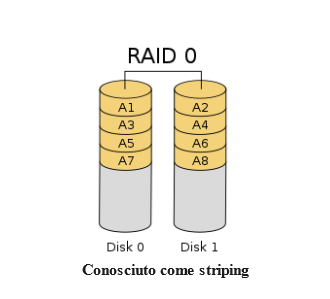
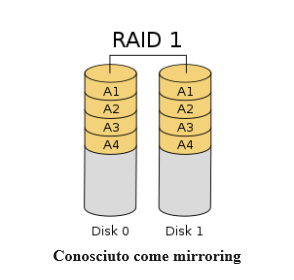
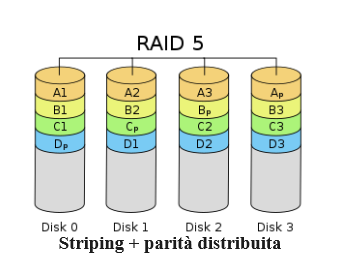
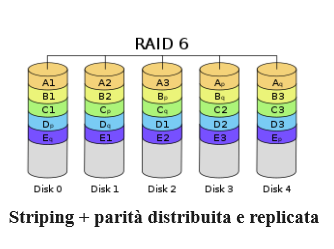
Come gestire gli array RAID con mdadm su Ubuntu 22.04
Introduzione
Gli array RAID forniscono prestazioni e ridondanza migliorate combinando singoli dischi in dispositivi di archiviazione virtuali in configurazioni specifiche. In Linux, l’utility mdadmcrea e gestisce array RAID software.
In questa guida eseguirai diverse configurazioni RAID che possono essere configurate utilizzando un server Ubuntu 22.04.
Prerequisiti
Per seguire questa guida, avrai bisogno dell’accesso a un utente non-root sudo.
Come accennato, questa guida riguarderà la gestione dell’array RAID. Segui la guida su come creare array RAID con mdadmsu Ubuntu 22.04 per creare uno o più array prima di continuare a leggere. Questa guida presuppone che tu abbia uno o più array su cui operare.
Richiesta di informazione sui dispositivi RAID
Uno dei requisiti più essenziali per una corretta gestione è la capacità di reperire informazioni sulla struttura, sui dispositivi che lo compongono e sullo stato attuale dell’array.
Per informazioni dettagliate su un dispositivo RAID, passare il dispositivo RAID con l’opzione -Do --detaila mdadm:
sudo mdadm -D /dev/md0
Verranno visualizzate informazioni importanti sull’array:
Output/dev/md0:
Version : 1.2
Creation Time : Thu Sep 29 17:07:10 2022
Raid Level : raid10
Array Size : 209582080 (199.87 GiB 214.61 GB)
Used Dev Size : 104791040 (99.94 GiB 107.31 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Sep 29 17:08:24 2022
State : clean, resyncing
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : raid2:0 (local to host raid2)
UUID : 8069bcc7:72e7b49f:fba1c780:560a85e0
Events : 35
Number Major Minor RaidDevice State
0 8 0 0 active sync set-A /dev/sda
1 8 16 1 active sync set-B /dev/sdb
2 8 32 2 active sync set-A /dev/sdc
3 8 48 3 active sync set-B /dev/sddL’output rivela il livello RAID, la dimensione dell’array, lo stato dei singoli pezzi, il file UUIDdell’array, i dispositivi componenti e i loro ruoli.
Per i dettagli abbreviati di un array, adatti per l’aggiunta al file /dev/mdadm/mdadm.conf, puoi passare il flag --briefO -bcon la vista dettagliata:
sudo mdadm -Db /dev/md0
Output
/dev/md0: 199.88GiB raid10 4 devices, 0 spares. Use mdadm --detail for more detail.Questo può essere utilizzato per trovare a colpo d’occhio le informazioni chiave su un dispositivo RAID.
Ottenere informazioni sui dispositivi componenti
Puoi anche usare mdadmper interrogare i singoli dispositivi componenti.
L’opzione -Q, se utilizzata con un dispositivo componente, ti dirà l’array di cui fa parte e il suo ruolo:
sudo mdadm -Q /dev/sdc
Output
/dev/sdc: is not an md array
/dev/sdc: device 2 in 4 device active raid10 /dev/md0. Use mdadm --examine for more detail.È possibile ottenere informazioni più dettagliate utilizzando le opzioni -Eo --examine:
sudo mdadm -E /dev/sdc
Output
/dev/sdc:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 8069bcc7:72e7b49f:fba1c780:560a85e0
Name : RAID2204:0 (local to host RAID2204)
Creation Time : Wed Oct 5 15:56:03 2022
Raid Level : raid10
Raid Devices : 4
Avail Dev Size : 209582080 sectors (99.94 GiB 107.31 GB)
Array Size : 209582080 KiB (199.87 GiB 214.61 GB)
Data Offset : 133120 sectors
Super Offset : 8 sectors
Unused Space : before=132968 sectors, after=0 sectors
State : clean
Device UUID : 027f74c5:6d488509:64844c7a:add75d88
Update Time : Wed Oct 5 16:13:57 2022
Bad Block Log : 512 entries available at offset 136 sectors
Checksum : 98edf3ae - correct
Events : 35
Layout : near=2
Chunk Size : 512K
Device Role : Active device 2
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)Queste informazioni sono simili a quelle visualizzate quando si utilizza l’opzione -Dcon il dispositivo dell’array, ma focalizzata sulla relazione del dispositivo componente con l’array.
Leggere le informazioni su /proc/mdstat
Per informazioni dettagliate su ciascuno degli array assemblati sul tuo server, controlla il file /proc/mdstat. Questo è spesso il modo migliore per trovare lo stato corrente degli array attivi sul tuo sistema:
cat /proc/mdstat
Output
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid10 sdd[3] sdc[2] sdb[1] sda[0]
209584128 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU]
unused devices: <none>L’output qui è piuttosto denso e fornisce molte informazioni in una piccola quantità di spazio:
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
. . .La riga Personalitiesdescrive i diversi livelli RAID e le configurazioni attualmente supportate dal kernel.
La riga che inizia con md0descrive l’inizio della descrizione di un dispositivo RAID. Le righe rientrate che seguono descrivono anche questo dispositivo:
. . .
md0 : active raid10 sdd[3] sdc[2] sdb[1] sda[0]
. . .La prima riga indica che l’array è attivo, non difettoso e configurato come RAID 10. Successivamente vengono elencati i dispositivi componenti utilizzati per costruire l’array. I numeri tra parentesi descrivono il ruolo attuale del dispositivo nell’array. Ciò influisce su quali copie dei dati vengono fornite al dispositivo.
. . .
209584128 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU]
. . .La seconda riga visualizzata in questo esempio fornisce il numero di blocchi forniti dai dispositivi virtuali, la versione dei metadati (1.2 in questo esempio) e la dimensione del blocco dell’array. Poiché si tratta di un array RAID 10, include anche informazioni sul layout dell’array. In questo esempio, è stato configurato per memorizzare due copie di ogni blocco di dati nel layout near.
Gli ultimi elementi tra parentesi quadre rappresentano entrambi i dispositivi attualmente disponibili di un set integro. Il primo numero tra parentesi numeriche indica la dimensione di un array integro mentre il secondo numero rappresenta il numero di dispositivi attualmente disponibili. Le altre parentesi sono un’indicazione visiva dello stato dell’array, con Uche rappresentano dispositivi sani e _che rappresentano dispositivi difettosi.
Se il tuo array è attualmente in fase di assemblaggio o ripristino, potresti avere un’altra riga che mostra l’avanzamento:
. . .
[>....................] resync = 0.9% (2032768/209584128) finish=15.3min speed=225863K/sec
. . .Descrive l’operazione applicata e lo stato di avanzamento attuale in diversi modi. Fornisce inoltre la velocità attuale e un tempo stimato fino al completamento.
Una volta che ti sei fatto un’idea di quali array sono attualmente in esecuzione sul tuo sistema, puoi intraprendere una serie di azioni.
Arresto di un array
Per arrestare un array, il primo passo è smontarlo.
Esci dalla directory montata con il comando cd ~:
cd ~
Quindi smonta il dispositivo:
sudo umount /mnt/md0
Puoi interrompere tutti gli array attivi eseguendo:
sudo mdadm --stop --scan
Se vuoi fermare un array specifico, passalo al comando mdadm --stop:
sudo mdadm --stop /dev/md0
Questo fermerà l’array. Dovrai riassemblare l’array per accedervi nuovamente.
Avvio di un array
Per avviare tutti gli array definiti nei file di configurazione o /proc/mdstat, esegui quanto segue:
sudo mdadm --assemble --scan
Per avviare un array specifico, puoi passarlo come argomento a mdadm --assemble:
sudo mdadm --assemble /dev/md0
Funziona se l’array è definito nel file di configurazione.
Se nel file di configurazione manca la definizione corretta dell’array, l’array può comunque essere avviato passando i dispositivi componenti:
sudo mdadm --assemble /dev/md0 /dev/sda /dev/sdb /dev/sdc /dev/sdd
Una volta assemblato l’array, è possibile montarlo come al solito:
sudo mount /dev/md0 /mnt/md0
Aggiunta di un dispositivo di riserva a un array
È possibile aggiungere dispositivi di riserva a qualsiasi array che offra ridondanza, come RAID 1, 5, 6 o 10. I dispositivi di riserva non verranno utilizzati attivamente dall’array a meno che un dispositivo attivo non si guasti. Quando ciò accade, l’array risincronizzerà i dati sull’unità di riserva per ripristinare l’integrità dell’array. Non è possibile aggiungere ricambi agli array non ridondanti (RAID 0) poiché l’array non sopravvivrà al guasto di un’unità.
Per aggiungere un dispositivo di riserva, passare l’array e il nuovo dispositivo al comando mdadm --add:
sudo mdadm /dev/md0 --add /dev/sde
Se l’array non è in uno stato degradato, il nuovo dispositivo verrà aggiunto come riserva. Se il dispositivo è attualmente danneggiato, inizierà immediatamente l’operazione di risincronizzazione utilizzando l’unità di riserva per sostituire l’unità difettosa.
Dopo aver aggiunto un ricambio, aggiorna il file di configurazione per riflettere il nuovo orientamento del dispositivo:
sudo nano /etc/mdadm/mdadm.conf
Rimuovi o commenta la riga corrente che corrisponde alla definizione dell’array:
. . .
# ARRAY /dev/md0 metadata=1.2 name=mdadmwrite:0 UUID=d81c843b:4d96d9fc:5f3f499c:6ee99294Successivamente, aggiungi la configurazione corrente:
sudo mdadm --detail --brief /dev/md0 | sudo tee -a /etc/mdadm/mdadm.conf
Le nuove informazioni verranno utilizzate dall’utility mdadmper assemblare l’array.
Aumento del numero di dispositivi attivi in un array
È possibile espandere un array aumentando il numero di dispositivi attivi all’interno dell’assieme. La procedura esatta dipende leggermente dal livello RAID che stai utilizzando.
Con RAID 1 o 10
Inizia aggiungendo il nuovo dispositivo come riserva, come dimostrato nell’ultima sezione:
sudo mdadm /dev/md0 --add /dev/sde
Scopri il numero attuale di dispositivi RAID nell’array:
sudo mdadm --detail /dev/md0
Output
/dev/md0:
Version : 1.2
Creation Time : Wed Aug 10 15:29:26 2016
Raid Level : raid1
Array Size : 104792064 (99.94 GiB 107.31 GB)
Used Dev Size : 104792064 (99.94 GiB 107.31 GB)
Raid Devices : 2
Total Devices : 3
Persistence : Superblock is persistent
. . .In questo esempio, l’array è configurato per utilizzare attivamente due dispositivi. Rivela, tuttavia, che il numero totale di dispositivi disponibili nell’array è tre a causa della riserva.
Ora riconfigura l’array per avere un dispositivo attivo aggiuntivo. La riserva verrà utilizzata per soddisfare i requisiti di drive extra. Ricorda di sostituire il numero di destinazione dei dispositivi RAID in questo comando. Qui stiamo aumentando il RAID 1 con 2 dispositivi a 3. Se sei nel RAID 10 con 4 dispositivi e hai l’unità aggiuntiva, aumentala a 5:
sudo mdadm --grow --raid-devices=3 /dev/md0
L’array inizierà a riconfigurarsi con un disco attivo aggiuntivo. Per visualizzare l’avanzamento della sincronizzazione dei dati, eseguire quanto segue:
cat /proc/mdstat
Puoi continuare a utilizzare il dispositivo una volta completato il processo.
Con RAID 5 o 6
Inizia aggiungendo il nuovo dispositivo come ricambio come dimostrato nell’ultima sezione:
sudo mdadm /dev/md0 --add /dev/sde
Scopri il numero attuale di dispositivi RAID nell’array:
sudo mdadm --detail /dev/md0
Output
/dev/md0:
Version : 1.2
Creation Time : Wed Oct 5 18:38:51 2022
Raid Level : raid5
Array Size : 209584128 (199.88 GiB 214.61 GB)
Used Dev Size : 104792064 (99.94 GiB 107.31 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
. . .In questo esempio, l’array è configurato per utilizzare attivamente tre dispositivi e il numero totale di dispositivi disponibili nell’array è quattro a causa del dispositivo di riserva aggiunto.
Ora riconfigura l’array per avere un dispositivo attivo aggiuntivo. La riserva verrà utilizzata per soddisfare i requisiti di drive extra. Quando si espande un array RAID 5 o RAID 6, è importante includere un’opzione aggiuntiva denominata --backup-file. Ciò indicherà una posizione fuori dall’array in cui verrà archiviato un file di backup contenente informazioni critiche:
Nota: durante questo processo il file di backup viene utilizzato solo per un periodo molto breve ma critico, dopodiché verrà eliminato automaticamente. Poiché il tempo in cui ciò è necessario è breve, probabilmente non vedrai mai il file sul disco, ma nel caso in cui qualcosa vada storto, può essere utilizzato per ricostruire l’array. Questo post contiene alcune informazioni aggiuntive se desideri saperne di più.
sudo mdadm --grow --raid-devices=4 --backup-file=/root/md0_grow.bak /dev/md0
Il seguente output indica che verrà eseguito il backup della sezione critica:
Output
mdadm: Need to backup 3072K of critical section..L’array inizierà a riconfigurarsi con un disco attivo aggiuntivo. Per visualizzare l’avanzamento della sincronizzazione dei dati, eseguire:
cat /proc/mdstat
Puoi continuare a utilizzare il dispositivo una volta completato questo processo.
Una volta completata la rimodellazione, dovrai espandere il filesystem sull’array per utilizzare lo spazio aggiuntivo:
sudo resize2fs /dev/md0
Il tuo array avrà ora un filesystem che corrisponde alla sua capacità.
Con RAID 0
Gli array RAID 0 non possono avere unità di riserva perché non esiste alcuna possibilità per una riserva di ricostruire un array RAID 0 danneggiato. È necessario aggiungere il nuovo dispositivo contemporaneamente all’espansione dell’array.
Innanzitutto, scopri il numero corrente di dispositivi RAID nell’array:
sudo mdadm --detail /dev/md0
Output
/dev/md0:
Version : 1.2
Creation Time : Wed Aug 10 19:17:14 2020
Raid Level : raid0
Array Size : 209584128 (199.88 GiB 214.61 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
. . .Ora puoi incrementare il numero di dispositivi RAID nella stessa operazione di aggiunta della nuova unità:
sudo mdadm --grow /dev/md0 --raid-devices=3 --add /dev/sdc
Riceverai un output che indica che l’array è stato modificato in RAID 4:
Output
mdadm: level of /dev/md0 changed to raid4
mdadm: added /dev/sdcQuesto è normale e previsto. L’array tornerà al RAID 0 quando i dati saranno stati ridistribuiti su tutti i dischi esistenti.
Puoi controllare lo stato di avanzamento dell’azione:
cat /proc/mdstat
Una volta completata la sincronizzazione, ridimensiona il filesystem per utilizzare lo spazio aggiuntivo:
sudo resize2fs /dev/md0
Il tuo array avrà ora un filesystem che corrisponde alla sua capacità.
Rimozione di un dispositivo da un array
Talvolta è necessario rimuovere un’unità da un array RAID in caso di guasto o se è necessario sostituire il disco.
Per poter rimuovere un dispositivo, è necessario prima contrassegnarlo come “guasto” all’interno dell’array. Puoi verificare se è presente un dispositivo guasto utilizzando mdadm --detail:
sudo mdadm --detail /dev/md0
Output
/dev/md0:
Version : 1.2
Creation Time : Wed Aug 10 21:42:12 2020
Raid Level : raid5
Array Size : 209584128 (199.88 GiB 214.61 GB)
Used Dev Size : 104792064 (99.94 GiB 107.31 GB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Thu Aug 11 14:10:43 2020
State : clean, degraded
Active Devices : 2
Working Devices : 2
Failed Devices : 1
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 64K
Name : mdadmwrite:0 (local to host mdadmwrite)
UUID : bf7a711b:b3aa9440:40d2c12e:79824706
Events : 144
Number Major Minor RaidDevice State
0 0 0 0 removed
1 8 0 1 active sync /dev/sda
2 8 16 2 active sync /dev/sdb
0 8 32 - faulty /dev/sdc
Tutte le linee evidenziate indicano che un’unità non funziona più. Come esempio, /dev/sdcin questo output rivela che l’unità è difettosa.
Se è necessario rimuovere un’unità che non presenta problemi, è possibile contrassegnarla manualmente come guasta con l’opzione--fail:
sudo mdadm /dev/md0 --fail /dev/sdc
Output
mdadm: set /dev/sdc faulty in /dev/md0È quindi possibile sostituirlo con una nuova unità, utilizzando lo stesso comando mdadm --addche usi per aggiungere un ricambio:
sudo mdadm /dev/md0 --add /dev/sdd
Output
mdadm: added /dev/sddL’array inizierà il ripristino copiando i dati sulla nuova unità.
Eliminazione di un array
Per distruggere un array, compresi tutti i dati in esso contenuti, iniziare seguendo il processo utilizzato per arrestare un array.
Esci dalla directory montata con il seguente comando:
cd ~
Quindi smonta il filesystem:
sudo umount /mnt/md0Quindi, interrompi l’array:
sudo mdadm --stop /dev/md0
Successivamente, elimina l’array stesso con il comando --removedestinato al dispositivo RAID:
sudo mdadm --remove /dev/md0
Una volta rimosso l’array stesso, utilizzare mdadm --zero-superblocksu ciascuno dei dispositivi componenti. Questo cancellerà il superblocco md, un’intestazione utilizzata da mdadmper assemblare e gestire i dispositivi componenti come parte di un array. Se è ancora presente, potrebbe causare problemi quando si tenta di riutilizzare il disco per altri scopi.
Controlla la colonna FSTYPE nell’output lsblk --fsper confermare che il superblocco è presente nell’array:
lsblk --fs
Output
NAME FSTYPE LABEL UUID MOUNTPOINT
…
sda linux_raid_member mdadmwrite:0 bf7a711b-b3aa-9440-40d2-c12e79824706
sdb linux_raid_member mdadmwrite:0 bf7a711b-b3aa-9440-40d2-c12e79824706
sdc linux_raid_member mdadmwrite:0 bf7a711b-b3aa-9440-40d2-c12e79824706
sdd
vda
├─vda1 ext4 DOROOT 4f8b85db-8c11-422b-83c4-c74195f67b91 /
└─vda15In questo esempio, /dev/sda, /dev/sdb e /dev/sdcfacevano tutti parte dell’array e sono ancora etichettati come tali.
Rimuovere le etichette con il seguente comando:
sudo mdadm --zero-superblock /dev/sda /dev/sdb /dev/sdc
Successivamente, assicurati di rimuovere o commentare qualsiasi riferimento all’array nel file /etc/fstab. Puoi farlo aggiungendo il simbolo dell’hashtag #all’inizio:
sudo nano /etc/fstab
. . .
# /dev/md0 /mnt/md0 ext4 defaults,nofail,discard 0 0Salva e chiudi il file quando hai finito.
Rimuovere o commentare eventuali riferimenti all’array anche dal file /etc/mdadm/mdadm.conf:
nano /etc/mdadm/mdadm.conf
# ARRAY /dev/md0 metadata=1.2 name=mdadmwrite:0 UUID=bf7a711b:b3aa9440:40d2c12e:79824706Salva e chiudi il file quando hai finito.
Quindi aggiorna l’initramfs:
sudo update-initramfs -u
Ciò rimuoverà il dispositivo dall’ambiente di avvio iniziale.