
Introduzione
La digital forensics è la disciplina che si occupa di individuare, preservare ed esaminare le evidenze digitali al fine di ricostruire eventi e azioni compiute su sistemi informatici. In particolare, nel contesto della risposta agli incidenti informatici, le tecniche forensi permettono di capire cosa è accaduto durante un attacco, quali sistemi sono stati compromessi e in che modo, fornendo informazioni critiche per prevenire futuri incidenti. A livello internazionale esistono standard e linee guida che definiscono le migliori pratiche in questo campo: ad esempio lo standard ISO/IEC 27042:2015 fornisce “linee guida per l’analisi e l’interpretazione delle evidenze digitali” mentre ISO/IEC 27043:2015 definisce “principi e processi di indagine sugli incidenti”. Analogamente, la guida NIST SP 800-86 del National Institute of Standards and Technology – intitolata “Guide to Integrating Forensic Techniques into Incident Response” – descrive processi efficaci per svolgere analisi forensi su vari tipi di dati (file, sistemi operativi, traffico di rete, applicazioni) e integrare queste attività nell’ambito di un’indagine di sicurezza . Questi riferimenti enfatizzano un approccio metodico e strutturato all’analisi forense, essenziale affinché le evidenze raccolte abbiano validità e siano utili sia in ottica tecnica sia, se necessario, in sede legale.
Analisi di file system
L’analisi forense di un file system consiste nell’esaminare la struttura e il contenuto di supporti di memoria (dischi fissi, SSD, pen drive, ecc.) al fine di scoprire tracce digitali significative. Ogni file e directory su un sistema operativo è organizzato secondo un file system (come NTFS per Windows, EXT4 per Linux, APFS per macOS, ecc.), il quale mantiene metadati cruciali: nomi dei file, dimensioni, permessi e timestamp (date di creazione, modifica, accesso, ecc.). L’analista forense ispeziona queste informazioni per ricostruire le attività svolte sul sistema e individuare anomalie. Ad esempio, nei file system NTFS di Windows il Master File Table (MFT) registra record per ogni file, includendo fino a quattro timestamp principali per ciascuno (creazione, ultima modifica, ultimo accesso, ultima modifica del record MFT). Questi dati temporali consentono di costruire una timeline degli eventi sul disco. In un’analisi tipica, si cercano file sospetti (ad esempio programmi malevoli camuffati), si esaminano gli attributi e i contenuti dei file e si analizzano gli artefatti del file system (come i journal di NTFS, la $Recycle.Bin, i punti di ripristino, ecc.) alla ricerca di evidenze. Inoltre, si verifica la presenza di file nascosti o di istanze di steganografia (informazioni occultate dentro file leciti) e si controlla l’integrità dei file confrontandone gli hash crittografici con valori noti.
Un aspetto fondamentale del file system forensics è il recupero di file cancellati. Molti utenti pensano che quando un file viene eliminato dal sistema scompaia definitivamente, ma in realtà non è così: l’eliminazione rimuove il riferimento al file dalla tabella di allocazione (ad esempio la File Allocation Table su FAT o la MFT su NTFS) ma i dati binari del file restano sui settori del disco finché non vengono sovrascritti. I file (o frammenti di essi) permangono nelle aree non allocate del disco e, con gli strumenti appropriati, è difficile ma non impossibile ricostruirli. Ciò significa che è spesso possibile recuperare documenti o altri artefatti anche dopo la cancellazione, soprattutto su supporti di grande capacità dove può trascorrere molto tempo prima che i blocchi vengano riutilizzati per nuovi dati.
L’analista forense utilizza tecniche di data carving (descritte più avanti) per scandagliare queste porzioni libere alla ricerca di header e footer noti di file (come le intestazioni JPEG, PDF, ecc.) e ricostruire file eliminati o corrotti. Un altro approccio consiste nel calcolare gli hash (MD5, SHA-1, SHA-256) di tutti i file presenti e confrontarli con database di indicatori di compromissione (IOC) noti o con liste di hash di software benigni, così da individuare rapidamente malware noti o file anomali. In contesto italiano, ad esempio, il CERT-AgID (Computer Emergency Response Team dell’Agenzia per l’Italia Digitale) fornisce alle Pubbliche Amministrazioni un servizio di feed IoC contenente hash di file malevoli osservati nelle campagne di attacco più recenti. Questo feed, combinato con appositi tool, consente di identificare file compromessi nei sistemi oggetto di analisi. Hashr è uno di questi strumenti sviluppati dal CERT-AgID: permette di cercare, all’interno di un filesystem, file noti come malevoli confrontando i loro hash con una lista di impronte note. L’uso di hashr è risultato particolarmente utile sia nelle indagini di sicurezza informatica sia nell’analisi forense, ad esempio per verificare l’integrità di grandi volumi di dati e scovare rapidamente malware presenti su disco.
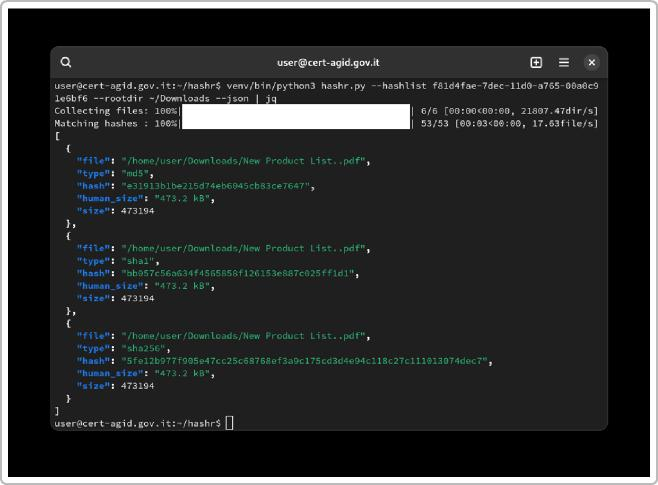
Figura 1: Schermata di output dello strumento hashr (open source di CERT-AGID) in azione. In questo esempio, l’utility ha analizzato la directory Downloads confrontando ogni file con una lista di hash indicanti malware noti, restituendo per ciascun file corrispondenze di hash MD5, SHA1 e SHA256. Tale strumento può velocizzare l’identificazione di file infetti all’interno di file system di grandi dimensioni, ed è utilizzabile anche a fini di verifica dell’integrità dei file.
Dal punto di vista operativo, l’analisi forense dei file system inizia con una corretta acquisizione della memoria di massa da esaminare. Si procede creando una copia forense bit-a-bit del supporto originale (disk image), operazione effettuata tipicamente a sistema spento (analisi dead) utilizzando tool come dd (in ambienti Unix) o strumenti dedicati (ad es. FTK Imager, Guymager), spesso impiegando un write-blocker hardware o software per evitare qualsiasi modifica accidentale al disco originale. L’immagine ottenuta viene poi sottoposta a hash (es. SHA-256) per calcolarne l’impronta univoca, che servirà a garantirne l’integrità: confrontando il valore hash della copia con quello calcolato sul disco originale, si verifica che la copia sia esatta e che nessuna alterazione sia avvenuta durante l’acquisizione. Solo a questo punto gli investigatori lavorano sull’immagine duplicata, lasciando intatto l’originale (principio fondamentale per assicurare la validità probatoria delle evidenze). Una volta montata o caricata l’immagine in appositi software, l’analisi può procedere: si passa in rassegna la struttura di directory, si cercano file sospetti (anche in base a nome, tipo o hash), si analizzano i contenuti con visualizzatori esadecimali o strumenti di parsing (per esempio analizzando il registro di configurazione di Windows, i file di Prefetch, i log di sistema, ecc.), e si ricostruiscono le attività avvenute sul file system. Il risultato finale è spesso una ricostruzione dettagliata (timeline) delle azioni svolte su quel supporto (creazione, modifica, cancellazione di file, installazione di programmi, collegamenti di dispositivi USB, ecc.), utile per comprendere la dinamica di un incidente e attribuire eventuali responsabilità.
Analisi di dump di memoria (memory forensics)
L’analisi forense della memoria RAM è una componente sempre più centrale nelle investigazioni digitali. La memory forensics si occupa di studiare il contenuto della memoria volatile di un sistema (dump RAM catturato da un computer o dispositivo) allo scopo di estrarre informazioni sulle attività in corso o recenti, spesso impossibili da reperire altrove. Infatti qualsiasi operazione compiuta da un sistema informatico – processi eseguiti, connessioni di rete, utilizzo di credenziali, ecc. – transita attraverso la RAM e può persistere in memoria per un certo tempo anche dopo la conclusione dell’evento. La RAM di un computer può contenere quindi una quantità enorme di dati utili: l’elenco dei processi e thread in esecuzione (con i relativi programmi e moduli caricati), le connessioni di rete attive o recentemente chiuse (comprese informazioni su indirizzi IP e porte remote), le chiavi crittografiche in uso, password in chiaro temporaneamente presenti, il contenuto della clipboard (appunti) e persino tracce di malware in esecuzione – inclusi rootkit o altri codici malevoli che potrebbero occultarsi al file system. In altri termini, la memoria è spesso il luogo migliore dove cercare le attività di un software malevolo: anche se un malware tenta di nascondersi eliminando file dal disco o operando solo in memoria (fileless malware), deve comunque essere caricato e mantenuto nella RAM per poter agire. Attraverso la memory forensics è possibile mettere in luce evidenze altrimenti invisibili, come malware residenti unicamente in memoria, sessioni di navigazione web in modalità incognita (che non lasciano cronologia su disco) o conversazioni in chat volatile, e persino modifiche apportate a chiavi di registro di Windows che risiedono solo in memoria e non ancora scritte su disco.
Le fasi di un’analisi della memoria includono innanzitutto l’acquisizione del dump: se il sistema è live, si utilizzano tool appositi (ad es. Magnet RAM Capture, FTK Imager in modalità live, Belkasoft RAM Capturer o comandi di sistema) per estrarre un’immagine completa della RAM e dei file di swap/paging, evitando per quanto possibile di alterare lo stato della macchina. Una volta ottenuto il file di dump grezzo, si passa alla fase di estrazione delle evidenze: qui entrano in gioco framework specializzati come Volatility o Rekall. Volatility, in particolare, è un framework open source scritto in Python, dotato di una collezione di plug-in che permettono di estrarre artefatti dal dump di memoria volatile. Tramite Volatility, l’analista può elencare tutti i processi attivi al momento dell’acquisizione (e quelli terminati di recente ma ancora residenti in memoria), ispezionare l’area di memoria di ciascun processo alla ricerca di stringhe o moduli caricati, ricostruire la lista delle connessioni di rete aperte (socket TCP/ UDP con relativi IP/porta), recuperare informazioni sui driver e i kernel module caricati, estrarre il contenuto della clipboard, delle cache DNS e molto altro. Si possono anche cercare firme note di malware in memoria o rilevare tecniche di offuscamento, come process injection, hooking di funzioni di sistema, presenza di eseguibili packed, ecc. Un esempio concreto: grazie all’analisi RAM è possibile recuperare credenziali o token di autenticazione temporanei che risiedono in memoria (ad esempio password di utenti o chiavi di sessione), elemento che talvolta consente di comprendere l’entità di una compromissione o di effettuare escalation controllate in laboratorio per studiare un attacco. L’analisi della memoria viene condotta preferibilmente off-line sull’immagine catturata, utilizzando i profili adeguati (profiling) per interpretare le strutture dati in base al sistema operativo target. Ad esempio, Volatility richiede di specificare il profilo (p.es. Windows 10 x64 build 19041) per poter tradurre correttamente indirizzi di memoria e simboli: un passaggio fondamentale, poiché l’uso di un profilo errato può portare a output incompleti o incoerenti.
Un aspetto importante è la correlazione delle evidenze di memoria con altre fonti. Spesso, i risultati dell’analisi RAM vanno messi in relazione con quanto emerge dall’analisi del disco e dei log di rete, al fine di costruire un quadro unificato dell’incidente. Ad esempio, processi sospetti individuati in RAM (come un powershell.exe lanciato con comandi anomali, oppure un processo senza file su disco indicativo di un malware fileless) dovrebbero poi essere cercati nelle evidenze del file system (esiste un file corrispondente su disco? Ci sono riferimenti nel Prefetch o nel registro di sistema?) e nei log (ci sono eventi che mostrano l’esecuzione di quel processo da parte di un certo utente?). Solo tramite questa visione d’insieme si può capire appieno l’accaduto. Nel contesto italiano, l’uso della memory forensics è ormai prassi sia nelle operazioni di incident response: ad esempio, per malware analysis su campioni attivi intercettati in sistemi compromessi o per identificare in tempo reale minacce come il malware Agent.Tesla o Ursnif che negli ultimi anni hanno preso di mira enti pubblici e privati.
Analisi di log di sicurezza e di rete
I log – registri degli eventi prodotti da sistemi operativi, applicazioni e dispositivi di rete – costituiscono una fonte informativa primaria nella gestione e analisi degli incidenti informatici. Ogni componente IT (e anche molti dispositivi non-IT) genera infatti una notevole quantità di informazioni sotto forma di log, che vengono tipicamente classificati per categorie e livelli di severità. Ad esempio, un server web produce log delle richieste HTTP con indicazione di timestamp, URL richiesto, indirizzo IP del client e codice di risposta; un firewall registra gli accessi consentiti o negati per ogni connessione (con dati su IP, porte, protocolli); un sistema operativo mantiene log di sicurezza (tentativi di login riusciti o falliti, cambi di privilegi, eventi del kernel) e così via. Analizzare questi log di sicurezza significa estrarre dai dati grezzi le informazioni rilevanti per un determinato incidente, identificare correlazioni tra eventi e riconoscere pattern anomali che possano indicare attività malevole o malfunzionamenti.
Un esempio concreto: in caso di sospetta intrusione su un server, l’analisi incrociata dei log potrebbe rivelare che un certo utente ha effettuato un login fuori orario (voce nel security log), subito seguito dall’esecuzione di comandi insoliti registrati nella shell history e da connessioni verso un IP esterno annotati nel log del firewall. Ciascun singolo evento, preso a sé, potrebbe passare inosservato; la correlazione temporale e funzionale tra i vari log permette invece di ricostruire la sequenza dell’attacco (es. accesso iniziale – movimenti laterali – esfiltrazione di dati) e di identificarne la sorgente. Per un responsabile CSIRT/SOC, saper orchestrare questa attività di analisi log è fondamentale: significa dover gestire potenzialmente decine di migliaia di eventi al secondo, filtrare i falsi positivi e isolare gli indicatori critici. A tal fine, ci si avvale comunemente di sistemi SIEM (Security Information and Event Management). Un SIEM è una piattaforma software che colleziona i log da sorgenti disparate, li normalizza (cioè li traduce in un formato comune), li correla in base a regole predefinite e spesso applica motori di analisi comportamentale per individuare minacce in tempo reale. In pratica, il SIEM funge da concentratore: al suo interno confluiscono log da firewall, IDS/IPS, sistemi endpoint, database, applicazioni, ecc., e l’analista può consultare da un’unica console l’andamento degli eventi. Ad esempio, il SIEM può generare un alert qualora rilevi, entro uno stesso intervallo temporale, più tentativi di accesso falliti su diversi sistemi seguiti da un accesso riuscito con un account amministrativo: segnale tipico di un possibile brute forcing andato a segno. Oppure può correlare l’apparizione di un file sospetto in un host (rilevato dall’antivirus) con una connessione uscente su porta non standard (dal log del proxy): anche qui producendo un avviso di possibile data exfiltration. I moderni SIEM integrano inoltre feed di threat intelligence (indicatori di minaccia esterni forniti da CERT e vendor) e funzionalità di orchestrazione automatica (SOAR), così da arricchire gli eventi grezzi con informazioni contestuali e, in alcuni casi, reagire automaticamente (per esempio isolando un host infetto).
Nell’analisi forense vera e propria, i log rivestono anche un ruolo chiave come evidenze: costituiscono spesso prova documentale di un’azione (si pensi ai log di autenticazione nel caso di accessi non autorizzati, o ai log di transazione di un database in caso di frodi). È importante perciò assicurarne la corretta conservazione e autenticità: un responsabile deve garantire che i log siano archiviati in forma write-once (immutabile) e con riferimenti temporali affidabili (sincronizzazione oraria via NTP, uso di timestamp in UTC, ecc.), in modo che possano essere esibiti come prova qualora necessario. Un aspetto non banale è la gestione dei tempi e della sincronizzazione: se i sistemi coinvolti in un incidente non hanno orologi allineati, la ricostruzione temporale può risultare complicata. Idealmente tutti i server e dispositivi devono sincronizzare l’ora con un time server preciso (via protocollo NTP); in pratica può capitare di trovare orologi sfasati. In fase di analisi forense occorre pertanto tener conto di eventuali offset temporali tra log diversi, effettuando opportune conversioni per costruire una timeline coerente degli eventi . Questo evidenzia ulteriormente l’importanza di un approccio sistematico e metodico nell’analisi dei log.
In Italia, il CERT-AgID e l’ACN/CSIRT Italia incoraggiano fortemente l’adozione di sistemi di logging centralizzato e di SIEM negli enti pubblici, fornendo anche indicazioni su come configurare al meglio il monitoraggio. Ad esempio, ACN ha pubblicato nel 2022 la Guida alla notifica degli incidenti al CSIRT Italia, che tra le varie cose elenca i tipi di log ed evidenze che gli enti devono raccogliere e conservare per facilitare le investigazioni post-incidente . Vi sono stati anche casi concreti in cui l’analisi dei log ha permesso di scoprire attacchi sofisticati: ad esempio, l’indagine su una serie di attacchi alle caselle PEC (Posta Elettronica Certificata) nel 2023 – coordinata da CERT-AgID in collaborazione con la Polizia Postale – ha visto come elemento chiave l’esame dei log di accesso ai server di posta e delle tracce lasciate dai malware nei log antivirus, consentendo di individuare i punti di ingresso dei criminali e di rafforzare le difese delle infrastrutture coinvolte.
Analisi del traffico di rete
L’analisi forense della rete (Network Forensics) riguarda la cattura, l’ispezione e l’interpretazione del traffico di rete con l’obiettivo di ottenere prove digitali relative a eventuali attacchi o attività malevole che si sono svolte attraverso i sistemi di comunicazione. In sostanza, mentre l’analisi dei log spesso si basa su dati già registrati dai sistemi, l’analisi del traffico va direttamente alla fonte: i pacchetti di rete scambiati tra sorgenti e destinazioni. Questa disciplina permette di determinare, ad esempio, l’origine di un attacco, le modalità di comunicazione di un malware con i server di comando e controllo (C2), o l’eventuale esfiltrazione di dati sensibili tramite canali nascosti. L’investigatore di rete inizia tipicamente con l’acquisizione del traffico: può trattarsi di file di cattura (.pcap) ottenuti mettendo in ascolto una scheda di rete in modalità promiscua (con strumenti di packet capture come tcpdump o Wireshark), oppure di flussi di log generati da sonde IDS/IPS, NetFlow, ecc. Spesso, durante un incidente, il team forense configura dei packet sniffer nei punti chiave (ad esempio sulla porta di uno switch core, o attivando port mirroring) per raccogliere tutto il traffico in transito da e verso i sistemi compromessi. I dati così acquisiti – idealmente corredati di timestamp precisi e sincronizzati – vengono poi analizzati nel dettaglio.
Nell’analisi del traffico di rete, alcuni elementi chiave da esaminare includono: i protocolli utilizzati in comunicazione (HTTP, HTTPS, DNS, SMTP, etc.), gli indirizzi IP sorgente e destinazione, i numeri di porta coinvolti, i timestamp delle connessioni, nonché il contenuto dei pacchetti stessi (payload) se in chiaro. Ad esempio, in un file PCAP catturato durante un attacco potremmo filtrare tutto il traffico HTTP non cifrato e ritrovare richieste sospette verso URL esterni, oppure osservare in un dump DNS delle richieste a domini anomali (indizi di malware che cerca il suo dominio di controllo). Strumenti come Wireshark forniscono potenti capacità di filtraggio e decodifica per ispezionare i pacchetti: l’analista può ricomporre flussi TCP, estrarre file trasferiti (ad esempio file scaricati via HTTP o FTP) e seguire la sequenza delle chiamate di rete. Esistono anche strumenti specializzati detti Network Forensic Analysis Tool (NFAT) – un esempio open source è Xplico – il cui scopo principale è estrarre e ricostruire automaticamente tutti i dati applicativi significativi da un’acquisizione di rete. Xplico, ad esempio, è in grado di ricavare da un file pcap tutto il contenuto delle email transitanti (protocolli SMTP/ POP/IMAP), le pagine web e i file scambiati via HTTP, le conversazioni VOIP (protocollo SIP/RTP) convertendole in registrazioni audio, e così via 23 24 . Ciò risulta estremamente utile per presentare le evidenze in forma comprensibile: piuttosto che sfogliare migliaia di pacchetti, l’analista può ottenere direttamente i messaggi e-mail inviati dall’attaccante o i file trafugati.
Un aspetto critico nell’analisi di rete è la presenza della crittografia. Oggi molto traffico (in primis HTTP tramite TLS, ma anche email con SMTPS/IMAPS, VPN cifrate, ecc.) è cifrato end-to-end, il che impedisce di leggere il contenuto dei pacchetti a meno di poter disporre delle chiavi private per decriptarlo. Questo ovviamente complica l’analisi forense: se l’attaccante ha usato solo canali cifrati, si dovrà fare affidamento su metadati (IP, porte, quantità di dati) e su eventuali side-channel (come l’individuazione del tipo di protocollo o l’osservazione di certificate exchange noti) per dedurre cosa sia successo. In ambienti aziendali, per mitigare il problema, talvolta si utilizzano sistemi di SSL/TLS inspection (proxy che terminano e re-instaurano le connessioni cifrate, consentendo l’ispezione del contenuto da parte del SOC) – ma ciò deve essere bilanciato con esigenze di privacy e normative. Nonostante la crittografia, alcuni indicatori di compromissione di rete possono comunque emergere: ad esempio, pattern di traffico anomalo (un host interno che fa centinaia di connessioni verso l’esterno di notte), oppure l’uso di protocolli o porte inusuali per la rete aziendale.
Un compito importante del forense di rete è anche quello di tracciare la sorgente di un attacco. I malintenzionati spesso utilizzano machine zombi o server proxy per celare la propria identità, rendendo arduo risalire all’IP originario dell’attaccante. Attraverso l’analisi incrociata dei log di diversi dispositivi (router, firewall di frontiera, server di autenticazione RADIUS/TACACS), si può tuttavia riuscire a seguire il percorso di un attacco e identificare l’ingresso iniziale. Ad esempio, se un attaccante ha sfruttato una VPN compromessa, i log VPN daranno l’IP pubblico utilizzato; correlando questo con log di altri provider o con segnalazioni di CERT internazionali, si può scoprire se quell’IP corrisponde a una nota botnet. Questo tipo di investigazione sfrutta sia le competenze tecniche che le cooperazioni inter-agenzia: CERT e forze di polizia spesso collaborano scambiandosi informazioni sugli indirizzi IP e le infrastrutture di attacco note.
A tal proposito, è utile menzionare alcuni casi concreti italiani. Le forze dell’ordine, in particolare la Polizia Postale, hanno sviluppato notevoli capacità di network forensics. Un esempio è l’uso proprio di Xplico citato in contesti operativi: in una presentazione del progetto DEFT Linux (una distribuzione forense live creata in Italia), Stefano Fratepietro mostrò come la Polizia, dopo aver catturato il traffico di rete relativo a un’attività illecita, utilizzi Xplico per analizzarlo e ricavare le prove applicative. Questo ha permesso in vari casi di “leggere” comunicazioni tra criminali che avvenivano su canali non cifrati e di raccogliere elementi probatori (e-mail, credenziali, conversazioni VoIP) direttamente dal traffico di rete salvato. Un altro caso noto è l’investigazione sulle botnet Mirai e varianti IoT in Italia: grazie al monitoraggio del traffico anomalo in uscita da dispositivi compromessi (camere IP, router), il CERT-AgID in coordinamento con l’ACN è riuscito a mappare le connessioni verso i server di comando esteri e a condividere con gli ISP le informazioni per la mitigazione, mostrando l’efficacia dell’analisi di rete su larga scala per la difesa nazionale. In sintesi, la network forensics fornisce al responsabile CSIRT uno sguardo “sul filo” delle comunicazioni, rivelando come e cosa è stato trasferito durante un attacco – informazioni imprescindibili per capire l’impatto dell’incidente (ad es. quali dati sono stati rubati) e per bloccare canali di attacco ancora attivi.
Analisi di memorie di massa
Con memorie di massa si intendono tutti i dispositivi di archiviazione persistente dei dati, come hard disk, SSD, chiavette USB, schede di memoria, e in senso lato anche i dischi virtuali di macchine virtuali o istanze cloud. L’analisi forense di queste memorie – strettamente collegata a quella dei file system – si focalizza sull’esame dell’intero supporto fisico o logico e non solo della struttura di files e cartelle. Ciò include aspetti come: l’identificazione di tutte le partizioni presenti (anche quelle nascoste o non standard), l’esame dei settori di boot (MBR o GPT) per individuare bootkit o alterazioni, la ricerca di volume shadow copies o backup nascosti, e in generale l’analisi di ogni area del disco, compresi lo spazio non allocato e lo slack space (lo spazio inutilizzato alla fine dei cluster allocati).
Operativamente, anche qui si parte dall’acquisizione forense del supporto di memoria, creando un’immagine bitstream come discusso in precedenza. Nel caso di dischi di grandi dimensioni, questa operazione può richiedere molto tempo e devono essere adottate opportune precauzioni (condizioni ambientali adeguate, UPS per evitare interruzioni di corrente, etc.). Una volta ottenuta l’immagine, l’investigatore può utilizzare software di analisi come EnCase, FTK o tool open source (ad es. The Sleuth Kit con interfaccia Autopsy) per caricarla. Questi strumenti permettono di navigare tra le partizioni individuate, montarle in sola lettura e analizzarne il contenuto. Un controllo importante è quello della consistenza tra il livello logico e fisico: per esempio, se la tabella delle partizioni indica che un certo spazio del disco non è allocato a nessuna partizione, potrebbe essere normale (spazio vuoto inutilizzato) oppure potrebbe celare una partizione nascosta contenente dati (talvolta i criminali usano partizioni con identificatori anomali o volutamente corrotte per nascondere informazioni). L’analista utilizza quindi tecniche di carving e scanning anche sull’intera immagine fisica per vedere se firme di file noti compaiono in zone altrimenti “mute” del disco.
Un altro scenario da affrontare è quello dei RAID o volumi cifrati. Nelle grandi infrastrutture, spesso i dischi sono in configurazione RAID: il forense dovrà poter ricostruire il volume logico aggregando le immagini dei singoli dischi (rispettando ordine e parametri RAID) per accedere ai dati. Se il volume è cifrato (es. tramite BitLocker, LUKS, VeraCrypt), serviranno le chiavi di decrittazione o tecniche specifiche (es. estrarre la master key dalla RAM acquisita, in caso di sistema acceso) per poter proseguire. Anche dispositivi come smartphone e tablet rientrano nelle “memorie di massa” in senso lato: qui le metodologie divergono (uso di strumenti come Cellebrite UFED o Magnet AXIOM per estrarre una immagine logica o fisica del telefono, sblocco tramite exploit, ecc.), ma per brevità ci focalizziamo sui sistemi tradizionali.
Durante l’analisi delle memorie di massa è importante mantenere la documentazione di ogni passo: ad esempio annotare i codici identificativi del supporto, i calcoli hash effettuati, l’orario di inizio e fine delle copie, le persone intervenute. Questo perché, trattandosi spesso di evidence da presentare eventualmente in tribunale, la catena di custodia deve essere chiara e ininterrotta: ogni spostamento o copia dell’evidenza dev’essere tracciato, e l’integrità deve essere costantemente verificata con hash. Gli standard internazionali (come ISO/IEC 27041 e la stessa 27042) sottolineano l’importanza di garantire l’idoneità e l’adeguatezza del metodo investigativo e la validità delle prove raccolte. In Italia, anche le linee guida del Consiglio d’Europa e del Framework Nazionale di Cybersecurity richiamano questi principi, e le forze dell’ordine (come i reparti di informatica forense dei Carabinieri e della Polizia) hanno protocolli rigorosi per l’acquisizione e la conservazione delle memorie digitali sequestrate.
In sintesi, l’analisi delle memorie di massa copre un ventaglio molto ampio di attività: dalla copia forense alla ricerca di dati nascosti, dall’individuazione di partizioni occulte al recupero di file cancellati, fino all’estrazione di informazioni residuali (ad es. nel pagefile o hibernation file di Windows potrebbero trovarsi frammenti di documenti o credenziali che vale la pena esaminare). Tutto questo richiede competenze tecniche approfondite sul funzionamento dei dispositivi di storage e dei file system, nonché padronanza degli strumenti software dedicati.
Data carving e recupero dei dati
Il data carving (o file carving) è una tecnica forense avanzata utilizzata per recuperare file o frammenti di dati direttamente dal contenuto grezzo di un supporto, senza fare affidamento sulle strutture logiche del file system. Si ricorre al carving soprattutto quando i metadati del file system – che normalmente indicano posizione e dimensione dei file – non sono più disponibili o affidabili: ad esempio, per file cancellati (le cui entry sono state rimosse dalla MFT/FAT) o in casi di file system corrotti/formattati dove la struttura directory è andata persa. Il principio base del carving è che molti tipi di file hanno una firma riconoscibile: delle sequenze specifiche di byte all’inizio (header) e talvolta alla fine (footer) del file. Ad esempio, i file JPEG iniziano tipicamente con i byte FF D8 FF E0 (o FF D8 FF E1 ), i file PDF iniziano con %PDF– , i file ZIP con PK\x03\x04 e così via. Un programma di carving scansiona l’immagine binaria del disco o della memoria alla ricerca di queste firme; quando ne trova una, cerca di estrapolare tutti i byte consecutivi fino al termine plausibile del file (spesso identificato da un footer noto, oppure da un cambio di contesto). Il risultato è l’estrazione di segmenti di dati che verosimilmente rappresentano file completi o parziali.
Ad esempio, se in uno spazio non allocato di un disco troviamo la firma di inizio di un documento Word (byte D0 CF 11 E0 per i vecchi .doc in formato OLE, o l’indicazione PK per i .docx che sono ZIP), il software tenterà di ricostruire il file Word recuperando tutti i settori successivi fino a quando i dati non hanno più senso compiuto o incontrano un’altra firma. Il carving può recuperare file interi se i cluster non sono stati ancora riutilizzati, ma può anche produrre file parziali o corrotti se parti di essi sono state sovrascritte. Tuttavia, anche frammenti di file possono contenere informazioni utili (ad esempio, un pezzo di testo in un documento, o i frame di un video). Questa tecnica è quindi fondamentale quando si analizzano supporti dove l’attaccante ha cercato di ripulire le tracce cancellando file o formattando volumi: spesso, i dati restanti sul disco raccontano ancora la storia. Va notato che il carving non garantisce che i file recuperati siano esattamente nella loro originaria integrità; è necessario validare poi tali file (ad esempio aprendo i documenti recuperati o verificandone gli hash se disponibili).
Esistono diversi strumenti per il data carving: tra gli open source noti vi sono Foremost e Scalpel, nonché PhotoRec (specializzato nel recupero di foto e multimedia). Suite forensi complete come Autopsy/TSK integrano anch’esse funzioni di carving. In ambito NIST, sono stati definiti anche test specifici per valutare l’efficacia dei carving tool (il progetto CFReDS). Il responsabile forense deve conoscere i limiti di questa tecnica: ad esempio, file frammentati (non contigui sul disco) sono difficili da ricostruire completamente via carving, perché tra un frammento e l’altro potrebbero esserci altri dati – alcuni strumenti avanzati tentano di riconoscere frammenti appartenenti allo stesso file sulla base di pattern, ma non è semplice. Inoltre il carving produce spesso falsi positivi (bytes casuali che assomigliano a una firma) – l’analista dovrà quindi verificare manualmente i risultati, soprattutto se l’evidenza estratta è critica.
In definitiva, il data carving aggiunge un tassello importante all’analisi forense, consentendo di scavare a livello di byte nel supporto alla ricerca di qualunque traccia residua. È un processo che può essere lungo e intensivo computazionalmente, ma che in indagini complesse ha portato a ritrovare, ad esempio, frammenti di email scambiate, immagini di reati, documenti eliminati poco prima di un sequestro, etc., rivelandosi spesso la chiave per incastrare i responsabili.
Timeline forense e analisi temporale
Il concetto di timeline in ambito forense si riferisce alla costruzione di una sequenza cronologica di eventi digitali che consenta di ricostruire in modo chiaro chi ha fatto cosa e quando su un sistema. La timeline forense è una delle tecniche più potenti a disposizione degli analisti, perché permette di collegare tra loro le diverse evidenze secondo l’asse temporale, fornendo una visione d’insieme dell’incidente. Come afferma un principio ben noto: “la timeline analysis consente di ricostruire gli eventi, individuare con precisione gli incidenti di sicurezza e comprendere il comportamento di un attaccante” . In pratica, creare una timeline significa prendere tutti i timestamp rilevanti – orari di modifica dei file, registrazioni di log, orari di esecuzione dei processi, etc. – e ordinarli, correlando poi ciascun evento con gli altri.
Per esempio, una timeline relativa a un attacco informatico complesso potrebbe mettere in fila: l’ora in cui un malware è stato eseguito (desunta dall’orario di creazione di un processo in memoria), subito seguita dall’ora in cui un nuovo file sospetto è comparso sul disco (timestamp di creazione del file), poi alcuni minuti dopo la connessione a un server esterno (da un log di rete), poi ancora la modifica di varie chiavi di registro (con orari registrati nel registro eventi), e infine magari l’esecuzione di un comando di cancellazione dati poco prima di un riavvio (log di shell). Vista in timeline, questa serie di azioni delinea chiaramente il modus operandi e l’impatto temporale dell’incidente, cosa che sarebbe difficile da cogliere esaminando isolatamente le singole fonti.
La costruzione di timeline forensi può essere fatta manualmente, esportando i dati temporali da varie fonti e inserendoli in un foglio cronologico, ma data l’enorme mole di informazioni spesso conviene usare strumenti specializzati. Uno dei più noti è Plaso (log2timeline), un framework open source che automaticamente estrae timestamp da un’ampia varietà di file di log e artefatti (file system, registro di Windows, cronologie browser, eventi di sistema) e crea una super timeline aggregata. Con Plaso, si può ad esempio prendere un intero disco e far generare tutti gli eventi temporali possibili in formato testuale o CSV, per poi analizzarli magari con un’interfaccia come Timesketch (piattaforma web per visualizzare e filtrare timeline). Ciò consente di effettuare ricerche veloci (es. “mostra eventi tra le 14:00 e le 15:00 del 12/05/2025” o “trova qualsiasi modifica di file .exe nella settimana precedente l’incidente”) e di applicare filtri per tipologia di evento.
Un concetto importante nella timeline analysis è quello dei pivot point: in un dataset cronologico enorme, si parte di solito da un evento chiave (ad esempio l’ora in cui è stato rilevato l’incidente, o l’orario di un alert antivirus) e si analizzano tutti gli eventi immediatamente precedenti e successivi a quello, allargando via via la finestra temporale. Questo aiuta a focalizzarsi sul periodo critico. Inoltre si distingue tra timeline completa (super timeline) e timeline mirata: la prima include tutto il possibile ed è utile per non perdere dettagli, ma può essere ridondante; la seconda invece si concentra su eventi di un certo tipo o su certe fonti (ad esempio solo la timeline dei file di un particolare directory, o solo gli eventi di login) rendendo più agevole l’analisi. In pratica l’analista forense spesso crea prima timeline parziali (ad esempio timeline del file system, timeline dei log di sicurezza) e poi le fonde assieme per l’analisi finale.
La timeline forense non è solo uno strumento tecnico, ma diventa spesso una parte integrante del report conclusivo di un’investigazione. Molti incident report contengono una sezione chiamata “Timeline of Events” in cui vengono elencati in ordine cronologico tutti gli eventi salienti scoperti, con data/ora, descrizione e fonte. Ciò fornisce ai decisori (manager, o eventualmente giudici in tribunale) una narrazione chiara di cosa è avvenuto. Per esempio: “08:42:15 – L’utente admin effettua login da remoto sull’host SERVER1; 08:45:10 – Viene creato il file malware.exe nella cartella C:\Windows\Temp; 08:45:15 – Il servizio antivirus genera un allarme (file infetto rilevato); 08:45:30 – Connessione di rete dall’host SERVER1 verso l’IP esterno 123.123.123.123 sulla porta 443 (presumibilmente HTTPS); 08:47:00 – Cancellazione di massa di file nella cartella DatiCondivisi…”, e così via. Una presentazione del genere consente di capire immediatamente la successione e l’impatto degli eventi.
Bisogna considerare, come accennato, eventuali problemi di sincronizzazione oraria: la timeline finale potrebbe includere eventi registrati da macchine con orologi non allineati, quindi l’analista deve normalizzare i tempi (ad esempio convertire tutti in UTC o applicare offset noti). Inoltre, la precisione dei timestamp può variare: alcuni log registrano l’ora al millisecondo, altri solo al secondo o al minuto. Quando si comparano eventi, queste differenze vanno tenute presenti (un evento con timestamp 10:00:00 e uno 10:00:30 potrebbero in realtà essere simultanei se il primo log è approssimato al minuto). Gli strumenti automatici spesso aiutano evidenziando potenziali correlazioni nonostante tali discrepanze.
In conclusione, il concetto di timeline rappresenta la spina dorsale dell’analisi forense: mette ordine nel caos di dati prodotti da un incidente e racconta la storia in modo lineare. Un responsabile CSIRT/ SOC deve saper sia costruire manualmente timeline (in contesti magari con pochi dati o in tempo reale) sia utilizzare tool avanzati per timeline complesse, così da poter spiegare efficacemente l’accaduto ai vari stakeholder e prendere decisioni informate sulle misure di contrasto e prevenzione da adottare.
Fondamenti di analisi dei malware
La malware analysis è il processo di esaminare un codice malevolo (malware) per capirne il funzionamento, l’origine, gli obiettivi e gli indicatori di compromissione, in modo da poter mitigare l’attacco e prevenire future infezioni. Nell’ambito della risposta agli incidenti, saper analizzare un malware trovato in un sistema compromesso è fondamentale: consente di determinare quali azioni ha compiuto (es. furto di dati, installazione di backdoor, cifratura ransomware), quali componenti ha installato e come rilevarlo/neutralizzarlo efficacemente. Si distinguono due approcci principali: analisi statica e analisi dinamica.
- Analisi statica: consiste nell’esaminare il malware senza eseguirlo, studiandone il file binario e il codice. Include tecniche come: il calcolo di hash e confronto con database di minacce noti (per vedere se il malware è già catalogato), l’estrazione di stringhe testuali presenti nel file (che spesso rivelano indizi su funzionalità, URL o messaggi interni), l’uso di antivirus e strumenti di scanning per rilevare firme o packer usati, l’analisi del PE header nel caso di eseguibili Windows (per capire compilatore, librerie importate, ecc.), e soprattutto il reverse engineering tramite disassembler e decompiler (come IDA Pro, Ghidra o radare2). Con il debugging statico si può leggere il codice assembly del malware per individuare, ad esempio, routine di rete (API chiamate per fare connessioni), routine di cifratura, oppure condizioni di attivazione (date/time bomb). L’analisi statica è svolta in isolamento, dunque è sicura (il codice non viene attivato sul serio), ma può essere molto complessa se il malware è offuscato o protetto da anti-disassembling. Ad ogni modo, utilizzando debugger e altri strumenti, l’analista può ottenere molte informazioni sulle operazioni svolte dal programma dannoso e identificare eventuali punti deboli del malware stesso (ad esempio errori di implementazione che permettono di creare un decryptor per ransomware).
- Analisi dinamica: complementare alla precedente, consiste nell’osservare il malware in esecuzione all’interno di un ambiente controllato e isolato (solitamente una sandbox o macchina virtuale di test). Si lancia il malware e si monitora il suo comportamento: quali processi crea, che file legge o scrive, quali chiavi di registro modifica, che traffico di rete genera, ecc… Per far ciò ci si avvale di strumenti come sandbox automatizzate (es. Cuckoo Sandbox, VMRay, Joe Sandbox) o monitor manuali (come Process Monitor, Regshot, sniffer di rete e simili) in una VM. L’analisi dinamica permette di vedere concretamente l’effetto del malware, ad esempio scoprendo l’URL di callback verso cui prova a connettersi, o vedendo che crea una copia di sé in una certa directory e stabilisce persistenza impostando una chiave di registro di run. Questo metodo può in alcuni casi essere più rapido nel fornire indicazioni (rispetto a dover leggere migliaia di righe di assembly), ma ha alcuni limiti: malware sofisticati possono rilevare l’ambiente virtuale/sandbox e cambiare comportamento (o non attivarsi proprio) in presenza di indicatori di analisi. Inoltre, se il malware è configurato per attivarsi solo in determinate condizioni (es. in un particolare giorno, o solo se rileva una certa configurazione di sistema), l’analista deve capire e soddisfare tali condizioni, altrimenti l’osservazione potrebbe non rivelare nulla di utile.
In una strategia completa di malware analysis, statica e dinamica si combinano: ad esempio, l’analisi statica preliminare può fornire IOC (hash, nomi di dominio, stringhe sospette) e indicazioni su come attivare il malware, mentre l’analisi dinamica conferma il comportamento e produce tracce di esecuzione (log delle azioni compiute). Oltre a questi approcci, esistono anche l’analisi automatizzata (utilizzo di motori AV e piattaforme cloud che già identificano la famiglia di malware e danno un report preconfezionato) e l’analisi della memoria specifica del malware (analizzare un dump di memoria del sistema infetto per estrarre parti di malware in esecuzione, utile per malware fileless o moduli iniettati).
Il fine ultimo dell’analisi malware è duplice: difensivo e conoscitivo. Dal lato difensivo, capire il funzionamento del malware consente di sviluppare contromisure mirate: ad esempio, scrivere firme per IDS/antivirus (basate su byte sequence uniche del malware), creare regole Yara per individuare varianti simili, implementare filtri su firewall/proxy per bloccare i domini di C&C emersi, o rafforzare le configurazioni di sistema contro le tecniche specifiche usate dal malware (es: se il malware sfrutta WMI per persistere, inserire controlli su WMI). Un’analisi approfondita “fornisce una comprensione del funzionamento delle minacce, consentendo alle organizzazioni di creare rilevamenti mirati invece di affidarsi a firme generiche”; in pratica, conoscere bene il malware permette di scoprirlo anche quando muta (perché si sa cosa tende a fare) e di reagire più velocemente. Inoltre gli analisti, esaminando gli Indicatori di Compromissione (IOC) del malware (indirizzi IP, hash di file, chiavi di registro modificate, ecc.), possono aggiornare i sistemi di monitoraggio: per esempio, inserendo nel SIEM gli hash in watchlist o caricando gli IP malevoli nei feed di blocco. Ciò aiuta anche a rilevare eventuali nuove infezioni da varianti analoghe (se altri host iniziano a contattare lo stesso C&C, potrebbe voler dire che il malware ha colpito anche lì). Dal lato conoscitivo, la malware analysis contribuisce a rintracciare le tattiche, tecniche e procedure (TTP) degli attaccanti e spesso a collegare un malware a una certa famiglia o gruppo (threat actor). Ad esempio, analizzando un ransomware si può scoprire che utilizza lo stesso algoritmo di cifratura e schema di riscatto di un gruppo noto, attribuendo così l’attacco e potenzialmente condividendo intel con le autorità. In alcuni casi, l’analisi porta anche a individuare eventuali zero-day exploit sfruttati dal malware: “aiutando i ricercatori di sicurezza a individuare exploit sconosciuti prima che si diffondano”. Ciò consente di avvisare i vendor software e far patchare le vulnerabilità, innalzando la sicurezza generale.
Per un analista CSIRT/SOC, non è richiesto essere un reverse engineer di livello avanzato, ma sicuramente avere i fondamenti di analisi malware: sapere come funziona un eseguibile, quali sono i metodi base per analizzarlo, quali strumenti usare e come interpretare un report tecnico di malware. Ad esempio, bisogna conoscere strumenti come VirusTotal (per un primo scan e reputazione di un file), Hybrid Analysis o ANY.RUN (sandbox online che mostrano un comportamento dinamico), debugger come OllyDbg/x64dbg (per tracciare manualmente l’esecuzione di malware a runtime), decompiler come Ghidra (per uno sguardo ad alto livello sul codice), e strumenti di dump e unpacking (poiché molti malware sono compressi o criptati). Durante un incidente grave, il responsabile potrebbe dover guidare il team nella scelta: “Abbiamo trovato questo eseguibile sospetto su un server, lo isoliamo e lo mandiamo in sandbox? oppure ne calcoliamo subito l’hash e vediamo se è noto? Quali IOC estraiamo?”. Il responsabile deve anche tradurre i risultati dell’analisi malware in azioni: ad esempio, se dall’analisi emerge che il malware si propaga via rete usando SMB exploit, andrà immediatamente disposto un controllo di tutti gli host per vedere se presentano quella vulnerabilità e applicare le patch. Oppure, se scopre che il malware ruba certi tipi di file, andranno monitorati accessi anomali a quei file su altri sistemi. Insomma, l’analisi malware fornisce la “intelligence tecnica” durante una crisi cyber, e il responsabile deve saperla sfruttare per il contenimento e la remediation dell’incidente.
Un esempio italiano di applicazione di queste competenze è il lavoro svolto dal CERT-AgID sulle campagne di malspam (email malevole) in Italia: i loro analisti analizzano quotidianamente malware come bancari (es. Ursnif, Dridex), ransomware (es. Cryptolocker, LockBit) e spyware diffusi via email di phishing, producendo report e IOC condivisi con tutte le amministrazioni. Nel Report “Le campagne malevole del 2024” pubblicato da CERT-AgID, ad esempio, si illustrano le tecniche di offuscamento osservate nei malware giunti via PEC, mostrando come la combinazione di analisi statica (per deoffuscare macro Office e script PowerShell allegati) e analisi dinamica (per osservare i contatti verso i server di destinazione e i file drop) abbia permesso di contrastare efficacemente tali minacce. Questo tipo di conoscenza, opportunamente integrata nei processi di un SOC, consente di innalzare significativamente il livello di protezione degli enti italiani contro attacchi mirati.
Principali strumenti software per l’analisi forense
In campo forense digitale esiste un’ampia gamma di strumenti software specializzati. Un responsabile CSIRT/SOC deve conoscerne i principali – sia commerciali sia open source – per scegliere di volta in volta quelli più adatti e per comprendere i risultati prodotti dal team tecnico. Di seguito elenchiamo alcuni dei tool più diffusi e riconosciuti, suddivisi per categoria.
- Suite di analisi su disco e file system: strumenti completi che permettono di esaminare immagini forensi di dischi, navigare tra file, estrarre artefatti e generare report. I più noti sono EnCase Forensic (Guidance Software/OpenText) e FTK – Forensic Toolkit (AccessData/Exterro), ampiamente usati dalle forze dell’ordine e dalle società di cybersecurity. In ambito open source, spicca Autopsy (con il motore The Sleuth Kit): interfaccia grafica che consente analisi dettagliate di file system (NTFS, FAT, EXT, HFS, ecc.), ricerca di keyword, carving, timeline e molto altro. Autopsy supporta plugin per l’analisi di specifici artifact (ad es. la cronologia di browser, i registri di sistema Windows, ecc.) e rappresenta una valida alternativa free ai prodotti commerciali. Un altro nome da citare è X-Ways Forensics (di X-Ways Software): un toolkit potentissimo e leggero molto apprezzato per la velocità e l’efficienza nell’analisi di dischi (popolare in contesti professionali europei). Queste suite includono funzioni di hashing di massa, confronto con liste di known files (hash set noti, come la NSRL), ricostruzione di RAID, esportazione di report completi per tribunale, e sono indispensabili per gestire casi complessi. Da menzionare anche software come Magnet AXIOM (della Magnet Forensics), che integra funzioni di analisi filesystem, mobile e cloud in un unico ambiente.
- Strumenti per memory forensics: il già discusso Volatility Framework è il riferimento open source per l’analisi dei dump RAM. Include decine di plugin per estrarre praticamente qualsiasi informazione dalla memoria di Windows, Linux, macOS e profili Android. La sua conoscenza è fondamentale per chi fa incident response. Un altro progetto simile (nato come fork) è Rekall. In ambito commerciale, Magnet AXIOM e Belkasoft Evidence Center offrono moduli di memory analysis integrati, ma spesso si finisce per utilizzare Volatility anche in tali contesti. Per facilitare l’uso di Volatility, esistono interfacce grafiche e tool correlati – ad esempio Volatility Workbench o Autopsy Memory Modules – ma anche linee di comando avanzate come KAPE che integrano flussi di lavoro di triage memoria + timeline. Infine, nel mondo enterprise, prodotti EDR (Endpoint Detection & Response) come CrowdStrike, FireEye HX, Microsoft Defender for Endpoint, spesso dispongono di capacità di acquisizione memoria e analisi automatizzata integrata, sebbene non flessibili come un’analisi manuale con Volatility.
- Strumenti per analisi di log e network forensics: per i log, oltre ai SIEM già citati (Splunk, Elastic Stack/ELK, IBM QRadar, ArcSight, etc.), in un laboratorio forense può essere utile log2timeline/Plaso per estrarre timeline come detto, oppure tool come Chainsaw (per analisi offline di Windows event logs usando regole Sigma), EVTX Explorer (visualizzazione avanzata di log Windows) e SysmonView (per tracciare eventi Sysmon). Per la parte network, l’insostituibile Wireshark permette di analizzare qualunque traccia di rete a basso livello. In aggiunta, strumenti come Zeek (ex Bro) servono a elaborare grandi moli di traffico producendo log sintetici su connessioni, file trasferiti, dns query, ecc. Utili anche NetworkMiner (che estrae in automatico elementi dal traffico, simile a Xplico ma con interfaccia diversa) e Moloch/Arkime (piattaforma di capture indexing su larga scala). Nel contesto italiano, come già accennato, la distribuzione DEFT Linux includeva Xplico e altre utility di rete, costituendo un riferimento per molti anni (ora il progetto è meno attivo, ma Xplico prosegue separatamente).
- Strumenti per analisi malware: qui troviamo disassembler e debugger come IDA Pro, Ghidra (open source della NSA), OllyDbg/x64dbg, essenziali per il reversing. Sandbox come Cuckoo (open) e varie soluzioni commerciali (VMRay, JoeSandbox, Any.Run) sono utilizzate per l’automated dynamic analysis. Inoltre, tool come Radare2 o Binary Ninja possono fornire analisi alternative. L’analista malware utilizza anche unpacker (es. UPX per eseguibili compressi) e strumenti di monitoraggio come Process Monitor, RegShot, ApateDNS (per ingannare le richieste DNS dei malware). Su un piano diverso, servizi online tipo VirusTotal e database come MalwareBazaar aiutano a contestualizzare il campione (vedere se hash è noto, se esistono Yara rules, ecc.). Conoscere questi strumenti e le relative tecniche di utilizzo rientra nel bagaglio di competenze che un responsabile deve quantomeno saper indirizzare: ad esempio, decidere quando inviare un campione sospetto a un servizio cloud per un’analisi veloce e quando invece è necessario allestire un ambiente isolato e approfondire manualmente.
- Piattaforme integrate e distribuzioni forensi: esistono delle vere e proprie distro o suite integrate che raccolgono decine di tool. Ad esempio CAINE (Computer Aided INvestigative Environment) è una distribuzione GNU/Linux live creata in Italia, specificamente per la digital forensics. CAINE contiene un ambiente grafico con script e interfacce che guidano attraverso le fasi classiche dell’investigazione (acquisizione, esame, report) e integra moduli software per analisi di database, memoria, rete, immagini file system NTFS/FAT/EXT, etc. 43 44 . Il tutto assicurando che le operazioni siano forensically sound (ad esempio montando le evidenze in sola lettura). Altre distro note sono SANS SIFT Workstation (Ubuntu-based, mantenuta da SANS Institute) e Kali Linux per la parte più “offensiva” e di test penetrativo ma comunque utile per alcuni strumenti forensi. Anche Tsurugi Linux è una distro recente orientata a DFIR. L’adozione di queste piattaforme consente ai team di avere un ambiente standard con tutti gli strumenti necessari pronti all’uso. Nel contesto lavorativo, spesso si usano macchine virtuali con tali distro per operare sulle evidenze in laboratorio.
In ambito CSIRT/SOC, è attesa “la conoscenza dei principali strumenti software di analisi forense quali Autopsy, Volatility, Magnet Forensics, EnCase Forensic”, come esplicitato anche in annunci di lavoro del settore. Questo significa avere familiarità almeno di base con l’interfaccia e le funzionalità di ciascuno di essi: ad esempio sapere come aprire un case in Autopsy e avviare l’ingest dei moduli, oppure come lanciare i plugin di Volatility da riga di comando per estrarre i processi o le connessioni di rete da un dump RAM, o ancora conoscere l’esistenza di Magnet AXIOM (suite commerciale all-in-one usata anche da forze dell’ordine per analizzare PC e dispositivi mobili). Naturalmente nessuno strumento è “universale” o adatto a tutti gli scopi: il bravo analista sceglie di volta in volta l’utensile più idoneo. Ad esempio, per una rapida triage su 100 endpoint potrebbe usare script e tool da riga di comando (es. KAPE per raccogliere artefatti chiave e Velociraptor per query live), mentre per un’analisi in depth di un singolo server compromesso potrebbe preferire montare l’immagine in Autopsy e lavorare di fino. L’importante è conoscere le potenzialità e i limiti di ogni strumento: saper leggere tra le righe di un output, capire se ad esempio un dato mancante è dovuto a un limite del tool o alla reale assenza di quell’artefatto, ecc.
Da ultimo, vale la pena citare che gli strumenti software sono in continua evoluzione: ogni anno emergono nuovi tool o nuove versioni con funzionalità potenziate (si pensi solo all’evoluzione di Volatility per supportare Windows 11, o ai tool di cloud forensics per AWS/Azure). Un responsabile forense deve mantenersi aggiornato, partecipando magari a community specializzate (come Forensic Focus, DFIR Training, o community locali IISFA) e testando in laboratorio i nuovi strumenti per valutarne l’efficacia.
Conclusioni
L’articolo ha passato in rassegna i principali ambiti dell’analisi forense digitale rilevanti per un responsabile di cybersecurity. Dall’analisi dei file system e delle memorie di massa (con le tecniche di recupero dati e carving) all’ispezione forense della memoria volatile, dall’interpretazione dei log di sicurezza alla dissezione del traffico di rete, fino allo studio dei malware e all’uso dei tool specializzati – ogni sezione evidenzia competenze e conoscenze che risultano oggi imprescindibili per gestire efficacemente incidenti informatici complessi. Queste attività non vivono isolate, ma confluiscono in un processo unificato di digital forensics & incident response (DFIR): ad esempio, i risultati dell’analisi malware influiscono sulle azioni di containment, la timeline forense orienta le indagini ulteriori, l’analisi dei log può suggerire dove cercare evidenze aggiuntive su disco o in memoria, e così via. Il responsabile deve quindi avere una visione olistica, sapendo integrare i vari filoni di analisi in una strategia coerente.
Gli standard internazionali citati (ISO/IEC 27042, 27043, NIST SP 800-86) forniscono un quadro metodologico solido: aderiscono a principi di rigor metodologico, validità, ripetibilità e legalità delle operazioni forensi. Anche nelle procedure italiane (dalle circolari di ACN/CERT-AgID ai manuali operativi delle forze dell’ordine) si ritrova l’enfasi sulla corretta gestione delle evidenze e sulla necessità di agire tempestivamente ma senza comprometterne l’integrità. Questo equilibrio – rapidità vs. accuratezza – è spesso la sfida principale in uno scenario di incidente reale: il responsabile deve decidere quando è il caso di scollegare un sistema per preservarne lo stato, oppure quando conviene lasciarlo online per raccogliere più dati; deve prioritizzare le analisi (ad esempio, prima la memoria per cogliere dati volatili, poi il disco) e allocare le risorse giuste (personale e strumenti) ai vari task.
In termini di contesto nazionale, abbiamo visto come l’Italia si stia allineando alle migliori pratiche: la creazione dell’ACN e il potenziamento di CSIRT Italia, le attività di CERT-AgID focalizzate su prevenzione e condivisione di informazioni, nonché la crescita di competenze nelle unità di Polizia Postale e altri organi investigativi in materia di cyber forensics, testimoniano una maggiore attenzione strategica verso la resilienza cibernetica. Casi concreti gestiti con successo – dalla mitigazione di campagne malware mirate alle PA, all’attribuzione di attacchi tramite analisi delle TTP, fino alla persecuzione penale di cybercriminali grazie a prove digitali forensi – dimostrano il valore di queste capacità.
Per chi aspira a coordinare la prevenzione e gestione degli incidenti informatici, è quindi cruciale non solo conoscere la teoria, ma anche aver maturato una certa esperienza pratica con le tecniche e gli strumenti descritti. La formazione continua, i laboratori su scenari simulati (ad esempio competizioni di Digital Forensics CTF o esercitazioni nazionali di cyber crisis) e l’aggiornamento sulle minacce emergenti (tramite report come quelli CERT-AgID o dell’ENISA) completeranno il bagaglio necessario. In un campo così dinamico, la curiosità investigativa e la mentalità analitica sono qualità preziose quanto la conoscenza tecnica. Un buon responsabile forense sa fare le domande giuste e seguire gli indizi digitali con rigore scientifico, consapevole che dietro ogni byte potrebbe celarsi la chiave per sventare un attacco o attribuirne la responsabilità.
In conclusione, l’analisi forense applicata al cyber-incident response è sia un’arte che una scienza: richiede metodo, strumenti e standard – ma anche intuito, esperienza e capacità di adattamento. L’obiettivo finale è sempre quello di far luce sull’accaduto (shed light on the incident), fornendo risposte chiare al chi, cosa, quando, come e aiutando così l’organizzazione a riprendersi dall’incidente e a imparare da esso per migliorare la propria postura di sicurezza.