetto critico nell’analisi di rete è la presenza della crittografia. Oggi molto traffico (in primis HTTP tramite TLS, ma anche email con SMTPS/IMAPS, VPN cifrate, ecc.) è cifrato end-to-end, il che impedisce di leggere il contenuto dei pacchetti a meno di poter disporre delle chiavi private per decriptarlo. Questo ovviamente complica l’analisi forense: se l’attaccante ha usato solo canali cifrati, si dovrà fare affidamento su metadati (IP, porte, quantità di dati) e su eventuali side-channel (come l’individuazione del tipo di protocollo o l’osservazione di certificate exchange noti) per dedurre cosa sia successo. In ambienti aziendali, per mitigare il problema, talvolta si utilizzano sistemi di SSL/TLS inspection (proxy che terminano e re-instaurano le connessioni cifrate, consentendo l’ispezione del contenuto da parte del SOC) – ma ciò deve essere bilanciato con esigenze di privacy e normative. Nonostante la crittografia, alcuni indicatori di compromissione di rete possono comunque emergere: ad esempio, pattern di traffico anomalo (un host interno che fa centinaia di connessioni verso l’esterno di notte), oppure l’uso di protocolli o porte inusuali per la rete aziendale.
Un compito importante del forense di rete è anche quello di tracciare la sorgente di un attacco. I malintenzionati spesso utilizzano machine zombi o server proxy per celare la propria identità, rendendo arduo risalire all’IP originario dell’attaccante. Attraverso l’analisi incrociata dei log di diversi dispositivi (router, firewall di frontiera, server di autenticazione RADIUS/TACACS), si può tuttavia riuscire a seguire il percorso di un attacco e identificare l’ingresso iniziale. Ad esempio, se un attaccante ha sfruttato una VPN compromessa, i log VPN daranno l’IP pubblico utilizzato; correlando questo con log di altri provider o con segnalazioni di CERT internazionali, si può scoprire se quell’IP corrisponde a una nota botnet. Questo tipo di investigazione sfrutta sia le competenze tecniche che le cooperazioni inter-agenzia: CERT e forze di polizia spesso collaborano scambiandosi informazioni sugli indirizzi IP e le infrastrutture di attacco note.
A tal proposito, è utile menzionare alcuni casi concreti italiani. Le forze dell’ordine, in particolare la Polizia Postale, hanno sviluppato notevoli capacità di network forensics. Un esempio è l’uso proprio di Xplico citato in contesti operativi: in una presentazione del progetto DEFT Linux (una distribuzione forense live creata in Italia), Stefano Fratepietro mostrò come la Polizia, dopo aver catturato il traffico di rete relativo a un’attività illecita, utilizzi Xplico per analizzarlo e ricavare le prove applicative. Questo ha permesso in vari casi di “leggere” comunicazioni tra criminali che avvenivano su canali non cifrati e di raccogliere elementi probatori (e-mail, credenziali, conversazioni VoIP) direttamente dal traffico di rete salvato. Un altro caso noto è l’investigazione sulle botnet Mirai e varianti IoT in Italia: grazie al monitoraggio del traffico anomalo in uscita da dispositivi compromessi (camere IP, router), il CERT-AgID in coordinamento con l’ACN è riuscito a mappare le connessioni verso i server di comando esteri e a condividere con gli ISP le informazioni per la mitigazione, mostrando l’efficacia dell’analisi di rete su larga scala per la difesa nazionale. In sintesi, la network forensics fornisce al responsabile CSIRT uno sguardo “sul filo” delle comunicazioni, rivelando come e cosa è stato trasferito durante un attacco – informazioni imprescindibili per capire l’impatto dell’incidente (ad es. quali dati sono stati rubati) e per bloccare canali di attacco ancora attivi.
Analisi di memorie di massa
Con memorie di massa si intendono tutti i dispositivi di archiviazione persistente dei dati, come hard disk, SSD, chiavette USB, schede di memoria, e in senso lato anche i dischi virtuali di macchine virtuali o istanze cloud. L’analisi forense di queste memorie – strettamente collegata a quella dei file system – si focalizza sull’esame dell’intero supporto fisico o logico e non solo della struttura di files e cartelle. Ciò include aspetti come: l’identificazione di tutte le partizioni presenti (anche quelle nascoste o non standard), l’esame dei settori di boot (MBR o GPT) per individuare bootkit o alterazioni, la ricerca di volume shadow copies o backup nascosti, e in generale l’analisi di ogni area del disco, compresi lo spazio non allocato e lo slack space (lo spazio inutilizzato alla fine dei cluster allocati).
Operativamente, anche qui si parte dall’acquisizione forense del supporto di memoria, creando un’immagine bitstream come discusso in precedenza. Nel caso di dischi di grandi dimensioni, questa operazione può richiedere molto tempo e devono essere adottate opportune precauzioni (condizioni ambientali adeguate, UPS per evitare interruzioni di corrente, etc.). Una volta ottenuta l’immagine, l’investigatore può utilizzare software di analisi come EnCase, FTK o tool open source (ad es. The Sleuth Kit con interfaccia Autopsy) per caricarla. Questi strumenti permettono di navigare tra le partizioni individuate, montarle in sola lettura e analizzarne il contenuto. Un controllo importante è quello della consistenza tra il livello logico e fisico: per esempio, se la tabella delle partizioni indica che un certo spazio del disco non è allocato a nessuna partizione, potrebbe essere normale (spazio vuoto inutilizzato) oppure potrebbe celare una partizione nascosta contenente dati (talvolta i criminali usano partizioni con identificatori anomali o volutamente corrotte per nascondere informazioni). L’analista utilizza quindi tecniche di carving e scanning anche sull’intera immagine fisica per vedere se firme di file noti compaiono in zone altrimenti “mute” del disco.
Un altro scenario da affrontare è quello dei RAID o volumi cifrati. Nelle grandi infrastrutture, spesso i dischi sono in configurazione RAID: il forense dovrà poter ricostruire il volume logico aggregando le immagini dei singoli dischi (rispettando ordine e parametri RAID) per accedere ai dati. Se il volume è cifrato (es. tramite BitLocker, LUKS, VeraCrypt), serviranno le chiavi di decrittazione o tecniche specifiche (es. estrarre la master key dalla RAM acquisita, in caso di sistema acceso) per poter proseguire. Anche dispositivi come smartphone e tablet rientrano nelle “memorie di massa” in senso lato: qui le metodologie divergono (uso di strumenti come Cellebrite UFED o Magnet AXIOM per estrarre una immagine logica o fisica del telefono, sblocco tramite exploit, ecc.), ma per brevità ci focalizziamo sui sistemi tradizionali.
Durante l’analisi delle memorie di massa è importante mantenere la documentazione di ogni passo: ad esempio annotare i codici identificativi del supporto, i calcoli hash effettuati, l’orario di inizio e fine delle copie, le persone intervenute. Questo perché, trattandosi spesso di evidence da presentare eventualmente in tribunale, la catena di custodia deve essere chiara e ininterrotta: ogni spostamento o copia dell’evidenza dev’essere tracciato, e l’integrità deve essere costantemente verificata con hash. Gli standard internazionali (come ISO/IEC 27041 e la stessa 27042) sottolineano l’importanza di garantire l’idoneità e l’adeguatezza del metodo investigativo e la validità delle prove raccolte. In Italia, anche le linee guida del Consiglio d’Europa e del Framework Nazionale di Cybersecurity richiamano questi principi, e le forze dell’ordine (come i reparti di informatica forense dei Carabinieri e della Polizia) hanno protocolli rigorosi per l’acquisizione e la conservazione delle memorie digitali sequestrate.
In sintesi, l’analisi delle memorie di massa copre un ventaglio molto ampio di attività: dalla copia forense alla ricerca di dati nascosti, dall’individuazione di partizioni occulte al recupero di file cancellati, fino all’estrazione di informazioni residuali (ad es. nel pagefile o hibernation file di Windows potrebbero trovarsi frammenti di documenti o credenziali che vale la pena esaminare). Tutto questo richiede competenze tecniche approfondite sul funzionamento dei dispositivi di storage e dei file system, nonché padronanza degli strumenti software dedicati.
Data carving e recupero dei dati
Il data carving (o file carving) è una tecnica forense avanzata utilizzata per recuperare file o frammenti di dati direttamente dal contenuto grezzo di un supporto, senza fare affidamento sulle strutture logiche del file system. Si ricorre al carving soprattutto quando i metadati del file system – che normalmente indicano posizione e dimensione dei file – non sono più disponibili o affidabili: ad esempio, per file cancellati (le cui entry sono state rimosse dalla MFT/FAT) o in casi di file system corrotti/formattati dove la struttura directory è andata persa. Il principio base del carving è che molti tipi di file hanno una firma riconoscibile: delle sequenze specifiche di byte all’inizio (header) e talvolta alla fine (footer) del file. Ad esempio, i file JPEG iniziano tipicamente con i byte FF D8 FF E0 (o FF D8 FF E1 ), i file PDF iniziano con %PDF– , i file ZIP con PK\x03\x04 e così via. Un programma di carving scansiona l’immagine binaria del disco o della memoria alla ricerca di queste firme; quando ne trova una, cerca di estrapolare tutti i byte consecutivi fino al termine plausibile del file (spesso identificato da un footer noto, oppure da un cambio di contesto). Il risultato è l’estrazione di segmenti di dati che verosimilmente rappresentano file completi o parziali.
Ad esempio, se in uno spazio non allocato di un disco troviamo la firma di inizio di un documento Word (byte D0 CF 11 E0 per i vecchi .doc in formato OLE, o l’indicazione PK per i .docx che sono ZIP), il software tenterà di ricostruire il file Word recuperando tutti i settori successivi fino a quando i dati non hanno più senso compiuto o incontrano un’altra firma. Il carving può recuperare file interi se i cluster non sono stati ancora riutilizzati, ma può anche produrre file parziali o corrotti se parti di essi sono state sovrascritte. Tuttavia, anche frammenti di file possono contenere informazioni utili (ad esempio, un pezzo di testo in un documento, o i frame di un video). Questa tecnica è quindi fondamentale quando si analizzano supporti dove l’attaccante ha cercato di ripulire le tracce cancellando file o formattando volumi: spesso, i dati restanti sul disco raccontano ancora la storia. Va notato che il carving non garantisce che i file recuperati siano esattamente nella loro originaria integrità; è necessario validare poi tali file (ad esempio aprendo i documenti recuperati o verificandone gli hash se disponibili).
Esistono diversi strumenti per il data carving: tra gli open source noti vi sono Foremost e Scalpel, nonché PhotoRec (specializzato nel recupero di foto e multimedia). Suite forensi complete come Autopsy/TSK integrano anch’esse funzioni di carving. In ambito NIST, sono stati definiti anche test specifici per valutare l’efficacia dei carving tool (il progetto CFReDS). Il responsabile forense deve conoscere i limiti di questa tecnica: ad esempio, file frammentati (non contigui sul disco) sono difficili da ricostruire completamente via carving, perché tra un frammento e l’altro potrebbero esserci altri dati – alcuni strumenti avanzati tentano di riconoscere frammenti appartenenti allo stesso file sulla base di pattern, ma non è semplice. Inoltre il carving produce spesso falsi positivi (bytes casuali che assomigliano a una firma) – l’analista dovrà quindi verificare manualmente i risultati, soprattutto se l’evidenza estratta è critica.
In definitiva, il data carving aggiunge un tassello importante all’analisi forense, consentendo di scavare a livello di byte nel supporto alla ricerca di qualunque traccia residua. È un processo che può essere lungo e intensivo computazionalmente, ma che in indagini complesse ha portato a ritrovare, ad esempio, frammenti di email scambiate, immagini di reati, documenti eliminati poco prima di un sequestro, etc., rivelandosi spesso la chiave per incastrare i responsabili.
Timeline forense e analisi temporale
Il concetto di timeline in ambito forense si riferisce alla costruzione di una sequenza cronologica di eventi digitali che consenta di ricostruire in modo chiaro chi ha fatto cosa e quando su un sistema. La timeline forense è una delle tecniche più potenti a disposizione degli analisti, perché permette di collegare tra loro le diverse evidenze secondo l’asse temporale, fornendo una visione d’insieme dell’incidente. Come afferma un principio ben noto: “la timeline analysis consente di ricostruire gli eventi, individuare con precisione gli incidenti di sicurezza e comprendere il comportamento di un attaccante” . In pratica, creare una timeline significa prendere tutti i timestamp rilevanti – orari di modifica dei file, registrazioni di log, orari di esecuzione dei processi, etc. – e ordinarli, correlando poi ciascun evento con gli altri.
Per esempio, una timeline relativa a un attacco informatico complesso potrebbe mettere in fila: l’ora in cui un malware è stato eseguito (desunta dall’orario di creazione di un processo in memoria), subito seguita dall’ora in cui un nuovo file sospetto è comparso sul disco (timestamp di creazione del file), poi alcuni minuti dopo la connessione a un server esterno (da un log di rete), poi ancora la modifica di varie chiavi di registro (con orari registrati nel registro eventi), e infine magari l’esecuzione di un comando di cancellazione dati poco prima di un riavvio (log di shell). Vista in timeline, questa serie di azioni delinea chiaramente il modus operandi e l’impatto temporale dell’incidente, cosa che sarebbe difficile da cogliere esaminando isolatamente le singole fonti.
La costruzione di timeline forensi può essere fatta manualmente, esportando i dati temporali da varie fonti e inserendoli in un foglio cronologico, ma data l’enorme mole di informazioni spesso conviene usare strumenti specializzati. Uno dei più noti è Plaso (log2timeline), un framework open source che automaticamente estrae timestamp da un’ampia varietà di file di log e artefatti (file system, registro di Windows, cronologie browser, eventi di sistema) e crea una super timeline aggregata. Con Plaso, si può ad esempio prendere un intero disco e far generare tutti gli eventi temporali possibili in formato testuale o CSV, per poi analizzarli magari con un’interfaccia come Timesketch (piattaforma web per visualizzare e filtrare timeline). Ciò consente di effettuare ricerche veloci (es. “mostra eventi tra le 14:00 e le 15:00 del 12/05/2025” o “trova qualsiasi modifica di file .exe nella settimana precedente l’incidente”) e di applicare filtri per tipologia di evento.
Un concetto importante nella timeline analysis è quello dei pivot point: in un dataset cronologico enorme, si parte di solito da un evento chiave (ad esempio l’ora in cui è stato rilevato l’incidente, o l’orario di un alert antivirus) e si analizzano tutti gli eventi immediatamente precedenti e successivi a quello, allargando via via la finestra temporale. Questo aiuta a focalizzarsi sul periodo critico. Inoltre si distingue tra timeline completa (super timeline) e timeline mirata: la prima include tutto il possibile ed è utile per non perdere dettagli, ma può essere ridondante; la seconda invece si concentra su eventi di un certo tipo o su certe fonti (ad esempio solo la timeline dei file di un particolare directory, o solo gli eventi di login) rendendo più agevole l’analisi. In pratica l’analista forense spesso crea prima timeline parziali (ad esempio timeline del file system, timeline dei log di sicurezza) e poi le fonde assieme per l’analisi finale.
La timeline forense non è solo uno strumento tecnico, ma diventa spesso una parte integrante del report conclusivo di un’investigazione. Molti incident report contengono una sezione chiamata “Timeline of Events” in cui vengono elencati in ordine cronologico tutti gli eventi salienti scoperti, con data/ora, descrizione e fonte. Ciò fornisce ai decisori (manager, o eventualmente giudici in tribunale) una narrazione chiara di cosa è avvenuto. Per esempio: “08:42:15 – L’utente admin effettua login da remoto sull’host SERVER1; 08:45:10 – Viene creato il file malware.exe nella cartella C:\Windows\Temp; 08:45:15 – Il servizio antivirus genera un allarme (file infetto rilevato); 08:45:30 – Connessione di rete dall’host SERVER1 verso l’IP esterno 123.123.123.123 sulla porta 443 (presumibilmente HTTPS); 08:47:00 – Cancellazione di massa di file nella cartella DatiCondivisi…”, e così via. Una presentazione del genere consente di capire immediatamente la successione e l’impatto degli eventi.
Bisogna considerare, come accennato, eventuali problemi di sincronizzazione oraria: la timeline finale potrebbe includere eventi registrati da macchine con orologi non allineati, quindi l’analista deve normalizzare i tempi (ad esempio convertire tutti in UTC o applicare offset noti). Inoltre, la precisione dei timestamp può variare: alcuni log registrano l’ora al millisecondo, altri solo al secondo o al minuto. Quando si comparano eventi, queste differenze vanno tenute presenti (un evento con timestamp 10:00:00 e uno 10:00:30 potrebbero in realtà essere simultanei se il primo log è approssimato al minuto). Gli strumenti automatici spesso aiutano evidenziando potenziali correlazioni nonostante tali discrepanze.
In conclusione, il concetto di timeline rappresenta la spina dorsale dell’analisi forense: mette ordine nel caos di dati prodotti da un incidente e racconta la storia in modo lineare. Un responsabile CSIRT/ SOC deve saper sia costruire manualmente timeline (in contesti magari con pochi dati o in tempo reale) sia utilizzare tool avanzati per timeline complesse, così da poter spiegare efficacemente l’accaduto ai vari stakeholder e prendere decisioni informate sulle misure di contrasto e prevenzione da adottare.
Fondamenti di analisi dei malware
La malware analysis è il processo di esaminare un codice malevolo (malware) per capirne il funzionamento, l’origine, gli obiettivi e gli indicatori di compromissione, in modo da poter mitigare l’attacco e prevenire future infezioni. Nell’ambito della risposta agli incidenti, saper analizzare un malware trovato in un sistema compromesso è fondamentale: consente di determinare quali azioni ha compiuto (es. furto di dati, installazione di backdoor, cifratura ransomware), quali componenti ha installato e come rilevarlo/neutralizzarlo efficacemente. Si distinguono due approcci principali: analisi statica e analisi dinamica.
Analisi statica: consiste nell’esaminare il malware senza eseguirlo, studiandone il file binario e il codice. Include tecniche come: il calcolo di hash e confronto con database di minacce noti (per vedere se il malware è già catalogato), l’estrazione di stringhe testuali presenti nel file (che spesso rivelano indizi su funzionalità, URL o messaggi interni), l’uso di antivirus e strumenti di scanning per rilevare firme o packer usati, l’analisi del PE header nel caso di eseguibili Windows (per capire compilatore, librerie importate, ecc.), e soprattutto il reverse engineering tramite disassembler e decompiler (come IDA Pro, Ghidra o radare2). Con il debugging statico si può leggere il codice assembly del malware per individuare, ad esempio, routine di rete (API chiamate per fare connessioni), routine di cifratura, oppure condizioni di attivazione (date/time bomb). L’analisi statica è svolta in isolamento, dunque è sicura (il codice non viene attivato sul serio), ma può essere molto complessa se il malware è offuscato o protetto da anti-disassembling. Ad ogni modo, utilizzando debugger e altri strumenti, l’analista può ottenere molte informazioni sulle operazioni svolte dal programma dannoso e identificare eventuali punti deboli del malware stesso (ad esempio errori di implementazione che permettono di creare un decryptor per ransomware).
Analisi dinamica: complementare alla precedente, consiste nell’osservare il malware in esecuzione all’interno di un ambiente controllato e isolato (solitamente una sandbox o macchina virtuale di test). Si lancia il malware e si monitora il suo comportamento: quali processi crea, che file legge o scrive, quali chiavi di registro modifica, che traffico di rete genera, ecc… Per far ciò ci si avvale di strumenti come sandbox automatizzate (es. Cuckoo Sandbox, VMRay, Joe Sandbox) o monitor manuali (come Process Monitor, Regshot, sniffer di rete e simili) in una VM. L’analisi dinamica permette di vedere concretamente l’effetto del malware, ad esempio scoprendo l’URL di callback verso cui prova a connettersi, o vedendo che crea una copia di sé in una certa directory e stabilisce persistenza impostando una chiave di registro di run. Questo metodo può in alcuni casi essere più rapido nel fornire indicazioni (rispetto a dover leggere migliaia di righe di assembly), ma ha alcuni limiti: malware sofisticati possono rilevare l’ambiente virtuale/sandbox e cambiare comportamento (o non attivarsi proprio) in presenza di indicatori di analisi. Inoltre, se il malware è configurato per attivarsi solo in determinate condizioni (es. in un particolare giorno, o solo se rileva una certa configurazione di sistema), l’analista deve capire e soddisfare tali condizioni, altrimenti l’osservazione potrebbe non rivelare nulla di utile.
In una strategia completa di malware analysis, statica e dinamica si combinano: ad esempio, l’analisi statica preliminare può fornire IOC (hash, nomi di dominio, stringhe sospette) e indicazioni su come attivare il malware, mentre l’analisi dinamica conferma il comportamento e produce tracce di esecuzione (log delle azioni compiute). Oltre a questi approcci, esistono anche l’analisi automatizzata (utilizzo di motori AV e piattaforme cloud che già identificano la famiglia di malware e danno un report preconfezionato) e l’analisi della memoria specifica del malware (analizzare un dump di memoria del sistema infetto per estrarre parti di malware in esecuzione, utile per malware fileless o moduli iniettati).
Il fine ultimo dell’analisi malware è duplice: difensivo e conoscitivo. Dal lato difensivo, capire il funzionamento del malware consente di sviluppare contromisure mirate: ad esempio, scrivere firme per IDS/antivirus (basate su byte sequence uniche del malware), creare regole Yara per individuare varianti simili, implementare filtri su firewall/proxy per bloccare i domini di C&C emersi, o rafforzare le configurazioni di sistema contro le tecniche specifiche usate dal malware (es: se il malware sfrutta WMI per persistere, inserire controlli su WMI). Un’analisi approfondita “fornisce una comprensione delfunzionamento delle minacce, consentendo alle organizzazioni di creare rilevamenti mirati invece di affidarsia firme generiche”; in pratica, conoscere bene il malware permette di scoprirlo anche quando muta (perché si sa cosa tende a fare) e di reagire più velocemente. Inoltre gli analisti, esaminando gli Indicatori di Compromissione (IOC) del malware (indirizzi IP, hash di file, chiavi di registro modificate, ecc.), possono aggiornare i sistemi di monitoraggio: per esempio, inserendo nel SIEM gli hash in watchlist o caricando gli IP malevoli nei feed di blocco. Ciò aiuta anche a rilevare eventuali nuove infezioni da varianti analoghe (se altri host iniziano a contattare lo stesso C&C, potrebbe voler dire che il malware ha colpito anche lì). Dal lato conoscitivo, la malware analysis contribuisce a rintracciare le tattiche, tecniche e procedure (TTP) degli attaccanti e spesso a collegare un malware a una certa famiglia o gruppo (threat actor). Ad esempio, analizzando un ransomware si può scoprire che utilizza lo stesso algoritmo di cifratura e schema di riscatto di un gruppo noto, attribuendo così l’attacco e potenzialmente condividendo intel con le autorità. In alcuni casi, l’analisi porta anche a individuare eventuali zero-day exploit sfruttati dal malware: “aiutando i ricercatori di sicurezza a individuare exploitsconosciuti prima che si diffondano”. Ciò consente di avvisare i vendor software e far patchare le vulnerabilità, innalzando la sicurezza generale.
Per un analista CSIRT/SOC, non è richiesto essere un reverse engineer di livello avanzato, ma sicuramente avere i fondamenti di analisi malware: sapere come funziona un eseguibile, quali sono i metodi base per analizzarlo, quali strumenti usare e come interpretare un report tecnico di malware. Ad esempio, bisogna conoscere strumenti come VirusTotal (per un primo scan e reputazione di un file), Hybrid Analysis o ANY.RUN (sandbox online che mostrano un comportamento dinamico), debugger come OllyDbg/x64dbg (per tracciare manualmente l’esecuzione di malware a runtime), decompiler come Ghidra (per uno sguardo ad alto livello sul codice), e strumenti di dump e unpacking (poiché molti malware sono compressi o criptati). Durante un incidente grave, il responsabile potrebbe dover guidare il team nella scelta: “Abbiamo trovato questo eseguibile sospetto su un server, lo isoliamo e lo mandiamo in sandbox? oppure ne calcoliamo subito l’hash e vediamo se è noto? Quali IOC estraiamo?”. Il responsabile deve anche tradurre i risultati dell’analisi malware in azioni: ad esempio, se dall’analisi emerge che il malware si propaga via rete usando SMB exploit, andrà immediatamente disposto un controllo di tutti gli host per vedere se presentano quella vulnerabilità e applicare le patch. Oppure, se scopre che il malware ruba certi tipi di file, andranno monitorati accessi anomali a quei file su altri sistemi. Insomma, l’analisi malware fornisce la “intelligence tecnica” durante una crisi cyber, e il responsabile deve saperla sfruttare per il contenimento e la remediation dell’incidente.
Un esempio italiano di applicazione di queste competenze è il lavoro svolto dal CERT-AgID sulle campagne di malspam (email malevole) in Italia: i loro analisti analizzano quotidianamente malware come bancari (es. Ursnif, Dridex), ransomware (es. Cryptolocker, LockBit) e spyware diffusi via email di phishing, producendo report e IOC condivisi con tutte le amministrazioni. Nel Report “Le campagnemalevole del 2024” pubblicato da CERT-AgID, ad esempio, si illustrano le tecniche di offuscamento osservate nei malware giunti via PEC, mostrando come la combinazione di analisi statica (per deoffuscare macro Office e script PowerShell allegati) e analisi dinamica (per osservare i contatti verso i server di destinazione e i file drop) abbia permesso di contrastare efficacemente tali minacce. Questo tipo di conoscenza, opportunamente integrata nei processi di un SOC, consente di innalzare significativamente il livello di protezione degli enti italiani contro attacchi mirati.
Principali strumenti software per l’analisi forense
In campo forense digitale esiste un’ampia gamma di strumenti software specializzati. Un responsabile CSIRT/SOC deve conoscerne i principali – sia commerciali sia open source – per scegliere di volta in volta quelli più adatti e per comprendere i risultati prodotti dal team tecnico. Di seguito elenchiamo alcuni dei tool più diffusi e riconosciuti, suddivisi per categoria.
Suite di analisi su disco e file system: strumenti completi che permettono di esaminare immagini forensi di dischi, navigare tra file, estrarre artefatti e generare report. I più noti sono EnCase Forensic (Guidance Software/OpenText) e FTK – Forensic Toolkit (AccessData/Exterro), ampiamente usati dalle forze dell’ordine e dalle società di cybersecurity. In ambito open source, spicca Autopsy (con il motore The Sleuth Kit): interfaccia grafica che consente analisi dettagliate di file system (NTFS, FAT, EXT, HFS, ecc.), ricerca di keyword, carving, timeline e molto altro. Autopsy supporta plugin per l’analisi di specifici artifact (ad es. la cronologia di browser, i registri di sistema Windows, ecc.) e rappresenta una valida alternativa free ai prodotti commerciali. Un altro nome da citare è X-Ways Forensics (di X-Ways Software): un toolkit potentissimo e leggero molto apprezzato per la velocità e l’efficienza nell’analisi di dischi (popolare in contesti professionali europei). Queste suite includono funzioni di hashing di massa, confronto con liste di known files (hash set noti, come la NSRL), ricostruzione di RAID, esportazione di report completi per tribunale, e sono indispensabili per gestire casi complessi. Da menzionare anche software come Magnet AXIOM (della Magnet Forensics), che integra funzioni di analisi filesystem, mobile e cloud in un unico ambiente.
Strumenti per memory forensics: il già discusso Volatility Framework è il riferimento open source per l’analisi dei dump RAM. Include decine di plugin per estrarre praticamente qualsiasi informazione dalla memoria di Windows, Linux, macOS e profili Android. La sua conoscenza è fondamentale per chi fa incident response. Un altro progetto simile (nato come fork) è Rekall. In ambito commerciale, Magnet AXIOM e Belkasoft Evidence Center offrono moduli di memory analysis integrati, ma spesso si finisce per utilizzare Volatility anche in tali contesti. Per facilitare l’uso di Volatility, esistono interfacce grafiche e tool correlati – ad esempio Volatility Workbench o Autopsy Memory Modules – ma anche linee di comando avanzate come KAPE che integrano flussi di lavoro di triage memoria + timeline. Infine, nel mondo enterprise, prodotti EDR (Endpoint Detection & Response) come CrowdStrike, FireEye HX, Microsoft Defender for Endpoint, spesso dispongono di capacità di acquisizione memoria e analisi automatizzata integrata, sebbene non flessibili come un’analisi manuale con Volatility.
Strumenti per analisi di log e network forensics: per i log, oltre ai SIEM già citati (Splunk, Elastic Stack/ELK, IBM QRadar, ArcSight, etc.), in un laboratorio forense può essere utile log2timeline/Plaso per estrarre timeline come detto, oppure tool come Chainsaw (per analisi offline di Windows event logs usando regole Sigma), EVTX Explorer (visualizzazione avanzata di log Windows) e SysmonView (per tracciare eventi Sysmon). Per la parte network, l’insostituibile Wireshark permette di analizzare qualunque traccia di rete a basso livello. In aggiunta, strumenti come Zeek (ex Bro) servono a elaborare grandi moli di traffico producendo log sintetici su connessioni, file trasferiti, dns query, ecc. Utili anche NetworkMiner (che estrae in automatico elementi dal traffico, simile a Xplico ma con interfaccia diversa) e Moloch/Arkime (piattaforma di capture indexing su larga scala). Nel contesto italiano, come già accennato, la distribuzione DEFT Linux includeva Xplico e altre utility di rete, costituendo un riferimento per molti anni (ora il progetto è meno attivo, ma Xplico prosegue separatamente).
Strumenti per analisi malware: qui troviamo disassembler e debugger come IDA Pro, Ghidra (open source della NSA), OllyDbg/x64dbg, essenziali per il reversing. Sandbox come Cuckoo (open) e varie soluzioni commerciali (VMRay, JoeSandbox, Any.Run) sono utilizzate per l’automated dynamic analysis. Inoltre, tool come Radare2 o Binary Ninja possono fornire analisi alternative. L’analista malware utilizza anche unpacker (es. UPX per eseguibili compressi) e strumenti di monitoraggio come Process Monitor, RegShot, ApateDNS (per ingannare le richieste DNS dei malware). Su un piano diverso, servizi online tipo VirusTotal e database come MalwareBazaar aiutano a contestualizzare il campione (vedere se hash è noto, se esistono Yara rules, ecc.). Conoscere questi strumenti e le relative tecniche di utilizzo rientra nel bagaglio di competenze che un responsabile deve quantomeno saper indirizzare: ad esempio, decidere quando inviare un campione sospetto a un servizio cloud per un’analisi veloce e quando invece è necessario allestire un ambiente isolato e approfondire manualmente.
Piattaforme integrate e distribuzioni forensi: esistono delle vere e proprie distro o suite integrate che raccolgono decine di tool. Ad esempio CAINE (Computer Aided INvestigative Environment) è una distribuzione GNU/Linux live creata in Italia, specificamente per la digital forensics. CAINE contiene un ambiente grafico con script e interfacce che guidano attraverso le fasi classiche dell’investigazione (acquisizione, esame, report) e integra moduli software per analisi di database, memoria, rete, immagini file system NTFS/FAT/EXT, etc. 43 44 . Il tutto assicurando che le operazioni siano forensically sound (ad esempio montando le evidenze in sola lettura). Altre distro note sono SANS SIFT Workstation (Ubuntu-based, mantenuta da SANS Institute) e Kali Linux per la parte più “offensiva” e di test penetrativo ma comunque utile per alcuni strumenti forensi. Anche Tsurugi Linux è una distro recente orientata a DFIR. L’adozione di queste piattaforme consente ai team di avere un ambiente standard con tutti gli strumenti necessari pronti all’uso. Nel contesto lavorativo, spesso si usano macchine virtuali con tali distro per operare sulle evidenze in laboratorio.
In ambito CSIRT/SOC, è attesa “la conoscenza dei principali strumenti softwaredi analisi forense quali Autopsy, Volatility, Magnet Forensics, EnCase Forensic”, come esplicitato anche in annunci di lavoro del settore. Questo significa avere familiarità almeno di base con l’interfaccia e le funzionalità di ciascuno di essi: ad esempio sapere come aprire un case in Autopsy e avviare l’ingest dei moduli, oppure come lanciare i plugin di Volatility da riga di comando per estrarre i processi o le connessioni di rete da un dump RAM, o ancora conoscere l’esistenza di Magnet AXIOM (suite commerciale all-in-one usata anche da forze dell’ordine per analizzare PC e dispositivi mobili). Naturalmente nessuno strumento è “universale” o adatto a tutti gli scopi: il bravo analista sceglie di volta in volta l’utensile più idoneo. Ad esempio, per una rapida triage su 100 endpoint potrebbe usare script e tool da riga di comando (es. KAPE per raccogliere artefatti chiave e Velociraptor per query live), mentre per un’analisi in depth di un singolo server compromesso potrebbe preferire montare l’immagine in Autopsy e lavorare di fino. L’importante è conoscere le potenzialità e i limiti di ogni strumento: saper leggere tra le righe di un output, capire se ad esempio un dato mancante è dovuto a un limite del tool o alla reale assenza di quell’artefatto, ecc.
Da ultimo, vale la pena citare che gli strumenti software sono in continua evoluzione: ogni anno emergono nuovi tool o nuove versioni con funzionalità potenziate (si pensi solo all’evoluzione di Volatility per supportare Windows 11, o ai tool di cloud forensics per AWS/Azure). Un responsabile forense deve mantenersi aggiornato, partecipando magari a community specializzate (come Forensic Focus, DFIR Training, o community locali IISFA) e testando in laboratorio i nuovi strumenti per valutarne l’efficacia.
Conclusioni
L’articolo ha passato in rassegna i principali ambiti dell’analisi forense digitale rilevanti per un responsabile di cybersecurity. Dall’analisi dei file system e delle memorie di massa (con le tecniche di recupero dati e carving) all’ispezione forense della memoria volatile, dall’interpretazione dei log di sicurezza alla dissezione del traffico di rete, fino allo studio dei malware e all’uso dei tool specializzati – ogni sezione evidenzia competenze e conoscenze che risultano oggi imprescindibili per gestire efficacemente incidenti informatici complessi. Queste attività non vivono isolate, ma confluiscono in un processo unificato di digital forensics & incident response (DFIR): ad esempio, i risultati dell’analisi malware influiscono sulle azioni di containment, la timeline forense orienta le indagini ulteriori, l’analisi dei log può suggerire dove cercare evidenze aggiuntive su disco o in memoria, e così via. Il responsabile deve quindi avere una visione olistica, sapendo integrare i vari filoni di analisi in una strategia coerente.
Gli standard internazionali citati (ISO/IEC 27042, 27043, NIST SP 800-86) forniscono un quadro metodologico solido: aderiscono a principi di rigor metodologico, validità, ripetibilità e legalità delle operazioni forensi. Anche nelle procedure italiane (dalle circolari di ACN/CERT-AgID ai manuali operativi delle forze dell’ordine) si ritrova l’enfasi sulla corretta gestione delle evidenze e sulla necessità di agire tempestivamente ma senza comprometterne l’integrità. Questo equilibrio – rapidità vs. accuratezza – è spesso la sfida principale in uno scenario di incidente reale: il responsabile deve decidere quando è il caso di scollegare un sistema per preservarne lo stato, oppure quando conviene lasciarlo online per raccogliere più dati; deve prioritizzare le analisi (ad esempio, prima la memoria per cogliere dati volatili, poi il disco) e allocare le risorse giuste (personale e strumenti) ai vari task.
In termini di contesto nazionale, abbiamo visto come l’Italia si stia allineando alle migliori pratiche: la creazione dell’ACN e il potenziamento di CSIRT Italia, le attività di CERT-AgID focalizzate su prevenzione e condivisione di informazioni, nonché la crescita di competenze nelle unità di Polizia Postale e altri organi investigativi in materia di cyber forensics, testimoniano una maggiore attenzione strategica verso la resilienza cibernetica. Casi concreti gestiti con successo – dalla mitigazione di campagne malware mirate alle PA, all’attribuzione di attacchi tramite analisi delle TTP, fino alla persecuzione penale di cybercriminali grazie a prove digitali forensi – dimostrano il valore di queste capacità.
Per chi aspira a coordinare la prevenzione e gestione degli incidenti informatici, è quindi cruciale non solo conoscere la teoria, ma anche aver maturato una certa esperienza pratica con le tecniche e gli strumenti descritti. La formazione continua, i laboratori su scenari simulati (ad esempio competizioni di Digital Forensics CTF o esercitazioni nazionali di cyber crisis) e l’aggiornamento sulle minacce emergenti (tramite report come quelli CERT-AgID o dell’ENISA) completeranno il bagaglio necessario. In un campo così dinamico, la curiosità investigativa e la mentalità analitica sono qualità preziose quanto la conoscenza tecnica. Un buon responsabile forense sa fare le domande giuste e seguire gli indizi digitali con rigore scientifico, consapevole che dietro ogni byte potrebbe celarsi la chiave per sventare un attacco o attribuirne la responsabilità.
In conclusione, l’analisi forense applicata al cyber-incident response è sia un’arte che una scienza: richiede metodo, strumenti e standard – ma anche intuito, esperienza e capacità di adattamento. L’obiettivo finale è sempre quello di far luce sull’accaduto (shed light on the incident), fornendo risposte chiare al chi, cosa, quando, come e aiutando così l’organizzazione a riprendersi dall’incidente e a imparare da esso per migliorare la propria postura di sicurezza.
Nel contesto della sicurezza nazionale, l’acquisizione forense delle evidenze digitali riveste un ruolo cruciale nella gestione degli incidenti informatici. Un CSIRT/SOC (Computer Security Incident Response Team/Security Operations Center) deve assicurare che ogni fase – dalla profilazione del sistema e triage iniziale, fino alla copia forense dei dati – sia condotta in modo rigoroso e conforme agli standard. Tali pratiche garantiscono sia la continuità operativa degli enti coinvolti che la valorizzazione probatoria delle informazioni raccolte, permettendo eventuali azioni legali. In questo articolo esamineremo le principali metodologie di acquisizione forense, distinguendo tra scenari live e post-mortem, le tecniche di copia bitstream di dischi e dump di RAM, gli artefatti tipici dei sistemi Windows e Linux, nonché gli strumenti hardware/software disponibili. Faremo riferimento ai principali standard internazionali (ad es. ISO/IEC 27037, NIST SP 800-86, RFC 3227) e con esempi concreti in contesto italiano.
System Profiling e Triage
La fase di triage forense consiste nel valutare rapidamente uno scenario compromesso e dare prioritàalle evidenze digitali in base alla loro rilevanza e urgenza. In pratica, significa eseguire una profilazione del sistema coinvolto nell’incidente: identificare il tipo di host (es. server, workstation), il sistema operativo e versione, i servizi attivi, gli utenti connessi e altri elementi chiave, ancor prima di procedere all’acquisizione completa. Lo scopo del triage è individuare subito i dati più critici – ad esempio processi sospetti in esecuzione, connessioni di rete attive verso IP anomali, file di log che mostrano segni di manomissione – che richiedono azione immediata o conservazione urgente. Questa rapida valutazione permette al responsabile di decidere i passi successivi: ad esempio, se isolare il sistema dalla rete per contenere una minaccia in corso, oppure se mantenere la macchina accesa per acquisire dati volatili (RAM, processi, ecc.) prima che vadano persi.
Durante il triage, è fondamentale rispettare il principio dell’ordine di volatilità indicato dall’RFC 3227: occorre procedere raccogliendo prima i dati più volatili e soggetti a cambiamento, per poi passare a quelli meno volatili. Ciò significa, ad esempio, che su un sistema attivo si dovrebbero salvare immediatamente informazioni come il contenuto della memoria RAM, la tabella dei processi e le connessioni di rete, prima di acquisire i dati persistenti su disco. Allo stesso tempo, bisogna evitare manovre che possano alterare o distruggere le evidenze: non spegnere il sistema prematuramente (l’attaccante potrebbe aver impostato script di wipe all’arresto), e utilizzare strumenti “puliti” (da supporti esterni) invece di quelli presenti sul sistema compromesso, che potrebbero essere stati modificati dall’attaccante. Il responsabile forense deve istruire i primi soccorritori digitali (first responder) a seguire procedure codificate – spesso definite in playbook di incidente – per effettuare un triage metodico. Ad esempio, può essere prevista una checklist: identificare e fotografare la schermata attiva, annotare o esportare rapidamente la lista dei processi e delle connessioni (usando tool come netstat o PowerShell in modalità forense), verificare la presenza di dispositivi USB collegati, e controllare il clock di sistema (per future correlazioni temporali). Queste attività di profilazione iniziale forniscono un quadro dello stato del sistema utile per orientare l’indagine e decidere quali evidenze raccogliere con priorità. In sintesi, system profiling e triage rappresentano la prima linea di azione di un responsabile CSIRT nella fase di Preparation/Identification di un incidente, gettando le basi per un’acquisizione forense mirata ed efficace.
Processo di acquisizione: modalità live vs post-mortem
Una volta completato il triage, si passa al processo di acquisizione delle evidenze digitali vero e proprio, che può avvenire in due modalità principali: live (a sistema acceso) o post-mortem (a sistema spento). La scelta dipende dalla situazione: in molti casi di risposta a incidenti, è necessario operare live forensics per catturare dati volatili critici; altre volte, soprattutto in scenari di analisi forense tradizionale (es. sequestro di un computer in un’indagine giudiziaria), si opta per spegnere il sistema e lavorare su copie a freddo per minimizzare modifiche.
Acquisizione live
In questa modalità si raccolgono evidenze a sistema funzionante. I vantaggi sono evidenti: si possono preservare informazioni che altrimenti andrebbero perse con lo spegnimento – ad esempio il contenuto della RAM, le chiavi di cifratura in uso, processi e connessioni attive, ecc. Tuttavia, l’acquisizione live comporta inevitabilmente qualche alterazione dello stato del sistema (ogni comando eseguito può modificare dati, come i timestamp di ultimo accesso) e va quindi condotta con strumenti e metodologie che riducano al minimo tale impatto. Best practice in questo ambito (formalizzate in ISO 27037 e RFC 3227) includono: usare tool forensi dedicati eseguendoli da supporti in sola lettura (per non introdurre nuovi file sul disco target) e documentare ogni operazione compiuta. Un esempio tipico di acquisizione live è il dump della memoria RAM (vedi sezione dedicata) oppure l’estrazione di informazioni volatili tramite script di risposta all’incidente. In situazioni dove si sospetta la presenza di malware avanzati o tecniche anti-forensi (come il timestomping o la cancellazione dei log di evento), l’analisi live può rivelare indizi (processi anomali in esecuzione, moduli kernel caricati in memoria) che un’analisi post-mortem potrebbe non evidenziare. È importante anche valutare i rischi: ad esempio, scollegare la rete di una macchina compromessa può essere opportuno per isolarla, ma va fatto in modo controllato (un malware potrebbe monitorare la connettività e reagire cancellando tracce se “perde” la rete ). Il responsabile deve quindi decidere, caso per caso, quali step eseguire live e in che sequenza, bilanciando la conservazione massima delle prove con la stabilizzazione dell’incidente (es. evitare che l’attacco prosegua).
Acquisizione post-mortem
Consiste nell’acquisire le evidenze a sistema spento, tipicamente tramite la rimozione dei supporti di memoria (hard disk, SSD) e la successiva copia forense bitstream in laboratorio. Questo approccio ha il vantaggio di assicurare che il supporto originale non venga modificato ulteriormente dal momento del sequestro in poi. Nel momento in cui si spegne un computer, però, si perde tutto il contenuto volatile: memoria RAM, stato dei processi, informazioni non salvate su disco, ecc. Pertanto, la decisione di spegnere dovrebbe essere ponderata: ad esempio, se si ritiene che le informazioni critiche risiedano su disco (non volatile) e non vi sia particolare interesse per lo stato attuale della RAM, può essere preferibile rimuovere l’alimentazione immediatamente per congelare la situazione. Al contrario, se si sospetta che informazioni vitali (come chiavi di cifratura, malware in RAM o volumi cifrati aperti) siano presenti in memoria, è fondamentale lasciare il sistema acceso finché non si sia effettuato un dump della memoria e di eventuali dati volatili. L’ISO/IEC 27037 fornisce linee guida proprio per decidere queste priorità: “se dati volatili di rilievo sono presenti, raccoglierli prima di rimuovere l’alimentazione; se invece il focus è sui dati non volatili su disco, si può procedere allo spegnimento in sicurezza”. In modalità post-mortem, l’operatore può impiegare tecniche come il “pull the plug” (scollegare brutalmente l’alimentazione anziché seguire la normale procedura di shutdown, per evitare che eventuali routine di spegnimento dell’attaccante distruggano dati). Naturalmente ciò potrebbe generare qualche inconsistenza nei file (es. journal non “puliti”), ma si preferisce questo rischio piuttosto che perdere prove volatili preziose. Una volta spento e messo in sicurezza il sistema, si passa all’imaging forense dei supporti (illustrato nella sezione successiva). L’acquisizione post-mortem è tipica nelle operazioni di polizia giudiziaria (sequestri) e nelle analisi che non richiedono intervento immediato sul campo. Un responsabile CSIRT deve saper indicare quando è appropriato seguire l’una o l’altra modalità, spesso anche combinandole (es.: acquisizione ibrida, dove prima si esegue un dump di RAM live e poi si spegne per copiare il disco). In ogni caso, che l’acquisizione sia live o a freddo, vanno seguiti i protocolli di documentazione e catena di custodia per garantire integrità e autenticità delle evidenze raccolte.
Acquisizione bitstream di memorie di massa
La copia forense bitstream di un supporto di memoria di massa (dischi fissi, SSD, memorie esterne) è un processo centrale nell’informatica forense. A differenza di una normale copia file-per-file, l’imaging bitstream duplica bit a bit l’intero contenuto del supporto – includendo settori non allocati, spazio slack, aree nascoste – in modo da ottenere un clone esatto dell’originale . Questo è fondamentale perché file cancellati o metadata residuali, non visibili al file system attivo, possono contenere informazioni cruciali in un’indagine.
Procedura di imaging: il processo standard prevede di collegare il supporto originale a una workstation forense (o a un dispositivo duplicatore) in modalità read-only e creare un file immagine o una copia clonata su un supporto di destinazione pulito. Una misura imprescindibile è l’uso di un write-blocker, un dispositivo hardware (o software) che si interpone tra il drive di origine e il sistema di acquisizione, e impedisce qualsiasi comando di scrittura verso il dispositivo sorgente. In questo modo, si può leggere ogni settore del disco senza rischiare modifiche accidentali (ad esempio aggiornamenti di timestamp di accesso, incrementi di contatori SMART, ecc.). I write-blocker hardware sono tipicamente connessi via USB/SATA o tramite dock, e devono essere verificati prima dell’uso; molti modelli forniscono indicatori che confermano lo stato di sola lettura. È importante che il personale ricontrolli che il blocco in scrittura sia attivo per tutti i dispositivi connessi e che i blocker siano periodicamente testati (come raccomandato anche dai laboratori NIST). In alternativa o in aggiunta, su sistemi nix si può montare il supporto in modo da non scrivere journal (opzione ro,noload* per NTFS, ad es.), ma il dispositivo hardware è preferibile perché più affidabile.
Durante l’imaging, si genera di solito un hash crittografico (tipicamente MD5 e/o SHA-1/SHA-256) sia del contenuto originale che della copia, per poter verificare in ogni momento la corrispondenza (integrità) tra i due. Un responsabile deve esigere che al termine dell’acquisizione questi hash combacino e che vengano registrati nei verbali. Come sottolineato da NIST, se si prevede un possibile uso probatorio, è opportuno conservare l’originale intatto come evidenza (ad esempio sigillando il disco originale) ed effettuare tutte le analisi successive sulla copia. L’ISO 27037 e le best practice internazionali insistono molto su questo punto: l’originale diventa evidence master conservato a fini legali, mentre la copia forense (opportunamente verificata) è quella su cui gli analisti lavorano, eventualmente potendone fare ulteriori copie di lavoro. Ogni passo eseguito deve essere documentato dettagliatamente: oltre ai comandi o software utilizzati per l’imaging, vanno annotati ad esempio il modello e seriale del disco originale, la capacità, il nome e versione dello strumento impiegato (software o duplicatore hardware), l’ora di inizio e fine copia, il nome del tecnico operatore e qualsiasi anomalia riscontrata. Queste informazioni supportano la catena di custodia e servono a dimostrare che la procedura è stata eseguita correttamente e senza contaminare le prove.
Formati di output: l’acquisizione bitstream può produrre sia copie fisiche (disk-to-disk, clonazione diretta su un altro drive) che immagini logiche in un file (disk-to-image). La scelta dipende dalle esigenze e dalle risorse: una copia disk-to-disk permette, ad esempio, di montare immediatamente il clone su un’altra macchina per un’analisi rapida, ma richiede un secondo dispositivo di capacità uguale o maggiore. La copia in un file immagine (spesso con estensione .dd se raw o .E01 se compressa con formato EnCase) è più flessibile: il file può essere trasferito, copiato e montato tramite software appositi; di contro, per accedervi occorre utilizzare applicativi forensi o montarlo in un ambiente che supporti tale formato. Molti strumenti consentono anche di comprimere al volo l’immagine, salvando spazio, e di segmentarla in più file (utile per gestire file system che non supportano file di grandi dimensioni). In contesti operativi, il responsabile deve definire uno schema di nomenclatura per le immagini e un sistema di storage sicuro: ad esempio, archiviare le immagini su NAS forense isolato, con controlli di integrità periodici (ricalcolo hash) e accesso ristretto.
In conclusione, l’acquisizione bitstream è un processo dispendioso in termini di tempo e risorse (copiare centinaia di GB può richiedere ore), ma è indispensabile per garantire un’analisi completa e la validità delle prove in tribunale. Organizzazioni ben preparate adottano linee guida interne per quando e come eseguire imaging completo (ad esempio, può non essere realistico fermare immediatamente un server critico per copiarlo; vanno stabiliti criteri di impatto). Il responsabile CSIRT bilancia quindi anche l’esigenza di continuità operativa con quella probatoria, pianificando acquisizioni a freddo in orari e modi che riducano il danno, ma senza compromettere la raccolta delle prove necessarie.
Acquisizione di dump di memoria (RAM)
Le informazioni contenute nella memoria volatile (RAM) di un sistema spesso non hanno equivalentisul disco e possono rivelare dettagli cruciali di un attacco informatico. La RAM ospita infatti lo stato vivo del sistema: processi in esecuzione, moduli di kernel e driver caricati, connessioni di rete aperte, file aperti (che magari non sono mai stati salvati su disco), chiavi di cifratura in uso, password in chiaro temporaneamente in memoria, e molto altro. Tutto questo viene perso definitivamente non appena il sistema viene spento, data la natura volatile della RAM. Per tale ragione, acquisire un dump dimemoria è una fase fondamentale nella risposta agli incidenti live: consente di “congelare” lo stato runtime del sistema al momento dell’incidente per analizzarlo successivamente in laboratorio.
Dal punto di vista pratico, un dump di RAM si ottiene tramite appositi strumenti che copiano byte per byte tutto il contenuto della memoria in un file (spesso chiamato memory.dmp con estensione .raw/.bin). Su sistemi Windows, esistono utilità consolidate come Magnet RAM Capture (fornito da Magnet Forensics) o Belkasoft Live RAM Capturer, nonché tool open-source come WinPmem (facente parte del progetto Rekall) e DumpIt. Questi programmi, tipicamente eseguiti dal tecnico sul sistema target (idealmente da una chiavetta USB, per ridurre scritture su disco), producono un file immagine della RAM che può poi essere scaricato per l’analisi. Su Linux, l’operazione richiede spesso il caricamento di un modulo kernel dedicato come LiME (Linux Memory Extractor) o l’utilizzo di interfacce /dev/mem (se abilitate) e utility dd. L’immagine di memoria così ottenuta viene poi analizzata con framework di memory forensics quali Volatility o Rekall, che permettono di estrarre dalle strutture binarie informazioni intelligibili: ad esempio la lista dei processi e dei relativi segmenti di memoria, le connessioni di rete attive, le DLL/caricate nei processi, eventuale codice iniettato, e persino di ricostruire contenuti testuali (come chat, email, cronologia web) presenti in memoria. Un’analisi approfondita della RAM può rivelare malware fileless (cioè che risiedono solo in memoria), evidenze di attacchi “pass the hash” o credenziali rubate in cleartext, e tante altre informazioni essenziali per capire come è avvenuta la compromissione e cosa sta facendo l’attaccante.
Vale la pena evidenziare due aspetti: temporalità e integrità. La RAM è estremamente dinamica: anche in pochi secondi lo stato può cambiare (processi che terminano, nuovi che si avviano, allocazioni che si spostano). Pertanto, l’operatore deve eseguire il dump il prima possibile durante il triage, minimizzando ritardi. Inoltre, va considerato che il processo di dumping stesso consuma un po’ di RAM e altera alcuni contenuti (ad esempio, parte della RAM viene occupata dal buffer di copia); questo è inevitabile, ma accettabile se si utilizzano strumenti progettati per minimizzare l’impatto. Si documenta in ogni caso quale tool è stato usato e in che orario. Sul fronte integrità, benché non sia possibile calcolare un hash prima (dato che la RAM è mutevole), si calcola almeno l’hash del file di dump generato e lo si conserva per verifiche future, trattandolo poi con la stessa cura di un’immagine disco.
Un altro motivo critico per effettuare il dump di RAM è la presenza di chiavi di cifratura o altri segreti volatili. Se un sistema impiega dischi cifrati (es. BitLocker su Windows, LUKS su Linux) o connessioni VPN cifrate attive, spesso la chiave di decrittazione risiede in RAM mentre il volume è montato o la sessione attiva. Estrarre la RAM può consentire di recuperare tali chiavi – tramite specifici plugin di Volatility – e quindi di accedere a dati altrimenti indecifrabili. ISO 27037 infatti avverte di considerare l’acquisizione di dati volatili prima dello shutdown proprio perché “chiavi di cifratura e altri dati crucialipotrebbero risiedere in memoria attiva”. Un caso concreto è quello dei ransomware: alcuni memorizzano la chiave di cifratura in RAM; se si interviene rapidamente e si cattura la memoria, si potrebbe estrarre la key e decriptare i file senza pagare riscatti.
In sintesi, l’acquisizione della memoria volatile è un tassello irrinunciabile nelle indagini su incidenti moderni. Un responsabile SOC deve prevedere nel piano di risposta la raccolta di dump di RAM per ogni server o endpoint compromesso (quando fattibile in sicurezza) e garantire che il personale sia addestrato all’uso degli strumenti di memory dump. Solamente catturando questa dimensione “effimera” dell’attacco si ottiene una visione completa dell’accaduto, che combini stato dinamico e dati statici.
Artefatti di sistemi operativi Microsoft Windows
I sistemi Windows conservano una vasta gamma di artefatti forensi – file di log, voci di registro, cache di sistema – che possono fornire preziose evidenze sulle attività avvenute prima, durante e dopo un incidente informatico. Un responsabile forense deve conoscere questi artefatti e includerne la raccolta nel processo di acquisizione. Ecco i principali artefatti Windows da considerare e il loro significato:
Event Logs (registri eventi): Windows registra eventi di sistema, sicurezza e applicazione nei file di log (.evtx) situati in C:\Windows\System32\winevt\Logs\. Questi log, consultabili tramite Event Viewer, sono fondamentali per ricostruire la sequenza di eventi di un sistema. Ad esempio, il Security Log documenta tentativi di accesso (Event ID 4625 per login falliti, 4624 per login riusciti) e cambi di privilegi, permettendo di identificare eventuali accessi non autorizzati o escalation di privilegi avvenute. Il log System registra informazioni su avvii/arresti di sistema, crash, o errori di driver; il log Application contiene eventi dalle applicazioni (es. errori applicativi, servizi custom). Durante un’incidente, copiare e mettere in sicurezza questi file di log è prioritario, in quanto potrebbero venire cancellati dall’attaccante per nascondere le tracce. Un esempio concreto: grazie ai Security Log si può scoprire l’ora esatta in cui un account amministrativo sospetto ha effettuato login, o se vi sono stati tentativi massivi di password guessing.
Registry (registro di configurazione): Il registro di Windows è una banca dati centralizzata che memorizza configurazioni di sistema, applicazioni, informazioni sugli utenti, dispositivi hardware e molto altro. È suddiviso in hive principali (SAM, SYSTEM, SOFTWARE, SECURITY, oltre ai NTUSER.DAT per ogni utente) che risiedono sul disco. Dal punto di vista forense, il registry è una miniera di informazioni: ad esempio, consente di identificare periferiche USB collegate in passato (chiavi di registro USBSTOR che elencano device ID, date e serial number dei dispositivi – utile per investigare esfiltrazioni tramite chiavette); permette di vedere programmi impostati per l’esecuzione automatica (Run keys) – spesso usati da malware per persistere; contiene gli MRU (Most Recently Used), liste di file o percorsi recentemente aperti da ciascun utente, che aiutano a capire quali documenti sono stati acceduti; tracce di installazione software, configurazioni di rete, e così via. Due artefatti peculiari meritano menzione: ShimCache e AmCache. Lo ShimCache (Application Compatibility Cache) è una cache mantenuta da Windows per compatibilità applicativa, che registra ogni eseguibile avviato sul sistema con timestamp (talora anche se l’eseguibile non esiste più); fornisce quindi una storia delle esecuzioni utile a rintracciare malware eseguiti e poi cancellati. L’AmCache è un file (Amcache.hve) introdotto dalle versioni moderne di Windows, che conserva dettagli sugli eseguibili lanciati, come nome, path, hash e primo timestamp di esecuzione. Analizzando AmCache si può determinare ad esempio la prima volta in cui un malware è stato eseguito, anche se non ci sono log di altro tipo. Durante l’acquisizione forense, è buona pratica estrarre copie dei file di registro ( C:\Windows\System32\Config\* e C:\Users\{utente}\NTUSER.DAT per ogni profilo) per analizzarli con strumenti forensi (Registry viewers, RegRipper, etc.).
Prefetch files: Windows utilizza la funzionalità Prefetch per velocizzare il caricamento dei programmi usati di frequente. Ogni volta che un eseguibile viene lanciato, il sistema crea/ aggiorna un file prefetch (estensione .pf) in C:\Windows\Prefetch\ contenente il nome del programma, un hash del percorso e riferimenti ai file caricati. Dal punto di vista forense, i prefetch file tracciano l’esecuzione dei programmi e ne registrano il timestamp di ultimo avvio . Ciò è prezioso per stabilire una timeline di esecuzione: ad esempio, se un malware è stato eseguito alle 3:00 AM e poi cancellato, rimarrà comunque un file .pf (es. MALWARE.EXE-3AD3B2.pf) con ultimo esecuzione a quell’ora. I prefetch indicano anche il numero di volte di esecuzione e quali librerie o file ha caricato il processo, dando indizi su cosa abbia fatto. È importante notare che il Prefetch è abilitato di default su desktop Windows, ma su Windows Server potrebbe essere disabilitato per impostazione predefinita. Nelle analisi di incidenti su client, i prefetch sono spesso tra le prime cose da controllare per vedere quali programmi anomali sono stati eseguiti di recente. Vanno quindi raccolti durante l’acquisizione (copiando l’intera cartella Prefetch). Un caso d’uso tipico: rilevare un tool di hacking (es. mimikatz.exe) dal prefetch, anche se l’eseguibile non è più presente – evidenza che qualcuno lo ha lanciato sul sistema.
LNK (Link) files: i file di collegamento .lnk sono scorciatoie Windows che si creano quando un utente accede a file o cartelle (ad es. i collegamenti nei “Recent Items”). Ogni LNK conserva metadati dettagliati sull’elemento target: percorso completo del file/cartella, dispositivo di origine (incluso il numero di serie di volume – utile per identificare unità USB), timestamp dell’ultimo accesso, dimensione del file target, e a volte coordinate della finestra o icona. In un’indagine, analizzare i LNK consente di scoprire attività utente come aperture di documenti o esecuzione di strumenti, anche se tali file non esistono più. Ad esempio, se un dipendente ha aperto un file riservato e copiato su USB, potrebbe restare un link in %APPDATA%\Microsoft\Windows\Recent\ che svela nome e percorso di quel file, nonché identifica la pennetta USB usata (dal seriale riportato nel LNK). I LNK possono anche indicare programmi lanciati da percorsi insoliti (es. C:\Temp\hacker_tool.exe), dando tracce di esecuzioni sospette. È quindi prassi acquisire la cartella Recent di ciascun profilo utente e altri percorsi dove possono annidarsi LNK (es. collegamenti sul desktop, nel menu Start, etc.).
Altri artefatti rilevanti: ce ne sono numerosi; tra i principali citiamo: i Jump Lists (liste dei file aperti di recente per applicazioni “pinned” sulla taskbar, memorizzate in %APPDATA\Microsoft\Windows\Recent\AutomaticDestinations\), utili per vedere cronologia di utilizzo di specifici programmi; i file di paging e ibernazione (C:\pagefile.sys e C:\hiberfil.sys), che contengono porzioni di RAM e stato del sistema scritti su disco – analizzandoli si possono estrarre password o frammenti di documenti presenti in memoria; i dump di crash (MEMORY.DMP generati da Blue Screen) che talvolta sopravvivono e contengono un’istantanea della RAM al momento del crash; il MFT (Master File Table) nei volumi NTFS, che elenca tutti i file con i loro timestamp e può essere estratto per analisi timeline; i log di sistema quali Firewall di Windows (p.e. pfirewall.log se attivato) e Windows Defender (eventi antimalware) che potrebbero rivelare tentativi di connessione o malware rilevati; infine, i file di configurazione e cache applicative (ad esempio i log di navigazione web, la cache DNS, i file di Outlook PST/OST per le email, etc.) da acquisire se pertinenti al caso.
In fase di risposta a un incidente, il responsabile CSIRT deve stilare un elenco di questi artefatti Windows e assicurarsi che la squadra li raccolga sistematicamente. Spesso si utilizzano strumenti di live response (come KAPE – Kroll Artifact Parser and Extractor, di Eric Zimmerman) che automaticamente collezionano copie di molti di questi artefatti chiave per una rapida analisi. La ricchezza di informazioni fornite dagli artefatti Windows consente, una volta in laboratorio, di ricostruire la linea temporale degli eventi (tramite analisi timeline correlando log, MFT e timestamp vari) e di attribuire azioni adaccount utente specifici, distinguendo attività lecite da quelle malevole. Ad esempio, combinando i dati di registro (es. chiave USBSTOR) con i LNK file, si può provare che un certo file è stato copiato su una chiavetta a una certa ora da un determinato utente. Per garantire ciò, la fase di acquisizione deve aver preservato intatti tali artefatti.
Artefatti di sistemi operativi Linux
Anche in ambienti Linux/Unix esistono artefatti forensi fondamentali per un’analisi post-incident. Sebbene Linux non abbia un Registro unificato come Windows, mantiene moltissime informazioni in file di log testuali e file di configurazione, che se raccolti e analizzati correttamente permettono di ricostruire intrusioni e attività anomale. Ecco alcuni elementi chiave che un responsabile dovrebbe includere nel piano di acquisizione da sistemi Linux compromessi:
Log di sistema e di sicurezza: la gran parte delle distribuzioni Linux registra gli eventi in /var/log/. In particolare, il syslog o log generale di sistema (tipicamente /var/log/syslog su Debian/Ubuntu o /var/log/messages su Red Hat/CentOS) contiene messaggi su una vasta gamma di attività: avvio di servizi, messaggi del kernel, connessioni di rete, errori generici. Esaminare il syslog consente di individuare quando sono stati avviati o fermati servizi (utile per vedere ad esempio se un servizio critico è andato in crash in concomitanza con l’attacco) e messaggi anomali del kernel che potrebbero indicare exploit (es. oops o segfault sospetti). Ancora più importanti spesso sono i log di autenticazione, come /var/log/auth.log (su sistemi Debian-like) o /var/log/secure (Red Hat-like), dove vengono tracciati tutti i tentativi di login, sia locali che remoti, con indicazione di utente, origine e successo/fallimento. In questi file si trovano anche i log di uso del comando sudo (elevazione di privilegi), gli accessi via SSH, eventuali cambi di password, ecc. Durante un’incidente, analizzare auth.log può rivelare ad esempio un attacco brute-force in atto (molti tentativi di login falliti in sequenza) o se un utente in particolare ha ottenuto accesso root via sudo in orari non autorizzati. Altri log utili sono quelli di servizi specifici: ad esempio, log di Apache/Nginx in /var/log/apache2/ o /var/log/nginx/ (per investigare compromissioni di web server), log di database (MySQL, PostgreSQL) se si sospetta un SQL injection, log di firewall/iptables, ecc. Il responsabile deve stilare una lista dei percorsi di log da prelevare in base ai servizi in esecuzione sul sistema bersaglio. È buona pratica includere sempre i log lastlog, wtmp, btmp: sono file binari (tipicamente in /var/log/ che registrano rispettivamente l’ultimo login di ogni utente, la cronologia di tutti i login (wtmp) e quella dei login falliti (btmp). Questi file, analizzabili con comandi come last e lastb, possono integrare le informazioni di auth.log riguardo gli accessi utente nel tempo.
Cronologia dei comandi e configurazioni utente: su Linux, ogni utente shell tipicamente ha un file di history (es. ~/.bash_history per Bash) in cui vengono salvati i comandi digitati in passato. Questa cronologia, se non cancellata dall’attaccante, è un artefatto estremamente prezioso: consente di vedere quali comandi sono stati eseguiti – ad esempio, un aggressore che abbia ottenuto accesso shell potrebbe aver lanciato comandi per creare nuovi utenti, modificare configurazioni o estrarre dati, e spesso tali comandi rimangono nella bash_history. Va notato che la history di solito si salva solo alla chiusura della sessione; se l’attaccante non ha terminato la sessione o ha disabilitato la logging della history, il file potrebbe non contenere tutto. In ogni caso, acquisire i file di history di tutti gli utenti (bash, zsh, etc.) è doveroso. Oltre ai comandi, le configurazioni utente come ~/.ssh/authorized_keys devono essere raccolte: questo file indica eventuali chiavi pubbliche autorizzate per login SSH senza password – spesso gli attaccanti ne aggiungono una per garantirsi l’accesso persistente. Anche i file ~/.ssh/known_hosts possono dare indizi su da quali macchine ci si è collegati. Il filesystem home degli utenti, in generale, può contenere script di persistenza (es. aggiunte in ~/.bashrc o ~/.profile che eseguono malware all’avvio della shell). Durante l’acquisizione forense, se non si effettua un’immagine completa del disco, almeno le home directory rilevanti dovrebbero essere copiate integralmente per preservare questi artefatti.
Configurazioni di sistema e job pianificati: un vettore comune di persistenza su Linux è l’uso di cron job maligni. I cron job si trovano in /etc/crontab, /etc/cron.hourly/cron.daily/... o nelle crontab per utente (/var/spool/cron/crontabs/). Analizzandoli, si potrebbe scoprire, ad esempio, che è stato inserito un job che esegue periodicamente un certo script (magari per ricollegarsi a una botnet o mantenere l’accesso). Durante l’incidente, si estraggono quindi tutte le configurazioni di cron. Un altro punto chiave sono le configurazioni di SSH in /etc/ssh/sshd_config : se un attaccante ha abilitato opzioni deboli o cambiato la porta del servizio potrebbe aver modificato questo file. Inoltre, i log di SSH (che in realtà confluiscono in auth.log) dovrebbero essere già considerati, ma è bene filtrarli per evidenziare, ad esempio, da quali IP sono avvenuti accessi SSH riusciti. Anche la configurazione di altri servizi (VPN, servizi cloud, Docker containers in /var/lib/docker/ etc.) può essere rilevante se l’incidente li coinvolge – la regola generale è collezionare tutto ciò che potrebbe aver registrato attività dell’attaccante.
Log di pacchetti e sistema: un aspetto peculiare di Linux è la presenza dei packagemanagement logs. Su Debian/Ubuntu c’è /var/log/dpkg.log che tiene traccia di ogni installazione/aggiornamento/rimozione di pacchetti, con timestamp. Su RedHat/CentOS analoghi sono i log di yum o dnf. Questi log sono utilissimi per vedere se durante l’intrusione l’attaccante ha installato nuovi software (es. un server web, uno strumento di hacking) oppure se il sistema ha aggiornato qualcosa di critico di recente. Ad esempio, se dpkg.log mostra l’installazione di netcat o nmap, è un red flag di attività sospetta. Altri log degni di nota: /var/log/lastlog (ultimi accessi utenti), /var/log/faillog (errori di login), /var/log/mail.log (attività del server mail, se presente, per vedere possibili esfiltrazioni via email) e i log di eventuali IDS/IPS installati. Se il sistema utilizza systemd, molti log tradizionali potrebbero essere nel journal binario (/var/log/journal/) accessibile con journalctl : in tal caso, è opportuno esportare l’intero journal (usando journalctl --since con un range temporale, oppure copiando i file journal) per l’analisi.
In fase di acquisizione, spesso la via più semplice è eseguire un package di raccolta (ad esempio uno script che copia tutto /var/log e alcune directory chiave di /etc e home utenti). Tuttavia, un responsabile attento specificherà quali sono gli “essential artifacts” Linux da non tralasciare. Magnet Forensics elenca 7 artefatti essenziali: history bash, syslog, auth.log, sudo logs, cron, SSH, package logs tutti punti che abbiamo toccato. Raccogliendo questi, un analista potrà: ricostruire latimeline di un attacco (dall’intrusione iniziale visibile in auth.log, alle azioni compiute visibili nella history e nei log di sistema, fino alla persistenza via cron), attribuire azioni a utenti/ip (log di autenticazione), e scoprire eventuali manomissioni (servizi disabilitati, configurazioni cambiate). Un esempio: tramite auth.log si individua che l’attaccante ha ottenuto accesso con l’utente “webadmin” via SSH; guardando nella bash_history di webadmin si vede che ha eseguito un certo script e aperto una connessione reverse shell; controllando crontab si trova un job aggiunto da webadmin che ogni ora tentava di riconnettersi ad un certo host (persistenza). Inoltre dpkg.log rivela che l’attaccante ha installato un pacchetto socat per facilitare le proxy. Tutto ciò costruisce una narrazione completa dell’incidente. È compito del responsabile assicurare che tali tasselli informativi non vadano perduti: ad esempio, evitando la rotazione o cancellazione dei log (in casi estremi, potrebbe decidere di spegnere subito un server Linux se teme che l’attaccante possa “ripulire” i log tramite rootkit, e acquisire a freddo).
In conclusione, gli artefatti Linux, sebbene sparsi in file diversi, coprono molti aspetti dell’attività di sistema e, se acquisiti integralmente, forniscono un quadro molto dettagliato agli investigatori. La sfida è sapere dove guardare: per questo esistono anche cheat-sheet e liste preparate (ad esempio Seven Linux Artefacts to Collect di SANS) che guidano i primi responder su cosa prendere. Un responsabile dovrebbe prevedere tali linee guida e aggiornarsi continuamente, dato che i percorsi e formati dei log possono variare con le versioni (es. il passaggio a systemd-journald). Garantire la raccolta coerente e completa di questi artefatti in ogni incidente significa accelerare l’analisi forense e migliorare l’efficacia della risposta.
Strumenti hardware e software per l’acquisizione forense
Per eseguire le operazioni sopra descritte, il responsabile deve assicurarsi che il team disponga dei giusti strumenti hardware e software di acquisizione forense, nonché delle competenze per usarli correttamente. Vediamo i principali.
Strumenti hardware
Write-blocker: come già menzionato, sono dispositivi (talora in forma di piccoli box USB/SATA o bay da laboratorio) che assicurano l’accesso in sola lettura ai supporti di memoria originali . Sono uno standard de-facto in qualsiasi acquisizione di dischi: marchi noti includono Tableau (ad es. Tableau T8u USB 3.0 Forensic Bridge), Logicube, Digital Intelligence UltraBlock, ecc. Esistono write-blocker per diverse interfacce: SATA/PATA, USB, NVMe, SCSI, ecc. Il loro impiego consente di collegare un hard disk sequestrato alla macchina forense senza rischio di contaminare i dati – condizione essenziale per mantenere l’integrità probatoria. Alcuni modelli hanno funzionalità avanzate come il logging interno delle operazioni o la possibilità di attivare/disattivare il blocco (ma in forense deve restare attivo!). Il NIST CFTT (Computer Forensic Tool Testing) conduce test periodici sui write-blocker per certificarne l’affidabilità; un responsabile può consultare tali risultati per scegliere dispositivi adeguati.
Duplicatori e unità di imaging hardware: si tratta di apparecchi dedicati che possono copiare un disco di origine verso uno o più dischi di destinazione senza bisogno di un computer intermedio. Spesso sono dispositivi portatili, alimentati a parte, con schermo integrato, usati sul campo dalle forze dell’ordine. Esempi: Tableau Forensic Duplicator, Logicube Falcon, Atola Insight. Questi strumenti eseguono copie bitstream con verifica hash incorporata e spesso supportano il cloning multi-target (una sorgente verso due copie identiche contemporaneamente). Il vantaggio è la velocità e il fatto che sono costruiti per non alterare l’originale (incorporano essi stessi funzioni di write-block). Inoltre, supportano formati di output multipli (raw, E01, ecc.) e generano report dettagliati. Secondo NIST SP 800-86, i tool hardware di imaging forniscono in genere log di audit trail e funzioni per garantire consistenza e ripetibilità dei risultati. L’uso di duplicatori è frequente nelle acquisizioni di numerosi supporti in poco tempo (es. per copiare velocemente decine di hard disk durante un sequestro contemporaneo).
Altri tool hardware: include adattatori e accessori, ad esempio: kit di cavi e adattatori per collegare dischi di laptop, telefoni o dispositivi proprietari; dispositivi per estrarre chip di memoria (nell’ambito mobile forensics, eMMC reader); strumenti per acquisire SIM card o smart card, ecc. Nel contesto specifico di incidenti informatici in enti, alcuni di questi sono meno rilevanti, ma un responsabile dovrebbe avere pronte soluzioni per connettere qualsiasi supporto si trovi (dai vecchi dischi IDE agli ultimi M.2 NVMe). Da citare anche i blocchi di rete (sebbene non hardware in senso stretto): quando si prende un computer acceso come evidenza, un’opzione è inserirlo in una “faraday bag” o scollegarlo da rete e Wi-Fi per isolarlo – questo più per preservare da modifiche remote che per acquisizione, ma fa parte dell’equipaggiamento di scena.
Strumenti software
Utility di imaging forense: sul lato software, un arsenale classico comprende tool come dd (il tool Unix per copie bitstream), con varianti forensi quali dcfldd o Guymager (GUI Linux) che aggiungono funzioni di hashing e log. Questi consentono di creare immagini raw bit-a-bit. In ambiente Windows, il popolare FTK Imager permette di acquisire dischi, cartelle o anche singoli file di memoria e di rete, generando immagini in diversi formati (incluso il compresso E01) e calcolando hash in automatico. Software commerciali come EnCase e X-Ways integrano funzioni di imaging: ad esempio EnCase permette di creare direttamente un case con immagini E01 e verifica integrità. Molti di questi software supportano sia l’acquisizione fisica (del disco intero) che logica (ad es. solo una partizione o solo certi file). La scelta dello strumento dipende dallo scenario: dd e affini sono ottimi per ambienti Linux e situazioni scriptabili; FTK Imager è spesso usato su postazioni Windows per copie “ad hoc” (ad esempio di pendrive o di piccoli volumi) grazie alla sua semplicità d’uso grafica. È importante che i tecnici verifichino i checksum generati e alleghino i log prodotti dallo strumento (ad es. FTK Imager produce un file di output con tutti i dettagli dell’operazione). Da ricordare: prima dell’imaging, il disco di destinazione va azzerato o comunque pulito, per evitare contaminazione (principio del “forensically clean media”).
Strumenti per acquisizione live e triage: in contesti di incidente, esistono suite pensate per automatizzare la raccolta di evidenze volatili e semi-volatili. Ad esempio, KAPE (Kroll Artifact Parser and Extractor) consente di definire “target” (artefatti noti di Windows) e raccoglierli rapidamente da un sistema live in un output centralizzato. Volatility (framework di memory forensics) ha moduli per dumping live memory su Windows (WinPmem) e ora anche su Linux. Belkasoft Evidence Center e Magnet AXIOM dispongono di agent da deployare su macchine live per estrarre dati chiave (RAM, registro eventi, ecc.) con un minimo impatto. Un altro strumento pratico è CyLR (Cyber Logos Rapid Response) – un leggero collector open source – o lo script Livessp (SANS SIFT). Questi tool aiutano il first responder a non dimenticare elementi importanti durante la concitazione di un incidente. Per il triage rapido di supporti spenti (es. decine di PC da controllare), esistono anche soluzioni come Paladin (distro live basata su Ubuntu con toolkit forense) o CAINE (Computer Aided Investigative Environment), che permettono di bootare la macchina da USB/DVD in un ambiente forense e copiare selettivamente evidenze (con write-block software attivo sul disco originale).
Tool per acquisizione della memoria: già evidenziati in parte, meritano un focus. Oltre a DumpIt e Magnet RAM Capture citati, c’è Microsoft LiveKd (Sysinternals) che consente di ottenere dump di memoria di macchine Windows partendo da un kernel debug; LiME su Linux è ormai standard per memdump su Android e server headless; AVML (Acquire Volatile Memory for Linux) è uno strumento più recente di Microsoft per estrarre RAM da VM Linux (utile in cloud). Qualunque strumento si usi, deve essere testato e validato prima in laboratorio. Ad esempio, si può verificare che il dump prodotto sia apribile in Volatility e che corrisponda (nel caso Windows) alla versione OS corretta. Il responsabile dovrebbe predisporre procedure e ambienti di prova per garantire la familiarità del team con tali strumenti: un errore nell’uso (es. dimenticare di eseguire come Administrator un RAM capture tool) potrebbe rendere nullo il dump.
In generale, la dotazione strumentale di un responsabile SOC/CSIRT deve essere allineata alle best practice internazionali. Gli standard NIST elencano dozzine di tool sia commerciali che open source, e raccomandano di avere politiche per l’uso corretto degli strumenti (ad esempio, mantenere una copia di ciascun software usato, con versioni, hash, in modo da poter dimostrare in tribunale esattamente cosa è stato usato e che non contiene backdoor). È inoltre importante monitorare il panorama: strumenti nuovi emergono (ad es. per acquisire dati da cloud, o dall’IoT), e un responsabile deve valutarne l’adozione. Nel kit non dovrebbero mancare anche strumenti di verifica: ad esempio, software per calcolare hash (md5deep, sha256sum), per confrontare file, per estrarre metadata. Anche se non direttamente di “acquisizione”, essi supportano la fase di accertamento dell’integrità dei dati acquisiti.
In conclusione, strumenti hardware e software ben selezionati sono il braccio armato dell’analista forense. La loro efficacia dipende dalla competenza d’uso e da procedure appropriate. Un responsabile deve assicurare formazione continua e magari predisporre ambienti di simulazione dove testare periodicamente l’intera catena (ad esempio, simulare un attacco e far eseguire ai tecnici l’acquisizione con i loro tool, verificando poi che tutto – hash, log, tempi – sia conforme). Questa preparazione fa la differenza tra un’acquisizione improvvisata e una condotta professionalmente, come richiesto in un contesto di sicurezza nazionale.
Standard e linee guida internazionali
Nel campo della digital forensics applicata agli incidenti informatici esistono standard e linee guida internazionali che definiscono principi, terminologie e procedure riconosciute. Un candidato al ruolo di responsabile CSIRT deve non solo conoscerli, ma saperli mettere in pratica e farvi aderire le operazioni del team. Di seguito, i riferimenti principali.
ISO/IEC 27037:2012 – “Information technology – Security techniques – Guidelines for identification, collection, acquisition and preservation of digital evidence”. È lo standard ISO specifico per la prima fase della gestione delle evidenze digitali. Esso stabilisce le linee guida per l’identificazione delle potenziali fonti di prova, la raccolta (intesa come acquisizione sul campo dei dispositivi/ evidenze), l’acquisizione forense vera e propria (creazione di copie bitstream) e la preservazione delle stesse. Vengono definiti i principi generali (ad es. minimizzare la contaminazione, assicurare la documentazione completa, mantenere la chain of custody) e identificati i ruoli chiave, in particolare il Digital Evidence First Responder (DEFR), ossia l’operatore iniziale che interviene sulla scena. L’ISO 27037 fornisce indicazioni su come valutare la volatilità delle evidenze e come dare priorità in base ad essa (ad esempio, suggerendo di acquisire per prima i dati che “scomparirebbero” se il dispositivo fosse spento). Inoltre, dedica sezioni alla corretta custodia, etichettatura e trasporto delle evidenze digitali, sottolineando l’uso di contenitori appropriati (es. buste antistatiche, custodie sigillabili) e precauzioni contro fattori ambientali che possano danneggiare i dispositivi raccolti. Questo standard – pur non essendo una procedura operativa dettagliata – costituisce un framework di riferimento ampiamente adottato da forze di polizia e team di risposta in tutto il mondo per garantire che fin dai primi istanti le evidenze siano trattate “as ISO compliant as possible”. In Italia, i principi di ISO 27037 sono stati recepiti in molte linee guida interne di Forze dell’Ordine e CERT aziendali.
NIST Special Publication 800-86 – “Guide to Integrating Forensic Techniques into Incident Response”. Pubblicata dal National Institute of Standards and Technology (USA), questa guida colma il gap tra digital forensics tradizionale e incident response. Il suo scopo è fornire un processo strutturato per utilizzare tecniche forensi durante la risposta a incidenti di sicurezza . NIST 800-86 descrive un modello di processo forense composto da quattro fasi: Collection (raccolta) – dove si acquisiscono i dati rilevanti dall’ambiente target (dischi, memorie, log di rete, ecc); Examination (esame) – che implica il filtro e l’estrazione preliminare di informazioni dai dati grezzi (ad es. parsing di log, carving di file dalla memoria); Analysis (analisi) – la fase interpretativa in cui gli analisti traggono conclusioni su cosa è successo, correlando le evidenze; Reporting (reportistica) – documentare i risultati e magari fornire raccomandazioni. Questa struttura viene integrata nel ciclo di vita di incident response (Preparation, Detection & Analysis, Containment, Eradication & Recovery, Lessons Learned) delineato da un altro noto documento NIST (SP 800-61). La SP 800-86 fornisce anche practical tips: ad esempio suggerisce fonti di evidenze per vari tipi di incidenti, tecniche di collezione specifiche (come fare imaging, come raccogliere dati di rete), considerazioni legali da tenere presenti (negli USA, aspetti di privacy, Fourth Amendment, ecc.), e importanza di policy e procedure interne per la forensics. In sostanza, questo documento aiuta un responsabile a capire come inserire le attività forensi in un piano di risposta senza improvvisarle. Ad esempio, se c’è un sospetto worm in rete, la guida consiglia di raccogliere non solo i sistemi infetti ma anche traffico di rete, memory dump per analizzare il malware, e di farlo in tempi rapidi dati i dati volatili. Fornisce quindi un utile complemento operativo agli standard ISO.
RFC 3227 – “Guidelines for Evidence Collection and Archiving” (IETF). Questo RFC (Request for Comments) del 2002, pur datato, è ancora citatissimo per il concetto di order of volatility che introduce. In poche pagine, fornisce una serie di raccomandazioni pratiche per chi raccoglie evidenze digitali in ambiente live. Oltre a ribadire l’importanza di partire dai dati più volatili (CPU, cache, RAM, processi) per poi passare a quelli meno volatili come dischi e infine backup e media esterni, include una lista di cose da non fare: ad esempio non spegnere il sistemaprematuramente, pena perdita di dati importanti; non fidarsi dei tool presenti sulsistema compromesso, ma usare software di raccolta su supporti protetti; non usarecomandi che possano alterare massivamente i file (come tool che cambiano tutti gli ultimi accessi); attenzione a “trappole” di rete (disconnecting la rete può attivare meccanismi distruttivi se il malware li prevede). Il documento tratta anche aspetti di privacy (invita a rispettare le policy aziendali e leggi durante la raccolta, minimizzando dati non necessari) e considerazioni legali generali sulla validità delle prove (ad esempio, ricorda che le prove devono essere autentiche, affidabili, complete e ottenute in modo lecito per essere ammissibili). Un altro punto fondamentale è la definizione di Chain of Custody (catena di custodia): RFC 3227 specifica che bisogna poter descrivere chiaramente quando, dove, da chi ogni evidenza è stata scoperta, raccolta, maneggiata, trasferita. Suggerisce di documentare tutti i passaggi, includendo date, nomi e persino numeri di tracking delle spedizioni se un supporto viene trasferito. Questo è pienamente in linea con le prassi forensi e in Italia corrisponde all’obbligo di verbale di sequestro e custodia delle copie forensi. In sintesi, l’RFC 3227 è una lettura obbligata per i first responder e rimane attuale: i suoi consigli vengono spesso citati nei corsi forensi e implementati nei manuali operativi.
Altri standard e guide rilevanti: oltre ai sopra citati, possiamo menzionare il NIST SP 800-101 (Guide to Mobile Forensics) per la parte di dispositivi mobili – utile se l’incidente coinvolge smartphone aziendali; lo standard ISO/IEC 27035 per la gestione degli incidenti di sicurezza, che include la fase di Incident Response e accenna alla preservazione delle evidenze come parte del processo di mitigazione; la serie ISO/IEC 27041, 27042, 27043 che forniscono rispettivamente guide sulla gestione delle attività forensi (assicurazione di processo), sull’analisi di evidenze digitali e sugli step per investigazioni digitali – evoluzioni post-27037 che entrano più nel dettaglio delle fasi successive all’acquisizione. In ambito law enforcement europeo, il Manuale di Valencia (European cybercrime training manual) e le linee guida dell’ENFSI (European Network of Forensic Science Institutes) replicano concetti simili per armonizzare le pratiche. Nel Regno Unito, la famosa ACPO Good Practice Guide for Digital Evidence enuncia 4 principi, tra cui il principio 1: non alterare i dati su un dispositivo a meno che non sia inevitabile; principio 2: chiunque acceda a dati digitali deve essere competente e tenere traccia di tutto; principio 3: va tenuta documentazione completa di tutti i processi; principio 4: la persona responsabile dell’indagine ha la responsabilità generale di assicurare conformità legale. Questi rispecchiano molto quanto detto in ISO 27037 e RFC 3227, enfatizzando integrità e documentazione. Infine, val la pena ricordare che in Italia anche la giurisprudenza ha affrontato il tema: la Corte di Cassazione (Sez. VI, sentenza n. 26887/2019) ha delineato un vero e proprio vademecum su come devono essere eseguiti i sequestri di dati informatici, richiamando la necessità di adottare cautele tecniche per garantire che la copia forense sia fedele e che gli originali siano conservati senza alterazioni, pena l’inutilizzabilità degli elementi raccolti. Ciò rafforza l’importanza per un responsabile di seguire standard riconosciuti, così che l’operato del team sia non solo efficace tecnicamente ma anche solido a livello legale.
In sintesi, standard e linee guida forniscono il quadro teorico e pratico entro cui muoversi: adottarli garantisce consistenza delle operazioni forensi e facilita la cooperazione con altri team (nazionali e internazionali) parlando lo stesso “linguaggio” procedurale. Un responsabile informato farà riferimento a questi documenti nella stesura delle procedure interne, nell’addestramento del personale e nella giustificazione delle scelte operative durante un incidente.
Casi d’uso in contesto nazionale
Per contestualizzare quanto esposto, consideriamo alcuni scenari nel panorama italiano dove le pratiche di acquisizione forense sono state – o potrebbero essere – determinanti. L’obiettivo è mostrare come un responsabile CSIRT/SOC applica tali conoscenze in situazioni reali, spesso in collaborazione con enti pubblici e forze dell’ordine.
1. Attacco ransomware a un ente pubblico (Regione Lazio, 2021): un caso emblematico è l’attacco ransomware che ha colpito la Regione Lazio nell’agosto 2021, paralizzando il portale vaccinale COVID-19 e numerosi servizi online per giorni. In un evento del genere, il responsabile della risposta (in sinergia con l’ACN/CERT nazionale e i tecnici regionali) ha dovuto immediatamente predisporre un triage su decine di server e sistemi: identificare quali erano criptati e fuori uso, isolare la rete per prevenire ulteriore propagazione, ma anche acquisire copie forensi dei sistemi colpiti per analizzare il malware e verificarne l’impatto. Nel caso Lazio, ad esempio, è stata effettuata l’acquisizione bitstream dei server critici, inclusi i controller di dominio e i server di gestione del portale sanitario, al fine di consegnare tali immagini agli esperti (anche stranieri) per l’analisi del ransomware e la ricerca di eventuali decryptor. Parallelamente, è probabile sia stato eseguito il dump della memoria su almeno uno dei server infetti ancora in esecuzione, per catturare la chiave di cifratura o tracce dell’attaccante in RAM. Questo incidente ha evidenziato l’importanza di avere procedure pronte: nonostante la gravità, il team forense doveva agire tempestivamente senza compromettere i servizi di ripristino. La raccolta dei log di sicurezza Windows e dei domain controller logs è stata fondamentale per ricostruire la dinamica: ad esempio, capire quale account iniziale è stato compromesso (si parlò di credenziali VPN rubate) e quando il malware ha iniziato a diffondersi. L’analisi forense, condotta sulle immagini acquisite, ha permesso di individuare i file di persistence creati dal ransomware e i movimenti laterali effettuati, dati con cui il responsabile ha potuto informare gli amministratori su come bonificare completamente la rete prima di rimetterla in produzione. Inoltre, queste evidenze sono state girate alla Polizia Postale per le indagini penali. Il lesson learned di Lazio 2021 ha probabilmente portato a migliorare ancora le pratiche di incident response italiane, ad esempio enfatizzando la necessità di separare le reti di backup e verificare che le copie di sicurezza non fossero cifrate (in quell’occasione, fortunatamente i backup erano salvi, ma in altri casi non è stato così). Un responsabile, da questo esempio, trae l’indicazione che avere un piano di acquisizione forense predefinito per scenari di ransomware massivi è essenziale: chi fa cosa, quali sistemi si copiano per primi, dove si stoccano le immagini in sicurezza, come coordinare più squadre sul territorio (nel Lazio intervenne anche il CNAIPIC e team di sicurezza privati). In definitiva, il caso Regione Lazio ha mostrato come l’acquisizione forense non sia una fase “postuma”, ma integrata nella gestione della crisi: mentre si lavora al ripristino, in parallelo si portano avanti imaging e raccolta evidenze, poiché attendere la fine dell’emergenza per iniziare l’acquisizione significherebbe perdere dati chiave o trovare sistemi completamente ripristinati (quindi privati delle tracce dell’attacco).
2. Compromissione di account email governativi: immaginiamo uno scenario in cui un Ministero o un’agenzia governativa rileva accessi sospetti a caselle di posta istituzionali (PEC o email interne). Questo potrebbe derivare da un attacco mirato (es. phishing avanzato) volto a carpire informazioni sensibili. Il responsabile CSIRT nazionale verrebbe allertato per supportare l’ente nell’indagine. In un caso del genere, una delle prime mosse sarebbe raccogliere in maniera forense i log del server di posta (ad esempio i log IMAP/POP/SMTP, o i log di accesso alla Webmail) per identificare da quali IP e quando si sono verificati gli accessi abusivi. Poi, si procederebbe all’acquisizione delle caselle di posta compromesse – ad esempio esportando i file .pst/.ost nel caso di Exchange/Outlook, o effettuando un dump delle caselle dal server – per analizzare quali email sono state lette o esfiltrate dall’attaccante. Se si sospetta che l’attaccante abbia usato una postazione interna compromessa, quel PC verrebbe sequestrato per un’analisi: in tal caso la squadra forense eseguirebbe un’acquisizione post-mortem completa del disco e della RAM (se la macchina è accesa) di tale computer. Dall’immagine del PC si cercherebbero artefatti come browser history (per vedere se l’attaccante ha navigato la webmail), eventuali keylogger o malware installati, e tracce di movimenti laterali. Un esempio reale simile è accaduto con attacchi APT a Ministeri esteri: in passato, malware come Remote Control System o Ursnif hanno infettato PC di dipendenti pubblici per rubare credenziali PEC e documenti riservati. In queste indagini, la collaborazione con Polizia Postale è stretta: il responsabile deve garantire che ogni acquisizione segua procedure ineccepibili così che le prove (log di accesso, immagini dei PC) siano valide per identificare gli autori e perseguirli. Un aspetto critico qui è la catena di custodia condivisa: ad esempio, i log del server mail potrebbero essere forniti dall’ente al CSIRT e poi da questo alla Polizia; bisogna documentare ogni passaggio, magari apponendo firme digitali ai file per garantirne l’immodificabilità durante il trasferimento. Questo scenario evidenzia l’importanza della normativa nazionale (es. obblighi di notifica incidenti secondo NIS/DORA) che impone tempi stretti: entro 24 ore l’ente deve informare l’ACN, e nei giorni seguenti fornire risultati preliminari. Un responsabile quindi attiverebbe subito le procedure di acquisizione forense parallelamente alla mitigazione (es. reset password account, blocco di IoC a firewall), per poter fornire rapidamente un quadro d’impatto. Il risultato tangibile sarebbe un rapporto forense con elenco delle caselle violate, l’analisi di come (es. malware su PC X che ha fatto da pivot), e le azioni raccomandate per evitare futuri attacchi (es. 2FA obbligatoria sulle caselle, campagne anti-phishing).
3. Indagine su dipendente infedele in un ente pubblico: un contesto diverso, ma non raro, è quello di un abuso interno – ad esempio un funzionario di un’amministrazione che sottrae dati riservati (liste di cittadini, documenti interni) per fini personali o per rivenderli. In tal caso, l’incidente può non essere un “attacco esterno” ma una violazione di policy interna. Tuttavia, le tecniche di acquisizione forense sono analoghe: supponiamo che si sospetti che il dipendente abbia copiato file su una USB personale. Il responsabile della sicurezza dell’ente, con supporto forense) disporrà il sequestro del PC aziendale dell’individuo e di eventuali supporti nel suo ufficio. Su quel PC si effettuerà un imaging completo del disco. Dall’analisi emergeranno ad esempio artefatti USB nel registro di Windows con l’identificativo di una pen drive non autorizzata e date di utilizzo. I log di accesso potrebbero mostrare che il soggetto ha lavorato fuori orario su quei file (Event Log con login serali, oppure timeline di $MFT che indica accessi in orari anomali). Anche i LNK files e la shellbag del registro potrebbero confermare che ha aperto cartelle contenenti i dati riservati e magari copiato file su un percorso esterno. Tutte queste prove, opportunamente raccolte e documentate, costituiranno materiale per un eventuale procedimento disciplinare o penale. In un caso simile è fondamentale che la copia forense del disco del dipendente sia effettuata in maniera impeccabile e che l’originale venga custodito in cassaforte: la difesa potrebbe contestare la manomissione dei dati, quindi poter esibire hash corrispondenti e documentazione di catena di custodia completa tutela l’ente e la validità probatoria. Inoltre, se coinvolto un sindacato o autorità, sapere di aver seguito standard ISO/NIST (dunque di non aver violato la privacy di altri dati se non quelli pertinenti, ecc.) mette al riparo da contestazioni sulla metodologia. Un esempio reale avvenne qualche anno fa in un comune italiano, dove un amministratore di sistema fu scoperto a curiosare nei dati anagrafici senza motivo: grazie alla analisi forense dei log applicativi e del suo computer, si individuò l’illecito. Il responsabile deve essere sensibile anche a questi scenari “interni”, predisponendo magari procedure semplificate di acquisizione (non sempre servirà un intervento della Polizia, a volte è un audit interno) ma ugualmente rigorose.
4. Coordinamento multi-ente in incidenti su infrastrutture critiche: In ambito nazionale, il responsabile per la prevenzione incidenti potrebbe trovarsi a gestire situazioni che coinvolgono più enti contemporaneamente – ad esempio una campagna di attacchi ransomware a vari ospedali o comuni. In queste situazioni, l’acquisizione forense deve scalare su più fronti: occorre inviare squadre locali (o guidare da remoto i tecnici sul posto) per raccogliere evidenze in ciascun luogo. Un caso ipotetico: una variante di ransomware colpisce simultaneamente 5 ospedali italiani. Il CSIRT nazionale emette allerta e invia digital forensics kits alle squadre IT locali con istruzioni su cosa fare: eseguire subito dump di RAM delle macchine critiche (server di cartelle cliniche) e poi spegnerle per imaging, raccogliere log di sicurezza e una copia dei malware trovati su disco. Ogni squadra segue lo stesso protocollo (magari fornito sotto forma di checklist derivata da ISO 27037). I dati raccolti vengono poi centralizzati al CSIRT per l’analisi aggregata – questo ha senso perché confrontando i dump di memoria o gli artefatti del malware, si può capire se gli attacchi sono correlati (stessa variante) e quindi fornire early warning agli altri. Un responsabile deve quindi saper orchestrare acquisizioni forensi in parallelo, mantenendo la qualità. Ciò comporta anche aspetti logistici, come assicurarsi che ogni ente abbia almeno un personale formato DEFR o che possa dare accesso rapido alle stanze server per le copie. La cooperazione con forze di polizia qui è doppiamente importante: incidenti su infrastrutture critiche vengono seguiti anche dall’autorità giudiziaria, quindi polizia scientifica e Postale lavoreranno con il CSIRT. Uniformare gli standard (ad es. concordare l’uso di determinate tipologie di supporti di custodia sigillati, condividere gli hash via canali sicuri) è qualcosa che va preparato prima dell’incidente, tramite accordi e protocolli tra ACN e forze dell’ordine. In Italia, il modello di intervento cooperativo è in evoluzione, ma eventi come quelli di Luglio 2023 (attacco ransomware a vari comuni toscani) hanno visto CERT-AgID e CNAIPIC lavorare fianco a fianco. Il risultato è duplice: mitigare l’incidente e raccogliere prove per perseguire i criminali. Il responsabile deve assicurarsi che nessuno dei due obiettivi comprometta l’altro (ad es. non ripristinare macchine senza prima averle acquisite, a costo di tenere giù un servizio un’ora in più – decisione spesso difficile ma necessaria in ottica strategica).
Questi esempi mostrano che, nel contesto italiano, l’acquisizione forense è ormai parte integrante della gestione degli incidenti informatici, sia che essi siano causati da hacker esterni sia da minacce interne. Adottare standard internazionali offre un linguaggio comune e una qualità garantita delle operazioni, mentre declinare tali standard nelle procedure specifiche nazionali (considerando normative locali e struttura organizzativa italiana) è il compito del responsabile. In ogni caso, le evidenze digitali raccolte – dai log di Windows alle memorie RAM – si sono rivelate l’elemento chiave per chiarire gli incidenti e trarne lezioni: ad esempio, l’analisi forense post-mortem dei sistemi di un comune colpito da ransomware può evidenziare come l’attaccante è entrato (RDP esposto, credenziali deboli), fornendo indicazioni per mettere in sicurezza tutti gli altri enti con configurazioni simili. Così, il ciclo prevenzione-incidenti-miglioramento si chiude, con la forensica digitale a fare da ponte tra reazione all’emergenza e strategia di sicurezza proattiva.
Conclusioni
L’acquisizione forense di sistemi informatici – con tutte le sue sfaccettature di triage, imaging e raccolta artefatti – rappresenta una pietra angolare della moderna risposta agli incidenti. Nel ruolo di responsabile per la prevenzione e gestione di incidenti informatici, queste competenze non sono solo tecniche, ma strategiche: bisogna saper orientare il team verso le azioni giuste nei momenti critici, garantendo che nessuna prova vada perduta e che l’integrità delle evidenze rimanga intatta. Come evidenziato dai principali standard (ISO/IEC 27037, NIST 800-86) e linee guida (RFC 3227), seguire metodologie strutturate assicura che l’indagine digitale sia condotta con rigore scientifico e validità legale.
Un buon responsabile CSIRT deve quindi agire su più fronti: prevenire – formando il personale e predisponendo procedure e toolkit per essere pronti all’acquisizione; gestire – durante l’incidente decidere rapidamente cosa acquisire live e cosa post-mortem, bilanciando la necessità di contenere la minaccia con quella di conservare le prove; analizzare – assicurarsi che i dati raccolti vengano esaminati a fondo (se non dal proprio team, passando il testimone a team forensi dedicati), traendo conclusioni solide; e comunicare – redigendo report post-incidente chiari che documentino l’accaduto e reggano a eventuali scrutini giudiziari.
In ambito nazionale, queste responsabilità si amplificano: il responsabile diventa l’anello di congiunzione tra diverse entità (enti colpiti, agenzie di sicurezza, forze dell’ordine, talvolta partner internazionali per attacchi globali), dovendo garantire un approccio unificato e conforme agli standard. Solo un processo di acquisizione forense ben gestito può fornire le risposte alle domande chiave dopo un incidente: come è successo? cosa è stato colpito? c’è ancora presenza dell’attaccante? quali dati sono stati compromessi? – e queste risposte informano tanto le azioni di recovery immediato quanto le strategie di miglioramento a lungo termine.
Concludendo, l’acquisizione forense non è una mera operazione tecnica ma un’attività dal forte impatto organizzativo e legale. Operare secondo le best practice internazionali, mantenere un alto livello di professionalità e documentazione, e sapersi adattare ai contesti concreti (tecnologici e normativi) italiani, sono caratteristiche imprescindibili per il responsabile CSIRT/SOC. Così facendo, ogni incidente informatico, per quanto grave, diventa anche un’opportunità di apprendimento e di rafforzamento della postura di sicurezza nazionale, trasformando l’esperienza sul campo in nuove misure preventive e in una resilienza cyber sempre maggiore. La sfida è elevata, ma come recita un principio forense: “le prove digitali non mentono” – sta a noi saperle preservare e interpretare correttamente, a tutela della sicurezza collettiva e della giustizia.
Molte telecamere di fascia consumer/prosumer adottano meccanismi P2P via cloud (UID + STUN/TURN/relay) per fornire accesso “zero-configurazione”. Questa convenienza introduce rischi strutturali: dipendenza da terze parti, esposizione a credential stuffing, aperture automatiche di porte tramite UPnP, ritardi o assenza di aggiornamenti firmware, applicazioni mobili invasive e scarsa trasparenza dei vendor. Il presente articolo propone un modello local-first con segmentazione (VLAN IoT), registrazione/visualizzazione in locale, accesso remoto esclusivamente via VPN, pratiche di hardening, logging e monitoraggio. Inoltre:
un playbook operativo completabile in ~90 minuti;
checklist per la valutazione dei fornitori;
errori ricorrenti da evitare;
indicazioni forensi in caso di incidente.
Introduzione
L’adozione massiva di telecamere “plug-and-play” ha ridotto la complessità di installazione, spostando però il baricentro della sicurezza verso infrastrutture cloud proprietarie. Questo paper affronta, con taglio tecnico-accademico, come funziona il P2P “magico”, perché è rischioso, e quali architetture e controlli consentono di mitigare i rischi con oneri limitati.
P2P “magico”: funzionamento e impatti
Meccanismo tecnico
UID: ogni camera espone un identificativo univoco associato al tuo account/app.
NAT traversal: la camera apre connessioni in uscita verso server del vendor (STUN/TURN) per superare NAT/firewall; in caso di fallimento si usa relay completo lato cloud.
Effetto: fruizione video senza configurazioni manuali (port-forward), al prezzo di un terzo attore—il vendor—nel percorso di segnalazione e talvolta nel trasporto.
Superfici d’attacco e criticità
Dipendenza dal cloud: indisponibilità, compromissioni o scarsa trasparenza impattano disponibilità e riservatezza.
Credential stuffing: l’account applicativo del vendor è un bersaglio distinto dall’infrastruttura domestica/aziendale.
UPnP: alcuni dispositivi richiedono aperture automatiche di porte; pratica rischiosa e spesso non tracciata.
Supply-chain & firmware: cicli di patch lenti/assenti; stack P2P proprietari difficili da auditare.
App mobili: permessi e telemetria eccessivi, potenziale esfiltrazione metadati.
Architetture di riferimento (ordine decrescente di sicurezza)
Solo locale (massima privacy)
VLAN IoT dedicata (es. VLAN20 192.168.20.0/24) senza accesso Internet.
NVR/NAS con RTSP/ONVIF nella stessa VLAN.
Visualizzazione da LAN amministrativa tramite jump host o ACL selettive.
Locale + VPN (equilibrio sicurezza/usabilità)
Come sopra, ma nessun port-forward pubblico.
Accesso remoto solo tramite VPN (WireGuard/OpenVPN) al router/firewall.
Notifiche push veicolate attraverso la VPN o bridge on-prem sicuro.
Cloud minimale e controllato (solo se indispensabile)
Abilitare funzioni cloud solo per notifiche, non per streaming continuativo.
Preferire vendor con E2E documentata; disabilitare UPnP, applicare ACL in uscita.
Controlli di sicurezza: rete, accesso, gestione
Segmentazione e policy
VLAN IoT (telecamere), VLAN Admin (NVR/management), VLAN User (PC/smartphone).
Regole firewall minimali: IoT → NVR (RTSP/ONVIF) solo, deny all per il resto.
Bloccare IoT → Internet, salvo finestre di update strettamente controllate.
Accesso remoto
VPN con MFA (WireGuard/OpenVPN). Evitare esposizioni dirette su Internet di NVR/telecamere.
Disabilitare UPnP su router e dispositivi; opzionale: bloccare domini cloud vendor se non utilizzati.
Autenticazione e cifratura
Password uniche e robuste; 2FA ovunque disponibile.
TLS per pannelli web interni; preferire E2E tra client e NVR quando possibile.
Patch management, inventario, backup
Inventariare modelli/seriali/firmware; pianificare finestre di patch mensili con changelog.
Backup configurazioni (router/firewall/NVR) e snapshot delle policy.
Logging e monitoraggio
NTP coerente; invio log a Syslog/SIEM (accessi, motion, riavvii).
Allarmi su autenticazioni fallite, cambi IP/MAC, variazioni di profilo stream.
Playbook operativo “90 minuti di hardening” (SOHO/PMI)
Prerequisiti: privilegi sul router/firewall, switch gestibile, NVR/NAS compatibile RTSP/ONVIF.
Router/Firewall (≈15′)
Disabilita UPnP.
Crea VLAN20 (IoT) e VLAN10 (Admin).
Regola: VLAN20 → solo NVR: 554 (RTSP), 80/443 se indispensabili; deny all per il resto.
Blocca VLAN20 → Internet; in alternativa, whitelist temporanea per update.
Switch/Access Point (≈10′)
SSID “IoT” ancorato a VLAN20.
Port isolation per ridurre movimento laterale intra-VLAN.
NVR/NAS (≈20′)
Cambia credenziali di default, abilita 2FA (se presente).
Crea utenti per ruolo (viewer/admin); invia log a syslog.
Abilita solo protocolli necessari (RTSP/ONVIF); disabilita il cloud.
Telecamere (≈20′)
Aggiorna firmware.
Disabilita P2P/cloud nelle impostazioni.
Configura stream RTSP verso NVR (H.265 se supportato, bitrate adeguato).
Configura WireGuard sul gateway; genera profili per smartphone/PC.
Verifica che la visualizzazione funzioni solo con VPN attiva.
Verifica finale (≈10′)
Da rete esterna: nessuna porta esposta su IP pubblico.
Dalla VLAN IoT: traffico verso Internet bloccato (se policy locale-only).
Verifiche tecniche: comandi esemplificativi
# Scansione porte esposte su IP pubblico (da rete esterna)
nmap -Pn -p- --min-rate 1000 <IP_PUBBLICO>
# Verifica outreach delle telecamere (dalla VLAN IoT)
tcpdump -i ethX host <IP_CAMERA> and not host <IP_NVR>
# Controllo stato UPnP (OpenWrt)
uci show upnpd
È possibile disabilitare completamente P2P/cloud e usare RTSP/ONVIF solo in LAN?
Esiste una politica di aggiornamento con changelog e tempi di remediation (CVE)?
L’app funziona in LAN senza Internet?
Sono disponibili 2FA, ruoli granulari e log esportabili (syslog/API)?
È documentata l’end-to-end encryption (ambito, limiti, gestione chiavi)? Come avviene l’eventuale relay?
Errori ricorrenti da evitare
Lasciare UPnP attivo “per comodità”.
Esporre NVR/telecamere con port-forward (80/554/8000) confidando solo nella password.
Riutilizzare le stesse credenziali e rinunciare al 2FA.
Trascurare la segmentazione (reti piatte ⇒ movimento laterale facilitato).
Aggiornare l’app ma non il firmware dei dispositivi.
Considerazioni forensi (DFIR)
Preservazione: esportare configurazioni NVR; acquisire log di accesso/motion/riavvii.
Timeline: correlare eventi di motion con autenticazioni remote, geolocalizzazione IP, modifiche impostazioni.
Acquisizioni: – Bitstream del disco NVR/NAS (per analisi di metadati, cancellazioni, rotazioni); – PCAP della VLAN IoT (24–48 h) per pattern anomali, DNS rari, cambi di bitrate/codec.
Indicatori: accessi fuori orario, up/down ricorrenti, variazioni di stream non programmate, contatti verso domini non standard.
Conclusioni
La sicurezza dei sistemi di videosorveglianza non dipende dalla “smartness” del dispositivo, ma dalla prevedibilità dell’architettura: isolamento di rete, minimizzazione della dipendenza dal cloud, aggiornamenti regolari, e accesso mediato da VPN. Un’impostazione local-first con policy chiare riduce drasticamente il profilo di rischio senza penalizzare la fruibilità. Le linee guida e il playbook proposti forniscono un percorso pratico e ripetibile per ambienti domestici evoluti e PMI.