Molte telecamere di fascia consumer/prosumer adottano meccanismi P2P via cloud (UID + STUN/TURN/relay) per fornire accesso “zero-configurazione”. Questa convenienza introduce rischi strutturali: dipendenza da terze parti, esposizione a credential stuffing, aperture automatiche di porte tramite UPnP, ritardi o assenza di aggiornamenti firmware, applicazioni mobili invasive e scarsa trasparenza dei vendor. Il presente articolo propone un modello local-first con segmentazione (VLAN IoT), registrazione/visualizzazione in locale, accesso remoto esclusivamente via VPN, pratiche di hardening, logging e monitoraggio. Inoltre:
un playbook operativo completabile in ~90 minuti;
checklist per la valutazione dei fornitori;
errori ricorrenti da evitare;
indicazioni forensi in caso di incidente.
Introduzione
L’adozione massiva di telecamere “plug-and-play” ha ridotto la complessità di installazione, spostando però il baricentro della sicurezza verso infrastrutture cloud proprietarie. Questo paper affronta, con taglio tecnico-accademico, come funziona il P2P “magico”, perché è rischioso, e quali architetture e controlli consentono di mitigare i rischi con oneri limitati.
P2P “magico”: funzionamento e impatti
Meccanismo tecnico
UID: ogni camera espone un identificativo univoco associato al tuo account/app.
NAT traversal: la camera apre connessioni in uscita verso server del vendor (STUN/TURN) per superare NAT/firewall; in caso di fallimento si usa relay completo lato cloud.
Effetto: fruizione video senza configurazioni manuali (port-forward), al prezzo di un terzo attore—il vendor—nel percorso di segnalazione e talvolta nel trasporto.
Superfici d’attacco e criticità
Dipendenza dal cloud: indisponibilità, compromissioni o scarsa trasparenza impattano disponibilità e riservatezza.
Credential stuffing: l’account applicativo del vendor è un bersaglio distinto dall’infrastruttura domestica/aziendale.
UPnP: alcuni dispositivi richiedono aperture automatiche di porte; pratica rischiosa e spesso non tracciata.
Supply-chain & firmware: cicli di patch lenti/assenti; stack P2P proprietari difficili da auditare.
App mobili: permessi e telemetria eccessivi, potenziale esfiltrazione metadati.
Architetture di riferimento (ordine decrescente di sicurezza)
Solo locale (massima privacy)
VLAN IoT dedicata (es. VLAN20 192.168.20.0/24) senza accesso Internet.
NVR/NAS con RTSP/ONVIF nella stessa VLAN.
Visualizzazione da LAN amministrativa tramite jump host o ACL selettive.
Locale + VPN (equilibrio sicurezza/usabilità)
Come sopra, ma nessun port-forward pubblico.
Accesso remoto solo tramite VPN (WireGuard/OpenVPN) al router/firewall.
Notifiche push veicolate attraverso la VPN o bridge on-prem sicuro.
Cloud minimale e controllato (solo se indispensabile)
Abilitare funzioni cloud solo per notifiche, non per streaming continuativo.
Preferire vendor con E2E documentata; disabilitare UPnP, applicare ACL in uscita.
Controlli di sicurezza: rete, accesso, gestione
Segmentazione e policy
VLAN IoT (telecamere), VLAN Admin (NVR/management), VLAN User (PC/smartphone).
Regole firewall minimali: IoT → NVR (RTSP/ONVIF) solo, deny all per il resto.
Bloccare IoT → Internet, salvo finestre di update strettamente controllate.
Accesso remoto
VPN con MFA (WireGuard/OpenVPN). Evitare esposizioni dirette su Internet di NVR/telecamere.
Disabilitare UPnP su router e dispositivi; opzionale: bloccare domini cloud vendor se non utilizzati.
Autenticazione e cifratura
Password uniche e robuste; 2FA ovunque disponibile.
TLS per pannelli web interni; preferire E2E tra client e NVR quando possibile.
Patch management, inventario, backup
Inventariare modelli/seriali/firmware; pianificare finestre di patch mensili con changelog.
Backup configurazioni (router/firewall/NVR) e snapshot delle policy.
Logging e monitoraggio
NTP coerente; invio log a Syslog/SIEM (accessi, motion, riavvii).
Allarmi su autenticazioni fallite, cambi IP/MAC, variazioni di profilo stream.
Playbook operativo “90 minuti di hardening” (SOHO/PMI)
Prerequisiti: privilegi sul router/firewall, switch gestibile, NVR/NAS compatibile RTSP/ONVIF.
Router/Firewall (≈15′)
Disabilita UPnP.
Crea VLAN20 (IoT) e VLAN10 (Admin).
Regola: VLAN20 → solo NVR: 554 (RTSP), 80/443 se indispensabili; deny all per il resto.
Blocca VLAN20 → Internet; in alternativa, whitelist temporanea per update.
Switch/Access Point (≈10′)
SSID “IoT” ancorato a VLAN20.
Port isolation per ridurre movimento laterale intra-VLAN.
NVR/NAS (≈20′)
Cambia credenziali di default, abilita 2FA (se presente).
Crea utenti per ruolo (viewer/admin); invia log a syslog.
Abilita solo protocolli necessari (RTSP/ONVIF); disabilita il cloud.
Telecamere (≈20′)
Aggiorna firmware.
Disabilita P2P/cloud nelle impostazioni.
Configura stream RTSP verso NVR (H.265 se supportato, bitrate adeguato).
Configura WireGuard sul gateway; genera profili per smartphone/PC.
Verifica che la visualizzazione funzioni solo con VPN attiva.
Verifica finale (≈10′)
Da rete esterna: nessuna porta esposta su IP pubblico.
Dalla VLAN IoT: traffico verso Internet bloccato (se policy locale-only).
Verifiche tecniche: comandi esemplificativi
# Scansione porte esposte su IP pubblico (da rete esterna)
nmap -Pn -p- --min-rate 1000 <IP_PUBBLICO>
# Verifica outreach delle telecamere (dalla VLAN IoT)
tcpdump -i ethX host <IP_CAMERA> and not host <IP_NVR>
# Controllo stato UPnP (OpenWrt)
uci show upnpd
È possibile disabilitare completamente P2P/cloud e usare RTSP/ONVIF solo in LAN?
Esiste una politica di aggiornamento con changelog e tempi di remediation (CVE)?
L’app funziona in LAN senza Internet?
Sono disponibili 2FA, ruoli granulari e log esportabili (syslog/API)?
È documentata l’end-to-end encryption (ambito, limiti, gestione chiavi)? Come avviene l’eventuale relay?
Errori ricorrenti da evitare
Lasciare UPnP attivo “per comodità”.
Esporre NVR/telecamere con port-forward (80/554/8000) confidando solo nella password.
Riutilizzare le stesse credenziali e rinunciare al 2FA.
Trascurare la segmentazione (reti piatte ⇒ movimento laterale facilitato).
Aggiornare l’app ma non il firmware dei dispositivi.
Considerazioni forensi (DFIR)
Preservazione: esportare configurazioni NVR; acquisire log di accesso/motion/riavvii.
Timeline: correlare eventi di motion con autenticazioni remote, geolocalizzazione IP, modifiche impostazioni.
Acquisizioni: – Bitstream del disco NVR/NAS (per analisi di metadati, cancellazioni, rotazioni); – PCAP della VLAN IoT (24–48 h) per pattern anomali, DNS rari, cambi di bitrate/codec.
Indicatori: accessi fuori orario, up/down ricorrenti, variazioni di stream non programmate, contatti verso domini non standard.
Conclusioni
La sicurezza dei sistemi di videosorveglianza non dipende dalla “smartness” del dispositivo, ma dalla prevedibilità dell’architettura: isolamento di rete, minimizzazione della dipendenza dal cloud, aggiornamenti regolari, e accesso mediato da VPN. Un’impostazione local-first con policy chiare riduce drasticamente il profilo di rischio senza penalizzare la fruibilità. Le linee guida e il playbook proposti forniscono un percorso pratico e ripetibile per ambienti domestici evoluti e PMI.
Un solido approccio alla cybersicurezza si basa su principi e sistemi fondamentali che ogni responsabile per la prevenzione e gestione degli incidenti informatici in ambito nazionale deve padroneggiare.
Questo documento vuole fornire una panoramica strutturata di tali fondamenti, toccando sia aspetti tecnologici (come firewall, sistemi di autenticazione, virtualizzazione) sia organizzativi (come gestione centralizzata degli accessi, gestione del rischio, team e centri dedicati alla sicurezza).
Ogni sezione include definizioni, esempi pratici e riferimenti a standard internazionali, best practice e casi di studio aggiornati, al fine di contestualizzare i concetti nelle competenze richieste a un ruolo di coordinamento in cybersicurezza.
Sistemi di sicurezza (Firewall, IDS/IPS, WAF, Endpoint)
I sistemi di sicurezza informatica proteggono reti e dispositivi dagli attacchi, attraverso controllo del traffico, rilevamento di intrusioni e blocco di malware. Tra i principali strumenti vi sono i firewall, i sistemi IDS/IPS, i Web Application Firewall (WAF) e le soluzioni di protezione endpoint. Questi componenti lavorano in sinergia per garantire difese perimetrali e interne, secondo il principio della difesa in profondità.
Firewall di rete
Il firewall è il componente perimetrale di base della sicurezza di rete. Esso può essere hardware o software e monitora, filtra e controlla il traffico in entrata e uscita sulla base di regole predefinite. In pratica, il firewall crea una barriera tra la rete interna sicura e le reti esterne non fidate (come Internet), permettendo solo il traffico autorizzato in conformità con la policy di sicurezza definita. I firewall moderni includono diverse tecnologie, tra cui packet filtering, stateful inspection (monitoraggio dello stato delle connessioni) e proxy firewall applicativi. L’adozione di firewall perimetrali è essenziale per bloccare attacchi noti e ridurre la superficie di attacco esposta, ad esempio bloccando tentativi di accesso non autorizzato e malware noti prima che raggiungano i sistemi interni. I Next-Generation Firewall (NGFW) integrano funzionalità avanzate come il filtraggio a livello applicativo, l’ispezione del traffico cifrato e persino moduli IDS/IPS integrati, offrendo protezione più granulare.
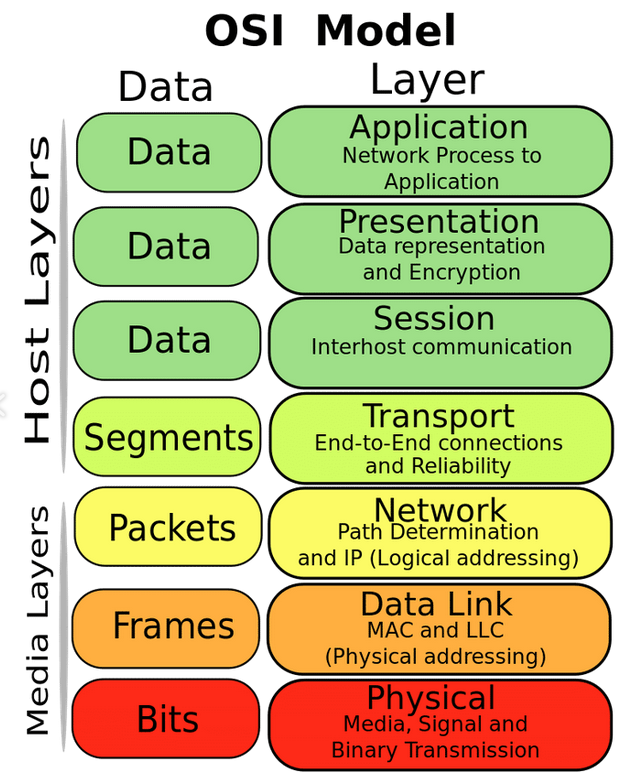
I firewall tradizionali operano principalmente sui livelli 3 e 4 del modello OSI, analizzando indirizzi IP e porte. Lo scopo primario è garantire la confidenzialità e integrità delle risorse interne, impedendo intrusioni, malware, attacchi DoS e accessi non autorizzati.
Sistemi IDS e IPS
Per rilevare e prevenire intrusioni più sofisticate, si usano sistemi IDS (Intrusion Detection System) e IPS (Intrusion Prevention System). Un IDS monitora il traffico di rete e genera allarmi agli amministratori quando identifica attività sospette o malevole, ma non interviene direttamente sul traffico. Un IPS, considerato un’evoluzione dell’IDS, lavora invece in linea sul percorso di comunicazione e può bloccare attivamente le minacce in tempo reale. In altre parole, mentre un IDS opera in modo passivo (fuori banda, analizzando copie del traffico) per fornire visibilità sulle possibili intrusioni, un IPS è posizionato inline e, oltre a rilevare le minacce, può filtrare o fermare i pacchetti malevoli prima che raggiungano la destinazione. Ad esempio, un IPS configurato adeguatamente può automaticamente bloccare tentativi di exploit noti o mettere in quarantena host compromessi. Entrambi i sistemi tipicamente utilizzano firme di attacco e analisi comportamentale: firme per riconoscere minacce note (es. identificando la “firma” di un virus o di un attacco specifico) e rilevamento delle anomalie per segnalare traffico anomalo rispetto alla baseline normale. In sintesi: l’IDS rileva e allerta, l’IPS previene e blocca, entrambi sono fondamentali per garantire l’integrità e la disponibilità dei sistemi. L’uso congiunto di firewall e IDS/IPS consente un approccio difensivo a più livelli: il firewall filtra il traffico in base a regole statiche, l’IDS allerta su possibili intrusioni e l’IPS interviene bloccandole proattivamente.
Firewall applicativo (WAF)
Un Web Application Firewall (WAF) è un firewall specializzato a protezione delle applicazioni web e dei servizi API a livello applicativo (Layer 7). Mentre un firewall di rete tradizionale opera sui livelli inferiori (indirizzi IP, porte, protocolli) fungendo da barriera tra rete interna ed esterna, il WAF monitora e filtra il traffico HTTP/HTTPS tra client esterni e server web applicativi. Lo scopo è intercettare attacchi a livello applicativo, come iniezioni SQL, Cross-Site Scripting (XSS), attacchi di tipo DDoS applicativo e altre richieste malevole dirette alle applicazioni web. Il WAF si interpone tra gli utenti e il server applicativo analizzando tutte le comunicazioni HTTP: in caso individui richieste dannose o non conformi alla policy, le blocca prima che raggiungano l’applicazione. Ciò consente di proteggere servizi web critici senza dover modificare il codice dell’applicazione stessa. Ad esempio, se un attaccante tenta di inviare input malevoli in un form web per sfruttare una vulnerabilità, il WAF può riconoscere la stringa sospetta e fermare la richiesta. È importante notare che il WAF non sostituisce il firewall tradizionale di rete, poiché ciascuno agisce su piani diversi: il firewall di rete protegge da minacce a livello IP/TCP (es. scansioni, exploit di protocollo), mentre il WAF si concentra sulle minacce al livello applicativo web. In un’architettura robusta, entrambi sono utilizzati in modo complementare, specialmente dato l’aumento delle applicazioni esposte sul web e delle relative minacce.
Il WAF funge quindi da scudo per la confidenzialità e integrità dei dati delle applicazioni web, prevenendo accessi non autorizzati, violazioni di dati e abusi di funzionalità dell’applicazione.
Protezione degli endpoint
Con l’aumento di dispositivi e postazioni connesse (client, server, dispositivi mobili, IoT), la sicurezza degli endpoint è divenuta cruciale (gli endpoint sono i dispositivi client – pc, laptop, smartphone, server – ai margini della rete aziendale – spesso rappresentano l’anello debole sfruttato dagli aggressori). Le soluzioni di protezione endpoint comprendono inizialmente l’antivirus/antimalware tradizionale, ma oggi includono suite più avanzate come gli Endpoint Protection Platform (EPP) e gli Endpoint Detection & Response (EDR). In generale, per protezione endpoint si intende un insieme di strumenti integrati per proteggere e gestire i dispositivi nella rete aziendale.
Un’Endpoint Protection Platform (EPP) fornisce funzionalità preventive: antivirus, firewall personale sul host, controllo degli accessi al dispositivo, cifratura dei dati e gestione delle patch, in modo da prevenire l’esecuzione di codice malevolo noto e ridurre le superfici d’attacco note. L’approccio EPP è spesso basato su firme (signature-based) e regole statiche: identifica malware conosciuti confrontandoli con un database di firme e applica policy predefinite.
Gli EDR, invece, sono strumenti più orientati alla rilevazione e risposta attiva: monitorano in tempo reale i comportamenti sui sistemi endpoint e sono in grado di individuare attività anomale o sospette (es. un processo che effettua operazioni insolite) anche in assenza di una firma di malware conosciuto. Quando un’attività sospetta viene identificata, l’EDR può allertare i responsabili di sicurezza e intraprendere azioni automatiche (come isolare il dispositivo dalla rete) per contenere una minaccia in corso. In pratica l’EDR adotta un approccio dinamico e reattivo, spesso potenziato da analisi comportamentale e algoritmi di intelligenza artificiale per riconoscere anche minacce zero-day o attacchi fileless. Data la complementarità, oggi molti vendor offrono soluzioni unificate (talvolta chiamate XDR, Extended Detection & Response) che combinano prevenzione (EPP) e risposta (EDR). Per un responsabile della sicurezza, è fondamentale garantire che tutti gli endpoint dell’organizzazione (dai server ai portatili dei dipendenti) siano coperti da queste soluzioni, assicurando aggiornamenti costanti delle firme antivirus, monitoraggio centralizzato degli incidenti sugli host e rapide capacità di intervento remoto su macchine compromesse. In sintesi, la protezione endpoint è l’ultima linea difensiva per impedire a malware e aggressori di prendere piede nei sistemi interni e, qualora ciò avvenga, per individuare, contenere ed eliminare rapidamente la minaccia, salvaguardando disponibilità e integrità dei dati su tali dispositivi.
Sistemi di virtualizzazione: principi e vantaggi per la sicurezza
La virtualizzazione è una tecnologia che permette di eseguire più sistemi operativi (come macchine virtuali o container) su un unico host fisico, isolandoli l’uno dall’altro. Oltre ai noti benefici di efficienza e flessibilità nell’IT, la virtualizzazione offre vantaggi significativi per la sicurezza, in particolare per quanto riguarda isolamento e segmentazione dei carichi di lavoro.
Ogni Macchina Virtuale (VM) opera in un ambiente isolato dalle altre VM sullo stesso hardware. Questo isolamento intrinseco significa che se una VM viene compromessa da un malware o un attaccante, quella compromissione non si propaga automaticamente alle altre VM né all’host, a patto che l’hypervisor (il software di virtualizzazione) mantenga la separazione. In pratica, le VM funzionano come “contenitori” separati: un attacco o crash su un server virtuale non impatta gli altri servizi che girano su VM distinte. Ciò aumenta la resilienza complessiva del sistema informatico, contenendo le minacce all’interno di un perimetro più piccolo (blast radius limitato). Ad esempio, in un’architettura tradizionale un singolo server fisico ospitava più applicazioni e se veniva bucato cadevano tutti i servizi su di esso; con la virtualizzazione, si possono suddividere le applicazioni in VM diverse, così che la violazione di una non comprometta le altre.
La virtualizzazione facilita anche la micro-segmentazione delle reti e il controllo granulare del traffico tra componenti: ambienti virtualizzati avanzati consentono di definire regole di firewall interne tra VM (ad es. mediante virtual firewall o policy di sicurezza software-defined) e di monitorare approfonditamente il traffico est-ovest all’interno dell’infrastruttura virtuale. Questo rende molto più difficile per un aggressore effettuare movimenti laterali: anche se riesce a violare una VM in un data center virtualizzato, dovrà superare ulteriori barriere per spostarsi verso altre VM, grazie alla segmentazione interna. Un responsabile della sicurezza può sfruttare ciò progettando architetture dove, ad esempio, i server con dati sensibili risiedono in segmenti virtuali separati, accessibili solo tramite passaggi filtrati, riducendo il rischio che un attacco su un servizio meno critico dia accesso a quelli critici.
Un altro vantaggio offerto dalla virtualizzazione è la capacità di creare ambienti di sandbox facilmente. Una sandbox è un ambiente isolato dove eseguire codice potenzialmente malevolo per osservarne il comportamento senza rischiare impatti sul sistema di produzione. Grazie alle VM, è possibile istanziare rapidamente sandbox per l’analisi di malware o per testare patch e aggiornamenti in sicurezza. Ad esempio, i team CSIRT spesso usano VM per detonare file sospetti e analizzarne gli effetti (tecniche di dynamic analysis dei malware) senza mettere in pericolo la rete aziendale. Analogamente, ambienti virtuali consentono di effettuare esercitazioni di sicurezza (cyber range), simulando attacchi e testando le capacità di risposta in un contesto realistico ma isolato.
La virtualizzazione agevola inoltre l’implementazione di strategie di disponibilità come backup e disaster recovery. È infatti possibile prendere snapshot periodici delle VM (istantanee dello stato del sistema) e replicarle su server diversi o in cloud. Ciò rende il ripristino dopo un incidente molto più rapido: se un server virtuale viene compromesso o guasto, lo si può ripristinare allo stato precedente in pochi minuti riattivando uno snapshot o una VM di riserva. In un’ottica di continuità operativa, le infrastrutture virtuali supportano anche la ridondanza e la migrazione a caldo: si può configurare l’alta disponibilità in modo che se l’host fisico di una VM fallisce, la VM venga avviata automaticamente su un altro host (failover), minimizzando i tempi di fermo. Allo stesso modo, test di recupero di disastri (DR drills) e patch testing possono essere condotti clonando VM in ambienti di prova senza impatto sugli ambienti live
In sintesi, i sistemi di virtualizzazione rafforzano la sicurezza informatica fornendo compartimentazione: ogni servizio in una VM isolata, micro-segmentazione del traffico fra VM, facilità nel predisporre sandbox e ambienti di test, e strumenti robusti per backup/recupero. Tuttavia, è importante ricordare che l’hypervisor stesso diventa un componente critico da proteggere (un attacco all’hypervisor potrebbe compromettere tutte le VM). Per questo, best practice includono il mantenimento aggiornato dell’hypervisor, il minimo di servizi attivi sull’host e controlli di accesso rigorosi all’infrastruttura di virtualizzazione.
Sistemi di autenticazione e metodi sicuri (Password, MFA, Biometria)
L’autenticazione è il processo mediante il quale un sistema verifica l’identità di un utente (o di un entità, come un dispositivo o processo) prima di concedergli accesso a risorse. Un solido sistema di autenticazione è fondamentale per garantire che solo soggetti autorizzati possano accedere a dati e sistemi sensibili. I metodi di autenticazione si dividono in categorie basate su ciò che l’utente conosce, ciò che possiede e ciò che è. In parallelo all’autenticazione, l’autorizzazione controlla cosa un utente autenticato può fare (diritti di accesso), ma qui ci concentriamo sui metodi per verificare l’identità in modo sicuro.
Autenticazione basata su conoscenza: password e gestione sicura
Tradizionalmente, l’autenticazione si è basata su credenziali note dall’utente, in primis le password (o PIN, passphrase). La password è un segreto che solo l’utente dovrebbe conoscere e che viene confrontato con ciò che è registrato nel sistema (idealmente in forma cifrata/hash). Nonostante la loro diffusione, le password presentano noti problemi di sicurezza: utenti tendono a sceglierle deboli (es. parole comuni) o a riutilizzarle su più servizi, rendendole vulnerabili ad attacchi di brute force, dizionario, e phishing. Best practice moderne – guidate anche da standard come NIST SP 800-63B – suggeriscono di utilizzare password lunghe e difficili da indovinare (passphrase complesse), evitando requisiti eccessivamente complicati che portano a cattive abitudini (come scriverle o riutilizzarle) . Inoltre è sconsigliato forzare cambi frequenti di password senza motivo (poiché ciò tende a far scegliere password prevedibili con variazioni minime). Un responsabile alla sicurezza deve promuovere politiche di gestione password solide: lunghezza minima elevata (ad es. 12-15 caratteri), divieto di password banali già note in violazioni pubbliche, hashing robusto sul server (per evitare l’esposizione in chiaro), e formazione agli utenti sui rischi di phishing. Deve anche prevedere sistemi di password manager aziendali e l’adozione di meccanismi aggiuntivi (come l’autenticazione multi-fattore) per i sistemi critici.
Autenticazione a più fattori (MFA) e fattori di possesso
Dato che qualsiasi singolo fattore di autenticazione può fallire (es. una password può essere rubata), la Multi-Factor Authentication (MFA) richiede due o più fattori distinti per verificare l’identità. Tipicamente, combina “qualcosa che conosci” (es. password) con “qualcosa che possiedi” (un token fisico virtuale) e/o “qualcosa che sei” (caratteristica biometrica). Un esempio comune è l’accesso a un servizio online con password più un codice temporaneo generato da un’app sullo smartphone (come Google Authenticator) o inviato via SMS. In questo modo, anche se la password venisse carpita, l’attaccante non avrebbe il secondo fattore (telefono/token) e l’accesso verrebbe negato. I metodi di autenticazione a possesso includono: token hardware (chiavette elettroniche che generano OTP, One Time Password, o chiavi USB di sicurezza FIDO2/U2F), token software (app di autenticazione che generano codici temporanei, QR code da scannerizzare, notifiche push da approvare) o certificati digitali installati su un dispositivo. Adottare MFA incrementa esponenzialmente la sicurezza: ad esempio, gran parte delle violazioni di account cloud aziendali tramite phishing o credenziali leaked può essere sventata se all’attaccante manca il secondo fattore. È importante anche implementare fattori resistenti al phishing: oggi si raccomandano dispositivi o app che utilizzano protocolli come FIDO2 (es. security keys USB/NFC) che non sono clonabili via phishing, in luogo di SMS (che è vulnerabile a SIM swap). Per un responsabile, è essenziale definire quali sistemi richiedono MFA (idealmente tutti gli accessi remoti e quelli a dati sensibili) e orchestrare l’onboarding degli utenti a questi sistemi, tenendo conto dell’usabilità.
Autenticazione biometrica
Il fattore biometrico (qualcosa che sei) sfrutta caratteristiche fisiche o comportamentali uniche dell’utente per l’autenticazione. Esempi comuni sono l’impronta digitale, il riconoscimento facciale, l’iride, la voce, oppure parametri comportamentali (dinamica di digitazione, modo di camminare). La biometria offre il vantaggio di legare l’identità a qualcosa di intrinseco all’utente, difficile da falsificare o condividere. Ad esempio, è molto improbabile che due persone abbiano impronte digitali o modelli dell’iride identici. Ciò riduce il rischio di furto di identità: un aggressore non può semplicemente “indovinare” o rubare un tratto biometrico come farebbe con una password. Inoltre, per l’utente è comodo: non deve ricordare segreti o portare con sé token (pensiamo allo sblocco del telefono con l’impronta o il volto). Non a caso, molte organizzazioni adottano l’autenticazione biometrica almeno come un fattore (es. smart card con impronta digitale per accedere a strutture sicure, sistemi di controllo accessi fisici e logici integrati). Tuttavia, la biometria presenta anche sfide: primo, non è revocabile – se un database di impronte digitali viene compromesso, l’utente non può cambiare la propria impronta come farebbe con una password; secondo, la biometria può avere tassi di falsi positivi/ negativi (una piccola percentuale di casi in cui utenti legittimi non vengono riconosciuti, o peggio viene accettato un impostore se il sensore/algoritmo non è accurato). Inoltre, c’è il tema della privacy: i dati biometrici sono sensibili e spesso regolati da normative stringenti (GDPR in Europa li considera dati personali particolari). In ambienti governativi, l’adozione di biometria deve quindi essere accompagnata da forti misure di protezione dei template biometrici (spesso memorizzati e confrontati in forma cifrata o con tecniche di match on card per cui il dato grezzo non esce mai dal dispositivo dell’utente).
In sintesi, un robusto sistema di autenticazione oggi tende ad essere multi-fattore: password robuste come prima linea, token fisici o virtuali come seconda linea, e in alcuni casi biometria come ulteriore verifica, soprattutto per accessi critici. Ad esempio, un responsabile alla sicurezza nazionale potrebbe implementare per i propri operatori l’uso di smart card crittografiche (fattore possesso) protette da PIN (fattore conoscenza) o impronta (fattore biometrico) per accedere ai sistemi classificati. Ciò assicura un elevato livello di certezza sull’identità di chi accede, riducendo drasticamente le possibilità di accesso non autorizzato anche in caso di furto di credenziali.
Sistemi di gestione centralizzata degli accessi (AD, IAM, OAuth2, SAML, Kerberos)
In organizzazioni complesse – specialmente a livello governativo o enterprise – la gestione delle identità digitali e dei diritti di accesso degli utenti richiede piattaforme centralizzate e standardizzati. I sistemi di gestione centralizzata degli accessi consentono di amministrare in modo unificato utenti, autenticazioni e autorizzazioni su molteplici sistemi. Ciò include directory di identità (come Active Directory), sistemi e framework di Identity and Access Management (IAM), e protocolli di federazione e Single Sign-On (come OAuth 2.0, SAML 2.0, Kerberos e OpenID Connect). Tali strumenti garantiscono che gli utenti giusti ottengano gli accessi giusti, mantenendo al contempo un forte controllo e visibilità per i responsabili della sicurezza.
Active Directory (AD)
Active Directory di Microsoft è un servizio di directory centralizzato ampiamente utilizzato nelle reti aziendali e governative basate su Windows. In termini semplici, AD gestisce un database di oggetti che include utenti, gruppi, computer e le relative credenziali e permessi, all’interno di un dominio Windows. È un sistema server centralizzato basato su concetti di dominio e directory service, controllato dai Domain Controller Windows . Tramite Active Directory Domain Services (AD DS), gli utenti effettuano l’autenticazione centralmente (es. con username/password di dominio) e ottengono token di accesso validi per risorse in quel dominio (cartelle condivise, computer, applicazioni integrate con AD). AD fornisce funzioni cruciali per un responsabile alla sicurezza: autenticazione centralizzata (implementata con protocolli come Kerberos e NTLM), autorizzazione tramite gruppi (si possono assegnare permessi a gruppi di AD, applicando il principio del privilegio minimo attraverso membership di gruppo), politiche centralizzate tramite Group Policy (GPO) – ad esempio per imporre configurazioni di sicurezza uniformi su tutti i computer del dominio – e la possibilità di gestire in un solo punto il ciclo di vita di utenti e credenziali (creazione account, modifica ruoli, disabilitazione quando un dipendente lascia l’ente, ecc.). In un contesto come un’agenzia nazionale, è probabile esista una foresta AD che copre vari dipartimenti, con trust tra domini, ecc., e il responsabile dovrà assicurare la corretta configurazione delle policy AD, il monitoraggio di eventi di autenticazione sospetti e l’integrazione di AD con sistemi di Single Sign-On per applicazioni web moderne.
AD è strettamente legato a Kerberos (vedi più sotto) per le autenticazioni interne: quando un utente fa login al dominio, ottiene dal Domain Controller un Ticket-Granting Ticket Kerberos che permette di accedere ai vari servizi senza dover reinserire le credenziali continuamente. Questo offre un’esperienza di Single Sign-On nel perimetro Windows. Active Directory può inoltre essere esteso con servizi come AD Federation Services (ADFS) per federare identità con servizi esterni, e LDAP per consentire a applicazioni non-Windows di utilizzare AD come archivio utenti. In breve, AD funge da spina dorsale IAM on-premises in molti ambienti, e la sua corretta gestione (hardening dei Domain Controller, controlli su account privilegiati, auditing di login/repliche, etc.) è fondamentale: compromissioni di AD (come attacchi Golden Ticket su Kerberos o l’uso di credenziali di Domain Admin rubate) possono portare a un completo dominio della rete da parte di un attaccante.
Identity and Access Management (IAM)
Il termine IAM (Identity and Access Management) si riferisce all’insieme di politiche, processi e tecnologie che permettono di gestire le identità digitali e controllare l’accesso alle risorse in modo centralizzato . Mentre sistemi come AD sono un’implementazione specifica (in ambiente Windows), in generale una soluzione IAM può essere una piattaforma che aggrega e gestisce utenti provenienti da diversi sistemi (on-premise e cloud) e regola, tramite regole di business, chi può accedere a cosa. Un sistema IAM tiene traccia di ogni identità (dipendenti, collaboratori, dispositivi, servizi) e assicura che ciascuna abbia solo le autorizzazioni appropriate al proprio ruolo – niente di più, niente di meno. Questo include concetti come principio del privilegio minimo (dare agli utenti solo i permessi minimi necessari per svolgere il loro lavoro) e separazione dei compiti (evitare che una singola identità accumuli troppi poteri senza controlli compensativi).
Le soluzioni IAM moderne spesso coprono funzionalità come: gestione delle identità (provisioning e de-provisioning automatizzato degli account quando le persone entrano, cambiano ruolo o lasciano l’organizzazione), Single Sign-On (SSO) che consente all’utente di autenticarsi una volta ed ottenere accesso a molte applicazioni diverse, autenticazione multifattore (MFA) integrata per aggiungere sicurezza agli accessi, gestione dei privilegi (ad es. soluzioni PAM – Privileged Access Management – per controllare gli account amministrativi), e reportistica e conformità (sapere in ogni momento chi ha accesso a cosa e poter dimostrare conformità a normative).
Esempi di sistemi IAM includono servizi cloud come Azure AD, Okta, AWS IAM, Google Workspace IAM, oppure sistemi enterprise come Oracle Identity Manager, IBM Security Verify, etc. Un buon sistema IAM permette anche l’integrazione federata: per risorse esterne o tra organizzazioni diverse, anziché gestire account separati per ogni sistema, si instaurano trust basati su standard (OAuth, SAML, OpenID Connect) dove un Identity Provider centrale autentica l’utente e segnala alle applicazioni (Service Provider) l’esito e le informazioni sull’utente. Questo riduce la molteplicità di credenziali e migliora l’esperienza utente e la sicurezza (poiché l’autenticazione è centralizzata e monitorabile). Ad esempio, un dipendente ministeriale potrebbe usare le stesse credenziali IAM per accedere al portale HR interno, a un sistema di posta governativo e a servizi cloud di collaborazione, grazie a federazione e SSO.
Dal punto di vista del responsabile alla sicurezza, l’IAM è essenziale per tenere lontani gli hacker assicurando che ogni utente abbia solo le autorizzazioni esatte necessarie per il suo lavoro. Significa che l’organizzazione sa in ogni momento quali account esistono, a quali risorse accedono e può revocare immediatamente gli accessi quando non più necessari (riducendo i rischi di account orfani usati per intrusioni). Inoltre, l’IAM centralizzato consente di applicare in modo coerente policy di sicurezza (come obbligare MFA per determinati accessi, o revisionare periodicamente gli accessi attraverso processi di certificazione). In ambito nazionale, l’IAM potrebbe includere anche la gestione di identità privilegiate inter-organizzative e sistemi di identità federata per consentire a diverse agenzie di collaborare scambiando informazioni in modo controllato.
OAuth 2.0 (Delegated Authorization)
OAuth 2.0 è un framework aperto standardizzato che consente la delega di autorizzazione tra servizi web. In altre parole, OAuth 2.0 permette a un utente di autorizzare un’applicazione terza ad accedere a certe risorse protette che lo riguardano, senza rivelare all’applicazione terza le proprie credenziali(password). È diventato uno degli standard cardine per l’autenticazione/autorità federata sul web, utilizzato da giganti come Google, Facebook, Microsoft, Amazon e molti altri per implementare il “Login con…”. Ad esempio, quando un sito ti offre di “accedere con il tuo account Google”, dietro le quinte sta usando OAuth: tu vieni rediretto a Google, fai login lì, e Google chiede “Vuoi autorizzare questo sito ad accedere al tuo indirizzo email e profilo base?”; se acconsenti, Google rilascia un token di accesso (access token) al sito, che questo userà per ottenere i dati richiesti dalle API di Google – senza mai conoscere la tua password Google.
Tecnicamente, OAuth 2.0 definisce vari grant types (flussi di autorizzazione) per diversi scenari (app server-side, app client-side, applicazioni native, dispositivi senza browser, ecc.), ma il concetto chiave è l’uso di token al posto delle credenziali. Quando l’utente autorizza, l’Identity Provider (detto Authorization Server in OAuth) rilascia un token (un insieme di stringhe cifrate o firmate) che l’applicazione client può presentare per accedere alla risorsa. Il token incarna i diritti concessi (es: “valido per leggere l’email dell’utente, scade tra 1 ora”). Ciò elimina la necessità per l’utente di condividere la propria password con terze parti – migliorando sicurezza e privacy. Se una terza parte viene compromessa, l’attaccante ottiene al massimo token limitati (spesso già scaduti o revocabili), non l’identità permanente dell’utente.
Per un responsabile alla sicurezza, comprendere OAuth 2.0 è importante perché molte integrazioni di servizi tra agenzie o con fornitori esterni oggi avvengono tramite API e deleghe OAuth. Ad esempio, un’app mobile governativa potrebbe usare OAuth 2.0 per far autenticare i cittadini tramite SPID (Sistema Pubblico di Identità Digitale) o tramite account di identità federati, delegando l’autenticazione a quel provider e ottenendo un token che rappresenta l’utente. OAuth 2.0 è spesso usato insieme a OpenID Connect (OIDC), che è un’estensione di OAuth per ottenere anche informazioni sull’identità verificata dell’utente (federated authentication). Mentre OAuth da solo è per autorizzare l’accesso a risorse, OIDC aggiunge un ID Token con dettagli sull’utente autenticato (nome, email, ecc.). Nel contesto interno, OAuth può essere usato ad esempio per permettere a microservizi di scambiarsi dati a nome di utenti o per integrare applicazioni legacy con sistemi IAM moderni.
In pratica, l’adozione di OAuth 2.0 comporta la gestione attenta dei permessi (scopes) richiesti dalle applicazioni (chiedere solo ciò che serve), la protezione dei token (che diventano un obiettivo per gli attaccanti, se rubano un token attivo potrebbero accedere alle risorse finché non scade) e la predisposizione di meccanismi di revoca. Standard moderni come OAuth sono preferibili a soluzioni “fatte in casa” di scambio credenziali, proprio perché ben testati e con ampio supporto librerie.
SAML 2.0 (Single Sign-On federato)
SAML (Security Assertion Markup Language) 2.0 è un altro standard aperto, usato principalmente per implementare il Single Sign-On (SSO) federato in contesti enterprise e inter-organizzativi. A differenza di OAuth/OIDC che sono più recenti e orientati al mondo API/mobile, SAML è nato in ambito XML per permettere a un utente di usare un’unica autenticazione per accedere a servizi diversi (tipicamente applicazioni web enterprise) con dominio di gestione separato. SAML definisce un formato di asserzione (assertion) che un Identity Provider (IdP) invia a un Service Provider (SP) contenente l’affermazione che “l’utente X ha effettuato con successo l’autenticazione ed ecco i suoi attributi”. In pratica, quando tenti di accedere a un servizio (SP) che delega l’autenticazione a un IdP, verrai reindirizzato all’IdP (ad es. il login centralizzato della tua organizzazione); dopo aver fatto login lì, l’IdP genera un’asserzione SAML firmata digitalmente che include la tua identità e magari il ruolo, e la invia al SP (solitamente tramite il browser dell’utente). Il SP verifica la firma e, se valida, ritiene l’utente autenticato senza chiedergli altre credenziali.
SAML è molto usato in contesti business-to-business e PA: per esempio, un dipendente del Ministero con account sul dominio interno può accedere al portale di un’altra Agenzia che ha trust SAML col suo Ministero, senza avere un account separato. Il portale (SP) si fida dell’asserzione prodotta dal IdP del Ministero. Questo semplifica la gestione delle identità e delle password perché l’utente gestisce un solo account (sul IdP) e accede a più servizi. Significativamente, SAML semplifica il processo diidentità: l’utente non deve ricordare credenziali diverse per ogni servizio e gli amministratori possono centralizzare controllo e revoca degli accessi sul IdP.
Un aspetto importante è che SAML trasmette attributi oltre alla semplice autenticazione, il che permette al Service Provider di applicare autorizzazioni basate su ruoli o attributi ricevuti. Ad esempio, l’asserzione SAML potrebbe dire che l’utente è “Mario Rossi” con ruolo “Coordinatore-Prevenzione” e il servizio può usare tale informazione per concedere i privilegi appropriati. Il protocollo opera su base di fiducia pre-configurata: IdP e SP scambiano metadati e certificati per le firme, e in genere l’integrazione richiede configurazioni amministrative da entrambe le parti. Per un responsabile alla sicurezza, SAML (così come OAuth/OIDC) rappresenta uno strumento abilitante per la cooperazione inter-ente. Ad esempio, l’IDPC (Infrastruttura di Identità Digitale della PA) potrebbe usare SAML per permettere ai dipendenti pubblici di usare le proprie credenziali aziendali per accedere a servizi di altre PA senza nuovo account, migliorando sia la sicurezza (meno password in giro, autenticazione forte centralizzata, audit unificato) sia la comodità. Tuttavia, vanno gestiti con attenzione i trust: una vulnerabilità su un IdP SAML può avere impatti notevoli (un attaccante che impersoni l’IdP potrebbe accedere a tutti i servizi federati). Quindi occorre assicurare la robustezza dell’IdP e avere monitoraggio sugli accessi federati.
Kerberos (Autenticazione basata su “biglietti”)
Kerberos è un protocollo di autenticazione di rete progettato per un ambiente con server di autenticazione fidato centralizzato. È ampiamente utilizzato (e quasi sinonimo) nell’autenticazione all’interno di domini Windows/Active Directory, ma è nato nel mondo Unix/MIT. Kerberos usa un meccanismo di ticket e chiavi segrete condivise per autenticare in modo sicuro un utente presso diversi servizi, senza inviare la password in chiaro sulla rete. In Kerberos, esiste un’entità fidata chiamata Key Distribution Center (KDC) (in AD coincide con il Domain Controller) che detiene le chiavi segrete di tutti gli utenti e servizi. Quando un client (utente) vuole autenticarsi per usare un servizio (ad es. accedere a una cartella condivisa), il client prima contatta il KDC (Authentication Server) e richiede un Ticket-Granting Ticket (TGT) presentando la propria identità. Ciò avviene in modo sicuro usando la password dell’utente come chiave per comunicare col KDC; il risultato è che il client ottiene un TGT crittografato, che è essenzialmente un “biglietto” che dimostra che l’utente è autenticato. Il client poi utilizza il TGT per chiedere al KDC un ticket di servizio per lo specifico servizio a cui vuole accedere (fase di Service Granting). Il KDC restituisce un ticket crittografato per quel servizio. Il client a questo punto presenta il ticket direttamente al server del servizio (ad esempio al file server), il quale – fidandosi del KDC – accetta il ticket come prova dell’identità e concede l’accesso. Tutto questo avviene senza mai inviare la password oltre la prima richiesta iniziale e usando challenge cifrati, prevenendo attacchi di replay e intercettazione.
In termini più generali, Kerberos è un protocollo di “terza parte fidata”: il KDC è l’autorità centrale che valida identità e distribuisce credentials temporanee (i ticket). I ticket hanno una durata limitata (es: 8 ore) e sono specifici per l’entità e il servizio e spesso includono flag sulle autorizzazioni. Kerberos fornisce anche mutua autenticazione – non solo il client prova chi è, ma anche il server prova la sua identità al client (tramite lo stesso meccanismo di ticket presentato e riflettuto), prevenendo man-in-the-middle. Un altro vantaggio di Kerberos: abilita il Single Sign-On interno – l’utente inserisce la password una volta per ottenere il TGT, poi accede a più servizi senza dover riautenticarsi ad ognuno, finché il ticket è valido.
Nel contesto Active Directory, Kerberos è il metodo di autenticazione predefinito e svolge un ruolo integrale: infatti AD associa ad ogni account una chiave derivata dalla password usata da Kerberos. Attacchi famosi come Pass-the-Ticket o Golden Ticket si riferiscono proprio a compromettere il funzionamento di Kerberos in AD rubando ticket o la chiave segreta principale del KDC. Un responsabile alla sicurezza deve quindi conoscere i princìpi di Kerberos sia per configurare correttamente i sistemi (sincronizzazione oraria dei server – Kerberos è sensibile allo skew di orario, robustezza delle password di servizio, policy di rinnovo ticket) sia per capire e mitigare le tecniche di attacco legate (es. rilevare ticket anomali, proteggere l’account krbtgt in AD). In altri ambienti, Kerberos può essere utilizzato anche su Unix/Linux per servizi NFS, database, etc., integrando con un KDC centrale. Ad esempio, il MIT mantiene ancora una distribuzione Kerberos indipendente. Per un uso moderno fuori da AD, Kerberos ha meno prevalenza rispetto a soluzioni federate (OAuth/OIDC), ma rimane fondamentale ovunque ci sia un dominio Windows o sistemi legacy integrati.
Riassumendo la gestione centralizzata degli accessi: Active Directory e sistemi IAM consentono di amministrare utenti e permessi in modo coerente su larga scala; protocolli come Kerberos e SAML forniscono meccanismi efficaci per l’autenticazione continua e federata rispettivamente; OAuth 2.0 permette deleghe di accesso sicure tra servizi. Un responsabile deve saper orchestrare questi elementi per garantire che gli utenti autorizzati possano accedere agevolmente alle risorse di cui hanno bisogno (anche inter-dominio) ma al contempo prevenire accessi non autorizzati, il tutto con tracciabilità completa (log centralizzati di autenticazione) e conformità alle normative di sicurezza.
Principi di Disponibilità, Integrità e Confidenzialità (Triade “CIA”)
Al cuore della sicurezza delle informazioni stanno i tre principi fondamentali di Confidenzialità, Integrità e Disponibilità, spesso chiamati triade CIA (dalle iniziali in inglese: Confidentiality, Integrity, Availability). Qualsiasi misura di sicurezza, controllo o politica ha tipicamente l’obiettivo di salvaguardare uno o più di questi requisiti. Per un responsabile alla sicurezza, è essenziale comprendere a fondo ciascun principio – le definizioni, gli esempi di minacce correlate e le contromisure – in modo da poter valutare l’impatto di un incidente o di un rischio secondo queste dimensioni.
Confidenzialità (Riservatezza): consiste nell’assicurare che informazioni e risorse siano accessibili solo a chi è autorizzato e che nessun soggetto non autorizzato possa vederle o usarle. In pratica, la confidenzialità tutela la privacy dei dati. Esempi: solo il personale medico può consultare certi referti clinici, solo destinatari previsti leggono un’email cifrata, un documento classificato è accessibile solo a persone con adeguata autorizzazione. Minacce alla confidenzialità includono la divulgazione non autorizzata di informazioni: esfiltrazione di dati tramite attacchi hacker (es. data breach dove milioni di record personali vengono rubati), intercettazione di comunicazioni (sniffing di rete non cifrata), accessi interni indebiti (un dipendente curioso che sfoglia dati a cui non dovrebbe accedere). Le contromisure per la confidenzialità spaziano dalla cifratura dei dati (sia a riposo che in transito) all’hardening degli accessi (autenticazione forte, controlli di accesso basati su ruoli – RBAC, o attributi – ABAC), fino a politiche di need-to-know. Ad esempio, per proteggere dati sensibili in transito si usa il protocollo TLS, per file riservati si usa crittografia e gestione delle chiavi adeguata, per limitare accessi interni si applicano permessi minimi e monitoraggio (Data Loss Prevention, logging di accessi ai dati). Mantenere la confidenzialità è cruciale soprattutto in contesti governativi: si pensi a informazioni personali dei cittadini, segreti di stato, indagini forensi, dove una violazione di riservatezza può avere impatti su privacy, reputazione, sicurezza nazionale.
Integrità: il principio di integrità implica garantire che dati, sistemi e risorse non vengano alterati o distrutti in modo non autorizzato e che siano accurati e completi rispetto allo stato atteso. In altre parole, l’informazione deve mantenere la propria veridicità e consistenza durante tutto il ciclo di vita e qualsiasi modifica deve essere fatta solo da soggetti legittimati e in maniera tracciabile. Esempi di integrità: un file di log di sistema che non deve essere manomesso (perché serve per audit), il contenuto di un database finanziario che deve rimanere corretto, un messaggio che deve arrivare a destinazione esattamente come è stato inviato (senza essere alterato). Le minacce all’integrità includono manomissioni intenzionali (un attaccante che modifica record di un database per coprire tracce o per frode, un malware che altera file di configurazione), errori o corruzioni accidentali (bug software o guasti hardware che corrompono dati, errori umani di modifica) e atti di sabotaggio (cancellazione di dati). Le contromisure tipiche sono: controllo degli accessi in scrittura (così solo entità autorizzate possano modificare), utilizzo di firme digitali e hash crittografici per rilevare modifiche non autorizzate (ad esempio la firma di un documento garantisce di accorgersi se viene alterato dopo la firma), versioning e backup per poter recuperare dati integri in caso di alterazioni indesiderate, e meccanismi di integrità nelle comunicazioni (come codici di autenticazione dei messaggi – MAC – per assicurare che un messaggio non sia stato alterato in transito). In ambito di infrastrutture critiche, l’integrità dei comandi e dei dati ha anche implicazioni di sicurezza fisica: ad es. garantire che i parametri inviati a uno SCADA non siano stati manomessi è vitale per operare correttamente un impianto. Il responsabile alla sicurezza deve dunque assicurare misure come il controllo dell’integrità dei software (ad es. tramite verifiche di hash su aggiornamenti, whitelisting delle applicazioni consentite) e politiche che prevedano il doppio controllo su modifiche di dati critici (four-eyes principle).
Disponibilità: è il requisito per cui le risorse e i servizi devono essere accessibili e utilizzabili dagli utenti autorizzati nel momento in cui ne hanno bisogno, senza interruzioni non pianificate. La disponibilità riguarda quindi la continuità operativa e la prontezza delle infrastrutture. Un sistema ad alta disponibilità minimizza i downtime e garantisce che, malgrado guasti o attacchi, gli utenti legittimi possano comunque accedere alle funzionalità necessarie. Esempi: un portale web pubblico di servizi al cittadino che deve essere online 24/7, un data center che deve avere alimentazione e connessione ridondanti per non fermarsi, un numero di emergenza (112) che deve essere sempre raggiungibile. Le minacce principali alla disponibilità sono gli incidenti che causano interruzioni: qui rientrano guasti hardware (un server che si rompe, un blackout elettrico), errori software (un bug che manda in crash un’applicazione critica), eventi catastrofici (incendi, alluvioni, terremoti colpendo i siti), ma anche attacchi deliberati come i DoS/DDoS (Denial of Service distribuiti che sovraccaricano i servizi rendendoli irraggiungibili). Un altro esempio attualissimo sono i ransomware, che cifrando i dati li rendono inaccessibili, causando interruzioni massive di servizi e perdita di disponibilità dei dati finché non vengono ripristinati da backup. Le contromisure per la disponibilità includono architetture ridondate e tolleranti ai guasti: ad esempio, avere cluster di server in configurazione High-Availability, duplicazione di componenti critiche (RAID per i dischi, più linee di rete, generatori di corrente di backup), disaster recovery pianificato (siti secondari su cui far failover in caso di disastro sul sito primario), e piani di Business Continuity per continuare almeno parzialmente le operazioni anche durante incidenti gravi. Dal lato attacchi, ci sono misure come sistemi anti-DDoS (filtri di traffico, servizi di scrubbing, CDN che assorbono il traffico), politiche di limitazione delle risorse per prevenire abusi (rate limiting). Inoltre, una robusta politica di backup offline garantisce che, in caso di attacco ransomware, i dati possano essere recuperati senza pagare riscatti, ripristinando così la disponibilità. Per un responsabile, la disponibilità ha anche una valenza di servizio pubblico: assicurare che servizi essenziali (sanità digitale, forze dell’ordine, servizi finanziari di stato, ecc.) restino attivi e accessibili alla popolazione e agli operatori, anche in scenari di attacco o calamità, è di vitale importanza (si pensi ad attacchi come quello che nel 2021 paralizzò la Regione Lazio bloccando temporaneamente i servizi sanitari, mostrando come la perdita di disponibilità possa avere impatti enormi sui cittadini).
In pratica, la gestione della sicurezza è spesso un bilanciamento tra questi tre principi: ad esempio, massimizzare la confidenzialità (cifratura forte ovunque) potrebbe introdurre qualche latenza o complessità che impatta disponibilità; aumentare la disponibilità con tante copie di dati deve fare i conti con mantenere l’integrità e confidenzialità in tutte le copie. Il ruolo del responsabile di sicurezza è valutare i requisiti di CIA per ogni sistema e applicare controlli adeguati. Alcuni sistemi avranno priorità diverse (un sistema militare potrebbe privilegiare la confidenzialità e integrità dei comandi anche a scapito della disponibilità; un servizio al cittadino di emergenza privilegerà la disponibilità; un registro contabile l’integrità, ecc.) ma in generale tutti e tre devono essere garantiti in misura sufficiente. Molti standard (ISO 27001, NIST) e normative richiedono esplicitamente l’analisi di impatto su CIA per ogni rischio identificato. In sede di esame, è utile saper fornire per ciascun principio esempi concreti di misure: Confidenzialità – crittografia, controllo accessi, classificazione dati; Integrità – hashing, firme digitali, controllo versioni, permessi di scrittura limitati; Disponibilità – ridondanza, backup, anti-DDoS, monitoraggio e incident response rapida.
Tipologie di attacchi cyber: Tattiche, Tecniche, Procedure (TTP) ed esempi attuali
Il panorama delle minacce informatiche è in continua evoluzione, con attaccanti che sviluppano nuove tattiche, tecniche e procedure (TTP) per eludere le difese. Tattiche sono gli obiettivi o le fasi generali di un attacco (ad es. ricognizione, iniziare l’esecuzione di codice, movimento laterale, esfiltrazione); tecniche sono i metodi specifici usati per compiere quelle tattiche (es. tecnica di phishing via email per ottenere credenziali, oppure utilizzo di exploit per escalation di privilegi); procedure sono le implementazioni dettagliate di queste tecniche, spesso specifiche di gruppi di attacco o malware (ad esempio, la sequenza particolare di comandi e script usata da un certo gruppo APT durante l’esfiltrazione). L’analisi delle TTP è un paradigma usato nella Cyber Threat Intelligence e nei framework come MITRE ATT&CK, e consente di profilare le minacce in base ai comportamenti anziché agli indicatori puntuali, migliorando la capacità di prevenire e individuare attacchi mirati.
Dal punto di vista difensivo, conoscere le TTP principali (specialmente di attori noti come gruppi APT sponsorizzati da Stati o cybercriminali sofisticati) aiuta un SOC/CSIRT a riconoscere pattern di attacco e a implementare contromisure specifiche. Ad esempio, se si sa che una certa minaccia usa la tecnica “Golden Ticket” su Kerberos per muoversi lateralmente, si possono predisporre allarmi su anomalie nei ticket; o se un ransomware in genere disabilita le shadow copies come prima mossa, un monitoraggio su quell’azione può far scattare un alert precoce.
Le tipologie di attacchi si possono classificare in vari modi; qui li descriviamo per categoria di obiettivo o metodo, fornendo esempi attuali rilevanti.
Attacchi di ingegneria sociale (phishing, spear phishing, social network): mirano a sfruttare l’errore umano inducendo le vittime a compiere azioni che compromettano la sicurezza. Il phishing via email rimane una delle tecniche più diffuse per iniziare una catena di attacco: l’aggressore invia email ingannevoli che inducono l’utente a fornire credenziali (falsi login a servizi bancari, cloud aziendali ecc.) o a cliccare allegati/link malevoli che installano malware. Varianti come lo spear phishing (email altamente personalizzate su un singolo bersaglio di alto profilo) e il whaling (mirato a dirigenti, es. CEO fraud) hanno avuto successo in furti finanziari e spionaggio. Un esempio recente è la campagna di phishing contro account email governativi che ha sfruttato documenti COVID-19 falsi per convincere i funzionari a inserire la password su un sito clone. Altre tecniche social includono l’impersonation al telefono (vishing) o via messaggi (smishing), e l’uso dei social media per raccogliere informazioni su abitudini e contatti (ricognizione per futuri attacchi). Difendersi richiede combinare formazione del personale (simulazioni di phishing, awareness) con filtri tecnici (email gateway con anti-phishing, autenticazione a più fattori che mitighi il furto di password, ecc.). Molti attacchi avanzati iniziano ancora con una mail di phishing ben fatta: ad esempio, il noto attacco SolarWinds del 2020 – uno supply chain attack – sembra abbia avuto origine anche con tecniche di spear phishing verso dipendenti chiave.
Malware (virus, worm, trojan) e in particolare ransomware: i malware sono codice malevolo introdotto nei sistemi per causare danni, rubare informazioni o prendere controllo. Negli ultimi anni il ransomware è emerso come una delle minacce più gravi: si tratta di malware che, una volta eseguito, cifra i dati dell’organizzazione e richiede un riscatto in criptovaluta per fornire la chiave di decrittazione. I ransomware moderni adottano tattiche di doppia estorsione – oltre a criptare, prima esfiltrano dati riservati minacciando di pubblicarli se non si paga. Questo li rende devastanti sia sul piano disponibilità (blocco operatività) sia confidenzialità (data breach). Esempi di attacchi ransomware di grande impatto: Colonial Pipeline (2021), dove un attacco ransomware (DarkSide) fermò l’erogazione di carburante lungo la costa est USA per giorni; Regione Lazio (2021), che bloccò i servizi sanitari regionali; e una miriade di casi su ospedali, comuni, aziende strategiche. Secondo l’ENISA Threat Landscape 2023, i ransomware rappresentano ancora la minaccia numero uno, costituendo il 34% di tutti gli incidenti analizzati nell’Unione Europea. Altre famiglie di malware includono: trojan (malware mascherati da software legittimi, es. backdoor RAT che danno controllo remoto all’attaccante), worm (che si auto-propagano, come il celebre worm Morris del 1988 che diede origine al primo CERT), virus classici che infettano file e spyware che spiano le attività (keylogger, stealer di dati). La diffusione spesso avviene via phishing (allegati con macro malevole, eseguibili camuffati), exploit kit su siti web compromessi, chiavette USB infette o altri vettori. La difesa anti-malware richiede un approccio stratificato: dai gateway con antivirus e sandbox, agli endpoint con EPP/EDR (come discusso sopra), backup offline frequenti, patch management per chiudere le vulnerabilità sfruttate dai malware, e procedure di incident response pronte per isolare rapidamente macchine infette appena rilevate.
Attacchi a servizi web e applicazioni (SQL injection, XSS, RCE): Molte minacce sfruttano vulnerabilità nel software applicativo. Le injection (in particolare SQL injection) rimangono una top threat secondo OWASP: un attaccante inserisce input malevolo in campi di una pagina web in modo da manipolare le query al database sottostante, potendo così ottenere dati non autorizzati o modificare/cancellare informazioni. Ad esempio, attacchi SQLi a siti governativi hanno in passato esfiltrato massicci archivi (ricordiamo il caso “Collection#1” dove furono trafugate milioni di credenziali anche da siti istituzionali con SQLi). Altre vulnerabilità comuni: Cross-Site Scripting (XSS), dove l’aggressore riesce a far eseguire script arbitrari nel browser di altri utenti (potenzialmente rubando sessioni o inducendo azioni a loro insaputa); buffer overflow e altre memory corruption che consentono esecuzione di codice sul server (Remote Code Execution); directory traversal per leggere file riservati; deserialization insecure; e così via. Gli attacchi alle applicazioni possono portare sia al furto di dati (violando confidenzialità, come nel caso dell’attacco a Equifax 2017 dove una falla web portò all’esfiltrazione di 145 milioni di record) che a prendere controllo dei server (minando integrità e disponibilità). Difendersi richiede secure coding, test di sicurezza (code review, penetration test), aggiornamenti continui e l’uso di protezioni come i Web Application Firewall (WAF) che bloccano exploit noti a livello applicativo. Per un responsabile è cruciale avere un programma di gestione vulnerabilità sulle proprie applicazioni (scansioni periodiche, aderenza a standard OWASP Top 10) e magari partecipare a iniziative di bug bounty o di collaborazione con la comunità per individuare falle prima che le sfruttino attori malevoli.
Attacchi sulla rete e infrastruttura (DDoS, MitM, exploit su protocolli): Gli aggressori possono puntare all’infrastruttura di rete stessa. I Distributed Denial of Service (DDoS) floodano un server o una rete di richieste o pacchetti al punto da saturarne le risorse e renderlo irraggiungibile agli utenti legittimi. Si va da attacchi volumetrici di molteplici Gbps (che saturano banda) ad attacchi applicativi che saturano risorse più specifiche (es. inviare migliaia di richieste costose al secondo). Gruppi di attivismo o Stati ostili hanno impiegato DDoS contro siti governativi o finanziari come atto di protesta o sabotaggio (noti gli attacchi del gruppo russo Killnet contro siti istituzionali europei nel 2022-2023). Altre minacce di rete includono gli attacchi Man-in-the-Middle (MitM), dove l’attaccante si interpone nelle comunicazioni (ad esempio in reti Wi-Fi aperte, o sfruttando ARP spoofing in LAN) per spiare o alterare dati in transito – mitigati dall’uso diffuso di cifratura TLS e VPN. Sul fronte protocolli, a volte emergono vulnerabilità in componenti di infrastruttura: ad es. falle nei protocolli di routing BGP (che possono permettere di dirottare traffico), exploitation di server DNS (DNS cache poisoning) o vulnerabilità su VPN, firewall, etc. Un esempio fu la vulnerabilità Log4Shell (fine 2021) nella libreria Log4j, che essendo ampiamente usata su server esposti (sistemi di gestione, security appliances, servizi cloud) ha messo a rischio infrastrutture globali: gli attaccanti l’hanno sfruttata massivamente per RCE su server vulnerabili, installando web shell e malware di ogni tipo. La risposta coordinata a livello globale (CERT che emettono allerte, patch rapide) ha limitato danni peggiori, ma è stato un campanello d’allarme su come una falla nei “tubi” di Internet possa avere effetti a cascata. Come difesa, oltre alle patch e hardening costante, è importante avere capacità di monitoraggio del traffico di rete (es. anomalie che suggeriscano MitM interni, o volumi insoliti preludio a DDoS) e accordi con provider per filtraggio DDoS a monte.
Attacchi avanzati e APT (Advanced Persistent Threat): Si tratta di campagne portate avanti tipicamente da gruppi ben finanziati (spesso collegati a governi o a grandi cyber-gang) che hanno obiettivi specifici e persistenza nell’operare. Un APT spesso combina varie tattiche: iniziale phishing o 0-day per entrare, poi movimento laterale silenzioso, escalations, stabilire backdoor persistenti, ed exfiltrare dati sensibili o compromettere infrastrutture critiche. Esempi noti includono l’APT29 (Cozy Bear) legato all’intelligence russa, che è accusato dell’hack di SolarWinds citato sopra (inserendo codice malevolo negli aggiornamenti software di Orion, compromettendo in un colpo solo migliaia di organizzazioni tra cui agenzie USA); oppure APT28 (Fancy Bear) implicato in attacchi a ministeri e organizzazioni NATO. Anche attori cinesi (es. APT40, Hafnium) e nordcoreani (Lazarus Group) hanno condotto attacchi notevoli: dal furto di segreti industriali all’acquisizione di valuta (crypto-heist), fino a sabotaggi (il WannaCry del 2017 è attribuito a Lazarus, combinando worm e ransomware). Le tattiche APT prevedono spesso l’uso di malware su misura, zero-day exploits (sfruttamento di vulnerabilità sconosciute al momento), e tecniche di offuscamento per restare sotto traccia. Difendersi da APT è complesso e richiede un mix di prevenzione (hardening, principio zero trust – nessun accesso implicito anche all’interno, segmentazione estrema), rilevamento approfondito (strumenti di EDR/XDR, analisi dei log con SIEM, threat hunting proattivo cercando indicatori delle note TTP), e risposta rapida con capacità di contenimento. Inoltre la condivisione di intelligence tra organizzazioni (es. tramite ISAC, CERT nazionali) è cruciale per conoscere indicatori di compromissione e tecniche emergenti e potersi preparare (si veda sezione 7 su ISAC).
In conclusione di questa sezione, è chiaro che il panorama delle minacce è molto ampio: da attacchi opportunisti di massa (phishing generico, ransomware random) a operazioni mirate di attori statali. Per un ruolo di coordinamento nazionale, oltre a conoscere le tipologie di attacco, è importante tenersi aggiornati sui casi di attacchi recenti e sulle relative lesson learned. Ad esempio, comprendere come un attacco come Colonial Pipeline è riuscito (compromissione di password VPN non protetta da MFA) può portare a migliorare subito certe difese nelle proprie strutture; oppure studiare l’attacco alla catena di fornitura di SolarWinds spinge a controllare meglio la sicurezza dei fornitori e software terzi utilizzati nelle proprie reti. Fortunatamente, esistono report e analisi (ENISA Threat Landscape, Verizon DBIR, rapporti di intelligence delle agenzie) che un buon responsabile deve consultare regolarmente per adeguare la strategia difensiva in base alle TTP emergenti e agli attacchi in voga.
Ruolo e funzioni di CSIRT, SOC e ISAC nella gestione degli incidenti
La sicurezza informatica non è solo una questione di tecnologie, ma anche di organizzazione e processi. Tre acronimi importanti in ambito di gestione degli incidenti e cooperazione in cybersicurezza sono CSIRT, SOC e ISAC. Ciascuno rappresenta una struttura con un ruolo specifico.
CSIRT (Computer Security Incident Response Team): è un gruppo di esperti di sicurezza deputato a gestire e rispondere agli incidenti informatici di una certa organizzazione o contesto. Il CSIRT ha tipicamente la responsabilità di monitorare le minacce, intercettareeventi di sicurezza, analizzare gli incidenti e orchestrare la risposta e mitigazione. In altre parole, è l’unità di pronto intervento cyber: quando scatta un allarme, il CSIRT attiva le procedure per contenere l’incidente (es. isolare i sistemi compromessi), investigarne le cause, eradicare la minaccia, ripristinare i servizi e fare follow-up (lezioni apprese, rafforzamento difese). I CSIRT possono esistere a vari livelli: aziendale (ogni grande organizzazione può avere il suo team di risposta), nazionale (es. il CSIRT Italia istituito dall’ACN per coordinare la risposta a livello Paese), settoriale (CSIRT di settore per coordinare in ambiti specifici come finanza, energia, sanità). Spesso i termini CERT (Computer Emergency Response Team) e CSIRT vengono usati in modo intercambiabile; storicamente “CERT” era un marchio del primo team presso Carnegie Mellon, ma oggi si parla tranquillamente di CERT aziendale/governativo. Le funzioni di un CSIRT includono: monitoraggio delle fonti di allerta (sensori, SOC, intelligence esterna), analisi forense degli incidenti per capirne portata e attori, coordinamento interno (tra IT, legal, comunicazione) ed esterno (con altri CSIRT, forze dell’ordine) durante la gestione dell’incidente, comunicazione di allerte preventivi se emergono minacce (ad esempio un CSIRT nazionale emette allerte su campagne di attacco in corso verso enti governativi), e raccomandazioni di sicurezza post-incidente. In un contesto nazionale, il CSIRT funge anche da punto di contatto a cui enti e aziende possono segnalare incidenti (spesso obbligatorio per legge, es. direttiva NIS richiede notifica al CSIRT nazionale di certi incidenti). Un responsabile per la prevenzione e gestione di incidenti a livello nazionale dovrà quindi interfacciarsi strettamente col CSIRT nazionale, contribuire alla condivisione di informazioni e assicurare che la propria organizzazione segua le linee guida emanate dal CSIRT (che spesso produce indicatori di compromissione, bollettini di sicurezza, guide di best practice in seguito ad incidenti osservati).
SOC (Security Operations Center): è il centro operativo di sicurezza, ovvero un team (spesso in un vero e proprio locale dedicato, fisico o virtuale) che ha il compito continuo di monitorare gli eventi di sicurezza nell’infrastruttura IT, rilevare potenziali incidenti e avviare la primarisposta. Un SOC tipicamente lavora 24/7, analizzando log e flussi da varie fonti (sistemi di detezione intrusioni, antivirus, firewall, sistemi di autenticazione, ecc.) attraverso una console centralizzata (es. un SIEM – Security Information and Event Management) per identificare anomalie o segni di compromissione. In altre parole, mentre il CSIRT entra in gioco in maniera più reattiva quando un incidente è conclamato, il SOC è la sentinella proattiva che cerca di individuare early warnings e attacchi in fase iniziale, e ferma sul nascere gli incidenti. Le responsabilità di un SOC possono includere: triage degli alert di sicurezza (filtrare i falsi positivi e riconoscere quelli reali), investigazione di eventi sospetti (es. tramite analisi approfondita di log, memoria volatile, traffico di rete), eseguire misure di contenimento immediate (ad esempio disabilitare un account compromesso, bloccare un IP in firewall), e inoltrare al CSIRT o ai team competenti gli incidenti più gravi per la gestione completa. Un SOC ben strutturato migliora notevolmente la capacità di rilevamento e risposta di un’organizzazione, coordinando tecnologie e operazioni in un unico hub. Spesso un SOC è organizzato su livelli (analisti di Livello 1 per monitoraggio base e escalation ai livelli superiori per analisi avanzate). Può essere interno o in outsourcing (MSSP – Managed Security Service Provider).
Importante, il SOC non lavora isolato: collabora con il CSIRT (che prende in carico gli incidenti gravi e la gestione globale), fornisce input alla gestione del rischio (e riceve da questa priorità su cosa monitorare con più attenzione), e in generale è un elemento tattico-operativo della strategia di sicurezza. Un esempio del ruolo SOC: supponiamo che arrivi un alert di “traffico anomalo in uscita” su una porta non usuale da un server. Il SOC analizza e scopre che il server potrebbe essere infetto da malware (comunicazione con IP noti malevoli); allora isola il server dalla rete (azione immediata), e passa la consegna al CSIRT per bonifica e analisi forense. Senza SOC, quell’anomalia poteva passare inosservata per giorni finché i danni non diventavano evidenti. Per questa ragione, la presenza di un SOC coordinato alle operazioni migliora le capacità di rilevamento, risposta e prevenzione di minacce dell’organizzazione, come sottolinea anche IBM e altri esperti. Un responsabile alla sicurezza nazionale deve quindi promuovere l’istituzione e il corretto funzionamento di SOC sia centralizzati (un SOC governativo o di settore che sorveglia entità più piccole che non hanno risorse proprie) sia locali dove possibile, assicurando anche che scambino informazioni (es: un SOC ministeriale notifica subito il CSIRT nazionale se vede indicatori di un attacco in corso che potrebbe riguardare altri enti, ecc.).
ISAC (Information Sharing and Analysis Center): gli ISAC sono organizzazioni no-profit collaborative in cui membri di un certo settore critico condividono informazioni su minacce, vulnerabilità e incidenti, costituendo un centro di raccolta e scambio di intelligence tra pubblico e privato. L’idea nacque negli USA nel 1998 per i settori delle infrastrutture critiche ed è ormai adottata a livello internazionale (in Europa ENISA promuove ISAC settoriali). Un ISAC tipicamente è focalizzato su un settore (es. finanziario – FS-ISAC a livello globale, energetico, sanità, trasporti, ecc.) e i membri sono le varie aziende/enti di quel settore. Fornisce un canale fidato per condividere in tempo reale informazioni su cyber threat: ad esempio, se una banca subisce un tentativo di attacco sofisticato, invia un’allerta all’ISAC finanziario in modo che le altre banche possano alzare le difese; oppure un CERT nazionale può diffondere tramite l’ISAC dati di indicatori (IOC) su campagne attive. Gli ISAC spesso producono anche analisi comuni, best practice specifiche di settore e talvolta esercitazioni congiunte.
Il valore di un ISAC sta nel superare l’isolamento informativo: “uniti si è più forti” contro attaccanti che spesso colpiscono in maniera sistematica attori simili. L’ISAC funge da “centrale” per raccogliere dati sulle minacce e redistribuirli, fungendo da ponte comunicativo tra privati e agenzie governative. Nel contesto italiano/europeo, possiamo citare ad esempio l’ISAC Sanità, l’ISAC Energia, ecc., dove aziende di quei settori collaborano con ACN e con tra loro. Anche organismi internazionali spingono i settori a dotarsi di ISAC (la direttiva NIS2 dell’UE incentiva l’information sharing).
Per un responsabile nazionale, partecipare attivamente agli ISAC significa avere accesso a informazioni aggiornate sulle minacce specifiche del proprio settore e poter implementare misure di prevenzione prima che gli attacchi ti colpiscano direttamente. Allo stesso modo, significa contribuire segnalando incidenti o scenari di attacco rilevati, in un’ottica di difesa collettiva. Un esempio di ISAC in azione: durante ondate di ransomware mirati a ospedali, l’ISAC sanitario può emanare allerte con dettagli tecnici (indicatori di compromissione, TTP usate, patch urgenti da applicare) che aiutano tutti gli ospedali membri a proteggersi in tempo. Senza quell’informazione condivisa, ogni struttura sarebbe da sola contro la minaccia e magari alcune cadrebbero vittime per non aver saputo per tempo ciò che altre avevano già visto.
In sintesi, CSIRT, SOC e ISAC sono tre pilastri complementari nella gestione del cyber rischio: – Il SOC è l’occhio vigile interno giorno e notte, che individua e reagisce immediatamente agli eventi nei sistemi di competenza. – Il CSIRT (aziendale o nazionale) è il team esperto che prende in carico la risposta più ampia e il coordinamento, fornendo anche supporto e guida per prevenire e prepararsi agli incidenti futuri. – L’ISAC estende la difesa oltre i confini della singola organizzazione, creando una comunità di fiducia dove conoscenza e allerta sono condivise, in modo da elevare la postura di sicurezza di tutti i partecipanti. Per un responsabile alla prevenzione e gestione degli incidenti informatici, è fondamentale saper interagire efficacemente con tutte queste entità: ad esempio, stabilire procedure interne perché il SOC escali prontamente al CSIRT; partecipare alle attività dell’ISAC di riferimento; magari organizzare esercitazioni congiunte (es: simulazioni di attacco su larga scala con coinvolgimento del CSIRT nazionale, vari SOC dipartimentali e le comunicazioni via ISAC). Questo garantisce una resilienza di sistema e non solo del singolo ente.
Gestione del rischio cyber: ciclo di gestione, framework (NIST, ISO 27005) e mitigazione
Nessuna organizzazione può proteggere tutto in modo assoluto; per questo si adotta un approccio di gestione del rischio per identificare le minacce e vulnerabilità più rilevanti, valutare l’impatto potenziale e adottare contromisure commisurate. La gestione del rischio cyber è un processo ciclico e continuo, strettamente allineato ai principi generali di risk management (come il ciclo Plan-Do-Check-Act). Secondo standard internazionali (ISO e NIST), le fasi fondamentali di questo processo sono: definizione del contesto, identificazione dei rischi, analisi e valutazione dei rischi, trattamento (o trattamento/risposta) del rischio, accettazione del rischio residuo, e monitoraggio/riesame continuo . Durante tutto il ciclo si svolgono attività trasversali di comunicazione e consultazione coinvolgendo stakeholder appropriati) e di documentazione/reporting.
Ecco in dettaglio come si articola questo ciclo.
Stabilire il contesto: consiste nel definire l’ambito del risk management (quali asset, processi, unità organizzative copre), i criteri per valutare impatto e probabilità, e gli obiettivi di sicurezza e compliance dell’organizzazione. Si raccolgono informazioni su asset di valore (es: dati personali, sistemi critici), si definiscono gli owner del rischio, e si stabilisce la propensione al rischio (risk appetite) e le soglie di accettabilità. Ad esempio, un’agenzia nazionale definirà come asset critici i database dei cittadini, le infrastrutture di rete centrali, ecc., e come criterio che qualsiasi rischio che possa causare indisponibilità > 24 ore di un servizio essenziale è considerato alto.
Identificazione del rischio: in questa fase si individuano i possibili scenari di rischio, ovvero combinazioni di minaccia e vulnerabilità che potrebbero portare a un incidente con impatto sui criteri CIA. Si cerca di rispondere alla domanda: “cosa potrebbe andare storto, e come potrebbe accadere?”. Si possono usare approcci basati sugli asset (identifico minacce e vulnerabilità per ciascun asset chiave) o basati sugli eventi (parto da possibili eventi avversi e vedo quali asset impattano). Ad esempio, per un sistema informativo X potrei identificare rischi come “furto di credenziali admin da parte di attaccante esterno via phishing”, “guasto hardware non ridondato”, “errore umano di configurazione aperta al pubblico”, “malware ransomware colpisce il file server” e così via. Fonti per identificare rischi includono: storico di incidenti passati (interni o nel settore), check-list di minacce comuni (come cataloghi OWASP, ENISA, MITRE), risultati di audit e test di penetrazione (che rivelano vulnerabilità tecniche). È cruciale coinvolgere esperti tecnici e di business affinché il set di rischi identificati sia il più completo e concreto possibile.
Analisi e valutazione: una volta elencati i rischi, per ciascuno si analizza probabilità (o frequenza) e impatto (o conseguenze) se si materializzasse. Dall’abbinamento si determina il livello di rischio (es. rischio = probabilità * impatto, se quantificato, oppure classifiche qualitativo tipo Alto/Medio/Basso). Qui entrano in gioco metriche e criteri decisi nel contesto: ad esempio, impatto può misurarsi in termini finanziari (euro di danno), reputazionali, di vite umane (in ambito sanità), legali, ecc., spesso su scala qualitativa (es. impatto Catastrofico, Grave, Moderato, Limitato, Negligibile). Probabilità può stimarsi da “molto probabile (atteso più volte l’anno)” a “rara (una volta in 10 anni)”. Si possono usare metodi quantitativi (come analisi statistica, simulazioni Monte Carlo) ove dati disponibili, ma spesso nel cyber si opera qualitativamente integrando giudizio esperto. L’output è una mappa dei rischi, spesso una matrice dove ciascun rischio è posizionato e classificato. Da qui deriva la valutazione: si confrontano i livelli di rischio con i criteri di accettabilità. I rischi sopra una certa soglia vengono segnalati come intollerabili e da mitigare, quelli bassi possono essere accettati. Ad esempio, uno scenario di attacco APT su infrastruttura critica potrebbe avere impatto altissimo ma probabilità bassa; la direzione dovrà decidere se quel rischio residuo è comunque inaccettabile (dato l’impatto potenziale) e quindi investire per ridurlo.
Trattamento del rischio: per i rischi identificati che eccedono le soglie di tolleranza, occorre decidere quali strategie adottare. Le classiche opzioni di trattamento sono: mitigare (implementare controlli per ridurre probabilità e/o impatto), trasferire (ad esempio stipulare assicurazioni cyber, o affidare a terzi la gestione di quel rischio contrattualmente), evitare (se un’attività è troppo rischiosa, decidere di non intraprenderla affatto, ad es. spegnere un servizio legacy insicuro), oppure accettare consapevolmente il rischio residuo (documentando la decisione) se ritenuto basso o se i costi di mitigazione superano i benefici. Nel contesto cyber, la mitigazione è la più frequente: significa implementare controlli di sicurezza adeguati. I controlli vanno scelti in base al rischio specifico e spesso si utilizzano framework di riferimento come l’ISO/IEC 27001 (che contiene un Annex A con controlli di sicurezza best practice) o il NIST Cybersecurity Framework. Ad esempio, per il rischio “ransomware su file server” si deciderà di mitigare con controlli tipo: backup giornalieri offline (riduce impatto, garantendo recupero dati), EDR con capacità anti-ransomware (riduce probabilità di successo), segmentazione di rete per limitare propagazione, e programma di formazione anti-phishing (riduce probabilità di infezione iniziale). Per il rischio “guasto data center per incendio” si può trasferire comprando assicurazione danni e mitigare predisponendo un sito di disaster recovery. Il risultato di questa fase è un piano di trattamento in cui per ciascun rischio vengono elencate le misure previste, i responsabili dell’attuazione e la tempistica.
Accettazione del rischio: dopo aver applicato (o pianificato) i trattamenti, rimane sempre un rischio residuo. La direzione deve consapevolmente decidere se quel residuo è accettabile. L’accettazione del rischio va formalizzata (in molti standard è richiesto evidenza dell’accettazione da parte del management per accountability). Ad esempio, si può accettare che permanga un rischio residuo di indisponibilità 1 giorno di un servizio non critico, per cui non vale la pena spendere oltre in ridondanze. L’importante è che la decisione sia informata e documentata, così come la ownership del rischio (es: “il responsabile XY accetta il rischio R di livello medio entro il limite stabilito”).
Monitoraggio e riesame: il rischio cyber è dinamico: compaiono nuove minacce, l’organizzazione cambia (nuovi sistemi, nuovi processi digitali), i controlli implementati possono risultare inefficaci nel tempo. Dunque è essenziale monitorare continuamente lo stato dei rischi e riesaminare periodicamente tutto il processo. Questo implica raccogliere dati sugli incidenti occorsi (per capire se le stime erano corrette, se qualcosa di non previsto è successo, ecc.), misurare la performance dei controlli (KPI/KRI di rischio, come numero di attacchi bloccati, vulnerabilità scoperte, etc.), e aggiornare di conseguenza valutazioni e trattamenti. In molti contesti normati (es. ISO 27001) si fanno riesami annuali del rischio, o immediatamente in caso di cambiamenti significativi (es. introduzione di una nuova tecnologia, o emergere di una vulnerabilità critica globale come Log4Shell). Il ciclo così riparte: re-identificazione dei rischi emergenti, nuova analisi, e così via, integrando la sicurezza nel ciclo di vita di ogni progetto.
Per supportare questo processo, esistono framework di riferimento e standard dedicati. Sul fronte internazionale: – ISO/IEC 27005 è lo standard specifico che fornisce linee guida per la gestione del rischio informatico e delle informazioni, complementare a ISO 27001. Si allinea a ISO 31000 (rischio generale) ma adattandola al contesto InfoSec. L’ultima versione (2022) mantiene l’approccio generale di identificare asset, minacce, vulnerabilità e valutare rischio, introducendo anche concetti come scenari di rischio ed eventi, e allineandosi con ISO 27001:2022 52 55 . ISO 27005 promuove metodi sia qualitativi che quantitativi e sottolinea l’importanza di un ciclo continuo e della documentazione di ogni fase. Adottare ISO 27005 aiuta a strutturare il risk assessment in modo coerente e accettato internazionalmente, facilitando anche le discussioni con auditor e stakeholder (dimostrare che i rischi sono gestiti secondo best practice).
NIST fornisce vari documenti: il NIST Risk Management Framework (RMF) (pubblicazione 800-37) delinea un processo simile di categorizzazione degli sistemi, selezione di controlli di sicurezza adeguati, implementazione, valutazione, autorizzazione (accreditamento) e monitoraggio continuo. È usato soprattutto nel contesto federale USA, ma i principi sono universali. Inoltre, il NIST Cybersecurity Framework (CSF) (2014, aggiornato in 2018 e in evoluzione) offre un approccio alto livello articolato in 5 funzioni – Identify, Protect, Detect,Respond, Recover – che aiutano a coprire l’intero ciclo di gestione del rischio cyber. Il CSF fornisce un set di categorie e controlli mappati su standard come ISO 27001, COBIT, ecc., ed è stato adottato da molte organizzazioni come base per valutare la propria maturità e guidare miglioramenti. Ad esempio, la funzione Identify include proprio attività di risk assessment e asset management. In Italia, il “Framework Nazionale di Cybersecurity” è basato sul NIST CSF, adattato al contesto italiano, incoraggiando aziende e PA a adottarlo.
ISO 31000 (Risk Management – Principles and Guidelines) non è specifica per IT ma fornisce principi e linee guida generali per qualsiasi tipo di rischio. Molte organizzazioni usano ISO 31000 come base comune del risk management aziendale, assicurando che il rischio cyber sia trattato con la stessa metodologia del rischio operativo, finanziario, etc., e quindi integrato nella governance complessiva. Ad esempio, ISO 31000 enfatizza l’integrazione del risk management nei processi decisionali, la personalizzazione del processo al contesto, e la responsabilità del management nel rischio residuo.
Implementare un ciclo di gestione del rischio cyber robusto consente di focalizzare le risorse di sicurezza dove contano di più e di dimostrare accountability. Per un responsabile, ciò significa poter rispondere a domande del tipo: “Quali sono i nostri rischi cyber più significativi? Cosa stiamo facendo per mitigarli? Qual è il rischio residuo e lo accettiamo consapevolmente? Siamo preparati se X accade?”. Ad esempio, se viene chiesto “siamo protetti contro attacchi DDoS massivi?”, invece di promettere protezione assoluta (impossibile), un risk manager informato potrà dire: “Abbiamo identificato il rischio DDoS come alto per il nostro servizio Y (probabilità media, impatto molto alto). Lo stiamo mitigando con un contratto con provider anti-DDoS e architettura ridondata; il rischio residuo è ridotto a medio e accettato dalla direzione, monitoriamo continuamente la situazione”. Questo approccio evita panico o, al contrario, compiacenza infondata, e consente di prendere decisioni di investimento razionali (es. giustificare budget cybersecurity in base alla riduzione di rischio ottenuta).
In termini di strategie di mitigazione specifiche, spesso si adottano controlli da diversi domini: controlli tecnici (firewall, IDS, crittografia, backup…), controlli procedurali (policy di sicurezza, procedure di gestione incidenti, classificazione delle informazioni), controlli fisici (sicurezza degli accessi ai locali, alimentazione elettrica protetta, etc.) e controlli organizzativi (formazione del personale, segregazione dei compiti, piani di continuità operativa). Il framework ISO 27001 Annex A ad esempio elenca controlli raggruppati per temi che coprono queste aree, e può fungere da checklist per non dimenticare aree di controllo. Un aspetto importante nella mitigazione è anche considerare il quadrante temporale: Prevenzione, Rilevazione, Risposta, Recupero (che ricalca le fasi del NIST CSF). Non si può prevenire tutto; quindi serve anche capacità di rilevare gli eventi (si torna al discorso SOC), rispondere efficacemente (CSIRT) e recuperare le funzionalità (disaster recovery, backup). Il risk management ben fatto alloca investimenti sulle quattro fasi in modo bilanciato secondo il profilo di rischio dell’organizzazione.
Infine, la gestione del rischio cyber deve rispettare eventuali framework normativi: ad esempio per le banche c’è l’obbligo di aderire a regole specifiche di Bankitalia/ESMA, per le infrastrutture critiche la direttiva NIS/NIS2 impone adozione di misure minime e valutazioni periodiche, per i dati personali il GDPR richiede una valutazione di impatto (DPIA) se ci sono rischi alti per i diritti delle persone. Un responsabile dovrà quindi fondere i requisiti di compliance con la propria analisi del rischio interna, garantendo che il processo soddisfi sia l’esigenza di sicurezza reale sia quella regolamentare (spesso queste coincidono, dato che normative e standard riflettono best practice).
Conclusione: I fondamenti affrontati – dai sistemi di sicurezza (firewall, IDS/IPS, WAF, endpoint), alla virtualizzazione, ai metodi di autenticazione, alla gestione centralizzata degli accessi, fino ai principi CIA, alle tipologie di attacco e alle strutture organizzative (CSIRT, SOC, ISAC) e al risk management – dipingono un quadro olistico della cybersicurezza moderna. Per un responsabileper la prevenzione e gestione di incidenti informatici in un contesto nazionale/governativo, la sfida consiste nell’integrare tutti questi elementi in una strategia coerente. Ciò significa: assicurare che le misure tecniche siano implementate secondo le best practice e continuamente aggiornate; che esistano team e processi pronti a rilevare e fronteggiare gli attacchi; e che la leadership prenda decisioni informate basate sul rischio.
La complessità del dominio richiede una formazione continua e la capacità di collaborare con molteplici attori (interni ed esterni). In particolare, la cooperazione a livello di sistema-Paese (tramite il CSIRT Italia, gli ISAC settoriali, ecc.) è fondamentale per elevare il livello di sicurezza collettiva: una minaccia che colpisce un ente può rapidamente propagarsi ad altri, ma un allarme condiviso in tempo può anche prevenirne il successo altrove. Allo stesso modo, un responsabile deve saper comunicare con sia tecnici (ad esempio interpretare un report di threat intelligence e tradurlo in azioni tecniche) sia dirigenti apicali (spiegando il valore delle iniziative di sicurezza e ottenendo supporto). In ultima analisi, i fondamenti di cybersicurezza qui presentati – supportati da riferimenti a standard internazionali (ISO, NIST), fonti istituzionali (ENISA, ACN) e casi di studio – forniscono il bagaglio teorico e pratico per affrontare l’esame e, più significativamente, per impostare un programma di sicurezza efficace. La continua evoluzione delle minacce impone di applicare questi fondamenti con adattabilità: le tecnologie cambieranno, nuovi attacchi emergeranno, ma i principi cardine (proteggere CIA, conoscere il proprio rischio, difendersi in profondità, monitorare e rispondere rapidamente, condividere informazioni) rimarranno la bussola per navigare nel complesso panorama cyber. Un responsabile preparato su questi temi potrà guidare la propria organizzazione attraverso le sfide attuali e future, contribuendo alla resilienza cibernetica nazionale.
Il presente articolo vuole fornire una panoramica strutturata dei fondamenti di informatica e reti di calcolatori, con un focus sull’applicazione pratica di tali conoscenze nel contesto della sicurezza informatica. Ciascuna sezione approfondisce un argomento chiave – dalla rappresentazione dei dati ai sistemi operativi, dalle basi di dati alle reti e protocolli – evidenziando i concetti teorici essenziali e collegandoli alle best practice per la prevenzione e gestione di incidenti informatici.
La trattazione è pensata per il responsabile della sicurezza informatica impegnato nella prevenzione e gestione di incidenti informatici.
Vengono inclusi esempi pratici, riferimenti a standard riconosciuti e citazioni da fonti autorevoli, il tutto organizzato in sezioni chiare per facilitare la consultazione e l’apprendimento.
Rappresentazione delle informazioni
Nella scienza dei calcolatori, rappresentare le informazioni significa tradurre qualsiasi tipo di dato (numeri, testo, immagini, audio, ecc.) in una forma binaria comprensibile e manipolabile dalle macchine digitali. In pratica, ogni informazione viene codificata come sequenze di bit (binary digits), ossia 0 e 1, che sono le unità elementari di dati. Un insieme di 8 bit forma un byte, che costituisce la minima unità indirizzabile di memoria. Usando sequenze di bit e byte, un computer può rappresentare qualsiasi tipo di contenuto: caratteri testuali, valori numerici, immagini, suoni, video, ecc. La conversione dei dati in sequenze di 0 e 1 prende il nome di codifica e risponde al requisito fondamentale per cui un computer elabora solo informazioni in formato binario.
Unità di misura e codifiche: poiché i bit da soli sarebbero poco maneggevoli, si utilizzano multipli come Kilobyte (KB), Megabyte (MB), Gigabyte (GB), tenendo presente che in informatica per ragioni storiche spesso 1 KB = 1024 byte (2^10) invece di 1000 (si parla più precisamente di Kibibyte). Sul versante delle codifiche, per rappresentare testi alfanumerici si impiegano sistemi standardizzati di mappatura tra numeri e caratteri. Uno dei più importanti è il codice ASCII, che associa a ogni simbolo (lettera, cifra, segno di punteggiatura, caratteri di controllo, ecc.) un valore numerico tra 0 e 127, rappresentabile con 7 bit. Ad esempio, il carattere ‘A’ in ASCII è codificato come 65 (in decimale), mentre ‘a’ è 97 e così via. Estensioni di ASCII utilizzano 8 bit (256 valori possibili) per supportare caratteri accentati e simboli aggiuntivi, sebbene queste estensioni non fossero unificate a livello internazionale. Oggi si utilizza ampiamente Unicode, un sistema di codifica che, nelle sue varianti come UTF-8 e UTF-16, può rappresentare decine di migliaia di caratteri (oltre i caratteri latini, anche alfabeti non latini, ideogrammi, emoji, ecc.). Unicode in UTF-8 è retro-compatibile con ASCII per i primi 128 valori e consente di codificare caratteri usando sequenze di 1-4 byte. Grazie a Unicode, applicazioni e sistemi possono gestire testi multilingue e simboli emoji in modo unificato.
Numeri e formati numerici: i numeri interi vengono rappresentati in binario utilizzando un certo numero di bit fissato (es. 32 bit o 64 bit). Per i numeri con segno (positivi/negativi) l’approccio più diffuso è la rappresentazione in complemento a due, in cui il bit più significativo indica il segno e l’operazione di inversione dei bit più aggiunta di 1 permette di ottenere il negativo di un valore. Il complemento a due è lo schema standard adottato nei moderni calcolatori per i numeri interi con segno, poiché facilita la progettazione dei circuiti aritmetici (addizione e sottrazione possono essere eseguite con lo stesso circuito sommatorio). Ad esempio, con 8 bit si possono rappresentare gli interi da -128 a +127 in complemento a due. Per i numeri reali (con virgola decimale), si utilizza la rappresentazione in virgola mobile secondo lo standard IEEE 754, che definisce formati a 32 bit (precisione singola) e 64 bit (precisione doppia), tra gli altri. Questo standard specifica come suddividere i bit di un numero reale in segno, esponente e mantissa, permettendo di rappresentare un ampio intervallo di valori (inclusi zero, infiniti e valori NaN per indicare risultati non numerici). La conformità allo standard IEEE 754 garantisce che diversi processori e linguaggi interpretino i numeri in virgola mobile nello stesso modo, importante per la consistenza dei calcoli (ad esempio in crittografia o analisi scientifiche).
Rappresentazione di immagini, audio e altri dati: oltre a testo e numeri, i computer rappresentano anche dati multimediali in forma binaria. Un’immagine digitale ad esempio è modellata come una griglia di elementi chiamati pixel, ciascuno associato a valori binari che ne determinano il colore. In una immagine raster (bitmap), ogni pixel ha componenti di colore (ad esempio rosso, verde, blu in RGB) codificate tipicamente su 8 bit ciascuna, per un totale di 24 bit per pixel (True Color). Ciò significa che un singolo pixel può assumere circa 16,7 milioni di combinazioni di colore. Immagini con palette più ridotte possono usare meno bit per pixel (ad esempio 8 bit/pixel in modalità 256 colori). Allo stesso modo, un’immagine in bianco e nero può essere codificata con 1 bit per pixel (0 = bianco, 1 = nero), eventualmente con livelli di grigio se si usano più bit. Per i suoni, la rappresentazione avviene mediante campionamento: l’onda sonora analogica viene misurata (campionata) a intervalli regolari e ogni campione viene quantizzato in formato digitale (ad esempio, audio CD utilizza 44.100 campioni al secondo, ciascuno rappresentato da 16 bit per canale). Il risultato è una sequenza binaria che descrive l’andamento dell’audio nel tempo. Video e altri tipi di dati sono combinazioni o estensioni di questi principi (sequenze di immagini per il video, eventualmente compresse; flussi di campioni audio, ecc.), sempre riconducibili a stringhe di bit.
Implicazioni per la sicurezza informatica: la corretta comprensione della rappresentazione dei dati è fondamentale nella sicurezza informatica per diversi motivi. In primo luogo, molte vulnerabilità di basso livello (come buffer overflow o integer overflow) derivano da limiti nella rappresentazione binaria: ad esempio un intero a 32 bit ha un massimo e se un calcolo eccede quel massimo si verifica un overflow con possibili esiti imprevisti. Conoscere come i numeri sono codificati (complemento a due, IEEE 754 per i float, ecc.) aiuta a prevenire errori di programmazione sfruttabili da attaccanti. Inoltre, la rappresentazione binaria è alla base della crittografia: bit e byte vengono manipolati con operazioni booleane e aritmetiche per cifrare/decifrare informazioni. Un esperto di sicurezza deve conoscere, ad esempio, come lavorano gli algoritmi bit-a-bit e come interpretare dumps binari o esadecimali di file e pacchetti di rete durante un’analisi forense. Anche l’encoding dei caratteri è rilevante: attacchi come Unicode spoofing (ingannare sistemi di autenticazione usando caratteri Unicode simili a quelli latini) o bypass di filtri basati su codifiche differenti (ad esempio doppia codifica in attacchi XSS) sfruttano dettagli della rappresentazione dei testi. Infine, la capacità di tradurre rapidamente dati binari in forme comprensibili (come visualizzare un file eseguibile in esadecimale, o un indirizzo IP nella notazione dotted-decimal) è una competenza pratica quotidiana per chi gestisce incidenti: consente di identificare payload malevoli nascosti, firme di file e altri indicatori di compromissione.
Architettura degli elaboratori
Un elaboratore (computer) moderno si basa sul modello concettuale di architettura di von Neumann, che prevede la suddivisione in componenti fondamentali: una Unità Centrale di Elaborazione (CPU), una memoria centrale, dispositivi di input/output (I/O) e interconnessioni dette bus. In tale architettura, sia i dati che le istruzioni di un programma sono memorizzati nella medesima memoria e la CPU li preleva ed esegue sequenzialmente. Di seguito esaminiamo ciascun componente e le implicazioni relative alla sicurezza.
CPU (Central Processing Unit): è il “cervello” del computer, responsabile dell’esecuzione delle istruzioni macchina. La CPU è internamente composta da un’unità di controllo (Control Unit, CU) che dirige l’esecuzione delle istruzioni, da un’unità aritmetico-logica (ALU) che effettua calcoli e operazioni logiche e da una serie di registri interni per l’immagazzinamento temporaneo di dati e indirizzi. La CPU esegue le istruzioni in un ciclo di fetch-decode-execute: preleva un’istruzione dalla memoria, la decodifica e la esegue, aggiornando eventualmente registri e memoria. Le istruzioni stesse costituiscono il cosiddetto linguaggio macchina specifico della famiglia di CPU in uso (ad esempio x86-64, ARMv8, etc.). La maggior parte delle CPU moderne supporta funzionalità come pipeling (esecuzione parallela sovrapposta di parti di istruzioni diverse) e multithreading (gestione di più flussi di istruzioni) per migliorare le prestazioni. Dal punto di vista della sicurezza, la CPU implementa meccanismi hardware essenziali, come i livelli di privilegio (es. modalità kernel vs user): le moderne CPU possono operare in almeno due modalità, in cui le istruzioni cosiddette privilegiate (che accedono a risorse critiche o configurazioni hardware) possono essere eseguite solo in modalità kernel (dove risiede il sistema operativo), ma non in modalità utente. Questo isolamento hardware garantisce che un programma in esecuzione applicativa non possa, ad esempio, modificare direttamente la memoria del kernel o interagire col dispositivo disco senza passare per il sistema operativo – prevenendo una vasta gamma di abusi. Tuttavia, sono noti attacchi (Meltdown, Spectre) che sfruttano caratteristiche delle CPU (esecuzione speculativa, branch prediction) per aggirare tali protezioni, sottolineando come l’architettura hardware sia anch’essa un fronte di sicurezza da curare.
Memoria centrale: è il luogo in cui risiedono i programmi in esecuzione e i dati su cui operano. La memoria centrale (di solito RAM, Random Access Memory, volatile) contiene sia le istruzioni macchina caricate dal disco sia le strutture dati necessarie alle applicazioni. La caratteristica è l’accesso diretto rapido agli indirizzi di memoria (a differenza delle memorie di massa più lente). La memoria centrale memorizza sia i dati da elaborare (o già elaborati) sia le istruzioni eseguibili. Tipicamente è organizzata in una sequenza di celle indirizzabili (parole di memoria) tutte della stessa dimensione (es. 8 byte), ognuna identificata da un indirizzo numerico univoco. La memoria è spesso distinta in RAM (lettura/scrittura, volatile) e ROM/EPROM (Read-Only Memory, memorie non volatili contenenti ad esempio il firmware di bootstrap). Un aspetto cruciale dell’architettura è la gerarchia di memoria: piccole memorie velocissime (registri nella CPU, cache L1/L2/L3) mitigano la differenza di velocità tra CPU e RAM; più in basso vi sono memorie di massa (SSD, HDD) e archivi esterni. Ai fini della sicurezza, la gestione della memoria è un terreno fertile di vulnerabilità: buffer overflow (scrittura oltre i limiti di un buffer), use-afterfree (uso di memoria già deallocata) e memory corruption in genere sono alla radice di exploit. Negli ultimi decenni, sono stati introdotti contromisure hardware come il bit NX (No-eXecute, che marca le pagine di memoria dati come non eseguibili per prevenire l’iniezione di shellcode) e tecniche come ASLR (Address Space Layout Randomization, implementata a livello di sistema operativo ma dipendente dal supporto CPU per la segmentazione/paginazione) per rendere più difficile sfruttare i bug di memoria. Un responsabile alla sicurezza deve comprendere come funzionano queste protezioni hardware/memory e i limiti che possono avere, per esempio sapere che buffer overflow su architetture moderne possono essere mitigati ma non eliminati (es. return-oriented programming è nato proprio come tecnica per bypassare NX-bit e ASLR sfruttando frammenti di codice legittimo in memoria).
Bus e dispositivi I/O: i vari componenti sono collegati da bus di sistema (insieme di linee di comunicazione). Esistono tipicamente bus separati o logici distinti per indirizzi, dati e controllo, che coordinano il flusso delle informazioni tra CPU, memoria e periferiche. Le periferiche di I/O (dispositivi di input/output come tastiera, mouse, schermo, disco, scheda di rete, ecc.) interagiscono col processore attraverso controller specifici collegati sul bus. Da una prospettiva di sicurezza, i dispositivi I/O possono rappresentare vettori di attacco se non gestiti correttamente: ad esempio, dispositivi esterni USB possono iniettare comandi (si pensi a Rubber Ducky che si presenta come tastiera HID); le schede di rete possono essere bersaglio di DMA attacks (accesso diretto alla memoria) se l’IOMMU non isola adeguatamente le periferiche. Inoltre, dal bus passano anche dati sensibili (ad esempio password digitate da tastiera o chiavi crittografiche in RAM) e attacchi di tipo side-channel hanno dimostrato che è possibile captare informazioni sul bus o analizzare i tempi di risposta del sistema per dedurre segreti.
Set di istruzioni e architetture: ogni CPU implementa un Instruction Set Architecture (ISA), l’insieme di istruzioni macchina che è in grado di eseguire. Architetture diverse (x86, ARM, MIPS, RISC-V, ecc.) hanno ISA differenti e anche modalità operative differenti (32-bit, 64-bit, little endian vs big endian nell’ordinamento dei byte in memoria, ecc.). Nello sviluppo di exploit o nella risposta a incidenti, è spesso necessario comprendere l’architettura bersaglio: ad esempio, malware scritto per ARM non girerà su un server x86 a meno di emulazione e viceversa. Inoltre, la sicurezza del software è strettamente legata all’architettura: un binario compilato per x86-64 con protezioni come stack canaries (canarini sullo stack) e Control Flow Guard sfrutta funzionalità specifiche dell’ISA e del compilatore; un analista deve sapere come riconoscerle ed eventualmente disattivarle in ambiente controllato per effettuare reverse engineering. Parimenti, alcune istruzioni privilegiate (come la gestione della tabella delle pagine di memoria) sono sfruttate nei rootkit in modalità kernel: conoscere il funzionamento interno della MMU (Memory Management Unit) e delle istruzioni correlate può aiutare a individuare manipolazioni malevole a basso livello.
In sintesi, l’architettura degli elaboratori fornisce il substrato hardware su cui operano i sistemi software. Un responsabile della sicurezza informatica deve padroneggiare almeno i concetti fondamentali (ciclo macchina, gestione memoria, modelli architetturali) per comprendere sia come prevenire incidenti (es. configurare correttamente protezioni hardware, scegliere architetture sicure per certi servizi critici) sia come analizzare incidenti avvenuti (es. dump di memoria, istruzioni eseguire da un malware, log di errori CPU come kernel panic o machine check exception). Inoltre, la cooperazione tra hardware e software in termini di sicurezza è sancita da standard e best practice: ad esempio, l’UEFI Secure Boot sfrutta funzionalità firmware/hardware per garantire che all’accensione vengano eseguiti solo bootloader firmati e tecnologie come TPM (Trusted Platform Module) offrono radici hardware di fiducia utilizzate dai sistemi operativi per funzionalità come BitLocker (crittografia disco) o l’attestazione di integrità. Tutti questi aspetti richiedono una conoscenza delle basi architetturali per essere implementati e gestiti con successo.
Sistemi operativi
Un sistema operativo (SO) è il software di base che funge da intermediario tra l’hardware del computer e i programmi applicativi, gestendo le risorse del sistema e fornendo servizi essenziali agli utenti e alle applicazioni. In altre parole, il sistema operativo è composto da vari componenti integrati (kernel, gestore dei processi, gestore della memoria, file system, driver di periferica, interfaccia utente, ecc.) che insieme assicurano il funzionamento coordinato del computer. Esempi comuni di sistemi operativi sono Windows, Linux, macOS per desktop/server e Android, iOS per dispositivi mobili. Di seguito analizziamo le principali funzioni di un SO, evidenziando la loro importanza nella sicurezza informatica.
Gestione dei processi e multitasking: il sistema operativo consente di eseguire più programmi in (pseudo)parallelismo attraverso la gestione dei processi e dei thread. Un processo è un’istanza in esecuzione di un programma, con un proprio spazio di indirizzamento in memoria, mentre un thread è un flusso di esecuzione all’interno di un processo (i thread di uno stesso processo condividono memoria e risorse). Il kernel (nocciolo del sistema operativo) include uno scheduler che assegna la CPU ai vari processi/thread attivi, implementando politiche di scheduling (round-robin, priorità, ecc.) per garantire reattività e far avanzare tutti i carichi di lavoro. In ambito sicurezza, la corretta separazione dei processi è cruciale: il sistema operativo deve isolare gli spazi di memoria in modo che un processo non possa leggere/scrivere la memoria di un altro (violando la confidenzialità o integrità). Ciò è realizzato tramite l’MMU (unità di gestione memoria) e meccanismi come la traduzione di indirizzi (paginazione) che il SO controlla. Un attaccante spesso cerca di rompere questo isolamento (es. tramite local privilege escalation exploits che da un processo utente permettono di eseguire codice in contesto kernel). Pertanto, funzioni come il caricamento di moduli kernel firmati, l’implementazione di sandbox (che confinano processi potenzialmente pericolosi in ambienti limitati) e la gestione attenta delle API di interprocess communication (pipe, socket, shared memory) sono aspetti di sicurezza legati alla gestione dei processi.
Gestione della memoria: il sistema operativo fornisce astrazioni di memoria ai processi, tipicamente sotto forma di memoria virtuale. Ogni processo vede uno spazio di indirizzi virtuali che il kernel mappa sulla memoria fisica reale, garantendo che processi diversi non interferiscano. Il gestore della memoria del SO si occupa di allocare e liberare memoria su richiesta dei programmi (tramite chiamate di sistema come malloc/free in C, o automaticamente tramite garbage collector in linguaggi gestiti), di swappare porzioni di memoria su disco se la RAM scarseggia (memoria virtuale paginata) e di proteggere regioni critiche (ad esempio lo spazio di indirizzi del kernel è reso non accessibile ai processi utente, solitamente). Tecniche come ASLR – Address Space Layout Randomization (randomizzazione dello spazio degli indirizzi) sono abilitate dal sistema operativo per rendere meno prevedibili gli indirizzi di librerie, stack e heap, mitigando gli exploit basati su buffer overflow. Il responsabile alla sicurezza deve conoscere queste tecniche e assicurarsi che siano abilitate (ad esempio, DEP/NX e ASLR attivi, stack guard pages, ecc.), nonché essere in grado di analizzare core dump o tracce di crash per capire se un incidente è dovuto a corruzione di memoria. Inoltre, la gestione della memoria comprende i permessi di accesso alle pagine (read/write/execute): un sistema operativo robusto segrega scrupolosamente codice ed esegue dati non eseguibili, sfruttando l’hardware (bit NX) e marcando anche regioni di memoria come non accessibili quando opportuno (es. mappe null pointer per catturare dereferenziazioni errate). Da un punto di vista offensivo, molti malware tentano di aggirare queste protezioni, ad esempio tramite Return-Oriented Programming (ROP) per eseguire codice malizioso pur in assenza di pagine eseguibili in user-space: analizzare un attacco del genere richiede padronanza di come il SO organizza la memoria di un processo.
File system e gestione delle risorse persistenti: un altro compito cardine del sistema operativo è la gestione dei file system, ovvero l’organizzazione dei dati su memoria di massa (dischi, SSD) in file e directory, con meccanismi di autorizzazione (permessi di lettura/scrittura/esecuzione per utenti e gruppi) e di protezione. Per esempio, sistemi POSIX (Linux, UNIX) adottano permessi rwx e proprietà utente/gruppo, oltre a meccanismi più avanzati come ACL (Access Control List) o selinux context per definire in modo granulare chi può accedere a cosa. Un responsabile della sicurezza deve assicurarsi che le politiche di permesso siano configurate secondo il principio del privilegio minimo (ad esempio, file di configurazione critici accessibili solo all’utente di sistema appropriato, directory con dati sensibili non eseguibili, ecc.). Inoltre, il file system registra metadati come timestamp (utili nelle analisi forensi per capire la timeline di un incidente) e, in alcuni sistemi, supporta cifratura trasparente (es. BitLocker su NTFS, LUKS su ext4) per proteggere i dati a riposo. Il sistema operativo è anche responsabile della gestione delle periferiche tramite driver – piccoli moduli software che fungono da traduttori tra il kernel e l’hardware. Driver vulnerabili possono introdurre gravi falle di sicurezza (poiché eseguono in kernel mode), quindi l’OS e i suoi aggiornamenti vanno monitorati per patch critiche relative ai driver (come ad esempio stuxnet, che sfruttò un driver malevolo con firma digitale rubata). Il sistema operativo implementa anche politiche di controllo degli accessi non solo a file ma a tutte le risorse (dispositivi, porte di rete, chiamate di sistema sensibili). Ad esempio, su sistemi UNIX esiste la distinzione tra utente normale e superutente (root): solo quest’ultimo può eseguire certe operazioni (binding di socket su porte <1024, caricamento di moduli kernel, modifiche alle tabelle di routing, ecc.). Meccanismi di sudo o capabilities permettono di limitare o delegare privilegi in modo controllato. La corretta configurazione di questi meccanismi è spesso l’ultima linea di difesa per prevenire che un attacco su un servizio in esecuzione con utente limitato comprometta tutto il sistema.
Interfaccia utente e modalità utente/kernel: il sistema operativo fornisce infine all’utente (e alle applicazioni) un’interfaccia per utilizzare il computer. Questa può essere una GUI (interfaccia grafica) con desktop, finestre e pulsanti, o una shell a riga di comando per lanciare comandi testuali. Indipendentemente dall’interfaccia, quando un’applicazione necessita di compiere operazioni privilegiate (es. accedere al disco, aprire una connessione di rete, allocare memoria), deve effettuare una chiamata di sistema (system call) al kernel. Le system call rappresentano il punto di controllo tra la modalità utente e la modalità kernel: l’OS espone una serie di servizi di sistema (come “open file”, “send packet”, “create process”) e gli unici modi per un programma di utente di ottenere questi servizi è invocare le relative chiamate, che comportano un trap in modalità privilegiata. Il sistema operativo verifica i parametri e i permessi ad ogni system call, garantendo che l’operazione sia lecita. Ad esempio, se un processo chiede di aprire un file, il kernel controlla che quel processo (identificato dal suo UID/GID di appartenenza) abbia i diritti necessari sul file. Questo meccanismo è fondamentale per la sicurezza: previene che un processo malevolo possa arbitrariamente manipolare risorse senza passare per controlli. D’altra parte, se esistono vulnerabilità nelle implementazioni delle system call (bug nel kernel), un attaccante potrebbe ottenere privilegi elevati – questi sono i famosi exploit local root che sfruttano race condition, buffer overflow o errori logici nel kernel. Un buon responsabile della sicurezza deve tenere i sistemi operativi aggiornati (patch management) proprio per correggere tali vulnerabilità non appena note.
In conclusione, il sistema operativo è il componente software più critico da un punto di vista di sicurezza, perché orchestra l’uso di tutte le risorse e applica le politiche di isolamento e controllo. Le best practice come la separazione dei privilegi (account utente vs amministratore), la riduzione della superficie d’attacco (disabilitare servizi di sistema non necessari, rimuovere driver inutilizzati), l’uso di meccanismi di logging e monitoraggio (Syslog, Event Viewer) e l’applicazione tempestiva di aggiornamenti di sicurezza, sono tutti ambiti afferenti al sistema operativo. Inoltre, standard e linee guida come quelle di CIS (Center for Internet Security) forniscono benchmark di hardening specifici per i vari sistemi operativi (ad esempio, CIS Controls e CIS Benchmarks per Windows Server, Red Hat, etc.), che il responsabile dovrebbe adottare per assicurare una configurazione robusta delle macchine. Un sistema operativo correttamente configurato e mantenuto è in grado di prevenire la maggior parte degli incidenti informatici comuni (attacchi malware, escalation di privilegi, esfiltrazione di dati), o quantomeno di registrare eventi utili a rilevare tempestivamente attività anomale.
Basi di dati relazionali e NoSQL
Le basi di dati (database) sono infrastrutture fondamentali per archiviare, organizzare e recuperare grandi quantità di informazioni in modo efficiente. Esistono vari modelli di database; i più diffusi si dividono in database relazionali (SQL) e database NoSQL (non relazionali). In questa sezione esamineremo entrambi, delineando caratteristiche, differenze e rilevanza per la sicurezza.
Database relazionali (modello SQL)
Un database relazionale organizza i dati in tabelle composte da righe e colonne, secondo il modello introdotto da Edgar F. Codd negli anni ‘70. Ogni tabella rappresenta un’entità, ogni riga (o record) rappresenta un’istanza dell’entità e ogni colonna rappresenta un attributo (campo) del record. Ad esempio, potremmo avere una tabella Utenti con colonne ID, Nome, Email, Ruolo dove ciascuna riga è un utente specifico con i suoi dati e una tabella Accessi con colonne UtenteID, DataOra, Esito per tracciare i login: le due tabelle sarebbero collegate attraverso il campo UtenteID (chiave esterna nella tabella Accessi che rimanda alla chiave primaria ID nella tabella Utenti). Le relazioni tra tabelle (one-to-one, one-to-many, many-to-many) vengono realizzate tramite queste chiavi: chiave primaria (un identificatore unico per ogni riga di una tabella) e chiavi esterne (valori che collegano una riga a una riga in un’altra tabella). Il modello relazionale è accompagnato da un linguaggio standard di interrogazione e manipolazione dei dati: SQL (Structured Query Language), che permette di definire lo schema (DDL – Data Definition Language), inserire/modificare/cancellare dati (DML – Data Manipulation Language) e effettuare query di ricerca e aggregazione (con SELECT, JOIN tra tabelle, ecc.).
Caratteristiche chiave dei database relazionali sono le cosiddette proprietà ACID delle transazioni, fondamentali in ambiti critici (bancari, gestionali, etc.): Atomicità (ogni transazione è un’unità indivisibile, o tutti gli step vengono applicati o nessuno), Coerenza (la transazione porta il database da uno stato consistente a un altro, non viola vincoli di integrità ), Isolamento (transazioni concorrenti non interferiscono tra loro, i risultati sono come se fossero state eseguite in sequenza) e Durabilità (una volta completata con successo, un’operazione diventa persistente anche in caso di guasti successivi). I DB relazionali sono tipicamente gestiti da un RDBMS (Relational Database Management System) – ad esempio Oracle, Microsoft SQL Server, MySQL/MariaDB, PostgreSQL – che si occupa di implementare queste garanzie e ottimizzare l’accesso ai dati (attraverso indici, piani di esecuzione delle query, caching, etc.).
Rilevanza per la sicurezza: i database relazionali spesso custodiscono informazioni sensibili (dati personali, credenziali, registri di attività) e sono bersagli appetibili per gli attaccanti. Due aspetti fondamentali vanno considerati: la sicurezza interna del DB e le vulnerabilità delle applicazioni che lo utilizzano. Sul primo fronte, un RDBMS deve essere configurato con opportune misure di sicurezza: controlli di accesso robusti (account separati con privilegi minimi per le applicazioni, ruoli e privilegi SQL assegnati con granularità), cifratura dei dati a riposo (molti DB supportano tablespace criptati o cifratura trasparente delle colonne), audit e logging delle operazioni (tracciare chi ha eseguito cosa e quando, per individuare accessi sospetti) e hardening generale (disabilitare funzionalità non utilizzate, applicare patch di sicurezza del motore DB). Ad esempio, esistono standard come lo SQL Server Security Guide o linee guida CIS Benchmarks per MySQL/PostgreSQL che elencano best practice: dal forzare l’autenticazione con password complesse, all’abilitare la cifratura TLS nelle connessioni client-DB, fino a restringere l’uso di stored procedure o comandi pericolosi solo ad account fidati.
Sul secondo fronte, il rischio più noto è la SQL Injection, una tecnica d’attacco applicativa in cui input malevoli forniti a un’applicazione web (o altro software) finiscono per alterare l’istruzione SQL eseguita sul database. Se l’applicazione non “sanitizza” correttamente gli input (ad esempio non usando query parametrizzate/preparate), un attaccante può inserire frammenti di SQL arbitrario nelle query, ottenendo potenzialmente accesso o manipolazione non autorizzata dei dati. Un classico incidente è quando un campo di login viene usato direttamente in una query tipo SELECT * FROM utenti WHERE user='${utente}' AND pass='${password}' : fornendo come utente qualcosa come ' OR '1'='1' , la query diventa sempre vera permettendo bypass di autenticazione. Dal punto di vista di un responsabile alla sicurezza, mitigare le SQL injection è prioritario: significa formare gli sviluppatori all’uso di parametri bindati, ORMs, stored procedure sicure e al filtraggio/escape degli input in ultima istanza. In aggiunta, predisporre Web Application Firewall (WAF) con regole per intercettare pattern di SQL injection può aggiungere un livello di difesa. Un altro esempio di attacco è il privilege escalation interno al DB: se un account di applicazione con pochi privilegi riesce a eseguire un comando di sistema attraverso una funzionalità di SQL estesa (ad esempio le xp_cmdshell di SQL Server, se abilitate impropriamente, consentono di eseguire comandi sul sistema operativo), l’attaccante potrebbe passare dal database al pieno controllo del server. Ciò evidenzia l’importanza di limitare al minimo i privilegi degli account DB usati dalle applicazioni e di disabilitare funzionalità di estensione (come esecuzione di codice esterno) se non necessarie.
In termini di standard, normative come il GDPR richiedono protezione rigorosa dei dati personali spesso contenuti nei database, includendo principi di data protection by design (ad esempio minimizzazione dei dati raccolti, pseudonimizzazione). Standard industriali come il PCI-DSS per i dati di carte di credito impongono cifratura degli storage e segmentazione di rete per i sistemi di database, oltre a monitoraggio continuo degli accessi.
Database NoSQL (non relazionali)
Negli ultimi anni, accanto ai sistemi relazionali tradizionali, si sono diffusi i database NoSQL, termine che sta per “Not Only SQL” ad indicare database non basati sul modello relazionale e spesso privi di schema fisso. I database NoSQL abbracciano diverse categorie: database documentali (che memorizzano dati in documenti strutturati tipicamente in formato JSON/BSON, es. MongoDB, CouchDB), database a colonne distribuite (simili a tabelle sparse con colonne flessibili, es. Cassandra, HBase), database a chiave-valore (memorizzano coppie key-value senza struttura interna, es. Redis, Riak) e database a grafo (ottimizzati per rappresentare entità e relazioni complesse come nodi e archi, es. Neo4j). Questi sistemi rinunciano alle rigide tabelle relazionali in favore di una struttura dati più flessibile e spesso distribuita su cluster di macchine.
Nei database NoSQL, i dati vengono spesso memorizzati nel loro formato nativo o “denormalizzato”. Ad esempio, un documento JSON può contenere in un unico record tutte le informazioni di un utente, compresa una lista dei suoi ordini, evitando di fare JOIN tra tabelle separate come accadrebbe in un modello relazionale. Questo porta vantaggi in termini di prestazioni e scalabilità su grandi volumi di dati o dati eterogenei: il sistema scala orizzontalmente, replicando e partizionando i dati su più nodi (sharding), ed è in grado di gestire variazioni di struttura tra diversi record (schema flessibile).
Tuttavia, spesso i database NoSQL sacrificano la coerenza immediata delle transazioni in favore della disponibilità e della partition tolerance, secondo i principi del teorema CAP. In ambienti distribuiti, garantire simultaneamente Coerenza, Disponibilità e Tolleranza alle partizioni è impossibile; molti database NoSQL scelgono di essere AP (available, partition-tolerant) sacrificando la consistenza forte: i dati possono essere eventualmente consistenti, ovvero gli aggiornamenti si propagano con tempo breve ma non istantaneo su tutte le repliche. In termini pratici, ciò significa che una lettura potrebbe restituire un dato lievemente obsoleto se appena modificato altrove, privilegiando però la reattività del sistema anche in caso di rete con latenze. Questo è spesso accettabile per scenari come social network (ad esempio, vedere per qualche secondo la vecchia foto profilo di un utente prima che arrivi la nuova non è critico), ma sarebbe inaccettabile in un’applicazione bancaria (dove i conti correnti richiedono consistenza forte). In compenso, le architetture NoSQL sono progettate per alta disponibilità e scalabilità: aggiungendo nodi al cluster, le performance di throughput aumentano linearmente in molti casi e la ridondanza dei dati su nodi multipli evita singoli punti di guasto.
Rilevanza per la sicurezza: i database NoSQL presentano sfide di sicurezza in parte analoghe a quelle dei relazionali, ma con alcune peculiarità. Innanzitutto, l’assenza di schema fisso significa che non ci sono vincoli intrinseci di tipo/forma dei dati: ciò può rendere più difficile validare l’input e più facile commettere errori logici (ad esempio, se un campo previsto come numero intero viene memorizzato come stringa in alcuni documenti, il comportamento dell’applicazione potrebbe essere imprevedibile). Dal punto di vista degli attacchi, esistono varianti di injection anche per NoSQL – le cosiddette NoSQL Injection – dove input malevoli manipolano le query di ricerca su database non relazionali. Ad esempio, in MongoDB una query è spesso costruita passando un JSON di filtro: se un’applicazione web inserisce direttamente parametri utente in questo JSON senza controlli, un attaccante potrebbe aggiungere operatori come $gt (greater than) o $ne (not equal) per alterare la logica della query. Pur meno note delle SQL injection, vulnerabilità analoghe sono state riscontrate (ad es. su applicazioni con backend MongoDB, Redis injection sfruttando comandi craftati, ecc.).
In termini di controlli di accesso, alcuni database NoSQL nelle prime versioni erano pensati per funzionare in ambienti fidati e mancavano di robusti sistemi di autenticazione/autorizzazione. Ci sono stati casi clamorosi di database NoSQL esposti online senza password (es. istanze di MongoDB o Elasticsearch lasciate aperte) che hanno portato a massivi furti di dati o attacchi ransomware (dove gli attaccanti esfiltravano e cancellavano i dati chiedendo un riscatto). Dunque, una prima regola di sicurezza è assicurarsi che l’accesso di rete ai database sia segregato (solo dagli application server, non dal pubblico internet) e che i meccanismi di autenticazione siano attivi e con credenziali robuste. Oggi i principali prodotti NoSQL (MongoDB, Cassandra, etc.) offrono meccanismi di autenticazione, cifratura in transito (SSL/TLS) e a riposo, controlli di autorizzazione basati su ruoli – ma sta ai configuratori abilitarli. In un contesto di sicurezza nazionale, dove si trattano dati sensibili, è imperativo che anche i database NoSQL rispettino standard di hardening: ad esempio, MongoDB Security Checklist suggerisce di abilitare l’autenticazione SCRAM-SHA, definire ruoli con minimo privilegio (lettura/scrittura su specifici database), usare IP binding solo su interfacce interne, abilitare auditing, ecc.
Dal punto di vista della consistenza dei dati, bisogna inoltre considerare la resilienza: in caso di incidenti (es. guasto di nodi, partizioni di rete), i database NoSQL possono entrare in stati degradati (consistenza ridotta) che, se non gestiti, potrebbero causare perdite o duplicazioni di dati. Un piano di sicurezza deve includere backup regolari anche per database NoSQL e test di ripristino, dato che la natura distribuita a volte complica le procedure di recovery (bisogna tenere conto di replica set, quorum di consenso per riottenere un primario in sistemi tipo MongoDB, etc.). Inoltre, la eventuale consistenza implica che nel monitoraggio degli incidenti bisogna tener conto di possibili discrepanze temporanee: ad esempio, analizzando i log di un sistema distribuito, un responsabile alla sicurezza deve sapere che l’ordine esatto delle operazioni potrebbe differire leggermente tra nodi – il che può complicare l’analisi forense e la ricostruzione esatta degli eventi. Strumenti specializzati per logging centralizzato (spesso basati essi stessi su stack NoSQL, come ELK – Elasticsearch, Logstash, Kibana) vanno configurati per correlare correttamente eventi multi-nodo.
Integrazione SQL/NoSQL e best practice: molte organizzazioni adottano architetture ibride dove convivono database relazionali per dati transazionali e database NoSQL per big data, analytics in tempo reale, cache in-memory, etc. Un coordinatore di sicurezza deve avere familiarità con entrambi e con le tecniche per proteggerli. Ad esempio, assicurarsi che i dati sensibili presenti in un cluster Hadoop/NoSQL siano cifrati (usando magari librerie come Google Tink o servizi KMS per gestire le chiavi) e segregati con tokenization o pseudonymization per minimizzare l’impatto di un breach. Allo stesso tempo, mantenere aggiornati i sistemi (le piattaforme NoSQL sono in continuo sviluppo, patch di sicurezza escono di frequente) e utilizzare strumenti di monitoraggio delle anomalie sulle query (Database Activity Monitoring) anche su NoSQL, dove possibile, per rilevare pattern inconsueti (es. un’esplosione di letture anomale alle 3 di notte da un certo IP potrebbe indicare un exfiltration in corso).
Riassumendo, la scelta tra database relazionali e NoSQL dipende dai requisiti di consistenza, scalabilità e struttura dei dati. Dal punto di vista della sicurezza, entrambi richiedono robuste misure di protezione, consapevoli delle rispettive architetture. I database relazionali brillano per maturità di strumenti di sicurezza integrati e transazioni ACID, mentre i NoSQL offrono flessibilità e prestazioni su scala, ma il professionista deve compensare eventuali mancanze (es. consistenza) a livello applicativo e prestare attenzione a configurazioni sicure che non sono sempre default. Conoscere standard come OWASP Top 10 (A03:2021 – Injection) per le injection o il NIST SP 800-123 (guide to general server security, applicabile anche ai server DB) aiuta a costruire un ambiente database – relazionale o no – robusto contro incidenti informatici.
Networking e principali protocolli di rete (TCP/IP, DNS, BGP)
Le reti di calcolatori permettono a sistemi differenti di comunicare e scambiarsi informazioni. La sicurezza informatica moderna è strettamente legata alle reti, poiché gran parte degli incidenti avviene attraverso connessioni di rete (attacchi remoti, malware che si propagano, esfiltrazioni di dati). In questa sezione esaminiamo i fondamenti del networking e tre protocolli chiave: la suite TCP/IP (base di Internet), il sistema dei nomi a dominio DNS e il protocollo di routing BGP. Comprendere questi protocolli è essenziale per prevenire e gestire incidenti che vanno dagli attacchi DDoS alla manipolazione del traffico internet.
Suite TCP/IP (Livelli di trasporto e rete)
TCP/IP non è un singolo protocollo ma una famiglia di protocolli organizzati in un modello di rete pratico (spesso semplificato in 4 livelli: Link, Internet, Trasporto, Applicazione) che corrisponde in parte al modello OSI (vedi sezione successiva). I due pilastri di questa suite sono il Protocollo IP (Internet Protocol) e il Protocollo TCP (Transmission Control Protocol), da cui prende nome.
IP (Internet Protocol): IP opera al livello di rete ed è il protocollo fondamentale che si occupa di indirizzamento e instradamento dei pacchetti attraverso reti differenti. IP fornisce un servizio di consegna di pacchetti non affidabile e senza connessione: ciò significa che invia i pacchetti dal mittente al destinatario secondo le informazioni di routing, ma non garantisce né che arrivino (possono perdersi) né che arrivino in ordine. Ogni dispositivo collegato in rete ha almeno un indirizzo IP univoco (32 bit per IPv4, rappresentati come quattro numeri es. 192.168.10.5, oppure 128 bit per IPv6, rappresentati in esadecimale). IP provvede a incapsulare i dati in un pacchetto IP contenente header (con mittente, destinatario, TTL, ecc.) e payload (i dati da trasportare, ad esempio un segmento TCP). Il protocollo IP è progettato per collegare reti eterogenee: è un protocollo di interconnessione di reti (internetworking) di livello 3 OSI, nato per far comunicare sottoreti differenti unificandole in un’unica rete logica (da cui “Internet”). IP compie l’instradamento: i router analizzano l’indirizzo di destinazione IP di ciascun pacchetto e lo inoltrano verso il router successivo più vicino alla destinazione, sulla base di tabelle di routing. Gli algoritmi di routing (OSPF, BGP, ecc. visti più avanti per BGP) costruiscono queste tabelle. Sul piano sicurezza, IP di per sé non prevede autenticazione né confidenzialità: i pacchetti possono essere falsificati (IP spoofing) e letti da intermediari. Per ovviare a ciò esistono estensioni come IPsec (una suite per la cifratura e autenticazione a livello IP) usata in VPN sicure. Inoltre, la natura non affidabile di IP significa che spetta ai livelli superiori occuparsi di ritrasmissioni e controllo di flusso (è qui che interviene TCP). Va citato che IPv4 soffre di spazio di indirizzi limitato e problemi di sicurezza (frammentazione IP usata in certi attacchi DoS, ad esempio Teardrop attack), mentre IPv6 migliora alcuni aspetti (spazio vastissimo, meccanismi di autoconfigurazione) ma porta nuove considerazioni di sicurezza (ad esempio, la presenza obbligatoria di ICMPv6 e multicast di rete locale richiede filtri specifici per evitare scansioni e attacchi di discovery non autorizzati).
TCP (Transmission Control Protocol): TCP opera a livello di trasporto e fornisce un canale di comunicazione affidabile e orientato alla connessione tra due host. In termini pratici, TCP si occupa di instaurare una connessione virtuale tra client e server (tramite la celebre stretta di mano 3-way handshake: SYN, SYN-ACK, ACK), di suddividere i dati da inviare in segmenti adeguati, di numerare i segmenti e ritrasmettere quelli non riconosciuti e di riordinare i segmenti al ricevente per presentare un flusso di byte continuo all’applicazione. Grazie a TCP, le applicazioni non devono preoccuparsi di perdita o disordine di pacchetti: TCP garantisce che i dati arrivino integri e nell’ordine corretto, o notifica un errore se la connessione si interrompe. Questo è essenziale per protocolli applicativi come HTTP, SMTP, FTP, in cui ricevere dati incompleti o scombinati equivarrebbe a corruzione dell’informazione. Tecnicamente, TCP identifica le connessioni tramite le porte: ogni segmento TCP ha una porta sorgente e una destinazione, permettendo a un singolo host di gestire più connessioni simultanee su porte diverse (es. 80 per HTTP, 443 per HTTPS, 25 per SMTP, ecc.). Dal punto di vista della sicurezza, il protocollo TCP è stato bersaglio di attacchi sin dai primordi di Internet. Un esempio classico è il TCP SYN flood: attaccando l’handshake di TCP, un aggressore invia una valanga di pacchetti SYN senza completare mai il 3° passo, lasciando il server con molte connessioni “mezze aperte” (in stato SYN_RECV) e esaurendo le risorse dedicate (la backlog queue). Ciò provoca un Denial of Service. Contromisure come SYN cookies o limiti sulla half-open queue aiutano a mitigare. Un altro attacco è il TCP reset (RST): inviando un pacchetto falsificato con bit RST si può forzare la chiusura di una connessione TCP esistente; se l’attaccante riesce a indovinare gli identificatori corretti (IP/porta e numero di sequenza), può interrompere comunicazioni di altri. Questo fu sfruttato in passato per bloccare traffico BGP (il cui trasporto è su TCP, vedi dopo) o per censura (come RST injection nel grande firewall cinese). Per integrità e confidenzialità, TCP da solo non offre nulla: la protezione dei dati deve avvenire a livello applicativo (ad es. TLS sopra TCP per cifrare la sessione). Tuttavia, dentro la suite TCP/IP esistono protocolli complementari come UDP (User Datagram Protocol, non affidabile e senza connessione, usato per streaming, DNS, etc.) che il responsabile sicurezza deve ugualmente conoscere: ad esempio, UDP è più soggetto a spoofing (essendo connectionless) e viene sfruttato in attacchi DDoS di riflessione/amplificazione (come DNS amplification, SSDP amplification), dunque vanno predisposti filtri (e.g. anti-spoofing con BCP 38, rate limiting su servizi UDP pubblici). In generale, la comprensione profonda di TCP/IP consente di analizzare i log di rete e i dump di pacchetto (es. con Wireshark) per rilevare attività sospette: sequenze anomale di flag TCP, tentativi su port scanning (che si evidenziano come connessioni SYN brevissime su molte porte), pacchetti malformati, etc. Standard come gli RFC (es. RFC 793 per TCP, RFC 791 per IP) definiscono il funzionamento lecito: molti attacchi inviano traffico che devia dallo standard (es. pacchetti con flag inconsuete come Xmas scan con FIN-PSH-URG) e sistemi IDS/IPS (Snort, Suricata, Zeek) sono in grado di rilevarlo se ben configurati.
In sintesi, TCP/IP è la colonna portante delle comunicazioni di rete. Un coordinatore di prevenzione incidenti deve: assicurare che le configurazioni di rete seguano le best practice (filtri su pacchetti ingressi/uscita, disabilitare protocolli legacy insicuri – es. Telnet, FTP – a favore di versioni cifrate – SSH, FTPS/SFTP), conoscere gli attacchi di rete comuni e le contromisure (firewall stateful per gestire SYN flood, IDS per rilevare scansioni e anomalie TCP/IP, IPsec per proteggere canali critici) e in caso di incidente saper leggere il traffico (analisi PCAP) per capire cosa è successo. Ad esempio, in un sospetto data breach, potrebbe trovarsi traffico TCP sulla porta 443 di volume insolitamente alto verso un IP esterno non riconosciuto: sapere che 443 è solitamente HTTPS e che l’esfiltrazione potrebbe avvenire cifrata fa sì che si debba guardare a meta-dati (SNI, quantità, pattern) e non al contenuto impossibile da decifrare senza la chiave. Allo stesso modo, la padronanza di TCP/IP è fondamentale per gestire incidenti come DDoS: riconoscere un flood TCP SYN o UDP, distinguere un traffico legittimo da uno malevolo in base a parametri di basso livello e interfacciarsi con ISP/CDN per attivare filtri o scrubbing.
DNS (Domain Name System)
DNS è il “servizio di nomi” di Internet, spesso paragonato a un “elenco telefonico” o a un servizio di rubrica per la rete globale. Il suo scopo principale è tradurre i nomi di dominio leggibili dagli umani (ad es. www.esempio.gov) nei corrispondenti indirizzi IP numerici che le macchine utilizzano per instradare il traffico. Senza DNS, dovremmo ricordare e digitare indirizzi come 93.184.216.34 per visitare un sito, cosa impraticabile su larga scala. Il DNS è dunque fondamentale per l’usabilità di Internet.
Il sistema DNS è gerarchico e distribuito. I nomi di dominio sono organizzati in una struttura ad albero rovesciato: al vertice ci sono i root server (indicati da un dominio radice vuoto, spesso rappresentato da un punto . ), subito sotto ci sono i domini di primo livello (TLD) come .com , .org , .it , .gov, ecc., poi i secondi livelli (es. esempio in esempio.gov ) e così via con possibili sottodomini aggiuntivi. L’operazione di risoluzione DNS consiste nel trovare l’indirizzo IP associato a un nome (risoluzione diretta) o viceversa trovare il nome dato un IP (risoluzione inversa). Quando un client (tipicamente tramite un resolver stub integrato nel sistema operativo) deve risolvere un nome, contatta un DNS resolver ricorsivo (spesso fornito dall’ISP o configurato manualmente come 8.8.8.8 di Google) il quale interroga a sua volta la gerarchia: parte dai root server (ce ne sono 13 indirizzi logici root disseminati globalmente) per sapere chi è autoritativo per il TLD richiesto, poi contatta il server autoritativo di quel TLD per sapere chi gestisce il dominio di secondo livello e così via fino ad ottenere dal server DNS autoritativo finale (gestito dal proprietario del dominio o dal suo provider) il record richiesto. Il DNS memorizza le risposte in cache per un certo periodo (TTL) per accelerare richieste future.
I record DNS più comuni includono: A/AAAA (indirizzo IPv4 o IPv6 associato a un nome), CNAME (nome canonico, alias verso un altro nome), MX (mail exchanger, indirizzo dei server di posta per il dominio), TXT (testo libero, usato anche per record SPF/DKIM nei contesti mail), SRV (service locator, utilizzato da alcuni protocolli), PTR (pointer per risoluzione inversa da IP a nome).
Minacce e sicurezza DNS: il DNS in origine è stato progettato senza meccanismi di autenticazione, il che l’ha reso vulnerabile a vari attacchi. Il più classico è il DNS cache poisoning: un attaccante induce un resolver a memorizzare una risposta falsa, cosicché gli utenti successivi vengano indirizzati all’IP sbagliato (ad esempio, credono di visitare bancopopolare.it ma in realtà il DNS avvelenato gli dà l’IP di un server dell’attaccante). Prima di correttivi, era possibile inviare risposte DNS fasulle con una certa facilità, approfittando del fatto che la porta UDP 53 e l’ID di transazione DNS erano prevedibili e non c’era verifica di origine. Ora i resolver usano porte effimere random e ID random a 16 bit, riducendo la fattibilità del poisoning, ma il rischio resta se l’attaccante può intralciare la comunicazione col vero server (ad es. tramite un man-in-the-middle). La risposta dell’industria è DNSSEC, un’estensione di sicurezza che aggiunge firme digitali alle risposte DNS: i domini firmati DNSSEC pubblicano chiavi pubbliche nei record DNSKEY e usano record RRSIG per firmare le mapping nome->IP. Un resolver con DNSSEC abilitato verifica che la firma sia valida e ancorata a una catena di fiducia (dal root in giù) evitando di accettare dati manomessi. DNSSEC, però, non è ancora ovunque adottato e introduce la complessità della gestione chiavi/rollover.
Un altro problema di sicurezza DNS è il DNS tunneling: usando richieste DNS (che spesso sono permesse anche quando altro traffico è bloccato) per incapsulare dati arbitrari, degli attaccanti possono esfiltrare informazioni o comandare malware (comandi e controllo) attraverso query DNS apparentemente legittime. Ad esempio, un malware potrebbe fare query a sottodomini come <data>.esempio-attaccante.com, dove <data> è un blocco di dati rubati codificato in base32; il server DNS sotto il controllo dell’attaccante riceve queste query e decodifica i dati dal nome richiesto. Dal punto di vista di un analista, è importante monitorare il traffico DNS verso domini insoliti o con nomi molto lunghi/strani, segnale tipico di tunneling o data exfiltration. Strumenti di sicurezza avanzata (DNS firewall, soluzioni di exfiltration detection) possono rilevare e bloccare questi abusi.
C’è poi il DNS hijacking o DNS spoofing: se un attaccante compromette un server DNS autoritativo o modifica i riferimenti (ad esempio alterando i record di un registrar DNS), può dirottare un dominio intero su altri IP. Questo è successo, ad esempio, in attacchi a provider DNS o in scenari di censura statale (dove i resolver ISP sono modificati per restituire IP “fake” per certi domini). Contromisure includono l’uso di registrar con protezioni robuste (2FA, lock) e monitoraggio continuo dei record DNS critici.
Best practice relative al DNS per un responsabile alla sicurezza includono: utilizzare resolver DNS ricorsivi sicuri (magari in-house o servizi con filtro malware), abilitare DNSSEC validation sui resolver interni per i propri utenti, implementare DNSSEC per i domini gestiti dall’organizzazione in modo da prevenire impersonificazioni, isolare e proteggere i server DNS autoritativi (pochi servizi devono contattarli, quindi regole firewall restrittive e monitoraggio). Inoltre, configurare correttamente i record per proteggere email e servizi (DNS è utilizzato in meccanismi di sicurezza come SPF, DKIM, DMARC per l’email authentication). Un altro aspetto è la privacy: le query DNS tradizionali sono in chiaro, quindi un attaccante che sniffa la rete vede tutti i nomi richiesti (che possono rivelare i siti visitati, ecc.). In risposta, si stanno diffondendo protocolli come DNS over HTTPS (DoH) o DNS over TLS (DoT) che cifrano il traffico DNS tra client e resolver. Questo migliora la riservatezza, ma pone sfide per i controlli aziendali (non si può più facilmente ispezionare il contenuto DNS). Un coordinatore dovrà quindi bilanciare privacy e capacità di monitoraggio, magari attivando DoT/DoH con server fidati ma anche usando sistemi di split-horizon DNS per risolvere internamente i nomi aziendali e avere visibilità.
BGP (Border Gateway Protocol)
BGP è il protocollo di routing globale che tiene unita Internet. Mentre protocolli come OSPF, EIGRP, IS-IS gestiscono il routing interno a una singola organizzazione o sistema autonomo (IGP – Interior Gateway Protocols), BGP è l’Exterior Gateway Protocol che connette tra loro i diversi Autonomous System (AS) – essenzialmente le reti di proprietà di fornitori di connettività (ISP, dorsali, grandi organizzazioni) identificate da un numero AS univoco. In parole semplici, BGP è il metodo con cui le reti annunciano ad altre reti quali prefissi IP possono raggiungere attraverso di loro, permettendo così di instradare pacchetti da un capo all’altro del mondo, passando per molte reti intermedie. BGP è dunque il “sistema di comunicazione tra router di confine” che consente a Internet di funzionare come un’unica grande rete. Senza BGP, i pacchetti oltre la propria rete locale non saprebbero dove andare.
Dal punto di vista tecnico, BGP è un protocollo di routing di tipo path-vector: ogni annuncio BGP informa su un prefisso IP raggiungibile e include l’AS-PATH, ovvero la sequenza di AS che bisogna attraversare per raggiungere quel prefisso. I router BGP (detti spesso Route Reflector o router di bordo) scambiano messaggi su connessioni TCP (porta 179). BGP è incrementale: invece di scambiare periodicamente l’intera tabella come alcuni IGP, dopo l’iniziale full routing table exchange, invia solo aggiornamenti quando cambia qualcosa (annuncio di nuova rotta o ritiro di una esistente). Questo lo rende scalabile per Internet dove esistono oltre 900k prefissi IPv4 annunciati. BGP permette politiche: ogni operatore può definire preferenze su quali rotte usare o annunciare (ad esempio preferire percorsi più corti in termini di AS-PATH, o quelli ricevuti da clienti su quelli ricevuti da provider per motivi economici).
Vulnerabilità e incidenti BGP: BGP si basa in gran parte sulla fiducia tra operatori e fino a tempi recenti non incorporava meccanismi crittografici robusti. Ciò lo rende vulnerabile al cosiddetto BGP hijacking: un AS malevolo (o mal configurato) può annunciare rotte per prefissi IP che non gli appartengono, deviando il traffico. Ad esempio, nel 2008 l’annuncio errato di una rotta per YouTube da parte di un ISP pakistano (nel tentativo di censurare YouTube localmente) propagò a livello globale, rendendo YouTube irraggiungibile per ore. In altri casi, attori malevoli hanno annunciato prefissi bancari o di criptovalute per intercettare dati. BGP hijack può portare a interruzione (se il traffico viene in un vicolo cieco) o Man-in-the-Middle (se il traffic hijacker lo inoltra verso la destinazione vera dopo averlo intercettato). Secondo analisi recenti, essendo BGP una tecnologia con ~35 anni di età, è “facile da manipolare per reinstradare il traffico Internet o addirittura isolare intere regioni”. Infatti, casi documentati mostrano come in situazioni geopolitiche (es. crisi Crimea/Ucraina), BGP sia stato usato intenzionalmente per deviare traffico di intere aree verso infrastrutture sotto controllo di governi, creando di fatto “frontiere digitali” coerenti con quelle militari.
Le contromisure emergenti sono: RPKI (Resource Public Key Infrastructure), un sistema di certificati digitali che associa prefissi IP e numeri AS a enti legittimi, permettendo ai router di verificare se un certo AS è autorizzato ad annunciare un certo prefisso. Implementare RPKI e filtri di validazione (droppare annunci BGP non validati) riduce i rischi di hijack accidentali e rende più difficile quelli malevoli (che richiederebbero compromissione dei certificati). Inoltre, buone pratiche come i filtri BCP 38 anti-spoofing e l’obbligo per gli ISP di filtrare annunci in ingresso da clienti che non corrispondono ai loro IP (route filtering) riducono la superficie di attacco. In ambito di sicurezza nazionale, è auspicabile una stretta collaborazione con gli operatori di rete per assicurare che tali misure siano adottate, dato che un attacco BGP può essere usato anche come vettore per isolare un paese o spostare traffico attraverso nodi di sorveglianza (si pensi a un hijack temporaneo che dirotta traffico europeo via AS in un altro continente per spiarlo, poi lo rilascia verso la destinazione – tattica rilevata in alcune analisi di routing).
Un altro rischio BGP è l’instabilità o errore di configurazione: BGP è complesso ed errori nelle politiche possono causare route leak (annuncio di rotte ricevute da un provider verso un altro provider quando non dovrebbe, saturando percorsi imprevisti) o flapping (rotte che oscillano ripetutamente su/giù causando overhead). Questi incidenti possono avere impatti collaterali di sicurezza: un route leak può congestionare link inattesi, rallentando comunicazioni critiche o firewall, oppure un flapping eccessivo potrebbe stressare i router fino a farli riavviare per carico (causando DoS su interi segmenti di rete).
Ruolo del responsabile della sicurezza su BGP: per un’organizzazione che potrebbe gestire proprie infrastrutture di rete, è cruciale avere visibilità BGP. Ciò include utilizzare servizi di monitoring (es. RouteViews, RIPE Atlas) che avvisino se i prefissi dell’organizzazione vengono annunciati da AS esterni (potenziale hijack in corso) o se route importanti spariscono. In caso di incidente BGP, il responsabile deve saper interfacciarsi con i Network Operator Groups e CERT/CSIRT di settore per coordinare una risposta (ad esempio, diffondere rapidamente la notizia di non accettare annunci da AS X, o contattare l’operatore responsabile dell’annuncio spurio).
Inoltre, la comprensione di BGP è importante per valutare la resilienza delle comunicazioni critiche: per servizi governativi essenziali, ci si può assicurare multihoming (connessione a più ISP con diverse rotte) e preferire percorsi che minimizzino passaggi in zone a rischio. Ad esempio, se un paese teme spionaggio, potrebbe voler monitorare se il suo traffico passa per AS di altri paesi non amici e magari accordarsi con gli ISP per restrizione di routing. Strumenti di tracciamento (traceroute a livello AS) aiutano a mappare i percorsi.
Riassumendo, BGP è un protocollo potente ma datato, core di Internet e allo stesso tempo punto debole sfruttabile. Lo sforzo collettivo di mettere in sicurezza BGP (attraverso RPKI, monitoring e cooperazione tra ISP) è in corso e i professionisti di sicurezza devono essere partecipi: conoscere gli incidenti storici, sostenere l’adozione di misure protettive e includere scenari di attacco BGP nei propri piani di rischio (specialmente in contesti di infrastrutture critiche dove un attacco di routing può significare blackout comunicativo).
Reti di elaboratori (Modello OSI)
Il modello OSI (Open Systems Interconnection) è un modello di riferimento concettuale, proposto dall’ISO (International Organization for Standardization), che suddivide le funzioni di rete in sette livelli astratti. Anche se Internet pratica quotidiana segue più da vicino il modello TCP/IP a 4-5 livelli, l’OSI rimane uno schema didattico e progettuale prezioso: fornisce un linguaggio comune per descrivere dove si collocano protocolli e apparecchiature e come le diverse parti di una comunicazione interagiscono. I sette livelli del modello OSI, dal più basso (fisico) al più alto (applicazione), sono i seguenti:
Livello 1: Fisico. Si occupa della trasmissione dei bit grezzi sul mezzo fisico di comunicazione. Definisce specifiche elettriche, meccaniche e funzionali per attivare, mantenere e disattivare collegamenti fisici. Ad esempio, stabilisce che forma d’onda e tensione rappresentano un “1” o uno “0”, il tipo di connettore e cavo (rame, fibra ottica), la modulazione usata in trasmissioni wireless, la sincronizzazione dei bit, etc.. Dispositivi tipici al livello fisico sono i repeater, gli hub Ethernet (che rigenerano il segnale su più porte) e i componenti come cavi, transceiver, antenne. Dal punto di vista della sicurezza, il livello fisico è spesso trascurato ma non privo di rischi: tapping su cavi (intercettazioni fisiche), interferenze elettromagnetiche intenzionali o accidentali e attacchi di jamming nel wireless (disturbo radio per negare il servizio) sono minacce di livello 1. Contromisure includono cablaggi schermati, monitoraggio di link (per rilevare disconnessioni o anomalie elettriche) e in ambienti critici l’uso di fibre ottiche (difficili da intercettare senza provocare perdite di segnale rilevabili).
Livello 2: Collegamento Dati. Fornisce il trasferimento dei dati tra due nodi adiacenti (collegati dallo stesso mezzo fisico) in modo affidabile, strutturando i bit in frame e implementando controlli di errore e controllo di flusso su ciascun collegamento. Qui troviamo protocolli come Ethernet (IEEE 802.3) per le LAN cablate, Wi-Fi (IEEE 802.11) per le LAN wireless, PPP per collegamenti punto-punto, HDLC, ecc. Il livello 2 utilizza indirizzi fisici (MAC address per Ethernet) per identificare le schede di rete sorgenti e destinazione su un segmento. Funzioni chiave includono l’error detection (es. CRC per individuare frame corrotti e scartarli) e a volte l’error recovery (es. in collegamenti PPP può esserci ritrasmissione). Switch e bridge operano a questo livello, instradando frame in base agli indirizzi MAC e segmentando collision domains. Dal punto di vista sicurezza, il livello data link presenta minacce come MAC flooding (in cui un attaccante inonda lo switch di frame con MAC fittizi, saturando la CAM table e facendolo passare in modalità hub, favorendo sniffing), spoofing di MAC (un dispositivo assume l’identità MAC di un altro, magari per bypassare filtri MAC ACL o dirottare traffico destinato al legittimo) e attacchi specifici di tecnologie: ad esempio, ARP poisoning (avvelenamento cache ARP) sfrutta il protocollo di risoluzione indirizzi (tra livello 2 e 3) per associare un MAC dell’attaccante all’IP della vittima, di fatto intercettando il traffico locale. Strumenti come ettercap facilitano questo attacco, che può essere mitigato con tecniche come ARP statici o protocolli di sicurezza come DHCP Snooping e Dynamic ARP Inspection sugli switch gestiti. Sul Wi-Fi, il livello 2 è dove operano misure di cifratura come WPA2/WPA3: la protezione delle trame radio con cifre come AES-CCMP avviene qui. Dunque, la robustezza del livello 2 wireless (chiavi forti, autenticazione 802.1X con EAP, ecc.) è essenziale contro sniffing e accessi non autorizzati.
Livello 3: Rete. È responsabile dell’instradamento (routing) dei pacchetti attraverso reti diverse, dal mittente finale al destinatario finale, potenzialmente passando per più nodi di commutazione (router). Il livello 3 introduce gli indirizzi logici (es. indirizzi IP) e si occupa di trovare percorsi e di gestire la congestione a livello di pacchetto. IP (Internet Protocol) è il protagonista (versione 4 e 6) a questo livello. Altri esempi includono protocolli legacy o specializzati come IPX, AppleTalk (quasi obsoleti) e protocolli di routing come ICMP potrebbe essere considerato tra 3 e 4 (di supporto al funzionamento di IP, es. con ping ed error message). I router operano al livello 3, guardando l’indirizzo di destinazione nei pacchetti IP e inoltrandoli secondo la routing table. La sicurezza a livello 3 coinvolge diversi aspetti: controllo degli accessi IP (liste di controllo accessi su router e firewall che permettono o bloccano traffico in base a IP sorgente/dest, protocollo e porta – benché la porta sia L4), protezione dell’integrità dei pacchetti (qui agisce ad esempio IPsec AH/ESP che aggiunge firma o cifratura a livello IP) e la robustezza contro attacchi di scansione e DoS basati su IP (ping of death, fragmentation attacks). Un amministratore deve implementare filtering appropriato (ad esempio: filtrare pacchetti in ingresso con IP sorgenti privati o palesemente spoofati – BCP 38, ingress filtering; bloccare protocolli non necessari come IPv6 se non in uso, o ICMP solo in modo controllato perché ICMP è utile per la diagnostica ma può essere abusato in tunneling o scansioni). Anche gli attacchi di tracciamento (es. traceroute abusato per mappare la rete) lavorano su livello 3/4 usando TTL manipolato; un SOC potrebbe rilevare e allertare se vede traceroute verso host interni, segno di ricognizione. In sintesi, il livello rete è dove si definiscono i confini della security perimeter: definire quali IP o segmenti possono comunicare, implementare segmentazione della rete (VLAN e routing intervlan con ACL) e applicare tecniche come network address translation (NAT) – che pur essendo nata per risparmiare IPv4, fornisce un effetto collaterale di mascheramento degli IP interni, aggiungendo oscurità verso l’esterno.
Livello 4: Trasporto. Offre comunicazione end-to-end affidabile o non affidabile tra processi applicativi su host differenti. Due protocolli cardine qui sono TCP (orientato alla connessione, affidabile, con controllo di flusso) e UDP (datagrammi non connessi, non garantiti). Il livello trasporto identifica anche le porte (numeri che distinguono i flussi applicativi: es. porta 80 per HTTP su TCP, 53 per DNS su UDP, ecc.), permettendo la multiplexing di più conversazioni sulla stessa connessione di rete. Qui troviamo anche concetti come segmento (TCP segment) o datagramma (UDP). Dal punto di vista sicurezza, sul livello 4 agiscono molti controlli nei firewall stateful, che monitorano lo stato delle connessioni TCP e possono bloccare tentativi anomali (ad esempio pacchetti TCP non appartenenti ad alcuna connessione nota). Il port scanning è una tecnica di ricognizione di livello 4: un attaccante invia tentativi di connessione su varie porte per scoprire quali servizi sono attivi; strumenti come nmap variano i tipi di pacchetto (SYN scan, ACK scan, UDP scan) per inferire regole firewall e servizi. Un analista deve saper interpretare log come “Dropped packet from X to Y: TCP flags SYN” e capire che è uno scan. Inoltre, attacchi DDoS spesso si manifestano su questo livello: SYN flood (già descritto), o saturazione di porte specifiche (es. attacco a un server web saturando la porta 80 con richieste incomplete). Difese includono meccanismi antidos sui firewall e anche a livello di sistema operativo (stack TCP robusti con backlog di connessioni ampia, cookies, ecc.). I protocolli di trasporto hanno anche implicazioni su performance e perciò su rilevamento anomalie: es. un flusso TCP legittimo ha una certa sincronia tra pacchetti e ack; se un flusso esce dalle statistiche usuali (troppi RST, troppi ritrasmissioni) potrebbe indicare un problema o un attacco in corso di blocco. A livello trasporto si implementa anche la sicurezza delle sessioni in alcuni casi: per es., TLS (il protocollo usato per HTTPS) in realtà risiede sopra TCP (livello 5 OSI se consideriamo session/present, o direttamente come parte dell’applicazione), ma concettualmente fornisce sicurezza a ciò che il trasporto trasmette. In un contesto OSI, potremmo dire che l’inizio handshake TLS è livello 5 sessione (instaura un canale) e la cifratura/decifratura è presentazione (livello 6). Comunque, il responsabile di sicurezza deve sapere che firewall di nuova generazione possono operare fino al livello 7, ma spesso regole efficaci si definiscono su combinazioni di criteri L3/L4 (IP/porta) per bloccare accessi a servizi indesiderati o limitare provenienze.
Livello 5: Sessione. Fornisce i meccanismi per controllare il dialogo tra due applicazioni, istituendo, gestendo e terminando sessioni di comunicazione. Una sessione è essenzialmente una comunicazione logica di lunga durata tra due entità, che può comprendere più scambi di dati. Funzioni tipiche del livello di sessione includono la gestione delle connessioni (apertura, autenticazione al livello di sessione, chiusura ordinata) e controllo del dialogo (chi può inviare in un dato momento, half-duplex vs full-duplex, sincronizzazione di checkpoint per riprendere trasferimenti interrotti). Nella pratica di Internet, il livello sessione non è molto distinto: protocolli come TLS/SSL possono essere visti come aggiungere una sessione sicura su TCP, o protocolli come NetBIOS session, RPC, PPTP ecc. definiscono sessioni sopra il trasporto. Dal punto di vista sicurezza, qui collochiamo concetti come autenticazione della sessione (per es., in TLS un client e server si autenticano e stabiliscono una sessione cifrata con ID di sessione), oppure gestione delle sessioni applicative (ad esempio i token di sessione HTTP per tenere traccia di un utente loggato su un sito – concettualmente livello 5/7). Le minacce includono il dirottamento di sessione (session hijacking), in cui un attaccante subentra in una sessione attiva rubando credenziali di sessione (es. cookie di autenticazione web non protetto) o per difetti del protocollo (un esempio storico: nel protocollo PPTP VPN c’erano weakness che permettevano di desincronizzare e prendere controllo della sessione). Un altro concetto di sessione è nel checkpointing: alcuni protocolli di trasferimento file lunghi implementano marker di sincronizzazione (per non ricominciare da capo se la sessione cade). Un attaccante potrebbe abusare del meccanismo di ripresa (resumption) se non ben protetto, per forzare trasferimenti incompleti o inserire dati. In contesti moderni, molti di questi dettagli sessione sono integrati nelle applicazioni (livello 7), quindi il livello 5 OSI è spesso citato in teoria più che implementato separatamente. Il coordinatore di sicurezza comunque deve assicurarsi che le sessioni, qualunque sia il contesto, siano protette: ad esempio, nelle applicazioni web la gestione sicura dei token di sessione (randomici, con scadenza, marcati HttpOnly e Secure se cookie) è cruciale per prevenire impersonificazione.
Livello 6: Presentazione. Si occupa della sintassi e semantica dei dati scambiati tra applicazioni. In pratica, fornisce trasformazioni di dati che permettono a sistemi con convenzioni diverse di comunicare. Ciò include conversioni di formato (esempio: codifica dei caratteri – convertire testo Unicode in ASCII se il destinatario supporta solo quello), serializzazione di strutture complesse in un formato standard (tipo JSON, XML, ASN.1), compressione (per ridurre la mole di dati da trasmettere) e cifratura per garantire confidenzialità. Il livello di presentazione è quindi dove i dati grezzi dell’applicazione vengono preparati per la trasmissione e viceversa all’arrivo vengono rielaborati in forma utilizzabile dall’app. Un esempio concreto: in una connessione HTTPS, il contenuto HTTP vero e proprio viene cifrato a livello presentazione (TLS) e poi passato come flusso cifrato al livello trasporto (TCP) per l’invio. Nella sicurezza informatica, il livello 6 è cruciale perché è dove avvengono crittografia/decrittografia e codifiche. Ad esempio, molti attacchi web come XSS, SQLi, ecc., sfruttano mancate conversioni di formato (un input utente che andava interpretato solo come testo viene invece eseguito come codice). Una robusta “presentazione” in un’applicazione web significa escaping appropriato di caratteri speciali quando dati non fidati vengono inseriti in HTML, SQL, XML, ecc., per prevenire l’esecuzione indesiderata – in altri termini, difese come output encoding per XSS o query parametrizzate (che separano i dati dalla sintassi SQL) attengono a questo concetto. Dal punto di vista delle comunicazioni di rete, standard come TLS garantiscono che i dati in presentazione siano cifrati end-to-end: un responsabile deve assicurarsi che i servizi critici usino protocolli sicuri (es. preferire FTPS/SFTP a FTP in chiaro, HTTPS a HTTP, SSH a Telnet, ecc.) cosicché anche se il traffico viene intercettato a livello inferiore, risulti incomprensibile. Inoltre, il livello presentazione include la gestione di certificati digitali e formati di scambio: competenze in PKI e negoziazione di protocolli (quali ciphersuite TLS sono consentite, usi di TLS 1.3 vs deprecazione di SSLv3/TLS1.0 insicuri) rientrano tra quelle richieste a un esperto di sicurezza per garantire che i dati “presentati” in rete siano sempre protetti secondo lo stato dell’arte.
Livello 7: Applicazione. È il livello più alto, quello con cui interagiscono direttamente le applicazioni software e, in ultima analisi, l’utente finale. Fornisce quindi i servizi di rete più vicini all’utilizzatore: protocolli di posta elettronica (SMTP per inviare, IMAP/POP3 per ricevere), web (HTTP/HTTPS), trasferimento file (FTP, SFTP), servizi directory (LDAP), accesso remoto (SSH, Telnet) e molti altri servizi specializzati (DNS stesso è considerato applicazione nel modello OSI, così come protocolli voce su IP come SIP/VoIP, etc.). Al livello applicazione si definiscono i formati dei messaggi di alto livello e le procedure di scambio specifiche di quello use case. Ad esempio, HTTP definisce come un client può richiedere una risorsa con un verbo (GET, POST, etc.) e come un server risponde con un codice di stato e eventuale contenuto; SMTP definisce i comandi per trasmettere email tra server; SSH definisce come incapsulare un terminale remoto sicuro. Dal punto di vista sicurezza, il livello applicazione è dove tipicamente risiedono le vulnerabilità logiche e di input più complesse: injection, buffer overflow applicativi, deserializzazione insicura, autenticazione debole, autorizzazioni errate e così via (molte delle categorie OWASP Top 10 per applicazioni web sono questioni di livello 7). Un responsabile per gli incidenti deve avere familiarità con i protocolli applicativi per riconoscere anomalie: es. traffico HTTP verso un server web che contiene comandi sospetti ( /admin/delete.php?id=1;DROP TABLE users) potrebbe indicare un attacco SQLi; oppure richieste LDAP malformate potrebbero segnalare un tentativo di exploit di Active Directory. Anche la modellazione delle minacce avviene in gran parte a livello applicazione: qui si chiede “cosa succede se un utente malintenzionato invia dati oltre i limiti?”, “cosa se effettua sequenze di API fuori ordine?”, etc. Ogni protocollo ha le sue particolarità: FTP ad esempio espone credenziali in chiaro se non è protetto e inoltre utilizza porte dinamiche (che i firewall devono gestire in modo speciale, con moduli helper, altrimenti può essere abusato per bypassare porte); SMTP può essere sfruttato per relay non autorizzati se non configurato bene (open relay) e per diffondere phishing/malware; HTTP è il veicolo di tantissimi attacchi, dai malware via download, al phishing via siti clone, fino alle exploit di librerie web.
Ai fini di prevenzione e gestione degli incidenti, è utile dotarsi di strumenti di Application Layer Security: WAF (Web Application Firewall) per analizzare il traffico HTTP e bloccare pattern malevoli noti (anche se non sostituisce il secure coding, è un utile layer difensivo), antivirus/antimalware gateway per controllare file trasferiti via protocolli applicativi (es. scanner SMTP per allegati email, o proxy HTTP con antimalware integrato) e sistemi di Data Loss Prevention (DLP) che analizzino il contenuto applicativo in uscita (es. per individuare stringhe che sembrano numeri di carta di credito o dati classificati e bloccarne l’esfiltrazione via email/web). Inoltre, la telemetria di livello 7 (log applicativi) è fondamentale in fase di risposta: i log di un server web (es. access log di Apache/Nginx) possono mostrare un pattern di exploit (decine di tentativi di accedere a wp-admin.php indicano un bot che cerca di violare WordPress), i log di un database possono mostrare query strane (tentativi di selezionare tabelle di sistema da un’app che non dovrebbe), i log di un server DNS possono indicare tunneling come detto. Un SOC ben organizzato correla eventi su più livelli: ad esempio, un alert IDS su un payload sospetto a livello 4+7 (un pacchetto TCP con dentro un comando SQL anomalo) incrociato con un log applicativo di errore database può confermare un tentativo di SQL injection riuscito o meno.
Integrazione e concetti trasversali: Una cosa importante da capire è che i livelli non sono completamente isolati: ogni livello aggiunge il suo overhead e le sue vulnerabilità possono propagarsi. Ad esempio, un attacco DDoS a livello 7 (come HTTP Flood, numerosissime richieste web) sfrutta comunque la connessione TCP sottostante: mitigarlo può richiedere azioni a livello 7 (rispondere con CAPTCHA, tarpit) ma anche a livello 4 (limitare connessioni per IP) e livello 3 (filtrare IP noti malevoli). Oppure, una falla a livello 2 come ARP poisoning può portare a Man-in-the-Middle che intercetta e poi manipola dati di livello 7 (inserendo script malevoli nel traffico web, se questo non è cifrato). Conoscere l’OSI aiuta a compartimentalizzare i problemi e a parlare con gli specialisti giusti: ad esempio, se si riscontra che “le email non arrivano a destinazione”, potrebbe essere un problema di livello 7 (misconfigurazione SMTP, o bloccate per contenuti), livello 3 (routing verso il mail server errato) o altro; il modello OSI offre un approccio per isolare: ping (L3), telnet porta 25 (L4), analisi logs SMTP (L7) e così via. Nella risoluzione di incidenti, spesso si “risale la pila OSI” per individuare dove esattamente risiede il fault o l’attacco.
In conclusione, il modello OSI con i suoi 7 livelli – Fisico, Collegamento dati, Rete, Trasporto, Sessione, Presentazione, Applicazione – è uno strumento concettuale che aiuta a progettare, proteggere e diagnosticare le reti di calcolatori. Ogni livello introduce considerazioni di sicurezza specifiche e un responsabile per la sicurezza informatica deve averne padronanza per implementare una strategia di difesa in profondità: multiple protezioni sovrapposte attraverso la pila, cosicché anche se un attacco aggira un livello (es. malware che viaggia cifrato su HTTPs – invisibile al firewall L7), venga intercettato a un altro (es. analisi comportamentale al livello applicazione endpoint, o decrittazione in un proxy per l’ispezione). Lo standard ISO/OSI stesso, pur teorico, ha generato protocolli e influenzato architetture – conoscere ad esempio che X.509 (certificati) nasce da standard OSI di presentazione, o che LDAP è figlio di X.500 (applicazione OSI), arricchisce la comprensione storica e pratica che torna utile quando si incrociano sistemi eterogenei (ad es. integrazione di vecchi sistemi mainframe o SCADA che a volte ancora usano stack particolari).
Fondamenti di algoritmi
Un algoritmo è una procedura definita, costituita da una sequenza finita di istruzioni, che risolve un problema o svolge un determinato compito. In informatica, gli algoritmi rappresentano le ricette operative per qualsiasi programma: dal semplice calcolo di una somma alla crittografia avanzata, tutto si riduce a passi elementari che il calcolatore esegue. Formalmente, si richiede che un algoritmo abbia alcune proprietà: finitezza (deve terminare in un numero finito di passi), determinismo (stessi input producono stessi output, a meno di componenti aleatorie volute), non ambiguità (ogni passo è definito in modo univoco, interpretabile senza dubbio) e generalità (risolve una classe di problemi, non un solo caso specifico).
Esempi di algoritmi classici includono: l’algoritmo di ordinamento (ordinare una lista di numeri o stringhe – con varianti famose come QuickSort, MergeSort, HeapSort, etc.), algoritmi di ricerca (trovare un elemento in una collezione – es. ricerca lineare vs ricerca binaria in una lista ordinata), algoritmi di grafi (cammini minimi, visite in profondità/ampiezza, ecc.), algoritmi di ottimizzazione (zaino, percorso più breve, flusso massimo) e tanti altri. Nella pratica quotidiana, un professionista di sicurezza può incontrare algoritmi ad esempio nell’analisi di performance di un sistema (sapere se una certa operazione è O(n) lineare o O(n^2) quadratica aiuta a capire se un attacco di stress potrebbe causare rallentamenti significativi), oppure nella comprensione di meccanismi crittografici (dove la solidità di un algoritmo di cifratura spesso si basa su problemi computazionalmente difficili, come la fattorizzazione dei grandi numeri primi per RSA).
Complessità computazionale: uno degli aspetti fondamentali nello studio degli algoritmi è la loro complessità, cioè la quantità di risorse (tempo di calcolo, spazio di memoria) che richiedono in funzione della dimensione dell’input. La complessità in termini di tempo viene di norma espressa tramite la notazione O-grande, che fornisce un limite superiore asintotico sulla crescita del costo computazionale al crescere di n (taglia input). Ad esempio, dire che un algoritmo è O(n log n) significa che per gestire input più grandi, il suo tempo cresce proporzionalmente a n log n. In generale, classifichiamo le complessità asintotiche in classi come: costante O(1), logaritmica O(log n), lineare O(n), quasi-lineare O(n log n), quadratica O(n^2), cubic O(n^3), …esponenziale O(2^n) e oltre. Chiaramente, algoritmi più efficienti sono preferibili – un problema risolvibile con un algoritmo O(n) sarà gestibile per input grandi molto meglio di uno O(n^2). Per contestualizzare: in un attacco di forza bruta, provare tutte le combinazioni di una password di lunghezza n può essere ~O(k^n) (esponenziale nel numero di caratteri se ogni posizione ha k possibilità), il che spiega perché aumentando lunghezza e complessità delle password la ricerca esaustiva diventa impraticabile.
Per un responsabile alla sicurezza, la teoria degli algoritmi ha ricadute pratiche. Un esempio evidente è nella crittografia: la sicurezza di molti algoritmi crittografici è legata alla complessità computazionale di certi problemi. RSA, ECC, Diffie-Hellman si basano sul fatto che alcuni problemi (fattorizzazione di interi grandi, logaritmo discreto in certi gruppi) sembrano richiedere tempo esponenziale con i migliori algoritmi noti: quindi, con chiavi abbastanza lunghe, la brute force diventa impossibile nei tempi dell’universo (a meno di progressi algoritmici o quantistici). Comprendere questo aiuta a scegliere parametri sicuri: ad esempio, sapere che il migliore algoritmo di fattorizzazione noto ha complessità sub-esponenziale (sì, c’è il Number Field Sieve che è circa O(exp( (64/9)^(1/3) * (log n)^(1/3) * (log log n)^(2/3) )) ), consente ai crittografi di stimare quanti bit di RSA servono (oggi almeno 2048-bit) per resistere X anni. Un altro esempio: gli algoritmi di hashing (SHA-256, SHA-3) sono progettati per essere veloci da calcolare ma non invertibili senza provare molte possibilità. La difficoltà di trovare collisioni in SHA-256 è legata a dover provare 2^128 operazioni (complessità bruteforce). Se un attaccante scoprisse un algoritmo molto migliore (es. O(2^64)), quell’hash non sarebbe più sicuro. Dunque, chi lavora in sicurezza deve seguire anche le scoperte nel mondo algoritmi (ad esempio, i recenti progressi su SHA-1 collisioni hanno reso questo hash deprecato). E ovviamente il calcolo quantistico promette di ridurre drasticamente la complessità di alcuni problemi: Shor’s algorithm porta la fattorizzazione a complessità polinomiale, distruggendo RSA/ECC una volta che avremo quantum computer abbastanza grandi.
Al di là della crittografia, l’analisi degli algoritmi è utile per ottimizzare le difese e attacchi. Dal lato difensivo: un SIEM che raccoglie log deve avere algoritmi di correlazione efficienti, altrimenti con milioni di eventi genererà ritardi – un buon coordinatore sa scegliere strumenti validi o architetture big data (es. utilizzare motori come Elasticsearch che usano algoritmi di ricerca efficaci). Dal lato offensivo: alcuni attacchi DoS sfruttano algorithmic complexity attacks, ad esempio l’HashDoS (inviare tanti input calibrati per provocare collisioni in una tabella hash usata dall’applicazione, degradando le look-up da O(1) a O(n) e bloccando il server) – questo fu dimostrato su Java, PHP e altri linguaggi, costringendo a migliorare gli algoritmi di hashing o introdurre randomizzazione. Un altro esempio sono i ReDoS (Regular Expression Denial of Service): usare input particolari per mandare in worst-case l’algoritmo di matching delle espressioni regolari (che in alcuni engine può diventare esponenziale). Questi sono attacchi sottili che richiedono comprensione di come un algoritmo risponde al worst-case.
Strutture dati e algoritmi: spesso insieme agli algoritmi si studiano le strutture dati (array, liste, pile, code, alberi, grafi, tabelle hash, ecc.), che influiscono sulle prestazioni. Una buona scelta di struttura può prevenire inefficienze – es: cercare elementi duplicati in un array fa O(n^2) naive, ma usando una hash set diventa O(n) mediamente. Nella sicurezza software, questo significa anche prevenire vulnerabilità di prestazioni: se un input controllato dall’utente potrebbe indurre il programma a usare un algoritmo quadratico, un attaccante può sfruttarlo per rallentarlo. Ad esempio, generare intenzionalmente situazioni pessime (come l’HashDoS citato). Dunque, parte del secure coding è anche evitare costrutti algoritmicamente rischiosi o porre limiti (ad esempio, limitare lunghezza massima di input per evitare loop troppo lunghi).
P vs NP e problemi intrattabili: un concetto teorico ma con implicazioni è la distinzione tra problemi in P (risolvibili in tempo polinomiale) e in NP (verificabili in polinomiale, ma non si conosce algoritmo polinomiale per risolverli). Molti problemi di ottimizzazione o ricerca combinatoria sono NP-difficili (come il Traveling Salesman, il Subset Sum, ecc.). Per la sicurezza, questo spiega perché certi obiettivi dell’attaccante sono difficili: ad esempio, craccare un cifrario robusto equivale a cercare nello spazio delle chiavi (che cresce esponenzialmente col numero di bit). Oppure, un software antivirus che voglia decidere in generale se un programma è malevolo va incontro al problema della fermata e questioni indecidibili; per questo gli antivirus usano euristiche imperfette – capire i limiti computazionali ci fa comprendere perché non esiste e probabilmente non esisterà mai “l’algoritmo perfetto” per distinguere malware da software legittimo in ogni caso (problema indecidibile, riducibile all’halting problem). Quindi si lavora per euristiche (firma, comportamento) sapendo che esisteranno falsi negativi/positivi.
Algoritmi distribuiti e fault tolerance: In un contesto come la sicurezza nazionale, con infrastrutture distribuite, è importante conoscere anche gli algoritmi per consenso distribuito (es. Paxos, Raft) e per gestione di guasti – questi sono algoritmi non banali che garantiscono consistenza e disponibilità su più nodi; la sicurezza di sistemi come blockchain, oppure di sistemi cluster per servizi critici, discende dalla solidità di tali algoritmi. Ad esempio, la robustezza di una blockchain dipende dall’algoritmo di consenso (Proof of Work è un “algoritmo” in senso lato con complessità regolata dalla difficoltà, BFT consensus ha tolleranza fino a f nodi corrotti se N > 3f, ecc.).
In sintesi, i fondamenti di algoritmi equipaggiano il professionista con un approccio analitico ai problemi: capire l’ordine di grandezza di un attacco brute-force, valutare l’impatto prestazionale di una misura di sicurezza (es. criptare tutto il traffico aggiunge overhead, ma di quanto?), scegliere strumenti in base alla scala (un SIEM con algoritmi subottimali funzionerà su 1k eventi al secondo ma non su 100k eps). La è quindi parte del bagaglio di un coordinatore, sebbene non debba implementare algoritmi da zero quotidianamente, deve saperne leggere i risultati e conversarci: ad esempio, comprendere un report che dice “la complessità computazionale di rompere AES-256 è di 2^254 operazioni, che con i mezzi attuali è impraticabile” oppure “un attacco di tipo meet-in-the-middle riduce la complessità su 2DES da 2^112 a 2^57, ecco perché 2DES non è considerato sicuro”. Senza basi sugli algoritmi, tali affermazioni sarebbero aride; con le basi, diventano guida all’azione (passare direttamente ad AES o 3DES perché 2DES è debole, ecc.). Dunque la padronanza degli algoritmi e della loro complessità permette di valutare rischi in modo quantificabile e di progettare contromisure efficaci.
Linguaggi di programmazione (imperativi, di scripting, orientati agli oggetti)
I linguaggi di programmazione sono gli strumenti con cui vengono implementati gli algoritmi e le funzionalità software. Esistono centinaia di linguaggi, ma essi possono essere classificati per paradigma in base allo stile con cui si descrivono le istruzioni e i dati. In questa sezione ci focalizziamo su tre categorie importanti: linguaggi imperativi, linguaggi di scripting e linguaggi orientati agli oggetti. Ognuno di questi paradigmi presenta caratteristiche peculiari, vantaggi, limitazioni e implicazioni per la sicurezza del codice prodotto.
Linguaggi imperativi (procedurali)
La programmazione imperativa è il paradigma classico in cui un programma è visto come una sequenza di istruzioni che modificano lo stato del programma stesso (variabili, strutture dati) per ottenere il risultato desiderato. In altre parole, l’attenzione è sul come fare le cose: si specificano esplicitamente i passi da seguire, in ordine, includendo strutture di controllo come assegnamenti, cicli ( for , while ), condizionali ( if / else ), chiamate di funzioni/procedure, ecc. La maggior parte dei linguaggi tradizionali rientrano in questo paradigma: linguaggi procedurali come C, Pascal, BASIC, Fortran (dove esistono procedure e funzioni come unità di modularizzazione) sono imperativi; anche il linguaggio Assembly (di basso livello) è imperativo puro, in quanto si scrivono istruzioni macchina che cambiano registri e memoria step-by-step. Persino linguaggi come Java o Python supportano uno stile imperativo (Python, ad esempio, pur essendo multi-paradigma, permette di scrivere codice procedurale imperativo). Caratteristiche tipiche di linguaggi imperativi/procedurali includono la gestione esplicita della memoria (in C, ad esempio, con malloc / free o lo stack frame delle funzioni), l’uso di variabili mutate nel corso dell’esecuzione e un flusso di controllo che può usare costrutti come goto (nei casi più base) o strutture strutturate. Il codice imperativo rispecchia l’architettura di von Neumann: infatti questi linguaggi sono “vicini al modo in cui lavora l’elaboratore”, aggiornando locazioni di memoria e eseguendo istruzioni in sequenza.
Implicazioni per la sicurezza: nei linguaggi imperativi a basso livello (es. C, C++, assembler) sta l’origine di molte vulnerabilità classiche, proprio perché lasciano molto controllo (e responsabilità) al programmatore. Ad esempio, la gestione manuale della memoria in C/C++ è fonte di bug quali buffer overflow, use-after-free, double free, integer overflow e così via, che se non prevenuti portano ad exploit di memoria e code execution arbitraria. Un responsabile della sicurezza deve conoscere bene questi rischi: ad esempio, l’attacco stack buffer overflow sfrutta il fatto che in C si possono scrivere dati fuori dai limiti di un array, andando a sovrascrivere il return address di funzione nello stack; mitigazioni come canary, ASLR, NX bit sono stati sviluppati per attutire il problema, ma la vera soluzione è scrivere codice robusto (o usare linguaggi che prevengono out-of-bounds, come Java o Rust). Nei contesti dove la performance e il controllo spingono a usare C/C++ (kernel OS, driver, sistemi embedded, highperformance computing), è cruciale adottare standard di codice sicuro (es. CERT C Coding Standard) e strumenti di analisi (sanitizer, static analysis) per ridurre i bug imperativi.
Nei linguaggi imperativi di più alto livello (es. Java, che è orientato agli oggetti ma si può vedere come imperativo nel flusso; o Python se scrivi script procedurali), molti errori di memoria sono evitati (garbage collector, check runtime su array, ecc.), ma persistono problemi come la gestione delle condizioni di errore, la concorrenza (race conditions se thread paralleli accedono a variabili condivise), etc. Il paradigma imperativo incoraggia l’uso di stato mutabile e questo è terreno di race condition e TOCTOU (Time-of-check to time-of-use) bugs: ad esempio, un programma imperativo multi-thread potrebbe controllare l’esistenza di un file e poi aprirlo; se tra check e open passa tempo e un attaccante cambia il file (symlink attack), abbiamo un TOCTOU bug. Un responsabile deve sapere che certe classi di vulnerabilità (soprattutto in codice multi-thread o multi-processo) derivano dalla difficoltà di ragionare su stato mutabile e tempi di esecuzione – ecco perché paradigmi alternativi (es. la programmazione funzionale, che evita stato mutabile) vengono talvolta adottati per ridurre bug, ma la maggioranza del codice rimane imperativo.
In campo offensivo, conoscere la natura imperativa dei programmi aiuta a fare reverse engineering: ad esempio, i malware scritti in C/C++ compilano in assembly macchina e un analista dovrà interpretare quell’assembly come un flusso di operazioni (imperative) per capire cosa fa il malware. Saper leggere pseudocodice imperativo o flusso di un binario è competenza essenziale in analisi malware/forense.
Esempi di linguaggi imperativi popolari: C (usato per kernel, sistemi operativi, software di rete; critico per exploit), C++ (che aggiunge oggetti ma resta principalmente imperativo, usato in applicativi veloci, anche in diversi malware avanzati), Ada (in ambito aerospaziale, focus su sicurezza e affidabilità), Go (Google Go, imperativo concurrent, con gestione memoria automatica e forte supporto al multithread – spesso usato per strumenti di rete e cloud, la sua semplicità riduce alcune classi di bug rispetto a C) e tanti altri incl. Rust (che pur supportando vari stili viene spesso usato in modo imperativo ma “memory safe” grazie al suo sistema di proprietà).
Linguaggi di scripting
Un linguaggio di scripting è tipicamente un linguaggio interpretato, di alto livello, pensato per automatizzare compiti in un ambiente runtime esistente. Il termine deriva dal fatto che inizialmente questi linguaggi erano usati per scrivere script (copioni) che eseguono operazioni su sistemi operativi o applicazioni, invece che per sviluppare applicazioni stand-alone complesse. Caratteristiche comuni dei linguaggi di scripting includono: tipizzazione dinamica (non occorre dichiarare esplicitamente il tipo delle variabili), gestione automatica della memoria (garbage collection), sintassi semplice e concisa, e disponibilità di un ambiente interpretativo (shell, REPL) dove eseguire i comandi al volo. Esempi classici sono bash/sh (scripting di shell Unix), JavaScript originariamente scripting client-side per i browser, oggi grazie a Node.js usato anche lato server), Python, Perl, Ruby, PHP, PowerShell (scripting avanzato su Windows), ecc. Questi linguaggi spesso interagiscono con un sistema più grande: ad esempio, JavaScript in una pagina web manipola l’HTML/CSS e il browser funge da runtime; Python può essere usato come script per automazione di task di sistema, o incorporato in applicazioni; PHP è un linguaggio di scripting lato server per generare contenuti web dinamici; Bash orchestrа comandi del sistema operativo e programmi.
Il vantaggio dei linguaggi di scripting è la produttività e la facilità d’uso: permettono di sviluppare rapidamente funzionalità senza gestire i dettagli di basso livello (gestione memoria, compilazione). Questo li rende ideali per la scrittura di strumenti di automazione, estrazione di dati, prototipazione, e (nel nostro contesto) per molti script e tool di sicurezza. Un analista di sicurezza scrive comunemente script Python o Bash per analizzare log, per eseguire scansioni personalizzate, per automatizzare reazioni a incidenti (es. uno script che disattiva automaticamente un account sospetto su più sistemi, integrandosi via API).
Implicazioni per la sicurezza: Da un lato, usando linguaggi di scripting si evitano molte vulnerabilità tipiche del C (buffer overflow, ecc.), quindi per script e tool interni spesso si preferisce Python o PowerShell per ridurre rischi di bug memory corruption. Dall’altro lato, i linguaggi di scripting portano sfide proprie: essendo spesso interpretati, il codice può essere più facilmente letto/modificato da un attaccante se trova gli script sul sistema (a meno di offuscazioni); e poiché molti sono usati in contesti di elevati privilegi (si pensi a script Bash lanciati come root per manutenzioni, o script PowerShell per amministrazione di dominio), diventano bersagli: gli attaccanti possono tentare di alterare script esistenti (supply chain, se uno script viene scaricato da internet e poi eseguito con fiducia – come a volte succede con script di installazione), oppure usarli a proprio vantaggio (es. se un webserver permette di caricare ed eseguire file PHP, l’attaccante può caricare una web shell PHP, sfruttando il linguaggio di scripting del server per eseguire comandi arbitrari sul sistema). Ciò sottolinea la necessità di trattare gli script come codice a tutti gli effetti: revisionare la sicurezza, proteggerli con controlli di integrità, limitarne i permessi di esecuzione, ecc.
Nei sistemi, spesso i linguaggi di scripting fungono da collante: ad esempio, un attaccante che abbia compromesso un server Linux potrebbe scrivere uno script bash per mantenere la persistenza (inserendolo magari in /etc/init.d per avviarsi al boot) o per esfiltrare dati periodicamente. Dunque, chi gestisce la sicurezza deve monitorare non solo eseguibili compilati ma anche i file di script, e utilizzare strumenti tipo OSSEC o Tripwire per notare modifiche anomale a script chiave. Le applicazioni web scritte in linguaggi di scripting (PHP, Python via Django/Flask, JavaScript via Node.js) ereditano i rischi di vulnerabilità applicative (XSS, injection, etc.), con la differenza che essendo i linguaggi spesso molto dinamici può essere più facile introdurre errori se non si seguono regole (es. in PHP, un tempo la registrazione globale delle variabili portava a vulnerabilità se non attenta; in Node.js, la presenza di un ricco ecosistema di package richiede attenzione alla supply chain e a aggiornare le dipendenze per evitare moduli malevoli).
Esempi pratici in scenario di sicurezza: uno script Python può essere scritto per analizzare i pacchetti di rete (usando Scapy) e rilevare un pattern di scansione, inviando alert. Oppure script Bash vengono usati negli SIEM per parsare formati di log e normalizzarli. Con PowerShell, un team di incident response può interrogare in modo massivo tutte le macchine di un dominio cercando indicatori di compromissione – infatti, oggi gli attaccanti stessi usano PowerShell per i loro scopi (PowerShell Empire e altri framework di post- exploitation): ciò perché con script si integrano nativamente nell’ambiente senza portare eseguibili che possano essere bloccati da whitelist. Un reaponsabile deve essere consapevole di queste tattiche e, ad esempio, abilitare PowerShell Logging e Constrained Language Mode su host Windows per avere visibilità e limitare l’uso malevolo.
In sintesi, i linguaggi di scripting sono potenti e flessibili; per la difesa informatica sono armi essenziali (per automazione e integrazione), ma vanno gestiti con regole di sicurezza come qualsiasi codice: controllo delle entrate (validazione input negli script), least privilege (non far girare script con privilegi oltre il necessario), mantenimento (aggiornare le versioni interpreter – molte falle in PHP/Python stesso corrette con patch), e rilevamento di abuso (monitorare esecuzioni anomale, come un utente non amministrativo che improvvisamente lancia script PowerShell con comandi di dumping credenziali).
Linguaggi orientati agli oggetti (OOP)
La programmazione orientata agli oggetti (Object-Oriented Programming, OOP) è un paradigma in cui il software viene modellato come un insieme di oggetti che interagiscono tra loro scambiandosi messaggi (chiamando metodi l’uno dell’altro). Un oggetto incapsula stato (dati, sotto forma di attributi/variabili) e comportamento (funzionalità, sotto forma di metodi/funzioni). I linguaggi OOP offrono costrutti come classi (definizioni generiche da cui istanziare oggetti concreti), ereditarietà (una classe può derivare da un’altra ereditando attributi e metodi, consentendo specializzazione e riuso del codice), polimorfismo (il fatto che chiamate a metodi possano riferirsi a implementazioni diverse in classi diverse, tipicamente via overriding – es. diversi oggetti tipo Figura con metodo disegna() implementato diversamente in Cerchio, Quadrato), e incapsulamento (detto sopra: la capacità di nascondere i dettagli interni di un oggetto e offrire solo interfacce pubbliche – spesso con modificatori di accesso come public/private/protected).
L’OOP nasce per gestire meglio la complessità di grandi progetti software, modellando entità vicine al dominio reale e promuovendo modularità e riusabilità. Ad esempio, in un sistema bancario si potrebbero avere classi Conto, Transazione, Cliente con relazioni di composizione e specializzazione (un ContoCorrente estende Conto aggiungendo un fido, etc.). Linguaggi strettamente OOP includono Java, C#, C++ (ibrido, multi-paradigma ma con forte supporto OOP), Python (multi-paradigma ma con OOP completo), Ruby, JavaScript (che in realtà è basato su prototipi, ma concettualmente OOP), ecc. Oggi, OOP è forse il paradigma dominante nello sviluppo di applicazioni enterprise.
Implicazioni per la sicurezza: la programmazione a oggetti porta benefici di organizzazione, ma introduce anche superfici di attacco peculiari. Ad esempio, la presenza di gerarchie di classi e funzioni virtuali apre il fianco a attacchi come l’overwrite di puntatori virtuali in exploit memory corruption (in C++ un oggetto ha un vtable pointer – se un buffer overflow sovrascrive quel puntatore, un attaccante può far eseguire codice arbitrario quando il programma chiamerà un metodo virtuale dell’oggetto). Questa è una considerazione bassa, valida solo in linguaggi non memory-safe (C++): mitigazioni come Control Flow Guard di Microsoft cercano proprio di impedire salto a vtable rogue.
Dal punto di vista di design, l’OOP a volte incoraggia un’eccessiva fiducia sugli oggetti – ad esempio, concetti come l’esecuzione di codice mobile: Java Applet, ActiveX, .NET assemblies, tutti casi in cui oggetti provenienti da terze parti vengono eseguiti localmente, con meccanismi di sandbox vari (Java aveva il security manager per applet, ActiveX si basava su firme digitali – con noti problemi se l’utente autorizzava un controllo malevolo). Questo scenario di mobile code necessita che i runtime siano robusti nel far rispettare i confini (spesso non lo furono, portando a deprecazione di tali tecnologie).
Un altro punto: i framework ad oggetti (tipici in Java, C#) che fanno ampio uso di riflessione e serializzazione. La serializzazione di oggetti è la capacità di convertire un oggetto in una forma (tipicamente binaria o testuale) per salvarlo o trasmetterlo, e poi ricostruirlo. Questo meccanismo ha portato a exploit come le deserialization vulnerabilities: se un’app accetta da input un oggetto serializzato (ad esempio, un token di sessione Java serializzato inviato nel cookie) un attaccante potrebbe manipolarlo per far istanziare oggetti malevoli o con stati inconsistenze. Ci sono state grosse vulnerabilità (es. CVE di Apache Commons-Collections e altri, dove un oggetto opportunamente costruito portava all’esecuzione di comandi arbitrari durante la deserializzazione, perché la classe aveva blocchi statici o metodi finalize con chiamate pericolose). Un responsabile deve conoscere questi pattern: ad esempio, in pen test su applicazioni Java enterprise, la deserializzazione non sicura è un must-check. La best practice è evitare la deserializzazione di oggetti da fonti non fidate, o usare formati sicuri (JSON, protocolli con schema), o whitelisting di classi deserializzabili.
Controllo degli accessi a oggetti: OOP a volte induce a pensare che i controlli possano essere fatti a livello di oggetto, ma in ambienti multi-utente/multi-tenant non basta. Ad esempio, in un’app web OOP potrebbe esserci metodo Documento.approva(); ma bisogna assicurarsi a livello applicativo che l’utente X possa approvare solo i documenti di sua competenza. Ciò porta a vulnerabilità come Insecure Direct Object Reference (IDOR): se l’app espone un endpoint /documento/approva?id=123 che chiama internamente doc.approva(), un utente malintenzionato potrebbe fornire un id di un documento che non dovrebbe poter modificare e se manca il controllo, l’oggetto viene comunque recuperato e il metodo invocato (violazione autorizzazione). L’approccio OOP puro a volte fa sottovalutare questo – perché a livello di codice, chiamare il metodo è lecito, ma manca il contesto di sicurezza. Quindi, un principio: integrare controlli di autorizzazione in tutti i metodi sensibili, oppure usare un framework di sicurezza (es. Spring Security) che si integri con l’OOP (annotation tipo @PreAuthorize su metodi, ecc.).
Benefici OOP per la sicurezza: d’altro canto, se ben applicato, OOP migliora la sicurezza del codice: l’incapsulamento può prevenire accessi indesiderati – se tutti gli campi sono private e l’oggetto valida i dati tramite setter, è più difficile corrompere lo stato. L’ereditarietà e polimorfismo possono favorire la scrittura di checker di sicurezza generici: ad esempio, una classe base Utente con metodo virtuale haPermesso(azione) può essere implementata diversamente in UtenteStandard e Admin, permettendo all’app di chiedere genericamente utente.haPermesso("DELETE_USER") senza conoscere la classe concreta – design pulito che centralizza logica di auth. Tuttavia, se un attaccante riesce a far istanziare una sottoclasse controllata (vedi problema deserialization su classpath), quell’interfaccia generica potrebbe rispondere “sì ho permesso” falsamente. Perciò la riflessione insegna: l’OOP va usato con coscienza e meccanismi magici come riflessione, dependency injection, ecc. vanno vigilati. Ad esempio, i container di inversion of control (Spring, etc.) automaticamente viranano dipendenze tra oggetti; se configurati male, potrebbero esporre bean sensibili su canali remoti (vedi ad es. JMX misconfigurato, o endpoint actuator in Spring Boot esposti senza auth, che permettono di manipolare runtime).
In termini di linguaggi concreti: Java e C# sono fortemente tipizzati e gestiti, riducono molti errori (no buffer overflow classici), ma ricordiamo incidenti come Log4Shell (una vulnerabilità in un logger che attraverso un lookup JNDI permetteva di scaricare un oggetto remoto – combinazione di serializzazione, rete e riflessione). Dunque, anche se il linguaggio previene certi bug, rimane la superficie dei runtime environment (JVM, .NET) e delle librerie di base. C++ aggiunge OOP al C ma mantiene la pericolosità del controllo manuale: così somma rischi (memory + OOP). Sviluppatori esperti possono scrivere codice sicuro, e moderne guidelines (C++ Core Guidelines) spingono a usare costrutti sicuri (smart pointer invece di raw pointer, etc.), ma molto codice legacy è vulnerabile. Python, JavaScript, PHP, Ruby supportano OOP ma in modo dinamico: qui la flessibilità è massima (es. in Python puoi aggiungere attributi a runtime agli oggetti, in JavaScript modificare prototipi al volo), e questo dinamismo può essere sfruttato malevolmente. Ad esempio, Prototype Pollution in JavaScript: se una libreria non isola bene i dati, un attaccante può iniettare proprietà nell’Object prototype globale, influenzando tutti gli oggetti (impatto a cascata su app intera). Ciò evidenzia che la surface di errori si sposta: meno memory corruption, più logiche e inconsistenze.
Paradigmi misti: molti team oggi adottano linguaggi multi-paradigma (es. Python, JavaScript) o abbracciano stili come la programmazione funzionale all’interno di contesti OOP (es. metodi immutabili, uso di lambda e stream in Java). La programmazione funzionale riduce certi bug (immutatibilità -> no race, no side effects difficili), ma non sempre è praticabile da sola (sistemi I/O, UI etc. spesso sono più facilmente espressi con oggetti). Tuttavia, un responsabile dovrebbe promuovere “il giusto strumento per il lavoro”: in componenti dove la robustezza è critica, valutare linguaggi memory-safe (Java, C#) o addirittura “provably safe” (es. Rust in sistemi), oppure script come Python per prototipi e analisi rapida sapendo che saranno un po’ più lenti. Per parti performance-critical ma delicate, considerare tecniche di verifica (es. strumenti di static analysis, o addirittura approcci formali se giustificato, come SPARK/Ada per software militare).
Sicurezza e ciclo di vita del software: indipendentemente dal linguaggio o paradigma, contano i processi: code review, static analysis, fuzzing, patching, gestione dipendenze (questo soprattutto in scripting: pip/npm composer – supply chain risk). Un responsabile dovrebbe assicurarsi che i team di sviluppo seguano secure coding guidelines e che ogni linguaggio usato abbia i suoi checker (es. linters, SonarQube ruleset per Java, ESLint/Retire.js per JS, Bandit per Python, PHPStan per PHP, ecc.).
In conclusione, comprendere i vari tipi di linguaggi e paradigmi consente a un responsabile della sicurezza di dialogare efficacemente con gli sviluppatori e valutare i rischi del software in esame. Ad esempio, se un nuovo sistema da proteggere è scritto in C++ con moduli Python embedded (come a volte succede in tool scientifici), egli saprà che deve considerare sia vulnerabilità a basso livello (C++) sia di alto livello (injection possibili in Python eval? ecc.). Se invece la sua organizzazione passa a microservizi in Node.js e Go, studierà gli specifici pitfalls (Prototype pollution, moduli npm malevoli, vs concurrency issues e memory usage in Go). In definitiva, la diversità di linguaggi riflette la diversità di problemi da risolvere; per la sicurezza informatica, ogni linguaggio/paradigma aggiunge un tassello: conoscendoli, si può implementare difese profonde (ad esempio: firewall WAF che riconosce attacchi comuni in PHP vs in Node), e soprattutto prevenire incidenti formando i team di sviluppo sulle giuste pratiche per quel contesto (ad es., per Java: “attenti alla deserializzazione di oggetti”; per C: “usa snprintf invece di sprintf per prevenire overflow”; per JavaScript: “valida bene input prima di usarli in DOM manipulations per evitare XSS”, e così via). Un professionista completo di sicurezza sa quindi muoversi trasversalmente tra il codice, individuando pattern pericolosi e suggerendo soluzioni appropriate al paradigma in uso.
Una breve guida introduttiva a Wireshark: “The world’s most popular network protocol analyzer”.
Wireshark è il più celebre e diffuso analizzatore di pacchetti di rete, utilizzato ampiamente sia nel mondo accademico che professionale. Originariamente lanciato nel 1998 sotto il nome di “Ethereal”, Wireshark ha guadagnato una reputazione solida per la sua efficacia e versatilità nella diagnosi di problemi di rete e nella comprensione approfondita dei protocolli di rete, tanto da essere utilizzato da:
sistemisti: usano Wireshark per diagnosticare e risolvere problemi di prestazioni della rete;
studenti: trovano in Wireshark uno strumento prezioso per apprendere e visualizzare il funzionamento dei protocolli di rete;
analisti di sicurezza: verificano con Wireshark la presenza di dati non autorizzati o sospetti nella rete.
Caratteristiche principali
licenza GPL: Wireshark è distribuito con una licenza GPL, rendendolo un software libero e gratuito disponibile per Windows, macOS e GNU/Linux. Sul sito ufficiale è possibile trovare i file per l’installazione oltre a una vasta documentazione di riferimento;
formati di file: Il formato nativo per il salvataggio dei dati è il .PCAP (Packet Capture), ma Wireshark supporta e può aprire molti altri formati di file di cattura e permette l’esportazione in vari formati;
riconoscimento dei protocolli: Wireshark è in grado di riconoscere automaticamente una vasta gamma di protocolli di rete, consentendo agli utenti di leggere tutti i dettagli relativi ai pacchetti catturati;
filtraggio e ricerca: Il software permette di filtrare i dati catturati e di svolgere ricerche selettive utilizzando una sintassi comprensiva ma accessibile.
Introduzione a Wireshark
Quando si avvia Wireshark, la prima cosa che si nota sarà l’elenco delle interfacce di rete rilevate dal proprio sistema. Questo permette di visualizzare facilmente quali interfacce sono attive e di iniziare immediatamente la cattura del traffico con un semplice doppio clic su un’interfaccia specifica. Accanto alle interfacce attive, apparirà anche un piccolo grafico che indica l’attività di rete in tempo reale.
Funzionalità chiave dell’area di lavoro di Wireshark:
cattura e analisi di traffico preesistente: oltre a catturare traffico in tempo reale (v. Appendice “Wireshark – uso dei filtri di cattura”), Wireshark permette di aprire e analizzare file di cattura .PCAP esistenti, facilitando l’analisi di dati raccolti in precedenza;
visualizzazione dei dati catturati: una volta avviata la cattura, i dati vengono visualizzati in tempo reale nell’area centrale della finestra di Wireshark, nota come “elenco pacchetti”. Qui è possibile interrompere la cattura cliccando sull’icona a forma di quadrato situata nella barra degli strumenti principale, sopra l’elenco pacchetti.
Figura 1 – L’interfaccia di Wireshark
Suddivisione dell’area di lavoro (Figura 1):
elenco dei pacchetti: questa è la parte principale dell’interfaccia di Wireshark (lettera A), dove tutti i pacchetti di dati catturati o caricati vengono elencati. Ogni riga rappresenta un pacchetto individuale con informazioni di base come il numero di sequenza, il protocollo utilizzato, la lunghezza del pacchetto e altro;
dettagli del pacchetto: selezionando un pacchetto dall’elenco, i dettagli specifici del pacchetto saranno mostrati in questa area (lettera B). I dettagli sono organizzati in un formato ad albero, che riflette l’incapsulamento dei protocolli all’interno del pacchetto. Questo aiuta a comprendere come i dati sono strutturati e quali informazioni trasportano;
dati contenuti nel pacchetto: in questa parte dell’interfaccia, il contenuto del pacchetto selezionato viene visualizzato in forma originale, sia in esadecimale che in ASCII (lettera C). Questo è particolarmente utile per l’analisi a basso livello dei dati e per l’individuazione di specifici pattern o informazioni all’interno del payload del pacchetto.
Barre degli strumenti e utilità:
barra degli strumenti principale: le icone che permettono di avviare e fermare la cattura, salvare i dati, configurare le opzioni di cattura e accedere ad altre funzioni comuni;
barra degli strumenti di filtraggio: posta sotto la barra degli strumenti principale, questa barra permette di inserire filtri per raffinare la visualizzazione dei pacchetti. Supporta l’evidenziazione sintattica per aiutarti a scrivere correttamente le espressioni di filtro;
barra di stato: situata in fondo alla finestra, mostra il numero di pacchetti catturati e fornisce accesso rapido alle proprietà del file di cattura e altre informazioni rilevanti.
L’elenco dei pacchetti è il cuore del flusso di lavoro per l’analisi di una cattura dati in Wireshark. Una volta avviata la cattura, i dati vengono decodificati e ordinati in una tabella, permettendo di seguire la sequenza di cattura dal primo all’ultimo pacchetto.
Informazioni chiave per ciascun pacchetto:
No.: numero progressivo del pacchetto, iniziando da 1.
Time: istante in cui il pacchetto è stato catturato.
Source: indirizzo IP sorgente.
Destination: indirizzo IP di destinazione.
Protocol: protocollo di più alto livello contenuto nel pacchetto.
Length: dimensione del pacchetto in byte.
Packet Info: estratto delle informazioni più rilevanti contenute nel pacchetto.
Wireshark, inoltre, utilizza diverse colorazioni per aiutare a identificare rapidamente i tipi di pacchetti.
La barra del menu contiene moltissime funzioni e strumenti utili per gestire e analizzare le catture di rete:
File: importazione ed esportazione dei dati in diversi formati.
Modifica: ricerca e selezione dei pacchetti, modifica del profilo di configurazione e accesso alle preferenze generali.
Visualizza: gestione delle barre, formato di visualizzazione del tempo di cattura, regole di colorazione.
Vai: navigazione e ricerca nell’elenco pacchetti.
Cattura: opzioni e comandi per la cattura dei dati.
Analizza: costruzione di filtri di visualizzazione e altre funzioni di analisi dei dati.
Statistiche: contiene statistiche pronte per l’analisi del traffico, grafici e proprietà del file di cattura.
Telefonia: strumenti per l’analisi e decodifica di flussi VoIP.
Wireless: dedicato al traffico Bluetooth e WiFi.
Strumenti: funzione per la creazione di regole per i firewall.
Aiuto: accesso alla guida web, wiki, FAQ, catture di esempio e altre risorse utili. Include anche informazioni sulla versione di Wireshark e sulle combinazioni di tasti.
Analizzare la cattura dati
Tra le diverse funzionalità di analisi fornite da Wireshark vi è il menu statistiche, una risorsa potente per effettuare una prima analisi generale dei dati catturati. Questo menu offre una varietà di strumenti che permettono di visualizzare informazioni dettagliate sul traffico di rete, gli host coinvolti, le connessioni stabilite e i protocolli utilizzati. Ecco una panoramica delle voci più utili disponibili nel menu Statistiche:
proprietà del file di cattura: questa opzione fornisce una visione generale dei metadati del file di cattura, come la dimensione in byte, la data e l’ora di cattura, il nome del file e altre informazioni simili. È utile per ottenere un riepilogo rapido delle caratteristiche principali della sessione di cattura;
terminatori (Endpoints): la voce “Endpoint” elenca tutti gli host coinvolti nel traffico di rete catturato. Per ciascun host, Wireshark mostra dettagli come gli indirizzi IP, gli indirizzi MAC, e le porte utilizzate per le connessioni TCP e UDP. Questo strumento è essenziale per identificare rapidamente gli attori chiave nella rete e per comprendere meglio la distribuzione del traffico;
conversazioni: simile alla voce “Endpoint”, “Conversazioni” mostra tutte le connessioni presenti nella cattura. Per ogni connessione, vengono dettagliati gli host coinvolti, i loro indirizzi IP, e le porte di connessione. Particolarmente utile per seguire il flusso di comunicazione tra specifici host e per identificare possibili pattern di traffico o connessioni sospette;
gerarchia dei protocolli: elenca tutti i protocolli di rete presenti nella cattura, organizzati per incapsulamento. Mostra chiaramente come i vari protocolli si stratificano e interagiscono tra loro nel flusso di dati, fornendo una visione comprensiva della struttura del traffico;
altre statistiche utili: il menu Statistiche contiene molte altre voci che forniscono dati specifici per protocollo e analisi più dettagliate, possono includere elementi come flussi di rete, utilizzi di banda, errori di trasmissione;
filtraggio automatico: una funzionalità particolarmente utile di ciascuna voce del menu Statistiche è la possibilità di costruire automaticamente filtri di visualizzazione basati sui dati analizzati.
I filtri di visualizzazione sono uno strumento essenziale in Wireshark per isolare specifiche parti del traffico di rete in base alle necessità di analisi. Questi filtri consentono di affinare la visualizzazione dei dati catturati, rendendo più efficiente l’analisi di grandi quantità di traffico (v. Appendice “Analizzare una cattura usando i filtri di visualizzazione”).
Identificati i pacchetti di interesse in Wireshark, il passo successivo è l’analisi approfondita dei dati che contengono. Wireshark offre un riquadro dedicato chiamato dettagli dei pacchetti, che consente di esplorare in dettaglio l’incapsulamento dei protocolli e i dati trasportati da ciascun pacchetto. I dettagli dei pacchetti sono organizzati gerarchicamente, rispecchiando l’incapsulamento dei protocolli all’interno del pacchetto. Questo permette di visualizzare ogni livello di dati, dal più esterno al più interno. Ecco un esempio tipico di come potrebbero essere strutturati i dettagli per un pacchetto contenente dati HTTP:
Figura 2 – Pacchetto frame
Frame: mostra il pacchetto dati catturato completo di tutti i metadati associati, come l’ora di cattura, la lunghezza del frame, e altre informazioni utili (Figura 2);
Figura 3 – Trama Ethernet II
Ethernet II: mostra la trama Ethernet, il primo livello di incapsulamento, che include dettagli come l’indirizzo MAC sorgente e destinazione e il tipo di protocollo, tipicamente IP (Figura 3);
Figura 4 – Pacchetto IPv4
IP Version 4:il pacchetto IP incapsulato dentro la trama Ethernet. Mostra i dettagli come l’indirizzo IP sorgente e destinazione, la versione del protocollo, il tipo di servizio, e altri parametri relativi al protocollo IP (Figura 4);
Figura 5 – Segmento TCP
TCP: il segmento TCP incapsulato dentro il pacchetto IP, include informazioni come le porte sorgente e destinazione, i numeri di sequenza e di conferma, e altri dettagli relativi alla gestione della connessione TCP (Figura 5);
Figura 6 – HTTP
HTTP: l’unità di dati HTTP trasportata nel segmento TCP. Qui vengono visualizzate informazioni specifiche dell’HTTP, come il metodo di richiesta (GET, POST, ecc.), l’URL richiesto e gli header HTTP (Figura 6).
Analisi dei Protocolli di rete su Wireshark
Nel vasto e complesso mondo delle reti, la capacità di monitorare e analizzare il traffico di rete è fondamentale per garantire la sicurezza, la stabilità e l’efficienza delle comunicazioni digitali. Wireshark offre gli strumenti necessari per esaminare dettagliatamente il flusso dei dati attraverso una rete, è in grado di catturare e visualizzare il contenuto dei pacchetti di rete in tempo reale, permettendo una profonda analisi di vari protocolli essenziali. Tra questi troviamo:
ARP risolve il problema di mappare un indirizzo IP, utilizzato nei pacchetti di rete, all’indirizzo MAC fisico della scheda di rete. L’analisi del traffico ARP è cruciale per (v. Appendice “Analizzare il traffico ARP utilizzando Wireshark”):
– identificare problemi di rete: come conflitti di indirizzi IP o problemi di risoluzione degli indirizzi;
– rilevare attività sospette: come attacchi di ARP spoofing o ARP poisoning, dove un malintenzionato potrebbe tentare di intercettare o alterare il traffico modificando le risposte ARP.
ICMP è fondamentale per la gestione e il debug delle reti IP. Viene spesso utilizzato per testare la connettività e tracciare il percorso dei pacchetti attraverso la rete ad esempio mediante i comandi come ping e traceroute (v. Appendice “Come analizzare i messaggi ICMP in Wireshark”)
TCP, UDP e porte associate. Quando si analizza il traffico di rete con Wireshark, è possibile vedere l’indirizzo IP e il numero di porta per i protocolli TCP e UDP in ogni pacchetto. Questo aiuta a identificare non solo l’origine e la destinazione dei dati a livello di rete, ma anche l’applicazione specifica a cui i dati sono destinati. L’identificazione delle porte utilizzate può fornire indizi vitali in scenari di troubleshooting di rete, sicurezza informatica e conformità di configurazione di rete (v. Appendice “Analisi di TCP e UDP in Wireshark”).
Domain Name System (DNS). Traduce i nomi di dominio facilmente memorizzabili in indirizzi IP numerici che le macchine possono comprendere e a cui possono connettersi (v. Appendice “Analisi del traffico DNS in Wireshark”):
– la maggior parte delle comunicazioni DNS avviene tramite UDP su porta 53, per la sua efficienza in termini di velocità e utilizzo ridotto delle risorse, ideale per le brevi query DNS;
– il DNS usa anche TCP, soprattutto per operazioni che richiedono affidabilità o per risposte che superano il limite di dimensione del pacchetto UDP (512 byte), come nei trasferimenti di zona tra server DNS.
Hyper Text Transfer Protocol (HTTP). Una conversazione HTTP tipica segue un modello di richiesta e risposta (v. Appendice “Analisi del Traffico HTTP in Wireshark”):
– richiesta (Request): il client web invia una richiesta al server per ottenere dati o per inviare informazioni. Le richieste più comuni includono il metodo GET per richiedere dati e POST per inviare dati al server;
– risposta (Response): il server elabora la richiesta e invia una risposta al client. La risposta include uno status code che indica il successo o il fallimento della richiesta, dati (se richiesti), e header che forniscono informazioni aggiuntive.
HTTPS (HTTP Secure). Utilizza il protocollo Transport Layer Security (TLS) per cifrare le comunicazioni tra il client e il server, garantendo così privacy e sicurezza dei dati trasmessi. Wireshark può essere usato per analizzare il traffico TLS/SSL, sebbene il contenuto specifico delle comunicazioni sia cifrato e non direttamente leggibile (v. Appendice “Analisi del Traffico HTTPS e Decodifica di TLS in Wireshark”). La decodifica del traffico TLS in Wireshark richiede l’accesso alle chiavi di sessione, che non sono trasmesse in rete ma generate localmente da client e server durante l’handshake TLS. Per analizzare i dati HTTPS (nascosti dentro il livello TLS) è necessario esportare queste chiavi mentre il browser web stabilisce una connessione TLS (v. Appendice “Decodifica del traffico TLS in Wireshark utilizzando le chiavi di sessione”). Ogni protocollo ha un ruolo unico e critico nella facilitazione e nella sicurezza delle comunicazioni su Internet e l’analisi di questi protocolli attraverso Wireshark è cruciale per diagnosticare problemi di rete, ottimizzarne le prestazioni nonché a mitigare gli attacchi informatici.
La decodifica del traffico TLS in Wireshark richiede l’accesso alle chiavi di sessione, che non sono trasmesse in rete ma generate localmente da client e server durante l’handshake TLS. Per analizzare i dati HTTPS (nascosti dentro il livello TLS) è necessario esportare queste chiavi mentre il browser web stabilisce una connessione TLS. Ogni protocollo ha un ruolo unico e critico nella facilitazione e nella sicurezza delle comunicazioni su Internet e l’analisi di questi protocolli attraverso Wireshark è cruciale per diagnosticare problemi di rete, ottimizzarne le prestazioni nonché a mitigare gli attacchi informatici.
Altri strumenti di analisi dei file PCAP e non
Oltre a Wireshark (v. Appendice “Wireshark – personalizzazione dell’area di lavoro” e Appendice “Wireshark – predisposizione dell’area di lavoro”), esistono diversi altri strumenti utili per l’analisi di file PCAP. Questi strumenti offrono funzionalità specializzate che possono completare o estendere le analisi effettuate con Wireshark, particolarmente utili per identificare minacce, analizzare malware, e visualizzare le connessioni di rete:
analisi generale: caricando un file PCAP su A-Packets, si ottiene un report dettagliato che include l’analisi dei protocolli di rete e i file presenti nel traffico;
estrazione di credenziali: il sito offre funzionalità per estrarre le credenziali che possono essere trasmesse nel traffico di rete;
visualizzazione di rete: mostra una rappresentazione grafica degli host e delle loro interconnessioni, facilitando la comprensione delle relazioni di rete.
Note: I file caricati su A-Packets diventano pubblicamente accessibili, quindi è importante considerare la sensibilità dei dati prima di utilizzare questo servizio.
analisi di rete: non si concentra sull’analisi di malware, ma offre strumenti per esaminare le connessioni di rete dentro il PCAP;
strumenti integrati: include funzionalità per il whois e la geolocalizzazione;
grafici del traffico: fornisce una rappresentazione grafica dello stream di dati, simile a quella di Wireshark, aiutando a visualizzare il flusso di traffico in maniera intuitiva.
Network Miner è un potente strumento forense che si specializza nell’estrarre e visualizzare informazioni dai file PCAP. È particolarmente utile per gli analisti che necessitano di un’analisi rapida e diretta delle comunicazioni di rete. Questo strumento è spesso usato in complemento a Wireshark per offrire una vista più orientata ai dati estratti piuttosto che alla pura analisi del traffico:
Hosts: mostra un elenco di host coinvolti nel traffico di rete;
Files: elenca i file trasferiti attraverso la rete, che possono essere esaminati o scaricati direttamente dall’interfaccia;
Sessions: fornisce una panoramica delle sessioni di comunicazione tra i dispositivi;
Credentials: rivela credenziali che potrebbero essere state trasmesse in chiaro.
ANY.RUN è un servizio di analisi malware basato su sandbox che permette agli utenti di eseguire file sospetti in un ambiente controllato e sicuro, garantisce:
ambiente isolato: utilizza una macchina virtuale (VM) Windows 7 per isolare il malware dal sistema operativo principale e dalla rete locale;
interattività: fornisce un ambiente interattivo, consentendo agli utenti di interagire direttamente con il sistema operativo della VM durante l’analisi;
monitoraggio in tempo reale: durante l’esecuzione del malware, ANY.RUN visualizza in tempo reale le connessioni di rete e l’albero dei processi generati dall’eseguibile;
community e database: gli utenti possono accedere a un database di analisi precedenti, che include i dettagli delle minacce più comuni e recenti, consentendo uno studio approfondito prima di iniziare nuove analisi.
CyberChef, sviluppato dall’agenzia di intelligence britannica GCHQ, è uno strumento versatile per l’analisi e la manipolazione di dati. Viene chiamato “il coltellino svizzero della cyber-security” vista la grande quantità di tools di cui dispone.
Tra le tante categorie di operazioni disponibili vi sono:
operatori aritmetici e logici;
conversione di formato;
codifica e decodifica, crittografia e hashing;
compressione e decompressione dati, strumenti di elaborazione grafica;
estrazione di dati, stringhe e files.
APPENDICI
Wireshark – uso dei filtri di cattura
Wireshark è uno strumento estremamente potente per l’analisi di rete e comprendere come utilizzare efficacemente i filtri di cattura può significativamente migliorare l’efficienza delle sessioni di monitoraggio. Ecco una guida per configurare e applicare filtri di cattura.
Configurazione Iniziale
All’avvio, Wireshark mostra l’elenco delle interfacce di rete disponibili:
grafico dell’interfaccia: accanto a ciascuna interfaccia c’è un grafico che mostra l’attività di rete in tempo reale, facilitando l’identificazione delle interfacce attive;
avvio della cattura: un doppio clic su un’interfaccia avvia la cattura del traffico su quella specifica interfaccia.
Finestra opzioni di cattura
Per accedere:
dal menu Cattura selezionare Opzioni;
Selezione Multipla: seleziona più interfacce per la cattura simultanea;
File di Cattura: definisce un file per salvare i dati catturati, specifica una dimensione massima e imposta la rotazione del file per gestire grandi quantità di dati;
Risoluzione dei Nomi: abilita la risoluzione dei nomi per gli indirizzi IP e per il livello di trasporto, facilitando la lettura e l’analisi del traffico.
Filtri di cattura
A differenza dei filtri di visualizzazione, i filtri di cattura limitano i dati al momento dell’acquisizione. Ciò significa che i dati non corrispondenti al filtro non saranno disponibili in Wireshark dopo la cattura.
Come inserire un filtro di cattura:
nella finestra Opzioni di Cattura, vi è un campo dedicato ai filtri di cattura;
scegliere un filtro predefinito cliccando il nastro verde accanto al campo di inserimento o scrivere manualmente il filtro.
Esempi di filtri di cattura
Cattura traffico da un singolo host:
host 192.168.0.99
Cattura traffico da una rete specifica:
src net 10.1.0.0/16
oppure:
src net 10.1.0.0 mask 255.255.0.0
Cattura traffico HTTP diretto a una porta specifica:
Analizzare una cattura usando i filtri di visualizzazione
La sintassi di base per creare un’espressione di filtraggio richiede la specifica di un protocollo seguito da un dettaglio del protocollo, utilizzando un formato protocollo.campo:
Esempio: ip.addr == 192.168.1.1 seleziona tutti i pacchetti che contengono l’indirizzo IP specificato, sia come mittente che come destinatario.
Gli operatori di confronto sono fondamentali nella costruzione dei filtri:
== oppure eq: uguale a;
!= oppure neq: diverso da;
> oppure gt: maggiore di;
< oppure lt: minore di.
Per combinare più condizioni, si utilizzano gli operatori logici:
&& oppure and: entrambe le condizioni devono essere soddisfatte;
|| oppure or: una delle condizioni deve essere soddisfatta;
Esempio: ip.src == 192.168.1.151 && ip.dst == 62.10.45.151 seleziona solo il traffico dall’indirizzo IP sorgente al destinatario specificato.
Filtraggio per protocollo o porta
Per selezionare traffico specifico basato su protocolli o porte, si possono utilizzare espressioni come:
tcp.port == 80 || http: seleziona tutto il traffico HTTP.
udp.port == 53 || dns: seleziona tutte le query DNS.
Ricerca di stringhe con contains
L’operatore contains è utilizzato per cercare specifiche stringhe all’interno dei pacchetti:
Esempio: dns contains “google” trova tutti i pacchetti DNS che includono il termine “google”.
Per analizzare il traffico ARP utilizzando Wireshark, seguire questi passaggi:
Filtrare il Traffico ARP: digitare arp nella barra di filtraggio di Wireshark per isolare il traffico ARP. Questo filtro visualizzerà tutti i pacchetti ARP scambiati nella rete.
Selezionare un Messaggio ARP: cliccare su un pacchetto ARP nell’elenco per visualizzarne i dettagli nel pannello dei dettagli.
Esaminare i Dettagli del Messaggio ARP: nel Pannello dettagli, sotto la voce “Ethernet II”, vi è la sezione ARP che include i seguenti campi:
Opcode: indica il tipo di messaggio ARP, dove 1 rappresenta una REQUEST e 2 un REPLY;
indirizzi IP e MAC: mostra gli indirizzi IP e MAC dell’host sorgente e del destinatario. Notare che l’ARP REQUEST è inviato al broadcast, cioè all’indirizzo MAC di destinazione ff:ff:ff:ff:ff:ff.
Per analizzare i Messaggi ICMP utilizzando Wireshark, seguire questi passaggi:
filtrare il Traffico ICMP: digitare icmp nella barra di filtraggio di Wireshark per isolare solo il traffico ICMP;
selezionare un pacchetto ICMP: nella lista dei pacchetti filtrati, selezionare un pacchetto che si desidera analizzare. I pacchetti di Echo Request e Echo Reply sono facilmente identificabili dai loro tipi;
esaminare i dettagli dei pacchetti:
nel pannello dei dettagli di Wireshark, cercare la sezione ICMP che si trova subito sotto la sezione di IPv4;
osservare il campo Type per identificare il tipo di messaggio ICMP:
Type 8: ICMP Echo Request;
Type 0: ICMP Echo Reply;
il Timestamp mostra l’orario esatto in cui il messaggio è stato inviato dall’host originale, che può essere utile per calcolare la latenza.
Quando si utilizza Wireshark per analizzare il traffico di rete, comprendere le differenze tra TCP (Transmission Control Protocol) e UDP (User Datagram Protocol) è fondamentale per l’interpretazione dei dati di rete. Ecco come analizzare questi due protocolli cruciali usando Wireshark.
Filtraggio TCP e UDP
Per iniziare l’analisi:
filtraggio: inserire tcp o udp nella barra di filtraggio di Wireshark per isolare il traffico corrispondente;
selezione del pacchetto: scegliere un pacchetto per analizzare i dettagli nel pannello dei dettagli, immediatamente sotto il livello di IPv4.
Dettagli TCP in Wireshark
Con TCP, si troveranno informazioni dettagliate utili per monitorare e diagnosticare la connessione:
Sequence Number e Acknowledge Number: questi numeri sono cruciali per il controllo di flusso e per garantire che i dati siano trasmessi in modo affidabile e in ordine.
flags di TCP: i flags come SYN, ACK, e FIN sono utilizzati per gestire lo stato della connessione. Ad esempio:
SYN: utilizzato per iniziare una connessione;
SYN-ACK: risposta dal server per accettare la connessione;
ACK: utilizzato per confermare la ricezione dei pacchetti;
FIN: indica la chiusura di una connessione;
RST: quando l’handshake a tre vie non viene concluso correttamente, ad esempio per indisponibilità del servizio, il server restituirà altri messaggi di controllo, come il RST (reset).
L’analisi dei flags è importante per identificare il comportamento della connessione, come l’inizio e la conclusione delle sessioni TCP o possibili anomalie nelle connessioni di rete.
Seguire il Flusso TCP
Per una visione più dettagliata della comunicazione tra client e server:
attivare “Segui il Flusso TCP”: dopo aver selezionato un pacchetto TCP, clic destro e selezionare “Segui” e poi “Flusso TCP”. Questo aprirà una nuova finestra con i dati trasmessi nel flusso TCP;
analisi del dialogo: I dati vengono visualizzati con i messaggi del client in rosso e quelli del server in blu, facilitando la visualizzazione della conversazione tra i due;
leggibilità dei dati: la facilità di lettura dei dati dipende dal protocollo di livello applicativo trasportato. Per esempio, il traffico HTTP è generalmente più facile da interpretare rispetto ad altri protocolli meno verbosi.
Dettagli UDP in Wireshark
UDP è meno complesso rispetto a TCP in quanto non stabilisce una connessione e non garantisce il controllo di flusso o la conferma di ricezione.
filtraggio del Traffico DNS: per analizzare il traffico DNS in Wireshark, digitare dns nella barra di filtraggio per isolare solo i pacchetti DNS;
esaminare le Query e le Risposte DNS:
nel pannello dei dettagli di Wireshark, è possibile vedere la struttura delle query e delle risposte DNS. Questo include i nomi di dominio richiesti, i tipi di record (come A, AAAA, MX), gli indirizzi IP risolti, e altri dettagli DNS;
ogni pacchetto DNS mostrerà se si tratta di una query o di una risposta e includerà dettagli come il numero di record nella risposta e gli eventuali errori (es. “Non-Existent Domain”).
monitoraggio per anomalie:
analizzare il traffico DNS può aiutare a identificare comportamenti anomali come attività di malware, che spesso utilizzano query DNS per comunicare con i server di comando e controllo;
l’alta frequenza di query DNS fallite o un volume insolitamente elevato di query può essere indicativo di configurazioni errate o attività sospette.
impostare il filtro: digitare http nella barra di filtraggio di Wireshark per visualizzare solo i pacchetti http;
selezionare un pacchetto: cliccare su un pacchetto di interesse per visualizzare i dettagli nel pannello inferiore.
Dettagli del traffico HTTP in Wireshark
Nel pannello dettagli di Wireshark, sotto il livello TCP, si trova il livello HTTP che include:
Content-Type: indica il tipo di dati trasferiti, come text/html per le pagine web o application/json per dati in formato JSON;
Server: il software server che gestisce la richiesta;
Request URI: l’URI specifico richiesto dal client;
User-Agent: identifica il client web e il sistema operativo utilizzato per fare la richiesta;
Referrer: l’URL della pagina che ha originato la richiesta.
Seguire il flusso TCP
Per una visione completa della conversazione:
selezionare “Segui Flusso TCP”: clic destro sul pacchetto quindi Analizza > Segui > Flusso TCP. Questo mostra l’intera conversazione tra client e server, inclusi tutti i dati trasmessi;
analisi: la finestra del flusso TCP permette di leggere l’interazione completa, visualizzando i dati trasferiti e gli header HTTP in un formato leggibile.
Utilizzare il Menu Statistiche
Per una panoramica più ampia:
gerarchia di protocolli: nel menu Statistiche, selezionare Gerarchia di Protocolli per vedere una sintesi dei protocolli usati nella cattura, inclusi quelli trasportati via http;
esportazione di oggetti HTTP: Da File > Esporta Oggetti > HTTP, è possibile esportare elementi come immagini, fogli di stile e script che sono stati trasferiti via HTTP.
Analisi del traffico HTTPS e decodifica di TLS in Wireshark
Analisi di HTTPS – TLS in Wireshark
filtrare il traffico TLS: inserire tls nella barra di filtraggio di Wireshark per isolare il traffico TLS;
esaminare i dettagli TLS:
nel pannello dettagli, sotto il livello TCP, si trova il livello TLS;
HTTP nascosto: poiché il traffico HTTP è cifrato, non comparirà esplicitamente. Sarà indicato come “Encrypted Application Data”;
dettagli TLS: analizzare i messaggi di “Client Hello” e “Server Hello” per vedere dettagli come la versione TLS, i metodi di cifratura negoziati e i numeri casuali usati per generare la chiave di sessione;
chiave pubblica: nel certificato del server, si può vedere la chiave pubblica usata per la negoziazione della cifratura;
visualizzazione di certificati e handshake: è possibile esaminare i certificati scambiati e i dettagli dei messaggi di handshake per avere un’idea di come viene stabilita la sicurezza prima di trasmettere dati sensibili.
Limitazioni nell’analisi di TLS in Wireshark
Decifrare i dati TLS: Wireshark non può decifrare i dati TLS senza le appropriate chiavi di decifrazione. Tuttavia, è possibile configurare Wireshark per decifrare il traffico TLS se si ha accesso alle chiavi di sessione o ai parametri di pre-master secret.
Decodifica del traffico TLS in Wireshark utilizzando le chiavi di sessione
Ecco come farlo utilizzando Firefox e configurando Wireshark per utilizzare il file di log delle chiavi.
Configurazione di Firefox per esportare le chiavi di sessione TLS
impostazione della variabile di ambiente SSLKEYLOGFILE:
chiudere Firefox e Wireshark: assicurarsi che entrambe le applicazioni siano chiuse prima di modificare le impostazioni;
aprire le impostazioni di sistema:
nel menu di Avvio cercare “env” o “environment variables”.
cliccare su “Modifica le variabili d’ambiente per il tuo account”;
aggiungere la variabile SSLKEYLOGFILE:
clicca su “Nuova…” per creare una nuova variabile d’ambiente;
assegnare come nome della variabile SSLKEYLOGFILE;
come valore della variabile, impostare un percorso per il file di log, ad esempio: %USERPROFILE%\Documents\sslkey.log.
salvare e chiudere: confermare e chiudi tutte le finestre di dialogo;
verifica della configurazione:
riaprire Firefox e visitare un sito HTTPS;
verificare che il file sslkey.log sia stato creato nel percorso specificato e controllare se contiene le chiavi di sessione;
Importazione delle chiavi di sessione in Wireshark
avviare Wireshark e iniziare una cattura: avviare una cattura di rete in Wireshark mentre si usa Firefox per generare traffico HTTPS;
configurazione delle preferenze di Wireshark per TLS:
da Modifica → Preferenze → Protocols → TLS;
trovare la voce “(Pre)-Master-Secret log filename” e cliccare su Sfoglia….
selezionare il file sslkey.log che si è precedentemente configurato e confermare;
analizzare il traffico decodificato:
con le chiavi di sessione importate, Wireshark sarà in grado di decodificare il traffico TLS e mostrare i dati HTTP in chiaro;
per esaminare un flusso di comunicazione specifico, cliccare con il tasto destro su un pacchetto e selezionare Segui → Flusso TLS o Flusso HTTP per visualizzare l’intera conversazione tra client e server.
Wireshark offre ampie possibilità di personalizzazione per adattarsi meglio alle esigenze specifiche di ciascun utente o tipo di analisi. La personalizzazione può aiutare a migliorare l’efficienza nell’analisi del traffico di rete.
Creazione e gestione dei profili di configurazione
Creare un nuovo profilo:
da Modifica → Profili di configurazione;
cliccare su Nuovo e assegnare un nome al nuovo profilo. Questo permette di personalizzare e salvare le impostazioni senza alterare il profilo Default.
Cambio del profilo: è possibile cambiare profilo ogni qual volta è necessario adattarsi a diversi scenari di analisi. Selezionare semplicemente il profilo desiderato dall’elenco nel menu dei profili di configurazione.
Esportazione e importazione di un profilo: questo è utile per trasferire le personalizzazioni su un’altra installazione di Wireshark. Dallo stesso menu dei profili, è possibile esportare un profilo e poi importarlo su un’altra macchina.
Modifica delle regole di colorazione
Accesso alle regole di colorazione:
da Visualizza → Regole di colorazione;
modificare le regole esistenti o aggiungerne di nuove cliccando sul simbolo +.
Personalizzazione dei colori: ogni regola è legata a un filtro di visualizzazione specifico. Definire il colore del testo e dello sfondo per rendere più intuitiva l’analisi visiva del traffico.
Configurazione delle colonne
Modifica delle colonne:
da Modifica → Preferenze → Aspetto;
eliminare colonne non necessarie o aggiungerne di nuove.
Aggiunta di nuove colonne:
assegna un nome alla nuova colonna e seleziona il dettaglio da visualizzare, come indirizzi IP o porte;
è possibile visualizzare i nomi risolti o mantenere i numeri con l’opzione resolved o unresolved.
Riorganizzazione delle colonne: è possibile trascina le colonne nella posizione desiderata per un’analisi più efficiente.
Memorizzazione dei filtri di visualizzazione
Aggiunta di filtri personalizzati:
utilizzare il pulsante + vicino alla barra di filtraggio per salvare i filtri utilizzati frequentemente.
assegnare un nome al filtro e, se necessario, aggiungere un commento per descriverne l’uso.
Utilizzo dei filtri salvati: i filtri salvati appariranno come pulsanti nella barra di filtraggio e saranno applicabili rapidamente con un clic.
Per rafforzare la capacità di rilevamento di malware nel traffico di rete, è possibile configurare specificamente Wireshark per analizzare le sessioni HTTP e HTTPS:
Creazione di un nuovo profilo di configurazione: da Modifica → Profili di configurazione e creare un nuovo profilo, es. “Analyst”.
Modifica delle colonne per analisi HTTP/HTTPS
aprire le preferenze: da Modifica → Preferenze → Aspetto.
configurazione delle colonne: rimuovere le colonne non necessarie e aggiungere le seguenti per ottimizzare l’analisi del traffico web:
Time: imposta il formato su UTC per garantire che l’ora sia uniforme e confrontabile globalmente;
Src e Dst: aggiungere colonne per gli indirizzi IP sorgente e destinatario;
Port: colonne per le porte sorgente e destinatario, utili per identificare il tipo di traffico;
Host: una colonna personalizzata che usa il filtro http.host o tls.handshake.extensions_server_name per visualizzare i nomi dei server web.
Info: per dettagli generali sulla trasmissione.
Impostazioni di data e ora: assicurarsi che il tempo sia impostato su UTC per la consistenza attraverso il menu Visualizza → Formato visualizzazione tempo → Data e ora del tempo UTC.
Creazione di pulsanti di filtraggio
Usare il pulsante + accanto alla barra di filtraggio per creare filtri rapidi:
(http.request or tls.handshake.type eq 1) and !(ssdp): filtra le richieste HTTP e i nomi di dominio HTTPS, escludendo il traffico SSDP;
(http.request or tls.handshake.type eq 1 or tcp.flags eq 0x0002 or dns) and !(ssdp): aggiunge TCP SYN e DNS alle sessioni HTTP e HTTPS.
Analisi delle conversazioni di rete e ricerca di minacce
Gerarchia dei protocolli: da Statistiche → Gerarchia di protocolli per vedere la distribuzione dei dati tra i protocolli;
Endpoint e conversazioni: utilizzare le opzioni sotto Statistiche per visualizzare gli endpoint e le conversazioni, che possono aiutare a identificare i “top talkers” o le connessioni sospette.
HTTP Requests: Statistiche → HTTP → Richieste per un elenco di richieste a server web, che può rivelare connessioni a domini sconosciuti o maligni.
Uso avanzato dei filtri di visualizzazione
udp.port eq 67: visualizza i messaggi DHCP inviati dai client che contengono l’indirizzo IP, l’indirizzo MAC e l’hostname;
nbns: mostra il traffico Netbios utilizzato tipicamente dagli host Windows, utile per ricavare l’hostname degli endpoint;
http.request: mostra tutte le richieste di accesso ai server web, che contengono utili info;
udp and !(dns): visualizza le connessioni UDP non attinenti al trasporto di DNS;
dns.qry.name contains dominio: mostra le richieste di risoluzione per il dominio indicato;
frame contains “MZ” and frame contains “DOS”: trova il trasferimento di eseguibili Windows. Le stringhe specificate sono i cosiddetti magic numbers (o anche file signatures[1]), piccole sequenze di caratteri poste all’inizio di ogni file grazie alle quali è possibile identificare il tipo di file; il magic number MZ identifica un file eseguibile per Windows.
l’operatore matches: simile a contains ma abilita l’uso delle espressioni regolari:
frame matches “\.(?i)(exe|zip|doc|xls|ppt|jar)”: visualizza i pacchetti che contengono file;
frame matches “(?i)(username|password)”: trova i pacchetti con credenziali;
frame matches “User-Agent: Mozilla.*”: visualizza solo le richieste HTTP dei client Mozilla
Attivazione della geolocalizzazione con MaxMind
Durante la ricerca di una minaccia risulta utile avere informazioni sulla provenienza geografica ovvero la nazionalità degli host coinvolti nelle conversazioni di rete; di base Wireshark non fornisce tali informazioni ma possono essere integrati grazie al database fornito dal sito di MAXMIND:
download dei database MaxMind: registrarsi e scaricare i file .mmdb[2] da MaxMind;
configurazione in Wireshark:
da Modifica → Preferenze → Name Resolution;
aggiungere la directory contenente i file .mmdb.
Utilizzo dei Filtri di Display per la Geolocalizzazione
Completata l’attivazione dei file di database si troveranno subito le nuove informazioni:
nel pannello dettagli di un pacchetto selezionato, espandendo il livello IPv4;
nella finestra dedicata alle statistiche per i terminatori di rete (endpoint), scheda IPv4, il pulsante Mappa posto a sinistra nella finestra permette di osservare gli indirizzi IP su di una mappa geografica.
Wireshark permette di utilizzare i dati di geolocalizzazione per filtrare il traffico di rete in base alla località geografica:
questo filtro visualizza tutti i pacchetti che hanno origine o destinazione nella città di Roma:
Appunti raccolti durante il relativo corso seguito su Skills for All by Cisco, alla cui piattaforma rimando per il materiale necessario.
Reliable Networks
Network Architecture
Sei mai stato impegnato a lavorare online, solo per vedere “Internet andare giù”? Molto probabilmente hai “solo” perso la connessione. È molto frustrante. Con così tante persone nel mondo che si affidano all’accesso alla rete per lavorare e imparare, è imperativo che le reti siano affidabili. In questo contesto, affidabilità significa più della tua connessione a Internet. Questo argomento si concentra sui quattro aspetti dell’affidabilità della rete.
Il ruolo della rete è cambiato da una rete di soli dati a un sistema che consente la connessione di persone, dispositivi e informazioni in un ambiente di rete convergente ricco di contenuti multimediali. Affinché le reti funzionino in modo efficiente e crescano in questo tipo di ambiente, la rete deve essere costruita su un’architettura di rete standard.
Le reti supportano anche un’ampia gamma di applicazioni e servizi. Devono operare su molti tipi diversi di cavi e dispositivi, che costituiscono l’infrastruttura fisica. Il termine architettura di rete, in questo contesto, si riferisce alle tecnologie che supportano l’infrastruttura ei servizi programmati e le regole, o protocolli, che spostano i dati attraverso la rete.
Man mano che le reti si evolvono, abbiamo appreso che ci sono quattro caratteristiche fondamentali che gli “architetti” di rete devono affrontare per soddisfare le aspettative degli utenti:
Tolleranza ai guasti
Scalabilità
Qualità del servizio (QoS)
Sicurezza
Fault Tolerance
Una rete tollerante ai guasti è quella che limita il numero di dispositivi interessati durante un guasto. È costruita per consentire un ripristino rapido quando si verifica un tale errore. Queste reti dipendono da più percorsi tra l’origine e la destinazione di un messaggio. Se un percorso fallisce, i messaggi vengono immediatamente inviati su un collegamento diverso. La presenza di più percorsi verso una destinazione è nota come ridondanza.
L’implementazione di una rete a commutazione di pacchetto è un modo in cui le reti affidabili forniscono ridondanza. La commutazione di pacchetto suddivide il traffico in pacchetti che vengono instradati su una rete condivisa. Un singolo messaggio, come un’e-mail o un flusso video, viene suddiviso in più blocchi di messaggi, chiamati pacchetti. Ogni pacchetto ha le necessarie informazioni di indirizzamento dell’origine e della destinazione del messaggio. I router all’interno della rete commutano i pacchetti in base alle condizioni della rete in quel momento. Ciò significa che tutti i pacchetti in un singolo messaggio potrebbero prendere percorsi molto diversi verso la stessa destinazione. Nella figura, l’utente non è a conoscenza e non è influenzato dal router che sta cambiando dinamicamente il percorso quando un collegamento fallisce.
Scalability
Una rete scalabile si espande rapidamente per supportare nuovi utenti e applicazioni. Lo fa senza degradare le prestazioni dei servizi a cui accedono gli utenti esistenti. La figura mostra come aggiungere facilmente una nuova rete a una rete esistente. Queste reti sono scalabili perché i progettisti seguono standard e protocolli accettati. Ciò consente ai fornitori di software e hardware di concentrarsi sul miglioramento di prodotti e servizi senza dover progettare un nuovo insieme di regole per operare all’interno della rete.
Quality of Service
La qualità del servizio (QoS) è oggi un requisito crescente delle reti. Le nuove applicazioni disponibili per gli utenti sulle reti, come le trasmissioni voce e video in diretta, creano maggiori aspettative per la qualità dei servizi forniti. Hai mai provato a guardare un video con interruzioni e pause costanti? Man mano che dati, voce e contenuti video continuano a convergere sulla stessa rete, QoS diventa un meccanismo primario per gestire la congestione e garantire una consegna affidabile dei contenuti a tutti gli utenti.
La congestione si verifica quando la domanda di larghezza di banda supera la quantità disponibile. La larghezza di banda della rete è misurata nel numero di bit che possono essere trasmessi in un singolo secondo, o bit al secondo (bps). Quando vengono tentate comunicazioni simultanee attraverso la rete, la richiesta di larghezza di banda di rete può superare la sua disponibilità, creando congestione di rete.
Quando il volume di traffico è maggiore di quello che può essere trasportato attraverso la rete, i dispositivi manterranno i pacchetti in memoria fino a quando le risorse non saranno disponibili per trasmetterli. Nella figura, un utente richiede una pagina Web e un altro è impegnato in una telefonata. Con una politica QoS in atto, il router può gestire il flusso di dati e traffico vocale, dando priorità alle comunicazioni vocali se la rete subisce una congestione. L’obiettivo di QoS è dare la priorità al traffico sensibile al tempo. Ciò che è importante è il tipo di traffico, non il contenuto del traffico.
Network Security
L’infrastruttura di rete, i servizi ei dati contenuti nei dispositivi collegati alla rete sono risorse personali e aziendali cruciali. Gli amministratori di rete devono affrontare due tipi di problemi di sicurezza della rete: sicurezza dell’infrastruttura di rete e sicurezza delle informazioni.
La protezione dell’infrastruttura di rete include la protezione fisica dei dispositivi che forniscono la connettività di rete e la prevenzione dell’accesso non autorizzato al software di gestione che risiede su di essi, come mostrato nella figura.
Gli amministratori di rete devono inoltre proteggere le informazioni contenute nei pacchetti trasmessi sulla rete e le informazioni memorizzate sui dispositivi collegati alla rete. Per raggiungere gli obiettivi della sicurezza della rete, ci sono tre requisiti principali.
Riservatezza – Riservatezza dei dati significa che solo i destinatari previsti e autorizzati possono accedere e leggere i dati.
Integrità – L’integrità dei dati assicura agli utenti che le informazioni non sono state alterate durante la trasmissione, dall’origine alla destinazione.
Disponibilità: la disponibilità dei dati garantisce agli utenti un accesso tempestivo e affidabile ai servizi dati per gli utenti autorizzati.
Hierarchical Network Design
Physical and Logical Addresses
Il nome di una persona di solito non cambia. L’indirizzo di una persona, d’altra parte, si riferisce a dove vive la persona e può cambiare. Su un host, l’indirizzo MAC non cambia; è fisicamente assegnato alla scheda NIC host ed è noto come indirizzo fisico. L’indirizzo fisico rimane lo stesso indipendentemente dalla posizione dell’host sulla rete.
L’indirizzo IP è simile all’indirizzo di una persona. È noto come indirizzo logico perché viene assegnato logicamente in base a dove si trova l’host. L’indirizzo IP, o indirizzo di rete, viene assegnato a ciascun host da un amministratore di rete in base alla rete locale.
Gli indirizzi IP contengono due parti. Una parte identifica la porzione di rete. La porzione di rete dell’indirizzo IP sarà la stessa per tutti gli host connessi alla stessa rete locale. La seconda parte dell’indirizzo IP identifica il singolo host su quella rete. All’interno della stessa rete locale, la parte host dell’indirizzo IP è univoca per ciascun host, come mostrato nella figura.
Sia il MAC fisico che gli indirizzi IP logici sono necessari affinché un computer comunichi su una rete gerarchica, proprio come sono necessari sia il nome che l’indirizzo di una persona per inviare una lettera.
Hierarchical Analogy
Immagina quanto sarebbe difficile la comunicazione se l’unico modo per inviare un messaggio a qualcuno fosse usare il nome della persona. Se non ci fossero indirizzi stradali, città, paesi o confini nazionali, consegnare un messaggio a una persona specifica in tutto il mondo sarebbe quasi impossibile.
Su una rete Ethernet, l’indirizzo MAC dell’host è simile al nome di una persona. Un indirizzo MAC indica l’identità individuale di un host specifico, ma non indica dove si trova l’host sulla rete. Se tutti gli host su Internet (milioni e milioni di essi) fossero identificati ciascuno solo dal proprio indirizzo MAC univoco, immagina quanto sarebbe difficile individuarne uno solo.
Inoltre, la tecnologia Ethernet genera una grande quantità di traffico di trasmissione affinché gli host possano comunicare. Le trasmissioni vengono inviate a tutti gli host all’interno di una singola rete. Le trasmissioni consumano larghezza di banda e rallentano le prestazioni della rete. Cosa accadrebbe se i milioni di host collegati a Internet fossero tutti in una rete Ethernet e utilizzassero le trasmissioni?
Per questi due motivi, le grandi reti Ethernet costituite da molti host non sono efficienti. È meglio dividere reti più grandi in parti più piccole e più gestibili. Un modo per dividere reti più grandi è utilizzare un modello di progettazione gerarchico.
Access, Distribution, and Core
Il traffico IP viene gestito in base alle caratteristiche e ai dispositivi associati a ciascuno dei tre livelli del modello di progettazione della rete gerarchica: accesso, distribuzione e nucleo.
Livello di accesso (Access Layer)
Il livello di accesso fornisce un punto di connessione per i dispositivi degli utenti finali alla rete e consente a più host di connettersi ad altri host tramite un dispositivo di rete, solitamente uno switch, come il Cisco 2960-XR mostrato nella figura, o un punto di accesso wireless. In genere, tutti i dispositivi all’interno di un singolo livello di accesso avranno la stessa porzione di rete dell’indirizzo IP.
Se un messaggio è destinato a un host locale, in base alla parte di rete dell’indirizzo IP, il messaggio rimane locale. Se è destinato a una rete diversa, viene passato al livello di distribuzione. Gli switch forniscono la connessione ai dispositivi del livello di distribuzione, in genere un dispositivo di livello 3 come un router o uno switch di livello 3.
Livello di distribuzione (Distribution Layer)
Il livello di distribuzione fornisce un punto di connessione per reti separate e controlla il flusso di informazioni tra le reti. In genere contiene switch più potenti, come la serie Cisco C9300 mostrata nella figura, rispetto al livello di accesso e ai router per l’instradamento tra le reti. I dispositivi del livello di distribuzione controllano il tipo e la quantità di traffico che fluisce dal livello di accesso al livello principale.
Livello centrale (Core Layer)
Il livello centrale è un livello backbone ad alta velocità con connessioni ridondanti (backup). È responsabile del trasporto di grandi quantità di dati tra più reti finali. I dispositivi del livello principale includono in genere switch e router molto potenti e ad alta velocità, come il Cisco Catalyst 9600 mostrato nella figura. L’obiettivo principale del livello principale è trasportare i dati rapidamente.
Reliable Networks – Riepilogo
Man mano che le reti si evolvono, abbiamo appreso che ci sono quattro caratteristiche di base che gli architetti di rete devono affrontare per soddisfare le aspettative degli utenti: tolleranza ai guasti, scalabilità, QoS e sicurezza.
Una rete tollerante ai guasti limita il numero di dispositivi interessati durante un guasto. Consente un ripristino rapido quando si verifica un tale errore. Queste reti dipendono da più percorsi tra l’origine e la destinazione di un messaggio. Se un percorso fallisce, i messaggi vengono immediatamente inviati su un collegamento diverso.
Una rete scalabile si espande rapidamente per supportare nuovi utenti e applicazioni. Lo fa senza degradare le prestazioni dei servizi a cui accedono gli utenti esistenti. Le reti possono essere scalabili perché i progettisti seguono standard e protocolli accettati.
QoS è oggi un requisito crescente delle reti. Man mano che dati, voce e contenuti video continuano a convergere sulla stessa rete, QoS diventa un meccanismo primario per gestire la congestione e garantire una consegna affidabile dei contenuti a tutti gli utenti. La larghezza di banda della rete è misurata in bps. Quando vengono tentate comunicazioni simultanee attraverso la rete, la richiesta di larghezza di banda di rete può superare la sua disponibilità, creando congestione di rete. L’obiettivo di QoS è dare la priorità al traffico sensibile al tempo. Ciò che è importante è il tipo di traffico, non il contenuto del traffico.
Gli amministratori di rete devono affrontare due tipi di problemi di sicurezza della rete: sicurezza dell’infrastruttura di rete e sicurezza delle informazioni. Gli amministratori di rete devono inoltre proteggere le informazioni contenute nei pacchetti trasmessi sulla rete e le informazioni memorizzate sui dispositivi collegati alla rete. Esistono tre requisiti principali per raggiungere gli obiettivi della sicurezza di rete: riservatezza, integrità e disponibilità.
Hierarchical Networks Design
Gli indirizzi IP contengono due parti. Una parte identifica la porzione di rete. La porzione di rete del’indirizzo IP sarà la stessa per tutti gli host connessi alla stessa rete locale. La seconda parte dell’indirizzo IP identifica il singolo host su quella rete. Sia il MAC fisico che gli indirizzi IP logici sono necessari affinché un computer comunichi su una rete gerarchica.
Il Centro connessioni di rete e condivisione su un PC mostra le informazioni di rete di base e imposta le connessioni, comprese le reti attive e se sei connesso via cavo o wireless a Internet e all’interno della tua LAN. Puoi visualizzare le proprietà delle tue connessioni qui.
Su una rete Ethernet, l’indirizzo MAC dell’host è simile al nome di una persona. Un indirizzo MAC indica l’identità individuale di un host specifico, ma non indica dove si trova l’host sulla rete. Se tutti gli host su Internet (milioni e milioni di essi) fossero identificati ciascuno solo dal proprio indirizzo MAC univoco, immagina quanto sarebbe difficile individuarne uno solo. È meglio dividere reti più grandi in parti più piccole e più gestibili. Un modo per dividere reti più grandi è utilizzare un modello di progettazione gerarchico.
Le reti gerarchiche si adattano bene. Il livello di accesso fornisce un punto di connessione per i dispositivi degli utenti finali alla rete e consente a più host di connettersi ad altri host tramite un dispositivo di rete, in genere uno switch o un punto di accesso wireless. In genere, tutti i dispositivi all’interno di un singolo livello di accesso avranno la stessa porzione di rete dell’indirizzo IP. Il livello di distribuzione fornisce un punto di connessione per reti separate e controlla il flusso di informazioni tra le reti. I dispositivi del livello di distribuzione controllano il tipo e la quantità di traffico che fluisce dal livello di accesso al livello principale. Il livello centrale è un livello backbone ad alta velocità con connessioni ridondanti. È responsabile del trasporto di grandi quantità di dati tra più reti finali. L’obiettivo principale del livello principale è trasportare i dati rapidamente.
Cloud and Virtualization
Types of Clouds
Esistono quattro modelli di cloud principali:
Cloud pubblici: le applicazioni e i servizi basati su cloud offerti in un cloud pubblico vengono resi disponibili alla popolazione in generale. I servizi possono essere gratuiti o offerti su un modello pay-per-use, come il pagamento per l’archiviazione online. Il cloud pubblico utilizza Internet per fornire servizi.
Cloud privati: le applicazioni e i servizi basati su cloud offerti in un cloud privato sono destinati a un’organizzazione o entità specifica, ad esempio il governo. Un cloud privato può essere configurato utilizzando la rete privata di un’organizzazione, sebbene ciò possa essere costoso da creare e mantenere. Un cloud privato può anche essere gestito da un’organizzazione esterna con una rigorosa sicurezza di accesso.
Cloud ibridi: un cloud ibrido è costituito da due o più cloud (ad esempio: parte privata, parte pubblica), in cui ogni parte rimane un oggetto separato, ma entrambi sono collegati tramite un’unica architettura. Gli individui su un cloud ibrido sarebbero in grado di avere gradi di accesso a vari servizi in base ai diritti di accesso degli utenti.
Cloud della comunità: viene creato un cloud della comunità per l’uso esclusivo da parte di una comunità specifica. Le differenze tra cloud pubblici e community cloud sono le esigenze funzionali che sono state personalizzate per la comunità. Ad esempio, le organizzazioni sanitarie devono rimanere conformi alle politiche e alle leggi che richiedono autenticazione e riservatezza speciali.
Cloud Computing and Virtualization
I termini “cloud computing” e “virtualizzazione” sono spesso usati in modo intercambiabile; tuttavia, significano cose diverse. La virtualizzazione è la base del cloud computing. Senza di esso, il cloud computing, poiché è ampiamente implementato, non sarebbe possibile.
Oltre un decennio fa, VMware ha sviluppato una tecnologia di virtualizzazione che ha consentito a un sistema operativo host di supportare uno o più sistemi operativi client. La maggior parte delle tecnologie di virtualizzazione ora si basa su questa tecnologia. La trasformazione dei server dedicati in server virtualizzati è stata adottata e viene rapidamente implementata nei data center e nelle reti aziendali.
Virtualizzazione significa creare una versione virtuale piuttosto che fisica di qualcosa, come un computer. Un esempio potrebbe essere l’esecuzione di un ‘computer Linux’ sul tuo PC Windows, cosa che farai più avanti in laboratorio.
Per apprezzare appieno la virtualizzazione, è innanzitutto necessario comprendere parte della storia della tecnologia dei server. Storicamente, i server aziendali erano costituiti da un sistema operativo server, come Windows Server o Linux Server, installato su hardware specifico, come mostrato nella figura. Tutta la RAM del server, la potenza di elaborazione e lo spazio su disco rigido sono stati dedicati al servizio fornito (ad es. Web, servizi di posta elettronica, ecc.).
Il problema principale con questa configurazione è che quando un componente si guasta, il servizio fornito da questo server diventa non disponibile. Questo è noto come un singolo punto di errore. Un altro problema era che i server dedicati erano sottoutilizzati. I server dedicati spesso sono rimasti inattivi per lunghi periodi di tempo, in attesa che si presentasse la necessità di fornire il servizio specifico che forniscono. Questi server sprecavano energia e occupavano più spazio di quanto fosse garantito dalla quantità di servizio fornito. Questo è noto come espansione incontrollata del server.
Advantages of Virtualization
Uno dei principali vantaggi della virtualizzazione è il costo complessivo ridotto:
Sono necessarie meno apparecchiature: la virtualizzazione consente il consolidamento dei server, che richiede meno dispositivi fisici e riduce i costi di manutenzione.
Viene consumata meno energia: il consolidamento dei server riduce i costi mensili di alimentazione e raffreddamento.
È richiesto meno spazio: il consolidamento dei server riduce la quantità di spazio richiesto.
Questi sono ulteriori vantaggi della virtualizzazione:
Prototipazione più semplice: è possibile creare rapidamente laboratori autonomi, operanti su reti isolate, per testare e creare prototipi di implementazioni di rete.
Provisioning del server più rapido: la creazione di un server virtuale è molto più rapida rispetto al provisioning di un server fisico.
Aumento del tempo di attività del server: la maggior parte delle piattaforme di virtualizzazione del server ora offre funzionalità avanzate di tolleranza agli errori ridondanti.
Ripristinodi emergenza migliorato: la maggior parte delle piattaforme di virtualizzazione dei server aziendali dispone di software che può aiutare a testare e automatizzare il failover prima che si verifichi un disastro.
Supporto legacy: la virtualizzazione può prolungare la durata dei sistemi operativi e delle applicazioni, fornendo più tempo alle organizzazioni per migrare verso soluzioni più recenti.
Hypervisors
L’hypervisor è un programma, firmware o hardware che aggiunge un livello di astrazione sopra l’hardware fisico. Il livello di astrazione viene utilizzato per creare macchine virtuali che hanno accesso a tutto l’hardware della macchina fisica come CPU, memoria, controller del disco e NIC. Ognuna di queste macchine virtuali esegue un sistema operativo completo e separato. Con la virtualizzazione, non è raro che 100 server fisici vengano consolidati come macchine virtuali su 10 server fisici che utilizzano hypervisor.
Hypervisor di tipo 1 – Approccio ‘Bare Metal’.
Gli hypervisor di tipo 1 sono anche chiamati approccio ‘bare metal’ perché l’hypervisor è installato direttamente sull’hardware. Gli hypervisor di tipo 1 vengono generalmente utilizzati su server aziendali e dispositivi di rete del data center.
Con gli hypervisor di tipo 1, l’hypervisor viene installato direttamente sul server o sull’hardware di rete. Quindi, le istanze di un sistema operativo vengono installate sull’hypervisor, come mostrato nella figura. Gli hypervisor di tipo 1 hanno accesso diretto alle risorse hardware; pertanto, sono più efficienti delle architetture ospitate. Gli hypervisor di tipo 1 migliorano scalabilità, prestazioni e robustezza.
Hypervisor di tipo 2 – Approccio ‘ospitato’.
Un hypervisor di tipo 2 è un software che crea ed esegue istanze VM. Il computer, su cui un hypervisor supporta una o più macchine virtuali, è una macchina host. Gli hypervisor di tipo 2 sono anche chiamati hypervisor ospitati. Questo perché l’hypervisor è installato sopra il sistema operativo esistente, come macOS, Windows o Linux. Quindi, una o più istanze aggiuntive del sistema operativo vengono installate sopra l’hypervisor, come mostrato nella figura. Un grande vantaggio degli hypervisor di tipo 2 è che non è necessario il software della console di gestione.
Nota: è importante assicurarsi che la macchina host sia sufficientemente robusta per installare ed eseguire le macchine virtuali, in modo che non esaurisca le risorse.
Cloud and Cloud Services – Rielpilogo
In generale, quando si parla di cloud, si parla di data center, cloud computing e virtualizzazione. I data center sono in genere strutture di grandi dimensioni che forniscono enormi quantità di alimentazione, raffreddamento e larghezza di banda. Solo le aziende molto grandi possono permettersi i propri data center. La maggior parte delle organizzazioni più piccole affitta i servizi da un fornitore di servizi cloud.
I servizi cloud includono quanto segue:
SaaS – Software come servizio
PaaS – Piattaforma come servizio
IaaS – Infrastruttura come servizio
Esistono quattro modelli di cloud primari, come mostrato nella figura.
Cloud pubblici: le applicazioni e i servizi basati su cloud offerti in un cloud pubblico vengono resi disponibili alla popolazione in generale.
Cloud privati: le applicazioni e i servizi basati su cloud offerti in un cloud privato sono destinati a un’organizzazione o entità specifica, ad esempio il governo.
Cloud ibridi: un cloud ibrido è costituito da due o più cloud, in cui ogni parte rimane un oggetto separato, ma entrambi sono collegati tramite un’unica architettura.
Cloud della comunità: viene creato un cloud della comunità per l’uso esclusivo da parte di una comunità specifica. Le differenze tra cloud pubblici e community cloud sono le esigenze funzionali che sono state personalizzate per la comunità.
La virtualizzazione è la base del cloud computing. Senza di esso, il cloud computing, poiché è ampiamente implementato, non sarebbe possibile. Virtualizzazione significa creare una versione virtuale piuttosto che fisica di qualcosa, come un computer. Un esempio potrebbe essere l’esecuzione di un ‘computer Linux’ sul tuo PC Windows.
Virtualization
Uno dei principali vantaggi della virtualizzazione è il costo complessivo ridotto:
Sono necessarie meno apparecchiature: la virtualizzazione consente il consolidamento dei server, che richiede meno dispositivi fisici e riduce i costi di manutenzione.
Viene consumata meno energia: il consolidamento dei server riduce i costi mensili di alimentazione e raffreddamento.
È richiesto meno spazio: il consolidamento dei server riduce la quantità di spazio richiesto.
Questi sono ulteriori vantaggi della virtualizzazione:
Prototipazione più semplice: è possibile creare rapidamente laboratori autonomi, operanti su reti isolate, per testare e creare prototipi di implementazioni di rete.
Provisioningdel server più rapido: la creazione di un server virtuale è molto più rapida rispetto al provisioning di un server fisico.
Aumentodel tempo di attività del server: la maggior parte delle piattaforme di virtualizzazione del server ora offre funzionalità avanzate di tolleranza agli errori ridondanti.
Ripristinodi emergenza migliorato: la maggior parte delle piattaforme di virtualizzazione dei server aziendali dispone di software che può aiutare a testare e automatizzare il failover prima che si verifichi un disastro.
Supportolegacy: la virtualizzazione può prolungare la durata dei sistemi operativi e delle applicazioni, fornendo più tempo alle organizzazioni per migrare verso soluzioni più recenti.
L’hypervisor è un programma, firmware o hardware che aggiunge un livello di astrazione sopra l’hardware fisico. Il livello di astrazione viene utilizzato per creare macchine virtuali che hanno accesso a tutto l’hardware della macchina fisica come CPU, memoria, controller del disco e NIC. Ognuna di queste macchine virtuali esegue un sistema operativo completo e separato.
Gli hypervisor di tipo 1 sono anche chiamati approccio ‘bare metal’ perché l’hypervisor è installato direttamente sull’hardware. Gli hypervisor di tipo 1 vengono generalmente utilizzati su server aziendali e dispositivi di rete del data center.
Un hypervisor di tipo 2 è un software che crea ed esegue istanze VM. Il computer, su cui un hypervisor supporta una o più macchine virtuali, è una macchina host. Gli hypervisor di tipo 2 sono anche chiamati hypervisor ospitati. Questo perché l’hypervisor è installato sopra il sistema operativo esistente, come macOS, Windows o Linux. Quindi, una o più istanze aggiuntive del sistema operativo vengono installate sopra l’hypervisor. Un grande vantaggio degli hypervisor di tipo 2 è che non è necessario il software della console di gestione.
Binary and IPv4 Addresses
Gli indirizzi IPv4 iniziano come binari, una serie di soli 1 e 0. Questi sono difficili da gestire, quindi gli amministratori di rete devono convertirli in decimale. Questo argomento mostra alcuni modi per farlo.
Il binario è un sistema di numerazione costituito dalle cifre 0 e 1 chiamate bit. Al contrario, il sistema di numerazione decimale è composto da 10 cifre che includono da 0 a 9.
Il binario è importante per noi da capire perché host, server e dispositivi di rete utilizzano l’indirizzamento binario. In particolare, utilizzano indirizzi IPv4 binari, come mostrato nella figura, per identificarsi a vicenda.
Ogni indirizzo è costituito da una stringa di 32 bit, suddivisa in quattro sezioni chiamate ottetti. Ogni ottetto contiene 8 bit (o 1 byte) separati da un punto. Ad esempio, al PC1 nella figura viene assegnato l’indirizzo IPv4 11000000.10101000.00001010.00001010. Il suo indirizzo gateway predefinito sarebbe quello dell’interfaccia R1 Gigabit Ethernet 11000000.10101000.00001010.00000001.
Il binario funziona bene con host e dispositivi di rete. Tuttavia, è molto difficile per gli esseri umani lavorare con loro.
Per facilità d’uso da parte delle persone, gli indirizzi IPv4 sono comunemente espressi in notazione decimale puntata. Al PC1 viene assegnato l’indirizzo IPv4 192.168.10.10 e il suo indirizzo gateway predefinito è 192.168.10.1, come mostrato nella figura.
Per una solida comprensione dell’indirizzamento di rete, è necessario conoscere l’indirizzamento binario e acquisire abilità pratiche nella conversione tra indirizzi IPv4 binari e decimali puntati. Questa sezione tratterà come eseguire la conversione tra i sistemi di numerazione in base due (binari) e in base 10 (decimali).
Hexadecimal and IPv6 Addresses
Ora sai come convertire binario in decimale e decimale in binario. Hai bisogno di quell’abilità per comprendere l’indirizzamento IPv4 nella tua rete. Ma è altrettanto probabile che utilizzi indirizzi IPv6 nella tua rete. Per comprendere gli indirizzi IPv6, devi essere in grado di convertire da esadecimale a decimale e viceversa.
Proprio come il decimale è un sistema numerico in base dieci, l’esadecimale è un sistema in base sedici. Il sistema numerico in base sedici utilizza le cifre da 0 a 9 e le lettere dalla A alla F. La figura mostra i valori decimali ed esadecimali equivalenti per il binario da 0000 a 1111.
Binario ed esadecimale funzionano bene insieme perché è più facile esprimere un valore come singola cifra esadecimale piuttosto che come quattro bit binari.
Il sistema di numerazione esadecimale viene utilizzato nelle reti per rappresentare gli indirizzi IP versione 6 e gli indirizzi MAC Ethernet.
Gli indirizzi IPv6 hanno una lunghezza di 128 bit e ogni 4 bit è rappresentato da una singola cifra esadecimale; per un totale di 32 valori esadecimali. Gli indirizzi IPv6 non fanno distinzione tra maiuscole e minuscole e possono essere scritti in minuscolo o maiuscolo.
Come mostrato nella figura, il formato preferito per scrivere un indirizzo IPv6 è x:x:x:x:x:x:x:x, con ogni “x” composta da quattro valori esadecimali. Quando ci riferiamo a 8 bit di un indirizzo IPv4 usiamo il termine ottetto. In IPv6, hextet è il termine non ufficiale usato per fare riferimento a un segmento di 16 bit o quattro valori esadecimali. Ogni “x” è un singolo hextet, 16 bit o quattro cifre esadecimali.
La topologia di esempio nella figura mostra gli indirizzi esadecimali IPv6.
The Rise of Ethernet
Agli albori del networking, ogni fornitore utilizzava i propri metodi proprietari per l’interconnessione dei dispositivi di rete e dei protocolli di rete. Se avevi acquistato apparecchiature da fornitori diversi, non c‘era alcuna garanzia che le apparecchiature funzionassero insieme. L’apparecchiatura di un fornitore poteva non comunicare con lapparecchiatura di un altro.
Man mano che le reti diventavano più diffuse, sono stati sviluppati standard che definivano le regole in base alle quali operavano le apparecchiature di rete di diversi fornitori. Gli standard sono utili per il networking in molti modi:
Facilitare la progettazione
Semplificare lo sviluppo del prodotto
Promuovere la concorrenza
Fornire interconnessioni coerenti
Facilitare la formazione
Fornire più scelte di fornitori per i clienti
Non esiste un protocollo standard di rete locale ufficiale, ma nel tempo una tecnologia, Ethernet, è diventata più comune delle altre. I protocolli Ethernet definiscono come vengono formattati i dati e come vengono trasmessi sulla rete cablata. Gli standard Ethernet specificano i protocolli che operano a livello 1 e livello 2 del modello OSI. Ethernet è diventato uno standard de facto, il che significa che è la tecnologia utilizzata da quasi tutte le reti locali cablate, come mostrato nella figura.
Ethernet Evolution
“The Institute of Electrical and Electronics Engineers, o IEE””, mantiene gli standard di rete, inclusi gli standard Ethernet e wireless. I comitati IEEE sono responsabili dell’approvazione e del mantenimento degli standard per le connessioni, i requisiti dei media e i protocolli di comunicazione. Ad ogni standard tecnologico viene assegnato un numero che fa riferimento al comitato responsabile dell’approvazione e del mantenimento dello standard. Il comitato responsabile degli standard Ethernet è 802.3.
Dalla creazione di Ethernet nel 1973, gli standard si sono evoluti per specificare versioni più veloci e flessibili della tecnologia. Questa capacità di Ethernet di migliorare nel tempo è uno dei motivi principali per cui è diventato così popolare. Ogni versione di Ethernet ha uno standard associato. Ad esempio, 802.3 100BASE-T rappresenta 100 Megabit Ethernet utilizzando standard di cavo a doppino intrecciato. La notazione standard si traduce come:
100 è la velocità in Mbps
BASE sta per trasmissione in banda base
T sta per il tipo di cavo, in questo caso doppino intrecciato.
Le prime versioni di Ethernet erano relativamente lente a 10 Mbps. Le ultime versioni di Ethernet funzionano a 10 Gigabit al secondo e oltre. Immagina quanto siano più veloci queste nuove versioni rispetto alle reti Ethernet originali.
Ethernet Frames
Ethernet Encapsulation
Ethernet è una delle due tecnologie LAN utilizzate oggi, insieme alle LAN wireless (WLAN). Ethernet utilizza comunicazioni cablate, inclusi doppino intrecciato, collegamenti in fibra ottica e cavi coassiali.
Ethernet opera nel livello di collegamento dati e nel livello fisico. È una famiglia di tecnologie di rete definite negli standard IEEE 802.2 e 802.3. Ethernet supporta larghezze di banda dati di quanto segue:
10 Mbps
100 Mbps
1000 Mbps (1 Gbps)
10,000 Mbps (10 Gbps)
40,000 Mbps (40 Gbps)
100,000 Mbps (100 Gbps)
Come mostrato nella figura, gli standard Ethernet definiscono sia i protocolli Layer 2 che le tecnologie Layer 1.
Ethernet and the OSI Model
Ethernet è definita dal livello di collegamento dati e dai protocolli del livello fisico.
Data Link Sublayers
I protocolli LAN/MAN IEEE 802, incluso Ethernet, utilizzano i seguenti due sottolivelli separati del livello di collegamento dati per funzionare. Sono il Logical Link Control (LLC) e il Media Access Control (MAC), come mostrato in figura.
Ricordiamo che LLC e MAC hanno i seguenti ruoli nel livello di collegamento dati:
Sottolivello LLC: questo sottolivello IEEE 802.2 comunica tra il software di rete ai livelli superiori e l’hardware del dispositivo ai livelli inferiori. Mette informazioni nel frame che identifica quale protocollo di livello di rete viene utilizzato per il frame. Queste informazioni consentono a più protocolli Layer 3, come IPv4 e IPv6, di utilizzare la stessa interfaccia di rete e lo stesso supporto.
Sottolivello MAC: questo sottolivello (IEEE 802.3, 802.11 o 802.15 ad esempio) è implementato nell’hardware ed è responsabile dell’incapsulamento dei dati e del controllo dell’accesso ai supporti. Fornisce l’indirizzamento del livello di collegamento dati ed è integrato con varie tecnologie di livello fisico.
MAC Sublayer
Il sottolivello MAC è responsabile dell’incapsulamento dei dati e dell’accesso ai media.
Incapsulamento dei dati
L’incapsulamento dei dati IEEE 802.3 include quanto segue:
Frame Ethernet – Questa è la struttura interna del frame Ethernet.
IndirizzamentoEthernet: il frame Ethernet include sia un indirizzo MAC di origine che uno di destinazione per fornire il frame Ethernet dalla scheda di rete Ethernet alla scheda di rete Ethernet sulla stessa LAN.
Rilevamentoerrori Ethernet: il frame Ethernet include un trailer FCS (frame check sequence) utilizzato per il rilevamento degli errori.
Accesso ai media
Come mostrato nella figura, il sottolivello MAC IEEE 802.3 include le specifiche per diversi standard di comunicazione Ethernet su vari tipi di supporti, tra cui rame e fibra.
Ethernet Standards in the MAC Sublayer
Ricordiamo che l’Ethernet legacy che utilizza una topologia a bus o hub è un mezzo half-duplex condiviso. Ethernet su un supporto half-duplex utilizza un metodo di accesso basato sulla contesa, CSMA/CD (Carrier Sense Multiple Access/Collision Detection), che garantisce che un solo dispositivo stia trasmettendo alla volta. CSMA/CD consente a più dispositivi di condividere lo stesso supporto half-duplex, rilevando una collisione quando più di un dispositivo tenta di trasmettere contemporaneamente. Fornisce inoltre un algoritmo di back-off per la ritrasmissione.
Le LAN Ethernet di oggi utilizzano switch che operano in full-duplex. Le comunicazioni full-duplex con switch Ethernet non richiedono il controllo degli accessi tramite CSMA/CD.
Ethernet Frame Fields
La dimensione minima del frame Ethernet è di 64 byte e il massimo previsto è di 1518 byte. Ciò include tutti i byte dal campo dell”indirizzo MAC di destinazione attraverso il campo FCS (frame check sequence). Il campo del preambolo non è incluso quando si descrive la dimensione della cornice.
Nota: la dimensione del frame può essere maggiore se sono inclusi requisiti aggiuntivi, come il tagging VLAN.
Qualsiasi frame di lunghezza inferiore a 64 byte è considerato un “frammento di collisione” o “frame runt” e viene automaticamente scartato dalle stazioni riceventi. I frame con più di 1500 byte di dati sono considerati “jumbo” o “baby giant frame”.
Se la dimensione di un frame trasmesso è inferiore al minimo o superiore al massimo, il dispositivo ricevente elimina il frame. È probabile che i frame persi siano il risultato di collisioni o altri segnali indesiderati. Sono considerati non validi. I frame jumbo sono in genere supportati dalla maggior parte degli switch e delle NIC Fast Ethernet e Gigabit Ethernet.
La figura mostra ciascun campo nel frame Ethernet. Fare riferimento alla tabella per ulteriori informazioni sulla funzione di ciascun campo.
MAC Address and Hexadecimal
Nel networking, gli indirizzi IPv4 sono rappresentati utilizzando il sistema numerico in base dieci decimale e il sistema numerico in base 2 binario. Gli indirizzi IPv6 e gli indirizzi Ethernet sono rappresentati utilizzando il sistema numerico a base esadecimale di sedici. Per capire l’esadecimale, devi prima avere molta familiarità con il binario e il decimale.
Il sistema di numerazione esadecimale utilizza i numeri da 0 a 9 e le lettere dalla A alla F.
Un indirizzo MAC Ethernet è costituito da un valore binario a 48 bit. L’esadecimale viene utilizzato per identificare un indirizzo Ethernet perché una singola cifra esadecimale rappresenta quattro bit binari. Pertanto, un indirizzo MAC Ethernet a 48 bit può essere espresso utilizzando solo 12 valori esadecimali.
La figura confronta i valori decimali ed esadecimali equivalenti per i binari da 0000 a 1111.
Equivalenti decimali e binari da 0 a F esadecimale
Dato che 8 bit (un byte) è un raggruppamento binario comune, il numero binario da 00000000 a 11111111 può essere rappresentato in esadecimale come l’intervallo da 00 a FF, come mostrato nella figura successiva.
Equivalenti decimali, binari ed esadecimali selezionati
Quando si utilizza l’esadecimale, gli zeri iniziali vengono sempre visualizzati per completare la rappresentazione a 8 bit. Ad esempio, nella tabella, il valore binario 0000 1010 è mostrato in esadecimale come 0A.
I numeri esadecimali sono spesso rappresentati dal valore preceduto da 0x (ad esempio, 0x73) per distinguere tra valori decimali ed esadecimali nella documentazione.
L’esadecimale può anche essere rappresentato da un pedice 16 o dal numero esadecimale seguito da una H (ad esempio, 73H).
Potrebbe essere necessario convertire tra valori decimali ed esadecimali. Se tali conversioni sono necessarie, convertire il valore decimale o esadecimale in binario, quindi convertire il valore binario in decimale o esadecimale a seconda dei casi.
Unicast MAC Address
In Ethernet, vengono utilizzati diversi indirizzi MAC per le comunicazioni unicast, broadcast e multicast di livello 2.
Un indirizzo MAC unicast è l’indirizzo univoco utilizzato quando un frame viene inviato da un singolo dispositivo di trasmissione a un singolo dispositivo di destinazione.
La figura mostra come viene elaborato un fotogramma unicast. In questo esempio l’indirizzo MAC di destinazione e l’indirizzo IP di destinazione sono entrambi unicast.
Nell’esempio mostrato, un host con indirizzo IPv4 192.168.1.5 (sorgente) richiede una pagina web dal server all’indirizzo IPv4 unicast 192.168.1.200. Per inviare e ricevere un pacchetto unicast, è necessario che nell’intestazione del pacchetto IP sia presente un indirizzo IP di destinazione. Nell’intestazione del frame Ethernet deve essere presente anche un indirizzo MAC di destinazione corrispondente. L’indirizzo IP e l’indirizzo MAC si combinano per fornire i dati a un host di destinazione specifico.
Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv4 è noto come ARP (Address Resolution Protocol). Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv6 è noto come Neighbor Discovery (ND).
Nota: l’indirizzo MAC di origine deve essere sempre un unicast.
Broadcast MAC Address
Un frame di trasmissione Ethernet viene ricevuto ed elaborato da ogni dispositivo sulla LAN Ethernet. Le caratteristiche di una trasmissione Ethernet sono le seguenti:
Ha un indirizzo MAC di destinazione di FF-FF-FF-FF-FF-FF in esadecimale (48 in binario).
Viene invaso da tutte le porte dello switch Ethernet tranne la porta in entrata.
Non viene inoltrato da un router.
Se i dati incapsulati sono un pacchetto broadcast IPv4, ciò significa che il pacchetto contiene un indirizzo IPv4 di destinazione che ha tutti quelli (1) nella parte host. Questa numerazione nell’indirizzo significa che tutti gli host su quella rete locale (dominio di trasmissione) riceveranno ed elaboreranno il pacchetto.
La figura mostra come viene elaborato un frame di trasmissione. In questo esempio l’indirizzo MAC di destinazione e l’indirizzo IP di destinazione sono entrambi broadcast.
Come mostrato , l’host di origine invia un pacchetto di trasmissione IPv4 a tutti i dispositivi sulla sua rete. L’indirizzo di destinazione IPv4 è un indirizzo di trasmissione, 192.168.1.255. Quando il pacchetto broadcast IPv4 è incapsulato nel frame Ethernet, l’indirizzo MAC di destinazione è l’indirizzo MAC broadcast di FF-FF-FF-FF-FF-FF in esadecimale (48 unità in binario).
DHCP per IPv4 è un esempio di protocollo che utilizza indirizzi broadcast Ethernet e IPv4.
Tuttavia, non tutte le trasmissioni Ethernet trasportano un pacchetto di trasmissione IPv4. Ad esempio, le richieste ARP non utilizzano IPv4, ma il messaggio ARP viene inviato come trasmissione Ethernet.
Multicast MAC Address
Un frame multicast Ethernet viene ricevuto ed elaborato da un gruppo di dispositivi sulla LAN Ethernet che appartengono allo stesso gruppo multicast. Le caratteristiche di un multicast Ethernet sono le seguenti:
Esiste un indirizzo MAC di destinazione 01-00-5E quando i dati incapsulati sono un pacchetto multicast IPv4 e un indirizzo MAC di destinazione 33-33 quando i dati incapsulati sono un pacchetto multicast IPv6.
Esistono altri indirizzi MAC di destinazione multicast riservati per quando i dati incapsulati non sono IP, come Spanning Tree Protocol (STP) e Link Layer Discovery Protocol (LLDP).
Viene allagato su tutte le porte dello switch Ethernet tranne la porta in entrata, a meno che lo switch non sia configurato per lo snooping multicast.
Non viene inoltrato da un router, a meno che il router non sia configurato per instradare pacchetti multicast.
Se i dati incapsulati sono un pacchetto multicast IP, ai dispositivi che appartengono a un gruppo multicast viene assegnato un indirizzo IP del gruppo multicast. L’intervallo di indirizzi multicast IPv4 va da 224.0.0.0 a 239.255.255.255. L’intervallo di indirizzi multicast IPv6 inizia con ff00::/8. Poiché gli indirizzi multicast rappresentano un gruppo di indirizzi (a volte chiamato gruppo host), possono essere utilizzati solo come destinazione di un pacchetto. L’origine sarà sempre un indirizzo unicast.
Come per gli indirizzi unicast e broadcast, l’indirizzo IP multicast richiede un indirizzo MAC multicast corrispondente per consegnare i frame su una rete locale. L’indirizzo MAC multicast è associato e utilizza le informazioni di indirizzamento provenienti dall’indirizzo multicast IPv4 o IPv6.
La figura mostra come viene elaborato un fotogramma multicast. In questo esempio, l’indirizzo MAC di destinazione e l’indirizzo IP di destinazione sono entrambi multicast.
I protocolli di routing e altri protocolli di rete utilizzano l’indirizzamento multicast. Anche applicazioni come software video e di imaging possono utilizzare l’indirizzamento multicast, sebbene le applicazioni multicast non siano così comuni.
Switch Fundamentals
Ora che sai tutto sugli indirizzi MAC Ethernet, è il momento di parlare di come uno switch utilizza questi indirizzi per inoltrare (o scartare) i frame ad altri dispositivi su una rete. Se uno switch inoltrasse semplicemente ogni frame ricevuto su tutte le porte, la tua rete sarebbe così congestionata che probabilmente si fermerebbe completamente.
Uno switch Ethernet di livello 2 utilizza gli indirizzi MAC di livello 2 per prendere decisioni di inoltro. È completamente all’oscuro dei dati (protocollo) trasportati nella porzione di dati del frame, come un pacchetto IPv4, un messaggio ARP o un pacchetto ND IPv6. Lo switch prende le sue decisioni di inoltro basandosi esclusivamente sugli indirizzi MAC Ethernet di livello 2.
Uno switch Ethernet esamina la sua tabella degli indirizzi MAC per prendere una decisione di inoltro per ciascun frame, a differenza degli hub Ethernet legacy che ripetono i bit su tutte le porte tranne la porta in entrata. Nella figura, lo switch a quattro porte è stato appena acceso. La tabella mostra la tabella degli indirizzi MAC che non ha ancora appreso gli indirizzi MAC per i quattro PC collegati.
Nota: gli indirizzi MAC vengono abbreviati in questo argomento a scopo dimostrativo.
La tabella degli indirizzi MAC dello switch è vuota.
Nota: la tabella degli indirizzi MAC viene talvolta definita tabella CAM (Content Addressable Memory). Sebbene il termine tabella CAM sia abbastanza comune, ai fini di questo corso ci riferiremo ad esso come tabella di indirizzi MAC.
Switch Learning and Forwarding
Lo switch crea dinamicamente la tabella degli indirizzi MAC esaminando l’indirizzo MAC di origine dei frame ricevuti su una porta. Lo switch inoltra i frame cercando una corrispondenza tra l’indirizzo MAC di destinazione nel frame e una voce nella tabella degli indirizzi MAC.
Esaminare l’indirizzo MAC di origine
Ogni frame che entra in uno switch viene controllato per nuove informazioni da apprendere. Lo fa esaminando l’indirizzo MAC di origine del frame e il numero di porta in cui il frame è entrato nello switch. Se l’indirizzo MAC di origine non esiste, viene aggiunto alla tabella insieme al numero di porta in entrata. Se l’indirizzo MAC di origine esiste, lo switch aggiorna il timer di aggiornamento per quella voce nella tabella. Per impostazione predefinita, la maggior parte degli switch Ethernet mantiene una voce nella tabella per 5 minuti.
Nella figura, ad esempio, il PC-A sta inviando un frame Ethernet al PC-D. La tabella mostra che lo switch aggiunge l’indirizzo MAC per PC-A alla tabella degli indirizzi MAC.
Nota: se l’indirizzo MAC di origine esiste nella tabella ma su una porta diversa, lo switch lo tratta come una nuova voce. La voce viene sostituita utilizzando lo stesso indirizzo MAC ma con il numero di porta più attuale.
PC-A invia un frame Ethernet.
Lo switch aggiunge il numero di porta e l’indirizzo MAC per il PC-A alla tabella degli indirizzi MAC.
Trova l’indirizzo MAC di destinazione
Se l’indirizzo MAC di destinazione è un indirizzo unicast, lo switch cercherà una corrispondenza tra l’indirizzo MAC di destinazione del frame e una voce nella sua tabella degli indirizzi MAC. Se l’indirizzo MAC di destinazione è nella tabella, inoltrerà il frame fuori dalla porta specificata. Se l’indirizzo MAC di destinazione non è nella tabella, lo switch inoltrerà il frame a tutte le porte tranne la porta in entrata. Questo è chiamato unicast sconosciuto.
Come mostrato nella figura, lo switch non ha l’indirizzo MAC di destinazione nella sua tabella per PC-D, quindi invia il frame a tutte le porte tranne la porta 1.
Nota: se l’indirizzo MAC di destinazione è un broadcast o un multicast, il frame viene distribuito anche su tutte le porte tranne la porta in ingresso.
L’indirizzo MAC di destinazione non è nella tabella.
Lo switch inoltra il frame a tutte le altre porte.
Filtering Frames
Poiché uno switch riceve frame da diversi dispositivi, è in grado di popolare la sua tabella di indirizzi MAC esaminando l’indirizzo MAC di origine di ogni frame. Quando la tabella degli indirizzi MAC dello switch contiene l’indirizzo MAC di destinazione, è in grado di filtrare il frame e inoltrare una singola porta.
PC-D to switch
Nella figura, PC-D sta rispondendo a PC-A. Lo switch rileva l’indirizzo MAC del PC-D nel frame in entrata sulla porta 4. Lo switch quindi inserisce l’indirizzo MAC del PC-D nella tabella degli indirizzi MAC associata alla porta 4.
Lo switch aggiunge il numero di porta e l’indirizzo MAC per PC-D alla sua tabella degli indirizzi MAC.
Switch to PC-A
Successivamente, poiché lo switch ha l’indirizzo MAC di destinazione per PC-A nella tabella degli indirizzi MAC, invierà il frame solo dalla porta 1, come mostrato nella figura.
Lo switch dispone di una voce dell’indirizzo MAC per la destinazione.
Lo switch filtra il frame, inviandolo solo alla porta 1.
PC-A to switch to PC-D
Successivamente, PC-A invia un altro frame a PC-D, come mostrato nella figura. La tabella degli indirizzi MAC contiene già l’indirizzo MAC per PC-A; pertanto, il timer di aggiornamento di cinque minuti per quella voce viene reimpostato. Successivamente, poiché la tabella degli switch contiene l’indirizzo MAC di destinazione per PC-D, invia il frame solo alla porta 4.
Lo switch riceve un altro frame dal PC-A e aggiorna il timer per l’immissione dell’indirizzo MAC per la porta 1.
Lo switch dispone di una voce recente per l’indirizzo MAC di destinazione e filtra il frame, inoltrandolo solo alla porta 4.
MAC Address Tables on Connected Switches
Uno switch può avere più indirizzi MAC associati a una singola porta. Questo è comune quando lo switch è collegato a un altro switch. Lo switch avrà una voce della tabella degli indirizzi MAC separata per ogni frame ricevuto con un indirizzo MAC di origine diverso.
Send the Frame to the Default Gateway
Quando un dispositivo ha un indirizzo IP che si trova su una rete remota, il frame Ethernet non può essere inviato direttamente al dispositivo di destinazione. Invece, il frame Ethernet viene inviato all’indirizzo MAC del gateway predefinito, il router.
Nota: il pacchetto IP inviato dal PC-A a una destinazione su una rete remota ha un indirizzo IP di origine di PC-A e un indirizzo IP di destinazione dell’host remoto. Il pacchetto IP di ritorno avrà l’indirizzo IP di origine dell’host remoto e l’indirizzo IP di destinazione sarà quello del PC-A.
Ethernet – Riepilogo
Non esiste un protocollo standard di rete locale ufficiale, ma nel tempo una tecnologia, Ethernet, è diventata più comune delle altre. I protocolli Ethernet definiscono come vengono formattati i dati e come vengono trasmessi sulla rete cablata. Gli standard Ethernet specificano i protocolli che operano a livello 1 e livello 2 del modello OSI. Ethernet è diventato uno standard de facto, il che significa che è la tecnologia utilizzata da quasi tutte le reti locali cablate.
IEEE mantiene gli standard di rete, inclusi gli standard Ethernet e wireless. Ad ogni standard tecnologico viene assegnato un numero che fa riferimento al comitato responsabile dell’approvazione e del mantenimento dello standard. Lo standard Ethernet 802.3 è migliorato nel tempo.
Gli switch Ethernet possono inviare un frame a tutte le porte (esclusa la porta da cui è stato ricevuto). Ogni host che riceve questo frame esamina l’indirizzo MAC di destinazione e lo confronta con il proprio indirizzo MAC. È la scheda NIC Ethernet che esamina e confronta l’indirizzo MAC. Se non corrisponde all’indirizzo MAC dell’host, il resto del frame viene ignorato. Quando è una corrispondenza, quell’host riceve il resto del frame e il messaggio che contiene.
Ethernet Frames
Ethernet è definita dai protocolli di livello di collegamento dati 802.2 e 802.3. Ethernet supporta larghezze di banda dati da 10 Mbps fino a 100 Gps. I protocolli LAN/MAN EEE 802, incluso Ethernet, utilizzano due sottolivelli separati del livello di collegamento dati per funzionare: LLC e MAC.
Sottolivello LLC: questo sottolivello IEEE 802.2 comunica tra il software di rete ai livelli superiori e l’hardware del dispositivo ai livelli inferiori. Mette informazioni nel frame che identifica quale protocollo di livello di rete viene utilizzato per il frame. Queste informazioni consentono a più protocolli Layer 3, come IPv4 e IPv6, di utilizzare la stessa interfaccia di rete e lo stesso supporto.
Sottolivello MAC: questo sottolivello (IEEE 802.3, 802.11 o 802.15 ad esempio) è implementato nell’hardware ed è responsabile dell’incapsulamento dei dati e del controllo dell’accesso ai supporti. Fornisce l’indirizzamento del livello di collegamento dati ed è integrato con varie tecnologie di livello fisico. L’incapsulamento dei dati include il frame Ethernet, l’indirizzamento Ethernet e il rilevamento degli errori Ethernet.
Le LAN Ethernet di oggi utilizzano switch che operano in full-duplex. Le comunicazioni full-duplex con switch Ethernet non richiedono il controllo degli accessi tramite CSMA/CD. La dimensione minima del frame Ethernet è di 64 byte e il massimo previsto è di 1518 byte. I campi sono Preambolo e Delimitatore frame iniziale, Indirizzo MAC di destinazione, Indirizzo MAC di origine, Tipo/Lunghezza, Dati e FCS. Ciò include tutti i byte dal campo dell’indirizzo MAC di destinazione attraverso il campo FCS.
Ethernet MAC Address
Un indirizzo MAC Ethernet è costituito da un valore binario a 48 bit. L’esadecimale viene utilizzato per identificare un indirizzo Ethernet perché una singola cifra esadecimale rappresenta quattro bit binari. Pertanto, un indirizzo MAC Ethernet a 48 bit può essere espresso utilizzando solo 12 valori esadecimali.
Un indirizzo MAC unicast è l’indirizzo univoco utilizzato quando un frame viene inviato da un singolo dispositivo di trasmissione a un singolo dispositivo di destinazione. Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv4 è ARP. Il processo utilizzato da un host di origine per determinare l’indirizzo MAC di destinazione associato a un indirizzo IPv6 è ND.
Le caratteristiche di una trasmissione Ethernet sono le seguenti:
Ha un indirizzo MAC di destinazione di FF-FF-FF-FF-FF-FF in esadecimale (48 in binario).
Viene invaso da tutte le porte dello switch Ethernet tranne la porta in entrata.
Non viene inoltrato da un router.
Le caratteristiche di un multicast Ethernet sono le seguenti:
Esiste un indirizzo MAC di destinazione 01-00-5E quando i dati incapsulati sono un pacchetto multicast IPv4 e un indirizzo MAC di destinazione 33-33 quando i dati incapsulati sono un pacchetto multicast IPv6.
Esistono altri indirizzi MAC di destinazione multicast riservati per quando i dati incapsulati non sono IP, come STP e LLDP.
Viene allagato su tutte le porte dello switch Ethernet tranne la porta in entrata, a meno che lo switch non sia configurato per lo snooping multicast.
Non viene inoltrato da un router, a meno che il router non sia configurato per instradare pacchetti multicast.
The MAC Address Table
Uno switch Ethernet di livello 2 utilizza gli indirizzi MAC di livello 2 per prendere decisioni di inoltro. È completamente all’oscuro dei dati (protocollo) trasportati nella porzione di dati del frame. Uno switch Ethernet esamina la sua tabella degli indirizzi MAC per prendere una decisione di inoltro per ciascun frame. La tabella degli indirizzi MAC viene talvolta definita tabella CAM.
Lo switch crea dinamicamente la tabella degli indirizzi MAC esaminando l’indirizzo MAC di origine dei frame ricevuti su una porta. Lo switch inoltra i frame cercando una corrispondenza tra l’indirizzo MAC di destinazione nel frame e una voce nella tabella degli indirizzi MAC. Se l’indirizzo MAC di destinazione è un indirizzo unicast, lo switch cercherà una corrispondenza tra l’indirizzo MAC di destinazione del frame e una voce nella sua tabella degli indirizzi MAC. Se l’indirizzo MAC di destinazione è nella tabella, inoltrerà il frame fuori dalla porta specificata. Se l’indirizzo MAC di destinazione non è nella tabella, lo switch inoltrerà il frame a tutte le porte tranne la porta in entrata. Questo è chiamato unicast sconosciuto.
Poiché uno switch riceve frame da diversi dispositivi, è in grado di popolare la sua tabella di indirizzi MAC esaminando l’indirizzo MAC di origine di ogni frame. Quando la tabella degli indirizzi MAC dello switch contiene l’indirizzo MAC di destinazione, è in grado di filtrare il frame e inoltrare una singola porta. Uno switch può avere più indirizzi MAC associati a una singola porta. Questo è comune quando lo switch è collegato a un altro switch. Lo switch avrà una voce della tabella degli indirizzi MAC separata per ogni frame ricevuto con un indirizzo MAC di origine diverso. Quando un dispositivo ha un indirizzo IP che si trova su una rete remota, il frame Ethernet non può essere inviato direttamente al dispositivo di destinazione. Invece, il frame Ethernet viene inviato all’indirizzo MAC del gateway predefinito, il router.
Network Layer Characteristics
Data Encapsulation
The Network Layer
Il livello di rete, o OSI Layer 3, fornisce servizi per consentire ai dispositivi finali di scambiare dati attraverso le reti. Come mostrato nella figura, IP versione 4 (IPv4) e IP versione 6 (IPv6) sono i principali protocolli di comunicazione a livello di rete. Altri protocolli a livello di rete includono protocolli di routing come OSPF (Open Shortest Path First) e protocolli di messaggistica come ICMP (Internet Control Message Protocol).
Per realizzare comunicazioni end-to-end attraverso i confini della rete, i protocolli del livello di rete eseguono quattro operazioni di base:
Indirizzamento dei dispositivi finali: i dispositivi finali devono essere configurati con un indirizzo IP univoco per l’identificazione sulla rete.
Incapsulamento: il livello di rete incapsula l’unità dati del protocollo (PDU) dal livello di trasporto in un pacchetto. Il processo di incapsulamento aggiunge informazioni sull’intestazione IP, come l’indirizzo IP degli host di origine (invio) e di destinazione (ricezione). Il processo di incapsulamento viene eseguito dall’origine del pacchetto IP.
Routing: il livello di rete fornisce servizi per indirizzare i pacchetti a un host di destinazione su un’altra rete. Per viaggiare su altre reti, il pacchetto deve essere elaborato da un router. Il ruolo del router è selezionare il percorso migliore e indirizzare i pacchetti verso l’host di destinazione in un processo noto come instradamento. Un pacchetto può attraversare molti router prima di raggiungere l’host di destinazione. Ogni router attraversato da un pacchetto per raggiungere l’host di destinazione è chiamato hop.
De-incapsulamento: quando il pacchetto arriva al livello di rete dell’host di destinazione, l’host controlla l’intestazione IP del pacchetto. Se l’indirizzo IP di destinazione all’interno dell’intestazione corrisponde al proprio indirizzo IP, l’intestazione IP viene rimossa dal pacchetto. Dopo che il pacchetto è stato de-incapsulato dal livello di rete, la PDU di livello 4 risultante viene passata al servizio appropriato al livello di trasporto. Il processo di de-incapsulamento viene eseguito dall’host di destinazione del pacchetto IP.
A differenza del livello di trasporto (OSI Layer 4), che gestisce il trasporto dei dati tra i processi in esecuzione su ciascun host, i protocolli di comunicazione del livello di rete (ovvero IPv4 e IPv6) specificano la struttura del pacchetto e l’elaborazione utilizzata per trasportare i dati da un host all’altro ospite. Il funzionamento indipendentemente dai dati contenuti in ciascun pacchetto consente al livello di rete di trasportare pacchetti per più tipi di comunicazioni tra più host.
IP Encapsulation
IP incapsula il segmento del livello di trasporto (il livello appena sopra il livello di rete) o altri dati aggiungendo un’intestazione IP. L’intestazione IP viene utilizzata per consegnare il pacchetto all’host di destinazione.
La figura illustra come la PDU del livello di trasporto viene incapsulata dalla PDU del livello di rete per creare un pacchetto IP.
Il processo di incapsulamento dei dati strato per strato consente ai servizi ai diversi livelli di svilupparsi e ridimensionarsi senza influire sugli altri livelli. Ciò significa che i segmenti del livello di trasporto possono essere prontamente impacchettati da IPv4 o IPv6 o da qualsiasi nuovo protocollo che potrebbe essere sviluppato in futuro.
L’intestazione IP viene esaminata dai dispositivi di livello 3 (ovvero router e switch di livello 3) mentre viaggia attraverso una rete fino alla sua destinazione. È importante notare che le informazioni sull’indirizzamento IP rimangono le stesse dal momento in cui il pacchetto lascia l’host di origine fino a quando non arriva all’host di destinazione, tranne quando vengono tradotte dal dispositivo che esegue la traduzione degli indirizzi di rete (NAT) per IPv4.
I router implementano protocolli di routing per instradare i pacchetti tra le reti. Il routing eseguito da questi dispositivi intermedi esamina l’indirizzamento del livello di rete nell’intestazione del pacchetto. In tutti i casi, la porzione di dati del pacchetto, cioè la PDU del livello di trasporto incapsulato o altri dati, rimane invariata durante i processi del livello di rete.
Characteristics of IP
L’IP è stato progettato come un protocollo con un sovraccarico ridotto. Fornisce solo le funzioni necessarie per consegnare un pacchetto da una sorgente a una destinazione su un sistema di reti interconnesse. Il protocollo non è stato progettato per tracciare e gestire il flusso di pacchetti. Queste funzioni, se richieste, vengono eseguite da altri protocolli su altri livelli, principalmente TCP a livello 4.
Queste sono le caratteristiche di base dell’IP:
Senza connessione: non esiste alcuna connessione con la destinazione stabilita prima dell’invio dei pacchetti di dati.
Best Effort: l’IP è intrinsecamente inaffidabile perché la consegna dei pacchetti non è garantita.
Indipendente dal supporto: il funzionamento è indipendente dal supporto (ad es. rame, fibra ottica o wireless) che trasporta i dati.
Connectionless
L’IP è senza connessione, il che significa che nessuna connessione end-to-end dedicata viene creata dall’’IP prima che i dati vengano inviati. La comunicazione senza connessione è concettualmente simile all’invio di una lettera a qualcuno senza avvisare il destinatario in anticipo. La figura riassume questo punto chiave.
Connectionless – Analogy
Le comunicazioni dati senza connessione funzionano secondo lo stesso principio. Come mostrato nella figura, l’IP non richiede uno scambio iniziale di informazioni di controllo per stabilire una connessione end-to-end prima che i pacchetti vengano inoltrati.
Connectionless – Network
Best Effort
IP inoltre non richiede campi aggiuntivi nell’intestazione per mantenere una connessione stabilita. Questo processo riduce notevolmente l’overhead dell’IP. Tuttavia, senza una connessione end-to-end prestabilita, i mittenti non sanno se i dispositivi di destinazione sono presenti e funzionanti durante l’invio dei pacchetti, né se la destinazione riceve il pacchetto o se il dispositivo di destinazione è in grado di accedere e leggere il pacchetto.
Il protocollo IP non garantisce che tutti i pacchetti consegnati vengano effettivamente ricevuti. La figura illustra la caratteristica di consegna inaffidabile o best-effort del protocollo IP.
In quanto protocollo a livello di rete inaffidabile, l’IP non garantisce che tutti i pacchetti inviati verranno ricevuti. Altri protocolli gestiscono il processo di tracciamento dei pacchetti e ne garantiscono la consegna.
Media Independent
Inaffidabile significa che l’IP non ha la capacità di gestire e recuperare pacchetti non consegnati o corrotti. Questo perché mentre i pacchetti IP vengono inviati con informazioni sulla posizione di consegna, non contengono informazioni che possono essere elaborate per informare il mittente se la consegna è andata a buon fine. I pacchetti possono arrivare a destinazione danneggiati, fuori sequenza o per niente. L’IP non fornisce alcuna capacità per la ritrasmissione dei pacchetti se si verificano errori.
Se vengono recapitati pacchetti fuori ordine o mancano pacchetti, le applicazioni che utilizzano i dati oi servizi di livello superiore devono risolvere questi problemi. Ciò consente all’IP di funzionare in modo molto efficiente. Nella suite di protocolli TCP/IP, l’affidabilità è il ruolo del protocollo TCP a livello di trasporto.
L’IP opera indipendentemente dai supporti che trasportano i dati ai livelli inferiori dello stack del protocollo. Come mostrato nella figura, i pacchetti IP possono essere comunicati come segnali elettronici su cavo in rame, come segnali ottici su fibra o in modalità wireless come segnali radio.
I pacchetti IP possono viaggiare su diversi media.
Il livello di collegamento dati OSI è responsabile di prendere un pacchetto IP e prepararlo per la trasmissione sul mezzo di comunicazione. Ciò significa che la consegna dei pacchetti IP non è limitata a nessun mezzo particolare.
C’è, tuttavia, una caratteristica principale del supporto che il livello di rete considera: la dimensione massima della PDU che ogni supporto può trasportare. Questa caratteristica è indicata come l’unità massima di trasmissione (MTU). Parte della comunicazione di controllo tra il livello di collegamento dati e il livello di rete è la definizione di una dimensione massima per il pacchetto. Il livello di collegamento dati trasmette il valore MTU al livello di rete. Il livello di rete determina quindi quanto possono essere grandi i pacchetti.
In alcuni casi, un dispositivo intermedio, solitamente un router, deve suddividere un pacchetto IPv4 quando lo inoltra da un supporto a un altro supporto con un MTU inferiore. Questo processo è chiamato frammentazione del pacchetto o frammentazione. La frammentazione causa latenza. I pacchetti IPv6 non possono essere frammentati dal router.
IPv4 Packet
IPv4 Packet Header
IPv4 è uno dei principali protocolli di comunicazione a livello di rete. L’intestazione del pacchetto IPv4 viene utilizzata per garantire che questo pacchetto venga consegnato alla fermata successiva lungo il percorso verso il dispositivo finale di destinazione.
L’intestazione di un pacchetto IPv4 è costituita da campi contenenti informazioni importanti sul pacchetto. Questi campi contengono numeri binari che vengono esaminati dal processo Layer 3.
IPv4 Packet Header Fields
I valori binari di ciascun campo identificano varie impostazioni del pacchetto IP. I diagrammi di intestazione del protocollo, che vengono letti da sinistra a destra e dall’alto verso il basso, forniscono un elemento visivo a cui fare riferimento quando si discute dei campi del protocollo. Il diagramma dell’intestazione del protocollo IP nella figura identifica i campi di un pacchetto IPv4.
Campi nell’intestazione del pacchetto IPv4
I campi significativi nell’intestazione IPv4 includono quanto segue:
Versione: contiene un valore binario a 4 bit impostato su 0100 che lo identifica come pacchetto IPv4.
Differentiated Services o DiffServ (DS): precedentemente chiamato campo del tipo di servizio (ToS), il campo DS è un campo a 8 bit utilizzato per determinare la priorità di ciascun pacchetto. I sei bit più significativi del campo DiffServ sono i bit del punto di codice dei servizi differenziati (DSCP) e gli ultimi due bit sono i bit di notifica esplicita della congestione (ECN).
Time to Live (TTL): TTL contiene un valore binario a 8 bit utilizzato per limitare la durata di un pacchetto. Il dispositivo di origine del pacchetto IPv4 imposta il valore TTL iniziale. Viene diminuito di uno ogni volta che il pacchetto viene elaborato da un router. Se il campo TTL scende a zero, il router scarta il pacchetto e invia un messaggio ICMP (Internet Control Message Protocol) Time Exceeded all’indirizzo IP di origine. Poiché il router diminuisce il TTL di ciascun pacchetto, il router deve anche ricalcolare il checksum dell’intestazione.
Protocollo: questo campo viene utilizzato per identificare il protocollo di livello successivo. Questo valore binario a 8 bit indica il tipo di payload di dati trasportato dal pacchetto, che consente al livello di rete di passare i dati al protocollo di livello superiore appropriato. I valori comuni includono ICMP (1), TCP (6) e UDP (17).
HeaderChecksum: viene utilizzato per rilevare la corruzione nell’intestazione IPv4.
Indirizzo IPv4 di origine: contiene un valore binario a 32 bit che rappresenta l’indirizzo IPv4 di origine del pacchetto. L’indirizzo IPv4 di origine è sempre un indirizzo unicast.
Indirizzo IPv4 di destinazione: contiene un valore binario a 32 bit che rappresenta l’indirizzo IPv4 di destinazione del pacchetto. L’indirizzo IPv4 di destinazione è un indirizzo unicast, multicast o broadcast.
I due campi a cui si fa più comunemente riferimento sono gli indirizzi IP di origine e di destinazione. Questi campi identificano da dove proviene il pacchetto e dove sta andando. In genere, questi indirizzi non cambiano durante il viaggio dall’origine alla destinazione.
I campi Internet Header Length (IHL), Total Length e Header Checksum vengono utilizzati per identificare e convalidare il pacchetto.
Altri campi vengono utilizzati per riordinare un pacchetto frammentato. Nello specifico, il pacchetto IPv4 utilizza i campi Identification, Flags e Fragment Offset per tenere traccia dei frammenti. Un router potrebbe dover frammentare un pacchetto IPv4 quando lo inoltra da un supporto a un altro con un MTU più piccolo.
I campi Opzioni e Padding sono usati raramente e non rientrano nell’ambito di questo modulo.
IPv6 Packet
Limitations of IPv4
IPv4 è ancora in uso oggi. Questo argomento riguarda IPv6, che alla fine sostituirà IPv4. Per capire meglio perché è necessario conoscere il protocollo IPv6, è utile conoscere i limiti di IPv4 e i vantaggi di IPv6.
Nel corso degli anni, sono stati sviluppati protocolli e processi aggiuntivi per affrontare nuove sfide. Tuttavia, anche con le modifiche, IPv4 presenta ancora tre problemi principali:
Impoverimento dell’indirizzo IPv4: IPv4 dispone di un numero limitato di indirizzi pubblici univoci. Sebbene esistano circa 4 miliardi di indirizzi IPv4, il numero crescente di nuovi dispositivi abilitati per IP, connessioni sempre attive e la potenziale crescita delle regioni meno sviluppate hanno aumentato la necessità di più indirizzi.
Mancanza di connettività end-to-end: la Network Address Translation (NAT) è una tecnologia comunemente implementata nelle reti IPv4. NAT consente a più dispositivi di condividere un singolo indirizzo IPv4 pubblico. Tuttavia, poiché l’indirizzo IPv4 pubblico è condiviso, l’indirizzo IPv4 di un host di rete interno è nascosto. Questo può essere problematico per le tecnologie che richiedono la connettività end-to-end.
Maggiore complessità della rete: sebbene NAT abbia esteso la durata di IPv4, era inteso solo come meccanismo di transizione a IPv6. NAT nelle sue varie implementazioni crea ulteriore complessità nella rete, creando latenza e rendendo più difficile la risoluzione dei problemi.
IPv6 Overview
All’inizio degli anni ’90, l’Internet Engineering Task Force (IETF) iniziò a preoccuparsi dei problemi con IPv4 e iniziò a cercare un sostituto. Questa attività ha portato allo sviluppo di IP versione 6 (IPv6). IPv6 supera i limiti di IPv4 ed è un potente miglioramento con funzionalità che si adattano meglio alle esigenze di rete attuali e prevedibili.
I miglioramenti forniti da IPv6 includono quanto segue:
Maggiore spazio degli indirizzi: gli indirizzi IPv6 si basano su un indirizzamento gerarchico a 128 bit rispetto a IPv4 a 32 bit.
Migliore gestione dei pacchetti: l’intestazione IPv6 è stata semplificata con meno campi.
Elimina la necessità di NAT: con un numero così elevato di indirizzi IPv6 pubblici, non è necessario NAT tra un indirizzo IPv4 privato e un IPv4 pubblico. Ciò evita alcuni dei problemi indotti dal NAT sperimentati dalle applicazioni che richiedono connettività end-to-end.
Lo spazio degli indirizzi IPv4 a 32 bit fornisce circa 4.294.967.296 indirizzi univoci. Lo spazio degli indirizzi IPv6 fornisce 340.282.366.920.938.463.463.374.607.431.768.211.456 o 340 indirizzi undecillion. Questo è più o meno equivalente a ogni granello di sabbia sulla Terra.
La figura fornisce un’immagine per confrontare lo spazio degli indirizzi IPv4 e IPv6.
Campi dell’intestazione del pacchetto IPv4 nell’intestazione del pacchetto IPv6
Uno dei principali miglioramenti del design di IPv6 rispetto a IPv4 è l’intestazione IPv6 semplificata.
Ad esempio, l’intestazione IPv4 è composta da un’intestazione di lunghezza variabile di 20 ottetti (fino a 60 byte se viene utilizzato il campo Opzioni) e 12 campi di intestazione di base, esclusi il campo Opzioni e il campo Padding.
Per IPv6, alcuni campi sono rimasti gli stessi, alcuni campi hanno cambiato nome e posizione e alcuni campi IPv4 non sono più obbligatori, come evidenziato nella figura.
IPv4 Packet Header
La figura mostra i campi dell’intestazione del pacchetto IPv4 che sono stati mantenuti, spostati, modificati, nonché quelli che non sono stati mantenuti nell’intestazione del pacchetto IPv6.
Al contrario, l’intestazione IPv6 semplificata mostrata nella figura successiva è costituita da un’intestazione di lunghezza fissa di 40 ottetti (in gran parte a causa della lunghezza degli indirizzi IPv6 di origine e di destinazione).
L’intestazione semplificata IPv6 consente un’elaborazione più efficiente delle intestazioni IPv6.
IPv6 Packet Header
La figura mostra i campi dell’intestazione del pacchetto IPv4 che sono stati mantenuti o spostati insieme ai nuovi campi dell’intestazione del pacchetto IPv6.
IPv6 Packet Header
Il diagramma dell’intestazione del protocollo IP nella figura identifica i campi di un pacchetto IPv6.
Campi nell’intestazione del pacchetto IPv6
I campi nell’intestazione del pacchetto IPv6 includono quanto segue:
Versione: questo campo contiene un valore binario a 4 bit impostato su 0110 che lo identifica come pacchetto IP versione 6.
Classe di traffico: questo campo a 8 bit è equivalente al campo Servizi differenziati IPv4 (DS).
Etichetta di flusso: questo campo a 20 bit suggerisce che tutti i pacchetti con la stessa etichetta di flusso ricevono lo stesso tipo di gestione da parte dei router.
Lunghezzapayload: questo campo a 16 bit indica la lunghezza della porzione di dati o payload del pacchetto IPv6. Ciò non include la lunghezza dell’intestazione IPv6, che è un’intestazione fissa di 40 byte.
Intestazionesuccessiva: questo campo a 8 bit equivale al campo Protocollo IPv4. Indica il tipo di carico utile dei dati trasportato dal pacchetto, consentendo al livello di rete di passare i dati al protocollo di livello superiore appropriato.
HopLimit: questo campo a 8 bit sostituisce il campo IPv4 TTL. Questo valore viene decrementato di un valore pari a 1 da ciascun router che inoltra il pacchetto. Quando il contatore raggiunge lo 0, il pacchetto viene scartato e un messaggio ICMPv6 Time Exceeded viene inoltrato all’host di invio. Questo indica che il pacchetto non ha raggiunto la sua destinazione perché il limite di hop è stato superato. A differenza di IPv4, IPv6 non include un checksum dell’intestazione IPv6, poiché questa funzione viene eseguita sia a livello inferiore che superiore. Ciò significa che il checksum non deve essere ricalcolato da ciascun router quando diminuisce il campo Hop Limit, il che migliora anche le prestazioni della rete.
Indirizzo IPv6 di origine: questo campo a 128 bit identifica l’indirizzo IPv6 dell’host di invio.
Indirizzo IPv6 di destinazione: questo campo a 128 bit identifica l’indirizzo IPv6 dell’host ricevente.
Un pacchetto IPv6 può anche contenere intestazioni di estensione (EH), che forniscono informazioni facoltative sul livello di rete. Le intestazioni di estensione sono facoltative e vengono posizionate tra l’intestazione IPv6 e il payload. Gli EH vengono utilizzati per la frammentazione, la sicurezza, per supportare la mobilità e altro ancora.
A differenza di IPv4, i router non frammentano i pacchetti IPv6 instradati.
Network Layer Summary
Caratteristiche del livello di rete
Il livello di rete, o OSI Layer 3, fornisce servizi per consentire ai dispositivi finali di scambiare dati attraverso le reti. IPv4 e IPv6 sono i principali protocolli di comunicazione a livello di rete. Altri protocolli a livello di rete includono protocolli di routing come OSPF e protocolli di messaggistica come ICMP.
I protocolli a livello di rete eseguono quattro operazioni: indirizzamento dei dispositivi finali, incapsulamento, instradamento e de-incapsulamento. IPv4 e IPv6 specificano la struttura del pacchetto e l’elaborazione utilizzata per trasportare i dati da un host a un altro host. Il funzionamento indipendentemente dai dati contenuti in ciascun pacchetto consente al livello di rete di trasportare pacchetti per più tipi di comunicazioni tra più host.
IP incapsula il segmento del livello di trasporto o altri dati aggiungendo un’intestazione IP. L’intestazione IP viene utilizzata per consegnare il pacchetto all’host di destinazione. L’intestazione IP viene esaminata dai router e dagli switch Layer 3 mentre viaggia attraverso una rete fino alla sua destinazione. Le informazioni sull’indirizzamento IP rimangono le stesse dal momento in cui il pacchetto lascia l’host di origine fino a quando non arriva all’host di destinazione, tranne quando viene tradotto dal dispositivo che esegue NAT per IPv4.
Le caratteristiche di base dell’IP sono che è: senza connessione, massimo sforzo e indipendente dai media. L’IP è senza connessione, il che significa che nessuna connessione end-to-end dedicata viene creata dall’IP prima che i dati vengano inviati. L’IP non richiede campi aggiuntivi nell’intestazione per mantenere una connessione stabilita. Ciò riduce l’overhead dell’IP. I mittenti non sanno se i dispositivi di destinazione sono presenti e funzionanti durante l’invio dei pacchetti, né sanno se la destinazione riceve il pacchetto o se il dispositivo di destinazione è in grado di accedere e leggere il pacchetto. L’IP opera indipendentemente dai supporti che trasportano i dati ai livelli inferiori dello stack del protocollo. I pacchetti IP possono essere comunicati come segnali elettronici su cavo in rame, come segnali ottici su fibra o in modalità wireless come segnali radio. Una caratteristica del supporto che il livello di rete considera è la dimensione massima della PDU che ogni supporto può trasportare, o MTU.
Pacchetto IPv4
L’intestazione del pacchetto IPv4 viene utilizzata per garantire che un pacchetto venga consegnato alla fermata successiva lungo il percorso verso il dispositivo finale di destinazione. L’intestazione di un pacchetto IPv4 è costituita da campi contenenti numeri binari che vengono esaminati dal processo di livello 3. I campi significativi nell’intestazione IPv4 includono: versione, DS, TTL, protocollo, checksum dell’intestazione, indirizzo IPv4 di origine e indirizzo IPv4 di destinazione.
I campi IHL, Total Length e Header Checksum vengono utilizzati per identificare e convalidare il pacchetto. Il pacchetto IPv4 utilizza i campi Identification, Flags e Fragment Offset per tenere traccia dei frammenti. Un router potrebbe dover frammentare un pacchetto IPv4 quando lo inoltra da un supporto a un altro con un MTU più piccolo.
Pacchetto IPv6
IPv4 presenta limitazioni, tra cui: esaurimento degli indirizzi IPv4, mancanza di connettività end-to-end e maggiore complessità della rete. IPv6 supera i limiti di IPv4. I miglioramenti forniti da IPv6 includono quanto segue: maggiore spazio degli indirizzi, migliore gestione dei pacchetti ed elimina la necessità di NAT.
Lo spazio degli indirizzi IPv4 a 32 bit fornisce circa 4.294.967.296 indirizzi univoci. Lo spazio degli indirizzi IPv6 fornisce 340.282.366.920.938.463.463.374.607.431.768.211.456 o 340 indirizzi undecillion. Questo è più o meno equivalente a ogni granello di sabbia sulla Terra.
I campi dell’intestazione semplificata IPv6 includono: versione, classe di traffico, etichetta di flusso, lunghezza del payload, intestazione successiva, limite hop, indirizzo IP di origine e indirizzo IP di destinazione. Un pacchetto IPv6 può anche contenere EH, che fornisce informazioni opzionali sul livello di rete. Le intestazioni di estensione sono facoltative e vengono posizionate tra l’intestazione IPv6 e il payload. Gli EH vengono utilizzati per la frammentazione, la sicurezza, per supportare la mobilità e altro ancora. A differenza di IPv4, i router non frammentano i pacchetti IPv6 instradati.
IPv4 Address Structure
Network and Host Portions
Un indirizzo IPv4 è un indirizzo gerarchico a 32 bit costituito da una parte di rete e una parte host. Quando si determina la porzione di rete rispetto alla porzione host, è necessario guardare il flusso a 32 bit, come mostrato nella figura.
IPv4 Address
I bit all’interno della porzione di rete dell’indirizzo devono essere identici per tutti i dispositivi che risiedono nella stessa rete. I bit all’interno della parte host dell’indirizzo devono essere univoci per identificare un host specifico all’interno di una rete. Se due host hanno lo stesso schema di bit nella porzione di rete specificata del flusso a 32 bit, questi due host risiederanno nella stessa rete.
Ma come fanno gli host a sapere quale parte dei 32 bit identifica la rete e quale identifica l’host? Questo è il ruolo della subnet mask.
The Subnet Mask
Come mostrato nella figura, l’assegnazione di un indirizzo IPv4 a un host richiede quanto segue:
IndirizzoIPv4: questo è l’indirizzo IPv4 univoco dell’host.
Mascheradi sottorete: viene utilizzata per identificare la parte di rete/host dell’indirizzo IPv4.
Configurazione IPv4 su un computer Windows
Nota: è necessario un indirizzo IPv4 del gateway predefinito per raggiungere le reti remote e gli indirizzi IPv4 del server DNS sono necessari per tradurre i nomi di dominio in indirizzi IPv4.
La maschera di sottorete IPv4 viene utilizzata per differenziare la parte di rete dalla parte host di un indirizzo IPv4. Quando un indirizzo IPv4 viene assegnato a un dispositivo, la maschera di sottorete viene utilizzata per determinare l’indirizzo di rete del dispositivo. L’indirizzo di rete rappresenta tutti i dispositivi sulla stessa rete.
La figura successiva mostra la maschera di sottorete a 32 bit nei formati decimale puntato e binario.
Maschera di sottorete
Si noti come la subnet mask sia una sequenza consecutiva di 1 bit seguita da una sequenza consecutiva di 0 bit.
Per identificare le porzioni di rete e host di un indirizzo IPv4, la maschera di sottorete viene confrontata bit per bit con l’indirizzo IPv4, da sinistra a destra, come mostrato nella figura.
Associazione di un indirizzo IPv4 alla sua subnet mask
Si noti che la subnet mask in realtà non contiene la rete o la parte host di un indirizzo IPv4, ma indica semplicemente al computer dove cercare la parte dell’indirizzo IPv4 che è la parte di rete e quale parte è la parte host.
Il processo effettivo utilizzato per identificare la parte di rete e la parte host è chiamato ANDing.
La lunghezza del prefisso
Esprimere gli indirizzi di rete e gli indirizzi host con l’indirizzo della maschera di sottorete decimale con punti può diventare complicato. Fortunatamente, esiste un metodo alternativo per identificare una subnet mask, un metodo chiamato lunghezza del prefisso.
La lunghezza del prefisso è il numero di bit impostati su 1 nella subnet mask. È scritto in “notazione barra”, che è indicato da una barra (/) seguita dal numero di bit impostato su 1. Pertanto, contare il numero di bit nella maschera di sottorete e anteporlo con una barra.
Fare riferimento alla tabella per gli esempi. La prima colonna elenca varie subnet mask che possono essere utilizzate con un indirizzo host. La seconda colonna visualizza l’indirizzo binario a 32 bit convertito. L’ultima colonna mostra la lunghezza del prefisso risultante.
Nota: un indirizzo di rete viene anche definito prefisso o prefisso di rete. Pertanto, la lunghezza del prefisso è il numero di 1 bit nella subnet mask.
Quando si rappresenta un indirizzo IPv4 utilizzando una lunghezza del prefisso, l’indirizzo IPv4 viene scritto seguito dalla lunghezza del prefisso senza spazi. Ad esempio, 192.168.10.10 255.255.255.0 verrebbe scritto come 192.168.10.10/24. L’utilizzo di vari tipi di lunghezze di prefisso verrà discusso in seguito. Per ora, l’attenzione sarà sul prefisso /24 (ovvero 255.255.255.0)
Determinazione della rete: AND logico
Un AND logico è una delle tre operazioni booleane utilizzate nella logica booleana o digitale. Gli altri due sono OR e NOT. L’operazione AND viene utilizzata per determinare l’indirizzo di rete.
L’AND logico è il confronto di due bit che producono i risultati mostrati di seguito. Nota come solo un 1 AND 1 produce un 1. Qualsiasi altra combinazione risulta in uno 0.
1 AND 1 = 1
0 AND 1 = 0
1 AND 0 = 0
0 AND 0 = 0
Nota: nella logica digitale, 1 rappresenta True e 0 rappresenta False. Quando si utilizza un’operazione AND, entrambi i valori di input devono essere True (1) affinché il risultato sia True (1).
Per identificare l’indirizzo di rete di un host IPv4, l’indirizzo IPv4 è logicamente AND, bit per bit, con la maschera di sottorete. L’operazione AND tra l’indirizzo e la maschera di sottorete produce l’indirizzo di rete
Per illustrare come viene utilizzato AND per rilevare un indirizzo di rete, si consideri un host con indirizzo IPv4 192.168.10.10 e subnet mask 255.255.255.0, come mostrato nella figura:
Indirizzo host IPv4 (192.168.10.10): l’indirizzo IPv4 dell’host nei formati decimale puntato e binario.
Subnet mask (255.255.255.0): la subnet mask dell’host nei formati decimale puntato e binario.
Indirizzo di rete (192.168.10.0): l’operazione AND logica tra l’indirizzo IPv4 e la maschera di sottorete genera un indirizzo di rete IPv4 mostrato nei formati decimale puntato e binario.
Utilizzando la prima sequenza di bit come esempio, si noti che l’operazione AND viene eseguita sull’1 bit dell’indirizzo host con l’1 bit della subnet mask. Ciò si traduce in un bit 1 per l’indirizzo di rete. 1 AND 1 = 1.
L’operazione AND tra un indirizzo host IPv4 e una maschera di sottorete determina l’indirizzo di rete IPv4 per questo host. In questo esempio, l’operazione AND tra l’indirizzo host di 192.168.10.10 e la subnet mask 255.255.255.0 (/24), risulta nell’indirizzo di rete IPv4 di 192.168.10.0/24. Questa è un’importante operazione IPv4, in quanto indica all’host a quale rete appartiene.
Struttura dell’indirizzo IPv4 – Riepilogo
Un indirizzo IPv4 è un indirizzo gerarchico a 32 bit costituito da una parte di rete e una parte host. Quando si determina la porzione di rete rispetto alla porzione host, è necessario esaminare il flusso a 32 bit. I bit all’interno della porzione di rete dell’indirizzo devono essere identici per tutti i dispositivi che risiedono nella stessa rete. I bit all’interno della parte host dell’indirizzo devono essere univoci per identificare un host specifico all’interno di una rete. Se due host hanno lo stesso schema di bit nella porzione di rete specificata del flusso a 32 bit, questi due host risiederanno nella stessa rete.
La maschera di sottorete IPv4 viene utilizzata per differenziare la parte di rete dalla parte host di un indirizzo IPv4. Quando un indirizzo IPv4 viene assegnato a un dispositivo, la maschera di sottorete viene utilizzata per determinare l’indirizzo di rete del dispositivo. L’indirizzo di rete rappresenta tutti i dispositivi sulla stessa rete.
Un metodo alternativo per identificare una subnet mask, un metodo chiamato lunghezza del prefisso. La lunghezza del prefisso è il numero di bit impostati su 1 nella subnet mask. È scritto in “notazione barra”, che è indicato da una barra (/) seguita dal numero di bit impostato su 1. Ad esempio, 192.168.10.10 255.255.255.0 verrebbe scritto come 192.168.10.10/24.
L’operazione AND viene utilizzata per determinare l’indirizzo di rete. L’AND logico è il confronto di due bit. Nota come solo un 1 AND 1 produce un 1. Qualsiasi altra combinazione risulta in uno 0.
1 AND 1 = 1
0 AND 1 = 0
1 AND 0 = 0
0 AND 0 = 0
Per identificare l’indirizzo di rete di un host IPv4, l’indirizzo IPv4 è logicamente AND, bit per bit, con la maschera di sottorete. L’operazione AND tra l’indirizzo e la maschera di sottorete produce l’indirizzo di rete.
Address Resolution
ARP
Se la tua rete utilizza il protocollo di comunicazione IPv4, l’Address Resolution Protocol, o ARP, è ciò di cui hai bisogno per mappare gli indirizzi IPv4 agli indirizzi MAC. Questo argomento spiega come funziona ARP.
Ogni dispositivo IP su una rete Ethernet ha un indirizzo MAC Ethernet univoco. Quando un dispositivo invia un frame Ethernet Layer 2, contiene questi due indirizzi:
Indirizzo MAC di destinazione: l’indirizzo MAC Ethernet del dispositivo di destinazione sullo stesso segmento di rete locale. Se l’host di destinazione si trova su un’altra rete, l’indirizzo di destinazione nel frame sarà quello del gateway predefinito (ovvero il router).
Indirizzo MAC di origine: l’indirizzo MAC della scheda di rete Ethernet sull’host di origine.
La figura illustra il problema quando si invia un frame a un altro host sullo stesso segmento su una rete IPv4.
Per inviare un pacchetto a un altro host sulla stessa rete IPv4 locale, un host deve conoscere l’indirizzo IPv4 e l’indirizzo MAC del dispositivo di destinazione. Gli indirizzi IPv4 di destinazione del dispositivo sono noti o risolti in base al nome del dispositivo. Tuttavia, gli indirizzi MAC devono essere rilevati.
Un dispositivo utilizza il protocollo ARP (Address Resolution Protocol) per determinare l’indirizzo MAC di destinazione di un dispositivo locale quando ne conosce l’indirizzo IPv4.
ARP fornisce due funzioni di base:
Risoluzione degli indirizzi IPv4 in indirizzi MAC
Mantenimento di una tabella di mappature da IPv4 a indirizzi MAC
Funzioni ARP
Quando un pacchetto viene inviato al livello di collegamento dati per essere incapsulato in un frame Ethernet, il dispositivo fa riferimento a una tabella nella sua memoria per trovare l’indirizzo MAC mappato all’indirizzo IPv4. Questa tabella è memorizzata temporaneamente nella memoria RAM e chiamata tabella ARP o cache ARP.
Il dispositivo di invio cercherà nella sua tabella ARP un indirizzo IPv4 di destinazione e un indirizzo MAC corrispondente.
Se l’indirizzo IPv4 di destinazione del pacchetto si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo cercherà l’indirizzo IPv4 di destinazione nella tabella ARP.
Se l’indirizzo IPv4 di destinazione si trova su una rete diversa dall’indirizzo IPv4 di origine, il dispositivo cercherà nella tabella ARP l’indirizzo IPv4 del gateway predefinito.
In entrambi i casi, la ricerca riguarda un indirizzo IPv4 e un indirizzo MAC corrispondente per il dispositivo.
Ogni voce, o riga, della tabella ARP associa un indirizzo IPv4 a un indirizzo MAC. Chiamiamo la relazione tra i due valori una mappa. Ciò significa semplicemente che è possibile individuare un indirizzo IPv4 nella tabella e scoprire l’indirizzo MAC corrispondente. La tabella ARP salva temporaneamente (memorizza nella cache) la mappatura per i dispositivi sulla LAN.
Se il dispositivo individua l’indirizzo IPv4, il suo indirizzo MAC corrispondente viene utilizzato come indirizzo MAC di destinazione nel frame. Se non viene trovata alcuna voce, il dispositivo invia una richiesta ARP.
Operazione ARP – Richiesta ARP
Una richiesta ARP viene inviata quando un dispositivo deve determinare l’indirizzo MAC associato a un indirizzo IPv4 e non dispone di una voce per l’indirizzo IPv4 nella sua tabella ARP.
I messaggi ARP sono incapsulati direttamente all’interno di un frame Ethernet. Non esiste un’intestazione IPv4. La richiesta ARP è incapsulata in un frame Ethernet utilizzando le seguenti informazioni di intestazione:
Indirizzo MAC di destinazione: si tratta di un indirizzo di trasmissione FF-FF-FF-FF-FF-FF che richiede a tutte le NIC Ethernet sulla LAN di accettare ed elaborare la richiesta ARP.
Indirizzo MAC di origine: questo è l’indirizzo MAC del mittente della richiesta ARP.
Tipo: i messaggi ARP hanno un campo tipo di 0x806. Questo informa la NIC ricevente che la porzione di dati del frame deve essere passata al processo ARP.
Poiché le richieste ARP sono broadcast, vengono inviate a tutte le porte dallo switch, ad eccezione della porta ricevente. Tutti i NIC Ethernet sulla LAN elaborano le trasmissioni e devono consegnare la richiesta ARP al proprio sistema operativo per l’elaborazione. Ogni dispositivo deve elaborare la richiesta ARP per verificare se l’indirizzo IPv4 di destinazione corrisponde al proprio. Un router non inoltrerà le trasmissioni su altre interfacce.
Solo un dispositivo sulla LAN avrà un indirizzo IPv4 che corrisponde all’indirizzo IPv4 di destinazione nella richiesta ARP. Tutti gli altri dispositivi non risponderanno.
Operazione ARP – Risposta ARP
Solo il dispositivo con l’indirizzo IPv4 di destinazione associato alla richiesta ARP risponderà con una risposta ARP. La risposta ARP è incapsulata in un frame Ethernet utilizzando le seguenti informazioni di intestazione:
Indirizzo MAC di destinazione: questo è l’indirizzo MAC del mittente della richiesta ARP.
Indirizzo MAC di origine: questo è l’indirizzo MAC del mittente della risposta ARP.
Tipo: i messaggi ARP hanno un campo tipo di 0x806. Questo informa la NIC ricevente che la porzione di dati del frame deve essere passata al processo ARP.
Solo il dispositivo che ha originariamente inviato la richiesta ARP riceverà la risposta ARP unicast. Dopo aver ricevuto la risposta ARP, il dispositivo aggiungerà l’indirizzo IPv4 e l’indirizzo MAC corrispondente alla sua tabella ARP. I pacchetti destinati a quell’indirizzo IPv4 possono ora essere incapsulati in frame utilizzando il corrispondente indirizzo MAC.
Se nessun dispositivo risponde alla richiesta ARP, il pacchetto viene eliminato perché non è possibile creare un frame.
Le voci nella tabella ARP sono contrassegnate da un timestamp. Se un dispositivo non riceve un frame da un particolare dispositivo prima della scadenza del timestamp, la voce per questo dispositivo viene rimossa dalla tabella ARP.
Inoltre, le voci della mappa statica possono essere inserite in una tabella ARP, ma ciò avviene raramente. Le voci della tabella ARP statica non scadono nel tempo e devono essere rimosse manualmente.
Nota: IPv6 utilizza un processo simile a ARP per IPv4, noto come ICMPv6 Neighbor Discovery (ND). IPv6 utilizza i messaggi di sollecitazione dei vicini e di annunci dei vicini, in modo simile alle richieste ARP IPv4 e alle risposte ARP.
Ruolo ARP nelle comunicazioni remote
Quando l’indirizzo IPv4 di destinazione non si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo di origine deve inviare il frame al proprio gateway predefinito. Questa è l’interfaccia del router locale. Ogni volta che un dispositivo di origine ha un pacchetto con un indirizzo IPv4 su un’altra rete, incapsula quel pacchetto in un frame utilizzando l’indirizzo MAC di destinazione del router.
L’indirizzo IPv4 del gateway predefinito è memorizzato nella configurazione IPv4 degli host. Quando un host crea un pacchetto per una destinazione, confronta l’indirizzo IPv4 di destinazione e il proprio indirizzo IPv4 per determinare se i due indirizzi IPv4 si trovano sulla stessa rete Layer 3. Se l’host di destinazione non si trova sulla stessa rete, l’origine controlla la sua tabella ARP per una voce con l’indirizzo IPv4 del gateway predefinito. Se non c’è una voce, utilizza il processo ARP per determinare un indirizzo MAC del gateway predefinito.
Rimozione di voci da una tabella ARP
Per ogni dispositivo, un timer della cache ARP rimuove le voci ARP che non sono state utilizzate per un periodo di tempo specificato. I tempi variano a seconda del sistema operativo del dispositivo. Ad esempio, i sistemi operativi Windows più recenti memorizzano le voci della tabella ARP tra 15 e 45 secondi, come illustrato nella figura.
I comandi possono essere utilizzati anche per rimuovere manualmente alcune o tutte le voci nella tabella ARP. Dopo che una voce è stata rimossa, il processo per l’invio di una richiesta ARP e la ricezione di una risposta ARP deve ripetersi per inserire la mappa nella tabella ARP.
Tabelle ARP sui dispositivi
Su un router Cisco, il comando show ip arp viene utilizzato per visualizzare la tabella ARP, come mostrato nella figura.
Su un PC Windows 10, il comando arp –a viene utilizzato per visualizzare la tabella ARP, come mostrato nella figura.
Problemi ARP – Trasmissioni ARP e Spoofing ARP
Come frame broadcast, una richiesta ARP viene ricevuta ed elaborata da ogni dispositivo sulla rete locale. Su una tipica rete aziendale, queste trasmissioni avrebbero probabilmente un impatto minimo sulle prestazioni della rete. Tuttavia, se un numero elevato di dispositivi viene acceso e tutti iniziano ad accedere ai servizi di rete contemporaneamente, potrebbe verificarsi una riduzione delle prestazioni per un breve periodo di tempo, come mostrato nella figura. Dopo che i dispositivi hanno inviato le trasmissioni ARP iniziali e hanno appreso gli indirizzi MAC necessari, qualsiasi impatto sulla rete sarà ridotto al minimo
In alcuni casi, l’uso di ARP può comportare un potenziale rischio per la sicurezza. Un attore di minacce può utilizzare lo spoofing ARP per eseguire un attacco di avvelenamento ARP. Questa è una tecnica utilizzata da un attore di minacce per rispondere a una richiesta ARP per un indirizzo IPv4 che appartiene a un altro dispositivo, come il gateway predefinito, come mostrato nella figura. L’autore della minaccia invia una risposta ARP con il proprio indirizzo MAC. Il destinatario della risposta ARP aggiungerà l’indirizzo MAC errato alla sua tabella ARP e invierà questi pacchetti all’autore della minaccia.
Gli switch di livello aziendale includono tecniche di mitigazione note come ispezione ARP dinamica (DAI).
Address Resolution – Riepilogo
ARP
Per inviare un pacchetto a un altro host sulla stessa rete IPv4 locale, un host deve conoscere l’indirizzo IPv4 e l’indirizzo MAC del dispositivo di destinazione. Gli indirizzi IPv4 di destinazione del dispositivo sono noti o risolti in base al nome del dispositivo. Tuttavia, gli indirizzi MAC devono essere rilevati. Un dispositivo utilizza ARP per determinare l’indirizzo MAC di destinazione di un dispositivo locale quando ne conosce l’indirizzo IPv4. ARP fornisce due funzioni di base: la risoluzione degli indirizzi IPv4 in indirizzi MAC e il mantenimento di una tabella di mappature da IPv4 a indirizzi MAC.
Il dispositivo di invio cercherà nella sua tabella ARP un indirizzo IPv4 di destinazione e un indirizzo MAC corrispondente.
Se l’indirizzo IPv4 di destinazione del pacchetto si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo cercherà l’indirizzo IPv4 di destinazione nella tabella ARP.
Se l’indirizzo IPv4 di destinazione si trova su una rete diversa dall’indirizzo IPv4 di origine, il dispositivo cercherà nella tabella ARP l’indirizzo IPv4 del gateway predefinito.
Ogni voce, o riga, della tabella ARP associa un indirizzo IPv4 a un indirizzo MAC. Chiamiamo la relazione tra i due valori una mappa. I messaggi ARP sono incapsulati direttamente all’interno di un frame Ethernet. Non esiste un’intestazione IPv4. La richiesta ARP è incapsulata in un frame Ethernet utilizzando le seguenti informazioni di intestazione:
Indirizzo MAC di destinazione: si tratta di un indirizzo di trasmissione FF-FF-FF-FF-FF-FF che richiede a tutte le NIC Ethernet sulla LAN di accettare ed elaborare la richiesta ARP.
Indirizzo MAC di origine: questo è l’indirizzo MAC del mittente della richiesta ARP.
Tipo: i messaggi ARP hanno un campo tipo di 0x806. Questo informa la NIC ricevente che la porzione di dati del frame deve essere passata al processo ARP.
Poiché le richieste ARP sono broadcast, vengono inviate a tutte le porte dallo switch, ad eccezione della porta ricevente. Solo il dispositivo con l’indirizzo IPv4 di destinazione associato alla richiesta ARP risponderà con una risposta ARP. Dopo aver ricevuto la risposta ARP, il dispositivo aggiungerà l’indirizzo IPv4 e l’indirizzo MAC corrispondente alla sua tabella ARP.
Quando l’indirizzo IPv4 di destinazione non si trova sulla stessa rete dell’indirizzo IPv4 di origine, il dispositivo di origine deve inviare il frame al proprio gateway predefinito. Questa è l’interfaccia del router locale. Ogni volta che un dispositivo di origine ha un pacchetto con un indirizzo IPv4 su un’altra rete, incapsula quel pacchetto in un frame utilizzando l’indirizzo MAC di destinazione del router. L’indirizzo IPv4 del gateway predefinito è memorizzato nella configurazione IPv4 degli host. Se l’host di destinazione non si trova sulla stessa rete, l’origine controlla la sua tabella ARP per una voce con l’indirizzo IPv4 del gateway predefinito. Se non c’è una voce, utilizza il processo ARP per determinare un indirizzo MAC del gateway predefinito.
Per ogni dispositivo, un timer della cache ARP rimuove le voci ARP che non sono state utilizzate per un periodo di tempo specificato. I tempi variano a seconda del sistema operativo del dispositivo. I comandi possono essere utilizzati per rimuovere manualmente alcune o tutte le voci nella tabella ARP.
Su un router Cisco, il comando show ip arp viene utilizzato per visualizzare la tabella ARP. Su un PC Windows 10, il comando arp –a viene utilizzato per visualizzare la tabella ARP.
Come frame broadcast, una richiesta ARP viene ricevuta ed elaborata da ogni dispositivo sulla rete locale. Se si accende un numero elevato di dispositivi e tutti iniziano ad accedere ai servizi di rete contemporaneamente, potrebbe verificarsi una riduzione delle prestazioni per un breve periodo di tempo. In alcuni casi, l’uso di ARP può comportare un potenziale rischio per la sicurezza.
Un attore di minacce può utilizzare lo spoofing ARP per eseguire un attacco di avvelenamento ARP. Questa è una tecnica utilizzata da un attore di minacce per rispondere a una richiesta ARP per un indirizzo IPv4 che appartiene a un altro dispositivo, come il gateway predefinito. L’autore della minaccia invia una risposta ARP con il proprio indirizzo MAC. Il destinatario della risposta ARP aggiungerà l’indirizzo MAC errato alla sua tabella ARP e invierà questi pacchetti all’autore della minaccia.
DNS Services
Domain Name System
Esistono altri protocolli specifici del livello dell’applicazione progettati per semplificare l’ottenimento degli indirizzi per i dispositivi di rete. Questi servizi sono essenziali perché sarebbe molto dispendioso in termini di tempo ricordare gli indirizzi IP anziché gli URL o configurare manualmente tutti i dispositivi in una rete medio-grande. Questo argomento approfondisce i servizi di indirizzamento IP, DNS e DHCP.
Nelle reti di dati, i dispositivi sono etichettati con indirizzi IP numerici per inviare e ricevere dati sulle reti. I nomi di dominio sono stati creati per convertire l’indirizzo numerico in un nome semplice e riconoscibile.
Su Internet, i nomi di dominio completi (FQDN), come http://www.cisco.com, sono molto più facili da ricordare per le persone rispetto a 198.133.219.25, che è l’effettivo indirizzo numerico di questo server. Se Cisco decide di modificare l’indirizzo numerico di www.cisco.com, è trasparente per l’utente perché il nome di dominio rimane lo stesso. Il nuovo indirizzo viene semplicemente collegato al nome di dominio esistente e la connettività viene mantenuta.
Il protocollo DNS definisce un servizio automatizzato che abbina i nomi delle risorse con l’indirizzo di rete numerico richiesto. Include il formato per query, risposte e dati. Le comunicazioni del protocollo DNS utilizzano un unico formato chiamato messaggio. Questo formato di messaggio viene utilizzato per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse tra i server.
Passo 1
L’utente digita un FQDN nel campo Indirizzo di un’applicazione browser.
Passo 2
Una query DNS viene inviata al server DNS designato per il computer client.
Passo 3
Il server DNS abbina l’FQDN con il suo indirizzo IP.
Passo 4
La risposta alla query DNS viene inviata al client con l’indirizzo IP per l’FQDN.
Passo 5
Il computer client utilizza l’indirizzo IP per effettuare richieste al server.
Formato del messaggio DNS
Il server DNS archivia diversi tipi di record di risorse utilizzati per risolvere i nomi. Questi record contengono il nome, l’indirizzo e il tipo di record. Alcuni di questi tipi di record sono i seguenti:
A – Un indirizzo IPv4 del dispositivo finale
NS – Un server dei nomi autorevole
AAAA – Un indirizzo IPv6 del dispositivo finale (pronunciato quad-A)
MX – Un record di scambio di posta
Quando un client effettua una query, il processo DNS del server esamina innanzitutto i propri record per risolvere il nome. Se non è in grado di risolvere il nome utilizzando i record archiviati, contatta altri server per risolvere il nome. Dopo che una corrispondenza è stata trovata e restituita al server richiedente originale, il server memorizza temporaneamente l’indirizzo numerico nel caso in cui venga richiesto nuovamente lo stesso nome.
Il servizio client DNS su PC Windows memorizza anche i nomi risolti in precedenza. Il comando ipconfig /displaydns visualizza tutte le voci DNS memorizzate nella cache.
Come mostrato nella tabella, il DNS utilizza lo stesso formato di messaggio tra i server, costituito da una domanda, una risposta, un’autorizzazione e informazioni aggiuntive per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse.
Gerarchia DNS
Il protocollo DNS utilizza un sistema gerarchico per creare un database per fornire la risoluzione dei nomi, come mostrato nella figura. Il DNS utilizza i nomi di dominio per formare la gerarchia.
La struttura dei nomi è suddivisa in piccole zone gestibili. Ogni server DNS mantiene un file di database specifico ed è responsabile solo della gestione delle mappature nome-IP per quella piccola porzione dell’intera struttura DNS. Quando un server DNS riceve una richiesta per la traduzione di un nome che non si trova all’interno della sua zona DNS, il server DNS inoltra la richiesta a un altro server DNS all’interno della zona appropriata per la traduzione. Il DNS è scalabile perché la risoluzione del nome host è distribuita su più server.
I diversi domini di primo livello (TLD: top-level domains) rappresentano il tipo di organizzazione o il paese di origine. Esempi di domini di primo livello sono i seguenti:
.com – un’azienda o un settore
.org – un’organizzazione senza scopo di lucro
.au – Australia
.co – Colombia
Il comando nslookup
Quando si configura un dispositivo di rete, vengono forniti uno o più indirizzi di server DNS che il client DNS può utilizzare per la risoluzione dei nomi. Di solito, l’ISP fornisce gli indirizzi da utilizzare per i server DNS. Quando un’applicazione utente richiede di connettersi a un dispositivo remoto in base al nome, il client DNS richiedente interroga il server dei nomi per risolvere il nome in un indirizzo numerico.
I sistemi operativi dei computer dispongono anche di un’utilità chiamata nslookup che consente all’utente di interrogare manualmente i server dei nomi per risolvere un determinato nome host. Questa utilità può anche essere utilizzata per risolvere i problemi di risoluzione dei nomi e per verificare lo stato corrente dei server dei nomi.
In questa figura, quando viene emesso il comando nslookup, viene visualizzato il server DNS predefinito configurato per l’host. Il nome di un host o di un dominio può essere inserito al prompt di nslookup. L’utilità nslookup ha molte opzioni disponibili per test approfonditi e verifica del processo DNS.
Controllo sintassi – Il comando nslookup
From the Windows command prompt, enter the nslookup command to begin a manual query of the name servers.
C:>nslookup
Default Server: Unknown
Address: 10.10.10.1
The output lists the name and IP address of the DNS server configured in the client. Note that the DNS server address can be manually configured, or dynamically learned, through DHCP. You are now in nslookup mode. Enter the domain name www.cisco.com.
www.cisco.com
Server: UnKnown
Address: 10.10.10.1
Non-authoritative answer:
Name: e2867.dsca.akamaiedge.net
Addresses: 2600:1404:a:395::b33
2600:1404:a:38e::b33
172.230.155.162
Aliases: www.cisco.com
www.cisco.com.akadns.net
wwwds.cisco.com.edgekey.net
wwwds.cisco.com.edgekey.net.globalredir.akadns.net
The output lists IP addresses related to www.cisco.com that the server ’e2867’ currently has in its database. Notice that IPv6 addresses are also listed. In addition, various aliases are shown that will resolve to www.cisco.com.
Enter the exit command to leave nslookup mode and return to the Windows command line.
exit
You can directly query the DNS servers by simply adding the domain name to the nslookup command.
Enter nslookup www.google.com.
C:>nslookup www.google.com
Server: UnKnown
Address: 10.10.10.1
Non-authoritative answer:
Name: www.google.com
Addresses: 2607:f8b0:4000:80f::2004
172.217.12.36
=========================================
You are now working from Linux command prompt. The nslookup command is the same.
Enter the nslookup command to begin a manual query of the name servers.
Enter www.cisco.com at the > prompt.
Enter the exit command to leave nslookup mode and return to the Linux command line.
user@cisconetacad$nslookup
Server: 127.0.1.1
Address: 127.0.1.1#53
www.cisco.com
Non-authoritative answer:
www.cisco.com canonical name = www.cisco.com.akadns.net.
www.cisco.com.akadns.net canonical name = wwwds.cisco.com.edgekey.net.
wwwds.cisco.com.edgekey.net canonical name = wwwds.cisco.com.edgekey.net.globalredir.akadns.net.
wwwds.cisco.com.edgekey.net.globalredir.akadns.net canonical name = e144.dscb.akamaiedge.net.
Name: e144.dscb.akamaiedge.net
Address: 23.60.112.170
exit
As in Windows, you can directly query the DNS servers by simply adding the domain name to the nslookup command. Enter nslookup www.google.com.
user@cisconetacad$nslookup www.google.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.6.164
Name: www.google.com
Address: 2607:f8b0:4000:812::2004
You successfully used the nslookup command to verify the status of domain names.
DHCP Services
Protocollo di configurazione dinamica dell’host
Il servizio DHCP (Dynamic Host Configuration Protocol) per IPv4 automatizza l’assegnazione di indirizzi IPv4, subnet mask, gateway e altri parametri di rete IPv4. Questo è indicato come indirizzamento dinamico. L’alternativa all’indirizzamento dinamico è l’indirizzamento statico. Quando si utilizza l’indirizzamento statico, l’amministratore di rete inserisce manualmente le informazioni sull’indirizzo IP sugli host.
Quando un host si connette alla rete, viene contattato il server DHCP e viene richiesto un indirizzo. Il server DHCP sceglie un indirizzo da un intervallo configurato di indirizzi chiamato pool e lo assegna (affitta) all’host.
Su reti più grandi o dove la popolazione di utenti cambia frequentemente, DHCP è preferito per l’assegnazione degli indirizzi. Potrebbero arrivare nuovi utenti e avere bisogno di connessioni; altri potrebbero avere nuovi computer che devono essere collegati. Piuttosto che utilizzare l’indirizzamento statico per ogni connessione, è più efficiente avere indirizzi IPv4 assegnati automaticamente tramite DHCP.
DHCP può allocare indirizzi IP per un periodo di tempo configurabile, chiamato periodo di lease. Il periodo di lease è un’impostazione DHCP importante. Quando il periodo di lease scade o il server DHCP riceve un messaggio DHCPRELEASE, l’indirizzo viene restituito al pool DHCP per il riutilizzo. Gli utenti possono spostarsi liberamente da un luogo all’altro e ristabilire facilmente le connessioni di rete tramite DHCP.
Come mostra la figura, vari tipi di dispositivi possono essere server DHCP. Il server DHCP nella maggior parte delle reti medio-grandi è in genere un server locale basato su PC dedicato. Con le reti domestiche, il server DHCP si trova solitamente sul router locale che collega la rete domestica all’ISP.
Molte reti utilizzano sia il DHCP che l’indirizzamento statico. DHCP viene utilizzato per host generici, come i dispositivi degli utenti finali. L’indirizzamento statico viene utilizzato per i dispositivi di rete, come router gateway, switch, server e stampanti.
DHCP per IPv6 (DHCPv6) fornisce servizi simili per i client IPv6. Una differenza importante è che DHCPv6 non fornisce un indirizzo gateway predefinito. Questo può essere ottenuto dinamicamente solo dal messaggio di annuncio del router.
DHCP Messages
Come mostrato nella figura, quando un dispositivo IPv4 configurato con DHCP si avvia o si connette alla rete, il client trasmette un messaggio di rilevamento DHCP (DHCPDISCOVER) per identificare eventuali server DHCP disponibili sulla rete. Un server DHCP risponde con un messaggio di offerta DHCP (DHCPOFFER), che offre un lease al client. Il messaggio di offerta contiene l’indirizzo IPv4 e la subnet mask da assegnare, l’indirizzo IPv4 del server DNS e l’indirizzo IPv4 del gateway predefinito. L’offerta di lease comprende anche la durata della lease stessa.
Il client può ricevere più messaggi DHCPOFFER se sulla rete locale è presente più di un server DHCP. Pertanto, deve scegliere tra di essi e invia un messaggio di richiesta DHCP (DHCPREQUEST) che identifica il server esplicito e l’offerta di lease che il client sta accettando. Un client può anche scegliere di richiedere un indirizzo che gli era stato precedentemente assegnato dal server.
Supponendo che l’indirizzo IPv4 richiesto dal client o offerto dal server sia ancora disponibile, il server restituisce un messaggio di riconoscimento DHCP (DHCPACK) che conferma al client che il lease è stato finalizzato. Se l’offerta non è più valida, il server selezionato risponde con un messaggio di riconoscimento negativo DHCP (DHCPNAK). Se viene restituito un messaggio DHCPNAK, il processo di selezione deve ricominciare con la trasmissione di un nuovo messaggio DHCPDISCOVER. Dopo che il client ha il lease, deve essere rinnovato prima della scadenza del lease tramite un altro messaggio DHCPREQUEST.
Il server DHCP garantisce che tutti gli indirizzi IP siano univoci (lo stesso indirizzo IP non può essere assegnato contemporaneamente a due diversi dispositivi di rete). La maggior parte degli ISP utilizza DHCP per assegnare gli indirizzi ai propri clienti.
DHCPv6 ha una serie di messaggi simili a quelli per DHCPv4. I messaggi DHCPv6 sono SOLICIT, ADVERTISE, INFORMATION REQUEST e REPLY.
IP Addressing Services – Riepilogo
Nelle reti di dati, i dispositivi sono etichettati con indirizzi IP numerici per inviare e ricevere dati sulle reti. I nomi di dominio sono stati creati per convertire l’indirizzo numerico in un nome semplice e riconoscibile. Il protocollo DNS definisce un servizio automatizzato che abbina i nomi delle risorse con l’indirizzo di rete numerico richiesto. Le comunicazioni del protocollo DNS utilizzano un unico formato chiamato messaggio. Questo formato di messaggio viene utilizzato per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse tra i server.
Il server DNS archivia diversi tipi di record di risorse utilizzati per risolvere i nomi. Questi record contengono il nome, l’indirizzo e il tipo di record. Il DNS utilizza lo stesso formato di messaggio tra i server, costituito da una domanda, risposta, autorità e informazioni aggiuntive per tutti i tipi di query client e risposte del server, messaggi di errore e trasferimento di informazioni sui record di risorse.
Il DNS utilizza i nomi di dominio per formare la gerarchia. La struttura dei nomi è suddivisa in zone. Ogni server DNS mantiene un file di database specifico ed è responsabile solo della gestione delle mappature nome-IP per quella piccola porzione dell’intera struttura DNS. Quando un server DNS riceve una richiesta per la traduzione di un nome che non si trova all’interno della sua zona DNS, il server DNS inoltra la richiesta a un altro server DNS all’interno della zona appropriata per la traduzione. Il DNS è scalabile perché la risoluzione del nome host è distribuita su più server.
I sistemi operativi dei computer dispongono di un’utilità chiamata Nslookup che consente all’utente di interrogare manualmente i server dei nomi per risolvere un determinato nome host. Questa utilità può anche essere utilizzata per risolvere i problemi di risoluzione dei nomi e per verificare lo stato corrente dei server dei nomi. Quando viene emesso il comando nslookup, viene visualizzato il server DNS predefinito configurato per l’host. Il nome di un host o di un dominio può essere inserito al prompt di nslookup.
Su reti più grandi, DHCP è preferito per l’assegnazione degli indirizzi. Piuttosto che utilizzare l’indirizzamento statico per ogni connessione, è più efficiente avere indirizzi IPv4 assegnati automaticamente tramite DHCP. DHCP può allocare indirizzi IP per un periodo di tempo configurabile, chiamato periodo di lease. Quando il periodo di lease scade o il server DHCP riceve un messaggio DHCPRELEASE, l’indirizzo viene restituito al pool DHCP per il riutilizzo. Gli utenti possono spostarsi liberamente da un luogo all’altro e ristabilire facilmente le connessioni di rete tramite DHCP.
DHCPv6 fornisce servizi simili per i client IPv6. Una differenza importante è che DHCPv6 non fornisce un indirizzo gateway predefinito. Questo può essere ottenuto dinamicamente solo dal messaggio “Router Advertisement” del router.
Quando un dispositivo IPv4 configurato con DHCP si avvia o si connette alla rete, il client trasmette un messaggio DHCPDISCOVER per identificare eventuali server DHCP disponibili sulla rete.
Un server DHCP risponde con un messaggio DHCPOFFER, che offre un lease al client. Il client invia un messaggio DHCPREQUEST che identifica il server esplicito e l’offerta di leasing che il client sta accettando.
Supponendo che l’indirizzo IPv4 richiesto dal client, o offerto dal server, sia ancora disponibile, il server restituisce un messaggio DHCPACK che conferma al client che il lease è stato finalizzato. Se l’offerta non è più valida, il server selezionato risponde con un messaggio DHCPNAK. Se viene restituito un messaggio DHCPNAK, il processo di selezione deve ricominciare con la trasmissione di un nuovo messaggio DHCPDISCOVER.
DHCPv6 ha una serie di messaggi simili a quelli per DHCPv4. I messaggi DHCPv6 sono SOLICIT, ADVERTISE, INFORMATION REQUEST, and REPLY.
Transport Layer
Transportation of Data – Role of the Transport Layer
I programmi a livello di applicazione generano dati che devono essere scambiati tra gli host di origine e di destinazione. Il livello di trasporto è responsabile delle comunicazioni logiche tra le applicazioni in esecuzione su host diversi. Ciò può includere servizi come la creazione di una sessione temporanea tra due host e la trasmissione affidabile di informazioni per un’applicazione.
Come mostrato nella figura, il livello di trasporto è il collegamento tra il livello dell’applicazione e i livelli inferiori responsabili della trasmissione in rete.
Il livello di trasporto non è a conoscenza del tipo di host di destinazione, del tipo di supporto su cui devono viaggiare i dati, del percorso seguito dai dati, della congestione su un collegamento o delle dimensioni della rete.
Il livello di trasporto include due protocolli:
Transmission Control Protocol (TCP)
User Datagram Protocol (UDP)
Responsabilità del livello di trasporto
Il livello di trasporto ha molte responsabilità.
-Monitoraggio delle singole conversazioni
A livello di trasporto, ogni set di dati che scorre tra un’applicazione di origine e un’applicazione di destinazione è noto come conversazione e viene monitorato separatamente. È responsabilità del livello di trasporto mantenere e tenere traccia di queste molteplici conversazioni.
Come illustrato nella figura, un host può avere più applicazioni che comunicano simultaneamente attraverso la rete.
La maggior parte delle reti ha una limitazione sulla quantità di dati che possono essere inclusi in un singolo pacchetto. Pertanto, i dati devono essere suddivisi in parti gestibili.
-Segmentazione dei dati e riassemblaggio dei segmenti
È responsabilità del livello di trasporto suddividere i dati dell’applicazione in blocchi di dimensioni adeguate. A seconda del protocollo del livello di trasporto utilizzato, i blocchi del livello di trasporto sono chiamati segmenti o datagrammi. La figura illustra il livello di trasporto utilizzando diversi blocchi per ogni conversazione.
Il livello di trasporto divide i dati in blocchi più piccoli (ad esempio, segmenti o datagrammi) che sono più facili da gestire e trasportare.
-Aggiunge informazioni di intestazione
Il protocollo del livello di trasporto aggiunge anche informazioni di intestazione contenenti dati binari organizzati in diversi campi a ciascun blocco di dati. Sono i valori in questi campi che consentono ai vari protocolli del livello di trasporto di eseguire diverse funzioni nella gestione della comunicazione dei dati.
Ad esempio, le informazioni di intestazione vengono utilizzate dall’host ricevente per riassemblare i blocchi di dati in un flusso di dati completo per il programma a livello di applicazione ricevente.
Il livello di trasporto garantisce che anche con più applicazioni in esecuzione su un dispositivo, tutte le applicazioni ricevano i dati corretti.
-Identificazione delle applicazioni
Il livello di trasporto deve essere in grado di separare e gestire più comunicazioni con diverse esigenze di requisiti di trasporto. Per passare i flussi di dati alle applicazioni appropriate, il livello di trasporto identifica l’applicazione di destinazione utilizzando un identificatore chiamato numero di porta. Come illustrato nella figura, a ogni processo software che deve accedere alla rete viene assegnato un numero di porta univoco per quell’host.
-Multiplexing di conversazione
L’invio di alcuni tipi di dati (ad esempio, un video in streaming) attraverso una rete, come un flusso di comunicazione completo, può consumare tutta la larghezza di banda disponibile. Ciò impedirebbe che si verifichino contemporaneamente altre conversazioni di comunicazione. Renderebbe inoltre difficile il recupero degli errori e la ritrasmissione dei dati danneggiati.
Come mostrato nella figura, il livello di trasporto utilizza la segmentazione e il multiplexing per consentire l’interlacciamento di diverse conversazioni di comunicazione sulla stessa rete.
Il controllo degli errori può essere eseguito sui dati nel segmento, per determinare se il segmento è stato alterato durante la trasmissione
Transport Layer Protocols
L’IP riguarda solo la struttura, l’indirizzamento e l’instradamento dei pacchetti. L’IP non specifica come avviene la consegna o il trasporto dei pacchetti.
I protocolli del livello di trasporto specificano come trasferire i messaggi tra host e sono responsabili della gestione dei requisiti di affidabilità di una conversazione. Il livello di trasporto include i protocolli TCP e UDP.
Diverse applicazioni hanno diversi requisiti di affidabilità del trasporto. Pertanto, TCP/IP fornisce due protocolli a livello di trasporto, come mostrato nella figura.
Transmission Control Protocol (TCP)
L’IP riguarda solo la struttura, l’indirizzamento e l’instradamento dei pacchetti, dal mittente originale alla destinazione finale. IP non è responsabile di garantire la consegna o di determinare se è necessario stabilire una connessione tra il mittente e il destinatario.
TCP è considerato un protocollo di livello di trasporto affidabile e completo, che garantisce che tutti i dati arrivino a destinazione. TCP include campi che garantiscono la consegna dei dati dell’applicazione. Questi campi richiedono un’ulteriore elaborazione da parte degli host di invio e ricezione.
Nota: TCP divide i dati in segmenti.
Il trasporto CP è analogo all’invio di pacchi tracciati dall’origine alla destinazione. Se un ordine di spedizione è suddiviso in più pacchi, un cliente può controllare online per vedere l’ordine della consegna.
TCP fornisce affidabilità e controllo del flusso utilizzando queste operazioni di base:
Numerare e tenere traccia dei segmenti di dati trasmessi a un host specifico da un’applicazione specifica;
Riconoscere i dati ricevuti;
Ritrasmettere tutti i dati non riconosciuti dopo un certo periodo di tempo;
Sequenza di dati che potrebbero arrivare nell’ordine sbagliato;
Invia i dati a una velocità efficiente, accettabile dal destinatario.
Per mantenere lo stato di una conversazione e tenere traccia delle informazioni, il TCP deve prima stabilire una connessione tra il mittente e il destinatario. Questo è il motivo per cui TCP è noto come protocollo orientato alla connessione.
User Datagram Protocol (UDP)
UDP è un protocollo a livello di trasporto più semplice di TCP. Non fornisce affidabilità e controllo del flusso, il che significa che richiede meno campi di intestazione. Poiché i processi UDP del mittente e del destinatario non devono gestire l’affidabilità e il controllo del flusso, ciò significa che i datagrammi UDP possono essere elaborati più velocemente dei segmenti TCP. UDP fornisce le funzioni di base per la consegna di datagrammi tra le applicazioni appropriate, con un sovraccarico e un controllo dei dati molto ridotti.
Nota: UDP divide i dati in datagrammi, detti anche segmenti.
UDP è un protocollo senza connessione. Poiché UDP non fornisce affidabilità o controllo del flusso, non richiede una connessione stabilita. Poiché UDP non tiene traccia delle informazioni inviate o ricevute tra il client e il server, UDP è noto anche come protocollo senza stato.
UDP è anche noto come protocollo di consegna best-effort perché non vi è alcun riconoscimento che i dati siano stati ricevuti a destinazione. Con UDP, non ci sono processi a livello di trasporto che informano il mittente di una consegna riuscita.
UDP è come inserire una normale lettera ordinaria nella posta. Il mittente della lettera non è a conoscenza della disponibilità del destinatario a ricevere la lettera. Né l’ufficio postale è responsabile del tracciamento della lettera o di informare il mittente se la lettera non arriva alla destinazione finale.
Il giusto protocollo del livello di trasporto per l’applicazione giusta
Alcune applicazioni possono tollerare una certa perdita di dati durante la trasmissione sulla rete, ma i ritardi nella trasmissione sono inaccettabili. Per queste applicazioni, UDP è la scelta migliore perché richiede meno overhead di rete. UDP è preferibile per applicazioni come Voice over IP (VoIP). I riconoscimenti e la ritrasmissione rallenterebbero la consegna e renderebbero inaccettabile la conversazione vocale.
UDP viene utilizzato anche dalle applicazioni di richiesta e risposta in cui i dati sono minimi e la ritrasmissione può essere eseguita rapidamente. Ad esempio, DNS (Domain Name System) utilizza UDP per questo tipo di transazione. Il client richiede indirizzi IPv4 e IPv6 per un nome di dominio noto da un server DNS. Se il client non riceve una risposta entro un tempo prestabilito, semplicemente invia nuovamente la richiesta.
Ad esempio, se uno o due segmenti di un flusso video in diretta non arrivano, si crea un’interruzione momentanea nel flusso. Ciò può apparire come distorsione nell’immagine o nel suono, ma potrebbe non essere visibile all’utente. Se il dispositivo di destinazione dovesse tenere conto della perdita di dati, lo streaming potrebbe essere ritardato durante l’attesa delle ritrasmissioni, causando un notevole degrado dell’immagine o del suono. In questo caso è meglio rendere il miglior media possibile con i segmenti ricevuti e rinunciare all’affidabilità.
Per altre applicazioni è importante che tutti i dati arrivino e che possano essere elaborati nella sequenza corretta. Per questi tipi di applicazioni, TCP viene utilizzato come protocollo di trasporto. Ad esempio, applicazioni come database, browser Web e client di posta elettronica richiedono che tutti i dati inviati arrivino a destinazione nelle condizioni originali. Eventuali dati mancanti potrebbero corrompere una comunicazione, rendendola incompleta o illeggibile. Ad esempio, è importante quando si accede alle informazioni bancarie sul Web per assicurarsi che tutte le informazioni siano inviate e ricevute correttamente.
Gli sviluppatori di applicazioni devono scegliere il tipo di protocollo di trasporto appropriato in base ai requisiti delle applicazioni. Il video può essere inviato tramite TCP o UDP. Le applicazioni che eseguono lo streaming di audio e video archiviati in genere utilizzano TCP. L’applicazione utilizza TCP per eseguire il buffering, il sondaggio della larghezza di banda e il controllo della congestione, al fine di controllare meglio l’esperienza dell’utente.
Il video e la voce in tempo reale di solito utilizzano UDP, ma possono anche utilizzare TCP o sia UDP che TCP. Un’applicazione di videoconferenza può utilizzare UDP per impostazione predefinita, ma poiché molti firewall bloccano UDP, l’applicazione può essere inviata anche tramite TCP.
Le applicazioni che eseguono lo streaming di audio e video archiviati utilizzano TCP. Ad esempio, se improvvisamente la tua rete non è in grado di supportare la larghezza di banda necessaria per guardare un film su richiesta, l’applicazione sospende la riproduzione. Durante la pausa, potresti vedere un messaggio “buffering…” mentre TCP lavora per ristabilire il flusso. Quando tutti i segmenti sono in ordine e viene ripristinato un livello minimo di larghezza di banda, la sessione TCP riprende e la riproduzione del film riprende.
La figura riassume le differenze tra UDP e TCP.
Proprietà del protocollo richieste: VeloceBasso sovraccaricoNon richiede riconoscimentiNon invia nuovamente i dati persiFornisce i dati non appena arrivano
Proprietà del protocollo richieste: AffidabileRiconosce i datiInvia nuovamente i dati persiFornisce i dati in ordine sequenziale
Panoramica del TCP
Funzionalità TCP
TCP e UDP sono i due protocolli del livello di trasporto. Ecco maggiori dettagli su cosa fa TCP e quando è una buona idea usarlo al posto di UDP.
Per comprendere le differenze tra TCP e UDP, è importante capire come ogni protocollo implementa specifiche caratteristiche di affidabilità e come ogni protocollo tiene traccia delle conversazioni.
Oltre a supportare le funzioni di base di segmentazione e riassemblaggio dei dati, TCP fornisce anche i seguenti servizi:
Stabilisce una sessione: TCP è un protocollo orientato alla connessione che negozia e stabilisce una connessione (o sessione) permanente tra i dispositivi di origine e di destinazione prima di inoltrare qualsiasi traffico. Attraverso l’istituzione della sessione, i dispositivi negoziano la quantità di traffico che può essere inoltrata in un determinato momento e i dati di comunicazione tra i due possono essere strettamente gestiti.
Garantisce una consegna affidabile: per molte ragioni, è possibile che un segmento venga danneggiato o perso completamente, mentre viene trasmesso sulla rete. TCP garantisce che ogni segmento inviato dall’origine arrivi a destinazione.
Fornisce la consegna nello stesso ordine: poiché le reti possono fornire più percorsi con velocità di trasmissione diverse, i dati possono arrivare nell’ordine sbagliato. Numerando e mettendo in sequenza i segmenti, TCP garantisce che i segmenti vengano riassemblati nell’ordine corretto.
Supporta il controllo del flusso: gli host di rete hanno risorse limitate (ad es. memoria e potenza di elaborazione). Quando TCP è consapevole che queste risorse sono sovraccaricate, può richiedere che l’applicazione mittente riduca la velocità del flusso di dati. Questo viene fatto dal TCP che regola la quantità di dati trasmessi dalla sorgente. Il controllo del flusso può impedire la necessità di ritrasmettere i dati quando le risorse dell’host ricevente sono sovraccariche.
Per ulteriori informazioni su TCP, cercare in Internet l’RFC 793.
TCP Header
TCP è un protocollo stateful, il che significa che tiene traccia dello stato della sessione di comunicazione. Per tenere traccia dello stato di una sessione, TCP registra quali informazioni ha inviato e quali informazioni sono state riconosciute. La sessione con stato inizia con l’istituzione della sessione e termina con la chiusura della sessione.
Un segmento TCP aggiunge 20 byte (ovvero 160 bit) di overhead durante l’incapsulamento dei dati del livello dell’applicazione. La figura mostra i campi in un’intestazione TCP.
Campi di intestazione TCP
La tabella identifica e descrive i dieci campi in un’intestazione TCP.
Applicazioni che utilizzano TCP
TCP è un buon esempio di come i diversi livelli della suite di protocolli TCP/IP abbiano ruoli specifici. TCP gestisce tutte le attività associate alla divisione del flusso di dati in segmenti, fornendo affidabilità, controllando il flusso di dati e riordinando i segmenti. TCP libera l’applicazione dalla necessità di gestire qualsiasi di queste attività. Le applicazioni, come quelle mostrate nella figura, possono semplicemente inviare il flusso di dati al livello di trasporto e utilizzare i servizi di TCP.
Panoramica dell’UDP
Funzionalità UDP
UDP, cosa fa e quando è una buona idea usarlo al posto di TCP. UDP è un protocollo di trasporto best-effort, leggero e offre la stessa segmentazione e riassemblaggio dei dati del TCP, ma senza l’affidabilità e il controllo del flusso del TCP.
UDP è un protocollo così semplice che di solito viene descritto in termini di ciò che non fa rispetto a TCP.
Le funzionalità UDP includono quanto segue:
I dati vengono ricostruiti nell’ordine in cui vengono ricevuti.
Tutti i segmenti persi non vengono reinviati.
Non è prevista la creazione di una sessione.
L’invio non viene informato sulla disponibilità delle risorse.
Per ulteriori informazioni su UDP, cercare RFC su Internet.
Intestazione UDP
UDP è un protocollo senza stato, ovvero né il client né il server tengono traccia dello stato della sessione di comunicazione. Se l’affidabilità è richiesta quando si utilizza UDP come protocollo di trasporto, deve essere gestito dall’applicazione.
Uno dei requisiti più importanti per fornire video e voce in diretta sulla rete è che i dati continuino a fluire rapidamente. Le applicazioni video e vocali dal vivo possono tollerare una certa perdita di dati con effetti minimi o nulli e sono perfettamente adatte a UDP.
I blocchi di comunicazione in UDP sono chiamati datagrammi o segmenti. Questi datagrammi vengono inviati al meglio dal protocollo del livello di trasporto.
L’intestazione UDP è molto più semplice dell’intestazione TCP perché ha solo quattro campi e richiede 8 byte (cioè 64 bit). La figura mostra i campi in un’intestazione UDP.
Campi di intestazione UDP
La tabella identifica e descrive i quattro campi in un’intestazione UDP.
Applicazioni che utilizzano UDP
Esistono tre tipi di applicazioni più adatte per UDP:
Applicazioni video e multimediali dal vivo: queste applicazioni possono tollerare una certa perdita di dati, ma richiedono un ritardo minimo o nullo. Gli esempi includono VoIP e video in streaming live.
Applicazioni di richiesta e risposta semplici: applicazioni con transazioni semplici in cui un host invia una richiesta e può ricevere o meno una risposta. Gli esempi includono DNS e DHCP.
Applicazioni che gestiscono autonomamente l’affidabilità: comunicazioni unidirezionali in cui il controllo del flusso, il rilevamento degli errori, i riconoscimenti e il ripristino degli errori non sono richiesti o possono essere gestiti dall’applicazione. Gli esempi includono SNMP e TFTP.
La figura identifica le applicazioni che richiedono UDP.
Sebbene DNS e SNMP utilizzino UDP per impostazione predefinita, entrambi possono utilizzare anche TCP. DNS utilizzerà TCP se la richiesta DNS o la risposta DNS supera i 512 byte, ad esempio quando una risposta DNS include molte risoluzioni di nomi. Analogamente, in alcune situazioni ’’amministratore di rete potrebbe voler configurare SNMP per l’utilizzo di TCP.
Port Numbers
Comunicazioni multiple separate
Ci sono alcune situazioni in cui TCP è il protocollo giusto per certe attività e altre situazioni in cui dovrebbe essere utilizzato UDP. Indipendentemente dal tipo di dati trasportati, sia TCP che UDP utilizzano i numeri di porta.
I protocolli del livello di trasporto TCP e UDP utilizzano i numeri di porta per gestire più conversazioni simultanee. Come mostrato nella figura, i campi di intestazione TCP e UDP identificano un numero di porta dell’applicazione di origine e di destinazione.
Il numero di porta di origine è associato all’applicazione di origine sull’host locale, mentre il numero di porta di destinazione è associato all’applicazione di destinazione sull’host remoto.
Ad esempio, supponiamo che un host stia avviando una richiesta di pagina web da un server web. Quando l’host avvia la richiesta della pagina Web, il numero della porta di origine viene generato dinamicamente dall’host per identificare in modo univoco la conversazione. Ogni richiesta generata da un host utilizzerà un diverso numero di porta di origine creato dinamicamente. Questo processo consente a più conversazioni di verificarsi contemporaneamente.
Nella richiesta, il numero della porta di destinazione è ciò che identifica il tipo di servizio richiesto al web server di destinazione. Ad esempio, quando un client specifica la porta 80 nella porta di destinazione, il server che riceve il messaggio sa che vengono richiesti servizi Web.
Un server può offrire più di un servizio contemporaneamente, come i servizi Web sulla porta 80, mentre offre la creazione di una connessione FTP (File Transfer Protocol) sulla porta 21.
Socket Pairs
Le porte di origine e di destinazione sono posizionate all’interno del segmento. I segmenti vengono quindi incapsulati all’interno di un pacchetto IP. Il pacchetto IP contiene l’indirizzo IP dell’origine e della destinazione. La combinazione dell’indirizzo IP di origine e del numero di porta di origine o dell’indirizzo IP di destinazione e del numero di porta di destinazione è nota come socket.
Nell’esempio in figura, il PC sta richiedendo contemporaneamente FTP e servizi web dal server di destinazione.
Nell’esempio, la richiesta FTP generata dal PC include gli indirizzi MAC Layer 2 e gli indirizzi IP Layer 3. La richiesta identifica anche il numero di porta sorgente 1305 (cioè generata dinamicamente dall’host) e la porta di destinazione, identificando i servizi FTP sulla porta 21. L’host ha anche richiesto una pagina web dal server utilizzando gli stessi indirizzi Layer 2 e Layer 3 . Tuttavia, utilizza il numero di porta di origine 1099 (ovvero generato dinamicamente dall’host) e la porta di destinazione che identifica il servizio Web sulla porta 80.
Il socket viene utilizzato per identificare il server e il servizio richiesto dal client. Un socket client potrebbe avere questo aspetto, con 1099 che rappresenta il numero della porta di origine: 192.168.1.5:1099
Il socket su un server Web potrebbe essere 192.168.1.7:80
Insieme, questi due socket si combinano per formare una coppia di socket: 192.168.1.5:1099, 192.168.1.7:80
I socket consentono a più processi, in esecuzione su un client, di distinguersi l’uno dall’altro e a più connessioni a un processo server di essere distinti l’uno dall’altro.
Il numero di porta di origine funge da indirizzo di ritorno per l’applicazione richiedente. Il livello di trasporto tiene traccia di questa porta e dell’applicazione che ha avviato la richiesta in modo che quando viene restituita una risposta, possa essere inoltrata all’applicazione corretta.
Gruppi di numeri di porta
L’Internet Assigned Numbers Authority (IANA) è l’organizzazione degli standard responsabile dell’assegnazione di vari standard di indirizzamento, inclusi i numeri di porta a 16 bit. I 16 bit utilizzati per identificare i numeri di porta di origine e di destinazione forniscono un intervallo di porte da 0 a 65535.
La IANA ha suddiviso la gamma di numeri nei seguenti tre gruppi di porte
Nota: alcuni sistemi operativi client possono utilizzare numeri di porta registrati anziché numeri di porta dinamici per l’assegnazione delle porte di origine.
La tabella mostra alcuni numeri di porta noti comuni e le relative applicazioni associate.
Alcune applicazioni possono utilizzare sia TCP che UDP. Ad esempio, DNS utilizza UDP quando i client inviano richieste a un server DNS. Tuttavia, la comunicazione tra due server DNS utilizza sempre il protocollo TCP.
Cerca nel sito Web IANA il registro delle porte per visualizzare l’elenco completo dei numeri di porta e delle applicazioni associate.
Il comando netstat
Le connessioni TCP inspiegabili possono rappresentare una grave minaccia per la sicurezza. Possono indicare che qualcosa o qualcuno è connesso all’host locale. A volte è necessario sapere quali connessioni TCP attive sono aperte e in esecuzione su un host in rete. Netstat è un’importante utility di rete che può essere utilizzata per verificare tali connessioni. Come mostrato di seguito, utilizzare il comando netstat per elencare i protocolli in uso, l’indirizzo locale e i numeri di porta, l’indirizzo esterno e i numeri di porta e lo stato della connessione.
Per impostazione predefinita, il comando netstat tenterà di risolvere gli indirizzi IP in nomi di dominio e numeri di porta in applicazioni note. L’opzione -n può essere utilizzata per visualizzare indirizzi IP e numeri di porta nella loro forma numerica.
Processo di comunicazione TCP
Processi del server TCP
Comprendere il ruolo dei numeri di porta aiuta a cogliere i dettagli del processo di comunicazione TCP. In questa parte verranno trattati anche i processi di handshake a tre vie TCP e di terminazione della sessione.
Ogni processo dell’applicazione in esecuzione su un server è configurato per utilizzare un numero di porta. Il numero di porta viene assegnato automaticamente o configurato manualmente da un amministratore di sistema.
Un singolo server non può avere due servizi assegnati allo stesso numero di porta all’interno degli stessi servizi del livello di trasporto. Ad esempio, un host che esegue un’applicazione server Web e un’applicazione di trasferimento file non può essere configurata per utilizzare la stessa porta, ad esempio la porta TCP 80.
Un’applicazione server attiva assegnata a una porta specifica è considerata aperta, il che significa che il livello di trasporto accetta ed elabora i segmenti indirizzati a quella porta. Qualsiasi richiesta client in entrata indirizzata al socket corretto viene accettata e i dati vengono passati all’applicazione server. Su un server possono essere aperte più porte contemporaneamente, una per ciascuna applicazione server attiva.
– Client che inviano richieste TCP
Il client 1 richiede i servizi Web e il client 2 richiede il servizio di posta elettronica dello stesso server.
– Richieste di porte di destinazione
Il client 1 richiede i servizi Web utilizzando la porta di destinazione nota 80 (HTTP) e il client 2 richiede il servizio di posta elettronica utilizzando la porta nota 25 (SMTP).
– Richieste di porte di origine
Le richieste del client generano dinamicamente un numero di porta di origine. In questo caso, il client 1 utilizza la porta di origine 49152 e il client 2 utilizza la porta di origine 51152.
– Porte di destinazione della risposta
Quando il server risponde alle richieste del client, inverte le porte di destinazione e di origine della richiesta iniziale. Si noti che la risposta del server alla richiesta Web ora ha la porta di destinazione 49152 e la risposta e-mail ora ha la porta di destinazione 51152.
– Porte di origine della risposta
La porta di origine nella risposta del server è la porta di destinazione originale nelle richieste iniziali.
Creazione della connessione TCP
In alcune culture, quando due persone si incontrano, spesso si salutano stringendosi la mano. Entrambe le parti interpretano l’atto di stringere la mano come un segnale per un saluto amichevole. Le connessioni sulla rete sono simili. Nelle connessioni TCP, il client host stabilisce la connessione con il server utilizzando il processo di handshake a tre vie.
Passo 1. SIN
Il client di avvio richiede una sessione di comunicazione client-server con il server.
Passo 2. ACK e SYN
Il server riconosce la sessione di comunicazione client-server e richiede una sessione di comunicazione server-client.
Passo 3. ACK
Il client di avvio riconosce la sessione di comunicazione server-client.
L’handshake a tre vie convalida che l’host di destinazione è disponibile per la comunicazione. In questo esempio, l’host A ha convalidato la disponibilità dell’host B.
Session Termination
Per chiudere una connessione, il flag di controllo Finish (FIN) deve essere impostato nell’intestazione del segmento. Per terminare ogni sessione TCP unidirezionale, viene utilizzato un handshake bidirezionale, costituito da un segmento FIN e un segmento di riconoscimento (ACK). Pertanto, per terminare una singola conversazione supportata da TCP, sono necessari quattro scambi per terminare entrambe le sessioni. Sia il client che il server possono avviare la terminazione.
Nell’esempio, i termini client e server vengono usati come riferimento per semplicità, ma qualsiasi coppia di host che ha una sessione aperta può avviare il processo di terminazione.
Passo 1. FIN
Quando il client non ha più dati da inviare nel flusso, invia un segmento con il flag FIN impostato.
Passo 2. ACK
Il server invia un ACK per confermare la ricezione del FIN per terminare la sessione dal client al server.
Passo 3. FIN
Il server invia un FIN al client per terminare la sessione server-client.
Passo 4. ACK
Il client risponde con un ACK per riconoscere il FIN dal server.
Quando tutti i segmenti sono stati riconosciuti, la sessione è chiusa.
Analisi dell’handshake a tre vie TCP
Gli host mantengono lo stato, tengono traccia di ogni segmento di dati all’interno di una sessione e scambiano informazioni su quali dati vengono ricevuti utilizzando le informazioni nell’intestazione TCP. TCP è un protocollo full-duplex, in cui ogni connessione rappresenta due sessioni di comunicazione unidirezionali. Per stabilire la connessione, gli host eseguono un handshake a tre vie. Come mostrato nella figura, i bit di controllo nell’intestazione TCP indicano l’avanzamento e lo stato della connessione.
Queste sono le funzioni dell’handshake a tre vie:
Stabilisce che il dispositivo di destinazione è presente sulla rete.
Verifica che il dispositivo di destinazione disponga di un servizio attivo e accetti richieste sul numero di porta di destinazione che il client di avvio intende utilizzare.
Informa il dispositivo di destinazione che il client di origine intende stabilire una sessione di comunicazione su quel numero di porta.
Al termine della comunicazione, le sessioni vengono chiuse e la connessione termina. I meccanismi di connessione e sessione abilitano la funzione di affidabilità TCP.
Campo dei bit di controllo
I sei bit nel campo Bit di controllo dell’intestazione del segmento TCP sono noti anche come flag. Un flag è un bit impostato su on o off.
I flag dei sei bit di controllo sono i seguenti:
URG – Campo puntatore urgente significativo
ACK – Flag di riconoscimento utilizzato per stabilire la connessione e terminare la sessione
PSH – Funzione push
RST – Ripristina la connessione quando si verifica un errore o un timeout
SYN – Sincronizza i numeri di sequenza utilizzati nella creazione della connessione
FIN – Niente più dati dal mittente e utilizzato per terminare la sessione
Cerca in Internet per saperne di più sui flag PSH e URG.
Affidabilità e controllo del flusso
Affidabilità TCP – Consegna garantita e ordinata
Il motivo per cui TCP è il protocollo migliore per alcune applicazioni è perché, a differenza di UDP, invia nuovamente i pacchetti scartati e il numero di pacchetti per indicare il loro ordine corretto prima della consegna. TCP può anche aiutare a mantenere il flusso di pacchetti in modo che i dispositivi non vengano sovraccaricati.
Ci possono essere momenti in cui i segmenti TCP non arrivano a destinazione. Altre volte, i segmenti TCP potrebbero arrivare fuori ordine. Affinché il messaggio originale sia compreso dal destinatario, tutti i dati devono essere ricevuti e i dati in questi segmenti devono essere riassemblati nell’ordine originale. I numeri di sequenza vengono assegnati nell’intestazione di ciascun pacchetto per raggiungere questo obiettivo. Il numero di sequenza rappresenta il primo byte di dati del segmento TCP.
Durante l’impostazione della sessione, viene impostato un numero di sequenza iniziale (ISN – initial sequence number). Questo ISN rappresenta il valore iniziale dei byte trasmessi all’applicazione ricevente. Man mano che i dati vengono trasmessi durante la sessione, il numero di sequenza viene incrementato del numero di byte che sono stati trasmessi. Questo tracciamento dei byte di dati consente di identificare e riconoscere in modo univoco ogni segmento. I segmenti mancanti possono quindi essere identificati.
L’ISN non inizia da uno ma è effettivamente un numero casuale. Questo serve a prevenire alcuni tipi di attacchi dannosi. Per semplicità, utilizzeremo un ISN pari a 1 per gli esempi di questo modulo.
I numeri di sequenza dei segmenti indicano come riassemblare e riordinare i segmenti ricevuti, come mostrato nella figura.
I segmenti TCP vengono riordinati alla destinazione
Il processo TCP di ricezione inserisce i dati da un segmento in un buffer di ricezione. I segmenti vengono quindi posizionati nell’ordine di sequenza corretto e passati al livello dell’applicazione una volta riassemblati. Tutti i segmenti che arrivano con numeri di sequenza non ordinati vengono trattenuti per un’elaborazione successiva. Quindi, quando arrivano i segmenti con i byte mancanti, questi segmenti vengono elaborati in ordine.
Affidabilità TCP – Numeri di sequenza e riconoscimenti
Una delle funzioni del TCP è garantire che ogni segmento raggiunga la sua destinazione. I servizi TCP sull’host di destinazione riconoscono i dati che sono stati ricevuti dall’applicazione di origine.
Affidabilità TCP – Perdita di dati e ritrasmissione
Non importa quanto sia ben progettata una rete, occasionalmente si verificano perdite di dati. TCP fornisce metodi per gestire queste perdite di segmento. Tra questi c’è un meccanismo per ritrasmettere segmenti per dati non riconosciuti.
Il numero di sequenza (SEQ) e il numero di riconoscimento (ACK) vengono utilizzati insieme per confermare la ricezione dei byte di dati contenuti nei segmenti trasmessi. Il numero SEQ identifica il primo byte di dati nel segmento che viene trasmesso. TCP utilizza il numero ACK inviato all’origine per indicare il byte successivo che il destinatario si aspetta di ricevere. Questo si chiama riconoscimento delle aspettative.
Prima dei miglioramenti successivi, TCP poteva riconoscere solo il byte successivo previsto. Ad esempio, nella figura, utilizzando i numeri di segmento per semplicità, l’host A invia i segmenti da 1 a 10 all’host B. Se arrivano tutti i segmenti tranne i segmenti 3 e 4, l’host B risponderà con un riconoscimento specificando che il prossimo segmento previsto è il segmento 3. L’host A non ha idea se siano arrivati o meno altri segmenti. L’host A, quindi, invierà nuovamente i segmenti da 3 a 10. Se tutti i segmenti inviati di nuovo sono arrivati correttamente, i segmenti da 5 a 10 sarebbero duplicati. Questo può portare a ritardi, congestioni e inefficienze.
I sistemi operativi host oggi in genere utilizzano una funzionalità TCP opzionale chiamata riconoscimento selettivo (SACK), negoziata durante l’handshake a tre vie. Se entrambi gli host supportano SACK, il ricevitore può riconoscere esplicitamente quali segmenti (byte) sono stati ricevuti, inclusi eventuali segmenti discontinui. L’host di invio dovrebbe quindi solo ritrasmettere i dati mancanti. Ad esempio, nella figura successiva, sempre utilizzando i numeri di segmento per semplicità, l’host A invia i segmenti da 1 a 10 all’host B. Se arrivano tutti i segmenti tranne i segmenti 3 e 4, l’host B può confermare di aver ricevuto i segmenti 1 e 2 (ACK 3) e riconoscere selettivamente i segmenti da 5 a 10 (SACK 5-10). L’host A dovrebbe solo inviare nuovamente i segmenti 3 e 4.
Nota: TCP in genere invia ACK per ogni altro pacchetto, ma altri fattori che esulano dall’ambito di questo argomento potrebbero alterare questo comportamento.
TCP utilizza i timer per sapere quanto tempo attendere prima di inviare nuovamente un segmento. Nella figura, riprodurre il video e fare clic sul collegamento per scaricare il file PDF. Il video e il file PDF esaminano la perdita e la ritrasmissione dei dati TCP.
TCP Flow Control – Window Size and Acknowledgments
TCP fornisce anche meccanismi per il controllo del flusso. Il controllo del flusso è la quantità di dati che la destinazione può ricevere ed elaborare in modo affidabile. Il controllo del flusso aiuta a mantenere l’affidabilità della trasmissione TCP regolando la velocità del flusso di dati tra origine e destinazione per una determinata sessione. Per fare ciò, l’intestazione TCP include un campo a 16 bit chiamato dimensione della finestra.
La figura mostra un esempio di dimensioni della finestra e riconoscimenti.
Esempio di dimensione della finestra TCP
La dimensione della finestra determina il numero di byte che possono essere inviati prima di attendere un riconoscimento. Il numero di riconoscimento è il numero del prossimo byte previsto.
La dimensione della finestra è il numero di byte che il dispositivo di destinazione di una sessione TCP può accettare ed elaborare contemporaneamente. In questo esempio, la dimensione della finestra iniziale del PC B per la sessione TCP è di 10.000 byte. A partire dal primo byte, numero di byte 1, l’ultimo byte che il PC A può inviare senza ricevere un riconoscimento è il byte 10.000. Questa è nota come finestra di invio del PC A. La dimensione della finestra è inclusa in ogni segmento TCP in modo che la destinazione possa modificare la dimensione della finestra in qualsiasi momento a seconda della disponibilità del buffer.
La dimensione iniziale della finestra viene concordata quando viene stabilita la sessione TCP durante l’handshake a tre vie. Il dispositivo di origine deve limitare il numero di byte inviati al dispositivo di destinazione in base alle dimensioni della finestra della destinazione. Solo dopo che il dispositivo di origine riceve una conferma che i byte sono stati ricevuti, può continuare a inviare altri dati per la sessione. In genere, la destinazione non attenderà la ricezione di tutti i byte della dimensione della finestra prima di rispondere con un riconoscimento. Man mano che i byte vengono ricevuti ed elaborati, la destinazione invierà conferme per informare l’origine che può continuare a inviare byte aggiuntivi.
Ad esempio, è tipico che il PC B non attenda fino a quando tutti i 10.000 byte sono stati ricevuti prima di inviare un riconoscimento. Ciò significa che il PC A può regolare la sua finestra di invio man mano che riceve riconoscimenti dal PC B. Come mostrato nella figura, quando il PC A riceve un riconoscimento con il numero di riconoscimento 2.921, che è il prossimo byte previsto. La finestra di invio del PC A incrementerà 2.920 byte. Ciò modifica la finestra di invio da 10.000 byte a 12.920. Il PC A può ora continuare a inviare altri 10.000 byte al PC B purché non invii più della sua nuova finestra di invio a 12.920.
Una destinazione che invia conferme mentre elabora i byte ricevuti e la regolazione continua della finestra di invio di origine sono note come finestre scorrevoli. Nell’esempio precedente, la finestra di invio del PC A aumenta o scorre di altri 2.921 byte da 10.000 a 12.920.
Se la disponibilità dello spazio del buffer della destinazione diminuisce, può ridurre le dimensioni della finestra per informare l’origine di ridurre il numero di byte che dovrebbe inviare senza ricevere un riconoscimento.
Nota: i dispositivi oggi utilizzano il protocollo di finestre scorrevoli. Il ricevitore in genere invia un riconoscimento dopo ogni due segmenti che riceve. Il numero di segmenti ricevuti prima di essere riconosciuti può variare. Il vantaggio delle finestre scorrevoli è che consente al mittente di trasmettere continuamente segmenti, purché il ricevitore riconosca i segmenti precedenti.
Controllo del flusso TCP – Dimensione massima del segmento (Maximum Segment Size – MSS)
Nella figura, la sorgente sta trasmettendo 1.460 byte di dati all’interno di ciascun segmento TCP. Si tratta in genere della dimensione massima del segmento (MSS) che il dispositivo di destinazione può ricevere. L’MSS fa parte del campo delle opzioni nell’intestazione TCP che specifica la massima quantità di dati, in byte, che un dispositivo può ricevere in un singolo segmento TCP. La dimensione MSS non include l’intestazione TCP. L’MSS è in genere incluso durante l’handshake a tre vie.
Un MSS comune è di 1.460 byte quando si utilizza IPv4. Un host determina il valore del suo campo MSS sottraendo le intestazioni IP e TCP dall’unità di trasmissione massima Ethernet (MTU – maximum transmission unit). Su un’interfaccia Ethernet, l’MTU predefinito è 1500 byte. Sottraendo l’intestazione IPv4 di 20 byte e l’intestazione TCP di 20 byte, la dimensione MSS predefinita sarà di 1460 byte, come mostrato nella figura.
Controllo del flusso TCP – Prevenzione della congestione
Quando si verifica una congestione su una rete, i pacchetti vengono scartati dal router sovraccarico. Quando i pacchetti contenenti segmenti TCP non raggiungono la loro destinazione, vengono lasciati senza riconoscimento. Determinando la velocità con cui i segmenti TCP vengono inviati ma non riconosciuti, la sorgente può assumere un certo livello di congestione della rete.
Ogni volta che si verifica una congestione, si verificherà altresì la ritrasmissione dei segmenti TCP persi dall’origine. Se la ritrasmissione non è adeguatamente controllata, la ritrasmissione aggiuntiva dei segmenti TCP può peggiorare ulteriormente la congestione. Non solo nuovi pacchetti con segmenti TCP vengono introdotti nella rete, ma anche l’effetto di feedback dei segmenti TCP ritrasmessi che sono stati persi si aggiungerà alla congestione. Per evitare e controllare la congestione, TCP utilizza diversi meccanismi, timer e algoritmi di gestione della congestione.
Se l’origine determina che i segmenti TCP non vengono riconosciuti o non vengono riconosciuti in modo tempestivo, può ridurre il numero di byte che invia prima di ricevere un riconoscimento. Come illustrato nella figura, il PC A rileva la presenza di congestione e, pertanto, riduce il numero di byte che invia prima di ricevere un riconoscimento dal PC B.
I numeri di riconoscimento sono per il prossimo byte previsto e non per un segmento. I numeri di segmento utilizzati sono semplificati a scopo illustrativo.
Si noti che è l’origine che sta riducendo il numero di byte non riconosciuti che invia e non la dimensione della finestra determinata dalla destinazione.
Nota: le spiegazioni dei meccanismi, dei timer e degli algoritmi di gestione della congestione effettivi esulano dallo scopo di questo corso.
Comunicazione UDP
UDP Low Overhead rispetto all’affidabilità
Come spiegato in precedenza, UDP è perfetto per le comunicazioni che devono essere veloci, come il VoIP. Questo argomento spiega in dettaglio perché UDP è perfetto per alcuni tipi di trasmissione. Come mostrato nella figura, UDP non stabilisce una connessione. UDP fornisce un trasporto di dati a basso sovraccarico perché ha un’intestazione di datagramma piccola e nessun traffico di gestione della rete.
Riassemblaggio del datagramma UDP
Come i segmenti con TCP, quando i datagrammi UDP vengono inviati a una destinazione, spesso prendono percorsi diversi e arrivano nell’ordine sbagliato. UDP non tiene traccia dei numeri di sequenza come fa TCP. UDP non ha modo di riordinare i datagrammi nel loro ordine di trasmissione, come mostrato nella figura.
Pertanto, UDP riassembla semplicemente i dati nell’ordine in cui sono stati ricevuti e li inoltra all’applicazione. Se la sequenza dei dati è importante per l’applicazione, l’applicazione stessa deve identificare la sequenza corretta e determinare come devono essere elaborati i dati.
UDP: senza connessione e inaffidabile
Processi e richieste del server UDP
Analogamente alle applicazioni basate su TCP, alle applicazioni server basate su UDP vengono assegnati numeri di porta noti o registrati, come mostrato nella figura. Quando queste applicazioni o processi sono in esecuzione su un server, accettano i dati abbinati al numero di porta assegnato. Quando UDP riceve un datagramma destinato a una di queste porte, inoltra i dati dell’applicazione all’applicazione appropriata in base al suo numero di porta.
Server UDP in ascolto richieste
Processi client UDP
Come con TCP, la comunicazione client-server viene avviata da un’applicazione client che richiede dati da un processo server. Il processo client UDP seleziona dinamicamente un numero di porta dall’intervallo di numeri di porta e lo utilizza come porta di origine per la conversazione. La porta di destinazione è in genere il numero di porta noto o registrato assegnato al processo del server.
Dopo che un client ha selezionato le porte di origine e di destinazione, la stessa coppia di porte viene utilizzata nell’intestazione di tutti i datagrammi della transazione. Per i dati restituiti al client dal server, i numeri di porta di origine e di destinazione nell’intestazione del datagramma sono invertiti.
Client che inviano richieste UDP
Il client 1 invia una richiesta DNS mentre il client 2 richiede i servizi di autenticazione RADIUS dello stesso server.
Porte di destinazione della richiesta UDP
Il client 1 invia una richiesta DNS utilizzando la porta di destinazione nota 53 mentre il client 2 richiede i servizi di autenticazione RADIUS utilizzando la porta di destinazione registrata 1812.
Porte di origine della richiesta UDP
Le richieste dei client generano dinamicamente i numeri di porta di origine. In questo caso, il client 1 utilizza la porta di origine 49152 e il client 2 utilizza la porta di origine 51152.
Destinazione risposta UDP
Quando il server risponde alle richieste del client, inverte le porte di destinazione e di origine della richiesta iniziale. Nella risposta del server alla richiesta DNS è ora la porta di destinazione 49152 e la risposta di autenticazione RADIUS è ora la porta di destinazione 51152.
Porte di origine della risposta UDP
Le porte di origine nella risposta del server sono le porte di destinazione originali nelle richieste iniziali.
Transport Layer – Riepilogo
I programmi a livello di applicazione generano dati che devono essere scambiati tra gli host di origine e di destinazione. Il livello di trasporto è responsabile delle comunicazioni logiche tra le applicazioni in esecuzione su host diversi. Il livello di trasporto include due protocolli: Transmission Control Protocol TCP e User Datagram Protocol UDP.
Monitoraggio delle singole conversazioni: a livello di trasporto, ogni set di dati che scorre tra un’applicazione di origine e un’applicazione di destinazione è noto come conversazione e viene monitorato separatamente. È responsabilità del livello di trasporto mantenere e tenere traccia di queste molteplici conversazioni.
Segmentazione dei dati e riassemblaggio dei segmenti: è responsabilità del livello di trasporto dividere i dati dell’applicazione in blocchi di dimensioni adeguate. A seconda del protocollo del livello di trasporto utilizzato, i blocchi del livello di trasporto sono chiamati segmenti o datagrammi.
Aggiungi informazioni di intestazione: il protocollo del livello di trasporto aggiunge anche informazioni di intestazione contenenti dati binari organizzati in diversi campi a ciascun blocco di dati.
Identificazione delle applicazioni: il livello di trasporto deve essere in grado di separare e gestire più comunicazioni con diverse esigenze di trasporto.
Conversation Multiplexing: l’invio di alcuni tipi di dati (ad esempio, un video in streaming) attraverso una rete, come un flusso di comunicazione completo, può consumare tutta la larghezza di banda disponibile. Il livello di trasporto utilizza la segmentazione e il multiplexing per consentire l’intercalazione di diverse conversazioni di comunicazione sulla stessa rete.
I protocolli del livello di trasporto specificano come trasferire i messaggi tra host e sono responsabili della gestione dei requisiti di affidabilità di una conversazione. Il livello di trasporto include i protocolli TCP e UDP.
TCP fornisce affidabilità e controllo del flusso utilizzando queste operazioni di base:
Numerare e tenere traccia dei segmenti di dati trasmessi a un host specifico da un’applicazione specifica
Riconoscere i dati ricevuti
Ritrasmettere tutti i dati non riconosciuti dopo un certo periodo di tempo
Sequenza di dati che potrebbero arrivare nell’ordine sbagliato
Invia i dati a una velocità efficiente accettabile dal destinatario
Per mantenere lo stato di una conversazione e tenere traccia delle informazioni, il TCP deve prima stabilire una connessione tra il mittente e il destinatario. Questo è il motivo per cui TCP è noto come protocollo orientato alla connessione.
UDP è un protocollo senza connessione. Poiché UDP non fornisce affidabilità o controllo del flusso, non richiede una connessione stabilita. Poiché UDP non tiene traccia delle informazioni inviate o ricevute tra il client e il server, UDP è noto anche come protocollo senza stato. UDP è anche noto come protocollo di consegna best-effort perché non vi è alcun riconoscimento che i dati siano stati ricevuti a destinazione. Con UDP, non ci sono processi a livello di trasporto che informano il mittente di una consegna riuscita. UDP è preferibile per applicazioni come VoIP. I riconoscimenti e la ritrasmissione rallenterebbero la consegna e renderebbero inaccettabile la conversazione vocale. UDP viene utilizzato anche dalle applicazioni di richiesta e risposta in cui i dati sono minimi e la ritrasmissione può essere eseguita rapidamente.
Per altre applicazioni è importante che tutti i dati arrivino e che possano essere elaborati nella sequenza corretta. Per questi tipi di applicazioni, TCP viene utilizzato come protocollo di trasporto. Ad esempio, applicazioni come database, browser Web e client di posta elettronica richiedono che tutti i dati inviati arrivino a destinazione nelle condizioni originali. Eventuali dati mancanti potrebbero corrompere una comunicazione, rendendola incompleta o illeggibile.
Panoramica TCP
Oltre a supportare le funzioni di base di segmentazione e riassemblaggio dei dati, TCP fornisce anche i seguenti servizi:
Stabilisce una sessione: TCP è un protocollo orientato alla connessione che negozia e stabilisce una connessione (o sessione) permanente tra i dispositivi di origine e di destinazione prima di inoltrare qualsiasi traffico. Attraverso l’istituzione della sessione, i dispositivi negoziano la quantità di traffico che può essere inoltrata in un determinato momento e i dati di comunicazione tra i due possono essere gestiti da vicino.
Garantisce una consegna affidabile: per molte ragioni, è possibile che un segmento venga danneggiato o perso completamente, mentre viene trasmesso sulla rete. TCP garantisce che ogni segmento inviato dall’origine arrivi a destinazione.
Fornisce la consegna nello stesso ordine: poiché le reti possono fornire più percorsi con velocità di trasmissione diverse, i dati possono arrivare nell’ordine sbagliato. Numerando e mettendo in sequenza i segmenti, TCP garantisce che i segmenti vengano riassemblati nell’ordine corretto.
Supporta il controllo del flusso: gli host di rete hanno risorse limitate (ad es. memoria e potenza di elaborazione). Quando TCP è consapevole che queste risorse sono sovraccaricate, può richiedere che l’applicazione mittente riduca la velocità del flusso di dati. Questo viene fatto dal TCP che regola la quantità di dati trasmessi dalla sorgente. Il controllo del flusso può impedire la necessità di ritrasmettere i dati quando le risorse dell’host ricevente sono sovraccariche.
TCP è un protocollo stateful, il che significa che tiene traccia dello stato della sessione di comunicazione. Per tenere traccia dello stato di una sessione, TCP registra quali informazioni ha inviato e quali informazioni sono state riconosciute. La sessione con stato inizia con l’istituzione della sessione e termina con la chiusura della sessione.
I dieci campi nell’intestazione TCP sono i seguenti:
Porta di origine: un campo a 16 bit utilizzato per identificare l’applicazione di origine in base al numero di porta.
Porta di destinazione: un campo a 16 bit utilizzato per identificare l’applicazione di destinazione in base al numero di porta.
Numero di sequenza: un campo a 32 bit utilizzato per il riassemblaggio dei dati.
Numero di riconoscimento: un campo a 32 bit utilizzato per indicare che i dati sono stati ricevuti e il byte successivo previsto dall’origine.
Lunghezza intestazione: un campo a 4 bit noto come “offset dati” che indica la lunghezza dell’intestazione del segmento TCP.
Riservato: un campo a 6 bit riservato per uso futuro.
Bit di controllo: un campo a 6 bit che include codici bit, o flag, che indicano lo scopo e la funzione del segmento TCP.
Dimensione finestra: campo a 16 bit utilizzato per indicare il numero di byte che possono essere accettati contemporaneamente.
Checksum: un campo a 16 bit utilizzato per il controllo degli errori dell’intestazione del segmento e dei dati.
Urgent: un campo a 16 bit utilizzato per indicare se i dati contenuti sono urgenti.
TCP è un buon esempio di come i diversi livelli della suite di protocolli TCP/IP abbiano ruoli specifici. TCP gestisce tutte le attività associate alla divisione del flusso di dati in segmenti, fornendo affidabilità, controllando il flusso di dati e riordinando i segmenti. TCP libera l’applicazione dalla necessità di gestire qualsiasi di queste attività. HTTP, FTP, SMTP e SSH possono semplicemente inviare il flusso di dati al livello di trasporto e utilizzare i servizi di TCP.
Panoramica UDP
UDP è un protocollo di trasporto leggero che offre la stessa segmentazione e riassemblaggio dei dati del TCP, ma senza l’affidabilità e il controllo del flusso del TCP.
Le funzionalità UDP includono quanto segue:
I dati vengono ricostruiti nell’ordine in cui vengono ricevuti.
Tutti i segmenti persi non vengono reinviati.
Non è prevista la creazione di una sessione.
L’invio non viene informato sulla disponibilità delle risorse.
UDP è un protocollo senza stato, ovvero né il client né il server tengono traccia dello stato della sessione di comunicazione. Se l’affidabilità è richiesta quando si utilizza UDP come protocollo di trasporto, deve essere gestito dall’applicazione.
I blocchi di comunicazione in UDP sono chiamati datagrammi o segmenti. Questi datagrammi vengono inviati al meglio dal protocollo del livello di trasporto. L’intestazione UDP è molto più semplice dell’intestazione TCP perché ha solo quattro campi e richiede 8 byte (cioè 64 bit).
I quattro campi nell’intestazione UDP sono i seguenti:
Porta di origine: un campo a 16 bit utilizzato per identificare l’applicazione di origine in base al numero di porta.
Porta di destinazione: un campo a 16 bit utilizzato per identificare l’applicazione di destinazione in base al numero di porta.
Lunghezza: un campo a 16 bit che indica la lunghezza dell’intestazione del datagramma UDP.
Checksum: un campo a 16 bit utilizzato per il controllo degli errori dell’intestazione e dei dati del datagramma.
Ci sono tre tipi di applicazioni che sono più adatte per UDP: video in diretta e applicazioni multimediali, semplici applicazioni di richiesta e risposta, applicazioni che gestiscono l’affidabilità da sole.
Numeri di porta
I protocolli del livello di trasporto TCP e UDP utilizzano i numeri di porta per gestire più conversazioni simultanee. I campi di intestazione TCP e UDP identificano un numero di porta dell’applicazione di origine e di destinazione. Il numero di porta di origine è associato all’applicazione di origine sull’host locale, mentre il numero di porta di destinazione è associato all’applicazione di destinazione sull’host remoto.
Le porte di origine e di destinazione sono posizionate all’interno del segmento. I segmenti vengono quindi incapsulati all’interno di un pacchetto IP. Il pacchetto IP contiene l’indirizzo IP dell’origine e della destinazione. La combinazione dell’indirizzo IP di origine e del numero di porta di origine o dell’indirizzo IP di destinazione e del numero di porta di destinazione è nota come socket.
Il socket viene utilizzato per identificare il server e il servizio richiesto dal client. Un socket client potrebbe avere questo aspetto, con 1099 che rappresenta il numero della porta di origine: 192.168.1.5:1099. Il socket su un server Web potrebbe essere 192.168.1.7:80. Insieme, questi due socket si combinano per formare una coppia di socket: 192.168.1.5:1099, 192.168.1.7:80. I socket consentono a più processi, in esecuzione su un client, di distinguersi l’uno dall’altro e a più connessioni a un processo server di essere distinti l’uno dall’altro.
IANA è l’organizzazione degli standard responsabile dell’assegnazione di vari standard di indirizzamento, inclusi i numeri di porta a 16 bit. I 16 bit utilizzati per identificare i numeri di porta di origine e di destinazione forniscono un intervallo di porte da 0 a 65535.
La IANA ha suddiviso la gamma di numeri nei seguenti tre gruppi di porte:
Porte note (da 0 a 1.023)
Porte registrate (da 1.024 a 49.151)
Porte private e/o dinamiche (da 49.152 a 65.535)
Le connessioni TCP inspiegabili possono rappresentare una grave minaccia per la sicurezza. Possono indicare che qualcosa o qualcuno è connesso all’host locale. Netstat è un’importante utility di rete che può essere utilizzata per verificare tali connessioni. Utilizzare il comando netstat per elencare i protocolli in uso, l’indirizzo locale e i numeri di porta, l’indirizzo esterno e i numeri di porta e lo stato della connessione. Per impostazione predefinita, il comando netstat tenterà di risolvere gli indirizzi IP in nomi di dominio e numeri di porta in applicazioni note.
Processo di comunicazione TCP
Il motivo per cui TCP è il protocollo migliore per alcune applicazioni è perché, a differenza di UDP, invia nuovamente i pacchetti scartati e il numero di pacchetti per indicare il loro ordine corretto prima della consegna. TCP può anche aiutare a mantenere il flusso di pacchetti in modo che i dispositivi non vengano sovraccaricati.
I numeri di sequenza vengono assegnati nell’intestazione di ciascun pacchetto per garantire che tutti i segmenti arrivino a destinazione nell’ordine corretto. Il numero di sequenza rappresenta il primo byte di dati del segmento TCP. Durante l’impostazione della sessione, viene impostato un ISN. Questo ISN rappresenta il valore iniziale dei byte trasmessi all’applicazione ricevente. Man mano che i dati vengono trasmessi durante la sessione, il numero di sequenza viene incrementato del numero di byte che sono stati trasmessi. Questo tracciamento dei byte di dati consente di identificare e riconoscere in modo univoco ogni segmento. I segmenti mancanti possono quindi essere identificati.
Il numero SEQ e il numero ACK sono usati insieme per confermare la ricezione dei byte di dati contenuti nei segmenti trasmessi. Il numero SEQ identifica il primo byte di dati nel segmento che viene trasmesso. TCP utilizza il numero ACK inviato all’origine per indicare il byte successivo che il destinatario si aspetta di ricevere. Questo si chiama riconoscimento delle aspettative.
TCP fornisce anche meccanismi per il controllo del flusso. Il controllo del flusso è la quantità di dati che la destinazione può ricevere ed elaborare in modo affidabile. Il controllo del flusso aiuta a mantenere l’affidabilità della trasmissione TCP regolando la velocità del flusso di dati tra origine e destinazione per una determinata sessione. Per fare ciò, l’intestazione TCP include un campo a 16 bit chiamato dimensione della finestra.
La dimensione della finestra determina il numero di byte che possono essere inviati prima di attendere un riconoscimento. Il numero di riconoscimento è il numero del prossimo byte previsto. La dimensione iniziale della finestra viene concordata quando viene stabilita la sessione TCP durante l’handshake a tre vie. Il dispositivo di origine deve limitare il numero di byte inviati al dispositivo di destinazione in base alle dimensioni della finestra della destinazione. Solo dopo che il dispositivo di origine riceve una conferma che i byte sono stati ricevuti, può continuare a inviare altri dati per la sessione.
L’MSS fa parte del campo delle opzioni nell’intestazione TCP che specifica la massima quantità di dati, in byte, che un dispositivo può ricevere in un singolo segmento TCP. La dimensione MSS non include l’intestazione TCP. L’MSS è in genere incluso durante l’handshake a tre vie.
Ogni volta che si verifica una congestione, si verificherà altresì la ritrasmissione dei segmenti TCP persi dall’origine. Se la ritrasmissione non è adeguatamente controllata, la ritrasmissione aggiuntiva dei segmenti TCP può peggiorare ulteriormente la congestione. Per evitare e controllare la congestione, TCP utilizza diversi meccanismi, timer e algoritmi di gestione della congestione.
Comunicazioni UDP
UDP non stabilisce una connessione. UDP fornisce un trasporto di dati a basso sovraccarico perché ha un’intestazione di datagramma piccola e nessun traffico di gestione della rete.
Come i segmenti con TCP, quando i datagrammi UDP vengono inviati a una destinazione, spesso prendono percorsi diversi e arrivano nell’ordine sbagliato. UDP non tiene traccia dei numeri di sequenza come fa TCP. Pertanto, UDP riassembla semplicemente i dati nell’ordine in cui sono stati ricevuti e li inoltra all’applicazione.
Analogamente alle applicazioni basate su TCP, alle applicazioni server basate su UDP vengono assegnati numeri di porta noti o registrati. Quando queste applicazioni o processi sono in esecuzione su un server, accettano i dati abbinati al numero di porta assegnato. Quando UDP riceve un datagramma destinato a una di queste porte, inoltra i dati dell’applicazione all’applicazione appropriata in base al suo numero di porta.
Dopo che un client ha selezionato le porte di origine e di destinazione, la stessa coppia di porte viene utilizzata nell’intestazione di tutti i datagrammi della transazione. Per i dati restituiti al client dal server, i numeri di porta di origine e di destinazione nell’intestazione del datagramma sono invertiti.
La riga di comando di Cisco IOS
IOS Navigation
L’interfaccia della riga di comando di Cisco IOS
L’interfaccia della riga di comando (command line interface – CLI) di Cisco IOS è un programma basato su testo che consente di immettere ed eseguire i comandi di Cisco IOS per configurare, monitorare e gestire i dispositivi Cisco. L’interfaccia a riga di comando di Cisco può essere utilizzata con attività di gestione in banda o fuori banda.
I comandi CLI vengono utilizzati per modificare la configurazione del dispositivo e per visualizzare lo stato corrente dei processi sul router. Per gli utenti esperti, la CLI offre molte funzionalità che consentono di risparmiare tempo per la creazione di configurazioni sia semplici che complesse. Quasi tutti i dispositivi di rete Cisco utilizzano una CLI simile. Quando il router ha completato la sequenza di accensione e viene visualizzato il prompt Router>, è possibile utilizzare la CLI per immettere i comandi Cisco IOS, come mostrato nell’output del comando.
I tecnici che hanno familiarità con i comandi IOS e il funzionamento della CLI trovano facile monitorare e configurare una varietà di dispositivi di rete diversi perché gli stessi comandi di base vengono utilizzati per configurare uno switch e un router. La CLI dispone di un ampio sistema di guida che assiste gli utenti nella configurazione e nel monitoraggio dei dispositivi.
Primary Command Modes
Tutti i dispositivi di rete richiedono un sistema operativo e possono essere configurati utilizzando la CLI o una GUI. L’utilizzo della CLI può fornire all’amministratore di rete un controllo e una flessibilità più precisi rispetto all’utilizzo della GUI. Questo argomento discute l’utilizzo della CLI per navigare in Cisco IOS.
Come funzione di sicurezza, il software Cisco IOS separa l’accesso alla gestione nelle seguenti due modalità di comando:
Modalità EXEC utente: questa modalità ha capacità limitate ma è utile per le operazioni di base. Consente solo un numero limitato di comandi di monitoraggio di base ma non consente l’esecuzione di comandi che potrebbero modificare la configurazione del dispositivo. La modalità EXEC dell’utente è identificata dal prompt CLI che termina con il simbolo >.
Modalità EXEC con privilegi: per eseguire i comandi di configurazione, un amministratore di rete deve accedere alla modalità EXEC con privilegi. Le modalità di configurazione superiori, come la modalità di configurazione globale, possono essere raggiunte solo dalla modalità EXEC privilegiata. La modalità EXEC privilegiata può essere identificata dal prompt che termina con il simbolo #.
La tabella riassume le due modalità e visualizza i prompt CLI predefiniti di uno switch e router Cisco.
Una nota sulle attività di verifica della sintassi
Quando stai imparando a modificare le configurazioni dei dispositivi, potresti voler iniziare in un ambiente sicuro e non di produzione prima di provarlo su apparecchiature reali. Esistono diversi strumenti di simulazione per aiutarti a sviluppare le tue capacità di configurazione e risoluzione dei problemi. Poiché si tratta di strumenti di simulazione, in genere non dispongono di tutte le funzionalità delle apparecchiature reali. Uno di questi strumenti è il Controllo sintassi. In ogni Syntax Checker, ti viene data una serie di istruzioni per inserire una serie specifica di comandi. Non è possibile avanzare in Syntax Checker a meno che non venga immesso il comando esatto e completo come specificato. Strumenti di simulazione più avanzati, come Packet Tracer, ti consentono di inserire comandi abbreviati, proprio come faresti su apparecchiature reali.
Controllo sintassi – Navigazione tra le modalità IOS
Utilizzare l’attività Controllo sintassi per navigare tra le righe di comando IOS su uno switch.
Enter privileged EXEC mode using the enable command.
Switch>enable
Return to user EXEC mode using the disable command.
Switch#disable
Re-enter privileged EXEC mode.
Switch>enable
Enter global configuration mode using the configure terminal command.
Switch#configure terminal
Exit global configuration mode and return to privileged EXEC mode using the exit command.
Switch(config)#exit
Re-enter global configuration mode.
Switch#configure terminal
Enter line subconfiguration mode for the console port using the line console 0 command.
Switch(config)#line console 0
Return to global configuration mode using the exit command.
Switch(config-line)#exit
Enter VTY line subconfiguration mode using the line vty 0 15 command.
Switch(config)#line vty 0 15
Return to global configuration mode.
Switch(config-line)#exit
Enter the VLAN 1 interface subconfiguration mode using the interface vlan 1 command.
Switch(config)#interface vlan 1
From interface configuration mode, switch to line console subconfiguration mode using the line console 0 global configuration command.
Switch(config-if)#line console 0
Return to privileged EXEC mode using the end command.
Switch(config-line)#end
You successfully navigated between the various IOS command line modes.
La struttura di comando
Struttura dei comandi IOS di base
Un amministratore di rete deve conoscere la struttura dei comandi IOS di base per poter utilizzare la CLI per la configurazione del dispositivo.
Un dispositivo Cisco IOS supporta molti comandi. Ogni comando IOS ha un formato specifico, o sintassi, e può essere eseguito solo nella modalità appropriata. La sintassi generale per un comando, mostrata nella figura, è il comando seguito da eventuali parole chiave e argomenti appropriati.
Parola chiave – Questo è un parametro specifico definito nel sistema operativo (nella figura, protocolli ip).
Argomento – Questo non è predefinito; è un valore o una variabile definita dall’utente (nella figura, 192.168.10.5).
Dopo aver immesso ogni comando completo, comprese eventuali parole chiave e argomenti, premere il tasto Invio per inviare il comando all’interprete dei comandi.
Sintassi dei comandi IOS
Un comando potrebbe richiedere uno o più argomenti. Per determinare le parole chiave e gli argomenti richiesti per un comando, fare riferimento alla sintassi del comando. La sintassi fornisce il modello, o formato, che deve essere utilizzato quando si immette un comando.
Come identificato nella tabella, il testo in grassetto indica i comandi e le parole chiave immessi come mostrato. Il testo in corsivo indica un argomento per il quale l’utente fornisce il valore.
Ad esempio, la sintassi per l’utilizzo del comando description è descriptionstring. L’argomento è un valore stringa fornito dall’utente. Il comando description viene in genere utilizzato per identificare lo scopo di un’interfaccia. Ad esempio, immettendo il comando description Connects to the main headquarter office switch, descrive dove si trova l’altro dispositivo alla fine della connessione.
I seguenti esempi dimostrano le convenzioni utilizzate per documentare e utilizzare i comandi IOS:
pingip-address – Il comando è ping e l’argomento definito dall’utente di indirizzo-ip è l’indirizzo IP del dispositivo di destinazione. Ad esempio, ping 10.10.10.5.
tracerouteip-address – Il comando è traceroute e l’argomento definito dall’utente di ip-address è l’indirizzo IP del dispositivo di destinazione. Ad esempio, traceroute 192.168.254.254.
Se un comando è complesso con più argomenti, potresti vederlo rappresentato in questo modo:
Il comando sarà in genere seguito da una descrizione dettagliata del comando e da ciascun argomento nel Cisco IOS Command Reference.
Il Cisco IOS Command Reference è l’ultima fonte di informazioni per un particolare comando IOS.
Tasti di scelta rapida e scorciatoie
La CLI IOS fornisce tasti di scelta rapida e scorciatoie che semplificano la configurazione, il monitoraggio e la risoluzione dei problemi.
I comandi e le parole chiave possono essere abbreviati al numero minimo di caratteri che identificano una selezione univoca. Ad esempio, il comando configure può essere abbreviato in conf perché configure è l’unico comando che inizia con conf. Una versione ancora più breve, con, non funzionerà perché più di un comando inizia con con. Le parole chiave possono anche essere abbreviate.
La tabella elenca le sequenze di tasti per migliorare la modifica della riga di comando.
Nota: mentre il tasto Delete in genere elimina il carattere a destra del prompt, la struttura dei comandi IOS non riconosce il tasto Delete.
Quando l’output di un comando produce più testo di quello che può essere visualizzato in una finestra di terminale, l’IOS visualizzerà un prompt “–More–”. La tabella seguente descrive le sequenze di tasti che possono essere utilizzate quando viene visualizzato questo prompt.
Questa tabella elenca i comandi utilizzati per uscire da un’operazione.
View Device Information
Cisco IOS Show Commands
Cisco IOS fornisce comandi per verificare il funzionamento delle interfacce router e switch.
I comandi show della CLI di Cisco IOS visualizzano informazioni rilevanti sulla configurazione e il funzionamento del dispositivo. I tecnici di rete utilizzano ampiamente i comandi show per visualizzare i file di configurazione, controllare lo stato delle interfacce e dei processi del dispositivo e verificare lo stato operativo del dispositivo. Lo stato di quasi ogni processo o funzione del router può essere visualizzato utilizzando un comando show.
I comandi show comunemente usati e quando usarli sono elencati nella tabella.
show running-config
Verifica la configurazione e le impostazioni correnti.
show interfaces
Verifica lo stato dell’interfaccia e visualizza eventuali messaggi di errore.
show ip interface
Verifica le informazioni di livello 3 di un’interfaccia.
show arp
Verifica l’elenco degli host conosciuti sulla LAN Ethernet locale.
show ip route
Verifica le informazioni di instradamento di livello 3.
show protocols
Verifica quali protocolli sono operativi.
show version
Verifica la memoria, le interfacce e le licenze del dispositivo.
The Cisco IOS Command Line – Riepilogo
Navigate the IOS
La CLI di Cisco IOS è un programma basato su testo che consente di immettere ed eseguire i comandi di Cisco IOS per configurare, monitorare e gestire i dispositivi Cisco. L’interfaccia a riga di comando di Cisco può essere utilizzata con attività di gestione in banda o fuori banda.
I comandi CLI vengono utilizzati per modificare la configurazione del dispositivo e per visualizzare lo stato corrente dei processi sul router. Quando il router ha completato la sequenza di accensione e viene visualizzato il prompt Router>, è possibile utilizzare la CLI per immettere i comandi Cisco IOS.
Come funzione di sicurezza, il software Cisco IOS separa l’accesso alla gestione nelle seguenti due modalità di comando:
Modalità EXEC utente: questa modalità è utile per le operazioni di base. Consente un numero limitato di comandi di monitoraggio di base ma non consente l’esecuzione di comandi che potrebbero modificare la configurazione del dispositivo. La modalità EXEC dell’utente è identificata dal prompt CLI che termina con il simbolo >.
Modalità EXEC con privilegi: per eseguire i comandi di configurazione, un amministratore di rete deve accedere alla modalità EXEC con privilegi. La modalità EXEC privilegiata può essere identificata dal prompt che termina con il simbolo #. Le modalità di configurazione superiori, come la global configuration mode, possono essere raggiunte solo dalla modalità EXEC privilegiata. La modalità di configurazione globale è identificata dal prompt della CLI che termina con (config)#.
I comandi utilizzati per navigare tra le diverse modalità di comando IOS sono:
enable
disable
configure terminal
exit
end
Ctrl+Z
line console 0
line vty 0 15
interface vlan 1
The Command Structure
Ogni comando IOS ha un formato specifico, o sintassi, e può essere eseguito solo nella modalità appropriata. La sintassi generale per un comando è il comando seguito da eventuali parole chiave e argomenti appropriati. La parola chiave è un parametro specifico definito nel sistema operativo. L’argomento non è predefinito; è un valore o una variabile definita dall’utente.
La sintassi fornisce il modello, o formato, che deve essere utilizzato quando si immette un comando. Il testo in grassetto indica i comandi e le parole chiave immessi come mostrato.
Il testo in corsivo indica un argomento per il quale l’utente fornisce il valore.
Le parentesi quadre [x] indicano un elemento facoltativo (parola chiave o argomento).
Le parentesi graffe {x} indicano un elemento obbligatorio (parola chiave o argomento).
Build a Small Cisco Network
Basic Switch Configuration
Allo switch Cisco devono essere assegnate solo le informazioni di sicurezza di base prima di essere connesso alla rete. Gli elementi solitamente configurati su uno switch LAN includono: nome host, informazioni sull’indirizzo IP di gestione, password e informazioni descrittive.
Il nome host dello switch è il nome configurato del dispositivo. Proprio come a ogni computer o stampante viene assegnato un nome, le apparecchiature di rete devono essere configurate con un nome descrittivo. È utile se il nome del dispositivo include la posizione in cui verrà installato lo switch. Un esempio potrebbe essere: SW_Bldg_R-Room_216.
Un indirizzo IP di gestione è necessario solo se si prevede di configurare e gestire lo switch tramite una connessione in banda sulla rete. Un indirizzo di gestione consente di raggiungere il dispositivo tramite client Telnet, SSH o HTTP. Le informazioni sull’indirizzo IP che devono essere configurate su uno switch sono essenzialmente le stesse configurate su un PC: indirizzo IP, subnet mask e gateway predefinito.
Per rendere sicuro uno switch LAN Cisco, è necessario configurare le password su ciascuno dei vari metodi di accesso alla riga di comando. I requisiti minimi includono l’assegnazione di password ai metodi di accesso remoto, come Telnet, SSH e la connessione alla console. È inoltre necessario assegnare una password alla modalità privilegiata in cui è possibile apportare modifiche alla configurazione.
Nota: Telnet invia il nome utente e la password in chiaro e non è considerato sicuro. SSH crittografa il nome utente e la password ed è, quindi, un metodo più sicuro.
Configuration Tasks
Prima di configurare uno switch, rivedere le seguenti attività iniziali di configurazione dello switch:
Configura il nome del dispositivo:
hostnamename
Secure user EXEC mode:
line console 0
passwordpassword
login
Secure remote Telnet / SSH access:
line vty 0 15
passwordpassword
login
Secure privileged EXEC mode:
enable secretpassword
Proteggi tutte le password nel file di configurazione:
service password-encryption
Fornire notifica legale:
banner motddelimiter message delimiter
Configurare l’SVI di gestione:
interface vlan 1
ip addressip-address subnet-mask
no shutdown
Salva la configurazione:
copy running-config startup-config
Sample Switch Configuration
Cambiare la configurazione dell’interfaccia virtuale
Per accedere allo switch in remoto, è necessario configurare un indirizzo IP e una subnet mask sull’interfaccia virtuale dello switch (SVI). Per configurare un SVI su uno switch, utilizzare il comando interface vlan 1 global configuration. Vlan 1 non è un’interfaccia fisica reale ma virtuale. Successivamente, assegnare un indirizzo IPv4 utilizzando il comando di configurazione dell’interfaccia ip addressip-address subnet-mask. Infine, abilita l’interfaccia virtuale utilizzando il comando di configurazione dell’interfaccia no shutdown.
Dopo che lo switch è stato configurato con questi comandi, lo switch dispone di tutti gli elementi IPv4 pronti per la comunicazione sulla rete locale.
Nota: analogamente agli host Windows, anche gli switch configurati con un indirizzo IPv4 in genere devono disporre di un gateway predefinito assegnato. Questo può essere fatto usando il comando di configurazione globale ip default-gatewayip-address. Il parametro ip-address sarebbe l’indirizzo IPv4 del router locale sulla rete, come mostrato nell’esempio. Tuttavia, in questo argomento configurerai solo una rete con switch e host. I router verranno configurati successivamente.
Configurare le impostazioni iniziali del router
Le seguenti attività devono essere completate durante la configurazione delle impostazioni iniziali su un router.
Step 1. Configurare il nome del dispositivo.
Step 2. Secure privileged EXEC mode.
Step 3. Secure user EXEC mode.
Step 4. Secure remote Telnet / SSH access.
Step 5. Secure all passwords in the config file.
Step 6. Provide legal notification.
Step 7. Save the configuration.
Esempio di configurazione di base del router
In questo esempio, il router R1 verrà configurato con le impostazioni iniziali. Per configurare il nome del dispositivo per R1, utilizzare i seguenti comandi.
Nota: notare come il prompt del router ora visualizza il nome host del router.
Tutti gli accessi al router devono essere protetti. La modalità EXEC privilegiata fornisce all’utente l’accesso completo al dispositivo e alla relativa configurazione, pertanto è necessario proteggerlo.
I seguenti comandi proteggono la modalità EXEC con privilegi e la modalità EXEC dell’utente, abilitano l’accesso remoto Telnet e SSH e crittografano tutte le password in testo normale (ad esempio, l’EXEC dell’utente e la linea vty). È molto importante utilizzare una password complessa quando si protegge la modalità EXEC privilegiata perché questa modalità consente l’accesso alla configurazione del dispositivo.
L’avviso legale avverte gli utenti che il dispositivo dovrebbe essere accessibile solo agli utenti autorizzati. La notifica legale è configurata come segue:
Se il router dovesse essere configurato con i comandi precedenti e perdesse accidentalmente l’alimentazione, la configurazione del router andrebbe persa. Per questo motivo è importante salvare la configurazione quando vengono implementate le modifiche. Il seguente comando salva la configurazione nella NVRAM:
Enter global configuration mode to configure the name of the router as “R1”.
Router>enable
Router#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Router(config)#hostname R1
Configure ’class’ as the secret password.
R1(config)#enable secret class
Configure ’cisco’ as the console line password, require users to login, and return to global configuration mode.
R1(config)#line console 0
R1(config-line)#password cisco
R1(config-line)#login
R1(config-line)#exit
For vty lines 0 through 4, configure ’cisco’ as the password, require users to login, enable SSH and Telnet access, and return to global configuration mode.
R1(config)#line vty 0 4
R1(config-line)#password cisco
R1(config-line)#login
R1(config-line)#transport input ssh telnet
R1(config-line)#exit
Encrypt all clear text passwords.
R1(config)#service password-encryption
Enter the banner ’Authorized Access Only!’ and use # as the delimiting character.
R1(config)#banner motd #Authorized Access Only!#
Exit global configuration mode.
R1(config)#exit
R1#
You have successfully configured the initial settings on router R1.
Mettere in sicurezza i dispositivi
Suggerimenti per la password
Per proteggere i dispositivi di rete, è importante utilizzare password complesse. Ecco le linee guida standard da seguire:
Utilizzare una password lunga almeno otto caratteri, preferibilmente 10 o più caratteri. Una password più lunga è una password più sicura.
Rendi le password complesse. Includere un mix di lettere maiuscole e minuscole, numeri, simboli e spazi, se consentito.
Evita password basate sulla ripetizione, parole comuni del dizionario, sequenze di lettere o numeri, nomi utente, nomi di parenti o animali domestici, informazioni biografiche, come date di nascita, numeri ID, nomi di antenati o altre informazioni facilmente identificabili.
Digitare deliberatamente una password in modo errato. Ad esempio, Smith = Smyth = 5mYth o Security = 5ecur1ty.
Cambia spesso le password. Se una password viene inconsapevolmente compromessa, la finestra di opportunità per l’autore della minaccia di utilizzare la password è limitata.
Non annotare le password e lasciarle in luoghi ovvi come sulla scrivania o sul monitor.
Le tabelle mostrano esempi di password complesse e deboli.
Sui router Cisco, gli spazi iniziali vengono ignorati per le password, ma gli spazi dopo il primo carattere no. Pertanto, un metodo per creare una password complessa consiste nell’usare la barra spaziatrice e creare una frase composta da molte parole. Questa è chiamata passphrase. Una passphrase è spesso più facile da ricordare di una semplice password. È anche più lungo e più difficile da indovinare.
Accesso remoto sicuro
Esistono diversi modi per accedere a un dispositivo per eseguire attività di configurazione. Uno di questi modi consiste nell’utilizzare un PC collegato alla porta della console sul dispositivo. Questo tipo di connessione viene spesso utilizzato per la configurazione iniziale del dispositivo.
L’impostazione di una password per l’accesso alla connessione della console viene eseguita in modalità di configurazione globale. Questi comandi impediscono agli utenti non autorizzati di accedere alla modalità utente dalla porta della console.
Quando il dispositivo è connesso alla rete, è possibile accedervi tramite la connessione di rete tramite SSH o Telnet. SSH è il metodo preferito perché è più sicuro. Quando si accede al dispositivo tramite la rete, viene considerata una connessione vty. La password deve essere assegnata alla porta vty. La seguente configurazione viene utilizzata per abilitare l’accesso SSH allo switch.
Un esempio di configurazione è mostrato nella finestra di comando.
Per impostazione predefinita, molti switch Cisco supportano fino a 16 linee vty numerate da 0 a 15. Il numero di linee vty supportate su un router Cisco varia in base al tipo di router e alla versione IOS. Tuttavia, cinque è il numero più comune di linee vty configurate su un router. Queste linee sono numerate da 0 a 4 per impostazione predefinita, anche se è possibile configurare linee aggiuntive. È necessario impostare una password per tutte le linee vty disponibili. La stessa password può essere impostata per tutte le connessioni.
Per verificare che le password siano impostate correttamente, utilizzare il comando show running-config. Queste password sono memorizzate nella configurazione in esecuzione in testo normale. È possibile impostare la crittografia su tutte le password memorizzate all’interno del router in modo che non vengano lette facilmente da persone non autorizzate. Il comando di configurazione globale service password-encryption assicura che tutte le password siano crittografate.
Con l’accesso remoto protetto sullo switch, ora puoi configurare SSH.
Abilita SSH
Prima di configurare SSH, lo switch deve essere configurato minimamente con un nome host univoco e le impostazioni di connettività di rete corrette.
Step 1. Verificare il supporto SSH.
Utilizzare il comando show ip ssh per verificare che lo switch supporti SSH. Se lo switch non esegue un IOS che supporta le funzionalità crittografiche, questo comando non viene riconosciuto.
Step 2. Configurare il dominio IP.
Configurare il nome di dominio IP della rete utilizzando il comando ip domain-namedomain-name global configuration mode. Nella configurazione di esempio riportata di seguito, il valore del domain-name è cisco.com.
Step 3. Genera coppie di chiavi RSA.
Non tutte le versioni dell’IOS sono predefinite per SSH versione 2 e SSH versione 1 presenta difetti di sicurezza noti. Per configurare SSH versione 2, eseguire il comando ip ssh version 2 global configuration mode. La generazione di una coppia di chiavi RSA abilita automaticamente SSH. Utilizzare il comando crypto key generate rsa global configuration mode per abilitare il server SSH sullo switch e generare una coppia di chiavi RSA. Durante la generazione delle chiavi RSA, all’amministratore viene richiesto di inserire una lunghezza del modulo. La configurazione di esempio nella figura utilizza una dimensione del modulo di 1.024 bit. Una lunghezza del modulo maggiore è più sicura, ma richiede più tempo per la generazione e l’utilizzo.
Nota: per eliminare la coppia di chiavi RSA, utilizzare il comando crypto key zeroize rsa global configuration mode. Dopo l’eliminazione della coppia di chiavi RSA, il server SSH viene disabilitato automaticamente.
Step 4. Configurare l’autenticazione utente.
Il server SSH può autenticare gli utenti localmente o utilizzare un server di autenticazione. Per utilizzare il metodo di autenticazione locale, creare una coppia nome utente e password con il comando usernameusernamesecretpassword global configuration mode. Nell’esempio, all’utente admin viene assegnata la password ccna.
Step 5. Configurare le linee vty.
Abilitare il protocollo SSH sulle linee vty utilizzando il comando transport input ssh line configuration mode. Catalyst 2960 ha linee vty che vanno da 0 a 15. Questa configurazione impedisce le connessioni non SSH (come Telnet) e limita lo switch ad accettare solo connessioni SSH. Utilizzare il comando line vty global configuration mode e quindi il comando login local line configuration mode per richiedere l’autenticazione locale per le connessioni SSH dal database dei nomi utente locale.
Step 6. Abilita SSH versione 2.
Per impostazione predefinita, SSH supporta entrambe le versioni 1 e 2. Quando si supportano entrambe le versioni, nell’output di show ip ssh viene visualizzato come supporto della versione 1.99. La versione 1 presenta vulnerabilità note. Per questo motivo, si consiglia di abilitare solo la versione 2. Abilitare la versione SSH utilizzando il comando di configurazione globale ip ssh version 2.
Controllo sintassi – Configura SSH
Utilizzare questo controllo sintassi per configurare SSH sullo switch S1
Set the domain name to cisco.com and generate the 1024 bit rsa key.
S1(config)#ip domain-name cisco.com
S1(config)#crypto key generate rsa
The name for the keys will be: S1.cisco.com
Choose the size of the key modulus in the range of 360 to 4096 for your General Purpose Keys. Choosing a key modulus greater than 512 may take a few minutes.
How many bits in the modulus [512]:1024
% Generating 1024 bit RSA keys, keys will be non-exportable...
[OK] (elapsed time was 4 seconds)
S1(config)#
*Mar 1 02:20:18.529: %SSH-5-ENABLED: SSH 1.99 has been enabled
Create a local user admin with the password ccna. Set all vty lines to use ssh and local login for remote connections. Exit out to global configuration mode.
S1(config)#username admin secret ccna
S1(config)#line vty 0 15
S1(config-line)#transport input ssh
S1(config-line)#login local
S1(config-line)#exit
S1(config)#
%SYS-5-CONFIG_I: Configured from console by console
Configure S1 to use SSH 2.0.
S1(config)#ip ssh version 2
S1(config)#
You successfully configured SSH on all VTY lines.
Verificare SSH
Su un PC, un client SSH come PuTTY viene utilizzato per connettersi a un server SSH. Per gli esempi sono stati configurati:
Nella figura, il tecnico sta avviando una connessione SSH all’indirizzo IPv4 della VLAN SVI di S1. Viene visualizzato il software del terminale PuTTY.
Dopo aver fatto clic su Apri in PuTTY, all’utente viene richiesto un nome utente e una password. Utilizzando la configurazione dell’esempio precedente, vengono immessi il nome utente admin e la password ccna. Dopo aver immesso la combinazione corretta, l’utente è connesso tramite SSH alla CLI sullo switch Catalyst 2960.
Per visualizzare i dati di versione e configurazione per SSH sul dispositivo configurato come server SSH, utilizzare il comando show ip ssh. Nell’esempio, SSH versione 2 è abilitato. Per verificare le connessioni SSH al dispositivo, utilizzare il comando show ssh.
Configurare il gateway predefinito
Gateway predefinito su un host
Se la tua rete locale ha un solo router, sarà il router del gateway e tutti gli host e gli switch sulla tua rete devono essere configurati con queste informazioni. Se la tua rete locale ha più router, devi selezionarne uno come router gateway predefinito. Questo argomento spiega come configurare il gateway predefinito su host e switch.
Affinché un dispositivo finale possa comunicare sulla rete, deve essere configurato con le informazioni sull’indirizzo IP corrette, incluso l’indirizzo del gateway predefinito. Il gateway predefinito viene utilizzato solo quando l’host desidera inviare un pacchetto a un dispositivo su un’altra rete. L’indirizzo del gateway predefinito è in genere l’indirizzo dell’interfaccia del router collegato alla rete locale dell’host. L’indirizzo IP del dispositivo host e l’indirizzo dell’interfaccia del router devono trovarsi nella stessa rete.
Ad esempio, si supponga una topologia di rete IPv4 costituita da un router che interconnette due LAN separate. G0/0/0 è connesso alla rete 192.168.10.0, mentre G0/0/1 è connesso alla rete 192.168.11.0. Ciascun dispositivo host è configurato con l’indirizzo gateway predefinito appropriato.
In questo esempio, se PC1 invia un pacchetto a PC2, il gateway predefinito non viene utilizzato. Invece, PC1 indirizza il pacchetto con l’indirizzo IPv4 di PC2 e inoltra il pacchetto direttamente a PC2 attraverso lo switch.
Cosa succede se PC1 ha inviato un pacchetto a PC3? PC1 indirizzerebbe il pacchetto con l’indirizzo IPv4 di PC3, ma inoltrerebbe il pacchetto al suo gateway predefinito, che è l’interfaccia G0/0/0 di R1. Il router accetta il pacchetto e accede alla sua tabella di instradamento per determinare che G0/0/1 è l’interfaccia di uscita appropriata in base all’indirizzo di destinazione. R1 quindi inoltra il pacchetto fuori dall’interfaccia appropriata per raggiungere PC3.
Lo stesso processo si verificherebbe su una rete IPv6, sebbene ciò non sia mostrato nella topologia. I dispositivi userebbero l’indirizzo IPv6 del router locale come gateway predefinito.
Gateway predefinito su uno switch
Uno switch che interconnette i computer client è in genere un dispositivo di livello 2. Pertanto, uno switch di livello 2 non richiede un indirizzo IP per funzionare correttamente. Tuttavia, è possibile configurare una configurazione IP su uno switch per fornire a un amministratore l’accesso remoto allo switch.
Per connettersi e gestire uno switch su una rete IP locale, deve disporre di un’interfaccia virtuale dello switch (SVI) configurata. L’SVI è configurata con un indirizzo IPv4 e una subnet mask sulla LAN locale. Lo switch deve inoltre disporre di un indirizzo gateway predefinito configurato per gestire in remoto lo switch da un’altra rete.
L’indirizzo del gateway predefinito è in genere configurato su tutti i dispositivi che comunicheranno oltre la loro rete locale.
Per configurare un gateway predefinito IPv4 su uno switch, utilizzare il comando di configurazione globale ip default-gatewayip-address. L’indirizzo IP configurato è l’indirizzo IPv4 dell’interfaccia del router locale connesso allo switch.
La figura mostra un amministratore che stabilisce una connessione remota per commutare S1 su un’altra rete.
In questo esempio, l’host amministratore utilizzerà il proprio gateway predefinito per inviare il pacchetto all’interfaccia G0/0/1 di R1. R1 inoltrerebbe il pacchetto a S1 dalla sua interfaccia G0/0/0. Poiché l’indirizzo IPv4 di origine del pacchetto proveniva da un’altra rete, S1 richiederebbe un gateway predefinito per inoltrare il pacchetto all’interfaccia G0/0/0 di R1. Pertanto, S1 deve essere configurato con un gateway predefinito per poter rispondere e stabilire una connessione SSH con l’host amministrativo.
Nota: i pacchetti originati dai computer host collegati allo switch devono già avere l’indirizzo del gateway predefinito configurato sui rispettivi sistemi operativi del computer host.
Uno switch per gruppi di lavoro può anche essere configurato con un indirizzo IPv6 su un SVI. Tuttavia, lo switch non richiede la configurazione manuale dell’indirizzo IPv6 del gateway predefinito. Lo switch riceverà automaticamente il gateway predefinito dal messaggio ICMPv6 Router Advertisement inviato dal router.
Controllo sintassi – Configurare il gateway predefinito
Utilizzare questo correttore di sintassi per esercitarsi nella configurazione del gateway predefinito di uno switch di livello 2.
Enter global configuration mode.
S1#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Configure 192.168.10.1 as the default gateway for S1.
S1(config)#ip default-gateway 192.168.10.1
S1(config)#
You have successfully set the default gateway on switch S1.
Costruire una piccola rete Cisco – Riepilogo
Basic Switch Configuration
Gli elementi da configurare su uno switch LAN includono nome host, informazioni sull’indirizzo IP di gestione, password e informazioni descrittive. Un indirizzo di gestione consente di raggiungere il dispositivo tramite client Telnet, SSH o HTTP. Le informazioni sull’indirizzo IP che devono essere configurate su uno switch includono l’indirizzo IP, la subnet mask e il gateway predefinito. Per proteggere uno switch LAN Cisco, configurare le password su ciascuno dei vari metodi di accesso alla riga di comando. Assegna le password ai metodi di accesso remoto, come Telnet, SSH e la connessione alla console. Assegnare anche una password alla modalità privilegiata in cui è possibile apportare modifiche alla configurazione.
Per accedere allo switch in remoto, configurare un indirizzo IP e una subnet mask su SVI. Utilizzare il comando di configurazione globale interface vlan 1. Assegnare un indirizzo IPv4 utilizzando il comando di configurazione dell’interfaccia ip addressip-address subnet-mask. Infine, abilita l’interfaccia virtuale utilizzando il comando di configurazione dell’interfaccia no shutdown. Dopo che lo switch è stato configurato con questi comandi, lo switch dispone di tutti gli elementi IPv4 pronti per la comunicazione sulla rete.
Step 5. Proteggi tutte le password nel file di configurazione.
Step 6. Fornire notifica legale.
Step 7. Salva la configurazione.
Tutti gli accessi al router devono essere protetti. La modalità EXEC privilegiata fornisce all’utente l’accesso completo al dispositivo e alla relativa configurazione, pertanto è necessario proteggerlo. È molto importante utilizzare una password complessa quando si protegge la modalità EXEC privilegiata perché questa modalità consente l’accesso alla configurazione del dispositivo. L’avviso legale avverte gli utenti che il dispositivo dovrebbe essere accessibile solo agli utenti autorizzati. La configurazione del router andrebbe persa se il router perdesse l’alimentazione. Per questo motivo è importante salvare la configurazione quando vengono implementate le modifiche.
Secure the Devices
Per proteggere i dispositivi di rete, è importante utilizzare password complesse. Una password complessa combina caratteri alfanumerici e, se consentito, include simboli e uno spazio. Un altro metodo per creare una password complessa consiste nell’usare la barra spaziatrice e creare una frase composta da molte parole, chiamata passphrase. Una passphrase è spesso più facile da ricordare rispetto a una password sicura. È anche più lungo e più difficile da indovinare.
L’impostazione di una password per l’accesso alla connessione della console viene eseguita in modalità di configurazione globale. Ciò impedisce agli utenti non autorizzati di accedere alla modalità utente dalla porta della console. Quando il dispositivo è connesso alla rete, è possibile accedervi tramite la connessione di rete tramite SSH o Telnet. SSH è il metodo preferito perché è più sicuro. Quando si accede al dispositivo tramite la rete, viene considerata una connessione vty. La password deve essere assegnata alla porta vty. Cinque è il numero più comune di linee vty configurate su un router. Queste linee sono numerate da 0 a 4 per impostazione predefinita, anche se è possibile configurare linee aggiuntive. È necessario impostare una password per tutte le linee vty disponibili. La stessa password può essere impostata per tutte le connessioni.
Per verificare che le password siano impostate correttamente, utilizzare il comando show running-config. Queste password sono memorizzate nella configurazione in esecuzione in testo normale. È possibile impostare la crittografia su tutte le password memorizzate all’interno del router. Il comando di configurazione globale service password-encryption assicura che tutte le password siano crittografate.
To enable SSH
Step 1. Verifica il supporto SSH: show ip ssh
Step 2. Configurare il dominio IP: ip domain-namedomain-name
Step 3. Genera coppie di chiavi RSA: crypto key generate rsa
Per visualizzare i dati di versione e configurazione per SSH sul dispositivo configurato come server SSH, utilizzare il comando show ip ssh. Nell’esempio, SSH versione 2 è abilitato. Per verificare le connessioni SSH al dispositivo, utilizzare il comando show ssh.
Configure the Default Gateway
Se la tua rete locale ha un solo router, sarà il router del gateway e tutti gli host e gli switch sulla tua rete devono essere configurati con queste informazioni. Se la tua rete locale ha più router, devi selezionarne uno come router gateway predefinito. Il gateway predefinito viene utilizzato solo quando l’host desidera inviare un pacchetto a un dispositivo su un’altra rete. L’indirizzo del gateway predefinito è in genere l’indirizzo dell’interfaccia del router collegato alla rete locale dell’host. L’indirizzo IP del dispositivo host e l’indirizzo dell’interfaccia del router devono trovarsi nella stessa rete.Per connettersi e gestire uno switch su una rete IP locale, deve disporre di un SVI configurato. L’SVI è configurato con un indirizzo IPv4 e una subnet mask sulla LAN locale. Lo switch deve inoltre disporre di un indirizzo gateway predefinito configurato per gestire in remoto lo switch da un’altra rete. Per configurare un gateway predefinito IPv4 su uno switch, utilizzare il comando di configurazione globale ip default-gatewayip-address. L’indirizzo IP configurato è l’indirizzo IPv4 dell’interfaccia del router locale connesso allo switch.
ICMP
Messaggi ICMP
Messaggi ICMPv4 e ICMPv6
Sebbene IP sia solo un protocollo best-effort, la suite TCP/IP fornisce messaggi di errore e messaggi informativi durante la comunicazione con un altro dispositivo IP. Questi messaggi vengono inviati utilizzando i servizi di ICMP. Lo scopo di questi messaggi è fornire feedback su problemi relativi all’elaborazione dei pacchetti IP in determinate condizioni, non rendere affidabile l’IP. I messaggi ICMP non sono richiesti e spesso non sono consentiti all’interno di una rete per motivi di sicurezza.
ICMP è disponibile sia per IPv4 che per IPv6. ICMPv4 è il protocollo di messaggistica per IPv4. ICMPv6 fornisce gli stessi servizi per IPv6 ma include funzionalità aggiuntive. In questo corso verrà utilizzato il termine ICMP in riferimento sia a ICMPv4 che a ICMPv6.
I tipi di messaggi ICMP e i motivi per cui vengono inviati sono numerosi. I messaggi ICMP comuni a ICMPv4 e ICMPv6 e discussi in questo modulo includono:
Raggiungibilità dell’host
Destinazione o servizio irraggiungibile
Tempo superato
Raggiungibilità dell’host
Un messaggio ICMP Echo può essere utilizzato per testare la raggiungibilità di un host su una rete IP. L’host locale invia una richiesta Echo ICMP a un host. Se l’host è disponibile, l’host di destinazione risponde con una risposta Echo. Questo utilizzo dei messaggi ICMP Echo è alla base dell’utilità ping.
Destinazione o servizio non raggiungibile
Quando un host o un gateway riceve un pacchetto che non può consegnare, può utilizzare un messaggio ICMP Destination Unreachable per notificare all’origine che la destinazione o il servizio non è raggiungibile. Il messaggio includerà un codice che indica il motivo per cui non è stato possibile consegnare il pacchetto.
Alcuni dei codici Destination Unreachable per ICMPv4 sono i seguenti:
0 – Net unreachable
1 – Host unreachable
2 – Protocol unreachable
3 – Port unreachable
Alcuni dei codici Destination Unreachable per ICMPv6 sono i seguenti:
0 – No route to destination
1 – Communication with the destination is administratively prohibited (e.g., firewall)
2 – Beyond scope of the source address
3 – Address unreachable
4 – Port unreachable
Nota: ICMPv6 ha codici simili ma leggermente diversi per i messaggi Destination Unreachable.
Tempo scaduto
Un messaggio ICMPv4 Time Exceeded viene utilizzato da un router per indicare che un pacchetto non può essere inoltrato perché il campo TTL (Time to Live) del pacchetto è stato decrementato a 0. Se un router riceve un pacchetto e diminuisce il campo TTL nel pacchetto IPv4 a zero, scarta il pacchetto e invia un messaggio Time Exceeded all’host di origine.
ICMPv6 invia anche un messaggio Time Exceeded se il router non può inoltrare un pacchetto IPv6 perché il pacchetto è scaduto. Invece del campo IPv4 TTL, ICMPv6 utilizza il campo IPv6 Hop Limit per determinare se il pacchetto è scaduto.
Nota: i messaggi Time Exceeded vengono utilizzati dallo strumento traceroute.
Messaggi ICMPv6
I messaggi informativi e di errore trovati in ICMPv6 sono molto simili ai messaggi di controllo e di errore implementati da ICMPv4. Tuttavia, ICMPv6 ha nuove caratteristiche e funzionalità migliorate che non si trovano in ICMPv4. I messaggi ICMPv6 sono incapsulati in IPv6.
ICMPv6 include quattro nuovi protocolli come parte del Neighbor Discovery Protocol (ND o NDP).
La messaggistica tra un router IPv6 e un dispositivo IPv6, inclusa l’allocazione dinamica degli indirizzi, è la seguente:
Messaggio di sollecitazione del router (RS) – Router Solicitation (RS) message
Messaggio di annuncio del router (RA) – Router Advertisement (RA) message
La messaggistica tra dispositivi IPv6, inclusi il rilevamento di indirizzi duplicati e la risoluzione degli indirizzi, è la seguente:
Messaggio di sollecitazione del vicino (NS) – Neighbor Solicitation (NS) message
Messaggio di annuncio del vicino (NA) – Neighbor Advertisement (NA) message
Nota: ICMPv6 ND include anche il messaggio di reindirizzamento, che ha una funzione simile al messaggio di reindirizzamento utilizzato in ICMPv4.
RA message
I messaggi RA vengono inviati dai router abilitati per IPv6 ogni 200 secondi per fornire informazioni di indirizzamento agli host abilitati per IPv6. Il messaggio RA può includere informazioni di indirizzamento per l’host come il prefisso, la lunghezza del prefisso, l’indirizzo DNS e il nome di dominio. Un host che utilizza la configurazione automatica dell’indirizzo senza stato (SLAAC – Stateless Address Autoconfiguration) imposterà il proprio gateway predefinito sull’indirizzo link-local del router che ha inviato la RA.
R1 invia un messaggio RA, “Ciao a tutti i dispositivi abilitati per IPv6. Sono R1 e puoi utilizzare SLAAC per creare un indirizzo unicast globale IPv6. Il prefisso è 2001:db8:acad:1::/64. A proposito, usa il mio indirizzo link-local fe80::1 come gateway predefinito.”
RS message
Un router abilitato per IPv6 invierà anche un messaggio RA in risposta a un messaggio RS. Nella figura, PC1 invia un messaggio RS per determinare come ricevere dinamicamente le informazioni sull’indirizzo IPv6.
R1 risponde alla RS con un messaggio RA.
PC1 invia un messaggio RS, “Ciao, ho appena avviato. C’è un router IPv6 sulla rete? Ho bisogno di sapere come ottenere dinamicamente le informazioni sull’indirizzo IPv6.”
R1 risponde con un messaggio RA. “Ciao a tutti i dispositivi abilitati per IPv6. Sono R1 e potete usare SLAAC per creare un indirizzo unicast globale IPv6. Il prefisso è 2001:db8:acad:1::/64. A proposito, usate il mio indirizzo link-local fe80::1 come gateway predefinito.”
NS message
Quando a un dispositivo viene assegnato un indirizzo unicast IPv6 globale o unicast link-local, può eseguire il rilevamento di indirizzi duplicati (DAD – duplicate address detection) per garantire che l’indirizzo IPv6 sia univoco. Per verificare l’univocità di un indirizzo, il dispositivo invierà un messaggio NS con il proprio indirizzo IPv6 come indirizzo IPv6 di destinazione, come mostrato nella figura.
Se un altro dispositivo sulla rete ha questo indirizzo, risponderà con un messaggio NA. Questo messaggio NA notificherà al dispositivo di invio che l’indirizzo è in uso. Se un messaggio NA corrispondente non viene restituito entro un certo periodo di tempo, l’indirizzo unicast è univoco e accettabile per l’uso.
Nota: DAD non è richiesto, ma RFC 4861 consiglia di eseguire DAD su indirizzi unicast.
PC1 invia un messaggio NS per verificare l’univocità di un indirizzo, “Chiunque abbia l’indirizzo IPv6 2001:db8:acad:1::10, mi manderà il suo indirizzo MAC?”
Test Ping e Traceroute
Ping – Verifica connettività
Nell’argomento precedente, sono stati presentati gli strumenti ping e traceroute (tracert). In questo argomento, imparerai a conoscere le situazioni in cui viene utilizzato ogni strumento e come utilizzarli. Ping è un’utilità di test IPv4 e IPv6 che utilizza la richiesta echo ICMP e i messaggi di risposta echo per testare la connettività tra gli host.
Per testare la connettività a un altro host su una rete, viene inviata una richiesta echo all’indirizzo host utilizzando il comando ping. Se l’host all’indirizzo specificato riceve la richiesta echo, risponde con una risposta echo. Quando viene ricevuta ogni risposta echo, ping fornisce un feedback sul tempo intercorso tra l’invio della richiesta e la ricezione della risposta. Questa può essere una misura delle prestazioni della rete.
Ping ha un valore di timeout per la risposta. Se non viene ricevuta una risposta entro il timeout, ping fornisce un messaggio che indica che non è stata ricevuta una risposta. Ciò potrebbe indicare che c’è un problema, ma potrebbe anche indicare che le funzionalità di sicurezza che bloccano i messaggi ping sono state abilitate sulla rete. È comune che il primo ping vada in timeout se è necessario eseguire la risoluzione dell’indirizzo (ARP o ND) prima di inviare la richiesta Echo ICMP.
Dopo che tutte le richieste sono state inviate, l’utilità ping fornisce un riepilogo che include la percentuale di successo e il tempo medio di andata e ritorno verso la destinazione.
I tipi di test di connettività eseguiti con ping includono quanto segue:
Ping del loopback locale
Ping del gateway predefinito
Ping dell’host remoto
Eseguire il ping del loopback
Il ping può essere utilizzato per testare la configurazione interna di IPv4 o IPv6 sull’host locale. Per eseguire questo test, eseguire il ping dell’indirizzo di loopback locale di 127.0.0.1 per IPv4 (::1 per IPv6).
Una risposta da 127.0.0.1 per IPv4 o ::1 per IPv6 indica che l’IP è installato correttamente sull’host. Questa risposta viene dal livello di rete. Questa risposta, tuttavia, non indica che gli indirizzi, le maschere o i gateway siano configurati correttamente. Né indica nulla sullo stato del livello inferiore dello stack di rete. Questo verifica semplicemente l’IP attraverso il livello di rete dell’IP. Un messaggio di errore indica che TCP/IP non è operativo sull’host.
Il ping dell’host locale conferma che TCP/IP è installato e funzionante sull’host locale.
Il ping 127.0.0.1 fa sì che un dispositivo esegua il ping da solo.
Eseguire il ping del gateway predefinito
È inoltre possibile utilizzare il ping per testare la capacità di un host di comunicare sulla rete locale. Questo viene generalmente fatto eseguendo il ping dell’indirizzo IP del gateway predefinito dell’host. Un ping riuscito al gateway predefinito indica che l’host e l’interfaccia del router che funge da gateway predefinito sono entrambi operativi sulla rete locale.
Per questo test, viene spesso utilizzato l’indirizzo del gateway predefinito perché il router è normalmente sempre operativo. Se l’indirizzo del gateway predefinito non risponde, è possibile inviare un ping all’indirizzo IP di un altro host sulla rete locale noto per essere operativo.
Se il gateway predefinito o un altro host risponde, l’host locale può comunicare correttamente sulla rete locale. Se il gateway predefinito non risponde ma un altro host lo fa, ciò potrebbe indicare un problema con l’interfaccia del router che funge da gateway predefinito.
Una possibilità è che sull’host sia stato configurato l’indirizzo del gateway predefinito errato. Un’altra possibilità è che l’interfaccia del router possa essere completamente operativa ma abbia una sicurezza applicata che le impedisce di elaborare o rispondere alle richieste di ping.
L’host esegue il ping del suo gateway predefinito, inviando una richiesta echo ICMP. Il gateway predefinito invia una risposta eco a conferma della connettività.
Eseguire il ping di un host remoto
Il ping può anche essere utilizzato per testare la capacità di un host locale di comunicare attraverso una rete. L’host locale può eseguire il ping di un host IPv4 operativo di una rete remota, come mostrato nella figura. Il router utilizza la sua tabella di routing IP per inoltrare i pacchetti.
Se questo ping ha esito positivo, è possibile verificare il funzionamento di un’ampia parte dell’internetwork. Un ping riuscito attraverso l’internetwork conferma la comunicazione sulla rete locale, il funzionamento del router che funge da gateway predefinito e il funzionamento di tutti gli altri router che potrebbero trovarsi nel percorso tra la rete locale e la rete dell’host remoto.
Inoltre, è possibile verificare la funzionalità dell’’host remoto. Se l’host remoto non fosse in grado di comunicare al di fuori della sua rete locale, non avrebbe risposto.
Nota: molti amministratori di rete limitano o proibiscono l’ingresso di messaggi ICMP nella rete aziendale; pertanto, la mancanza di una risposta ping potrebbe essere dovuta a restrizioni di sicurezza.
Traceroute – Prova il percorso
Il ping viene utilizzato per testare la connettività tra due host ma non fornisce informazioni sui dettagli dei dispositivi tra gli host. Traceroute (tracert) è un’utilità che genera un elenco di hop che sono stati raggiunti con successo lungo il percorso. Questo elenco può fornire importanti informazioni di verifica e risoluzione dei problemi. Se i dati raggiungono la destinazione, la traccia elenca l’interfaccia di ogni router nel percorso tra gli host. Se i dati falliscono in qualche salto lungo il percorso, l’indirizzo dell’ultimo router che ha risposto alla traccia può fornire un’indicazione di dove si trovano il problema o le restrizioni di sicurezza.
Tempo di andata e ritorno (RTT – Round Trip Time)
L’utilizzo di traceroute fornisce il tempo di andata e ritorno per ogni hop lungo il percorso e indica se un hop non risponde. Il tempo di andata e ritorno è il tempo impiegato da un pacchetto per raggiungere l’host remoto e per il ritorno della risposta dell’host. Un asterisco (*) viene utilizzato per indicare un pacchetto perso o senza risposta.
Queste informazioni possono essere utilizzate per individuare un router problematico nel percorso o possono indicare che il router è configurato per non rispondere. Se il display mostra tempi di risposta elevati o perdite di dati da un particolare hop, ciò indica che le risorse del router o le sue connessioni potrebbero essere stressate.
IPv4 TTL e IPv6 Hop Limit
Traceroute utilizza una funzione del campo TTL in IPv4 e del campo Hop Limit in IPv6 nelle intestazioni di livello 3, insieme al messaggio ICMP Time Exceeded.
La prima sequenza di messaggi inviati da traceroute avrà un valore di campo TTL pari a 1. Ciò fa sì che il TTL del pacchetto IPv4 scada al primo router. Questo router risponde quindi con un messaggio ICMPv4 Time Exceeded. Traceroute ora ha l’indirizzo del primo hop.
Traceroute quindi incrementa progressivamente il campo TTL (2, 3, 4…) per ogni sequenza di messaggi. Ciò fornisce la traccia dell’indirizzo di ciascun hop man mano che i pacchetti scadono ulteriormente lungo il percorso. Il campo TTL continua ad essere incrementato fino al raggiungimento della destinazione oppure viene incrementato fino a un massimo predefinito.
Una volta raggiunta la destinazione finale, l’host risponde con un messaggio ICMP Port Unreachable o un messaggio ICMP Echo Reply invece del messaggio ICMP Time Exceeded
ICMP – Riepilogo
ICMP Message
Sebbene IP sia solo un protocollo best-effort, la suite TCP/IP fornisce messaggi di errore e messaggi informativi durante la comunicazione con un altro dispositivo IP. Questi messaggi vengono inviati utilizzando i servizi di ICMP. Lo scopo di questi messaggi è fornire feedback su problemi relativi all’elaborazione dei pacchetti IP in determinate condizioni, non rendere affidabile l’IP. ICMP è disponibile sia per IPv4 che per IPv6. ICMPv4 è il protocollo di messaggistica per IPv4. ICMPv6 fornisce gli stessi servizi per IPv6 ma include funzionalità aggiuntive.
Un messaggio ICMP Echo può essere utilizzato per testare la raggiungibilità di un host su una rete IP. L’host locale invia una richiesta Echo ICMP a un host. Se l’host è disponibile, l’host di destinazione risponde con una risposta Echo.
Quando un host o un gateway riceve un pacchetto che non può consegnare, può utilizzare un messaggio ICMP Destination Unreachable per notificare all’origine che la destinazione o il servizio non è raggiungibile. Il messaggio includerà un codice che indica il motivo per cui non è stato possibile consegnare il pacchetto.
Un messaggio ICMPv4 Time Exceeded viene utilizzato da un router per indicare che un pacchetto non può essere inoltrato perché il campo TTL del pacchetto è stato decrementato a 0. Se un router riceve un pacchetto e riduce a zero il campo TTL nel pacchetto IPv4, scarta il pacchetto e invia un messaggio Time Exceeded all’host di origine.
ICMPv6 invia anche un messaggio Time Exceeded se il router non può inoltrare un pacchetto IPv6 perché il pacchetto è scaduto. I messaggi informativi e di errore trovati in ICMPv6 sono molto simili ai messaggi di controllo e di errore implementati da ICMPv4. Tuttavia, ICMPv6 include quattro nuovi protocolli come parte di ND o NDP, come segue:
RS message
RA message
NS message
NA message
Test Ping e Traceroute
Per testare la connettività a un altro host su una rete, viene inviata una richiesta echo all’indirizzo host utilizzando il comando ping. Se l’host all’indirizzo specificato riceve la richiesta echo, risponde con una risposta echo. Quando viene ricevuta ogni risposta echo, ping fornisce un feedback sul tempo intercorso tra l’invio della richiesta e la ricezione della risposta. Questa può essere una misura delle prestazioni della rete. Ping ha un valore di timeout per la risposta. Se non viene ricevuta una risposta entro il timeout, ping fornisce un messaggio che indica che non è stata ricevuta una risposta.
I tipi di test di connettività eseguiti con ping includono quanto segue:
Pinging del loopback locale: il ping può essere utilizzato per testare la configurazione interna di IPv4 o IPv6 sull’host locale. Per eseguire questo test, eseguire il ping dell’indirizzo di loopback locale.
Pinging del gateway predefinito: questo viene generalmente eseguito eseguendo il ping dell’indirizzo IP del gateway predefinito dell’host. Un ping riuscito al gateway predefinito indica che l’host e l’interfaccia del router che funge da gateway predefinito sono entrambi operativi sulla rete locale.
Pinging dell’host remoto: un ping riuscito attraverso l’internetwork conferma la comunicazione sulla rete locale, il funzionamento del router che funge da gateway predefinito e il funzionamento di tutti gli altri router che potrebbero trovarsi nel percorso tra la rete locale e la rete di l’host remoto.
tracert è un’utilità che genera un elenco di hop che sono stati raggiunti con successo lungo il percorso. Questo elenco può fornire importanti informazioni di verifica e risoluzione dei problemi. Se i dati raggiungono la destinazione, trace elenca l’interfaccia di ogni router nel percorso tra gli host. Se i dati falliscono in qualche salto lungo il percorso, l’indirizzo dell’ultimo router che ha risposto al trace può fornire un’indicazione di dove si trovano il problema o le restrizioni di sicurezza.
Il tempo di andata e ritorno è il tempo impiegato da un pacchetto per raggiungere l’host remoto e per il ritorno della risposta dell’host. Un asterisco (*) viene utilizzato per indicare un pacchetto perso o senza risposta. Traceroute utilizza una funzione del campo TTL in IPv4 e del campo Hop Limit in IPv6 nelle intestazioni di livello 3, insieme al messaggio ICMP Time Exceeded.