L’acquisizione live della memoria RAM su sistemi Windows richiede una strategia che minimizzi l’alterazione dello stato del sistema, dato che il tool di acquisizione stesso deve essere eseguito sul sistema target e inevitabilmente ne modifica in parte i dati. È fondamentale non spegnere nériavviare la macchina (per evitare la perdita completa dei dati volatili) e procedere piuttosto a isolare il sistema dalla rete (es. scollegando il cavo o disabilitando il Wi-Fi) per prevenire interazioni esterne durante la raccolta. Prima di iniziare, è buona prassi preparare un supporto esterno (come una chiavetta USB) contenente l’eseguibile di acquisizione, in modo da eseguire il tool da un supportorimovibile e salvare il dump di memoria su un’unità esterna o share di rete. Ciò riduce le scritture sul disco locale del sistema in esame e limita la possibilità che malware o altri processi notino l’operazione, oltre a diminuire il rischio di sovrascrivere dati volatili critici. Ad esempio, è comune avviare WinPmem da USB e salvare l’immagine di memoria direttamente su un server remoto. Durante l’acquisizione, i tool tentano spesso di mettere in pausa altri processi o utilizzano driver kernel per accedere direttamente alla RAM, mitigando problemi di consistenza (il cosiddetto memory smear, cioè piccole discrepanze dovute al continuo cambiamento dei dati in RAM). In ogni caso, è consigliato avviare la cattura il prima possibile, prima che ulteriori attività del sistema sovrascrivano informazioni potenzialmente importanti. Nel processo di acquisizione bisogna anche documentare orario e modalità di cattura (utile per correlare in seguito gli eventi di memoria con log di sistema) e, completata l’operazione, calcolare hash crittografici (MD5/SHA) del file di dump ottenuto. Ciò garantisce l’integrità dell’evidenza e permette di attestare che l’immagine di memoria analizzata corrisponda esattamente a quella acquisita sul sistema live. L’originale va conservato in modo sicuro e l’analisi va eseguita su copie, mantenendo una chiara chain of custody qualora l’evidenza dovesse essere presentata in sede legale.
Strumenti principali per l’acquisizione di memoria volatile
In ambiente Windows esistono diversi strumenti specializzati per acquisire il contenuto della memoria fisica in modo forense. Tutti questi caricano un driver kernel per accedere alla RAM a basso livello e producono un file (tipicamente in formato raw o mem) contenente l’intera memoria volatile. Di seguito alcuni dei tool comunemente impiegati.
WinPmem – strumento open source (parte del progetto Rekall) che permette il dump completo della RAM; utilizza un driver kernel dedicato e salva l’immagine in formato raw. È un tool a riga di comando ed è apprezzato per la sua affidabilità.
FTK Imager (Memory Capture) – il noto tool di imaging forense FTK Imager include una funzione “Capture Memory” per acquisire la RAM live; tramite un’interfaccia grafica consente di specificare destinazione del file di output e offre l’opzione di includere automaticamente il pagefile di Windows.
DumpIt – utility stand-alone a riga di comando (originariamente di MoonSols, ora disponibile tramite Magnet Forensics) che esegue un dump completo con un semplice doppio click. Genera per default un file .dmp (formato crash dump di Windows) contenente la memoria fisica, opzionalmente anche in formato raw; è popolare per la sua facilità d’uso one-click, sebbene introduca un footprint in memoria molto ridotto (carica pochissimi DLL).
Mandiant Redline – strumento freeware di FireEye con interfaccia GUI che include funzionalità sia di acquisizione live (tramite un driver kernel) sia di analisi basica. Redline può essere eseguito da USB e consente di collezionare la RAM in un file di dump; internamente utilizza la componente Memoryze per l’accesso raw alla memoria.
Belkasoft Live RAM Capturer – tool gratuito orientato all’acquisizione rapida anche in presenza di tecniche anti-debug/anti-dump. Ha un’interfaccia semplice (“Capture” button) e produce un file raw; supporta sia x86 che x64 e cerca di bypassare eventuali protezioni del malware durante la lettura della RAM.
F-Response – soluzione commerciale che permette di acquisire memoria da macchine live da remoto. Consiste in un driver e connettore di rete che espone la RAM del sistema target come una periferica accessibile dall’analista, consentendo il dump anche via LAN/WAN. È usato in contesti enterprise per incident response distribuito.
Nota: Indipendentemente dallo strumento scelto per l’acquisizione, il file grezzo ottenuto (immagine di memoria) è generalmente analizzabile con i principali framework di memory forensics (Volatility, Rekall, etc.), a prescindere dal tool che lo ha generato.
L’importante è assicurarsi che il tool supporti il sistema operativo target (versione e architettura) e sia testato in anticipo, per evitare incompatibilità al momento critico.
Principali artefatti estratti da un dump di memoria
Una volta ottenuta un’immagine di memoria, l’analisi forense si concentra sull’estrazione degli artefatti volatili, ossia tutte le informazioni significative sullo stato del sistema al momento della cattura. La memoria RAM conserva tracce di quasi ogni attività del sistema; infatti, qualsiasi operazione software passa in RAM e molti dati possono persistere anche dopo la cessazione di un processo. Tra i principali artefatti estraibili da un dump di memoria (e le relative strutture di dati che li contengono) vi sono i seguenti.
Processi e thread in esecuzione: l’elenco dei processi attivi al momento della cattura può essere ricostruito attraversando la doubly-linked list dei processi in kernel mode. In Windows il kernel mantiene una lista concatenata di strutture _EPROCESS (puntata da PsActiveProcessHead), ciascuna rappresentante un processo attivo. Ogni record EPROCESS contiene vari metadata (PID, nome eseguibile, stato, ecc.) e un puntatore al PEB (Process Environment Block) in user mode, dove sono presenti ulteriori info come i parametri di avvio, le variabili d’ambiente e i moduli caricati del processo. Dal PEB si può risalire anche al tree VAD (Virtual Address Descriptors) che descrive le regioni di memoria allocate dal processo. L’analisi dell’elenco dei processi (ad es. tramite plugin Volatility pslist/pstree) consente di identificare processi sospetti – ad esempio nomi anomali o processi senza parent legittimo. Un esempio tipico: individuare un svchost.exe il cui parent process non è services.exe può indicare un processo spoofed o iniettato. Si controllano anche indicatori come processi con numero di thread/handle pari a zero o timestamp inconsueti, che suggeriscono processi terminati o nascosti (in questi casi si può incrociare con una scansione di strutture non collegate tramite plugin psscan per trovare eventuali EPROCESS orfani). In sintesi, la lista dei processi attivi fornisce una “fotografia” dello stato di esecuzione del sistema, analoga a ciò che mostrerebbe un Task Manager al momento del dump.
Moduli e DLL caricati nei processi: per ogni processo, la memoria contiene l’elenco delle DLL e librerie caricate nello spazio di indirizzamento di quel processo. Questa informazione è ottenuta leggendo le strutture di loader del PEB (lista dei moduli in memoria) o tramite scanning delle pagine di memoria alla ricerca di intestazioni PE in uso. Un’analisi dei moduli caricati (dlllist in Volatility) permette di rilevare DLL sospette, ad esempio librerie con percorsi insoliti o iniettate in modo riflessivo (presenti in RAM ma non sul disco). Un modulo in memoria senza un corrispettivo file su disco è un forte indicatore di code injection. Analogamente, driver e moduli del kernel caricati possono essere elencati tramite la struttura globale PsLoadedModuleList(o plugin Volatility modules/modscan): eventuali driver non firmati o posizionati fuori dalle directory di sistema standard potrebbero indicare rootkit in kernel space.
Connessioni di rete e socket: le informazioni sulle connessioni di rete attive (socket aperti TCP/ UDP) sono dati volatili tipicamente persi allo shutdown, ma restano presenti nel dump di RAM. Tramite strutture del driver di rete (ad es. oggetti _TCPT_OBJECT per connessioni TCP in Windows Vista+), è possibile elencare connessioni con relativi endpoint locali/remoti e processo associato. I tool forensi (es. plugin netscan di Volatility) effettuano una scansione della memoria kernel alla ricerca di queste strutture per recuperare connessioni di rete live e anche recentemente chiuse. Ciò consente di scoprire eventuali comunicazioni con server esterni (es. indirizzi IP di C2 malware, porte sospette aperte da processi che normalmente non dovrebbero avere traffico di rete). Ad esempio, se un malware era connesso a un IP esterno al momento del dump, l’analisi della memoria ne rivelerà l’IP e la porta, informazione preziosa per comprendere canali di command-and-control o esfiltrazione dati. Anche socket in ascolto (porte aperte in listening) possono essere identificate attraverso le strutture di socket in memoria (es. plugin sockets). Le connessioni individuate in RAM offrono evidenze che spesso non lasciano altre tracce persistenti (una volta chiusa la connessione, solo la memoria ne serba traccia).
File e handle aperti: la tabella degli handle di ogni processo (puntata dalla struttura EPROCESS) elenca riferimenti a risorse aperte, tra cui file, registry key, pipe, ecc., in uso da quel processo. Analizzando gli handle aperti (plugin Volatility handles o files) si possono scoprire file temporanei o nascosti utilizzati da malware. Ad esempio, se un processo malware ha aperto un file in una directory insolita o con un nome random, o ha una handle verso un file già cancellato sul disco, tali informazioni emergono dalla memoria (poiché l’handle resta in vita finché il file è aperto, anche se è stato cancellato dal filesystem). Questo tipo di analisi aiuta a identificare quali file un malware stava leggendo/scrivendo in quel momento, fornendo indizi su componenti aggiuntivi o dati esfiltrati.
Informazioni di registro e configurazione: parte del Registro di Windows risiede in memoria quando il sistema è acceso, in particolare le hive principali e le chiavi recentemente accedute. Tramite un dump di memoria è possibile estrarre intere hive di registro o singole chiavi/pair valore che erano caricate in RAM. Ad esempio, la Volatility con plugin come hivelist individua le basi di registro in memoria, e printkey può leggerne il contenuto. Ciò consente di rilevare modifiche al registro effettuate da malware solo in memoria (che non siano state ancora scaricate su disco) oppure configurazioni di persistenza: chiavi di Run/RunOnce, chiavi di servizi, ecc., che malware ha modificato per auto-avviarsi. Anche informazioni di configurazione volatile, come le chiavi di registro che mantengono le connessioni di rete recenti le ultime chiavi aperte, possono essere recuperate. In sintesi, il dump di RAM può rivelare l’ultimo stato noto di alcune parti del registro di sistema, anche meglio di un’analisi post-mortem sul disco.
Dati sensibili in memoria (credenziali, input utente): la memoria può contenere frammenti di dati in chiaro che non sono salvati altrove. Un esempio notevole sono le credenziali utente e hash conservati nei processi di sistema come lsass.exe: un dump di LSASS dal file di memoria permette spesso di estrarre hash NTLM o persino password in chiaro delle sessioni di login attive. Strumenti come Mimikatz sfruttano proprio questo. In ambito forense, analizzando la memoria si possono individuare anche testi in chiaro digitati o copiati: ad esempio, la clipboard utente (appunti) può contenere l’ultimo testo copiato, e ciò risiede in RAM; oppure buffer di console che rivelano comandi PowerShell o CLI eseguiti (spesso in Unicode/ASCII facilmente cercabile). Gli analisti utilizzano spesso il string carving sulla memoria per trovare indicatori (es. URL, indirizzi IP, chiavi di registro, nomi di file sospetti, porzioni di codice malicioso, ecc.). Inoltre, malware complessi che usano crittografia possono lasciare in memoria le chiavi di cifratura durante l’esecuzione: se catturate in tempo, queste chiavi (ad es. di ransomware) possono essere recuperate e utilizzate per decifrare i dati colpiti. Qualsiasi informazione volatile, dalle conversazioni in chat non salvate su disco fino alla cronologia dei comandi di shell, rientra tra gli artefatti analizzabili nella RAM.
Strutture del kernel e segni di rootkit: un’analisi approfondita del dump include l’esame di strutture del kernel per individuare manipolazioni malevole. Ad esempio, un rootkit in kernel mode potrebbe nascondere un processo rimuovendolo dalla lista dei processi (modificando i link ActiveProcessLinks in EPROCESS). Un analista, tuttavia, può eseguire scansioni grezze della memoria alla ricerca di pattern di EPROCESS non collegati (Volatility psscan) e scoprire così processi “nascosti” nonostante non appaiano nella lista attiva. Analogamente, si controllano le SSDT e IDT (tabelle di system call e interrupt) per rilevare eventuali hook, oppure si esaminano i puntatori a funzioni di driver per vedere se puntano a regioni non standard (segno di hooking in memoria). La presenza di moduli anomali nel kernel, di sezioni di memoria marcate come eseguibili ma non appartenenti a moduli noti (malfind plugin per individuare codice iniettato in processi), o di driver nascosti, sono tutti artefatti rilevabili solo tramite memory forensics. Queste strutture di basso livello forniscono indizi su tecniche di occultamento utilizzate da malware avanzati (DKOM – Direct Kernel Object Manipulation, hooking di funzioni, patch in-line in memoria, ecc.) e completano il quadro evidenziale individuando anche minacce che non lasciano tracce nei file system.
In sintesi, dall’analisi di un dump di memoria si possono estrarre moltissime evidenze: processi attivi e terminati, moduli e codice iniettato, connessioni di rete, attività utente recente, credenziali, chiavi crittografiche, stato di configurazioni volatili, ecc. Queste informazioni, incrociate tra loro (ad es. correlando un processo malware con le sue connessioni di rete e i file che ha aperto), permettono di ricostruire le azioni svolte da un attaccante o da un malware in un intervallo temporale vicino all’incidente, offrendo una visibilità unica che integra l’analisi dei dischi e di altri log persistenti. La memory forensics fornisce dunque uno snapshot puntuale dello stato di un sistema compromesso, fondamentale per comprendere attività altrimenti inaccessibili dopo lo shutdown.
Ruolo complementare di pagefile.sys e hiberfil.sys nell’arricchimento delle evidenze
Nel contesto Windows, oltre alla RAM fisica, esistono file di sistema su disco che catturano porzioni della memoria volatile e possono fornire evidenze aggiuntive durante un’indagine forense. In particolare pagefile.sys (file di paging) e hiberfil.sys (file di ibernazione) svolgono un ruolo complementare nell’arricchire i dati acquisiti dalla RAM.
Pagefile.sys: è il file di paging usato da Windows come estensione della RAM sul disco. Quando la memoria fisica si riempie, parti dei dati meno usati in RAM vengono “swappati” nel pagefile, per poi essere ricaricati in memoria al bisogno. Dal punto di vista forense, il pagefile.sys spesso contiene frammenti di dati che erano presenti in RAM in precedenza e che potrebbero non trovarsi nell’istantanea della memoria acquisita (perché paginati su disco al momento del dump) . Ad esempio, nel pagefile possono emergere porzioni di documenti, contenuti di pagine web, stringhe di testo, codici malevoli caricati in memoria e poi rimossi, cronologie di navigazione, immagini o altri artefatti di attività utente che non risiedono più nella RAM attiva. In un caso pratico, l’analisi del pagefile ha permesso di estrarre centinaia di URL di siti visitati dall’utente e immagini relative alla navigazione web, informazioni non presenti altrove poiché la cronologia del browser era stata cancellata ma rimasta in pagine di memoria virtuale. Tuttavia, va notato che il pagefile non mantiene la struttura allocativa della RAM bensì solo pagine isolate: di conseguenza, non è direttamente “montabile” con tool come Volatility per estrarre processi o socket. L’analisi forense del pagefile si basa su techiche di carving e ricerca stringhe nei suoi contenuti non strutturati. Ad esempio, si possono estrarre stringhe Unicode/ASCII dal pagefile alla ricerca di indicatori (URL, nomi di file, chiavi di registro, ecc.) oppure utilizzare strumenti di carving per ricostruire file o immagini frammentate al suo interno. In sintesi, il pagefile.sys funge da miniera di dati residuali: qualsiasi informazione che sia passata per la RAM potrebbe aver lasciato traccia in questo file di swap, rendendolo una fonte preziosa di evidenze supplementari (sebbene la sua interpretazione richieda più lavoro manuale e possa produrre anche falsi positivi, dato che include frammenti di pagine appartenenti anche a software di sicurezza, sistema operativo, ecc.).
Hiberfil.sys: è il file in cui Windows salva il contenuto completo della RAM quando il sistema entra in modalità ibernazione (sospensione su disco). In pratica, hiberfil.sys rappresenta un’istantanea byte-per-byte della memoria al momento in cui il sistema è stato ibernato. Questo significa che, dal punto di vista forense, esso equivale a un dump di memoria effettuato dal sistema stesso durante il processo di ibernazione. Se un computer sospetto viene trovato spento in modalità ibernata (o se si dispone del file hiberfil.sys da un’immagine disco), analizzarlo consente di recuperare uno stato della memoria di interesse. L’hiberfil.sys conserva lo stato completo del sistema al momento dell’ibernazione, inclusi tutti i processi attivi, le loro memorie, le connessioni di rete aperte, le impostazioni correnti e così via. È dunque una miniera d’oro forense che permette di sbirciare “l’ultimo respiro” del sistema prima dello stop. In termini pratici, esistono strumenti per convertire hiberfil.sys in un’immagine di RAM standard: ad esempio Volatility (v2 o v3) offre plugin imagecopy/hiberfile per trasformare il file di ibernazione in un file raw analizzabile e tool dedicati come Hibernation Recon supportano i vari formati di hiberfil (che differiscono tra Windows 7 e Windows 8+ a causa di compressione). Una volta convertito, l’analista può trattarlo come un normale dump di memoria e applicare gli stessi plugin per estrarre processi, rete, ecc., col vantaggio che spesso l’ibernazione cattura anche informazioni che un’acquisizione live potrebbe perdere (ad es. perché il sistema era troppo attivo per ottenere un snapshot coerente). Va considerato che su Windows 10/11 il file hiberfil.sys è usato anche per la funzione di Fast Startup (avvio ibrido): in tale caso il file può contenere solo una parte della memoria (kernel/sessione0), ma comunque arricchisce le evidenze con dati volatili aggiuntivi (es. record MFT e hive di registro SYSTEM recenti nel caso del Fast Startup). In conclusione, l’hiberfil.sys fornisce uno storico dellostato della RAM che può integrare un’analisi: ad esempio, se un incidente è avvenuto prima dell’ultimo ibernamento, il file conterrà ancora tracce di quel evento anche se la RAM live successiva è cambiata. È un complemento prezioso soprattutto quando non è stato possibile ottenere un dump live al momento dell’incidente – l’analisi dell’hiberfil può svelare informazioni altrimenti andate perdute.
In sintesi, pagefile.sys e hiberfil.sys arricchiscono l’indagine forense mettendo a disposizione dati della memoria volatile che altrimenti potrebbero sfuggire. Il pagefile estende l’orizzonte temporale delle evidenze volatili conservando tracce di attività passate (come uno storage ausiliario della RAM per dati paginati), mentre l’hiberfil offre un vero snapshot congelato della RAM in un momento specifico (ibernazione). Integrando l’analisi dell’immagine di memoria live con questi file, l’analista può ottenere una visione più completa e retrospettiva degli eventi, aumentando le chance di trovare indicatori utili (es. parti di malware in memoria virtuale, chiavi o password in pagine di swap, stato di sistema precedente all’incident response, ecc.). Di fatto, nelle fasi iniziali di acquisizione della memoria andrebbero sempre considerati anche questi file: ad esempio, copiando il pagefile.sys e l’hiberfil.sys dal disco del sistema target (quando presenti) per poi analizzarli assieme al dump della RAM . Questa visione integrata permette di colmare eventuali lacune e di corroborare le evidenze trovate, migliorando la robustezza delle conclusioni forensi.
Il CSIRT Italia ha segnalato la presenza online di file riservati appartenenti ai clienti di uno studio legale, presumibilmente sottratti dal file server interno dello studio. In qualità di consulente forense incaricato, l’obiettivo primario è preservare e acquisire in modo forense tutte le evidenze digitali rilevanti (server, workstation e dispositivi di rete) garantendone integrità e autenticità, in vista di una possibile indagine giudiziaria. Si seguiranno rigorosamente le best practice internazionali (es. standard ISO/IEC 27037) per identificare, raccogliere, acquisire e conservare le prove digitali. È fondamentale minimizzare qualsiasi alterazione dei dati durante la raccolta e documentare ogni attività svolta, mantenendo una catena di custodia rigorosa delle evidenze.
Assunzioni Operative: si assume che l’incidente sia recente e che i sistemi coinvolti siano ancora disponibili in sede. Il file server Linux è identificato come potenziale fonte dei dati esfiltrati; tuttavia, non si esclude il coinvolgimento di una o più delle 5 workstation Windows (ad esempio come punto d’ingresso iniziale dell’attacco). Il firewall perimetrale potrebbe contenere log utili sulle connessioni di esfiltrazione. Si dispone dell’accesso fisico a tutti i dispositivi e del consenso dello studio per procedere all’acquisizione forense. Si prevede inoltre di avere a disposizione strumenti forensi (hardware e software) adeguati, inclusi supporti di memorizzazione esterni capienti per salvare le immagini acquisite. Ogni attività verrà coordinata in modo da ridurre al minimo l’impatto sull’operatività dello studio, pur privilegiando la preservazione delle prove rispetto alla continuità di servizio.
Identificazione e preservazione delle evidenze
Come primo passo, identifichiamo tutte le potenziali fonti di evidenza digitale nell’infrastruttura compromessa. In questo caso includono:
File server Linux (contenente i dati dei clienti) – sorgente probabile dell’esfiltrazione.
Workstation Windows 10 (5 unità) – potrebbero aver subito compromissioni (ad es. tramite malware o furto credenziali) usate per accedere al server.
Firewall perimetrale – dispositivo di rete con possibili log di traffico in uscita e regole di accesso.
Copie dei file esfiltrati rinvenuti online – per confronti con i dati originali e conferma dell’effettiva violazione.
Una volta identificate, si procede alla preservazione immediata dello stato dei sistemi per evitare alterazioni o perdite di informazioni volatili. In particolare:
Isolamento dei dispositivi dalla rete: scolleghiamo il file server e le workstation dalla rete (cavo Ethernet o Wi-Fi) per impedire ulteriori comunicazioni con l’esterno o possibili azioni di copertura da parte di un eventuale attaccante ancora connesso. Anche il firewall, se compromesso, viene isolato (ad es. rimuovendo temporaneamente la connessione WAN) mantenendolo però acceso se necessario per preservare i log in memoria.
Valutazione dello stato (acceso/spento) dei sistemi: se i computer sono accesi, si considera di eseguire un’acquisizione live di dati volatili. In base all’ordine di volatilità (RFC 3227), le informazioni più volatili come il contenuto della RAM e le connessioni di rete attive vanno acquisite prima di spegnere i sistemi. La memoria RAM può contenere informazioni cruciali (password in chiaro, processi malware in esecuzione, connessioni di rete attive, ecc.) che andrebbero perse allo spegnimento. Dunque, per server e workstation accesi si pianifica di catturare un dump della memoria prima di procedere oltre.
Documentazione della scena: prima di manipolare i dispositivi, si documenta accuratamente la scena: fotografia dei cablaggi, posizione dei dispositivi, stato dei sistemi (acceso/spento, schermate visibili), etichette o seriali. Questo aiuta a ricostruire il contesto e dimostrare che ogni passaggio è stato eseguito correttamente. Ogni attività viene annotata con data, ora, luogo e persone coinvolte, pronto per essere inserita nel registro di catena di custodia.
Stabilizzazione del sistema compromesso: in caso il file server Linux sia in esecuzione e si tema la presenza di malware attivo (es. una backdoor), si valuterà se conviene spegnere immediatamente dopo la raccolta della RAM. Spesso, in incidenti gravi, l’arresto immediato (es. scollegando l’alimentazione) è consigliato dopo la raccolta dei dati volatili, per evitare che malware distruttivi cancellino tracce all’arresto ordinato. Tuttavia, questa decisione va ponderata in base alla situazione (ad esempio, la presenza di servizi critici potrebbe richiedere un arresto controllato). Nel dubbio, è preferibile privilegiare l’integrità delle prove rispetto alla continuità operativa.
Acquisizione forense dei sistemi coinvolti
Dopo aver messo in sicurezza l’ambiente, si procede con l’acquisizione forense bit-a-bit dei supporti di memoria e la raccolta dei log, utilizzando strumenti e procedure tali da garantire copie esatte e immodificabili degli originali. Tutte le acquisizioni avverranno utilizzando strumentazione forense dedicata (write blocker, software di imaging) e seguendo protocolli standard. Di seguito, il dettaglio per ciascun componente:
File server Linux (acquisizione disco e memoria)
Il file server è il principale indiziato da cui sarebbero stati esfiltrati i dati. Le attività previste sono:
Dump della memoria RAM: ce il server è ancora acceso, si esegue una copia della memoria volatile. Su sistemi Linux, si può utilizzare ad esempio Linux Memory Extractor (LiME) (modulo kernel) o strumenti come Magnet DumpIt for Linux (tool standalone) per ottenere un file dump della RAM completo. L’operazione viene svolta rapidamente, salvando l’output su un supporto esterno montato in sola lettura. Questa acquisizione live è fondamentale perché la RAM potrebbe contenere indicazioni di processi sospetti, chiavi di cifratura, o connessioni attive dell’attaccante. Si annotano orario e configurazione del sistema al momento del dump (es. elenco processi e connessioni aperte, utilizzando comandi come ps, netstat o tool forensi,se possibile, evitando però alterazioni significative).
Acquisizione forense del disco: successivamente, si procede allo shutdown del server per eseguire l’acquisizione del disco in modo sicuro. Idealmente, il disco fisso del server viene rimosso dalla macchina per evitare qualsiasi modifica dovuta all’avvio del sistema operativo. Il disco viene collegato a una workstation forense tramite un write-blocker hardware (es. un Tableau) che impedisce qualsiasi scrittura accidentale sul supporto originale. In alternativa, se non fosse possibile estrarre il disco (ad es. array RAID complesso in produzione), si potrebbe avviare il server da un bootable USB forense (es. distribuzione CAINE basata su Linux Ubuntu o Kali Linux in modalità forense) che non altera i dischi interni (automount disabilitato, accesso in sola lettura). Avviato l’ambiente forense, si può usare il tool dd o dcfldd per creare un’immagine bitstream di ogni unità logica. Ad esempio: dcfldd if=/dev/sda of=/media/esterna/server-image.img hash=sha256 log=server-img.log (dove si calcola anche l’hash durante la copia). È preferibile usare dcfldd o strumenti analoghi in quanto progettati per scopi forensi (permettono di calcolare direttamente hash MD5/SHA e suddividere l’immagine in segmenti, se necessario). In alternativa, si può impiegare Guymager (tool con interfaccia grafica su Linux) che consente di creare immagini in formato raw E01 con calcolo automatico degli hash. Durante l’acquisizione, non si deve mai salvare l’immagine sullo stesso disco oggetto dell’acquisizione ma su un dispositivo di destinazione separato (ad esempio un drive USB esterno capiente formattato exFAT/NTFS). Si raccomanda il formato E01 (EnCase Evidence File) per il disco del server, poiché comprime i dati e consente di includere metadati (es. informazioni del caso, timestamp di acquisizione, etc.) utili per la catena di custodia. Al termine, viene calcolato e registrato l’hash (tipicamente MD5 e SHA-1) dell’immagine e confrontato con quello calcolato sul disco originale, per verificare la conformità bit-a-bit. Un match degli hash conferma che la copia è identica all’originale e non alterata, garantendo l’autenticità dell’evidenza. Tutte le operazioni vengono registrate nel log di acquisizione (nome del dispositivo, orari di inizio/fine, dimensione dell’immagine, algoritmi di hash utilizzati, ecc.). Il supporto originale (disco server) viene poi sigillato e conservato come evidenza originale.
Raccolta di log e configurazioni: oltre all’immagine completa del file system (che include comunque i log di sistema), si può procedere a estrarre copie logiche di file di log chiave per un’analisi immediata. Ad esempio, i file in /var/log/ (log di autenticazione SSH, log di Samba NFS se il server fungeva da file server di rete, log di sistema) sono cruciali per ricostruire gli accessi e le operazioni avvenute. Tali log, se disponibili, vengono copiati separatamente (sempre tramite strumenti che garantiscano l’integrità, ad es. usando cp in ambiente forense o esportandoli con nc su un’altra macchina) e i loro hash calcolati, così da poterli utilizzare per un’analisi più rapida senza dover montare subito l’intera immagine del disco. Naturalmente l’integrità di questi file è garantita anche dal fatto che provengono da un’immagine forense verificata.
Workstation Windows 10 (acquisizione disco e, se opportuno, memoria)
Le cinque workstation Windows potrebbero aver giocato un ruolo nell’incidente (es. come punto di ingresso iniziale tramite phishing o malware, o come postazioni da cui è partito l’accesso non autorizzato al server). Il piano prevede:
Dump della RAM (se accese): per ogni workstation ancora accesa al momento dell’intervento, si effettua prima la cattura della memoria volatile. Su Windows, uno strumento pratico è Magnet Forensics RAM Capture (DumpIt), eseguibile da chiavetta USB: con un doppio click esegue il dump completo della RAM su un file .raw o .mem. Questo richiede pochi minuti per decine di GB di RAM e fornisce istantanee dei processi in esecuzione, connessioni di rete attive, moduli caricati, ecc. Spesso i ransomware o altri malware lasciano tracce in memoria (processi o librerie iniettate) che possono essere scoperte con analisi successive (es. con Volatility). Anche credenziali o token temporanei possono risiedere in RAM, quindi questa è un’evidenza preziosa. Si salva il dump su un disco esterno, annotando ora e macchina, e si calcola l’hash anche per questi file di memoria.
Spegnimento e rimozione dischi: subito dopo il dump (o immediatamente, se la macchina era spenta), si spengono le workstation. Idealmente, nel caso di sospetto malware attivo, è accettabile uno spegnimento improvviso (staccando l’alimentazione o la batteria) per evitare che eventuali programmi malevoli intercettino la normale procedura di shutdown (p.es. alcuni malware possono cancellare tracce al momento dello spegnimento). Dato che abbiamo già acquisito la RAM, il rischio di perdere dati volatili importanti è mitigato. Una volta spento il sistema, si procede a rimuovere il disco interno (HDD/SSD) dalla workstation.
Imaging forense dei dischi: ogni disco viene etichettato univocamente (es. WS1, WS2, … WS5) e collegato tramite write-blocker a una postazione forense. Su sistemi Windows, useremo FTK Imager (software forense gratuito di AccessData/Exterro) sulla nostra workstation forense per creare immagini bitstream dei dischi. FTK Imager permette di scegliere il formato (raw dd, E01, AFF, etc.) e di calcolare automaticamente hash MD5/SHA1 durante l’acquisizione. Prima di procedere, ci assicuriamo che Windows non effettui mount automatico delle partizioni del disco inserito: infatti Windows tende a montare qualsiasi volume riconosciuto, rischiando di alterare last access time o altri metadata. L’uso del write-blocker hardware previene questo problema, garantendo che il sistema operativo forense veda il disco come sola lettura. In FTK Imager, useremo l’opzione Create Disk Image selezionando la sorgente fisica (Physical Drive) e specificando come destinazione un percorso su un drive esterno. Scegliamo il formato E01 (EnCase Evidence) per coerenza e compressione, inserendo nei metadati dell’immagine i dettagli del caso (nome caso, numero evidenza, esaminatore, etc.). Abilitiamo l’opzione di verifica hash al termine (FTK Imager calcolerà hash MD5/SHA1 e li comparerà automaticamente). Procediamo quindi all’imaging completo. Ad acquisizione terminata, verifichiamo i log di FTK Imager che riporteranno gli hash calcolati; un confronto positivo tra hash di origine e copia conferma la bontà dell’immagine. Ripetiamo questo processo per tutti i dischi delle 5 postazioni.
Acquisizione dati di interesse dalle workstation: le immagini dei dischi Windows conterranno informazioni quali i log di Windows (eventi di sicurezza nel registro eventi), file temporanei, cronologia di navigazione, eventuali malware presenti, ecc. Sebbene l’analisi dettagliata avverrà successivamente in laboratorio, in sede di acquisizione si può già valutare di estrarre rapidamente alcuni artefatti se immediatamente utili. Ad esempio, log di Windows Event Viewer (Security.evtx) per vedere login sospetti, o la lista di utenti e gruppi locali, possono essere esportati usando strumenti come FTK Imager stesso (che consente di sfogliare il file system e salvare file singoli) prima di smontare il disco. Tuttavia, tali operazioni non sono strettamente necessarie in campo se l’obiettivo principale è acquisire tutto per analisi approfondita successiva. L’essenziale è che le immagini siano integre e complete.
Firewall perimetrale (raccolta log e configurazione)
Il firewall costituisce il punto di ingresso/uscita della rete aziendale. Anche se potrebbe non essere opportuno spegnerlo (specie se fornisce connettività Internet allo studio) prima di aver analizzato la situazione, ai fini forensi occorre acquisire i dati che possono testimoniare le connessioni di esfiltrazione. Le azioni prevedono:
Esportazione dei log di traffico: la maggior parte dei firewall di classe enterprise o SMB consente di esportare i log di sistema (ad esempio file di log di sessione, eventi di intrusion detection se integrato, log VPN, ecc.) tramite interfaccia di amministrazione o SSH. Si accede al firewall (in sola lettura) e si scaricano i log relativi al periodo sospetto dell’incidente. In particolare, interessano log di connessioni uscenti (egress) dal file server o dalle workstation verso l’esterno. Questi log possono rivelare indirizzi IP di destinazione e volumi di datitrasferiti durante l’esfiltrazione. Ad esempio, se i dati sono stati caricati su un sito web o cloud, il firewall potrebbe mostrare un flusso FTP/HTTP/HTTPS anomalo in uscita da un IP interno (quello del server) verso un IP esterno sconosciuto, magari con un volume di svariati gigabyte. Tali evidenze sono cruciali per ricostruire il canale di esfiltrazione. I log vengono salvati (in formato testo o CSV) su supporto forense e ne vengono calcolati gli hash per garantirne l’integrità.
Configurazione e regole: si acquisisce anche la configurazione del firewall (spesso esportabile come file di backup) per vedere che porte/servizi erano aperti verso l’esterno. Ad esempio, se il file server aveva porte aperte (SSH, SMB) o se esistevano regole di port forwarding, ciò può essere rilevante. La config, una volta esportata, viene sottoposta a hash e conservata.
Eventuale immagine del dispositivo: se il firewall è un appliance software (ad es. basato su Linux/BSD come pfSense) con storage interno, e se l’hardware lo permette, si può anche considerare di fare un’immagine forense del suo drive (similmente a quanto fatto per server/PC). Tuttavia, molti firewall commerciali hanno filesystem proprietari o sono crittografati; spesso è sufficiente raccogliere log e config. Nel caso di un firewall standard PC-based, si potrebbe spegnere e clonare il disco con gli stessi metodi (write-blocker, etc.), ma solo dopo aver ottenuto i log volatili se non persistenti.
Evidenze dei file esfiltrati online
Parallelamente all’acquisizione interna, recuperiamo i file trapelati sul sito Internet segnalato dal CSIRT. Questi file costituiscono prova dell’avvenuta violazione e saranno utili per confronti. Le attività sono:
Download dei file dal sito esterno: utilizzando un computer sicuro, si scaricano i file trovati online, preservandone i metadati ove possibile. Ad esempio, se disponibili via web, si può usare wget o browser, evitando di modificarli (impostando l’orario di modifica come originario se indicato). Si registra l’URL e l’ora del download e, se possibile, si fa uno screenshot della pagina web dove erano disponibili, come documentazione.
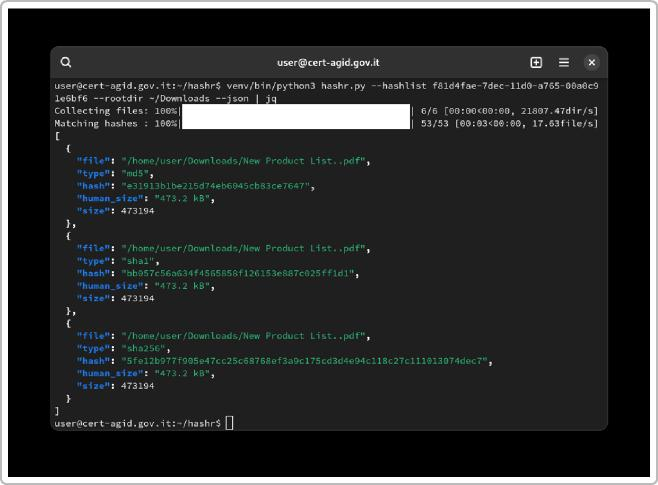
Calcolo hash e conservazione: su ogni file esfiltrato scaricato, si calcolano hash (MD5/SHA1) per poterli confrontare successivamente con gli hash dei file originali sul server. In ambito forense, il confronto degli hash permetterà di dimostrare che il file online è esattamente uguale a quello presente sul server (qualora nelle immagini acquisite del server sia rinvenuto lo stesso hash), confermando così l’origine dell’esfiltrazione. Questi file scaricati diventano anch’essi evidenze digitali e vengono inseriti nella catena di custodia.
Metadati e attributi: si analizzano brevemente i metadati di tali file (es. proprietà del documento, autore, date di creazione/modifica) poiché potrebbero rivelare informazioni sull’origine (ad es. username del sistema dal quale provengono, versione software, etc.). Tali informazioni, se trovate, saranno poi corroborate con l’analisi interna (ad esempio, se i documenti recano come autore il nome di un dipendente dello studio, ciò può suggerire da quale PC/server provenivano).
Verifica dell’integrità e documentazione della Catena di Custodia
Durante e dopo ogni acquisizione, si verifica l’integrità delle evidenze digitali e si aggiornano i documenti che compongono la Catena di Custodia:
Calcolo e verifica degli hash crittografici: come standard, per ogni immagine forense creata (dischi di server, PC) e per ogni file rilevante copiato (dump di RAM, log, file esfiltrati, ecc.), si calcola almeno un algoritmo di hash (tipicamente MD5 e SHA-1, oppure SHA-256 per maggiore sicurezza). Il valore di hash viene confrontato con quello ricalcolato all’occorrenza sulle stesse evidenze per assicurare che non vi siano alterazioni. Ad esempio, FTK Imager e altri tool riportano automaticamente hash MD5/SHA1 post-acquisizione. Questi hash vengono annotati nel verbale di acquisizione accanto all’identificativo dell’evidenza. La corrispondenza degli hash tra originale e copia forense prova formalmente che la copia è identica al bit all’originale, requisito fondamentale per la validità probatoria.
Documentazione dettagliata: si redige un verbale tecnico di acquisizione in cui per ogni dispositivo analizzato si riportano: descrizione (marca, modello, S/N), identificativo assegnato come evidenza, persona che ha eseguito l’operazione, data/ora di inizio e fine imaging, strumento usato, hash dell’immagine ottenuta, eventuali osservazioni (es. errori di lettura, settori danneggiati se presenti). Inoltre, come previsto dalle linee guida, si documenta ognioperazione svolta su ciascun reperto in ordine cronologico. La Catena di Custodia descrive l’intero ciclo di vita dell’evidenza digitale, dalla raccolta iniziale fino all’eventuale presentazione in tribunale. Ad esempio: “Evidenza E01: Disco fisso server SN… prelevato in data … ore … da Tizio, acquisito in copia forense file XYZ.E01 hash MD5=…, SHA1=…, da Caio con strumento FTK Imager vX, consegnato in custodia a Sempronio alle ore …”. Ogni trasferimento di custodia (passaggi di mano dell’evidenza, spostamento dal luogo di raccolta al laboratorio, etc.) viene parimenti registrato con data, ora, persona che consegna e persona che riceve e firma (quando possibile). Questo garantisce tracciabilità completa: in ogni momento si può stabilire chi ha avuto accesso all’evidenza e quando.
Protezione fisica delle evidenze: dopo l’acquisizione, i supporti originali (dischi rimossi, ecc.) vengono riposti in contenitori sigillati con etichette anti-manomissione (ad es. evidenziatori di apertura). Si appone un sigillo sia sull’originale sia su una delle copie forensi conservate (la seconda copia sarà utilizzata per l’analisi). Eventuali violazioni dei sigilli sarebbero evidenti e renderebbero dubbia l’integrità del reperto. Oltre ai sigilli fisici, si proteggono i dati da fattori esterni: ad esempio, i supporti vengono conservati in ambiente a temperatura e umidità controllata, lontano da campi elettromagnetici che potrebbero danneggiarli. Nel nostro caso, i dischi originali delle workstation e del server, dopo l’imaging, verranno ad esempio inseriti in sacchetti antistatici, sigillati, etichettati e messi in una cassaforte o armadio blindato. Lo stesso per eventuali USB contenenti i dump di RAM o i file scaricati: se tali dati sono salvati su supporti rimovibili (es. SSD esterno), anche questi supporti vengono sigillati e custoditi.
Conservazione delle copie forensi: le immagini forensi acquisite (file .E01, .dd, dump RAM, ecc.) verranno duplicate se possibile: una copia master immutabile, conservata come evidenza intoccabile, e una o più copie di lavoro su cui effettuare l’analisi tecnica. La copia master (ad es. su hard disk dedicato) viene anch’essa sigillata e custodita, mentre la copia di lavoro potrà essere caricata sulle workstation forensi per l’analisi senza rischiare di compromettere l’originale. In caso di contestazioni, la copia master potrà sempre essere riesaminata per verifica indipendente.
Consegna e destinazione delle evidenze
Una volta concluse le acquisizioni, le evidenze dovranno essere consegnate e/o conservate in modo appropriato in vista di procedimenti futuri:
Reportistica e verbali ufficiali: si consegna allo studio legale un rapporto forense preliminare che elenca tutte le evidenze raccolte e descrive sinteticamente le modalità di acquisizione seguite, certificando che sono stati rispettati i protocolli per assicurare conformità degli originali e immodificabilità delle copie. Questo rapporto include in allegato i verbali di cui sopra e i documenti costituenti la Catena di Custodia firmati dal consulente.
Consegna a autorità inquirenti (se previsto): se lo studio intende sporgere denuncia o se l’incidente configura reati perseguibili d’ufficio, le evidenze digitali dovranno essere messe a disposizione dell’Autorità Giudiziaria. In tal caso, si preparano i reperti secondo le regole richieste: ogni evidenza viene identificata con un numero di repertazione, descritta nel verbale di consegna e consegnata (es. alla Polizia Postale o altra forza di polizia competente). I rappresentanti dell’autorità firmano per ricevuta, entrando così loro nella catena di custodia come nuovi custodi dell’evidenza. Da quel momento, ogni accesso ai dati dovrà avvenire sotto il loro controllo o con la loro autorizzazione. È importante evidenziare che la documentazione della Catena di Custodia accompagna le evidenze: fornisce al giudice la garanzia che dal momento della raccolta alla presentazione in giudizio non vi siano state manomissioni.
Conservazione a lungo termine: sia lo studio sia l’autorità (se coinvolta) dovranno conservare le evidenze digitali in modo sicuro fino alla conclusione di ogni procedura legale, ed anche oltre se richiesto. Ciò significa storage in ambienti controllati, con accesso limitato solo a personale autorizzato. Ad esempio, i supporti sigillati possono essere custoditi in una sala prove dedicata con registro accessi, e le copie digitali possono essere conservate anche in cassaforte ignifuga (per prevenire perdita in caso di incendio). Si ricorda che anche i dati digitali soffrono il passare del tempo (bit rot, obsolescenza hardware): pertanto, per conservazioni prolungate, si potrebbero effettuare periodiche verifiche dell’integrità (ricalcolando gli hash a distanza di tempo per verificare che coincidano ancora) e migrazioni su nuovi supporti in caso di necessità, sempre documentando ogni passaggio.
Strumentazione e tecniche utilizzate
Di seguito un riepilogo degli strumenti specifici impiegati e la motivazione della loro scelta, in accordo con le best practice forensi:
Write Blocker Hardware (es. Tableau, Digital Intelligence UltraBay): dispositivo essenziale che si interpone tra il supporto originale (es. SATA/SAS/USB) e la macchina forense, consentendo solo comandi di lettura. Ciò previene modifiche accidentali ai dati originali durante l’imaging . L’uso del write blocker garantisce l’immodificabilità del reperto originale in linea con i requisiti legali (copia conforme e non alterata). Abbiamo utilizzato write blocker per tutti i dischi rimossi prima di leggerli sui nostri sistemi di acquisizione.
Software di imaging forense
FTK Imager: scelto per l’acquisizione delle workstation Windows. È uno strumento gratuito e affidabile, in grado di creare immagini forensi (raw, E01, AFF) e di calcolare hash integrati. Supporta anche la cattura della RAM su macchine Windows con pochi click. Lo abbiamo usato per comodità e per mantenere un formato standard (E01) ampiamente accettato nelle corti. Inoltre FTK Imager genera un log dettagliato utile per testimoniare la correttezza delle operazioni.
dd/dc3dd: utilizzato in ambienti Linux per la sua ubiquità e controllo. dc3dd in particolare è una variante di dd orientata al digital forensics, che permette hashing on the fly e log avanzati. È stato impiegato per duplicare il disco del server Linux in maniera forense.
Guymager: alternativa GUI su Linux per imaging, scelta nel caso di acquisizioni tramite live CD CAINE. Genera direttamente file .E01 e calcola hash, semplificando l’operatività.
Tableau TD3/TX1 Forensic Imager (opzionale): si tratta di unità hardware dedicate che clonano dischi a livello hardware senza bisogno di PC. Se disponibile, avremmo potuto usarla per velocizzare l’acquisizione dei dischi grandi (soprattutto il server) con copia diretta disk-to-disk. Tali dispositivi garantiscono velocità ottimizzata e logging automatico, con verifica hash in hardware. Nel nostro scenario, abbiamo ipotizzato l’uso prevalente di software, ma è menzionato per completezza.
Strumenti per il dump della memoria volatile
Magnet RAM Capture (DumpIt): utilizzato per dump veloci della RAM sulle macchine Windows. Scelto per la sua semplicità (eseguibile portabile) e velocità. Il dump risultante è compatibile con i più diffusi framework di analisi della memoria (Volatility, Rekall).
LiME (Linux Memory Extractor): modulo kernel per Linux usato per dump di RAM del server. Scelto perché consente di ottenere un dump consistente direttamente da kernel space, con un impatto minimo sul sistema. Richiede preparazione (compilazione modulo ad hoc per la versione di kernel), perciò si potrebbe optare in alternativa per AVML (Azure VM Memory Leaker) di Microsoft, un tool user-space che non necessita compilazione. In ogni caso, l’importante è aver ottenuto la memoria prima dello spegnimento.
Volatility Framework (analisi post acquisizione): citato come strumento che useremo successivamente per analizzare i dump di memoria e cercare indizi (processi anomali, moduli sospetti, connessioni residue, credenziali in chiaro, ecc.).
Utilities di sistema e log collection
Comandi come ifconfig/ipconfig, netstat, tasklist/ps, wmic etc., possonoessere stati eseguiti durante la fase live (se fatta) per raccogliere informazioni di stato (es. elenco connessioni di rete, processi attivi, utenti loggati). Tali informazioni sono state annotate e salvate come parte delle evidenze (es. reindirizzando l’output su file di testo).
Per il firewall, l’interfaccia di amministrazione web/SSH integrata è stata lo strumento per estrarre i log e configurazioni. In mancanza di esportazione diretta, si poteva eseguire uno script o screenshot.
Hashing tools: utilizzo di algoritmi MD5, SHA-1, SHA-256 tramite tool integrati (ad es. md5sum/sha1sum su Linux, o utilità come HashCalc su Windows) per calcolare le impronte digitali delle evidenze.
In sintesi, la combinazione di questi strumenti e tecniche è stata scelta per massimizzare l’affidabilità e la completezza della raccolta delle prove, minimizzando al contempo il rischio di alterazione dei dati originali. Ogni scelta (dall’uso del write blocker all’acquisizione della RAM) è motivata da esigenze probatorie: garantire che ogni bit di informazione utile venga conservato e possa essere presentato in giudizio con adeguato fondamento di autenticità.
Conclusione
Al termine di queste operazioni, lo studio legale disporrà di copie forensi integre di tutti i sistemi coinvolti, pronte per l’analisi approfondita. Nelle fasi successive, in laboratorio, si potranno esaminare le immagini acquisite con software di analisi forense (come Autopsy, EnCase, X-Ways o altri) per ricostruire la timeline dell’intrusione, identificare l’eventuale malware o tecnica di attacco utilizzata, e confermare quali dati sono stati esfiltrati e come. I log di firewall e di sistema aiuteranno a determinare quando everso dove sono stati trasmessi i dati rubati . Tutto questo, unito alle evidenze conservate in modo corretto, permetterà eventualmente di presentare una prova tecnica solida alle autorità competenti e in sede legale, sostenendo le azioni che lo studio legale deciderà di intraprendere a tutela dei propri clienti e contro gli autori della violazione.
Fonti e riferimenti: le procedure adottate seguono gli standard riconosciuti in ambito digital forensics e incident response, tra cui le linee guida ISO/IEC 27037:2012 per la gestione delle evidenze digitali. Strumenti come FTK Imager e write-blocker hardware sono prassi comune per garantire copie forens affidabili, così come l’uso di hash crittografici per assicurare la conformità delle copie. La catena di custodia e la sigillatura dei reperti vengono gestite secondo le indicazioni della migliore dottrina forense 19 21 , assicurando in ogni momento l’integrità e l’autenticità del materiale probatorio raccolto. Con questo approccio metodico e documentato, l’indagine potrà proseguire sapendo di avere solide basi probatorie su cui fare affidamento.
Standard internazionali e processi di Incident Response (NIST SP 800-61, ISO/IEC 27035)
Una gestione efficace degli incidenti informatici richiede processi strutturati e aderenza a standard internazionali riconosciuti. Il NIST SP 800-61 (Computer Security Incident Handling Guide) definisce un processo ciclico per l’Incident Response, articolato in quattro fasi fondamentali: Preparazione, Rilevamento e Analisi, Contenimento, Eradicazione e Ripristino, e Attività Post-Incidente. La fase di Preparazione consiste nel predisporre politiche, procedure e risorse (come un team CSIRT formato, strumenti di monitoraggio, playbook) per poter gestire efficacemente eventuali incidenti. Segue la fase di Rilevamento e Analisi, in cui si monitorano gli eventi di sicurezza, identificando possibili segnali d’incidente e raccogliendo evidenze; qui il team valuta i sintomi per determinare se si tratti effettivamente di un incidente e ne classifica la gravità. Durante la fase di Contenimento,Eradicazione e Ripristino si mettono in atto misure per limitare i danni (ad esempio isolando sistemi compromessi), eliminare la minaccia (rimuovendo malware, chiudendo vulnerabilità) e ripristinare operatività e dati colpiti (ad es. da backup puliti). Infine, la fase di Post-Incidente prevede attività di lesson learned: analisi retrospettiva dell’incidente e della risposta fornita, al fine di estrarre insegnamenti, migliorare procedure interne e prevenire il ripetersi di attacchi analoghi. Questo ciclo ricalca l’approccio di miglioramento continuo (ciclo di Deming Plan-Do-Check-Act) tipico anche degli standard ISO di gestione, evidenziando come l’Incident Response sia un processo iterativo in cui l’esperienza di ogni incidente rafforza la preparazione per il futuro.
In parallelo al NIST, lo standard internazionale ISO/IEC 27035 offre linee guida complete per l’Information Security Incident Management. Esso enfatizza l’importanza di una preparazione proattiva, di strategie di risposta chiare e di piani di recupero strutturati allineati alle politiche di sicurezza organizzative. La serie ISO 27035 (aggiornata nel 2023 in più parti) copre l’intero ciclo di gestione: dalla pianificazione e preparazione (ISO 27035-2 fornisce dettagli su come prepararsi, rilevare e segnalare gli incidenti) fino alle attività di risposta, mitigazione e miglioramento continuo. In sostanza, ISO 27035 integra e approfondisce i controlli di Incident Response già accennati in ISO/IEC 27001/27002, fornendo un framework operativo che assicura che le organizzazioni siano pronte a identificare, gestire e recuperare efficacemente da un incidente di sicurezza. Aderire a standard come NIST SP 800-61 e ISO 27035 aiuta le organizzazioni a definire ruoli e responsabilità (ad esempio l’istituzione di un CSIRT/SOC interno), instaurare procedure di escalation e comunicazione (verso il top management e verso enti esterni), e garantire la conformità a normative di settore. Questi standard rappresentano dunque un riferimento imprescindibile per un reaponsabile per la prevenzione e gestione di incidenti in contesti critici, fornendo sia un linguaggio comune sia best practice riconosciute a livello internazionale.
Indicatori di compromissione e firme di attacco (IoC, YARA, SIGMA, Snort)
Un aspetto centrale nell’identificazione e risposta agli incidenti informatici è l’utilizzo degli Indicatori di Compromissione (IoC) e delle signature di attacco. Gli IoC sono evidenze osservabili che suggeriscono con buona probabilità che si sia verificata una compromissione; esempi tipici includono hash di file maligni, indirizzi IP o domini di command and contro!, chiavi di registro anomale, stringhe univoche di malware, ecc. Riconoscere tempestivamente questi indicatori permette ai team di sicurezza di individuare attacchi in corso o passati e di attivare misure di contenimento prima che il danno si propaghi. A tal fine, la comunità di cybersecurity ha sviluppato vari formati standardizzati per esprimere e condividere IoC e regole di rilevamento, tra cui spiccano YARA, SIGMA e Snort.
YARA (acronimo ricorsivo di “YARA is Another Recursive Acronym”) è uno strumento pensato per aiutare i ricercatori e analisti malware nell’identificazione di file malevoli attraverso pattern noti. Le regole YARA sono scritte in un linguaggio dedicato che consente di definire firme basate su pattern di byte,stringhe testuali o espressioni regolari presenti in un file. In pratica, una regola YARA descrive caratteristiche distintive di una famiglia di malware (ad esempio stringhe uniche nel codice, impronte binarie, sequenze in memoria), così che scansionando file o processi in un sistema si possano “far scattare” allarmi quando vi è match con le firme definite. YARA viene ampiamente usato nei CERT/SOC per analizzare campioni sospetti: ad esempio, dopo un incidente si possono ricavare regole YARA dai file malware individuati e distribuirle per verificare se altri sistemi siano stati infetti dallo stesso attacco. Questo strumento ha trovato impiego in numerosi casi operativi anche in Italia, dove CERT-AgID e CSIRT Italia hanno pubblicato regole YARA per identificare vari malware osservati nelle campagne malevole rivolte alla Pubblica Amministrazione.
Mentre YARA si focalizza su pattern statici in file e payload malevoli, SIGMA affronta il problema della detection in modo diverso, operando a livello di !og e eventi. SIGMA è infatti un formato di regole generico e indipendente dal fornitore, pensato per descrivere pattern sospetti nei log in un linguaggio unificato (sintassi YAML) che poi può essere tradotto nelle query specifiche di diversi sistemi SIEM. L’obiettivo di SIGMA è fornire una “lingua franca” per le regole di correlazione, in modo da condividere facilmente tra organizzazioni schemi di rilevamento per attacchi noti. Ad esempio, una regola SIGMA può definire la ricerca di eventi di autenticazione anomali (come molti tentativi falliti seguiti da un accesso riuscito – sintomo di brute forcing) o l’uso sospetto di comandi di PowerShell in una macchina Windows. Tali regole, una volta scritte in SIGMA, vengono poi convertite con appositi tool (es. sigmac) nei linguaggi di query di prodotti come Splunk, Elastic, QRadar, ecc., permettendo a qualsiasi SOC di implementare rapidamente controlli anche senza doverli riscrivere da zero per la propria piattaforma. L’uso di SIGMA sta favorendo la condivisione di conoscenza sulle minacce: community internazionali e anche il CERT-AgID pubblicano di frequente regole SIGMA per rilevare gli IoC di campagne attive, consentendo ai difensori di reagire in modo uniforme.
Un altro pilastro del rilevamento basato su firme è rappresentato da Snort, uno dei più diffusi motori IDS/IPS open-source a livello di rete. Snort utilizza un linguaggio di regole proprietario ma abbastanza leggibile, con cui si possono descrivere pattern di traffico malevolo o anomalo. Una regola Snort è tipicamente composta da un header (che specifica l’azione da intraprendere – ad es. a!ert vs drop –, il protocollo, IP/porta sorgente e destinazione) e da un blocco di opzioni che definiscono la condizione di matching (es. contenuto di pacchetto, sequenze di byte, flag TCP, stringhe nel payload, espressioni regolari). Grazie a questo meccanismo, Snort può effettuare analisi in tempo reale del traffico direte, confrontando ogni pacchetto con la libreria di firme: al rilevamento di una corrispondenza, può generare allarmi o bloccare il traffico se usato in modalità IPS. La forza di Snort risiede nella grande comunità che sviluppa e aggiorna continuamente regole per nuove minacce (es. per individuare exploit noti, pattern di comunicazione di botnet, tentativi di SQL injection, scansioni di porte, ecc.). In un SOC aziendale o in un CSIRT nazionale, Snort (o il suo successore Suricata) è uno strumento chiave per la rilevazione degli attacchi sulla rete, complementare alle analisi host-based come quelle guidate da YARA e alle correlazioni su log abilitate da SIGMA.
Questi strumenti e formati evidenziano l’importanza degli IoC nella cyber difesa moderna. La capacità di generare, condividere e utilizzare efficacemente IoC e signature consente ai team di Incident Response di rilevare attacchi noti in modo rapido e di contenerli prima che producano danni gravi. In contesti governativi come quello italiano, ad esempio, il CERT-AgID mantiene un feed IoC pubblico e collabora con il CSIRT Italia per diffondere indicatori relativi a campagne malevole correnti, permettendo alle varie amministrazioni di aggiornare i propri sistemi di detection. Il valore di questa condivisione è tangibile: nel solo 2024, il CERT-AgID ha individuato ben 1.767 campagne malevole indirizzate alle PA e condiviso 19.939 indicatori di compromissione con la comunità, segno di un’intensa attività di threat intelligence a supporto della difesa collettiva. In definitiva, IoC e firme (YARA, SIGMA, Snort) rappresentano il “linguaggio operativo” quotidiano in cui si concretizza l’Incident Response: dal malware analizzato in laboratorio (YARA), ai log di sistema (SIGMA), fino al traffico internet (Snort), ogni traccia viene codificata e utilizzata per rilevare e bloccare le minacce quanto prima possibile.
La Cyber Kill Chain e le fasi di un’intrusione cyber
Per comprendere come si svolge un attacco informatico e dove intervenire per fermarlo, è utile fare riferimento a modelli concettuali come la Cyber Kill Chain. Sviluppata dal team di ricerca Lockheed Martin circa un decennio fa, la Cyber Kill Chain descrive le sette fasi tipiche di un’intrusione mirata . Queste fasi rappresentano il percorso seguito da un avversario, dalla pianificazione iniziale fino agli obiettivi finali, e sono così denominate:
Ricognizione (Reconnaissance): l’aggressore raccoglie informazioni sul bersaglio, studiandone l’infrastruttura, individuando possibili vulnerabilità e punti d’ingresso. In questa fase preliminare rientrano attività come l’OSINT (raccolta di dati pubblici da siti web e social), scansioni di rete, identificazione di sistemi esposti e ricerca di credenziali o dati trapelati nel dark web. L’obiettivo è conoscere l’ambiente della vittima per preparare un attacco efficace.
Armamento (Weaponization): sulla base delle informazioni raccolte, l’attaccante prepara effettivamente il “carico offensivo”. Ciò può consistere nello sviluppo o adattamento di un malware, nella costruzione di un exploit per una vulnerabilità nota, oppure nella creazione di un documento esca maligno (ad esempio un PDF o documento Office infetto) da inviare al bersaglio. In pratica, in questa fase si crea l’arma digitale da utilizzare contro la vittima, spesso combinando un exploit con un payload (es. un trojan) da consegnare successivamente.
Consegna (Delivery): è la fase in cui l’attaccante invia il payload al target. I vettori di delivery più comuni includono l’invio di email phishing con allegati maligni o link a siti compromessi, l’ingegneria sociale per far scaricare un file infetto, l’upload di un exploit tramite un servizio esposto su internet, o l’utilizzo di supporti fisici (drop USB). La delivery rappresenta il momento in cui il bersaglio viene effettivamente raggiunto dal contenuto malevolo preparato in precedenza.
Sfruttamento (Exploitation): una volta consegnato, il malware o exploit viene attivato sfruttando una vulnerabilità sul sistema della vittima. Può trattarsi dell’esecuzione di codice attraverso una falla (buffer overflow, RCE, ecc.), dell’apertura inconsapevole di un documento con macro dannose da parte dell’utente, o di un’esecuzione automatica di codice al collegamento di una periferica USB. Lo sfruttamento segna il passaggio in cui l’attaccante ottiene un primo accesso al sistema bersaglio compromettendone la sicurezza.
Installazione (Installation): in questa fase, l’attaccante consolida la propria presenza inserendo malware persistente nel sistema compromesso. Ad esempio, installa una backdoor, un trojan, o modifica configurazioni in modo da mantenere l’accesso anche dopo reboot o nel lungo periodo. L’installazione spesso coinvolge anche l’ottenimento di privilegi elevati (escalation di privilegi) per assicurarsi il controllo dell’host. Al termine di questa fase, l’attaccante dispone di un punto d’appoggio stabile all’interno dell’infrastruttura vittima.
Comando e Controllo (Command & Control): il malware installato stabilisce una comunicazione con l’infrastruttura dell’attaccante (server C2). Tipicamente, tramite canali cifrati o camuffati (HTTP/HTTPS, DNS tunneling, ecc.), il sistema infetto contatta un server di comando per ricevere istruzioni aggiuntive o esfiltrare informazioni iniziali. Questa fase consente all’aggressore di controllare da remoto i sistemi compromessi, impartendo comandi, spostandosi lateralmente su altre macchine e così via.
Azioni sull’obiettivo (Actions on Objective): è l’ultima fase, in cui l’attaccante realizza i suoi scopi finali una volta ottenuto pieno accesso. A seconda della motivazione, queste azioni possono consistere in furto di dati sensibili (esfiltrazione di database, email, IP aziendale), sabotaggio e distruzione (cifratura ransomware, cancellazione di dati, interferenza con operazioni critiche), spionaggio prolungato, o uso delle risorse compromesse per ulteriori attacchi (es. per sferrare attacchi verso terzi). È il momento in cui l’intrusione raggiunge il suo obiettivo ultimo, che sia lucro finanziario, spionaggio o danneggiamento.
Il modello della Cyber Kill Chain è prezioso per i difensori poiché offre una visione strutturata dell’attacco, aiutando a identificare punti di intervento in ciascuna fase. Ad esempio, durante la ricognizione si possono rilevare e bloccare attività sospette (come scansioni di port scan), in fase di consegna si può puntare a filtrare email phishing o oggetti malevoli, durante il comando e controllo si possono individuare e bloccare le comunicazioni con IP malevoli, e così via. Spezzare anche uno solo degli anelli della “catena di uccisione” può fermare l’attacco prima che giunga a compimento. Inoltre, il framework Kill Chain è utile in fase di post-mortem: analizzando un incidente si possono mappare le azioni dell’attaccante sulle sette fasi, per capire dove la difesa ha fallito e come migliorare (ad es. se un attacco è arrivato fino all’esfiltrazione dati, significa che tutte le difese nelle fasi precedenti non hanno rilevato/fermato l’avversario). In ambienti di sicurezza avanzati, si utilizzano anche simulazioni di attacco ispirate alla Kill Chain (come i penetration test o esercizi red team) per testare la resilienza: ciò consente di valutare se i controlli presenti riescono a individuare o mitigare le azioni in ciascuna fase e, in caso contrario, di colmare le lacune. In definitiva, la Cyber Kill Chain fornisce al coordinatore CSIRT/SOC un quadro di riferimento per orchestrare difese e risposte calibrate su ogni stadio di un’intrusione, trasformando un concetto militare (kill chain) in uno strumento operativo di cyber defense.
Tattiche, Tecniche e Procedure (TTP) degli attaccanti
Accanto alla prospettiva “temporale” fornita dalla Kill Chain, un responsabile di Incident Response deve anche comprendere la natura e le modalità delle azioni compiute dall’attaccante. In gergo di cyber threat intelligence si parla di Tattiche, Tecniche e Procedure (TTP) per descrivere i comportamenti e le metodologie degli attori malevoli. Le Tattiche rappresentano gli obiettivi o scopi di alto livello che l’avversario cerca di conseguire (ad es. movimento laterale, raccolta credenziali, esfiltrazione dati); le Tecniche sono i modi specifici con cui l’attaccante realizza una certa tattica (ad esempio, per la tattica “movimento laterale”, una tecnica potrebbe essere l’uso di credenziali rubate per accedere ad altri host); infine, le Procedure sono i dettagli esecutivi di basso livello di una tecnica, ovvero la particolare implementazione o variante utilizzata (ad esempio lo script o comando preciso usato per eseguire la tecnica di dump delle password in memoria). In altre parole, i TTP forniscono un sistema gerarchico di categorizzazione del “come” operano i threat actor: dalla strategia generale (tattica), passando per il metodo concreto (tecnica), fino all’esecuzione specifica (procedura).
Questa tassonomia è fondamentale in un contesto di risposta agli incidenti e intelligence, perché consente di profilare gli attacchi e collegarli potenzialmente a gruppi avversari noti. Ad esempio, si potrà dire che un certo attacco ha utilizzato la tattica “Initial Access” con la tecnica “Spear Phishing Attachment” e una procedura consistente in un documento di Microsoft Word contenente macro malevole. Riconoscere queste caratteristiche permette di confrontarle con database di minacce note: spesso gruppi APT (Advanced Persistent Threat) ricorrono a insiemi specifici di TTP che diventano la loro “firma” operativa. Per un coordinatore SOC, sapere che un incidente presenta TTP coerenti con quelli di un dato attore (es. un APT statale noto per colpire il settore energetico) può orientare la risposta, far elevare il livello di allerta e attivare collaborazioni con l’intelligence. Viceversa, l’analisi dei TTP consente di passare dall’indicatore puntuale (es. un hash malware) alla tecnica generale: questo aiuta a predisporre difese più robuste. Ad esempio, invece di limitarsi a bloccare l’hash di un singolo malware (che un attaccante può facilmente modificare), focalizzarsi sulla tecnica soggiacente (es. “utilizzo di strumenti Living-off-the-Land come Mimikatz per furto di credenziali”) permette di implementare controlli e rilevamenti più ampi (monitoraggio chiamate sospette alle API di Windows per estrarre credenziali).
Le TTP sono quindi il linguaggio comune tra threat intelligence e incident response. Un analista forense, nel suo rapporto post-incidente, non si limiterà a elencare gli IoC trovati, ma li inquadrerà nelle tecniche e tattiche utilizzate dall’avversario. Allo stesso modo, un threat hunter nel SOC conduce le sue ricerche ipotizzando la presenza di certe tecniche in rete (es. “cerca evidenze di lateral movement via Pass-the-Hash”). Questa formalizzazione è talmente importante che attorno ai TTP si è sviluppato un intero framework di conoscenza: il MITRE ATT&CK, divenuto riferimento de facto per catalogare e condividere le tattiche e tecniche avversarie a livello mondiale.
Il framework MITRE ATT&CK
Il MITRE ATT&CK è una knowledge base globale e continuamente aggiornata dei comportamenti ostili noti, nata per catalogare in modo sistematico le Tattiche, Tecniche (e relative Sottotecniche) impiegate dai vari attaccanti informatici. Il nome stesso “ATT&CK” è un acronimo che sta per “Adversarial Tactics, Techniques & Common Knowledge”, indicativo del focus sugli elementi comuni di conoscenza delle tecniche avversarie. In pratica, MITRE ATT&CK elenca e organizza, in una struttura a matrice, tutte le tattiche che compongono il ciclo di vita di un attacco informatico, e per ciascuna tattica fornisce l’insieme delle tecniche conosciute con cui può essere perseguita. Ad esempio, una tattica è “Privilege Escalation” (Escalation di privilegi): ATT&CK raccoglie tutte le diverse tecniche con cui un malware o attore può ottenere privilegi più elevati su un sistema (dall’exploit del kernel, al bypass di UAC, alla modifica di token di accesso, ecc.), ciascuna documentata con descrizione, esempi di uso reale e riferimenti a gruppi e campagne noti.
Il framework copre l’intero spettro di un attacco, dalla fase iniziale di ricognizione e ottenimento dell’accesso (tattiche di Initial Access, Execution, Persistence, ecc.) fino alle fasi finali (esfiltrazione, impatto sull’obiettivo). Originato inizialmente per ambienti Windows enterprise, si è esteso con matrici specifiche per altri domini: esiste la matrice Enterprise generale (che include sotto-matrici per Windows, Linux, macOS, ambienti cloud, container, ecc.), una matrice Mobile per attacchi su dispositivi mobili, e una matrice ICS per sistemi di controllo industriale. Questa strutturazione permette di adattare l’analisi dei TTP ai diversi contesti tecnologici.
Uno degli aspetti chiave di MITRE ATT&CK è che non si limita a essere un elenco statico, ma piuttosto funge da linguaggio comune e base di partenza per molte applicazioni pratiche nella difesa informatica. Ad esempio:
I team di threat hunting usano ATT&CK per pianificare le loro ipotesi di ricerca, assicurandosi di coprire tecniche specifiche (es: “cerchiamo evidenze di tecniche di Persistence come Registry Run Keys nei log degli endpoint”).
I red team e gli esercizi di adversary simulation mappano i propri scenari di attacco in termini di tecniche ATT&CK, così da testare se il SOC riesce a rilevarle.
Nella risposta agli incidenti, al momento di riportare un incidente o condividerne i dettagli con altri enti, si possono indicare le tecniche ATT&CK osservate (es: T1566.001 Spear Phishing Attachment, T1218.011 “Rundll32”, etc.) per dare immediata chiarezza sulle modalità dell’attacco.
Molti strumenti di sicurezza (SIEM, EDR, XDR) integrano MITRE ATT&CK nelle loro interfacce: ad esempio, correlano alert o rilevamenti con le tecniche corrispondenti, fornendo al SOC un quadro consolidato. Questo aiuta a capire rapidamente quali fasi dell’attacco siano state rilevate e quali possano essere sfuggite.
La valenza strategica di MITRE ATT&CK risiede inoltre nel permettere di identificare aree di miglioramento nelle difese. Mappando i controlli di sicurezza esistenti sulle tecniche della matrice, un’organizzazione può individuare tecniche per le quali non ha visibilità o contromisure – queste diventano priorità da colmare (concetto di coverage ATT&CK). Allo stesso modo, consente di seguire l’evoluzione delle minacce: il framework viene aggiornato man mano che emergono nuove tecniche o varianti, riflettendo lo stato dell’arte del comportamento avversario.
Dal punto di vista di un coordinatore CSIRT/SOC, ATT&CK è dunque uno strumento fondamentale di knowledge management: offre un vocabolario standardizzato per descrivere gli attacchi e una mappa su cui costruire sia le capacità di detection che le procedure di risposta. Ad esempio, se emergono segnalazioni di nuove campagne di attacco globali, il reaponsabile può rapidamente comprendere di cosa si tratta leggendo le tecniche ATT&CK coinvolte (che spesso sono riportate negli advisory), e verificare se la propria organizzazione ha già predisposto controlli per quelle specifiche tecniche. IBM Security in un suo whitepaper in italiano sintetizza bene questo concetto, affermando che il framework MITRE ATT&CK fornisce una base di conoscenza accessibile per modellare, rilevare, impedire e contrastare le minacce sulla base dei comportamenti noti dei criminali informatici. Inoltre, la tassonomia ATT&CK crea un linguaggio comune attraverso cui i professionisti di sicurezza possono condividere informazioni e collaborare in modo più efficace nella prevenzione e risposta alle minacce.
In sintesi, MITRE ATT&CK incarna e integra tutti i concetti discussi finora: suddivide le attività malevole nelle varie fasi/tattiche (richiamando la Kill Chain), elenca tecniche e procedure (TTP) per ciascuna fase, e alimenta la definizione di indicatori di compromissione e regole di detection (molte regole YARA/ Sigma sono categorizzate secondo tecniche ATT&CK). Per un responsabile dell’Incident Response, una solida familiarità con ATT&CK è oggi requisito essenziale, sia per comunicare con efficacia (all’interno e con l’ecosistema esterno) sia per valutare in modo completo le proprie difese e le mosse dell’avversario.
Esperienze operative e contesto italiano (CSIRT Italia, CERT-AgID, ACN)
In Italia, la gestione degli incidenti di sicurezza informatica a livello nazionale fa riferimento al quadro normativo introdotto dal Perimetro di Sicurezza Nazionale Cibernetica e al ruolo centrale dell’Agenzia per la Cybersicurezza Nazionale (ACN), istituita nel 2021. L’ACN ospita al suo interno il CSIRT Italia (Computer Security Incident Response Team Italia), che funge da team di riferimento nazionale per la gestione e prevenzione degli incidenti cyber, in coordinamento con i CERT settoriali (come il CERT-AgID per la Pubblica Amministrazione). Un responsabile per la prevenzione e gestione di incidenti informatici deve quindi conoscere non solo i framework internazionali, ma anche come questi vengono applicati praticamente nel contesto italiano.
Negli ultimi anni, il CSIRT Italia è stato protagonista nella risposta a numerosi incidenti significativi, spesso in collaborazione con altri enti e con le forze dell’ordine. Ad esempio, nel maggio 2022 il sito istituzionale del CSIRT Italia stesso è finito nel mirino del collettivo hacker filorusso Killnet, nell’ambito di una campagna di attacchi DDoS contro varie infrastrutture italiane. Grazie alle contromisure predisposte e a un monitoraggio costante, l’attacco (durato oltre 10 ore) è stato mitigato con successo dai sistemi anti-DDoS, senza interrompere la disponibilità del portale per gli utenti legittimi . Questo episodio – poi pubblicamente riconosciuto dagli stessi attaccanti con un paradossale “complimento” alla competenza tecnica del team italiano – dimostra l’efficacia di una pronta risposta coordinata: il CSIRT aveva già emanato alert preventivi sulle minacce DDoS in corso e raccomandato misure di protezione, e al momento dell’attacco ha saputo contenerlo, proteggendo sia i propri sistemi sia, per estensione, la fiducia nella capacità di reazione del Paese.
Un altro caso emblematico si è verificato a febbraio 2023, quando una ondata di attacchi ransomware su scala mondiale (campagna ESXiArgs) ha preso di mira migliaia di server VMware ESXi non aggiornati. L’ACN, attraverso il CSIRT Italia, ha lanciato immediatamente un allarme pubblico evidenziando la gravità della minaccia e sollecitando tutte le organizzazioni italiane a applicare le patch e verificare i propri sistemi 30 31 . Questa tempestiva azione di allerta – ripresa anche da agenzie di stampa internazionali – ha permesso a molti amministratori di sistema di attivarsi preventivamente, limitando l’impatto nazionale di un attacco che altrove ha causato ingenti danni. Contestualmente, il CSIRT ha coordinato lo scambio di indicatori di compromissione relativi al ransomware (come indirizzi IP di server di comando e hash dei file di criptazione) in modo che i CERT aziendali potessero aggiornare le loro difese (ad esempio caricando regole Snort per bloccare traffico verso gli IP malevoli e regole YARA per individuare il malware ESXiArgs sui server). Questo approccio proattivo è proprio quanto previsto dalle best practice NIST/ISO: preparazione (piano di patch management), detection (uso di IoC condivisi), contenimento (isolamento host vulnerabili) e post-analisi (rapporto sull’accaduto per migliorare i processi).
Per quanto riguarda il CERT-AgID, esso svolge un ruolo cruciale nel contesto della Pubblica Amministrazione italiana, operando come CERT settoriale dedicato. Negli ultimi anni CERT-AgID ha gestito e supportato numerosi incidenti che hanno coinvolto enti pubblici, tra cui campagne di phishing mirate a PEC istituzionali, ransomware che hanno colpito infrastrutture regionali e comunali, nonché massicce compromissioni di siti web della PA utilizzati per diffondere malware. Un esempio rilevante è la serie di attacchi ransomware avvenuti nel 2021-2022 a danno di aziende sanitarie locali e pubbliche amministrazioni (tra cui il noto attacco alla Regione Lazio nell’estate 2021): in tali frangenti, il CERT-AgID ha fornito supporto tecnico nell’analisi del malware, nella triage degli indicatori e nel ripristino, fungendo da tramite tra le strutture colpite, il CSIRT nazionale e i venditori di soluzioni di sicurezza. Inoltre, CERT-AgID cura un report periodico sulle campagne malevole che funge da panoramica strategica del threat landscape verso la PA. Questi rapporti non solo quantificano le minacce (come visto, quasi 1.800 campagne e 20 mila IoC condivisi in un anno), ma dettagliano le tecniche prevalenti, i vettori di attacco usati (es. percentuale di phishing via email, supply chain compromise, etc.) e trend emergenti. Tali informazioni sono preziose per un responsabile, che può calibrare le misure di prevenzione sapendo quali sono le minacce più probabili per il proprio settore.
Va sottolineato come il quadro italiano dell’Incident Response sia ormai strettamente allineato agli standard internazionali. L’ACN ha emanato linee guida, come la recente Guida alla notifica degliincidenti al CSIRT Italia, che definisce procedure e tempistiche per comunicare gli incidenti significativi al team nazionale, in ottemperanza anche alla direttiva NIS e alla normativa nazionale. Questo garantisce un flusso informativo centralizzato e rapido, permettendo di attivare supporto ed eventualmente diffondere early warning ad altri enti a rischio. In parallelo, si investe in formazione e addestramento del personale SOC/CSIRT su temi come quelli trattati in questo elaborato: conoscere e applicare framework come NIST e MITRE ATT&CK, saper scrivere e utilizzare regole YARA/Sigma, interpretare una kill chain e riconoscere i TTP di un attacco. L’Italia partecipa inoltre attivamente a network europei e internazionali di condivisione cyber (come la rete dei CSIRT europei sotto ENISA), consapevole che le minacce sono globali e la cooperazione è fondamentale.
In conclusione, un responsdabile per la prevenzione e gestione di incidenti informatici dovrà padroneggiare sia gli aspetti teorici che quelli pratico-operativi dell’Incident Response. Ciò significa saper coniugare le best practice codificate nei principali standard (NIST 800-61, ISO 27035) con l’uso efficiente di strumenti e indicatori (IoC, YARA, Sigma, Snort), mantenere una visione d’insieme sulle fasi di un attacco (Cyber Kill Chain) e sui pattern di comportamento avversario (TTP, MITRE ATT&CK), e infine muoversi con sicurezza nel contesto organizzativo italiano, orchestrando la collaborazione tra CSIRT Italia, CERT-AgID, forze dell’ordine e soggetti privati. Questo insieme organico di conoscenze e competenze tecniche, unite a capacità di coordinamento, comunicazione e visione strategica, costituisce la base per fronteggiare con successo le sfide poste dagli incidenti cyber.
La digital forensics è la disciplina che si occupa di individuare, preservare ed esaminare le evidenze digitali al fine di ricostruire eventi e azioni compiute su sistemi informatici. In particolare, nel contesto della risposta agli incidenti informatici, le tecniche forensi permettono di capire cosa è accaduto durante un attacco, quali sistemi sono stati compromessi e in che modo, fornendo informazioni critiche per prevenire futuri incidenti. A livello internazionale esistono standard e linee guida che definiscono le migliori pratiche in questo campo: ad esempio lo standard ISO/IEC 27042:2015 fornisce “linee guida per l’analisi e l’interpretazione delle evidenze digitali” mentre ISO/IEC 27043:2015 definisce “principi e processi di indagine sugli incidenti”. Analogamente, la guida NIST SP 800-86 del National Institute of Standards and Technology – intitolata “Guide to Integrating Forensic Techniques into Incident Response” – descrive processi efficaci per svolgere analisi forensi su vari tipi di dati (file, sistemi operativi, traffico di rete, applicazioni) e integrare queste attività nell’ambito di un’indagine di sicurezza . Questi riferimenti enfatizzano un approccio metodico e strutturato all’analisi forense, essenziale affinché le evidenze raccolte abbiano validità e siano utili sia in ottica tecnica sia, se necessario, in sede legale.
Analisi di file system
L’analisi forense di un file system consiste nell’esaminare la struttura e il contenuto di supporti di memoria (dischi fissi, SSD, pen drive, ecc.) al fine di scoprire tracce digitali significative. Ogni file e directory su un sistema operativo è organizzato secondo un file system (come NTFS per Windows, EXT4 per Linux, APFS per macOS, ecc.), il quale mantiene metadati cruciali: nomi dei file, dimensioni, permessi e timestamp (date di creazione, modifica, accesso, ecc.). L’analista forense ispeziona queste informazioni per ricostruire le attività svolte sul sistema e individuare anomalie. Ad esempio, nei file system NTFS di Windows il Master File Table (MFT) registra record per ogni file, includendo fino a quattro timestamp principali per ciascuno (creazione, ultima modifica, ultimo accesso, ultima modifica del record MFT). Questi dati temporali consentono di costruire una timeline degli eventi sul disco. In un’analisi tipica, si cercano file sospetti (ad esempio programmi malevoli camuffati), si esaminano gli attributi e i contenuti dei file e si analizzano gli artefatti del file system (come i journal di NTFS, la $Recycle.Bin, i punti di ripristino, ecc.) alla ricerca di evidenze. Inoltre, si verifica la presenza di file nascosti o di istanze di steganografia (informazioni occultate dentro file leciti) e si controlla l’integrità dei file confrontandone gli hash crittografici con valori noti.
Un aspetto fondamentale del file system forensics è il recupero di file cancellati. Molti utenti pensano che quando un file viene eliminato dal sistema scompaia definitivamente, ma in realtà non è così: l’eliminazione rimuove il riferimento al file dalla tabella di allocazione (ad esempio la File Allocation Table su FAT o la MFT su NTFS) ma i dati binari del file restano sui settori del disco finché non vengono sovrascritti. I file (o frammenti di essi) permangono nelle aree non allocate del disco e, con gli strumenti appropriati, è difficile ma non impossibile ricostruirli. Ciò significa che è spesso possibile recuperare documenti o altri artefatti anche dopo la cancellazione, soprattutto su supporti di grande capacità dove può trascorrere molto tempo prima che i blocchi vengano riutilizzati per nuovi dati.
L’analista forense utilizza tecniche di data carving (descritte più avanti) per scandagliare queste porzioni libere alla ricerca di header e footer noti di file (come le intestazioni JPEG, PDF, ecc.) e ricostruire file eliminati o corrotti. Un altro approccio consiste nel calcolare gli hash (MD5, SHA-1, SHA-256) di tutti i file presenti e confrontarli con database di indicatori di compromissione (IOC) noti o con liste di hash di software benigni, così da individuare rapidamente malware noti o file anomali. In contesto italiano, ad esempio, il CERT-AgID (Computer Emergency Response Team dell’Agenzia per l’Italia Digitale) fornisce alle Pubbliche Amministrazioni un servizio di feed IoC contenente hash di file malevoli osservati nelle campagne di attacco più recenti. Questo feed, combinato con appositi tool, consente di identificare file compromessi nei sistemi oggetto di analisi. Hashr è uno di questi strumenti sviluppati dal CERT-AgID: permette di cercare, all’interno di un filesystem, file noti come malevoli confrontando i loro hash con una lista di impronte note. L’uso di hashr è risultato particolarmente utile sia nelle indagini di sicurezza informatica sia nell’analisi forense, ad esempio per verificare l’integrità di grandi volumi di dati e scovare rapidamente malware presenti su disco.
Figura 1: Schermata di output dello strumento hashr (open source di CERT-AGID) in azione. In questo esempio, l’utility ha analizzato la directory Downloads confrontando ogni file con una lista di hash indicanti malware noti, restituendo per ciascun file corrispondenze di hash MD5, SHA1 e SHA256. Tale strumento può velocizzarel’identificazione di file infetti all’interno di file system di grandi dimensioni, ed è utilizzabile anche a fini di verifica dell’integrità dei file.
Dal punto di vista operativo, l’analisi forense dei file system inizia con una corretta acquisizione della memoria di massa da esaminare. Si procede creando una copia forense bit-a-bit del supporto originale (disk image), operazione effettuata tipicamente a sistema spento (analisi dead) utilizzando tool come dd (in ambienti Unix) o strumenti dedicati (ad es. FTK Imager, Guymager), spesso impiegando un write-blocker hardware o software per evitare qualsiasi modifica accidentale al disco originale. L’immagine ottenuta viene poi sottoposta a hash (es. SHA-256) per calcolarne l’impronta univoca, che servirà a garantirne l’integrità: confrontando il valore hash della copia con quello calcolato sul disco originale, si verifica che la copia sia esatta e che nessuna alterazione sia avvenuta durante l’acquisizione. Solo a questo punto gli investigatori lavorano sull’immagine duplicata, lasciando intatto l’originale (principio fondamentale per assicurare la validità probatoria delle evidenze). Una volta montata o caricata l’immagine in appositi software, l’analisi può procedere: si passa in rassegna la struttura di directory, si cercano file sospetti (anche in base a nome, tipo o hash), si analizzano i contenuti con visualizzatori esadecimali o strumenti di parsing (per esempio analizzando il registro di configurazione di Windows, i file di Prefetch, i log di sistema, ecc.), e si ricostruiscono le attività avvenute sul file system. Il risultato finale è spesso una ricostruzione dettagliata (timeline) delle azioni svolte su quel supporto (creazione, modifica, cancellazione di file, installazione di programmi, collegamenti di dispositivi USB, ecc.), utile per comprendere la dinamica di un incidente e attribuire eventuali responsabilità.
Analisi di dump di memoria (memory forensics)
L’analisi forense della memoria RAM è una componente sempre più centrale nelle investigazioni digitali. La memory forensics si occupa di studiare il contenuto della memoria volatile di un sistema (dump RAM catturato da un computer o dispositivo) allo scopo di estrarre informazioni sulle attività in corso o recenti, spesso impossibili da reperire altrove. Infatti qualsiasi operazione compiuta da un sistema informatico – processi eseguiti, connessioni di rete, utilizzo di credenziali, ecc. – transita attraverso la RAM e può persistere in memoria per un certo tempo anche dopo la conclusione dell’evento. La RAM di un computer può contenere quindi una quantità enorme di dati utili: l’elenco dei processi e thread in esecuzione (con i relativi programmi e moduli caricati), le connessioni di rete attive o recentemente chiuse (comprese informazioni su indirizzi IP e porte remote), le chiavi crittografiche in uso, password in chiaro temporaneamente presenti, il contenuto della clipboard (appunti) e persino tracce di malware in esecuzione – inclusi rootkit o altri codici malevoli che potrebbero occultarsi al file system. In altri termini, la memoria è spesso il luogo migliore dove cercare le attività di un software malevolo: anche se un malware tenta di nascondersi eliminando file dal disco o operando solo in memoria (fileless malware), deve comunque essere caricato e mantenuto nella RAM per poter agire. Attraverso la memory forensics è possibile mettere in luce evidenze altrimenti invisibili, come malware residenti unicamente in memoria, sessioni di navigazione web in modalità incognita (che non lasciano cronologia su disco) o conversazioni in chat volatile, e persino modifiche apportate a chiavi di registro di Windows che risiedono solo in memoria e non ancora scritte su disco.
Le fasi di un’analisi della memoria includono innanzitutto l’acquisizione del dump: se il sistema è live, si utilizzano tool appositi (ad es. Magnet RAM Capture, FTK Imager in modalità live, Belkasoft RAM Capturer o comandi di sistema) per estrarre un’immagine completa della RAM e dei file di swap/paging, evitando per quanto possibile di alterare lo stato della macchina. Una volta ottenuto il file di dump grezzo, si passa alla fase di estrazione delle evidenze: qui entrano in gioco framework specializzati come Volatility o Rekall. Volatility, in particolare, è un framework open source scritto in Python, dotato di una collezione di plug-in che permettono di estrarre artefatti dal dump di memoria volatile. Tramite Volatility, l’analista può elencare tutti i processi attivi al momento dell’acquisizione (e quelli terminati di recente ma ancora residenti in memoria), ispezionare l’area di memoria di ciascun processo alla ricerca di stringhe o moduli caricati, ricostruire la lista delle connessioni di rete aperte (socket TCP/ UDP con relativi IP/porta), recuperare informazioni sui driver e i kernel module caricati, estrarre il contenuto della clipboard, delle cache DNS e molto altro. Si possono anche cercare firme note di malware in memoria o rilevare tecniche di offuscamento, come process injection, hooking di funzioni di sistema, presenza di eseguibili packed, ecc. Un esempio concreto: grazie all’analisi RAM è possibile recuperare credenziali o token di autenticazione temporanei che risiedono in memoria (ad esempio password di utenti o chiavi di sessione), elemento che talvolta consente di comprendere l’entità di una compromissione o di effettuare escalation controllate in laboratorio per studiare un attacco. L’analisi della memoria viene condotta preferibilmente off-line sull’immagine catturata, utilizzando i profili adeguati (profiling) per interpretare le strutture dati in base al sistema operativo target. Ad esempio, Volatility richiede di specificare il profilo (p.es. Windows 10 x64 build 19041) per poter tradurre correttamente indirizzi di memoria e simboli: un passaggio fondamentale, poiché l’uso di un profilo errato può portare a output incompleti o incoerenti.
Un aspetto importante è la correlazione delle evidenze di memoria con altre fonti. Spesso, i risultati dell’analisi RAM vanno messi in relazione con quanto emerge dall’analisi del disco e dei log di rete, al fine di costruire un quadro unificato dell’incidente. Ad esempio, processi sospetti individuati in RAM (come un powershell.exe lanciato con comandi anomali, oppure un processo senza file su disco indicativo di un malware fileless) dovrebbero poi essere cercati nelle evidenze del file system (esiste un file corrispondente su disco? Ci sono riferimenti nel Prefetch o nel registro di sistema?) e nei log (ci sono eventi che mostrano l’esecuzione di quel processo da parte di un certo utente?). Solo tramite questa visione d’insieme si può capire appieno l’accaduto. Nel contesto italiano, l’uso della memory forensics è ormai prassi sia nelle operazioni di incident response: ad esempio, per malware analysis su campioni attivi intercettati in sistemi compromessi o per identificare in tempo reale minacce come il malware Agent.Tesla o Ursnif che negli ultimi anni hanno preso di mira enti pubblici e privati.
Analisi di log di sicurezza e di rete
I log – registri degli eventi prodotti da sistemi operativi, applicazioni e dispositivi di rete – costituiscono una fonte informativa primaria nella gestione e analisi degli incidenti informatici. Ogni componente IT (e anche molti dispositivi non-IT) genera infatti una notevole quantità di informazioni sotto forma di log, che vengono tipicamente classificati per categorie e livelli di severità. Ad esempio, un server web produce log delle richieste HTTP con indicazione di timestamp, URL richiesto, indirizzo IP del client e codice di risposta; un firewall registra gli accessi consentiti o negati per ogni connessione (con dati su IP, porte, protocolli); un sistema operativo mantiene log di sicurezza (tentativi di login riusciti o falliti, cambi di privilegi, eventi del kernel) e così via. Analizzare questi log di sicurezza significa estrarre dai dati grezzi le informazioni rilevanti per un determinato incidente, identificare correlazioni tra eventi e riconoscere pattern anomali che possano indicare attività malevole o malfunzionamenti.
Un esempio concreto: in caso di sospetta intrusione su un server, l’analisi incrociata dei log potrebbe rivelare che un certo utente ha effettuato un login fuori orario (voce nel security log), subito seguito dall’esecuzione di comandi insoliti registrati nella shell history e da connessioni verso un IP esterno annotati nel log del firewall. Ciascun singolo evento, preso a sé, potrebbe passare inosservato; la correlazione temporale e funzionale tra i vari log permette invece di ricostruire la sequenzadell’attacco (es. accesso iniziale – movimenti laterali – esfiltrazione di dati) e di identificarne la sorgente. Per un responsabile CSIRT/SOC, saper orchestrare questa attività di analisi log è fondamentale: significa dover gestire potenzialmente decine di migliaia di eventi al secondo, filtrare i falsi positivi e isolare gli indicatori critici. A tal fine, ci si avvale comunemente di sistemi SIEM (Security Information and Event Management). Un SIEM è una piattaforma software che colleziona i log da sorgenti disparate, li normalizza (cioè li traduce in un formato comune), li correla in base a regole predefinite e spesso applica motori di analisi comportamentale per individuare minacce in tempo reale. In pratica, il SIEM funge da concentratore: al suo interno confluiscono log da firewall, IDS/IPS, sistemi endpoint, database, applicazioni, ecc., e l’analista può consultare da un’unica console l’andamento degli eventi. Ad esempio, il SIEM può generare un alert qualora rilevi, entro uno stesso intervallo temporale, più tentativi di accesso falliti su diversi sistemi seguiti da un accesso riuscito con un account amministrativo: segnale tipico di un possibile brute forcing andato a segno. Oppure può correlare l’apparizione di un file sospetto in un host (rilevato dall’antivirus) con una connessione uscente su porta non standard (dal log del proxy): anche qui producendo un avviso di possibile data exfiltration. I moderni SIEM integrano inoltre feed di threat intelligence (indicatori di minaccia esterni forniti da CERT e vendor) e funzionalità di orchestrazione automatica (SOAR), così da arricchire gli eventi grezzi con informazioni contestuali e, in alcuni casi, reagire automaticamente (per esempio isolando un host infetto).
Nell’analisi forense vera e propria, i log rivestono anche un ruolo chiave come evidenze: costituiscono spesso prova documentale di un’azione (si pensi ai log di autenticazione nel caso di accessi non autorizzati, o ai log di transazione di un database in caso di frodi). È importante perciò assicurarne la corretta conservazione e autenticità: un responsabile deve garantire che i log siano archiviati in forma write-once (immutabile) e con riferimenti temporali affidabili (sincronizzazione oraria via NTP, uso di timestamp in UTC, ecc.), in modo che possano essere esibiti come prova qualora necessario. Un aspetto non banale è la gestione dei tempi e della sincronizzazione: se i sistemi coinvolti in un incidente non hanno orologi allineati, la ricostruzione temporale può risultare complicata. Idealmente tutti i server e dispositivi devono sincronizzare l’ora con un time server preciso (via protocollo NTP); in pratica può capitare di trovare orologi sfasati. In fase di analisi forense occorre pertanto tener conto di eventuali offset temporali tra log diversi, effettuando opportune conversioni per costruire una timeline coerente degli eventi . Questo evidenzia ulteriormente l’importanza di un approccio sistematico e metodico nell’analisi dei log.
In Italia, il CERT-AgID e l’ACN/CSIRT Italia incoraggiano fortemente l’adozione di sistemi di logging centralizzato e di SIEM negli enti pubblici, fornendo anche indicazioni su come configurare al meglio il monitoraggio. Ad esempio, ACN ha pubblicato nel 2022 la Guida alla notifica degli incidenti al CSIRT Italia, che tra le varie cose elenca i tipi di log ed evidenze che gli enti devono raccogliere e conservare per facilitare le investigazioni post-incidente . Vi sono stati anche casi concreti in cui l’analisi dei log ha permesso di scoprire attacchi sofisticati: ad esempio, l’indagine su una serie di attacchi alle caselle PEC (Posta Elettronica Certificata) nel 2023 – coordinata da CERT-AgID in collaborazione con la Polizia Postale – ha visto come elemento chiave l’esame dei log di accesso ai server di posta e delle tracce lasciate dai malware nei log antivirus, consentendo di individuare i punti di ingresso dei criminali e di rafforzare le difese delle infrastrutture coinvolte.
Analisi del traffico di rete
L’analisi forense della rete (Network Forensics) riguarda la cattura, l’ispezione e l’interpretazione del traffico di rete con l’obiettivo di ottenere prove digitali relative a eventuali attacchi o attività malevole che si sono svolte attraverso i sistemi di comunicazione. In sostanza, mentre l’analisi dei log spesso si basa su dati già registrati dai sistemi, l’analisi del traffico va direttamente alla fonte: i pacchetti di rete scambiati tra sorgenti e destinazioni. Questa disciplina permette di determinare, ad esempio, l’origine di un attacco, le modalità di comunicazione di un malware con i server di comando e controllo (C2), o l’eventuale esfiltrazione di dati sensibili tramite canali nascosti. L’investigatore di rete inizia tipicamente con l’acquisizione del traffico: può trattarsi di file di cattura (.pcap) ottenuti mettendo in ascolto una scheda di rete in modalità promiscua (con strumenti di packet capture come tcpdump o Wireshark), oppure di flussi di log generati da sonde IDS/IPS, NetFlow, ecc. Spesso, durante un incidente, il team forense configura dei packet sniffer nei punti chiave (ad esempio sulla porta di uno switch core, o attivando port mirroring) per raccogliere tutto il traffico in transito da e verso i sistemi compromessi. I dati così acquisiti – idealmente corredati di timestamp precisi e sincronizzati – vengono poi analizzati nel dettaglio.
Nell’analisi del traffico di rete, alcuni elementi chiave da esaminare includono: i protocolli utilizzati in comunicazione (HTTP, HTTPS, DNS, SMTP, etc.), gli indirizzi IP sorgente e destinazione, i numeri di porta coinvolti, i timestamp delle connessioni, nonché il contenuto dei pacchetti stessi (payload) se in chiaro. Ad esempio, in un file PCAP catturato durante un attacco potremmo filtrare tutto il traffico HTTP non cifrato e ritrovare richieste sospette verso URL esterni, oppure osservare in un dump DNS delle richieste a domini anomali (indizi di malware che cerca il suo dominio di controllo). Strumenti come Wireshark forniscono potenti capacità di filtraggio e decodifica per ispezionare i pacchetti: l’analista può ricomporre flussi TCP, estrarre file trasferiti (ad esempio file scaricati via HTTP o FTP) e seguire la sequenza delle chiamate di rete. Esistono anche strumenti specializzati detti Network Forensic Analysis Tool (NFAT) – un esempio open source è Xplico – il cui scopo principale è estrarre e ricostruire automaticamente tutti i dati applicativi significativi da un’acquisizione di rete. Xplico, ad esempio, è in grado di ricavare da un file pcap tutto il contenuto delle email transitanti (protocolli SMTP/ POP/IMAP), le pagine web e i file scambiati via HTTP, le conversazioni VOIP (protocollo SIP/RTP) convertendole in registrazioni audio, e così via 23 24 . Ciò risulta estremamente utile per presentare le evidenze in forma comprensibile: piuttosto che sfogliare migliaia di pacchetti, l’analista può ottenere direttamente i messaggi e-mail inviati dall’attaccante o i file trafugati.
Un aspetto critico nell’analisi di rete è la presenza della crittografia. Oggi molto traffico (in primis HTTP tramite TLS, ma anche email con SMTPS/IMAPS, VPN cifrate, ecc.) è cifrato end-to-end, il che impedisce di leggere il contenuto dei pacchetti a meno di poter disporre delle chiavi private per decriptarlo. Questo ovviamente complica l’analisi forense: se l’attaccante ha usato solo canali cifrati, si dovrà fare affidamento su metadati (IP, porte, quantità di dati) e su eventuali side-channel (come l’individuazione del tipo di protocollo o l’osservazione di certificate exchange noti) per dedurre cosa sia successo. In ambienti aziendali, per mitigare il problema, talvolta si utilizzano sistemi di SSL/TLS inspection (proxy che terminano e re-instaurano le connessioni cifrate, consentendo l’ispezione del contenuto da parte del SOC) – ma ciò deve essere bilanciato con esigenze di privacy e normative. Nonostante la crittografia, alcuni indicatori di compromissione di rete possono comunque emergere: ad esempio, pattern di traffico anomalo (un host interno che fa centinaia di connessioni verso l’esterno di notte), oppure l’uso di protocolli o porte inusuali per la rete aziendale.
Un compito importante del forense di rete è anche quello di tracciare la sorgente di un attacco. I malintenzionati spesso utilizzano machine zombi o server proxy per celare la propria identità, rendendo arduo risalire all’IP originario dell’attaccante. Attraverso l’analisi incrociata dei log di diversi dispositivi (router, firewall di frontiera, server di autenticazione RADIUS/TACACS), si può tuttavia riuscire a seguire il percorso di un attacco e identificare l’ingresso iniziale. Ad esempio, se un attaccante ha sfruttato una VPN compromessa, i log VPN daranno l’IP pubblico utilizzato; correlando questo con log di altri provider o con segnalazioni di CERT internazionali, si può scoprire se quell’IP corrisponde a una nota botnet. Questo tipo di investigazione sfrutta sia le competenze tecniche che le cooperazioni inter-agenzia: CERT e forze di polizia spesso collaborano scambiandosi informazioni sugli indirizzi IP e le infrastrutture di attacco note.
A tal proposito, è utile menzionare alcuni casi concreti italiani. Le forze dell’ordine, in particolare la Polizia Postale, hanno sviluppato notevoli capacità di network forensics. Un esempio è l’uso proprio di Xplico citato in contesti operativi: in una presentazione del progetto DEFT Linux (una distribuzione forense live creata in Italia), Stefano Fratepietro mostrò come la Polizia, dopo aver catturato il traffico di rete relativo a un’attività illecita, utilizzi Xplico per analizzarlo e ricavare le prove applicative. Questo ha permesso in vari casi di “leggere” comunicazioni tra criminali che avvenivano su canali non cifrati e di raccogliere elementi probatori (e-mail, credenziali, conversazioni VoIP) direttamente dal traffico di rete salvato. Un altro caso noto è l’investigazione sulle botnet Mirai e varianti IoT in Italia: grazie al monitoraggio del traffico anomalo in uscita da dispositivi compromessi (camere IP, router), il CERT-AgID in coordinamento con l’ACN è riuscito a mappare le connessioni verso i server di comando esteri e a condividere con gli ISP le informazioni per la mitigazione, mostrando l’efficacia dell’analisi di rete su larga scala per la difesa nazionale. In sintesi, la network forensics fornisce al responsabile CSIRT uno sguardo “sul filo” delle comunicazioni, rivelando come e cosa è stato trasferito durante un attacco – informazioni imprescindibili per capire l’impatto dell’incidente (ad es. quali dati sono stati rubati) e per bloccare canali di attacco ancora attivi.
Analisi di memorie di massa
Con memorie di massa si intendono tutti i dispositivi di archiviazione persistente dei dati, come hard disk, SSD, chiavette USB, schede di memoria, e in senso lato anche i dischi virtuali di macchine virtuali o istanze cloud. L’analisi forense di queste memorie – strettamente collegata a quella dei file system – si focalizza sull’esame dell’intero supporto fisico o logico e non solo della struttura di files e cartelle. Ciò include aspetti come: l’identificazione di tutte le partizioni presenti (anche quelle nascoste o non standard), l’esame dei settori di boot (MBR o GPT) per individuare bootkit o alterazioni, la ricerca di volume shadow copies o backup nascosti, e in generale l’analisi di ogni area del disco, compresi lo spazio non allocato e lo slack space (lo spazio inutilizzato alla fine dei cluster allocati).
Operativamente, anche qui si parte dall’acquisizione forense del supporto di memoria, creando un’immagine bitstream come discusso in precedenza. Nel caso di dischi di grandi dimensioni, questa operazione può richiedere molto tempo e devono essere adottate opportune precauzioni (condizioni ambientali adeguate, UPS per evitare interruzioni di corrente, etc.). Una volta ottenuta l’immagine, l’investigatore può utilizzare software di analisi come EnCase, FTK o tool open source (ad es. The Sleuth Kit con interfaccia Autopsy) per caricarla. Questi strumenti permettono di navigare tra le partizioni individuate, montarle in sola lettura e analizzarne il contenuto. Un controllo importante è quello della consistenza tra il livello logico e fisico: per esempio, se la tabella delle partizioni indica che un certo spazio del disco non è allocato a nessuna partizione, potrebbe essere normale (spazio vuoto inutilizzato) oppure potrebbe celare una partizione nascosta contenente dati (talvolta i criminali usano partizioni con identificatori anomali o volutamente corrotte per nascondere informazioni). L’analista utilizza quindi tecniche di carving e scanning anche sull’intera immagine fisica per vedere se firme di file noti compaiono in zone altrimenti “mute” del disco.
Un altro scenario da affrontare è quello dei RAID o volumi cifrati. Nelle grandi infrastrutture, spesso i dischi sono in configurazione RAID: il forense dovrà poter ricostruire il volume logico aggregando le immagini dei singoli dischi (rispettando ordine e parametri RAID) per accedere ai dati. Se il volume è cifrato (es. tramite BitLocker, LUKS, VeraCrypt), serviranno le chiavi di decrittazione o tecniche specifiche (es. estrarre la master key dalla RAM acquisita, in caso di sistema acceso) per poter proseguire. Anche dispositivi come smartphone e tablet rientrano nelle “memorie di massa” in senso lato: qui le metodologie divergono (uso di strumenti come Cellebrite UFED o Magnet AXIOM per estrarre una immagine logica o fisica del telefono, sblocco tramite exploit, ecc.), ma per brevità ci focalizziamo sui sistemi tradizionali.
Durante l’analisi delle memorie di massa è importante mantenere la documentazione di ogni passo: ad esempio annotare i codici identificativi del supporto, i calcoli hash effettuati, l’orario di inizio e fine delle copie, le persone intervenute. Questo perché, trattandosi spesso di evidence da presentare eventualmente in tribunale, la catena di custodia deve essere chiara e ininterrotta: ogni spostamento o copia dell’evidenza dev’essere tracciato, e l’integrità deve essere costantemente verificata con hash. Gli standard internazionali (come ISO/IEC 27041 e la stessa 27042) sottolineano l’importanza di garantire l’idoneità e l’adeguatezza del metodo investigativo e la validità delle prove raccolte. In Italia, anche le linee guida del Consiglio d’Europa e del Framework Nazionale di Cybersecurity richiamano questi principi, e le forze dell’ordine (come i reparti di informatica forense dei Carabinieri e della Polizia) hanno protocolli rigorosi per l’acquisizione e la conservazione delle memorie digitali sequestrate.
In sintesi, l’analisi delle memorie di massa copre un ventaglio molto ampio di attività: dalla copia forense alla ricerca di dati nascosti, dall’individuazione di partizioni occulte al recupero di file cancellati, fino all’estrazione di informazioni residuali (ad es. nel pagefile o hibernation file di Windows potrebbero trovarsi frammenti di documenti o credenziali che vale la pena esaminare). Tutto questo richiede competenze tecniche approfondite sul funzionamento dei dispositivi di storage e dei file system, nonché padronanza degli strumenti software dedicati.
Data carving e recupero dei dati
Il data carving (o file carving) è una tecnica forense avanzata utilizzata per recuperare file o frammenti di dati direttamente dal contenuto grezzo di un supporto, senza fare affidamento sulle strutture logiche del file system. Si ricorre al carving soprattutto quando i metadati del file system – che normalmente indicano posizione e dimensione dei file – non sono più disponibili o affidabili: ad esempio, per file cancellati (le cui entry sono state rimosse dalla MFT/FAT) o in casi di file system corrotti/formattati dove la struttura directory è andata persa. Il principio base del carving è che molti tipi di file hanno una firma riconoscibile: delle sequenze specifiche di byte all’inizio (header) e talvolta alla fine (footer) del file. Ad esempio, i file JPEG iniziano tipicamente con i byte FF D8 FF E0 (o FF D8 FF E1 ), i file PDF iniziano con %PDF– , i file ZIP con PK\x03\x04 e così via. Un programma di carving scansiona l’immagine binaria del disco o della memoria alla ricerca di queste firme; quando ne trova una, cerca di estrapolare tutti i byte consecutivi fino al termine plausibile del file (spesso identificato da un footer noto, oppure da un cambio di contesto). Il risultato è l’estrazione di segmenti di dati che verosimilmente rappresentano file completi o parziali.
Ad esempio, se in uno spazio non allocato di un disco troviamo la firma di inizio di un documento Word (byte D0 CF 11 E0 per i vecchi .doc in formato OLE, o l’indicazione PK per i .docx che sono ZIP), il software tenterà di ricostruire il file Word recuperando tutti i settori successivi fino a quando i dati non hanno più senso compiuto o incontrano un’altra firma. Il carving può recuperare file interi se i cluster non sono stati ancora riutilizzati, ma può anche produrre file parziali o corrotti se parti di essi sono state sovrascritte. Tuttavia, anche frammenti di file possono contenere informazioni utili (ad esempio, un pezzo di testo in un documento, o i frame di un video). Questa tecnica è quindi fondamentale quando si analizzano supporti dove l’attaccante ha cercato di ripulire le tracce cancellando file o formattando volumi: spesso, i dati restanti sul disco raccontano ancora la storia. Va notato che il carving non garantisce che i file recuperati siano esattamente nella loro originaria integrità; è necessario validare poi tali file (ad esempio aprendo i documenti recuperati o verificandone gli hash se disponibili).
Esistono diversi strumenti per il data carving: tra gli open source noti vi sono Foremost e Scalpel, nonché PhotoRec (specializzato nel recupero di foto e multimedia). Suite forensi complete come Autopsy/TSK integrano anch’esse funzioni di carving. In ambito NIST, sono stati definiti anche test specifici per valutare l’efficacia dei carving tool (il progetto CFReDS). Il responsabile forense deve conoscere i limiti di questa tecnica: ad esempio, file frammentati (non contigui sul disco) sono difficili da ricostruire completamente via carving, perché tra un frammento e l’altro potrebbero esserci altri dati – alcuni strumenti avanzati tentano di riconoscere frammenti appartenenti allo stesso file sulla base di pattern, ma non è semplice. Inoltre il carving produce spesso falsi positivi (bytes casuali che assomigliano a una firma) – l’analista dovrà quindi verificare manualmente i risultati, soprattutto se l’evidenza estratta è critica.
In definitiva, il data carving aggiunge un tassello importante all’analisi forense, consentendo di scavare a livello di byte nel supporto alla ricerca di qualunque traccia residua. È un processo che può essere lungo e intensivo computazionalmente, ma che in indagini complesse ha portato a ritrovare, ad esempio, frammenti di email scambiate, immagini di reati, documenti eliminati poco prima di un sequestro, etc., rivelandosi spesso la chiave per incastrare i responsabili.
Timeline forense e analisi temporale
Il concetto di timeline in ambito forense si riferisce alla costruzione di una sequenza cronologica di eventi digitali che consenta di ricostruire in modo chiaro chi ha fatto cosa e quando su un sistema. La timeline forense è una delle tecniche più potenti a disposizione degli analisti, perché permette di collegare tra loro le diverse evidenze secondo l’asse temporale, fornendo una visione d’insieme dell’incidente. Come afferma un principio ben noto: “la timeline analysis consente di ricostruire gli eventi, individuare con precisione gli incidenti di sicurezza e comprendere il comportamento di un attaccante” . In pratica, creare una timeline significa prendere tutti i timestamp rilevanti – orari di modifica dei file, registrazioni di log, orari di esecuzione dei processi, etc. – e ordinarli, correlando poi ciascun evento con gli altri.
Per esempio, una timeline relativa a un attacco informatico complesso potrebbe mettere in fila: l’ora in cui un malware è stato eseguito (desunta dall’orario di creazione di un processo in memoria), subito seguita dall’ora in cui un nuovo file sospetto è comparso sul disco (timestamp di creazione del file), poi alcuni minuti dopo la connessione a un server esterno (da un log di rete), poi ancora la modifica di varie chiavi di registro (con orari registrati nel registro eventi), e infine magari l’esecuzione di un comando di cancellazione dati poco prima di un riavvio (log di shell). Vista in timeline, questa serie di azioni delinea chiaramente il modus operandi e l’impatto temporale dell’incidente, cosa che sarebbe difficile da cogliere esaminando isolatamente le singole fonti.
La costruzione di timeline forensi può essere fatta manualmente, esportando i dati temporali da varie fonti e inserendoli in un foglio cronologico, ma data l’enorme mole di informazioni spesso conviene usare strumenti specializzati. Uno dei più noti è Plaso (log2timeline), un framework open source che automaticamente estrae timestamp da un’ampia varietà di file di log e artefatti (file system, registro di Windows, cronologie browser, eventi di sistema) e crea una super timeline aggregata. Con Plaso, si può ad esempio prendere un intero disco e far generare tutti gli eventi temporali possibili in formato testuale o CSV, per poi analizzarli magari con un’interfaccia come Timesketch (piattaforma web per visualizzare e filtrare timeline). Ciò consente di effettuare ricerche veloci (es. “mostra eventi tra le 14:00 e le 15:00 del 12/05/2025” o “trova qualsiasi modifica di file .exe nella settimana precedente l’incidente”) e di applicare filtri per tipologia di evento.
Un concetto importante nella timeline analysis è quello dei pivot point: in un dataset cronologico enorme, si parte di solito da un evento chiave (ad esempio l’ora in cui è stato rilevato l’incidente, o l’orario di un alert antivirus) e si analizzano tutti gli eventi immediatamente precedenti e successivi a quello, allargando via via la finestra temporale. Questo aiuta a focalizzarsi sul periodo critico. Inoltre si distingue tra timeline completa (super timeline) e timeline mirata: la prima include tutto il possibile ed è utile per non perdere dettagli, ma può essere ridondante; la seconda invece si concentra su eventi di un certo tipo o su certe fonti (ad esempio solo la timeline dei file di un particolare directory, o solo gli eventi di login) rendendo più agevole l’analisi. In pratica l’analista forense spesso crea prima timeline parziali (ad esempio timeline del file system, timeline dei log di sicurezza) e poi le fonde assieme per l’analisi finale.
La timeline forense non è solo uno strumento tecnico, ma diventa spesso una parte integrante del report conclusivo di un’investigazione. Molti incident report contengono una sezione chiamata “Timeline of Events” in cui vengono elencati in ordine cronologico tutti gli eventi salienti scoperti, con data/ora, descrizione e fonte. Ciò fornisce ai decisori (manager, o eventualmente giudici in tribunale) una narrazione chiara di cosa è avvenuto. Per esempio: “08:42:15 – L’utente admin effettua login da remoto sull’host SERVER1; 08:45:10 – Viene creato il file malware.exe nella cartella C:\Windows\Temp; 08:45:15 – Il servizio antivirus genera un allarme (file infetto rilevato); 08:45:30 – Connessione di rete dall’host SERVER1 verso l’IP esterno 123.123.123.123 sulla porta 443 (presumibilmente HTTPS); 08:47:00 – Cancellazione di massa di file nella cartella DatiCondivisi…”, e così via. Una presentazione del genere consente di capire immediatamente la successione e l’impatto degli eventi.
Bisogna considerare, come accennato, eventuali problemi di sincronizzazione oraria: la timeline finale potrebbe includere eventi registrati da macchine con orologi non allineati, quindi l’analista deve normalizzare i tempi (ad esempio convertire tutti in UTC o applicare offset noti). Inoltre, la precisione dei timestamp può variare: alcuni log registrano l’ora al millisecondo, altri solo al secondo o al minuto. Quando si comparano eventi, queste differenze vanno tenute presenti (un evento con timestamp 10:00:00 e uno 10:00:30 potrebbero in realtà essere simultanei se il primo log è approssimato al minuto). Gli strumenti automatici spesso aiutano evidenziando potenziali correlazioni nonostante tali discrepanze.
In conclusione, il concetto di timeline rappresenta la spina dorsale dell’analisi forense: mette ordine nel caos di dati prodotti da un incidente e racconta la storia in modo lineare. Un responsabile CSIRT/ SOC deve saper sia costruire manualmente timeline (in contesti magari con pochi dati o in tempo reale) sia utilizzare tool avanzati per timeline complesse, così da poter spiegare efficacemente l’accaduto ai vari stakeholder e prendere decisioni informate sulle misure di contrasto e prevenzione da adottare.
Fondamenti di analisi dei malware
La malware analysis è il processo di esaminare un codice malevolo (malware) per capirne il funzionamento, l’origine, gli obiettivi e gli indicatori di compromissione, in modo da poter mitigare l’attacco e prevenire future infezioni. Nell’ambito della risposta agli incidenti, saper analizzare un malware trovato in un sistema compromesso è fondamentale: consente di determinare quali azioni ha compiuto (es. furto di dati, installazione di backdoor, cifratura ransomware), quali componenti ha installato e come rilevarlo/neutralizzarlo efficacemente. Si distinguono due approcci principali: analisi statica e analisi dinamica.
Analisi statica: consiste nell’esaminare il malware senza eseguirlo, studiandone il file binario e il codice. Include tecniche come: il calcolo di hash e confronto con database di minacce noti (per vedere se il malware è già catalogato), l’estrazione di stringhe testuali presenti nel file (che spesso rivelano indizi su funzionalità, URL o messaggi interni), l’uso di antivirus e strumenti di scanning per rilevare firme o packer usati, l’analisi del PE header nel caso di eseguibili Windows (per capire compilatore, librerie importate, ecc.), e soprattutto il reverse engineering tramite disassembler e decompiler (come IDA Pro, Ghidra o radare2). Con il debugging statico si può leggere il codice assembly del malware per individuare, ad esempio, routine di rete (API chiamate per fare connessioni), routine di cifratura, oppure condizioni di attivazione (date/time bomb). L’analisi statica è svolta in isolamento, dunque è sicura (il codice non viene attivato sul serio), ma può essere molto complessa se il malware è offuscato o protetto da anti-disassembling. Ad ogni modo, utilizzando debugger e altri strumenti, l’analista può ottenere molte informazioni sulle operazioni svolte dal programma dannoso e identificare eventuali punti deboli del malware stesso (ad esempio errori di implementazione che permettono di creare un decryptor per ransomware).
Analisi dinamica: complementare alla precedente, consiste nell’osservare il malware in esecuzione all’interno di un ambiente controllato e isolato (solitamente una sandbox o macchina virtuale di test). Si lancia il malware e si monitora il suo comportamento: quali processi crea, che file legge o scrive, quali chiavi di registro modifica, che traffico di rete genera, ecc… Per far ciò ci si avvale di strumenti come sandbox automatizzate (es. Cuckoo Sandbox, VMRay, Joe Sandbox) o monitor manuali (come Process Monitor, Regshot, sniffer di rete e simili) in una VM. L’analisi dinamica permette di vedere concretamente l’effetto del malware, ad esempio scoprendo l’URL di callback verso cui prova a connettersi, o vedendo che crea una copia di sé in una certa directory e stabilisce persistenza impostando una chiave di registro di run. Questo metodo può in alcuni casi essere più rapido nel fornire indicazioni (rispetto a dover leggere migliaia di righe di assembly), ma ha alcuni limiti: malware sofisticati possono rilevare l’ambiente virtuale/sandbox e cambiare comportamento (o non attivarsi proprio) in presenza di indicatori di analisi. Inoltre, se il malware è configurato per attivarsi solo in determinate condizioni (es. in un particolare giorno, o solo se rileva una certa configurazione di sistema), l’analista deve capire e soddisfare tali condizioni, altrimenti l’osservazione potrebbe non rivelare nulla di utile.
In una strategia completa di malware analysis, statica e dinamica si combinano: ad esempio, l’analisi statica preliminare può fornire IOC (hash, nomi di dominio, stringhe sospette) e indicazioni su come attivare il malware, mentre l’analisi dinamica conferma il comportamento e produce tracce di esecuzione (log delle azioni compiute). Oltre a questi approcci, esistono anche l’analisi automatizzata (utilizzo di motori AV e piattaforme cloud che già identificano la famiglia di malware e danno un report preconfezionato) e l’analisi della memoria specifica del malware (analizzare un dump di memoria del sistema infetto per estrarre parti di malware in esecuzione, utile per malware fileless o moduli iniettati).
Il fine ultimo dell’analisi malware è duplice: difensivo e conoscitivo. Dal lato difensivo, capire il funzionamento del malware consente di sviluppare contromisure mirate: ad esempio, scrivere firme per IDS/antivirus (basate su byte sequence uniche del malware), creare regole Yara per individuare varianti simili, implementare filtri su firewall/proxy per bloccare i domini di C&C emersi, o rafforzare le configurazioni di sistema contro le tecniche specifiche usate dal malware (es: se il malware sfrutta WMI per persistere, inserire controlli su WMI). Un’analisi approfondita “fornisce una comprensione delfunzionamento delle minacce, consentendo alle organizzazioni di creare rilevamenti mirati invece di affidarsia firme generiche”; in pratica, conoscere bene il malware permette di scoprirlo anche quando muta (perché si sa cosa tende a fare) e di reagire più velocemente. Inoltre gli analisti, esaminando gli Indicatori di Compromissione (IOC) del malware (indirizzi IP, hash di file, chiavi di registro modificate, ecc.), possono aggiornare i sistemi di monitoraggio: per esempio, inserendo nel SIEM gli hash in watchlist o caricando gli IP malevoli nei feed di blocco. Ciò aiuta anche a rilevare eventuali nuove infezioni da varianti analoghe (se altri host iniziano a contattare lo stesso C&C, potrebbe voler dire che il malware ha colpito anche lì). Dal lato conoscitivo, la malware analysis contribuisce a rintracciare le tattiche, tecniche e procedure (TTP) degli attaccanti e spesso a collegare un malware a una certa famiglia o gruppo (threat actor). Ad esempio, analizzando un ransomware si può scoprire che utilizza lo stesso algoritmo di cifratura e schema di riscatto di un gruppo noto, attribuendo così l’attacco e potenzialmente condividendo intel con le autorità. In alcuni casi, l’analisi porta anche a individuare eventuali zero-day exploit sfruttati dal malware: “aiutando i ricercatori di sicurezza a individuare exploitsconosciuti prima che si diffondano”. Ciò consente di avvisare i vendor software e far patchare le vulnerabilità, innalzando la sicurezza generale.
Per un analista CSIRT/SOC, non è richiesto essere un reverse engineer di livello avanzato, ma sicuramente avere i fondamenti di analisi malware: sapere come funziona un eseguibile, quali sono i metodi base per analizzarlo, quali strumenti usare e come interpretare un report tecnico di malware. Ad esempio, bisogna conoscere strumenti come VirusTotal (per un primo scan e reputazione di un file), Hybrid Analysis o ANY.RUN (sandbox online che mostrano un comportamento dinamico), debugger come OllyDbg/x64dbg (per tracciare manualmente l’esecuzione di malware a runtime), decompiler come Ghidra (per uno sguardo ad alto livello sul codice), e strumenti di dump e unpacking (poiché molti malware sono compressi o criptati). Durante un incidente grave, il responsabile potrebbe dover guidare il team nella scelta: “Abbiamo trovato questo eseguibile sospetto su un server, lo isoliamo e lo mandiamo in sandbox? oppure ne calcoliamo subito l’hash e vediamo se è noto? Quali IOC estraiamo?”. Il responsabile deve anche tradurre i risultati dell’analisi malware in azioni: ad esempio, se dall’analisi emerge che il malware si propaga via rete usando SMB exploit, andrà immediatamente disposto un controllo di tutti gli host per vedere se presentano quella vulnerabilità e applicare le patch. Oppure, se scopre che il malware ruba certi tipi di file, andranno monitorati accessi anomali a quei file su altri sistemi. Insomma, l’analisi malware fornisce la “intelligence tecnica” durante una crisi cyber, e il responsabile deve saperla sfruttare per il contenimento e la remediation dell’incidente.
Un esempio italiano di applicazione di queste competenze è il lavoro svolto dal CERT-AgID sulle campagne di malspam (email malevole) in Italia: i loro analisti analizzano quotidianamente malware come bancari (es. Ursnif, Dridex), ransomware (es. Cryptolocker, LockBit) e spyware diffusi via email di phishing, producendo report e IOC condivisi con tutte le amministrazioni. Nel Report “Le campagnemalevole del 2024” pubblicato da CERT-AgID, ad esempio, si illustrano le tecniche di offuscamento osservate nei malware giunti via PEC, mostrando come la combinazione di analisi statica (per deoffuscare macro Office e script PowerShell allegati) e analisi dinamica (per osservare i contatti verso i server di destinazione e i file drop) abbia permesso di contrastare efficacemente tali minacce. Questo tipo di conoscenza, opportunamente integrata nei processi di un SOC, consente di innalzare significativamente il livello di protezione degli enti italiani contro attacchi mirati.
Principali strumenti software per l’analisi forense
In campo forense digitale esiste un’ampia gamma di strumenti software specializzati. Un responsabile CSIRT/SOC deve conoscerne i principali – sia commerciali sia open source – per scegliere di volta in volta quelli più adatti e per comprendere i risultati prodotti dal team tecnico. Di seguito elenchiamo alcuni dei tool più diffusi e riconosciuti, suddivisi per categoria.
Suite di analisi su disco e file system: strumenti completi che permettono di esaminare immagini forensi di dischi, navigare tra file, estrarre artefatti e generare report. I più noti sono EnCase Forensic (Guidance Software/OpenText) e FTK – Forensic Toolkit (AccessData/Exterro), ampiamente usati dalle forze dell’ordine e dalle società di cybersecurity. In ambito open source, spicca Autopsy (con il motore The Sleuth Kit): interfaccia grafica che consente analisi dettagliate di file system (NTFS, FAT, EXT, HFS, ecc.), ricerca di keyword, carving, timeline e molto altro. Autopsy supporta plugin per l’analisi di specifici artifact (ad es. la cronologia di browser, i registri di sistema Windows, ecc.) e rappresenta una valida alternativa free ai prodotti commerciali. Un altro nome da citare è X-Ways Forensics (di X-Ways Software): un toolkit potentissimo e leggero molto apprezzato per la velocità e l’efficienza nell’analisi di dischi (popolare in contesti professionali europei). Queste suite includono funzioni di hashing di massa, confronto con liste di known files (hash set noti, come la NSRL), ricostruzione di RAID, esportazione di report completi per tribunale, e sono indispensabili per gestire casi complessi. Da menzionare anche software come Magnet AXIOM (della Magnet Forensics), che integra funzioni di analisi filesystem, mobile e cloud in un unico ambiente.
Strumenti per memory forensics: il già discusso Volatility Framework è il riferimento open source per l’analisi dei dump RAM. Include decine di plugin per estrarre praticamente qualsiasi informazione dalla memoria di Windows, Linux, macOS e profili Android. La sua conoscenza è fondamentale per chi fa incident response. Un altro progetto simile (nato come fork) è Rekall. In ambito commerciale, Magnet AXIOM e Belkasoft Evidence Center offrono moduli di memory analysis integrati, ma spesso si finisce per utilizzare Volatility anche in tali contesti. Per facilitare l’uso di Volatility, esistono interfacce grafiche e tool correlati – ad esempio Volatility Workbench o Autopsy Memory Modules – ma anche linee di comando avanzate come KAPE che integrano flussi di lavoro di triage memoria + timeline. Infine, nel mondo enterprise, prodotti EDR (Endpoint Detection & Response) come CrowdStrike, FireEye HX, Microsoft Defender for Endpoint, spesso dispongono di capacità di acquisizione memoria e analisi automatizzata integrata, sebbene non flessibili come un’analisi manuale con Volatility.
Strumenti per analisi di log e network forensics: per i log, oltre ai SIEM già citati (Splunk, Elastic Stack/ELK, IBM QRadar, ArcSight, etc.), in un laboratorio forense può essere utile log2timeline/Plaso per estrarre timeline come detto, oppure tool come Chainsaw (per analisi offline di Windows event logs usando regole Sigma), EVTX Explorer (visualizzazione avanzata di log Windows) e SysmonView (per tracciare eventi Sysmon). Per la parte network, l’insostituibile Wireshark permette di analizzare qualunque traccia di rete a basso livello. In aggiunta, strumenti come Zeek (ex Bro) servono a elaborare grandi moli di traffico producendo log sintetici su connessioni, file trasferiti, dns query, ecc. Utili anche NetworkMiner (che estrae in automatico elementi dal traffico, simile a Xplico ma con interfaccia diversa) e Moloch/Arkime (piattaforma di capture indexing su larga scala). Nel contesto italiano, come già accennato, la distribuzione DEFT Linux includeva Xplico e altre utility di rete, costituendo un riferimento per molti anni (ora il progetto è meno attivo, ma Xplico prosegue separatamente).
Strumenti per analisi malware: qui troviamo disassembler e debugger come IDA Pro, Ghidra (open source della NSA), OllyDbg/x64dbg, essenziali per il reversing. Sandbox come Cuckoo (open) e varie soluzioni commerciali (VMRay, JoeSandbox, Any.Run) sono utilizzate per l’automated dynamic analysis. Inoltre, tool come Radare2 o Binary Ninja possono fornire analisi alternative. L’analista malware utilizza anche unpacker (es. UPX per eseguibili compressi) e strumenti di monitoraggio come Process Monitor, RegShot, ApateDNS (per ingannare le richieste DNS dei malware). Su un piano diverso, servizi online tipo VirusTotal e database come MalwareBazaar aiutano a contestualizzare il campione (vedere se hash è noto, se esistono Yara rules, ecc.). Conoscere questi strumenti e le relative tecniche di utilizzo rientra nel bagaglio di competenze che un responsabile deve quantomeno saper indirizzare: ad esempio, decidere quando inviare un campione sospetto a un servizio cloud per un’analisi veloce e quando invece è necessario allestire un ambiente isolato e approfondire manualmente.
Piattaforme integrate e distribuzioni forensi: esistono delle vere e proprie distro o suite integrate che raccolgono decine di tool. Ad esempio CAINE (Computer Aided INvestigative Environment) è una distribuzione GNU/Linux live creata in Italia, specificamente per la digital forensics. CAINE contiene un ambiente grafico con script e interfacce che guidano attraverso le fasi classiche dell’investigazione (acquisizione, esame, report) e integra moduli software per analisi di database, memoria, rete, immagini file system NTFS/FAT/EXT, etc. 43 44 . Il tutto assicurando che le operazioni siano forensically sound (ad esempio montando le evidenze in sola lettura). Altre distro note sono SANS SIFT Workstation (Ubuntu-based, mantenuta da SANS Institute) e Kali Linux per la parte più “offensiva” e di test penetrativo ma comunque utile per alcuni strumenti forensi. Anche Tsurugi Linux è una distro recente orientata a DFIR. L’adozione di queste piattaforme consente ai team di avere un ambiente standard con tutti gli strumenti necessari pronti all’uso. Nel contesto lavorativo, spesso si usano macchine virtuali con tali distro per operare sulle evidenze in laboratorio.
In ambito CSIRT/SOC, è attesa “la conoscenza dei principali strumenti softwaredi analisi forense quali Autopsy, Volatility, Magnet Forensics, EnCase Forensic”, come esplicitato anche in annunci di lavoro del settore. Questo significa avere familiarità almeno di base con l’interfaccia e le funzionalità di ciascuno di essi: ad esempio sapere come aprire un case in Autopsy e avviare l’ingest dei moduli, oppure come lanciare i plugin di Volatility da riga di comando per estrarre i processi o le connessioni di rete da un dump RAM, o ancora conoscere l’esistenza di Magnet AXIOM (suite commerciale all-in-one usata anche da forze dell’ordine per analizzare PC e dispositivi mobili). Naturalmente nessuno strumento è “universale” o adatto a tutti gli scopi: il bravo analista sceglie di volta in volta l’utensile più idoneo. Ad esempio, per una rapida triage su 100 endpoint potrebbe usare script e tool da riga di comando (es. KAPE per raccogliere artefatti chiave e Velociraptor per query live), mentre per un’analisi in depth di un singolo server compromesso potrebbe preferire montare l’immagine in Autopsy e lavorare di fino. L’importante è conoscere le potenzialità e i limiti di ogni strumento: saper leggere tra le righe di un output, capire se ad esempio un dato mancante è dovuto a un limite del tool o alla reale assenza di quell’artefatto, ecc.
Da ultimo, vale la pena citare che gli strumenti software sono in continua evoluzione: ogni anno emergono nuovi tool o nuove versioni con funzionalità potenziate (si pensi solo all’evoluzione di Volatility per supportare Windows 11, o ai tool di cloud forensics per AWS/Azure). Un responsabile forense deve mantenersi aggiornato, partecipando magari a community specializzate (come Forensic Focus, DFIR Training, o community locali IISFA) e testando in laboratorio i nuovi strumenti per valutarne l’efficacia.
Conclusioni
L’articolo ha passato in rassegna i principali ambiti dell’analisi forense digitale rilevanti per un responsabile di cybersecurity. Dall’analisi dei file system e delle memorie di massa (con le tecniche di recupero dati e carving) all’ispezione forense della memoria volatile, dall’interpretazione dei log di sicurezza alla dissezione del traffico di rete, fino allo studio dei malware e all’uso dei tool specializzati – ogni sezione evidenzia competenze e conoscenze che risultano oggi imprescindibili per gestire efficacemente incidenti informatici complessi. Queste attività non vivono isolate, ma confluiscono in un processo unificato di digital forensics & incident response (DFIR): ad esempio, i risultati dell’analisi malware influiscono sulle azioni di containment, la timeline forense orienta le indagini ulteriori, l’analisi dei log può suggerire dove cercare evidenze aggiuntive su disco o in memoria, e così via. Il responsabile deve quindi avere una visione olistica, sapendo integrare i vari filoni di analisi in una strategia coerente.
Gli standard internazionali citati (ISO/IEC 27042, 27043, NIST SP 800-86) forniscono un quadro metodologico solido: aderiscono a principi di rigor metodologico, validità, ripetibilità e legalità delle operazioni forensi. Anche nelle procedure italiane (dalle circolari di ACN/CERT-AgID ai manuali operativi delle forze dell’ordine) si ritrova l’enfasi sulla corretta gestione delle evidenze e sulla necessità di agire tempestivamente ma senza comprometterne l’integrità. Questo equilibrio – rapidità vs. accuratezza – è spesso la sfida principale in uno scenario di incidente reale: il responsabile deve decidere quando è il caso di scollegare un sistema per preservarne lo stato, oppure quando conviene lasciarlo online per raccogliere più dati; deve prioritizzare le analisi (ad esempio, prima la memoria per cogliere dati volatili, poi il disco) e allocare le risorse giuste (personale e strumenti) ai vari task.
In termini di contesto nazionale, abbiamo visto come l’Italia si stia allineando alle migliori pratiche: la creazione dell’ACN e il potenziamento di CSIRT Italia, le attività di CERT-AgID focalizzate su prevenzione e condivisione di informazioni, nonché la crescita di competenze nelle unità di Polizia Postale e altri organi investigativi in materia di cyber forensics, testimoniano una maggiore attenzione strategica verso la resilienza cibernetica. Casi concreti gestiti con successo – dalla mitigazione di campagne malware mirate alle PA, all’attribuzione di attacchi tramite analisi delle TTP, fino alla persecuzione penale di cybercriminali grazie a prove digitali forensi – dimostrano il valore di queste capacità.
Per chi aspira a coordinare la prevenzione e gestione degli incidenti informatici, è quindi cruciale non solo conoscere la teoria, ma anche aver maturato una certa esperienza pratica con le tecniche e gli strumenti descritti. La formazione continua, i laboratori su scenari simulati (ad esempio competizioni di Digital Forensics CTF o esercitazioni nazionali di cyber crisis) e l’aggiornamento sulle minacce emergenti (tramite report come quelli CERT-AgID o dell’ENISA) completeranno il bagaglio necessario. In un campo così dinamico, la curiosità investigativa e la mentalità analitica sono qualità preziose quanto la conoscenza tecnica. Un buon responsabile forense sa fare le domande giuste e seguire gli indizi digitali con rigore scientifico, consapevole che dietro ogni byte potrebbe celarsi la chiave per sventare un attacco o attribuirne la responsabilità.
In conclusione, l’analisi forense applicata al cyber-incident response è sia un’arte che una scienza: richiede metodo, strumenti e standard – ma anche intuito, esperienza e capacità di adattamento. L’obiettivo finale è sempre quello di far luce sull’accaduto (shed light on the incident), fornendo risposte chiare al chi, cosa, quando, come e aiutando così l’organizzazione a riprendersi dall’incidente e a imparare da esso per migliorare la propria postura di sicurezza.
Nel contesto della sicurezza nazionale, l’acquisizione forense delle evidenze digitali riveste un ruolo cruciale nella gestione degli incidenti informatici. Un CSIRT/SOC (Computer Security Incident Response Team/Security Operations Center) deve assicurare che ogni fase – dalla profilazione del sistema e triage iniziale, fino alla copia forense dei dati – sia condotta in modo rigoroso e conforme agli standard. Tali pratiche garantiscono sia la continuità operativa degli enti coinvolti che la valorizzazione probatoria delle informazioni raccolte, permettendo eventuali azioni legali. In questo articolo esamineremo le principali metodologie di acquisizione forense, distinguendo tra scenari live e post-mortem, le tecniche di copia bitstream di dischi e dump di RAM, gli artefatti tipici dei sistemi Windows e Linux, nonché gli strumenti hardware/software disponibili. Faremo riferimento ai principali standard internazionali (ad es. ISO/IEC 27037, NIST SP 800-86, RFC 3227) e con esempi concreti in contesto italiano.
System Profiling e Triage
La fase di triage forense consiste nel valutare rapidamente uno scenario compromesso e dare prioritàalle evidenze digitali in base alla loro rilevanza e urgenza. In pratica, significa eseguire una profilazione del sistema coinvolto nell’incidente: identificare il tipo di host (es. server, workstation), il sistema operativo e versione, i servizi attivi, gli utenti connessi e altri elementi chiave, ancor prima di procedere all’acquisizione completa. Lo scopo del triage è individuare subito i dati più critici – ad esempio processi sospetti in esecuzione, connessioni di rete attive verso IP anomali, file di log che mostrano segni di manomissione – che richiedono azione immediata o conservazione urgente. Questa rapida valutazione permette al responsabile di decidere i passi successivi: ad esempio, se isolare il sistema dalla rete per contenere una minaccia in corso, oppure se mantenere la macchina accesa per acquisire dati volatili (RAM, processi, ecc.) prima che vadano persi.
Durante il triage, è fondamentale rispettare il principio dell’ordine di volatilità indicato dall’RFC 3227: occorre procedere raccogliendo prima i dati più volatili e soggetti a cambiamento, per poi passare a quelli meno volatili. Ciò significa, ad esempio, che su un sistema attivo si dovrebbero salvare immediatamente informazioni come il contenuto della memoria RAM, la tabella dei processi e le connessioni di rete, prima di acquisire i dati persistenti su disco. Allo stesso tempo, bisogna evitare manovre che possano alterare o distruggere le evidenze: non spegnere il sistema prematuramente (l’attaccante potrebbe aver impostato script di wipe all’arresto), e utilizzare strumenti “puliti” (da supporti esterni) invece di quelli presenti sul sistema compromesso, che potrebbero essere stati modificati dall’attaccante. Il responsabile forense deve istruire i primi soccorritori digitali (first responder) a seguire procedure codificate – spesso definite in playbook di incidente – per effettuare un triage metodico. Ad esempio, può essere prevista una checklist: identificare e fotografare la schermata attiva, annotare o esportare rapidamente la lista dei processi e delle connessioni (usando tool come netstat o PowerShell in modalità forense), verificare la presenza di dispositivi USB collegati, e controllare il clock di sistema (per future correlazioni temporali). Queste attività di profilazione iniziale forniscono un quadro dello stato del sistema utile per orientare l’indagine e decidere quali evidenze raccogliere con priorità. In sintesi, system profiling e triage rappresentano la prima linea di azione di un responsabile CSIRT nella fase di Preparation/Identification di un incidente, gettando le basi per un’acquisizione forense mirata ed efficace.
Processo di acquisizione: modalità live vs post-mortem
Una volta completato il triage, si passa al processo di acquisizione delle evidenze digitali vero e proprio, che può avvenire in due modalità principali: live (a sistema acceso) o post-mortem (a sistema spento). La scelta dipende dalla situazione: in molti casi di risposta a incidenti, è necessario operare live forensics per catturare dati volatili critici; altre volte, soprattutto in scenari di analisi forense tradizionale (es. sequestro di un computer in un’indagine giudiziaria), si opta per spegnere il sistema e lavorare su copie a freddo per minimizzare modifiche.
Acquisizione live
In questa modalità si raccolgono evidenze a sistema funzionante. I vantaggi sono evidenti: si possono preservare informazioni che altrimenti andrebbero perse con lo spegnimento – ad esempio il contenuto della RAM, le chiavi di cifratura in uso, processi e connessioni attive, ecc. Tuttavia, l’acquisizione live comporta inevitabilmente qualche alterazione dello stato del sistema (ogni comando eseguito può modificare dati, come i timestamp di ultimo accesso) e va quindi condotta con strumenti e metodologie che riducano al minimo tale impatto. Best practice in questo ambito (formalizzate in ISO 27037 e RFC 3227) includono: usare tool forensi dedicati eseguendoli da supporti in sola lettura (per non introdurre nuovi file sul disco target) e documentare ogni operazione compiuta. Un esempio tipico di acquisizione live è il dump della memoria RAM (vedi sezione dedicata) oppure l’estrazione di informazioni volatili tramite script di risposta all’incidente. In situazioni dove si sospetta la presenza di malware avanzati o tecniche anti-forensi (come il timestomping o la cancellazione dei log di evento), l’analisi live può rivelare indizi (processi anomali in esecuzione, moduli kernel caricati in memoria) che un’analisi post-mortem potrebbe non evidenziare. È importante anche valutare i rischi: ad esempio, scollegare la rete di una macchina compromessa può essere opportuno per isolarla, ma va fatto in modo controllato (un malware potrebbe monitorare la connettività e reagire cancellando tracce se “perde” la rete ). Il responsabile deve quindi decidere, caso per caso, quali step eseguire live e in che sequenza, bilanciando la conservazione massima delle prove con la stabilizzazione dell’incidente (es. evitare che l’attacco prosegua).
Acquisizione post-mortem
Consiste nell’acquisire le evidenze a sistema spento, tipicamente tramite la rimozione dei supporti di memoria (hard disk, SSD) e la successiva copia forense bitstream in laboratorio. Questo approccio ha il vantaggio di assicurare che il supporto originale non venga modificato ulteriormente dal momento del sequestro in poi. Nel momento in cui si spegne un computer, però, si perde tutto il contenuto volatile: memoria RAM, stato dei processi, informazioni non salvate su disco, ecc. Pertanto, la decisione di spegnere dovrebbe essere ponderata: ad esempio, se si ritiene che le informazioni critiche risiedano su disco (non volatile) e non vi sia particolare interesse per lo stato attuale della RAM, può essere preferibile rimuovere l’alimentazione immediatamente per congelare la situazione. Al contrario, se si sospetta che informazioni vitali (come chiavi di cifratura, malware in RAM o volumi cifrati aperti) siano presenti in memoria, è fondamentale lasciare il sistema acceso finché non si sia effettuato un dump della memoria e di eventuali dati volatili. L’ISO/IEC 27037 fornisce linee guida proprio per decidere queste priorità: “se dati volatili di rilievo sono presenti, raccoglierli prima di rimuovere l’alimentazione; se invece il focus è sui dati non volatili su disco, si può procedere allo spegnimento in sicurezza”. In modalità post-mortem, l’operatore può impiegare tecniche come il “pull the plug” (scollegare brutalmente l’alimentazione anziché seguire la normale procedura di shutdown, per evitare che eventuali routine di spegnimento dell’attaccante distruggano dati). Naturalmente ciò potrebbe generare qualche inconsistenza nei file (es. journal non “puliti”), ma si preferisce questo rischio piuttosto che perdere prove volatili preziose. Una volta spento e messo in sicurezza il sistema, si passa all’imaging forense dei supporti (illustrato nella sezione successiva). L’acquisizione post-mortem è tipica nelle operazioni di polizia giudiziaria (sequestri) e nelle analisi che non richiedono intervento immediato sul campo. Un responsabile CSIRT deve saper indicare quando è appropriato seguire l’una o l’altra modalità, spesso anche combinandole (es.: acquisizione ibrida, dove prima si esegue un dump di RAM live e poi si spegne per copiare il disco). In ogni caso, che l’acquisizione sia live o a freddo, vanno seguiti i protocolli di documentazione e catena di custodia per garantire integrità e autenticità delle evidenze raccolte.
Acquisizione bitstream di memorie di massa
La copia forense bitstream di un supporto di memoria di massa (dischi fissi, SSD, memorie esterne) è un processo centrale nell’informatica forense. A differenza di una normale copia file-per-file, l’imaging bitstream duplica bit a bit l’intero contenuto del supporto – includendo settori non allocati, spazio slack, aree nascoste – in modo da ottenere un clone esatto dell’originale . Questo è fondamentale perché file cancellati o metadata residuali, non visibili al file system attivo, possono contenere informazioni cruciali in un’indagine.
Procedura di imaging: il processo standard prevede di collegare il supporto originale a una workstation forense (o a un dispositivo duplicatore) in modalità read-only e creare un file immagine o una copia clonata su un supporto di destinazione pulito. Una misura imprescindibile è l’uso di un write-blocker, un dispositivo hardware (o software) che si interpone tra il drive di origine e il sistema di acquisizione, e impedisce qualsiasi comando di scrittura verso il dispositivo sorgente. In questo modo, si può leggere ogni settore del disco senza rischiare modifiche accidentali (ad esempio aggiornamenti di timestamp di accesso, incrementi di contatori SMART, ecc.). I write-blocker hardware sono tipicamente connessi via USB/SATA o tramite dock, e devono essere verificati prima dell’uso; molti modelli forniscono indicatori che confermano lo stato di sola lettura. È importante che il personale ricontrolli che il blocco in scrittura sia attivo per tutti i dispositivi connessi e che i blocker siano periodicamente testati (come raccomandato anche dai laboratori NIST). In alternativa o in aggiunta, su sistemi nix si può montare il supporto in modo da non scrivere journal (opzione ro,noload* per NTFS, ad es.), ma il dispositivo hardware è preferibile perché più affidabile.
Durante l’imaging, si genera di solito un hash crittografico (tipicamente MD5 e/o SHA-1/SHA-256) sia del contenuto originale che della copia, per poter verificare in ogni momento la corrispondenza (integrità) tra i due. Un responsabile deve esigere che al termine dell’acquisizione questi hash combacino e che vengano registrati nei verbali. Come sottolineato da NIST, se si prevede un possibile uso probatorio, è opportuno conservare l’originale intatto come evidenza (ad esempio sigillando il disco originale) ed effettuare tutte le analisi successive sulla copia. L’ISO 27037 e le best practice internazionali insistono molto su questo punto: l’originale diventa evidence master conservato a fini legali, mentre la copia forense (opportunamente verificata) è quella su cui gli analisti lavorano, eventualmente potendone fare ulteriori copie di lavoro. Ogni passo eseguito deve essere documentato dettagliatamente: oltre ai comandi o software utilizzati per l’imaging, vanno annotati ad esempio il modello e seriale del disco originale, la capacità, il nome e versione dello strumento impiegato (software o duplicatore hardware), l’ora di inizio e fine copia, il nome del tecnico operatore e qualsiasi anomalia riscontrata. Queste informazioni supportano la catena di custodia e servono a dimostrare che la procedura è stata eseguita correttamente e senza contaminare le prove.
Formati di output: l’acquisizione bitstream può produrre sia copie fisiche (disk-to-disk, clonazione diretta su un altro drive) che immagini logiche in un file (disk-to-image). La scelta dipende dalle esigenze e dalle risorse: una copia disk-to-disk permette, ad esempio, di montare immediatamente il clone su un’altra macchina per un’analisi rapida, ma richiede un secondo dispositivo di capacità uguale o maggiore. La copia in un file immagine (spesso con estensione .dd se raw o .E01 se compressa con formato EnCase) è più flessibile: il file può essere trasferito, copiato e montato tramite software appositi; di contro, per accedervi occorre utilizzare applicativi forensi o montarlo in un ambiente che supporti tale formato. Molti strumenti consentono anche di comprimere al volo l’immagine, salvando spazio, e di segmentarla in più file (utile per gestire file system che non supportano file di grandi dimensioni). In contesti operativi, il responsabile deve definire uno schema di nomenclatura per le immagini e un sistema di storage sicuro: ad esempio, archiviare le immagini su NAS forense isolato, con controlli di integrità periodici (ricalcolo hash) e accesso ristretto.
In conclusione, l’acquisizione bitstream è un processo dispendioso in termini di tempo e risorse (copiare centinaia di GB può richiedere ore), ma è indispensabile per garantire un’analisi completa e la validità delle prove in tribunale. Organizzazioni ben preparate adottano linee guida interne per quando e come eseguire imaging completo (ad esempio, può non essere realistico fermare immediatamente un server critico per copiarlo; vanno stabiliti criteri di impatto). Il responsabile CSIRT bilancia quindi anche l’esigenza di continuità operativa con quella probatoria, pianificando acquisizioni a freddo in orari e modi che riducano il danno, ma senza compromettere la raccolta delle prove necessarie.
Acquisizione di dump di memoria (RAM)
Le informazioni contenute nella memoria volatile (RAM) di un sistema spesso non hanno equivalentisul disco e possono rivelare dettagli cruciali di un attacco informatico. La RAM ospita infatti lo stato vivo del sistema: processi in esecuzione, moduli di kernel e driver caricati, connessioni di rete aperte, file aperti (che magari non sono mai stati salvati su disco), chiavi di cifratura in uso, password in chiaro temporaneamente in memoria, e molto altro. Tutto questo viene perso definitivamente non appena il sistema viene spento, data la natura volatile della RAM. Per tale ragione, acquisire un dump dimemoria è una fase fondamentale nella risposta agli incidenti live: consente di “congelare” lo stato runtime del sistema al momento dell’incidente per analizzarlo successivamente in laboratorio.
Dal punto di vista pratico, un dump di RAM si ottiene tramite appositi strumenti che copiano byte per byte tutto il contenuto della memoria in un file (spesso chiamato memory.dmp con estensione .raw/.bin). Su sistemi Windows, esistono utilità consolidate come Magnet RAM Capture (fornito da Magnet Forensics) o Belkasoft Live RAM Capturer, nonché tool open-source come WinPmem (facente parte del progetto Rekall) e DumpIt. Questi programmi, tipicamente eseguiti dal tecnico sul sistema target (idealmente da una chiavetta USB, per ridurre scritture su disco), producono un file immagine della RAM che può poi essere scaricato per l’analisi. Su Linux, l’operazione richiede spesso il caricamento di un modulo kernel dedicato come LiME (Linux Memory Extractor) o l’utilizzo di interfacce /dev/mem (se abilitate) e utility dd. L’immagine di memoria così ottenuta viene poi analizzata con framework di memory forensics quali Volatility o Rekall, che permettono di estrarre dalle strutture binarie informazioni intelligibili: ad esempio la lista dei processi e dei relativi segmenti di memoria, le connessioni di rete attive, le DLL/caricate nei processi, eventuale codice iniettato, e persino di ricostruire contenuti testuali (come chat, email, cronologia web) presenti in memoria. Un’analisi approfondita della RAM può rivelare malware fileless (cioè che risiedono solo in memoria), evidenze di attacchi “pass the hash” o credenziali rubate in cleartext, e tante altre informazioni essenziali per capire come è avvenuta la compromissione e cosa sta facendo l’attaccante.
Vale la pena evidenziare due aspetti: temporalità e integrità. La RAM è estremamente dinamica: anche in pochi secondi lo stato può cambiare (processi che terminano, nuovi che si avviano, allocazioni che si spostano). Pertanto, l’operatore deve eseguire il dump il prima possibile durante il triage, minimizzando ritardi. Inoltre, va considerato che il processo di dumping stesso consuma un po’ di RAM e altera alcuni contenuti (ad esempio, parte della RAM viene occupata dal buffer di copia); questo è inevitabile, ma accettabile se si utilizzano strumenti progettati per minimizzare l’impatto. Si documenta in ogni caso quale tool è stato usato e in che orario. Sul fronte integrità, benché non sia possibile calcolare un hash prima (dato che la RAM è mutevole), si calcola almeno l’hash del file di dump generato e lo si conserva per verifiche future, trattandolo poi con la stessa cura di un’immagine disco.
Un altro motivo critico per effettuare il dump di RAM è la presenza di chiavi di cifratura o altri segreti volatili. Se un sistema impiega dischi cifrati (es. BitLocker su Windows, LUKS su Linux) o connessioni VPN cifrate attive, spesso la chiave di decrittazione risiede in RAM mentre il volume è montato o la sessione attiva. Estrarre la RAM può consentire di recuperare tali chiavi – tramite specifici plugin di Volatility – e quindi di accedere a dati altrimenti indecifrabili. ISO 27037 infatti avverte di considerare l’acquisizione di dati volatili prima dello shutdown proprio perché “chiavi di cifratura e altri dati crucialipotrebbero risiedere in memoria attiva”. Un caso concreto è quello dei ransomware: alcuni memorizzano la chiave di cifratura in RAM; se si interviene rapidamente e si cattura la memoria, si potrebbe estrarre la key e decriptare i file senza pagare riscatti.
In sintesi, l’acquisizione della memoria volatile è un tassello irrinunciabile nelle indagini su incidenti moderni. Un responsabile SOC deve prevedere nel piano di risposta la raccolta di dump di RAM per ogni server o endpoint compromesso (quando fattibile in sicurezza) e garantire che il personale sia addestrato all’uso degli strumenti di memory dump. Solamente catturando questa dimensione “effimera” dell’attacco si ottiene una visione completa dell’accaduto, che combini stato dinamico e dati statici.
Artefatti di sistemi operativi Microsoft Windows
I sistemi Windows conservano una vasta gamma di artefatti forensi – file di log, voci di registro, cache di sistema – che possono fornire preziose evidenze sulle attività avvenute prima, durante e dopo un incidente informatico. Un responsabile forense deve conoscere questi artefatti e includerne la raccolta nel processo di acquisizione. Ecco i principali artefatti Windows da considerare e il loro significato:
Event Logs (registri eventi): Windows registra eventi di sistema, sicurezza e applicazione nei file di log (.evtx) situati in C:\Windows\System32\winevt\Logs\. Questi log, consultabili tramite Event Viewer, sono fondamentali per ricostruire la sequenza di eventi di un sistema. Ad esempio, il Security Log documenta tentativi di accesso (Event ID 4625 per login falliti, 4624 per login riusciti) e cambi di privilegi, permettendo di identificare eventuali accessi non autorizzati o escalation di privilegi avvenute. Il log System registra informazioni su avvii/arresti di sistema, crash, o errori di driver; il log Application contiene eventi dalle applicazioni (es. errori applicativi, servizi custom). Durante un’incidente, copiare e mettere in sicurezza questi file di log è prioritario, in quanto potrebbero venire cancellati dall’attaccante per nascondere le tracce. Un esempio concreto: grazie ai Security Log si può scoprire l’ora esatta in cui un account amministrativo sospetto ha effettuato login, o se vi sono stati tentativi massivi di password guessing.
Registry (registro di configurazione): Il registro di Windows è una banca dati centralizzata che memorizza configurazioni di sistema, applicazioni, informazioni sugli utenti, dispositivi hardware e molto altro. È suddiviso in hive principali (SAM, SYSTEM, SOFTWARE, SECURITY, oltre ai NTUSER.DAT per ogni utente) che risiedono sul disco. Dal punto di vista forense, il registry è una miniera di informazioni: ad esempio, consente di identificare periferiche USB collegate in passato (chiavi di registro USBSTOR che elencano device ID, date e serial number dei dispositivi – utile per investigare esfiltrazioni tramite chiavette); permette di vedere programmi impostati per l’esecuzione automatica (Run keys) – spesso usati da malware per persistere; contiene gli MRU (Most Recently Used), liste di file o percorsi recentemente aperti da ciascun utente, che aiutano a capire quali documenti sono stati acceduti; tracce di installazione software, configurazioni di rete, e così via. Due artefatti peculiari meritano menzione: ShimCache e AmCache. Lo ShimCache (Application Compatibility Cache) è una cache mantenuta da Windows per compatibilità applicativa, che registra ogni eseguibile avviato sul sistema con timestamp (talora anche se l’eseguibile non esiste più); fornisce quindi una storia delle esecuzioni utile a rintracciare malware eseguiti e poi cancellati. L’AmCache è un file (Amcache.hve) introdotto dalle versioni moderne di Windows, che conserva dettagli sugli eseguibili lanciati, come nome, path, hash e primo timestamp di esecuzione. Analizzando AmCache si può determinare ad esempio la prima volta in cui un malware è stato eseguito, anche se non ci sono log di altro tipo. Durante l’acquisizione forense, è buona pratica estrarre copie dei file di registro ( C:\Windows\System32\Config\* e C:\Users\{utente}\NTUSER.DAT per ogni profilo) per analizzarli con strumenti forensi (Registry viewers, RegRipper, etc.).
Prefetch files: Windows utilizza la funzionalità Prefetch per velocizzare il caricamento dei programmi usati di frequente. Ogni volta che un eseguibile viene lanciato, il sistema crea/ aggiorna un file prefetch (estensione .pf) in C:\Windows\Prefetch\ contenente il nome del programma, un hash del percorso e riferimenti ai file caricati. Dal punto di vista forense, i prefetch file tracciano l’esecuzione dei programmi e ne registrano il timestamp di ultimo avvio . Ciò è prezioso per stabilire una timeline di esecuzione: ad esempio, se un malware è stato eseguito alle 3:00 AM e poi cancellato, rimarrà comunque un file .pf (es. MALWARE.EXE-3AD3B2.pf) con ultimo esecuzione a quell’ora. I prefetch indicano anche il numero di volte di esecuzione e quali librerie o file ha caricato il processo, dando indizi su cosa abbia fatto. È importante notare che il Prefetch è abilitato di default su desktop Windows, ma su Windows Server potrebbe essere disabilitato per impostazione predefinita. Nelle analisi di incidenti su client, i prefetch sono spesso tra le prime cose da controllare per vedere quali programmi anomali sono stati eseguiti di recente. Vanno quindi raccolti durante l’acquisizione (copiando l’intera cartella Prefetch). Un caso d’uso tipico: rilevare un tool di hacking (es. mimikatz.exe) dal prefetch, anche se l’eseguibile non è più presente – evidenza che qualcuno lo ha lanciato sul sistema.
LNK (Link) files: i file di collegamento .lnk sono scorciatoie Windows che si creano quando un utente accede a file o cartelle (ad es. i collegamenti nei “Recent Items”). Ogni LNK conserva metadati dettagliati sull’elemento target: percorso completo del file/cartella, dispositivo di origine (incluso il numero di serie di volume – utile per identificare unità USB), timestamp dell’ultimo accesso, dimensione del file target, e a volte coordinate della finestra o icona. In un’indagine, analizzare i LNK consente di scoprire attività utente come aperture di documenti o esecuzione di strumenti, anche se tali file non esistono più. Ad esempio, se un dipendente ha aperto un file riservato e copiato su USB, potrebbe restare un link in %APPDATA%\Microsoft\Windows\Recent\ che svela nome e percorso di quel file, nonché identifica la pennetta USB usata (dal seriale riportato nel LNK). I LNK possono anche indicare programmi lanciati da percorsi insoliti (es. C:\Temp\hacker_tool.exe), dando tracce di esecuzioni sospette. È quindi prassi acquisire la cartella Recent di ciascun profilo utente e altri percorsi dove possono annidarsi LNK (es. collegamenti sul desktop, nel menu Start, etc.).
Altri artefatti rilevanti: ce ne sono numerosi; tra i principali citiamo: i Jump Lists (liste dei file aperti di recente per applicazioni “pinned” sulla taskbar, memorizzate in %APPDATA\Microsoft\Windows\Recent\AutomaticDestinations\), utili per vedere cronologia di utilizzo di specifici programmi; i file di paging e ibernazione (C:\pagefile.sys e C:\hiberfil.sys), che contengono porzioni di RAM e stato del sistema scritti su disco – analizzandoli si possono estrarre password o frammenti di documenti presenti in memoria; i dump di crash (MEMORY.DMP generati da Blue Screen) che talvolta sopravvivono e contengono un’istantanea della RAM al momento del crash; il MFT (Master File Table) nei volumi NTFS, che elenca tutti i file con i loro timestamp e può essere estratto per analisi timeline; i log di sistema quali Firewall di Windows (p.e. pfirewall.log se attivato) e Windows Defender (eventi antimalware) che potrebbero rivelare tentativi di connessione o malware rilevati; infine, i file di configurazione e cache applicative (ad esempio i log di navigazione web, la cache DNS, i file di Outlook PST/OST per le email, etc.) da acquisire se pertinenti al caso.
In fase di risposta a un incidente, il responsabile CSIRT deve stilare un elenco di questi artefatti Windows e assicurarsi che la squadra li raccolga sistematicamente. Spesso si utilizzano strumenti di live response (come KAPE – Kroll Artifact Parser and Extractor, di Eric Zimmerman) che automaticamente collezionano copie di molti di questi artefatti chiave per una rapida analisi. La ricchezza di informazioni fornite dagli artefatti Windows consente, una volta in laboratorio, di ricostruire la linea temporale degli eventi (tramite analisi timeline correlando log, MFT e timestamp vari) e di attribuire azioni adaccount utente specifici, distinguendo attività lecite da quelle malevole. Ad esempio, combinando i dati di registro (es. chiave USBSTOR) con i LNK file, si può provare che un certo file è stato copiato su una chiavetta a una certa ora da un determinato utente. Per garantire ciò, la fase di acquisizione deve aver preservato intatti tali artefatti.
Artefatti di sistemi operativi Linux
Anche in ambienti Linux/Unix esistono artefatti forensi fondamentali per un’analisi post-incident. Sebbene Linux non abbia un Registro unificato come Windows, mantiene moltissime informazioni in file di log testuali e file di configurazione, che se raccolti e analizzati correttamente permettono di ricostruire intrusioni e attività anomale. Ecco alcuni elementi chiave che un responsabile dovrebbe includere nel piano di acquisizione da sistemi Linux compromessi:
Log di sistema e di sicurezza: la gran parte delle distribuzioni Linux registra gli eventi in /var/log/. In particolare, il syslog o log generale di sistema (tipicamente /var/log/syslog su Debian/Ubuntu o /var/log/messages su Red Hat/CentOS) contiene messaggi su una vasta gamma di attività: avvio di servizi, messaggi del kernel, connessioni di rete, errori generici. Esaminare il syslog consente di individuare quando sono stati avviati o fermati servizi (utile per vedere ad esempio se un servizio critico è andato in crash in concomitanza con l’attacco) e messaggi anomali del kernel che potrebbero indicare exploit (es. oops o segfault sospetti). Ancora più importanti spesso sono i log di autenticazione, come /var/log/auth.log (su sistemi Debian-like) o /var/log/secure (Red Hat-like), dove vengono tracciati tutti i tentativi di login, sia locali che remoti, con indicazione di utente, origine e successo/fallimento. In questi file si trovano anche i log di uso del comando sudo (elevazione di privilegi), gli accessi via SSH, eventuali cambi di password, ecc. Durante un’incidente, analizzare auth.log può rivelare ad esempio un attacco brute-force in atto (molti tentativi di login falliti in sequenza) o se un utente in particolare ha ottenuto accesso root via sudo in orari non autorizzati. Altri log utili sono quelli di servizi specifici: ad esempio, log di Apache/Nginx in /var/log/apache2/ o /var/log/nginx/ (per investigare compromissioni di web server), log di database (MySQL, PostgreSQL) se si sospetta un SQL injection, log di firewall/iptables, ecc. Il responsabile deve stilare una lista dei percorsi di log da prelevare in base ai servizi in esecuzione sul sistema bersaglio. È buona pratica includere sempre i log lastlog, wtmp, btmp: sono file binari (tipicamente in /var/log/ che registrano rispettivamente l’ultimo login di ogni utente, la cronologia di tutti i login (wtmp) e quella dei login falliti (btmp). Questi file, analizzabili con comandi come last e lastb, possono integrare le informazioni di auth.log riguardo gli accessi utente nel tempo.
Cronologia dei comandi e configurazioni utente: su Linux, ogni utente shell tipicamente ha un file di history (es. ~/.bash_history per Bash) in cui vengono salvati i comandi digitati in passato. Questa cronologia, se non cancellata dall’attaccante, è un artefatto estremamente prezioso: consente di vedere quali comandi sono stati eseguiti – ad esempio, un aggressore che abbia ottenuto accesso shell potrebbe aver lanciato comandi per creare nuovi utenti, modificare configurazioni o estrarre dati, e spesso tali comandi rimangono nella bash_history. Va notato che la history di solito si salva solo alla chiusura della sessione; se l’attaccante non ha terminato la sessione o ha disabilitato la logging della history, il file potrebbe non contenere tutto. In ogni caso, acquisire i file di history di tutti gli utenti (bash, zsh, etc.) è doveroso. Oltre ai comandi, le configurazioni utente come ~/.ssh/authorized_keys devono essere raccolte: questo file indica eventuali chiavi pubbliche autorizzate per login SSH senza password – spesso gli attaccanti ne aggiungono una per garantirsi l’accesso persistente. Anche i file ~/.ssh/known_hosts possono dare indizi su da quali macchine ci si è collegati. Il filesystem home degli utenti, in generale, può contenere script di persistenza (es. aggiunte in ~/.bashrc o ~/.profile che eseguono malware all’avvio della shell). Durante l’acquisizione forense, se non si effettua un’immagine completa del disco, almeno le home directory rilevanti dovrebbero essere copiate integralmente per preservare questi artefatti.
Configurazioni di sistema e job pianificati: un vettore comune di persistenza su Linux è l’uso di cron job maligni. I cron job si trovano in /etc/crontab, /etc/cron.hourly/cron.daily/... o nelle crontab per utente (/var/spool/cron/crontabs/). Analizzandoli, si potrebbe scoprire, ad esempio, che è stato inserito un job che esegue periodicamente un certo script (magari per ricollegarsi a una botnet o mantenere l’accesso). Durante l’incidente, si estraggono quindi tutte le configurazioni di cron. Un altro punto chiave sono le configurazioni di SSH in /etc/ssh/sshd_config : se un attaccante ha abilitato opzioni deboli o cambiato la porta del servizio potrebbe aver modificato questo file. Inoltre, i log di SSH (che in realtà confluiscono in auth.log) dovrebbero essere già considerati, ma è bene filtrarli per evidenziare, ad esempio, da quali IP sono avvenuti accessi SSH riusciti. Anche la configurazione di altri servizi (VPN, servizi cloud, Docker containers in /var/lib/docker/ etc.) può essere rilevante se l’incidente li coinvolge – la regola generale è collezionare tutto ciò che potrebbe aver registrato attività dell’attaccante.
Log di pacchetti e sistema: un aspetto peculiare di Linux è la presenza dei packagemanagement logs. Su Debian/Ubuntu c’è /var/log/dpkg.log che tiene traccia di ogni installazione/aggiornamento/rimozione di pacchetti, con timestamp. Su RedHat/CentOS analoghi sono i log di yum o dnf. Questi log sono utilissimi per vedere se durante l’intrusione l’attaccante ha installato nuovi software (es. un server web, uno strumento di hacking) oppure se il sistema ha aggiornato qualcosa di critico di recente. Ad esempio, se dpkg.log mostra l’installazione di netcat o nmap, è un red flag di attività sospetta. Altri log degni di nota: /var/log/lastlog (ultimi accessi utenti), /var/log/faillog (errori di login), /var/log/mail.log (attività del server mail, se presente, per vedere possibili esfiltrazioni via email) e i log di eventuali IDS/IPS installati. Se il sistema utilizza systemd, molti log tradizionali potrebbero essere nel journal binario (/var/log/journal/) accessibile con journalctl : in tal caso, è opportuno esportare l’intero journal (usando journalctl --since con un range temporale, oppure copiando i file journal) per l’analisi.
In fase di acquisizione, spesso la via più semplice è eseguire un package di raccolta (ad esempio uno script che copia tutto /var/log e alcune directory chiave di /etc e home utenti). Tuttavia, un responsabile attento specificherà quali sono gli “essential artifacts” Linux da non tralasciare. Magnet Forensics elenca 7 artefatti essenziali: history bash, syslog, auth.log, sudo logs, cron, SSH, package logs tutti punti che abbiamo toccato. Raccogliendo questi, un analista potrà: ricostruire latimeline di un attacco (dall’intrusione iniziale visibile in auth.log, alle azioni compiute visibili nella history e nei log di sistema, fino alla persistenza via cron), attribuire azioni a utenti/ip (log di autenticazione), e scoprire eventuali manomissioni (servizi disabilitati, configurazioni cambiate). Un esempio: tramite auth.log si individua che l’attaccante ha ottenuto accesso con l’utente “webadmin” via SSH; guardando nella bash_history di webadmin si vede che ha eseguito un certo script e aperto una connessione reverse shell; controllando crontab si trova un job aggiunto da webadmin che ogni ora tentava di riconnettersi ad un certo host (persistenza). Inoltre dpkg.log rivela che l’attaccante ha installato un pacchetto socat per facilitare le proxy. Tutto ciò costruisce una narrazione completa dell’incidente. È compito del responsabile assicurare che tali tasselli informativi non vadano perduti: ad esempio, evitando la rotazione o cancellazione dei log (in casi estremi, potrebbe decidere di spegnere subito un server Linux se teme che l’attaccante possa “ripulire” i log tramite rootkit, e acquisire a freddo).
In conclusione, gli artefatti Linux, sebbene sparsi in file diversi, coprono molti aspetti dell’attività di sistema e, se acquisiti integralmente, forniscono un quadro molto dettagliato agli investigatori. La sfida è sapere dove guardare: per questo esistono anche cheat-sheet e liste preparate (ad esempio Seven Linux Artefacts to Collect di SANS) che guidano i primi responder su cosa prendere. Un responsabile dovrebbe prevedere tali linee guida e aggiornarsi continuamente, dato che i percorsi e formati dei log possono variare con le versioni (es. il passaggio a systemd-journald). Garantire la raccolta coerente e completa di questi artefatti in ogni incidente significa accelerare l’analisi forense e migliorare l’efficacia della risposta.
Strumenti hardware e software per l’acquisizione forense
Per eseguire le operazioni sopra descritte, il responsabile deve assicurarsi che il team disponga dei giusti strumenti hardware e software di acquisizione forense, nonché delle competenze per usarli correttamente. Vediamo i principali.
Strumenti hardware
Write-blocker: come già menzionato, sono dispositivi (talora in forma di piccoli box USB/SATA o bay da laboratorio) che assicurano l’accesso in sola lettura ai supporti di memoria originali . Sono uno standard de-facto in qualsiasi acquisizione di dischi: marchi noti includono Tableau (ad es. Tableau T8u USB 3.0 Forensic Bridge), Logicube, Digital Intelligence UltraBlock, ecc. Esistono write-blocker per diverse interfacce: SATA/PATA, USB, NVMe, SCSI, ecc. Il loro impiego consente di collegare un hard disk sequestrato alla macchina forense senza rischio di contaminare i dati – condizione essenziale per mantenere l’integrità probatoria. Alcuni modelli hanno funzionalità avanzate come il logging interno delle operazioni o la possibilità di attivare/disattivare il blocco (ma in forense deve restare attivo!). Il NIST CFTT (Computer Forensic Tool Testing) conduce test periodici sui write-blocker per certificarne l’affidabilità; un responsabile può consultare tali risultati per scegliere dispositivi adeguati.
Duplicatori e unità di imaging hardware: si tratta di apparecchi dedicati che possono copiare un disco di origine verso uno o più dischi di destinazione senza bisogno di un computer intermedio. Spesso sono dispositivi portatili, alimentati a parte, con schermo integrato, usati sul campo dalle forze dell’ordine. Esempi: Tableau Forensic Duplicator, Logicube Falcon, Atola Insight. Questi strumenti eseguono copie bitstream con verifica hash incorporata e spesso supportano il cloning multi-target (una sorgente verso due copie identiche contemporaneamente). Il vantaggio è la velocità e il fatto che sono costruiti per non alterare l’originale (incorporano essi stessi funzioni di write-block). Inoltre, supportano formati di output multipli (raw, E01, ecc.) e generano report dettagliati. Secondo NIST SP 800-86, i tool hardware di imaging forniscono in genere log di audit trail e funzioni per garantire consistenza e ripetibilità dei risultati. L’uso di duplicatori è frequente nelle acquisizioni di numerosi supporti in poco tempo (es. per copiare velocemente decine di hard disk durante un sequestro contemporaneo).
Altri tool hardware: include adattatori e accessori, ad esempio: kit di cavi e adattatori per collegare dischi di laptop, telefoni o dispositivi proprietari; dispositivi per estrarre chip di memoria (nell’ambito mobile forensics, eMMC reader); strumenti per acquisire SIM card o smart card, ecc. Nel contesto specifico di incidenti informatici in enti, alcuni di questi sono meno rilevanti, ma un responsabile dovrebbe avere pronte soluzioni per connettere qualsiasi supporto si trovi (dai vecchi dischi IDE agli ultimi M.2 NVMe). Da citare anche i blocchi di rete (sebbene non hardware in senso stretto): quando si prende un computer acceso come evidenza, un’opzione è inserirlo in una “faraday bag” o scollegarlo da rete e Wi-Fi per isolarlo – questo più per preservare da modifiche remote che per acquisizione, ma fa parte dell’equipaggiamento di scena.
Strumenti software
Utility di imaging forense: sul lato software, un arsenale classico comprende tool come dd (il tool Unix per copie bitstream), con varianti forensi quali dcfldd o Guymager (GUI Linux) che aggiungono funzioni di hashing e log. Questi consentono di creare immagini raw bit-a-bit. In ambiente Windows, il popolare FTK Imager permette di acquisire dischi, cartelle o anche singoli file di memoria e di rete, generando immagini in diversi formati (incluso il compresso E01) e calcolando hash in automatico. Software commerciali come EnCase e X-Ways integrano funzioni di imaging: ad esempio EnCase permette di creare direttamente un case con immagini E01 e verifica integrità. Molti di questi software supportano sia l’acquisizione fisica (del disco intero) che logica (ad es. solo una partizione o solo certi file). La scelta dello strumento dipende dallo scenario: dd e affini sono ottimi per ambienti Linux e situazioni scriptabili; FTK Imager è spesso usato su postazioni Windows per copie “ad hoc” (ad esempio di pendrive o di piccoli volumi) grazie alla sua semplicità d’uso grafica. È importante che i tecnici verifichino i checksum generati e alleghino i log prodotti dallo strumento (ad es. FTK Imager produce un file di output con tutti i dettagli dell’operazione). Da ricordare: prima dell’imaging, il disco di destinazione va azzerato o comunque pulito, per evitare contaminazione (principio del “forensically clean media”).
Strumenti per acquisizione live e triage: in contesti di incidente, esistono suite pensate per automatizzare la raccolta di evidenze volatili e semi-volatili. Ad esempio, KAPE (Kroll Artifact Parser and Extractor) consente di definire “target” (artefatti noti di Windows) e raccoglierli rapidamente da un sistema live in un output centralizzato. Volatility (framework di memory forensics) ha moduli per dumping live memory su Windows (WinPmem) e ora anche su Linux. Belkasoft Evidence Center e Magnet AXIOM dispongono di agent da deployare su macchine live per estrarre dati chiave (RAM, registro eventi, ecc.) con un minimo impatto. Un altro strumento pratico è CyLR (Cyber Logos Rapid Response) – un leggero collector open source – o lo script Livessp (SANS SIFT). Questi tool aiutano il first responder a non dimenticare elementi importanti durante la concitazione di un incidente. Per il triage rapido di supporti spenti (es. decine di PC da controllare), esistono anche soluzioni come Paladin (distro live basata su Ubuntu con toolkit forense) o CAINE (Computer Aided Investigative Environment), che permettono di bootare la macchina da USB/DVD in un ambiente forense e copiare selettivamente evidenze (con write-block software attivo sul disco originale).
Tool per acquisizione della memoria: già evidenziati in parte, meritano un focus. Oltre a DumpIt e Magnet RAM Capture citati, c’è Microsoft LiveKd (Sysinternals) che consente di ottenere dump di memoria di macchine Windows partendo da un kernel debug; LiME su Linux è ormai standard per memdump su Android e server headless; AVML (Acquire Volatile Memory for Linux) è uno strumento più recente di Microsoft per estrarre RAM da VM Linux (utile in cloud). Qualunque strumento si usi, deve essere testato e validato prima in laboratorio. Ad esempio, si può verificare che il dump prodotto sia apribile in Volatility e che corrisponda (nel caso Windows) alla versione OS corretta. Il responsabile dovrebbe predisporre procedure e ambienti di prova per garantire la familiarità del team con tali strumenti: un errore nell’uso (es. dimenticare di eseguire come Administrator un RAM capture tool) potrebbe rendere nullo il dump.
In generale, la dotazione strumentale di un responsabile SOC/CSIRT deve essere allineata alle best practice internazionali. Gli standard NIST elencano dozzine di tool sia commerciali che open source, e raccomandano di avere politiche per l’uso corretto degli strumenti (ad esempio, mantenere una copia di ciascun software usato, con versioni, hash, in modo da poter dimostrare in tribunale esattamente cosa è stato usato e che non contiene backdoor). È inoltre importante monitorare il panorama: strumenti nuovi emergono (ad es. per acquisire dati da cloud, o dall’IoT), e un responsabile deve valutarne l’adozione. Nel kit non dovrebbero mancare anche strumenti di verifica: ad esempio, software per calcolare hash (md5deep, sha256sum), per confrontare file, per estrarre metadata. Anche se non direttamente di “acquisizione”, essi supportano la fase di accertamento dell’integrità dei dati acquisiti.
In conclusione, strumenti hardware e software ben selezionati sono il braccio armato dell’analista forense. La loro efficacia dipende dalla competenza d’uso e da procedure appropriate. Un responsabile deve assicurare formazione continua e magari predisporre ambienti di simulazione dove testare periodicamente l’intera catena (ad esempio, simulare un attacco e far eseguire ai tecnici l’acquisizione con i loro tool, verificando poi che tutto – hash, log, tempi – sia conforme). Questa preparazione fa la differenza tra un’acquisizione improvvisata e una condotta professionalmente, come richiesto in un contesto di sicurezza nazionale.
Standard e linee guida internazionali
Nel campo della digital forensics applicata agli incidenti informatici esistono standard e linee guida internazionali che definiscono principi, terminologie e procedure riconosciute. Un candidato al ruolo di responsabile CSIRT deve non solo conoscerli, ma saperli mettere in pratica e farvi aderire le operazioni del team. Di seguito, i riferimenti principali.
ISO/IEC 27037:2012 – “Information technology – Security techniques – Guidelines for identification, collection, acquisition and preservation of digital evidence”. È lo standard ISO specifico per la prima fase della gestione delle evidenze digitali. Esso stabilisce le linee guida per l’identificazione delle potenziali fonti di prova, la raccolta (intesa come acquisizione sul campo dei dispositivi/ evidenze), l’acquisizione forense vera e propria (creazione di copie bitstream) e la preservazione delle stesse. Vengono definiti i principi generali (ad es. minimizzare la contaminazione, assicurare la documentazione completa, mantenere la chain of custody) e identificati i ruoli chiave, in particolare il Digital Evidence First Responder (DEFR), ossia l’operatore iniziale che interviene sulla scena. L’ISO 27037 fornisce indicazioni su come valutare la volatilità delle evidenze e come dare priorità in base ad essa (ad esempio, suggerendo di acquisire per prima i dati che “scomparirebbero” se il dispositivo fosse spento). Inoltre, dedica sezioni alla corretta custodia, etichettatura e trasporto delle evidenze digitali, sottolineando l’uso di contenitori appropriati (es. buste antistatiche, custodie sigillabili) e precauzioni contro fattori ambientali che possano danneggiare i dispositivi raccolti. Questo standard – pur non essendo una procedura operativa dettagliata – costituisce un framework di riferimento ampiamente adottato da forze di polizia e team di risposta in tutto il mondo per garantire che fin dai primi istanti le evidenze siano trattate “as ISO compliant as possible”. In Italia, i principi di ISO 27037 sono stati recepiti in molte linee guida interne di Forze dell’Ordine e CERT aziendali.
NIST Special Publication 800-86 – “Guide to Integrating Forensic Techniques into Incident Response”. Pubblicata dal National Institute of Standards and Technology (USA), questa guida colma il gap tra digital forensics tradizionale e incident response. Il suo scopo è fornire un processo strutturato per utilizzare tecniche forensi durante la risposta a incidenti di sicurezza . NIST 800-86 descrive un modello di processo forense composto da quattro fasi: Collection (raccolta) – dove si acquisiscono i dati rilevanti dall’ambiente target (dischi, memorie, log di rete, ecc); Examination (esame) – che implica il filtro e l’estrazione preliminare di informazioni dai dati grezzi (ad es. parsing di log, carving di file dalla memoria); Analysis (analisi) – la fase interpretativa in cui gli analisti traggono conclusioni su cosa è successo, correlando le evidenze; Reporting (reportistica) – documentare i risultati e magari fornire raccomandazioni. Questa struttura viene integrata nel ciclo di vita di incident response (Preparation, Detection & Analysis, Containment, Eradication & Recovery, Lessons Learned) delineato da un altro noto documento NIST (SP 800-61). La SP 800-86 fornisce anche practical tips: ad esempio suggerisce fonti di evidenze per vari tipi di incidenti, tecniche di collezione specifiche (come fare imaging, come raccogliere dati di rete), considerazioni legali da tenere presenti (negli USA, aspetti di privacy, Fourth Amendment, ecc.), e importanza di policy e procedure interne per la forensics. In sostanza, questo documento aiuta un responsabile a capire come inserire le attività forensi in un piano di risposta senza improvvisarle. Ad esempio, se c’è un sospetto worm in rete, la guida consiglia di raccogliere non solo i sistemi infetti ma anche traffico di rete, memory dump per analizzare il malware, e di farlo in tempi rapidi dati i dati volatili. Fornisce quindi un utile complemento operativo agli standard ISO.
RFC 3227 – “Guidelines for Evidence Collection and Archiving” (IETF). Questo RFC (Request for Comments) del 2002, pur datato, è ancora citatissimo per il concetto di order of volatility che introduce. In poche pagine, fornisce una serie di raccomandazioni pratiche per chi raccoglie evidenze digitali in ambiente live. Oltre a ribadire l’importanza di partire dai dati più volatili (CPU, cache, RAM, processi) per poi passare a quelli meno volatili come dischi e infine backup e media esterni, include una lista di cose da non fare: ad esempio non spegnere il sistemaprematuramente, pena perdita di dati importanti; non fidarsi dei tool presenti sulsistema compromesso, ma usare software di raccolta su supporti protetti; non usarecomandi che possano alterare massivamente i file (come tool che cambiano tutti gli ultimi accessi); attenzione a “trappole” di rete (disconnecting la rete può attivare meccanismi distruttivi se il malware li prevede). Il documento tratta anche aspetti di privacy (invita a rispettare le policy aziendali e leggi durante la raccolta, minimizzando dati non necessari) e considerazioni legali generali sulla validità delle prove (ad esempio, ricorda che le prove devono essere autentiche, affidabili, complete e ottenute in modo lecito per essere ammissibili). Un altro punto fondamentale è la definizione di Chain of Custody (catena di custodia): RFC 3227 specifica che bisogna poter descrivere chiaramente quando, dove, da chi ogni evidenza è stata scoperta, raccolta, maneggiata, trasferita. Suggerisce di documentare tutti i passaggi, includendo date, nomi e persino numeri di tracking delle spedizioni se un supporto viene trasferito. Questo è pienamente in linea con le prassi forensi e in Italia corrisponde all’obbligo di verbale di sequestro e custodia delle copie forensi. In sintesi, l’RFC 3227 è una lettura obbligata per i first responder e rimane attuale: i suoi consigli vengono spesso citati nei corsi forensi e implementati nei manuali operativi.
Altri standard e guide rilevanti: oltre ai sopra citati, possiamo menzionare il NIST SP 800-101 (Guide to Mobile Forensics) per la parte di dispositivi mobili – utile se l’incidente coinvolge smartphone aziendali; lo standard ISO/IEC 27035 per la gestione degli incidenti di sicurezza, che include la fase di Incident Response e accenna alla preservazione delle evidenze come parte del processo di mitigazione; la serie ISO/IEC 27041, 27042, 27043 che forniscono rispettivamente guide sulla gestione delle attività forensi (assicurazione di processo), sull’analisi di evidenze digitali e sugli step per investigazioni digitali – evoluzioni post-27037 che entrano più nel dettaglio delle fasi successive all’acquisizione. In ambito law enforcement europeo, il Manuale di Valencia (European cybercrime training manual) e le linee guida dell’ENFSI (European Network of Forensic Science Institutes) replicano concetti simili per armonizzare le pratiche. Nel Regno Unito, la famosa ACPO Good Practice Guide for Digital Evidence enuncia 4 principi, tra cui il principio 1: non alterare i dati su un dispositivo a meno che non sia inevitabile; principio 2: chiunque acceda a dati digitali deve essere competente e tenere traccia di tutto; principio 3: va tenuta documentazione completa di tutti i processi; principio 4: la persona responsabile dell’indagine ha la responsabilità generale di assicurare conformità legale. Questi rispecchiano molto quanto detto in ISO 27037 e RFC 3227, enfatizzando integrità e documentazione. Infine, val la pena ricordare che in Italia anche la giurisprudenza ha affrontato il tema: la Corte di Cassazione (Sez. VI, sentenza n. 26887/2019) ha delineato un vero e proprio vademecum su come devono essere eseguiti i sequestri di dati informatici, richiamando la necessità di adottare cautele tecniche per garantire che la copia forense sia fedele e che gli originali siano conservati senza alterazioni, pena l’inutilizzabilità degli elementi raccolti. Ciò rafforza l’importanza per un responsabile di seguire standard riconosciuti, così che l’operato del team sia non solo efficace tecnicamente ma anche solido a livello legale.
In sintesi, standard e linee guida forniscono il quadro teorico e pratico entro cui muoversi: adottarli garantisce consistenza delle operazioni forensi e facilita la cooperazione con altri team (nazionali e internazionali) parlando lo stesso “linguaggio” procedurale. Un responsabile informato farà riferimento a questi documenti nella stesura delle procedure interne, nell’addestramento del personale e nella giustificazione delle scelte operative durante un incidente.
Casi d’uso in contesto nazionale
Per contestualizzare quanto esposto, consideriamo alcuni scenari nel panorama italiano dove le pratiche di acquisizione forense sono state – o potrebbero essere – determinanti. L’obiettivo è mostrare come un responsabile CSIRT/SOC applica tali conoscenze in situazioni reali, spesso in collaborazione con enti pubblici e forze dell’ordine.
1. Attacco ransomware a un ente pubblico (Regione Lazio, 2021): un caso emblematico è l’attacco ransomware che ha colpito la Regione Lazio nell’agosto 2021, paralizzando il portale vaccinale COVID-19 e numerosi servizi online per giorni. In un evento del genere, il responsabile della risposta (in sinergia con l’ACN/CERT nazionale e i tecnici regionali) ha dovuto immediatamente predisporre un triage su decine di server e sistemi: identificare quali erano criptati e fuori uso, isolare la rete per prevenire ulteriore propagazione, ma anche acquisire copie forensi dei sistemi colpiti per analizzare il malware e verificarne l’impatto. Nel caso Lazio, ad esempio, è stata effettuata l’acquisizione bitstream dei server critici, inclusi i controller di dominio e i server di gestione del portale sanitario, al fine di consegnare tali immagini agli esperti (anche stranieri) per l’analisi del ransomware e la ricerca di eventuali decryptor. Parallelamente, è probabile sia stato eseguito il dump della memoria su almeno uno dei server infetti ancora in esecuzione, per catturare la chiave di cifratura o tracce dell’attaccante in RAM. Questo incidente ha evidenziato l’importanza di avere procedure pronte: nonostante la gravità, il team forense doveva agire tempestivamente senza compromettere i servizi di ripristino. La raccolta dei log di sicurezza Windows e dei domain controller logs è stata fondamentale per ricostruire la dinamica: ad esempio, capire quale account iniziale è stato compromesso (si parlò di credenziali VPN rubate) e quando il malware ha iniziato a diffondersi. L’analisi forense, condotta sulle immagini acquisite, ha permesso di individuare i file di persistence creati dal ransomware e i movimenti laterali effettuati, dati con cui il responsabile ha potuto informare gli amministratori su come bonificare completamente la rete prima di rimetterla in produzione. Inoltre, queste evidenze sono state girate alla Polizia Postale per le indagini penali. Il lesson learned di Lazio 2021 ha probabilmente portato a migliorare ancora le pratiche di incident response italiane, ad esempio enfatizzando la necessità di separare le reti di backup e verificare che le copie di sicurezza non fossero cifrate (in quell’occasione, fortunatamente i backup erano salvi, ma in altri casi non è stato così). Un responsabile, da questo esempio, trae l’indicazione che avere un piano di acquisizione forense predefinito per scenari di ransomware massivi è essenziale: chi fa cosa, quali sistemi si copiano per primi, dove si stoccano le immagini in sicurezza, come coordinare più squadre sul territorio (nel Lazio intervenne anche il CNAIPIC e team di sicurezza privati). In definitiva, il caso Regione Lazio ha mostrato come l’acquisizione forense non sia una fase “postuma”, ma integrata nella gestione della crisi: mentre si lavora al ripristino, in parallelo si portano avanti imaging e raccolta evidenze, poiché attendere la fine dell’emergenza per iniziare l’acquisizione significherebbe perdere dati chiave o trovare sistemi completamente ripristinati (quindi privati delle tracce dell’attacco).
2. Compromissione di account email governativi: immaginiamo uno scenario in cui un Ministero o un’agenzia governativa rileva accessi sospetti a caselle di posta istituzionali (PEC o email interne). Questo potrebbe derivare da un attacco mirato (es. phishing avanzato) volto a carpire informazioni sensibili. Il responsabile CSIRT nazionale verrebbe allertato per supportare l’ente nell’indagine. In un caso del genere, una delle prime mosse sarebbe raccogliere in maniera forense i log del server di posta (ad esempio i log IMAP/POP/SMTP, o i log di accesso alla Webmail) per identificare da quali IP e quando si sono verificati gli accessi abusivi. Poi, si procederebbe all’acquisizione delle caselle di posta compromesse – ad esempio esportando i file .pst/.ost nel caso di Exchange/Outlook, o effettuando un dump delle caselle dal server – per analizzare quali email sono state lette o esfiltrate dall’attaccante. Se si sospetta che l’attaccante abbia usato una postazione interna compromessa, quel PC verrebbe sequestrato per un’analisi: in tal caso la squadra forense eseguirebbe un’acquisizione post-mortem completa del disco e della RAM (se la macchina è accesa) di tale computer. Dall’immagine del PC si cercherebbero artefatti come browser history (per vedere se l’attaccante ha navigato la webmail), eventuali keylogger o malware installati, e tracce di movimenti laterali. Un esempio reale simile è accaduto con attacchi APT a Ministeri esteri: in passato, malware come Remote Control System o Ursnif hanno infettato PC di dipendenti pubblici per rubare credenziali PEC e documenti riservati. In queste indagini, la collaborazione con Polizia Postale è stretta: il responsabile deve garantire che ogni acquisizione segua procedure ineccepibili così che le prove (log di accesso, immagini dei PC) siano valide per identificare gli autori e perseguirli. Un aspetto critico qui è la catena di custodia condivisa: ad esempio, i log del server mail potrebbero essere forniti dall’ente al CSIRT e poi da questo alla Polizia; bisogna documentare ogni passaggio, magari apponendo firme digitali ai file per garantirne l’immodificabilità durante il trasferimento. Questo scenario evidenzia l’importanza della normativa nazionale (es. obblighi di notifica incidenti secondo NIS/DORA) che impone tempi stretti: entro 24 ore l’ente deve informare l’ACN, e nei giorni seguenti fornire risultati preliminari. Un responsabile quindi attiverebbe subito le procedure di acquisizione forense parallelamente alla mitigazione (es. reset password account, blocco di IoC a firewall), per poter fornire rapidamente un quadro d’impatto. Il risultato tangibile sarebbe un rapporto forense con elenco delle caselle violate, l’analisi di come (es. malware su PC X che ha fatto da pivot), e le azioni raccomandate per evitare futuri attacchi (es. 2FA obbligatoria sulle caselle, campagne anti-phishing).
3. Indagine su dipendente infedele in un ente pubblico: un contesto diverso, ma non raro, è quello di un abuso interno – ad esempio un funzionario di un’amministrazione che sottrae dati riservati (liste di cittadini, documenti interni) per fini personali o per rivenderli. In tal caso, l’incidente può non essere un “attacco esterno” ma una violazione di policy interna. Tuttavia, le tecniche di acquisizione forense sono analoghe: supponiamo che si sospetti che il dipendente abbia copiato file su una USB personale. Il responsabile della sicurezza dell’ente, con supporto forense) disporrà il sequestro del PC aziendale dell’individuo e di eventuali supporti nel suo ufficio. Su quel PC si effettuerà un imaging completo del disco. Dall’analisi emergeranno ad esempio artefatti USB nel registro di Windows con l’identificativo di una pen drive non autorizzata e date di utilizzo. I log di accesso potrebbero mostrare che il soggetto ha lavorato fuori orario su quei file (Event Log con login serali, oppure timeline di $MFT che indica accessi in orari anomali). Anche i LNK files e la shellbag del registro potrebbero confermare che ha aperto cartelle contenenti i dati riservati e magari copiato file su un percorso esterno. Tutte queste prove, opportunamente raccolte e documentate, costituiranno materiale per un eventuale procedimento disciplinare o penale. In un caso simile è fondamentale che la copia forense del disco del dipendente sia effettuata in maniera impeccabile e che l’originale venga custodito in cassaforte: la difesa potrebbe contestare la manomissione dei dati, quindi poter esibire hash corrispondenti e documentazione di catena di custodia completa tutela l’ente e la validità probatoria. Inoltre, se coinvolto un sindacato o autorità, sapere di aver seguito standard ISO/NIST (dunque di non aver violato la privacy di altri dati se non quelli pertinenti, ecc.) mette al riparo da contestazioni sulla metodologia. Un esempio reale avvenne qualche anno fa in un comune italiano, dove un amministratore di sistema fu scoperto a curiosare nei dati anagrafici senza motivo: grazie alla analisi forense dei log applicativi e del suo computer, si individuò l’illecito. Il responsabile deve essere sensibile anche a questi scenari “interni”, predisponendo magari procedure semplificate di acquisizione (non sempre servirà un intervento della Polizia, a volte è un audit interno) ma ugualmente rigorose.
4. Coordinamento multi-ente in incidenti su infrastrutture critiche: In ambito nazionale, il responsabile per la prevenzione incidenti potrebbe trovarsi a gestire situazioni che coinvolgono più enti contemporaneamente – ad esempio una campagna di attacchi ransomware a vari ospedali o comuni. In queste situazioni, l’acquisizione forense deve scalare su più fronti: occorre inviare squadre locali (o guidare da remoto i tecnici sul posto) per raccogliere evidenze in ciascun luogo. Un caso ipotetico: una variante di ransomware colpisce simultaneamente 5 ospedali italiani. Il CSIRT nazionale emette allerta e invia digital forensics kits alle squadre IT locali con istruzioni su cosa fare: eseguire subito dump di RAM delle macchine critiche (server di cartelle cliniche) e poi spegnerle per imaging, raccogliere log di sicurezza e una copia dei malware trovati su disco. Ogni squadra segue lo stesso protocollo (magari fornito sotto forma di checklist derivata da ISO 27037). I dati raccolti vengono poi centralizzati al CSIRT per l’analisi aggregata – questo ha senso perché confrontando i dump di memoria o gli artefatti del malware, si può capire se gli attacchi sono correlati (stessa variante) e quindi fornire early warning agli altri. Un responsabile deve quindi saper orchestrare acquisizioni forensi in parallelo, mantenendo la qualità. Ciò comporta anche aspetti logistici, come assicurarsi che ogni ente abbia almeno un personale formato DEFR o che possa dare accesso rapido alle stanze server per le copie. La cooperazione con forze di polizia qui è doppiamente importante: incidenti su infrastrutture critiche vengono seguiti anche dall’autorità giudiziaria, quindi polizia scientifica e Postale lavoreranno con il CSIRT. Uniformare gli standard (ad es. concordare l’uso di determinate tipologie di supporti di custodia sigillati, condividere gli hash via canali sicuri) è qualcosa che va preparato prima dell’incidente, tramite accordi e protocolli tra ACN e forze dell’ordine. In Italia, il modello di intervento cooperativo è in evoluzione, ma eventi come quelli di Luglio 2023 (attacco ransomware a vari comuni toscani) hanno visto CERT-AgID e CNAIPIC lavorare fianco a fianco. Il risultato è duplice: mitigare l’incidente e raccogliere prove per perseguire i criminali. Il responsabile deve assicurarsi che nessuno dei due obiettivi comprometta l’altro (ad es. non ripristinare macchine senza prima averle acquisite, a costo di tenere giù un servizio un’ora in più – decisione spesso difficile ma necessaria in ottica strategica).
Questi esempi mostrano che, nel contesto italiano, l’acquisizione forense è ormai parte integrante della gestione degli incidenti informatici, sia che essi siano causati da hacker esterni sia da minacce interne. Adottare standard internazionali offre un linguaggio comune e una qualità garantita delle operazioni, mentre declinare tali standard nelle procedure specifiche nazionali (considerando normative locali e struttura organizzativa italiana) è il compito del responsabile. In ogni caso, le evidenze digitali raccolte – dai log di Windows alle memorie RAM – si sono rivelate l’elemento chiave per chiarire gli incidenti e trarne lezioni: ad esempio, l’analisi forense post-mortem dei sistemi di un comune colpito da ransomware può evidenziare come l’attaccante è entrato (RDP esposto, credenziali deboli), fornendo indicazioni per mettere in sicurezza tutti gli altri enti con configurazioni simili. Così, il ciclo prevenzione-incidenti-miglioramento si chiude, con la forensica digitale a fare da ponte tra reazione all’emergenza e strategia di sicurezza proattiva.
Conclusioni
L’acquisizione forense di sistemi informatici – con tutte le sue sfaccettature di triage, imaging e raccolta artefatti – rappresenta una pietra angolare della moderna risposta agli incidenti. Nel ruolo di responsabile per la prevenzione e gestione di incidenti informatici, queste competenze non sono solo tecniche, ma strategiche: bisogna saper orientare il team verso le azioni giuste nei momenti critici, garantendo che nessuna prova vada perduta e che l’integrità delle evidenze rimanga intatta. Come evidenziato dai principali standard (ISO/IEC 27037, NIST 800-86) e linee guida (RFC 3227), seguire metodologie strutturate assicura che l’indagine digitale sia condotta con rigore scientifico e validità legale.
Un buon responsabile CSIRT deve quindi agire su più fronti: prevenire – formando il personale e predisponendo procedure e toolkit per essere pronti all’acquisizione; gestire – durante l’incidente decidere rapidamente cosa acquisire live e cosa post-mortem, bilanciando la necessità di contenere la minaccia con quella di conservare le prove; analizzare – assicurarsi che i dati raccolti vengano esaminati a fondo (se non dal proprio team, passando il testimone a team forensi dedicati), traendo conclusioni solide; e comunicare – redigendo report post-incidente chiari che documentino l’accaduto e reggano a eventuali scrutini giudiziari.
In ambito nazionale, queste responsabilità si amplificano: il responsabile diventa l’anello di congiunzione tra diverse entità (enti colpiti, agenzie di sicurezza, forze dell’ordine, talvolta partner internazionali per attacchi globali), dovendo garantire un approccio unificato e conforme agli standard. Solo un processo di acquisizione forense ben gestito può fornire le risposte alle domande chiave dopo un incidente: come è successo? cosa è stato colpito? c’è ancora presenza dell’attaccante? quali dati sono stati compromessi? – e queste risposte informano tanto le azioni di recovery immediato quanto le strategie di miglioramento a lungo termine.
Concludendo, l’acquisizione forense non è una mera operazione tecnica ma un’attività dal forte impatto organizzativo e legale. Operare secondo le best practice internazionali, mantenere un alto livello di professionalità e documentazione, e sapersi adattare ai contesti concreti (tecnologici e normativi) italiani, sono caratteristiche imprescindibili per il responsabile CSIRT/SOC. Così facendo, ogni incidente informatico, per quanto grave, diventa anche un’opportunità di apprendimento e di rafforzamento della postura di sicurezza nazionale, trasformando l’esperienza sul campo in nuove misure preventive e in una resilienza cyber sempre maggiore. La sfida è elevata, ma come recita un principio forense: “le prove digitali non mentono” – sta a noi saperle preservare e interpretare correttamente, a tutela della sicurezza collettiva e della giustizia.
Molte telecamere di fascia consumer/prosumer adottano meccanismi P2P via cloud (UID + STUN/TURN/relay) per fornire accesso “zero-configurazione”. Questa convenienza introduce rischi strutturali: dipendenza da terze parti, esposizione a credential stuffing, aperture automatiche di porte tramite UPnP, ritardi o assenza di aggiornamenti firmware, applicazioni mobili invasive e scarsa trasparenza dei vendor. Il presente articolo propone un modello local-first con segmentazione (VLAN IoT), registrazione/visualizzazione in locale, accesso remoto esclusivamente via VPN, pratiche di hardening, logging e monitoraggio. Inoltre:
un playbook operativo completabile in ~90 minuti;
checklist per la valutazione dei fornitori;
errori ricorrenti da evitare;
indicazioni forensi in caso di incidente.
Introduzione
L’adozione massiva di telecamere “plug-and-play” ha ridotto la complessità di installazione, spostando però il baricentro della sicurezza verso infrastrutture cloud proprietarie. Questo paper affronta, con taglio tecnico-accademico, come funziona il P2P “magico”, perché è rischioso, e quali architetture e controlli consentono di mitigare i rischi con oneri limitati.
P2P “magico”: funzionamento e impatti
Meccanismo tecnico
UID: ogni camera espone un identificativo univoco associato al tuo account/app.
NAT traversal: la camera apre connessioni in uscita verso server del vendor (STUN/TURN) per superare NAT/firewall; in caso di fallimento si usa relay completo lato cloud.
Effetto: fruizione video senza configurazioni manuali (port-forward), al prezzo di un terzo attore—il vendor—nel percorso di segnalazione e talvolta nel trasporto.
Superfici d’attacco e criticità
Dipendenza dal cloud: indisponibilità, compromissioni o scarsa trasparenza impattano disponibilità e riservatezza.
Credential stuffing: l’account applicativo del vendor è un bersaglio distinto dall’infrastruttura domestica/aziendale.
UPnP: alcuni dispositivi richiedono aperture automatiche di porte; pratica rischiosa e spesso non tracciata.
Supply-chain & firmware: cicli di patch lenti/assenti; stack P2P proprietari difficili da auditare.
App mobili: permessi e telemetria eccessivi, potenziale esfiltrazione metadati.
Architetture di riferimento (ordine decrescente di sicurezza)
Solo locale (massima privacy)
VLAN IoT dedicata (es. VLAN20 192.168.20.0/24) senza accesso Internet.
NVR/NAS con RTSP/ONVIF nella stessa VLAN.
Visualizzazione da LAN amministrativa tramite jump host o ACL selettive.
Locale + VPN (equilibrio sicurezza/usabilità)
Come sopra, ma nessun port-forward pubblico.
Accesso remoto solo tramite VPN (WireGuard/OpenVPN) al router/firewall.
Notifiche push veicolate attraverso la VPN o bridge on-prem sicuro.
Cloud minimale e controllato (solo se indispensabile)
Abilitare funzioni cloud solo per notifiche, non per streaming continuativo.
Preferire vendor con E2E documentata; disabilitare UPnP, applicare ACL in uscita.
Controlli di sicurezza: rete, accesso, gestione
Segmentazione e policy
VLAN IoT (telecamere), VLAN Admin (NVR/management), VLAN User (PC/smartphone).
Regole firewall minimali: IoT → NVR (RTSP/ONVIF) solo, deny all per il resto.
Bloccare IoT → Internet, salvo finestre di update strettamente controllate.
Accesso remoto
VPN con MFA (WireGuard/OpenVPN). Evitare esposizioni dirette su Internet di NVR/telecamere.
Disabilitare UPnP su router e dispositivi; opzionale: bloccare domini cloud vendor se non utilizzati.
Autenticazione e cifratura
Password uniche e robuste; 2FA ovunque disponibile.
TLS per pannelli web interni; preferire E2E tra client e NVR quando possibile.
Patch management, inventario, backup
Inventariare modelli/seriali/firmware; pianificare finestre di patch mensili con changelog.
Backup configurazioni (router/firewall/NVR) e snapshot delle policy.
Logging e monitoraggio
NTP coerente; invio log a Syslog/SIEM (accessi, motion, riavvii).
Allarmi su autenticazioni fallite, cambi IP/MAC, variazioni di profilo stream.
Playbook operativo “90 minuti di hardening” (SOHO/PMI)
Prerequisiti: privilegi sul router/firewall, switch gestibile, NVR/NAS compatibile RTSP/ONVIF.
Router/Firewall (≈15′)
Disabilita UPnP.
Crea VLAN20 (IoT) e VLAN10 (Admin).
Regola: VLAN20 → solo NVR: 554 (RTSP), 80/443 se indispensabili; deny all per il resto.
Blocca VLAN20 → Internet; in alternativa, whitelist temporanea per update.
Switch/Access Point (≈10′)
SSID “IoT” ancorato a VLAN20.
Port isolation per ridurre movimento laterale intra-VLAN.
NVR/NAS (≈20′)
Cambia credenziali di default, abilita 2FA (se presente).
Crea utenti per ruolo (viewer/admin); invia log a syslog.
Abilita solo protocolli necessari (RTSP/ONVIF); disabilita il cloud.
Telecamere (≈20′)
Aggiorna firmware.
Disabilita P2P/cloud nelle impostazioni.
Configura stream RTSP verso NVR (H.265 se supportato, bitrate adeguato).
Configura WireGuard sul gateway; genera profili per smartphone/PC.
Verifica che la visualizzazione funzioni solo con VPN attiva.
Verifica finale (≈10′)
Da rete esterna: nessuna porta esposta su IP pubblico.
Dalla VLAN IoT: traffico verso Internet bloccato (se policy locale-only).
Verifiche tecniche: comandi esemplificativi
# Scansione porte esposte su IP pubblico (da rete esterna)
nmap -Pn -p- --min-rate 1000 <IP_PUBBLICO>
# Verifica outreach delle telecamere (dalla VLAN IoT)
tcpdump -i ethX host <IP_CAMERA> and not host <IP_NVR>
# Controllo stato UPnP (OpenWrt)
uci show upnpd
È possibile disabilitare completamente P2P/cloud e usare RTSP/ONVIF solo in LAN?
Esiste una politica di aggiornamento con changelog e tempi di remediation (CVE)?
L’app funziona in LAN senza Internet?
Sono disponibili 2FA, ruoli granulari e log esportabili (syslog/API)?
È documentata l’end-to-end encryption (ambito, limiti, gestione chiavi)? Come avviene l’eventuale relay?
Errori ricorrenti da evitare
Lasciare UPnP attivo “per comodità”.
Esporre NVR/telecamere con port-forward (80/554/8000) confidando solo nella password.
Riutilizzare le stesse credenziali e rinunciare al 2FA.
Trascurare la segmentazione (reti piatte ⇒ movimento laterale facilitato).
Aggiornare l’app ma non il firmware dei dispositivi.
Considerazioni forensi (DFIR)
Preservazione: esportare configurazioni NVR; acquisire log di accesso/motion/riavvii.
Timeline: correlare eventi di motion con autenticazioni remote, geolocalizzazione IP, modifiche impostazioni.
Acquisizioni: – Bitstream del disco NVR/NAS (per analisi di metadati, cancellazioni, rotazioni); – PCAP della VLAN IoT (24–48 h) per pattern anomali, DNS rari, cambi di bitrate/codec.
Indicatori: accessi fuori orario, up/down ricorrenti, variazioni di stream non programmate, contatti verso domini non standard.
Conclusioni
La sicurezza dei sistemi di videosorveglianza non dipende dalla “smartness” del dispositivo, ma dalla prevedibilità dell’architettura: isolamento di rete, minimizzazione della dipendenza dal cloud, aggiornamenti regolari, e accesso mediato da VPN. Un’impostazione local-first con policy chiare riduce drasticamente il profilo di rischio senza penalizzare la fruibilità. Le linee guida e il playbook proposti forniscono un percorso pratico e ripetibile per ambienti domestici evoluti e PMI.
In ambito enterprise, i sistemi di gestione centralizzati (come i servizi di directory) svolgono un ruolo chiave nella sicurezza informatica. Forniscono un punto unico per gestire identità, autenticazione e autorizzazione degli utenti su tutta l’infrastruttura, semplificando l’amministrazione e migliorando la consistenza delle policy di sicurezza. Ad esempio, Active Directory (AD) di Microsoft è ampiamente utilizzato (oltre il 90% delle organizzazioni lo impiega in forma on-premises, cloud Azure AD o ibrida[1]) come soluzione di identità principale. Grazie a questi sistemi, un team CSIRT/SOC può applicare controlli di sicurezza uniformi (es. criteri di password, restrizioni di accesso) e raccogliere centralmente gli eventi di sicurezza per il monitoraggio. Questo approccio riduce le vulnerabilità dovute a configurazioni incoerenti e permette di reagire più rapidamente agli incidenti. Al contempo, però, la natura centralizzata rende questi sistemi un bersaglio privilegiato per i cyber attaccanti, poiché comprometterli significa ottenere accesso esteso alla rete[2].
Active Directory: Architettura e componenti principali
Active Directory (AD) è un servizio di directory per reti Windows domain che organizza e memorizza informazioni su utenti, computer e altre risorse in modo gerarchico[1]. L’architettura logica di AD comprende i seguenti elementi fondamentali:
Domain (Dominio): Un dominio AD è un contenitore amministrativo che raggruppa oggetti (utenti, computer, gruppi) sotto un unico database di directory e un unico spazio dei nomi DNS (es: azienda.local). Rappresenta un boundary di sicurezza e replicazione: tutti i controller di dominio di un dominio condividono il database e autenticano gli utenti di quel dominio.
Organizational Unit (OU): Sono unità organizzative, ovvero sottocontenitori all’interno di un dominio, usati per organizzare gli oggetti (ad esempio per dipartimento o sede) e delegare autorizzazioni di amministrazione. Le OU facilitano l’applicazione di Criteri di Gruppo specifici per gruppi di utenti/computer.
Tree (Albero) e Forest (Foresta): Un albero è un insieme di domini in relazione gerarchica (ad es. domini figlio europe.azienda.local sotto il dominio radice azienda.local). Più alberi possono essere collegati in una foresta, che è l’insieme più ampio: domini multipli che condividono la stessa struttura logica AD (schema comune, catalogo globale, configurazione) e instaurano trust bidirezionali transitivi fra di loro[3][4]. La foresta è il boundary di sicurezza massimo di AD: tutti i domini in foresta si fidano reciprocamente. In genere la foresta coincide con l’organizzazione complessiva, mentre i domini separano unità organizzative maggiori (es. divisioni aziendali o regioni).
Site (Sito): Configurazione opzionale che rappresenta la topologia fisica (es. sedi geografiche) per ottimizzare la replicazione e l’autenticazione (i DC all’interno di un sito replicano frequentemente tra loro e servono preferibilmente client locali).
Componenti fisici: i Domain Controller (DC) sono i server Windows che ospitano Active Directory Domain Services (AD DS) e contengono ciascuno una copia replicata del database AD (file NTDS.dit). I DC gestiscono le richieste di autenticazione (login utenti) e le query al directory. In un dominio vi sono tipicamente più DC per ridondanza e alta disponibilità (almeno due per tollerare guasti)[5]. Tra i DC avviene una replica multi-master continua dei dati AD. Alcuni DC possono avere ruoli speciali (vedi FSMO sotto). Un altro componente chiave è il Global Catalog (GC): un DC (o insieme di DC) che ospita una copia parziale di tutti gli oggetti della foresta, rendendo possibili ricerche rapide su oggetti in qualsiasi dominio. Inoltre, AD supporta Read-Only Domain Controller (RODC), DC di sola lettura pensati per sedi periferiche meno sicure fisicamente, i quali mantengono una copia in sola lettura del database (nessuna modifica locale)[6].
Database AD e schema: AD memorizza gli oggetti con i loro attributi in un database basato su Jet Database. Lo Schema AD definisce la struttura dei dati, ovvero i tipi di oggetti e attributi ammessi (es: utenti con attributi come nome, telefono, gruppi con elenco membri, computer con nome host, ecc.). Lo schema è estensibile ma unico a livello di foresta, ed è gestito centralmente (vedi ruolo Master schema).
Protocolli utilizzati e ruoli FSMO in Active Directory
Active Directory supporta diversi protocolli di rete standard per le sue funzioni: – LDAP (Lightweight Directory Access Protocol): protocollo directory su porta 389/TCP (o 636/LDAPS cifrato) utilizzato per interrogare e modificare il database AD. Client e applicazioni usano LDAP per cercare utenti, gruppi, autenticare su servizi (LDAP bind) ecc. – Kerberos: protocollo predefinito per l’autenticazione in un dominio AD (porta 88/UDP/TCP). Su Kerberos approfondiremo nelle sezioni successive. – NTLM: metodo di autenticazione legacy (challenge/response) usato come fallback se Kerberos non è disponibile (ad es. PC non in dominio o alcuni scenari particolari). È meno sicuro e soggetto ad attacchi pass-the-hash, quindi AD ne limita l’uso in favore di Kerberos. – RPC/SMB: protocolli usati per funzioni interne come la replicazione tra DC, la gestione remota, l’applicazione di policy, etc. Ad esempio il File Replication Service (FRS) o DFS-R per replicare le Sysvol (che contengono script di login e Group Policy) usano SMB, mentre molte operazioni di amministrazione AD usano RPC (porta 135 e porte dinamiche).
Ruoli FSMO (Flexible Single Master Operations)
In AD alcune operazioni critiche sono demandate a ruoli unici detti FSMO (o ruoli operazioni master flessibili) per evitare conflitti nella rete multi-master. I 5 ruoli FSMO in un’infrastruttura Active Directory sono[7]:
Master schema – uno per foresta: detiene la unica copia scrivibile dello schema AD. Solo il DC con questo ruolo può aggiornare lo schema (es. aggiunta di nuovi attributi o classi di oggetti).
Master per la denominazione dei domini – uno per foresta: responsabile di aggiungere/rimuovere domini nella foresta e assicurare unicità dei nomi di dominio[8]. Previene la creazione di due domini con lo stesso nome.
Master RID (Relative ID) – uno per dominio: assegna blocchi di RID unici ai DC del dominio. Ogni oggetto in AD ha un SID (Security ID); il RID è la parte finale variabile del SID. Questo ruolo garantisce che ogni DC usi RID diversi per creare nuovi oggetti, evitando SID duplicati[9].
Emulatore PDC – uno per dominio: il DC che agisce da Primary Domain Controller Emulator. È un ruolo chiave per retrocompatibilità e funzioni centralizzate: risponde alle richieste di sincronizzazione oraria, gestisce cambi password immediati, funge da server primario per le autenticazioni NTLM e coordina la distribuzione delle Group Policy. In pratica, è considerato il DC di riferimento principale per il dominio (simulando il vecchio PDC di Windows NT)[10]. Inoltre, in un ambiente con più DC, è il PDC Emulator a essere contattato per operazioni come lock/unlock account.
Master infrastrutture – uno per dominio: si occupa di mantenere riferimenti consistenti tra oggetti di domini differenti (in particolare converte SID e GUID di oggetti esterni in nomi canonici, aggiornando riferimenti nei gruppi qualora utenti vengano spostati tra domini)[11]. In una singola foresta con un solo dominio, questo ruolo può passare inosservato; in foreste multi-dominio evita problemi di referenze “orfane” mostrando SID non risolti nelle ACL se non funzionasse.
Tali ruoli possono essere spostati tra DC (tramite strumenti grafici o PowerShell) per bilanciare il carico o in caso di decommissionamento di un controller. È fondamentale monitorare lo stato dei ruoli FSMO perché, pur avendo AD un meccanismo flessibile (in caso di DC offline i ruoli possono essere sequestrati da un altro DC), la perdita prolungata di un FSMO può impedire operazioni importanti (ad es. senza Master RID non si possono creare nuovi utenti quando i RID disponibili sui DC finiscono).
Gestione della sicurezza in Active Directory
Group Policy e controllo centralizzato
Una delle funzionalità più potenti di AD in ottica sicurezza è la Group Policy. I Criteri di Gruppo (GPO) permettono di applicare impostazioni di configurazione e di sicurezza in modo centralizzato a gruppi di computer o utenti all’interno del dominio (ad es. impostare la policy password complessa, i limiti di lockout, le impostazioni del firewall client, restrizioni software, etc.). Le GPO possono essere collegate a livello di sito, dominio o OU e vengono applicate automaticamente ai sistemi/utenti interessati all’avvio o login. Questo consente un controllo uniforme: invece di configurare manualmente ogni host, gli amministratori definiscono il criterio una volta in AD e assicurano conformità su larga scala. Ad esempio, tramite GPO si può imporre che tutte le macchine del dominio abbiano login screen banner di avviso, che gli utenti non possano installare software non autorizzato, o che vengano eseguite specifiche configurazioni di auditing (vedi dopo). Un’altra area critica gestibile via GPO è la politica password: a livello di dominio si definisce lunghezza minima, complessità e durata delle password utente, nonché soglie di blocco account per tentativi falliti (mitigando brute force)[12]. In contesti avanzati, AD supporta anche fine-grained password policies (PSO) per eccezioni su gruppi specifici, ma la policy di dominio resta fondamentale. Il vantaggio per il SOC è chiaro: uniformità delle configurazioni di sicurezza e riduzione degli errori manuali.
Autenticazione e autorizzazione centralizzate
Active Directory gestisce in modo integrato autenticazione (verifica dell’identità) e autorizzazione (controllo degli accessi) in rete[13]. Quando un utente si logga a un computer membro del dominio, le sue credenziali vengono verificate dal Domain Controller usando Kerberos (per default). AD quindi emette token contenenti l’identità utente e i suoi gruppi di appartenenza (SIDs), che saranno usati per autorizzare l’accesso alle risorse. L’autenticazione centralizzata garantisce che solo utenti validi (presenti nel database AD) possano accedere e che la loro password sia verificata secondo le policy del dominio. L’Single Sign-On (SSO) è un beneficio: un utente, autenticandosi al dominio una volta, riceve i ticket Kerberos per accedere a più servizi senza dover reinserire credenziali per ognuno[14].
L’autorizzazione nelle risorse Windows avviene tramite ACL che contengono SID di utenti/gruppi AD; grazie a AD, i gruppi possono essere usati per gestire ruoli e permessi (es: mettere un utente nel gruppo “Finance” gli dà automaticamente accesso alle cartelle riservate a Finance se le ACL sono configurate di conseguenza). La centralizzazione AD consente di modificare un membership di gruppo e influenzare immediatamente i privilegi su molte risorse. AD fornisce anche meccanismi avanzati come il Delegation of Control (possibilità di delegare permessi amministrativi granulari su OU ad esempio a un IT locale, senza dare privilegi globali) e funzionalità di trust tra domini/foreste per estendere l’autenticazione federata (un utente di un dominio trusted può essere autenticato nel dominio trusting).
Auditing e monitoraggio
Dal punto di vista di un SOC, monitorare Active Directory è cruciale perché molte tracce di compromissione emergono negli eventi di sicurezza del dominio. Windows Server fornisce una serie di Security Auditing che, se abilitati tramite policy, registrano eventi come logon riusciti e falliti, utilizzo di credenziali, modifiche a utenti o gruppi, cambi ACL, ecc. Tramite Group Policy (es. configurando la Default Domain Controllers Policy per i DC) si possono attivare audit dettagliati: ad esempio Audit account logon events, Audit account management (creazione/modifica utenti/gruppi), Directory Service Access (accessi a oggetti AD), ecc. Una volta abilitati (spesso definendo sia Success che Failure per ottenere tracce di tentativi falliti) i Domain Controller iniziano a generare eventi nel registro di Sicurezza Windows.
Per gestire l’auditing AD: 1. Si attivano le categorie di audit via GPO (sotto Computer Configuration > Windows Settings > Security Settings > Advanced Audit Policy Configuration[15][16]). 2. Si raccolgono i log di sicurezza dai DC centralmente (tipicamente inviandoli a un SIEM o aggregatore) per analisi. Ad esempio, un evento 4625 (logon failed) su un DC con codice errore indica un tentativo di accesso fallito, un 4720 indica creazione di un nuovo account utente, un 4723 tentativo di cambio password, 4728 aggiunta a gruppo privilegiato, ecc. 3. Si configurano alert su eventi sensibili (es: molteplici lockout account possono indicare brute force; modifica di membership Domain Admins genera evento 4728 da attenzionare).
L’auditing nativo può essere complesso (molti eventi verbosi), ma esistono soluzioni che aiutano (strumenti Microsoft come Advanced Threat Analytics/Defender for Identity, o soluzioni terze) per individuare anomalie. Indipendentemente dagli strumenti, è fondamentale che un CSIRT/SOC abiliti e utilizzi l’auditing AD: modifiche anomale su AD spesso sono segnale di compromissione in atto. Come raccomandato da guide specializzate, tutte le azioni privilegiate dovrebbero essere tracciate e riviste regolarmente[17]. In sintesi, AD offre gli elementi per un controllo centralizzato, ma spetta all’organizzazione implementare una robusta politica di logging, monitoring e auditing per trarne vantaggio.
Kerberos: principio di funzionamento
Kerberos è un protocollo di autenticazione di rete, progettato dal MIT, basato su un sistema di ticket che permettono a nodi (client e server) di autenticarsi reciprocamente su una rete insicura senza trasmettere password in chiaro. Il nome deriva da Cerbero, il cane a tre teste della mitologia greca, ad indicare le sue tre componenti principali: un client (principal), un servizio richiesto e un Key Distribution Center (KDC) centrale che funge da guardiano[18][19]. In ambiente Windows/AD, il KDC è implementato sui Domain Controller.
Figura – Le “tre teste” di Kerberos: Principale (l’entità che si autentica, ad es. un utente), Risorsa/Servizio a cui vuole accedere, e KDC (Key Distribution Center) che media l’autenticazione.[18]
Kerberos opera secondo un meccanismo di fiducia centralizzata: il KDC possiede una chiave segreta condivisa con ogni utente (derivata dalla password) e con ogni servizio/server (derivata dalla password dell’account computer o account servizio registrato in AD). Il processo di autenticazione Kerberos (versione Kerberos V5 usata in AD) avviene in più fasi (detto ticketing):
Client richiede un Ticket-Granting Ticket (TGT) – Quando, ad esempio, un utente inserisce credenziali per accedere al dominio, il suo computer invia al KDC (servizio di Authentication Service, in esecuzione sul DC) un’autenticazione iniziale AS-REQ con il proprio principal (es. nome utente). Il KDC verifica le credenziali (nel caso di AD, controlla l’hash della password dell’utente confrontandolo con quello memorizzato in AD) e, se corrette, genera un Ticket-Granting Ticket. Il TGT è un ticket crittografato con la chiave segreta del KDC (nota solo al KDC stesso), contenente l’identità dell’utente, timestamp e una chiave di sessione. Il TGT viene restituito al client nell’AS-REP, insieme a una copia della chiave di sessione cifrata con la chiave dell’utente (così solo l’utente – conoscendo la propria password – può decifrarla). Da notare che a questo punto il KDC ha autenticato l’utente, ma l’utente non ha ancora accesso a nessun servizio di rete, solo al diritto di chiedere ticket ulteriori.
Client richiede un ticket di servizio (TGS) – Quando il client vuole accedere a una risorsa specifica (es. un file server o un’applicazione web che supporta Kerberos), utilizza il TGT ottenuto per fare una richiesta TGS-REQ al Ticket-Granting Service (sempre sul KDC) per un ticket verso quel servizio. La richiesta include il TGT e indica il Service Principal Name (SPN) del servizio desiderato (ad es. HTTP/nomeServer per un sito web, o cifs/fileserver1 per un file share SMB). Il KDC verifica il TGT (che essendo firmato dalla sua chiave può essere validato e considerato prova dell’identità del client) e controlla nei propri database AD se l’utente ha diritto di accedere al servizio richiesto. Se tutto ok, il KDC genera un Ticket di Servizio (detto anche service ticket o TGS), crittografato con la chiave segreta del servizio target (nota solo a quel server). Questo ticket contiene l’identità del client, un nuovo session key client-server e le autorizzazioni (nel contesto AD, include il PAC – vedi dopo). Il KDC invia al client il ticket di servizio nell’TGS-REP, insieme a una copia della session key client-server (cifrata con la chiave già condivisa col client tramite il TGT). A questo punto il client ha un ticket valido per presentarsi al servizio.
Accesso al servizio (AP-REQ/AP-REP) – Il client contatta il server target presentando il ticket di servizio (messaggio AP-REQ). Il server, che conosce la propria chiave segreta, decifra il ticket e ottiene così la session key e l’identità del client. Può opzionalmente inviare una risposta AP-REP per confermare al client la propria identità (mutua autenticazione). Da questo momento, client e server hanno stabilito una fiducia reciproca e possono comunicare in modo sicuro. Il client è autenticato presso il servizio senza aver trasmesso la password in rete (solo ticket cifrati). Il servizio, grazie alle informazioni nel ticket (come i gruppi di appartenenza dell’utente nel PAC), può effettuare il controllo di autorizzazione e concedere o negare l’accesso alla risorsa richiesta.
Questo sistema di ticket fa sì che le credenziali sensibili (password) non circolino mai sulla rete; inoltre i ticket hanno una durata limitata (tipicamente il TGT dura 8-10 ore, i ticket di servizio alcune ore) e includono timestamp per prevenire replay. Kerberos fornisce anche mutua autenticazione (il client si fida del server solo se quest’ultimo dimostra di aver decifrato il ticket, quindi di essere legittimo). In Windows, Kerberos è integrato: il processo avviene in gran parte in background quando un utente esegue il logon al dominio e quando accede a risorse domain-based.
Crittografia e sicurezza in Kerberos
Kerberos si basa su crittografia simmetrica forte per proteggere i ticket e le comunicazioni[20]. Nel contesto Active Directory, le versioni moderne usano algoritmi AES (Advanced Encryption Standard) per cifrare ticket e chiavi (Windows Server 2008+ supporta AES, mentre versioni più vecchie usavano DES o RC4-HMAC[21]). Ogni principal (utente o servizio) ha in AD una chiave segreta derivata dalla password: per utenti è l’hash della password NT, per i computer/servizi è la password dell’account macchina o service account. Il KDC conosce tutte queste chiavi, perciò può creare ticket cifrati destinati sia al client (cifrati con chiave dell’utente) sia al servizio (cifrati con chiave del servizio).
Alcuni dettagli di sicurezza: – Pre-autenticazione: Kerberos v5 in AD richiede che l’utente provi di conoscere la propria chiave già nella richiesta AS-REQ (inviando un timestamp cifrato con la propria chiave). Ciò previene attacchi offline: senza pre-auth, un attacker potrebbe chiedere un TGT e riceverlo cifrato con la chiave dell’utente, tentando poi di crackare offline la password da quel ticket (attacco AS-REP Roasting). Con la pre-auth attiva, il KDC non risponde se l’utente non dimostra prima la conoscenza della chiave. Nota: è importante che tutti gli account AD mantengano abilitata la pre-auth (è di default, ma può essere disabilitata per compatibilità): account senza pre-auth sono esposti ad attacchi di password guessing offline[22]. – Time synchronization: Kerberos dipende da orologi sincronizzati: i ticket hanno timestamp e scadenze. In AD è tollerato tipicamente un skew di 5 minuti; se l’orologio di un client differisce troppo, l’autenticazione fallirà. Per questo, parte delle best practice è assicurare NTP attivo su DC e client. – Session keys: per ogni autenticazione a un servizio, Kerberos genera chiavi di sessione uniche che il client e il server useranno per cifrare la sessione (ad esempio integrità e/o confidenzialità dei dati scambiati dopo l’autenticazione, se l’applicazione lo supporta). Ciò garantisce che anche se qualcuno intercettasse il ticket, non potrebbe usare la sessione senza la session key (che è protetta). – PAC (Privilege Attribute Certificate): è un campo aggiuntivo che Microsoft ha inserito nei ticket Kerberos in ambiente AD. Il PAC contiene gli identificatori di sicurezza e privilegi dell’utente (SID utente, SID dei gruppi di appartenenza, attributi come il SIDHistory, ecc.). Quando un utente presenta un ticket a un server, quest’ultimo può (ed è tenuto a) validare il PAC contattando un DC (procedura di PAC validation) per assicurarsi che non sia stato manomesso[23]. Il PAC consente al server di conoscere i gruppi e quindi applicare le ACL adeguate, ed è firmato dal KDC per garantirne l’integrità. Attacchi sofisticati come Golden Ticket coinvolgono la falsificazione del PAC, come vedremo.
Vulnerabilità note del protocollo Kerberos
Nonostante Kerberos sia considerato un protocollo molto sicuro, esistono vulnerabilità e attacchi noti legati al suo utilizzo in Active Directory: – Kerberoasting: è una tecnica di attacco che sfrutta il fatto che i ticket di servizio Kerberos per account di servizio AD (spesso associati a SPN) sono cifrati con hash derivati dalla password dell’account servizio. Un attacker che ha un accesso minimo al dominio (anche solo un account non privilegiato) può richiedere un ticket di servizio per un determinato SPN (operazione consentita a chiunque), ottenendo un ticket TGS cifrato con la chiave del servizio. Se l’account servizio ha una password debole, l’attaccante può fare cracking offline del ticket per risalire alla password in chiaro del servizio[24][25]. Questo attacco prende di mira account di servizio privilegiati (es. con diritti amministrativi) con password non abbastanza robuste. – Golden Ticket: attacco devastante in cui un aggressore riesce a compromettere l’account krbtgt (l’account del servizio KDC in AD). Con la chiave di krbtgt, l’attaccante può generare arbitrariamente Ticket-Granting Ticket validi per qualsiasi identità nel dominio, essenzialmente impersonando chiunque (anche un Domain Admin) e ottenendo accesso illimitato[26][27]. Il Golden Ticket consente accesso non autorizzato a qualsiasi sistema come utente privilegiato (Domain Admin) e può restare valido per un lungo periodo senza essere rilevato se non si monitorano attentamente i ticket (l’attaccante può anche personalizzare durata e attributi del ticket). È chiamato “Golden” perché garantisce controllo totale del “regno” AD. – Silver Ticket: simile al Golden, ma invece di compromettere krbtgt, l’attaccante compromette la chiave di un singolo servizio (ad esempio rubando l’hash di password di un account computer o account servizio). Con quella chiave può falsificare ticket di servizio validi per quel particolare servizio solamente. Ad esempio, ottenendo la password di un server applicazioni, può creare un ticket Kerberos per farsi passare per qualsiasi utente verso quel server. Non richiede contattare il KDC, quindi può sfuggire più facilmente al monitoraggio. È limitato a uno specifico servizio, ma se quel servizio gira su un server membro, l’attaccante può usare il Silver Ticket per eseguire code injection e magari arrivare comunque a privilegi di sistema su quell’host, poi muoversi lateralmente. – Pass-the-Ticket: attacco in cui un aggressore ruba un ticket Kerberos valido dalla macchina di un utente (tipicamente un TGT in cache, estraendolo dalla memoria con strumenti come Mimikatz) e lo riutilizza su un altro sistema per impersonare quell’utente senza conoscere le credenziali[28]. In pratica “passa” il ticket rubato, potendo accedere a risorse di rete come se fosse l’utente legittimo. Questo è possibile se l’attaccante ha compromesso una macchina e può estrarre i ticket dalla sessione utente. – Overpass-the-Hash (Pass-the-Key): variante avanzata dove l’attaccante usa l’hash NTLM di un utente per ottenere un TGT Kerberos (convincendo il sistema a generare un ticket con quell’hash). Combina tecniche di pass-the-hash con Kerberos, permettendo di trasformare un furto di hash in un ticket Kerberos valido[29]. – Delegation abuse: Kerberos supporta meccanismi di delegazione che consentono a un servizio di impersonare gli utenti verso altri servizi (utile, ad esempio, per frontend web che devono accedere a un database usando l’identità dell’utente). Esistono la delega non vincolata, vincolata e vincolata alle risorse. Se mal configurate, un utente malintenzionato che compromette un servizio con delega può ottenere ticket che gli consentono di impersonare utenti di alto livello verso altri servizi, realizzando escalation di privilegi[30][31]. In particolare, la unconstrained delegation è pericolosa: qualsiasi account con delega non vincolata può agire come qualsiasi utente che si autentichi su di esso, spesso includendo Domain Admin che accedono al servizio compromesso. – Vulnerabilità crittografiche: L’uso di vecchi algoritmi (DES, RC4) è oggi sconsigliato; Microsoft negli ultimi anni ha rilasciato patch per forzare l’uso di AES e migliorare la protezione del PAC (es. CVE-2021-42287/42278 e aggiornamenti 2022/2023 che richiedono PAC signature sempre valida). Se l’infrastruttura non è aggiornata, un attacker potrebbe sfruttare debolezze note, come spoof del PAC signature (varie CVE 2021-2022) o attacchi brute force agevolati da DES abilitato.
In generale, Kerberos in AD resta robusto, ma la sua sicurezza dipende dalla protezione delle chiavi segrete (password degli account, in primis quella di krbtgt e dei service account) e dalla corretta configurazione. Molti attacchi puntano a estrarre o riutilizzare ticket (pass-the-ticket) o falsificarli conoscendo le chiavi (Golden/Silver). L’evoluzione delle minacce e l’uso scorretto di Kerberos in ambienti complessi ha portato ad una maggiore esposizione nel tempo[32], rendendo fondamentale l’adozione di contromisure adeguate.
Integrazione di Kerberos in Active Directory
In un dominio Active Directory, Kerberos è strettamente integrato e rappresenta la spina dorsale dell’autenticazione. Ogni Domain Controller AD funge da KDC per il suo dominio: in particolare, sul DC girano i servizi Kerberos Authentication Service e Ticket-Granting Service. Quando un client Windows parte di un dominio esegue il logon, di default contatta un DC per ottenere un TGT Kerberos; analogamente, ogni volta che accede a una risorsa di rete (file server, SQL, web app) in grado di Kerberos, utilizza Kerberos con il DC per ottenere i relativi ticket.
L’integrazione comporta alcuni aspetti tecnici importanti: – Account krbtgt: in ogni dominio AD esiste un account utente speciale chiamato krbtgt. Esso non ha login interattivo ma possiede la chiave segreta del KDC. Questa chiave (derivata dalla password random generata all’installazione del dominio) è usata da ogni DC per cifrare e firmare i TGT che emette. Tutti i DC del dominio condividono la stessa chiave krbtgt (replicata come parte di AD). Proteggere l’account krbtgt è fondamentale: come detto, se un attaccante ne ottiene l’hash, può firmare Golden Ticket validi ovunque nel dominio. – Service Principal Name (SPN): AD tiene traccia di tutti i servizi di rete registrati per Kerberos tramite gli SPN associati agli account computer o servizio. Ad esempio, un server SQL di nome DB01 avrà un SPN del tipo MSSQLSvc/DB01.dominio.local. Quando un client chiede un ticket per MSSQLSvc/DB01.dominio.local, il KDC cerca in AD quale account ha quell’SPN (in questo caso l’account computer DB01 se SQL gira sotto Local System, oppure un account utente dedicato se SQL ha un service account) e userà la chiave di quell’account per cifrare il ticket di servizio. La gestione corretta degli SPN è essenziale per Kerberos: SPN duplicati o errati causano errori di autenticazione. Inoltre gli SPN sono sfruttati nell’attacco Kerberoasting, come visto, per individuare account servizio. – PAC e autorizzazioni: Quando un DC AD emette un ticket Kerberos (TGT o service), vi include il Privilege Attribute Certificate con i SID dei gruppi e altri dettagli di privilegio dell’utente. Ciò significa che l’autorizzazione alle risorse può essere valutata dai server immediatamente leggendo il PAC nel ticket presentato. Un file server, ad esempio, quando riceve un ticket da un utente, estrae dal PAC i gruppi dell’utente e può determinare se l’ACL sulla cartella consente accesso. Questa integrazione rende Kerberos in AD più di un semplice autenticatore: trasporta anche informazioni di autorizzazione. Il rovescio della medaglia è che un PAC falsificato (come in Golden Ticket) può ingannare i server facendogli credere che l’utente abbia privilegi che non ha. Per mitigare, i server Windows possono convalidare i PAC chiedendo conferma a un DC (PAC validation). – Trust tra domini: In AD, se un dominio A ha un trust (bidirezionale, transitivo tipicamente) verso dominio B, Kerberos supporta l’autenticazione inter-dominio. Un KDC del dominio A può emettere un Referral Ticket che il client userà per farsi riconoscere da un KDC del dominio B, ottenendo poi ticket per servizi nel dominio B. Questo meccanismo cross-realm (multi-foresta se c’è trust) consente SSO tra domini diversi. Dal punto di vista di un SOC, la fiducia tra domini estende la superficie d’attacco (un attaccante in un dominio potrebbe muoversi su un dominio trusted se riesce a ottenere credenziali valide). È importante quindi gestire con attenzione i trust (limitare quelli esterni non necessari, o usare trust con autenticazione selettiva). – Fallback NTLM: Nonostante Kerberos sia predefinito, AD consente fallback a NTLM in scenari come: client non domain-joined che accedono a risorse tramite credenziali, alcuni protocolli legacy che non supportano Kerberos, o casi di errori (es. orologio fuori sync). Il Domain Controller dunque gestisce anche l’NTLM Authentication Service (tramite il servizio NETLOGON). In un’ottica di sicurezza, ridurre l’uso di NTLM è consigliato perché è meno sicuro; AD offre policy (per esempio via GPO) per rifiutare NTLM in vari scope, preferendo Kerberos.
In sintesi, Active Directory è costruito intorno a Kerberos: senza Kerberos (o NTLM come riserva), gli utenti non potrebbero autenticarsi nel dominio. Per questo la compromissione di componenti Kerberos (come krbtgt o account servizio) equivale alla compromissione di AD stesso. Viceversa, solide policy su AD (password forti, account protetti) rafforzano Kerberos. Un amministratore AD deve avere competenza di Kerberos per capire fenomeni come errori di SPN, scadenza di ticket, e un analista SOC deve sapere interpretare eventi Kerberos (ad esempio i log di Kerberos su DC – Event ID 4768, 4769, 4771 che indicano emissione di TGT, TGS o fallimenti). L’integrazione consente anche funzionalità avanzate come Smartcard logon (Kerberos supporta autenticazione tramite certificati mappati a un utente AD) e protocollo Kerberos Armoring (Flexible Authentication Secure Tunneling – FAST – che mitiga alcuni attacchi come brute force su PA). Queste caratteristiche possono essere implementate per incrementare la sicurezza dell’ambiente.
Esempio pratico: Implementazione di un dominio Active Directory con autenticazione Kerberos
Di seguito descriviamo un esempio pratico di installazione e configurazione di un dominio Active Directory (su Windows Server) e come ciò fornisce autenticazione Kerberos centralizzata:
Installazione di Active Directory Domain Services: Si parte da un server Windows (es. Windows Server 2022). Tramite Server Manager, si aggiunge il ruolo Active Directory Domain Services (AD DS). Completata l’installazione, si esegue il promuovi a controller di dominio per creare una nuova foresta. Durante questa procedura si sceglie il nome del dominio (ad es. laboratorio.local), si imposta la modalità di funzionamento (livello funzionale), si definisce una password DSRM (per il ripristino di Directory Service). Dopo il riavvio, il server diventa il Domain Controller del dominio laboratorio.local. Automaticamente vengono configurati i servizi Kerberos KDC e DNS integrato.
Aggiunta di client e membri al dominio: Su una macchina client (Windows 10/11) si esegue join al dominio (impostando nei dettagli di sistema il dominio laboratorio.local e fornendo credenziali di un amministratore del dominio). Una volta unito, all’avvio l’utente potrà effettuare il logon scegliendo account di dominio. Questo processo implica che il client contatta il DC e utilizza Kerberos per autenticare l’utente: se inseriamo le credenziali di un utente di dominio valido, il DC rilascerà al client un TGT Kerberos e consentirà l’accesso. Da notare che se il DC non fosse raggiungibile, l’utente potrebbe ancora loggarsi con cache delle credenziali (Cached Logon), ma non otterrebbe ticket aggiornati per risorse di rete.
Creazione di utenti, gruppi e unità organizzative: Tramite la console Active Directory Users and Computers (ADUC) si possono creare nuove OU (ad esempio “Uffici” con sottocartelle “Vendite”, “IT”), quindi creare utenti (es. utente alice in OU Vendite e utente admin-it in OU IT) e gruppi globali (es. gruppo VenditeTeam). Quindi si aggiunge l’utente alice al gruppo VenditeTeam. Queste operazioni di fatto centralizzano la gestione: invece di creare account su ogni singolo server, abbiamo un unico account dominio per Alice che vale su tutte le macchine del dominio.
Configurazione dei permessi di accesso alle risorse: Supponiamo che su un file server membro del dominio vi sia una cartella riservata al team Vendite. Tramite le ACL NTFS di Windows, si può assegnare i diritti di Lettura/Scrittura al gruppo di dominio VenditeTeam su quella cartella. Così, quando Alice (membro del gruppo) accede al file server, il suo token (derivato dal ticket Kerberos con PAC) indicherà l’appartenenza a VenditeTeam e il server le concederà l’accesso. Se invece Bob, che non è nel gruppo, provasse, verrebbe negato. Questo mostra la comodità: basta gestire i membri del gruppo in AD per controllare l’accesso, senza dover definire utenti locali su ogni server o permessi individuali.
Implementazione di criteri di sicurezza via Group Policy: Tramite la console Group Policy Management, creiamo o modifichiamo per esempio la Default Domain Policy per applicare regole di sicurezza a tutti gli utenti del dominio. Si può abilitare la complessità delle password, impostare il blocco dell’account dopo 5 tentativi falliti, definire che i membri del gruppo “Domain Admins” ricevano auditing speciale, ecc. Queste impostazioni vengono automaticamente applicate dai DC a tutti i sistemi. Possiamo anche creare GPO mirate: ad esempio una GPO collegata all’OU “IT” che disabilita l’uso di dispositivi USB per i computer IT e impone l’MFA per gli account amministrativi (se infrastruttura ADFS/Azure AD disponibile). Nell’ambito Kerberos, attraverso i Kerberos Policy Settings (in Default Domain Policy > Account Policies > Kerberos Policy) possiamo regolare parametri come la durata massima dei ticket (es. 4 ore per TGT e 8 ore per ticket di servizio), il tempo massimo di skew, e il numero massimo di rinnovi. Di solito si lasciano i default, ma è importante sapere che esistono – ad esempio in ambienti ad alta sicurezza si potrebbe ridurre la durata dei ticket per mitigare il rischio di reuse.
Abilitazione dell’auditing di sicurezza: Per assicurare la tracciabilità, tramite GPO Default Domain Controllers Policy (che si applica ai DC), abilitiamo le audit policy: ad esempio in Computer Configuration > Windows Settings > Security Settings > Advanced Audit Policy Configuration abilitiamo Account Logon, Account Management, Directory Service Access, Logon/Logoff sia Success che Failure[15][16]. Applichiamo la GPO ed eseguiamo gpupdate. Da questo momento i Domain Controller inizieranno a loggare eventi come logon utente, creazione account, ecc. Per esempio, se l’utente admin-it aggiunge Alice al gruppo Domain Admins, sul DC verrà generato un evento ID 4728 (A member was added to a security-enabled global group) con i dettagli; un SOC potrebbe ricevere un alert immediato su questo.
Test e verifica: Ora Alice può loggarsi su qualsiasi PC del dominio con il suo account unico. Quando lo fa, il PC contatta il DC e (trasparentemente) ottiene un TGT Kerberos per Alice. Se Alice accede alla cartella condivisa del file server, il suo PC utilizza il TGT per richiedere al DC un ticket di servizio per cifs/fileserver; DC glielo fornisce, e Alice accede senza reinserire credenziali (SSO). Possiamo verificare con il comando klist sul PC di Alice che nella cache Kerberos ci sono i ticket ottenuti (TGT e ticket per il file server). Sul file server, se tentasse l’accesso Bob (non nel gruppo), Windows loggerebbe un evento di accesso negato.
Strumenti amministrativi aggiuntivi: L’esempio può includere l’uso di Active Directory Administrative Center (ADAC) per gestione avanzata (con interfaccia più moderna e PowerShell integrato), oppure l’uso di PowerShell (modulo ActiveDirectory) per automatizzare operazioni (es: creare più utenti da CSV). Inoltre, implementare LAPS (Local Administrator Password Solution) su client e server membri garantisce che ogni macchina abbia password amministratore locale univoca e archiviata in AD, migliorando la sicurezza (mitiga pass-the-hash su account locali). Le migliori pratiche suggeriscono di usare account amministrativi separati per l’amministrazione (es. admin-it) diversi dagli account personali (Alice), di posizionare gli amministratori in OU con policy più restrittive (es. blocco login interattivo su workstation non amministrative, enforcement di MFA), ecc., tutte cose configurabili via AD.
Questo scenario illustra come Active Directory centralizzi la gestione: un amministratore controlla da un unico punto utenti, gruppi, policy, e Kerberos fa sì che le autenticazioni e le autorizzazioni funzionino automaticamente su tutti i servizi membri del dominio. Per un SOC ciò significa anche che la compromissione di AD (ad esempio un DC violato, o un account admin rubato) ha impatto ovunque, quindi grande attenzione va posta nel monitorare e proteggere AD.
Vulnerabilità e rischi in ambienti AD/Kerberos (CSIRT/SOC)
Active Directory e Kerberos essendo componenti critici e diffusissimi, presentano un’ampia superficie d’attacco. Come notato, AD è spesso un obiettivo primario dei cyber attacchi per via del suo ruolo centrale[2]. In un contesto CSIRT/SOC, è essenziale conoscere le principali tecniche di attacco che i malintenzionati utilizzano contro AD/Kerberos e predisporre contromisure. Di seguito esaminiamo alcune delle tecniche di attacco comuni e i rischi associati, con relative contromisure:
Pass-the-Ticket: Consente a un attaccante di rubare ticket Kerberos dalla memoria di una macchina compromessa e riutilizzarli altrove. Ad esempio, tramite malware o tool post-exploitation (es. Mimikatz) l’attaccante estrae il TGT dell’utente corrente (in formato Kerberos Cache). Con quel TGT valido può impersonare l’utente su altri sistemi del dominio, ottenendo accesso non autorizzato senza conoscere la password[28]. Contromisure: rendere difficile l’estrazione di credenziali dalla memoria – abilitare LSA Protection su sistemi Windows (protezione dei processi LSA), usare Windows Defender Credential Guard sulle workstation (che isola i ticket Kerberos in un ambiente virtualizzato), limitare l’adesione di macchine non sicure al dominio. Inoltre, implementare rigorosi controlli sugli account privilegiati (che non dovrebbero lavorare su macchine esposte dove un malware potrebbe rubarne i ticket) e monitorare eventi di autenticazione anomali, ad esempio TGT usati da device insoliti.
Golden Ticket: Come descritto, è la capacità di generare TGT arbitrari dopo aver compromesso krbtgt. Il rischio qui è massimo: un Golden Ticket consente di impersonare qualsiasi account (anche non esistente) e dura fino a 10 anni di default se non specificato diversamente, con possibilità di rinnovo infinito. Un attaccante con Golden Ticket può continuare ad avere accesso anche se la violazione iniziale (es. un malware su un server) viene rimossa, perché può crearsi nuovi TGT a piacimento. Contromisure: l’unica difesa efficace è prevenire la compromissione iniziale – quindi proteggere gli account con privilegi che potrebbero portare a Domain Admin e quindi a krbtgt. Ma se si sospetta un Golden Ticket, l’azione da fare è reimpostare due volte la password dell’account krbtgt (due volte perché AD mantiene due chiavi attive per tollerare un cambio, la seconda rotazione invalida sicuramente tutti i ticket generati con la chiave vecchia). Questo è distruttivo (tutti i TGT esistenti diventano invalidi, forzando ri-autenticazione globale) ma necessario in caso di compromissione. Inoltre, monitorare i DC per segni di Golden Ticket: ad esempio ticket con durata anomala o ID fuori range (il Golden Ticket spesso ha un SID 500 amministratore o attributi anomali). Strumenti di detection come Microsoft ATA/Defender Identity segnalano pattern noti di Golden Ticket[33]. Best practice: cambiare l’account krbtgt periodicamente (es. ogni 6-12 mesi) per limitare la finestra di abuso, e soprattutto evitare che un attacker ottenga Domain Admin in primo luogo.
Silver Ticket: Permette attacchi mirati a singoli servizi. Un aggressore con hash di un account computer può autenticarsi presso quel servizio quanto vuole. Contromisure: proteggere gli hash degli account macchina e servizio. Questo significa principalmente mantenere i server al sicuro (se un attacker ottiene System su un server, ne estrae l’hash e può creare Silver Ticket per servizi offerti da quel server). L’uso di Managed Service Accounts (MSA/gMSA) aiuta: queste speciali tipologie di account servizio hanno password lunghe gestite automaticamente da AD e non recuperabili in chiaro dagli admin, riducendo il rischio di furto hash. Inoltre, su servizi critici si può abilitare l’AES-only per Kerberos (evitando RC4 che è più facile da usare negli attacchi Silver Ticket in combinazione con pass-the-hash).
Kerberoasting: Punta alle password dei service account. Contromisure: adottare password molto robuste per tutti gli account con SPN (ideale >25 caratteri casuali) in modo che il cracking offline sia impraticabile in tempi ragionevoli. Meglio ancora, utilizzare gMSA per i servizi: le gMSA randomizzano automaticamente la password ogni 30 giorni e di solito hanno 120 caratteri, virtualmente impossibili da crackare. Inoltre, eseguire periodicamente un audit degli SPN registrati in AD e individuare account “deboli” (es. con password semplici o mai cambiate) da mettere in sicurezza. Disabilitare la pre-auth è sconsigliato, come già detto, quindi verificare che tutti gli account utente abbiano “Do not require Kerberos preauthentication” non selezionato (solo rarissimi servizi legacy richiedono di toglierla). Un altro controllo: mettere account sensibili nel gruppo “Protected Users” di AD – i membri di questo gruppo non possono usare cifrature deboli né essere soggetti a Kerberoasting in quanto non ottengono ticket TGS rilasciati con chiavi RC4 (usano sempre AES) e hanno TGT con vita breve non rinnovabile.
Pass-the-Hash / Overpass-the-Hash: Queste tecniche spesso precedono o seguono quelle Kerberos. Un attaccante che ha l’hash NTLM di un admin può usarlo per autenticarsi (NTLM) o per generare ticket Kerberos (overpass). Contromisure: adottare misure di protezione credenziali sulle macchine (LsaProtect, CredentialGuard come già detto) e minimizzare la presenza di hash di admin su sistemi meno sicuri. Microsoft consiglia il modello Tiered Administration: account amministratore del dominio usati solo sui DC o sistemi Tier-0; account admin di server solo su server, ecc. Così, anche se viene compromesso un PC di un utente, non dovrebbe trovarsi in RAM l’hash di un Domain Admin (che non vi ha mai fatto login). Utilizzare soluzioni come Privileged Access Workstations dedicate agli amministratori per evitare di esporre credenziali alte su macchine esposte a internet o userland.
Attacchi alla delega Kerberos: Un attacker che compromette un servizio con delega non vincolata potrebbe impersonare utenti. Contromisure: evitare per quanto possibile la delega non vincolata; preferire la constrained delegation con protocol transition solo dove necessario e aggiungendo l’opzione “ProtocolcTransition e Constrained only to specific services (Resource-based constrained delegation)” introdotta in Windows 2012+; monitorare gli account configurati con delega (sono un potenziale rischio se compromessi). Microsoft offre comandi PowerShell (Get-ADObject -Filter {TrustedForDelegation -eq $True}) per elencarli.
Attacchi ai DC (DCSync, DCShadow): Un attaccante con privilegi di Domain Admin può utilizzare tool come mimikatz per simulare il comportamento di un DC e estrarre tutti gli hash delle password (DCSync) o iniettare oggetti malevoli nel directory (DCShadow). Questi sono attacchi post-exploit avanzati. Contromisure: impedire di arrivare a Domain Admin è la chiave. Inoltre, monitorare chiamate replicate anomale: un server che non è DC non dovrebbe mai richiedere replicazioni come se fosse un DC. I log di Directory Service Event ID 4662 con operazioni sospette possono rivelare DCSync (accesso a repliche di segreti). Abilitare l’Advanced Auditing per Directory Service Replication aiuta a catturare questi eventi.
Riassumendo i rischi: se AD viene compromesso in uno dei modi sopra, l’intera rete è a rischio – l’attaccante può leggere email, rubare dati, distribuire malware tramite GPO, o distruggere il dominio. È compito del SOC rilevare segnali precoci: ad esempio, un account che passa improvvisamente a membro di Domain Admin, o l’utilizzo di un account krbtgt (che non dovrebbe mai eseguire logon), o ancora volumi anomali di ticket TGS richiesti (indicatore di Kerberoasting). La difesa è in profondità: prevenzione, durevoli misure di protezione e robusto monitoring.
Contromisure e best practice di sicurezza
La protezione di AD/Kerberos richiede un insieme di best practice procedurali e tecniche. Elenchiamo le più importanti che un team di sicurezza dovrebbe implementare:
Principio del minimo privilegio: Limitare rigorosamente il numero di utenti con diritti amministrativi sul dominio. Gli account privilegiati (Domain Admins, Enterprise Admins) dovrebbero essere pochissimi e utilizzati solo quando necessario. Creare ruoli amministrativi delegati per attività specifiche (es. helpdesk può reset password ma non aggiungere membri a Domain Admins). Questo limita l’impatto di eventuali credenziali compromesse.
Account amministrativi protetti: Per gli amministratori di dominio, utilizzare account separati dall’utenza normale (es. Mario Rossi usa account standard per email/browsing e un account admin dedicato solo per AD). Tali account vanno collocati in OU con GPO restrittive (es. impedirne l’uso per login interattivo su workstation utenti, forzare MFA, negare accesso da macchine non amministrative). Impiegare workstation sicure dedicate (PAW) per le operazioni amministrative, isolate da internet e da attività a rischio.
Protezione delle credenziali e delle chiavi sensibili: Implementare strumenti come LAPS per gestire password locali univoche su ogni macchina (mitiga movimenti laterali via pass-the-hash). Abilitare Credential Guard sui sistemi client se possibile. Per gli account “krbtgt” e quelli di servizio ad alto privilegio, prevedere un cambio password periodico (per krbtgt, come detto, idealmente 2 cambi consecutivi ogni tot mesi) e monitorare il suo utilizzo. Assicurarsi che la pre-autenticazione Kerberos sia sempre abilitata per tutti gli account utente e servizio[34]. Utilizzare Group Managed Service Accounts (gMSA) per i servizi: queste password lunghe e ruotate automaticamente riducono enormemente il rischio di Kerberoasting e la necessità di gestire manualmente credenziali di servizio[35].
Hardening dei Domain Controller: I DC dovrebbero essere trattati come sistemi altamente sensibili (Tier 0). Eseguirli su hardware/VM dedicate, con accesso fisico/logico limitato. Disattivare sui DC qualsiasi software o servizio non necessario (niente navigazione internet, niente software di produttività). Mantenere i DC aggiornati con le patch di sicurezza di Windows senza eccezioni – molte patch critiche negli ultimi anni riguardavano Kerberos (es. vulnerabilità PAC, privilege escalation). Considerare di isolare la rete dei DC (segmentazione) così che solo gli host autorizzati possano comunicare con essi sulle porte LDAP/Kerberos.
Adozione di misure avanzate Kerberos: Valutare l’uso della funzionalità “Protected Users” in AD – mettendo gli account amministrativi in questo gruppo si applicano restrizioni automatiche: niente NTLM, niente ticket TGT longevi (max 4 ore), richiesta AES obbligatoria, nessuna delega Kerberos consentita, etc. Questo mitiga diversi attacchi. Attivare inoltre le policy di sicurezza Kerberos: ad esempio, abilitare “Kerberos client supporta solo AES” su client e server (impedisce fallback a RC4), e assicurarsi che “PAC Signature Required” sia attiva (ci sono stati aggiornamenti che ora lo rendono obbligatorio per evitare PAC spoofing).
Monitoraggio continuo e analisi dei log: Implementare una soluzione SIEM per raccogliere centralmente i log di sicurezza da DC, server e magari anche workstation chiave. Configurare regole di correlazione per eventi AD: ad esempio, alert se un account viene aggiunto ai gruppi Admins, se vengono creati utenti con privilegi, se compaiono autenticazioni di computer fuori orario o da IP insoliti, se un singolo utente richiede tanti ticket per servizi diversi (pattern di Kerberoasting), ecc. Il monitoring continuo e proattivo è essenziale per individuare tempestivamente attività sospette[36]. Microsoft offre strumenti come Defender for Identity (ex Azure ATP) che analizzano in tempo reale i domain controller alla ricerca di indicatori noti (tentativi di DCSync, Golden Ticket, ecc.). Anche senza soluzioni commerciali, molto può essere fatto con il tuning dei log e script personalizzati.
Procedure di risposta e recovery pianificate: Un team CSIRT deve predisporre piani specifici per scenari di compromissione AD. Ad esempio, procedure per rotazione urgente di krbtgt (script predefiniti da eseguire su DC), per isolare un DC sospetto, per ripristinare AD da backup in caso di attacco distruttivo (ransomware su DC). Esercitazioni periodiche di recovery AD (incluse prove di Active Directory Forest Recovery) dovrebbero essere svolte, dato che AD è critico (“se AD non funziona, non funziona nulla”[37]). Mantenere backup offline della foresta AD e testarne la validità regolarmente fa parte delle best practice.
Migliorare la postura di sicurezza continuamente: Effettuare regolarmente un AD Health Check e un security assessment dell’AD[38]. Ci sono strumenti (es. PingCastle, Purple Knight[38]) che analizzano la configurazione AD evidenziando configurazioni deboli (account con SPN senza pre-auth, deleghe pericolose, permessi ACL anomali, trust deboli, ecc.). Dare seguito a queste raccomandazioni aiuta a ridurre la superficie d’attacco. Documentare e aggiornare costantemente le policy di sicurezza AD, allineandosi alle linee guida Microsoft e CIS Benchmark[39][40].
User awareness e formazione amministratori: Non trascurare l’aspetto umano. Formare gli amministratori e i membri del SOC sulle minacce AD (attacchi Golden Ticket, pass-the-hash, ecc.) e sulle procedure di sicurezza (es. non inserire credenziali Domain Admin su prompt sospetti, attenzione al phishing mirato agli admin, etc.). Erogare anche agli utenti awareness sul non installare software non autorizzato, riconoscere email di phishing – tutto ciò riduce le chance iniziali di compromissione che poi potrebbe propagarsi su AD. In caso di incidenti, un amministratore preparato saprà come controllare i DC, dove cercare gli indicatori (log di evento Kerberos, registro replicazione, etc.) e potrà reagire tempestivamente.
In conclusione, Active Directory con Kerberos offre una gestione centralizzata potentissima e conveniente, ma richiede disciplina di sicurezza elevata. Un proverbio in ambito AD dice: “Active Directory detiene le chiavi del tuo regno, ma è sicuro?”[41]. Spetta all’organizzazione implementare difese in profondità: hardening, monitoring e readiness alla risposta. Con le giuste best practice, AD/Kerberos può rimanere un pilastro affidabile dell’infrastruttura, offrendo i vantaggi del single sign-on e dell’amministrazione centralizzata senza diventare il singolo punto di falla. Continuo scrutinio, patching e miglioramento dei controlli sono necessari poiché anche le minacce evolvono e prendono di mira Kerberos ed AD in modi sempre nuovi. Con un’adeguata messa in sicurezza, il team CSIRT/SOC potrà sfruttare al meglio le funzionalità di AD e Kerberos mantenendo l’ambiente protetto e resiliente.
Un solido approccio alla cybersicurezza si basa su principi e sistemi fondamentali che ogni responsabile per la prevenzione e gestione degli incidenti informatici in ambito nazionale deve padroneggiare.
Questo documento vuole fornire una panoramica strutturata di tali fondamenti, toccando sia aspetti tecnologici (come firewall, sistemi di autenticazione, virtualizzazione) sia organizzativi (come gestione centralizzata degli accessi, gestione del rischio, team e centri dedicati alla sicurezza).
Ogni sezione include definizioni, esempi pratici e riferimenti a standard internazionali, best practice e casi di studio aggiornati, al fine di contestualizzare i concetti nelle competenze richieste a un ruolo di coordinamento in cybersicurezza.
Sistemi di sicurezza (Firewall, IDS/IPS, WAF, Endpoint)
I sistemi di sicurezza informatica proteggono reti e dispositivi dagli attacchi, attraverso controllo del traffico, rilevamento di intrusioni e blocco di malware. Tra i principali strumenti vi sono i firewall, i sistemi IDS/IPS, i Web Application Firewall (WAF) e le soluzioni di protezione endpoint. Questi componenti lavorano in sinergia per garantire difese perimetrali e interne, secondo il principio della difesa in profondità.
Firewall di rete
Il firewall è il componente perimetrale di base della sicurezza di rete. Esso può essere hardware o software e monitora, filtra e controlla il traffico in entrata e uscita sulla base di regole predefinite. In pratica, il firewall crea una barriera tra la rete interna sicura e le reti esterne non fidate (come Internet), permettendo solo il traffico autorizzato in conformità con la policy di sicurezza definita. I firewall moderni includono diverse tecnologie, tra cui packet filtering, stateful inspection (monitoraggio dello stato delle connessioni) e proxy firewall applicativi. L’adozione di firewall perimetrali è essenziale per bloccare attacchi noti e ridurre la superficie di attacco esposta, ad esempio bloccando tentativi di accesso non autorizzato e malware noti prima che raggiungano i sistemi interni. I Next-Generation Firewall (NGFW) integrano funzionalità avanzate come il filtraggio a livello applicativo, l’ispezione del traffico cifrato e persino moduli IDS/IPS integrati, offrendo protezione più granulare.
I firewall tradizionali operano principalmente sui livelli 3 e 4 del modello OSI, analizzando indirizzi IP e porte. Lo scopo primario è garantire la confidenzialità e integrità delle risorse interne, impedendo intrusioni, malware, attacchi DoS e accessi non autorizzati.
Sistemi IDS e IPS
Per rilevare e prevenire intrusioni più sofisticate, si usano sistemi IDS (Intrusion Detection System) e IPS (Intrusion Prevention System). Un IDS monitora il traffico di rete e genera allarmi agli amministratori quando identifica attività sospette o malevole, ma non interviene direttamente sul traffico. Un IPS, considerato un’evoluzione dell’IDS, lavora invece in linea sul percorso di comunicazione e può bloccare attivamente le minacce in tempo reale. In altre parole, mentre un IDS opera in modo passivo (fuori banda, analizzando copie del traffico) per fornire visibilità sulle possibili intrusioni, un IPS è posizionato inline e, oltre a rilevare le minacce, può filtrare o fermare i pacchetti malevoli prima che raggiungano la destinazione. Ad esempio, un IPS configurato adeguatamente può automaticamente bloccare tentativi di exploit noti o mettere in quarantena host compromessi. Entrambi i sistemi tipicamente utilizzano firme di attacco e analisi comportamentale: firme per riconoscere minacce note (es. identificando la “firma” di un virus o di un attacco specifico) e rilevamento delle anomalie per segnalare traffico anomalo rispetto alla baseline normale. In sintesi: l’IDS rileva e allerta, l’IPS previene e blocca, entrambi sono fondamentali per garantire l’integrità e la disponibilità dei sistemi. L’uso congiunto di firewall e IDS/IPS consente un approccio difensivo a più livelli: il firewall filtra il traffico in base a regole statiche, l’IDS allerta su possibili intrusioni e l’IPS interviene bloccandole proattivamente.
Firewall applicativo (WAF)
Un Web Application Firewall (WAF) è un firewall specializzato a protezione delle applicazioni web e dei servizi API a livello applicativo (Layer 7). Mentre un firewall di rete tradizionale opera sui livelli inferiori (indirizzi IP, porte, protocolli) fungendo da barriera tra rete interna ed esterna, il WAF monitora e filtra il traffico HTTP/HTTPS tra client esterni e server web applicativi. Lo scopo è intercettare attacchi a livello applicativo, come iniezioni SQL, Cross-Site Scripting (XSS), attacchi di tipo DDoS applicativo e altre richieste malevole dirette alle applicazioni web. Il WAF si interpone tra gli utenti e il server applicativo analizzando tutte le comunicazioni HTTP: in caso individui richieste dannose o non conformi alla policy, le blocca prima che raggiungano l’applicazione. Ciò consente di proteggere servizi web critici senza dover modificare il codice dell’applicazione stessa. Ad esempio, se un attaccante tenta di inviare input malevoli in un form web per sfruttare una vulnerabilità, il WAF può riconoscere la stringa sospetta e fermare la richiesta. È importante notare che il WAF non sostituisce il firewall tradizionale di rete, poiché ciascuno agisce su piani diversi: il firewall di rete protegge da minacce a livello IP/TCP (es. scansioni, exploit di protocollo), mentre il WAF si concentra sulle minacce al livello applicativo web. In un’architettura robusta, entrambi sono utilizzati in modo complementare, specialmente dato l’aumento delle applicazioni esposte sul web e delle relative minacce.
Il WAF funge quindi da scudo per la confidenzialità e integrità dei dati delle applicazioni web, prevenendo accessi non autorizzati, violazioni di dati e abusi di funzionalità dell’applicazione.
Protezione degli endpoint
Con l’aumento di dispositivi e postazioni connesse (client, server, dispositivi mobili, IoT), la sicurezza degli endpoint è divenuta cruciale (gli endpoint sono i dispositivi client – pc, laptop, smartphone, server – ai margini della rete aziendale – spesso rappresentano l’anello debole sfruttato dagli aggressori). Le soluzioni di protezione endpoint comprendono inizialmente l’antivirus/antimalware tradizionale, ma oggi includono suite più avanzate come gli Endpoint Protection Platform (EPP) e gli Endpoint Detection & Response (EDR). In generale, per protezione endpoint si intende un insieme di strumenti integrati per proteggere e gestire i dispositivi nella rete aziendale.
Un’Endpoint Protection Platform (EPP) fornisce funzionalità preventive: antivirus, firewall personale sul host, controllo degli accessi al dispositivo, cifratura dei dati e gestione delle patch, in modo da prevenire l’esecuzione di codice malevolo noto e ridurre le superfici d’attacco note. L’approccio EPP è spesso basato su firme (signature-based) e regole statiche: identifica malware conosciuti confrontandoli con un database di firme e applica policy predefinite.
Gli EDR, invece, sono strumenti più orientati alla rilevazione e risposta attiva: monitorano in tempo reale i comportamenti sui sistemi endpoint e sono in grado di individuare attività anomale o sospette (es. un processo che effettua operazioni insolite) anche in assenza di una firma di malware conosciuto. Quando un’attività sospetta viene identificata, l’EDR può allertare i responsabili di sicurezza e intraprendere azioni automatiche (come isolare il dispositivo dalla rete) per contenere una minaccia in corso. In pratica l’EDR adotta un approccio dinamico e reattivo, spesso potenziato da analisi comportamentale e algoritmi di intelligenza artificiale per riconoscere anche minacce zero-day o attacchi fileless. Data la complementarità, oggi molti vendor offrono soluzioni unificate (talvolta chiamate XDR, Extended Detection & Response) che combinano prevenzione (EPP) e risposta (EDR). Per un responsabile della sicurezza, è fondamentale garantire che tutti gli endpoint dell’organizzazione (dai server ai portatili dei dipendenti) siano coperti da queste soluzioni, assicurando aggiornamenti costanti delle firme antivirus, monitoraggio centralizzato degli incidenti sugli host e rapide capacità di intervento remoto su macchine compromesse. In sintesi, la protezione endpoint è l’ultima linea difensiva per impedire a malware e aggressori di prendere piede nei sistemi interni e, qualora ciò avvenga, per individuare, contenere ed eliminare rapidamente la minaccia, salvaguardando disponibilità e integrità dei dati su tali dispositivi.
Sistemi di virtualizzazione: principi e vantaggi per la sicurezza
La virtualizzazione è una tecnologia che permette di eseguire più sistemi operativi (come macchine virtuali o container) su un unico host fisico, isolandoli l’uno dall’altro. Oltre ai noti benefici di efficienza e flessibilità nell’IT, la virtualizzazione offre vantaggi significativi per la sicurezza, in particolare per quanto riguarda isolamento e segmentazione dei carichi di lavoro.
Ogni Macchina Virtuale (VM) opera in un ambiente isolato dalle altre VM sullo stesso hardware. Questo isolamento intrinseco significa che se una VM viene compromessa da un malware o un attaccante, quella compromissione non si propaga automaticamente alle altre VM né all’host, a patto che l’hypervisor (il software di virtualizzazione) mantenga la separazione. In pratica, le VM funzionano come “contenitori” separati: un attacco o crash su un server virtuale non impatta gli altri servizi che girano su VM distinte. Ciò aumenta la resilienza complessiva del sistema informatico, contenendo le minacce all’interno di un perimetro più piccolo (blast radius limitato). Ad esempio, in un’architettura tradizionale un singolo server fisico ospitava più applicazioni e se veniva bucato cadevano tutti i servizi su di esso; con la virtualizzazione, si possono suddividere le applicazioni in VM diverse, così che la violazione di una non comprometta le altre.
La virtualizzazione facilita anche la micro-segmentazione delle reti e il controllo granulare del traffico tra componenti: ambienti virtualizzati avanzati consentono di definire regole di firewall interne tra VM (ad es. mediante virtual firewall o policy di sicurezza software-defined) e di monitorare approfonditamente il traffico est-ovest all’interno dell’infrastruttura virtuale. Questo rende molto più difficile per un aggressore effettuare movimenti laterali: anche se riesce a violare una VM in un data center virtualizzato, dovrà superare ulteriori barriere per spostarsi verso altre VM, grazie alla segmentazione interna. Un responsabile della sicurezza può sfruttare ciò progettando architetture dove, ad esempio, i server con dati sensibili risiedono in segmenti virtuali separati, accessibili solo tramite passaggi filtrati, riducendo il rischio che un attacco su un servizio meno critico dia accesso a quelli critici.
Un altro vantaggio offerto dalla virtualizzazione è la capacità di creare ambienti di sandbox facilmente. Una sandbox è un ambiente isolato dove eseguire codice potenzialmente malevolo per osservarne il comportamento senza rischiare impatti sul sistema di produzione. Grazie alle VM, è possibile istanziare rapidamente sandbox per l’analisi di malware o per testare patch e aggiornamenti in sicurezza. Ad esempio, i team CSIRT spesso usano VM per detonare file sospetti e analizzarne gli effetti (tecniche di dynamic analysis dei malware) senza mettere in pericolo la rete aziendale. Analogamente, ambienti virtuali consentono di effettuare esercitazioni di sicurezza (cyber range), simulando attacchi e testando le capacità di risposta in un contesto realistico ma isolato.
La virtualizzazione agevola inoltre l’implementazione di strategie di disponibilità come backup e disaster recovery. È infatti possibile prendere snapshot periodici delle VM (istantanee dello stato del sistema) e replicarle su server diversi o in cloud. Ciò rende il ripristino dopo un incidente molto più rapido: se un server virtuale viene compromesso o guasto, lo si può ripristinare allo stato precedente in pochi minuti riattivando uno snapshot o una VM di riserva. In un’ottica di continuità operativa, le infrastrutture virtuali supportano anche la ridondanza e la migrazione a caldo: si può configurare l’alta disponibilità in modo che se l’host fisico di una VM fallisce, la VM venga avviata automaticamente su un altro host (failover), minimizzando i tempi di fermo. Allo stesso modo, test di recupero di disastri (DR drills) e patch testing possono essere condotti clonando VM in ambienti di prova senza impatto sugli ambienti live
In sintesi, i sistemi di virtualizzazione rafforzano la sicurezza informatica fornendo compartimentazione: ogni servizio in una VM isolata, micro-segmentazione del traffico fra VM, facilità nel predisporre sandbox e ambienti di test, e strumenti robusti per backup/recupero. Tuttavia, è importante ricordare che l’hypervisor stesso diventa un componente critico da proteggere (un attacco all’hypervisor potrebbe compromettere tutte le VM). Per questo, best practice includono il mantenimento aggiornato dell’hypervisor, il minimo di servizi attivi sull’host e controlli di accesso rigorosi all’infrastruttura di virtualizzazione.
Sistemi di autenticazione e metodi sicuri (Password, MFA, Biometria)
L’autenticazione è il processo mediante il quale un sistema verifica l’identità di un utente (o di un entità, come un dispositivo o processo) prima di concedergli accesso a risorse. Un solido sistema di autenticazione è fondamentale per garantire che solo soggetti autorizzati possano accedere a dati e sistemi sensibili. I metodi di autenticazione si dividono in categorie basate su ciò che l’utente conosce, ciò che possiede e ciò che è. In parallelo all’autenticazione, l’autorizzazione controlla cosa un utente autenticato può fare (diritti di accesso), ma qui ci concentriamo sui metodi per verificare l’identità in modo sicuro.
Autenticazione basata su conoscenza: password e gestione sicura
Tradizionalmente, l’autenticazione si è basata su credenziali note dall’utente, in primis le password (o PIN, passphrase). La password è un segreto che solo l’utente dovrebbe conoscere e che viene confrontato con ciò che è registrato nel sistema (idealmente in forma cifrata/hash). Nonostante la loro diffusione, le password presentano noti problemi di sicurezza: utenti tendono a sceglierle deboli (es. parole comuni) o a riutilizzarle su più servizi, rendendole vulnerabili ad attacchi di brute force, dizionario, e phishing. Best practice moderne – guidate anche da standard come NIST SP 800-63B – suggeriscono di utilizzare password lunghe e difficili da indovinare (passphrase complesse), evitando requisiti eccessivamente complicati che portano a cattive abitudini (come scriverle o riutilizzarle) . Inoltre è sconsigliato forzare cambi frequenti di password senza motivo (poiché ciò tende a far scegliere password prevedibili con variazioni minime). Un responsabile alla sicurezza deve promuovere politiche di gestione password solide: lunghezza minima elevata (ad es. 12-15 caratteri), divieto di password banali già note in violazioni pubbliche, hashing robusto sul server (per evitare l’esposizione in chiaro), e formazione agli utenti sui rischi di phishing. Deve anche prevedere sistemi di password manager aziendali e l’adozione di meccanismi aggiuntivi (come l’autenticazione multi-fattore) per i sistemi critici.
Autenticazione a più fattori (MFA) e fattori di possesso
Dato che qualsiasi singolo fattore di autenticazione può fallire (es. una password può essere rubata), la Multi-Factor Authentication (MFA) richiede due o più fattori distinti per verificare l’identità. Tipicamente, combina “qualcosa che conosci” (es. password) con “qualcosa che possiedi” (un token fisico virtuale) e/o “qualcosa che sei” (caratteristica biometrica). Un esempio comune è l’accesso a un servizio online con password più un codice temporaneo generato da un’app sullo smartphone (come Google Authenticator) o inviato via SMS. In questo modo, anche se la password venisse carpita, l’attaccante non avrebbe il secondo fattore (telefono/token) e l’accesso verrebbe negato. I metodi di autenticazione a possesso includono: token hardware (chiavette elettroniche che generano OTP, One Time Password, o chiavi USB di sicurezza FIDO2/U2F), token software (app di autenticazione che generano codici temporanei, QR code da scannerizzare, notifiche push da approvare) o certificati digitali installati su un dispositivo. Adottare MFA incrementa esponenzialmente la sicurezza: ad esempio, gran parte delle violazioni di account cloud aziendali tramite phishing o credenziali leaked può essere sventata se all’attaccante manca il secondo fattore. È importante anche implementare fattori resistenti al phishing: oggi si raccomandano dispositivi o app che utilizzano protocolli come FIDO2 (es. security keys USB/NFC) che non sono clonabili via phishing, in luogo di SMS (che è vulnerabile a SIM swap). Per un responsabile, è essenziale definire quali sistemi richiedono MFA (idealmente tutti gli accessi remoti e quelli a dati sensibili) e orchestrare l’onboarding degli utenti a questi sistemi, tenendo conto dell’usabilità.
Autenticazione biometrica
Il fattore biometrico (qualcosa che sei) sfrutta caratteristiche fisiche o comportamentali uniche dell’utente per l’autenticazione. Esempi comuni sono l’impronta digitale, il riconoscimento facciale, l’iride, la voce, oppure parametri comportamentali (dinamica di digitazione, modo di camminare). La biometria offre il vantaggio di legare l’identità a qualcosa di intrinseco all’utente, difficile da falsificare o condividere. Ad esempio, è molto improbabile che due persone abbiano impronte digitali o modelli dell’iride identici. Ciò riduce il rischio di furto di identità: un aggressore non può semplicemente “indovinare” o rubare un tratto biometrico come farebbe con una password. Inoltre, per l’utente è comodo: non deve ricordare segreti o portare con sé token (pensiamo allo sblocco del telefono con l’impronta o il volto). Non a caso, molte organizzazioni adottano l’autenticazione biometrica almeno come un fattore (es. smart card con impronta digitale per accedere a strutture sicure, sistemi di controllo accessi fisici e logici integrati). Tuttavia, la biometria presenta anche sfide: primo, non è revocabile – se un database di impronte digitali viene compromesso, l’utente non può cambiare la propria impronta come farebbe con una password; secondo, la biometria può avere tassi di falsi positivi/ negativi (una piccola percentuale di casi in cui utenti legittimi non vengono riconosciuti, o peggio viene accettato un impostore se il sensore/algoritmo non è accurato). Inoltre, c’è il tema della privacy: i dati biometrici sono sensibili e spesso regolati da normative stringenti (GDPR in Europa li considera dati personali particolari). In ambienti governativi, l’adozione di biometria deve quindi essere accompagnata da forti misure di protezione dei template biometrici (spesso memorizzati e confrontati in forma cifrata o con tecniche di match on card per cui il dato grezzo non esce mai dal dispositivo dell’utente).
In sintesi, un robusto sistema di autenticazione oggi tende ad essere multi-fattore: password robuste come prima linea, token fisici o virtuali come seconda linea, e in alcuni casi biometria come ulteriore verifica, soprattutto per accessi critici. Ad esempio, un responsabile alla sicurezza nazionale potrebbe implementare per i propri operatori l’uso di smart card crittografiche (fattore possesso) protette da PIN (fattore conoscenza) o impronta (fattore biometrico) per accedere ai sistemi classificati. Ciò assicura un elevato livello di certezza sull’identità di chi accede, riducendo drasticamente le possibilità di accesso non autorizzato anche in caso di furto di credenziali.
Sistemi di gestione centralizzata degli accessi (AD, IAM, OAuth2, SAML, Kerberos)
In organizzazioni complesse – specialmente a livello governativo o enterprise – la gestione delle identità digitali e dei diritti di accesso degli utenti richiede piattaforme centralizzate e standardizzati. I sistemi di gestione centralizzata degli accessi consentono di amministrare in modo unificato utenti, autenticazioni e autorizzazioni su molteplici sistemi. Ciò include directory di identità (come Active Directory), sistemi e framework di Identity and Access Management (IAM), e protocolli di federazione e Single Sign-On (come OAuth 2.0, SAML 2.0, Kerberos e OpenID Connect). Tali strumenti garantiscono che gli utenti giusti ottengano gli accessi giusti, mantenendo al contempo un forte controllo e visibilità per i responsabili della sicurezza.
Active Directory (AD)
Active Directory di Microsoft è un servizio di directory centralizzato ampiamente utilizzato nelle reti aziendali e governative basate su Windows. In termini semplici, AD gestisce un database di oggetti che include utenti, gruppi, computer e le relative credenziali e permessi, all’interno di un dominio Windows. È un sistema server centralizzato basato su concetti di dominio e directory service, controllato dai Domain Controller Windows . Tramite Active Directory Domain Services (AD DS), gli utenti effettuano l’autenticazione centralmente (es. con username/password di dominio) e ottengono token di accesso validi per risorse in quel dominio (cartelle condivise, computer, applicazioni integrate con AD). AD fornisce funzioni cruciali per un responsabile alla sicurezza: autenticazione centralizzata (implementata con protocolli come Kerberos e NTLM), autorizzazione tramite gruppi (si possono assegnare permessi a gruppi di AD, applicando il principio del privilegio minimo attraverso membership di gruppo), politiche centralizzate tramite Group Policy (GPO) – ad esempio per imporre configurazioni di sicurezza uniformi su tutti i computer del dominio – e la possibilità di gestire in un solo punto il ciclo di vita di utenti e credenziali (creazione account, modifica ruoli, disabilitazione quando un dipendente lascia l’ente, ecc.). In un contesto come un’agenzia nazionale, è probabile esista una foresta AD che copre vari dipartimenti, con trust tra domini, ecc., e il responsabile dovrà assicurare la corretta configurazione delle policy AD, il monitoraggio di eventi di autenticazione sospetti e l’integrazione di AD con sistemi di Single Sign-On per applicazioni web moderne.
AD è strettamente legato a Kerberos (vedi più sotto) per le autenticazioni interne: quando un utente fa login al dominio, ottiene dal Domain Controller un Ticket-Granting Ticket Kerberos che permette di accedere ai vari servizi senza dover reinserire le credenziali continuamente. Questo offre un’esperienza di Single Sign-On nel perimetro Windows. Active Directory può inoltre essere esteso con servizi come AD Federation Services (ADFS) per federare identità con servizi esterni, e LDAP per consentire a applicazioni non-Windows di utilizzare AD come archivio utenti. In breve, AD funge da spina dorsale IAM on-premises in molti ambienti, e la sua corretta gestione (hardening dei Domain Controller, controlli su account privilegiati, auditing di login/repliche, etc.) è fondamentale: compromissioni di AD (come attacchi Golden Ticket su Kerberos o l’uso di credenziali di Domain Admin rubate) possono portare a un completo dominio della rete da parte di un attaccante.
Identity and Access Management (IAM)
Il termine IAM (Identity and Access Management) si riferisce all’insieme di politiche, processi e tecnologie che permettono di gestire le identità digitali e controllare l’accesso alle risorse in modo centralizzato . Mentre sistemi come AD sono un’implementazione specifica (in ambiente Windows), in generale una soluzione IAM può essere una piattaforma che aggrega e gestisce utenti provenienti da diversi sistemi (on-premise e cloud) e regola, tramite regole di business, chi può accedere a cosa. Un sistema IAM tiene traccia di ogni identità (dipendenti, collaboratori, dispositivi, servizi) e assicura che ciascuna abbia solo le autorizzazioni appropriate al proprio ruolo – niente di più, niente di meno. Questo include concetti come principio del privilegio minimo (dare agli utenti solo i permessi minimi necessari per svolgere il loro lavoro) e separazione dei compiti (evitare che una singola identità accumuli troppi poteri senza controlli compensativi).
Le soluzioni IAM moderne spesso coprono funzionalità come: gestione delle identità (provisioning e de-provisioning automatizzato degli account quando le persone entrano, cambiano ruolo o lasciano l’organizzazione), Single Sign-On (SSO) che consente all’utente di autenticarsi una volta ed ottenere accesso a molte applicazioni diverse, autenticazione multifattore (MFA) integrata per aggiungere sicurezza agli accessi, gestione dei privilegi (ad es. soluzioni PAM – Privileged Access Management – per controllare gli account amministrativi), e reportistica e conformità (sapere in ogni momento chi ha accesso a cosa e poter dimostrare conformità a normative).
Esempi di sistemi IAM includono servizi cloud come Azure AD, Okta, AWS IAM, Google Workspace IAM, oppure sistemi enterprise come Oracle Identity Manager, IBM Security Verify, etc. Un buon sistema IAM permette anche l’integrazione federata: per risorse esterne o tra organizzazioni diverse, anziché gestire account separati per ogni sistema, si instaurano trust basati su standard (OAuth, SAML, OpenID Connect) dove un Identity Provider centrale autentica l’utente e segnala alle applicazioni (Service Provider) l’esito e le informazioni sull’utente. Questo riduce la molteplicità di credenziali e migliora l’esperienza utente e la sicurezza (poiché l’autenticazione è centralizzata e monitorabile). Ad esempio, un dipendente ministeriale potrebbe usare le stesse credenziali IAM per accedere al portale HR interno, a un sistema di posta governativo e a servizi cloud di collaborazione, grazie a federazione e SSO.
Dal punto di vista del responsabile alla sicurezza, l’IAM è essenziale per tenere lontani gli hacker assicurando che ogni utente abbia solo le autorizzazioni esatte necessarie per il suo lavoro. Significa che l’organizzazione sa in ogni momento quali account esistono, a quali risorse accedono e può revocare immediatamente gli accessi quando non più necessari (riducendo i rischi di account orfani usati per intrusioni). Inoltre, l’IAM centralizzato consente di applicare in modo coerente policy di sicurezza (come obbligare MFA per determinati accessi, o revisionare periodicamente gli accessi attraverso processi di certificazione). In ambito nazionale, l’IAM potrebbe includere anche la gestione di identità privilegiate inter-organizzative e sistemi di identità federata per consentire a diverse agenzie di collaborare scambiando informazioni in modo controllato.
OAuth 2.0 (Delegated Authorization)
OAuth 2.0 è un framework aperto standardizzato che consente la delega di autorizzazione tra servizi web. In altre parole, OAuth 2.0 permette a un utente di autorizzare un’applicazione terza ad accedere a certe risorse protette che lo riguardano, senza rivelare all’applicazione terza le proprie credenziali(password). È diventato uno degli standard cardine per l’autenticazione/autorità federata sul web, utilizzato da giganti come Google, Facebook, Microsoft, Amazon e molti altri per implementare il “Login con…”. Ad esempio, quando un sito ti offre di “accedere con il tuo account Google”, dietro le quinte sta usando OAuth: tu vieni rediretto a Google, fai login lì, e Google chiede “Vuoi autorizzare questo sito ad accedere al tuo indirizzo email e profilo base?”; se acconsenti, Google rilascia un token di accesso (access token) al sito, che questo userà per ottenere i dati richiesti dalle API di Google – senza mai conoscere la tua password Google.
Tecnicamente, OAuth 2.0 definisce vari grant types (flussi di autorizzazione) per diversi scenari (app server-side, app client-side, applicazioni native, dispositivi senza browser, ecc.), ma il concetto chiave è l’uso di token al posto delle credenziali. Quando l’utente autorizza, l’Identity Provider (detto Authorization Server in OAuth) rilascia un token (un insieme di stringhe cifrate o firmate) che l’applicazione client può presentare per accedere alla risorsa. Il token incarna i diritti concessi (es: “valido per leggere l’email dell’utente, scade tra 1 ora”). Ciò elimina la necessità per l’utente di condividere la propria password con terze parti – migliorando sicurezza e privacy. Se una terza parte viene compromessa, l’attaccante ottiene al massimo token limitati (spesso già scaduti o revocabili), non l’identità permanente dell’utente.
Per un responsabile alla sicurezza, comprendere OAuth 2.0 è importante perché molte integrazioni di servizi tra agenzie o con fornitori esterni oggi avvengono tramite API e deleghe OAuth. Ad esempio, un’app mobile governativa potrebbe usare OAuth 2.0 per far autenticare i cittadini tramite SPID (Sistema Pubblico di Identità Digitale) o tramite account di identità federati, delegando l’autenticazione a quel provider e ottenendo un token che rappresenta l’utente. OAuth 2.0 è spesso usato insieme a OpenID Connect (OIDC), che è un’estensione di OAuth per ottenere anche informazioni sull’identità verificata dell’utente (federated authentication). Mentre OAuth da solo è per autorizzare l’accesso a risorse, OIDC aggiunge un ID Token con dettagli sull’utente autenticato (nome, email, ecc.). Nel contesto interno, OAuth può essere usato ad esempio per permettere a microservizi di scambiarsi dati a nome di utenti o per integrare applicazioni legacy con sistemi IAM moderni.
In pratica, l’adozione di OAuth 2.0 comporta la gestione attenta dei permessi (scopes) richiesti dalle applicazioni (chiedere solo ciò che serve), la protezione dei token (che diventano un obiettivo per gli attaccanti, se rubano un token attivo potrebbero accedere alle risorse finché non scade) e la predisposizione di meccanismi di revoca. Standard moderni come OAuth sono preferibili a soluzioni “fatte in casa” di scambio credenziali, proprio perché ben testati e con ampio supporto librerie.
SAML 2.0 (Single Sign-On federato)
SAML (Security Assertion Markup Language) 2.0 è un altro standard aperto, usato principalmente per implementare il Single Sign-On (SSO) federato in contesti enterprise e inter-organizzativi. A differenza di OAuth/OIDC che sono più recenti e orientati al mondo API/mobile, SAML è nato in ambito XML per permettere a un utente di usare un’unica autenticazione per accedere a servizi diversi (tipicamente applicazioni web enterprise) con dominio di gestione separato. SAML definisce un formato di asserzione (assertion) che un Identity Provider (IdP) invia a un Service Provider (SP) contenente l’affermazione che “l’utente X ha effettuato con successo l’autenticazione ed ecco i suoi attributi”. In pratica, quando tenti di accedere a un servizio (SP) che delega l’autenticazione a un IdP, verrai reindirizzato all’IdP (ad es. il login centralizzato della tua organizzazione); dopo aver fatto login lì, l’IdP genera un’asserzione SAML firmata digitalmente che include la tua identità e magari il ruolo, e la invia al SP (solitamente tramite il browser dell’utente). Il SP verifica la firma e, se valida, ritiene l’utente autenticato senza chiedergli altre credenziali.
SAML è molto usato in contesti business-to-business e PA: per esempio, un dipendente del Ministero con account sul dominio interno può accedere al portale di un’altra Agenzia che ha trust SAML col suo Ministero, senza avere un account separato. Il portale (SP) si fida dell’asserzione prodotta dal IdP del Ministero. Questo semplifica la gestione delle identità e delle password perché l’utente gestisce un solo account (sul IdP) e accede a più servizi. Significativamente, SAML semplifica il processo diidentità: l’utente non deve ricordare credenziali diverse per ogni servizio e gli amministratori possono centralizzare controllo e revoca degli accessi sul IdP.
Un aspetto importante è che SAML trasmette attributi oltre alla semplice autenticazione, il che permette al Service Provider di applicare autorizzazioni basate su ruoli o attributi ricevuti. Ad esempio, l’asserzione SAML potrebbe dire che l’utente è “Mario Rossi” con ruolo “Coordinatore-Prevenzione” e il servizio può usare tale informazione per concedere i privilegi appropriati. Il protocollo opera su base di fiducia pre-configurata: IdP e SP scambiano metadati e certificati per le firme, e in genere l’integrazione richiede configurazioni amministrative da entrambe le parti. Per un responsabile alla sicurezza, SAML (così come OAuth/OIDC) rappresenta uno strumento abilitante per la cooperazione inter-ente. Ad esempio, l’IDPC (Infrastruttura di Identità Digitale della PA) potrebbe usare SAML per permettere ai dipendenti pubblici di usare le proprie credenziali aziendali per accedere a servizi di altre PA senza nuovo account, migliorando sia la sicurezza (meno password in giro, autenticazione forte centralizzata, audit unificato) sia la comodità. Tuttavia, vanno gestiti con attenzione i trust: una vulnerabilità su un IdP SAML può avere impatti notevoli (un attaccante che impersoni l’IdP potrebbe accedere a tutti i servizi federati). Quindi occorre assicurare la robustezza dell’IdP e avere monitoraggio sugli accessi federati.
Kerberos (Autenticazione basata su “biglietti”)
Kerberos è un protocollo di autenticazione di rete progettato per un ambiente con server di autenticazione fidato centralizzato. È ampiamente utilizzato (e quasi sinonimo) nell’autenticazione all’interno di domini Windows/Active Directory, ma è nato nel mondo Unix/MIT. Kerberos usa un meccanismo di ticket e chiavi segrete condivise per autenticare in modo sicuro un utente presso diversi servizi, senza inviare la password in chiaro sulla rete. In Kerberos, esiste un’entità fidata chiamata Key Distribution Center (KDC) (in AD coincide con il Domain Controller) che detiene le chiavi segrete di tutti gli utenti e servizi. Quando un client (utente) vuole autenticarsi per usare un servizio (ad es. accedere a una cartella condivisa), il client prima contatta il KDC (Authentication Server) e richiede un Ticket-Granting Ticket (TGT) presentando la propria identità. Ciò avviene in modo sicuro usando la password dell’utente come chiave per comunicare col KDC; il risultato è che il client ottiene un TGT crittografato, che è essenzialmente un “biglietto” che dimostra che l’utente è autenticato. Il client poi utilizza il TGT per chiedere al KDC un ticket di servizio per lo specifico servizio a cui vuole accedere (fase di Service Granting). Il KDC restituisce un ticket crittografato per quel servizio. Il client a questo punto presenta il ticket direttamente al server del servizio (ad esempio al file server), il quale – fidandosi del KDC – accetta il ticket come prova dell’identità e concede l’accesso. Tutto questo avviene senza mai inviare la password oltre la prima richiesta iniziale e usando challenge cifrati, prevenendo attacchi di replay e intercettazione.
In termini più generali, Kerberos è un protocollo di “terza parte fidata”: il KDC è l’autorità centrale che valida identità e distribuisce credentials temporanee (i ticket). I ticket hanno una durata limitata (es: 8 ore) e sono specifici per l’entità e il servizio e spesso includono flag sulle autorizzazioni. Kerberos fornisce anche mutua autenticazione – non solo il client prova chi è, ma anche il server prova la sua identità al client (tramite lo stesso meccanismo di ticket presentato e riflettuto), prevenendo man-in-the-middle. Un altro vantaggio di Kerberos: abilita il Single Sign-On interno – l’utente inserisce la password una volta per ottenere il TGT, poi accede a più servizi senza dover riautenticarsi ad ognuno, finché il ticket è valido.
Nel contesto Active Directory, Kerberos è il metodo di autenticazione predefinito e svolge un ruolo integrale: infatti AD associa ad ogni account una chiave derivata dalla password usata da Kerberos. Attacchi famosi come Pass-the-Ticket o Golden Ticket si riferiscono proprio a compromettere il funzionamento di Kerberos in AD rubando ticket o la chiave segreta principale del KDC. Un responsabile alla sicurezza deve quindi conoscere i princìpi di Kerberos sia per configurare correttamente i sistemi (sincronizzazione oraria dei server – Kerberos è sensibile allo skew di orario, robustezza delle password di servizio, policy di rinnovo ticket) sia per capire e mitigare le tecniche di attacco legate (es. rilevare ticket anomali, proteggere l’account krbtgt in AD). In altri ambienti, Kerberos può essere utilizzato anche su Unix/Linux per servizi NFS, database, etc., integrando con un KDC centrale. Ad esempio, il MIT mantiene ancora una distribuzione Kerberos indipendente. Per un uso moderno fuori da AD, Kerberos ha meno prevalenza rispetto a soluzioni federate (OAuth/OIDC), ma rimane fondamentale ovunque ci sia un dominio Windows o sistemi legacy integrati.
Riassumendo la gestione centralizzata degli accessi: Active Directory e sistemi IAM consentono di amministrare utenti e permessi in modo coerente su larga scala; protocolli come Kerberos e SAML forniscono meccanismi efficaci per l’autenticazione continua e federata rispettivamente; OAuth 2.0 permette deleghe di accesso sicure tra servizi. Un responsabile deve saper orchestrare questi elementi per garantire che gli utenti autorizzati possano accedere agevolmente alle risorse di cui hanno bisogno (anche inter-dominio) ma al contempo prevenire accessi non autorizzati, il tutto con tracciabilità completa (log centralizzati di autenticazione) e conformità alle normative di sicurezza.
Principi di Disponibilità, Integrità e Confidenzialità (Triade “CIA”)
Al cuore della sicurezza delle informazioni stanno i tre principi fondamentali di Confidenzialità, Integrità e Disponibilità, spesso chiamati triade CIA (dalle iniziali in inglese: Confidentiality, Integrity, Availability). Qualsiasi misura di sicurezza, controllo o politica ha tipicamente l’obiettivo di salvaguardare uno o più di questi requisiti. Per un responsabile alla sicurezza, è essenziale comprendere a fondo ciascun principio – le definizioni, gli esempi di minacce correlate e le contromisure – in modo da poter valutare l’impatto di un incidente o di un rischio secondo queste dimensioni.
Confidenzialità (Riservatezza): consiste nell’assicurare che informazioni e risorse siano accessibili solo a chi è autorizzato e che nessun soggetto non autorizzato possa vederle o usarle. In pratica, la confidenzialità tutela la privacy dei dati. Esempi: solo il personale medico può consultare certi referti clinici, solo destinatari previsti leggono un’email cifrata, un documento classificato è accessibile solo a persone con adeguata autorizzazione. Minacce alla confidenzialità includono la divulgazione non autorizzata di informazioni: esfiltrazione di dati tramite attacchi hacker (es. data breach dove milioni di record personali vengono rubati), intercettazione di comunicazioni (sniffing di rete non cifrata), accessi interni indebiti (un dipendente curioso che sfoglia dati a cui non dovrebbe accedere). Le contromisure per la confidenzialità spaziano dalla cifratura dei dati (sia a riposo che in transito) all’hardening degli accessi (autenticazione forte, controlli di accesso basati su ruoli – RBAC, o attributi – ABAC), fino a politiche di need-to-know. Ad esempio, per proteggere dati sensibili in transito si usa il protocollo TLS, per file riservati si usa crittografia e gestione delle chiavi adeguata, per limitare accessi interni si applicano permessi minimi e monitoraggio (Data Loss Prevention, logging di accessi ai dati). Mantenere la confidenzialità è cruciale soprattutto in contesti governativi: si pensi a informazioni personali dei cittadini, segreti di stato, indagini forensi, dove una violazione di riservatezza può avere impatti su privacy, reputazione, sicurezza nazionale.
Integrità: il principio di integrità implica garantire che dati, sistemi e risorse non vengano alterati o distrutti in modo non autorizzato e che siano accurati e completi rispetto allo stato atteso. In altre parole, l’informazione deve mantenere la propria veridicità e consistenza durante tutto il ciclo di vita e qualsiasi modifica deve essere fatta solo da soggetti legittimati e in maniera tracciabile. Esempi di integrità: un file di log di sistema che non deve essere manomesso (perché serve per audit), il contenuto di un database finanziario che deve rimanere corretto, un messaggio che deve arrivare a destinazione esattamente come è stato inviato (senza essere alterato). Le minacce all’integrità includono manomissioni intenzionali (un attaccante che modifica record di un database per coprire tracce o per frode, un malware che altera file di configurazione), errori o corruzioni accidentali (bug software o guasti hardware che corrompono dati, errori umani di modifica) e atti di sabotaggio (cancellazione di dati). Le contromisure tipiche sono: controllo degli accessi in scrittura (così solo entità autorizzate possano modificare), utilizzo di firme digitali e hash crittografici per rilevare modifiche non autorizzate (ad esempio la firma di un documento garantisce di accorgersi se viene alterato dopo la firma), versioning e backup per poter recuperare dati integri in caso di alterazioni indesiderate, e meccanismi di integrità nelle comunicazioni (come codici di autenticazione dei messaggi – MAC – per assicurare che un messaggio non sia stato alterato in transito). In ambito di infrastrutture critiche, l’integrità dei comandi e dei dati ha anche implicazioni di sicurezza fisica: ad es. garantire che i parametri inviati a uno SCADA non siano stati manomessi è vitale per operare correttamente un impianto. Il responsabile alla sicurezza deve dunque assicurare misure come il controllo dell’integrità dei software (ad es. tramite verifiche di hash su aggiornamenti, whitelisting delle applicazioni consentite) e politiche che prevedano il doppio controllo su modifiche di dati critici (four-eyes principle).
Disponibilità: è il requisito per cui le risorse e i servizi devono essere accessibili e utilizzabili dagli utenti autorizzati nel momento in cui ne hanno bisogno, senza interruzioni non pianificate. La disponibilità riguarda quindi la continuità operativa e la prontezza delle infrastrutture. Un sistema ad alta disponibilità minimizza i downtime e garantisce che, malgrado guasti o attacchi, gli utenti legittimi possano comunque accedere alle funzionalità necessarie. Esempi: un portale web pubblico di servizi al cittadino che deve essere online 24/7, un data center che deve avere alimentazione e connessione ridondanti per non fermarsi, un numero di emergenza (112) che deve essere sempre raggiungibile. Le minacce principali alla disponibilità sono gli incidenti che causano interruzioni: qui rientrano guasti hardware (un server che si rompe, un blackout elettrico), errori software (un bug che manda in crash un’applicazione critica), eventi catastrofici (incendi, alluvioni, terremoti colpendo i siti), ma anche attacchi deliberati come i DoS/DDoS (Denial of Service distribuiti che sovraccaricano i servizi rendendoli irraggiungibili). Un altro esempio attualissimo sono i ransomware, che cifrando i dati li rendono inaccessibili, causando interruzioni massive di servizi e perdita di disponibilità dei dati finché non vengono ripristinati da backup. Le contromisure per la disponibilità includono architetture ridondate e tolleranti ai guasti: ad esempio, avere cluster di server in configurazione High-Availability, duplicazione di componenti critiche (RAID per i dischi, più linee di rete, generatori di corrente di backup), disaster recovery pianificato (siti secondari su cui far failover in caso di disastro sul sito primario), e piani di Business Continuity per continuare almeno parzialmente le operazioni anche durante incidenti gravi. Dal lato attacchi, ci sono misure come sistemi anti-DDoS (filtri di traffico, servizi di scrubbing, CDN che assorbono il traffico), politiche di limitazione delle risorse per prevenire abusi (rate limiting). Inoltre, una robusta politica di backup offline garantisce che, in caso di attacco ransomware, i dati possano essere recuperati senza pagare riscatti, ripristinando così la disponibilità. Per un responsabile, la disponibilità ha anche una valenza di servizio pubblico: assicurare che servizi essenziali (sanità digitale, forze dell’ordine, servizi finanziari di stato, ecc.) restino attivi e accessibili alla popolazione e agli operatori, anche in scenari di attacco o calamità, è di vitale importanza (si pensi ad attacchi come quello che nel 2021 paralizzò la Regione Lazio bloccando temporaneamente i servizi sanitari, mostrando come la perdita di disponibilità possa avere impatti enormi sui cittadini).
In pratica, la gestione della sicurezza è spesso un bilanciamento tra questi tre principi: ad esempio, massimizzare la confidenzialità (cifratura forte ovunque) potrebbe introdurre qualche latenza o complessità che impatta disponibilità; aumentare la disponibilità con tante copie di dati deve fare i conti con mantenere l’integrità e confidenzialità in tutte le copie. Il ruolo del responsabile di sicurezza è valutare i requisiti di CIA per ogni sistema e applicare controlli adeguati. Alcuni sistemi avranno priorità diverse (un sistema militare potrebbe privilegiare la confidenzialità e integrità dei comandi anche a scapito della disponibilità; un servizio al cittadino di emergenza privilegerà la disponibilità; un registro contabile l’integrità, ecc.) ma in generale tutti e tre devono essere garantiti in misura sufficiente. Molti standard (ISO 27001, NIST) e normative richiedono esplicitamente l’analisi di impatto su CIA per ogni rischio identificato. In sede di esame, è utile saper fornire per ciascun principio esempi concreti di misure: Confidenzialità – crittografia, controllo accessi, classificazione dati; Integrità – hashing, firme digitali, controllo versioni, permessi di scrittura limitati; Disponibilità – ridondanza, backup, anti-DDoS, monitoraggio e incident response rapida.
Tipologie di attacchi cyber: Tattiche, Tecniche, Procedure (TTP) ed esempi attuali
Il panorama delle minacce informatiche è in continua evoluzione, con attaccanti che sviluppano nuove tattiche, tecniche e procedure (TTP) per eludere le difese. Tattiche sono gli obiettivi o le fasi generali di un attacco (ad es. ricognizione, iniziare l’esecuzione di codice, movimento laterale, esfiltrazione); tecniche sono i metodi specifici usati per compiere quelle tattiche (es. tecnica di phishing via email per ottenere credenziali, oppure utilizzo di exploit per escalation di privilegi); procedure sono le implementazioni dettagliate di queste tecniche, spesso specifiche di gruppi di attacco o malware (ad esempio, la sequenza particolare di comandi e script usata da un certo gruppo APT durante l’esfiltrazione). L’analisi delle TTP è un paradigma usato nella Cyber Threat Intelligence e nei framework come MITRE ATT&CK, e consente di profilare le minacce in base ai comportamenti anziché agli indicatori puntuali, migliorando la capacità di prevenire e individuare attacchi mirati.
Dal punto di vista difensivo, conoscere le TTP principali (specialmente di attori noti come gruppi APT sponsorizzati da Stati o cybercriminali sofisticati) aiuta un SOC/CSIRT a riconoscere pattern di attacco e a implementare contromisure specifiche. Ad esempio, se si sa che una certa minaccia usa la tecnica “Golden Ticket” su Kerberos per muoversi lateralmente, si possono predisporre allarmi su anomalie nei ticket; o se un ransomware in genere disabilita le shadow copies come prima mossa, un monitoraggio su quell’azione può far scattare un alert precoce.
Le tipologie di attacchi si possono classificare in vari modi; qui li descriviamo per categoria di obiettivo o metodo, fornendo esempi attuali rilevanti.
Attacchi di ingegneria sociale (phishing, spear phishing, social network): mirano a sfruttare l’errore umano inducendo le vittime a compiere azioni che compromettano la sicurezza. Il phishing via email rimane una delle tecniche più diffuse per iniziare una catena di attacco: l’aggressore invia email ingannevoli che inducono l’utente a fornire credenziali (falsi login a servizi bancari, cloud aziendali ecc.) o a cliccare allegati/link malevoli che installano malware. Varianti come lo spear phishing (email altamente personalizzate su un singolo bersaglio di alto profilo) e il whaling (mirato a dirigenti, es. CEO fraud) hanno avuto successo in furti finanziari e spionaggio. Un esempio recente è la campagna di phishing contro account email governativi che ha sfruttato documenti COVID-19 falsi per convincere i funzionari a inserire la password su un sito clone. Altre tecniche social includono l’impersonation al telefono (vishing) o via messaggi (smishing), e l’uso dei social media per raccogliere informazioni su abitudini e contatti (ricognizione per futuri attacchi). Difendersi richiede combinare formazione del personale (simulazioni di phishing, awareness) con filtri tecnici (email gateway con anti-phishing, autenticazione a più fattori che mitighi il furto di password, ecc.). Molti attacchi avanzati iniziano ancora con una mail di phishing ben fatta: ad esempio, il noto attacco SolarWinds del 2020 – uno supply chain attack – sembra abbia avuto origine anche con tecniche di spear phishing verso dipendenti chiave.
Malware (virus, worm, trojan) e in particolare ransomware: i malware sono codice malevolo introdotto nei sistemi per causare danni, rubare informazioni o prendere controllo. Negli ultimi anni il ransomware è emerso come una delle minacce più gravi: si tratta di malware che, una volta eseguito, cifra i dati dell’organizzazione e richiede un riscatto in criptovaluta per fornire la chiave di decrittazione. I ransomware moderni adottano tattiche di doppia estorsione – oltre a criptare, prima esfiltrano dati riservati minacciando di pubblicarli se non si paga. Questo li rende devastanti sia sul piano disponibilità (blocco operatività) sia confidenzialità (data breach). Esempi di attacchi ransomware di grande impatto: Colonial Pipeline (2021), dove un attacco ransomware (DarkSide) fermò l’erogazione di carburante lungo la costa est USA per giorni; Regione Lazio (2021), che bloccò i servizi sanitari regionali; e una miriade di casi su ospedali, comuni, aziende strategiche. Secondo l’ENISA Threat Landscape 2023, i ransomware rappresentano ancora la minaccia numero uno, costituendo il 34% di tutti gli incidenti analizzati nell’Unione Europea. Altre famiglie di malware includono: trojan (malware mascherati da software legittimi, es. backdoor RAT che danno controllo remoto all’attaccante), worm (che si auto-propagano, come il celebre worm Morris del 1988 che diede origine al primo CERT), virus classici che infettano file e spyware che spiano le attività (keylogger, stealer di dati). La diffusione spesso avviene via phishing (allegati con macro malevole, eseguibili camuffati), exploit kit su siti web compromessi, chiavette USB infette o altri vettori. La difesa anti-malware richiede un approccio stratificato: dai gateway con antivirus e sandbox, agli endpoint con EPP/EDR (come discusso sopra), backup offline frequenti, patch management per chiudere le vulnerabilità sfruttate dai malware, e procedure di incident response pronte per isolare rapidamente macchine infette appena rilevate.
Attacchi a servizi web e applicazioni (SQL injection, XSS, RCE): Molte minacce sfruttano vulnerabilità nel software applicativo. Le injection (in particolare SQL injection) rimangono una top threat secondo OWASP: un attaccante inserisce input malevolo in campi di una pagina web in modo da manipolare le query al database sottostante, potendo così ottenere dati non autorizzati o modificare/cancellare informazioni. Ad esempio, attacchi SQLi a siti governativi hanno in passato esfiltrato massicci archivi (ricordiamo il caso “Collection#1” dove furono trafugate milioni di credenziali anche da siti istituzionali con SQLi). Altre vulnerabilità comuni: Cross-Site Scripting (XSS), dove l’aggressore riesce a far eseguire script arbitrari nel browser di altri utenti (potenzialmente rubando sessioni o inducendo azioni a loro insaputa); buffer overflow e altre memory corruption che consentono esecuzione di codice sul server (Remote Code Execution); directory traversal per leggere file riservati; deserialization insecure; e così via. Gli attacchi alle applicazioni possono portare sia al furto di dati (violando confidenzialità, come nel caso dell’attacco a Equifax 2017 dove una falla web portò all’esfiltrazione di 145 milioni di record) che a prendere controllo dei server (minando integrità e disponibilità). Difendersi richiede secure coding, test di sicurezza (code review, penetration test), aggiornamenti continui e l’uso di protezioni come i Web Application Firewall (WAF) che bloccano exploit noti a livello applicativo. Per un responsabile è cruciale avere un programma di gestione vulnerabilità sulle proprie applicazioni (scansioni periodiche, aderenza a standard OWASP Top 10) e magari partecipare a iniziative di bug bounty o di collaborazione con la comunità per individuare falle prima che le sfruttino attori malevoli.
Attacchi sulla rete e infrastruttura (DDoS, MitM, exploit su protocolli): Gli aggressori possono puntare all’infrastruttura di rete stessa. I Distributed Denial of Service (DDoS) floodano un server o una rete di richieste o pacchetti al punto da saturarne le risorse e renderlo irraggiungibile agli utenti legittimi. Si va da attacchi volumetrici di molteplici Gbps (che saturano banda) ad attacchi applicativi che saturano risorse più specifiche (es. inviare migliaia di richieste costose al secondo). Gruppi di attivismo o Stati ostili hanno impiegato DDoS contro siti governativi o finanziari come atto di protesta o sabotaggio (noti gli attacchi del gruppo russo Killnet contro siti istituzionali europei nel 2022-2023). Altre minacce di rete includono gli attacchi Man-in-the-Middle (MitM), dove l’attaccante si interpone nelle comunicazioni (ad esempio in reti Wi-Fi aperte, o sfruttando ARP spoofing in LAN) per spiare o alterare dati in transito – mitigati dall’uso diffuso di cifratura TLS e VPN. Sul fronte protocolli, a volte emergono vulnerabilità in componenti di infrastruttura: ad es. falle nei protocolli di routing BGP (che possono permettere di dirottare traffico), exploitation di server DNS (DNS cache poisoning) o vulnerabilità su VPN, firewall, etc. Un esempio fu la vulnerabilità Log4Shell (fine 2021) nella libreria Log4j, che essendo ampiamente usata su server esposti (sistemi di gestione, security appliances, servizi cloud) ha messo a rischio infrastrutture globali: gli attaccanti l’hanno sfruttata massivamente per RCE su server vulnerabili, installando web shell e malware di ogni tipo. La risposta coordinata a livello globale (CERT che emettono allerte, patch rapide) ha limitato danni peggiori, ma è stato un campanello d’allarme su come una falla nei “tubi” di Internet possa avere effetti a cascata. Come difesa, oltre alle patch e hardening costante, è importante avere capacità di monitoraggio del traffico di rete (es. anomalie che suggeriscano MitM interni, o volumi insoliti preludio a DDoS) e accordi con provider per filtraggio DDoS a monte.
Attacchi avanzati e APT (Advanced Persistent Threat): Si tratta di campagne portate avanti tipicamente da gruppi ben finanziati (spesso collegati a governi o a grandi cyber-gang) che hanno obiettivi specifici e persistenza nell’operare. Un APT spesso combina varie tattiche: iniziale phishing o 0-day per entrare, poi movimento laterale silenzioso, escalations, stabilire backdoor persistenti, ed exfiltrare dati sensibili o compromettere infrastrutture critiche. Esempi noti includono l’APT29 (Cozy Bear) legato all’intelligence russa, che è accusato dell’hack di SolarWinds citato sopra (inserendo codice malevolo negli aggiornamenti software di Orion, compromettendo in un colpo solo migliaia di organizzazioni tra cui agenzie USA); oppure APT28 (Fancy Bear) implicato in attacchi a ministeri e organizzazioni NATO. Anche attori cinesi (es. APT40, Hafnium) e nordcoreani (Lazarus Group) hanno condotto attacchi notevoli: dal furto di segreti industriali all’acquisizione di valuta (crypto-heist), fino a sabotaggi (il WannaCry del 2017 è attribuito a Lazarus, combinando worm e ransomware). Le tattiche APT prevedono spesso l’uso di malware su misura, zero-day exploits (sfruttamento di vulnerabilità sconosciute al momento), e tecniche di offuscamento per restare sotto traccia. Difendersi da APT è complesso e richiede un mix di prevenzione (hardening, principio zero trust – nessun accesso implicito anche all’interno, segmentazione estrema), rilevamento approfondito (strumenti di EDR/XDR, analisi dei log con SIEM, threat hunting proattivo cercando indicatori delle note TTP), e risposta rapida con capacità di contenimento. Inoltre la condivisione di intelligence tra organizzazioni (es. tramite ISAC, CERT nazionali) è cruciale per conoscere indicatori di compromissione e tecniche emergenti e potersi preparare (si veda sezione 7 su ISAC).
In conclusione di questa sezione, è chiaro che il panorama delle minacce è molto ampio: da attacchi opportunisti di massa (phishing generico, ransomware random) a operazioni mirate di attori statali. Per un ruolo di coordinamento nazionale, oltre a conoscere le tipologie di attacco, è importante tenersi aggiornati sui casi di attacchi recenti e sulle relative lesson learned. Ad esempio, comprendere come un attacco come Colonial Pipeline è riuscito (compromissione di password VPN non protetta da MFA) può portare a migliorare subito certe difese nelle proprie strutture; oppure studiare l’attacco alla catena di fornitura di SolarWinds spinge a controllare meglio la sicurezza dei fornitori e software terzi utilizzati nelle proprie reti. Fortunatamente, esistono report e analisi (ENISA Threat Landscape, Verizon DBIR, rapporti di intelligence delle agenzie) che un buon responsabile deve consultare regolarmente per adeguare la strategia difensiva in base alle TTP emergenti e agli attacchi in voga.
Ruolo e funzioni di CSIRT, SOC e ISAC nella gestione degli incidenti
La sicurezza informatica non è solo una questione di tecnologie, ma anche di organizzazione e processi. Tre acronimi importanti in ambito di gestione degli incidenti e cooperazione in cybersicurezza sono CSIRT, SOC e ISAC. Ciascuno rappresenta una struttura con un ruolo specifico.
CSIRT (Computer Security Incident Response Team): è un gruppo di esperti di sicurezza deputato a gestire e rispondere agli incidenti informatici di una certa organizzazione o contesto. Il CSIRT ha tipicamente la responsabilità di monitorare le minacce, intercettareeventi di sicurezza, analizzare gli incidenti e orchestrare la risposta e mitigazione. In altre parole, è l’unità di pronto intervento cyber: quando scatta un allarme, il CSIRT attiva le procedure per contenere l’incidente (es. isolare i sistemi compromessi), investigarne le cause, eradicare la minaccia, ripristinare i servizi e fare follow-up (lezioni apprese, rafforzamento difese). I CSIRT possono esistere a vari livelli: aziendale (ogni grande organizzazione può avere il suo team di risposta), nazionale (es. il CSIRT Italia istituito dall’ACN per coordinare la risposta a livello Paese), settoriale (CSIRT di settore per coordinare in ambiti specifici come finanza, energia, sanità). Spesso i termini CERT (Computer Emergency Response Team) e CSIRT vengono usati in modo intercambiabile; storicamente “CERT” era un marchio del primo team presso Carnegie Mellon, ma oggi si parla tranquillamente di CERT aziendale/governativo. Le funzioni di un CSIRT includono: monitoraggio delle fonti di allerta (sensori, SOC, intelligence esterna), analisi forense degli incidenti per capirne portata e attori, coordinamento interno (tra IT, legal, comunicazione) ed esterno (con altri CSIRT, forze dell’ordine) durante la gestione dell’incidente, comunicazione di allerte preventivi se emergono minacce (ad esempio un CSIRT nazionale emette allerte su campagne di attacco in corso verso enti governativi), e raccomandazioni di sicurezza post-incidente. In un contesto nazionale, il CSIRT funge anche da punto di contatto a cui enti e aziende possono segnalare incidenti (spesso obbligatorio per legge, es. direttiva NIS richiede notifica al CSIRT nazionale di certi incidenti). Un responsabile per la prevenzione e gestione di incidenti a livello nazionale dovrà quindi interfacciarsi strettamente col CSIRT nazionale, contribuire alla condivisione di informazioni e assicurare che la propria organizzazione segua le linee guida emanate dal CSIRT (che spesso produce indicatori di compromissione, bollettini di sicurezza, guide di best practice in seguito ad incidenti osservati).
SOC (Security Operations Center): è il centro operativo di sicurezza, ovvero un team (spesso in un vero e proprio locale dedicato, fisico o virtuale) che ha il compito continuo di monitorare gli eventi di sicurezza nell’infrastruttura IT, rilevare potenziali incidenti e avviare la primarisposta. Un SOC tipicamente lavora 24/7, analizzando log e flussi da varie fonti (sistemi di detezione intrusioni, antivirus, firewall, sistemi di autenticazione, ecc.) attraverso una console centralizzata (es. un SIEM – Security Information and Event Management) per identificare anomalie o segni di compromissione. In altre parole, mentre il CSIRT entra in gioco in maniera più reattiva quando un incidente è conclamato, il SOC è la sentinella proattiva che cerca di individuare early warnings e attacchi in fase iniziale, e ferma sul nascere gli incidenti. Le responsabilità di un SOC possono includere: triage degli alert di sicurezza (filtrare i falsi positivi e riconoscere quelli reali), investigazione di eventi sospetti (es. tramite analisi approfondita di log, memoria volatile, traffico di rete), eseguire misure di contenimento immediate (ad esempio disabilitare un account compromesso, bloccare un IP in firewall), e inoltrare al CSIRT o ai team competenti gli incidenti più gravi per la gestione completa. Un SOC ben strutturato migliora notevolmente la capacità di rilevamento e risposta di un’organizzazione, coordinando tecnologie e operazioni in un unico hub. Spesso un SOC è organizzato su livelli (analisti di Livello 1 per monitoraggio base e escalation ai livelli superiori per analisi avanzate). Può essere interno o in outsourcing (MSSP – Managed Security Service Provider).
Importante, il SOC non lavora isolato: collabora con il CSIRT (che prende in carico gli incidenti gravi e la gestione globale), fornisce input alla gestione del rischio (e riceve da questa priorità su cosa monitorare con più attenzione), e in generale è un elemento tattico-operativo della strategia di sicurezza. Un esempio del ruolo SOC: supponiamo che arrivi un alert di “traffico anomalo in uscita” su una porta non usuale da un server. Il SOC analizza e scopre che il server potrebbe essere infetto da malware (comunicazione con IP noti malevoli); allora isola il server dalla rete (azione immediata), e passa la consegna al CSIRT per bonifica e analisi forense. Senza SOC, quell’anomalia poteva passare inosservata per giorni finché i danni non diventavano evidenti. Per questa ragione, la presenza di un SOC coordinato alle operazioni migliora le capacità di rilevamento, risposta e prevenzione di minacce dell’organizzazione, come sottolinea anche IBM e altri esperti. Un responsabile alla sicurezza nazionale deve quindi promuovere l’istituzione e il corretto funzionamento di SOC sia centralizzati (un SOC governativo o di settore che sorveglia entità più piccole che non hanno risorse proprie) sia locali dove possibile, assicurando anche che scambino informazioni (es: un SOC ministeriale notifica subito il CSIRT nazionale se vede indicatori di un attacco in corso che potrebbe riguardare altri enti, ecc.).
ISAC (Information Sharing and Analysis Center): gli ISAC sono organizzazioni no-profit collaborative in cui membri di un certo settore critico condividono informazioni su minacce, vulnerabilità e incidenti, costituendo un centro di raccolta e scambio di intelligence tra pubblico e privato. L’idea nacque negli USA nel 1998 per i settori delle infrastrutture critiche ed è ormai adottata a livello internazionale (in Europa ENISA promuove ISAC settoriali). Un ISAC tipicamente è focalizzato su un settore (es. finanziario – FS-ISAC a livello globale, energetico, sanità, trasporti, ecc.) e i membri sono le varie aziende/enti di quel settore. Fornisce un canale fidato per condividere in tempo reale informazioni su cyber threat: ad esempio, se una banca subisce un tentativo di attacco sofisticato, invia un’allerta all’ISAC finanziario in modo che le altre banche possano alzare le difese; oppure un CERT nazionale può diffondere tramite l’ISAC dati di indicatori (IOC) su campagne attive. Gli ISAC spesso producono anche analisi comuni, best practice specifiche di settore e talvolta esercitazioni congiunte.
Il valore di un ISAC sta nel superare l’isolamento informativo: “uniti si è più forti” contro attaccanti che spesso colpiscono in maniera sistematica attori simili. L’ISAC funge da “centrale” per raccogliere dati sulle minacce e redistribuirli, fungendo da ponte comunicativo tra privati e agenzie governative. Nel contesto italiano/europeo, possiamo citare ad esempio l’ISAC Sanità, l’ISAC Energia, ecc., dove aziende di quei settori collaborano con ACN e con tra loro. Anche organismi internazionali spingono i settori a dotarsi di ISAC (la direttiva NIS2 dell’UE incentiva l’information sharing).
Per un responsabile nazionale, partecipare attivamente agli ISAC significa avere accesso a informazioni aggiornate sulle minacce specifiche del proprio settore e poter implementare misure di prevenzione prima che gli attacchi ti colpiscano direttamente. Allo stesso modo, significa contribuire segnalando incidenti o scenari di attacco rilevati, in un’ottica di difesa collettiva. Un esempio di ISAC in azione: durante ondate di ransomware mirati a ospedali, l’ISAC sanitario può emanare allerte con dettagli tecnici (indicatori di compromissione, TTP usate, patch urgenti da applicare) che aiutano tutti gli ospedali membri a proteggersi in tempo. Senza quell’informazione condivisa, ogni struttura sarebbe da sola contro la minaccia e magari alcune cadrebbero vittime per non aver saputo per tempo ciò che altre avevano già visto.
In sintesi, CSIRT, SOC e ISAC sono tre pilastri complementari nella gestione del cyber rischio: – Il SOC è l’occhio vigile interno giorno e notte, che individua e reagisce immediatamente agli eventi nei sistemi di competenza. – Il CSIRT (aziendale o nazionale) è il team esperto che prende in carico la risposta più ampia e il coordinamento, fornendo anche supporto e guida per prevenire e prepararsi agli incidenti futuri. – L’ISAC estende la difesa oltre i confini della singola organizzazione, creando una comunità di fiducia dove conoscenza e allerta sono condivise, in modo da elevare la postura di sicurezza di tutti i partecipanti. Per un responsabile alla prevenzione e gestione degli incidenti informatici, è fondamentale saper interagire efficacemente con tutte queste entità: ad esempio, stabilire procedure interne perché il SOC escali prontamente al CSIRT; partecipare alle attività dell’ISAC di riferimento; magari organizzare esercitazioni congiunte (es: simulazioni di attacco su larga scala con coinvolgimento del CSIRT nazionale, vari SOC dipartimentali e le comunicazioni via ISAC). Questo garantisce una resilienza di sistema e non solo del singolo ente.
Gestione del rischio cyber: ciclo di gestione, framework (NIST, ISO 27005) e mitigazione
Nessuna organizzazione può proteggere tutto in modo assoluto; per questo si adotta un approccio di gestione del rischio per identificare le minacce e vulnerabilità più rilevanti, valutare l’impatto potenziale e adottare contromisure commisurate. La gestione del rischio cyber è un processo ciclico e continuo, strettamente allineato ai principi generali di risk management (come il ciclo Plan-Do-Check-Act). Secondo standard internazionali (ISO e NIST), le fasi fondamentali di questo processo sono: definizione del contesto, identificazione dei rischi, analisi e valutazione dei rischi, trattamento (o trattamento/risposta) del rischio, accettazione del rischio residuo, e monitoraggio/riesame continuo . Durante tutto il ciclo si svolgono attività trasversali di comunicazione e consultazione coinvolgendo stakeholder appropriati) e di documentazione/reporting.
Ecco in dettaglio come si articola questo ciclo.
Stabilire il contesto: consiste nel definire l’ambito del risk management (quali asset, processi, unità organizzative copre), i criteri per valutare impatto e probabilità, e gli obiettivi di sicurezza e compliance dell’organizzazione. Si raccolgono informazioni su asset di valore (es: dati personali, sistemi critici), si definiscono gli owner del rischio, e si stabilisce la propensione al rischio (risk appetite) e le soglie di accettabilità. Ad esempio, un’agenzia nazionale definirà come asset critici i database dei cittadini, le infrastrutture di rete centrali, ecc., e come criterio che qualsiasi rischio che possa causare indisponibilità > 24 ore di un servizio essenziale è considerato alto.
Identificazione del rischio: in questa fase si individuano i possibili scenari di rischio, ovvero combinazioni di minaccia e vulnerabilità che potrebbero portare a un incidente con impatto sui criteri CIA. Si cerca di rispondere alla domanda: “cosa potrebbe andare storto, e come potrebbe accadere?”. Si possono usare approcci basati sugli asset (identifico minacce e vulnerabilità per ciascun asset chiave) o basati sugli eventi (parto da possibili eventi avversi e vedo quali asset impattano). Ad esempio, per un sistema informativo X potrei identificare rischi come “furto di credenziali admin da parte di attaccante esterno via phishing”, “guasto hardware non ridondato”, “errore umano di configurazione aperta al pubblico”, “malware ransomware colpisce il file server” e così via. Fonti per identificare rischi includono: storico di incidenti passati (interni o nel settore), check-list di minacce comuni (come cataloghi OWASP, ENISA, MITRE), risultati di audit e test di penetrazione (che rivelano vulnerabilità tecniche). È cruciale coinvolgere esperti tecnici e di business affinché il set di rischi identificati sia il più completo e concreto possibile.
Analisi e valutazione: una volta elencati i rischi, per ciascuno si analizza probabilità (o frequenza) e impatto (o conseguenze) se si materializzasse. Dall’abbinamento si determina il livello di rischio (es. rischio = probabilità * impatto, se quantificato, oppure classifiche qualitativo tipo Alto/Medio/Basso). Qui entrano in gioco metriche e criteri decisi nel contesto: ad esempio, impatto può misurarsi in termini finanziari (euro di danno), reputazionali, di vite umane (in ambito sanità), legali, ecc., spesso su scala qualitativa (es. impatto Catastrofico, Grave, Moderato, Limitato, Negligibile). Probabilità può stimarsi da “molto probabile (atteso più volte l’anno)” a “rara (una volta in 10 anni)”. Si possono usare metodi quantitativi (come analisi statistica, simulazioni Monte Carlo) ove dati disponibili, ma spesso nel cyber si opera qualitativamente integrando giudizio esperto. L’output è una mappa dei rischi, spesso una matrice dove ciascun rischio è posizionato e classificato. Da qui deriva la valutazione: si confrontano i livelli di rischio con i criteri di accettabilità. I rischi sopra una certa soglia vengono segnalati come intollerabili e da mitigare, quelli bassi possono essere accettati. Ad esempio, uno scenario di attacco APT su infrastruttura critica potrebbe avere impatto altissimo ma probabilità bassa; la direzione dovrà decidere se quel rischio residuo è comunque inaccettabile (dato l’impatto potenziale) e quindi investire per ridurlo.
Trattamento del rischio: per i rischi identificati che eccedono le soglie di tolleranza, occorre decidere quali strategie adottare. Le classiche opzioni di trattamento sono: mitigare (implementare controlli per ridurre probabilità e/o impatto), trasferire (ad esempio stipulare assicurazioni cyber, o affidare a terzi la gestione di quel rischio contrattualmente), evitare (se un’attività è troppo rischiosa, decidere di non intraprenderla affatto, ad es. spegnere un servizio legacy insicuro), oppure accettare consapevolmente il rischio residuo (documentando la decisione) se ritenuto basso o se i costi di mitigazione superano i benefici. Nel contesto cyber, la mitigazione è la più frequente: significa implementare controlli di sicurezza adeguati. I controlli vanno scelti in base al rischio specifico e spesso si utilizzano framework di riferimento come l’ISO/IEC 27001 (che contiene un Annex A con controlli di sicurezza best practice) o il NIST Cybersecurity Framework. Ad esempio, per il rischio “ransomware su file server” si deciderà di mitigare con controlli tipo: backup giornalieri offline (riduce impatto, garantendo recupero dati), EDR con capacità anti-ransomware (riduce probabilità di successo), segmentazione di rete per limitare propagazione, e programma di formazione anti-phishing (riduce probabilità di infezione iniziale). Per il rischio “guasto data center per incendio” si può trasferire comprando assicurazione danni e mitigare predisponendo un sito di disaster recovery. Il risultato di questa fase è un piano di trattamento in cui per ciascun rischio vengono elencate le misure previste, i responsabili dell’attuazione e la tempistica.
Accettazione del rischio: dopo aver applicato (o pianificato) i trattamenti, rimane sempre un rischio residuo. La direzione deve consapevolmente decidere se quel residuo è accettabile. L’accettazione del rischio va formalizzata (in molti standard è richiesto evidenza dell’accettazione da parte del management per accountability). Ad esempio, si può accettare che permanga un rischio residuo di indisponibilità 1 giorno di un servizio non critico, per cui non vale la pena spendere oltre in ridondanze. L’importante è che la decisione sia informata e documentata, così come la ownership del rischio (es: “il responsabile XY accetta il rischio R di livello medio entro il limite stabilito”).
Monitoraggio e riesame: il rischio cyber è dinamico: compaiono nuove minacce, l’organizzazione cambia (nuovi sistemi, nuovi processi digitali), i controlli implementati possono risultare inefficaci nel tempo. Dunque è essenziale monitorare continuamente lo stato dei rischi e riesaminare periodicamente tutto il processo. Questo implica raccogliere dati sugli incidenti occorsi (per capire se le stime erano corrette, se qualcosa di non previsto è successo, ecc.), misurare la performance dei controlli (KPI/KRI di rischio, come numero di attacchi bloccati, vulnerabilità scoperte, etc.), e aggiornare di conseguenza valutazioni e trattamenti. In molti contesti normati (es. ISO 27001) si fanno riesami annuali del rischio, o immediatamente in caso di cambiamenti significativi (es. introduzione di una nuova tecnologia, o emergere di una vulnerabilità critica globale come Log4Shell). Il ciclo così riparte: re-identificazione dei rischi emergenti, nuova analisi, e così via, integrando la sicurezza nel ciclo di vita di ogni progetto.
Per supportare questo processo, esistono framework di riferimento e standard dedicati. Sul fronte internazionale: – ISO/IEC 27005 è lo standard specifico che fornisce linee guida per la gestione del rischio informatico e delle informazioni, complementare a ISO 27001. Si allinea a ISO 31000 (rischio generale) ma adattandola al contesto InfoSec. L’ultima versione (2022) mantiene l’approccio generale di identificare asset, minacce, vulnerabilità e valutare rischio, introducendo anche concetti come scenari di rischio ed eventi, e allineandosi con ISO 27001:2022 52 55 . ISO 27005 promuove metodi sia qualitativi che quantitativi e sottolinea l’importanza di un ciclo continuo e della documentazione di ogni fase. Adottare ISO 27005 aiuta a strutturare il risk assessment in modo coerente e accettato internazionalmente, facilitando anche le discussioni con auditor e stakeholder (dimostrare che i rischi sono gestiti secondo best practice).
NIST fornisce vari documenti: il NIST Risk Management Framework (RMF) (pubblicazione 800-37) delinea un processo simile di categorizzazione degli sistemi, selezione di controlli di sicurezza adeguati, implementazione, valutazione, autorizzazione (accreditamento) e monitoraggio continuo. È usato soprattutto nel contesto federale USA, ma i principi sono universali. Inoltre, il NIST Cybersecurity Framework (CSF) (2014, aggiornato in 2018 e in evoluzione) offre un approccio alto livello articolato in 5 funzioni – Identify, Protect, Detect,Respond, Recover – che aiutano a coprire l’intero ciclo di gestione del rischio cyber. Il CSF fornisce un set di categorie e controlli mappati su standard come ISO 27001, COBIT, ecc., ed è stato adottato da molte organizzazioni come base per valutare la propria maturità e guidare miglioramenti. Ad esempio, la funzione Identify include proprio attività di risk assessment e asset management. In Italia, il “Framework Nazionale di Cybersecurity” è basato sul NIST CSF, adattato al contesto italiano, incoraggiando aziende e PA a adottarlo.
ISO 31000 (Risk Management – Principles and Guidelines) non è specifica per IT ma fornisce principi e linee guida generali per qualsiasi tipo di rischio. Molte organizzazioni usano ISO 31000 come base comune del risk management aziendale, assicurando che il rischio cyber sia trattato con la stessa metodologia del rischio operativo, finanziario, etc., e quindi integrato nella governance complessiva. Ad esempio, ISO 31000 enfatizza l’integrazione del risk management nei processi decisionali, la personalizzazione del processo al contesto, e la responsabilità del management nel rischio residuo.
Implementare un ciclo di gestione del rischio cyber robusto consente di focalizzare le risorse di sicurezza dove contano di più e di dimostrare accountability. Per un responsabile, ciò significa poter rispondere a domande del tipo: “Quali sono i nostri rischi cyber più significativi? Cosa stiamo facendo per mitigarli? Qual è il rischio residuo e lo accettiamo consapevolmente? Siamo preparati se X accade?”. Ad esempio, se viene chiesto “siamo protetti contro attacchi DDoS massivi?”, invece di promettere protezione assoluta (impossibile), un risk manager informato potrà dire: “Abbiamo identificato il rischio DDoS come alto per il nostro servizio Y (probabilità media, impatto molto alto). Lo stiamo mitigando con un contratto con provider anti-DDoS e architettura ridondata; il rischio residuo è ridotto a medio e accettato dalla direzione, monitoriamo continuamente la situazione”. Questo approccio evita panico o, al contrario, compiacenza infondata, e consente di prendere decisioni di investimento razionali (es. giustificare budget cybersecurity in base alla riduzione di rischio ottenuta).
In termini di strategie di mitigazione specifiche, spesso si adottano controlli da diversi domini: controlli tecnici (firewall, IDS, crittografia, backup…), controlli procedurali (policy di sicurezza, procedure di gestione incidenti, classificazione delle informazioni), controlli fisici (sicurezza degli accessi ai locali, alimentazione elettrica protetta, etc.) e controlli organizzativi (formazione del personale, segregazione dei compiti, piani di continuità operativa). Il framework ISO 27001 Annex A ad esempio elenca controlli raggruppati per temi che coprono queste aree, e può fungere da checklist per non dimenticare aree di controllo. Un aspetto importante nella mitigazione è anche considerare il quadrante temporale: Prevenzione, Rilevazione, Risposta, Recupero (che ricalca le fasi del NIST CSF). Non si può prevenire tutto; quindi serve anche capacità di rilevare gli eventi (si torna al discorso SOC), rispondere efficacemente (CSIRT) e recuperare le funzionalità (disaster recovery, backup). Il risk management ben fatto alloca investimenti sulle quattro fasi in modo bilanciato secondo il profilo di rischio dell’organizzazione.
Infine, la gestione del rischio cyber deve rispettare eventuali framework normativi: ad esempio per le banche c’è l’obbligo di aderire a regole specifiche di Bankitalia/ESMA, per le infrastrutture critiche la direttiva NIS/NIS2 impone adozione di misure minime e valutazioni periodiche, per i dati personali il GDPR richiede una valutazione di impatto (DPIA) se ci sono rischi alti per i diritti delle persone. Un responsabile dovrà quindi fondere i requisiti di compliance con la propria analisi del rischio interna, garantendo che il processo soddisfi sia l’esigenza di sicurezza reale sia quella regolamentare (spesso queste coincidono, dato che normative e standard riflettono best practice).
Conclusione: I fondamenti affrontati – dai sistemi di sicurezza (firewall, IDS/IPS, WAF, endpoint), alla virtualizzazione, ai metodi di autenticazione, alla gestione centralizzata degli accessi, fino ai principi CIA, alle tipologie di attacco e alle strutture organizzative (CSIRT, SOC, ISAC) e al risk management – dipingono un quadro olistico della cybersicurezza moderna. Per un responsabileper la prevenzione e gestione di incidenti informatici in un contesto nazionale/governativo, la sfida consiste nell’integrare tutti questi elementi in una strategia coerente. Ciò significa: assicurare che le misure tecniche siano implementate secondo le best practice e continuamente aggiornate; che esistano team e processi pronti a rilevare e fronteggiare gli attacchi; e che la leadership prenda decisioni informate basate sul rischio.
La complessità del dominio richiede una formazione continua e la capacità di collaborare con molteplici attori (interni ed esterni). In particolare, la cooperazione a livello di sistema-Paese (tramite il CSIRT Italia, gli ISAC settoriali, ecc.) è fondamentale per elevare il livello di sicurezza collettiva: una minaccia che colpisce un ente può rapidamente propagarsi ad altri, ma un allarme condiviso in tempo può anche prevenirne il successo altrove. Allo stesso modo, un responsabile deve saper comunicare con sia tecnici (ad esempio interpretare un report di threat intelligence e tradurlo in azioni tecniche) sia dirigenti apicali (spiegando il valore delle iniziative di sicurezza e ottenendo supporto). In ultima analisi, i fondamenti di cybersicurezza qui presentati – supportati da riferimenti a standard internazionali (ISO, NIST), fonti istituzionali (ENISA, ACN) e casi di studio – forniscono il bagaglio teorico e pratico per affrontare l’esame e, più significativamente, per impostare un programma di sicurezza efficace. La continua evoluzione delle minacce impone di applicare questi fondamenti con adattabilità: le tecnologie cambieranno, nuovi attacchi emergeranno, ma i principi cardine (proteggere CIA, conoscere il proprio rischio, difendersi in profondità, monitorare e rispondere rapidamente, condividere informazioni) rimarranno la bussola per navigare nel complesso panorama cyber. Un responsabile preparato su questi temi potrà guidare la propria organizzazione attraverso le sfide attuali e future, contribuendo alla resilienza cibernetica nazionale.
Il presente articolo vuole fornire una panoramica strutturata dei fondamenti di informatica e reti di calcolatori, con un focus sull’applicazione pratica di tali conoscenze nel contesto della sicurezza informatica. Ciascuna sezione approfondisce un argomento chiave – dalla rappresentazione dei dati ai sistemi operativi, dalle basi di dati alle reti e protocolli – evidenziando i concetti teorici essenziali e collegandoli alle best practice per la prevenzione e gestione di incidenti informatici.
La trattazione è pensata per il responsabile della sicurezza informatica impegnato nella prevenzione e gestione di incidenti informatici.
Vengono inclusi esempi pratici, riferimenti a standard riconosciuti e citazioni da fonti autorevoli, il tutto organizzato in sezioni chiare per facilitare la consultazione e l’apprendimento.
Rappresentazione delle informazioni
Nella scienza dei calcolatori, rappresentare le informazioni significa tradurre qualsiasi tipo di dato (numeri, testo, immagini, audio, ecc.) in una forma binaria comprensibile e manipolabile dalle macchine digitali. In pratica, ogni informazione viene codificata come sequenze di bit (binary digits), ossia 0 e 1, che sono le unità elementari di dati. Un insieme di 8 bit forma un byte, che costituisce la minima unità indirizzabile di memoria. Usando sequenze di bit e byte, un computer può rappresentare qualsiasi tipo di contenuto: caratteri testuali, valori numerici, immagini, suoni, video, ecc. La conversione dei dati in sequenze di 0 e 1 prende il nome di codifica e risponde al requisito fondamentale per cui un computer elabora solo informazioni in formato binario.
Unità di misura e codifiche: poiché i bit da soli sarebbero poco maneggevoli, si utilizzano multipli come Kilobyte (KB), Megabyte (MB), Gigabyte (GB), tenendo presente che in informatica per ragioni storiche spesso 1 KB = 1024 byte (2^10) invece di 1000 (si parla più precisamente di Kibibyte). Sul versante delle codifiche, per rappresentare testi alfanumerici si impiegano sistemi standardizzati di mappatura tra numeri e caratteri. Uno dei più importanti è il codice ASCII, che associa a ogni simbolo (lettera, cifra, segno di punteggiatura, caratteri di controllo, ecc.) un valore numerico tra 0 e 127, rappresentabile con 7 bit. Ad esempio, il carattere ‘A’ in ASCII è codificato come 65 (in decimale), mentre ‘a’ è 97 e così via. Estensioni di ASCII utilizzano 8 bit (256 valori possibili) per supportare caratteri accentati e simboli aggiuntivi, sebbene queste estensioni non fossero unificate a livello internazionale. Oggi si utilizza ampiamente Unicode, un sistema di codifica che, nelle sue varianti come UTF-8 e UTF-16, può rappresentare decine di migliaia di caratteri (oltre i caratteri latini, anche alfabeti non latini, ideogrammi, emoji, ecc.). Unicode in UTF-8 è retro-compatibile con ASCII per i primi 128 valori e consente di codificare caratteri usando sequenze di 1-4 byte. Grazie a Unicode, applicazioni e sistemi possono gestire testi multilingue e simboli emoji in modo unificato.
Numeri e formati numerici: i numeri interi vengono rappresentati in binario utilizzando un certo numero di bit fissato (es. 32 bit o 64 bit). Per i numeri con segno (positivi/negativi) l’approccio più diffuso è la rappresentazione in complemento a due, in cui il bit più significativo indica il segno e l’operazione di inversione dei bit più aggiunta di 1 permette di ottenere il negativo di un valore. Il complemento a due è lo schema standard adottato nei moderni calcolatori per i numeri interi con segno, poiché facilita la progettazione dei circuiti aritmetici (addizione e sottrazione possono essere eseguite con lo stesso circuito sommatorio). Ad esempio, con 8 bit si possono rappresentare gli interi da -128 a +127 in complemento a due. Per i numeri reali (con virgola decimale), si utilizza la rappresentazione in virgola mobile secondo lo standard IEEE 754, che definisce formati a 32 bit (precisione singola) e 64 bit (precisione doppia), tra gli altri. Questo standard specifica come suddividere i bit di un numero reale in segno, esponente e mantissa, permettendo di rappresentare un ampio intervallo di valori (inclusi zero, infiniti e valori NaN per indicare risultati non numerici). La conformità allo standard IEEE 754 garantisce che diversi processori e linguaggi interpretino i numeri in virgola mobile nello stesso modo, importante per la consistenza dei calcoli (ad esempio in crittografia o analisi scientifiche).
Rappresentazione di immagini, audio e altri dati: oltre a testo e numeri, i computer rappresentano anche dati multimediali in forma binaria. Un’immagine digitale ad esempio è modellata come una griglia di elementi chiamati pixel, ciascuno associato a valori binari che ne determinano il colore. In una immagine raster (bitmap), ogni pixel ha componenti di colore (ad esempio rosso, verde, blu in RGB) codificate tipicamente su 8 bit ciascuna, per un totale di 24 bit per pixel (True Color). Ciò significa che un singolo pixel può assumere circa 16,7 milioni di combinazioni di colore. Immagini con palette più ridotte possono usare meno bit per pixel (ad esempio 8 bit/pixel in modalità 256 colori). Allo stesso modo, un’immagine in bianco e nero può essere codificata con 1 bit per pixel (0 = bianco, 1 = nero), eventualmente con livelli di grigio se si usano più bit. Per i suoni, la rappresentazione avviene mediante campionamento: l’onda sonora analogica viene misurata (campionata) a intervalli regolari e ogni campione viene quantizzato in formato digitale (ad esempio, audio CD utilizza 44.100 campioni al secondo, ciascuno rappresentato da 16 bit per canale). Il risultato è una sequenza binaria che descrive l’andamento dell’audio nel tempo. Video e altri tipi di dati sono combinazioni o estensioni di questi principi (sequenze di immagini per il video, eventualmente compresse; flussi di campioni audio, ecc.), sempre riconducibili a stringhe di bit.
Implicazioni per la sicurezza informatica: la corretta comprensione della rappresentazione dei dati è fondamentale nella sicurezza informatica per diversi motivi. In primo luogo, molte vulnerabilità di basso livello (come buffer overflow o integer overflow) derivano da limiti nella rappresentazione binaria: ad esempio un intero a 32 bit ha un massimo e se un calcolo eccede quel massimo si verifica un overflow con possibili esiti imprevisti. Conoscere come i numeri sono codificati (complemento a due, IEEE 754 per i float, ecc.) aiuta a prevenire errori di programmazione sfruttabili da attaccanti. Inoltre, la rappresentazione binaria è alla base della crittografia: bit e byte vengono manipolati con operazioni booleane e aritmetiche per cifrare/decifrare informazioni. Un esperto di sicurezza deve conoscere, ad esempio, come lavorano gli algoritmi bit-a-bit e come interpretare dumps binari o esadecimali di file e pacchetti di rete durante un’analisi forense. Anche l’encoding dei caratteri è rilevante: attacchi come Unicode spoofing (ingannare sistemi di autenticazione usando caratteri Unicode simili a quelli latini) o bypass di filtri basati su codifiche differenti (ad esempio doppia codifica in attacchi XSS) sfruttano dettagli della rappresentazione dei testi. Infine, la capacità di tradurre rapidamente dati binari in forme comprensibili (come visualizzare un file eseguibile in esadecimale, o un indirizzo IP nella notazione dotted-decimal) è una competenza pratica quotidiana per chi gestisce incidenti: consente di identificare payload malevoli nascosti, firme di file e altri indicatori di compromissione.
Architettura degli elaboratori
Un elaboratore (computer) moderno si basa sul modello concettuale di architettura di von Neumann, che prevede la suddivisione in componenti fondamentali: una Unità Centrale di Elaborazione (CPU), una memoria centrale, dispositivi di input/output (I/O) e interconnessioni dette bus. In tale architettura, sia i dati che le istruzioni di un programma sono memorizzati nella medesima memoria e la CPU li preleva ed esegue sequenzialmente. Di seguito esaminiamo ciascun componente e le implicazioni relative alla sicurezza.
CPU (Central Processing Unit): è il “cervello” del computer, responsabile dell’esecuzione delle istruzioni macchina. La CPU è internamente composta da un’unità di controllo (Control Unit, CU) che dirige l’esecuzione delle istruzioni, da un’unità aritmetico-logica (ALU) che effettua calcoli e operazioni logiche e da una serie di registri interni per l’immagazzinamento temporaneo di dati e indirizzi. La CPU esegue le istruzioni in un ciclo di fetch-decode-execute: preleva un’istruzione dalla memoria, la decodifica e la esegue, aggiornando eventualmente registri e memoria. Le istruzioni stesse costituiscono il cosiddetto linguaggio macchina specifico della famiglia di CPU in uso (ad esempio x86-64, ARMv8, etc.). La maggior parte delle CPU moderne supporta funzionalità come pipeling (esecuzione parallela sovrapposta di parti di istruzioni diverse) e multithreading (gestione di più flussi di istruzioni) per migliorare le prestazioni. Dal punto di vista della sicurezza, la CPU implementa meccanismi hardware essenziali, come i livelli di privilegio (es. modalità kernel vs user): le moderne CPU possono operare in almeno due modalità, in cui le istruzioni cosiddette privilegiate (che accedono a risorse critiche o configurazioni hardware) possono essere eseguite solo in modalità kernel (dove risiede il sistema operativo), ma non in modalità utente. Questo isolamento hardware garantisce che un programma in esecuzione applicativa non possa, ad esempio, modificare direttamente la memoria del kernel o interagire col dispositivo disco senza passare per il sistema operativo – prevenendo una vasta gamma di abusi. Tuttavia, sono noti attacchi (Meltdown, Spectre) che sfruttano caratteristiche delle CPU (esecuzione speculativa, branch prediction) per aggirare tali protezioni, sottolineando come l’architettura hardware sia anch’essa un fronte di sicurezza da curare.
Memoria centrale: è il luogo in cui risiedono i programmi in esecuzione e i dati su cui operano. La memoria centrale (di solito RAM, Random Access Memory, volatile) contiene sia le istruzioni macchina caricate dal disco sia le strutture dati necessarie alle applicazioni. La caratteristica è l’accesso diretto rapido agli indirizzi di memoria (a differenza delle memorie di massa più lente). La memoria centrale memorizza sia i dati da elaborare (o già elaborati) sia le istruzioni eseguibili. Tipicamente è organizzata in una sequenza di celle indirizzabili (parole di memoria) tutte della stessa dimensione (es. 8 byte), ognuna identificata da un indirizzo numerico univoco. La memoria è spesso distinta in RAM (lettura/scrittura, volatile) e ROM/EPROM (Read-Only Memory, memorie non volatili contenenti ad esempio il firmware di bootstrap). Un aspetto cruciale dell’architettura è la gerarchia di memoria: piccole memorie velocissime (registri nella CPU, cache L1/L2/L3) mitigano la differenza di velocità tra CPU e RAM; più in basso vi sono memorie di massa (SSD, HDD) e archivi esterni. Ai fini della sicurezza, la gestione della memoria è un terreno fertile di vulnerabilità: buffer overflow (scrittura oltre i limiti di un buffer), use-afterfree (uso di memoria già deallocata) e memory corruption in genere sono alla radice di exploit. Negli ultimi decenni, sono stati introdotti contromisure hardware come il bit NX (No-eXecute, che marca le pagine di memoria dati come non eseguibili per prevenire l’iniezione di shellcode) e tecniche come ASLR (Address Space Layout Randomization, implementata a livello di sistema operativo ma dipendente dal supporto CPU per la segmentazione/paginazione) per rendere più difficile sfruttare i bug di memoria. Un responsabile alla sicurezza deve comprendere come funzionano queste protezioni hardware/memory e i limiti che possono avere, per esempio sapere che buffer overflow su architetture moderne possono essere mitigati ma non eliminati (es. return-oriented programming è nato proprio come tecnica per bypassare NX-bit e ASLR sfruttando frammenti di codice legittimo in memoria).
Bus e dispositivi I/O: i vari componenti sono collegati da bus di sistema (insieme di linee di comunicazione). Esistono tipicamente bus separati o logici distinti per indirizzi, dati e controllo, che coordinano il flusso delle informazioni tra CPU, memoria e periferiche. Le periferiche di I/O (dispositivi di input/output come tastiera, mouse, schermo, disco, scheda di rete, ecc.) interagiscono col processore attraverso controller specifici collegati sul bus. Da una prospettiva di sicurezza, i dispositivi I/O possono rappresentare vettori di attacco se non gestiti correttamente: ad esempio, dispositivi esterni USB possono iniettare comandi (si pensi a Rubber Ducky che si presenta come tastiera HID); le schede di rete possono essere bersaglio di DMA attacks (accesso diretto alla memoria) se l’IOMMU non isola adeguatamente le periferiche. Inoltre, dal bus passano anche dati sensibili (ad esempio password digitate da tastiera o chiavi crittografiche in RAM) e attacchi di tipo side-channel hanno dimostrato che è possibile captare informazioni sul bus o analizzare i tempi di risposta del sistema per dedurre segreti.
Set di istruzioni e architetture: ogni CPU implementa un Instruction Set Architecture (ISA), l’insieme di istruzioni macchina che è in grado di eseguire. Architetture diverse (x86, ARM, MIPS, RISC-V, ecc.) hanno ISA differenti e anche modalità operative differenti (32-bit, 64-bit, little endian vs big endian nell’ordinamento dei byte in memoria, ecc.). Nello sviluppo di exploit o nella risposta a incidenti, è spesso necessario comprendere l’architettura bersaglio: ad esempio, malware scritto per ARM non girerà su un server x86 a meno di emulazione e viceversa. Inoltre, la sicurezza del software è strettamente legata all’architettura: un binario compilato per x86-64 con protezioni come stack canaries (canarini sullo stack) e Control Flow Guard sfrutta funzionalità specifiche dell’ISA e del compilatore; un analista deve sapere come riconoscerle ed eventualmente disattivarle in ambiente controllato per effettuare reverse engineering. Parimenti, alcune istruzioni privilegiate (come la gestione della tabella delle pagine di memoria) sono sfruttate nei rootkit in modalità kernel: conoscere il funzionamento interno della MMU (Memory Management Unit) e delle istruzioni correlate può aiutare a individuare manipolazioni malevole a basso livello.
In sintesi, l’architettura degli elaboratori fornisce il substrato hardware su cui operano i sistemi software. Un responsabile della sicurezza informatica deve padroneggiare almeno i concetti fondamentali (ciclo macchina, gestione memoria, modelli architetturali) per comprendere sia come prevenire incidenti (es. configurare correttamente protezioni hardware, scegliere architetture sicure per certi servizi critici) sia come analizzare incidenti avvenuti (es. dump di memoria, istruzioni eseguire da un malware, log di errori CPU come kernel panic o machine check exception). Inoltre, la cooperazione tra hardware e software in termini di sicurezza è sancita da standard e best practice: ad esempio, l’UEFI Secure Boot sfrutta funzionalità firmware/hardware per garantire che all’accensione vengano eseguiti solo bootloader firmati e tecnologie come TPM (Trusted Platform Module) offrono radici hardware di fiducia utilizzate dai sistemi operativi per funzionalità come BitLocker (crittografia disco) o l’attestazione di integrità. Tutti questi aspetti richiedono una conoscenza delle basi architetturali per essere implementati e gestiti con successo.
Sistemi operativi
Un sistema operativo (SO) è il software di base che funge da intermediario tra l’hardware del computer e i programmi applicativi, gestendo le risorse del sistema e fornendo servizi essenziali agli utenti e alle applicazioni. In altre parole, il sistema operativo è composto da vari componenti integrati (kernel, gestore dei processi, gestore della memoria, file system, driver di periferica, interfaccia utente, ecc.) che insieme assicurano il funzionamento coordinato del computer. Esempi comuni di sistemi operativi sono Windows, Linux, macOS per desktop/server e Android, iOS per dispositivi mobili. Di seguito analizziamo le principali funzioni di un SO, evidenziando la loro importanza nella sicurezza informatica.
Gestione dei processi e multitasking: il sistema operativo consente di eseguire più programmi in (pseudo)parallelismo attraverso la gestione dei processi e dei thread. Un processo è un’istanza in esecuzione di un programma, con un proprio spazio di indirizzamento in memoria, mentre un thread è un flusso di esecuzione all’interno di un processo (i thread di uno stesso processo condividono memoria e risorse). Il kernel (nocciolo del sistema operativo) include uno scheduler che assegna la CPU ai vari processi/thread attivi, implementando politiche di scheduling (round-robin, priorità, ecc.) per garantire reattività e far avanzare tutti i carichi di lavoro. In ambito sicurezza, la corretta separazione dei processi è cruciale: il sistema operativo deve isolare gli spazi di memoria in modo che un processo non possa leggere/scrivere la memoria di un altro (violando la confidenzialità o integrità). Ciò è realizzato tramite l’MMU (unità di gestione memoria) e meccanismi come la traduzione di indirizzi (paginazione) che il SO controlla. Un attaccante spesso cerca di rompere questo isolamento (es. tramite local privilege escalation exploits che da un processo utente permettono di eseguire codice in contesto kernel). Pertanto, funzioni come il caricamento di moduli kernel firmati, l’implementazione di sandbox (che confinano processi potenzialmente pericolosi in ambienti limitati) e la gestione attenta delle API di interprocess communication (pipe, socket, shared memory) sono aspetti di sicurezza legati alla gestione dei processi.
Gestione della memoria: il sistema operativo fornisce astrazioni di memoria ai processi, tipicamente sotto forma di memoria virtuale. Ogni processo vede uno spazio di indirizzi virtuali che il kernel mappa sulla memoria fisica reale, garantendo che processi diversi non interferiscano. Il gestore della memoria del SO si occupa di allocare e liberare memoria su richiesta dei programmi (tramite chiamate di sistema come malloc/free in C, o automaticamente tramite garbage collector in linguaggi gestiti), di swappare porzioni di memoria su disco se la RAM scarseggia (memoria virtuale paginata) e di proteggere regioni critiche (ad esempio lo spazio di indirizzi del kernel è reso non accessibile ai processi utente, solitamente). Tecniche come ASLR – Address Space Layout Randomization (randomizzazione dello spazio degli indirizzi) sono abilitate dal sistema operativo per rendere meno prevedibili gli indirizzi di librerie, stack e heap, mitigando gli exploit basati su buffer overflow. Il responsabile alla sicurezza deve conoscere queste tecniche e assicurarsi che siano abilitate (ad esempio, DEP/NX e ASLR attivi, stack guard pages, ecc.), nonché essere in grado di analizzare core dump o tracce di crash per capire se un incidente è dovuto a corruzione di memoria. Inoltre, la gestione della memoria comprende i permessi di accesso alle pagine (read/write/execute): un sistema operativo robusto segrega scrupolosamente codice ed esegue dati non eseguibili, sfruttando l’hardware (bit NX) e marcando anche regioni di memoria come non accessibili quando opportuno (es. mappe null pointer per catturare dereferenziazioni errate). Da un punto di vista offensivo, molti malware tentano di aggirare queste protezioni, ad esempio tramite Return-Oriented Programming (ROP) per eseguire codice malizioso pur in assenza di pagine eseguibili in user-space: analizzare un attacco del genere richiede padronanza di come il SO organizza la memoria di un processo.
File system e gestione delle risorse persistenti: un altro compito cardine del sistema operativo è la gestione dei file system, ovvero l’organizzazione dei dati su memoria di massa (dischi, SSD) in file e directory, con meccanismi di autorizzazione (permessi di lettura/scrittura/esecuzione per utenti e gruppi) e di protezione. Per esempio, sistemi POSIX (Linux, UNIX) adottano permessi rwx e proprietà utente/gruppo, oltre a meccanismi più avanzati come ACL (Access Control List) o selinux context per definire in modo granulare chi può accedere a cosa. Un responsabile della sicurezza deve assicurarsi che le politiche di permesso siano configurate secondo il principio del privilegio minimo (ad esempio, file di configurazione critici accessibili solo all’utente di sistema appropriato, directory con dati sensibili non eseguibili, ecc.). Inoltre, il file system registra metadati come timestamp (utili nelle analisi forensi per capire la timeline di un incidente) e, in alcuni sistemi, supporta cifratura trasparente (es. BitLocker su NTFS, LUKS su ext4) per proteggere i dati a riposo. Il sistema operativo è anche responsabile della gestione delle periferiche tramite driver – piccoli moduli software che fungono da traduttori tra il kernel e l’hardware. Driver vulnerabili possono introdurre gravi falle di sicurezza (poiché eseguono in kernel mode), quindi l’OS e i suoi aggiornamenti vanno monitorati per patch critiche relative ai driver (come ad esempio stuxnet, che sfruttò un driver malevolo con firma digitale rubata). Il sistema operativo implementa anche politiche di controllo degli accessi non solo a file ma a tutte le risorse (dispositivi, porte di rete, chiamate di sistema sensibili). Ad esempio, su sistemi UNIX esiste la distinzione tra utente normale e superutente (root): solo quest’ultimo può eseguire certe operazioni (binding di socket su porte <1024, caricamento di moduli kernel, modifiche alle tabelle di routing, ecc.). Meccanismi di sudo o capabilities permettono di limitare o delegare privilegi in modo controllato. La corretta configurazione di questi meccanismi è spesso l’ultima linea di difesa per prevenire che un attacco su un servizio in esecuzione con utente limitato comprometta tutto il sistema.
Interfaccia utente e modalità utente/kernel: il sistema operativo fornisce infine all’utente (e alle applicazioni) un’interfaccia per utilizzare il computer. Questa può essere una GUI (interfaccia grafica) con desktop, finestre e pulsanti, o una shell a riga di comando per lanciare comandi testuali. Indipendentemente dall’interfaccia, quando un’applicazione necessita di compiere operazioni privilegiate (es. accedere al disco, aprire una connessione di rete, allocare memoria), deve effettuare una chiamata di sistema (system call) al kernel. Le system call rappresentano il punto di controllo tra la modalità utente e la modalità kernel: l’OS espone una serie di servizi di sistema (come “open file”, “send packet”, “create process”) e gli unici modi per un programma di utente di ottenere questi servizi è invocare le relative chiamate, che comportano un trap in modalità privilegiata. Il sistema operativo verifica i parametri e i permessi ad ogni system call, garantendo che l’operazione sia lecita. Ad esempio, se un processo chiede di aprire un file, il kernel controlla che quel processo (identificato dal suo UID/GID di appartenenza) abbia i diritti necessari sul file. Questo meccanismo è fondamentale per la sicurezza: previene che un processo malevolo possa arbitrariamente manipolare risorse senza passare per controlli. D’altra parte, se esistono vulnerabilità nelle implementazioni delle system call (bug nel kernel), un attaccante potrebbe ottenere privilegi elevati – questi sono i famosi exploit local root che sfruttano race condition, buffer overflow o errori logici nel kernel. Un buon responsabile della sicurezza deve tenere i sistemi operativi aggiornati (patch management) proprio per correggere tali vulnerabilità non appena note.
In conclusione, il sistema operativo è il componente software più critico da un punto di vista di sicurezza, perché orchestra l’uso di tutte le risorse e applica le politiche di isolamento e controllo. Le best practice come la separazione dei privilegi (account utente vs amministratore), la riduzione della superficie d’attacco (disabilitare servizi di sistema non necessari, rimuovere driver inutilizzati), l’uso di meccanismi di logging e monitoraggio (Syslog, Event Viewer) e l’applicazione tempestiva di aggiornamenti di sicurezza, sono tutti ambiti afferenti al sistema operativo. Inoltre, standard e linee guida come quelle di CIS (Center for Internet Security) forniscono benchmark di hardening specifici per i vari sistemi operativi (ad esempio, CIS Controls e CIS Benchmarks per Windows Server, Red Hat, etc.), che il responsabile dovrebbe adottare per assicurare una configurazione robusta delle macchine. Un sistema operativo correttamente configurato e mantenuto è in grado di prevenire la maggior parte degli incidenti informatici comuni (attacchi malware, escalation di privilegi, esfiltrazione di dati), o quantomeno di registrare eventi utili a rilevare tempestivamente attività anomale.
Basi di dati relazionali e NoSQL
Le basi di dati (database) sono infrastrutture fondamentali per archiviare, organizzare e recuperare grandi quantità di informazioni in modo efficiente. Esistono vari modelli di database; i più diffusi si dividono in database relazionali (SQL) e database NoSQL (non relazionali). In questa sezione esamineremo entrambi, delineando caratteristiche, differenze e rilevanza per la sicurezza.
Database relazionali (modello SQL)
Un database relazionale organizza i dati in tabelle composte da righe e colonne, secondo il modello introdotto da Edgar F. Codd negli anni ‘70. Ogni tabella rappresenta un’entità, ogni riga (o record) rappresenta un’istanza dell’entità e ogni colonna rappresenta un attributo (campo) del record. Ad esempio, potremmo avere una tabella Utenti con colonne ID, Nome, Email, Ruolo dove ciascuna riga è un utente specifico con i suoi dati e una tabella Accessi con colonne UtenteID, DataOra, Esito per tracciare i login: le due tabelle sarebbero collegate attraverso il campo UtenteID (chiave esterna nella tabella Accessi che rimanda alla chiave primaria ID nella tabella Utenti). Le relazioni tra tabelle (one-to-one, one-to-many, many-to-many) vengono realizzate tramite queste chiavi: chiave primaria (un identificatore unico per ogni riga di una tabella) e chiavi esterne (valori che collegano una riga a una riga in un’altra tabella). Il modello relazionale è accompagnato da un linguaggio standard di interrogazione e manipolazione dei dati: SQL (Structured Query Language), che permette di definire lo schema (DDL – Data Definition Language), inserire/modificare/cancellare dati (DML – Data Manipulation Language) e effettuare query di ricerca e aggregazione (con SELECT, JOIN tra tabelle, ecc.).
Caratteristiche chiave dei database relazionali sono le cosiddette proprietà ACID delle transazioni, fondamentali in ambiti critici (bancari, gestionali, etc.): Atomicità (ogni transazione è un’unità indivisibile, o tutti gli step vengono applicati o nessuno), Coerenza (la transazione porta il database da uno stato consistente a un altro, non viola vincoli di integrità ), Isolamento (transazioni concorrenti non interferiscono tra loro, i risultati sono come se fossero state eseguite in sequenza) e Durabilità (una volta completata con successo, un’operazione diventa persistente anche in caso di guasti successivi). I DB relazionali sono tipicamente gestiti da un RDBMS (Relational Database Management System) – ad esempio Oracle, Microsoft SQL Server, MySQL/MariaDB, PostgreSQL – che si occupa di implementare queste garanzie e ottimizzare l’accesso ai dati (attraverso indici, piani di esecuzione delle query, caching, etc.).
Rilevanza per la sicurezza: i database relazionali spesso custodiscono informazioni sensibili (dati personali, credenziali, registri di attività) e sono bersagli appetibili per gli attaccanti. Due aspetti fondamentali vanno considerati: la sicurezza interna del DB e le vulnerabilità delle applicazioni che lo utilizzano. Sul primo fronte, un RDBMS deve essere configurato con opportune misure di sicurezza: controlli di accesso robusti (account separati con privilegi minimi per le applicazioni, ruoli e privilegi SQL assegnati con granularità), cifratura dei dati a riposo (molti DB supportano tablespace criptati o cifratura trasparente delle colonne), audit e logging delle operazioni (tracciare chi ha eseguito cosa e quando, per individuare accessi sospetti) e hardening generale (disabilitare funzionalità non utilizzate, applicare patch di sicurezza del motore DB). Ad esempio, esistono standard come lo SQL Server Security Guide o linee guida CIS Benchmarks per MySQL/PostgreSQL che elencano best practice: dal forzare l’autenticazione con password complesse, all’abilitare la cifratura TLS nelle connessioni client-DB, fino a restringere l’uso di stored procedure o comandi pericolosi solo ad account fidati.
Sul secondo fronte, il rischio più noto è la SQL Injection, una tecnica d’attacco applicativa in cui input malevoli forniti a un’applicazione web (o altro software) finiscono per alterare l’istruzione SQL eseguita sul database. Se l’applicazione non “sanitizza” correttamente gli input (ad esempio non usando query parametrizzate/preparate), un attaccante può inserire frammenti di SQL arbitrario nelle query, ottenendo potenzialmente accesso o manipolazione non autorizzata dei dati. Un classico incidente è quando un campo di login viene usato direttamente in una query tipo SELECT * FROM utenti WHERE user='${utente}' AND pass='${password}' : fornendo come utente qualcosa come ' OR '1'='1' , la query diventa sempre vera permettendo bypass di autenticazione. Dal punto di vista di un responsabile alla sicurezza, mitigare le SQL injection è prioritario: significa formare gli sviluppatori all’uso di parametri bindati, ORMs, stored procedure sicure e al filtraggio/escape degli input in ultima istanza. In aggiunta, predisporre Web Application Firewall (WAF) con regole per intercettare pattern di SQL injection può aggiungere un livello di difesa. Un altro esempio di attacco è il privilege escalation interno al DB: se un account di applicazione con pochi privilegi riesce a eseguire un comando di sistema attraverso una funzionalità di SQL estesa (ad esempio le xp_cmdshell di SQL Server, se abilitate impropriamente, consentono di eseguire comandi sul sistema operativo), l’attaccante potrebbe passare dal database al pieno controllo del server. Ciò evidenzia l’importanza di limitare al minimo i privilegi degli account DB usati dalle applicazioni e di disabilitare funzionalità di estensione (come esecuzione di codice esterno) se non necessarie.
In termini di standard, normative come il GDPR richiedono protezione rigorosa dei dati personali spesso contenuti nei database, includendo principi di data protection by design (ad esempio minimizzazione dei dati raccolti, pseudonimizzazione). Standard industriali come il PCI-DSS per i dati di carte di credito impongono cifratura degli storage e segmentazione di rete per i sistemi di database, oltre a monitoraggio continuo degli accessi.
Database NoSQL (non relazionali)
Negli ultimi anni, accanto ai sistemi relazionali tradizionali, si sono diffusi i database NoSQL, termine che sta per “Not Only SQL” ad indicare database non basati sul modello relazionale e spesso privi di schema fisso. I database NoSQL abbracciano diverse categorie: database documentali (che memorizzano dati in documenti strutturati tipicamente in formato JSON/BSON, es. MongoDB, CouchDB), database a colonne distribuite (simili a tabelle sparse con colonne flessibili, es. Cassandra, HBase), database a chiave-valore (memorizzano coppie key-value senza struttura interna, es. Redis, Riak) e database a grafo (ottimizzati per rappresentare entità e relazioni complesse come nodi e archi, es. Neo4j). Questi sistemi rinunciano alle rigide tabelle relazionali in favore di una struttura dati più flessibile e spesso distribuita su cluster di macchine.
Nei database NoSQL, i dati vengono spesso memorizzati nel loro formato nativo o “denormalizzato”. Ad esempio, un documento JSON può contenere in un unico record tutte le informazioni di un utente, compresa una lista dei suoi ordini, evitando di fare JOIN tra tabelle separate come accadrebbe in un modello relazionale. Questo porta vantaggi in termini di prestazioni e scalabilità su grandi volumi di dati o dati eterogenei: il sistema scala orizzontalmente, replicando e partizionando i dati su più nodi (sharding), ed è in grado di gestire variazioni di struttura tra diversi record (schema flessibile).
Tuttavia, spesso i database NoSQL sacrificano la coerenza immediata delle transazioni in favore della disponibilità e della partition tolerance, secondo i principi del teorema CAP. In ambienti distribuiti, garantire simultaneamente Coerenza, Disponibilità e Tolleranza alle partizioni è impossibile; molti database NoSQL scelgono di essere AP (available, partition-tolerant) sacrificando la consistenza forte: i dati possono essere eventualmente consistenti, ovvero gli aggiornamenti si propagano con tempo breve ma non istantaneo su tutte le repliche. In termini pratici, ciò significa che una lettura potrebbe restituire un dato lievemente obsoleto se appena modificato altrove, privilegiando però la reattività del sistema anche in caso di rete con latenze. Questo è spesso accettabile per scenari come social network (ad esempio, vedere per qualche secondo la vecchia foto profilo di un utente prima che arrivi la nuova non è critico), ma sarebbe inaccettabile in un’applicazione bancaria (dove i conti correnti richiedono consistenza forte). In compenso, le architetture NoSQL sono progettate per alta disponibilità e scalabilità: aggiungendo nodi al cluster, le performance di throughput aumentano linearmente in molti casi e la ridondanza dei dati su nodi multipli evita singoli punti di guasto.
Rilevanza per la sicurezza: i database NoSQL presentano sfide di sicurezza in parte analoghe a quelle dei relazionali, ma con alcune peculiarità. Innanzitutto, l’assenza di schema fisso significa che non ci sono vincoli intrinseci di tipo/forma dei dati: ciò può rendere più difficile validare l’input e più facile commettere errori logici (ad esempio, se un campo previsto come numero intero viene memorizzato come stringa in alcuni documenti, il comportamento dell’applicazione potrebbe essere imprevedibile). Dal punto di vista degli attacchi, esistono varianti di injection anche per NoSQL – le cosiddette NoSQL Injection – dove input malevoli manipolano le query di ricerca su database non relazionali. Ad esempio, in MongoDB una query è spesso costruita passando un JSON di filtro: se un’applicazione web inserisce direttamente parametri utente in questo JSON senza controlli, un attaccante potrebbe aggiungere operatori come $gt (greater than) o $ne (not equal) per alterare la logica della query. Pur meno note delle SQL injection, vulnerabilità analoghe sono state riscontrate (ad es. su applicazioni con backend MongoDB, Redis injection sfruttando comandi craftati, ecc.).
In termini di controlli di accesso, alcuni database NoSQL nelle prime versioni erano pensati per funzionare in ambienti fidati e mancavano di robusti sistemi di autenticazione/autorizzazione. Ci sono stati casi clamorosi di database NoSQL esposti online senza password (es. istanze di MongoDB o Elasticsearch lasciate aperte) che hanno portato a massivi furti di dati o attacchi ransomware (dove gli attaccanti esfiltravano e cancellavano i dati chiedendo un riscatto). Dunque, una prima regola di sicurezza è assicurarsi che l’accesso di rete ai database sia segregato (solo dagli application server, non dal pubblico internet) e che i meccanismi di autenticazione siano attivi e con credenziali robuste. Oggi i principali prodotti NoSQL (MongoDB, Cassandra, etc.) offrono meccanismi di autenticazione, cifratura in transito (SSL/TLS) e a riposo, controlli di autorizzazione basati su ruoli – ma sta ai configuratori abilitarli. In un contesto di sicurezza nazionale, dove si trattano dati sensibili, è imperativo che anche i database NoSQL rispettino standard di hardening: ad esempio, MongoDB Security Checklist suggerisce di abilitare l’autenticazione SCRAM-SHA, definire ruoli con minimo privilegio (lettura/scrittura su specifici database), usare IP binding solo su interfacce interne, abilitare auditing, ecc.
Dal punto di vista della consistenza dei dati, bisogna inoltre considerare la resilienza: in caso di incidenti (es. guasto di nodi, partizioni di rete), i database NoSQL possono entrare in stati degradati (consistenza ridotta) che, se non gestiti, potrebbero causare perdite o duplicazioni di dati. Un piano di sicurezza deve includere backup regolari anche per database NoSQL e test di ripristino, dato che la natura distribuita a volte complica le procedure di recovery (bisogna tenere conto di replica set, quorum di consenso per riottenere un primario in sistemi tipo MongoDB, etc.). Inoltre, la eventuale consistenza implica che nel monitoraggio degli incidenti bisogna tener conto di possibili discrepanze temporanee: ad esempio, analizzando i log di un sistema distribuito, un responsabile alla sicurezza deve sapere che l’ordine esatto delle operazioni potrebbe differire leggermente tra nodi – il che può complicare l’analisi forense e la ricostruzione esatta degli eventi. Strumenti specializzati per logging centralizzato (spesso basati essi stessi su stack NoSQL, come ELK – Elasticsearch, Logstash, Kibana) vanno configurati per correlare correttamente eventi multi-nodo.
Integrazione SQL/NoSQL e best practice: molte organizzazioni adottano architetture ibride dove convivono database relazionali per dati transazionali e database NoSQL per big data, analytics in tempo reale, cache in-memory, etc. Un coordinatore di sicurezza deve avere familiarità con entrambi e con le tecniche per proteggerli. Ad esempio, assicurarsi che i dati sensibili presenti in un cluster Hadoop/NoSQL siano cifrati (usando magari librerie come Google Tink o servizi KMS per gestire le chiavi) e segregati con tokenization o pseudonymization per minimizzare l’impatto di un breach. Allo stesso tempo, mantenere aggiornati i sistemi (le piattaforme NoSQL sono in continuo sviluppo, patch di sicurezza escono di frequente) e utilizzare strumenti di monitoraggio delle anomalie sulle query (Database Activity Monitoring) anche su NoSQL, dove possibile, per rilevare pattern inconsueti (es. un’esplosione di letture anomale alle 3 di notte da un certo IP potrebbe indicare un exfiltration in corso).
Riassumendo, la scelta tra database relazionali e NoSQL dipende dai requisiti di consistenza, scalabilità e struttura dei dati. Dal punto di vista della sicurezza, entrambi richiedono robuste misure di protezione, consapevoli delle rispettive architetture. I database relazionali brillano per maturità di strumenti di sicurezza integrati e transazioni ACID, mentre i NoSQL offrono flessibilità e prestazioni su scala, ma il professionista deve compensare eventuali mancanze (es. consistenza) a livello applicativo e prestare attenzione a configurazioni sicure che non sono sempre default. Conoscere standard come OWASP Top 10 (A03:2021 – Injection) per le injection o il NIST SP 800-123 (guide to general server security, applicabile anche ai server DB) aiuta a costruire un ambiente database – relazionale o no – robusto contro incidenti informatici.
Networking e principali protocolli di rete (TCP/IP, DNS, BGP)
Le reti di calcolatori permettono a sistemi differenti di comunicare e scambiarsi informazioni. La sicurezza informatica moderna è strettamente legata alle reti, poiché gran parte degli incidenti avviene attraverso connessioni di rete (attacchi remoti, malware che si propagano, esfiltrazioni di dati). In questa sezione esaminiamo i fondamenti del networking e tre protocolli chiave: la suite TCP/IP (base di Internet), il sistema dei nomi a dominio DNS e il protocollo di routing BGP. Comprendere questi protocolli è essenziale per prevenire e gestire incidenti che vanno dagli attacchi DDoS alla manipolazione del traffico internet.
Suite TCP/IP (Livelli di trasporto e rete)
TCP/IP non è un singolo protocollo ma una famiglia di protocolli organizzati in un modello di rete pratico (spesso semplificato in 4 livelli: Link, Internet, Trasporto, Applicazione) che corrisponde in parte al modello OSI (vedi sezione successiva). I due pilastri di questa suite sono il Protocollo IP (Internet Protocol) e il Protocollo TCP (Transmission Control Protocol), da cui prende nome.
IP (Internet Protocol): IP opera al livello di rete ed è il protocollo fondamentale che si occupa di indirizzamento e instradamento dei pacchetti attraverso reti differenti. IP fornisce un servizio di consegna di pacchetti non affidabile e senza connessione: ciò significa che invia i pacchetti dal mittente al destinatario secondo le informazioni di routing, ma non garantisce né che arrivino (possono perdersi) né che arrivino in ordine. Ogni dispositivo collegato in rete ha almeno un indirizzo IP univoco (32 bit per IPv4, rappresentati come quattro numeri es. 192.168.10.5, oppure 128 bit per IPv6, rappresentati in esadecimale). IP provvede a incapsulare i dati in un pacchetto IP contenente header (con mittente, destinatario, TTL, ecc.) e payload (i dati da trasportare, ad esempio un segmento TCP). Il protocollo IP è progettato per collegare reti eterogenee: è un protocollo di interconnessione di reti (internetworking) di livello 3 OSI, nato per far comunicare sottoreti differenti unificandole in un’unica rete logica (da cui “Internet”). IP compie l’instradamento: i router analizzano l’indirizzo di destinazione IP di ciascun pacchetto e lo inoltrano verso il router successivo più vicino alla destinazione, sulla base di tabelle di routing. Gli algoritmi di routing (OSPF, BGP, ecc. visti più avanti per BGP) costruiscono queste tabelle. Sul piano sicurezza, IP di per sé non prevede autenticazione né confidenzialità: i pacchetti possono essere falsificati (IP spoofing) e letti da intermediari. Per ovviare a ciò esistono estensioni come IPsec (una suite per la cifratura e autenticazione a livello IP) usata in VPN sicure. Inoltre, la natura non affidabile di IP significa che spetta ai livelli superiori occuparsi di ritrasmissioni e controllo di flusso (è qui che interviene TCP). Va citato che IPv4 soffre di spazio di indirizzi limitato e problemi di sicurezza (frammentazione IP usata in certi attacchi DoS, ad esempio Teardrop attack), mentre IPv6 migliora alcuni aspetti (spazio vastissimo, meccanismi di autoconfigurazione) ma porta nuove considerazioni di sicurezza (ad esempio, la presenza obbligatoria di ICMPv6 e multicast di rete locale richiede filtri specifici per evitare scansioni e attacchi di discovery non autorizzati).
TCP (Transmission Control Protocol): TCP opera a livello di trasporto e fornisce un canale di comunicazione affidabile e orientato alla connessione tra due host. In termini pratici, TCP si occupa di instaurare una connessione virtuale tra client e server (tramite la celebre stretta di mano 3-way handshake: SYN, SYN-ACK, ACK), di suddividere i dati da inviare in segmenti adeguati, di numerare i segmenti e ritrasmettere quelli non riconosciuti e di riordinare i segmenti al ricevente per presentare un flusso di byte continuo all’applicazione. Grazie a TCP, le applicazioni non devono preoccuparsi di perdita o disordine di pacchetti: TCP garantisce che i dati arrivino integri e nell’ordine corretto, o notifica un errore se la connessione si interrompe. Questo è essenziale per protocolli applicativi come HTTP, SMTP, FTP, in cui ricevere dati incompleti o scombinati equivarrebbe a corruzione dell’informazione. Tecnicamente, TCP identifica le connessioni tramite le porte: ogni segmento TCP ha una porta sorgente e una destinazione, permettendo a un singolo host di gestire più connessioni simultanee su porte diverse (es. 80 per HTTP, 443 per HTTPS, 25 per SMTP, ecc.). Dal punto di vista della sicurezza, il protocollo TCP è stato bersaglio di attacchi sin dai primordi di Internet. Un esempio classico è il TCP SYN flood: attaccando l’handshake di TCP, un aggressore invia una valanga di pacchetti SYN senza completare mai il 3° passo, lasciando il server con molte connessioni “mezze aperte” (in stato SYN_RECV) e esaurendo le risorse dedicate (la backlog queue). Ciò provoca un Denial of Service. Contromisure come SYN cookies o limiti sulla half-open queue aiutano a mitigare. Un altro attacco è il TCP reset (RST): inviando un pacchetto falsificato con bit RST si può forzare la chiusura di una connessione TCP esistente; se l’attaccante riesce a indovinare gli identificatori corretti (IP/porta e numero di sequenza), può interrompere comunicazioni di altri. Questo fu sfruttato in passato per bloccare traffico BGP (il cui trasporto è su TCP, vedi dopo) o per censura (come RST injection nel grande firewall cinese). Per integrità e confidenzialità, TCP da solo non offre nulla: la protezione dei dati deve avvenire a livello applicativo (ad es. TLS sopra TCP per cifrare la sessione). Tuttavia, dentro la suite TCP/IP esistono protocolli complementari come UDP (User Datagram Protocol, non affidabile e senza connessione, usato per streaming, DNS, etc.) che il responsabile sicurezza deve ugualmente conoscere: ad esempio, UDP è più soggetto a spoofing (essendo connectionless) e viene sfruttato in attacchi DDoS di riflessione/amplificazione (come DNS amplification, SSDP amplification), dunque vanno predisposti filtri (e.g. anti-spoofing con BCP 38, rate limiting su servizi UDP pubblici). In generale, la comprensione profonda di TCP/IP consente di analizzare i log di rete e i dump di pacchetto (es. con Wireshark) per rilevare attività sospette: sequenze anomale di flag TCP, tentativi su port scanning (che si evidenziano come connessioni SYN brevissime su molte porte), pacchetti malformati, etc. Standard come gli RFC (es. RFC 793 per TCP, RFC 791 per IP) definiscono il funzionamento lecito: molti attacchi inviano traffico che devia dallo standard (es. pacchetti con flag inconsuete come Xmas scan con FIN-PSH-URG) e sistemi IDS/IPS (Snort, Suricata, Zeek) sono in grado di rilevarlo se ben configurati.
In sintesi, TCP/IP è la colonna portante delle comunicazioni di rete. Un coordinatore di prevenzione incidenti deve: assicurare che le configurazioni di rete seguano le best practice (filtri su pacchetti ingressi/uscita, disabilitare protocolli legacy insicuri – es. Telnet, FTP – a favore di versioni cifrate – SSH, FTPS/SFTP), conoscere gli attacchi di rete comuni e le contromisure (firewall stateful per gestire SYN flood, IDS per rilevare scansioni e anomalie TCP/IP, IPsec per proteggere canali critici) e in caso di incidente saper leggere il traffico (analisi PCAP) per capire cosa è successo. Ad esempio, in un sospetto data breach, potrebbe trovarsi traffico TCP sulla porta 443 di volume insolitamente alto verso un IP esterno non riconosciuto: sapere che 443 è solitamente HTTPS e che l’esfiltrazione potrebbe avvenire cifrata fa sì che si debba guardare a meta-dati (SNI, quantità, pattern) e non al contenuto impossibile da decifrare senza la chiave. Allo stesso modo, la padronanza di TCP/IP è fondamentale per gestire incidenti come DDoS: riconoscere un flood TCP SYN o UDP, distinguere un traffico legittimo da uno malevolo in base a parametri di basso livello e interfacciarsi con ISP/CDN per attivare filtri o scrubbing.
DNS (Domain Name System)
DNS è il “servizio di nomi” di Internet, spesso paragonato a un “elenco telefonico” o a un servizio di rubrica per la rete globale. Il suo scopo principale è tradurre i nomi di dominio leggibili dagli umani (ad es. www.esempio.gov) nei corrispondenti indirizzi IP numerici che le macchine utilizzano per instradare il traffico. Senza DNS, dovremmo ricordare e digitare indirizzi come 93.184.216.34 per visitare un sito, cosa impraticabile su larga scala. Il DNS è dunque fondamentale per l’usabilità di Internet.
Il sistema DNS è gerarchico e distribuito. I nomi di dominio sono organizzati in una struttura ad albero rovesciato: al vertice ci sono i root server (indicati da un dominio radice vuoto, spesso rappresentato da un punto . ), subito sotto ci sono i domini di primo livello (TLD) come .com , .org , .it , .gov, ecc., poi i secondi livelli (es. esempio in esempio.gov ) e così via con possibili sottodomini aggiuntivi. L’operazione di risoluzione DNS consiste nel trovare l’indirizzo IP associato a un nome (risoluzione diretta) o viceversa trovare il nome dato un IP (risoluzione inversa). Quando un client (tipicamente tramite un resolver stub integrato nel sistema operativo) deve risolvere un nome, contatta un DNS resolver ricorsivo (spesso fornito dall’ISP o configurato manualmente come 8.8.8.8 di Google) il quale interroga a sua volta la gerarchia: parte dai root server (ce ne sono 13 indirizzi logici root disseminati globalmente) per sapere chi è autoritativo per il TLD richiesto, poi contatta il server autoritativo di quel TLD per sapere chi gestisce il dominio di secondo livello e così via fino ad ottenere dal server DNS autoritativo finale (gestito dal proprietario del dominio o dal suo provider) il record richiesto. Il DNS memorizza le risposte in cache per un certo periodo (TTL) per accelerare richieste future.
I record DNS più comuni includono: A/AAAA (indirizzo IPv4 o IPv6 associato a un nome), CNAME (nome canonico, alias verso un altro nome), MX (mail exchanger, indirizzo dei server di posta per il dominio), TXT (testo libero, usato anche per record SPF/DKIM nei contesti mail), SRV (service locator, utilizzato da alcuni protocolli), PTR (pointer per risoluzione inversa da IP a nome).
Minacce e sicurezza DNS: il DNS in origine è stato progettato senza meccanismi di autenticazione, il che l’ha reso vulnerabile a vari attacchi. Il più classico è il DNS cache poisoning: un attaccante induce un resolver a memorizzare una risposta falsa, cosicché gli utenti successivi vengano indirizzati all’IP sbagliato (ad esempio, credono di visitare bancopopolare.it ma in realtà il DNS avvelenato gli dà l’IP di un server dell’attaccante). Prima di correttivi, era possibile inviare risposte DNS fasulle con una certa facilità, approfittando del fatto che la porta UDP 53 e l’ID di transazione DNS erano prevedibili e non c’era verifica di origine. Ora i resolver usano porte effimere random e ID random a 16 bit, riducendo la fattibilità del poisoning, ma il rischio resta se l’attaccante può intralciare la comunicazione col vero server (ad es. tramite un man-in-the-middle). La risposta dell’industria è DNSSEC, un’estensione di sicurezza che aggiunge firme digitali alle risposte DNS: i domini firmati DNSSEC pubblicano chiavi pubbliche nei record DNSKEY e usano record RRSIG per firmare le mapping nome->IP. Un resolver con DNSSEC abilitato verifica che la firma sia valida e ancorata a una catena di fiducia (dal root in giù) evitando di accettare dati manomessi. DNSSEC, però, non è ancora ovunque adottato e introduce la complessità della gestione chiavi/rollover.
Un altro problema di sicurezza DNS è il DNS tunneling: usando richieste DNS (che spesso sono permesse anche quando altro traffico è bloccato) per incapsulare dati arbitrari, degli attaccanti possono esfiltrare informazioni o comandare malware (comandi e controllo) attraverso query DNS apparentemente legittime. Ad esempio, un malware potrebbe fare query a sottodomini come <data>.esempio-attaccante.com, dove <data> è un blocco di dati rubati codificato in base32; il server DNS sotto il controllo dell’attaccante riceve queste query e decodifica i dati dal nome richiesto. Dal punto di vista di un analista, è importante monitorare il traffico DNS verso domini insoliti o con nomi molto lunghi/strani, segnale tipico di tunneling o data exfiltration. Strumenti di sicurezza avanzata (DNS firewall, soluzioni di exfiltration detection) possono rilevare e bloccare questi abusi.
C’è poi il DNS hijacking o DNS spoofing: se un attaccante compromette un server DNS autoritativo o modifica i riferimenti (ad esempio alterando i record di un registrar DNS), può dirottare un dominio intero su altri IP. Questo è successo, ad esempio, in attacchi a provider DNS o in scenari di censura statale (dove i resolver ISP sono modificati per restituire IP “fake” per certi domini). Contromisure includono l’uso di registrar con protezioni robuste (2FA, lock) e monitoraggio continuo dei record DNS critici.
Best practice relative al DNS per un responsabile alla sicurezza includono: utilizzare resolver DNS ricorsivi sicuri (magari in-house o servizi con filtro malware), abilitare DNSSEC validation sui resolver interni per i propri utenti, implementare DNSSEC per i domini gestiti dall’organizzazione in modo da prevenire impersonificazioni, isolare e proteggere i server DNS autoritativi (pochi servizi devono contattarli, quindi regole firewall restrittive e monitoraggio). Inoltre, configurare correttamente i record per proteggere email e servizi (DNS è utilizzato in meccanismi di sicurezza come SPF, DKIM, DMARC per l’email authentication). Un altro aspetto è la privacy: le query DNS tradizionali sono in chiaro, quindi un attaccante che sniffa la rete vede tutti i nomi richiesti (che possono rivelare i siti visitati, ecc.). In risposta, si stanno diffondendo protocolli come DNS over HTTPS (DoH) o DNS over TLS (DoT) che cifrano il traffico DNS tra client e resolver. Questo migliora la riservatezza, ma pone sfide per i controlli aziendali (non si può più facilmente ispezionare il contenuto DNS). Un coordinatore dovrà quindi bilanciare privacy e capacità di monitoraggio, magari attivando DoT/DoH con server fidati ma anche usando sistemi di split-horizon DNS per risolvere internamente i nomi aziendali e avere visibilità.
BGP (Border Gateway Protocol)
BGP è il protocollo di routing globale che tiene unita Internet. Mentre protocolli come OSPF, EIGRP, IS-IS gestiscono il routing interno a una singola organizzazione o sistema autonomo (IGP – Interior Gateway Protocols), BGP è l’Exterior Gateway Protocol che connette tra loro i diversi Autonomous System (AS) – essenzialmente le reti di proprietà di fornitori di connettività (ISP, dorsali, grandi organizzazioni) identificate da un numero AS univoco. In parole semplici, BGP è il metodo con cui le reti annunciano ad altre reti quali prefissi IP possono raggiungere attraverso di loro, permettendo così di instradare pacchetti da un capo all’altro del mondo, passando per molte reti intermedie. BGP è dunque il “sistema di comunicazione tra router di confine” che consente a Internet di funzionare come un’unica grande rete. Senza BGP, i pacchetti oltre la propria rete locale non saprebbero dove andare.
Dal punto di vista tecnico, BGP è un protocollo di routing di tipo path-vector: ogni annuncio BGP informa su un prefisso IP raggiungibile e include l’AS-PATH, ovvero la sequenza di AS che bisogna attraversare per raggiungere quel prefisso. I router BGP (detti spesso Route Reflector o router di bordo) scambiano messaggi su connessioni TCP (porta 179). BGP è incrementale: invece di scambiare periodicamente l’intera tabella come alcuni IGP, dopo l’iniziale full routing table exchange, invia solo aggiornamenti quando cambia qualcosa (annuncio di nuova rotta o ritiro di una esistente). Questo lo rende scalabile per Internet dove esistono oltre 900k prefissi IPv4 annunciati. BGP permette politiche: ogni operatore può definire preferenze su quali rotte usare o annunciare (ad esempio preferire percorsi più corti in termini di AS-PATH, o quelli ricevuti da clienti su quelli ricevuti da provider per motivi economici).
Vulnerabilità e incidenti BGP: BGP si basa in gran parte sulla fiducia tra operatori e fino a tempi recenti non incorporava meccanismi crittografici robusti. Ciò lo rende vulnerabile al cosiddetto BGP hijacking: un AS malevolo (o mal configurato) può annunciare rotte per prefissi IP che non gli appartengono, deviando il traffico. Ad esempio, nel 2008 l’annuncio errato di una rotta per YouTube da parte di un ISP pakistano (nel tentativo di censurare YouTube localmente) propagò a livello globale, rendendo YouTube irraggiungibile per ore. In altri casi, attori malevoli hanno annunciato prefissi bancari o di criptovalute per intercettare dati. BGP hijack può portare a interruzione (se il traffico viene in un vicolo cieco) o Man-in-the-Middle (se il traffic hijacker lo inoltra verso la destinazione vera dopo averlo intercettato). Secondo analisi recenti, essendo BGP una tecnologia con ~35 anni di età, è “facile da manipolare per reinstradare il traffico Internet o addirittura isolare intere regioni”. Infatti, casi documentati mostrano come in situazioni geopolitiche (es. crisi Crimea/Ucraina), BGP sia stato usato intenzionalmente per deviare traffico di intere aree verso infrastrutture sotto controllo di governi, creando di fatto “frontiere digitali” coerenti con quelle militari.
Le contromisure emergenti sono: RPKI (Resource Public Key Infrastructure), un sistema di certificati digitali che associa prefissi IP e numeri AS a enti legittimi, permettendo ai router di verificare se un certo AS è autorizzato ad annunciare un certo prefisso. Implementare RPKI e filtri di validazione (droppare annunci BGP non validati) riduce i rischi di hijack accidentali e rende più difficile quelli malevoli (che richiederebbero compromissione dei certificati). Inoltre, buone pratiche come i filtri BCP 38 anti-spoofing e l’obbligo per gli ISP di filtrare annunci in ingresso da clienti che non corrispondono ai loro IP (route filtering) riducono la superficie di attacco. In ambito di sicurezza nazionale, è auspicabile una stretta collaborazione con gli operatori di rete per assicurare che tali misure siano adottate, dato che un attacco BGP può essere usato anche come vettore per isolare un paese o spostare traffico attraverso nodi di sorveglianza (si pensi a un hijack temporaneo che dirotta traffico europeo via AS in un altro continente per spiarlo, poi lo rilascia verso la destinazione – tattica rilevata in alcune analisi di routing).
Un altro rischio BGP è l’instabilità o errore di configurazione: BGP è complesso ed errori nelle politiche possono causare route leak (annuncio di rotte ricevute da un provider verso un altro provider quando non dovrebbe, saturando percorsi imprevisti) o flapping (rotte che oscillano ripetutamente su/giù causando overhead). Questi incidenti possono avere impatti collaterali di sicurezza: un route leak può congestionare link inattesi, rallentando comunicazioni critiche o firewall, oppure un flapping eccessivo potrebbe stressare i router fino a farli riavviare per carico (causando DoS su interi segmenti di rete).
Ruolo del responsabile della sicurezza su BGP: per un’organizzazione che potrebbe gestire proprie infrastrutture di rete, è cruciale avere visibilità BGP. Ciò include utilizzare servizi di monitoring (es. RouteViews, RIPE Atlas) che avvisino se i prefissi dell’organizzazione vengono annunciati da AS esterni (potenziale hijack in corso) o se route importanti spariscono. In caso di incidente BGP, il responsabile deve saper interfacciarsi con i Network Operator Groups e CERT/CSIRT di settore per coordinare una risposta (ad esempio, diffondere rapidamente la notizia di non accettare annunci da AS X, o contattare l’operatore responsabile dell’annuncio spurio).
Inoltre, la comprensione di BGP è importante per valutare la resilienza delle comunicazioni critiche: per servizi governativi essenziali, ci si può assicurare multihoming (connessione a più ISP con diverse rotte) e preferire percorsi che minimizzino passaggi in zone a rischio. Ad esempio, se un paese teme spionaggio, potrebbe voler monitorare se il suo traffico passa per AS di altri paesi non amici e magari accordarsi con gli ISP per restrizione di routing. Strumenti di tracciamento (traceroute a livello AS) aiutano a mappare i percorsi.
Riassumendo, BGP è un protocollo potente ma datato, core di Internet e allo stesso tempo punto debole sfruttabile. Lo sforzo collettivo di mettere in sicurezza BGP (attraverso RPKI, monitoring e cooperazione tra ISP) è in corso e i professionisti di sicurezza devono essere partecipi: conoscere gli incidenti storici, sostenere l’adozione di misure protettive e includere scenari di attacco BGP nei propri piani di rischio (specialmente in contesti di infrastrutture critiche dove un attacco di routing può significare blackout comunicativo).
Reti di elaboratori (Modello OSI)
Il modello OSI (Open Systems Interconnection) è un modello di riferimento concettuale, proposto dall’ISO (International Organization for Standardization), che suddivide le funzioni di rete in sette livelli astratti. Anche se Internet pratica quotidiana segue più da vicino il modello TCP/IP a 4-5 livelli, l’OSI rimane uno schema didattico e progettuale prezioso: fornisce un linguaggio comune per descrivere dove si collocano protocolli e apparecchiature e come le diverse parti di una comunicazione interagiscono. I sette livelli del modello OSI, dal più basso (fisico) al più alto (applicazione), sono i seguenti:
Livello 1: Fisico. Si occupa della trasmissione dei bit grezzi sul mezzo fisico di comunicazione. Definisce specifiche elettriche, meccaniche e funzionali per attivare, mantenere e disattivare collegamenti fisici. Ad esempio, stabilisce che forma d’onda e tensione rappresentano un “1” o uno “0”, il tipo di connettore e cavo (rame, fibra ottica), la modulazione usata in trasmissioni wireless, la sincronizzazione dei bit, etc.. Dispositivi tipici al livello fisico sono i repeater, gli hub Ethernet (che rigenerano il segnale su più porte) e i componenti come cavi, transceiver, antenne. Dal punto di vista della sicurezza, il livello fisico è spesso trascurato ma non privo di rischi: tapping su cavi (intercettazioni fisiche), interferenze elettromagnetiche intenzionali o accidentali e attacchi di jamming nel wireless (disturbo radio per negare il servizio) sono minacce di livello 1. Contromisure includono cablaggi schermati, monitoraggio di link (per rilevare disconnessioni o anomalie elettriche) e in ambienti critici l’uso di fibre ottiche (difficili da intercettare senza provocare perdite di segnale rilevabili).
Livello 2: Collegamento Dati. Fornisce il trasferimento dei dati tra due nodi adiacenti (collegati dallo stesso mezzo fisico) in modo affidabile, strutturando i bit in frame e implementando controlli di errore e controllo di flusso su ciascun collegamento. Qui troviamo protocolli come Ethernet (IEEE 802.3) per le LAN cablate, Wi-Fi (IEEE 802.11) per le LAN wireless, PPP per collegamenti punto-punto, HDLC, ecc. Il livello 2 utilizza indirizzi fisici (MAC address per Ethernet) per identificare le schede di rete sorgenti e destinazione su un segmento. Funzioni chiave includono l’error detection (es. CRC per individuare frame corrotti e scartarli) e a volte l’error recovery (es. in collegamenti PPP può esserci ritrasmissione). Switch e bridge operano a questo livello, instradando frame in base agli indirizzi MAC e segmentando collision domains. Dal punto di vista sicurezza, il livello data link presenta minacce come MAC flooding (in cui un attaccante inonda lo switch di frame con MAC fittizi, saturando la CAM table e facendolo passare in modalità hub, favorendo sniffing), spoofing di MAC (un dispositivo assume l’identità MAC di un altro, magari per bypassare filtri MAC ACL o dirottare traffico destinato al legittimo) e attacchi specifici di tecnologie: ad esempio, ARP poisoning (avvelenamento cache ARP) sfrutta il protocollo di risoluzione indirizzi (tra livello 2 e 3) per associare un MAC dell’attaccante all’IP della vittima, di fatto intercettando il traffico locale. Strumenti come ettercap facilitano questo attacco, che può essere mitigato con tecniche come ARP statici o protocolli di sicurezza come DHCP Snooping e Dynamic ARP Inspection sugli switch gestiti. Sul Wi-Fi, il livello 2 è dove operano misure di cifratura come WPA2/WPA3: la protezione delle trame radio con cifre come AES-CCMP avviene qui. Dunque, la robustezza del livello 2 wireless (chiavi forti, autenticazione 802.1X con EAP, ecc.) è essenziale contro sniffing e accessi non autorizzati.
Livello 3: Rete. È responsabile dell’instradamento (routing) dei pacchetti attraverso reti diverse, dal mittente finale al destinatario finale, potenzialmente passando per più nodi di commutazione (router). Il livello 3 introduce gli indirizzi logici (es. indirizzi IP) e si occupa di trovare percorsi e di gestire la congestione a livello di pacchetto. IP (Internet Protocol) è il protagonista (versione 4 e 6) a questo livello. Altri esempi includono protocolli legacy o specializzati come IPX, AppleTalk (quasi obsoleti) e protocolli di routing come ICMP potrebbe essere considerato tra 3 e 4 (di supporto al funzionamento di IP, es. con ping ed error message). I router operano al livello 3, guardando l’indirizzo di destinazione nei pacchetti IP e inoltrandoli secondo la routing table. La sicurezza a livello 3 coinvolge diversi aspetti: controllo degli accessi IP (liste di controllo accessi su router e firewall che permettono o bloccano traffico in base a IP sorgente/dest, protocollo e porta – benché la porta sia L4), protezione dell’integrità dei pacchetti (qui agisce ad esempio IPsec AH/ESP che aggiunge firma o cifratura a livello IP) e la robustezza contro attacchi di scansione e DoS basati su IP (ping of death, fragmentation attacks). Un amministratore deve implementare filtering appropriato (ad esempio: filtrare pacchetti in ingresso con IP sorgenti privati o palesemente spoofati – BCP 38, ingress filtering; bloccare protocolli non necessari come IPv6 se non in uso, o ICMP solo in modo controllato perché ICMP è utile per la diagnostica ma può essere abusato in tunneling o scansioni). Anche gli attacchi di tracciamento (es. traceroute abusato per mappare la rete) lavorano su livello 3/4 usando TTL manipolato; un SOC potrebbe rilevare e allertare se vede traceroute verso host interni, segno di ricognizione. In sintesi, il livello rete è dove si definiscono i confini della security perimeter: definire quali IP o segmenti possono comunicare, implementare segmentazione della rete (VLAN e routing intervlan con ACL) e applicare tecniche come network address translation (NAT) – che pur essendo nata per risparmiare IPv4, fornisce un effetto collaterale di mascheramento degli IP interni, aggiungendo oscurità verso l’esterno.
Livello 4: Trasporto. Offre comunicazione end-to-end affidabile o non affidabile tra processi applicativi su host differenti. Due protocolli cardine qui sono TCP (orientato alla connessione, affidabile, con controllo di flusso) e UDP (datagrammi non connessi, non garantiti). Il livello trasporto identifica anche le porte (numeri che distinguono i flussi applicativi: es. porta 80 per HTTP su TCP, 53 per DNS su UDP, ecc.), permettendo la multiplexing di più conversazioni sulla stessa connessione di rete. Qui troviamo anche concetti come segmento (TCP segment) o datagramma (UDP). Dal punto di vista sicurezza, sul livello 4 agiscono molti controlli nei firewall stateful, che monitorano lo stato delle connessioni TCP e possono bloccare tentativi anomali (ad esempio pacchetti TCP non appartenenti ad alcuna connessione nota). Il port scanning è una tecnica di ricognizione di livello 4: un attaccante invia tentativi di connessione su varie porte per scoprire quali servizi sono attivi; strumenti come nmap variano i tipi di pacchetto (SYN scan, ACK scan, UDP scan) per inferire regole firewall e servizi. Un analista deve saper interpretare log come “Dropped packet from X to Y: TCP flags SYN” e capire che è uno scan. Inoltre, attacchi DDoS spesso si manifestano su questo livello: SYN flood (già descritto), o saturazione di porte specifiche (es. attacco a un server web saturando la porta 80 con richieste incomplete). Difese includono meccanismi antidos sui firewall e anche a livello di sistema operativo (stack TCP robusti con backlog di connessioni ampia, cookies, ecc.). I protocolli di trasporto hanno anche implicazioni su performance e perciò su rilevamento anomalie: es. un flusso TCP legittimo ha una certa sincronia tra pacchetti e ack; se un flusso esce dalle statistiche usuali (troppi RST, troppi ritrasmissioni) potrebbe indicare un problema o un attacco in corso di blocco. A livello trasporto si implementa anche la sicurezza delle sessioni in alcuni casi: per es., TLS (il protocollo usato per HTTPS) in realtà risiede sopra TCP (livello 5 OSI se consideriamo session/present, o direttamente come parte dell’applicazione), ma concettualmente fornisce sicurezza a ciò che il trasporto trasmette. In un contesto OSI, potremmo dire che l’inizio handshake TLS è livello 5 sessione (instaura un canale) e la cifratura/decifratura è presentazione (livello 6). Comunque, il responsabile di sicurezza deve sapere che firewall di nuova generazione possono operare fino al livello 7, ma spesso regole efficaci si definiscono su combinazioni di criteri L3/L4 (IP/porta) per bloccare accessi a servizi indesiderati o limitare provenienze.
Livello 5: Sessione. Fornisce i meccanismi per controllare il dialogo tra due applicazioni, istituendo, gestendo e terminando sessioni di comunicazione. Una sessione è essenzialmente una comunicazione logica di lunga durata tra due entità, che può comprendere più scambi di dati. Funzioni tipiche del livello di sessione includono la gestione delle connessioni (apertura, autenticazione al livello di sessione, chiusura ordinata) e controllo del dialogo (chi può inviare in un dato momento, half-duplex vs full-duplex, sincronizzazione di checkpoint per riprendere trasferimenti interrotti). Nella pratica di Internet, il livello sessione non è molto distinto: protocolli come TLS/SSL possono essere visti come aggiungere una sessione sicura su TCP, o protocolli come NetBIOS session, RPC, PPTP ecc. definiscono sessioni sopra il trasporto. Dal punto di vista sicurezza, qui collochiamo concetti come autenticazione della sessione (per es., in TLS un client e server si autenticano e stabiliscono una sessione cifrata con ID di sessione), oppure gestione delle sessioni applicative (ad esempio i token di sessione HTTP per tenere traccia di un utente loggato su un sito – concettualmente livello 5/7). Le minacce includono il dirottamento di sessione (session hijacking), in cui un attaccante subentra in una sessione attiva rubando credenziali di sessione (es. cookie di autenticazione web non protetto) o per difetti del protocollo (un esempio storico: nel protocollo PPTP VPN c’erano weakness che permettevano di desincronizzare e prendere controllo della sessione). Un altro concetto di sessione è nel checkpointing: alcuni protocolli di trasferimento file lunghi implementano marker di sincronizzazione (per non ricominciare da capo se la sessione cade). Un attaccante potrebbe abusare del meccanismo di ripresa (resumption) se non ben protetto, per forzare trasferimenti incompleti o inserire dati. In contesti moderni, molti di questi dettagli sessione sono integrati nelle applicazioni (livello 7), quindi il livello 5 OSI è spesso citato in teoria più che implementato separatamente. Il coordinatore di sicurezza comunque deve assicurarsi che le sessioni, qualunque sia il contesto, siano protette: ad esempio, nelle applicazioni web la gestione sicura dei token di sessione (randomici, con scadenza, marcati HttpOnly e Secure se cookie) è cruciale per prevenire impersonificazione.
Livello 6: Presentazione. Si occupa della sintassi e semantica dei dati scambiati tra applicazioni. In pratica, fornisce trasformazioni di dati che permettono a sistemi con convenzioni diverse di comunicare. Ciò include conversioni di formato (esempio: codifica dei caratteri – convertire testo Unicode in ASCII se il destinatario supporta solo quello), serializzazione di strutture complesse in un formato standard (tipo JSON, XML, ASN.1), compressione (per ridurre la mole di dati da trasmettere) e cifratura per garantire confidenzialità. Il livello di presentazione è quindi dove i dati grezzi dell’applicazione vengono preparati per la trasmissione e viceversa all’arrivo vengono rielaborati in forma utilizzabile dall’app. Un esempio concreto: in una connessione HTTPS, il contenuto HTTP vero e proprio viene cifrato a livello presentazione (TLS) e poi passato come flusso cifrato al livello trasporto (TCP) per l’invio. Nella sicurezza informatica, il livello 6 è cruciale perché è dove avvengono crittografia/decrittografia e codifiche. Ad esempio, molti attacchi web come XSS, SQLi, ecc., sfruttano mancate conversioni di formato (un input utente che andava interpretato solo come testo viene invece eseguito come codice). Una robusta “presentazione” in un’applicazione web significa escaping appropriato di caratteri speciali quando dati non fidati vengono inseriti in HTML, SQL, XML, ecc., per prevenire l’esecuzione indesiderata – in altri termini, difese come output encoding per XSS o query parametrizzate (che separano i dati dalla sintassi SQL) attengono a questo concetto. Dal punto di vista delle comunicazioni di rete, standard come TLS garantiscono che i dati in presentazione siano cifrati end-to-end: un responsabile deve assicurarsi che i servizi critici usino protocolli sicuri (es. preferire FTPS/SFTP a FTP in chiaro, HTTPS a HTTP, SSH a Telnet, ecc.) cosicché anche se il traffico viene intercettato a livello inferiore, risulti incomprensibile. Inoltre, il livello presentazione include la gestione di certificati digitali e formati di scambio: competenze in PKI e negoziazione di protocolli (quali ciphersuite TLS sono consentite, usi di TLS 1.3 vs deprecazione di SSLv3/TLS1.0 insicuri) rientrano tra quelle richieste a un esperto di sicurezza per garantire che i dati “presentati” in rete siano sempre protetti secondo lo stato dell’arte.
Livello 7: Applicazione. È il livello più alto, quello con cui interagiscono direttamente le applicazioni software e, in ultima analisi, l’utente finale. Fornisce quindi i servizi di rete più vicini all’utilizzatore: protocolli di posta elettronica (SMTP per inviare, IMAP/POP3 per ricevere), web (HTTP/HTTPS), trasferimento file (FTP, SFTP), servizi directory (LDAP), accesso remoto (SSH, Telnet) e molti altri servizi specializzati (DNS stesso è considerato applicazione nel modello OSI, così come protocolli voce su IP come SIP/VoIP, etc.). Al livello applicazione si definiscono i formati dei messaggi di alto livello e le procedure di scambio specifiche di quello use case. Ad esempio, HTTP definisce come un client può richiedere una risorsa con un verbo (GET, POST, etc.) e come un server risponde con un codice di stato e eventuale contenuto; SMTP definisce i comandi per trasmettere email tra server; SSH definisce come incapsulare un terminale remoto sicuro. Dal punto di vista sicurezza, il livello applicazione è dove tipicamente risiedono le vulnerabilità logiche e di input più complesse: injection, buffer overflow applicativi, deserializzazione insicura, autenticazione debole, autorizzazioni errate e così via (molte delle categorie OWASP Top 10 per applicazioni web sono questioni di livello 7). Un responsabile per gli incidenti deve avere familiarità con i protocolli applicativi per riconoscere anomalie: es. traffico HTTP verso un server web che contiene comandi sospetti ( /admin/delete.php?id=1;DROP TABLE users) potrebbe indicare un attacco SQLi; oppure richieste LDAP malformate potrebbero segnalare un tentativo di exploit di Active Directory. Anche la modellazione delle minacce avviene in gran parte a livello applicazione: qui si chiede “cosa succede se un utente malintenzionato invia dati oltre i limiti?”, “cosa se effettua sequenze di API fuori ordine?”, etc. Ogni protocollo ha le sue particolarità: FTP ad esempio espone credenziali in chiaro se non è protetto e inoltre utilizza porte dinamiche (che i firewall devono gestire in modo speciale, con moduli helper, altrimenti può essere abusato per bypassare porte); SMTP può essere sfruttato per relay non autorizzati se non configurato bene (open relay) e per diffondere phishing/malware; HTTP è il veicolo di tantissimi attacchi, dai malware via download, al phishing via siti clone, fino alle exploit di librerie web.
Ai fini di prevenzione e gestione degli incidenti, è utile dotarsi di strumenti di Application Layer Security: WAF (Web Application Firewall) per analizzare il traffico HTTP e bloccare pattern malevoli noti (anche se non sostituisce il secure coding, è un utile layer difensivo), antivirus/antimalware gateway per controllare file trasferiti via protocolli applicativi (es. scanner SMTP per allegati email, o proxy HTTP con antimalware integrato) e sistemi di Data Loss Prevention (DLP) che analizzino il contenuto applicativo in uscita (es. per individuare stringhe che sembrano numeri di carta di credito o dati classificati e bloccarne l’esfiltrazione via email/web). Inoltre, la telemetria di livello 7 (log applicativi) è fondamentale in fase di risposta: i log di un server web (es. access log di Apache/Nginx) possono mostrare un pattern di exploit (decine di tentativi di accedere a wp-admin.php indicano un bot che cerca di violare WordPress), i log di un database possono mostrare query strane (tentativi di selezionare tabelle di sistema da un’app che non dovrebbe), i log di un server DNS possono indicare tunneling come detto. Un SOC ben organizzato correla eventi su più livelli: ad esempio, un alert IDS su un payload sospetto a livello 4+7 (un pacchetto TCP con dentro un comando SQL anomalo) incrociato con un log applicativo di errore database può confermare un tentativo di SQL injection riuscito o meno.
Integrazione e concetti trasversali: Una cosa importante da capire è che i livelli non sono completamente isolati: ogni livello aggiunge il suo overhead e le sue vulnerabilità possono propagarsi. Ad esempio, un attacco DDoS a livello 7 (come HTTP Flood, numerosissime richieste web) sfrutta comunque la connessione TCP sottostante: mitigarlo può richiedere azioni a livello 7 (rispondere con CAPTCHA, tarpit) ma anche a livello 4 (limitare connessioni per IP) e livello 3 (filtrare IP noti malevoli). Oppure, una falla a livello 2 come ARP poisoning può portare a Man-in-the-Middle che intercetta e poi manipola dati di livello 7 (inserendo script malevoli nel traffico web, se questo non è cifrato). Conoscere l’OSI aiuta a compartimentalizzare i problemi e a parlare con gli specialisti giusti: ad esempio, se si riscontra che “le email non arrivano a destinazione”, potrebbe essere un problema di livello 7 (misconfigurazione SMTP, o bloccate per contenuti), livello 3 (routing verso il mail server errato) o altro; il modello OSI offre un approccio per isolare: ping (L3), telnet porta 25 (L4), analisi logs SMTP (L7) e così via. Nella risoluzione di incidenti, spesso si “risale la pila OSI” per individuare dove esattamente risiede il fault o l’attacco.
In conclusione, il modello OSI con i suoi 7 livelli – Fisico, Collegamento dati, Rete, Trasporto, Sessione, Presentazione, Applicazione – è uno strumento concettuale che aiuta a progettare, proteggere e diagnosticare le reti di calcolatori. Ogni livello introduce considerazioni di sicurezza specifiche e un responsabile per la sicurezza informatica deve averne padronanza per implementare una strategia di difesa in profondità: multiple protezioni sovrapposte attraverso la pila, cosicché anche se un attacco aggira un livello (es. malware che viaggia cifrato su HTTPs – invisibile al firewall L7), venga intercettato a un altro (es. analisi comportamentale al livello applicazione endpoint, o decrittazione in un proxy per l’ispezione). Lo standard ISO/OSI stesso, pur teorico, ha generato protocolli e influenzato architetture – conoscere ad esempio che X.509 (certificati) nasce da standard OSI di presentazione, o che LDAP è figlio di X.500 (applicazione OSI), arricchisce la comprensione storica e pratica che torna utile quando si incrociano sistemi eterogenei (ad es. integrazione di vecchi sistemi mainframe o SCADA che a volte ancora usano stack particolari).
Fondamenti di algoritmi
Un algoritmo è una procedura definita, costituita da una sequenza finita di istruzioni, che risolve un problema o svolge un determinato compito. In informatica, gli algoritmi rappresentano le ricette operative per qualsiasi programma: dal semplice calcolo di una somma alla crittografia avanzata, tutto si riduce a passi elementari che il calcolatore esegue. Formalmente, si richiede che un algoritmo abbia alcune proprietà: finitezza (deve terminare in un numero finito di passi), determinismo (stessi input producono stessi output, a meno di componenti aleatorie volute), non ambiguità (ogni passo è definito in modo univoco, interpretabile senza dubbio) e generalità (risolve una classe di problemi, non un solo caso specifico).
Esempi di algoritmi classici includono: l’algoritmo di ordinamento (ordinare una lista di numeri o stringhe – con varianti famose come QuickSort, MergeSort, HeapSort, etc.), algoritmi di ricerca (trovare un elemento in una collezione – es. ricerca lineare vs ricerca binaria in una lista ordinata), algoritmi di grafi (cammini minimi, visite in profondità/ampiezza, ecc.), algoritmi di ottimizzazione (zaino, percorso più breve, flusso massimo) e tanti altri. Nella pratica quotidiana, un professionista di sicurezza può incontrare algoritmi ad esempio nell’analisi di performance di un sistema (sapere se una certa operazione è O(n) lineare o O(n^2) quadratica aiuta a capire se un attacco di stress potrebbe causare rallentamenti significativi), oppure nella comprensione di meccanismi crittografici (dove la solidità di un algoritmo di cifratura spesso si basa su problemi computazionalmente difficili, come la fattorizzazione dei grandi numeri primi per RSA).
Complessità computazionale: uno degli aspetti fondamentali nello studio degli algoritmi è la loro complessità, cioè la quantità di risorse (tempo di calcolo, spazio di memoria) che richiedono in funzione della dimensione dell’input. La complessità in termini di tempo viene di norma espressa tramite la notazione O-grande, che fornisce un limite superiore asintotico sulla crescita del costo computazionale al crescere di n (taglia input). Ad esempio, dire che un algoritmo è O(n log n) significa che per gestire input più grandi, il suo tempo cresce proporzionalmente a n log n. In generale, classifichiamo le complessità asintotiche in classi come: costante O(1), logaritmica O(log n), lineare O(n), quasi-lineare O(n log n), quadratica O(n^2), cubic O(n^3), …esponenziale O(2^n) e oltre. Chiaramente, algoritmi più efficienti sono preferibili – un problema risolvibile con un algoritmo O(n) sarà gestibile per input grandi molto meglio di uno O(n^2). Per contestualizzare: in un attacco di forza bruta, provare tutte le combinazioni di una password di lunghezza n può essere ~O(k^n) (esponenziale nel numero di caratteri se ogni posizione ha k possibilità), il che spiega perché aumentando lunghezza e complessità delle password la ricerca esaustiva diventa impraticabile.
Per un responsabile alla sicurezza, la teoria degli algoritmi ha ricadute pratiche. Un esempio evidente è nella crittografia: la sicurezza di molti algoritmi crittografici è legata alla complessità computazionale di certi problemi. RSA, ECC, Diffie-Hellman si basano sul fatto che alcuni problemi (fattorizzazione di interi grandi, logaritmo discreto in certi gruppi) sembrano richiedere tempo esponenziale con i migliori algoritmi noti: quindi, con chiavi abbastanza lunghe, la brute force diventa impossibile nei tempi dell’universo (a meno di progressi algoritmici o quantistici). Comprendere questo aiuta a scegliere parametri sicuri: ad esempio, sapere che il migliore algoritmo di fattorizzazione noto ha complessità sub-esponenziale (sì, c’è il Number Field Sieve che è circa O(exp( (64/9)^(1/3) * (log n)^(1/3) * (log log n)^(2/3) )) ), consente ai crittografi di stimare quanti bit di RSA servono (oggi almeno 2048-bit) per resistere X anni. Un altro esempio: gli algoritmi di hashing (SHA-256, SHA-3) sono progettati per essere veloci da calcolare ma non invertibili senza provare molte possibilità. La difficoltà di trovare collisioni in SHA-256 è legata a dover provare 2^128 operazioni (complessità bruteforce). Se un attaccante scoprisse un algoritmo molto migliore (es. O(2^64)), quell’hash non sarebbe più sicuro. Dunque, chi lavora in sicurezza deve seguire anche le scoperte nel mondo algoritmi (ad esempio, i recenti progressi su SHA-1 collisioni hanno reso questo hash deprecato). E ovviamente il calcolo quantistico promette di ridurre drasticamente la complessità di alcuni problemi: Shor’s algorithm porta la fattorizzazione a complessità polinomiale, distruggendo RSA/ECC una volta che avremo quantum computer abbastanza grandi.
Al di là della crittografia, l’analisi degli algoritmi è utile per ottimizzare le difese e attacchi. Dal lato difensivo: un SIEM che raccoglie log deve avere algoritmi di correlazione efficienti, altrimenti con milioni di eventi genererà ritardi – un buon coordinatore sa scegliere strumenti validi o architetture big data (es. utilizzare motori come Elasticsearch che usano algoritmi di ricerca efficaci). Dal lato offensivo: alcuni attacchi DoS sfruttano algorithmic complexity attacks, ad esempio l’HashDoS (inviare tanti input calibrati per provocare collisioni in una tabella hash usata dall’applicazione, degradando le look-up da O(1) a O(n) e bloccando il server) – questo fu dimostrato su Java, PHP e altri linguaggi, costringendo a migliorare gli algoritmi di hashing o introdurre randomizzazione. Un altro esempio sono i ReDoS (Regular Expression Denial of Service): usare input particolari per mandare in worst-case l’algoritmo di matching delle espressioni regolari (che in alcuni engine può diventare esponenziale). Questi sono attacchi sottili che richiedono comprensione di come un algoritmo risponde al worst-case.
Strutture dati e algoritmi: spesso insieme agli algoritmi si studiano le strutture dati (array, liste, pile, code, alberi, grafi, tabelle hash, ecc.), che influiscono sulle prestazioni. Una buona scelta di struttura può prevenire inefficienze – es: cercare elementi duplicati in un array fa O(n^2) naive, ma usando una hash set diventa O(n) mediamente. Nella sicurezza software, questo significa anche prevenire vulnerabilità di prestazioni: se un input controllato dall’utente potrebbe indurre il programma a usare un algoritmo quadratico, un attaccante può sfruttarlo per rallentarlo. Ad esempio, generare intenzionalmente situazioni pessime (come l’HashDoS citato). Dunque, parte del secure coding è anche evitare costrutti algoritmicamente rischiosi o porre limiti (ad esempio, limitare lunghezza massima di input per evitare loop troppo lunghi).
P vs NP e problemi intrattabili: un concetto teorico ma con implicazioni è la distinzione tra problemi in P (risolvibili in tempo polinomiale) e in NP (verificabili in polinomiale, ma non si conosce algoritmo polinomiale per risolverli). Molti problemi di ottimizzazione o ricerca combinatoria sono NP-difficili (come il Traveling Salesman, il Subset Sum, ecc.). Per la sicurezza, questo spiega perché certi obiettivi dell’attaccante sono difficili: ad esempio, craccare un cifrario robusto equivale a cercare nello spazio delle chiavi (che cresce esponenzialmente col numero di bit). Oppure, un software antivirus che voglia decidere in generale se un programma è malevolo va incontro al problema della fermata e questioni indecidibili; per questo gli antivirus usano euristiche imperfette – capire i limiti computazionali ci fa comprendere perché non esiste e probabilmente non esisterà mai “l’algoritmo perfetto” per distinguere malware da software legittimo in ogni caso (problema indecidibile, riducibile all’halting problem). Quindi si lavora per euristiche (firma, comportamento) sapendo che esisteranno falsi negativi/positivi.
Algoritmi distribuiti e fault tolerance: In un contesto come la sicurezza nazionale, con infrastrutture distribuite, è importante conoscere anche gli algoritmi per consenso distribuito (es. Paxos, Raft) e per gestione di guasti – questi sono algoritmi non banali che garantiscono consistenza e disponibilità su più nodi; la sicurezza di sistemi come blockchain, oppure di sistemi cluster per servizi critici, discende dalla solidità di tali algoritmi. Ad esempio, la robustezza di una blockchain dipende dall’algoritmo di consenso (Proof of Work è un “algoritmo” in senso lato con complessità regolata dalla difficoltà, BFT consensus ha tolleranza fino a f nodi corrotti se N > 3f, ecc.).
In sintesi, i fondamenti di algoritmi equipaggiano il professionista con un approccio analitico ai problemi: capire l’ordine di grandezza di un attacco brute-force, valutare l’impatto prestazionale di una misura di sicurezza (es. criptare tutto il traffico aggiunge overhead, ma di quanto?), scegliere strumenti in base alla scala (un SIEM con algoritmi subottimali funzionerà su 1k eventi al secondo ma non su 100k eps). La è quindi parte del bagaglio di un coordinatore, sebbene non debba implementare algoritmi da zero quotidianamente, deve saperne leggere i risultati e conversarci: ad esempio, comprendere un report che dice “la complessità computazionale di rompere AES-256 è di 2^254 operazioni, che con i mezzi attuali è impraticabile” oppure “un attacco di tipo meet-in-the-middle riduce la complessità su 2DES da 2^112 a 2^57, ecco perché 2DES non è considerato sicuro”. Senza basi sugli algoritmi, tali affermazioni sarebbero aride; con le basi, diventano guida all’azione (passare direttamente ad AES o 3DES perché 2DES è debole, ecc.). Dunque la padronanza degli algoritmi e della loro complessità permette di valutare rischi in modo quantificabile e di progettare contromisure efficaci.
Linguaggi di programmazione (imperativi, di scripting, orientati agli oggetti)
I linguaggi di programmazione sono gli strumenti con cui vengono implementati gli algoritmi e le funzionalità software. Esistono centinaia di linguaggi, ma essi possono essere classificati per paradigma in base allo stile con cui si descrivono le istruzioni e i dati. In questa sezione ci focalizziamo su tre categorie importanti: linguaggi imperativi, linguaggi di scripting e linguaggi orientati agli oggetti. Ognuno di questi paradigmi presenta caratteristiche peculiari, vantaggi, limitazioni e implicazioni per la sicurezza del codice prodotto.
Linguaggi imperativi (procedurali)
La programmazione imperativa è il paradigma classico in cui un programma è visto come una sequenza di istruzioni che modificano lo stato del programma stesso (variabili, strutture dati) per ottenere il risultato desiderato. In altre parole, l’attenzione è sul come fare le cose: si specificano esplicitamente i passi da seguire, in ordine, includendo strutture di controllo come assegnamenti, cicli ( for , while ), condizionali ( if / else ), chiamate di funzioni/procedure, ecc. La maggior parte dei linguaggi tradizionali rientrano in questo paradigma: linguaggi procedurali come C, Pascal, BASIC, Fortran (dove esistono procedure e funzioni come unità di modularizzazione) sono imperativi; anche il linguaggio Assembly (di basso livello) è imperativo puro, in quanto si scrivono istruzioni macchina che cambiano registri e memoria step-by-step. Persino linguaggi come Java o Python supportano uno stile imperativo (Python, ad esempio, pur essendo multi-paradigma, permette di scrivere codice procedurale imperativo). Caratteristiche tipiche di linguaggi imperativi/procedurali includono la gestione esplicita della memoria (in C, ad esempio, con malloc / free o lo stack frame delle funzioni), l’uso di variabili mutate nel corso dell’esecuzione e un flusso di controllo che può usare costrutti come goto (nei casi più base) o strutture strutturate. Il codice imperativo rispecchia l’architettura di von Neumann: infatti questi linguaggi sono “vicini al modo in cui lavora l’elaboratore”, aggiornando locazioni di memoria e eseguendo istruzioni in sequenza.
Implicazioni per la sicurezza: nei linguaggi imperativi a basso livello (es. C, C++, assembler) sta l’origine di molte vulnerabilità classiche, proprio perché lasciano molto controllo (e responsabilità) al programmatore. Ad esempio, la gestione manuale della memoria in C/C++ è fonte di bug quali buffer overflow, use-after-free, double free, integer overflow e così via, che se non prevenuti portano ad exploit di memoria e code execution arbitraria. Un responsabile della sicurezza deve conoscere bene questi rischi: ad esempio, l’attacco stack buffer overflow sfrutta il fatto che in C si possono scrivere dati fuori dai limiti di un array, andando a sovrascrivere il return address di funzione nello stack; mitigazioni come canary, ASLR, NX bit sono stati sviluppati per attutire il problema, ma la vera soluzione è scrivere codice robusto (o usare linguaggi che prevengono out-of-bounds, come Java o Rust). Nei contesti dove la performance e il controllo spingono a usare C/C++ (kernel OS, driver, sistemi embedded, highperformance computing), è cruciale adottare standard di codice sicuro (es. CERT C Coding Standard) e strumenti di analisi (sanitizer, static analysis) per ridurre i bug imperativi.
Nei linguaggi imperativi di più alto livello (es. Java, che è orientato agli oggetti ma si può vedere come imperativo nel flusso; o Python se scrivi script procedurali), molti errori di memoria sono evitati (garbage collector, check runtime su array, ecc.), ma persistono problemi come la gestione delle condizioni di errore, la concorrenza (race conditions se thread paralleli accedono a variabili condivise), etc. Il paradigma imperativo incoraggia l’uso di stato mutabile e questo è terreno di race condition e TOCTOU (Time-of-check to time-of-use) bugs: ad esempio, un programma imperativo multi-thread potrebbe controllare l’esistenza di un file e poi aprirlo; se tra check e open passa tempo e un attaccante cambia il file (symlink attack), abbiamo un TOCTOU bug. Un responsabile deve sapere che certe classi di vulnerabilità (soprattutto in codice multi-thread o multi-processo) derivano dalla difficoltà di ragionare su stato mutabile e tempi di esecuzione – ecco perché paradigmi alternativi (es. la programmazione funzionale, che evita stato mutabile) vengono talvolta adottati per ridurre bug, ma la maggioranza del codice rimane imperativo.
In campo offensivo, conoscere la natura imperativa dei programmi aiuta a fare reverse engineering: ad esempio, i malware scritti in C/C++ compilano in assembly macchina e un analista dovrà interpretare quell’assembly come un flusso di operazioni (imperative) per capire cosa fa il malware. Saper leggere pseudocodice imperativo o flusso di un binario è competenza essenziale in analisi malware/forense.
Esempi di linguaggi imperativi popolari: C (usato per kernel, sistemi operativi, software di rete; critico per exploit), C++ (che aggiunge oggetti ma resta principalmente imperativo, usato in applicativi veloci, anche in diversi malware avanzati), Ada (in ambito aerospaziale, focus su sicurezza e affidabilità), Go (Google Go, imperativo concurrent, con gestione memoria automatica e forte supporto al multithread – spesso usato per strumenti di rete e cloud, la sua semplicità riduce alcune classi di bug rispetto a C) e tanti altri incl. Rust (che pur supportando vari stili viene spesso usato in modo imperativo ma “memory safe” grazie al suo sistema di proprietà).
Linguaggi di scripting
Un linguaggio di scripting è tipicamente un linguaggio interpretato, di alto livello, pensato per automatizzare compiti in un ambiente runtime esistente. Il termine deriva dal fatto che inizialmente questi linguaggi erano usati per scrivere script (copioni) che eseguono operazioni su sistemi operativi o applicazioni, invece che per sviluppare applicazioni stand-alone complesse. Caratteristiche comuni dei linguaggi di scripting includono: tipizzazione dinamica (non occorre dichiarare esplicitamente il tipo delle variabili), gestione automatica della memoria (garbage collection), sintassi semplice e concisa, e disponibilità di un ambiente interpretativo (shell, REPL) dove eseguire i comandi al volo. Esempi classici sono bash/sh (scripting di shell Unix), JavaScript originariamente scripting client-side per i browser, oggi grazie a Node.js usato anche lato server), Python, Perl, Ruby, PHP, PowerShell (scripting avanzato su Windows), ecc. Questi linguaggi spesso interagiscono con un sistema più grande: ad esempio, JavaScript in una pagina web manipola l’HTML/CSS e il browser funge da runtime; Python può essere usato come script per automazione di task di sistema, o incorporato in applicazioni; PHP è un linguaggio di scripting lato server per generare contenuti web dinamici; Bash orchestrа comandi del sistema operativo e programmi.
Il vantaggio dei linguaggi di scripting è la produttività e la facilità d’uso: permettono di sviluppare rapidamente funzionalità senza gestire i dettagli di basso livello (gestione memoria, compilazione). Questo li rende ideali per la scrittura di strumenti di automazione, estrazione di dati, prototipazione, e (nel nostro contesto) per molti script e tool di sicurezza. Un analista di sicurezza scrive comunemente script Python o Bash per analizzare log, per eseguire scansioni personalizzate, per automatizzare reazioni a incidenti (es. uno script che disattiva automaticamente un account sospetto su più sistemi, integrandosi via API).
Implicazioni per la sicurezza: Da un lato, usando linguaggi di scripting si evitano molte vulnerabilità tipiche del C (buffer overflow, ecc.), quindi per script e tool interni spesso si preferisce Python o PowerShell per ridurre rischi di bug memory corruption. Dall’altro lato, i linguaggi di scripting portano sfide proprie: essendo spesso interpretati, il codice può essere più facilmente letto/modificato da un attaccante se trova gli script sul sistema (a meno di offuscazioni); e poiché molti sono usati in contesti di elevati privilegi (si pensi a script Bash lanciati come root per manutenzioni, o script PowerShell per amministrazione di dominio), diventano bersagli: gli attaccanti possono tentare di alterare script esistenti (supply chain, se uno script viene scaricato da internet e poi eseguito con fiducia – come a volte succede con script di installazione), oppure usarli a proprio vantaggio (es. se un webserver permette di caricare ed eseguire file PHP, l’attaccante può caricare una web shell PHP, sfruttando il linguaggio di scripting del server per eseguire comandi arbitrari sul sistema). Ciò sottolinea la necessità di trattare gli script come codice a tutti gli effetti: revisionare la sicurezza, proteggerli con controlli di integrità, limitarne i permessi di esecuzione, ecc.
Nei sistemi, spesso i linguaggi di scripting fungono da collante: ad esempio, un attaccante che abbia compromesso un server Linux potrebbe scrivere uno script bash per mantenere la persistenza (inserendolo magari in /etc/init.d per avviarsi al boot) o per esfiltrare dati periodicamente. Dunque, chi gestisce la sicurezza deve monitorare non solo eseguibili compilati ma anche i file di script, e utilizzare strumenti tipo OSSEC o Tripwire per notare modifiche anomale a script chiave. Le applicazioni web scritte in linguaggi di scripting (PHP, Python via Django/Flask, JavaScript via Node.js) ereditano i rischi di vulnerabilità applicative (XSS, injection, etc.), con la differenza che essendo i linguaggi spesso molto dinamici può essere più facile introdurre errori se non si seguono regole (es. in PHP, un tempo la registrazione globale delle variabili portava a vulnerabilità se non attenta; in Node.js, la presenza di un ricco ecosistema di package richiede attenzione alla supply chain e a aggiornare le dipendenze per evitare moduli malevoli).
Esempi pratici in scenario di sicurezza: uno script Python può essere scritto per analizzare i pacchetti di rete (usando Scapy) e rilevare un pattern di scansione, inviando alert. Oppure script Bash vengono usati negli SIEM per parsare formati di log e normalizzarli. Con PowerShell, un team di incident response può interrogare in modo massivo tutte le macchine di un dominio cercando indicatori di compromissione – infatti, oggi gli attaccanti stessi usano PowerShell per i loro scopi (PowerShell Empire e altri framework di post- exploitation): ciò perché con script si integrano nativamente nell’ambiente senza portare eseguibili che possano essere bloccati da whitelist. Un reaponsabile deve essere consapevole di queste tattiche e, ad esempio, abilitare PowerShell Logging e Constrained Language Mode su host Windows per avere visibilità e limitare l’uso malevolo.
In sintesi, i linguaggi di scripting sono potenti e flessibili; per la difesa informatica sono armi essenziali (per automazione e integrazione), ma vanno gestiti con regole di sicurezza come qualsiasi codice: controllo delle entrate (validazione input negli script), least privilege (non far girare script con privilegi oltre il necessario), mantenimento (aggiornare le versioni interpreter – molte falle in PHP/Python stesso corrette con patch), e rilevamento di abuso (monitorare esecuzioni anomale, come un utente non amministrativo che improvvisamente lancia script PowerShell con comandi di dumping credenziali).
Linguaggi orientati agli oggetti (OOP)
La programmazione orientata agli oggetti (Object-Oriented Programming, OOP) è un paradigma in cui il software viene modellato come un insieme di oggetti che interagiscono tra loro scambiandosi messaggi (chiamando metodi l’uno dell’altro). Un oggetto incapsula stato (dati, sotto forma di attributi/variabili) e comportamento (funzionalità, sotto forma di metodi/funzioni). I linguaggi OOP offrono costrutti come classi (definizioni generiche da cui istanziare oggetti concreti), ereditarietà (una classe può derivare da un’altra ereditando attributi e metodi, consentendo specializzazione e riuso del codice), polimorfismo (il fatto che chiamate a metodi possano riferirsi a implementazioni diverse in classi diverse, tipicamente via overriding – es. diversi oggetti tipo Figura con metodo disegna() implementato diversamente in Cerchio, Quadrato), e incapsulamento (detto sopra: la capacità di nascondere i dettagli interni di un oggetto e offrire solo interfacce pubbliche – spesso con modificatori di accesso come public/private/protected).
L’OOP nasce per gestire meglio la complessità di grandi progetti software, modellando entità vicine al dominio reale e promuovendo modularità e riusabilità. Ad esempio, in un sistema bancario si potrebbero avere classi Conto, Transazione, Cliente con relazioni di composizione e specializzazione (un ContoCorrente estende Conto aggiungendo un fido, etc.). Linguaggi strettamente OOP includono Java, C#, C++ (ibrido, multi-paradigma ma con forte supporto OOP), Python (multi-paradigma ma con OOP completo), Ruby, JavaScript (che in realtà è basato su prototipi, ma concettualmente OOP), ecc. Oggi, OOP è forse il paradigma dominante nello sviluppo di applicazioni enterprise.
Implicazioni per la sicurezza: la programmazione a oggetti porta benefici di organizzazione, ma introduce anche superfici di attacco peculiari. Ad esempio, la presenza di gerarchie di classi e funzioni virtuali apre il fianco a attacchi come l’overwrite di puntatori virtuali in exploit memory corruption (in C++ un oggetto ha un vtable pointer – se un buffer overflow sovrascrive quel puntatore, un attaccante può far eseguire codice arbitrario quando il programma chiamerà un metodo virtuale dell’oggetto). Questa è una considerazione bassa, valida solo in linguaggi non memory-safe (C++): mitigazioni come Control Flow Guard di Microsoft cercano proprio di impedire salto a vtable rogue.
Dal punto di vista di design, l’OOP a volte incoraggia un’eccessiva fiducia sugli oggetti – ad esempio, concetti come l’esecuzione di codice mobile: Java Applet, ActiveX, .NET assemblies, tutti casi in cui oggetti provenienti da terze parti vengono eseguiti localmente, con meccanismi di sandbox vari (Java aveva il security manager per applet, ActiveX si basava su firme digitali – con noti problemi se l’utente autorizzava un controllo malevolo). Questo scenario di mobile code necessita che i runtime siano robusti nel far rispettare i confini (spesso non lo furono, portando a deprecazione di tali tecnologie).
Un altro punto: i framework ad oggetti (tipici in Java, C#) che fanno ampio uso di riflessione e serializzazione. La serializzazione di oggetti è la capacità di convertire un oggetto in una forma (tipicamente binaria o testuale) per salvarlo o trasmetterlo, e poi ricostruirlo. Questo meccanismo ha portato a exploit come le deserialization vulnerabilities: se un’app accetta da input un oggetto serializzato (ad esempio, un token di sessione Java serializzato inviato nel cookie) un attaccante potrebbe manipolarlo per far istanziare oggetti malevoli o con stati inconsistenze. Ci sono state grosse vulnerabilità (es. CVE di Apache Commons-Collections e altri, dove un oggetto opportunamente costruito portava all’esecuzione di comandi arbitrari durante la deserializzazione, perché la classe aveva blocchi statici o metodi finalize con chiamate pericolose). Un responsabile deve conoscere questi pattern: ad esempio, in pen test su applicazioni Java enterprise, la deserializzazione non sicura è un must-check. La best practice è evitare la deserializzazione di oggetti da fonti non fidate, o usare formati sicuri (JSON, protocolli con schema), o whitelisting di classi deserializzabili.
Controllo degli accessi a oggetti: OOP a volte induce a pensare che i controlli possano essere fatti a livello di oggetto, ma in ambienti multi-utente/multi-tenant non basta. Ad esempio, in un’app web OOP potrebbe esserci metodo Documento.approva(); ma bisogna assicurarsi a livello applicativo che l’utente X possa approvare solo i documenti di sua competenza. Ciò porta a vulnerabilità come Insecure Direct Object Reference (IDOR): se l’app espone un endpoint /documento/approva?id=123 che chiama internamente doc.approva(), un utente malintenzionato potrebbe fornire un id di un documento che non dovrebbe poter modificare e se manca il controllo, l’oggetto viene comunque recuperato e il metodo invocato (violazione autorizzazione). L’approccio OOP puro a volte fa sottovalutare questo – perché a livello di codice, chiamare il metodo è lecito, ma manca il contesto di sicurezza. Quindi, un principio: integrare controlli di autorizzazione in tutti i metodi sensibili, oppure usare un framework di sicurezza (es. Spring Security) che si integri con l’OOP (annotation tipo @PreAuthorize su metodi, ecc.).
Benefici OOP per la sicurezza: d’altro canto, se ben applicato, OOP migliora la sicurezza del codice: l’incapsulamento può prevenire accessi indesiderati – se tutti gli campi sono private e l’oggetto valida i dati tramite setter, è più difficile corrompere lo stato. L’ereditarietà e polimorfismo possono favorire la scrittura di checker di sicurezza generici: ad esempio, una classe base Utente con metodo virtuale haPermesso(azione) può essere implementata diversamente in UtenteStandard e Admin, permettendo all’app di chiedere genericamente utente.haPermesso("DELETE_USER") senza conoscere la classe concreta – design pulito che centralizza logica di auth. Tuttavia, se un attaccante riesce a far istanziare una sottoclasse controllata (vedi problema deserialization su classpath), quell’interfaccia generica potrebbe rispondere “sì ho permesso” falsamente. Perciò la riflessione insegna: l’OOP va usato con coscienza e meccanismi magici come riflessione, dependency injection, ecc. vanno vigilati. Ad esempio, i container di inversion of control (Spring, etc.) automaticamente viranano dipendenze tra oggetti; se configurati male, potrebbero esporre bean sensibili su canali remoti (vedi ad es. JMX misconfigurato, o endpoint actuator in Spring Boot esposti senza auth, che permettono di manipolare runtime).
In termini di linguaggi concreti: Java e C# sono fortemente tipizzati e gestiti, riducono molti errori (no buffer overflow classici), ma ricordiamo incidenti come Log4Shell (una vulnerabilità in un logger che attraverso un lookup JNDI permetteva di scaricare un oggetto remoto – combinazione di serializzazione, rete e riflessione). Dunque, anche se il linguaggio previene certi bug, rimane la superficie dei runtime environment (JVM, .NET) e delle librerie di base. C++ aggiunge OOP al C ma mantiene la pericolosità del controllo manuale: così somma rischi (memory + OOP). Sviluppatori esperti possono scrivere codice sicuro, e moderne guidelines (C++ Core Guidelines) spingono a usare costrutti sicuri (smart pointer invece di raw pointer, etc.), ma molto codice legacy è vulnerabile. Python, JavaScript, PHP, Ruby supportano OOP ma in modo dinamico: qui la flessibilità è massima (es. in Python puoi aggiungere attributi a runtime agli oggetti, in JavaScript modificare prototipi al volo), e questo dinamismo può essere sfruttato malevolmente. Ad esempio, Prototype Pollution in JavaScript: se una libreria non isola bene i dati, un attaccante può iniettare proprietà nell’Object prototype globale, influenzando tutti gli oggetti (impatto a cascata su app intera). Ciò evidenzia che la surface di errori si sposta: meno memory corruption, più logiche e inconsistenze.
Paradigmi misti: molti team oggi adottano linguaggi multi-paradigma (es. Python, JavaScript) o abbracciano stili come la programmazione funzionale all’interno di contesti OOP (es. metodi immutabili, uso di lambda e stream in Java). La programmazione funzionale riduce certi bug (immutatibilità -> no race, no side effects difficili), ma non sempre è praticabile da sola (sistemi I/O, UI etc. spesso sono più facilmente espressi con oggetti). Tuttavia, un responsabile dovrebbe promuovere “il giusto strumento per il lavoro”: in componenti dove la robustezza è critica, valutare linguaggi memory-safe (Java, C#) o addirittura “provably safe” (es. Rust in sistemi), oppure script come Python per prototipi e analisi rapida sapendo che saranno un po’ più lenti. Per parti performance-critical ma delicate, considerare tecniche di verifica (es. strumenti di static analysis, o addirittura approcci formali se giustificato, come SPARK/Ada per software militare).
Sicurezza e ciclo di vita del software: indipendentemente dal linguaggio o paradigma, contano i processi: code review, static analysis, fuzzing, patching, gestione dipendenze (questo soprattutto in scripting: pip/npm composer – supply chain risk). Un responsabile dovrebbe assicurarsi che i team di sviluppo seguano secure coding guidelines e che ogni linguaggio usato abbia i suoi checker (es. linters, SonarQube ruleset per Java, ESLint/Retire.js per JS, Bandit per Python, PHPStan per PHP, ecc.).
In conclusione, comprendere i vari tipi di linguaggi e paradigmi consente a un responsabile della sicurezza di dialogare efficacemente con gli sviluppatori e valutare i rischi del software in esame. Ad esempio, se un nuovo sistema da proteggere è scritto in C++ con moduli Python embedded (come a volte succede in tool scientifici), egli saprà che deve considerare sia vulnerabilità a basso livello (C++) sia di alto livello (injection possibili in Python eval? ecc.). Se invece la sua organizzazione passa a microservizi in Node.js e Go, studierà gli specifici pitfalls (Prototype pollution, moduli npm malevoli, vs concurrency issues e memory usage in Go). In definitiva, la diversità di linguaggi riflette la diversità di problemi da risolvere; per la sicurezza informatica, ogni linguaggio/paradigma aggiunge un tassello: conoscendoli, si può implementare difese profonde (ad esempio: firewall WAF che riconosce attacchi comuni in PHP vs in Node), e soprattutto prevenire incidenti formando i team di sviluppo sulle giuste pratiche per quel contesto (ad es., per Java: “attenti alla deserializzazione di oggetti”; per C: “usa snprintf invece di sprintf per prevenire overflow”; per JavaScript: “valida bene input prima di usarli in DOM manipulations per evitare XSS”, e così via). Un professionista completo di sicurezza sa quindi muoversi trasversalmente tra il codice, individuando pattern pericolosi e suggerendo soluzioni appropriate al paradigma in uso.
Nel mondo odierno, dove la dipendenza dalla tecnologia è crescente, la cybersecurity è diventata un pilastro fondamentale. La sicurezza informatica non riguarda solo la protezione di dati e risorse, ma anche la gestione delle vulnerabilità che emergono nei sistemi e nelle applicazioni software. Uno degli errori comuni è la fiducia cieca nella fonte da cui si ottiene il software: installare programmi da fonti non verificate può esporre a gravi rischi, poiché software dannosi come trojan e virus sono spesso distribuiti tramite siti web malevoli o email fraudolente. In questi casi, la vulnerabilità risiede non solo nel software ma anche negli utenti, i quali, se non adeguatamente formati, possono commettere errori nella valutazione delle fonti e dei rischi associati.
La sicurezza della fonte e le minacce nascoste
Affidarsi solo all’affidabilità della fonte di download non è sufficiente. Anche quando scarichiamo software da siti web legittimi, potremmo comunque trovarci esposti a minacce come attacchi “man in the middle” che compromettono il file durante il trasferimento. Inoltre, errori logici interni al software o input inattesi (non è detto che l’input sia fidato, ovvero “soddisfi le precondizioni”), possono compromettere l’intero sistema. Pertanto, la correttezza del software, intesa come aderenza ai requisiti funzionali e prevenzione degli errori, diventa un aspetto cruciale.
Gestione delle vulnerabilità: l’intervento di CERT e CSIRT
Quando una vulnerabilità viene scoperta, l’utente deve segnalarla a un team di risposta agli incidenti informatici, come i CERT (Computer Emergency Response Team) o i CSIRT (Computer Security Incident Response Team). Questi enti, spesso supportati da università o enti governativi, verificano la presenza della vulnerabilità e avvisano i produttori del software, prima di pubblicare un avviso di sicurezza. Tuttavia, esiste anche un mercato illecito per queste vulnerabilità, detto mercato degli “zero-day”, dove le falle sconosciute e non documentate possono essere vendute e sfruttate dai criminali.
Il cybercrime market e le minacce digitali
L’economia del crimine informatico non si limita alle vulnerabilità zero-day. Esistono veri e propri mercati per exploit, malware, botnet e credenziali rubate, spesso venduti come servizi “as-a-service”. Questi mercati prosperano nel dark web, sfruttando reti anonime come TOR per garantire la segretezza e l’intracciabilità delle transazioni. Ad esempio, i dati delle carte di credito o gli account compromessi possono essere venduti a prezzi che variano a seconda del livello di compromissione e del valore dell’account.
Il database delle vulnerabilità e i framework di sicurezza
Per catalogare e analizzare le vulnerabilità, sono stati sviluppati database come il National Vulnerability Database (NVD) e il Common Vulnerabilities and Exposures (CVE), che documentano le vulnerabilità note e forniscono indicazioni su come mitigare i rischi. Le vulnerabilità vengono inoltre classificate tramite il Common Vulnerability Scoring System (CVSS), un sistema di valutazione che attribuisce un punteggio alla gravità del rischio, guidando le aziende nelle priorità di intervento.
Il Common Weakness Enumeration (CWE): una tassonomia delle debolezze del software
Il Common Weakness Enumeration (CWE) è un elenco standardizzato delle debolezze più comuni nella sicurezza del software, sviluppato per facilitare l’identificazione e la prevenzione di vulnerabilità. A differenza del CVE, che si concentra su vulnerabilità specifiche e istanze particolari in software o sistemi, il CWE descrive debolezze generali che possono essere sfruttate in una vasta gamma di contesti. Tra le debolezze più rilevanti troviamo problemi come il “buffer overflow”, che può portare a corruzione della memoria e attacchi di esecuzione arbitraria di codice, la “SQL Injection”, dove l’immissione di comandi non validati può compromettere database e sistemi, e l’“out-of-bounds write”, dove l’accesso a memoria al di fuori dei limiti previsti può causare crash o vulnerabilità critiche. Il CWE non solo funge da linguaggio comune per discutere di questi problemi, ma fornisce anche una base per sviluppare strumenti di testing e pratiche di sicurezza, aiutando gli sviluppatori a progettare sistemi più robusti e resilienti fin dalle fasi iniziali di sviluppo.
Sfide e falsi miti sulla sicurezza del software
Uno dei miti più diffusi è che un software sia “sicuro” se funziona come previsto. Tuttavia, affidabilità e sicurezza non sono sinonimi: un software può soddisfare i requisiti funzionali ma essere comunque vulnerabile ad abusi e attacchi. Inoltre, la sicurezza non dipende solo dalle caratteristiche visibili come la crittografia o il controllo degli accessi, ma anche dall’integrazione sicura di ogni funzione. Le minacce derivano anche dall’imprevedibilità dell’uso del software: moderni sistemi connessi e complessi sono difficili da proteggere completamente.
Alcuni “falsi miti” e la realtà
Funziona in modo affidabile, soddisfacendo tutti i requisiti funzionali. Affidabilità non vuol dire sicurezza: “Il software affidabile fa quello che deve fare. Il software sicuro fa quello che deve fare e nient’altro” (Ivan Arce). Non si tratta solo di come il software deve essere usato, ma anche di come può essere abusato: in quanto i requisiti funzionali sono guidati dai casi d’uso, mentre i requisiti di sicurezza sono guidati da casi di abuso.
Dispone di tutte le caratteristiche di sicurezza appropriate. Funzionalità di sicurezza non vuol dire funzionalità sicure: le funzionalità di sicurezza sono caratteristiche direttamente collegate agli obiettivi di sicurezza, come l’uso della crittografia, la gestione delle password, il controllo degli accessi, ecc. Devono essere implementate con attenzione, ma lo sviluppo non può concentrarsi solo sulle caratteristiche di sicurezza (Seven Pernicious Kingdoms). Le funzionalità sicure sono qualsiasi funzionalità, anche se non direttamente correlate a un requisito di sicurezza, che possono mettere a rischio la sicurezza.
I possibili utilizzi sono ben noti e sotto controllo. Non è possibile prevedere tutti i possibili usi di un sistema software. Il software moderno è soggetto alla “The Trinity of Trouble” (ToT) (Trinità dei problemi) :
Connettività: i sistemi software sono connessi.
Complessità: la loro organizzazione può essere intricata e complessa.
Estensibilità: si evolvono e possono essere estesi in modo imprevedibile.
Tutti questi aspetti sono naturalmente correlati tra loro.
Principio n. 1: il difensore deve difendere tutti i punti; l’attaccante può scegliere il punto più debole.
Principio n. 2: il difensore può difendersi solo da attacchi noti; l’attaccante può sondare le vulnerabilità sconosciute.
Principio n. 3: il difensore deve essere costantemente vigile; l’attaccante può colpire a piacimento.
Principio n. 4: il difensore deve rispettare le regole; l’attaccante può giocare sporco.
Il codice è “chiuso” e le versioni binarie sono offuscate. Anche i nostri meccanismi di crittografia sono segreti. “Security by design vs security by obscurity”: security by obscurity si basa sulla segretezza come metodo generale per la sicurezza. Funziona come deterrente, aumenta il lavoro dell’attaccante, ma i segreti sono difficili da mantenere a lungo (ad es. considerare le fughe di notizie, le tecniche di reverse engineering). In generale, ricordiamo i principi dei “vantaggi dell’attaccante”. Security by design si basa su 10 principi generali di sicurezza:
Semplicità
Design Open
Suddivisione
Esposizione minima
Minimo privilegio
Minima fiducia e massima affidabilità
Difetti sicuri e a prova di errore
Mediazione completa
Nessun singolo punto di errore
Tracciabilità
Per quanto riguarda la sicurezza, conduciamo un pentest approfondito alla fine del ciclo di sviluppo del software. Software development life cycle (SDLC) e il “modello touchpoint”. Il Software Development Life Cycle (SDLC) è un processo strutturato per lo sviluppo di software di alta qualità. Include una serie di fasi che gli sviluppatori seguono per pianificare, progettare, costruire, testare e distribuire un software. L’SDLC fornisce una mappa per il team di sviluppo e garantisce che il prodotto finale soddisfi i requisiti e sia affidabile. Le fasi tipiche dell’SDLC sono:
Pianificazione e analisi dei requisiti: si identificano le esigenze del cliente e si definiscono i requisiti che il software deve soddisfare. Si stabiliscono obiettivi, risorse e tempistiche.
Progettazione: si pianifica l’architettura del software, definendo l’organizzazione del sistema, l’interfaccia utente e il flusso di dati.
Implementazione e codifica: in questa fase si scrive il codice del software. Gli sviluppatori traducono il progetto in codice funzionante, seguendo standard e pratiche di programmazione.
Test: si eseguono vari tipi di test (unit testing, integration testing, system testing, ecc.) per verificare che il software funzioni correttamente e soddisfi i requisiti.
Deployment (distribuzione): una volta che il software è stato testato e considerato pronto, viene distribuito agli utenti finali.
Manutenzione e supporto: dopo il rilascio, il software entra in una fase di manutenzione in cui si correggono bug, si ottimizza il funzionamento e si gestiscono aggiornamenti.
Il modello Touchpoint, sviluppato da Gary McGraw, è una metodologia per incorporare la sicurezza in ogni fase dell’SDLC. A differenza di un approccio “a cascata”, dove la sicurezza è spesso trattata come una fase separata o come un controllo finale, il modello touchpoint incoraggia la sicurezza come parte integrante di tutte le fasi dello sviluppo. I “touchpoint” sono punti strategici dell’SDLC in cui vengono applicate pratiche di sicurezza specifiche. Le principali attività di sicurezza nel modello touchpoint includono:
Code review (revisione del codice): effettuare revisioni del codice manuali o automatiche per identificare vulnerabilità, come SQL injection o buffer overflow. Questo consente di correggere errori di sicurezza direttamente nel codice.
Design review (revisione del progetto): rivedere l’architettura e la progettazione del software per assicurarsi che le decisioni di design non introducano vulnerabilità. Questo può includere un’analisi dei controlli di accesso, della crittografia e delle interazioni con altri sistemi.
Testing di sicurezza: durante i test funzionali, è essenziale includere anche test di sicurezza, come penetration testing o test di fuzzing, per verificare che il software non sia vulnerabile a exploit.
Gestione delle minacce (threat modeling): in questa fase si identificano e valutano le potenziali minacce al sistema, pianificando contromisure e strategie di mitigazione. Il threat modeling può avvenire in diverse fasi, ma è tipicamente più efficace nella fase di progettazione.
Configurazione sicura (security configuration): assicurarsi che i componenti del software, così come i server e le reti, siano configurati in modo sicuro, riducendo al minimo le superfici di attacco.
Incident response planning (piano di risposta agli incidenti): peparare un piano di risposta agli incidenti per gestire eventuali attacchi e violazioni. Avere questo piano in atto sin dalle prime fasi consente di ridurre l’impatto di eventuali exploit.
Formazione sulla sicurezza per gli sviluppatori: assicurarsi che il team di sviluppo sia informato sulle migliori pratiche di sicurezza, per evitare errori comuni durante la scrittura del codice.
Abbiamo appena rilasciato una patch che ha risolto tutti i problemi di sicurezza ed è protetta contro ogni exploit conosciuto. Finestra di vulnerabilità, exploit zero-day. La finestra di vulnerabilità è un concetto utilizzato in sicurezza informatica per descrivere l’intervallo di tempo in cui una vulnerabilità è nota ma non ancora corretta. Durante questo periodo, i sistemi e le applicazioni che presentano la vulnerabilità sono a rischio di attacco, poiché i difetti possono essere sfruttati dagli attaccanti prima che i proprietari del sistema o i fornitori del software rilascino una patch o una correzione.
Ciclo di vita delle vulnerabilità di sicurezza – Fonte OWASP
Caratteristiche della finestra di vulnerabilità
Inizio della finestra: la finestra di vulnerabilità inizia nel momento in cui una falla di sicurezza è scoperta e viene resa pubblica o comunque conosciuta dagli attaccanti.
Fine della finestra: la finestra termina quando viene distribuita e applicata una patch di sicurezza che corregge la vulnerabilità su tutti i sistemi interessati.
Durata variabile: la durata della finestra di vulnerabilità può variare. In alcuni casi, i fornitori rilasciano rapidamente una patch, riducendo il tempo di esposizione. In altri casi, la correzione può richiedere più tempo, prolungando la finestra e aumentando il rischio.
Un exploit zero-day (o attacco zero-day) è una tipologia di attacco che sfrutta una vulnerabilità nel software non ancora conosciuta dai produttori o dal pubblico. In altre parole, si tratta di una vulnerabilità “a giorno zero” perché non è stata ancora scoperta o affrontata con un aggiornamento di sicurezza, lasciando il sistema completamente esposto.
Caratteristiche degli Exploit Zero-Day
Ignoranza del fornitore: un exploit zero-day sfrutta una vulnerabilità di cui il fornitore non è ancora a conoscenza. Questo significa che non esiste alcuna patch o correzione disponibile al momento dell’attacco.
Alta efficacia: gli exploit zero-day sono particolarmente pericolosi perché possono bypassare le misure di sicurezza esistenti, proprio perché non sono ancora stati catalogati né gestiti.
Difficoltà di rilevamento: questi exploit sono difficili da rilevare e mitigare, poiché le soluzioni di sicurezza non hanno ancora aggiornamenti o regole specifiche per bloccare l’attacco.
Relazione tra finestra di vulnerabilità ed exploit zero-day. Quando viene scoperta una vulnerabilità zero-day, si apre immediatamente una finestra di vulnerabilità. Finché la falla non è nota pubblicamente, il rischio è limitato a un numero ristretto di attaccanti che conoscono l’exploit. Tuttavia, quando l’exploit diventa di dominio pubblico, la finestra di vulnerabilità può aumentare considerevolmente in termini di esposizione.
Mitigazione della finestra di vulnerabilità e degli exploit zero-day. Per gestire la finestra di vulnerabilità e ridurre il rischio associato agli exploit zero-day, è possibile adottare le seguenti misure:
Patch management: implementare un sistema di gestione delle patch efficace per applicare rapidamente gli aggiornamenti di sicurezza appena disponibili.
Threat intelligence: utilizzare fonti di threat intelligence per rimanere aggiornati sulle nuove minacce e sugli exploit zero-day che potrebbero colpire i sistemi.
Implementazione di sicurezza multi-livello: avere sistemi di sicurezza su più livelli, come firewall, sistemi di rilevamento e prevenzione delle intrusioni (IDS/IPS) e controlli di accesso rigorosi, può ridurre l’impatto di un exploit zero-day.
Analisi del comportamento e anomaly detection: tecniche di rilevamento basate sull’analisi del comportamento aiutano a identificare attività anomale anche se un attacco zero-day cerca di eludere i controlli di sicurezza convenzionali.
Segmentazione della rete: segmentare la rete può limitare i danni che un attaccante può causare in caso di sfruttamento di una vulnerabilità zero-day.
La “Security by Design” e il Ciclo di Sviluppo Sicuro
È quindi necessario sviluppare software secondo i principi della “security by design”, in contrasto alla “security by obscurity”. I principi di sicurezza da incorporare includono semplicità, suddivisione dei privilegi, esposizione minima, tracciabilità e l’assenza di punti di errore singoli. A differenza del classico test di sicurezza svolto a fine sviluppo, un ciclo di vita dello sviluppo del software (SDLC) ben pianificato include la sicurezza in ogni fase, minimizzando le vulnerabilità di design.
In sintesi, la cybersecurity non è un obiettivo raggiungibile con un unico intervento. Essa richiede un approccio integrato, che combini formazione, adozione di tecniche sicure nello sviluppo e costante monitoraggio delle minacce emergenti. Una comprensione profonda delle vulnerabilità e l’implementazione di una sicurezza “by design” rappresentano i fondamenti per proteggere i sistemi in un panorama digitale in continua evoluzione.
Seven Pernicious Kingdoms
Una tassonomia creata per aiutare gli sviluppatori a comprendere gli errori di programmazione più comuni che influiscono sulla sicurezza.
Il modello del Seven Pernicious Kingdoms è un framework utilizzato per classificare le principali categorie di vulnerabilità nel codice, in particolare in ambito di sicurezza applicativa. Sviluppato dai ricercatori di Cigital (in particolare Gary McGraw), il modello è un modo per raggruppare le vulnerabilità in base alla loro natura e impatto. I “Sette Regni” rappresentano tipi distinti di difetti nel codice, che possono essere utilizzati per strutturare e migliorare la sicurezza del software.
Input validation and representation: si riferisce ai difetti che derivano da una gestione impropria dei dati di input o dalla rappresentazione inadeguata dei dati, portando a vulnerabilità come SQL injection, command injection e cross-site scripting (XSS).
API abuse: riguarda l’uso improprio delle API, spesso dovuto a una mancata comprensione dei limiti o delle modalità d’uso corrette delle stesse, che può consentire exploit a livello di API.
Security features: include difetti legati all’implementazione errata delle caratteristiche di sicurezza, come l’autenticazione, la gestione delle sessioni, e il controllo degli accessi. Difetti in questo “regno” possono portare a problemi come session hijacking o bypass delle restrizioni di accesso.
Time and state: questo “regno” riguarda vulnerabilità legate alla gestione del tempo e degli stati. Problemi come race conditions (condizioni di corsa) o gestione inadeguata delle risorse possono far sì che un utente malintenzionato prenda il controllo di una risorsa o esegua azioni dannose.
Errors: si riferisce alla gestione errata degli errori, come la visualizzazione di messaggi d’errore dettagliati che rivelano informazioni sensibili o la mancanza di controllo su errori imprevisti, che possono facilitare l’enumerazione o l’accesso a dettagli interni.
Code quality: questo “regno” comprende le vulnerabilità derivanti da una scarsa qualità del codice, come buffer overflow, pointer dereferencing e altri errori che possono portare a comportamenti imprevisti o a falle di sicurezza.
Encapsulation: si riferisce a difetti nella separazione dei dati e nella gestione dell’accesso. Problemi di incapsulamento possono portare a fughe di informazioni o all’alterazione di dati interni che dovrebbero essere inaccessibili all’utente.